无涯教程-TensorFlow - 单词嵌入
Word embedding是从离散对象(如单词)映射到向量和实数的概念,可将离散的输入对象有效地转换为有用的向量。
Word embedding的输入如下所示:
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259) blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158) orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213) oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)
Word2vec
Word2vec是用于无监督最常见方法,它以一种方式训练模型,即给定的输入单词通过使用跳跃语法来预测单词的上下文。
TensorFlow提供了多种方法来实现这种模型,从而提高了复杂性和优化级别,并使用了多线程概念和更高级别的抽象。
import os import math import numpy as np import tensorflow as tf from tensorflow.contrib.tensorboard.plugins import projector batch_size = 64 embedding_dimension = 5 negative_samples = 8 LOG_DIR = "logs/word2vec_intro" digit_to_word_map = {1: "One", 2: "Two", 3: "Three", 4: "Four", 5: "Five", 6: "Six", 7: "Seven", 8: "Eight", 9: "Nine"} sentences = [] # 创建两种句子 - 奇数和偶数序列。for i in range(10000): rand_odd_ints = np.random.choice(range(1, 10, 2), 3) sentences.append(" ".join([digit_to_word_map[r] for r in rand_odd_ints])) rand_even_ints = np.random.choice(range(2, 10, 2), 3) sentences.append(" ".join([digit_to_word_map[r] for r in rand_even_ints])) # 将单词映射到索引 word2index_map = {} index = 0 for sent in sentences: for word in sent.lower().split(): if word not in word2index_map: word2index_map[word] = index index += 1 index2word_map = {index: word for word, index in word2index_map.items()} vocabulary_size = len(index2word_map) # 生成skip-gram对 skip_gram_pairs = [] for sent in sentences: tokenized_sent = sent.lower().split() for i in range(1, len(tokenized_sent)-1): word_context_pair = [[word2index_map[tokenized_sent[i-1]], word2index_map[tokenized_sent[i+1]]], word2index_map[tokenized_sent[i]]] skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][0]]) skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][1]]) def get_skipgram_batch(batch_size): instance_indices = list(range(len(skip_gram_pairs))) np.random.shuffle(instance_indices)batch = instance_indices[:batch_size] x = [skip_gram_pairs[i][0] for i in batch] y = [[skip_gram_pairs[i][1]] for i in batch] return x, y #批处理示例 x_batch, y_batch = get_skipgram_batch(8) x_batch y_batch [index2word_map[word] for word in x_batch] [index2word_map[word[0]] for word in y_batch] #输入数据,标签 train_inputs=tf.placeholder(tf.int32, shape=[batch_size])train_labels = tf.placeholder(tf.int32, shape = [batch_size, 1]) # 嵌入查找表目前仅在 CPU 中实现tf.name_scope("embeddings"): embeddings = tf.Variable( tf.random_uniform([vocabulary_size, embedding_dimension], -1.0, 1.0), name = embedding) # 这本质上是一个查找表embed = tf.nn.embedding_lookup(embeddings, train_inputs) # 为 NCE 损失创建变量 nce_weights = tf.Variable( tf.truncated_normal([vocabulary_size, embedding_dimension], stddev = 1.0/math.sqrt(embedding_dimension))) nce_biases = tf.Variable(tf.zeros([vocabulary_size])) loss = tf.reduce_mean( tf.nn.nce_loss(weights = nce_weights, biases = nce_biases, inputs = embed, labels = train_labels,num_sampled = negative_samples, num_classes = vocabulary_size)) tf.summary.scalar("NCE_loss", loss) # 学习率衰减 global_step = tf.Variable(0, trainable = False) learningRate = tf.train.exponential_decay(learning_rate = 0.1, global_step = global_step, decay_steps = 1000, decay_rate = 0.95, staircase = True) train_step = tf.train.GradientDescentOptimizer(learningRate).minimize(loss) merged = tf.summary.merge_all() with tf.Session() as sess: train_writer = tf.summary.FileWriter(LOG_DIR, graph = tf.get_default_graph()) saver = tf.train.Saver() with open(os.path.join(LOG_DIR, metadata.tsv), "w") as metadata: metadata.write(Name Class ) for k, v in index2word_map.items(): metadata.write(%s %d % (v, k)) config = projector.ProjectorConfig() embedding = config.embeddings.add() embedding.tensor_name = embeddings.name # 将此张量链接到其元数据文件(例如标签)。embedding.metadata_path = os.path.join(LOG_DIR, metadata.tsv) projector.visualize_embeddings(train_writer, config) tf.global_variables_initializer().run() for step in range(1000): x_batch, y_batch = get_skipgram_batch(batch_size) summary, _ = sess.run([merged, train_step], feed_dict = {train_inputs: x_batch, train_labels: y_batch})train_writer.add_summary(summary, step)if step % 100 == 0:saver.save(sess, os.path.join(LOG_DIR, "w2v_model.ckpt"), step)loss_value = sess.run(loss, feed_dict = {train_inputs: x_batch, train_labels: y_batch})print("Loss at %d: %.5f" % (step, loss_value))# 在使用之前规范化嵌入norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims = True))normalized_embeddings = embeddings /norm normalized_embeddings_matrix = sess.run(normalized_embeddings)ref_word = normalized_embeddings_matrix[word2index_map["one"]]cosine_dists = np.dot(normalized_embeddings_matrix, ref_word) ff = np.argsort(cosine_dists)[::-1][1:10] for f in ff: print(index2word_map[f]) print(cosine_dists[f])
上面的代码生成以下输出-

TensorFlow - 单词嵌入 - 无涯教程网无涯教程网提供Word embedding是从离散对象(如单词)映射到向量和实数的概念,可将离散的输入对象有效... https://www.learnfk.com/tensorflow/tensorflow-word-embedding.html
https://www.learnfk.com/tensorflow/tensorflow-word-embedding.html
相关文章:
无涯教程-TensorFlow - 单词嵌入
Word embedding是从离散对象(如单词)映射到向量和实数的概念,可将离散的输入对象有效地转换为有用的向量。 Word embedding的输入如下所示: blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259) blues: (0.01396, 0.11887, -0.48963, ..., 0.03…...
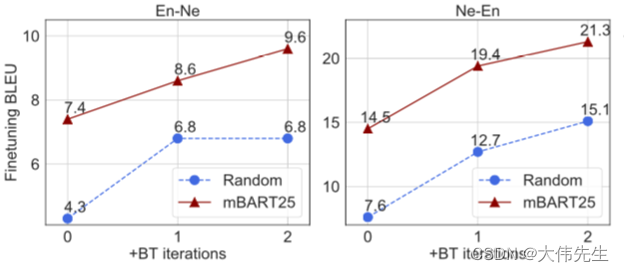
Facebook AI mBART:巴别塔的硅解
2018年,谷歌发布了BERT(来自transformers的双向编码器表示),这是一种预训练的语言模型,在一系列自然语言处理(NLP)任务中对SOTA结果进行评分,并彻底改变了研究领域。类似的基于变压器…...

BDA初级分析——SQL清洗和整理数据
一、数据处理 数据处理之类型转换 字符格式与数值格式存储的数据,同样是进行大小排序, 会有什么区别? 以rev为例,看看字符格式与数值格式存储时,排序会有什么区别? 用cast as转换为字符后进行排序 SEL…...

汽车后视镜反射率测定仪
后视镜是驾驶员坐在驾驶室座位上直接获取汽车后方、侧方和下方等外部信息的工具。它起着“第三只眼睛”的作用。后视镜按安装位置划分通常分为车外后视镜、监视镜和内后视镜。外后视镜观察汽车后侧方监视镜观察汽车前下方内后视镜观察汽车后方及车内情况。用途不一样镜面结构也…...

Redis学习笔记
redis相关内容 默认端口6379 默认16个数据库,初始默认使用0号库 使用select 切换数据库 统一密码管理,所有库密码相同 dbsize:查看当前库key的数量 flushdb:清空当前库 flushall:清空全部库 redis是单线程 多路…...

韩顺平Linux 四十四--
四十四、rwx权限 权限的基本介绍 输入指令 ls -l 显示的内容如下 -rwxrw-r-- 1 root 1213 Feb 2 09:39 abc0-9位说明 第0位确定文件类型(d , - , l , c , b) l 是链接,相当于 windows 的快捷方式- 代表是文件是普通文件d 是目录,相…...

【支付宝小程序】分包优化教程
🦖我是Sam9029,一个前端 Sam9029的CSDN博客主页:Sam9029的博客_CSDN博客-JS学习,CSS学习,Vue-2领域博主 🐱🐉🐱🐉恭喜你,若此文你认为写的不错,不要吝啬你的赞扬,求收…...
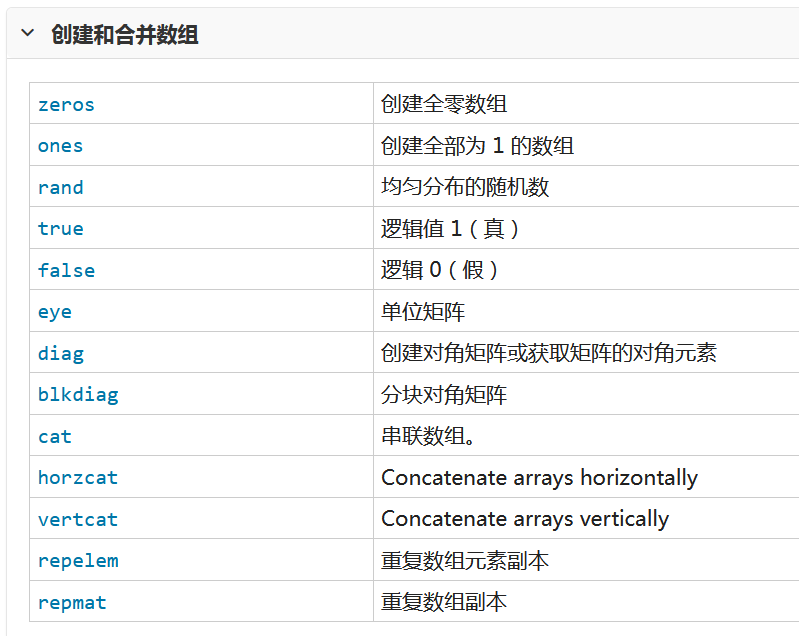
语言基础2 矩阵和数组
语言基础2 矩阵和数组 矩阵和数组是matlab中信息和数据的基本表示形式 可以创建常用的数组和网格 合并现有的数组 操作数组的形状和内容 以及使用索引访问数组元素 用到的函数列表如下 一 创建 串联和扩展矩阵 矩阵时按行和列排列的数据元素的二维数据元素的二维矩…...

springMVC中过滤器抛出异常,自定义异常捕获
在过滤器中引入org.springframework.web.servlet.HandlerExceptionResolver AutowiredQualifier("handlerExceptionResolver")private HandlerExceptionResolver resolver; // doFilter中处理if (条件1) {if (条件2) {resolver.resolveException(request, response, …...

图像检索技术研究:深度度量与深度散列在相似性学习中的应用比较与实践 - 使用Python与Jupyter环境
引言 在计算机视觉领域,图像检索是一个长期存在并持续受到研究者关注的重要话题。随着大数据时代的到来,如何高效、准确地从海量数据中检索到相似的图像成为一个巨大的挑战。传统的检索方法在大数据环境下表现不佳,而深度学习技术的崛起为图…...

CSS加载失败的6个原因
有很多刚刚接触 CSS 的新手有时会遇到 CSS 加载失败这个问题,但测试时,网页上没有显示该样式的问题,这就说明 CSS 加载失败了。出现这种状况一般是因为的 CSS 路径书写错,或者是在浏览器中禁止掉了 CSS 的加载,可以重新…...
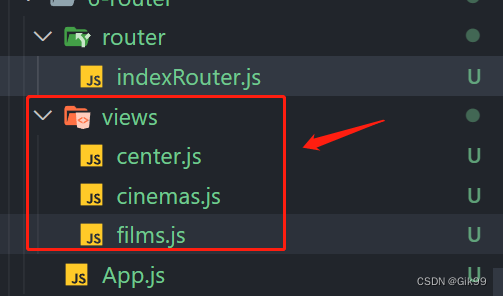
react之路由的安装与使用
一、路由安装 路由官网2021.11月初,react-router 更新到 v6 版本。使用最广泛的 v5 版本的使用 npm i react-router-dom5.3.0二、路由使用 2.1 路由的简单使用 第一步 在根目录下 创建 views 文件夹 ,用于放置路由页面 films.js示例代码 export default functio…...

基于RoCE的应用程序的MTU注意事项
目录 基于RoCE的应用程序的MTU注意事项 探测网络中的MTU设置 概要 原文 MTU测试结果 DOC: CentOS安装tshark抓包工具 基于RoCE的应用程序的MTU注意事项 原文:https://support.mellanox.com/s/article/MLNX2-117-1682kn InfiniBand协议最大传输单元ÿ…...

springboot集成Graphql相关问题汇总
1、idea在debug运行时出现java.lang.NoClassDefFoundError:kotlin/collections/AbstractMutableMap 解决:禁用idea dubugger中kotlin coroutine agent 见:https://stackoverflow.com/questions/70796177/after-the-spring-boot-source-code-is-compile…...

Angular16的路由守卫基础使用
Angular16的路由守卫基础使用 使用ng generate guard /guard/login命令生成guard文件因新版Angular取消了CanActivate的使用,改用CanActivateFn,因此使用router跳转需要通过inject的方式导入。 import { inject } from angular/core; import { CanActi…...

leetcode228. 汇总区间
题目 给定一个 无重复元素 的 有序 整数数组 nums 。 返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表 。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。 列表中的每个区间范围 [a,b]…...

删除有序链表中重复的元素-II(链表)
乌!蒙!山!连!着!山!外!山! 题目: 思路: 双指针,slow和fast,并且增加标记flag初始为1。 如果slow指向节点值等于fast指向节点值&…...

element单独检验form表单中的一项
<el-form-item prop"limitDays" style"margin-left: 5px;"><el-input v-model"ruleForm.limitDays" placeholder"天数" style"width: 100px;" /> </el-form-item> <el-form-item prop"limitCount…...

Webpack node、output.jsonpFunction 配置详解
Webpack node、output.jsonpFunction 配置详解 最近尝试给一些用到 webpack 的项目升级到最新 webpack5 版本,其中遇到了一些问题,我挑了两个比较典型的问题,其中主要涉及到了 webpack 的 node 属性跟 output.jsonpFunction (web…...

要跟静音开关说再见了!iPhone15新变革,Action按钮引领方向
有很多传言称iPhone 15 Pro会有很多变化,但其中一个变化可能意味着iPhone体验从第一天起就有的一项功能的终结。我说的是静音开关,它可以让你轻松地打开或关闭iPhone的铃声。 根据越来越多的传言,iPhone 15 Pro和iPhone 15 Pro Max将拆除静音…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...