Java【七大排序】算法详细图解,一篇文章吃透
文章目录
- 一、排序相关概念
- 二、七大排序
- 1,直接插入排序
- 2,希尔排序
- 3,选择排序
- 4,堆排序
- 5,冒泡排序
- 5.1冒泡排序的优化
- 6,快速排序
- 6.1 快速排序的优化
- 7,归并排序
- 三、排序算法总体分析对比
- 总结
提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之处欢迎评论区指点~ 废话不多说,直接发车~
一、排序相关概念
📌排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增📈或递减📉的排列起来的操作
👉以 int 类型数据从小到大排序为例:
排序前:4,1,3,6,8,7,2,5
排序后:1,2,3,4,5,6,7,8
📌稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
👉以 int 类型数据从小到大排序为例:
排序前:4,1,3a,6,8,7,2,3b,5(3a 在 3b 之前)
排序后:1,2,3a,3b,4,5,6,7,8(3a 还在 3b 之前,稳定)
排序后:1,2,3b,3a,4,5,6,7,8(3a 不在 3b 之前,不稳定)
以下是常见的 7大排序 算法
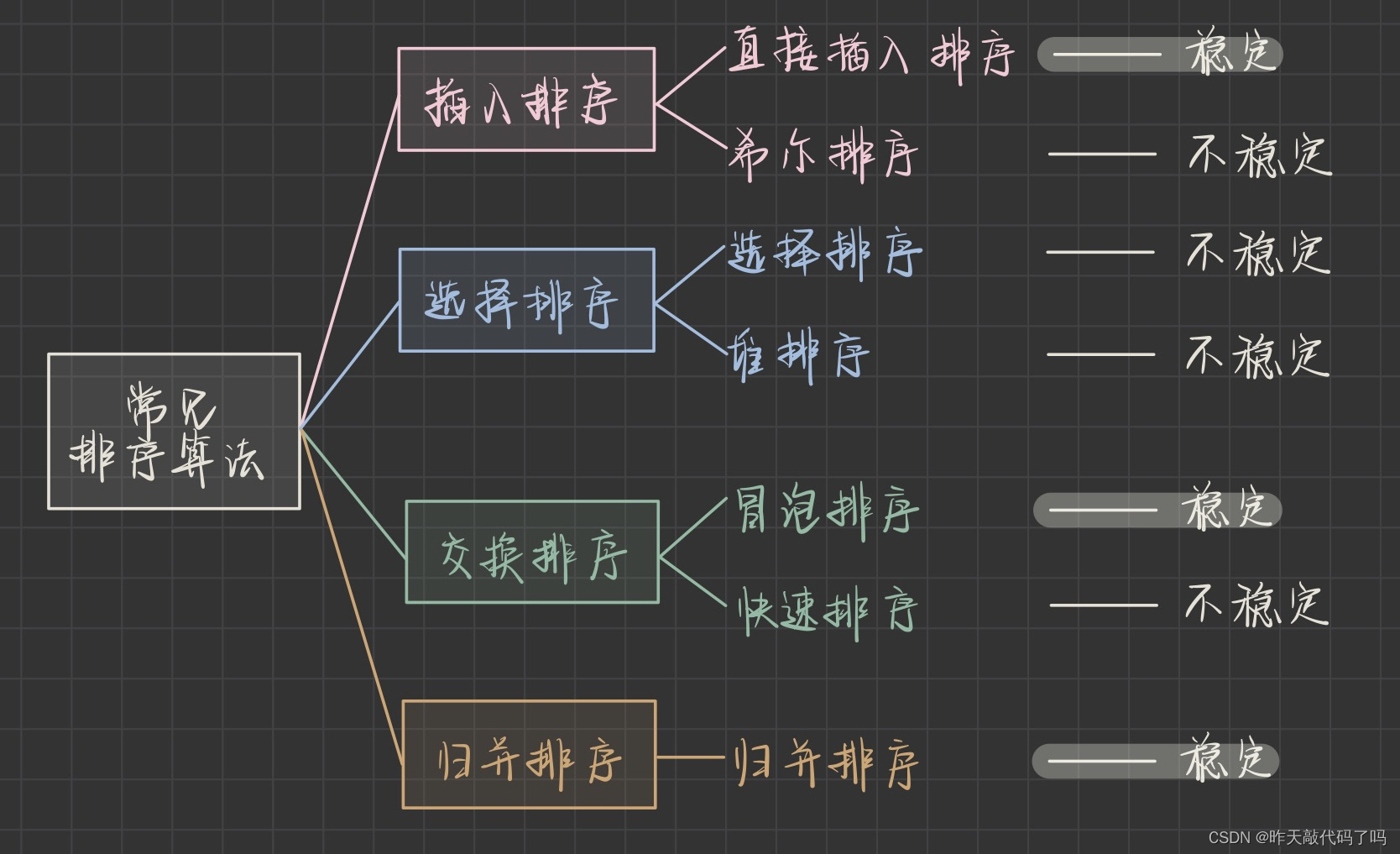
二、七大排序
1,直接插入排序
📌直接插入排序的基本操作是将一个记录插入到已经排有序的有序表中, 从而得到一个新的有序表
📌基本思想 : 类似于打扑克牌, 比如你现在手上有三张牌:3, 5, 10, 现在轮到你摸牌了, 你摸了一张7, 你应该把7放在哪里呢?
对于手上已有的3, 5, 10来说, 这几张牌已经排好序了, 那么把7插在那里还能保持有序呢? 很简单, 就在5和10的中间
🚗🚗🚗
那么给定一组无序的数据, 实现直接插入排序的具体过程是什么呢? 如图所示
注意 i , j 下标的变化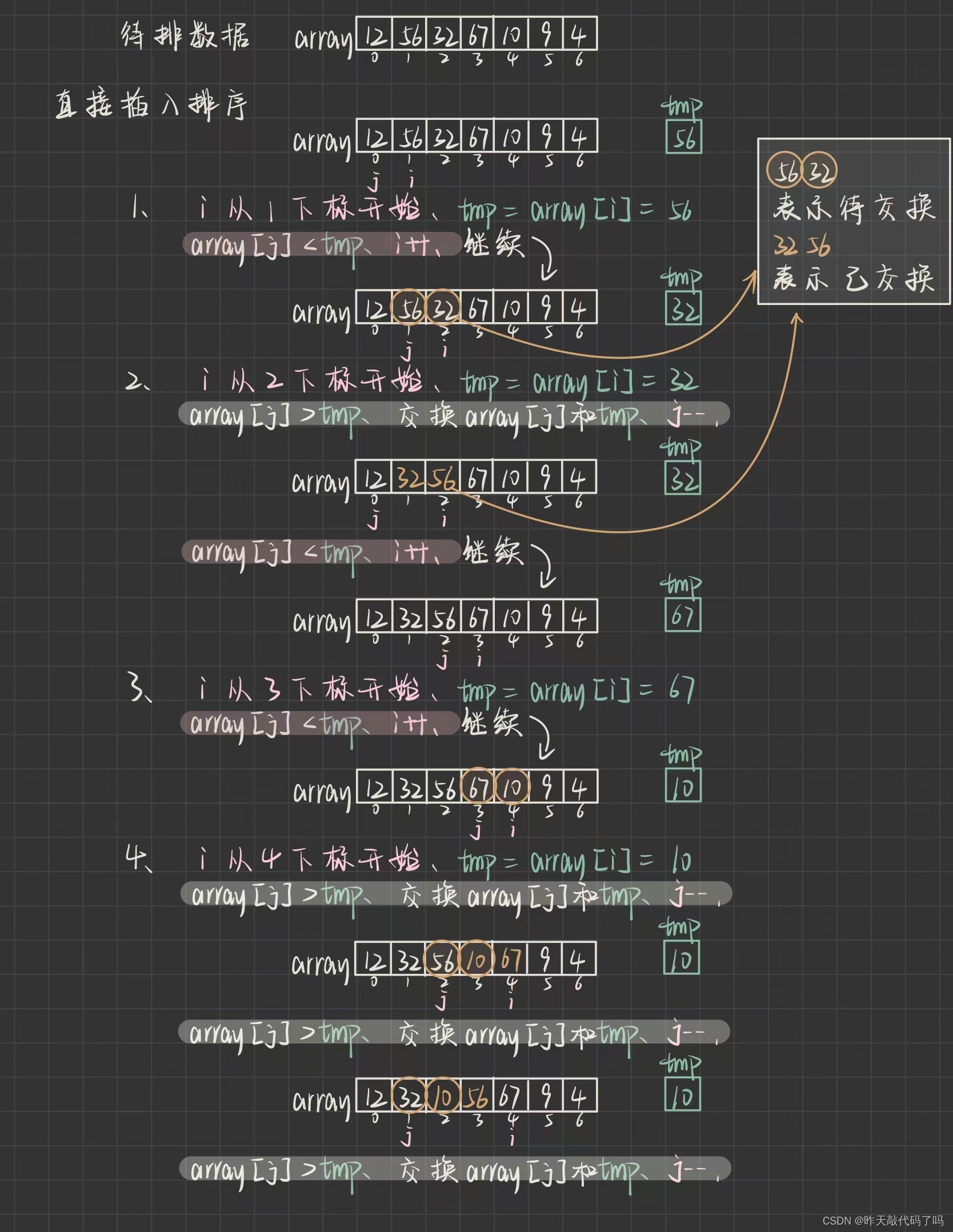

弄懂了过程,看一下代码如何实现
为了方便在Test类中测试,把所有的方法设置为static修饰的静态方法
/*** 直接插入排序* 时间复杂度:最坏 O(N^2),最好 O(N)* 空间复杂度:O(1)* 稳定性:稳定* @param array :待排序数组趋于有序时,使用插入排序效率高*/public static void insertSort(int[] array) {// 从小到大排序if(array == null) {return;}int tmp = 0;for (int i = 1; i < array.length; i++) {tmp = array[i];for (int j = i - 1; j >= 0; j--) {// j往后走if (array[j] > tmp) {array[j + 1] = array[j];array[j] = tmp;} else {break;}}}}
👉时间复杂度:
如果数组有序的情况下, 只需要 i 遍历一次数组即可,此时时间复杂度为O(N)
如果数组逆序的情况下, i 在便利数组的同时, j 也要多次遍历数组,此时时间复杂度为O(N^2)
👉空间复杂度:
所以在数组趋近于有序的情况下, 直接插入排序的效率比较高
只有常数个用于记录的额外空间,空间复杂度为O(1)
👉稳定性:
稳定 , 不过也可以修改代码使其变成不稳定的算法
只需要把 if (array[j] > tmp) {
这一行代码中的大于号改成大于等于就变成了不稳定的排序算法
❗️任何稳定的排序算法都是可以实现不稳定的
2,希尔排序
起初,排序算法只有简单类型的:直接插入排序,冒泡排序,选择排序,平均情况下时间复杂都是O(NN),希尔算法是第一批突破O(NN)这个是激昂复杂度的算法之一
📌算法思路:把待排序数组分成X组,每组内有Y个元素进行直接插入排序,然后减小组数X,每组内数据个数Y随之增大,但X为1时,即可整体进行直接插入排序。这样只能够保证每次各组内插入排序完后都是有序的,但算不上数组基本有序,基本有序是指,数组内较小数据基本都在前,较大数据基本都在后
例如给你一组数据:3,1,5,7,9,8,6,4,1
如果分组情况是:1️⃣第一组是3,1,5;2️⃣第二组是7,9,8;3️⃣第三组是6,4,1,这样可以吗
答案是不可以,因为这样各组内排序之后得到:1,3,5,7,8,9,1,4,6。很显然不满足基本有序,这叫局部有序
希尔排序的组数划分规则是进行跳跃式分割:将相距某个增量(也就是X的值,为啥?先别管)的记录组成一个子序列,这样才能保证子序列内分别进行插入排序后得到的结果是基本有序
有点晦涩,图解如下:
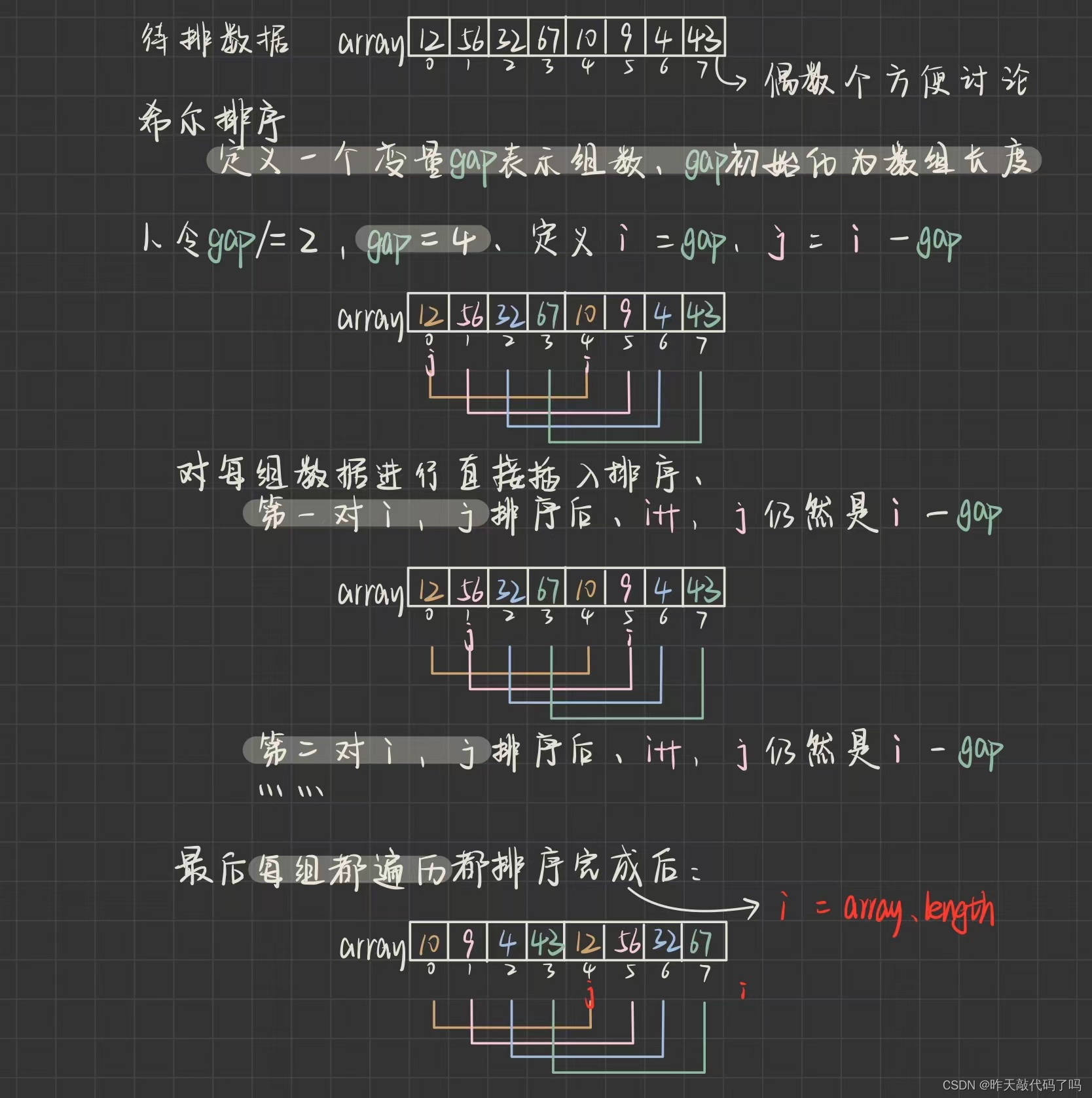
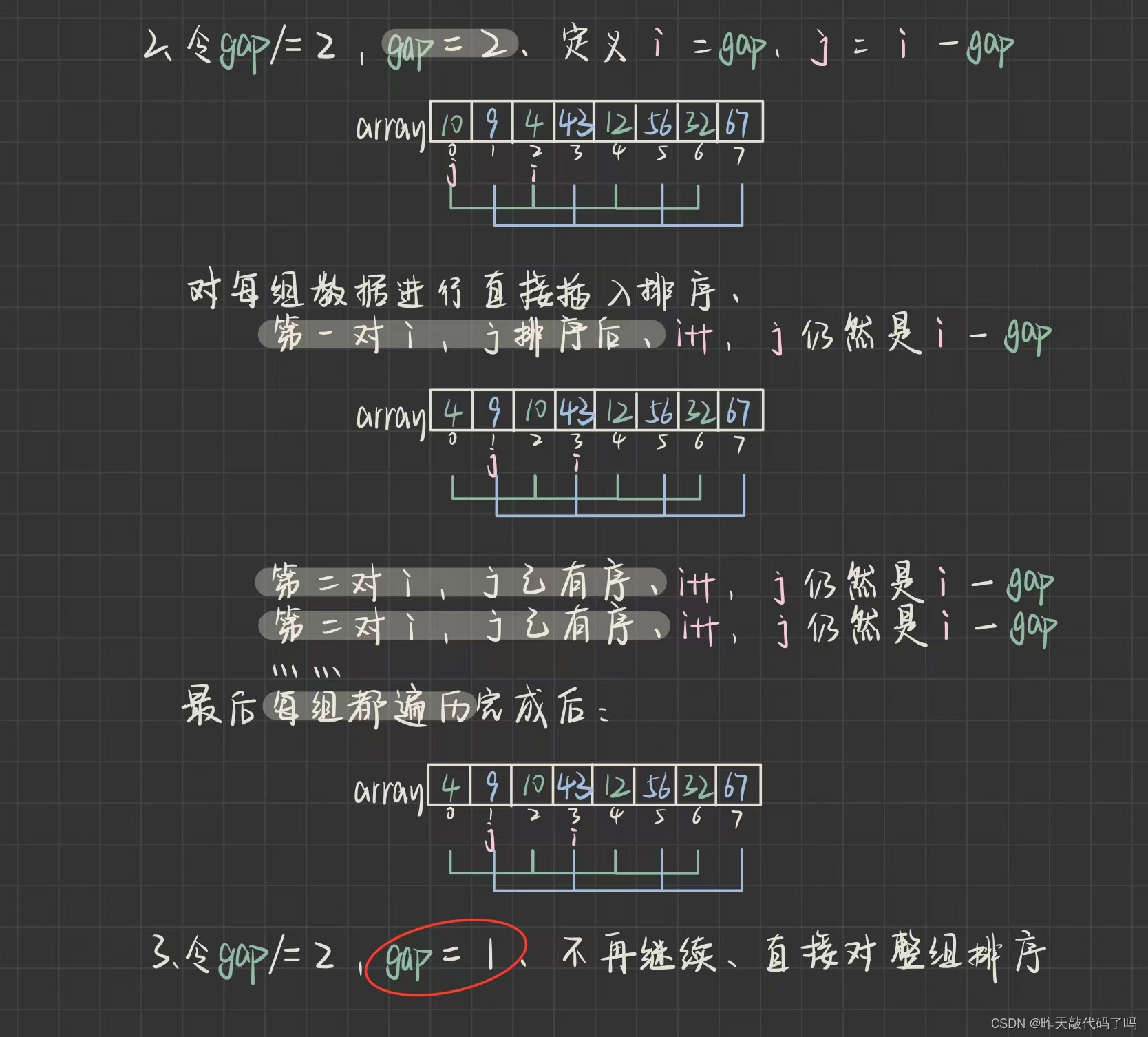
看完了图解过程,应该理解了希尔算法的核心思想就是“缩小增量”,而增量就是所谓的组数gap,理解了过程,来看代码如何实现:
/*** 希尔排序* 时间复杂度:O(N^1.3~N^1.5)* 空间复杂度:O(1)* 稳定性:不稳定* @param array*/public static void shellSort(int[] array) {int gap = array.length; ;while (gap > 1) {gap /= 2;shell(array, gap);}}private static void shell(int[] array, int gap) {// 从小到大排序if(array == null) {return;}int tmp = 0;for (int i = gap; i < array.length; i++) {tmp = array[i];for (int j = i - gap; j >= 0; j -= gap) {// j往后走if (array[j] > tmp) {array[j + gap] = array[j];array[j] = tmp;} else {break;}}}}
👉时间复杂度:
希尔排序的时间复杂度却决于增量,增量大小决定了循环次数,而因为数据量不同,很难确定一个最合适的增量大小,这也是迄今为止的数学难题,一般认为是O(N^1.3 ~ N ^1.5)
👉空间复杂度:
没有额外空间的开销,只有常数个记录的辅助空间,空间复杂度为O(1)
👉稳定性:不稳定
3,选择排序
📌选择排序 就是通过 n-i次比较,从n-i+1个数据中找到最小的一个记录, 并且和第 i 个数据交换
📌算法思想: 每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
比如你预算充足的情况的下, 想选择一辆座驾🚗
1️⃣一开始在网上看上了一台 50w 奔驰E, 觉得蛮不错,这是你的第一个目标座驾
2️⃣然后你到了 4s 店, 往里走看到了 120w 的奔驰S比奔驰E的内饰更漂亮舒适, 外观更霸气, 于是又想买奔驰S
3️⃣接着再往里走看到了 180w 的奔驰AMGE63, 觉得这要性能有性能,要外观有外观, 于是又想买奔驰AMGE63
4️⃣最后等到去交钱签合同的时候,看到了奔驰最尊贵的座驾----- 500w 的迈巴赫更符合你尊贵的身份, 于是当机立断选择了迈巴赫
50w 是一个标准,然后找到了 120w , 暂时选择了1 20w ----后来又找到了 180w , 暂时选择了 180w ----最后又找到了 500w 的迈巴赫, 这已经是最贵的得了, 所以最终选择了 500w 的代替了 50w 的
这就是选则排序的思想
我们反过来,给定你一组数据
1️⃣第一个数据是300,暂时作为标准,
2️⃣在数组中往后找,找到了180,把180记录为最小值
3️⃣又找到了120,把120作为最小值
4️⃣又找到了50,把50最为最小值
没有比50更小的了,让最小值50和300 交换 , 值最小的50来到了前面,而相对比较大的300来到了后面
那么给定一组无序的数据, 实现直接插入排序的具体过程是什么呢? 如图所示
注意 i , j 下标的变化
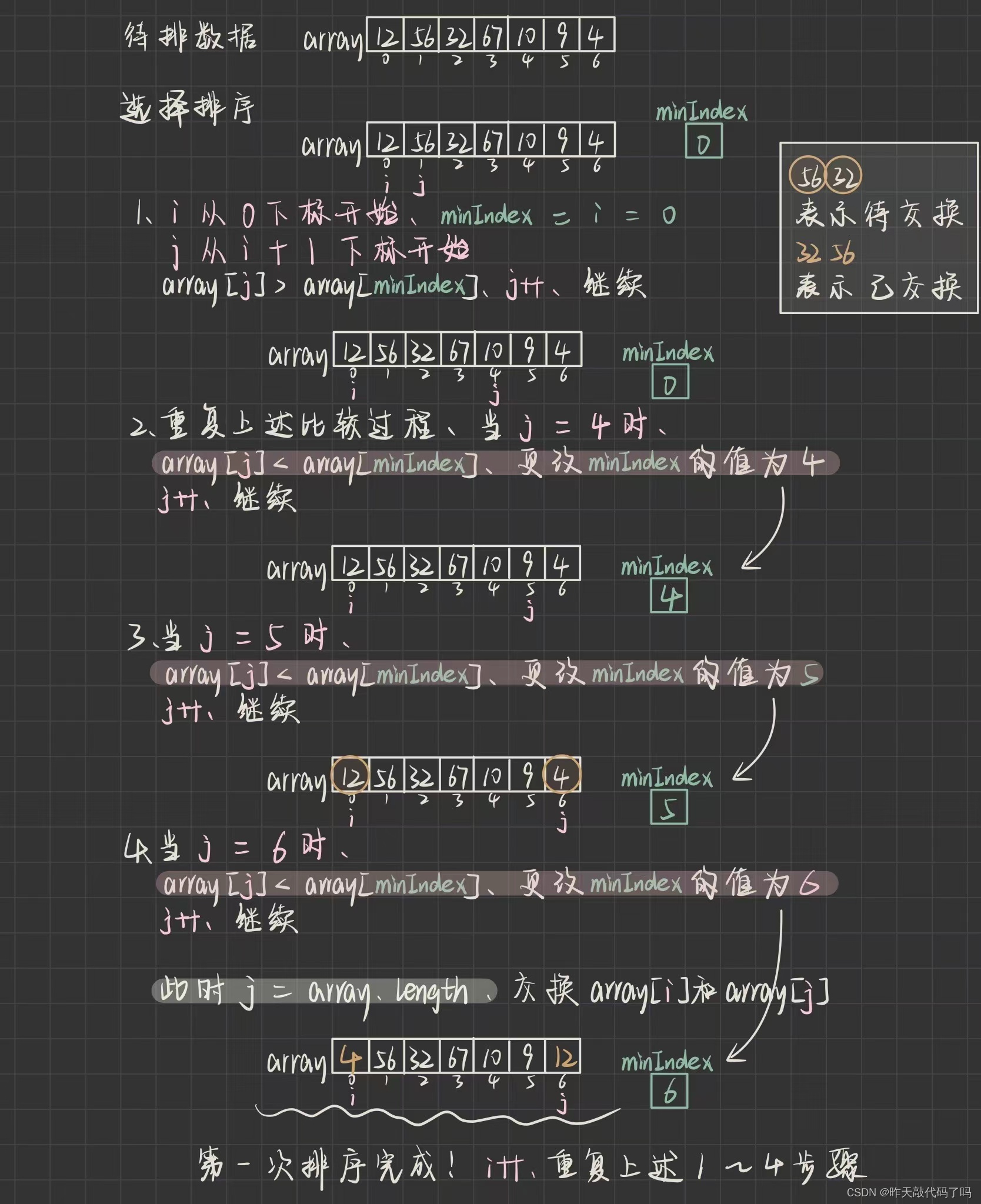
❗️❗️注意,这里只分析了一躺排序,并没有把整个数组排有序
理解了过程,来看一下代码如何实现
/*** 选择排序* 时间复杂度:O(N^2)* 空间复杂度:O(1)* 稳定性:不稳定* @param array*/public static void selectSort(int[] array) {if(array == null) {return;}for (int i = 0; i < array.length; i++) {int minInedx = i;int j = i + 1;for (; j < array.length; j++) {if (array[j] < array[minInedx]) {minInedx = j;}}swap(array, minInedx, i);}}
本篇中还会经常使用到交换,所以单独封装一个方法出来
private static void swap(int[] array,int i, int j) {int tmp = array[i];array[i] = array[j];array[j] = tmp;}
👉时间复杂度:
最好最差情况,选择排序的数据之间的比较次数都是固定的,
而最好情况:数组有序时,需要交换0次,最坏情况:数组无序时,交换n-1次
总体的排序时间是比较+交换的总和,所以时间复杂度为O(N^2)
选择排序理解和实现起来都比较简单,但效率比较低,一般很少使用选择排序
👉空间复杂度:
没有额外空间的开销,只有常数个记录的辅助空间,空间复杂度为O(1)
👉稳定性:
不稳定
4,堆排序
显然,堆排序是在堆这种数据结构的基础上进行的,是对选择排序的一种优化:
在选择排序中,多次比较之后交换了两个数据,最终目的达到了,但是 并没有记录比较过程, 导致后续数据的排序,可能进行了相同的重复🤦
堆排序就做到了当找到最小数据时,根据比较结果,对其他数据做出相应调整✅
首先我们要把待排序数组建立一个堆的结构,那么,问题来了,应该建立大根堆,还是小根堆呢?
答案是大根堆
尽管建成了大根堆,物理结构仍然是数组,只是更改了数组的下标,重新安排了数据在数组中的位置,所以可以理解成堆
如果建立小根堆,就无法对其他数据做出相应调整了
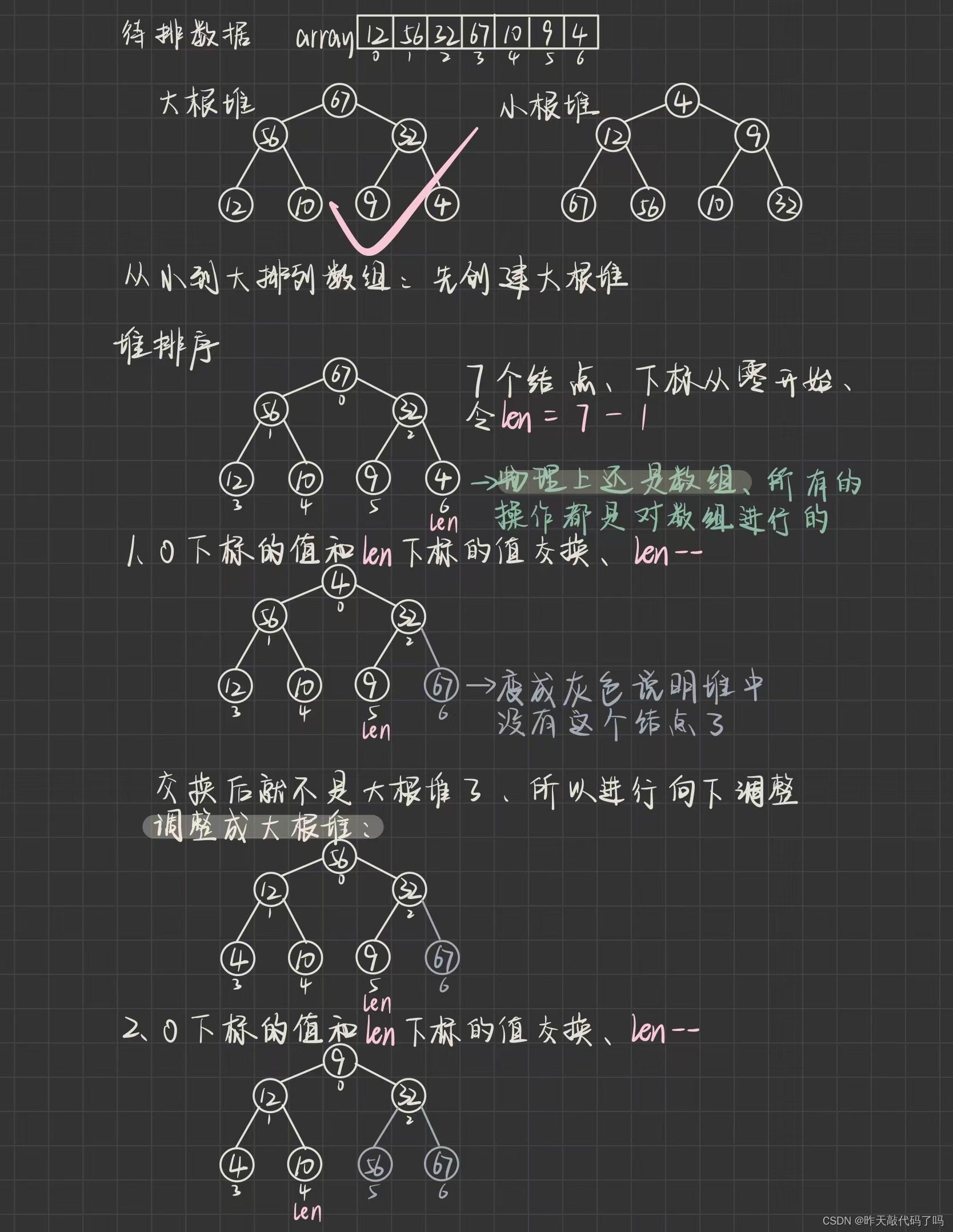
结点变成灰色表示已经完成了对这个数据的排序,其余结点继续向下调整,范围是0~len
所以变灰的结点就可以不再考虑了
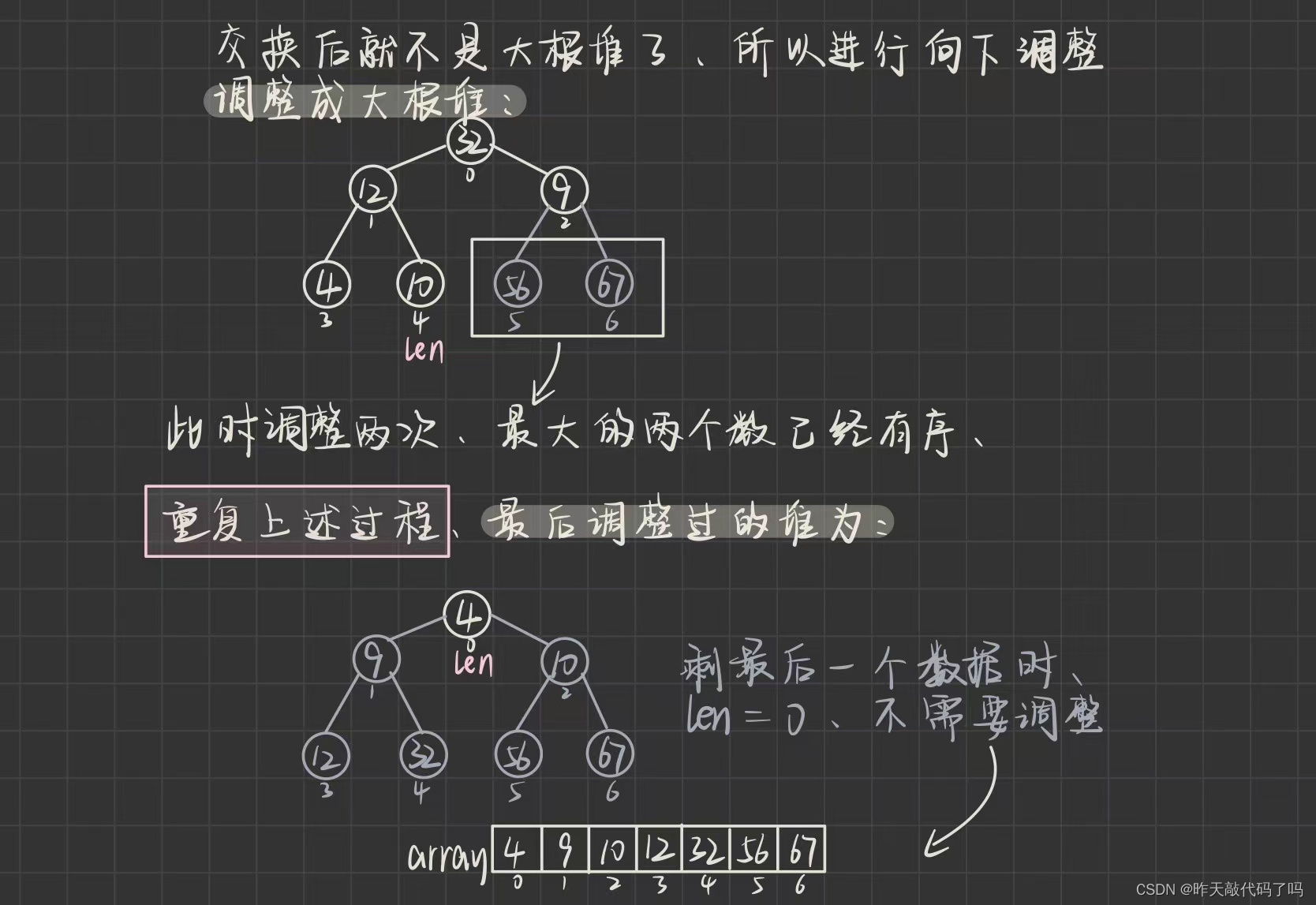
理解了过程,来看代码是如何实现的
/*** 堆排序* 时间复杂度:O(N*log₂N)* 空间复杂度:O(1)* 稳定性:不稳定* @param array*/public static void heapSort(int[] array) {creatHeap(array);int len = array.length - 1;while (len > 0) {swap(array, 0, len);shiftDown(array,0,len);len--;}}private static void creatHeap(int[] array) {// 从最后一个树的根结点开始向下调整for (int parent = (array.length - 1 - 1) / 2; parent >= 0; parent--) {shiftDown(array, parent, array.length);}}private static void shiftDown(int[] array, int parent, int length) {int child = parent * 2 + 1;while(child < length){if (child + 1 < length && array[child] < array[child + 1]) {child ++;}if (array[child] > array[parent]) {swap(array, child, parent);parent = child;child = parent * 2 + 1;}else {break;}}}
👉时间复杂度:
主要有两个部分:建堆➕重建堆
首先是把数组转化成大根堆的时间复杂度是O(N),然后是多次重建堆的时间复杂度是O(NlogN)
所以整体的时间复杂度是O(NlogN)
堆排序的时间复杂度对待排序数据的状态不敏感,所以没有最好最坏情况,性能上比较优越
👉空间复杂度:
没有额外空间的开销,只有常数个记录的辅助空间,空间复杂度为O(1)
👉稳定性:
不稳定
5,冒泡排序
📌冒泡排序是一种交换排序,他的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到有序为止
冒泡应该是最早接触的一种排序算法了,因为它很简单易懂,尽管如此,还是来看一看冒泡的图解过程:
注意 i , j 下标的变化


❓❓❓为什么 每趟冒泡排序之后, i++;而 j 总是从0下标开始呢,
因为一趟冒泡排序结束后只是做到了把 待排序数据的最大值 放在 待排序数据的最后, 而最小值不一定在最前面,所以 i 要从 0 下标开始重新找目前待排序数组的最大值,让他往后放, 循环往复, 最后剩下的那个数据一定是最小的
理解了过程, 代码如下:
/*** 冒泡排序* 时间复杂度:最坏 O(N*N) 最好 O(N)* 时间复杂度:O(1)* 稳定性:稳定*/public static void bubleSort(int[] array){for (int i = 0; i < array.length; i++) {for (int j = 0; j < array.length - i - 1; j++) {if (array[j] > array[j + 1]) {swap(array, j, j + 1);}}}}
5.1冒泡排序的优化
其实 j < array.length - i - 1; 这一句代码也是经过简单的优化的, 避免了 j 的无效循环🔄
但这 还是存在效率较低 的情况, 当 待排数据有序 时, i 还是会继续遍历, 从而带动 j 的遍历, 是纯纯浪费❌
👉所以对上述代码的优化方案是:
每次 i 开始循环时 定义一个标记 false , 如果 j 遍历完数组, 发生了交换, 把 false 改成 true , 如果 j 的循环结束发现标记还是false,说明什么?
说明没有发生交换, 待排数据是整体有序的, 那么就不让 i 继续遍历了,直接返回即可
优化后代码:
public static void bubleSort(int[] array){for (int i = 0; i < array.length; i++) {boolean mark = false;for (int j = 0; j < array.length - i - 1; j++) {if (array[j] > array[j + 1]) {swap(array, j, j + 1);mark = true;}}if (mark == false) {return;}}}
👉时间复杂度:
最好情况下(数组整体有序),也需要 j 遍历一遍数组,时间复杂度是O(N)
最坏情况下(数组逆序),此时时间复杂度是O(N^2)
👉空间复杂度:
没有额外空间的开销,只有常数个记录的辅助空间,空间复杂度是O(1)
👉稳定性:
稳定
6,快速排序
🔎希尔排序是对直接插入排序的优化,同属于插入排序
🔎堆排序是选择排序的优化,同属于选择排序
🔎快速排序是对冒泡排序的优化,同属于交换排序
快速排序被称为20世纪十大算法之一,也是很多语言的源码中使用的排序算法
基本思想: 通过一趟排序,找到基准(枢轴)📍,将待排序数组分割成独立的两部分,基准(枢轴)📍的一边的数据均比另一边的大/小,再对两边的数据分别继续快速排序,最终整个数组有序
有点晦涩难懂,如图所示:
快速排序有几个不同的实现方式,这里介绍:Hoare法和挖坑法,效率上没有区别,只是核心代码的实现方式有细微差异
挖坑法:

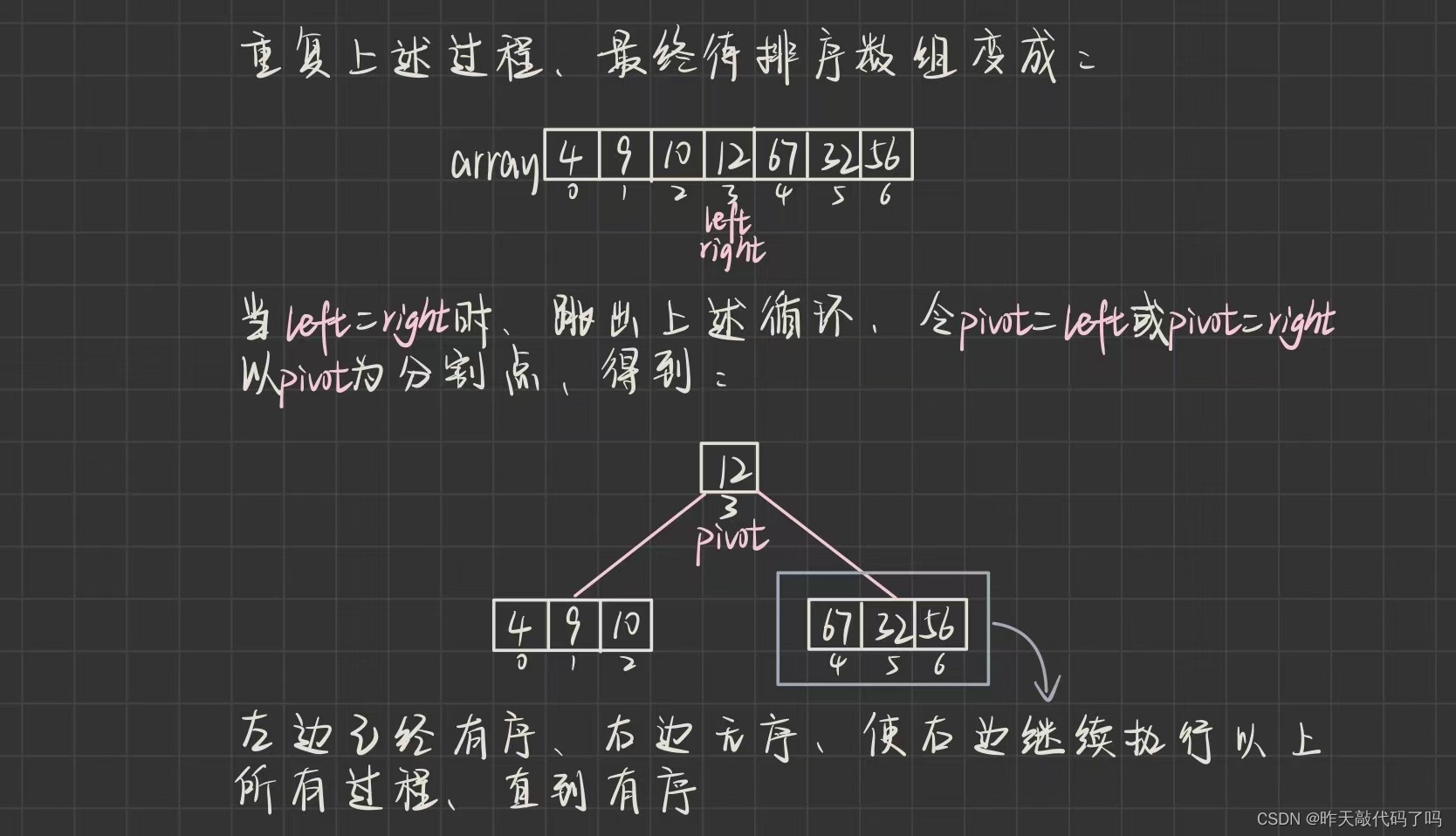
挖坑法可以理解为,数据每移动一次,就会在原地留下一个“坑”,实际上数组还在原处,只是覆盖到了目标位置上,可是这个数据已经走了,可以当它不在了,空出来一个“坑”
以上是找到快速排序算法中最核心的部分:**找到基准(枢轴)**📍
同时算法中加入了二叉树的思想,找到基准后,把基本当作 “根” ,利用 “左右子树” 递归遍历的思想完成整个数组的排序
所以我们把找到基准这个方法 pirtiton1() 独立封装出来
/*** 快排* 时间复杂度:最好情况:O(N^log₂N)* 最坏情况:有序或逆序:O(N^N) 数据量大时有可能栈溢出异常* 空间复杂度:最好情况:O(logN)* 最坏情况:有序或逆序:O(N)* 稳定性:不稳定*/public static void quickSort(int[] array) {quick(array, 0, array.length - 1);}private static void quick(int[] array, int start, int end) {// 取大于号,防止 start > endif (start >= end) {return;}int pivot = pirtiton2(array, start, end);quick(array, start, pivot - 1);quick(array, pivot + 1, end);}// 挖坑法private static int pirtiton1(int[] array, int left, int right) {int tmp = array[left];while (left < right) {// 为什么判断条件加等号,// 用int[] arr = {5, 7, 3, 1, 4, 9, 6, 5}测试while (left < right && array[right] >= tmp) {right--;}array[left] = array[right];while (left < right && array[left] <= tmp) {left++;}array[right] = array[left];}array[left] = tmp;return left;}
以上是挖坑法的实现,下面图解 Hoare法的实现方式
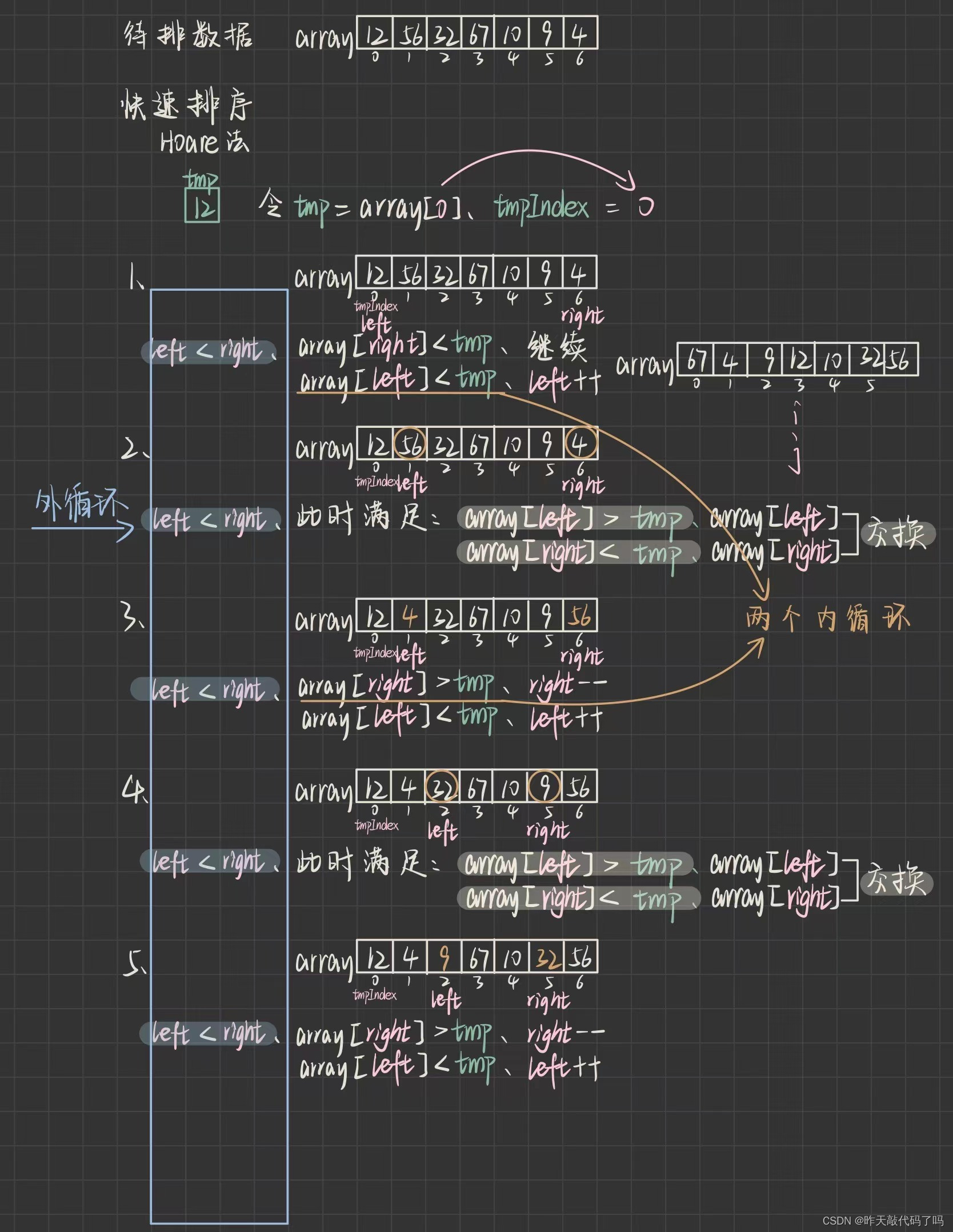

由于快速排序算法最早是由Tony Hoare设计出来的,所以Hoare法算是比挖坑法更原始正统的算法
挖坑法和 Hoare 法的不同体现在找到基准的实现方式,二者效率上基本一致
理解了过程,来看代码如何实现:
// Hoare法private static int pirtiton2(int[] array, int left, int right) {int tmp = array[left];int tmpIndex = left;while (left < right) {while (left < right && array[right] >= tmp) {right--;}while (left < right && array[left] <= tmp) {left++;}swap(array, left, right);}swap(array, tmpIndex, left);return left;}
👉时间复杂度:
时间性能取决于递归的深度
最好情况:二叉树几乎平衡的时候,也就是数组划分的比较均匀,递归的作用发挥到最大,递归次数最少,只需要 log₂N 次,时间复杂度是O(log₂N),递归过程中还要对 i,j 下标一起扫描数组,所以总体时间复杂度是O(N* log₂N)
最坏情况:二叉树极度不平衡时,也就是二叉树是一颗单分支的斜树(每次划分完基准后,基准总是当前数组中的最小/大值,导致左/右侧没有数据),这种情况下,递归就是一个“冤种”,递归的作用只有徒增时间空间的开销,要递归N-1次,并且加上 i,j 下标一起扫描数组,整体时间复杂度达到(N*N)
👉空间复杂度:
空间性能取决于递归消耗的栈空间
最好情况:已经分析过,需要递归 log₂N 次,空间复杂度为O(log₂N )
最坏情况,已经分析过,需要递归 N-1 次,空间复杂度为O(N)
👉稳定性:
不稳定
6.1 快速排序的优化
上述的快速排序还有很多值得优化的地方,刚刚分析过时间复杂度最坏情况下 达到O(N*N),是因为基准(枢轴)📍的位置太“刁钻”
那么第一步优化就是,如何让基准的位置更合适一些,让他每次都尽量出现在数组的中间
🟥1️⃣优化选取基准
不能使用生成随机数,这也是看运气的,如果数据量很大,而刚好运气很差,随机值生成在极端,还是在做无用功,生成随机数本身也有时间上的开销,更合适的改进方法应该是 三数取中法✅,一般选取 left,right,mid 下标三个数
比如 left,right,mid 下标的值分别是,200,300,50,一眼就能看出中间大小的数是200,那么就选取200作为基准,200和300交换即可
对于一组待排序数据来说, left,right,mid 下标的值都相对很小/大的概率是很小的,因此取 mid 的值作为中间值的可能性是相对比较高的
来看代码实现:
private static int getMid(int[] array, int left, int right) {int mid = (left + right) >>> 1;if (array[left] < array[right]) {// 左比右小if (array[mid] < array[left]) {return left;} else if (array[mid] > array[right]) {return right;}else {return mid;}}else {if (array[mid] < array[right]) {return right;} else if (array[mid] > array[left]) {return left;}else {return mid;}}}
对于数据非常大的情况下,三数取中还是不足以保证取到合适的中间值,所以可以再改进为九数取中法,感兴趣的可以自己了解一下
改进之后,数组被划分的过程可以更近似于平衡二叉树,那么问题又来了
当结点个数越来越多,树深度最大的两层结点个数占了整棵树的很大一部分
而放在快速排序当中,这 “结点” 就是被划分之后的 子区间
对于这些数组片段来说还是会继续使用递归,那么深度最大的两层结点的子区间递归开销就会变得非常大,极有可能会导致栈溢出❗️
基于这一点,就必须考虑如何才能减少递归次数
🟥2️⃣优化小数组的排序方案
答案是可以使用直接插入排序
好处:
🔎无论什么排序,一定是越排约有序,总不能越排越无序,那得排到猴年马月天荒地老海枯石烂,而直接插入排序!!!是数据集合越有序,效率越高!!!
🔎不仅是原始待排序数组很大时需要避免栈溢出,当 给定的原始数组很小 的时候也不太适合用递归,因为数据量太小了,再使用递归实际上是”大材小用“”杀鸡用牛刀“”大炮打蚊子“,所以更加适合简单的排序算法
解决方案很简单,就是每次递归前判断此时数组的长度,可以给定一个界限,看心情,这里给定10
在原本的直接插入排序代码上稍作修改即可
private static void insertSort2(int[] array, int left, int right) {// 从小到大排序if (array == null) {return;}int tmp = 0;for (int i = left+1; i <= right; i++) {tmp = array[i];for (int j = i - 1; j >= left; j--) {// j往后走if (array[j] > tmp) {array[j + 1] = array[j];array[j] = tmp;} else {break;}}}}
优化后的 quick()方法:
private static void quick(int[] array, int start, int end) {// 取大于号,防止 start > endif (start >= end) {return;}// 优化1,三数取中法,让start位置尽量靠近中间int mid = getMid(array, start, end);swap(array, start, mid);// 优化2,最后小区间使用插入排序,减少递归次数if(end-start+1 <= 10) {insertSort2(array, start, end);return;}int pivot = pirtiton2(array, start, end);quick(array, start, pivot - 1);quick(array, pivot + 1, end);}
7,归并排序
📌归并排序 是建立在归并操作上的一种有效的排序算法, 该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
📌基本思想:假如一个学校只有两个班,怎么算出全校成绩排名呢,是现在各自班里排好序,然后两个班再一起排序,在两个班的成绩表各自有序的情况下,合并起来排序肯定要比整体混乱着排序效率高
假如一个班1000个人,那在班内排名也是相对效率低的,那咋办?可以分成若干个小组先排,再合并几个小组整体排序,这不就是递归吗
归并归并,我的理解就是,递归分割原始数组,分割到足够小时,递归结束,然后返回时合并,并且完成排序
过程图解:

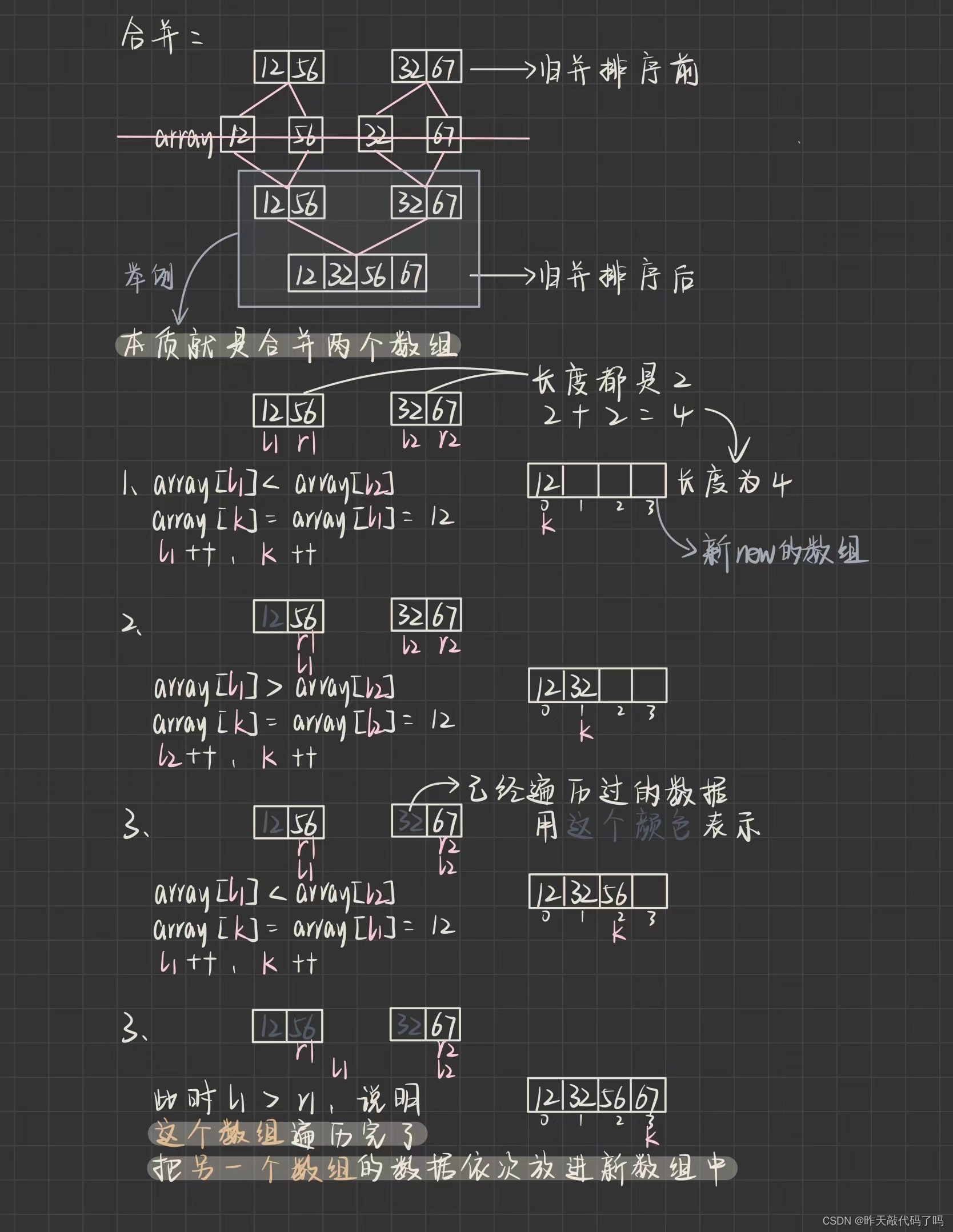
⚠️⚠️需要重点理解的是;
❗️❗️在递归进行分割的过程中,是没有真正把数组切开(new了新空间)的,只是函数传参中是有数组,left 和 right 下标的,只是改变了 left 和 right 的值
❗️❗️但是在归并的过程中,是真正的把两个数组的数据合起来(new了新的数组空间),然后再遍历挨个拷贝回原始数组中的。
体现封装的思想:把分割和合并两个方法独立封装起来,并设置成private
/*** 归并排序* 时间复杂度:O(N^logN)* 空间复杂度:O(N)* 稳定性:稳定* @param array*/public static void mergeSort(int[] array) {divid(array, 0, array.length - 1);}private static void divid(int[] array, int left, int right) {if (left >= right) {return;}int mid = (left + right) >>> 1;divid(array, left, mid);divid(array, mid + 1, right);merge(array, left, right, mid);}private static void merge(int[] array, int left, int right, int mid) {// 其实就是合并两个数组,并使合并后的数组有序int l1 = left;int l2 = mid + 1;int[] tmp = new int[right - left + 1];int i = 0;while(l1 <= mid && l2 <= right) {// 为什么要加等号,防止死循环if(array[l1] <= array[l2]) {tmp[i++] = array[l1++];}if (array[l2] <= array[l1]) {tmp[i++] = array[l2++];}}// 判断哪个数组还有数据while(l1 <= mid) {tmp[i++] = array[l1++];}while(l2 <= right) {tmp[i++] = array[l2++];}for (int j = 0; j < tmp.length; j++) {array[j + left] = tmp[j];}}
⚠️⚠️注意最后一个for循环,这段代码作用是把合并好的有序子数组挨个拷贝回原始数组,但是 array[ j + left ] = tmp[j] 如何理解❓
因为你左右树都递归进行分割合并啊!你总不能把原本在原始数组右边的子数组排有序之后挨个从原始数组的0下标开始拷贝吧!
👉时间复杂度:
和快速排序类似,也是递归次数+每次的 i,j 遍历时间,最好最坏平均情况的时间复杂度都是O(N*log₂N)
👉空间复杂度:
递归的开销是O(log₂N),但是需要总长度为N的额外数组空间的消耗,所有总体空间复杂度是O(N+log₂N)
👉稳定性:
稳定
三、排序算法总体分析对比
没有完美的排序算法,任何一种算法都是有优点和缺陷的,即便是大名鼎鼎的快速排序,也只是整体上效率比较高,性能优越
现在就整体分析一下各种排序的优缺点📊
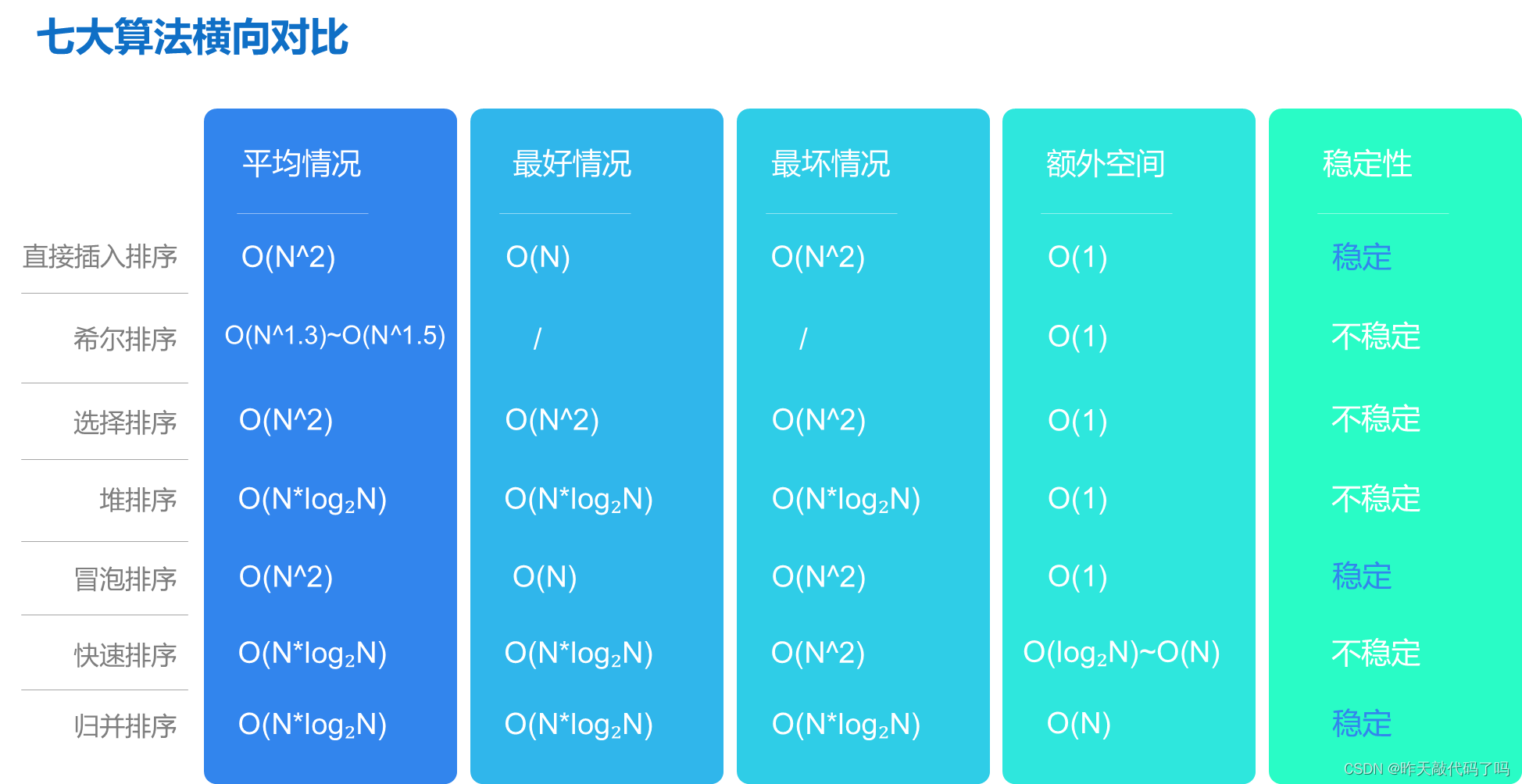
在分析希尔排序时提到, 早期的排序算法平均时间复杂度都是O(N^2); 因为原理比较简单, 但性能较差, 所以 一般把直接插入排序,选择排序,冒泡排序归为简单排序一类 其他的都归于 改进排序
📚从平均情况看:
改进过的排序: 希尔排序, 堆排序, 归并排序, 快速排序要胜过 简单排序的性能, 而四个改进算法中, 希尔排序的性能最差
📚从最好情况看:
直接插入排序和冒泡排序最快
📚从最坏情况看:
堆排序和归并排序的性能更胜过快排和其他简单排序
📚综合来看:
堆排序和归并排序比较稳定和强大, 情况最坏时好使
直接插入排序和冒泡排序在基本有序时最好用,
而快速排序比较极端, 最好最坏情况都有缺陷 但是 快速排序能够称之为快速排序, 是因为它的综合性能最强💪,一般情况下是最快的
📚从稳定性来看:
改进排序中只有归并排序
📚从数据个数上看:
数据量越少, 越适合用简单排序, 因为堆排, 快速排序, 归并排序, 都用到了递归, 对于少量数据排序有点"炮弹打蚊子"
只要是交换时, 两数据相邻就是稳定的算法,只要是跳跃式的交换就是不稳定, 当然别忘了, 稳定的算法也可以修改代码更改成不稳定的
总结
以上就是七大算法的全部解析, 最后对比了他们的优缺点, 不过通过各项指标来看, 快速排序还是王者👑, 但是对于不同的场景, 还是要选择更符合需求的算法
如果本篇对你有帮助,请点赞收藏支持一下,小手一抖就是对作者莫大的鼓励啦😋😋😋~
上山总比下山辛苦
下篇文章见
相关文章:
Java【七大排序】算法详细图解,一篇文章吃透
文章目录一、排序相关概念二、七大排序1,直接插入排序2,希尔排序3,选择排序4,堆排序5,冒泡排序5.1冒泡排序的优化6,快速排序6.1 快速排序的优化7,归并排序三、排序算法总体分析对比总结提示&…...

Autosar OS IOC
Inter-OS-Application Communicator 背景和基本原理General purposeIOC functionalityCommunicationNotificationIOC interface背景和基本原理 The IOC implementation shall be part of the Operating System IOC和操作系统紧密相关,是操作系统实现的一部分 The IO…...
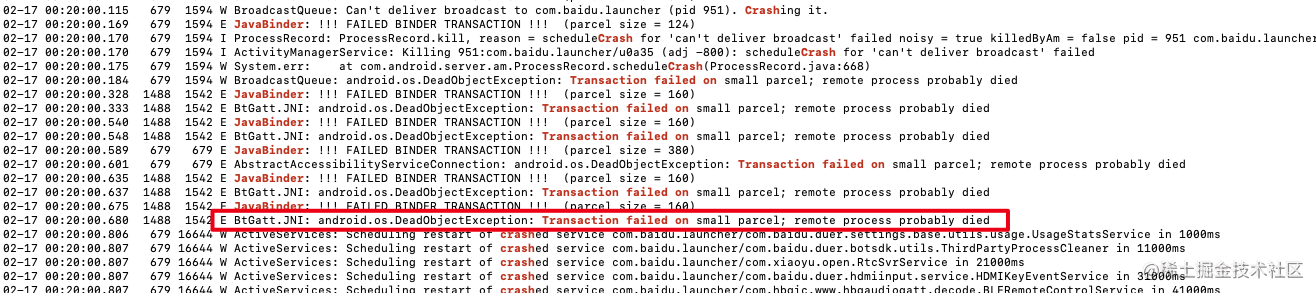
记录一次Binder内存相关的问题导致APP被杀的BUG排查过程
事情的起因的QA压测过程发生进程号变更,怀疑APP被杀掉过,于是开始看日志 APP的压测平台会上报进程号变更时间点,发现是在临晨12:20分,先大概确定在哪个日志文件去找关键信息一开始怀疑是crash,然后就在日志…...
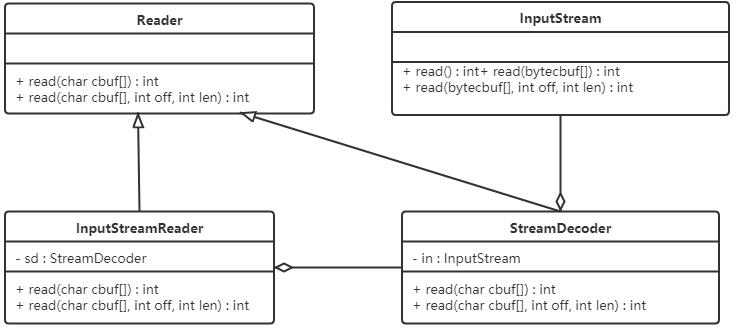
设计模式(十)----结构型模式之适配器模式
1、概述 如果去欧洲国家去旅游的话,他们的插座如下图最左边,是欧洲标准。而我们使用的插头如下图最右边的。因此我们的笔记本电脑,手机在当地不能直接充电。所以就需要一个插座转换器,转换器第1面插入当地的插座,第2面…...
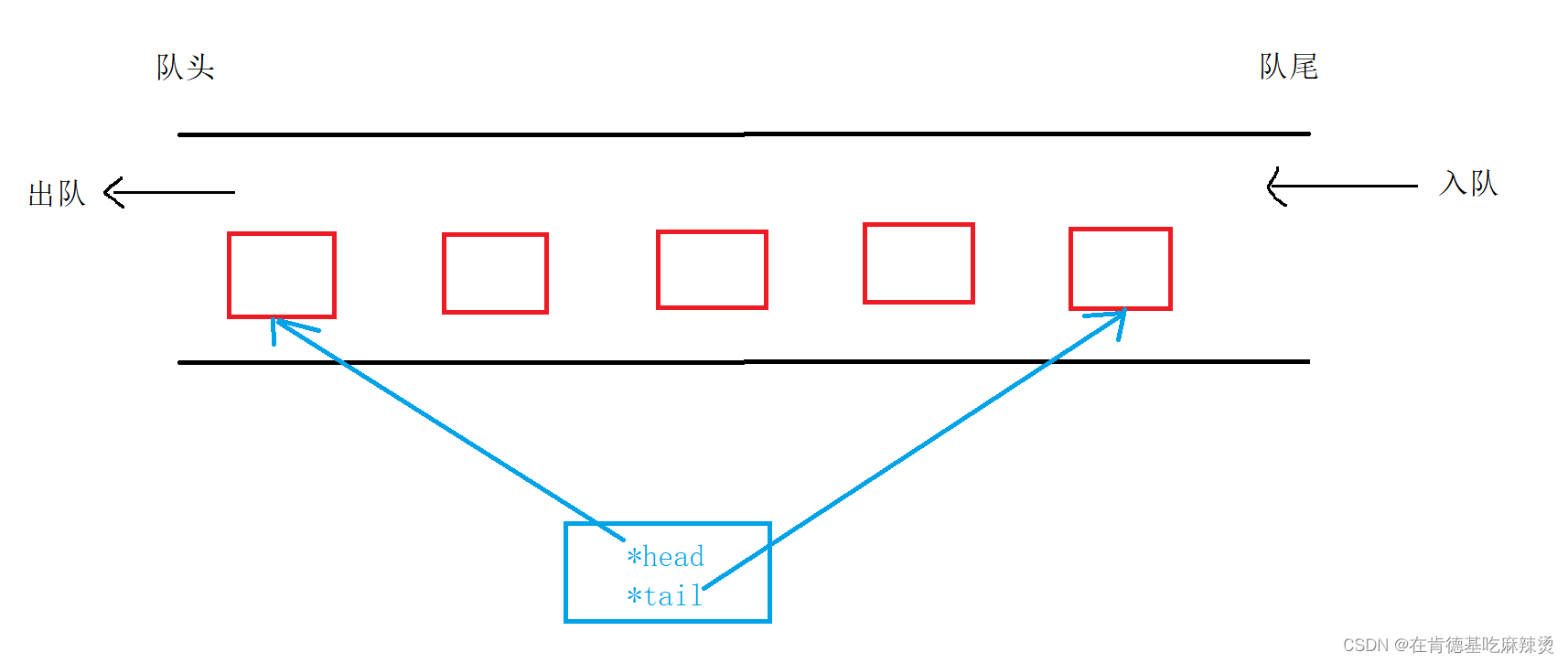
【数据结构】——队列
文章目录前言一.什么是队列,队列的特点二、队列相关操作队列的相关操作声明队列的创建1.队列的初始化2.对队列进行销毁3.判断队列是否为空队列4.入队操作5.出队操作6.取出队头数据7. 取出队尾数据8.计算队伍的人数总结前言 本文章讲述的是数据结构的特殊线性表——…...
Android OTA升级常见问题的解决方法
1.1 多服务器编译 OTA 报错 Android7 以后引入了 jack-server 功能,也导致在公共服务器上 编译 Android7 以上的版本时,会出现 j ack-server 报错问题。 在多用户服务器上 编译 dist 时 会出现编译过程中 会将 port_service 和 port_admin 改为 默认的 …...
说说Hibernate
当你在实战项目中需要用到SSH时, 如果你之前只用过Mybatis那自然是不能解决问题的, 因为在很多银行类金融类项目中你可能会使用到Hibernate, 那么关于Hibernate你应该要了解什么呢, 本篇文章就以学习Hibernate框架为目的, 巩固在工作中可能需要用到的这种ORM技术, 同时也欢迎家…...

目标检测论文阅读:DETR算法笔记
标题:End-to-End Object Detection with Transformers 会议:ECCV2020 论文地址:https://link.springer.com/10.1007/978-3-030-58452-8_13 官方代码:https://github.com/facebookresearch/detr 作者单位:巴黎第九大学、…...

Golang sync.Once 源码浅析
本文分析了Golang sync.Once 源码,并由此引申,简单讨论了单例模式的实现、 atomic 包的作用和 Java volatile 的使用。 sync.Once 使用例子 sync.Once 用于保证一个函数只被调用一次。它可以用于实现单例模式。 有如下类型: type instanc…...
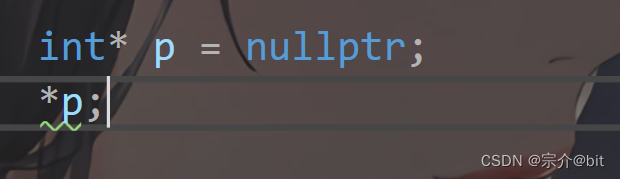
C++面向对象(上)
文章目录前言1.面向过程和面向对象初步认识2.引入类的概念1.概念与用法2.类的访问限定符及封装3.类的作用域和实例化4.类的大小计算5.this指针3.总结前言 本文将对C面向对象进行初步介绍,引入类和对象的概念。围绕类和对象介绍一些基础知识,为以后深入学…...

经常用但是不知道什么是BFC?
BFC学习 block formatting context 块级格式上下文 简单理解: 一个独立容器,内部布局不会受到外面的影响 形成条件: 1.浮动元素:float除none之外的值 2.绝对定位:position:absolute,fixed 3.display:inline-blo…...

GO的临时对象池sync.Pool
GO的临时对象池sync.Pool 文章目录GO的临时对象池sync.Pool一、临时对象池:sync.Pool1.1 临时对象的特点1.2 临时对象池的用途1.3 sync.Pool 的用法二、临时对象池中的值会被及时清理掉2.1 池清理函数2.2 池汇总列表2.3 临时对象池存储值所用的数据结构2.4 临时对象…...
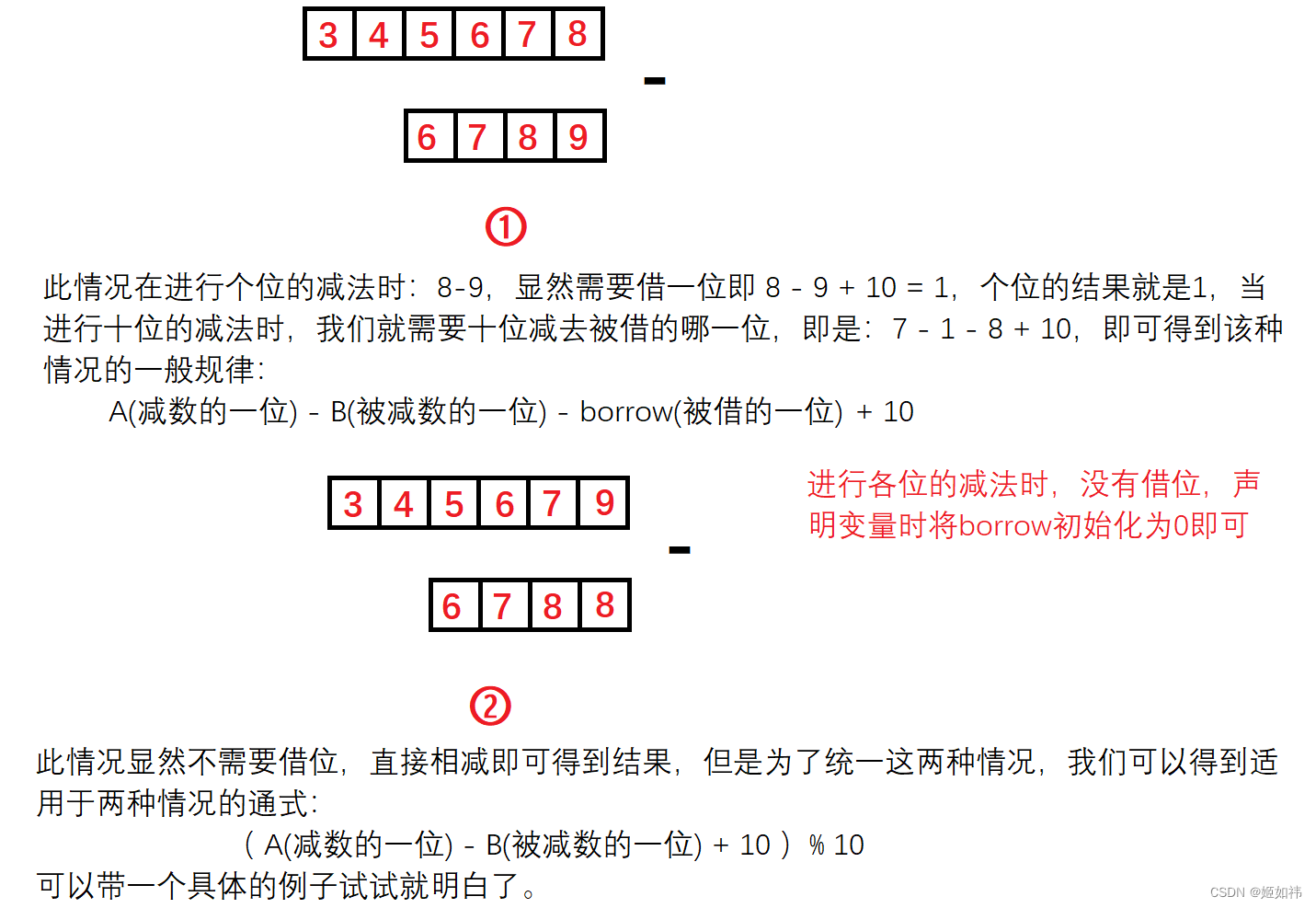
高精度算法一
目录 1. 基础知识 2. 大整数 大整数 3. 大整数 - 大整数 1. 基础知识 利用计算机进行数值计算,有时会遇到这样的问题:有些计算要求精度高,希望计算的数的位数可达几十位甚至几百位,虽然计算机的计算精度也算较高了,…...

2023年全国最新食品安全管理员精选真题及答案1
百分百题库提供食品安全管理员考试试题、食品安全员考试预测题、食品安全管理员考试真题、食品安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.预包装食品的标签内容应使用规范的汉字,但可以同时使用&a…...
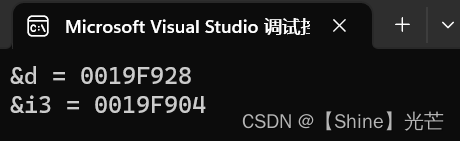
C++入门:引用
目录 一. 什么是引用 1.1 引用的概念 1.2 引用的定义 二. 引用的性质和用途 2.1 引用的三大主要性质 2.2 引用的主要应用 三. 引用的效率测试 3.1 传值调用和传引用调用的效率对比 3.2 值返回和引用返回的效率对比 四. 常引用 4.1 权限放大和权限缩小问题 4.2 跨…...
SpringSecurity的权限校验详解说明(附完整代码)
说明 SpringSecurity的权限校是基于SpringSecurity的安全认证的详解说明(附完整代码) (https://blog.csdn.net/qq_51076413/article/details/129102660)的讲解,如果不了解SpringSecurity是怎么认证,请先看下【SpringSecurity的安…...
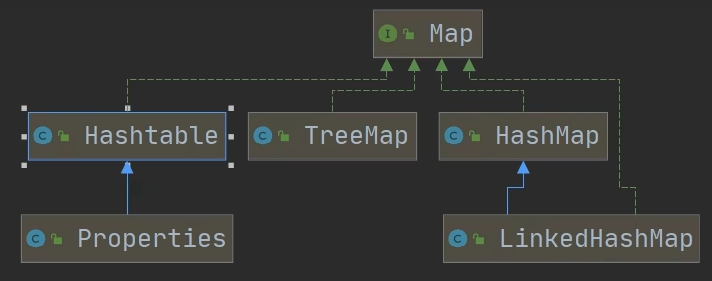
Java-集合(5)
Map接口 JDK8 Map接口实现子类的特点 Map和Collection是并列关系,Map用于保存具有映射关系的数据:Key-ValueMap中的key和value可以是任何引用类型的数据,会封装到HashMap$Node对象中Map中的key不允许重复,原因和HashSet一样Map…...
设计定型阶段)
研制过程评审活动(四)设计定型阶段
1、设计定型阶段主要任务 设计定型的主要任务是对武器装备性能和使用要求进行全面考核,以确认产品是否达到《研制任务书》和《研制合同》的要求。 设计定型阶段应最终确定《产品规范》、《工艺规范》和《材料规范》的正式版本,并形成正式的全套生产图样、有关技术文件及目…...
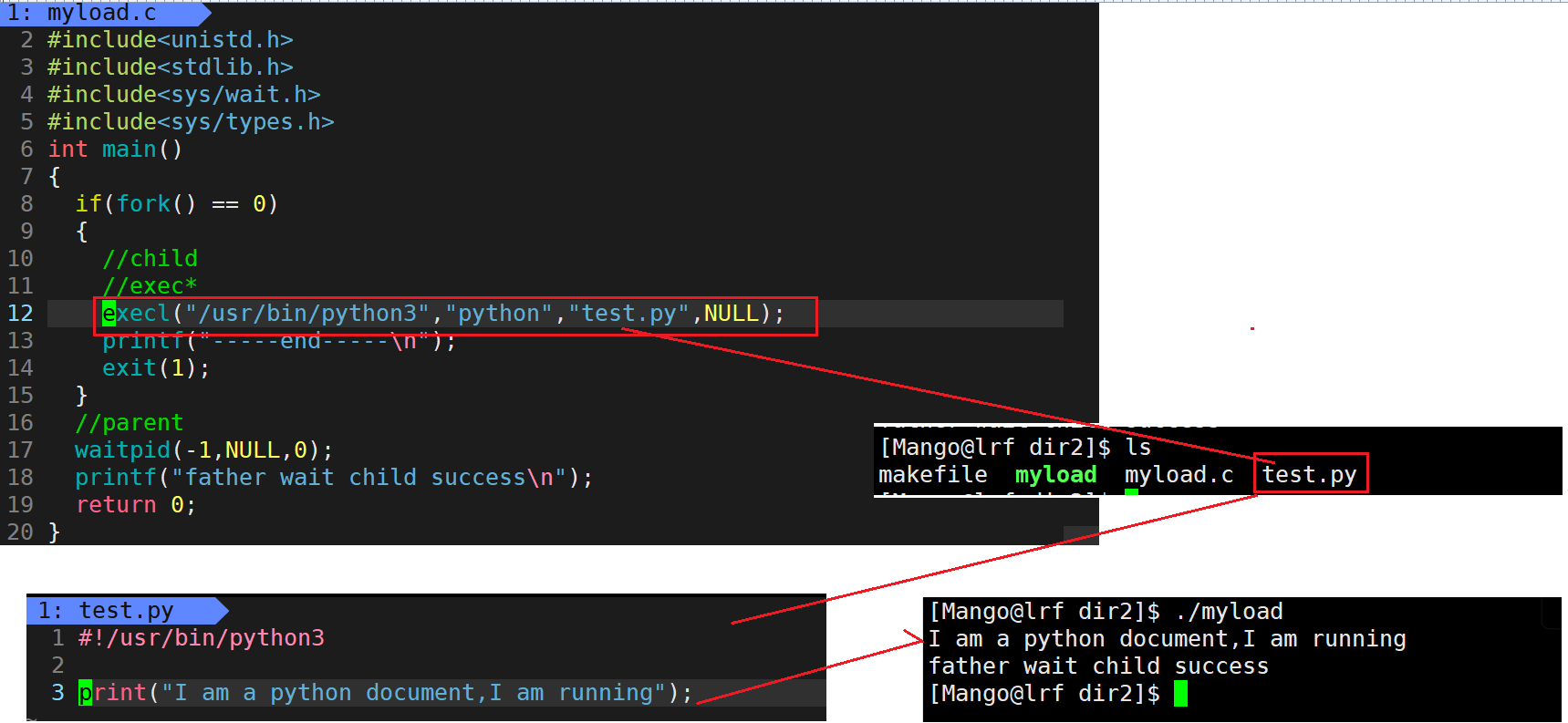
【Linux】进程替换
文章目录进程程序替换替换原理替换函数函数返回值函数命名理解在makefile文件中一次生成两个可执行文件总结:程序替换时运行其它语言程序进程程序替换 程序要运行要先加载到内存当中 , 如何做到? 加载器加载进来,然后程序替换 为什么? ->冯诺依曼 因为CPU读取数据的时候只…...

LeetCode171-Excel表列序号(进制转换问题)
LeetCode171-Excel表列序号1、问题描述2、解题思路:进制转换3、代码实现1、问题描述 给你一个字符串columnTitle,表示Excel表格中得列名称。返回该列名称对应得列序号。 例如: A -> 1 B -> 2 C -> 3 ... Z -> 26 AA -> 27 AB -> 28 …...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...