Elasticsearch集群shard过多后导致的性能问题分析
1.问题现象
上午上班以后发现ES日志集群状态不正确,集群频繁地重新发起选主操作。对外不能正常提供数据查询服务,相关日志数据入库也产生较大延时
2.问题原因
相关日志
查看ES集群日志如下:
00:00:51开始集群各个节点与当时的master节点通讯超时
| Time | level | data |
|---|---|---|
| 00:00:51.140 | WARN | Received response for a request that has timed out, sent [12806ms] ago, timed out [2802ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [864657514] |
| 00:01:24.912 | WARN | Received response for a request that has timed out, sent [12205ms] ago, timed out [2201ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [143113108] |
| 00:01:24.912 | WARN | Received response for a request that has timed out, sent [12206ms] ago, timed out [2201ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [835936906] |
| 00:01:27.731 | WARN | Received response for a request that has timed out, sent [20608ms] ago, timed out [10604ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [137999525] |
| 00:01:44.686 | WARN | Received response for a request that has timed out, sent [18809ms] ago, timed out [8804ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [143114372] |
| 00:01:44.686 | WARN | Received response for a request that has timed out, sent [18643ms] ago, timed out [8639ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [835938242] |
| 00:01:56.523 | WARN | Received response for a request that has timed out, sent [20426ms] ago, timed out [10423ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [137250155] |
| 00:01:56.523 | WARN | Received response for a request that has timed out, sent [31430ms] ago, timed out [21426ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [137249119] |
触发各个节点发起重新选主的操作
| Time | level | data |
|---|---|---|
| 00:00:51.140 | WARN | Received response for a request that has timed out, sent [12806ms] ago, timed out [2802ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [864657514] |
| 00:01:24.912 | WARN | Received response for a request that has timed out, sent [12206ms] ago, timed out [2201ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [835936906] |
| 00:01:24.912 | WARN | Received response for a request that has timed out, sent [12205ms] ago, timed out [2201ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [143113108] |
| 00:01:27.731 | WARN | Received response for a request that has timed out, sent [20608ms] ago, timed out [10604ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [137999525] |
| 00:01:44.686 | WARN | Received response for a request that has timed out, sent [18643ms] ago, timed out [8639ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [835938242] |
| 00:01:44.686 | WARN | Received response for a request that has timed out, sent [18809ms] ago, timed out [8804ms] ago, action [internal:coordination/fault_detection/leader_check], node [{hot}{tUvNI22CRAanSsJdircGlA}{crDi96kOQl6J944HZqNB0w}{131}{131:9300}{dim}{xpack.installed=true, box_type=hot}], id [143114372] |
新的主节点被选出,但频繁在3个候选节点间切换,集群状态始终处于不稳定状态
| Time | level | data |
|---|---|---|
| 00:52:37.264 | DEBUG | executing cluster state update for [elected-as-master ([2] nodes joined)[{hot}{g7zfvt_3QI6cW6ugxIkSRw}{bELGusphTpy6RBeArNo8MA}{129}{129:9300}{dim}{xpack.installed=true, box_type=hot} elect leader, {hot}{GDyoKXPmQyC42JBjNP0tzA}{llkC7-LgQbi4BdcPiX_oOA}{130}{130:9300}{dim}{xpack.installed=true, box_type=hot} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_]] |
| 00:52:37.264 | TRACE | will process [elected-as-master ([2] nodes joined)[_FINISH_ELECTION_]] |
| 00:52:37.264 | TRACE | will process [elected-as-master ([2] nodes joined)[_BECOME_MASTER_TASK_]] |
| 00:52:37.264 | TRACE | will process [elected-as-master ([2] nodes joined)[{hot}{g7zfvt_3QI6cW6ugxIkSRw}{bELGusphTpy6RBeArNo8MA}{129}{129:9300}{dim}{xpack.installed=true, box_type=hot} elect leader]] |
| 00:52:37.264 | TRACE | will process [elected-as-master ([2] nodes joined)[{hot}{GDyoKXPmQyC42JBjNP0tzA}{llkC7-LgQbi4BdcPiX_oOA}{130}{130:9300}{dim}{xpack.installed=true, box_type=hot} elect leader]] |
| 00:52:37.584 | DEBUG | took [200ms] to compute cluster state update for [elected-as-master ([2] nodes joined)[{hot}{g7zfvt_3QI6cW6ugxIkSRw}{bELGusphTpy6RBeArNo8MA}{129}{129:9300}{dim}{xpack.installed=true, box_type=hot} elect leader, {hot}{GDyoKXPmQyC42JBjNP0tzA}{llkC7-LgQbi4BdcPiX_oOA}{130}{130:9300}{dim}{xpack.installed=true, box_type=hot} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_]] |
| 00:52:37.828 | TRACE | cluster state updated, source [elected-as-master ([2] nodes joined)[{hot}{g7zfvt_3QI6cW6ugxIkSRw}{bELGusphTpy6RBeArNo8MA}{129}{129:9300}{dim}{xpack.installed=true, box_type=hot} elect leader, {hot}{GDyoKXPmQyC42JBjNP0tzA}{llkC7-LgQbi4BdcPiX_oOA}{130}{130:9300}{dim}{xpack.installed=true, box_type=hot} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_]] |
问题分析
综合上述日志、集群状态及近期所做的操作后,发现这是由于为解决前期ES集群SSD磁盘IO不均,部分磁盘达到IO上限的问题,为平衡各节点、各SSD磁盘的IO,将index的shard均匀分配至每个节点的每块SSD上,增加了在每个节点上的shard分配数量。这虽然避免了热点盘的问题,有效地均衡了磁盘IO,但导致了shard数目的快速增加 (之前集群shard总数一般控制在2万左右,出现问题时集群shard数目接近6万)进而触发如下ES bug(该bug在ES 7.6及以上版本被修复),导致平时可以在短时间内正常完成的处理(freeze index,delete index,create index)长时间不能完成,同时造成master节点负载过高,最终出现大量处理超时等错误:
-
https://github.com/elastic/elasticsearch/pull/47817
-
https://github.com/elastic/elasticsearch/issues/46941
-
https://github.com/elastic/elasticsearch/pull/48579
这3个bug所表述的事情是同一个,即:为了确定节点中一个shard是否需要发生移动,ES集群需要查看集群中所有shard是否处于RELOCATING或者INITIALIZING状态,以获取其shard的大小。在bug未修复版本中,集群里的每个shard都会重复上述操作,而这些工作都由master节点通过实时计算来完成。当集群的shard数增多后,master节点计算工作量会急剧上升,从而导致master节点处理缓慢,引发一系列的问题。由于集群shard数上升,导致master节点的工作负载急剧上升,出现相关处理缓慢的情况,进而导致以下问题:
(1)Master节点由于负载过高长时间不能响应其他节点的请求导致超时,进而触发集群重新选主,但由于新选出的Master仍然不能承载集群相关工作,再次导致超时,再次触发重新选主,周而复始,最后集群异常。
(2)Master节点处理缓慢,导致大面积作业堆积(冷冻索引、创建索引、删除索引、数据迁移等作业)
该问题最早是由华为工程师发现并提交社区的,相关堆栈信息为:
"elasticsearch[iZ2ze1ymtwjqspsn3jco0tZ][masterService#updateTask][T#1]" #39 daemon prio=5 os_prio=0 cpu=150732651.74ms elapsed=258053.43s tid=0x00007f7c98012000 nid=0x3006 runnable [0x00007f7ca28f8000]java.lang.Thread.State: RUNNABLEat java.util.Collections$UnmodifiableCollection$1.hasNext(java.base@13/Collections.java:1046)at org.elasticsearch.cluster.routing.RoutingNode.shardsWithState(RoutingNode.java:148)at org.elasticsearch.cluster.routing.allocation.decider.DiskThresholdDecider.sizeOfRelocatingShards(DiskThresholdDecider.java:111)at org.elasticsearch.cluster.routing.allocation.decider.DiskThresholdDecider.getDiskUsage(DiskThresholdDecider.java:345)at org.elasticsearch.cluster.routing.allocation.decider.DiskThresholdDecider.canRemain(DiskThresholdDecider.java:290)at org.elasticsearch.cluster.routing.allocation.decider.AllocationDeciders.canRemain(AllocationDeciders.java:108)at org.elasticsearch.cluster.routing.allocation.allocator.BalancedShardsAllocator$Balancer.decideMove(BalancedShardsAllocator.java:668)at org.elasticsearch.cluster.routing.allocation.allocator.BalancedShardsAllocator$Balancer.moveShards(BalancedShardsAllocator.java:628)at org.elasticsearch.cluster.routing.allocation.allocator.BalancedShardsAllocator.allocate(BalancedShardsAllocator.java:123)at org.elasticsearch.cluster.routing.allocation.AllocationService.reroute(AllocationService.java:405)at org.elasticsearch.cluster.routing.allocation.AllocationService.reroute(AllocationService.java:370)at org.elasticsearch.cluster.metadata.MetaDataIndexStateService$1$1.execute(MetaDataIndexStateService.java:168)at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:47)at org.elasticsearch.cluster.service.MasterService.executeTasks(MasterService.java:702)at org.elasticsearch.cluster.service.MasterService.calculateTaskOutputs(MasterService.java:324)at org.elasticsearch.cluster.service.MasterService.runTasks(MasterService.java:219)at org.elasticsearch.cluster.service.MasterService.access$000(MasterService.java:73)at org.elasticsearch.cluster.service.MasterService$Batcher.run(MasterService.java:151)at org.elasticsearch.cluster.service.TaskBatcher.runIfNotProcessed(TaskBatcher.java:150)at org.elasticsearch.cluster.service.TaskBatcher$BatchedTask.run(TaskBatcher.java:188)at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:703)at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252)at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215)at java.util.concurrent.ThreadPoolExecutor.runWorker(java.base@13/ThreadPoolExecutor.java:1128)at java.util.concurrent.ThreadPoolExecutor$Worker.run(java.base@13/ThreadPoolExecutor.java:628)at java.lang.Thread.run(java.base@13/Thread.java:830)
/*** Determine the shards with a specific state* @param states set of states which should be listed* @return List of shards*/public List<ShardRouting> shardsWithState(ShardRoutingState... states) {List<ShardRouting> shards = new ArrayList<>();for (ShardRouting shardEntry : this) {for (ShardRoutingState state : states) {if (shardEntry.state() == state) {shards.add(shardEntry);}}}return shards;}
在shardsWithState中会对所有shard进行遍历找到符合状态的shard,并返回。在ES7.2后由于pr#39499功能的引入,导致即使index被关闭也将被统计,随着集群shard数的增加需要遍历的工作量急剧增加,导致处理缓慢
下面是ES官方给出的统计数据:
Shards Nodes Shards per node Reroute time without relocations Reroute time with relocations 60000 10 6000 ~250ms ~15000ms 60000 60 1000 ~250ms ~4000ms 10000 10 1000 ~60ms ~250ms 由此可见即使在正常情况下,随着集群shard数的增加系统的处理耗时也是在快速增加的,需要进行优化
代码改进
为修复该问题,在新版本的ES中修改了RoutingNode的结构,在原来的基础上新增了两个LinkedHashSet结构的initializingShards和relocatingShards,分别用来存储INITIALIZING状态和RELOCATING状态的shard。在其构造函数中添加了对shard分类的逻辑,将INITIALIZING状态和RELOCATING状态的shard信息分别存储在两个LinkedHashSet结构中,具体代码如下:
+ private final LinkedHashSet<ShardRouting> initializingShards;
+ private final LinkedHashSet<ShardRouting> relocatingShards;RoutingNode(String nodeId, DiscoveryNode node, LinkedHashMap<ShardId, ShardRouting> shards) {this.nodeId = nodeId;this.node = node;this.shards = shards;
+ this.relocatingShards = new LinkedHashSet<>();
+ this.initializingShards = new LinkedHashSet<>();
+ for (ShardRouting shardRouting : shards.values()) {
+ if (shardRouting.initializing()) {
+ initializingShards.add(shardRouting);
+ } else if (shardRouting.relocating()) {
+ relocatingShards.add(shardRouting);
+ }
+ }
+ assert invariant();
}
由于RoutingNode的结构中新增了initializingShards和relocatingShards,所以其add、update、remove、numberOfShardsWithState和shardsWithState也需要同步做改动,具体如下:
void add(ShardRouting shard) {
+ assert invariant();if (shards.containsKey(shard.shardId())) {throw new IllegalStateException("Trying to add a shard " + shard.shardId() + " to a node [" + nodeId+ "] where it already exists. current [" + shards.get(shard.shardId()) + "]. new [" + shard + "]");}shards.put(shard.shardId(), shard);+ if (shard.initializing()) {
+ initializingShards.add(shard);
+ } else if (shard.relocating()) {
+ relocatingShards.add(shard);
+ }
+ assert invariant();}
void update(ShardRouting oldShard, ShardRouting newShard) {
+ assert invariant();if (shards.containsKey(oldShard.shardId()) == false) {// Shard was already removed by routing nodes iterator// TODO: change caller logic in RoutingNodes so that this check can go awayreturn;}ShardRouting previousValue = shards.put(newShard.shardId(), newShard);assert previousValue == oldShard : "expected shard " + previousValue + " but was " + oldShard;+ if (oldShard.initializing()) {
+ boolean exist = initializingShards.remove(oldShard);
+ assert exist : "expected shard " + oldShard + " to exist in initializingShards";
+ } else if (oldShard.relocating()) {
+ boolean exist = relocatingShards.remove(oldShard);
+ assert exist : "expected shard " + oldShard + " to exist in relocatingShards";
+ }
+ if (newShard.initializing()) {
+ initializingShards.add(newShard);
+ } else if (newShard.relocating()) {
+ relocatingShards.add(newShard);
+ }
+ assert invariant();}
void remove(ShardRouting shard) {
+ assert invariant();ShardRouting previousValue = shards.remove(shard.shardId());assert previousValue == shard : "expected shard " + previousValue + " but was " + shard;
+ if (shard.initializing()) {
+ boolean exist = initializingShards.remove(shard);
+ assert exist : "expected shard " + shard + " to exist in initializingShards";
+ } else if (shard.relocating()) {
+ boolean exist = relocatingShards.remove(shard);
+ assert exist : "expected shard " + shard + " to exist in relocatingShards";
+ }
+ assert invariant();
+ }
public int numberOfShardsWithState(ShardRoutingState... states) {
+ if (states.length == 1) {
+ if (states[0] == ShardRoutingState.INITIALIZING) {
+ return initializingShards.size();
+ } else if (states[0] == ShardRoutingState.RELOCATING) {
+ return relocatingShards.size();
+ }
+ }int count = 0;for (ShardRouting shardEntry : this) {for (ShardRoutingState state : states) {if (shardEntry.state() == state) {count++;}}}return count;}
public List<ShardRouting> shardsWithState(String index, ShardRoutingState... states) {List<ShardRouting> shards = new ArrayList<>();+ if (states.length == 1) {
+ if (states[0] == ShardRoutingState.INITIALIZING) {
+ for (ShardRouting shardEntry : initializingShards) {
+ if (shardEntry.getIndexName().equals(index) == false) {
+ continue;
+ }
+ shards.add(shardEntry);
+ }
+ return shards;
+ } else if (states[0] == ShardRoutingState.RELOCATING) {
+ for (ShardRouting shardEntry : relocatingShards) {
+ if (shardEntry.getIndexName().equals(index) == false) {
+ continue;
+ }
+ shards.add(shardEntry);
+ }
+ return shards;
+ }
+ }for (ShardRouting shardEntry : this) {if (!shardEntry.getIndexName().equals(index)) {continue;}for (ShardRoutingState state : states) {if (shardEntry.state() == state) {shards.add(shardEntry);}}}return shards;}
public int numberOfOwningShards() {
- int count = 0;
- for (ShardRouting shardEntry : this) {
- if (shardEntry.state() != ShardRoutingState.RELOCATING) {
- count++;
- }
- }
-
- return count;
+ return shards.size() - relocatingShards.size();}+ private boolean invariant() {
+
+ // initializingShards must consistent with that in shards
+ Collection<ShardRouting> shardRoutingsInitializing =
+ shards.values().stream().filter(ShardRouting::initializing).collect(Collectors.toList());
+ assert initializingShards.size() == shardRoutingsInitializing.size();
+ assert initializingShards.containsAll(shardRoutingsInitializing);+ // relocatingShards must consistent with that in shards
+ Collection<ShardRouting> shardRoutingsRelocating =
+ shards.values().stream().filter(ShardRouting::relocating).collect(Collectors.toList());
+ assert relocatingShards.size() == shardRoutingsRelocating.size();
+ assert relocatingShards.containsAll(shardRoutingsRelocating);+ return true;
+ }
上面的add、update、remove方法的开始和结尾处都添加了assert invariant(),这个确保了initializingShards和relocatingShards中存储的INITIALIZING状态和RELOCATING状态的shard在任何时候都是最新的,但是,随着shard的数量级的增长,invariant()方法花费的时间也会增大,所以在shard进行add、update、remove操作时所耗费的时间也会增大。
该修复通过使用两个LinkedHashSet结构来存储initializingShards和relocatingShards的信息,同时在每次shard更新时同步更新LinkedHashSet里面的信息,由此降低了每次使用时都需要重新统计全量shard信息的开销,提高了处理效率。该问题在ES 7.2-7.5间的版本上,当集群shard超过50000以上就极有可能触发。BUG在ES 7.6上被修复。
3.问题处理
当时为快速恢复服务,对集群进行了重启操作。但集群相关作业处理仍然很慢,整个恢复过程持续很长时间。后续我们的处理方法是:
-
临时设置设置集群参数"cluster.routing.allocation.disk.include_relocations":"false"(不推荐使用,在ES 7.5后该参数被废弃。在磁盘使用率接近高水位时会出现错误的计算,导致频繁的数据迁移)
-
减少集群的shard数目,缩短在线数据查询时间范围为最近20天,目前控制集群shard总数在5万左右
上面的处理方法只能缓解问题,没有从根本上解决,如果要解决该问题可以进行以下处理:
-
升级ES的版本至已修复bug的版本
-
控制集群总shard数目在合理范围内
相关文章:

Elasticsearch集群shard过多后导致的性能问题分析
1.问题现象 上午上班以后发现ES日志集群状态不正确,集群频繁地重新发起选主操作。对外不能正常提供数据查询服务,相关日志数据入库也产生较大延时 2.问题原因 相关日志 查看ES集群日志如下: 00:00:51开始集群各个节点与当时的master节点…...
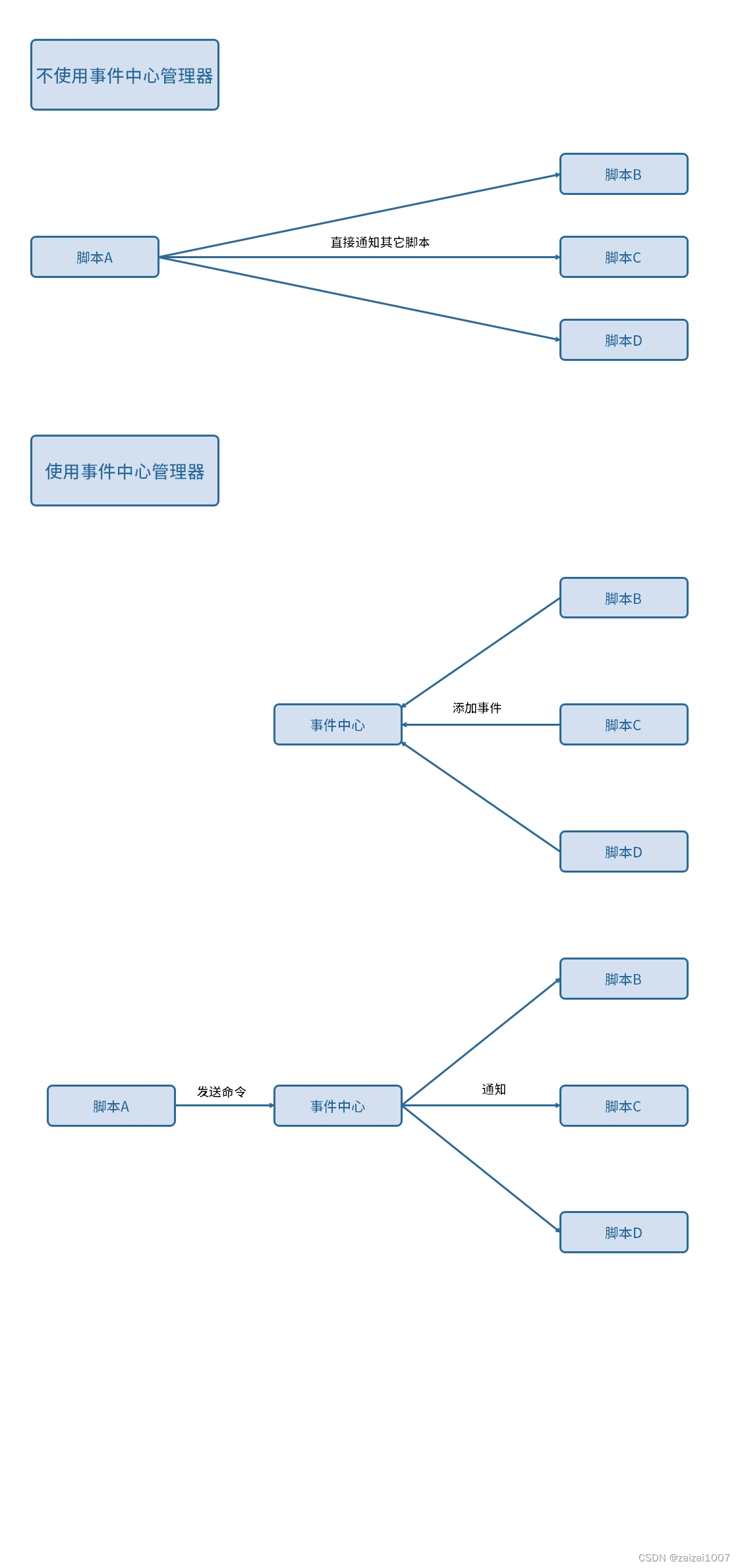
Unity框架学习--5 事件中心管理器
作用:访问其它脚本时,不直接访问,而是通过发送一条“命令”,让监听了这条“命令”的脚本自动执行对应的逻辑。 原理: 1、让脚本向事件中心添加事件,监听对应的“命令”。 2、发送“命令”,事件…...
结构型模式:3、过滤器模式(Filter、Criteria Pattern)(C++示例))
(二)结构型模式:3、过滤器模式(Filter、Criteria Pattern)(C++示例)
目录 1、过滤器模式(Filter、Criteria Pattern)含义 2、过滤器模式应用场景 3、过滤器模式主要几个关键角色 4、C实现过滤器模式的示例 1、过滤器模式(Filter、Criteria Pattern)含义 (1)过滤器模式是…...
谷歌在Chrome浏览器中推进抗量子加密技术
近日,Chromium博客上发表的一篇博文称,为了加强网络安全,应对迫在眉睫的量子计算机威胁,谷歌各个团队密切合作,为网络向抗量子密码学的过渡做好准备。 谷歌的Chrome团队在博客中写道,该项目涉及修订技术标准…...

Kotlin的数组
在 Kotlin 中,数组是一种固定大小的有序集合,可以存储相同类型的元素。Kotlin 提供了两种类型的数组:原生数组和数组类。以下是 Kotlin 中数组的详细使用方法: 1.创建数组 Kotlin 支持使用 arrayOf() 函数来创建数组:…...

centos 安装docker
1.更新你的系统: sudo yum update -y2.安装必需的软件包: Docker 需要 yum-utils, device-mapper-persistent-data 和 lvm2 软件包来运行。安装它们: sudo yum install -y yum-utils device-mapper-persistent-data lvm23.设置 Docker 的仓库: 使用以下命令添加 D…...
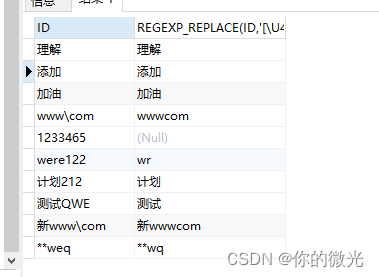
Oracle-如何判断字符串包含中文字符串(汉字),删除中文内容及保留中文内容
今天遇见一个问题需要将字段中包含中文字符串的筛选出来 --建表 CREATE TABLE HADOOP1.AAA ( ID VARCHAR2(255) ); --添加字段INSERT INTO HADOOP1.AAA(ID)VALUES(理解);....--查询表内容SELECT * FROM HADOOP1.AAA;在网上查找了一下有以下三种方式: 第一种&#…...
File 类的用法, InputStream和Reader, OutputStream和Writer 的用法
前言 普通的文件长这样: 其实目录也是一种特殊文件: 一、文件前缀知识 (一)绝对路径和相对路径 以盘符开头的的路径,叫做绝对路径,如:D:\360Downloads\cat.jpg 以.或..开头的路径,…...

AtCoder Beginner Contest 315 Task:A/B/C/E
A - tcdr 处理字符串简单题,题目要求去除字符串中的a,e,i,o,u即可 #include<iostream> using namespace std; int main() {string s;cin>>s;for(int i0;i<s.length();i){if(s[i]a||s[i]e||s[i]i||s[i]o||s[i]u)continue;cout<<s[i];} }B - T…...

【项目实践】基于LSTM的一维数据扩展与预测
基于LSTM的一维数据拟合扩展 一、引(fei)言(hua) 我在做Sri Lanka生态系统服务价值计算时,中间遇到了一点小问题。从世界粮农组织(FAO)上获得Sri Lanka主要农作物产量和价格数据时,其中的主要作物Sorghum仅有2001-2006年的数据,而Millet只有…...

webshell实践,在nginx上实现负载均衡
1、配置多台虚拟机,用作服务器 在不同的虚拟机上安装httpd服务 我采用了三台虚拟机进行服务器设置:192.168.240.11、192.168.240.12、192.168.240.13 [rootnode0-8 /]# yum install httpd -y #使用yum安装httpd服务#开启httpd服务 [rootnode0-8 /]# …...

LVS+Keepalived集群
keepalived Keepalived及其工作原理 Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题 在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务…...

Java的网络编程
网络编程 两台设备之间通过网络实现数据传输,将数据通过网络从一台设备传输到另一台设备 网络 两台或多台设备通过一定物理设备连接起来构成了网络 网络又分为: 局域网:覆盖范围最小,仅仅覆盖一个教室或一个机房城域网:覆盖范围较大,可以…...

kafka配置远程连接
要想实现在本地连接服务器的kafka,则必须在远程kafka配置远程连接 默认的 kafka 配置是无法远程访问的,解决该问题有几个方案。 方案1 advertised.listenersPLAINTEXT://IP:9092 注意必须是 ip,不能是 hostname 方案2 advertised.listene…...

css实现渐变色border
方式1 div {border: 4px solid;border-image: linear-gradient(to right, #8f41e9, #578aef) 1; }/* 或者 */ div {border: 4px solid;border-image-source: linear-gradient(to right, #8f41e9, #578aef);border-image-slice: 1; }作者:MudOnTire 链接:…...

管理 IBM Spectrum LSF
管理 IBM Spectrum LSF 了解如何管理 IBM Spectrum LSF 集群,控制守护程序,更改集群配置以及使用主机和队列。 管理 LSF 作业和作业调度策略。 查看作业信息和控制作业。 了解如何配置资源并将其分配给 LSF 作业。 了解如何在 LSF 集群中提交࿰…...

117页数字化转型与产业互联网发展趋势及机会分析报告PPT
导读:原文《》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 喜欢文章,您可以点赞评论转发本文,了解更多内容请私信:方…...
【JavaWeb】实训的长篇笔记(上)
JavaWeb的实训是学校的一门课程,老师先讲解一些基础知识,然后让我们自己开发一个比较简单的Web程序。可涉及的知识何其之多,不是实训课的 3 周时间可以讲得完的,只是快速带过。他说:重点是Web开发的流程。 我的实训草草…...

如何使用Docker安装AWVS?
前言 还记得很早的时候使用AWVS,还需要找位置,贴补丁,放文件,现在慢慢掌握Docker后发现,使用Docker去部署一些东西就很方便,当然也包括AWVS。 我们今天带大家通过Docker部署AWVS(有中文哦&…...

vue命名规范
文件和文件夹的命名: 文件夹命名: Vue 项目中通常可以根据功能或页面来划分文件夹。例如,您可以为每个页面创建一个文件夹,并将相关的组件、样式和资源文件放在其中。文件夹的命名最好使用短横线分隔的小写字母(kebab …...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...