了解生成对抗网络 (GAN)

一、介绍
Yann LeCun将其描述为“过去10年来机器学习中最有趣的想法”。当然,来自深度学习领域如此杰出的研究人员的赞美总是对我们谈论的主题的一个很好的广告!事实上,生成对抗网络(简称GAN)自2014年由Ian J. Goodfellow和共同作者在《生成对抗网络》一文中引入以来取得了巨大的成功。
那么什么是生成对抗网络?是什么让他们如此“有趣”?在这篇文章中,我们将看到对抗训练是一个启发性的想法,它的简单性很美,它代表了机器学习的真正概念进步,尤其是对于生成模型(就像反向传播是一个简单但非常聪明的技巧一样,它使神经网络的基本思想变得如此流行和高效)。
在详细介绍之前,让我们快速概述一下 GAN 的用途。生成对抗网络属于生成模型集。这意味着他们能够产生/生成(我们将看到如何)新内容。为了说明“生成模型”的概念,我们可以看一些众所周知的GANs获得的结果示例。

Ian Goodfellow和合著者对GAN的能力的插图。这些是生成对抗网络在两个数据集上训练后生成的样本:MNIST 和 TFD。对于两者,最右侧的列包含与直接相邻生成的样本最近的真实数据。这向我们表明,生成的数据是真正生成的,而不仅仅是由网络记忆的。(来源:《生成对抗网》论文)
当然,这种生成新内容的能力使GAN看起来有点“魔术”,至少乍一看是这样。在以下部分中,我们将克服GAN的明显魔力,以便深入研究这些模型背后的想法,数学和建模。我们不仅将讨论生成对抗网络所依赖的基本概念,而且,我们将逐步构建并从头开始导致这些想法的推理。
事不宜迟,让我们一起重新发现 GAN!
注意:尽管我们试图使本文尽可能独立,但仍需要机器学习的基本先验知识。然而,大多数概念将在需要时保留,一些参考将另行提供。我们真的试图使这篇文章尽可能流畅地阅读。不要犹豫,在评论部分提及您想内容的内容(有关该主题的可能进一步文章)。
大纲
在下面的第一节中,我们将讨论从给定分布生成随机变量的过程。然后,在第 2 节中,我们将通过一个例子来展示 GAN 试图解决的问题可以表示为随机变量生成问题。在第 3 节中,我们将讨论基于匹配的生成网络,并展示它们如何回答第 2 节中描述的问题。最后在第 4 节中,我们将介绍 GAN。更特别的是,我们将介绍一般架构及其损失函数,并将与前面的所有部分建立联系。
- 本文已完成以下备忘单:
https://drive.google.com/drive/folders/1lHtjHQ8K7aemRQAnYMylrrwZp6Bsqqrb
- 本文通过以下简短视频进行了部分说明:
二、生成随机变量
在本节中,我们将讨论生成随机变量的过程:我们提醒一些现有方法,尤其是允许从简单的均匀随机变量生成复杂随机变量的逆变换方法。尽管所有这些似乎与我们的主题GANs相去甚远,但我们将在下一节中看到生成模型存在的深层链接。
2.1 均匀随机变量可以是伪随机生成的
计算机基本上是确定性的。因此,从理论上讲,不可能生成真正随机的数字(即使我们可以说“什么是真正的随机性?”这个问题很困难)。但是,可以定义生成数字序列的算法,这些数字序列的属性非常接近理论随机数序列的属性。特别是,计算机能够使用伪随机数生成器生成一个数字序列,该序列近似地遵循 0 到 1 之间的均匀随机分布。统一情况非常简单,可以在其上以不同的方式构建更复杂的随机变量。
2.2 表示为操作或过程结果的随机变量
存在旨在生成更复杂的随机变量的不同技术。其中我们可以找到,例如,逆变换方法,拒绝采样,大都会-黑斯廷算法等。所有这些方法都依赖于不同的数学技巧,主要包括表示我们想要生成的随机变量作为操作(在更简单的随机变量上)或过程的结果。
拒绝抽样将随机变量表示为一个过程的结果,该过程不是从复分布中采样,而是从众所周知的简单分布中采样,并根据某些条件接受或拒绝采样值。重复此过程直到接受采样值,我们可以证明,在正确的接受条件下,将有效采样的值将遵循正确的分布。
在 Metropolis-Hasting 算法中,这个想法是找到一个马尔可夫链 (MC),使得这个 MC 的平稳分布对应于我们要从中采样随机变量的分布。一旦找到这个 MC,我们就可以在这个 MC 上模拟足够长的轨迹,以认为我们已经达到了一个稳定状态,然后我们以这种方式获得的最后一个值可以被认为是从感兴趣的分布中得出的。
我们不会进一步讨论拒绝抽样和Metropolis-Hasting的细节,因为这些方法不会引导我们了解GAN背后的概念(尽管如此,感兴趣的读者可以参考指向的维基百科文章和其中的链接)。但是,让我们更多地关注逆变换方法。
2.3 逆变换方法
逆变换方法的想法只是简单地表示我们的复数——在本文中,“复杂”应该始终理解为“不简单”而不是数学意义上的——随机变量是应用于我们知道如何生成的均匀随机变量的函数的结果。
我们将在下面的一维示例中考虑。设 X 是我们想要从中采样的复杂随机变量,U 是 [0,1] 上的均匀随机变量,我们知道如何从中采样。我们提醒,随机变量完全由其累积分布函数(CDF)定义。随机变量的 CDF 是从随机变量定义域到区间 [0,1] 的函数,并在一维中定义,使得
![]()
在我们的均匀随机变量 U 的特殊情况下,我们有
![]()
为简单起见,我们在这里假设函数CDF_X是可逆的,其逆函数表示为
![]()
(通过使用函数的广义逆,该方法可以很容易地扩展到不可逆的情况,但它实际上不是我们在这里要关注的重点)。那么如果我们定义
![]()
我们有
![]()
如我们所见,Y 和 X 具有相同的 CDF,然后定义相同的随机变量。因此,通过如上所述定义Y(作为统一随机变量的函数),我们设法定义了具有目标分布的随机变量。
总而言之,逆变换方法是一种通过使均匀随机变量通过精心设计的“变换函数”(逆 CDF)来生成遵循给定分布的随机变量的方法。事实上,这种“逆变换法”的概念可以扩展到“变换法”的概念,更一般地说,包括生成随机变量作为一些更简单的随机变量的函数(不一定是均匀的,然后变换函数不再是逆 CDF)。从概念上讲,“变换函数”的目的是变形/重塑初始概率分布:变换函数从初始分布与目标分布相比太高的地方获取,并将其放在太低的位置。
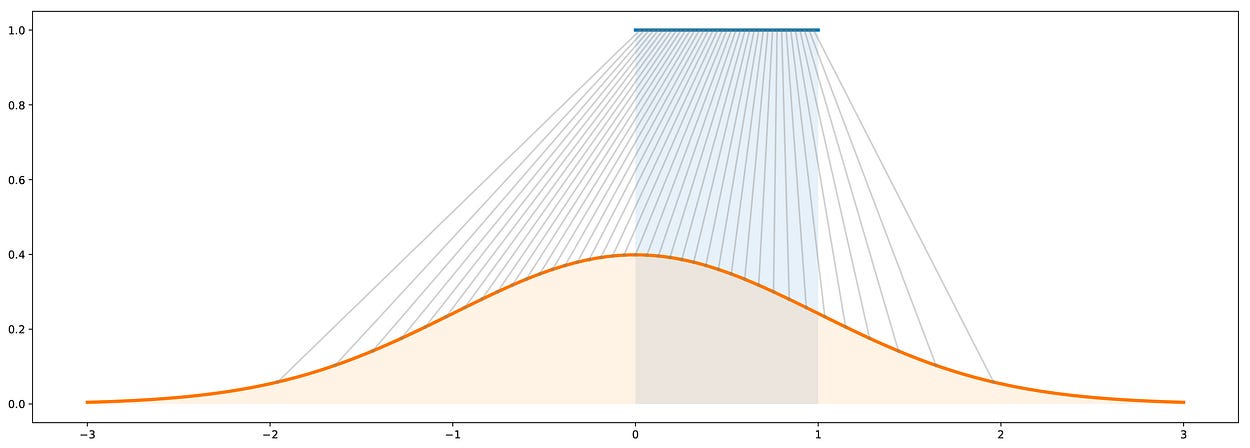
逆变换方法的图示。蓝色:[0,1] 上的均匀分布。橙色:标准高斯分布。灰色:从均匀分布到高斯分布的映射(逆 CDF)。
三、创成模型
3.1 我们尝试生成非常复杂的随机变量...
假设我们对生成大小为 n x n 像素的狗的黑白正方形图像感兴趣。我们可以将每个数据重塑为 N=nxn 维向量(通过将列堆叠在彼此之上),以便狗的图像可以用向量表示。然而,这并不意味着所有的向量都代表一只狗,一旦被塑造成正方形!因此,我们可以说,有效地给出看起来像狗的东西的 N 维向量是根据整个 N 维向量空间上非常特定的概率分布分布的(该空间的某些点很可能代表狗,而其他一些点则不太可能)。本着同样的精神,在这个N维向量空间上,存在猫、鸟等图像的概率分布。
然后,生成狗的新图像的问题等效于在N维向量空间上按照“狗概率分布”生成新向量的问题。因此,我们实际上面临着生成相对于特定概率分布的随机变量的问题。
在这一点上,我们可以提到两件重要的事情。首先,我们提到的“狗概率分布”是一个非常大的空间上的非常复杂的分布。其次,即使我们可以假设存在这种底层分布(实际上存在看起来像狗的图像和其他看起来不像的图像),我们显然不知道如何明确地表达这种分布。前面的两点都使得从这个分布生成随机变量的过程非常困难。然后,让我们尝试在下面解决这两个问题。
3.2 ...因此,让我们使用带有神经网络的变换方法作为函数!
我们在尝试生成狗的新图像时的第一个问题是,N维向量空间上的“狗概率分布”是一个非常复杂的分布,我们不知道如何直接生成复杂的随机变量。然而,由于我们非常了解如何生成 N 个不相关的均匀随机变量,我们可以使用变换方法。为此,我们需要将我们的 N 维随机变量表示为应用于简单 N 维随机变量的非常复杂的函数的结果!
在这里,我们可以强调这样一个事实,即找到变换函数并不像我们在描述逆变换方法时所做的那样简单地采用累积分布函数的闭式逆函数(我们显然不知道)。转换函数不能显式表达,然后,我们必须从数据中学习它。
大多数情况下,在这些情况下,非常复杂的函数自然意味着神经网络建模。然后,这个想法是通过神经网络对变换函数进行建模,该神经网络将一个简单的 N 维均匀随机变量作为输入,并返回另一个 N 维随机变量作为输出,该随机变量在训练后应遵循正确的“狗概率分布”。一旦设计了网络的架构,我们仍然需要对其进行训练。在接下来的两节中,我们将讨论训练这些生成网络的两种方法,包括 GAN 背后的对抗训练的想法!
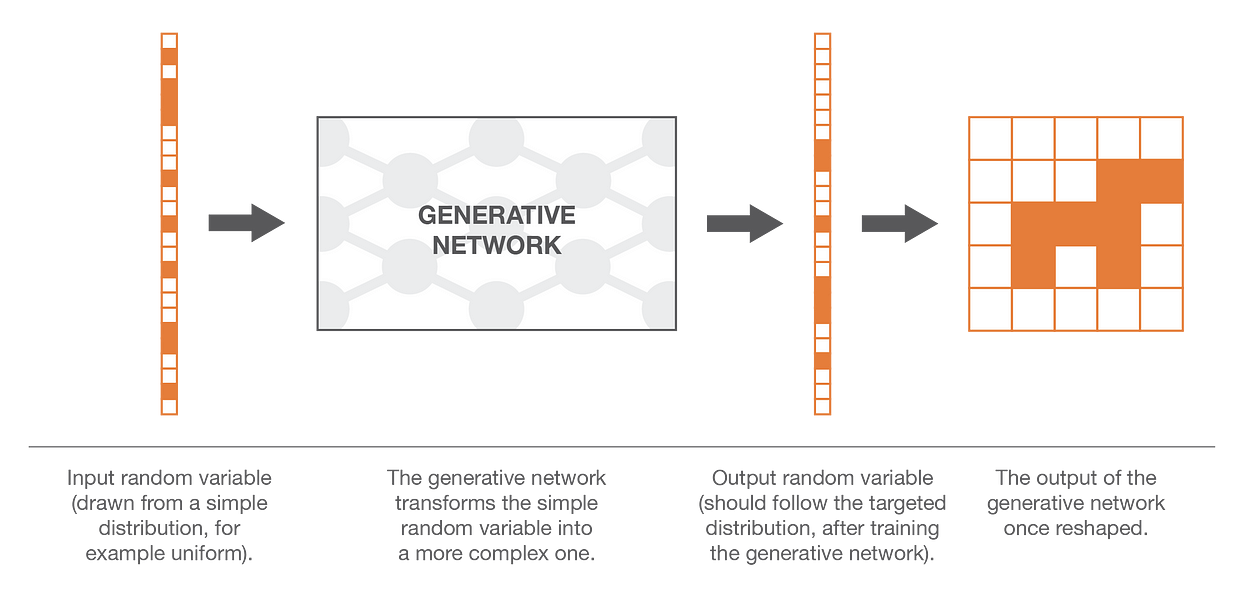
使用神经网络的生成模型概念的说明。显然,我们真正谈论的维度比这里表示的要高得多。
四、生成匹配网络
免责声明:“生成匹配网络”的名称不是标准的。但是,我们可以在文献中找到,例如“生成时刻匹配网络”或“生成特征匹配网络”。我们只是想在这里使用一个稍微笼统的面额来描述我们描述波纹管的内容。
4.1 训练创成模型
到目前为止,我们已经表明,我们生成狗的新图像的问题可以改写为在N维向量空间中生成遵循“狗概率分布”的随机向量的问题,我们建议使用变换方法,使用神经网络来模拟变换函数。
现在,我们仍然需要训练(优化)网络来表达正确的转换函数。为此,我们可以建议两种不同的训练方法:直接训练方法和间接训练方法。直接训练方法包括比较真实分布和生成的概率分布,并通过网络反向传播差值(误差)。这就是规则生成匹配网络(GMN)的想法。对于间接训练方法,我们不直接比较真实分布和生成的分布。相反,我们通过使这两个分布通过选择的下游任务来训练生成网络,以便生成网络相对于下游任务的优化过程将强制生成的分布接近真实分布。最后一个想法是生成对抗网络(GAN)背后的想法,我们将在下一节中介绍。但现在,让我们从直接方法和 GMN 开始。
4.2 基于样本比较两个概率分布
如前所述,GMN 的想法是通过直接将生成的分布与真实分布进行比较来训练生成网络。然而,我们不知道如何明确表达真正的“狗概率分布”,我们也可以说生成的分布太复杂了,无法明确表达。因此,基于显式表达式的比较是不可能的。但是,如果我们有一种方法可以比较基于样本的概率分布,我们可以使用它来训练网络。事实上,我们有一个真实数据的样本,我们可以在训练过程的每次迭代中生成生成的数据样本。
虽然从理论上讲,任何能够有效地比较基于样本的两个分布的距离(或相似性度量),但我们可以特别提到最大平均差异(MMD)方法。MMD 定义了两个概率分布之间的距离,可以根据这些分布的样本计算(估计)。虽然它并不完全超出本文的范围,但我们决定不再花更多的时间来描述MMD。但是,我们的项目将很快发布一篇文章,其中包含有关它的更多详细信息。现在想了解更多关于MMD的读者可以参考这些幻灯片,这篇文章或这篇文章。
4.3 分布匹配误差的反向传播
因此,一旦我们定义了一种基于样本比较两个分布的方法,我们就可以在 GMN 中定义生成网络的训练过程。给定一个具有均匀概率分布的随机变量作为输入,我们希望生成的输出的概率分布为“狗概率分布”。GMN 的想法是通过重复以下步骤来优化网络:
- 生成一些统一的输入
- 使这些输入通过网络并收集生成的输出
- 比较真实的“狗概率分布”和基于可用样本生成的分布(例如计算真实狗图像样本与生成样本之间的MMD距离)
- 使用反向传播进行一步梯度下降,以降低真实分布和生成分布之间的距离(例如 MMD)
如上所述,在执行这些步骤时,我们将在网络上应用梯度下降,损失函数是当前迭代中真实分布和生成分布之间的距离。

生成匹配网络采用简单的随机输入,生成新数据,直接将生成数据的分布与真实数据的分布进行比较,并反向传播匹配误差以训练网络。
五、生成对抗网络
5.1 “间接”训练方法
上面介绍的“直接”方法在训练生成网络时直接将生成的分布与真实分布进行比较。规则 GAN 的绝妙想法在于用间接比较取代这种直接比较,该比较采用这两个分布的下游任务的形式。然后,生成网络的训练是针对此任务完成的,这样它就会迫使生成的分布越来越接近真实分布。
GAN 的下游任务是区分真实样本和生成的样本。或者我们可以说是“非歧视”任务,因为我们希望歧视尽可能失败。因此,在GAN架构中,我们有一个鉴别器,它采集真实和生成的数据的样本,并尝试尽可能好地对它们进行分类,还有一个经过训练以尽可能愚弄鉴别器的生成器。让我们看看一个简单的例子,为什么我们提到的直接和间接方法在理论上应该导致相同的最优生成器。
5.2 理想情况:完美的生成器和鉴别器
为了更好地理解为什么训练生成器来欺骗鉴别器会导致与直接训练生成器匹配目标分布相同的结果,让我们举一个简单的一维示例。我们暂时忘记生成器和鉴别器是如何表示的,并将它们视为抽象概念(将在下一小节中指定)。此外,两者都被认为是“完美的”(具有无限的能力),因为它们不受任何类型的(参数化)模型的约束。
假设我们有一个真实的分布,例如一维高斯分布,并且我们想要一个从这个概率分布中采样的生成器。我们所谓的“直接”训练方法将包括迭代调整生成器(梯度下降迭代),以纠正真实分布和生成分布之间的测量差异/误差。最后,假设优化过程完美,我们最终应该得到与真实分布完全匹配的生成分布。
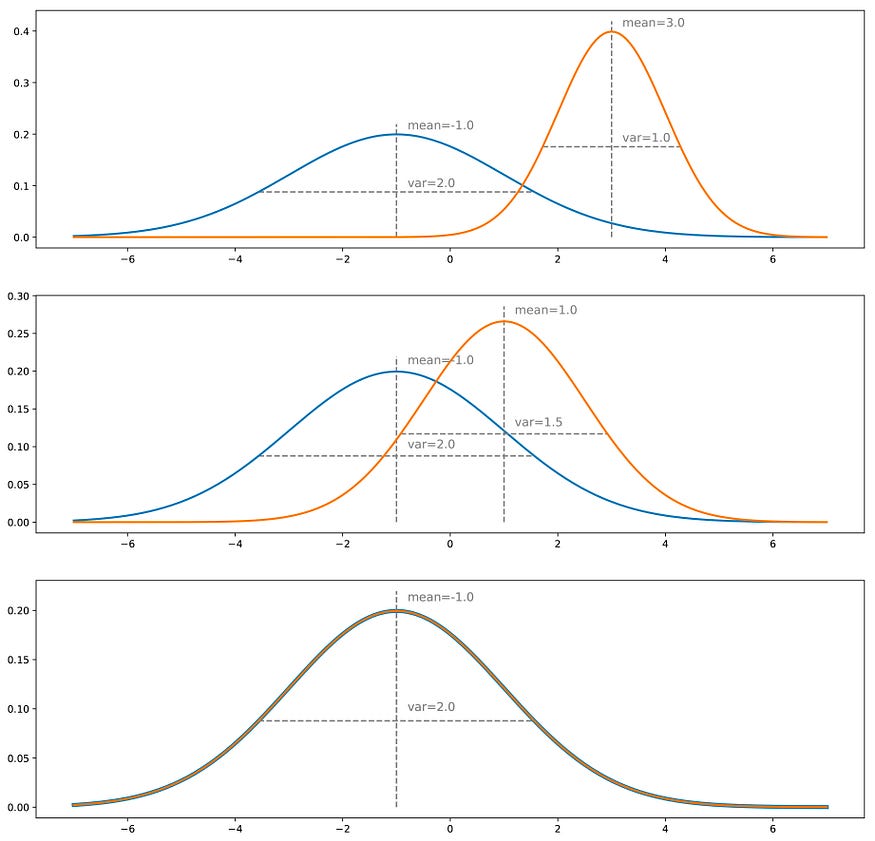
直接匹配方法概念的说明。蓝色分布为真实分布,而生成的分布表示为橙色。通过一次迭代,我们比较了两个分布,并通过梯度下降步骤调整了网络权重。此处对均值和方差进行比较(类似于截断矩匹配方法)。请注意,(显然)这个例子非常简单,不需要迭代方法:目的只是为了说明上面给出的直觉。
对于“间接”方法,我们还必须考虑一个鉴别器。我们现在假设这个鉴别器是一种预言机,它确切地知道什么是真实和生成的分布,并且能够根据这些信息预测任何给定点的类(“真”或“生成”)。如果这两个分布相距甚远,鉴别器将能够轻松且具有高置信度地对我们呈现给它的大部分点进行分类。如果我们想愚弄鉴别器,我们必须使生成的分布接近真实分布。当两个分布在所有点上相等时,鉴别器将最难预测类:在这种情况下,对于每个点,它“为真”或“生成”的机会相等,然后判别器在平均两种情况下不能比在两种情况下为真更好。
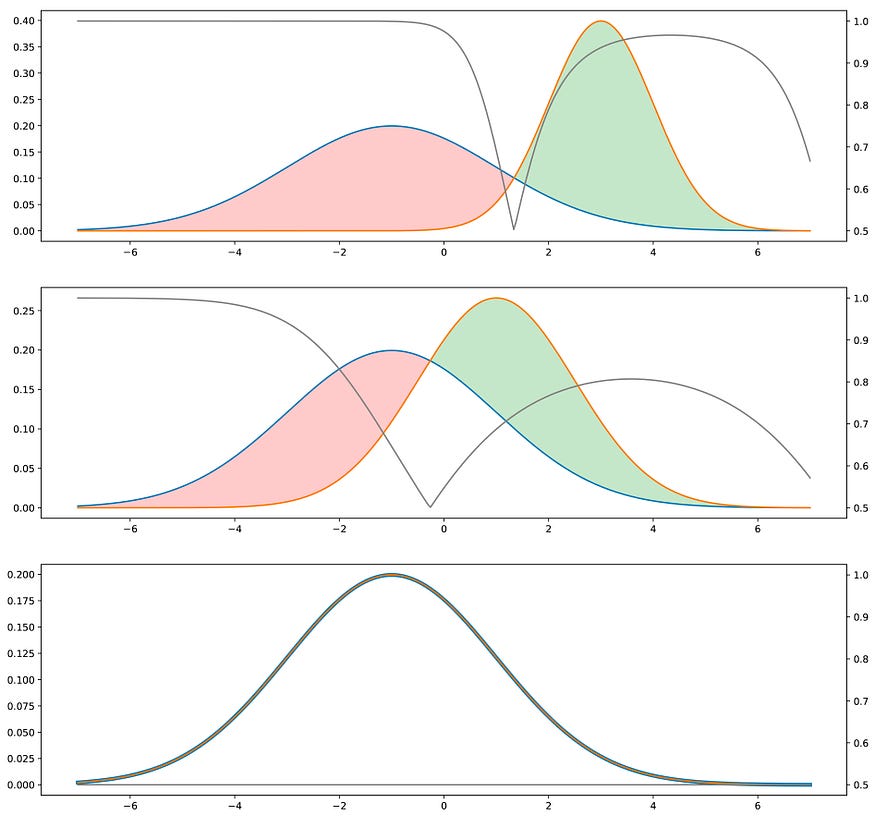
对抗方法的直觉。蓝色分布是真实的分布,橙色是生成的分布。灰色,右侧有相应的 y 轴,如果鉴别器在每个点中选择密度较高的类(假设“true”和“生成”数据比例相等),我们显示了判别器的概率为真。两个分布越接近,判别器出错的频率就越高。训练时,目标是“将绿色区域”(生成的分布太高)向红色区域(生成的分布太低)移动。
在这一点上,怀疑这种间接方法是否真的是一个好主意似乎是合理的。事实上,它似乎更复杂(我们必须根据下游任务优化生成器,而不是直接基于分布),并且它需要一个鉴别器,我们在这里将其视为给定的预言机,但实际上,既不已知也不完美。对于第一点,直接比较基于样本的两个概率分布的难度抵消了间接方法明显更高的复杂性。对于第二点,很明显,鉴别器是未知的。但是,这是可以学习的!
5.3 近似:对抗性神经网络
现在让我们描述一下在 GAN 架构中采用生成器和鉴别器的特定形式。生成器是模拟转换函数的神经网络。它接受一个简单的随机变量作为输入,并且必须在训练后返回一个遵循目标分布的随机变量。由于它非常复杂和未知,我们决定用另一个神经网络对鉴别器进行建模。该神经网络模拟判别函数。它接受一个点作为输入(在我们的狗示例中为 N 维向量),并将该点的概率作为输出返回为“真”的概率。
请注意,我们现在强加一个参数化模型来表达生成器和鉴别器(而不是上一小节中的理想化版本)这一事实在实践中对上面给出的理论论证/直觉没有太大影响:我们只是在一些参数化空间而不是理想的全空间中工作,并且, 因此,在理想情况下我们应该达到的最佳点可以被参数化模型的精度能力视为“四舍五入”。
一旦定义,两个网络就可以(同时)以相反的目标联合训练:
- 生成器的目标是欺骗鉴别器,因此生成神经网络被训练以最大化最终分类误差(在真实数据和生成的数据之间)
- 鉴别器的目标是检测虚假生成的数据,因此训练判别神经网络以最小化最终分类错误
因此,在训练过程的每次迭代中,生成网络的权重都会更新以增加分类误差(误差梯度在生成器参数上上升),而判别网络的权重会更新,以减少这种误差(判别器参数上的误差梯度下降)。

生成对抗网络表示。生成器将简单的随机变量作为输入并生成新数据。鉴别器获取“真实”和“生成”的数据并尝试区分它们,从而构建分类器。生成器的目标是欺骗鉴别器(通过将尽可能多的生成数据与真实数据混合来增加分类误差),鉴别器的目标是区分真实数据和生成数据。
这些相反的目标和两个网络的对抗训练的隐含概念解释了“对抗网络”的名称:两个网络都试图击败对方,这样做,它们都变得越来越好。它们之间的竞争使这两个网络在各自的目标方面“进步”。从博弈论的角度来看,我们可以将此设置视为最小最大值双人博弈,其中均衡状态对应于生成器从精确的目标分布生成数据的情况,并且鉴别器预测“真”或“生成”的概率为1/2接收的任何点。
六、关于 GAN 的数学细节
注意:本节技术性更强,对于全面了解 GAN 并不是绝对必要的。因此,现在不想阅读一些数学的读者可以暂时跳过本节。对于其他人,让我们看看上面给出的直觉是如何在数学上形式化的。
免责声明:以下方程式不是伊恩·古德费罗文章中的方程式。我们在这里提出另一种数学形式化有两个原因:第一,更接近上面给出的直觉,第二,因为原始论文的方程已经非常清晰,重写它们是没有用的。另请注意,我们绝对不会考虑与不同的可能损失函数相关的实际考虑因素(梯度消失或其他)。我们强烈建议读者也看看原始论文的方程:主要区别在于Ian Goodfellow和合著者使用交叉熵误差而不是绝对误差(正如我们在下面所做的那样)。此外,在下文中,我们假设一个具有无限容量的生成器和一个鉴别器。
神经网络建模本质上需要定义两件事:架构和损失函数。我们已经描述了生成对抗网络的架构。它由两个网络组成:
- 一个生成网络 G(.),它采用密度为 p_z 的随机输入 z,并返回一个输出 x_g = G(z),该输出应遵循(训练后)目标概率分布
- 一个判别网络 D(.),它采用的输入 x 可以是“真”的(x_t,其密度表示为 p_t)或“生成的”(x_g,其密度p_g是由密度p_z通过 G 引起的密度),并返回 x 的概率 D(x) 为“真”数据
现在让我们仔细看看 GAN 的“理论”损失函数。如果我们以相同的比例向鉴别器发送“真实”和“生成”数据,则判别器的预期绝对误差可以表示为
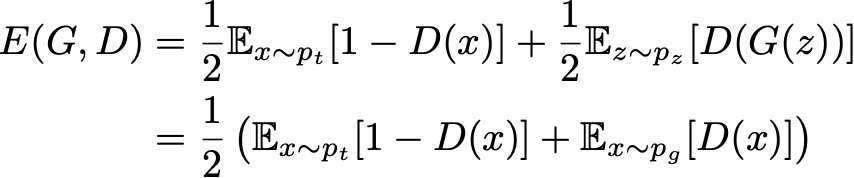
生成器的目标是欺骗鉴别器,其目标是能够区分真实数据和生成的数据。因此,在训练生成器时,我们希望最大化这个误差,同时尝试最小化判别器的误差。它给了我们
![]()
对于任何给定的生成器 G(以及诱导概率密度 p_g),最好的鉴别器是最小化
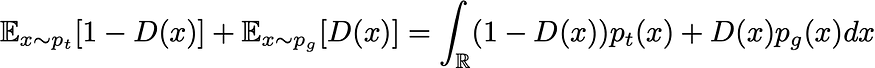
为了最小化(相对于 D)这个积分,我们可以最小化积分内每个 x 值的函数。然后,它为给定生成器定义最佳鉴别器
![]()
(事实上,这是最好的之一,因为 x 值使得 p_t(x)=p_g(x) 可以用另一种方式处理,但对于下面的内容无关紧要)。然后我们搜索最大化的 G

同样,为了最大化(相对于 G)这个积分,我们可以最大化 x 的每个值的积分内的函数。由于密度p_t与生成器 G 无关,因此我们不能比设置 G 更好
![]()
当然,由于p_g是应该积分为 1 的概率密度,因此我们必然具有最佳 G
![]()
因此,我们已经证明,在具有无限容量生成器和鉴别器的理想情况下,对抗设置的最佳点是生成器产生与真实密度相同的密度,并且鉴别器不能比在两种情况下的一种情况下为真更好,就像直觉告诉我们的那样。最后,还要注意 G 最大化
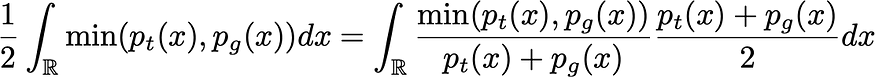
在这种形式下,我们更好地看到 G 想要最大化判别器出错的预期概率。
七、总结
本文的主要内容是:
- 计算机基本上可以生成简单的伪随机变量(例如,它们可以生成非常接近均匀分布的变量)
- 存在不同的方法来生成更复杂的随机变量,包括“变换方法”的概念,该方法包括将随机变量表示为一些更简单的随机变量的函数
- 在机器学习中,生成模型尝试从给定的(复杂)概率分布生成数据。
- 深度学习生成模型被建模为神经网络(非常复杂的函数),它将一个简单的随机变量作为输入,并返回一个遵循目标分布的随机变量(类似于“变换方法”)
- 这些生成网络可以“直接”训练(通过将生成的数据的分布与真实分布进行比较):这就是生成匹配网络的思想
- 这些生成网络也可以“间接”训练(通过试图欺骗另一个同时训练的网络,以区分“生成的”数据和“真实”数据):这就是生成对抗网络的思想。
即使围绕GAN的“炒作”可能有点夸张,我们可以说Ian Goodfellow及其合著者提出的对抗训练的想法确实很棒。这种将损失函数从直接比较扭曲为间接比较的方法确实可以非常鼓舞人心,这对于深度学习领域的进一步工作非常有启发性。总而言之,假设我们不知道 GAN 的想法是否真的是“过去 10 年来机器学习中最有趣的想法”.....
参考阅读:约瑟夫·罗卡
相关文章:
了解生成对抗网络 (GAN)
一、介绍 Yann LeCun将其描述为“过去10年来机器学习中最有趣的想法”。当然,来自深度学习领域如此杰出的研究人员的赞美总是对我们谈论的主题的一个很好的广告!事实上,生成对抗网络(简称GAN)自2014年由Ian J. Goodfel…...

opencv-人脸关键点定位
#导入工具包 from collections import OrderedDict import numpy as np import argparse import dlib import cv2#https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/ #http://dlib.net/files/# 参数 ap argparse.ArgumentParser() ap.add_argument("-p&quo…...
)
言语理解与表达 郭熙(一)
40题 35min 逻辑填空 (20题) 题型:实词填空;成语填空;混搭填空 解题思路 词义辨析:词义侧重;固定搭配;程度较重;感情色彩 语境分析: 关联关系ÿ…...
【stable-diffusion使用扩展+插件和模型资源(上】
文章目录 前言一、插件推荐1.qrcode-monster2.sd-webui-openpose-editor3.sd-webui-depth-lib4.roop(换脸插件)5.sd-webui-qrcode-toolkit(艺术二维码)5.光源控制6.二次元转真人7.动态视频转场(loopback-waveÿ…...

面试之快速学习STL-无序关联式容器
和关联式容器一样,无序容器也使用键值对(pair 类型)的方式存储数据。不过,本教程将二者分开进行讲解,因为它们有本质上的不同: 关联式容器的底层实现采用的树存储结构,更确切的说是红黑树结构&a…...
C++线程库
C线程库是C11新增的重要的技术之一,接下来来简单学习一下吧! thread类常用接口 函数名功能thread()构造一个线程对象,没有关联任何线程函数,即没有启动任何线程。thread(fn, args1, args2, ...)构造一个线程对象,并…...
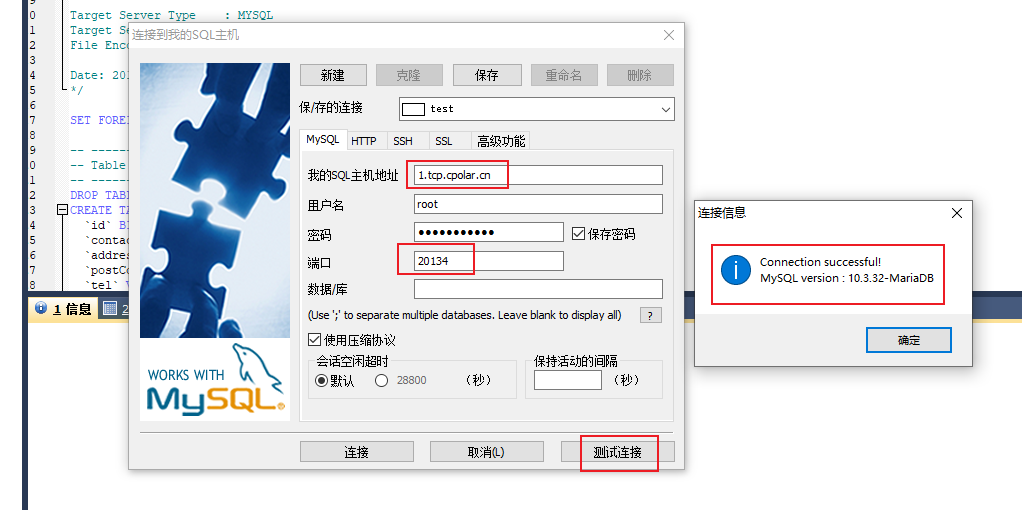
一文看懂群晖 NAS 安装 Mysql 远程访问连接
文章目录 1. 安装Mysql2. 安装phpMyAdmin3. 修改User 表4. 本地测试连接5. 安装cpolar6. 配置公网访问地址7. 固定连接公网地址 群晖安装MySQL具有高效、安全、可靠、灵活等优势,可以为用户提供一个优秀的数据管理和分析环境。同时具有良好的硬件性能和稳定性&#…...
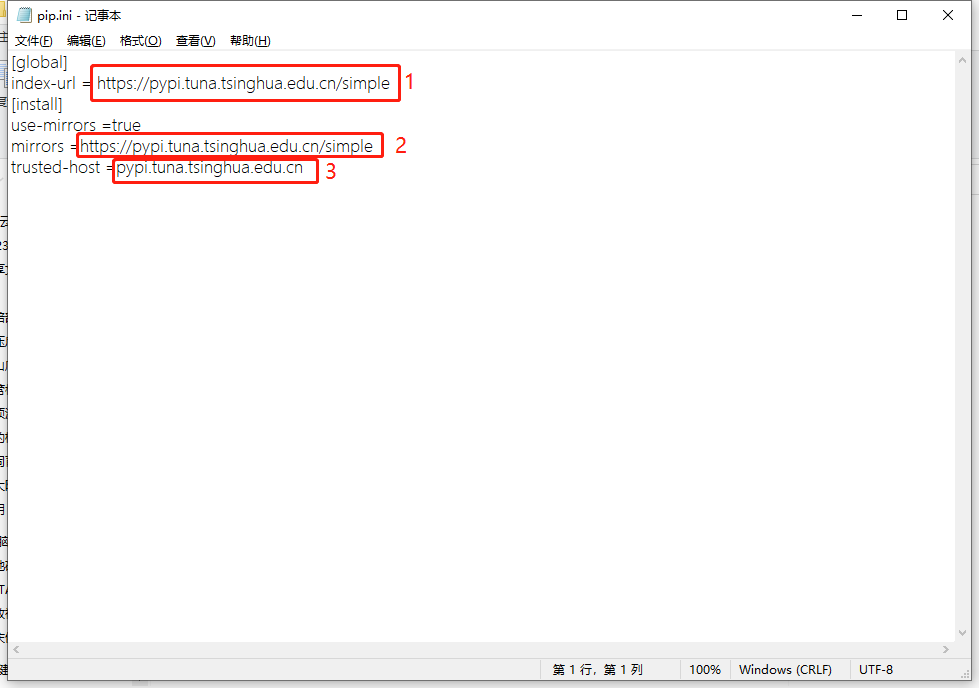
永久设置pip指定国内镜像源(windows内)
1.首先列出国内四个镜像源网站: 一、清华源 https://pypi.tuna.tsinghua.edu.cn/simple/ 二、阿里源 https://mirrors.aliyun.com/pypi/simple 三、中科大源 https://pypi.mirrors.ustc.edu.cn/simple/ 四、豆瓣源 http://pypi.douban.com/simple/ 2.一般下载所需要…...

【SA8295P 源码分析】27 - QNX Ethernet MAC 驱动 之 emac_tx_thread_handler 数据发送线程 源码分析
【SA8295P 源码分析】27 - QNX Ethernet MAC 驱动 之 emac_tx_thread_handler 数据发送线程 源码分析 系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》 本文链接:《【SA8295P 源码分析】27 - QNX Ethernet MAC 驱动 之 emac_tx_thread_handler() 数据发送线程…...

爬虫抓取数据时显示超时,是代理IP质量不行?
很多人在做数据抓取的时候,会遇到显示超时了,然后就没有响应了。这是什么原因的?有的人回答是使用的代理IP质量不行,这种答案,对也不对。 数据抓取时,出现超时的原因时多方面影响的,主要分为目标…...

【管理运筹学】第 5 章 | 整数规划 (2,割平面法及 0-1 变量的特性)
文章目录 引言三、割平面法四、0-1 型整数规划4.1 0-1 变量的特性4.1.1 投资问题4.1.2 约束条件满足个数问题 写在最后 引言 前文我们介绍了整数规划的一种求解方法——分支定界法,可以求解纯整数和混合整数规划问题。现在我们来学习另一种整数规划求解方法——割平…...
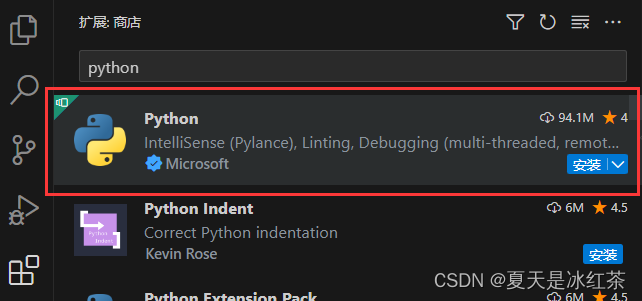
Vscode详细安装教程
Vscode官网下载 官网地址:Download Visual Studio Code - Mac, Linux, Windows 通过链接可以直接跳转到下面的页面当中,支持的版本有Windows、Linux、Mac,可以选择适配自己电脑的版本,一般来说应该是Windows x64的。不要直接点W…...
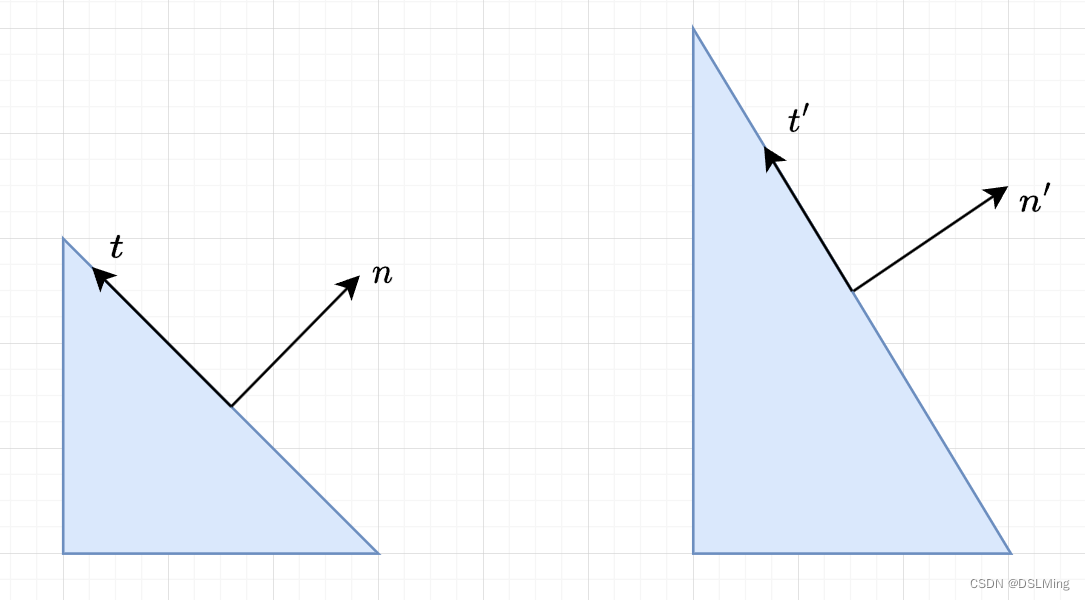
法线矩阵推导
法线矩阵推导 https://zhuanlan.zhihu.com/p/72734738 https://juejin.cn/post/7113952418613690382 https://blog.csdn.net/wangjianxin97?typeblog 1、为什么需要法线矩阵 vec3 normalEyeSpace modelViewMatrix * normal;如果模型矩阵执行了非等比缩放, 顶点的改变会导致法…...
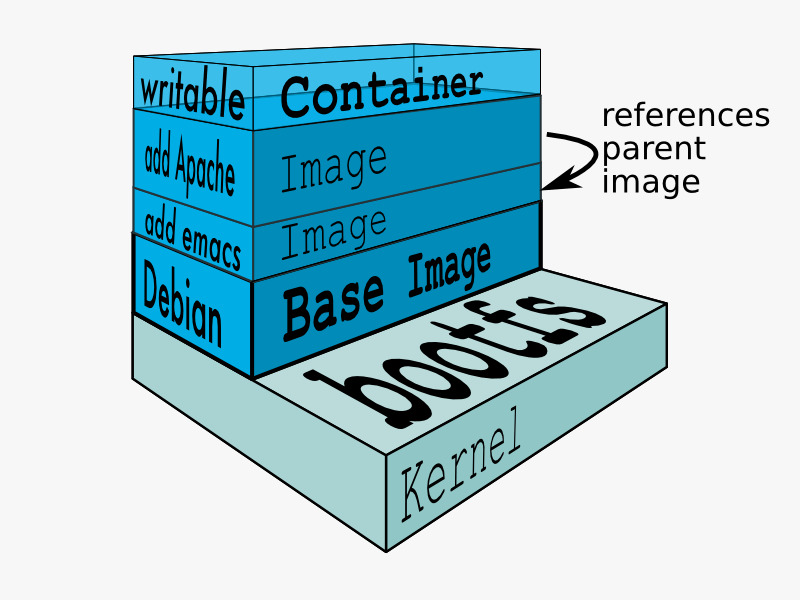
对容器、虚拟机和 Docker 的初学者友好介绍
一、说明 如果你是一个程序员或技术人员,你可能至少听说过Docker:一个有用的工具,用于在“容器”中打包,运输和运行应用程序。很难不这样做,这些天它得到了所有的关注 - 来自开发人员和系统管理员。即使是像谷歌、VMwa…...

linux部署clickhouse(单机)
一、下载安装 1.1、下载地址 阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区阿里巴巴开源镜像站,免费提供Linux镜像下载服务,拥有Ubuntu、CentOS、Deepin、MongoDB、Apache、Maven、Composer等多种开源软件镜像源,此外还提供域名解析DNS、…...

vue组件注册
组件注册分为全局注册和局部注册 全局注册 在 main.js 或者入口文件中 import { createApp } from vue; import MyComponent from ./components/MyComponent.vue;const app createApp();app.component(my-component, MyComponent);app.mount(#app); 我们首先通过createApp…...
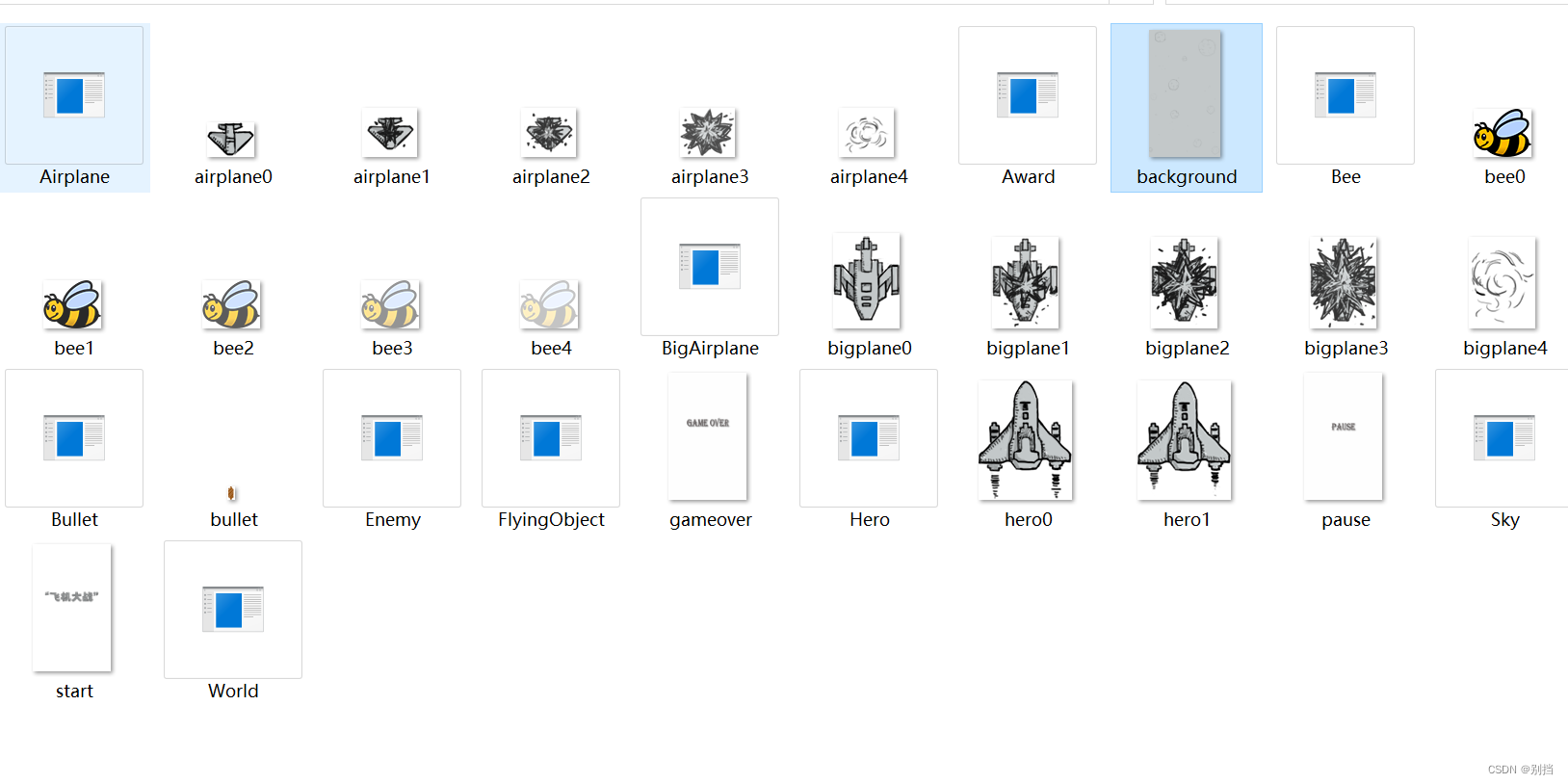
day20 飞机大战射击游戏
有飞行物类 飞行 爆炸 的连环画, 飞行的背景图 , 子弹图, 还有游戏开始 暂停 结束 的画面图。 设计一个飞机大战的小游戏, 玩家用鼠标操作hero飞行机, 射出子弹杀死敌机,小蜜蜂。 敌机可以获得分数&…...
iOS设计规范是什么?都有哪些具体规范
iOS设计规范是苹果为移动设备操作系统iOS制定的设计指南。iOS设计规范的制定保证了苹果应用在外观和操作上的一致性和可用性,从而提高了苹果界面设计的用户体验和应用程序的成功性。本文将从七个方面全面分析iOS设计规范。 1.iOS设计规范完整版分享 由「即时设计」…...

动手学深度学习-pytorch版本(二):线性神经网络
参考引用 动手学深度学习 1. 线性神经网络 神经网络的整个训练过程,包括: 定义简单的神经网络架构、数据处理、指定损失函数和如何训练模型。经典统计学习技术中的线性回归和 softmax 回归可以视为线性神经网络 1.1 线性回归 回归 (regression) 是能为一个或多个…...
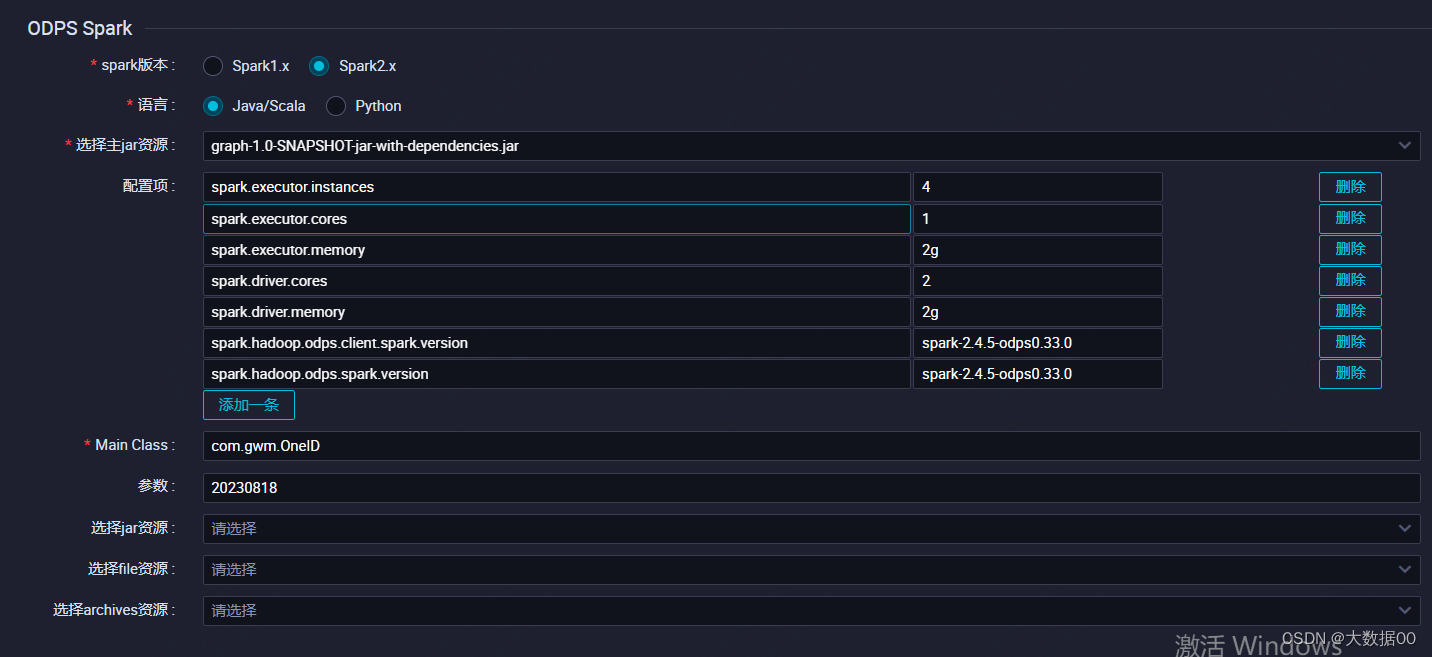
Spark 图计算ONEID 进阶版
0、环境信息 本文采用阿里云maxcompute的spark环境为基础进行的,搭建本地spark环境参考搭建Windows开发环境_云原生大数据计算服务 MaxCompute-阿里云帮助中心 版本spark 2.4.5,maven版本大于3.8.4 ①配置pom依赖 详见2-1 ②添加运行jar包 ③添加配置信…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...