oracle分析函数学习
0、建表及插入测试数据
--CREATE TEST TABLE AND INSERT TEST DATA.
create table students
(id number(15,0),
area varchar2(10),
stu_type varchar2(2),
score number(20,2));insert into students values(1, '111', 'g', 80 );
insert into students values(1, '111', 'j', 80 );
insert into students values(1, '222', 'g', 89 );
insert into students values(1, '222', 'g', 68 );
insert into students values(2, '111', 'g', 80 );
insert into students values(2, '111', 'j', 70 );
insert into students values(2, '222', 'g', 60 );
insert into students values(2, '222', 'j', 65 );
insert into students values(3, '111', 'g', 75 );
insert into students values(3, '111', 'j', 58 );
insert into students values(3, '222', 'g', 58 );
insert into students values(3, '222', 'j', 90 );
insert into students values(4, '111', 'g', 89 );
insert into students values(4, '111', 'j', 90 );
insert into students values(4, '222', 'g', 90 );
insert into students values(4, '222', 'j', 89 );
commit;col score format 999999999999.991、GROUP BY子句的增强
A、GROUPING SETS
select id,area,stu_type,sum(score) score
from students
group by grouping sets((id,area,stu_type),(id,area),id)
order by id,area,stu_type;--------理解grouping sets
select a, b, c, sum( d ) from t
group by grouping sets ( a, b, c )
等效于
select * from (
select a, null, null, sum( d ) from t group by a
union all
select null, b, null, sum( d ) from t group by b
union all
select null, null, c, sum( d ) from t group by c
)
B、ROLLUP
select id,area,stu_type,sum(score) score
from students
group by rollup(id,area,stu_type)
order by id,area,stu_type;--------理解rollup
select a, b, c, sum( d )
from t
group by rollup(a, b, c);
等效于
select * from (
select a, b, c, sum( d ) from t group by a, b, c
union all
select a, b, null, sum( d ) from t group by a, b
union all
select a, null, null, sum( d ) from t group by a
union all
select null, null, null, sum( d ) from t
)
C、CUBE
select id,area,stu_type,sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type;--------理解cube
select a, b, c, sum( d ) from t
group by cube( a, b, c)
等效于
select a, b, c, sum( d ) from t
group by grouping sets(
( a, b, c ),
( a, b ), ( a ), ( b, c ),
( b ), ( a, c ), ( c ),
() )
D、GROUPING函数
从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,如何来区分到底是根据那个字段做的汇总呢,grouping函数判断是否合计列!
select decode(grouping(id),1,'all id',id) id,
decode(grouping(area),1,'all area',to_char(area)) area,
decode(grouping(stu_type),1,'all_stu_type',stu_type) stu_type,
sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type; 2、OVER()函数的使用
A、RANK()、DENSE_RANK() 、ROW_NUMBER()、CUME_DIST()、MAX()、AVG()
break on id skip 1
select id,area,score from students order by id,area,score desc;select id,rank() over(partition by id order by score desc) rk,score from students;--允许并列名次、名次不间断
select id,dense_rank() over(partition by id order by score desc) rk,score from students;--即使SCORE相同,ROW_NUMBER()结果也是不同
select id,row_number() over(partition by ID order by SCORE desc) rn,score from students;select cume_dist() over(order by id) a, --该组最大row_number/所有记录row_number
row_number() over (order by id) rn,id,area,score from students;select id,max(score) over(partition by id order by score desc) as mx,score from students;select id,area,avg(score) over(partition by id order by area) as avg,score from students; --注意有无order by的区别--按照ID求AVG
select id,avg(score) over(partition by id order by score desc rows between unbounded preceding
and unbounded following ) as ag,score from students;B、SUM()
select id,area,score from students order by id,area,score desc;select id,area,score,
sum(score) over (order by id,area) 连续求和, --按照OVER后边内容汇总求和
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;select id,area,score,
sum(score) over (partition by id order by area ) 连id续求和, --按照id内容汇总求和
sum(score) over (partition by id) id总和, --各id的分数总和
100*round(score/sum(score) over (partition by id),4) "id份额(%)",
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;C、LAG(COL,n,default)、LEAD(OL,n,default) --取前后边N条数据
select id,lag(score,1,0) over(order by id) lg,score from students;select id,lead(score,1,0) over(order by id) lg,score from students;D、FIRST_VALUE()、LAST_VALUE()
select id,first_value(score) over(order by id) fv,score from students;
select id,last_value(score) over(order by id) fv,score from students; --而对于last_value() over(order by id),结果是有问题的,因为我们没有按照id分区,所以应该出来的效果应该全部是90(最后一条)
--再看个例子
select id,last_value(score) over(order by rownum),score from students;--当使用last_value分析函数的时候,缺省的WINDOWING范围是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,在进行比较的时候从当前行向前进行比较,所以会出现上边的结果。加上如下的参数,结果就正常了。呵呵。默认窗口范围为所有处理结果。
select id,last_value(score) over(order by rownum RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING),score from students;相关文章:

oracle分析函数学习
0、建表及插入测试数据 --CREATE TEST TABLE AND INSERT TEST DATA. create table students (id number(15,0), area varchar2(10), stu_type varchar2(2), score number(20,2));insert into students values(1, 111, g, 80 ); insert into students values(1, 111, j, 80 ); …...

代码随想录训练营day17|110.平衡二叉树 257. 二叉树的所有路径 404.左叶子之和 v...
TOC 前言 代码随想录算法训练营day17 一、Leetcode 110.平衡二叉树 1.题目 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 示例 1&#x…...

C# Thread用法
C# 中的线程(Thread)是一种并发执行的机制,允许同时执行多个代码块,从而提高程序的性能和响应性。下面是关于如何使用 C# 线程的一些基本用法: 1. 创建线程: 使用 System.Threading 命名空间中的 Thread 类…...
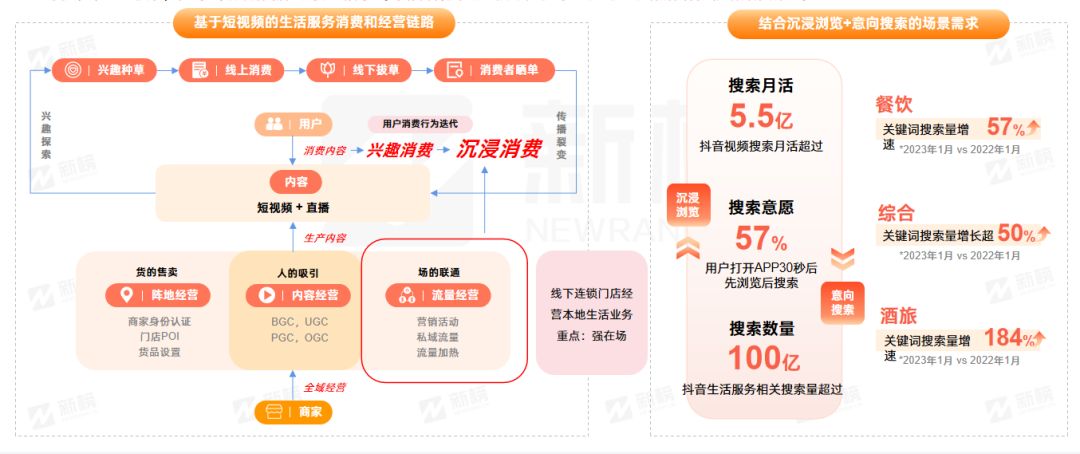
新榜 | CityWalk本地生活商业价值洞察报告
如果说现在有人问,最新的网络热词是什么? “CityWalk”,这可能是大多数人的答案。 近段时间,“CityWalk”刷屏了各种社交媒体,给网友们带来了一场“城市漫步”之旅。 脱离群体狂欢,这个在社交媒体引发热议的词汇背后又…...
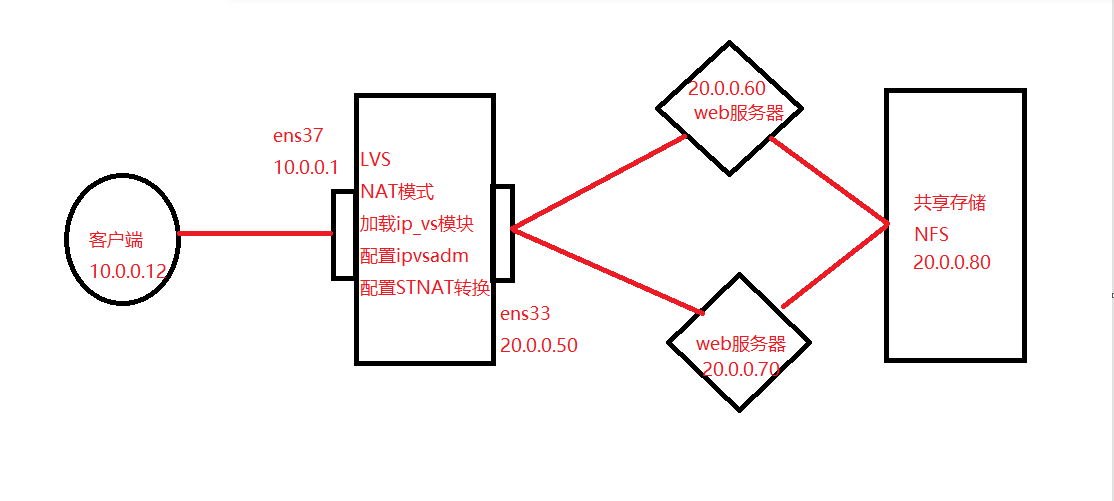
LVS负载均衡集群-NAT模式部署
集群 集群:将多台主机作为一个整体,然后对外提供相同的服务 集群使用场景:高并发的场景 集群的分类 1.负载均衡器集群 减少响应延迟,提高并发处理的能力 2,高可用集群 增强系统的稳定性可靠性&…...

C++学习笔记总结练习:effective 学习日志
准则 1.少使用define define所定义的常量会在预处理的时候被替代,出错编译器不容易找到错误。而且还没有作用范围限制,推荐使用constdefine宏定义的函数,容易出错,而且参数需要加上小括号,推荐使用inline有的类中例如…...

Vue教程(五):样式绑定——class和style
1、样式代码准备 样式提前准备 <style>.basic{width: 400px;height: 100px;border: 1px solid black;}.happy{border: 4px solid red;background-color: rgba(255, 255, 0, 0.644);background: linear-gradient(30deg, yellow, pink, orange, yellow);}.sad{border: 4px …...
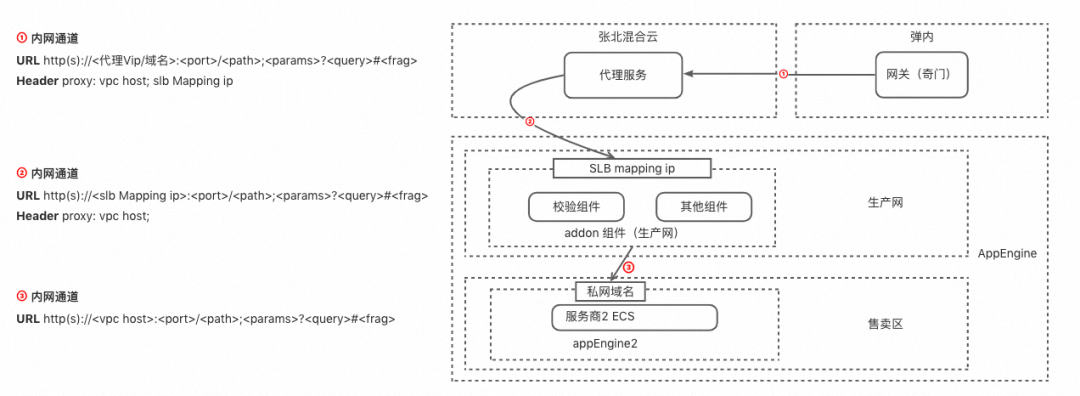
开放网关架构演进
作者:庄文弘(弘智) 淘宝开放平台是阿里与外部生态互联互通的重要开放途径,通过开放的产品技术把阿里经济体一系列基础服务,像水、电、煤一样输送给我们的商家、开发者、社区媒体以及其他合作伙伴,推动行业的…...

torch一些操作
Pytorch文档 Pytorch 官方文档 https://pytorch.org/docs/stable/index.html pytorch 里的一些基础tensor操作讲的不错 https://blog.csdn.net/abc13526222160/category_8614343.html 关于pytorch的Broadcast,合并与分割,数学运算,属性统计以及高阶操作 https://blog.csd…...
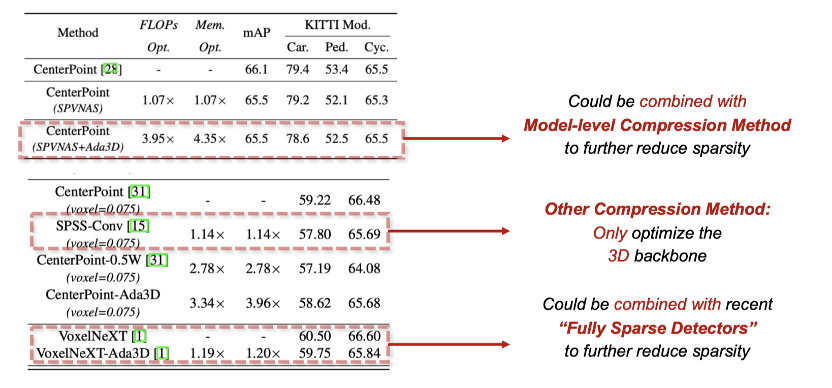
ICCV23 | Ada3D:利用动态推理挖掘3D感知任务中数据冗余性
论文地址:https://arxiv.org/abs/2307.08209 项目主页:https://a-suozhang.xyz/ada3d.github.io/ 01. 背景与动因 3D检测(3D Detection)任务是自动驾驶任务中的重要任务。由于自动驾驶任务的安全性至关重要(safety-critic),对感知算法的延…...

软件工程模型-架构师之路(四)
软件工程模型 敏捷开发: 个体和交互 胜过 过程和工具、可以工作的软件 胜过 面面俱到的文件、客户合作胜过合同谈判、响应变化 胜过 循序计划。(适应需求变化,积极响应) 敏捷开发与其他结构化方法区别特点:面向人的…...
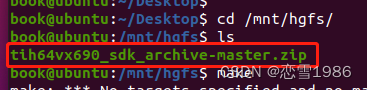
ubuntu20.04共享文件夹—— /mnt/hgfs里没有共享文件夹
参考文章:https://blog.csdn.net/Edwinwzy/article/details/129580636 虚拟机启用共享文件夹后,/mnt/hgfs下面为空,使用 vmware-hgfsclient 查看设置的共享文件夹名字也是为空。 解决方法: 1. 重新安装vmware tools. 在菜单…...
Redis中的有序集合及其底层跳表
前言 本文着重介绍Redis中的有序集合的底层实现中的跳表 有序集合 Sorted Set Redis中的Sorted Set 是一个有序的无重复值的集合,他底层是使用压缩列表和跳表实现的,和Java中的HashMap底层数据结构(1.8)链表红黑树异曲同工之妙…...
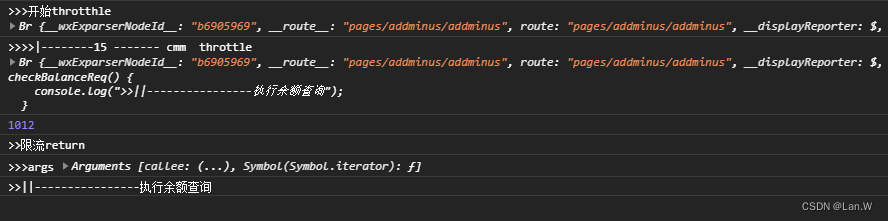
js 小程序限流函数 return闭包函数执行不了
问题: 调用限流 ,没走闭包的函数: checkBalanceReq() loadsh.js // 限流 const throttle (fn, context, interval) > {console.log(">>>>cmm throttle", context, interval)let canRun…...

【数据结构】堆的初始化——如何初始化一个大根堆?
文章目录 源码是如何插入的?扩容向上调整实现大根堆代码: 源码是如何插入的? 扩容 在扩容的时候,如果容量小于64,那就2倍多2的扩容;如果大于64,那就1.5倍扩容。 还会进行溢出的判断,…...

【韩顺平 零基础30天学会Java】程序流程控制(2days)
day1 程序流程控制:顺序控制、分支控制、循环控制 顺序控制:从上到下逐行地执行,中间没有任何判断和跳转。 Java中定义变量时要采用合法的前向引用。 分支控制if-else:单分支、双分支和多分支。 单分支 import java.util.Scann…...

从入门到精通Python隧道代理的使用与优化
哈喽,Python爬虫小伙伴们!今天我们来聊聊如何从入门到精通地使用和优化Python隧道代理,让我们的爬虫程序更加稳定、高效!今天我们将对使用和优化进行一个简单的梳理,并且会提供相应的代码示例。 1. 什么是隧道代理&…...

19万字智慧城市总体规划与设计方案WORD
导读:原文《19万字智慧城市总体规划与设计方案WORD》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 感知基础设施 感知基础设施架构由感知范围、感知手…...
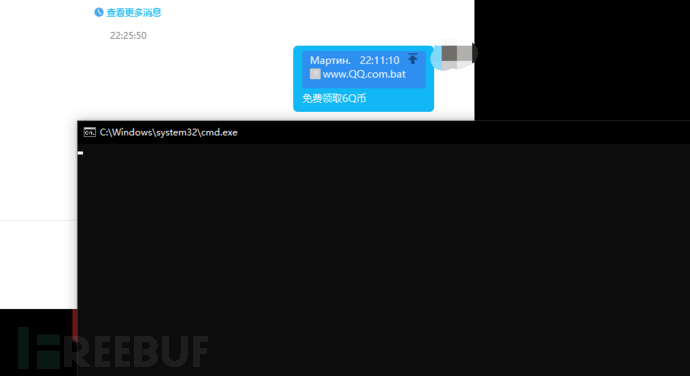
[赛博昆仑] 腾讯QQ_PC端,逻辑漏洞导致RCE漏洞
简介 !! 内容仅供学习,请不要进行非法网络活动,网络不是法外之地!! 赛博昆仑是国内一家较为知名的网络安全公司,该公司今日报告称 Windows 版腾讯 QQ 桌面客户端出现高危安全漏洞,据称“黑客利用难度极低、危害较大”,腾讯刚刚已经紧急发布…...
python Requests
Requests概述 官方文档:http://cn.python-requests.org/zh_CN/latest/,Requests是python的HTTP的库,我们可以安全的使用 Requests安装 pip install Requests -i https://pypi.tuna.tsinghua.edu.cn/simple Requests的使用 Respose的属性 属性说明url响…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...