Python自动化实战之使用Selenium进行Web自动化详解
概要
为了完成一项重复的任务,你需要在网站上进行大量的点击和操作,每次都要浪费大量的时间和精力。Python的Selenium库就可以自动化完成这些任务。
在本篇文章中,我们将会介绍如何使用Python的Selenium库进行Web自动化,以及如何将它应用于实际项目中。如果你是一名Python爱好者或者正在寻找一种方法来提高工作效率,那么这篇文章将会对你有所帮助。
什么是Selenium?
Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击、输入、选择等等。它支持多种浏览器,包括Chrome、Firefox、Safari等等,并且可以在多个平台上运行。
安装和配置Selenium
在使用Selenium之前,需要安装Selenium和相应的浏览器驱动程序。这里我们以Chrome浏览器为例,介绍如何安装和配置Selenium。
首先,我们需要安装Selenium库。可以通过以下命令来安装:
pip install selenium
接下来,我们需要下载Chrome浏览器驱动程序。可以从ChromeDriver官网 ↗上下载适合自己的版本。下载完成后,将驱动程序所在的路径添加到环境变量中。
from selenium import webdriver# 指定驱动程序所在路径
driver_path = '/path/to/chromedriver'# 创建Chrome浏览器实例
browser = webdriver.Chrome(executable_path=driver_path)# 打开网页
browser.get("https://www.baidu.com")
上面的代码中,我们首先导入了webdriver模块,并指定了Chrome浏览器驱动程序所在的路径。接下来,我们创建了一个Chrome浏览器实例,并打开了百度首页。
模拟用户操作
接下来,我们将介绍如何使用Selenium模拟用户在浏览器中的操作。比如,我们可以使用Selenium来自动登录某个网站,或者自动填写表单等等。
点击元素
要点击一个元素,可以使用click()方法。比如,我们可以点击一个链接:
# 点击百度首页的新闻链接
news_link = browser.find_element_by_link_text("新闻")
news_link.click()
上面的代码中,我们首先找到了百度首页中的新闻链接,然后使用click()方法来点击它。
输入文本
要输入文本,可以使用send_keys()方法。比如,我们可以在搜索框中输入关键字:
# 在百度搜索框中输入关键字
search_box = browser.find_element_by_id("kw")
search_box.send_keys("Python")
上面的代码中,我们首先找到了百度搜索框,然后使用send_keys()方法来输入关键字。
选择元素
有时候,我们需要从下拉列表或者单选框中选择一个选项。可以使用select()方法来实现这个功能。比如,我们可以选择一个下拉列表中的选项:
from selenium.webdriver.support.ui import Select# 选择一个下拉列表中的选项
select = Select(browser.find_element_by_name("select"))
select.select_by_value("value")
上面的代码中,我们首先找到了一个下拉列表,然后创建了一个Select对象。接下来,我们使用select_by_value()方法来选择一个选项。
等待元素
有时候,我们需要等待某个元素出现再进行操作。可以使用WebDriverWait类来实现这个功能。比如,我们可以等待一个元素出现后再点击它:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 等待一个元素出现后再点击它
element = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, "element_id"))
)
element.click()
上面的代码中,我们使用WebDriverWait类来等待一个元素的出现,然后使用click()方法来点击它。
实战应用
在实际项目中,我们可以使用Selenium来完成一些重复性的任务,比如自动化测试、数据采集等等。下面,我们将介绍如何使用Selenium来爬取某个网站的数据。
分析网站结构
在爬取网站数据之前,我们需要先了解网站的结构。比如,我们可以使用Chrome浏览器的开发者工具来查看网站的HTML代码和CSS样式。
爬取数据
假设我们要爬取某个电商网站的商品数据,包括商品名称、价格、销量等等。我们可以通过以下步骤来实现:
-
打开网站,并搜索关键字;
-
获取搜索结果页面中的商品列表;
-
遍历商品列表,获取每个商品的名称、价格、销量等信息;
-
将商品信息保存到文件中。
下面是代码示例:
# 打开网站,并搜索关键字
browser.get("https://www.example.com/")
search_box = browser.find_element_by_id("search_box")
search_box.send_keys("Python")
search_button = browser.find_element_by_id("search_button")
search_button.click()# 获取搜索结果页面中的商品列表
product_list = browser.find_elements_by_class_name("product")# 遍历商品列表,获取每个商品的名称、价格、销量等信息
for product in product_list:name = product.find_element_by_class_name("name").textprice = product.find_element_by_class_name("price").textsales = product.find_element_by_class_name("sales").text# 将商品信息保存到文件中with open("products.txt", "a") as f:f.write(f"{name}\t{price}\t{sales}\n")
上面的代码中,我们首先打开了某个电商网站,并搜索了关键字。然后获取搜索结果页面中的商品列表,遍历商品列表,获取每个商品的名称、价格、销量等信息,并将商品信息保存到文件中。
技术总结
在本篇文章中,我们介绍了如何使用Python的Selenium库进行Web自动化,并且演示了如何将它应用于实际项目中。如果你想要提高工作效率,或者想要学习如何进行自动化测试、数据采集等等,那么Selenium是一个非常好的选择。
相关文章:

Python自动化实战之使用Selenium进行Web自动化详解
概要 为了完成一项重复的任务,你需要在网站上进行大量的点击和操作,每次都要浪费大量的时间和精力。Python的Selenium库就可以自动化完成这些任务。 在本篇文章中,我们将会介绍如何使用Python的Selenium库进行Web自动化,以及如何…...

“之江数据安全治理论坛”暨《浙江省汽车数据处理活动规定(专家建议稿)》研讨会顺利召开
研讨会主题 8月10日,“之江数据安全治理论坛”暨《浙江省汽车数据处理活动规定(专家建议稿)》研讨会在浙江大学计算机创新技术研究院举办。 本次研讨会的主题聚焦于“智能网联汽车的数据安全与数据合规”,邀请行业主管部门和数据…...

消息中间件面试题
异步发送(验证码、短信、邮件…) MYSQL和Redis,ES之间的数据同步 分布式事务 削峰填谷 RabbitMQ如何保证消息不丢失? 开启生产者确认机制,确保生产者的消息能到达队列 开启持久化功能,确保消息未消费前在队列中不会丢失 开启消费…...
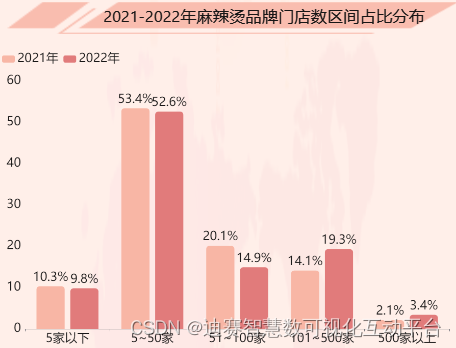
麻辣烫数据可视化,麻辣烫市场将持续蓬勃发展
麻辣烫,这道源自中国的美食,早已成为人们生活中不可或缺的一部分。它独特的香辣口味,让人忍不住每每流连忘返。与人们的关系,简直如同挚友一般。每当寒冷的冬日或疲惫的时刻,麻辣烫总是悄然走进人们的心房,…...

大数据课程J1——Scala的概述
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Scala的特点; ⚪ 了解Scala的开发环境搭建; ⚪ 了解Scala的开发工具; 一、概述 1.简介 Scala既是面向对象的语言,也是面向函数的语言。scala可以为你在做大量代码重用和扩展是提…...
)
第二章:25+ Python 数据操作教程(第十三节NUMPY 教程与练习)
NumPy(“Numerical Python”或“Numeric Python”的缩写)是 Python 中对数组和矩阵进行快速数学计算的最基本的软件包之一。在处理多维数据时它也非常有用。集成C、C++和FORTRAN工具是一件幸事。它还提供了许多傅里叶变换 (FT) 和线性代数函数。 为什么使用 NumPy 而不是列…...
,会出现什么问题?)
【Java面试】如果一个线程两次调用start(),会出现什么问题?
这个问题出自阿里p6岗位第一面的提问,你会回答吗? 在Java里面,一个线程只能调用一次start()方法,第二次调用会抛出IllegalThreadStateException异常。 一个线程本身是具备一个生命周期的。 在Java里面,线程的生命周…...

购买steam余额有风险吗?以及N种被红锁的情况
购买steam余额有风险吗?以及N种被红锁的情况 无论是打游戏的玩家,还是像我们这类靠倒卖装备赚钱的小商贩,都面临充值美金余额的问题,我们现在主要是找的专业充值渠道做代充。 最近我发现群里有极个别学员通过自己的方法找到了一…...

使用 BERT 进行文本分类 (02/3)
一、说明 在使用BERT(1)进行文本分类中,我向您展示了一个BERT如何标记文本的示例。在下面的文章中,让我们更深入地研究是否可以使用 BERT 来预测文本是使用 PyTorch 传达积极还是消极的情绪。首先,我们需要准备数据…...

基于Hadoop的表级监管
现状 大数据平台中,采用hadoop的方式存储数据,hdfs本质上是文件系统,而文件系统对数据的监管能力有限,但是数据安全领域问题日渐凸显,现目前,大数据平台一般以分层结构进行授权,但是对于一线开发人员而言,是能够接触到整个大数据平台中的所有表的,那么如何实现这样一…...

【学习日记】【FreeRTOS】延时列表的实现
前言 本文在前面文章的基础上实现了延时列表,取消了 TCB 中的延时参数。 本文是对野火 RTOS 教程的笔记,融入了笔者的理解,代码大部分来自野火。 一、如何更高效地查找延时到期的任务 1. 朴素方式 在本文之前,我们使用了一种朴…...

LeetCode解法汇总833. 字符串中的查找与替换
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 你会得到一…...
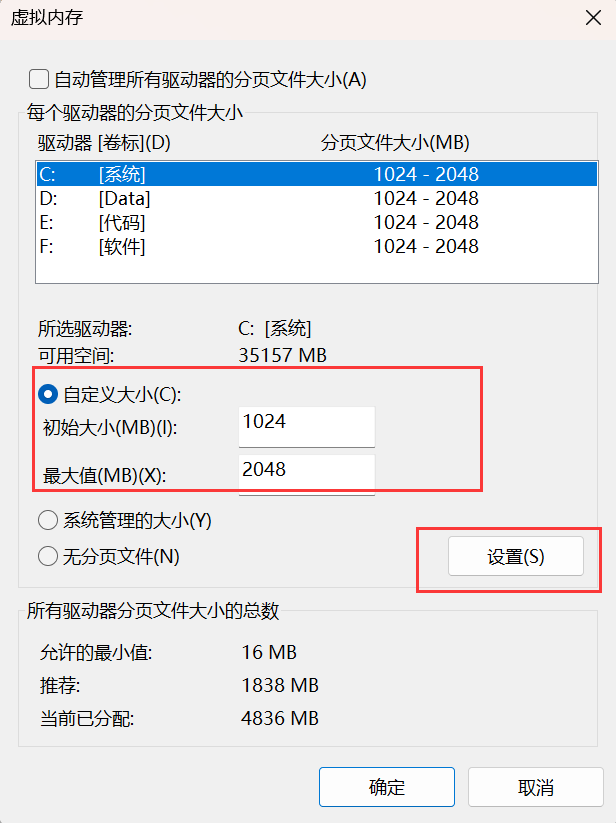
ide internal errors【bug】
ide internal errors【bug】 前言版权ide internal errors错误产生相关资源解决1解决2 设置虚拟内存最后 前言 2023-8-15 12:36:59 以下内容源自《【bug】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是h…...

阿里云与中国中医科学院合作,推动中医药行业数字化和智能化发展
据相关媒体消息,阿里云与中国中医科学院的合作旨在推动中医药行业的数字化和智能化发展。随着互联网的进步和相关政策的支持,中医药产业受到了国家的高度关注。这次合作将以“互联网 中医药”为载体,致力于推进中医药文化的传承和创新发展。…...

【Redis】Redis 的学习教程(五)之 SpringBoot 集成 Redis
在前几篇文章中,我们详细介绍了 Redis 的一些功能特性以及主流的 java 客户端 api 使用方法。 在当前流行的微服务以及分布式集群环境下,Redis 的使用场景可以说非常的广泛,能解决集群环境下系统中遇到的不少技术问题,在此列举几…...
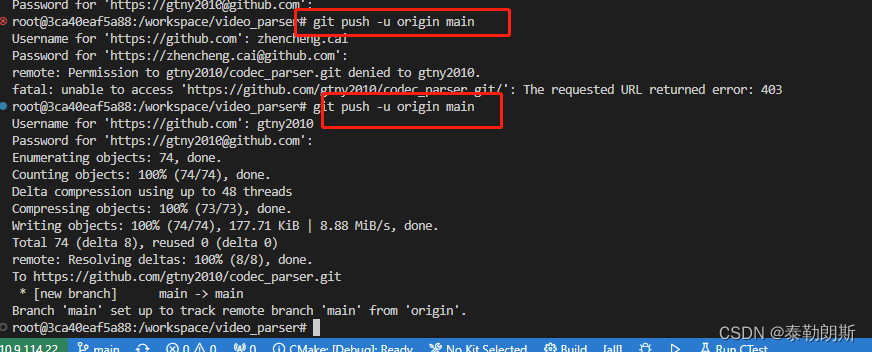
github以及上传代码处理
最近在github上传代码的时候出现了: /video_parser# git push -u origin main Username for https://github.com: gtnyxxx Password for https://gtny2010github.com: remote: Support for password authentication was removed on August 13, 2021. remote: Plea…...
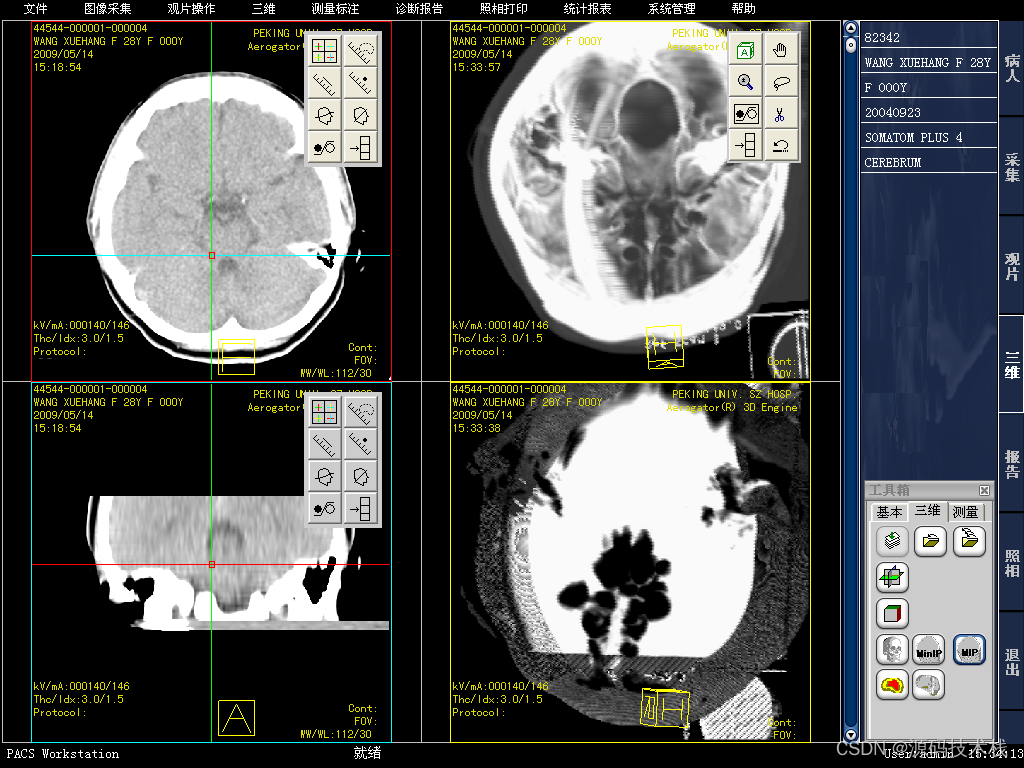
【PACS源码】认识PACS的架构和工作流程
(一)PACS系统的组成及架构 PACS系统的基本组成部分包括:数字影像采集、通讯和网络、医学影像存储、医学影像管理、各类工作站五个部分。 而目前PACS系统的软件架构选型上看,主要有C/S和B/S两种形式。 C/S架构,即Client…...

【C++】开源:跨平台Excel处理库-libxlsxwriter配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍Excel处理库-libxlsxwriter配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下&…...

前端-轮询
一、轮询定义 轮询是指在一定的时间间隔内,定时向服务器发送请求,获取最新数据的过程。轮询通常用于从服务器获取实时更新的数据。 二、轮询和长轮询区别 轮询是在固定的时间间隔内向服务器发送请求,即使服务器没有数据更新也会继续发送请求…...
Python “贪吃蛇”游戏,在不断改进中学习pygame编程
目录 前言 改进过程一 增加提示信息 原版帮助摘要 pygame.draw pygame.font class Rect class Surface 改进过程二 增加显示得分 改进过程三 增加背景景乐 增加提示音效 音乐切换 静音切换 mixer.music.play 注意事项 原版帮助摘要 pygame.mixer pygame.mix…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...