用 PyTorch 编写分布式应用程序
用 PyTorch 编写分布式应用程序
在这个简短的教程中,我们将介绍 PyTorch 的分布式软件包。 我们将了解如何设置分布式设置,使用不同的交流策略以及如何仔细查看软件包的内部结构。
设定
PyTorch 中包含的分布式软件包(即torch.distributed)使研究人员和从业人员可以轻松地并行化他们在跨进程和机器集群的计算。 为此,它利用了传递消息的语义,从而允许每个进程将数据传递给其他任何进程。 与并行处理(HTG1)包相反,进程可以使用不同的通信后端,而不仅限于在同一台计算机上执行。
为了开始,我们需要能够同时运行多个进程的能力。 如果您有权访问计算群集,则应咨询本地系统管理员或使用您喜欢的协调工具。 (例如 pdsh , clustershell 或其他)。出于本教程的目的,我们将使用以下模板使用一台计算机并分叉多个进程。
"""run.py:"""
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
from torch.multiprocessing import Processdef run(rank, size):""" Distributed function to be implemented later. """passdef init_process(rank, size, fn, backend='gloo'):""" Initialize the distributed environment. """os.environ['MASTER_ADDR'] = '127.0.0.1'os.environ['MASTER_PORT'] = '29500'dist.init_process_group(backend, rank=rank, world_size=size)fn(rank, size)if __name__ == "__main__":size = 2processes = []for rank in range(size):p = Process(target=init_process, args=(rank, size, run))p.start()processes.append(p)for p in processes:p.join()上面的脚本产生了两个进程,每个进程将设置分布式环境,初始化进程组(dist.init_process_group),最后执行给定的run函数。
让我们看一下init_process功能。 它确保每个进程将能够使用相同的 IP 地址和端口通过主机进行协调。 请注意,我们使用了gloo后端,但其他后端也可用。 (请参阅 5.1 节),我们将在本教程的结尾部分介绍dist.init_process_group中发生的魔术,但实际上,它允许进程通过共享位置相互进行通信。
点对点通讯
发送和接收
数据从一个进程到另一个进程的传输称为点对点通信。 这些是通过send和recv功能或它们的_直接_对应部分isend和irecv实现的。
"""Blocking point-to-point communication."""def run(rank, size):tensor = torch.zeros(1)if rank == 0:tensor += 1# Send the tensor to process 1dist.send(tensor=tensor, dst=1)else:# Receive tensor from process 0dist.recv(tensor=tensor, src=0)print('Rank ', rank, ' has data ', tensor[0])在上面的示例中,两个进程都从零张量开始,然后进程 0 递增张量并将其发送到进程 1,以便它们都以 1.0 结尾。 请注意,进程 1 需要分配内存以存储它将接收的数据。
另请注意,send / recv被阻塞:两个过程都停止,直到通信完成。 另一方面,无阻塞; 脚本继续执行,方法返回Work对象,我们可以选择wait()对象。
"""Non-blocking point-to-point communication."""def run(rank, size):tensor = torch.zeros(1)req = Noneif rank == 0:tensor += 1# Send the tensor to process 1req = dist.isend(tensor=tensor, dst=1)print('Rank 0 started sending')else:# Receive tensor from process 0req = dist.irecv(tensor=tensor, src=0)print('Rank 1 started receiving')req.wait()print('Rank ', rank, ' has data ', tensor[0])使用立即数时,我们必须谨慎使用已发送和已接收的张量。 由于我们不知道何时将数据传递给其他进程,因此在req.wait()完成之前,我们既不应该修改发送的张量也不应该访问接收的张量。 换一种说法,
- 在
dist.isend()之后写入tensor将导致不确定的行为。 - 在
dist.irecv()之后从tensor读取将导致不确定的行为。
但是,在执行req.wait()之后,我们可以确保进行了通信,并且tensor[0]中存储的值为 1.0。
当我们希望对流程的通信进行精细控制时,点对点通信非常有用。 它们可用于实现精美的算法,例如百度的 DeepSpeech 或 Facebook 的大规模实验中使用的算法。(请参阅 4.1 节)
集体交流
与点对点通信相反,集合允许跨组中所有进程的通信模式。 小组是我们所有过程的子集。 要创建组,我们可以将等级列表传递给dist.new_group(group)。 默认情况下,集合在所有进程(也称为世界)上执行。 例如,为了获得所有过程中所有张量的总和,我们可以使用dist.all_reduce(tensor, op, group)集合。
""" All-Reduce example."""
def run(rank, size):""" Simple point-to-point communication. """group = dist.new_group([0, 1])tensor = torch.ones(1)dist.all_reduce(tensor, op=dist.reduce_op.SUM, group=group)print('Rank ', rank, ' has data ', tensor[0])由于我们需要组中所有张量的总和,因此我们将dist.reduce_op.SUM用作化简运算符。 一般来说,任何可交换的数学运算都可以用作运算符。 PyTorch 开箱即用,带有 4 个这样的运算符,它们都在元素级运行:
dist.reduce_op.SUM,dist.reduce_op.PRODUCT,dist.reduce_op.MAX,dist.reduce_op.MIN。
除了dist.all_reduce(tensor, op, group)之外,PyTorch 中目前共有 6 个集合体。
dist.broadcast(tensor, src, group):将tensor从src复制到所有其他进程。dist.reduce(tensor, dst, op, group):将op应用于所有tensor,并将结果存储在dst中。dist.all_reduce(tensor, op, group):与 reduce 相同,但是结果存储在所有进程中。
(img/56c0ad0f1ad17f666308d58b7389493c.jpg)]过程。dist.gather(tensor, dst, gather_list, group):从dst中的所有进程复制tensor。dist.all_gather(tensor_list, tensor, group):将所有进程中的tensor从所有进程复制到tensor_list。dist.barrier(group):阻止<cite>组</cite>中的所有进程,直到每个进程都进入此功能。
分布式训练
**注意:**您可以在此 GitHub 存储库的中找到本节的示例脚本。
现在我们了解了分布式模块的工作原理,让我们用它编写一些有用的东西。 我们的目标是复制 DistributedDataParallel 的功能。 当然,这将是一个教学示例,在现实世界中,您应该使用上面链接的经过官方测试,优化的最佳版本。
很简单,我们想要实现随机梯度下降的分布式版本。 我们的脚本将允许所有进程在其数据批次上计算其模型的梯度,然后平均其梯度。 为了在更改进程数时确保相似的收敛结果,我们首先必须对数据集进行分区。 (您也可以使用 tnt.dataset.SplitDataset 代替下面的代码段。)
""" Dataset partitioning helper """
class Partition(object):def __init__(self, data, index):self.data = dataself.index = indexdef __len__(self):return len(self.index)def __getitem__(self, index):data_idx = self.index[index]return self.data[data_idx]class DataPartitioner(object):def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234):self.data = dataself.partitions = []rng = Random()rng.seed(seed)data_len = len(data)indexes = [x for x in range(0, data_len)]rng.shuffle(indexes)for frac in sizes:part_len = int(frac * data_len)self.partitions.append(indexes[0:part_len])indexes = indexes[part_len:]def use(self, partition):return Partition(self.data, self.partitions[partition])使用上面的代码片段,我们现在可以使用以下几行简单地对任何数据集进行分区:
""" Partitioning MNIST """
def partition_dataset():dataset = datasets.MNIST('./data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))]))size = dist.get_world_size()bsz = 128 / float(size)partition_sizes = [1.0 / size for _ in range(size)]partition = DataPartitioner(dataset, partition_sizes)partition = partition.use(dist.get_rank())train_set = torch.utils.data.DataLoader(partition,batch_size=bsz,shuffle=True)return train_set, bsz假设我们有 2 个副本,则每个进程的train_set为 60000/2 = 30000 个样本。 我们还将批量大小除以副本数,以使_整体_批量大小保持为 128。
现在,我们可以编写通常的向前-向后优化训练代码,并添加一个函数调用以平均模型的梯度。 (以下内容主要是受 PyTorch MNIST 官方示例的启发)。
""" Distributed Synchronous SGD Example """
def run(rank, size):torch.manual_seed(1234)train_set, bsz = partition_dataset()model = Net()optimizer = optim.SGD(model.parameters(),lr=0.01, momentum=0.5)num_batches = ceil(len(train_set.dataset) / float(bsz))for epoch in range(10):epoch_loss = 0.0for data, target in train_set:optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)epoch_loss += loss.item()loss.backward()average_gradients(model)optimizer.step()print('Rank ', dist.get_rank(), ', epoch ',epoch, ': ', epoch_loss / num_batches)仍然需要执行average_gradients(model)函数,该函数只需要一个模型并在整个世界上平均其梯度即可。
""" Gradient averaging. """
def average_gradients(model):size = float(dist.get_world_size())for param in model.parameters():dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)param.grad.data /= size等! 我们成功实现了分布式同步 SGD,并且可以在大型计算机集群上训练任何模型。
**注意:**尽管从技术上来说最后一句话是是正确的,但要实现同步 SGD 的生产级实现,还需要更多技巧。 同样,请使用经过测试和优化的。
我们自己的环减少
另一个挑战是,假设我们要实现 DeepSpeech 的高效环网减少。 使用点对点集合很容易实现。
""" Implementation of a ring-reduce with addition. """
def allreduce(send, recv):rank = dist.get_rank()size = dist.get_world_size()send_buff = th.zeros(send.size())recv_buff = th.zeros(send.size())accum = th.zeros(send.size())accum[:] = send[:]left = ((rank - 1) + size) % sizeright = (rank + 1) % sizefor i in range(size - 1):if i % 2 == 0:# Send send_buffsend_req = dist.isend(send_buff, right)dist.recv(recv_buff, left)accum[:] += recv[:]else:# Send recv_buffsend_req = dist.isend(recv_buff, right)dist.recv(send_buff, left)accum[:] += send[:]send_req.wait()recv[:] = accum[:]在上面的脚本中,allreduce(send, recv)函数的签名与 PyTorch 中的签名略有不同。 它需要一个recv张量,并将所有send张量的总和存储在其中。 作为练习留给读者,我们的版本与 DeepSpeech 中的版本之间仍然有一个区别:它们的实现将梯度张量划分为_个块_,以便最佳地利用通信带宽。 (提示: torch.chunk)
进阶主题
现在,我们准备发现torch.distributed的一些更高级的功能。 由于涉及的内容很多,因此本节分为两个小节:
- 通讯后端:我们在这里学习如何使用 MPI 和 Gloo 进行 GPU-GPU 通讯。
- 初始化方法:我们了解如何最好地设置
dist.init_process_group()中的初始协调阶段。
通讯后端
torch.distributed最优雅的方面之一是它具有抽象能力,并且可以在不同的后端之上构建。 如前所述,目前在 PyTorch 中实现了三个后端:Glo,NCCL 和 MPI。 它们各自具有不同的规格和权衡,具体取决于所需的用例。 可以在中找到支持功能的对照表。
Gloo 后端
到目前为止,我们已经广泛使用 Gloo 后端。 它作为开发平台非常方便,因为它已包含在预编译的 PyTorch 二进制文件中,并且可在 Linux(自 0.2 开始)和 macOS(自 1.3 开始)上运行。 它支持 CPU 上的所有点对点和集合操作,以及 GPU 上的所有集合操作。 CUDA 张量的集体运算的实现未像 NCCL 后端提供的那样优化。
如您所知,如果将model放在 GPU 上,我们的分布式 SGD 示例将无法正常工作。 为了使用多个 GPU,让我们还进行以下修改:
- 使用
device = torch.device("cuda:{}".format(rank)) model = Net()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t748GofX-1692404941159)(img/84b92171e855642e5bbfa912f0cdb093.jpg)]model = Net().to(device)- 使用
data, target = data.to(device), target.to(device)
经过上述修改,我们的模型现在可以在两个 GPU 上训练,您可以使用watch nvidia-smi监视其使用情况。
MPI 后端
消息传递接口(MPI)是来自高性能计算领域的标准化工具。 它允许进行点对点和集体通信,并且是torch.distributed API 的主要灵感。 存在几种针对不同目的而优化的 MPI 实现(例如 Open-MPI , MVAPICH2 , Intel MPI)。 使用 MPI 后端的优势在于 MPI 在大型计算机群集上的广泛可用性和高水平的优化。 一些 最近的 实现也能够利用 CUDA IPC 和 GPU Direct 技术来避免通过 CPU 进行内存复制。
不幸的是,PyTorch 的二进制文件不能包含 MPI 实现,我们将不得不手动对其进行重新编译。 幸运的是,鉴于编译后,PyTorch 会单独查看以查找可用的 MPI 实现,因此此过程相当简单。 以下步骤通过从源安装 PyTorch 来安装 MPI 后端。
- 创建并激活您的 Anaconda 环境,按照指南的要求安装所有先决条件,但是尚未运行。
- 选择并安装您喜欢的 MPI 实现。 请注意,启用支持 CUDA 的 MPI 可能需要一些其他步骤。 在我们的情况下,我们将坚持不支持 GPU 的 Open-MPI :
conda install -c conda-forge openmpi - 现在,转到克隆的 PyTorch 存储库并执行
python setup.py install。
为了测试我们新安装的后端,需要进行一些修改。
- 将
if __name__ == '__main__':下的内容替换为init_process(0, 0, run, backend='mpi')。 - 运行
mpirun -n 4 python myscript.py。
这些更改的原因是,MPI 需要在生成流程之前创建自己的环境。 MPI 也将生成自己的进程,并执行初始化方法中描述的握手,使init_process_group的rank和size参数多余。 实际上,这非常强大,因为您可以将附加参数传递给mpirun,以便为每个进程定制计算资源。 (诸如每个进程的内核数量,将计算机手动分配给特定等级,以及等之类的东西。)这样做,您应该获得与其他通信后端相同的熟悉输出。
NCCL 后端
NCCL 后端提供了针对 CUDA 张量的集体操作的优化实现。 如果仅将 CUDA 张量用于集体操作,请考虑使用此后端以获得最佳性能。 NCCL 后端包含在具有 CUDA 支持的预构建二进制文件中。
初始化方法
为了完成本教程,我们来谈谈我们称为的第一个功能:dist.init_process_group(backend, init_method)。 特别是,我们将介绍负责每个过程之间初始协调步骤的不同初始化方法。 这些方法使您可以定义协调方式。 根据您的硬件设置,这些方法之一自然应该比其他方法更合适。 除了以下各节之外,您还应该查看官方文档。
环境变量
在本教程中,我们一直在使用环境变量初始化方法。 通过在所有计算机上设置以下四个环境变量,所有进程将能够正确连接到主服务器,获取有关其他进程的信息,最后与它们握手。
MASTER_PORT:计算机上的空闲端口,它将托管等级为 0 的进程。MASTER_ADDR:将以等级 0 托管进程的计算机的 IP 地址。WORLD_SIZE:进程总数,这样主机可以知道要等待多少个工人。RANK:每个进程的等级,因此他们将知道它是否是工人的主人。
共享文件系统
共享文件系统要求所有进程都有权访问共享文件系统,并将通过共享文件进行协调。 这意味着每个进程都将打开文件,写入文件信息,然后等到每个人都打开文件。 之后,所有必需的信息将可用于所有过程。 为了避免争用情况,文件系统必须通过 fcntl 支持锁定。
dist.init_process_group(init_method='file:///mnt/nfs/sharedfile',rank=args.rank,world_size=4)TCP
通过提供等级 0 和可访问的端口号的进程的 IP 地址,可以实现通过 TCP 进行初始化。 在这里,所有工作人员都可以连接到等级为 0 的流程,并交换有关如何相互联系的信息。
dist.init_process_group(init_method='tcp://10.1.1.20:23456',rank=args.rank,world_size=4)致谢
我要感谢 PyTorch 开发人员在实现,文档和测试方面做得如此出色。 当代码不清楚时,我总是可以依靠文档或测试来找到答案。 我要特别感谢 Soumith Chintala,Adam Paszke 和 Natalia Gimelshein 提供的有见地的评论并回答了有关初稿的问题。
相关文章:

用 PyTorch 编写分布式应用程序
用 PyTorch 编写分布式应用程序 在这个简短的教程中,我们将介绍 PyTorch 的分布式软件包。 我们将了解如何设置分布式设置,使用不同的交流策略以及如何仔细查看软件包的内部结构。 设定 PyTorch 中包含的分布式软件包(即torch.distributed)…...

空间分析专属 Python 学习资料
空间数据分析能够帮助我们更好地理解地理空间中的模式和关系,从而为决策提供支持。例如,城市规划者可以使用空间数据分析来确定城市发展的最佳方向,环境科学家可以使用空间数据分析来评估污染的影响,而商业分析师可以使用空间数据…...

2. Linux Server 20.04 Qt5.14.2配置Jetson Orin Nano Developer Kit 交叉编译环境
最近公司给了我一块Jetson Orin Nano的板子,先刷了系统(1.Jetson Orin Nano Developer Kit系统刷机)又让我搭建交叉编译环境,所以有了下面的文章 一 :Qt5.14.2交叉编译环境安装 1.准备 1.1设备环境 1.1.1 Server: Ubuntu20.0…...

vue入门
Attribute 绑定 v-bind:取值方式 开发前准备 安装node.js需要高于15.0 创建vue项目 npm init vuelatest安装 npm install 启动 npm run dev模板语法 文本插值 {{ 变量 }} <p> {{ mesg }} </p>这种方式公支持单一表达式,也可以是js代码…...

区块链中slot、epoch、以及在slot和epoch中的出块机制,分叉原理(自己备用)
以太坊2.0中有两个时间概念:时隙槽slot 和 时段(周期)epoch。其中一个slot为12秒,而每个 epoch 由 32 个 slots 组成,所以每个epoch共384秒,也就是 6.4 分钟。 对于每个epoch,使用RANDAO伪随机…...

免费开源的vue+express搭建的后台管理系统
此项目已开源 前端git地址:exp后台管理系统前端: exp后台管理系统前端 后端git地址:express后台管理系统: express后台管理系统 安装运行 npm i yarn i 前端: npm run dev | yarn dev 后端: npm run start | yarn start 主要技术栈 前端后端名称版本名…...
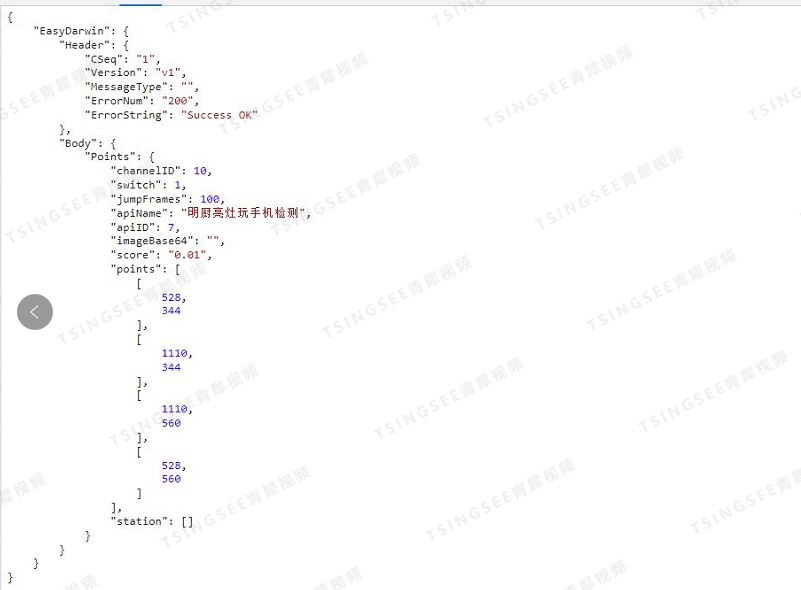
【开发】视频云存储EasyCVR视频汇聚平台AI智能算法定制
安防视频集中存储EasyCVR视频汇聚平台,可支持海量视频的轻量化接入与汇聚管理。平台能提供视频存储磁盘阵列、视频监控直播、视频轮播、视频录像、云存储、回放与检索、智能告警、服务器集群、语音对讲、云台控制、电子地图、平台级联、H.265自动转码等功能。为了便…...
Ribbon:负载均衡及Ribbon
什么是负载均衡? 第一种轮询算法,依次遍历去执行,达到负载均衡 集成Ribbon 导入pom,在消费者服务里的pom文件导入 <!-- Ribbon 集成 --><!-- https://mvnrepository.com/artifact/org.springframework.cloud/spr…...
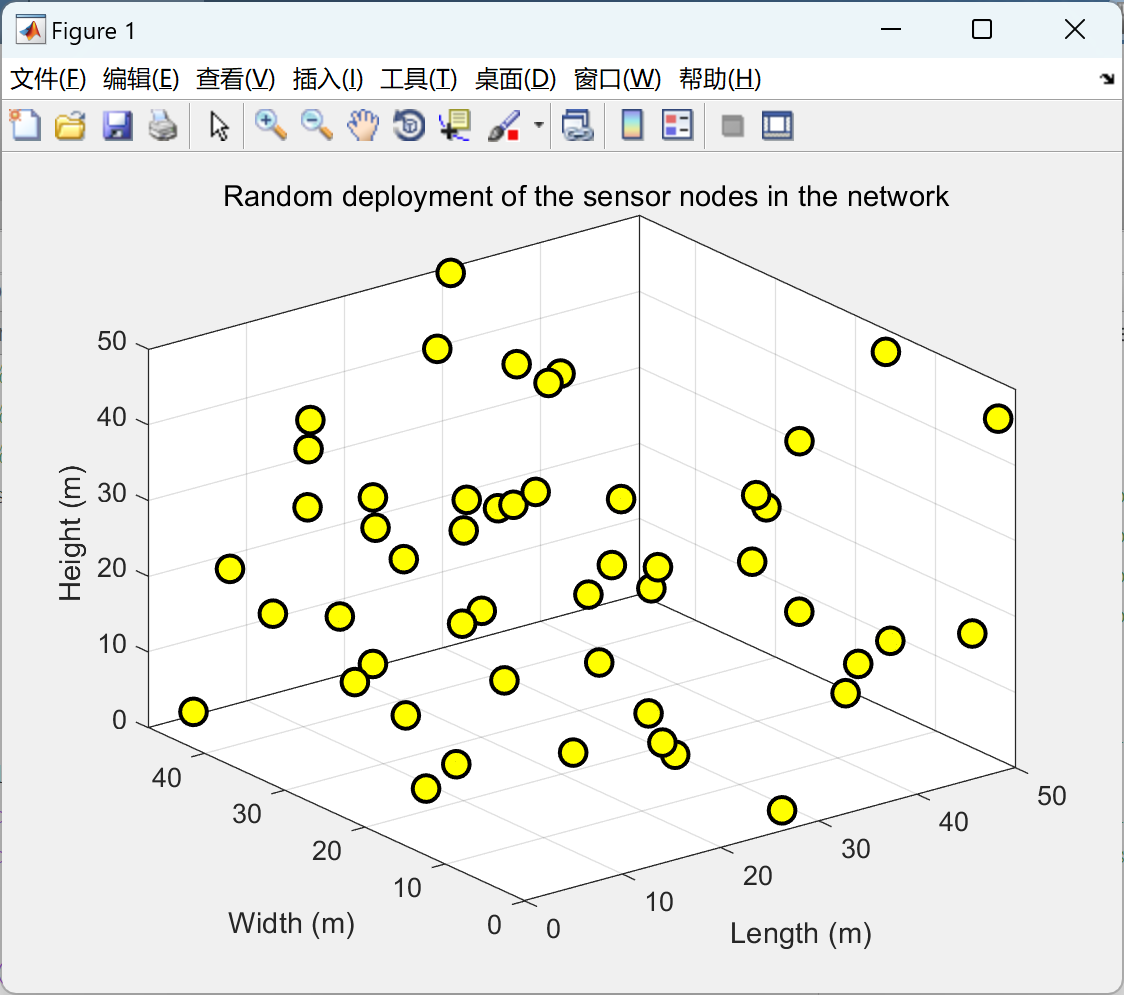
【声波】声波在硼酸、硫酸镁 (MgSO4) 和纯水中的吸收研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
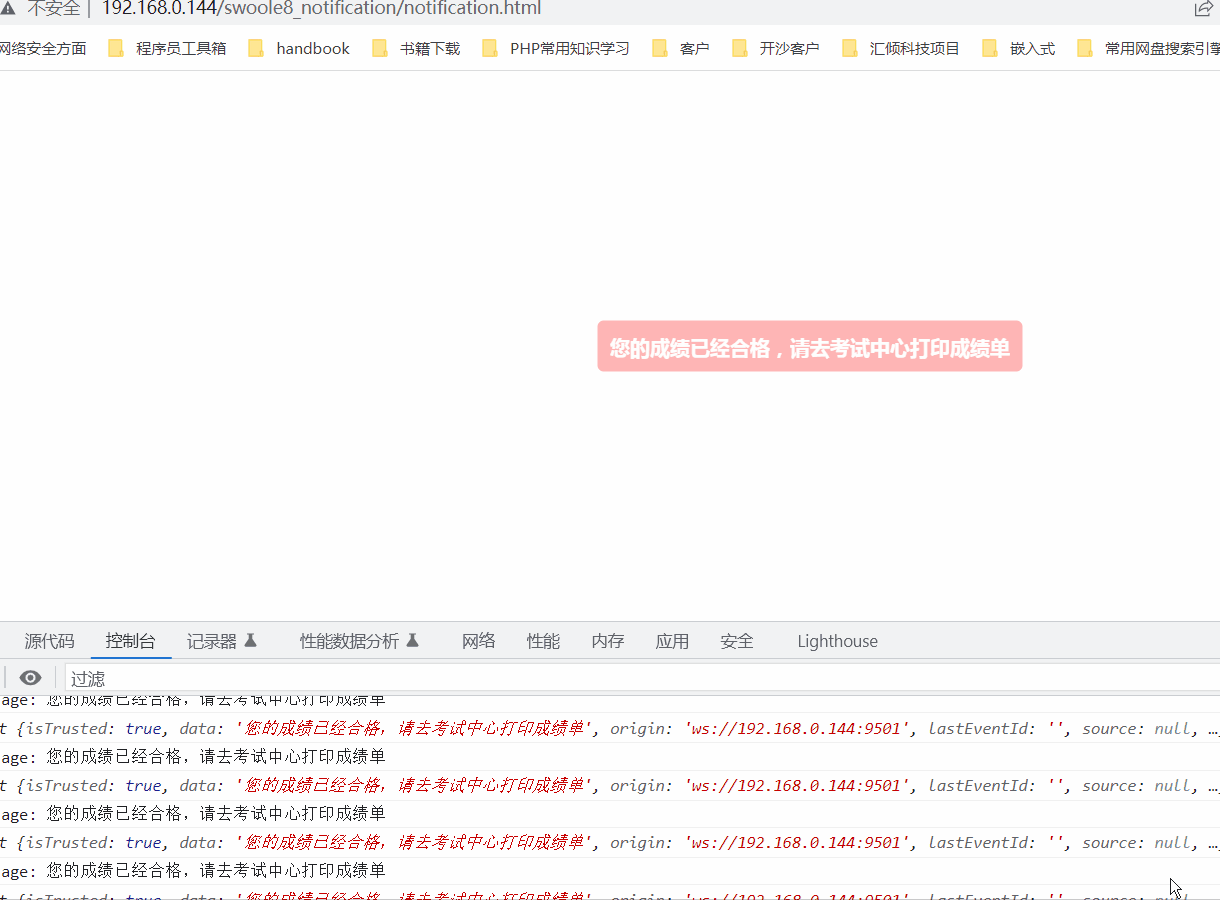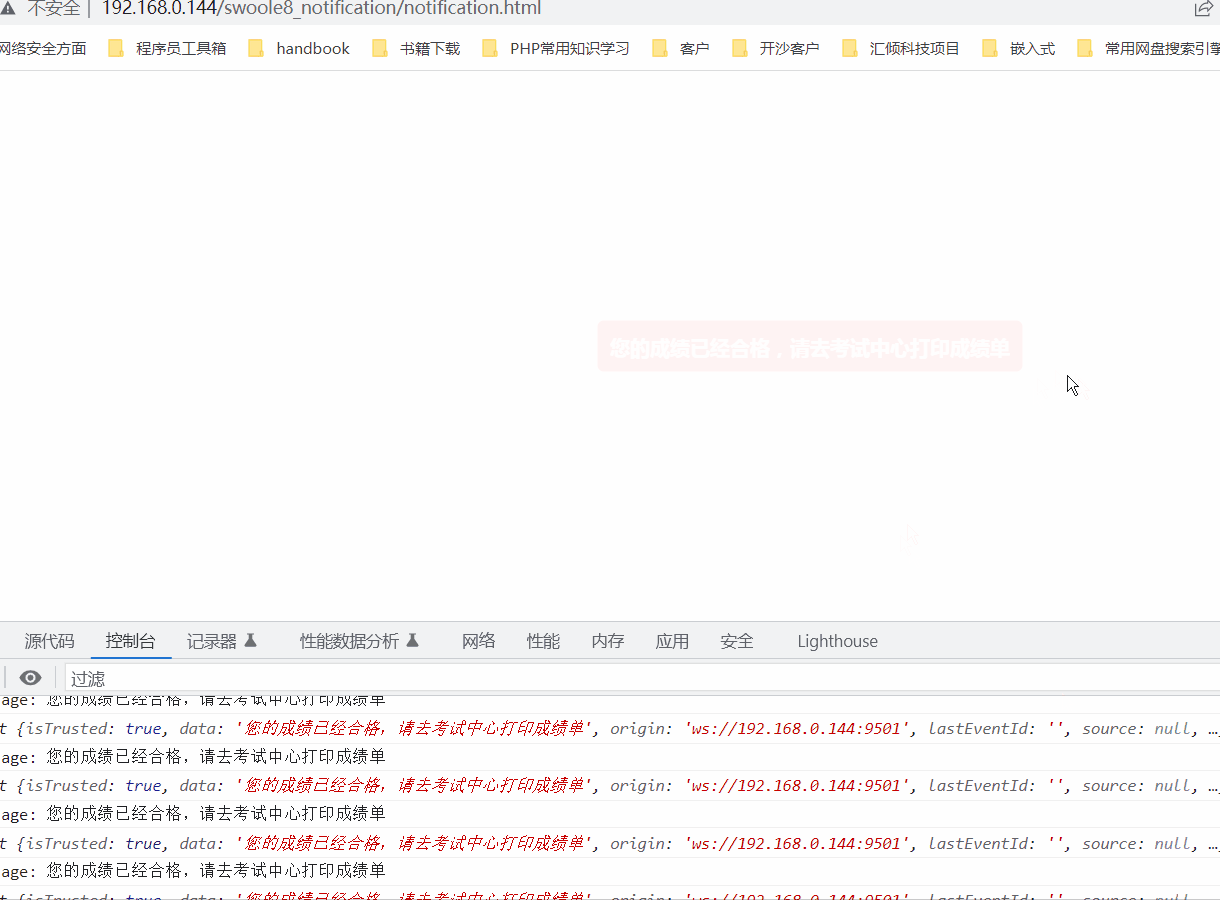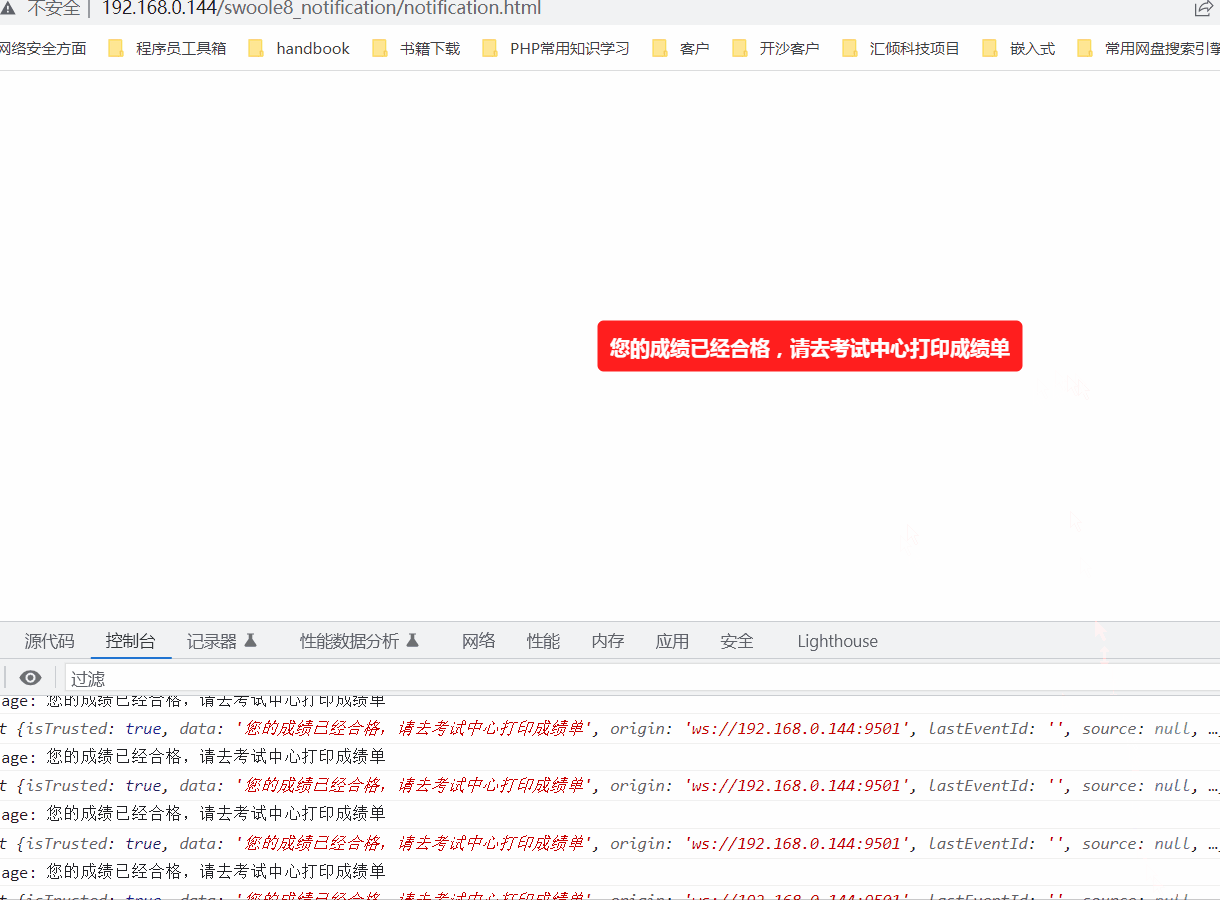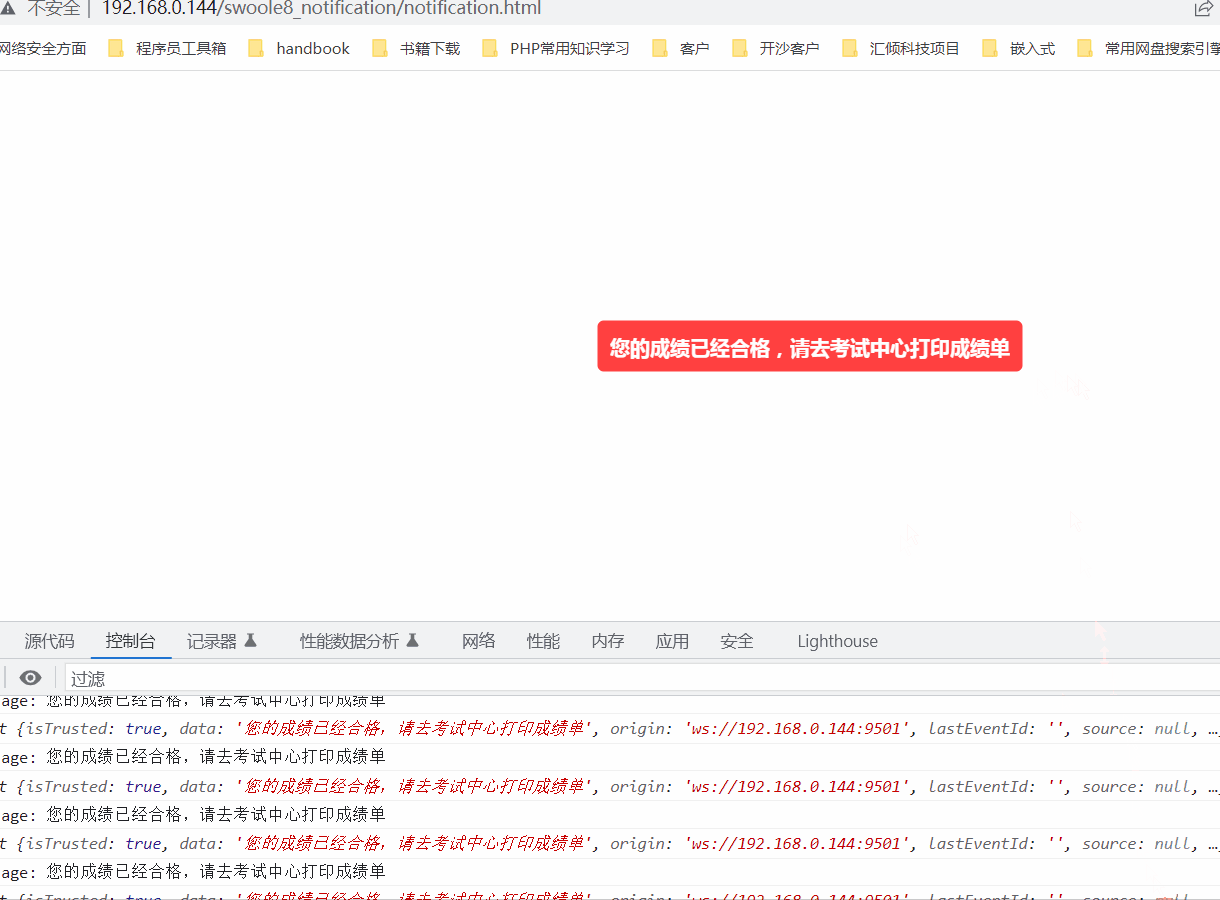
使用swoole实现实时消息推送给客户端
一. 测试服务端 //测试服务端public function testServer(){$server new Server(192.168.0.144, 9501, SWOOLE_BASE, SWOOLE_SOCK_TCP);$server->on(request, function ($request, $response) {$response->header(Content-Type, text/plain);$response->end("He…...

Ordinals 之后,以太坊铭文协议 Ethscriptions 如何再塑 NFT 资产形态
随着加密市场的发展,NFT 赛道逐渐形成了其独有的市场。但在加密熊市的持续影响下,今年 NFT 赛道的发展充满坎坷与挑战。据 NFTGO 数据显示,截至 8 月 7 日,与去年相比,NFT 市值总计约 56.4 亿美元,过去 1 年…...

Python绘制爱心代码(七夕限定版)
写在前面: 又到了一年一度的七夕节啦!你还在发愁送女朋友什么礼物,不知道怎样表达你满满的爱意吗?别担心,我来帮你!今天,我将教你使用Python绘制一个跳动的爱心,用创意和幽默为这个…...

Java两整数相除向上取整
方法一:通过三目运算符 (简单移动) x / y (x % y ! 0 ? 1 : 0);方法二:通过ceil函数(不推荐使用,涉及类型转换) (int)Math.ceil((double)x/y);// 或者(int)Math.ceil(x * 1.0 /y);方法三&…...
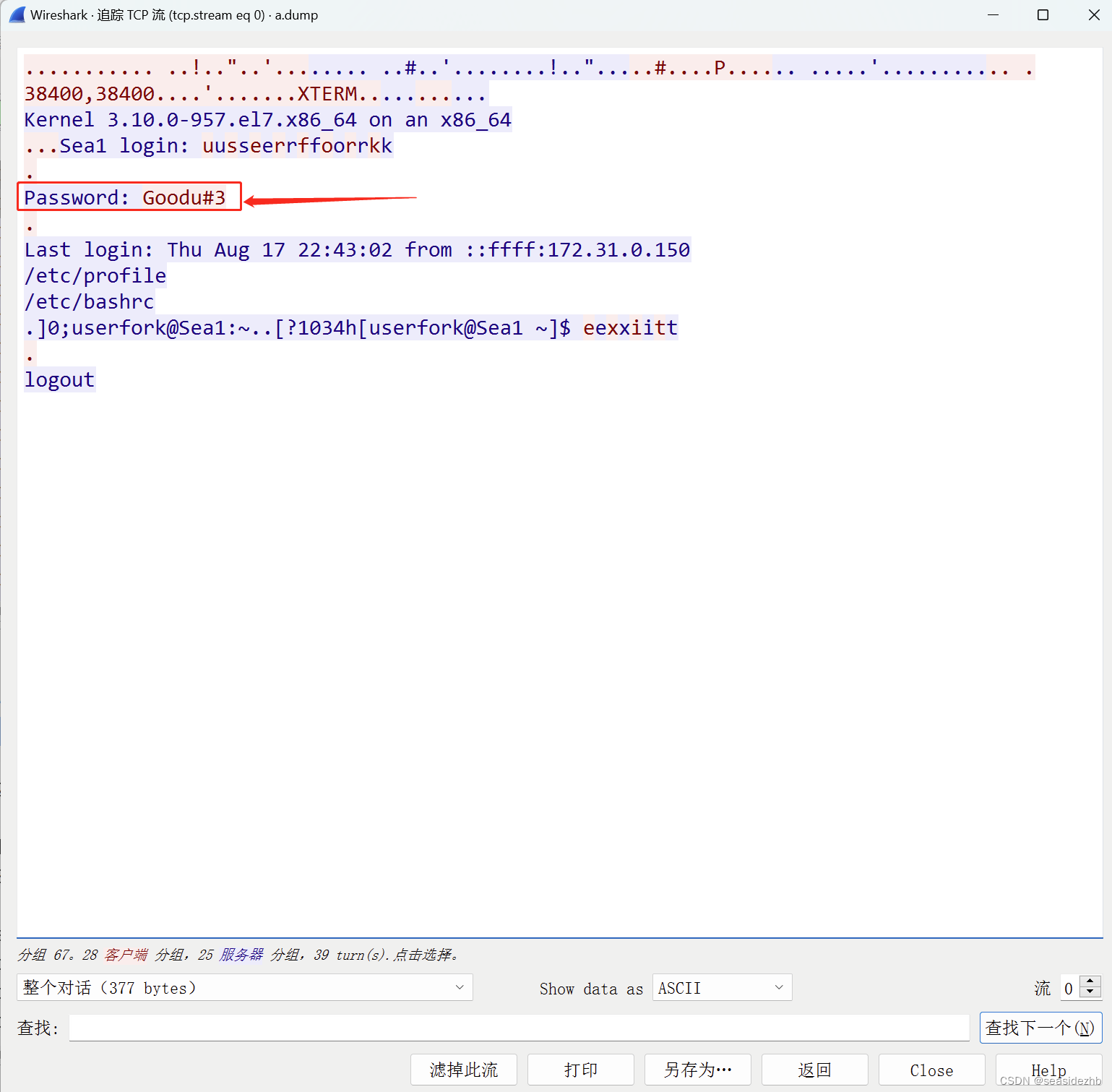
Linux学习之Telnet明文漏洞
yum install telnet telnet-server xinetd -y安装软件。 systemctl start xinetd.service开启xinetd,systemctl start telnet.socket开启telnet。 xinetd来监控端口,然后把数据传给telnet。 ifconfig eth0看一下eth0网卡信息,。 iptable…...
产品经理如何提高用户画像效果?SIKT模型
产品经理做用户画像,最担心被业务方反馈:没效果。这往往是由用户画像与业务场景脱节造成的。那么我们该如何从业务场景出发,让用户画像更有效?一般来说,我们可以采用SIKT模型解决这个问题。 用户画像 1、SIK…...
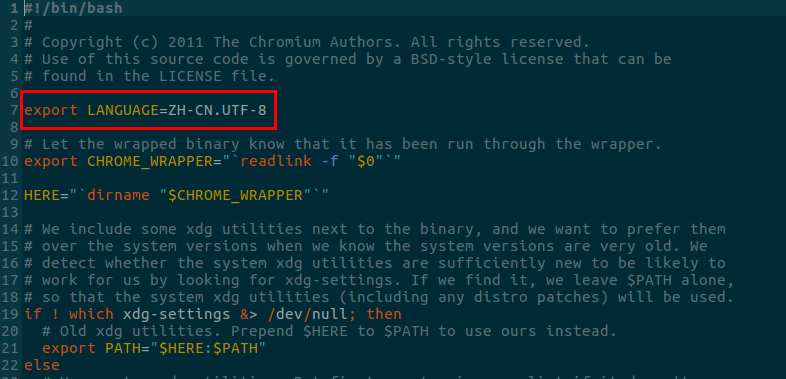
ubuntu安装Microsoft Edge并设置为中文
1、下载 edge.deb 版本并安装 sudo dpkg -i microsoft-edg.deb 2. 设置默认中文显示 如果是通过.deb方式安装的: 打开默认安装路径下的microsoft-edge-dev文件,在文件最开头加上: export LANGUAGEZH-CN.UTF-8 ,保存退出。 cd /opt/micr…...

Host/ KVM/ Docker/ K8s/ OpenStack/ Mesos简单介绍和区别
Host/ KVM/ Docker/ Kubernetes/ OpenStack 和 Mesos 的简单介绍: - Host: Host 是指物理服务器或虚拟机主机,它们可以运行多个虚拟机或容器来提供计算和存储资源。Host 是云计算和容器化技术中的基本组成部分。 - KVM: KVM 是…...
关于Transformer中的位置编码
位置编码 (Positional Encoding) 位置编码是在自然语言处理中,特别是在 Transformer 架构中使用的一个重要概念。Transformer 架构由于其自注意力机制 (Self-Attention Mechanism) 的特性,对序列中的元素没有固有的顺序感知。这意味着,如果不…...

ABAP 期初库存批量导入 demo1
&--------------------------------------------------------------------- *& Report ZMMCP005 &--------------------------------------------------------------------- 作者: Liv完成日期:描述: 期初库存导入需求简要说明&…...

想用 Python 写游戏,都有哪些好用的游戏开发库?
虽然 Python 在网络爬虫、人工智能、数据分析方面有广泛应用,但它并不是一门专门做游戏开发的编程语言,不过对于小型的游戏开发,Python 还是挺香的。下面为大家介绍几个支持 Python 的 2D、3D 游戏开发库,使用它们,你可以设计出很多有意思的小游戏! Cocos2d Cocos2d 是…...

MFC界面现代化---自定义标题栏与控件美化实战
1. 为什么需要MFC界面现代化改造 很多老牌企业软件和工业控制系统都基于MFC框架开发,这些系统通常运行了十几年甚至更久。我接手过不少这类项目,最直观的感受就是界面实在太"复古"了——灰底蓝框的窗口、生硬的按钮、像素感明显的图标…...

类OpenClaw智能体优选指南,企业级+个人级全覆盖
2026年初,OpenClaw开源智能体框架凭借“自主规划、工具调用、端到端执行”的核心能力,打破传统AI“只对话不行动”的壁垒,在GitHub迅速斩获25万星标,引发全球科技圈热潮,国内厂商纷纷入局推出类OpenClaw产品࿰…...

Phi-4-mini-reasoning vLLM参数详解:context_length=131072配置与性能调优
Phi-4-mini-reasoning vLLM参数详解:context_length131072配置与性能调优 1. 模型概述 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学推理…...

FanControl完全攻略:智能风扇控制的动态平衡技术与多场景应用
FanControl完全攻略:智能风扇控制的动态平衡技术与多场景应用 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

wordpress数据迁移---没有验证
迁移 WordPress 完整数据(文章、页面、媒体、主题、插件、设置、评论、用户),核心是 备份旧站文件 数据库 → 新服务器配置环境 → 上传文件 导入数据库 → 修改配置 替换域名 / URL → 测试。下面分 插件一键迁移(新手推荐&am…...

终极指南:如何在Windows上安装和使用FlipIt翻页时钟屏保
终极指南:如何在Windows上安装和使用FlipIt翻页时钟屏保 【免费下载链接】FlipIt Flip Clock screensaver 项目地址: https://gitcode.com/gh_mirrors/fl/FlipIt 想要为你的Windows电脑增添一抹复古优雅的时间艺术吗?FlipIt翻页时钟屏保正是你需要…...

3步安全卸载:EdgeRemover的非强制解决方案
3步安全卸载:EdgeRemover的非强制解决方案 【免费下载链接】EdgeRemover PowerShell script to remove Microsoft Edge in a non-forceful manner. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover Windows Edge卸载过程中如何确保系统安全&#x…...
)
【飞机】倾转旋翼飞机齿轮箱建模与Matlab仿真(含非线性阻尼和立方摩擦效应)
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

LaTeX模板-主流SCI期刊模板-IEEE模板-Elsevier模板-Springer模板-Science模板-ACM模板-arXiv模板-MDPI模板
出版商模板下载链接适用领域IEEEIEEE-Template Selector电气工程、通信、计算机科学等SpringerSpringerLaTeX模板计算机、数学、生物、医学等多个领域ElsevierElsevier工程、物理、化学、医学、社会科学等ScienceScience跨学科顶刊ACMACM模板计算机科学会议与期刊MDPIMDPI模板自…...

快手无水印下载深度解析:从技术原理到商业应用的完整方案
快手无水印下载深度解析:从技术原理到商业应用的完整方案 【免费下载链接】KS-Downloader 快手(KuaiShou)视频/图片下载工具;数据采集工具 项目地址: https://gitcode.com/gh_mirrors/ks/KS-Downloader 在短视频内容管理日…...