Python学习-----模块3.0(正则表达式-->re模块)
目录
前言:
导入模块
1.re.match() 函数
(1)匹配单个字符
(2)匹配多个字符
(3) 匹配开头和结尾
2.re.search() 函数
3.re.findall() 函数
4.re.finditer() 函数
5.re.split() 函数
6.re.sub() 函数
7.re.subn() 函数
前言:
re模块(正则表达)是Python中的重要组成部分,这里涉及到字符串的匹配,转换,自定义格式化……等等,尤其是对于后面要学的Python爬虫是经常用到的。这个模块是Python自带的,不需要pip下载,导入使用就行了。
之前我们学过了r原始字符串标识符,比如:r'123\n' 输出结果就是123\n,是表示输出原始字符串,里面的转义符就当做普通的一个字符直接输出就行了,这个也是一种正则表达方式。
print(r'hello\n123\t')
#输出结果:hello\n123\t导入模块
import re1.re.match() 函数
语法格式:re.match(pat,string,flag=0)
用法:re.match('正则表达式’,'要匹配的字符串',flag= )
参数说明:
pat:是表示参与匹配的正则表达式
string:是表示要匹配的字符串
flag:是标志符,用于控制正则表达式的匹配方式(设置条件之类的)
函数说明:
这个函数是从开头第一个字符开始匹配的,如果匹配成功的话就返回一个匹配对象,如果失败就返回none。如果我们想要获取到返回的对象就用group(num)函数来获取,这个函数获取的结果就是匹配成功的字符串,如果num为0的话,其实等效于group(),如果num为1的话就返回正则表达式第一个括号匹配成功的字符串,如果num为2的话就返回正则表达式第二个括号匹配成功的字符串
(1)匹配单个字符
| 字符 | 功能 | 位置 |
| . | 匹配任意一个字符(除了\n) | |
| [ ] | 匹配[ ]中列举的字符(可以是 一个范围) | |
| \d | 匹配数字,0~9 | 可以写在[ ]中 |
| \D | 匹配非数字,除了数字以外 都可以匹配成功 | 可以写在[ ]中 |
| \s | 匹配空白符,空格 ,Tab | 可以写在[ ]中 |
| \S | 匹配非空白符 | 可以写在[ ]中 |
| \w | 匹配0-9,a-z,A-Z,中文等 等除了特殊符号以外的范围 内的字符 | 可以写在[ ]中 |
| \W | 匹配非单词子串,除了\w范围 以内的都可以匹配 | 可以写在[ ]中 |
示例
import re
string='hello word!'
pat=re.match('.',string)
print(pat)
print(pat.group())
#输出结果:<re.Match object; span=(0, 1), match='h'>
# h其中第一个输出的结果就是返回的对象,span=(0,1)是表示匹配范围为字符串的第0位(区间是左闭右开),匹配成功的字符串match='h'
如果用group()去获取对象字符串就直接输出 h
示例1:
import re
#单个匹配示例#1.'.'号匹配
a='123hello你好'
a1=re.match('..',a)#正则表达式有两个..那么就匹配字符串a前两个字符
print(a1,a1.group())
#输出结果:<re.Match object; span=(0, 2), match='12'> 12#2.'.'号匹配
b='garrymod555'
b1=re.match('g..r',b)
print(b1,b1.group())
#输出结果:<re.Match object; span=(0, 4), match='garr'> garr#3.直接匹配:被匹配的字符串首字符要与正则表达式相同,大小写一一对应
c='python欧尼酱'
c1=re.match('p',c)
print(c1,c1.group())
#输出结果:<re.Match object; span=(0, 1), match='p'> p#4.利用[],枚举匹配
d='Haolow'
d1=re.match('[hH]',d) #这时候d 的开头大小写都可以匹配成功
print(d1,d1.group())
#输出结果:<re.Match object; span=(0, 1), match='H'> H#利用[],枚举匹配0~9范围的数字
num='51997asd'
num1=re.match('[0123456789]',num)
print(num1,num1.group())
#输出结果:<re.Match object; span=(0, 1), match='5'> 5#5.利用[],范围匹配
e='ikuncxk'
e1=re.match('[a-z]',e) #[]内是表示a~z在字符范围
print(e1,e1.group())
#输出结果:<re.Match object; span=(0, 1), match='i'> i#6.利用[],匹配多个范围
f='567hhh'
f1=re.match('[2-68-9]',f) #这个是表示匹配2~6和8~9 范围以内的数字(字母也是同样的道理)
print(f1,f1.group())
#输出结果:<re.Match object; span=(0, 1), match='5'> 5#7.利用\d,匹配数字(另外一个是\D,这里就不讲了,正则表达式匹配添加是跟\d完全相反的)
g='666985www'
g1=re.match('\d',g) #
print(g1,g1.group())
#输出结果:<re.Match object; span=(0, 1), match='6'> 6#8.利用\s,匹配空白符(跟上面一样\S,是\s反过来的,用法一样,不讲)
h=' 91呵呵'
h1=re.match('\s',h)
print(h1,h1.group())
#输出结果:<re.Match object; span=(0, 1), match=' '>#9.利用\w,匹配0-9,a-z,A-Z,中文等等除了特色符号以外的范围内的字符
i='天问1号'
i1=re.match('\w',i)
print(i1,i1.group())
#输出结果:<re.Match object; span=(0, 4), match='天问1号'> 天问1号#10.利用\W,匹配特殊字符(\w范围以外的字符)
k='@qq.com'
k1=re.match('\W',k)
print(k1,k1.group())
#输出结果:<re.Match object; span=(0, 1), match='@'> @示例2:(匹配失败)
import re
kun='hellosad'
k=re.match('5',kun)
print(k)
#输出结果:None(2)匹配多个字符
| 字符 | 功能/说明 | 位置 |
| * | 匹配前一个字符, 这个字符出现 0次到无限次(可有 可无) | 可以用在 字符或者 ()之后 |
| + | 匹配前一个字符, 这个字符必须出现 一次以上(否则报错) 上限为无限 | 可以用在 字符或者 ()之后 |
| ? | 匹配前一个字符, 这个字符出现0次 到1次 | 可以用在 字符或者 ()之后 |
| {m} | 匹配前⼀个字符出现 m次 | 可以用在 字符或者 ()之后 |
| {m,n} | 匹配前⼀个字符出现 从m到n次,若省略m, 则匹配0到n次,若省略n, 则匹配m到无限次;若省略 m,这匹配m,这匹配0到 n次 | 可以用在 字符或者 ()之后 |
import re# * 匹配多个字符
p='1112223haowww.com'
#示例1
p1=re.match('[\d]*',p)
print(p1.group())
#输出结果:1112223
#示例2
p2=re.match('1*',p)
print(p2.group())
#输出结果:111
#示例3
p3=re.match('1t*',p)
print(p3.group()) #不会报错
#输出结果:1# + 匹配多个字符
q='aaa112python'
#示例1
q1=re.match('[a-z]+',q)
print(q1.group())
#输出结果:aaa
#示例2
q2=re.match('ai+',q)
#print(q2.group()) #报错
print(q2)
#输出结果:None# { }综合使用
#示例1:匹配由大小写字母以及数字组成的密码
ret=re.match('[a-zA-Z0-9]{6}','321uyg88') #如果{}里面的数字大于8就会报错,超过范围了
print(ret.group()) #输出结果:321uyg
#示例2:匹配8~12为由小写字母和数字组成的密码
res=re.match('[a-z0-9]{8,12}','123520ikun')
print(res.group())#输出结果123520ikun(3) 匹配开头和结尾
| 字符 | 功能 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
示例:
import re
#实战示例:
#我要匹配3899ojk@qq.com的QQ邮箱
emails=['3899ojk@qq.com','3899ojk@qq.comxiaolan','9554xio@qq.com']
for email in emails:qq=re.match('[0-9a-zA-Z]{1,10}@qq.com$',email)if qq:print('匹配成功')else:print('匹配失败')
2.re.search() 函数
格式:
re.search('正则表达式','字符串')
说明:这个函数是从整个字符串去进行匹配的,跟re.match()不同,re.match()是从开头去匹配,如果开头不一样就返回None,而re.search()是看字符串的全局,直到匹配到满足正则表达式才返回匹配对象,如果整个字符串都没有找到匹配对象才会返回None
示例:
import re
r=re.search('wao','123waohhhq')
print(r.group())
#输出结果:waos=re.search('q[0-9]?j','heheqq5jbye')
print(s.group())
#输出结果:q5j3.re.findall() 函数
格式:
re.findall('正则表达式','字符串')
说明:整个函数同样也是从整个字符串来匹配,但是这个函数是吧整个字符串所以满足正则表达式的子串以列表的形式返回(前面的函数都是返回一个对象,需要用group()函数来获取对象的子串),而这个函数是直接返回一个含有全部子串的列表
示例:
import re
ret=re.findall('\d+','123www555abc789')
print(ret)
#输出结果:['123', '555', '789']4.re.finditer() 函数
格式:
re.finditer('正则表达式','字符串')
说明:这个函数跟re.findall() 差不多,只是前者是返回一个迭代器(需要用循环去依次获取里面的对象),而后者是返回一个列表
示例:
import re
ret=re.finditer('\d+','Python999,C++555,Java666')
print(ret) #输出的是迭代器地址
for i in ret:print(i.group(),end=' ')
#输出结果:<callable_iterator object at 0x000001E35504B5E0>
# 999 555 666 5.re.split() 函数
split()整个函数在之前的字符串操作初步讲过,是一个切割函数Python学习------起步7(字符串的连接、删除、修改、查询与统计、类型判断及字符串字母大小写转换)_Python欧尼酱的博客-CSDN博客
格式:
re.split(pat,string,times)
参数说明:
pat:是正则表达式
string:是字符串
times:是分割次数
功能作用:在整个字符串中,根据匹配成功的子串作为切割点,对字符串进行切割,然后返回一个列表类型
示例:
import re
cut=re.split('\d','hello 1 my 2 friend')
print(cut)
#输出结果:['hello ', ' my ', ' friend']cut_1=re.split(r':| ','Jack say:"I can do this all day"') #r表示后面为原字符串
print(cut_1)
#输出结果:['Jack', 'say', '"I', 'can', 'do', 'this', 'all', 'day"']6.re.sub() 函数
格式:
re.sub(pat,repalc,string,count,flag)
参数:
pat:是表示正则表达式
replac:是要替换的字符串(必写)
string:是匹配的字符串
count:是替换的最大次数,如果不写就默认全部替换
flag:可选参数,标志符,用于控制正则表达式的匹配条件
功能说明:sub是substitute的缩写,意思是取代,这个函数可以将匹配到的子串进行取代替换,然后返回一个字符串类型
import re
kun=re.sub('\d[A-Z]','鹜','hello,4Baww5Kc8P')
print(kun)
#输出结果:hello,鹜aww鹜c鹜KUN=re.sub('\d[A-Z]','鹜','hello,4Baww5Kc8P',count=2) #这里设置了count的值为2
print(KUN)
#输出结果:hello,鹜aww鹜c8P7.re.subn() 函数
说明:这个函数的用法跟re.sub() 的用法是一样的,只是返回值不一样,这个函数的返回值是一个元组,格式:('返回的字符串','次数')
import re
def rep(temp):temp='GBT'return temp
su=re.subn('\d+',rep,'hao,w1q2d3') #不设置count,此时就是全部的替换次数
print(su)
#输出结果:('hao,wGBTqGBTdGBT', 3)感谢各位的支持,我们下一期再见~~~
日常分享一张壁纸

相关文章:
Python学习-----模块3.0(正则表达式-->re模块)
目录 前言: 导入模块 1.re.match() 函数 (1)匹配单个字符 (2)匹配多个字符 (3) 匹配开头和结尾 2.re.search() 函数 3.re.findall() 函数 4.re.finditer() 函数 5.re.split() 函数 6.re.sub() 函数 7.re.sub…...
JSP中http与内置对象学习笔记
本博文讲述jsp客户端与服务器端的http、jsp内置对象与控制流和数据流实现 1.HTTP请求响应机制 HTTP协议是TCP/IP协议中的一个应用层协议,用于定义客户端与服务器之间交换数据的过程 1.1 HTTP请求 HTTP请求由请求行、消息报头、空行和请求数据4部分组成。 请求行…...
Windows Server 2016远程桌面配置全过程
镜像下载 系统镜像网址 本次下载的是 Windows Server 2016 (Updated Feb 2018) (x64) - DVD (Chinese-Simplified) 远程桌面配置 Step 1 在开始菜单搜索服务,打开服务器管理器,点击右上角的管理按钮 Step 2 添加角色控制,点击下一步 S…...
SPI通讯简介
一、基本概念 SPI是串行外设接口(Serial Peripheral Interface)的缩写,是一种高速的,全双工,同步的通信总线,主要应用在EEPROM,FLASH,实时时钟,AD转换器,多MCU间通讯等等,SPI端口可以在多主器件…...

Python 迭代器
迭代器协议 对象必须提供一个 next() 方法,执行该方法要么迭代下一项,要么就引起一个 StopIteration异常以终止迭代(只能往后不能往前)—— 迭代器协议 协议是一种约定,可迭代对象实现了迭代器协议(for、…...
Python语言零基础入门教程(二十七)
Python OS 文件/目录方法 Python语言零基础入门教程(二十六) 61、Python os.utime() 方法 概述 os.utime() 方法用于设置指定路径文件最后的修改和访问时间。 在Unix,Windows中有效。 语法 utime()方法语法格式如下: os.uti…...

Redis基础操作以及数据类型
目录 Redis基础操作 java中的i是不是原子操作?不是 数据类型 1. list 2. set 3. Hash哈希 4. Zset有序集合 Redis基础操作 set [key] [value] 设置值 (设置相同的会将原先的覆盖) get [key] 获取值 不能覆盖和替换 ttl [key] 以秒为单…...
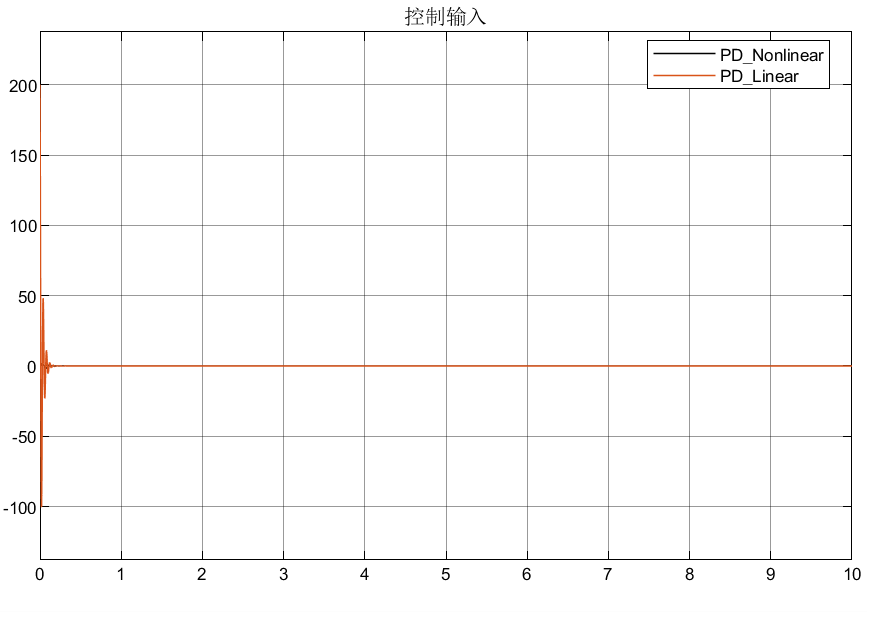
自抗扰控制ADRC之反馈控制律(NLSEF)
目录 前言 1.非线性状态误差反馈控制律(NLSEF) 1.1 控制律形式 1.2 控制量的生成(或者说扰动的补偿) 1.2.1补偿形式① 1.2.1补偿形式② 2.仿真分析 2.1仿真模型 2.2仿真结果 前言 前面的两篇博客依次介绍了TD微分跟踪器安排过渡过程、扩张观测器: 自抗扰…...
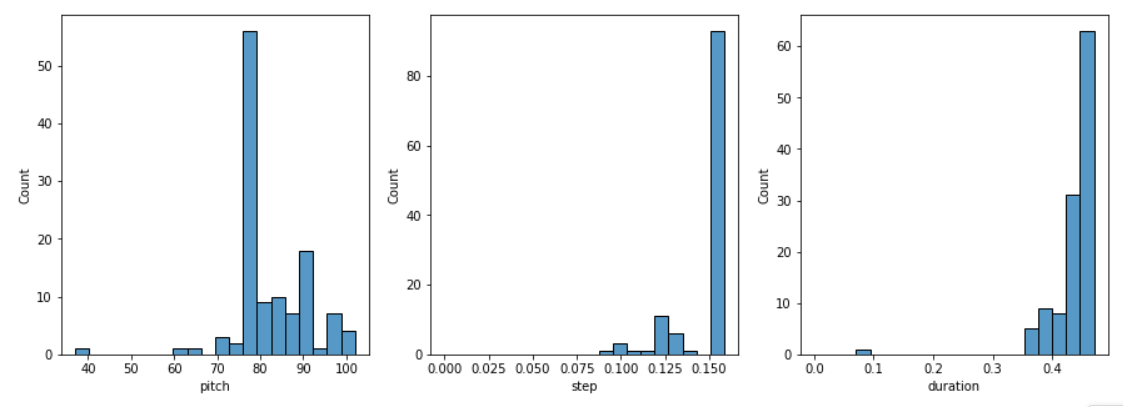
“生成音乐“ 【循环神经网络】
前言 本文介绍循环神经网络的进阶案例,通过搭建和训练一个模型,来对钢琴的音符进行预测,通过重复调用模型来进而生成一段音乐; 使用到Maestro的钢琴MIDI文件 ,每个文件由不同音符组成,音符用三个量来表示…...

能否手写vue3响应式原理-面试进阶
(二)响应式原理 利用ES6中Proxy作为拦截器,在get时收集依赖,在set时触发依赖,来实现响应式。 (三)手写实现 1、实现Reactive 基于原理,我们可以先写一下测试用例 //reactive.spe…...
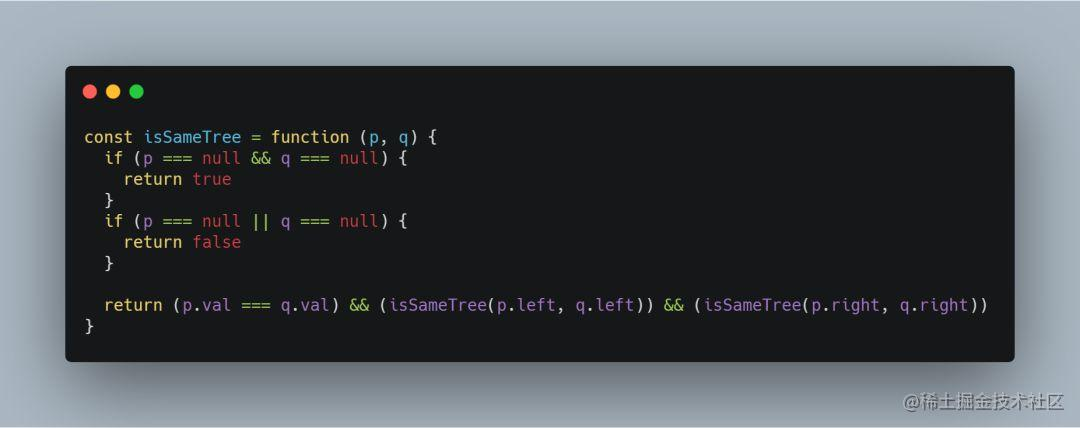
前端工程师leetcode算法面试必备-简单的二叉树
一、前言 本难度的题目主要考察二叉树的基本概念和操作。 1、基本概念 树是计算机科学中经常用到的一种非线性数据结构,以分层的形式存储数据。二叉树是一种特殊的树结构,每个节点最多有两个子树,通常子树被称作“左子树”和“右子树”。 …...

【什么程度叫熟悉linux系统】
一、编译内核 1、Linux系统背景:Ubuntu 2、内核源码kernel.org进行下载 3、解压内核源文件linux-6.1.12.tar.xz、命令:tar -xvf linux-6.1.12.tar.xz 4、进入解压好的文件inux-6.1.12 5、配置内核命令:make menuconfig(需要进…...

编译安装MySQL
MySQL 5.7主要特性 随机root 密码:MySQL 5.7 数据库初始化完成后,会自动生成一个 rootlocalhost 用户,root 用户的密码不为空,而是随机产生一个密码。原生支持:Systemd 更好的性能:对于多核CPU、固态硬盘、…...
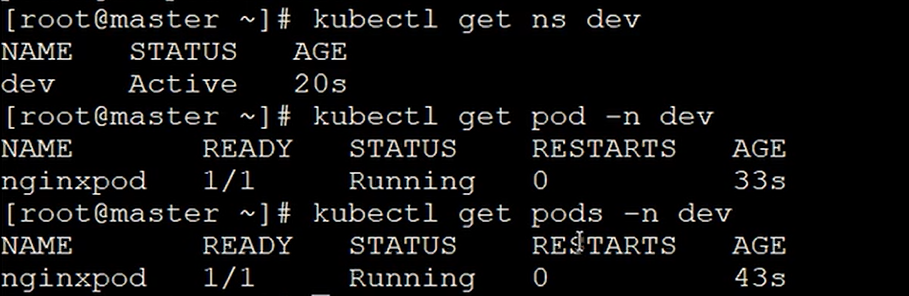
Kubernetes一 Kubernetes之入门
二 Kubernetes介绍 1.1 应用部署方式演变 在部署应用程序的方式上,主要经历了三个时代: 传统部署:互联网早期,会直接将应用程序部署在物理机上 优点:简单,不需要其它技术的参与 缺点:不能为应…...

SQLServer2000 断电后数据库suspect“置疑”处理
SQLServer2000 断电后数据库suspect“置疑”处理 背景介绍: 前些天加班时候,接到小舅子微信,说一个客户的winXP 机器上sql2000的数据库在断电重启后,数据库执行命令时提示suspect“置疑”错误。小舅子电子工程师,对数…...

多模态机器学习入门Tutorial on MultiModal Machine Learning——第一堂课个人学习内容
文章目录课程记录核心技术Core Technical Challengesrepresentation表示alignment对齐转换translationFusion融合co-learning共同学习总结Course Syllabus教学大纲个人总结第一周的安排相关连接课程记录 这部分是自己看视频,然后截屏,记录下来的这部分的…...
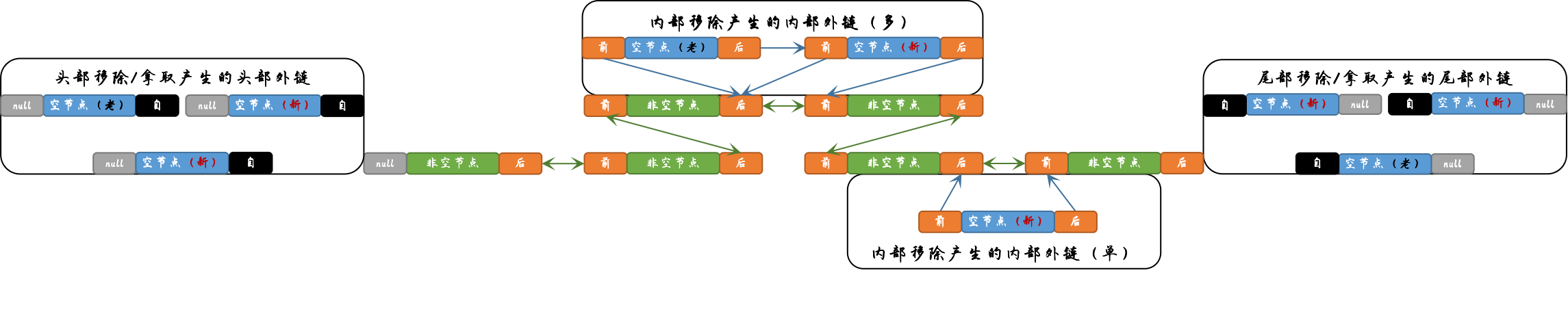
Java ~ Collection/Executor ~ LinkedBlockingDeque【总结】
一 概述 简介 LinkedBlockingDeque(链接阻塞双端队列)类(下文简称链接阻塞双端队列)是BlockingDeqeue(阻塞双端队列)接口的唯一实现类,采用链表的方式实现。链接阻塞双端队列与LinkedBlockingQu…...
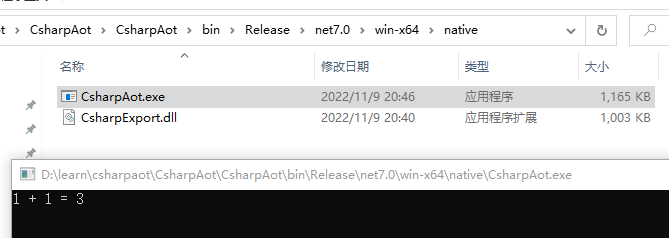
.NET7的AOT的使用
背景其实,规划这篇文章有一段时间了,但是比较懒,所以一直拖着没写。最近时总更新太快了,太卷了,所以借着 .NET 7 正式版发布,熬夜写完这篇文章,希望能够追上时总的一点距离。本文主要介绍如何在…...
分布式缓存的问题
1,Redis缓存穿透问题 Redis缓存穿透问题是指查询一个一定不存在的数据,由于这样的数据缓存一定不命中,所以这样的请求一定会打到数据库上。但是由于数据库里面也没有这样数据,且也没有将这样的null值缓存到数据库,从而造成这样的…...
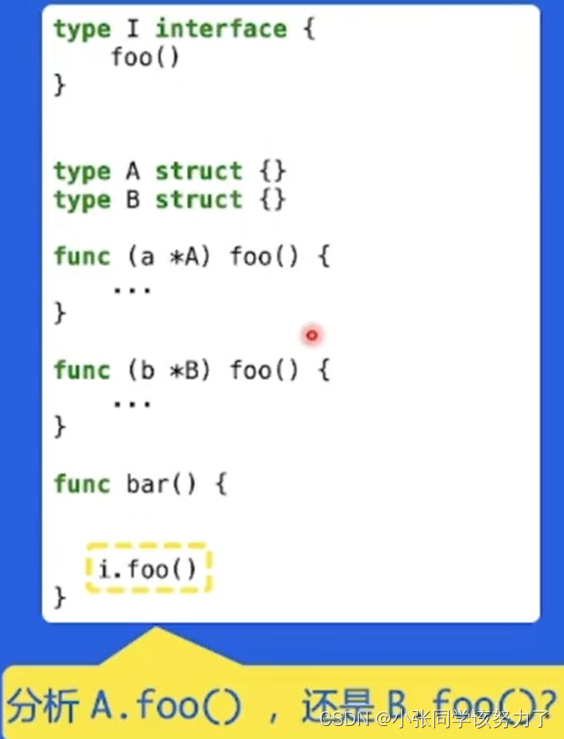
golang入门笔记——内存管理和编译器优化
静态分析 静态分析:不执行程序代码,推导程序的行为,分析程序的性质 控制流(control flow):程序的执行流程 数据流(data flow):数据在控制流上的传递 通过分析控制流和…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...