C++学习笔记总结练习:primer 学习日志
文章目录
- 针对自己的引言
- 学习内容
- c++语言基础知识
- 1.为什么要声明变量
- 2.cout ,cin
- 3.c++ 不容许一个函数定义嵌套到另一个函数的定义中。
- 4.编译指令using
- 5.c++基本类型长度
- 6.在定义常量时尽可能使用const 关键字而不用#define
- 9.前缀递增符与后缀递增符的区别
- 10.c++中的cctype库
- 11.c++ 中的stack
- 12.c++中关于const 与指针的问题
- 13.c++关于指针数组
- 14.函数指针
- 15.内联函数
- 16.引用
- 17.函数的默认参数
- 18.函数模板,泛型
- 19.将代码进行分装(头文件)
- 20.c++存储持续性
- 21.namespece 命名空间
- 23.自动类型转换和强制类型转换
- 24.类的默认定义的成员函数
- 25.类的继承
- 26.虚函数
- 27.访问控制protected
- 28.类的值返回
- 29.类函数小结
- 30.多继承
- 31.模板类
- 32.string类
- 33.智能指针模板
- 35.STL模板库
- 36.运算符
- 37.c++新标准
- 39.union
- 40.enum
- 41.指针
- 42.运算符重载
针对自己的引言
1.C语言C++语言,为什么需要加头文件?
因为C++,C语言在编译的时候是相互独立编译的。当一个函数在a.cpp文件中定义后,如果想要在b.cpp文件中使用,则需要进行链接。而头文件里面写着关于a.cpp中函数的声明。在文件 b.cpp 中,在调用 “void a()” 函数之前,先声明一下这个函数 “voida();”,就可以了。这是因为编译器在编译 b.cpp 的时候会生成一个符号表(symbol table),像 “void a()” 这样的看不到定义的符号,就会被存放在这个表中。再进行链接的时候,编译器就会在别的目标文件中去寻找这个符号的定义。一旦找到了,程序也就可以顺利地生成了。
2.定义和声明的区别
"定义"就是把一个符号完完整整地描述出来:它是变量还是函数,返回什么类型,需要什么参数等等。而"声明"则只是声明这个符号的存在,即告诉编译器,这个符号是在其他文件中定义的,我这里先用着,你链接的时候再到别的地方去找找看它到底是什么吧**。定义的时候要按 C++ 语法完整地定义一个符号(变量或者函数),而声明的时候就只需要写出这个符号的原型了。需要注意的是,一个符号,在整个程序中可以被声明多次,但却要且仅要被定义一次**。这也是头文件里面只写声明不写定义的原因。试想,如果一个符号出现了两种不同的定义,编译器该听谁的?
3.#include
#include 是一个来自 C 语言的宏命令,它在编译器进行编译之前,即在预编译的时候就会起作用。#include 的作用是把它后面所写的那个文件的内容,完完整整地、一字不改地包含到当前的文件中来。值得一提的是,它本身是没有其它任何作用与副功能的,它的作用就是把每一个它出现的地方,替换成它后面所写的那个文件的内容。简单的文本替换,别无其他。因此,main.cpp 文件中的第一句(#include"math.h"),在编译之前就会被替换成 math.h 文件的内容。
4.using namespace std使用的原因
C++标准为了和C区别开,也为了正确地使用命名空间,规定头文件不使用后缀.h。因此,当使用<iostream.h>时,相当于在C中调用库函数,使用的是全局命名空间,也就是早期的C++实现。当使用时,该头文件没有定义全局命名空间,必须使用namespace std,指明在哪里的命名空间,这样才能使用类似于cout这样的C++标识符。也可以用 命名空间名::变量名 这种方法访问
using namespace std; 意义就是你其中所用到的一些函数或者别的类都是被封装在了 名字空间为 std 的 space 中,如果你自己试图去定义同样的东西,就会出错,当然可以重载,不过你应该明白重载的用法和意义;
可以不用 using namespace std; 不过这个时候你就需要在每个引用到的 std 函数或者类中加入这样一条: std::, 如: std::cout, std::cin 等
学习内容
c++语言基础知识
1.为什么要声明变量
编译器要给变量分配内存空间,变量的声明提供了两种信息,一是变量的类型,二是变量所需的存储内存
2.cout ,cin
cout表示流出程序的字符流,cout<<2 表示将2给输入字符流
cin表示流入程序的字符流,cin>>a 表示将控制台输入的字符给变量a,会根据a的类型做转化
3.c++ 不容许一个函数定义嵌套到另一个函数的定义中。
4.编译指令using
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OmcL9TWm-1692172569911)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1659097168347.png)]
5.c++基本类型长度
| 基本类型 | 字节 |
|---|---|
| char | 1 |
| short | 2 |
| int | 4 |
| long | 4 |
| long long | 8 |
| float | 4 |
| double | 8 |
6.在定义常量时尽可能使用const 关键字而不用#define
- 首先const 可以明确指定的类型 例如 const int Month=12
- 其次,使用const 可以将变量只指定在你想指定的范围中,#define指定在全局中
- 最后,const可用于更复杂的数据结构,例如数组等等
7.c++中字符例如’s‘zaiASCII中表示83,但是”s“可能表示两个字符’s’与’/0‘,其次”s“表示的是地址。
8.对于c++ std中的strlen()函数与sizeof()函数的区别
首先strlen()计算一个字符串中的字符个数,而sizeof()函数计算的是整个字符串的字节个数
其次对于字符串 char s4[] = { ‘a’,‘\0’,‘c’,‘\0’ }; strlen(s4)的值为1,而sizeof(s4)的值为4。strlen()只计算到’\0‘字符为止,而sizeof()函数计算整个字符串的长度。
9.前缀递增符与后缀递增符的区别
- 前缀递增符是使用当前值+1的值计算表达式,后缀地增幅是使用当前值计算表达式。
int a = 4;
int b = 4;
int c = ++a + 1;//c=6
int b = b++ + 1;//b=5
- 当前缀递增符与后缀递增符所达到效果一致时,采用前缀递增符比后缀递增符效率要高。因为递增符直接返回递增结果,而后缀递增符首先要复制一个副本将其加1后再将副本返回。
for (int i = 0; i < 10; ++i)a += 1;
for (int i = 0; i < 10; i++)a += 1;
10.c++中的cctype库
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nvdzuWNf-1692172569912)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1659364051984.png)]
11.c++ 中的stack
stack.pop();移除栈顶元素,但不返回。
stack.top();返回栈顶元素,不移除。
12.c++中关于const 与指针的问题
const int* a;//说明不能修改指针a指向的值,但是可以修改指针a的值
int const *temp;//int const * 与const int * 等价;
int b = 10;
a = &b;
int d = 20;
a = &d;
int * const c = &b;//不能修改指针c的值,但是可以修改指针c指向的值
*c = 50;
const int* const e = &b;//表示e不能修改,e指向的值也不能修改
13.c++关于指针数组
int* a[4];//声明是四个指向int类型的指针组成的数组
int (* a)[4]//申明是4个int类型组成的数组,等价于a[][4];
14.函数指针
C在编译时,每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址。有了指向函数的指 针变量后,可用该指针变量调用函数,就如同用指针变量可引用其他类型变量一样。
用函数指针的应用:例如需要衡量每个函数的运行时间和代码长度。只需要定义一个统计的函数,将函数当作形参传入。
int sumNum(int);
int computeTime(int (*function)(int));
int main(){computeTime(sumNum);
}int sumNum(int n) {int sum = 0;while (n-- > 0)sum += n;return sum;
}int computeTime(int (*function)(int )) {time_t start, stop;start = time(NULL);int sum =(*function)(100000);cout << "sum == " << sum<<endl;cout << "sumNum == " <<function << endl;stop = time(NULL);cout << "expend time is " << stop - start << endl;return sum;}函数指针定义过程中的容易混淆的
//定义一个形参是Int 返回值是int的函数指针
int (*a)(int);
//定义一个形参是int 返回值是指向int类型的指针的函数
int* b(int);
a = sumNum;
15.内联函数
-
为什么要用内联函数
普通函数的运行过程是当编译器将代码编译成机器语言指令后,在运行程序时,操作系统会将这些指令存在计算机内存中,计算机会逐步执行这些指令。当执行到函数调用指令后,程序会在函数调用后立即将调用函数的指令地址储存,然后将函数的参数进行复制到堆栈,跳到标记函数起始的内存单元进行函数代码,有返回值存到寄存器中。然后跳回保存指令的地址处。来回跳跃浪费了时间。内联函数意外编译器将函数代码替换成函数调用。内联函数无需跳到对应位置再跳回来。
-
什么时候用内联函数
如果函数执行时间小于函数调用机制的时间,则可以用。
-
内联函数在程序中的定义
在函数定义和声明前加关键字 inline;
//声明和定义必须放在一起,不然没有效果
inline int sum(int a, int b);
inline int sum(int a, int b) {return a + b;
}
int main(){
sum(10,20);
}
-
内联函数不能进行递归
-
inline定义完函数后,不一定是内联函数,只是人为建议,由编译器决定
-
内联函数与宏定义函数的区别
内联函数和宏的区别在于:宏是由预处理器对宏进行替换的,而内联函数是通过编译器控制实现的,宏是在预处理阶段进行替换,内联函数是在编译阶展开的。而且内联函数是真正的函数,只是在需要用到的时候内联函数像宏一样的展开,所以取消了函数的参数压栈,减少了调用的开销。所以可以像调用函数一样来调用内联函数,而不必担心会产生像宏出现的问题
(127条消息) 大厂面试重要C++知识(二)—— 内联函数和宏的区别与联系_暗夜无风的博客-CSDN博客_c++内联函数和宏函数区别
16.引用
- 什么是引用
引用是已定义变量的别名
- 引用的作用
引用变量大多数用途作为函数的形参,可以让函数直接操作原始数据,而不产生副本。大多数为了类和结构
- 如何定义引用变量
int a = 10;
int& b = a;//b是a的 别名 b和a指向一个地址
int c=cure(a,b);
//引用类型作为形参,不能传常数,不能传表达式
int cure(int& a, int& b) {int sum = 0;while (b-- > 0)a *= a;return a;
}
//当用const 关键字修饰后,可以传常数与表达式,c++会自动创建临时变量对形参进行存储,函数结束后,释放
int d = recure(a + 2, b + 3);
int recure(const int& a,const int & b) {int sum = 0;return a+b;
}
//当改变引用对象的值时,被引用的对象值也会改变
int a = 1;
int b = 10;
int c = 100;
int &d = sum3(a, b);//a=11,d=11,d是a的别名
d = c;//d=100,a=100,c=100
cout << "a =" << a << " address of a=" << &a << endl;
cout << "c =" << c << " address of c =" << &c << endl;
cout << "d =" << d << " address of d =" << &d << endl;
int& sum3(int& a, const int& b) {a = a + b;return a;
}[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eOZOweXd-1692172569912)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1659529226577.png)]
- 引用与指针的区别
本质:引用是别名,指针是地址,具体的:
①从现象上看,指针在运行时可改变其所指向的值,而引用一旦和某个对象绑定后就不在改变。这句话可以这样理解:指针可以被重新赋值以指向另一个不同的对象。但是引用总指向在初始化时被指定的对象,以后不能改变,但是指定的对象内容可以改变。
②从内存上分配看,程序为指针变量分配内存区域,而不用为引用分配内存区域,引用声明时必须初始化,从而指向一个已经存在的对象,引用不能指向空值。
③从编译上看,程序在编译时分别将指针和引用添加到符号表上,符号表上记录的是变量名及变量所对应地址。指针变量在符号表上对应的地址值是指针变量的地址值,而引用在符号表上对应的地址值是引用对象的地址值。符号表生成后就不会再改变,因此至真可以改变指向的对象(指针变量的值可以改),而引用对象不能改。这是使用指针不安全而使用引用安全的主要原因。
- 什么时候用引用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-poSEzJrg-1692172569913)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1659528334945.png)]
17.函数的默认参数
- 如何设置
//在声明处加上初始值
int add(int a = 1, int b = 2);
int add(int a, int b) {return a + b;
}
//函数形参需要将由默认值的参数放在后面
int substract(int a,int b=1);
int substract(int a=1,int b);//这样是错的,如果这样声明,当使用substract(1)时,编译器不知道将1赋给那个形参,编译器的赋值,是根据从左往右的顺序进行
18.函数模板,泛型
如何定义
//模板和声明必须紧挨着
template<typename T>
T add(T a, T b);
int add(int a = 1, int b = 2);
int main(){cout<<add(3,4)<<endl;//调用函数int add(int a, int b);cout<<add(3.0,4.0)<<endl;//调用函数模板//说明,当由明确类型存在且符合参数条件时,优先于泛型return 0;
}
int add(int a, int b) {return a + b;
}template<typename T>
T add(T a, T b) {return a + b;
}
19.将代码进行分装(头文件)
头文件
#ifndef FASH//写ifndef 当编译器执行到这里,如果发现已经定义了FASH 则直接跳到endif ,否则会导致一个结构定义多次
#define FASH
struct people {int age;char c;int wage;
};
int add(int a=1, int b=1);
//模板函数的定义要写在头文件中
template <typename T>
T add(T a, T b) {return a + b;
}
#endif成员文件
#include<iostream>//用<>的头文件,会让编译器默认去包含标准库的目录中找
#include "functionAndStruction.h"//用“”的头文件使编译器先在本地目录找,然后再去标准库找
using namespace std;
int add(int a, int b) {return a + b;
}
20.c++存储持续性
-
自动存储持续性
在函数定义中的变量,随着函数开始与结束,变量的数量增加与减少。将变量存储在栈中。栈中有个栈顶指针与栈低指针。每当变量入栈时,栈顶指针上移,当函数执行完后,栈顶指针下移。下一个函数的变量的值会将上一个函数的变量的值覆盖。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pCmdQDYw-1692172569913)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1659621566183.png)]
-
静态持续变量
外部链接性–可在其他文件中访问
内部链接性–只能在当前文件中访问
无链接性–只能在当前函数与代码中访问
这三种链接性都在程序执行的过程中存在,且变量的数目不变,因此采用固定内存块去存储
//三种变量的申明 //test1.cpp int glabel=100;//外部连接性,在代码块外进行申明 static int a=10;//内部链接性,在代码块外申明并使用static 关键字 const int b=100;//也表示内部链接性 int main(){ static int b= 1;//无链接性,在代码块内进行申明并使用static关键字 return 0; } //test2.cpp extern int glabel;//在test2.cpp中使用关键字extern引用外部链接 //如果想定义const修饰的外部变量 extern const int d=1;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nuoU51Iv-1692172569913)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1659622804723.png)]
21.namespece 命名空间
- 为什么使用命名空间?
我们的代码可能与开发者使用相同的类名和接口名,因此使用名称空间可以避开这些冲突。
-
如何定义一个名称空间,以及一些使用技巧
这里使用结构体做了例子,因此还没有学类。
namespace wxd {struct people {string name;int age;};struct debt {string company;int amount;};
}
namespace lsw {struct people {string name;int age;int wage;};struct debt {string company;int amount;};struct car {string color;int price;int size[2];};namespace dog {struct kj {int weight;int size;};}
}
int main() {/*people wxd = { 25,'n',1000};cout << add() << endl;cout << add(3.0, 4.0) << endl;*/using lsw::car;car bwm;//同名中以第一个声明命名空间中的数据类型为主,其余被隐藏using lsw:: people;using wxd::people;people ybz = {"sb",23,10000};people wzy = { "dsb",24,1000 };wxd::people lj = { "handsome",23 };//命名空间中包含命名空间时,可以这样减少嵌套namespace dog = lsw::dog;dog::kj duoduo;return 0;
}
22.对象和类
- 为什么要定义类
为了体现面向对象编程的重要特性,比如抽象,封装和数据隐藏,多态,继承,代码的可重用性。
- 如何去定义类
//类的属性与方法的声明
//放在头文件中 people.h
#ifndef peopleH
#define peopleH
#include<string>
class people
{
private:int age;std::string name;
public:people();~people();int add(int a, int b);
};
#endif // !peopleH//类方法的实现
//放在people.cpp
#include "people.h"
#include<string>
people::people() {
}
people::~people()
{
}
int people::add(int a,int b){return a + b;
}//类成员的创建 ,放在主程序文件,或者其他需要定义此数据结构的文件
int main() {people sss;sss.add(5,4);return 0;
}
-
类与结构的区别
结构默认访问类型是public,而c++则是private
类的多个实例化对象拥有自己的存储空间。用来存储自己的内部变量和类成员,但是同一个类的所有对象共用同一套方法。
类只能有一个默认构造函数。
对象的析构函数可以用来释放对象在构造函数的过程中new的一些存储空间,构造函数的执行顺序和对象被创建的时间相反,因为如果没有加关键字限定,在函数中申明的对象也属于自动存储持续性,会被压栈和出栈。
-
new类对象
//.h文件 class Apple { private:int weight; public:Apple(int weight);~Apple(); }; //.cpp文件 Apple::Apple(int weight) {this->weight = weight;cout << "Apple class weight address =" << &weight << endl; } Apple::~Apple() {}int main(){char* c = new char[50];Apple* apple = new (c) Apple(50);Apple *b=new Apple(40);//对于指定位置new出来的对象,要手动调用析构函数b->~Apple();//对于直接new出来的对象,用delete然后调用类的析构函数return 0; }
23.自动类型转换和强制类型转换
//.h文件
class Stone {
private:int weight;
public:Stone();explicit Stone(int weight);//定义为内联函数void show(){ cout << "weight ==" << weight << endl;}explicit operator int() {return weight;}
};
int main()
{//如果在构造函数声明时,未加explicit关键字可以创建对象Stone s=10;//但是这种隐式自动转换可能会来带错误,在不想转换时转换//因此加上explicit关键字Stone s(10);//防止隐式转换,减少错误//如果在重载int函数之前未加explicit关键字,不想转换时抓换int a=s;//加上explic关键字,减少出错int a=int(s);
}
24.类的默认定义的成员函数
- 默认构造函数,如果没有定义
- 默认析构函数,如果没有定义
- 默认复制构造函数,如果没有定义
- 默认赋值符号函数,如果没有定义
- 默认取地址函数,如果没有定义。
默认复制构造函数与默认赋值符号函数的默认实现是将传入的对象的所有属性复制给当前对象。有时候会导致出问题。因此需要重写。
//.h文件,对类的属性与成员函数进行声明
class stringBad {
private:char* str;static int numLen;
public:stringBad();stringBad(const char* c);~stringBad();stringBad(const stringBad &);stringBad & operator=(const stringBad &);
};
//.cpp文件 对类中成员函数进行定义
int stringBad::numLen = 0;
stringBad::stringBad(const char * c) {int size = strlen(c);str = new char[size + 1];strcpy(str, c);numLen += 1;
}stringBad::stringBad() {}
stringBad::~stringBad() {cout << str << endl;numLen -= 1;delete[]str;
}
stringBad& stringBad::operator=(const stringBad& temp) {if (this == &temp)return *this;int size = strlen(temp.str);str = new char[size + 1];numLen += 1;strcpy(str, temp.str);return *this;
}
stringBad::stringBad(const stringBad& temp) {if (this == &temp)return;int size = strlen(temp.str);str = new char[size + 1];strcpy(str, temp.str);numLen += 1;
}//主函数
int main(){stringBad str1("adads");//如果使用默认的复制构造函数,则将执行str2.str=str1.str,//两个对象的str指向同一地址,当str2执行析构函数时,str2.str内存会被delete,当st1在进行析构时就会报错stringBad str2(str1);stringBad str3("dadad");//原因同上stringBad str4 = str3;
}
25.类的继承
-
为什么要进行类的继承
进行类的继承使代码可重用性高
多态
-
如何进行类的继承
//.h文件 class Animal { private:double weight;double length; public:Animal(double weight,double length);double getWeight() { return weight; };double getLength() { return length; }; }; //dog类继承animal类,继承方式是pulic class Dog :public Animal { private:int age; public:Dog(int age, double weight, double length) ;//由于是pulic继承,派生类不能直接访问基类friend ostream& operator<<(ostream& _START, Dog& dog) {_START << "dog age =" << dog.age << "dog weight ==" << dog.getWeight() << " dog length ==" << dog.getWeight() << endl;return _START;} };//.cpp文件 Animal::Animal(double weight, double length) {this->weight = weight;this->length = length; } Dog::Dog(int age, double weight, double length):Animal( weight, length) {this->age = age; }//main文件 int main(){Animal animal(50.0, 30.0);Dog dog(100, 50.0, 30.0);cout << dog << endl;return 0;}关于派生类的构造函数的要点:
首先创建基类对象;
派生类构造函数应通过成员初始化列表将基类信息传递给基类构造器
派生类构造器应初始化派生类新增数据成员。
释放对象的顺序与构造相反,先释放派生类再释放基类。因为派生类依赖着基类。
三种类继承方式
公有继承(public):建立的是 is-a的关系,派生类可以重用基类代码
保护继承(protected):建立的是has-a的关系,基类公有成员和保护类成员都成为派生类保护类成员
私有继承(privary):建立的是has-a的关系,基类公有成员和保护类成员都成为基类私有成员。
私有继承和保护继承
相同点:基类方法都只能在派生类中使用
不同点:当从派生类中派生出新类时,私有继承中新类不能使用基类的方法,保护继承则可以。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nawMcDI-1692172569914)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1660228597361.png)]
26.虚函数
什么是虚函数
当一个函数定义为虚函数事,程序将根据引用或者指针指向的对象类型来选择方法。
当没有声明为虚函数时,根据引用类型或者指针类型来选择方法
为什么要用虚函数
为了多态,可以正确调用派生类方法,正确调用派生类析构函数。
如何定义虚函数
// .h文件
class Animal {
private:double weight;double length;
public:Animal(double weight,double length);double getWeight() { return weight; };double getLength() { return length; };virtual void show();virtual ~Animal();
};class Dog :public Animal {
private:int age;
public:Dog(int age, double weight, double length) ;friend ostream& operator<<(ostream& _START, Dog& dog) {_START << "dog age =" << dog.age << "dog weight ==" << dog.getWeight() << " dog length ==" << dog.getWeight() << endl;return _START;}virtual void show();virtual ~Dog();/*ostream& operator <<(ostream& _START); {}*/};//.cpp
Animal::Animal(double weight, double length) {this->weight = weight;this->length = length;
}
Animal::~Animal(){};
void Animal::show() {cout << "weight == " <<this->weight<< " length == " << this->length << endl;
}
Dog::Dog(int age, double weight, double length):Animal( weight, length) {this->age = age;
}
Dog::~Dog(){};
void Dog::show() {cout << "weight == " << this->getWeight() << " length == " << this->getLength() <<"age == "<<this->age<<endl;
}
//main()
Animal animal(50.0, 30.0);
Dog dog(100, 50.0, 30.0);
Animal& a = animal;
Animal& b = dog;
a.show();
b.show();
未定义虚函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AaWfLwz7-1692172569914)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1660050380361.png)]
定义虚函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ce37qURI-1692172569914)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1660050449260.png)]
-
为什么使用虚析构函数
使用虚析构函数是保证在多态的情况下调用正确的析构函数。
-
静态联编和动态联编
在编译的过程中决定使用那种函数进行联编叫做静态联编
在函数执行的过程中决定使用那种对象的函数叫做动态联编(由于虚函数的存在)
-
虚函数工作原理
编译器给每个对象添加一个隐藏成员,该成员保存了一个指向函数地址数组的指针。这种数组称为虚函数表,类如基类对象包含一个这个指针,指向基类定义的所有虚函数的地址表,派生类也有一个指针,如果派生类中的函数重写了基类定义的虚函数,就让对应虚函数的地址指向重写的虚函数的地址,如果没有改变则与基类对应虚函数地址保持一直。派生新增的虚函数的地址,添加在派生类虚函数表中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7bXF9EMv-1692172569914)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1660052191881.png)]
因此虚函数在内存和速度上有一定执行成本,因此采用静态编联比动态编联效率高
- 友元不能作为虚函数,因为友元不是成员函数
- 重写基类函数时,派生类函数参数应与基类相同
27.访问控制protected
派生类可以访问protected修饰的成员属性
28.类的值返回
Dog Dog::returnDog(int age, double weight, double length) {Dog d = Dog(age, weight, length);//构造一个临时对象,当函数结束后就会被析构掉cout << "d addresss is" << &d << endl;//用d的值重新创建一个新的对象return d;
}int main(){Dog dog(100, 50.0, 30.0);Dog c = dog.returnDog(2, 50, 6);cout << "c address is" << &c << endl;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0jOAPN6-1692172569915)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1660055483644.png)]
29.类函数小结
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s5KsjIdP-1692172569915)(C:\Users\pro\AppData\Roaming\Typora\typora-user-images\1660055807573.png)]
30.多继承
- 从两个不同的类中继承两个同名的成员,需要在派生类中使用限定词去区分它们。例如从类Waiter和类Singer派生的类WaiterSinger,则需要分别需要Waiter::show()和Singer::show()进行区分。
class Waiter{
public:
void show();
}class Singer{
public:void show();
}
class WaiterSinger:pulic Waiter,pulic Singer{public:void show(){Waiter::show();Singer::show();}
}
类B和类C从类A中派生出来,类D同时继承类B和类C,这是在类D进行构造时会先对父类进行构造,因此会产生两个基类A导致二义性。因此需要虚基类解决二义性。这样B和C就共享一个A类副本。
class A{};
class B:virtual public A{};
class c:virtual public A{}:
class D:public A,public B{};
31.模板类
- 模板类定义
//模板类的声明和实现要写在一起
//名字叫做栈实际写了个队列
#include<math.h>
#ifndef Stack_H
#define Stack_H
template <class Type>
class Stack {
private:enum {Max=10};Type items[Max];int top;int bottom;
public:Stack();bool isEmpty();bool isFull();bool push(const Type& item);Type pop();};
template<class Type>
Stack<Type>::Stack() {top = 0;bottom = 0;
}
template<class Type>
bool Stack<Type>::isEmpty() {return top == bottom;
}template<class Type>
bool Stack<Type>::isFull() {return abs(top - bottom) == Max;
}
template<class Type>
bool Stack<Type>::push(const Type& item) {if (isFull())return false;else {items[top % Max] =item;top += 1;return true;}
}
template<class Type>
Type Stack<Type>::pop() {if (isEmpty())cout << "栈已空" << endl;else {return items[bottom++];}
}
#endif // !Stach_H
#pragma once//主函数
#include"stack.h"
int main(){
Stack<int> stack;
stack.push(10);
stack.pop();
return 0;
}
-
非类型参数
非类型参数只能为整型,指针类型,引用类型和枚举类型。
#ifndef Stack_H
#define Stack_H
template <class Type,int n>
class Stack {
private:Type items[n];int top;int bottom;
public:Stack();bool isEmpty();}
int main(){//直接初始化Stack的大小
Stack<int ,10> stack1;
Stack<int ,11>stack2;//stack1和stack2是两个不同的类。
}
- 模板多功能化
//模板递归
Stack<<Stack,5>,10>
//模板多个类型参数,
TempleName<T1,T2>//map<string,char>
//默认参数
TempleName<T1,T2=int>
- 模板别名
typedef Stack<int> stacki
typedef Stack<double> stackd32.string类
- string类的构造函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V8vqxHQ6-1692172569915)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220816215116041.png)]
//string(const char*s);string str1("sdad");cout << "str1 ==" << str1 << endl;//string(size_type n,char c)string str2(10, 'c');cout << "str2 ==" << str2 << endl;//string(const string &str) 幅值构造函数string str3(str1);cout << "str3 ==" << str3 << endl;//string() 创建默认string 长度是0string str4;cout << "str4 ==" << str4 << endl;//string(const char *s,n)将string对象初始化为s前n个字符string str5("dadadadff",4);cout << "str5 ==" << str5 << endl;//string(pr,pl);char alls[] = "dadad dada adadad";string str6(alls + 5, alls + 12);cout << "str6 ==" << str6 << endl;//string(str,n1,n2);string temp = "dadada dadadsadad";string str7(temp, 5, 10);cout << "str7 ==" << str7 << endl;
- string的自动调整大小功能
每当程序给字符串末尾添加一个字符时,不能仅将已有的字符串加大,因为相邻的内存可能被占用。因为,可能需要分配一个新的内存块,将原有的内容添加到新的内存块中,但是大量的这种操作会使效率降低,因此c++实际分配一个比实际内存大的内存块,为字符串提供增大空间。但是如果字符串不断增大超过这个内存,就会给分配一个二倍的内存。方法capacity()返回当前分配给字符串的内存的大小,reverse()方法让您能够请求内存块的最小长度.
33.智能指针模板
- 为什么要用智能指针模板?
当我们new一个内存时,常常会忘了释放,或者程序出现异常时导致无法释放。当时如果一个指针为一个对象时,当对象过期时就会调用析构函数去释放掉内存。
- 智能指针都有啥?
三种智能指针:auto_ptr,unique_ptr,shared_ptr
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e0d5tlsv-1692172569916)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220816224759844.png)]
-
如何创建一个智能指针
智能指针实际上也是一个模板类,通过将指针转为对象
#include<memory>
int main(){
//new 一个指向double的指针
auto_ptr<double> pr(new double);return 0;
}
- 智能指针指针应该避免的一点
string vacation("I wanted lonely ad a cloud");
shared_ptr<string> pvac(&vacation);
//pvac过期时,程序会将delete运算符用于非堆内存,这是错误的
- 三种智能指针的区别
auto_ptr<string> ps(new string("i reigned lonely as oa cloud"));
auto_ptr<string> vocation;
vocation =ps;//不能将两个指针指向一个string地址,会导致删除同一对象删除两次
- auto_ptr:采用建立所有权的概念,对于特定的对象,只能由一个智能指针拥有它,这样只有拥有独对象的智能指针的构造函数才会删除该对象,然后让赋值操作转让所有权。auto_ptr和unqiue_ptr采用这种措施。
- auto_ptr与unqiue_ptr的区别就是 unqiue_ptr将不容许将当源智能指针赋值给新的智能指针后还存在一段时间的操作,这样可能会导致程序在使用源智能指针。在下属代码中如果是unqiue_ptr将不容许赋值操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hq0OIcd6-1692172569916)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220816231223763.png)]
会报错,因为filems[2]丢失所有权
- shared_ptr:跟踪引用特定对象的智能指针数,当赋值时,计数加一,而当指针过期时,技术减一。当最后一个指针过期时,才调用delete。
- unique_ptr可以使用new分配内存也可以使用new[]分配内存,而auto_ptr和shared_ptr只能使用new
35.STL模板库
- 模板类vector
采用动态内存分配,可以指定初始化参数确定需要多少矢量
template<class T,class Allocator =allocator<T>>class vector{...}//默认Alloctor是allocator 这个类使用new和delete-
迭代器
迭代器是个广义指针
迭代器定义
vector<double> ::iterator pd; //pd是一个迭代器
vector<double> scores;
pd=scores.begin();
//可以用自动内型推断去实现
autor pd=scores.begin();
socres.begin()//指向scores中第一个元素的位置
socres.end()//指向scores中最后一个元素的位置之后的位置
//遍历scores中所有元素的值
for(auto temp=scores.begin();temp!=socres.end();++temp){cout<<*temp<<endl;
}//一些函数
vector<int> oldpr;//0,1,2,3,4
vector<int>newpr;//5,6,7,8,9
for (int i = 0; i < 5; ++i) {oldpr.push_back(i);newpr.push_back(i + 5);
}
//erase删除容器中一部分数据
oldpr.erase(oldpr.begin(),oldpr.begin()+2);//2,3,4,5
//将older.end()是插入的位置,newpr.begin(), newpr.end()是要插入的区间
oldpr.insert(oldpr.end(), newpr.begin(), newpr.end());//0,1,2,3,4,5,6,7,8,9
//for_each,将区间中每个元素赋给showValue函数,对应函数不能改变元素的值
for_each(oldpr.begin(),oldpr.end(),showValue);
void showValue(vector<int>::iteator pr){cout<<*pr<<endl;
}
//random_shuffle,对区间内的元素进行随机打乱
random_shuffle(newpr.begin(),newpr.end());
//sort(),对区间内的元素进行排序,对于用户自定义的对象,需要重写类中operator<()函数
- 为什么要使用迭代器
模板函数让函数与数据类型进行独立,而迭代器可以使算法独立于使用的容器。(例如让数组和链表都进行遍历)
-
迭代器的种类和功能
输入迭代器:使程序读取容器中的信息,但不能修改。
输出迭代器:使程序将值传给容器,但不能读取容器中信息
正向迭代器:既可以读也可以写
双向迭代器
随机访问迭代器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hCQ20x9J-1692172569916)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220817192644261.png)]
-
为什么要定义多种迭代器
不同的算法需要不同的迭代器,例如遍历算法就需要输入,输入迭代器。排序算法就需要随机访问迭代器。而且在编写算法时,让适用要求最低的迭代器,防止出错。
-
概念,模型,改进
算法需要一些系列要求的迭代器,这种要求叫做概念
对这种概念进行实现,提出相应的数据结构,这种数据结构叫做模型
可以看出正向迭代器拥有输入迭代器和输出迭代器的功能,但是还具有额外功能,随机访问迭代器拥有双向迭代器所有功能,但是还还具有额外功能。但是这种并不叫作继承,而叫做改进。
-
关联容器
map,set,multiset,multimap,
可以有序存储在定义的时候,需要添加比较函数operator<,作为第三个参数,比较的是键值,底层存储是树结构
multiset中可以存在多个相同的键值,multimap一个键可以和多个值关联
无序关联容器
unordered_set,unordered_map,unordered_multiset,unordered_multiset。
存储是无序的,利用哈希表哈希值存储
36.运算符
运算符是STL算法中运用的,比如for_each中的函数参数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VtixpA7h-1692172569916)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220817224459745.png)]
37.c++新标准
- 移动语义和右值引用
c++中的右值一般为值,而左值一般代表着地址,所以将在表达式中一般将右值的值复制拷贝给左值。然后销毁右值。这样做会造成大量复制拷贝工作,因此采用移动语义,通过将右值属性中的地址给左值中属性,然后将右值中属性地址赋予nullptr,这样不会导致析构函数删除一个空间两次。同时节省时间。
std::move()函数是将一个左值转换为右值引用。
- lambda表达式
使用lambda表达式的主要目的时,能够将类似函数表达式用作函数指针或者函数符的函数参数
//当语句只有一条时,可以不用声明返回值,会进行自动类型推断,[]代表匿名函数名,{int x}代表参数值 ,
[]{int x} {return x%3==0;}
//当语句有有两条时,要申明返回值
[]{int x}->double{int y=x;return x+y;}
-
可变参数函数模板
void show_list() {} template<typename T, typename ...Arage> void show_list(const T& arge1, const Arage& ...arges) {std::cout << arge1 << ",";show_list(arges...); } template<typename T> void show_list(const T& arge) {std::cout << arge << ","; } int main() {show_list(5 , 's', "adad","adads");return 0; }
39.union
共用体,能够存储不同的数据结构,但是只能同时存储一种数据结构。
用途 例如一件货物的id可能是数字也可能是字符串因此可以用union
union Id {long a;char c[20];
};struct Good {int type;Id id;
};
int main(){Good good;if(good.type==1)good.id.a=1;elsegood.id.c="da";}40.enum
枚举,一次可以定义多个const
//默认从0开始给枚举中元素赋值
enum Spectum1 {one,two,three,four,five,six,seven,eight,nine};
//one =0,two =0,seven=100,eight=101
enum Spectum2 { one, two=0, three, four, five, six, seven=100, eight, nine };
int main(){one = 3;//错误 ,int不能给枚举int a=two;//正确int b=three+3;//正确int c=two+four;//正确
}
41.指针
为什么要用指针
- 可以直接通过指针来操作元素
- 在运行阶段分配未命名的内存以及储存值。因此在编译阶段如果给一个数组给定大小,但是不确定它是否够用,往往给的比较大。但是容易造成内存的浪费。
变量一般处于栈中,而new 出来的地址一般处于堆中。
关于new 的一些知识点
- new 出来的地址,要用delete进行删除,不然会导致一直new 而不删的话可能导致内存不足
- delete 删除后的空间,不要进行二次删除
- delete 的数据要和new的保持一致。例如 int * intArray=new int[10]; delete [] intArray; 不能delete intArray;这样只删除了第一个地址。
- delete 删除的只是new出来的地址和指针变量无关。
int a = 1000;cout << "a of address is" << &a << endl;//int* 说明初始化的指针是int型的,不同类型的数据所占用的位置大小不同int* b = &a;cout << "b of value is" << b << endl;int* c;//c指向地址为100000的地方c = (int*) (100000);//系统自动分配内存 typeName name = new typeName;int* d = new int;//delete 删除只是new出来的的地址与指针变量无关delete d;d = new int;delete d;//delete 要和new 一致int* e = new int;delete e;int* intArray = new int[10];delete[] intArray;
42.运算符重载
- 为什么要重载
例如类与类之间进行基本运算符操作时,运算符重载可以让操作看起来更直观,更简单。
- 怎么进行运算符重载
//以加法运算符重载为例
//time.h
#ifndef timeH
#define timeH
class time
{
private:int hour;int minute;
public:time();time(int hour, int minute);~time();//运算符重载声明time operator+ (const time& t);void showTime();
};
#endif//time.cpp
#include<iostream>
#include "time.h"
using namespace std;time::time()
{
}
time::time(int hour, int minute)
{this->hour = hour;this->minute = minute;
}time::~time()
{
}
//运算符重载定义
time time::operator+(const time& t) {int newHour = this->hour + t.hour + (this->minute + t.minute) / 60;int newMinute = (this->minute + t.minute) % 60;return time(newHour, newMinute);
}
void time::showTime() {cout << "hour == " << hour << " minute == " << minute << endl;
}//test.cpp
#include<iostream>
#include"time.h"
using namespace std;int main() {time t1 = time(5,20);time t2 = time(6, 40);time t3 = t1 + t2;t3.showTime();
}
- 那些运算符可以重载,那些不可以重载
不可以重载
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vLjvfMR5-1692172569917)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220807174423473.png)]
可以重载
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1UiWpI5O-1692172569917)(C:\Users\18440\AppData\Roaming\Typora\typora-user-images\image-20220807174450188.png)]
相关文章:

C++学习笔记总结练习:primer 学习日志
文章目录 针对自己的引言学习内容c语言基础知识1.为什么要声明变量2.cout ,cin3.c 不容许一个函数定义嵌套到另一个函数的定义中。4.编译指令using5.c基本类型长度6.在定义常量时尽可能使用const 关键字而不用#define9.前缀递增符与后缀递增符的区别10.c中的cctype库11.c 中的s…...
发布一个开源的新闻api(整理后就开源)
目录 说明: 基础说明 其他说明: 通用接口: 登录: 注册: 更改密码(需要token) 更换头像(需要token) 获取用户列表(需要token): 上传文件(5000端口): 获取文件(5000端口)源码文件,db文件均不能获取: 验证token(需要token): 获取系统时间: 文件…...

3d max省时插件CG MAGIC功能中的材质参数可一键优化!
渲染的最终结果就是为了让渲染效果更加真实的体现。 对于一些操作上,可能还是费些时间,VRay可以说是在给材质做加法的路上越走越远,透明度、凹凸、反射等等参数细节越做越多。 对于材质参数调节的重要性大家都心里有数的。 VRay材质系统的每…...

什么是变量提升(hoisting)?它在JavaScript中是如何工作的?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 变量提升(Hoisting)⭐ 变量提升的示例:⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅&…...

.git内存清理方式
查看前15个大文件 git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -15 | awk {print$1})"删除文件夹(public/housimg文件夹目录) git filter-branch --tree-filter rm -rf publ…...

i.MX6ULL开发板无法进入NFS挂载文件系统的解决办法
问题 使用NFS网络挂载文件系统后卡住无法进入系统。 解决办法 此处不详细讲述NFS安装流程 查看板卡挂载在/home/etc/rc.init下的自启动程序 进入到../../home/etc目录下,查看rc.init文件,首先从第一行排查,查看/home/etc/netcfg文件代码内容&…...

七夕特辑——3D爱心(可监听鼠标移动)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
C++函数模板和类模板
C另一种编程思想称为泛型编程,主要利用的技术是模板 C提供两种模板机制:函数模板和类模板 C提供了模板(template)编程的概念。所谓模板,实际上是建立一个通用函数或类, 其类内部的类型和函数的形参类型不具体指定, 用…...

【Unity】编辑器下查找制定文件下的所有特定资源
需求上很简单,就是在编辑器下,找到某个制定文件下的所有特定资源(UnityEngine.Object)。Unity 没有提供专门的 API,我一开始想在网上搜索代码,发现没有现成可以直接用的。 功能实现本身并不复杂,…...
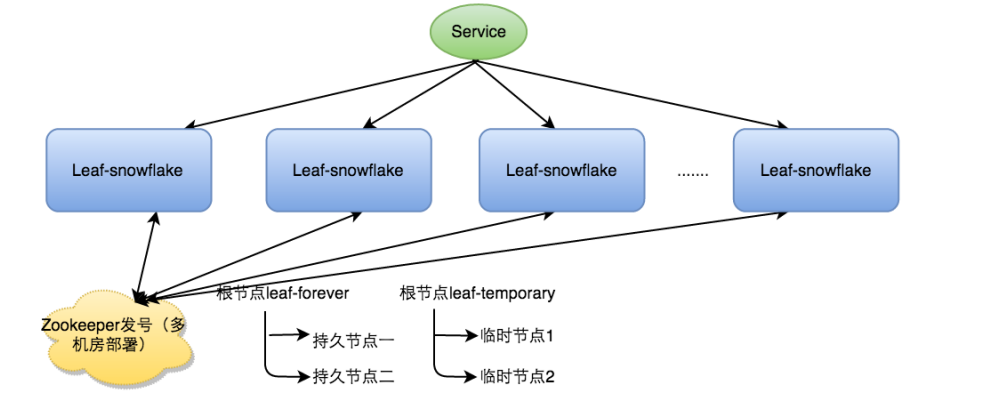
分布式唯一ID实战
目录 一、UUID二、数据库方式1、数据库生成之简单方式2、数据库生成 - 多台机器和设置步长,解决性能问题3、Leaf-segment 方案实现4、双 buffer 优化5、Leaf高可用容灾 三、基于Redis实现分布式ID四、雪花算法1、雪花算法介绍2、 雪花算法生产环境架构:3…...

el-element日期时间组件限制可选时间范围
<el-date-pickerv-model"formData.meetingTime"type"datetime"value-format"yyyy-MM-dd HH:mm:ss"style"width: 100%"placeholder"请选择日期"clearable:picker-options"pickerOptions"></el-date-picke…...

【李沐】3.3线性回归的简洁实现
1、生成数据集 import numpy as np import torch from torch.utils import data from d2l import torch as d2l true_w torch.tensor([2, -3.4]) # 定义真实权重 true_w,其中 [2, -3.4] 表示两个特征的权重值 true_b 4.2 # 定义真实偏差 true_b,表示…...

Ghost-free High Dynamic Range Imaging withContext-aware Transformer
Abstract 高动态范围(HDR)去鬼算法旨在生成具有真实感细节的无鬼HDR图像。 受感受野局部性的限制,现有的基于CNN的方法在大运动和严重饱和度的情况下容易产生重影伪影和强度畸变。 本文提出了一种新的上下文感知视觉转换器(CA-VIT)用于高动态…...

过来,我告诉你个秘密:送给程序员男友最好的礼物,快教你对象学习磁盘分区啦!小点声哈,别让其他人学会了!
[原文连接:来自给点知识](过来,我告诉你个秘密:送给程序员男友最好的礼物,快教你对象学习磁盘分区啦!小点声哈,别让其他人学会了!) 再唱不出那样的歌曲 听到都会红着脸躲避 虽然会经常忘了我依然爱着你 …...

Cadence+硬件每日学习十个知识点(38)23.8.18 (Cadence的使用,界面介绍)
文章目录 1.Cadence有共享数据库的途径2.Cadence启动3.Cadence界面菜单简介(file、edit、view、place、options)4.Cadence界面的图标简介5.我的下载资源有三本书 1.Cadence有共享数据库的途径 答: AD缺少共享数据库的途径,目前我…...
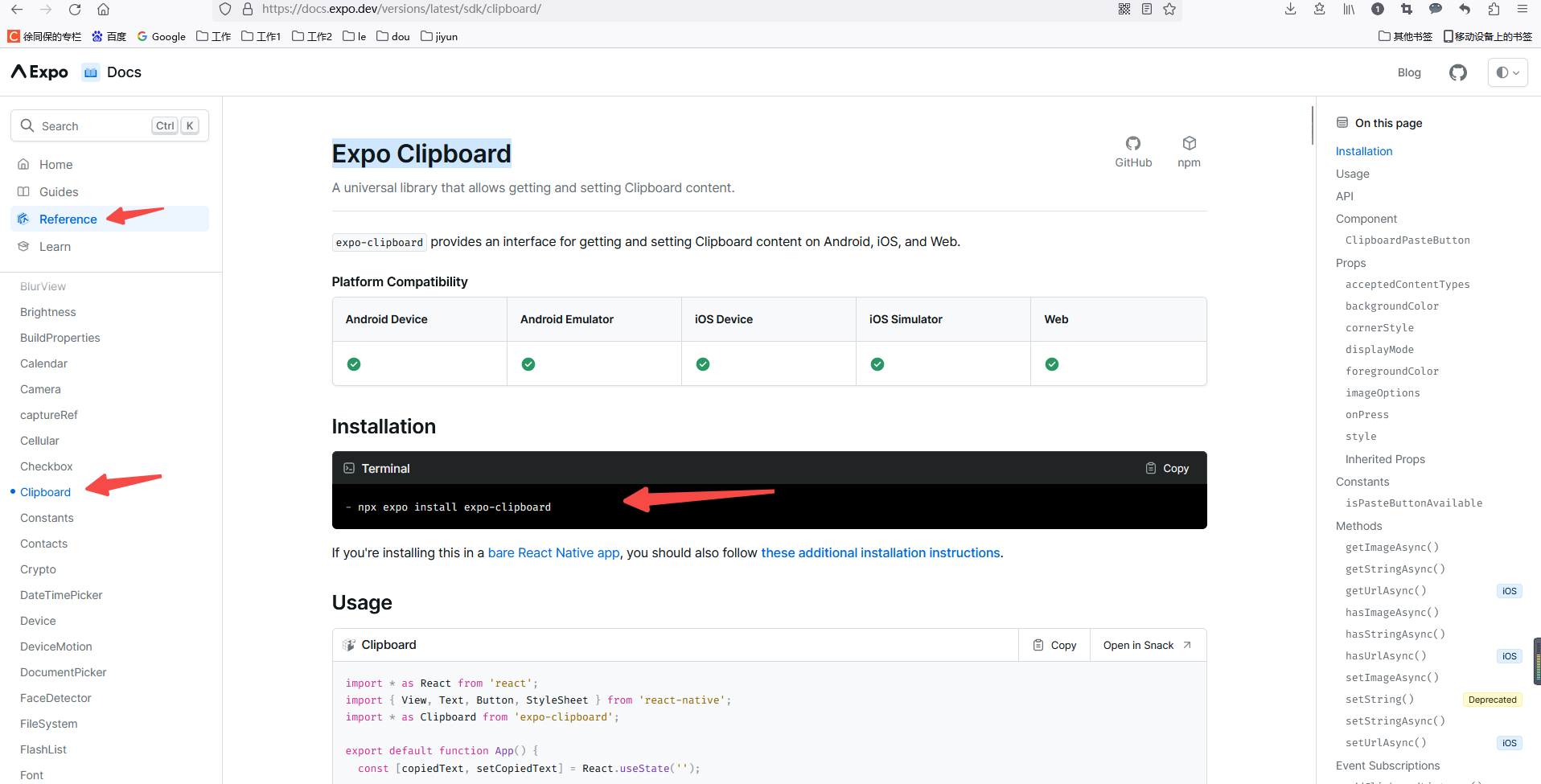
React Native Expo项目,复制文本到剪切板
装包: npx expo install expo-clipboard import * as Clipboard from expo-clipboardconst handleCopy async (text) > {await Clipboard.setStringAsync(text)Toast.show(复制成功, {duration: 3000,position: Toast.positions.CENTER,})} 参考链接:…...
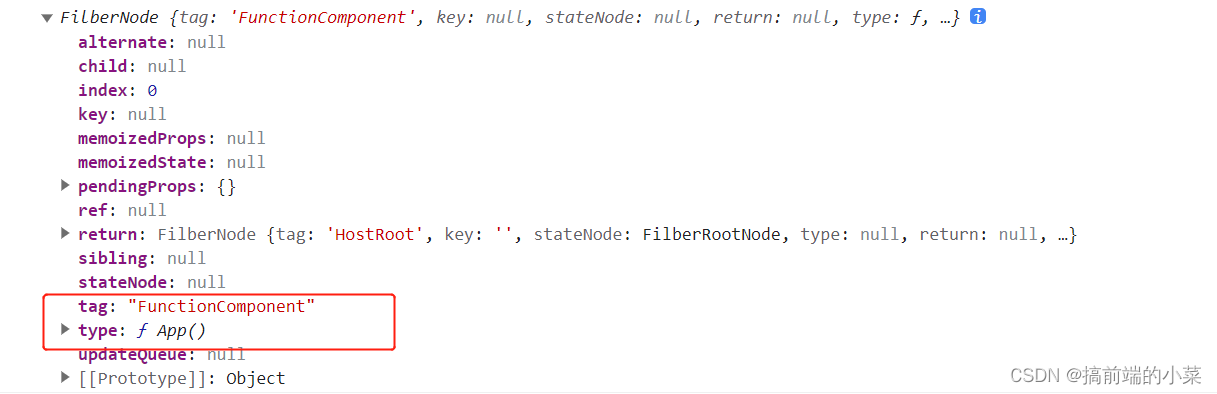
React源码解析18(5)------ 实现函数组件【修改beginWork和completeWork】
摘要 经过之前的几篇文章,我们实现了基本的jsx,在页面渲染的过程。但是如果是通过函数组件写出来的组件,还是不能渲染到页面上的。 所以这一篇,主要是对之前写得方法进行修改,从而能够显示函数组件,所以现…...
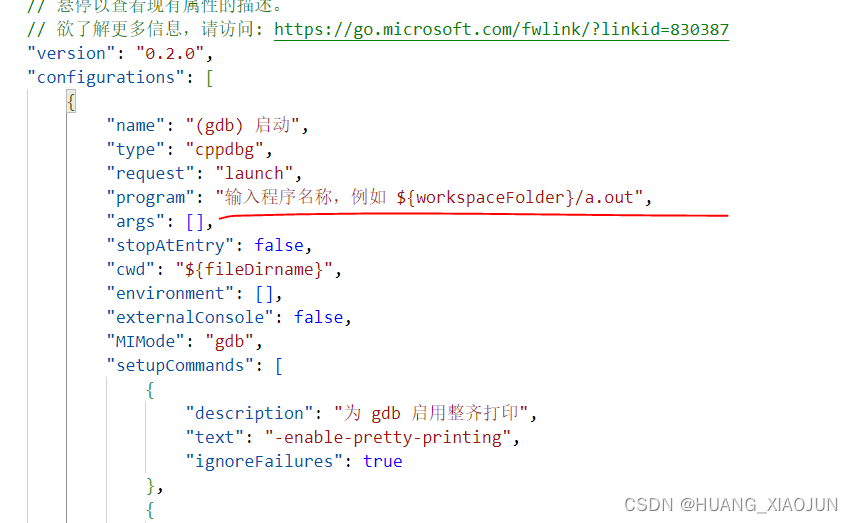
vscode ssh 远程 gdb 调试
一、点运行与调试,生成launch.json 文件 二、点添加配置,选择GDB 三、修改启动程序路径...
云原生 AI 工程化实践之 FasterTransformer 加速 LLM 推理
作者:颜廷帅(瀚廷) 01 背景 OpenAI 在 3 月 15 日发布了备受瞩目的 GPT4,它在司法考试和程序编程领域的惊人表现让大家对大语言模型的热情达到了顶点。人们纷纷议论我们是否已经跨入通用人工智能的时代。与此同时,基…...
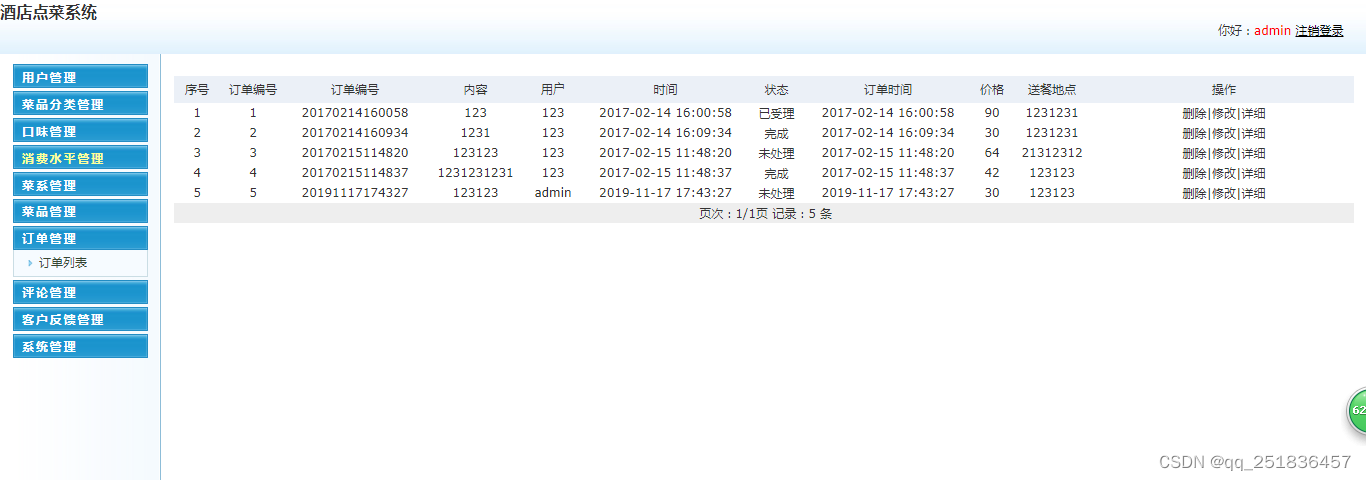
PHP酒店点菜管理系统mysql数据库web结构apache计算机软件工程网页wamp
一、源码特点 PHP 酒店点菜管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 代码下载 https://download.csdn.net/download/qq_41221322/88232051 论文 https://…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...