解决方案:如何在 Amazon EMR Serverless 上执行纯 SQL 文件?
 | 《大数据平台架构与原型实现:数据中台建设实战》一书由博主历时三年精心创作,现已通过知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
长久已来,SQL以其简单易用、开发效率高等优势一直是ETL的首选编程语言,在构建数据仓库和数据湖的过程中发挥着不可替代的作用。Hive和Spark SQL也正是立足于这一点,才在今天的大数据生态中牢牢占据着主力位置。在常规的Spark环境中,开发者可以使用spark-sql命令直接执行SQL文件,这是一项看似平平无奇实则非常重要的功能:一方面,这一方式极大地降低了Spark的使用门槛,用户只要会写SQL就可以使用Spark;另一方面,通过命令行驱动SQL文件的执行可以极大简化SQL作业的提交工作,使得作业提交本身被“代码化”,为大规模工程开发和自动化部署提供了便利。
但遗憾的是,Amazon EMR Serverless 未能针对执行SQL文件提供原生支持,用户只能在Scala/Python代码中嵌入SQL语句,这对于倚重纯SQL开发数仓或数据湖的用户来说并不友好。为此,我们专门开发了一组用于读取、解析和执行SQL文件的工具类,借助这组工具类,用户可以在 Amazon EMR Serverless 上直接执行SQL文件,本文将详细介绍一下这一方案。
1. 方案设计
鉴于在Spark编程环境中执行SQL语句的方法是:spark.sql("..."),我们可以设计一个通用的作业类,该类在启动时会根据传入的参数读取指定位置上的SQL文件,然后拆分成单条SQL并调用spark.sql("...")执行。为了让作业类更加灵活和通用,还可以引入通配符一次加载并执行多个SQL文件。此外,ETL作业经常需要根据作业调度工具生成的时间参数去执行相应的批次,这些参数同样会作用到SQL中,所以,作业类还应允许用户在SQL文件中嵌入自定义变量,并在提交作业时以参数形式为自定义变量赋值。基于这种设计思路,我们开发了一个项目,实现了上述功能,项目地址为:
| 项目名称 | 项目地址 |
|---|---|
| Amazon EMR Serverless Utilities | https://github.com/bluishglc/emr-serverless-utils |
项目中的com.github.emr.serverless.SparkSqlJob类即为通用的SQL作业类,该类接受两个可选参数,分别是:
| 参数 | 说明 | 取值示例 |
|---|---|---|
| –sql-files | 指定要执行的SQL文件路径,支持Java文件系统通配符,可指定多个文件一起执行 | s3://my-spark-sql-job/sqls/insert-into-*.sql |
| –sql-params | 以K1=V1,K2=V2,...形式为SQL文件中定义的${K1},${K2},…形式的变量设值 | CUST_CITY=NEW YORK,ORD_DATE=2008-07-15 |
该方案具备如下特性:
① 允许单一SQL文件包含多条SQL语句
② 允许在SQL文件中使用${K1},${K2},…的形式定义变量,并在执行作业时使用K1=V1,K2=V2,...形式的参数进行变量赋值
③ 支持Java文件系统通配符,可一次执行多个SQL文件
下面,我们将分别在AWS控制台和命令行两种环境下介绍并演示如何使用该项目的工具类提交纯SQL作业。
2. 实操演示
2.1. 环境准备
在EMR Serverless上提交作业时需要准备一个“EMR Serverless Application”和一个“EMR Serverless Job Execution Role”,其中后者应具有S3和Glue Data Catalog的读写权限。Application可以在EMR Serverless控制台(EMR Studio)上通过向导轻松创建(全默认配置即可),Execution Role可以使用 《CDC一键入湖:当 Apache Hudi DeltaStreamer 遇见 Serverless Spark》 一文第5节提供的脚本快速创建。
接下来要准备提交作业所需的Jar包和SQL文件。首先在S3上创建一个存储桶,本文使用的桶取名:my-spark-sql-job(当您在自己的环境中操作时请注意替换桶名),然后从 [ 此处 ] 下载编译好的 emr-serverless-utils.jar包并上传至s3://my-spark-sql-job/jars/目录下:
在演示过程中还将使用到5个SQL示例文件,从 [ 此处 ] 下载解压后上传至s3://my-spark-sql-job/sqls/目录下:
2.2. 在控制台上提交纯SQL文件作业
2.2.1. 执行单一SQL文件
打开EMR Serverless的控制台(EMR Studio),在选定的EMR Serverless Application下提交一个如下的Job:
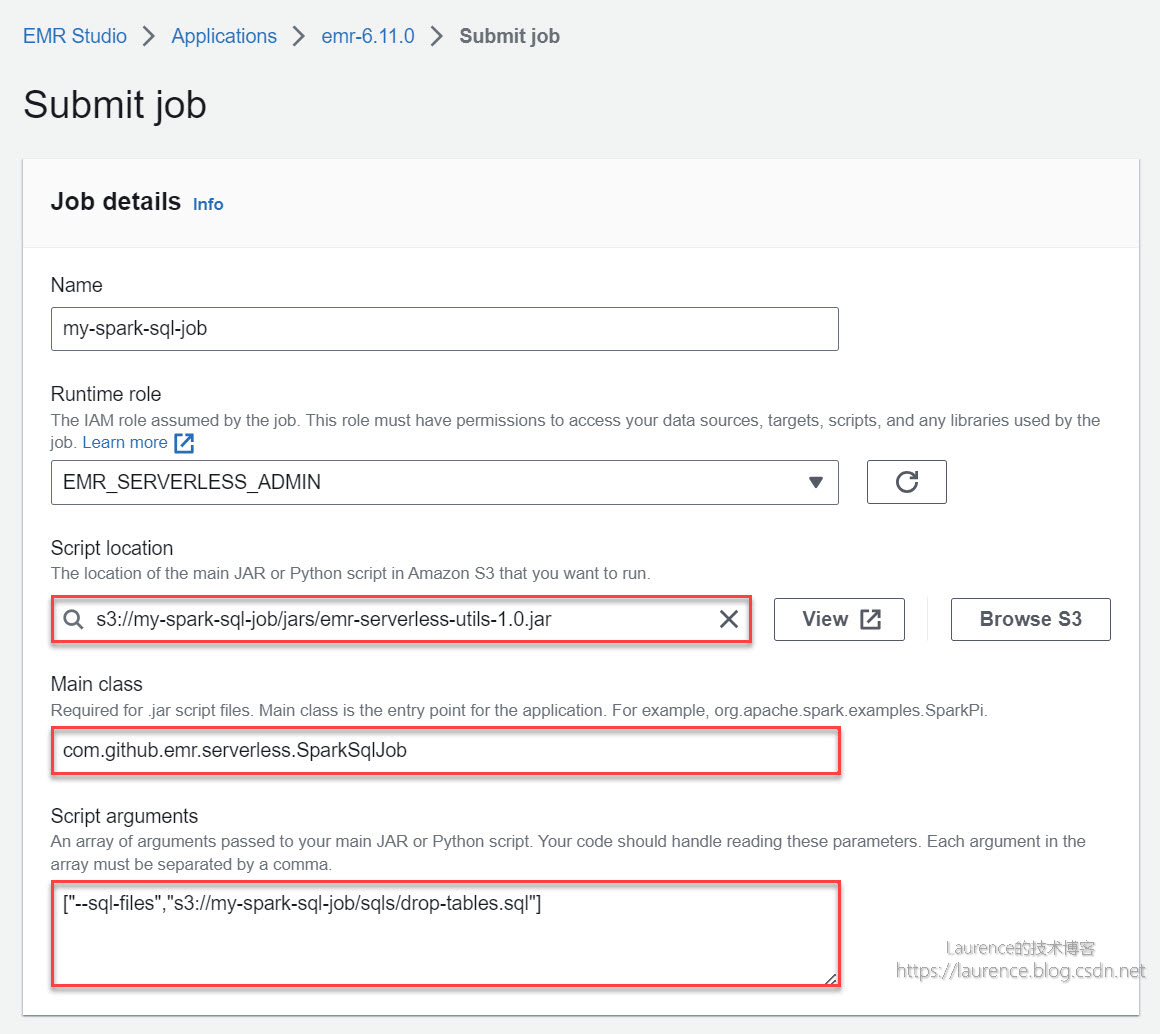
① Script location:设定为此前上传的Jar包路径 s3://my-spark-sql-job/jars/emr-serverless-utils-1.0.jar
② Main class:设定为 com.github.emr.serverless.SparkSqlJob
③ Script arguments:设定为 ["--sql-files","s3://my-spark-sql-job/sqls/drop-tables.sql"]
至于其他选项,无需特别设定,保持默认配置即可,对于在生产环境中部署的作业,您可以结合自身作业的需要灵活配置,例如Spark Driver/Executor的资源分配等。需要提醒的是:通过控制台创建的作业默认会启用Glue Data Catalog(即:Additional settings -> Metastore configuration -> Use AWS Glue Data Catalog 默认是勾选的),为了方便在Glue和Athena中检查SQL脚本的执行结果,建议您不要修改此项默认配置。
上述配置描述了这样一项工作:以s3://my-spark-sql-job/jars/emr-serverless-utils-1.0.jar中的com.github.emr.serverless.SparkSqlJob作为主类,提起一个Spark作业。其中["--sql-files","s3://my-spark-sql-job/sqls/drop-tables.sql"]是传递给SparkSqlJob的参数,用于告知作业所要执行的SQL文件位置。本次作业执行的SQL文件只有三条简单的DROP TABLE语句,是一个基础示例,用以展示工具类执行单一文件内多条SQL语句的能力。
2.2.2. 执行带自定义参数的SQL文件
接下来要演示的是工具类的第二项功能:执行带自定义参数的SQL文件。新建或直接复制上一个作业(在控制台上选定上一个作业,依次点击 Actions -> Clone job),然后将“Script arguments”的值设定为:
["--sql-files","s3://my-spark-sql-job/sqls/create-tables.sql","--sql-params","APP_S3_HOME=s3://my-spark-sql-job"]
如下图所示:
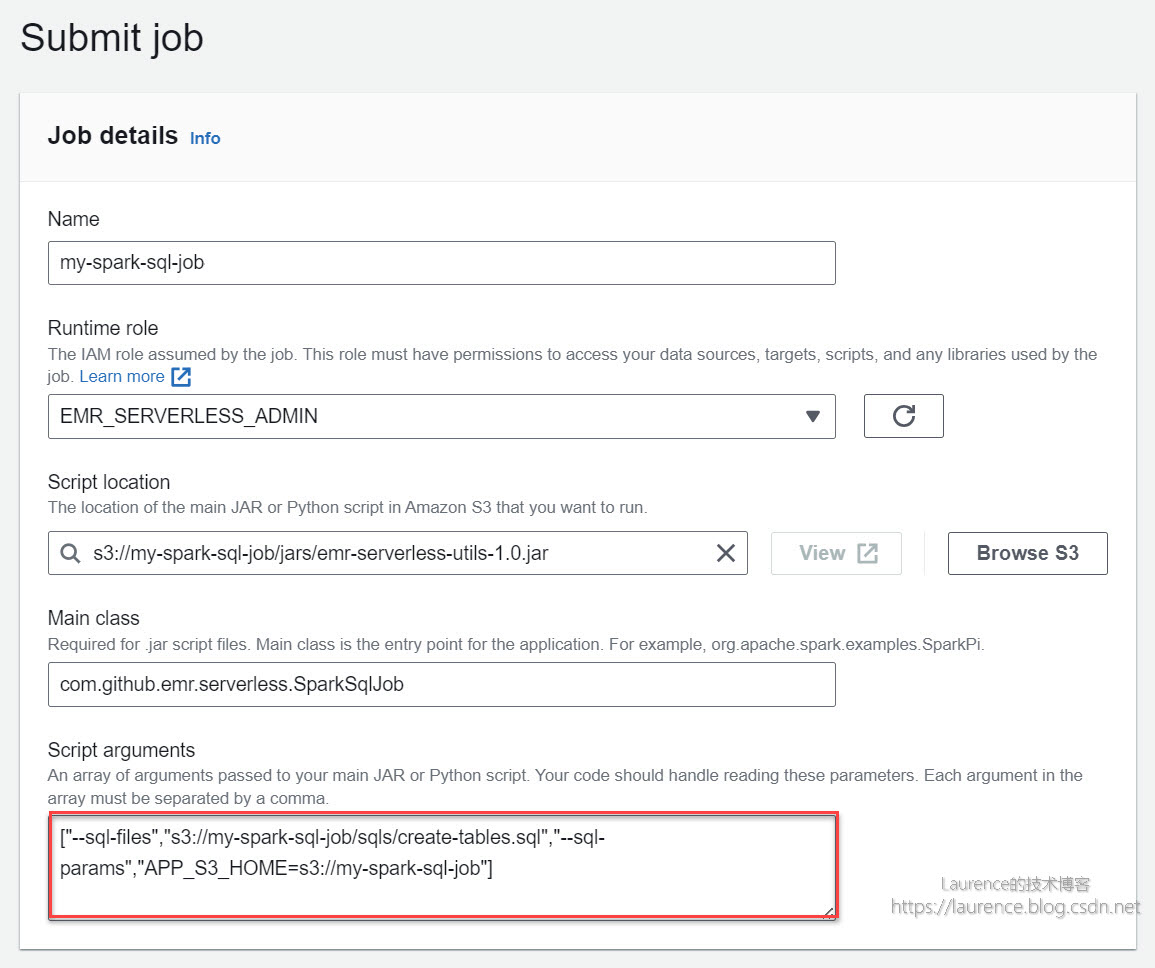
这次的作业设定除了使用--sql-files参数指定了SQL文件外,还通过--sql-params参数为SQL中出现的用户自定义变量进行了赋值。根据此前的介绍,APP_S3_HOME=s3://my-spark-sql-job是一个“Key=Value”字符串,其含义是将值s3://my-spark-sql-job赋予了变量APP_S3_HOME,SQL中所有出现${APP_S3_HOME}的地方都将被s3://my-spark-sql-job所替代。查看create-tables.sql文件,在建表语句的LOCATION部分可以发现自定义变量${APP_S3_HOME}:
CREATE EXTERNAL TABLE IF NOT EXISTS ORDERS (... ...
)
... ...
LOCATION '${APP_S3_HOME}/data/orders/';
当SparkSqlJob读取该SQL文件时,会根据键值对字符串APP_S3_HOME=s3://my-spark-sql-job将SQL文件中所有的${APP_S3_HOME}替换为s3://my-spark-sql-job,实际执行的SQL将变为:
CREATE EXTERNAL TABLE IF NOT EXISTS ORDERS (... ...
)
... ...
LOCATION 's3://my-spark-sql-job/data/orders/';
提交作业并执行完毕后,可登录Athena控制台,查看数据表是否创建成功。
2.2.3. 使用通配符执行多个文件
有时候,我们需要批量执行一个文件夹下的所有SQL文件,或者使用通配符选择性的执行部分SQL文件,SparkSqlJob使用了Java文件系统通配符来支持这类需求。下面的作业就演示了通配符的使用方法,同样是新建或直接复制上一个作业,然后将“Script arguments”的值设定为:
["--sql-files","s3://my-spark-sql-job/sqls/insert-into-*.sql"]
如下图所示:

这次作业的--sql-files参数使用了路径通配符,insert-into-*.sql将同时匹配insert-into-orders.sql和insert-into-customers.sql两个SQL文件,它们将分别向ORDERS和CUSTOMERS两张表插入多条记录。执行完毕后,可以可登录Athena控制台,查看数据表中是否有数据产生。
2.2.4. 一个复合示例
最后,我们来提交一个更有代表性的复合示例:文件通配符 + 用户自定义参数。再次新建或直接复制上一个作业,然后将“Script arguments”的值设定为:
["--sql-files","s3://my-spark-sql-job/sqls/select-*.sql","--sql-params","APP_S3_HOME=s3://my-spark-sql-job,CUST_CITY=NEW YORK,ORD_DATE=2008-07-15"]
如下图所示:
![emr-serverless-snapshot-4.jpg-150.8kB][6]
本次作业的--sql-files参数使用路径通配符select-*.sql匹配select-tables.sql文件,该文件中存在三个用户自定义变量,分别是${APP_S3_HOME}、${CUST_CITY}、${ORD_DATE}:
CREATE EXTERNAL TABLE ORDERS_CUSTOMERS... ...LOCATION '${APP_S3_HOME}/data/orders_customers/'
AS SELECT... ...
WHEREC.CUST_CITY = '${CUST_CITY}' ANDO.ORD_DATE = CAST('${ORD_DATE}' AS DATE);
--sql-params参数为这三个自定义变量设置了取值,分别是:APP_S3_HOME=s3://my-spark-sql-job,CUST_CITY=NEW YORK,ORD_DATE=2008-07-15,于是上述SQL将被转化为如下内容去执行:
CREATE EXTERNAL TABLE ORDERS_CUSTOMERS... ...LOCATION 's3://my-spark-sql-job/data/orders_customers/'
AS SELECT... ...
WHEREC.CUST_CITY = 'NEW YORK' ANDO.ORD_DATE = CAST('2008-07-15' AS DATE);
至此,通过控制台提交纯SQL文件作业的所有功能演示完毕。
2.3. 通过命令行提交纯SQL文件作业
实际上,很多EMR Serverless用户并不在控制台上提交自己的作业,而是通过AWS CLI提交,这种方式方式多见于工程代码或作业调度中。所以,我们再来介绍一下如何通过命令行提交纯SQL文件作业。
本文使用命令行提交EMR Serverless作业的方式遵循了《最佳实践:如何优雅地提交一个 Amazon EMR Serverless 作业?》一文给出的最佳实践。首先,登录一个安装了AWS CLI并配置有用户凭证的Linux环境(建议使用Amazon Linux2),先使用命令sudo yum -y install jq安装操作json文件的命令行工具:jq(后续脚本会使用到它),然后完成如下前期准备工作:
① 创建或选择一个作业专属工作目录和S3存储桶
② 创建或选择一个EMR Serverless Execution Role
③ 创建或选择一个EMR Serverless Application
接下来将所有环境相关变量悉数导出(请根据您的AWS账号和本地环境替换命令行中的相应值):
export APP_NAME='change-to-your-app-name'
export APP_S3_HOME='change-to-your-app-s3-home'
export APP_LOCAL_HOME='change-to-your-app-local-home'
export EMR_SERVERLESS_APP_ID='change-to-your-application-id'
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='change-to-your-execution-role-arn'
以下是一份示例:
export APP_NAME='my-spark-sql-job'
export APP_S3_HOME='s3://my-spark-sql-job'
export APP_LOCAL_HOME='/home/ec2-user/my-spark-sql-job'
export EMR_SERVERLESS_APP_ID='00fbfel40ee59k09'
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='arn:aws:iam::123456789000:role/EMR_SERVERLESS_ADMIN'
《最佳实践:如何优雅地提交一个 Amazon EMR Serverless 作业?》一文提供了多个操作Job的通用脚本,都非常实用,本文也会直接复用这些脚本,但是由于我们需要多次提交且每次的参数又有所不同,为了便于使用和简化行文,我们将原文中的部分脚本封装为一个Shell函数,取名为submit-spark-sql-job:
submit-spark-sql-job() {sqlFiles="$1"sqlParams="$2"cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{"name":"my-spark-sql-job","applicationId":"$EMR_SERVERLESS_APP_ID","executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN","jobDriver":{"sparkSubmit":{"entryPoint":"$APP_S3_HOME/jars/emr-serverless-utils-1.0.jar","entryPointArguments":[$([[ -n "$sqlFiles" ]] && echo "\"--sql-files\", \"$sqlFiles\"")$([[ -n "$sqlParams" ]] && echo ",\"--sql-params\", \"$sqlParams\"")],"sparkSubmitParameters":"--class com.github.emr.serverless.SparkSqlJob --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}},"configurationOverrides":{"monitoringConfiguration":{"s3MonitoringConfiguration":{"logUri":"$APP_S3_HOME/logs"}}}
}
EOFjq . $APP_LOCAL_HOME/start-job-run.jsonexport EMR_SERVERLESS_JOB_RUN_ID=$(aws emr-serverless start-job-run \--no-paginate --no-cli-pager --output text \--name my-spark-sql-job \--application-id $EMR_SERVERLESS_APP_ID \--execution-role-arn $EMR_SERVERLESS_EXECUTION_ROLE_ARN \--execution-timeout-minutes 0 \--cli-input-json file://$APP_LOCAL_HOME/start-job-run.json \--query jobRunId)now=$(date +%s)secwhile true; dojobStatus=$(aws emr-serverless get-job-run \--no-paginate --no-cli-pager --output text \--application-id $EMR_SERVERLESS_APP_ID \--job-run-id $EMR_SERVERLESS_JOB_RUN_ID \--query jobRun.state)if [ "$jobStatus" = "PENDING" ] || [ "$jobStatus" = "SCHEDULED" ] || [ "$jobStatus" = "RUNNING" ]; thenfor i in {0..5}; doecho -ne "\E[33;5m>>> The job [ $EMR_SERVERLESS_JOB_RUN_ID ] state is [ $jobStatus ], duration [ $(date -u --date now-$now +%H:%M:%S) ] ....\r\E[0m"sleep 1doneelseprintf "The job [ $EMR_SERVERLESS_JOB_RUN_ID ] is [ $jobStatus ]%50s\n\n"breakfidone
}
该函数接受两个位置参数:
① 第一位置上的参数用于指定SQL文件路径,其值会传递给SparkSqlJob的--sql-files
② 第二位置上的参数用于指定SQL文件中的用户自定义变量,其值会传递给SparkSqlJob的--sql-params
函数中使用的Jar包和SQL文件与《2.1. 环境准备》一节准备的Jar包和SQL文件一致,所以使用脚本提交作业前同样需要完成2.1节的环境准备工作。接下来,我们就使用该函数完成与2.2节一样的操作。
2.3.1. 执行单一SQL文件
本节操作与2.2.1节完全一致,只是改用了命令行方式实现,命令如下:
submit-spark-sql-job "$APP_S3_HOME/sqls/drop-tables.sql"
2.3.2. 执行带自定义参数的SQL文件
本节操作与2.2.2节完全一致,只是改用了命令行方式实现,命令如下:
submit-spark-sql-job "$APP_S3_HOME/sqls/create-tables.sql" "APP_S3_HOME=$APP_S3_HOME"
2.3.3. 使用通配符执行多个文件
本节操作与2.2.3节完全一致,只是改用了命令行方式实现,命令如下:
submit-spark-sql-job "$APP_S3_HOME/sqls/insert-into-*.sql"
2.3.4. 一个复合示例
本节操作与2.2.4节完全一致,只是改用了命令行方式实现,命令如下:
submit-spark-sql-job "$APP_S3_HOME/sqls/select-tables.sql" "APP_S3_HOME=$APP_S3_HOME,CUST_CITY=NEW YORK,ORD_DATE=2008-07-15"
3. 在源代码中调用工具类
尽管在Spark编程环境中可以使用spark.sql(...)形式直接执行SQL语句,但是,从前文示例中可以看出 emr-serverless-utils 提供的SQL文件执行能力更便捷也更强大一些,所以,最后我们简单介绍一下如何在源代码中调用相关的工具类获得上述SQL文件的处理能力。具体做法非常简单,你只需要:
① 将emr-serverless-utils-1.0.jar加载到你的类路径中
② 声明隐式类型转换
③ 在spark上直接调用execSqlFile()
# 初始化SparkSession及其他操作
...# 声明隐式类型转换
import com.github.emr.serverless.SparkSqlSupport._# 在spark上直接调用execSqlFile()
spark.execSqlFile("s3://YOUR/XXX.sql")# 在spark上直接调用execSqlFile()
spark.execSqlFile("s3://YOUR/XXX.sql", "K1=V1,K2=V2,...")# 其他操作
...
相关文章:
解决方案:如何在 Amazon EMR Serverless 上执行纯 SQL 文件?
《大数据平台架构与原型实现:数据中台建设实战》一书由博主历时三年精心创作,现已通过知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详…...
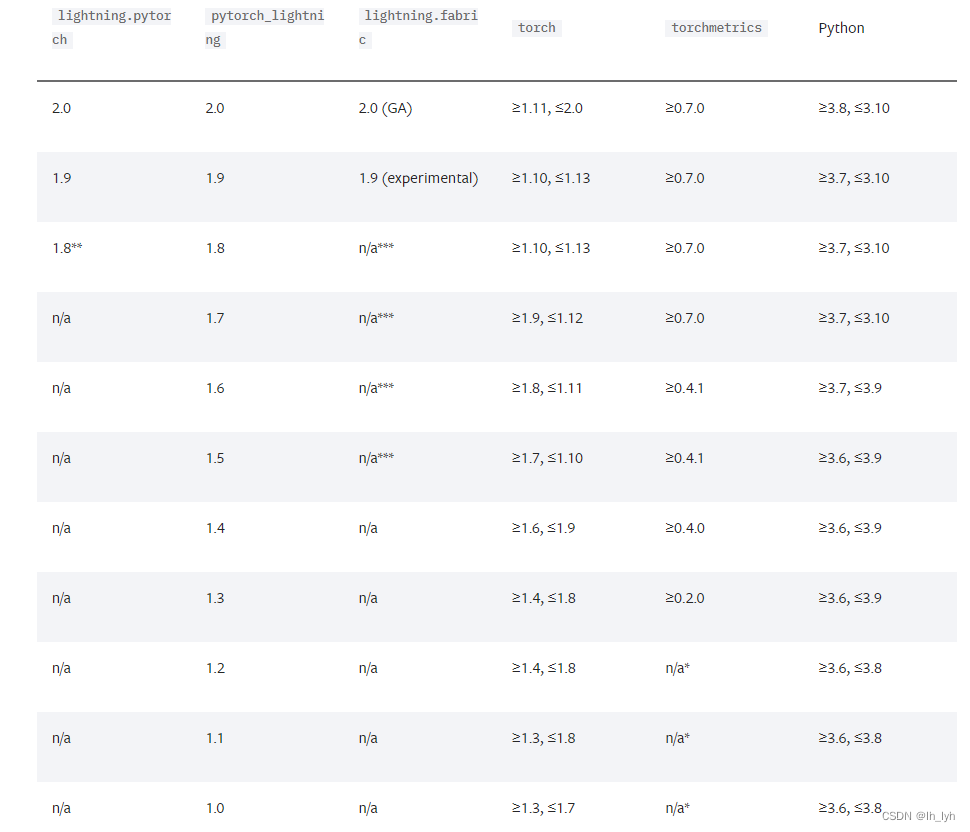
pytorch lightning和pytorch版本对应
参见官方文档: https://lightning.ai/docs/pytorch/latest/versioning.html#compatibility-matrix 下图左一列(lightning.pytorch)安装命令:pip install lightning --use-feature2020-resolver 下图左一列(pytorch_lig…...

Postman返回了一个html页面
问题记录 调用公司的测试环境接口,从浏览器控制台接口处cCopy as cURL(cmd),获取完整的请求内容,然后导入postman发起请求 提测时发现返回一个html页面,明显是被请求在网管处被拦截了,网关返回的这个报错html页面 …...

centos服务器搭建宝塔面板
因为电脑无线网无法登录宝塔,也无法ssh到服务器,但是热点可以连接,网上没找到解决方法,重装下。 解决办法,先追路由,结果是被防火墙拦截了,解封以后还不行,重新查,联动的…...

【微信小程序】记一次自定义微信小程序组件的思路
最近来个需求,要求给小程序的 modal 增加个关闭按钮,上网一查发现原来 2018 年就有人给出解决方案了,于是总结下微信小程序自定义组件的思路:一句话,用 wxml css实现和原生组件类似的样式和效果,之后用 JS…...

TiDB数据库从入门到精通系列之四:SQL 基本操作
TiDB数据库从入门到精通系列之四:SQL 基本操作 一、SQL 语言分类二、查看、创建和删除数据库三、创建、查看和删除表四、创建、查看和删除索引五、记录的增删改六、查询数据七、创建、授权和删除用户 成功部署 TiDB 集群之后,便可以在 TiDB 中执行 SQL 语…...
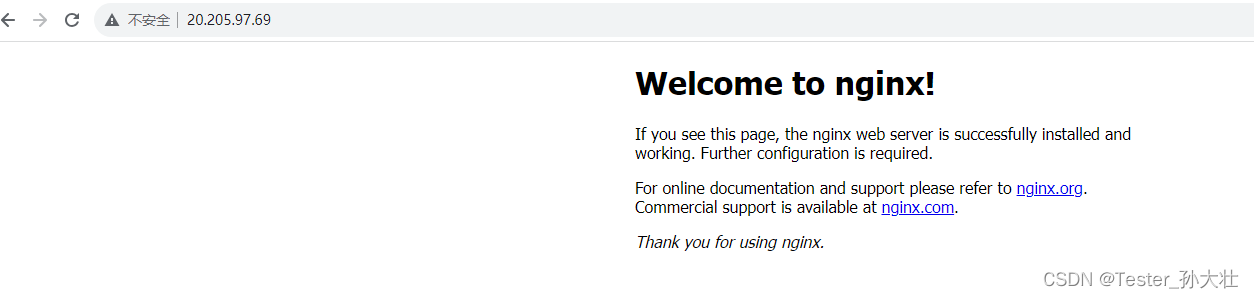
Azure创建自定义VM镜像
创建一个虚拟机,参考 https://blog.csdn.net/m0_48468018/article/details/132267096,入站端口开启80,22 进行远程远程连接 使用CLI命令部署NGINX,输入如下命令 sudo su apt-get update -y apt-get install nginx git -y最后的效果 4. 关闭…...
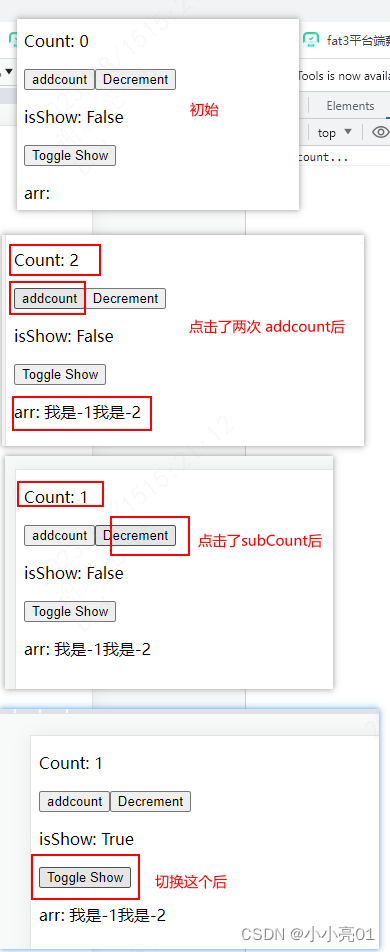
react 10之状态管理工具2 redux + react-redux +redux-saga
目录 react 10之状态管理工具2 redux store / index.js 入口文件actionType.js actions常量的文件rootReducer.js 总的reducer 用于聚合所有模块的 reducerrootSaga.js 总的saga 用于聚合所有模块的 sagastore / form / formActions.js 同步修改 isShowstore / form / formRedu…...

gor工具http流量复制、流量回放,生产运维生气
gor是一款流量复制回放工具,gor工具的官网:https://goreplay.org/ 1、对某个端口的http流量进行打印 ./gor --input-raw :8000 --output-stdout 2、对流量实时转发,把81端口流量转发到192.168.3.221:80端口 ./gor --input-raw :81--output-ht…...
设计模式之单例设计模式
单例设计模式 2.1 孤独的太阳盘古开天,造日月星辰。2.2 饿汉造日2.3 懒汉的队伍2.4 大道至简 读《秒懂设计模式总结》 单例模式(Singleton)是一种非常简单且容易理解的设计模式。顾名思义,单例即单一的实例,确切地讲就是指在某个系统中只存在…...

Java自学到什么程度就可以去找工作了?
引言 Java作为一门广泛应用于软件开发领域的编程语言,对于初学者来说,了解到什么程度才能开始寻找实习和入职机会是一个常见的问题。 本文将从实习和入职这两个方面,分点详细介绍Java学习到什么程度才能够开始进入职场。并在文章末尾给大家安…...

三、Kafka生产者
目录 3.1 生产者消息发送流程3.1.1 发送原理 3.2 异步发送 API3.3 同步发送数据3.4 生产者分区3.4.1 kafka分区的好处3.4.2 生产者发送消息的分区策略3.4.3 自定义分区器 3.5 生产者如何提高吞吐量3.6 数据可靠性 3.1 生产者消息发送流程 3.1.1 发送原理 3.2 异步发送 API 3…...

【SA8295P 源码分析】19 - QNX Host NFS 文件系统配置
【SA8295P 源码分析】19 - QNX Host NFS 文件系统配置 一、NFS Server二、NFS Client三、NFS 相关的文件及目录四、将文件放入QNX 文件系统中五、编译下载验证系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》 本文链接:《【SA8295P 源码分析】19 - QNX Host N…...

JRE、JDK、JVM及JIT之间有什么不同?_java基础知识总结
当涉及Java编程和执行时,以下术语具有不同的含义: 1.JRE (Java Runtime Environment) JRE是Java运行时环境的缩写。它是一个包含用于在计算机上运行Java应用程序所需的组件集合。JRE包括了以下几个主要部分: Java虚拟机(JVM):用…...

sqlite3数据库的实现
sqlite3代码实现数据库的插入、删除、修改、退出功能 #include <head.h> #include <sqlite3.h> #include <unistd.h> int do_insert(sqlite3 *db); int do_delete(sqlite3 *db); int do_update(sqlite3 *db);int main(int argc, const char *argv[]) {sqlit…...
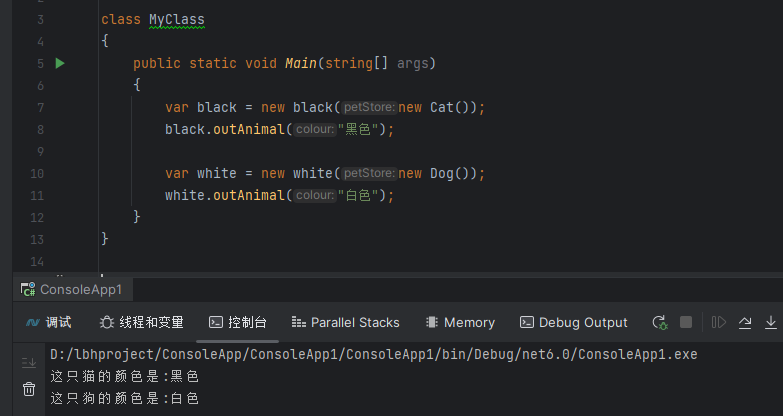
c#设计模式-结构型模式 之 桥接模式
前言 桥接模式是一种设计模式,它将抽象与实现分离,使它们可以独立变化。这种模式涉及到一个接口作为桥梁,使实体类的功能独立于接口实现类。这两种类型的类可以结构化改变而互不影响。 桥接模式的主要目的是通过将实现和抽象分离,…...
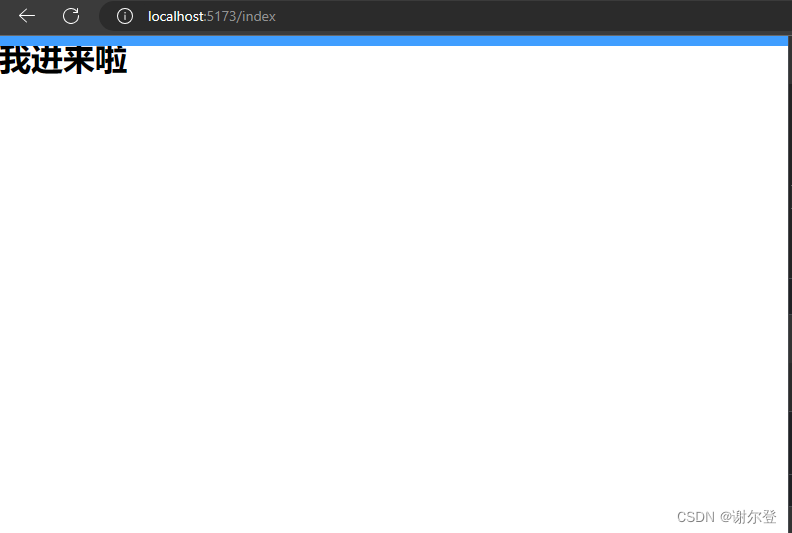
【Vue-Router】导航守卫
前置守卫 main.ts import { createApp } from vue import App from ./App.vue import {router} from ./router // import 引入 import ElementPlus from element-plus import element-plus/dist/index.css const app createApp(App) app.use(router) // use 注入 ElementPlu…...

07无监督学习——降维
1.降维的概述 维数灾难(Curse of Dimensionality):通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。 1.1什么是降维? 1.降维(Dimensionality Reduction)是将训练数据中的样本(实例)从高维空间转换到低维…...
)
系列七、IOC操作bean管理(xml自动装配)
一、概述 自动装配是根据指定规则(属性名称或者属性类型),Spring自动将匹配的属性值进行注入。 二、分类 xml自动装配分为按照属性名称自动装配(byName)和按照属性类型自动装配(byType)。 2.1…...
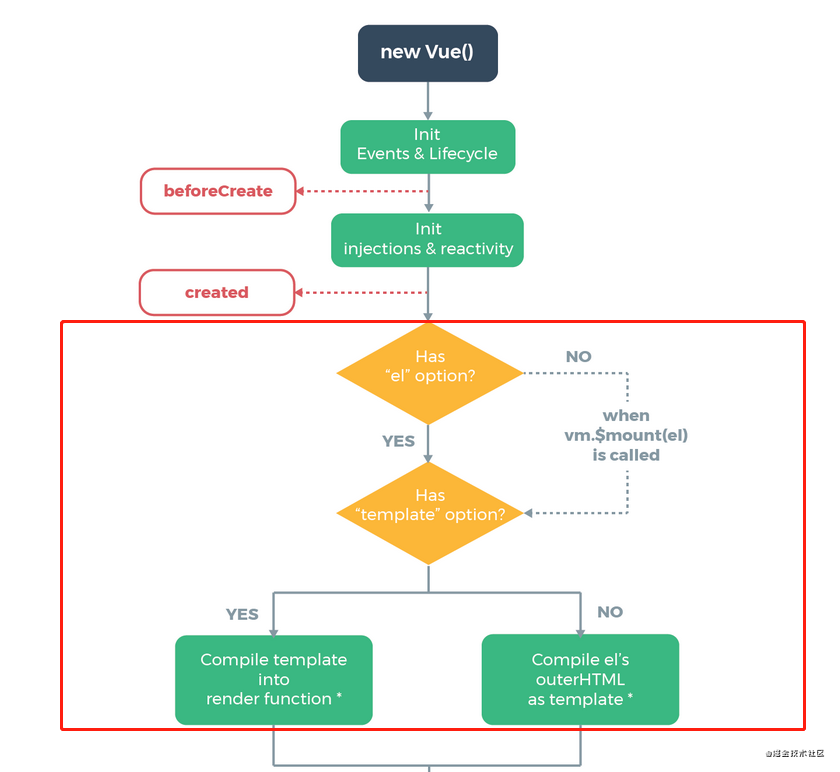
01- vdom 和模板编译源码
组件渲染的过程 template --> ast --> render --> vDom --> 真实的Dom --> 页面 Runtime-Compiler和Runtime-Only的区别 - 简书 编译步骤 模板编译是Vue中比较核心的一部分。关于 Vue 编译原理这块的整体逻辑主要分三个部分,也可以说是分三步&am…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
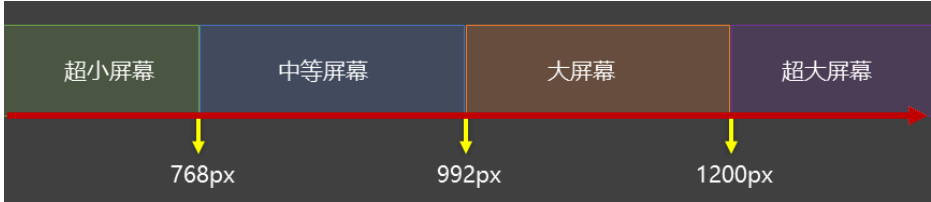
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...