2023年Java核心技术面试第五篇(篇篇万字精讲)
目录
十 . HashMap,ConcurrentHashMap源码解析
10.1 HashMap 的源码解析:
10.1.1数据结构:
10.1.2哈希算法:
10.1.3解决哈希冲突:
10.1.4扩容机制:
10.1.5如何使用 HashMap:
10.2 HashMap 关注以下几个方面:
10.2.1 初始容量和负载因子:
10.2.2 put() 方法:
10.2.3 get() 方法:
10.2.4 remove() 方法:
10.2.5 扩容机制:
10.2.6 并发安全性:
10.3 ConcurrentHashMap解析:
10.3.1 描述:
10.3.2 ConcurrentHashMap 的一些关键特点和实现原理:
10.3.2.1分段锁设计:
10.3.2.1.1 分段锁设计 详细解释:
10.3.2.1.1.1 举个例子:
10.3.2.1.1.2 具体分段锁解释的话:
10.3.2.1.1.3 选择段的细节场景:
10.3.2.1.1.4 CAS操作:
10.3.2.1.1.5 具体的CAS操作执行流程:
10.3.2.1.1.6 原子性操作:
10.3.2.2 锁粒度降低:
10.3.2.3 put() 方法:
10.3.2.3.1 put()方法用于向哈希表中插入键值对流程:
10.3.2.3.1.1 例子:
10.3.2.4 get() 方法:
10.3.2.4.1 详细解释:
10.3.2.4.1.1 例子:
10.3.2.5 键值对的可见性:
10.3.2.5 .1 详细解释:
10.3.2.5.2 例子:
十 . HashMap,ConcurrentHashMap源码解析
HashMap 是 Java 中常用的散列表(哈希表)实现,它提供了快速的插入、查找和删除操作。
10.1 HashMap 的源码解析:
-
10.1.1数据结构:
- HashMap 内部通过数组和链表(或红黑树)实现。数组被称为桶(bucket),每个桶存储一个链表(或红黑树)的头节点。
- 每个元素通过哈希值确定它在数组中的位置,具有相同哈希值的元素以链表(或红黑树)的形式存储在同一个桶中。
-
10.1.2哈希算法:
- 在 HashMap 中,通过 key 的 hashCode() 方法获取键的哈希值。
- 通过哈希值与数组长度取模得到元素在数组中的索引位置。
-
10.1.3解决哈希冲突:
- 当两个不同的 key 对应的哈希值相同时,发生了哈希冲突。
- HashMap 采用开放寻址法(拉链法)来解决哈希冲突,即将冲突的元素以链表(或红黑树)的形式存储在同一个桶中。
-
10.1.4扩容机制:
- 当 HashMap 中的元素数量超过负载因子乘以数组长度时,会触发扩容操作。
- 扩容会创建一个更大的数组,并将所有元素重新插入到新的数组中,这个过程可能比较耗时。
-
10.1.5如何使用 HashMap:
- 使用 put(key, value) 方法将键值对存储到 HashMap 中。
- 使用 get(key) 方法通过键获取对应的值。
- 使用 remove(key) 方法删除指定键的映射关系。
- 使用 containsKey(key) 方法检查 HashMap 是否包含指定的键。
- 迭代 HashMap 可以使用 entrySet() 方法来获取键值对的集合,然后进行遍历操作。
HashMap 在实际开发中被广泛使用,具有高效的插入和查找性能。但需要注意的是,HashMap 不是线程安全的,如果在多线程环境下使用,需要进行适当的同步处理或选择线程安全的替代类(如 ConcurrentHashMap)。
10.2 HashMap 关注以下几个方面:
-
10.2.1 初始容量和负载因子:
- HashMap 的初始容量是指创建 HashMap 时底层数组的大小,默认为 16。
- 负载因子是指 HashMap 在进行扩容操作之前可以达到的填充比例,默认为 0.75。
- 当 HashMap 中元素数量达到负载因子乘以当前容量时,会触发扩容操作。
-
10.2.2 put() 方法:
- 当调用 put(key, value) 方法向 HashMap 中插入一个键值对时,首先会计算 key 的哈希值。
- 然后根据哈希值找到对应的桶(数组索引),如果该桶为空,则直接将键值对插入到桶中。
- 如果桶不为空,则遍历链表(或红黑树):
- 如果链表中已存在相同的 key,则更新对应的值。
- 如果链表中不存在相同的 key,则将新的键值对插入到链表末尾(或红黑树中)。
- 如果链表长度大于阈值(默认为 8),则将链表转换为红黑树来提高查找效率。
- 插入完成后,检查是否需要触发扩容操作。
-
10.2.3 get() 方法:
- 当调用 get(key) 方法获取指定 key 对应的值时,首先计算 key 的哈希值。
- 根据哈希值找到对应的桶,然后遍历链表(或红黑树):
- 如果链表中存在相同的 key,则返回对应的值。
- 如果链表中不存在相同的 key,则返回 null。
-
10.2.4 remove() 方法:
- 当调用 remove(key) 方法删除指定 key 对应的键值对时,首先计算 key 的哈希值。
- 根据哈希值找到对应的桶,然后遍历链表(或红黑树):
- 如果链表中存在相同的 key,则将该节点从链表(或红黑树)中移除。
- 如果链表中不存在相同的 key,则不执行任何操作。
-
10.2.5 扩容机制:
- 当 HashMap 中元素数量达到负载因子乘以当前容量时,会触发扩容操作。
- 扩容会创建一个新的数组,并将所有元素重新插入到新的数组中。
- 扩容时需要重新计算每个元素在新数组中的位置并重新分配桶。
-
10.2.6 并发安全性:
- HashMap 不是线程安全的,如果在多线程环境下使用,需要进行适当的同步处理或选择线程安全的替代类,如 ConcurrentHashMap。
10.3 ConcurrentHashMap解析:
10.3.1 描述:
ConcurrentHashMap 是 JDK 提供的线程安全的哈希表实现,它是在多线程环境下使用的一种高效的并发容器。相对于传统的 HashMap,ConcurrentHashMap 在并发场景下提供了更好的性能和线程安全性。
10.3.2 ConcurrentHashMap 的一些关键特点和实现原理:
10.3.2.1分段锁设计:
- ConcurrentHashMap 内部采用了分段锁(Segment)的设计。
- 将整个哈希表分成多个段(Segment),每个段都维护着一个小的哈希表。
- 线程在访问不同的段时可以并行进行,从而提高了并发性能。
10.3.2.1.1 分段锁设计 详细解释:
分段锁设计是ConcurrentHashMap中的一种并发控制机制。它将整个哈希表分成多个段(Segment),每个段都维护着一个小的哈希表,每个段拥有独立的锁。
目的是为了减小并发冲突的粒度,使得线程在访问不同的段时可以并行进行,从而提高并发性能。当多个线程同时操作ConcurrentHashMap时,只有位于同一个段内的数据才会互斥竞争锁资源,而处于不同段的数据则可以被多个线程同时访问和修改,避免了无谓的阻塞。
10.3.2.1.1.1 举个例子:
假设有一个包含16个段的ConcurrentHashMap,当前有两个线程同时进行操作,线程A操作的是段1的数据,线程B操作的是段2的数据。
在没有分段锁设计的情况下,如果线程A和线程B同时修改同一个段的数据,则需要进行互斥竞争锁资源,其中一个线程必须等待另一个线程释放锁后才能执行,这会导致性能下降。
而有了分段锁设计后,线程A和线程B可以并行进行,因为它们操作的是不同的段,不会产生竞争。这样就提高了并发性能,同时避免了无谓的等待。
需要注意的是,虽然分段锁设计提高了并发性能,但在高并发场景下仍可能存在竞争和阻塞情况。因此,在使用ConcurrentHashMap时,还需要根据实际需求合理选择段的数量,以及考虑其他并发控制机制,如CAS操作等,来进一步提升性能。
10.3.2.1.1.2 具体分段锁解释的话:
假设我们有一个包含4个段的ConcurrentHashMap:
Segment 1: | Key-Value Pair 1 | Key-Value Pair 2 |
Segment 2: | Key-Value Pair 3 | Key-Value Pair 4 |
Segment 3: | Key-Value Pair 5 | Key-Value Pair 6 |
Segment 4: | Key-Value Pair 7 | Key-Value Pair 8 |
每个段都维护着一个小的哈希表,其中包含一些键值对。每个段都有自己的锁,用于保护该段内的数据。
现在假设有两个线程同时进行操作:
线程A要更新Key-Value Pair 1,而线程B要更新Key-Value Pair 4。
由于这两个键位于不同的段中(Key-Value Pair 1位于Segment 1,Key-Value Pair 4位于Segment 2),所以它们可以并发进行操作,不会相互阻塞。
线程A只需要获取Segment 1的锁,而线程B只需要获取Segment 2的锁,它们之间没有竞争关系。
这样,分段锁设计使得线程在操作不同段的数据时可以并行进行,提高了并发性能。
10.3.2.1.1.3 选择段的细节场景:
-
并发度:段的数量应该与并发操作的线程数相匹配,以确保每个线程都可以在自己的段上进行并发操作。如果段的数量过少,可能会导致线程之间频繁竞争同一个段的锁,降低并发性能。反之,如果段的数量过多,可能会增加内存开销,并且在锁粒度较小的情况下可能导致额外的竞争开销。
-
冲突率:如果哈希表中的键值对分布均匀,那么段的数量可以相对较少。但是,如果冲突率较高,即哈希表中的键值对集中在某些特定的段中,那么可能需要适当增加段的数量,以减小冲突造成的竞争。
除了选择段的数量,还可以考虑其他并发控制机制来进一步提升性能,例如CAS(Compare and Swap)操作。CAS操作是一种非阻塞算法,可以在无锁情况下实现并发操作。ConcurrentHashMap中使用CAS操作来进行数据的插入、更新和删除等操作,减少了对锁的依赖,提高了并发性能。
具体解释:
当使用ConcurrentHashMap时,哈希表是被分割为多个段(Segment)的,每个段都维护着一个小的哈希表来存储键值对。段的数量决定了哈希表被划分的粒度。
如果哈希表中的键值对分布均匀,即在每个段中都有大致相等数量的键值对,那么可以选择较少的段数。因为这样可以减少锁的竞争和额外的开销,提高并发性能。
举个例子,假设有一个ConcurrentHashMap,有8个键值对需要存储,而我们选择了4个段:
Segment 1: | Key-Value Pair 1 |
Segment 2: | Key-Value Pair 2 |
Segment 3: | Key-Value Pair 3 |
Segment 4: | Key-Value Pair 4 |
在这种情况下,这8个键值对被均匀地分配到了4个段中,每个段里有2个键值对。如果多个线程同时对这些键值对进行访问或修改,由于它们位于不同的段中,线程之间可以并发进行操作,不会发生锁竞争,从而提高并发性能。
然而,如果哈希表中的键值对分布存在偏差,即某些特定的键值对集中在某些段中,那么可能会造成冲突和竞争。
举个例子,假设我们有一个ConcurrentHashMap,仍然有6个键值对需要存储,但是这次只选择了2个段:
Segment 1: | Key-Value Pair 1 | Key-Value Pair 2 | Key-Value Pair 3 |
Segment 2: | Key-Value Pair 4 | Key-Value Pair 5 | Key-Value Pair 6 |
在这种情况下,前三个键值对集中在Segment 1,后三个键值对集中在Segment 2。如果多个线程同时对这些键值对进行访问或修改,可能会导致Segment 1和Segment 2的锁竞争增加,从而降低并发性能。
为了减小冲突造成的竞争,可以适当增加段的数量,将键值对更均匀地分布到不同的段中。比如,可以将上述例子中的2个段增加到6个段:
Segment 1: | Key-Value Pair 1 |
Segment 2: | Key-Value Pair 2 |
Segment 3: | Key-Value Pair 3 |
Segment 4: | Key-Value Pair 4 |
Segment 5: | Key-Value Pair 5 |
Segment 6: | Key-Value Pair 6 |
这样,每个段中都只有1个键值对,分布相对均匀,减小了锁的竞争,提高了并发性能。
综上所述,如果哈希表中的键值对分布均匀,可以选择较少的段的数量;而如果冲突率较高,可能需要适当增加段的数量来减小冲突造成的竞争,并提高并发性能。
10.3.2.1.1.4 CAS操作:
一种并发控制机制,通常用于实现无锁算法。它通过比较内存中的值与预期值是否相等,并在相等的情况下将新值写入内存,从而实现原子性的更新操作。
CAS操作包含三个操作数:内存地址(或称为变量)、预期值和新值。CAS操作的执行过程如下:
- 读取内存地址中的当前值。
- 比较当前值与预期值是否相等。
- 如果相等,则将新值写入内存地址;否则,放弃更新操作。
CAS操作执行时不需要加锁,因此避免了传统锁机制所带来的竞争和阻塞。它可以提供更高的并发性能,并减少对锁的依赖。然而,CAS操作也存在ABA问题(即在某些情况下,数据的实际状态可能与预期值相等,但实际上已经被修改过),需要额外的处理机制来解决。
以下是一个简单的CAS操作的示例:
假设有两个线程同时对一个共享的计数器进行自增操作。初始时,计数器的值为0。
- 线程A执行CAS操作,预期值为0,新值为1。
- 线程B执行CAS操作,预期值为0,新值为1。
执行过程如下:
- 线程A读取计数器的当前值为0。
- 线程A比较当前值与预期值是否相等,发现相等。
- 线程A将新值1写入计数器内存地址,成功更新计数器的值为1。
而线程B在执行CAS操作时,由于预期值不再是0(因为线程A已经更新了计数器的值),所以比较失败,不会执行写入操作。
10.3.2.1.1.5 具体的CAS操作执行流程:
假设有一个共享的计数器变量count,初始值为0。现在有两个线程A和B同时进行自增操作。
- 初始时,count的值为0。
- 线程A先执行CAS操作,预期值为0,新值为1。
- 线程A读取内存地址中的当前值,发现count的值为0。
- 线程A比较当前值与预期值是否相等,即比较0与预期值0是否相等,结果为相等。
- 由于当前值与预期值相等,线程A将新值1写入内存地址,成功完成更新操作。
- 最终,count的值被线程A更新为1。
此时,线程B也开始执行CAS操作。
- 线程B读取内存地址中的当前值,发现count的值已经被线程A更新为1。
- 线程B比较当前值与预期值是否相等,即比较1与预期值0是否相等,结果为不相等。
- 由于当前值与预期值不相等,线程B放弃更新操作,不对count进行修改。
通过CAS操作,多个线程可以同时进行自增操作,但只有其中一个线程能够成功修改count的值。其他线程在比较当前值与预期值不相等时,会放弃更新操作。
需要注意的是,如果多个线程同时执行CAS操作,可能会出现竞争的情况。当多个线程同时读取到相同的预期值时,只有一个线程能够成功将新值写入内存地址,其他线程需要重新尝试CAS操作或采取其他处理方式。
这种原子性的CAS操作可以保证共享数据的一致性和正确性,避免了竞态条件和数据不一致的问题。它是实现无锁算法和并发控制的重要机制之一。
![]()
这样,通过CAS操作,多个线程可以同时对共享数据进行操作,避免了锁竞争的开销,提高了并发性能。
10.3.2.1.1.6 原子性操作:
在并发环境下,一个操作要么完全执行成功,要么完全不执行,不存在中间状态或部分执行的情况。即原子性操作是不可被中断的,可以看作是一个不可分割的单元。
在并发编程中,原子性操作是确保数据一致性和避免竞态条件的重要机制。当多个线程同时对共享资源进行读取和修改时,如果没有原子性操作的保障,就可能出现数据错误、不一致或竞争条件等问题。
举个例子,假设有一个计数器变量count,初始值为0,多个线程同时对该计数器进行自增操作,每次自增1。
如果自增操作不具备原子性,那么可能会发生以下情况:
- 线程A和线程B同时读取到count的当前值为2。
- 线程A将count加1得到3。
- 线程B将count加1得到3。
- 两个线程都将自增后的值写回到count,最终结果为3,而不是我们期望的4。
这种情况下,由于自增操作不是原子的,造成了数据的不一致。
而如果自增操作具备原子性,那么无论多少个线程同时执行自增操作,最终的结果都会正确:
- 线程A和线程B同时读取到count的当前值为2。
- 线程A将count加1得到3。
- 线程B将count加1得到4。
- 两个线程都将自增后的值写回到count,最终结果为4,符合预期。
原子性操作可以通过锁机制、CAS(Compare and Swap)操作、原子类等实现。它是保证并发程序正确性和一致性的重要手段之一。
10.3.2.2 锁粒度降低:
在传统的哈希表中,当多个线程同时访问哈希表时,需要对整个哈希表进行加锁操作,从而保证数据的一致性和并发安全。然而,在高并发场景下,由于多个线程同时争抢一个全局锁,会导致较高的锁竞争和冲突,降低系统的并发性能。
为了解决这个问题,ConcurrentHashMap引入了锁粒度降低的机制。它将整个哈希表分成多个段(Segment),每个段内部维护着一个小型的哈希表。不同的段之间是相互独立的,因此可以同时被多个线程访问,互不干扰。
每个段内部的操作仍然需要加锁来保证线程安全,但是不同段之间的操作可以同时进行,减少了锁的竞争和冲突。这样一来,当多个线程同时访问ConcurrentHashMap时,并发度得到了提高,系统的性能也会相应地提升。
锁粒度降低的机制使得ConcurrentHashMap具备了更好的并发性能,适用于高并发读写的场景。它通过将锁的范围缩小到段级别,允许多个线程同时进行读操作,并且只有在进行写操作时才需要对整个段进行加锁。这种方式有效地减少了线程之间的争抢和等待,提高了系统的并发处理能力。
锁粒度降低是ConcurrentHashMap中的一种优化策略,通过将哈希表分成多个独立的段,并行处理不同段的操作,从而降低了锁的竞争和冲突,提高了并发性能。
10.3.2.3 put() 方法:
- ConcurrentHashMap 的 put() 方法在插入键值对时会先根据键的哈希值确定所属的段。
- 首先尝试在非锁定状态下插入节点,如果成功则直接返回。
- 如果遇到竞争,会通过自旋+CAS(Compare and Swap)来保证线程安全,直到成功插入节点或者达到最大自旋次数。
10.3.2.3.1 put()方法用于向哈希表中插入键值对流程:
- 根据键的哈希值确定所属的段(Segment)。
- 首先尝试在非锁定状态下插入节点,即尝试直接将节点插入到对应段的链表中。
- 如果成功插入节点,则直接返回。
- 如果遇到竞争,即有其他线程正在对该段进行写操作,会进行自旋+CAS(Compare and Swap)来保证线程安全。
自旋是一种忙等待的方式,即线程会不断重复尝试执行某个操作,直到满足特定的条件为止。在这里,自旋是为了等待竞争的线程释放锁,以便当前线程能够继续进行插入操作。
CAS是一种无锁算法,通过比较并交换的方式来更新共享变量的值。在ConcurrentHashMap中,CAS用于保证多线程并发插入节点时的线程安全性。具体步骤如下:
- 当前线程读取当前段的头节点。
- 判断头节点是否为空,如果为空则说明该段还没有节点,当前线程可以直接插入新节点。
- 如果头节点不为空,则通过CAS操作尝试将新节点插入到链表的头部。
- 如果CAS操作成功,说明当前线程成功插入节点,可以直接返回。
- 如果CAS操作失败,说明有其他线程也在竞争插入节点,当前线程会进行自旋等待,不断尝试CAS操作,直到成功插入或达到最大自旋次数。
10.3.2.3.1.1 例子:
假设ConcurrentHashMap的大小为4,有两个线程同时执行put()方法,插入键值对("key1", "value1")和("key2", "value2")。假设哈希函数将"key1"和"key2"映射到同一个段上。
- 线程A确定插入键值对("key1", "value1")所属的段为Segment1,尝试在非锁定状态下插入节点,成功插入。
- 线程B确定插入键值对("key2", "value2")所属的段为Segment1,发现Segment1已经有锁,开始自旋+CAS。
- 线程B重复进行自旋等待,在一次自旋中成功执行了CAS操作,并成功将节点("key2", "value2")插入到Segment1的链表头部。
- 线程A和线程B都成功插入节点,插入操作完成。
通过自旋+CAS机制,ConcurrentHashMap保证了多线程并发插入节点时的线程安全性,避免了数据的覆盖或丢失问题。这种方式提高了并发性能,使得多个线程可以同时进行插入操作,从而提高了系统的并发处理能力。
10.3.2.4 get() 方法:
- ConcurrentHashMap 的 get() 方法在获取值时也会根据键的哈希值确定所属的段。
- 首先会尝试在非锁定状态下直接获取值,如果存在则返回。
- 如果遇到竞争,会通过自旋来等待其他线程释放锁,然后再次尝试获取值。
10.3.2.4.1 详细解释:
- 根据键的哈希值确定所属的段(Segment)。
- 首先尝试在非锁定状态下直接获取值,即直接从对应段的链表中查找对应的节点。
- 如果成功找到节点,则返回对应的值。
- 如果遇到竞争,即有其他线程正在对该段进行写操作或者在同一时间内执行了put()方法导致链表结构发生变化,会进行自旋等待。
自旋是一种忙等待的方式,即线程会不断重复尝试执行某个操作,直到满足特定的条件为止。在这里,自旋是为了等待竞争的线程释放锁或者链表结构稳定,以便当前线程能够继续进行查找操作。
10.3.2.4.1.1 例子:
假设ConcurrentHashMap的大小为4,有两个线程同时执行get()方法,获取键"key1"和"key2"对应的值。假设哈希函数将"key1"和"key2"映射到同一个段上。
- 线程A确定键"key1"所属的段为Segment1,尝试在非锁定状态下直接查找节点,成功找到值"value1"并返回。
- 线程B确定键"key2"所属的段为Segment1,发现Segment1有锁,开始自旋等待。
- 线程B重复进行自旋等待,直到其他线程释放了锁或链表结构稳定。
- 线程B再次尝试获取值时,在Segment1的链表中成功找到键"key2"对应的节点,并返回值"value2"。
通过自旋等待,ConcurrentHashMap保证了在竞争情况下线程能够安全地获取到正确的值。自旋等待可以避免阻塞线程,提高系统的并发性能。如果等待时间过长或自旋次数达到上限,可能会转为阻塞等待,具体实现可能会根据具体的JVM实现而有所不同。
总结来说,ConcurrentHashMap的get()方法通过自旋等待,确保多线程并发获取值的线程安全性。当线程遇到竞争时,会等待其他线程释放锁或链表结构稳定,然后再次尝试获取值。这种方式提高了并发性能,使得多个线程可以同时进行查找操作。
10.3.2.5 键值对的可见性:
- ConcurrentHashMap 使用了使用volatile和其他机制来保证线程之间对共享数据的修改保证键值对的可见性。
- 当一个线程修改某个段中的数据时,其他线程能够立即看到该修改。
10.3.2.5 .1 详细解释:
ConcurrentHashMap通过使用volatile和其他机制来保证线程之间对共享数据的修改能够及时被其他线程观察到。
具体来说,ConcurrentHashMap使用的是基于分段锁(Segment)的并发控制机制。每个Segment都维护了一个数组或链表的结构用于存储键值对,而每个节点都包含了一个volatile修饰的value字段(该字段存储着具体的值)。通过volatile修饰,value字段可以确保对该字段的写操作具有可见性。
当一个线程修改某个Segment中的数据时,由于该Segment对应的数组或链表在进行修改时会获取相应的锁,其他线程必须等待锁释放后才能访问该Segment。而等待的线程会在自旋等待期间不断检查共享数据的状态,以确保最新修改的可见性。
此外,ConcurrentHashMap还使用了一些非阻塞的算法和CAS(Compare and Swap)操作来实现线程安全和可见性。这些机制使得ConcurrentHashMap能够提供高效的并发操作,并确保对共享数据的修改能够及时反映到其他线程中。
综上所述,ConcurrentHashMap并没有直接使用volatile修饰符来保证键值对的可见性。它通过内部的分段锁、非阻塞算法和CAS操作等机制来确保共享数据的修改能够及时被其他线程观察到。这样可以保证在并发环境下对ConcurrentHashMap进行安全的读写操作。
10.3.2.5.2 例子:
ConcurrentHashMap使用了一种称为"volatile读写"的技术来确保共享数据的可见性。这个技术是通过内部的分段锁、非阻塞算法和CAS操作等机制来实现的。下面我将更详细地解释这些机制:
-
分段锁(Segment Locking):ConcurrentHashMap将整个存储空间分割成多个独立的段(Segments),每个段都拥有自己的锁。这样不同线程在访问不同段时可以并发进行读写操作,提高了并发性能。当一个线程要进行写操作时,只需要获取对应段的锁,而其他段的读写操作不受影响。
-
非阻塞算法:ConcurrentHashMap内部使用了一些非阻塞的算法,例如链表或红黑树的插入、删除和查找操作都采用了非阻塞的方式。非阻塞算法是指线程在执行操作时,不会阻塞等待其他线程释放锁,而是通过循环自旋等待或采用CAS操作来实现对共享数据的修改。
-
CAS操作(Compare and Swap):CAS操作是一种原子性操作,用于实现无锁算法。ConcurrentHashMap使用CAS操作来确保对共享数据的修改是原子性的。通过比较当前值和期望值是否相等,如果相等则进行更新,否则重试操作。这样可以避免了使用传统的锁机制带来的性能开销。
这些机制的综合应用使得ConcurrentHashMap能够在并发环境下安全地进行读写操作
import java.util.concurrent.ConcurrentHashMap;public class ConcurrentHashMapExample {public static void main(String[] args) {ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();// 线程1:插入键值对Thread thread1 = new Thread(() -> {map.put("key", 1);});// 线程2:获取键值对Thread thread2 = new Thread(() -> {Integer value = map.get("key");System.out.println(value);});thread1.start();thread2.start();}
}
线程1向ConcurrentHashMap中插入键值对"key: 1",而线程2尝试从ConcurrentHashMap中获取"key"对应的值。由于ConcurrentHashMap的内部机制,线程2可以立即看到线程1插入的修改,从而正确地获取到值1。
总结来说,ConcurrentHashMap并没有直接使用volatile修饰符来保证键值对的可见性。它通过内部的分段锁、非阻塞算法和CAS操作等机制,确保共享数据的修改能够及时被其他线程观察到,并实现了在并发环境下的安全读写操作。
相关文章:
2023年Java核心技术面试第五篇(篇篇万字精讲)
目录 十 . HashMap,ConcurrentHashMap源码解析 10.1 HashMap 的源码解析: 10.1.1数据结构: 10.1.2哈希算法: 10.1.3解决哈希冲突: 10.1.4扩容机制: 10.1.5如何使用 HashMap: 10.2 HashMap 关注…...
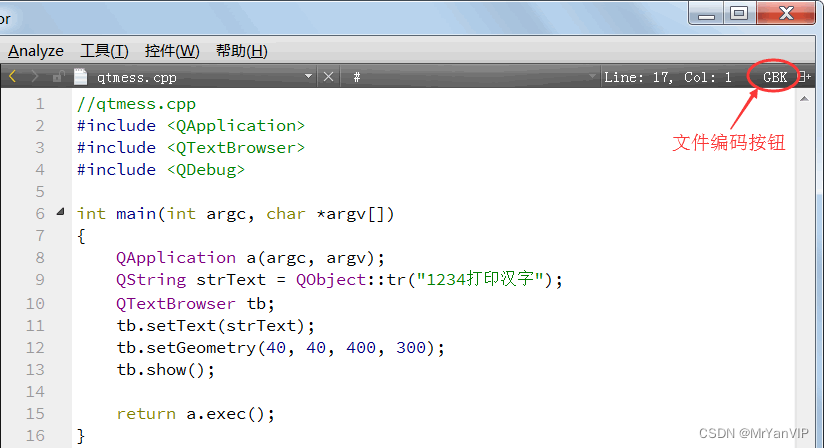
第十课:Qt 字符编码和中文乱码相关问题
功能描述:最全的 Qt 字符编码相关知识以及中文乱码的原因与解决办法 一、字符编码种类 ASCII 码 美国人对信息交流的编码,包括 26 个字母(大小写)、数字和标点符号等,用一个字节(8 位)表示这些…...

Go语言基础:Interface接口、Goroutines线程、Channels通道详细案例教程
目录标题 一、Interface1. Declaring and implementing an interface2. Practical use of an interface3. Nterface internal representation4. Empty interface5. Type assertion6. Type switch7. Implementing interfaces using pointer receivers VS value receivers8. Impl…...
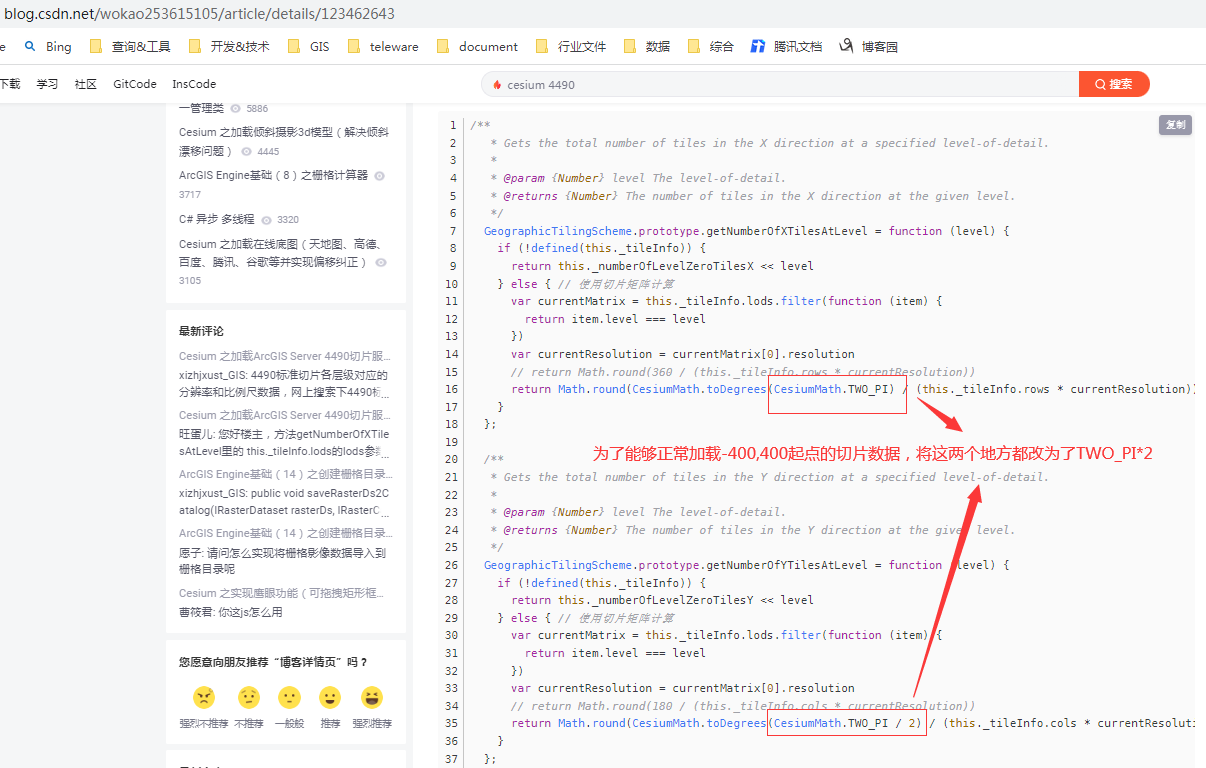
Cesium加载ArcGIS Server4490且orgin -400 400的切片服务
Cesium在使用加载Cesium.ArcGisMapServerImageryProvider加载切片服务时,默认只支持wgs84的4326坐标系,不支持CGCS2000的4490坐标系。 如果是ArcGIS发布的4490坐标系的切片服务,如果原点在orgin X: -180.0Y: 90.0的情况下,我们可…...

Objectarx 2021使用vs2019生成报错 /RTCc rejects conformant code
error C2338: /RTCc rejects conformant code错误解决 使用VS2019/VS2022生成项目报错 严重性 代码 说明 项目 文件 行 禁止显示状态 错误 C1189 #error: /RTCc rejects conformant code, so it is not supported by the C Standard Library. Either remove this compiler opti…...

QT中使用QtXlsx库的三种方法 QT基础入门【Excel的操作】
对于Linux用户,如果Qt是通过“ apt-get”之类的软件包管理器工具安装的,请确保已安装Qt5开发软件包qtbase5-private-dev QtXlsx是一个可以读写Excel文件的库。它不需要Microsoft Excel,可以在Qt5支持的任何平台上使用。该库可用于从头开始生成新的.xlsx文件从现有.xlsx文件中…...

容器和云原生(二):Docker容器化技术
目录 Docker容器的使用 Docker容器关键技术 Namespace Cgroups UnionFS Docker容器的使用 首先直观地了解docker如何安装使用,并快速启动mysql服务的,启动时候绑定主机上的3306端口,查找mysql容器的ip,使用mysql -h contain…...

学习总结(TAT)
项目写完了,来写一个总的总结啦: 1.后期错误 Connection,Statement,Prestatement,ResultSet都要记得关闭接口;(一定要按顺序关闭); 在写群聊的时候写数据库名的时候不要…...

2023java异常之八股文——面试题
Java异常架构与异常关键字 Java异常简介 Java异常是Java提供的一种识别及响应错误的一致性机制。 Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。在有效使用异常的情况下,异常能清晰的…...

数据可视化和数字孪生相互促进的关系
数据可视化和数字孪生是当今数字化时代中备受关注的两大领域,它们在不同层面和领域为我们提供了深入洞察和智能决策的机会,随着两种技术的不断融合发展,很多人会将他们联系在一起,本文就带大家浅谈一下二者之间相爱相杀的关系。 …...

axios使用axiosSource.cancel取消请求后怎么恢复请求,axios取消请求和恢复请求实现
在前端做大文件分片上传,或者其它中断请求时,需要暂停或重新请求,比如这里大文件上传时,可能会需要暂停、继续上传,如下GIF演示: 这里不详细说文件上传的处理和切片细节,后续有时间在出一篇&a…...
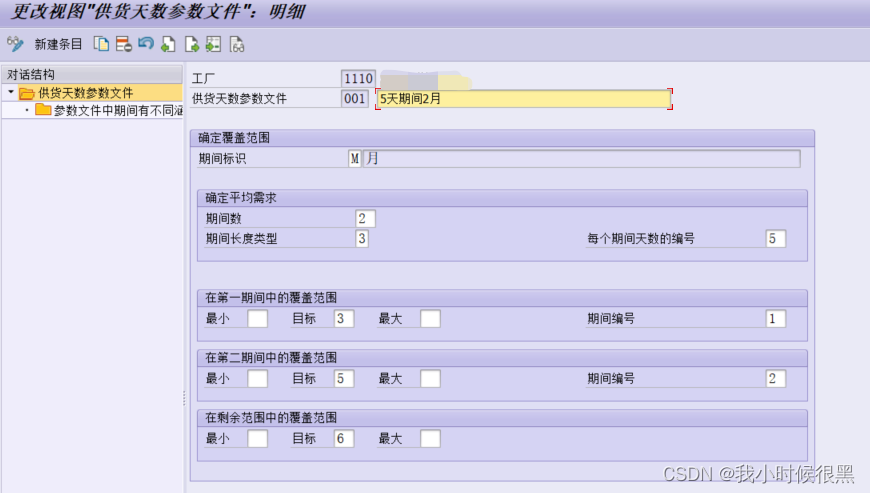
SAP动态安全库存简介
动态安全库存:跑需求计划时,ERP系统按设置的库存方式自动计算出满足一定时间内可保障生产的库存数量 SAP动态安全库存的计算公式:动态安全库存=平均日需求*覆盖范围。 平均日需求=特定时期内的总需求/特定时期内的工作天数 覆盖范围指在没又货物供应的情况下,库存可以维…...

JVM基础了解
JVM 是java虚拟机。 作用:运行并管理java源码文件锁生成的Class文件;在不同的操作系统上安装不同的JVM,从而实现了跨平台的保证。一般在安装完JDK或者JRE之后,其中就已经内置了JVM,只需要将Class文件交给JVM即可 写好的…...
)
QT:event事件分发器,事件过滤器(了解)
Event事件分发器 用于事件的分发 可以用事件分发器做拦截,从而不进入到后面的虚函数中,但是不建议 bool event(QEvent *e); 返回值 如果是true 代表用户处理这个事件,不向下进行分发 e->type()中可选择进行拦截的类…...
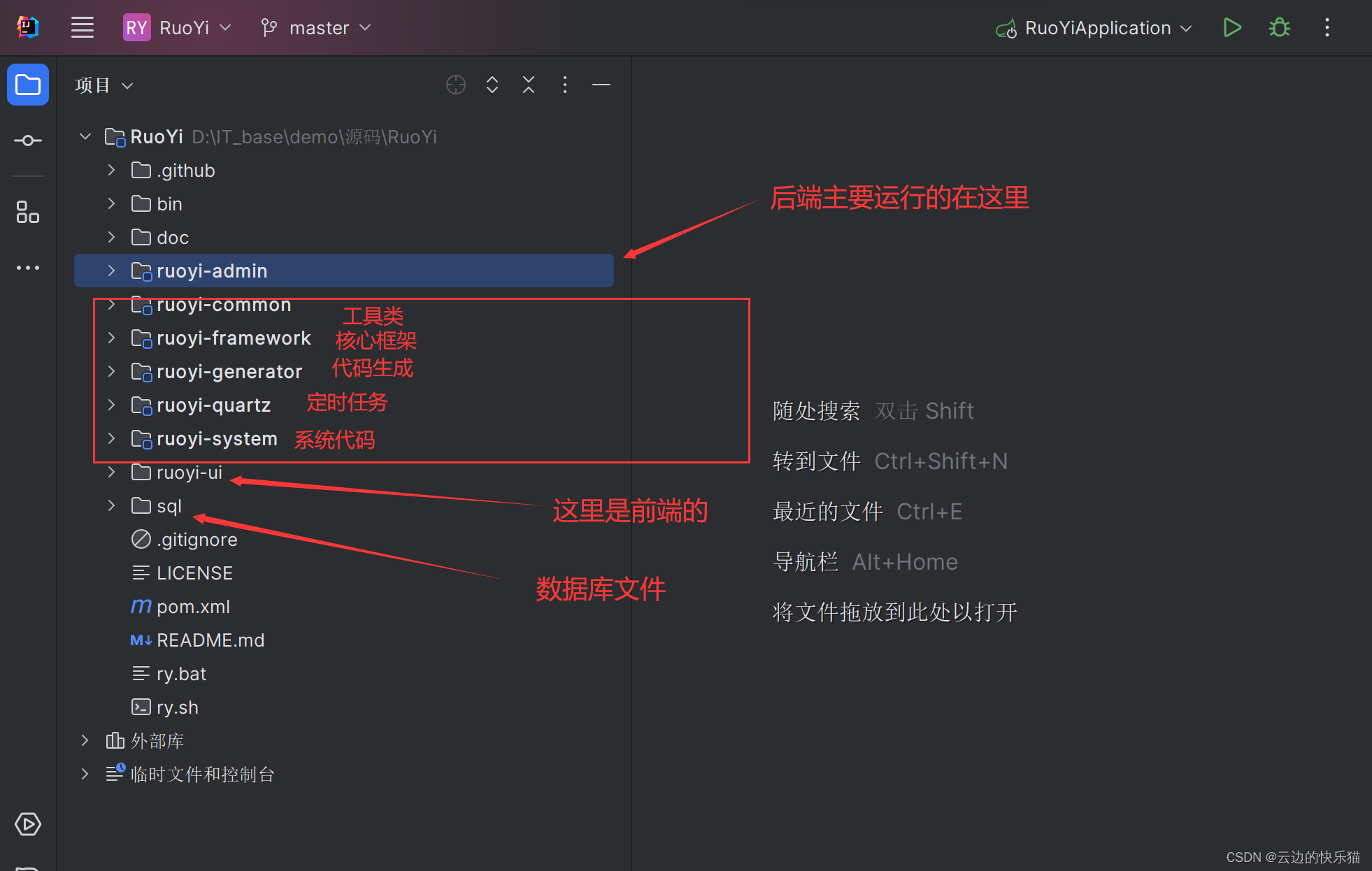
若依项目的介绍(前后端分离版本)
目录 一、若依介绍 (一)简单介绍 (二)若依版本 (三)Git远程拉取步骤 二、项目的技术介绍 (一)后端技术 1.spring boot 2.Spring Security安全控制 3.MyBatis 4.MySQL和R…...

DT游乐场建模
丢了一个...

Servlet+JDBC实战开发书店项目讲解第9篇:VIP等级优惠实现
ServletJDBC实战开发书店项目讲解第9篇:VIP等级优惠实现 介绍 在这篇博客中,我们将讲解如何在书店项目中实现VIP等级优惠功能。VIP等级优惠是一种常见的商业策略,可以吸引更多的顾客并提高销售额。我们将使用Servlet和JDBC来实现这个功能。…...
Azure文件共享
什么是Azure文件共享 Azure文件共享是一种在云中存储和访问文件的服务。它允许用户在不同的计算机、虚拟机和服务之间共享数据,并在应用程序中进行访问、修改和管理。 Azure文件共享可以用于各种用途,例如: 共享文件资源给多个虚拟机或服务…...
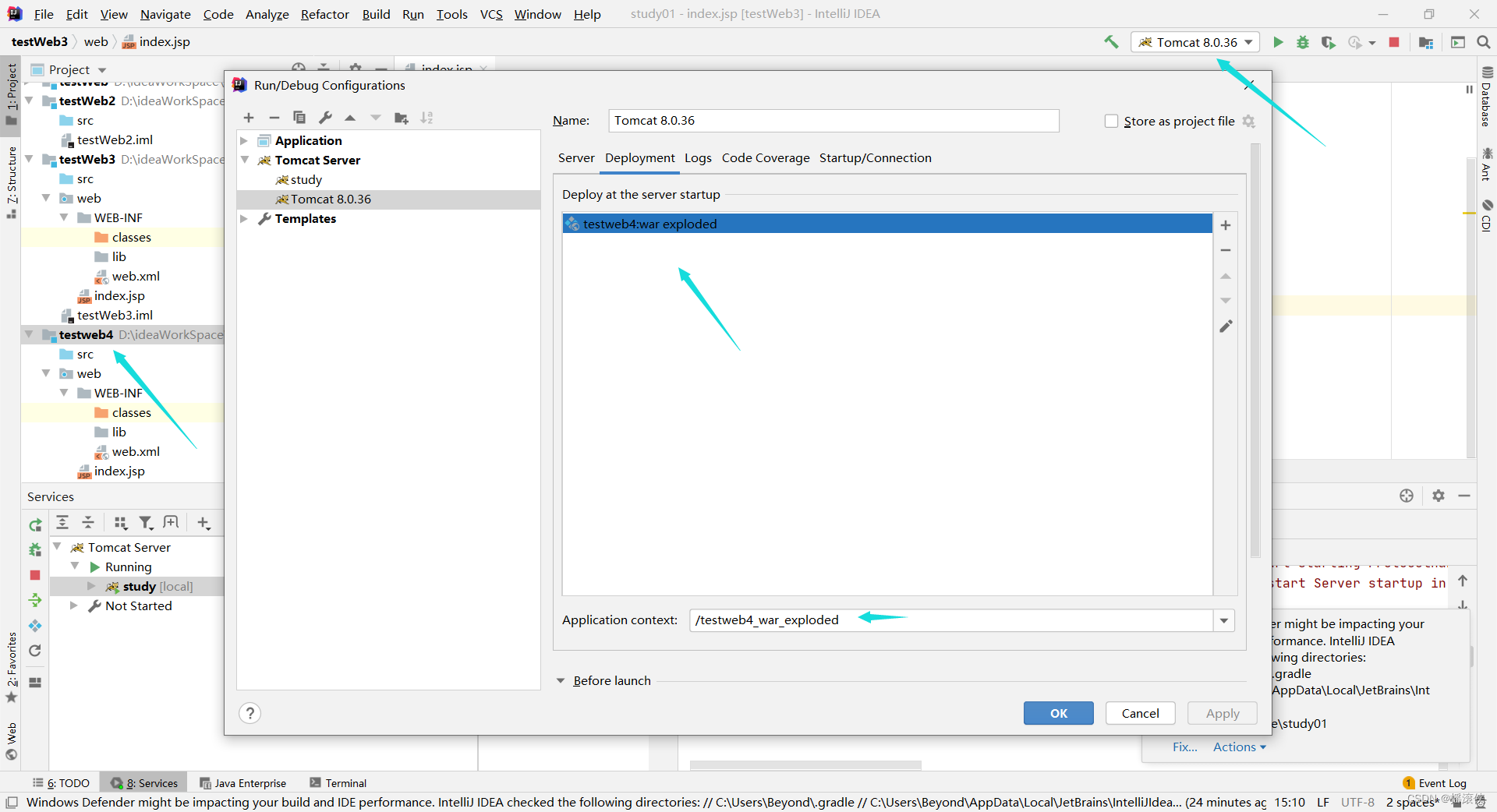
idea新建web项目
步骤一 步骤二 步骤三 新建两个目录lib、classes 步骤四 设置两个目录的功能lib、classes 步骤五 发布到tomcat...

回归预测 | MATLAB实现BES-SVM秃鹰搜索优化算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现BES-SVM秃鹰搜索优化算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现BES-SVM秃鹰搜索优化算法优化支持向量机多输入单输出回归预测(多指标,多图)效…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...