使用Java和ChatGPT Api来创建自己的大模型聊天机器人
文章目录
- 前言
- ChatGPT Api简析
- Chat
- function call
- Embeddings
- 制作机器人
- 上下文
- 向量数据库
- 更多场景介绍
- 扩展阅读
前言
什么是大模型?
大型语言模型(LLM)是一种深度学习模型,它使用大量数据进行预训练,并能够通过提示工程解决各种下游任务。LLM 的出发点是建立一个适用于自然语言处理的基础模型,通过预训练和提示工程的方式实现模型在新的数据分布和任务上的强大泛化能力。LLM 旨在解决自然语言处理中的一些关键问题,例如文本分类、命名实体识别、情感分析等。
LLM 由多个主要组件组成,包括图像编码器、提示编码器和掩码解码器。图像编码器主要用于对输入图像进行编码,以便将其转换为可供模型处理的格式。提示编码器用于将不同类型的提示(如点、框、文本和掩码)表示为模型可以理解的形式。掩码解码器则将图像编码器和提示编码器生成的嵌入映射到分割掩码。
LLM 的训练过程涉及多个步骤,包括预训练、提示工程和微调。在预训练阶段,模型在大量无监督数据上进行训练,以学习自然语言处理中的基本模式和规律。在提示工程阶段,模型根据特定任务的提示进行调整,以使其能够解决该任务。最后,在微调阶段,模型在少量标注数据上进行训练,以进一步优化其性能。
LLM 的优点在于其强大的泛化能力和适用性。由于它们在大量数据上进行预训练,因此它们可以轻松地适应新的数据集和任务,并且只需要很少的微调数据。此外,LLM 还可以应用于多种自然语言处理任务,例如文本分类、命名实体识别、情感分析等。
然而,LLM 也存在一些缺点。首先,由于它们在大量数据上进行预训练,因此它们需要大量的计算资源和时间。其次,LLM 的训练和部署可能需要大量的内存和计算资源,这可能会限制它们的实际应用。
上面一段话是我询问大模型后,大模型给出的一个回答。
大模型英文缩写LLM,全程是Large Language Model(大语言模型)。根据我的理解,大模型就是参数量规模很大的一个语言模型。ChatGPT等大模型的体验效果就是,能很好地进行对话交互,感觉它是一个很聪明“机器人”,有时候甚至根本就感觉不出来它是“机器人”。
这篇文章我们就来介绍一下如何使用chatGPT的Api来构建一个属于自己的大模型聊天机器人。
ChatGPT Api简析
首先来介绍一下chatGPT该如何使用。OpenAI除了给提供了网页的直接交互体验外,还提供了一套完整的API接口,这也是我们能够制造自己机器人的前提。使用这套API接口就能实现和OpenAI能力一样的效果了。这里贴一个需要魔法的官网:官网API文档 和一个不需要的国内网站:API文档中文版。我们重点介绍其中的Chat、Embeddings两个接口。
建议:如果对chatGPT的api比较熟悉,可以跳过这一部分。或者在浏览后面的代码部分感到困惑时再返回来参考。
Chat
这个是聊天接口的url:https://api.openai.com/v1/chat/completions
参数格式是这样的:
{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "Hello!"}]
}
响应体格式是这样的:
{"id": "chatcmpl-123","object": "chat.completion","created": 1677652288,"choices": [{"index": 0,"message": {"role": "assistant","content": " Hello there, how may I assist you today?",},"finish_reason": "stop"}],"usage": {"prompt_tokens": 9,"completion_tokens": 12,"total_tokens": 21}
}
对于请求参数来说,需要在其中的messages里添加内容。role参数描述的是角色,分为system(用于系统指示,比如指示chat gpt要扮演什么角色。此时应该用这个参数。)、assistant(chat gpt返回消息的标识,说明这个message是chat gpt响应的。)、user(一般用户进行对话时应该使用这个角色参数。)和function(下文分析)。content里要放的内容文本,这里就不再多解释了。
对于响应体来说,前面的一堆都可以忽略,重点还是看messages节点,我们只要取到了messages里的消息就够了。
function call
有些时候我们除了和大模型交互外,还希望来点别的东西。比如,我自己数据库里的一些内容,这个大模型总没办法知道的吧?例如,我有一些客户的订单信息,希望当客户在和大模型对话的之后能查到自己的订单相关的内容,这时候要怎么做呢?
首先能确定的是,肯定需要借助外界的力量。我们希望当用户询问订单相关信息时,大模型能够根据我们提供的信息,去我们的数据库中进行查询操作。但是我需要声明一下,让大模型去数据库查询是做不到的。大模型只是相当于一个大脑,单纯有脑子的话,既不能吃饭也不能走路。但是呢,脑子可以下达指令啊!我们希望大模型在识别到客户想要查询订单信息时,告诉我们一下就行,然后我们自己查询完数据库,再把相关的信息告诉大模型,这样不就简介地解决了这个问题吗。
在介绍我们的主角function call之前,先说一下如果没有它该怎么做:我们会给出一个system指令,“当客户想要查询订单信息时,询问客户的姓名和订单号”。我们通过客户的姓名和订单号就能确认出客户的订单信息了。然后这个时候大模型会主动地去询问客户的姓名和订单号。当获取到这两个信息以后,我们再给出一个system指令“将姓名和订单号按照json格式返回,示例如下:{“name”: “张三”, “orderNo”: “0001”}”。这样,我们就能获取到大模型返回的格式化数据了(想想如果不是格式化的数据会怎么样?即便正确返回了信息,我们也根本没有办法去识别)。随后我们将json数据进行解析,然后去数据库里查询,再将查询到的结果给出一个system指令:“客户的订单信息是:买了xxx,在xxx时间,发货地址是xxx”。到这里,大模型就完成了与客户的“外界交流”。
上面的过程一看就是很麻烦的,好在OpenAI给我们开放出了这个function call接口。用function call将上面的例子实现一下就是:
{"name": "findOrder","description": "通过客户的姓名和订单号,查询客户订单的详细信息。","parameters": {"type": "object","properties": {"name": {"type": "string","description": "客户的姓名"},"orderNo": {"type": "number","description": "客户的订单号"}},"required": ["name", "orderNo"],},}
大脑需要借助这个函数调用来得到这个能力。其中,description是对函数调用的说明,告诉大模型该什么时候来执行这个函数调用。properties节点下的内容是我们要获取的具体参数,如name和orderNo。这两个节点下的description是对参数的说明。是不是和我们开发语言中的函数调用非常的相似?只是将参数和函数的作用的注释告诉了大模型。当大模型根据函数的描述,觉得需要的时候就会进行执行,返回:
{"role": "assistant","function_call": {"name": "findOrder","arguments": "{"name": "张三", "orderNo": "0001"}"}
}
注意哦,这两个属性应该是大模型询问用户后得到的信息。
Embeddings
再介绍一个重量级接口Embeddings。
这个接口是输入一段文本,输出这段文本的向量。使用这个api只能用指定的模型,比如text-embedding-ada-002,这个是专门用来文本转向量的模型。返回结果类似这样的:
{"object": "list","data": [{"object": "embedding","embedding": [0.018990106880664825,-0.0073809814639389515,.... (1024 floats total for ada)0.021276434883475304,],"index": 0}],"model": "text-similarity-ada:002"
}
那么什么是向量呢?其实就是字面意思,向量。我们可以把文本按照一定的规则在三维空间中表示,那么每个文本就都有它在这个规则下对应的向量。比如我要定义:”你好“的向量是[1,0,0],”你好啊“的向量是[1,0,1],比你好多一个啊。当然实际要比这个复杂的多,通过api返回的结果也可见一斑。不过通俗的理解,就是将一段文本用数字进行表示了。有了这个数字,我们就可以根据文本在空间中向量距离由多进来判断这两个文本有多相似了。
制作机器人
有了上面的基础就可以动手制作自己的聊天机器人了。上面的api介绍过了,再介绍一个java封装的api包:github地址。
使用maven导入:
<dependency><groupId>com.theokanning.openai-gpt3-java</groupId><artifactId>{api|client|service}</artifactId><version>version</version> </dependency>
使用grdle导入:
implementation 'com.theokanning.openai-gpt3-java:<api|client|service>:<version>
使用起来呢也是非常简单,配置好你的api key就可以直接用了。只需要调用chat completion接口就能实现自己的聊天机器人了。
上下文
携带上下文的方式也很简单,只需要将自己要输入的和大模型返回的都放入那个List<ChatMessage>就可以了。不过需要注意一点,不同的模型允许携带的最大上下文是不同的,对于gpt3.5-turbo只能携带4096个token,这就意味着不能将所有的历史上下文都带上。并且,携带越多的上下文,资费也会越多。
由上下文问题,我们想到了一个解决办法,就是使用前面提到的向量。通常来说,即便用户需要使用上下文,也一般都在3-5论历史对话中选取。这样,我们首先想到的是只携带3-5论历史,对于多余的内容就按时间先后顺序删除掉。但是还有另外一种情况,比如我希望让大模型结合我给出的文档内容,我当然不想每次对话都将文档里的内容全部携带上,并且对于较长的文档来说,也没有办法全部携带。另外,对于长文档提问也具有局部性,往往只会用到文档的一小部分内容。
使用向量就能很好的解决这个问题。首先将我们的文档内容调用向量接口进行向量化,然后存入到我们的数据库中。当想要问问题时,先将问题向量化,然后去库中对比,取取最接近的几条数据交给大模型参考,再返回我们对应问题的答案。
向量数据库
直接使用关系型数据库是很难来保存向量的,因此我们考虑直接使用向量数据库。这种专门存储向量的数据库不仅能提供存储的功能,一般还有比较相似的功能。比如我们可以让它返回库中和一段指定文本最相似的前三个,并且必须高于某个分数。
向量数据库有很多,这里我们介绍一下milvus,这是它的地址。安装等步骤就不再介绍了,按照文档的步骤做就可以了,具体的使用方式在文档里也有比较详细的说明。
安装完后,我们就可以是用它来实现我们上面提到了存储向量的功能l。
更多场景介绍
其实我们算是介绍了大模型的两个应用场景:一个是作为聊天机器人,需要注意的是要想连续对话就需要携带上下文。另外一个是文档的问答助手,需要用到向量数据库来作为仓库存储我们的文档内容。
除此之外,聊天型的大模型还可以有很多的应用呢,比如能够进行文本内容总结,文本信息提取,文章摘要生成等等。总之,大模型对于语言处理能力还是很强的。可以发挥一些想象力来将大模型融入到生活中,提高我们的工作效率和提供生活便捷。
扩展阅读
文章主要是介绍的使用ChatGPT的api来完成,我们还可以部署自己的大模型来实现前面提到的场景。现在有一些开源的大模型,能以“比较”低的成本继续本地化部署使用。虽然由于参数量较小,无法媲美ChatGPT,但总归是数据掌握在自己手里,而且有些场景下费用会更低。
目前比较流行开源的大模型有:
- ChatGLM2 这是一个由清华大学联合智谱AI开源的模型,github地址。
- 通义千问 由阿里巴巴开源的大模型
- Llama2 meta公司开源的大模型,不过对中文的支持较差
- moss-moon 复旦大学根据流浪地球中moss的灵感起名,也是一个不错的大模型
除了开源模型外,还有一些商业模型,比如科大讯飞的星火大模型,百度的文心一言等。感性的同学可以去网上搜一下,截至目前为止有一些还在内测阶段,需要申请才可能允许使用。
相关文章:

使用Java和ChatGPT Api来创建自己的大模型聊天机器人
文章目录 前言ChatGPT Api简析Chatfunction call Embeddings 制作机器人上下文向量数据库 更多场景介绍扩展阅读 前言 什么是大模型? 大型语言模型(LLM)是一种深度学习模型,它使用大量数据进行预训练,并能够通过提示工…...
Maven介绍_下载_安装_使用_原理
文章目录 1 Maven介绍1.1 Maven是介绍1.2 Maven的作用 2 Maven下载与安装2.1 官网下载2.2 文件目录2.3 环境配置 3 Maven基础概念3.1 仓库分类3.2 依赖坐标3.3 坐标组成 4 Maven配置4.1 本地仓库配置4.2 远程仓库的设置4.3 镜像仓库配置4.4 IDEA配置Maven 5 Maven项目创建5.1 M…...

算法通关村十一关 | 位运算的规则
1.数字在计算机中的表示 机器数:一个数在计算机中的二进制表示形式,叫做这个数的机器数。机器数是自带符号的,在计算机用一个数的最高位存放符号,整数为0,负数为1。比如,十进制中的数3,计算机字…...
【Rust】Rust学习 第十五章智能指针
指针 (pointer)是一个包含内存地址的变量的通用概念。这个地址引用,或 “指向”(points at)一些其他数据。Rust 中最常见的指针是第四章介绍的 引用(reference)。引用以 & 符号为标志并借用…...

炒股怎样加杠杆?关于股票杠杠平台比例的选择知识分析
在股票市场中,加杠杆是一种常见的投资策略,可以帮助投资者提升收益,但也伴随着更高的风险。本文将介绍炒股加杠杆的具体步骤和股票杠杆平台比例选择的知识分析,帮助读者更好地了解并使用这一策略。 一、炒股加杠杆的步骤 1. 选择…...
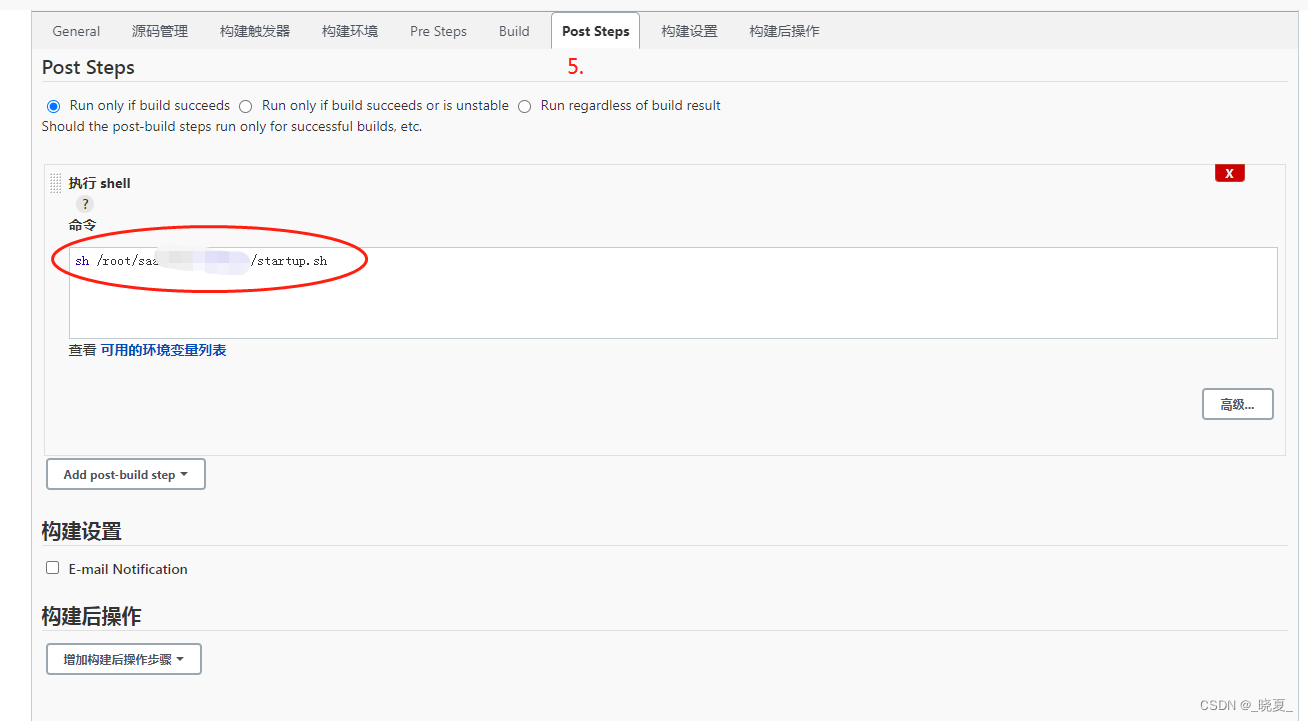
【jenkins】jenkins流水线构建打包jar,生成docker镜像,重启docker服务的过程,在jenkins上一键完成,实现提交代码自动构建的功能
【jenkins】jenkins流水线构建打包jar,生成docker镜像,重启docker服务的过程,在jenkins上一键完成,实现提交代码自动构建,服务重启,服务发布的功能。一键实现。非常的舒服。 1. 启动脚本 shell脚本 这是 s…...

Pytest使用fixture实现token共享
同学们在做pytest接口自动化时,会遇到一个场景就是不同的测试用例需要有一个登录的前置步骤,登录完成后会获取到token,用于之后的代码中。首先我先演示一个常规的做法。 首先在conftest定义一个login的方法,方法返回token pytes…...

You have docker-compose v1 installed, but we require Docker Compose v2.
curl -SL https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose chmod x /usr/local/bin/docker-compose docker-compose --version...

nlopt在windows上的安装使用
nlopt在windows上的安装使用 目录 nlopt在windows上的安装使用一、nlopt下载二、def转lib三、代码 一、nlopt下载 1.下载nlopt库:https://nlopt.readthedocs.io/en/latest/ 2.解压 3.下载dll和def:http://ab-initio.mit.edu/wiki/index.php?titleNLopt…...

【React学习】React中的setState方法
1. setState概述 setState 是React框架中,用于更新组件状态的方法。 setState 方法由React组件继承自 React.Component 类的一部分。通过调用 setState,可以告诉 React要更新组件的状态,并触发组件的重新渲染。 this.setState(newState, ca…...
ATTCK实战系列——红队实战(一)
目录 搭建环境问题 靶场环境 web 渗透 登录 phpmyadmin 应用 探测版本 写日志获得 webshell 写入哥斯拉 webshell 上线到 msf 内网信息收集 主机发现 流量转发 端口扫描 开启 socks 代理 服务探测 getshell 内网主机 浏览器配置 socks 代理 21 ftp 6002/700…...
服务器感染了.360勒索病毒,如何确保数据文件完整恢复?
引言: 随着科技的不断进步,互联网的普及以及数字化生活的发展,网络安全问题也逐渐成为一个全球性的难题。其中,勒索病毒作为一种危害性极高的恶意软件,在近年来频频袭扰用户。本文91数据恢复将重点介绍 360 勒索病毒&a…...
【idea】社区版idea运行Tomcat
使用 Smart Tomcat插件 配置运行:...

网络安全面试题整理
目录标题 1.你常用的渗透工具有哪些?2.xss盲打到内网服务器的利用3.鱼叉式攻击和水坑攻击是什么?4.什么是虚拟机逃逸?5.中间人攻击的原理和防御?6.TCP三次握手过程?7.七层模型有哪七层?8.对云安全的理解&am…...

docker使用code-server搭建开发环境 v2.0
安装docker docker安装 下载安装nodejs、rust等环境 1、设置安装目录 # 创建路径 mkdir /usr/local/node # 切换路径 cd /usr/local/node2、安装nodejs16 # 下载 wget https://nodejs.org/dist/latest-v18.x/node-v18.17.1-linux-x64.tar.xz#解压 tar -xvf node-v18.17.1…...

Python写一个创意五子棋游戏
前言 在本教程中,我们将使用Python写一个创意五子棋游戏 📝个人主页→数据挖掘博主ZTLJQ的主页 个人推荐python学习系列: ☄️爬虫JS逆向系列专栏 - 爬虫逆向教学 ☄️python系列专栏 - 从零开始学python 首先 GomokuGame 类的构造函数 __ini…...
Nvidia Jetson 编解码开发(1)介绍
前言 由于项目需要,需要开发Jetson平台的硬件编解码; 优化CPU带宽,后续主要以介绍硬件编解码为主 1.Jetson各平台编解码性能说明 如下是拿了Jetson nano/tx2/Xavier等几个平台做对比; 这里说明的编解码性能主要是对硬件来说的…...

【操作系统】24王道考研笔记——第一章 计算机系统概述
第一章 计算机系统概述 一、操作系统基本概念 1.1 定义 1.2 特征 并发 (并行:指两个或多个事件在同一时刻同时发生) 共享 (并发性指计算机系统中同时存在中多个运行着的程序,共享性指系统中的资源可供内存中多个并…...
菜鸟Vue教程 - 实现带国际化的注册登陆页面
初接触vue的时候觉得vue好难,因为项目中要用到,就硬着头皮上,慢慢的发现也不难,无外乎画个布局,然后通过样式调整界面。在通过属性和方法跟js交互。js就和我们写的java代码差不多了,复杂一点的就是引用这种…...

Mybatis ORDER BY 排序失效 ORDER BY 与 CASE WHEN THEN 排序问题
一、ORDER BY 排序失效 如果传递给 mapper 的参数值是以 #{test_参数} 的形式,那么就会报错 具体如下: 传递参数是 name 排序规则是升序 asc package com.ruoyi.web.mapper; public interface TestMapper {List<TestEntity> getTestData( Para…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...
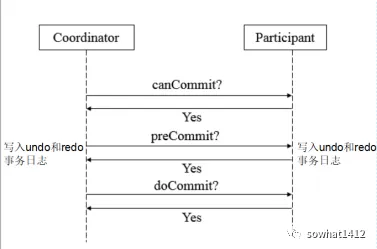
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...
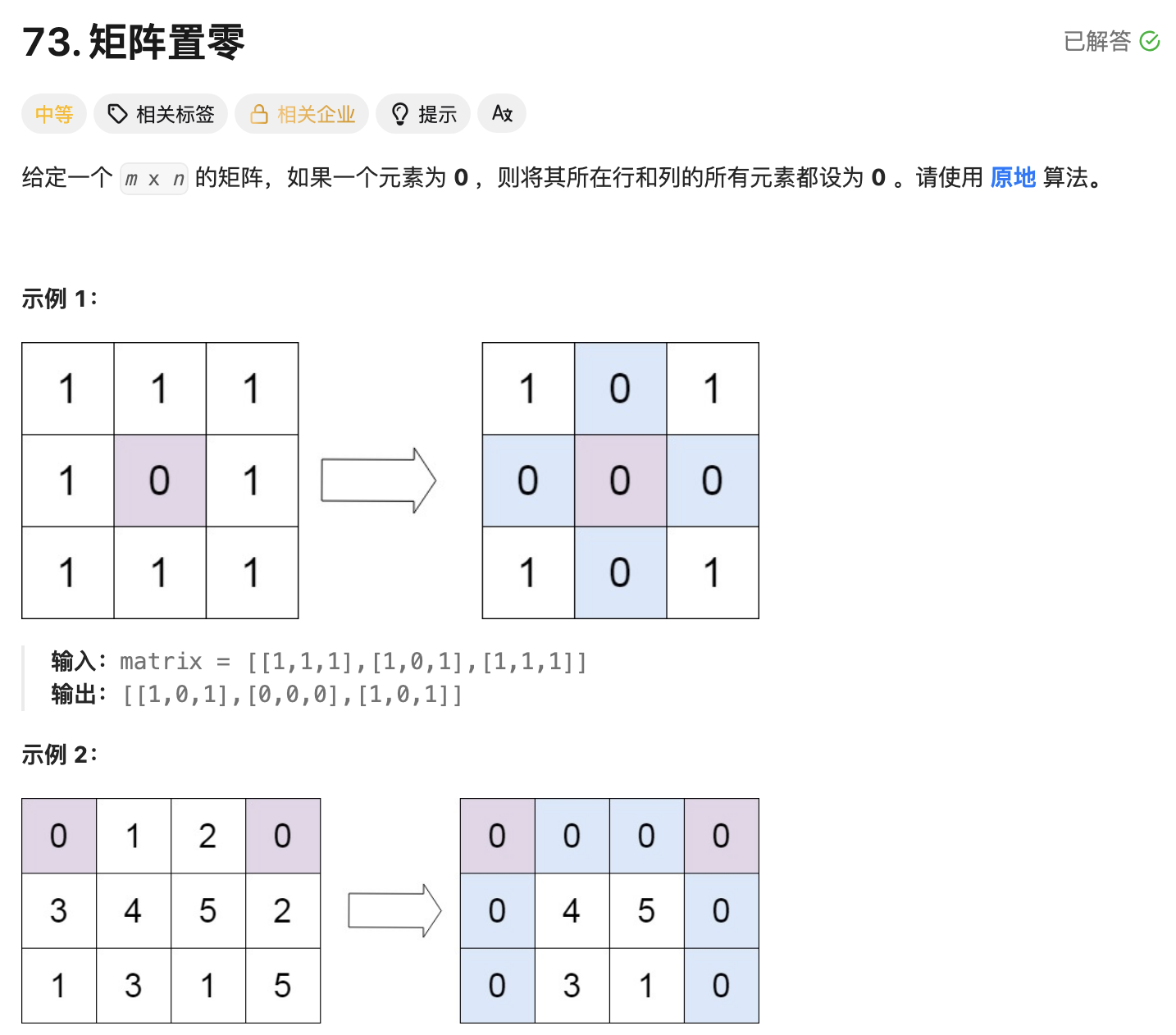
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...