大语言模型之四-LlaMA-2从模型到应用
最近开源大语言模型LlaMA-2火出圈,从huggingface的Open LLM Leaderboard开源大语言模型排行榜可以看到LlaMA-2还是非常有潜力的开源商用大语言模型之一,相比InstructGPT,LlaMA-2在数据质量、培训技术、能力评估、安全评估和责任发布方面进行了大量的技术更新,此外在商业许可、huggingface等社区支持等方面也做的比较好,本篇文章以7B模型为例介绍LlaMA-2的推理、训练以及应用。
相对来说LlaMA-2模型结构比Transformer简单一些,关于Transformer可以参见博客《大语言模型之一 Attention is all you need —Transformer》本篇文章重点参考了LlaMA(Meta)的官方Paper。
LlaMA-2是基于Transformer的Decoder部分,其训练数据45TB、2万亿个token,预训练上下文长度为4096,采用了GQA(分组查询注意力机制)提高推理速度,使用了超过100万个人类注释训练对SFT模型模型,伯克利大学的人工智能专业博士Nathan Lambert 则在自己的博客表示,经过一些列基准测试,除了编程能力,LlaMA-2达到了ChatGPT水平,Meta提出了一种提高多轮一致性的新方法GAtt,灵感来源于上下文蒸馏法,论文中还有一些对于奖励模型、RLHF流程、安全评估和许可申明的观点。
奖励模型是强化学习的关键,为了得到一个好的奖励模型,Meta收集了大量偏好数据,量级远远超过了开源社区目前使用的数据量,Meta采用二分类得分模型评价指标,没有使用更加复杂的反馈模型,数据收集的重点在有用性和安全性,对每个数据源使用了不同的指导原则,添加了安全元数据,迭代式数据收集方式,每周分配收集人工注释,随着收集到更多偏好数据,奖励模型也得到改进,数据这一项LlaMA-2大概得花费大约是2000万美元,奖励模型部分Meta训练了两个独立的奖励模型,一个是针对有用性进行了优化,另一个是针对安全性进行了优化;
在训练硬件方面,Meta 在其研究超级集群(Research Super Cluster, RSC)以及内部生产集群上对模型进行了预训练。两个集群均使用了 NVIDIA A100。在 Meta 的评估中,多项测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
当然,对于今天的大模型来说,「安全」是一个重要性不亚于「性能」的指标。在 Llama 2 的研发过程中,Meta 使用了三个常用基准评估其安全性:
- 真实性,指语言模型是否会产生错误信息,采用 TruthfulQA 基准;
- 毒性,指语言模型是否会产生「有毒」、粗鲁、有害的内容,采用 ToxiGen 基准;
- 偏见,指语言模型是否会产生存在偏见的内容,采用 BOLD 基准。
huggingface构建了一个脚本,其中使用了 QLoRA 和 trl 中的 SFTTrainer 来对 Llama 2 进行指令微调。,现在可以用短短几行代码中对所有 Llama-2 模型使用自己的数据进行训练!通过使用 4-bit 和 PEFT,即使在单个 A100 GPU 上,这个脚本也可以用于 70B 模型的训练。你可以在 T4 GPU 上进行 7B 的训练(即在 Colab 上可以免费获取的资源),或者在 A100 GPU 上进行 70B 的训练。
TRL——Transformer Reinforcement Learning。这是huggingface一个超全面的全栈库,包含了一整套工具用于使用强化学习 (Reinforcement Learning) 训练 transformer 语言模型。从监督调优 (Supervised Fine-tuning step, SFT),到训练奖励模型 (Reward Modeling),再到近端策略优化 (Proximal Policy Optimization),实现了全面覆盖!并且 TRL 库已经与 transformers 集成,方便直接使用!

PEFT(Parameter Efficient Fine-Tuning)是一种用于微调神经网络模型的技术,旨在在保持模型性能的同时,显著减少微调所需的计算资源和时间。这对于在资源有限的环境下进行模型微调非常有用。PEFT 的主要思想是通过使用较小的学习率来微调模型的一部分参数,而不是对整个模型的所有参数进行微调。具体来说,PEFT 将模型的参数分为不同的组,然后在每个组上应用不同的学习率。这样可以将微调的计算开销分布到多个小批次中,从而减少了每个小批次的计算负担,使得模型可以在较小的设备上进行高效微调。
在推理阶段,针对不同的模型,huggingface的建议如下:
- 要推理 7B 模型,建议选择 “GPU [medium] - 1x Nvidia A10G”。
- 要推理 13B 模型,建议选择 “GPU [xlarge] - 1x Nvidia A100”。
- 要推理 70B 模型,建议选择 “GPU [xxxlarge] - 8x Nvidia A100”。
不过这并不是唯一的选择,但是模型结果的并行性质决定了,GPU的效率会比CPU高出很多。
LlaMA-2 模型推理和结构
这里参考了karpathy/llama2.c,以Prompt输入,“你好!”为例说明推理这一过程,这里是7B模型,
- 首先从训练得到的token_embedding_table表(embedding矩阵)中找到“你”这个token的对应的向量表示,即4096个浮点数组成的向量(因为表示的是词,所以常称为词向量,后文用词向量统一表示),获得词向量之后,进行RMSNorm。,如下图中的圈1示意,每一个token(LlaMA-2共32000个token)的向量长度是4096,即token_embedding_table表的大小是[32000, 4096]。
float* content_row = &(w->token_embedding_table[token * dim]);
- 在获得该词向量之后,进行了RMSNorm运算,圈二位置所示。这里没用使用LayerNorm,说是在梯度下降时RMSNorm可以使损失更加平滑。RMSNorm论文中对LayerNorm的公式做了改造。在原有LayerNorm中借助了每个layer统计的mean和variance对参数进行了调整,但RMSNorm认为re-centering invariance property是不必要的,只用保留re-scaling invariance property。
// attention rmsnormrmsnorm(s->xb, x, w->rms_att_weight + l*dim, dim);
-
RMS之后的进入linear层,获得QKV,图中圈3,圈4,圈5分别是[4096,4096]大小的矩阵,经过Linear之后得到了,Q、K、V,这里需要注意的是,K,V是需要保留历史值得,比如图中在输入“好”这个token时,KV的你是保留在这的。关于QKV这里可以做个简单的解释。
Transformer的原文中一个很重要的词是Attention,比如问你 “鸣人是哪部动漫里的人物?”,你会将注意力(Attention)放在“鸣人”并从你的记忆中搜索,然后给出答案鸣人,由此可见一个语句中每个token的重要性并不是均等的,有些token需要给以更多的注意力(Attention)。
QKV的作用如名字所示,因为google是做搜索引擎的,所以这里的Qurey,Key和Value的意义可以参考如下的搜索引擎结果对标图。
从这里可以看到Query和Key是有相似性的,根据Query和Key的相似性展示Value的内容。所以Attention中的核心公式是。
s o f t m a x ( Q K T ) ∗ V softmax(\mathbf Q \mathbf K^T)* \mathbf V softmax(QKT)∗V
其中 s o f t m a x ( Q K T ) ∗ softmax(\mathbf Q \mathbf K^T)* softmax(QKT)∗是根据Query和Key的相似性,获取 V \mathbf V V中应该注意的掩码(Query中不是每个token都有相同的重要性, Value中的每个token的重要性也是不同的)这一不同性,可以通过softmax(按和等与一归一化)给Value的每个token分配权重。

-
有了上面的QKV的初步理解之后,接下来看看LlaMA-2的Multi-Head,LlaMA-2 7B模型(Meta官方)的参数内容如下:
(venv) ➜ localGPT git:(main) ✗ cat ~/llama/llama-2-7b/params.json
{"dim": 4096, "multiple_of": 256, "n_heads": 32, "n_layers": 32, "norm_eps": 1e-05, "vocab_size": -1}
这里的n_heads:32就是对应于Attention score里面的32,将步骤3中的QKV(长度为4096)都分为32个head,每个head的长度为128(128*32=4096),圈6和圈7,圈8和圈9是因为时序上是有依赖关系的,比如“好”这个token和“你”这个token是存在时序上的关系。圈6和圈8是计算“你”的Attention score,圈7和圈8是计算“好”的Attention score,然后将“好”当前以及之前历史所有的token Attention score的影响叠加到当前的“好”这个token,得到圈10计算的累积Attention score。
LLama2的注意力机制使用了GQA
MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
MQA(Multi-Query Attention,Fast Transformer Decoding: One Write-Head is All You Need)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA(Grouped-Query Attention,GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
- 计算Attention out,就是将累积Attention score和Wo做Linear运算,然后将Attention out和步骤圈2的RMSNorm和其相加(resnet结构),然后再计算RMSNorm得到Attention Norm结果,即圈13。
- FFN运算,将圈13的结果,分别通过W1,W3以及W2计算后得到前向网络的输出,然后再进行类似步骤5的resnet步骤得到一个Transformer block的输出,
- Transformer block重复32次,然后再经过RMSNorm输出,再经过logits运算后得到输出。
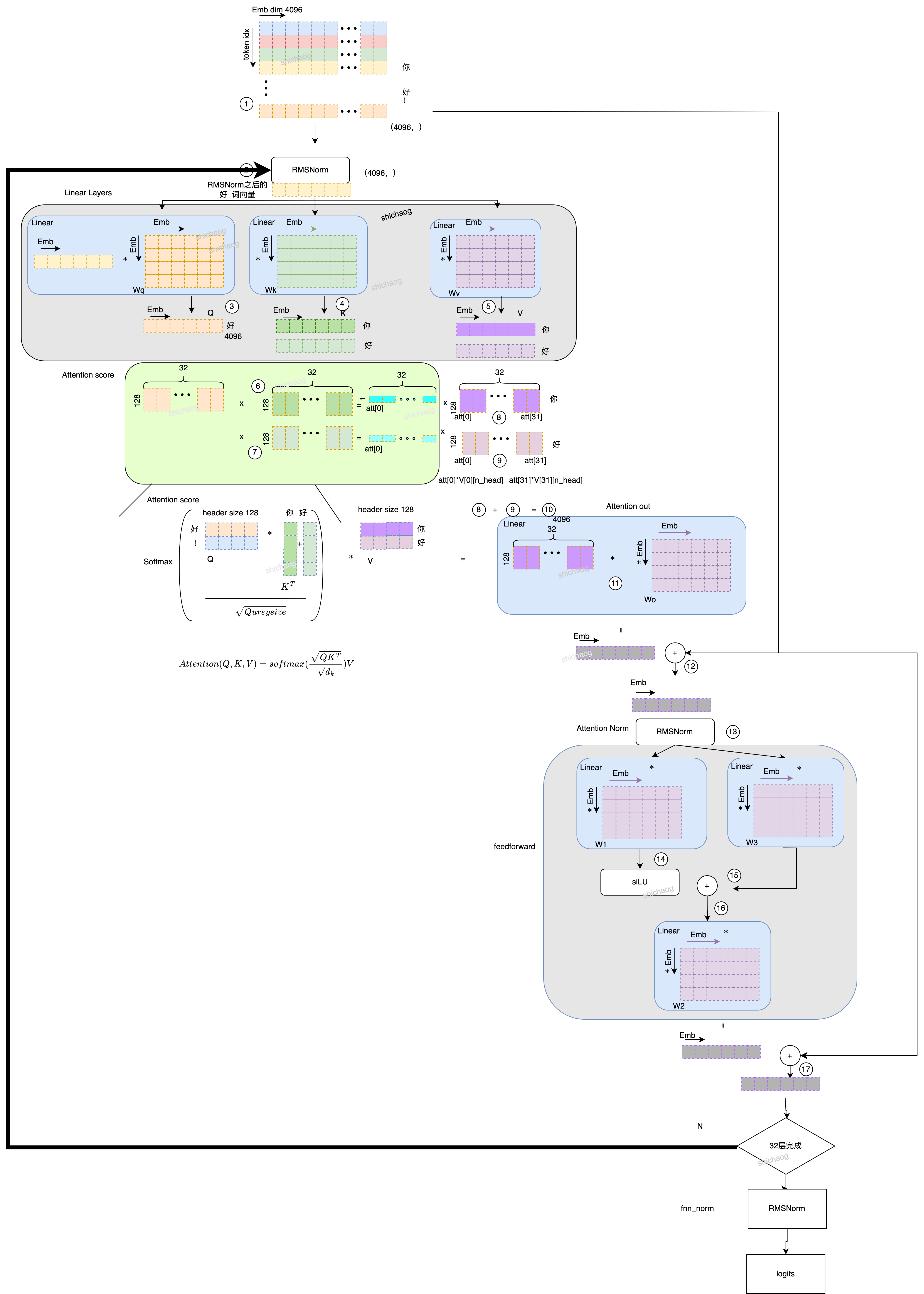
至此,模型的推理部分完成了。
因为llama2.c是基于c代码的,因而其效率和速度理论上可以更快(SIMD),此外,该库的作者还给了tinystories的一个参数量少很多简化版的LlaMA模型预训练例子。tinystories的数据集是从Hugging face下载的地址。
大模型训练相关
预训练模型从上面的tinystories可以看出来,这到不是什么难事,接下里就是指令微调以及基于人类反馈的强化学习。指令微调(SFT)和预训练模型最大的差异在于数据集,当然为了SFT算力需求更少,也会采用诸如LoRA等方法,当然Hugging face已经将这些都做成了先从的API供调用使用了。Huggingface上有很多数据集,除了这里大语言模型,还有多模态数据集,详见Huggingface官网。
指令微调数据集
开源的大语言模型训练数据集基本在Huggingface上都可以找到。
- 斯坦福开源数据集,alpaca_data.json,包含了微调Alpaca模型的52k条指令跟随数据,json文件是一个字典列表,每个字典包含instruction:str,描述模型应执行的任务。
- Generated_Chat_0.4M,包含约40万条由BELLE项目生成的个性化角色对话数据,包含角色介绍。
注意:此数据集是由ChatGPT产生的,未经过严格校验,题目或解题过程可能包含错误。使用过程中请注意这一点。 - School Math 0.25M,包含约25万条由BELLE项目生成的中文数学题数据,包含解题过程。
注意:此数据集是由ChatGPT产生的,未经过严格校验,题目或解题过程可能包含错误。使用过程中请注意这一点。 - JosephusCheung/GuanacoDataset,该数据集共534,530条,花费了6k美金,是一个多语言数据集,包括英文、中文、日语。
此外还有Fifefly数据集,alpaca_chinese_datase等。
Huggingface的trl库提供的API如下:
- Model Classes: A brief overview of what each public model class does.
- SFTTrainer: Supervise Fine-tune your model easily with SFTTrainer
- RewardTrainer: Train easily your reward model using RewardTrainer.
- PPOTrainer: Further fine-tune the supervised fine-tuned model using PPO algorithm
- Best-of-N Samppling: Use best of n sampling as an alternative way to sample predictions from your active model
- DPOTrainer: Direct Preference Optimization training using DPOTrainer.
并且贴心的附上了一些例子 - Sentiment Tuning: Fine tune your model to generate positive movie contents
- Training with PEFT: Memory efficient RLHF training using adapters with PEFT
- Detoxifying LLMs: Detoxify your language model through RLHF
- StackLlama: End-to-end RLHF training of a Llama model on Stack exchange dataset
- Multi-Adapter Training: Use a single base model and multiple adapters for memory efficient end-to-end training
raining with PEFT
该例子使用LoRA技术给出了内测高效的预训练例子。
LoRA(Low-Rank Adaption of Large Language Models)是微软提出的处理大语言模型fine-tunning的技术,大语言模型的参数量有数十亿,为了让其适合特定任务fine-tune的过程成本是很高的,LoRA方法建议冻结预训练模型参数并在每个Transformer block中注入可训练层(rank-decomposition matrics),因为冻结的预训练模型参数并不参与梯度计算,这极大缩减了可训练参数以及GPU内存的需求,研究人员发现,只集中于大语言模型的Transform attention blocks ,LoRA的微调质量与全模型微调相当,同时速度更快,需要更少的计算。
尽管LoRA是针对大语言模型提出的,并且这一技术在Transformer blocks上得到验证,但是这个技术可以用在其它模型上,比如对Stable Diffusion模型的fine-tune,LoRA可以应用于将图像表示与描述它们的提示相关联的交叉注意力层(cross-attention layers)。
这里就不进一步罗列原理和代码片段了,感兴趣可以自己去Huggingface官网查看。
构建本地化GPT
如果不想与OpenAI、讯飞、百度或其他类似的AI提供商共享私有(比如金融、医疗等具体行业和公司)信息或数据,或者一些新的知识并不在预训练模型中,这时不得不借助外部知识库来解决这些问题。本文概述了如何使用LocalGPT API创建您自己的个人AI助手。
LocalGPT是一个强大的工具,适合任何希望在本地运行类似GPT的模型的人,允许隐私、自定义和离线使用。
它提供了一种方法来向特定文档或数据集提问,从这些文档中找到答案,并在不依赖互联网连接或外部服务器的情况下执行这些操作。
LocalGPT使用起来是很简单的,其支持在各种类型架构上推理模型。但需要再Huggingface确认和想要的模型,在Model card的说明下有该模型支持的架构,在File and versions上可以下载想要版本的模型(量化位数等等)。

LangChain
LangChain是开发用于大语言模型应用的一套框架。它支持以下特性:
- 数据感知:将语言模型连接到其他数据源
- 代理:允许语言模型与其环境交互
LangChain官网的quickstart是基于openAI为例的,不过这里我们以LlaMA-2为例,LocaGPT已经封装好了。
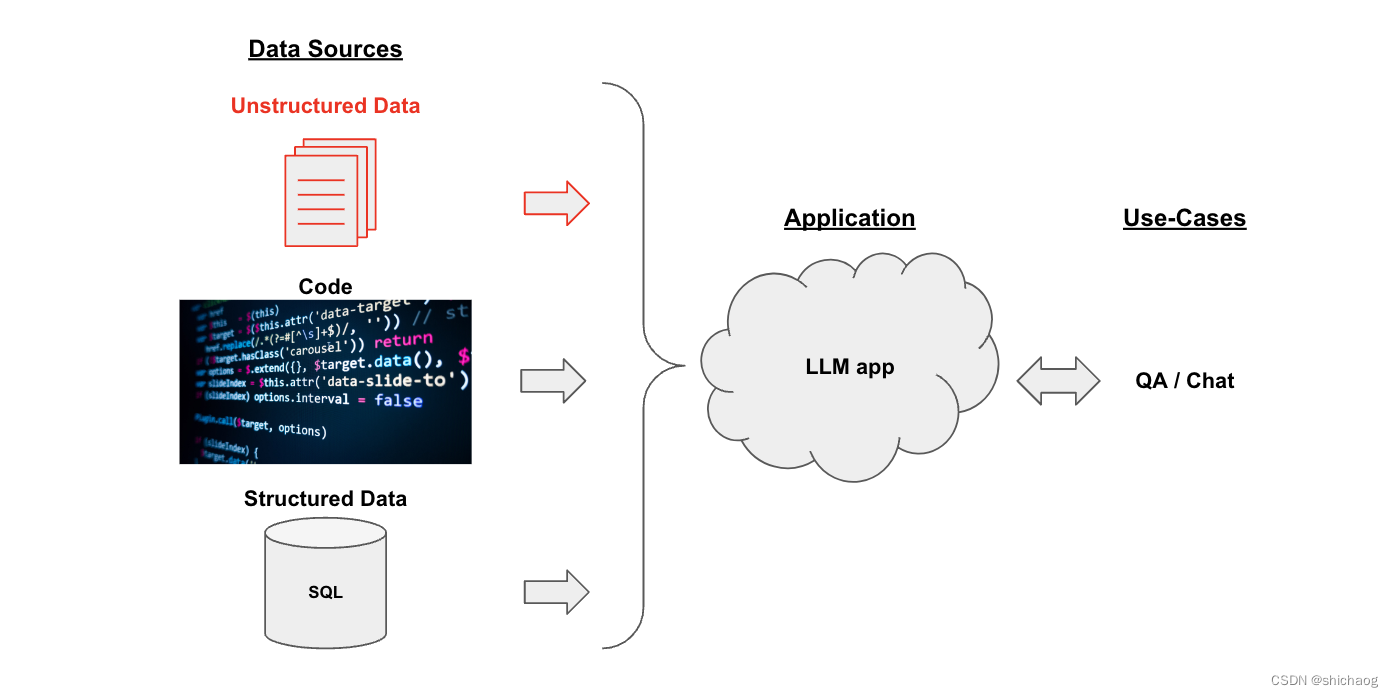
对于QA场景,首先需要将数据源(非结构化的数据)转为结构化的数据,然后将其注入大语言模型,大概得关系图如下。
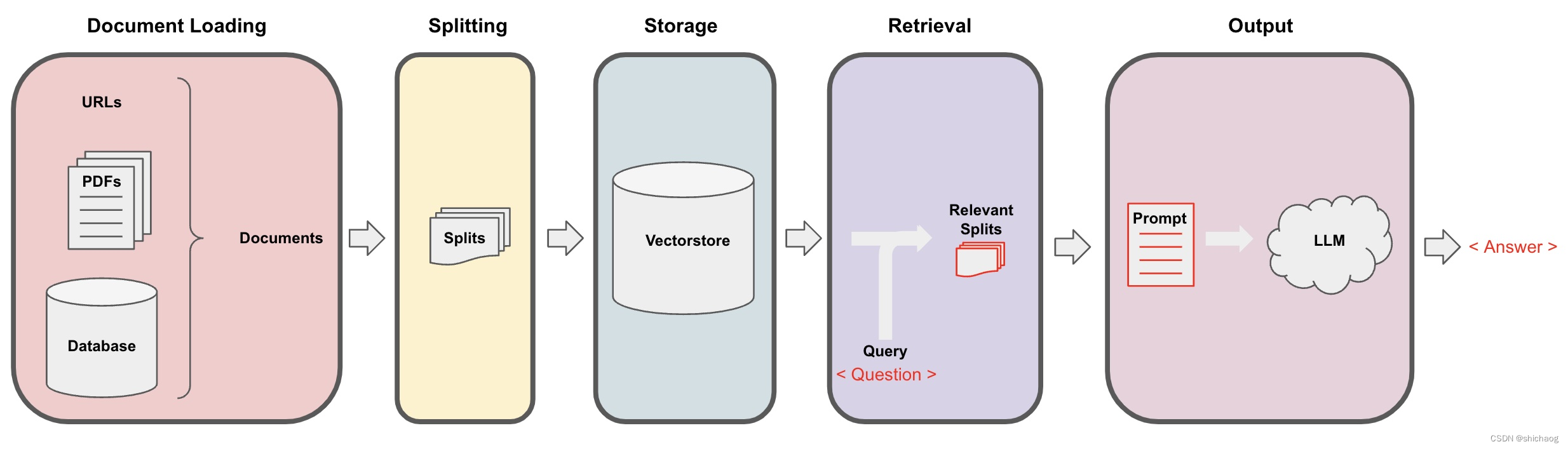
转成结构化的又分为分割、存储和提取几个步骤,其大概过程如下:
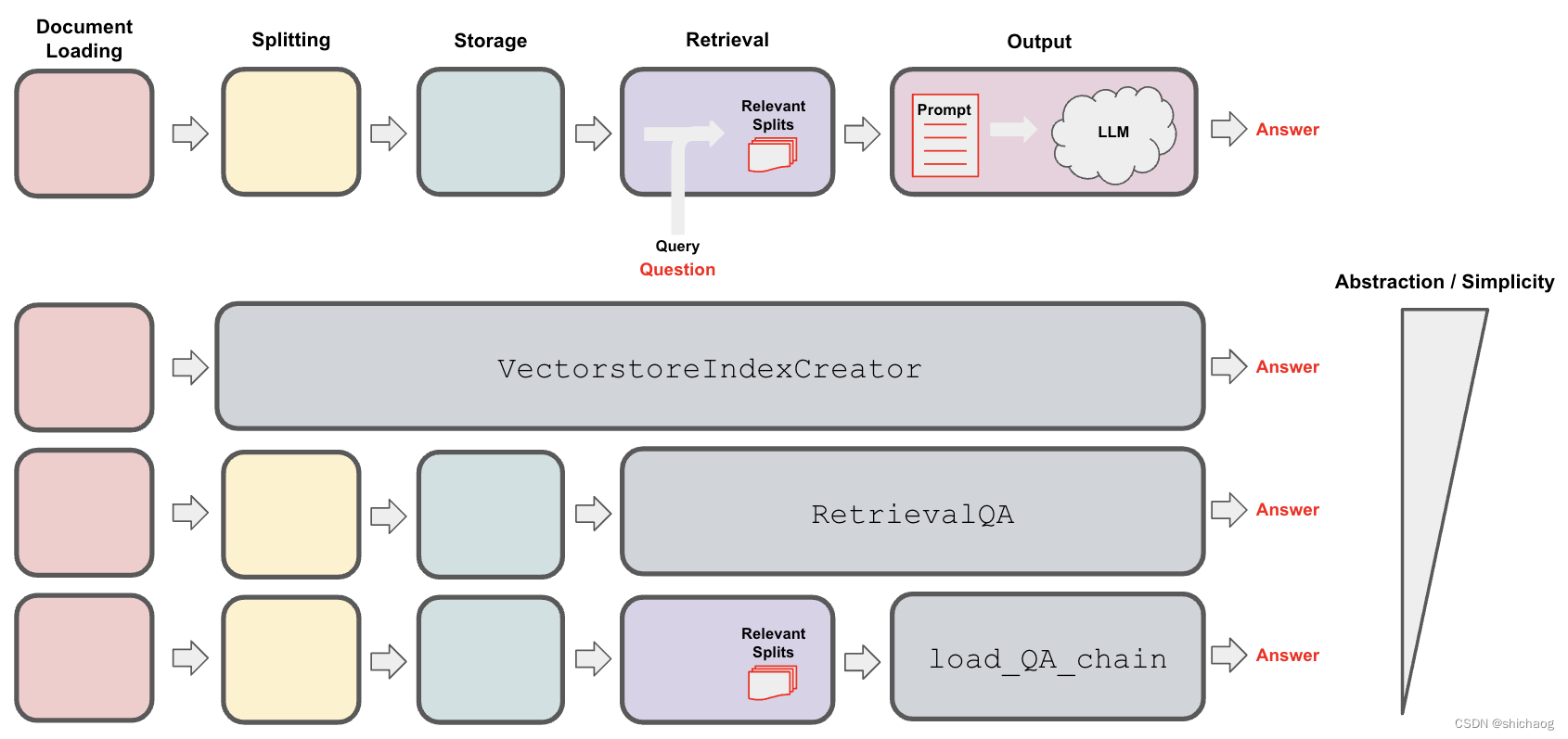
对于QA的详细过程如下。
相关文章:
大语言模型之四-LlaMA-2从模型到应用
最近开源大语言模型LlaMA-2火出圈,从huggingface的Open LLM Leaderboard开源大语言模型排行榜可以看到LlaMA-2还是非常有潜力的开源商用大语言模型之一,相比InstructGPT,LlaMA-2在数据质量、培训技术、能力评估、安全评估和责任发布方面进行了…...
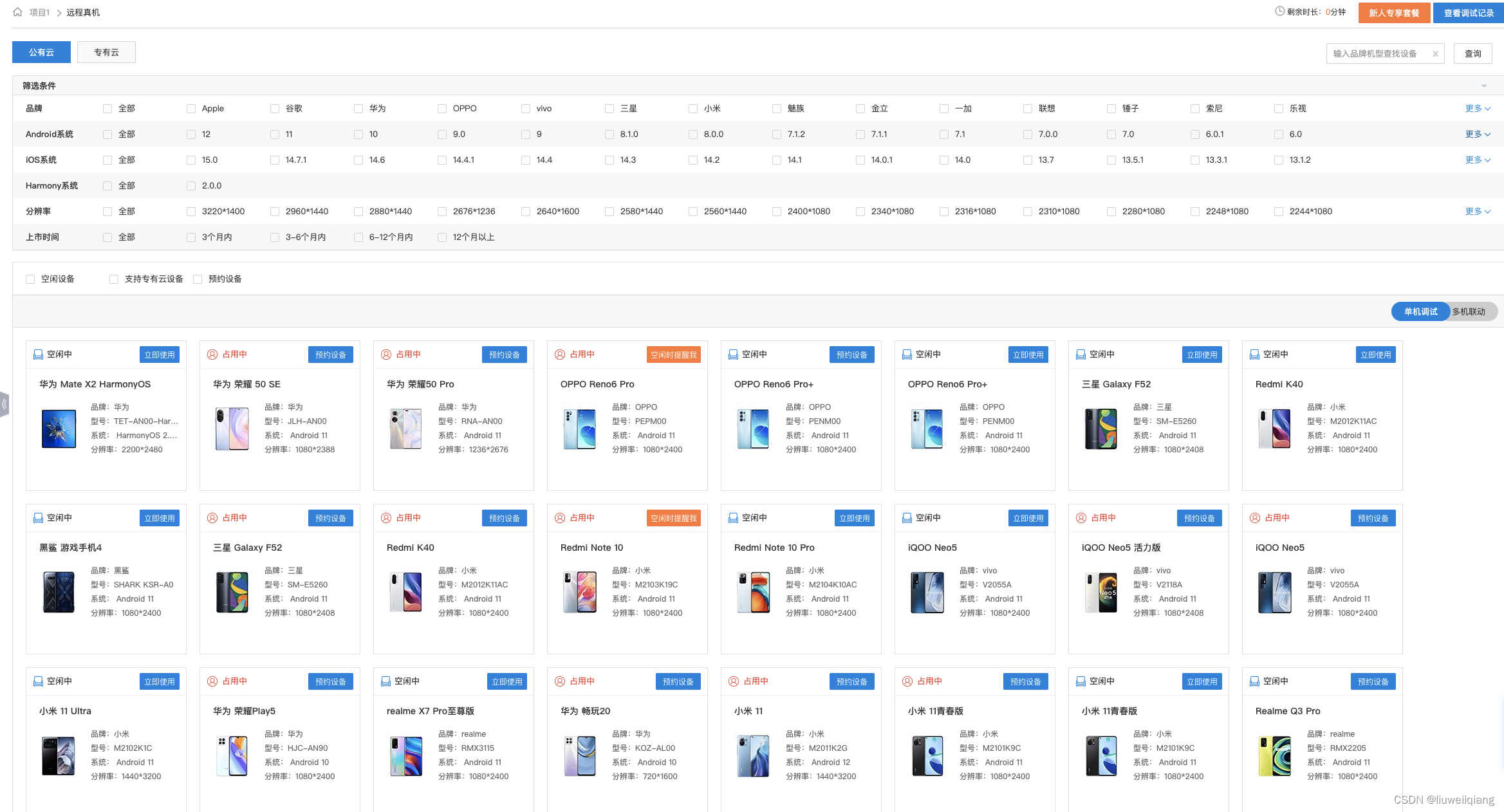
Android 远程真机调研
背景 现有的安卓测试机器较少,很难满足 SDK 的兼容性测试及线上问题(特殊机型)验证,基于真机成本较高且数量较多的前提下,可以考虑使用云测平台上的机器进行验证,因此需要针对各云测平台进行调研、比较。 …...
)
B. 攻防演练 (2021CCPC女生赛)
题意: 给出一个长度为n的字符,字符是前m个小写字母,有q个询问,每次询问一个最短子序列的长度满足不是[l,r]内任意一个子序列 思路: [l,r]中子序列可以看成是从[l,r]中的某个位置开始,跳到下一个字符的位…...
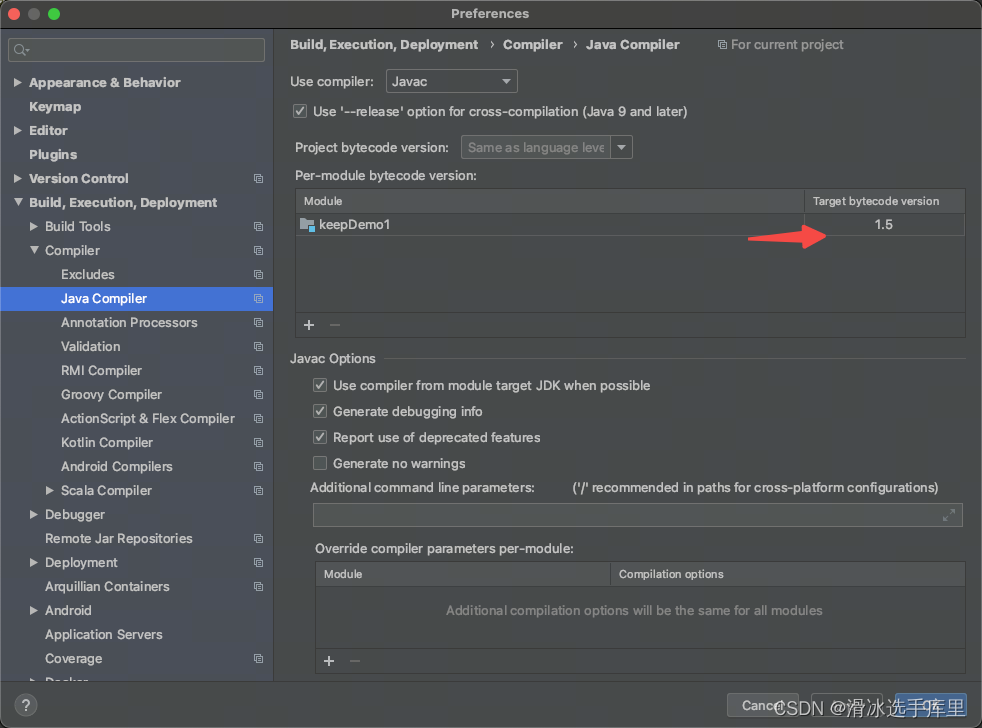
MAC环境,在IDEA执行报错java: -source 1.5 中不支持 diamond 运算符
Error:(41, 51) java: -source 1.5 中不支持 diamond 运算符 (请使用 -source 7 或更高版本以启用 diamond 运算符) 进入设置 修改java版本 pom文件中加入 <plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin&l…...
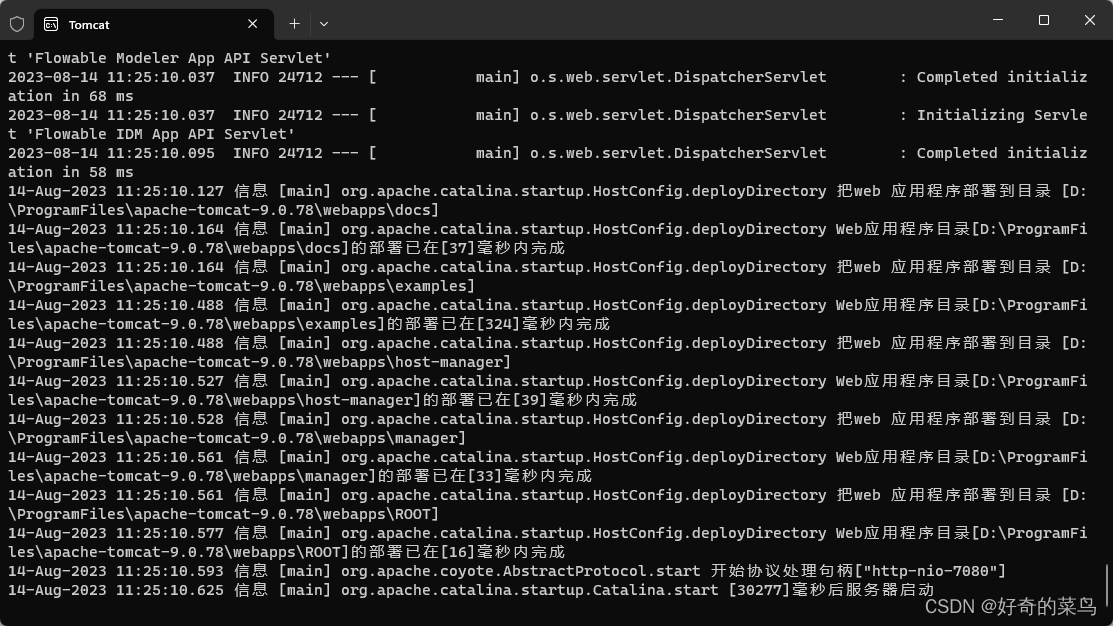
Tomcat日志中文乱码
修改安装目录下的日志配置 D:\ProgramFiles\apache-tomcat-9.0.78\conf\logging.properties java.util.logging.ConsoleHandler.encoding GBK...
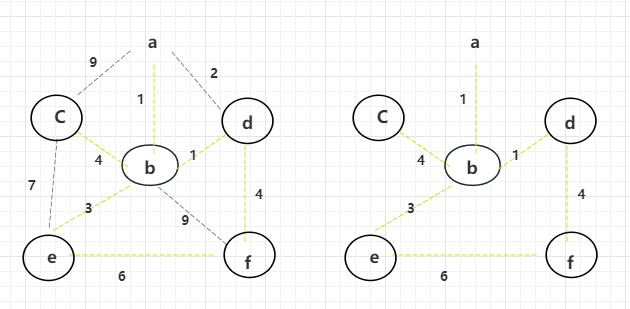
最小生成树 — Prim算法
同Kruskal算法一样,Prim算法也是最小生成树的算法,但与Kruskal算法有较大的差别。 Prim算法整体是通过“解锁” “选中”的方式,点 -> 边 -> 点 -> 边。 因为是最小生成树,所以针对的也是无向图,所以可以随意…...

如何使用PHP Smarty模板进行AJAX交互?
首先,我们要明白,AJAX是一种在无需刷新整个页面的情况下,与服务器进行通信的技术。这对于改善用户体验来说,是个大宝贝。而PHP Smarty模板则是PHP的一种模板引擎,它使得设计和开发人员能够更好地分离逻辑和显示。 现在…...
nginx反向代理、负载均衡
修改nginx.conf的配置 upstream nginx_boot{# 30s内检查心跳发送两次包,未回复就代表该机器宕机,请求分发权重比为1:2server 192.168.87.143 weight100 max_fails2 fail_timeout30s; server 192.168.87.1 weight200 max_fails2 fail_timeout30s;# 这里的…...
React Native文本添加下划线
import { StyleSheet } from react-nativeconst styles StyleSheet.create({mExchangeCopyText: {fontWeight: bold, color: #1677ff, textDecorationLine: underline} })export default styles...

微服务-Nacos(配置管理)
配置更改热更新 在Nacos中添加配置信息: 在弹出表单中填写配置信息: 配置获取的步骤如下: 1.引入Nacos的配置管理客户端依赖(A、B服务): <!--nacos的配置管理依赖--><dependency><groupId&…...

UML图绘制 -- 类图
1.类图的画法 类 整体是个矩形,第一层类名,第二层属性,第三层方法。 :public- : private# : protected空格: 默认的default 对应的类写法。 public class Student {public String name;public Integer age;protected I…...
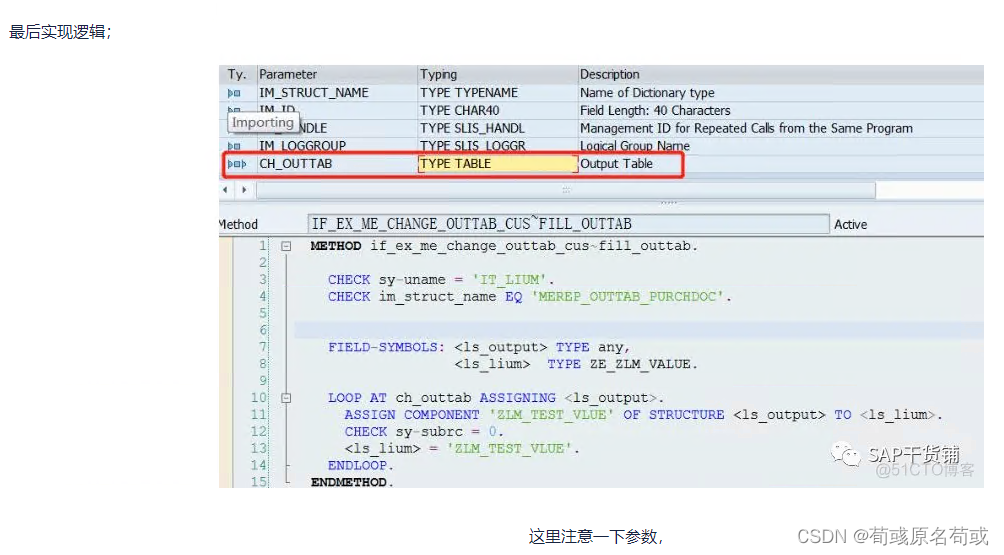
SAP ME2L/ME2M/ME3M报表增强添加字段(包含:LMEREPI02、SE18:ES_BADI_ME_REPORTING)
ME2L、ME2M、ME3M这三个报表的字段增强,核心点都在同一个结构里 SE11:MEREP_OUTTAB_PURCHDOC 在这里加字段,如果要加的字段是EKKO、EKPO里的数据,直接加进去,啥都不用做,就完成了 如果要加的字段不在EKKO和EKPO这两个…...

探讨uniapp的数据缓存问题
异步就是不管保没保存成功,程序都会继续往下执行。同步是等保存成功了,才会执行下面的代码。使用异步,性能会更好;而使用同步,数据会更安全。 1 uni.setStorage(OBJECT) 将数据存储在本地缓存中指定的 key 中&#x…...

服务的拆分
纵向拆分 是从业务维度进行拆分。标准是按照业务的关联程度来决定,关联比较密切的业务适合拆分为一个微服务,而功能相对比较独立的业务适合单独拆分为一个微服务。 以社交App为例,你可以认为首页信息流是一个服务,评论是一个服务…...

Uniapp Syntax Error: Error: Unbalanced delimiter found in string
报错 in ./src/pages/user/components/tasks.vue?vue&typescript&langjs&Syntax Error: Error: Unbalanced delimiter found in string...这边导致文件的原因:可能是条件编译语法不小心删了某个字符,导致不全,无法形成一对。 //…...
视频集中存储EasyCVR视频汇聚平台定制项目增加AI智能算法
安防视频集中存储EasyCVR视频汇聚平台,可支持海量视频的轻量化接入与汇聚管理。平台能提供视频存储磁盘阵列、视频监控直播、视频轮播、视频录像、云存储、回放与检索、智能告警、服务器集群、语音对讲、云台控制、电子地图、平台级联、H.265自动转码等功能。为了便…...

确保Django项目的稳定运行和持续改进
确保Django项目的稳定运行和持续改进 引言 Django是一个强大的Python Web框架,用于构建高效、可靠的Web应用程序。然而,部署一个Django项目并不意味着工作已经完成。在项目上线之后,确保项目的稳定运行并不断进行改进是非常重要的。本博客将…...

HAProxy负载均衡 代理
1.安装 yum -y install haproxy 2.配置文件 /etc/haproxy 下 global log 127.0.0.1 local2 #日志定义级别 chroot /var/lib/haproxy #当前工作目录 pidfile /var/run/haproxy.pid #进程id maxconn 4000 #最大连接…...
每天10个小知识点)
前端面试的游览器部分(8)每天10个小知识点
目录 系列文章目录前端面试的游览器部分(1)每天10个小知识点前端面试的游览器部分(2)每天10个小知识点前端面试的游览器部分(3)每天10个小知识点前端面试的游览器部分(4)每天10个小知…...
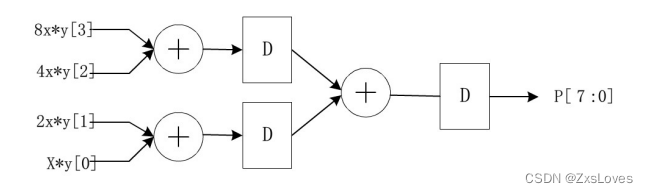
【【verilog典型电路设计之流水线结构】】
verilog典型电路设计之流水线结构 下图是一个4位的乘法器结构,用verilog HDL 设计一个两级流水线加法器树4位乘法器 对于流水线结构 其实需要做的是在每级之间增加一个暂存的数据用来存储 我们得到的东西 我们一般来说会通过在每一级之间插入D触发器来保证数据的联…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...