【排序算法】堆排序(Heap Sort)
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序介绍
学习堆排序之前,有必要了解堆!若读者不熟悉堆,建议先了解堆(建议可以通过二叉堆,左倾堆,斜堆,二项堆或斐波那契堆等文章进行了解),然后再来学习本章。
我们知道,堆分为"最大堆"和"最小堆"。最大堆通常被用来进行"升序"排序,而最小堆通常被用来进行"降序"排序。 鉴于最大堆和最小堆是对称关系,理解其中一种即可。本文将对最大堆实现的升序排序进行详细说明。
最大堆进行升序排序的基本思想: ① 初始化堆: 将数列a[1...n]构造成最大堆。 ② 交换数据: 将a[1]和a[n]交换,使a[n]是a[1...n]中的最大值;然后将a[1...n-1]重新调整为最大堆。 接着,将a[1]和a[n-1]交换,使a[n-1]是a[1...n-1]中的最大值;然后将a[1...n-2]重新调整为最大值。 依次类推,直到整个数列都是有序的。
下面,通过图文来解析堆排序的实现过程。注意实现中用到了"数组实现的二叉堆的性质"。 在第一个元素的索引为 0 的情形中:
性质一: 索引为i的左孩子的索引是 (2*i+1);
性质二: 索引为i的右孩子的索引是 (2*i+2);
性质三: 索引为i的父结点的索引是 floor((i-1)/2);
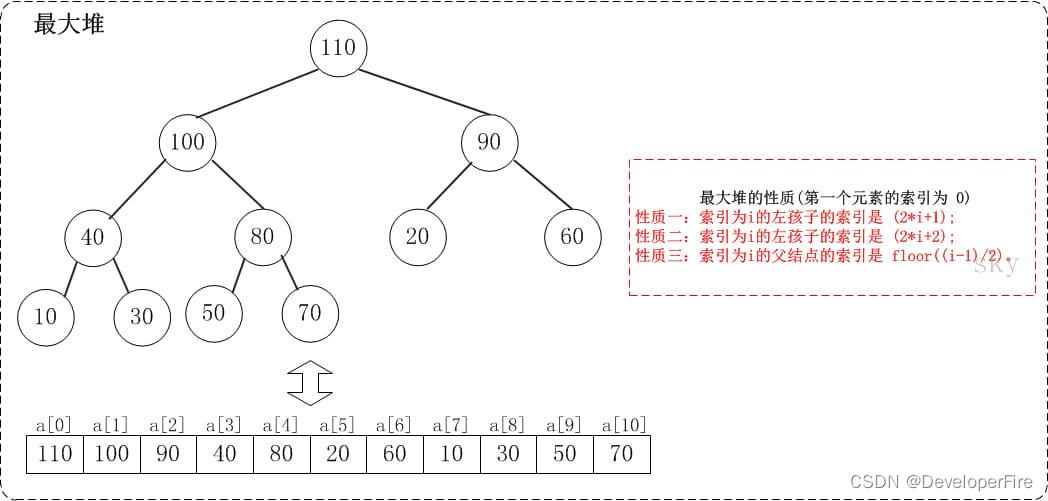
例如,对于最大堆{110,100,90,40,80,20,60,10,30,50,70}而言: 索引为0的左孩子的所有是1;索引为0的右孩子是2;索引为8的父节点是3。
堆排序实现
下面演示heap_sort_asc(a, n)对a={20,30,90,40,70,110,60,10,100,50,80}, n=11进行堆排序过程。下面是数组a对应的初始化结构:
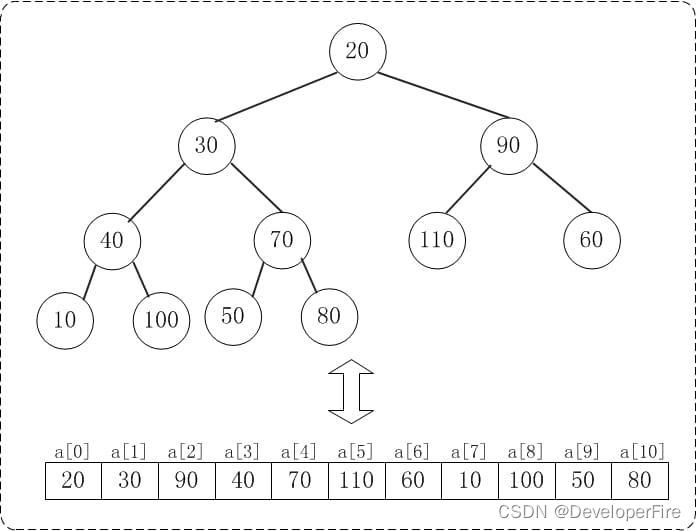
初始化堆
在堆排序算法中,首先要将待排序的数组转化成二叉堆。 下面演示将数组{20,30,90,40,70,110,60,10,100,50,80}转换为最大堆{110,100,90,40,80,20,60,10,30,50,70}的步骤。
1.1 i=11/2-1,即i=4

上面是maxheap_down(a, 4, 9)调整过程。maxheap_down(a, 4, 9)的作用是将a[4...9]进行下调;a[4]的左孩子是a[9],右孩子是a[10]。调整时,选择左右孩子中较大的一个(即a[10])和a[4]交换。
1.2 i=3
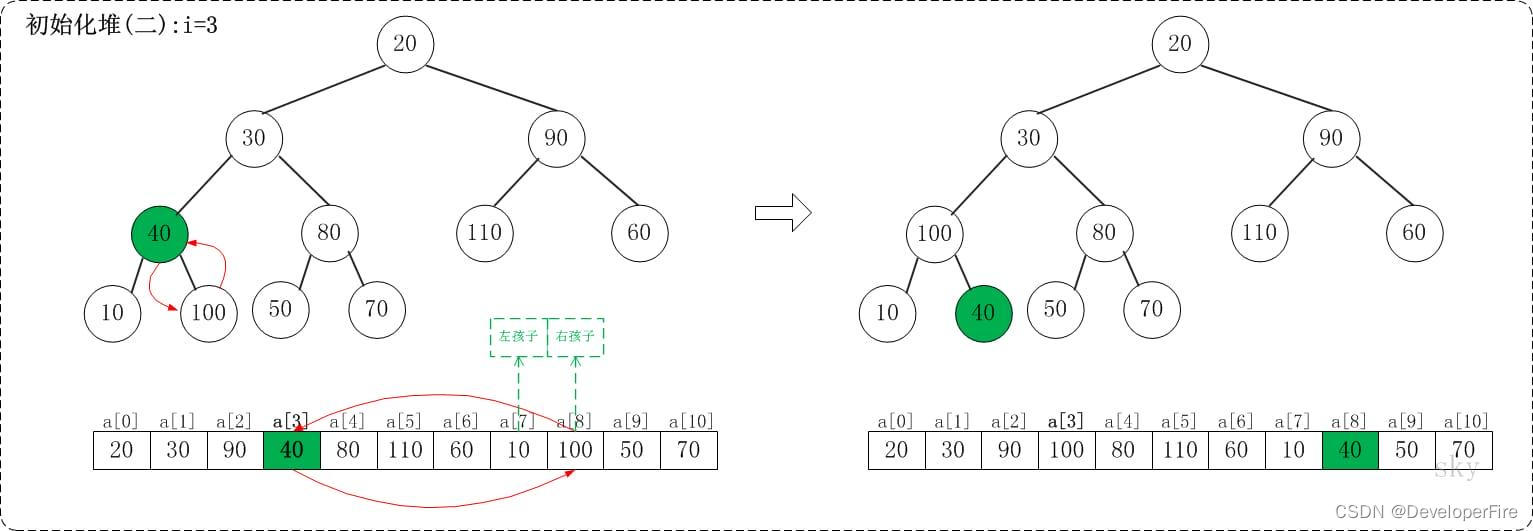
上面是maxheap_down(a, 3, 9)调整过程。maxheap_down(a, 3, 9)的作用是将a[3...9]进行下调;a[3]的左孩子是a[7],右孩子是a[8]。调整时,选择左右孩子中较大的一个(即a[8])和a[4]交换。
1.3 i=2
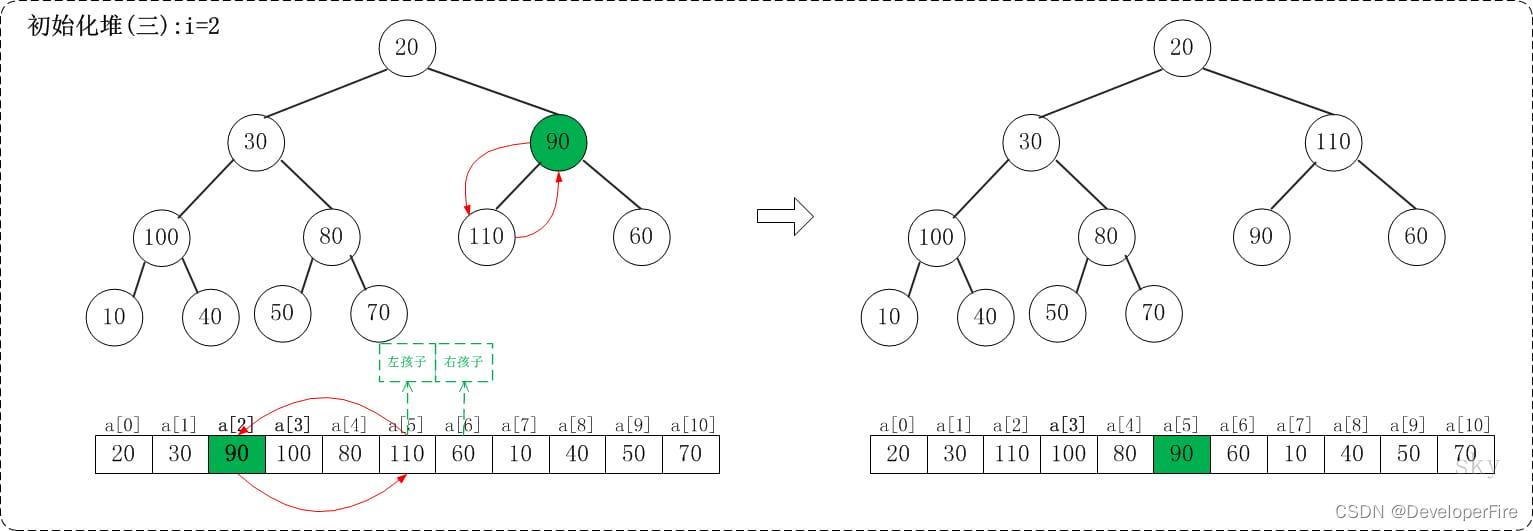
上面是maxheap_down(a, 2, 9)调整过程。maxheap_down(a, 2, 9)的作用是将a[2...9]进行下调;a[2]的左孩子是a[5],右孩子是a[6]。调整时,选择左右孩子中较大的一个(即a[5])和a[2]交换。
1.4 i=1

上面是maxheap_down(a, 1, 9)调整过程。maxheap_down(a, 1, 9)的作用是将a[1...9]进行下调;a[1]的左孩子是a[3],右孩子是a[4]。调整时,选择左右孩子中较大的一个(即a[3])和a[1]交换。交换之后,a[3]为30,它比它的右孩子a[8]要大,接着,再将它们交换。
1.5 i=0
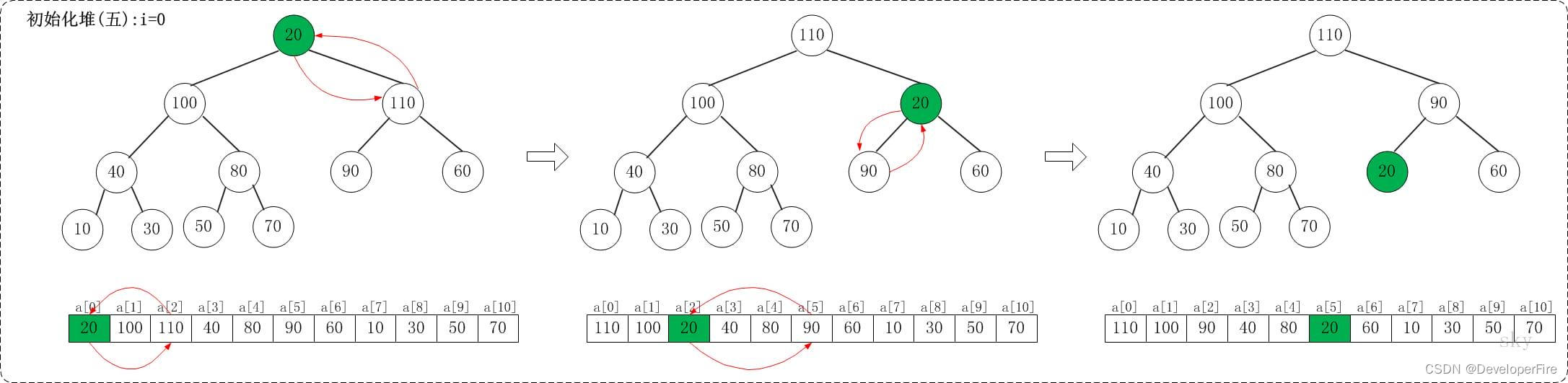
上面是maxheap_down(a, 0, 9)调整过程。maxheap_down(a, 0, 9)的作用是将a[0...9]进行下调;a[0]的左孩子是a[1],右孩子是a[2]。调整时,选择左右孩子中较大的一个(即a[2])和a[0]交换。交换之后,a[2]为20,它比它的左右孩子要大,选择较大的孩子(即左孩子)和a[2]交换。
调整完毕,就得到了最大堆。此时,数组{20,30,90,40,70,110,60,10,100,50,80}也就变成了{110,100,90,40,80,20,60,10,30,50,70}。
交换数据
在将数组转换成最大堆之后,接着要进行交换数据,从而使数组成为一个真正的有序数组。 交换数据部分相对比较简单,下面仅仅给出将最大值放在数组末尾的示意图。
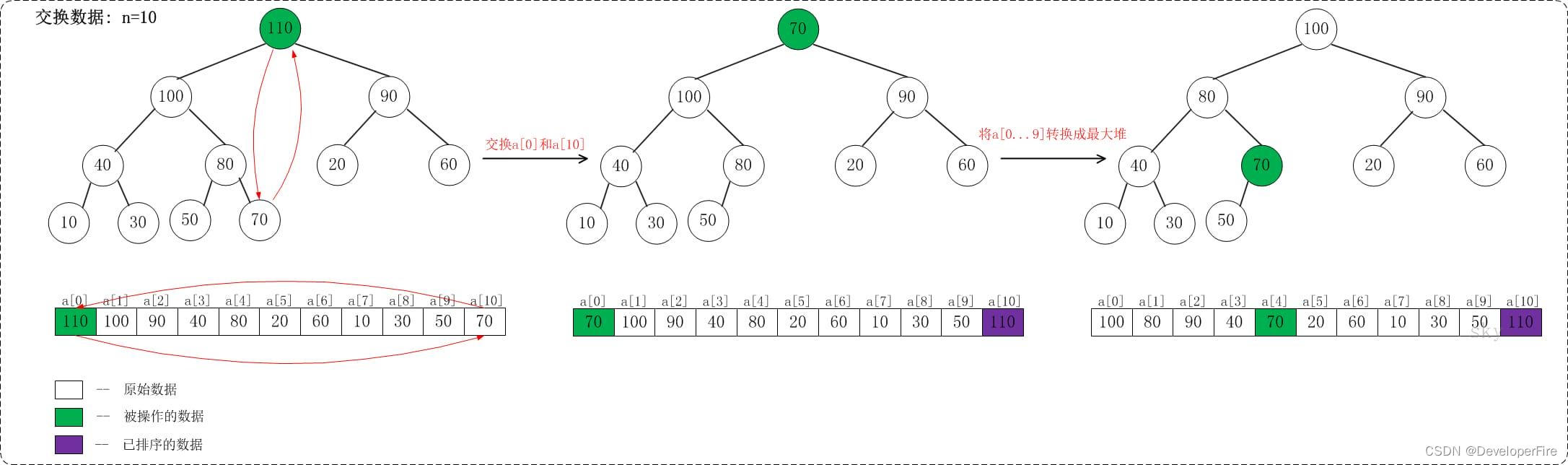
上面是当n=10时,交换数据的示意图。 当n=10时,首先交换a[0]和a[10],使得a[10]是a[0...10]之间的最大值;然后,调整a[0...9]使它称为最大堆。交换之后: a[10]是有序的! 当n=9时, 首先交换a[0]和a[9],使得a[9]是a[0...9]之间的最大值;然后,调整a[0...8]使它称为最大堆。交换之后: a[9...10]是有序的! ... 依此类推,直到a[0...10]是有序的。
堆排序复杂度和稳定性
堆排序时间复杂度
堆排序的时间复杂度是O(N*lgN)。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢? 堆排序是采用的二叉堆进行排序的,二叉堆就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。最多是多少呢? 由于二叉堆是完全二叉树,因此,它的深度最多也不会超过lg(2N)。因此,遍历一趟的时间复杂度是O(N),而遍历次数介于lg(N+1)和lg(2N)之间;因此得出它的时间复杂度是O(N*lgN)。
堆排序稳定性
堆排序是不稳定的算法,它不满足稳定算法的定义。它在交换数据的时候,是比较父结点和子节点之间的数据,所以,即便是存在两个数值相等的兄弟节点,它们的相对顺序在排序也可能发生变化。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
代码实现
/*** 堆排序: Java** @author skywang* @date 2014/03/11*/public class HeapSort {/* * (最大)堆的向下调整算法** 注: 数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。** 参数说明: * a -- 待排序的数组* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)* end -- 截至范围(一般为数组中最后一个元素的索引)*/public static void maxHeapDown(int[] a, int start, int end) {int c = start; // 当前(current)节点的位置int l = 2*c + 1; // 左(left)孩子的位置int tmp = a[c]; // 当前(current)节点的大小for (; l <= end; c=l,l=2*l+1) {// "l"是左孩子,"l+1"是右孩子if ( l < end && a[l] < a[l+1])l++; // 左右两孩子中选择较大者,即m_heap[l+1]if (tmp >= a[l])break; // 调整结束else { // 交换值a[c] = a[l];a[l]= tmp;}}}/** 堆排序(从小到大)** 参数说明: * a -- 待排序的数组* n -- 数组的长度*/public static void heapSortAsc(int[] a, int n) {int i,tmp;// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。for (i = n / 2 - 1; i >= 0; i--)maxHeapDown(a, i, n-1);// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素for (i = n - 1; i > 0; i--) {// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。tmp = a[0];a[0] = a[i];a[i] = tmp;// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。// 即,保证a[i-1]是a[0...i-1]中的最大值。maxHeapDown(a, 0, i-1);}}/* * (最小)堆的向下调整算法** 注: 数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。** 参数说明: * a -- 待排序的数组* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)* end -- 截至范围(一般为数组中最后一个元素的索引)*/public static void minHeapDown(int[] a, int start, int end) {int c = start; // 当前(current)节点的位置int l = 2*c + 1; // 左(left)孩子的位置int tmp = a[c]; // 当前(current)节点的大小for (; l <= end; c=l,l=2*l+1) {// "l"是左孩子,"l+1"是右孩子if ( l < end && a[l] > a[l+1])l++; // 左右两孩子中选择较小者if (tmp <= a[l])break; // 调整结束else { // 交换值a[c] = a[l];a[l]= tmp;}}}/** 堆排序(从大到小)** 参数说明: * a -- 待排序的数组* n -- 数组的长度*/public static void heapSortDesc(int[] a, int n) {int i,tmp;// 从(n/2-1) --> 0逐次遍历每。遍历之后,得到的数组实际上是一个最小堆。for (i = n / 2 - 1; i >= 0; i--)minHeapDown(a, i, n-1);// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素for (i = n - 1; i > 0; i--) {// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最小的。tmp = a[0];a[0] = a[i];a[i] = tmp;// 调整a[0...i-1],使得a[0...i-1]仍然是一个最小堆。// 即,保证a[i-1]是a[0...i-1]中的最小值。minHeapDown(a, 0, i-1);}}public static void main(String[] args) {int i;int a[] = {20,30,90,40,70,110,60,10,100,50,80};System.out.printf("before sort:");for (i=0; i<a.length; i++)System.out.printf("%d ", a[i]);System.out.printf("\n");heapSortAsc(a, a.length); // 升序排列//heapSortDesc(a, a.length); // 降序排列System.out.printf("after sort:");for (i=0; i<a.length; i++)System.out.printf("%d ", a[i]);System.out.printf("\n");}
}相关文章:
【排序算法】堆排序(Heap Sort)
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序介绍学习堆排序之前,有必要了解堆!若…...
分类预测 | Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测
分类预测 |Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测 目录分类预测 |Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测分类效果基本介绍模型描述程序设计参考资料分类效果 基本介绍 Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机…...
Allegro如何添加ICT操作指导
Allegro如何添加ICT操作指导 当PCB板需要做飞针测试的时候,通常需要在PCB设计的时候给需要测试的网络添加上ICT。 如图: Allegro支持给网络添加ICT,具体操作如下 首先在库中创建一个阻焊开窗的过孔,比如via10-ict一般阻焊开窗的尺寸比盘单边大2mil 在PCB中选择Manufacture…...

软件架构设计(二)——领域架构、基于架构的软件开发方法
目录 一、架构描述语言 ADL 二、特定领域软件架构 DSSA 三、DSSA的三层次架构模型 . 四、基于架构的软件开发方法 (1)基于架构的软件设计(ABSD) (2)开发过程 一、架构描述语言 ADL ADL是一种形式化语言,它在底层语义模型的支持下,为软件系统概念体…...
---数组遍历方法)
数组常用方法(2)---数组遍历方法
1. forEach(cb) 回调函数中有三个参数,第一个是当前遍历项(必须),第二个是索引,第三个是遍历的数组本身。forEach() 对于空数组不会执行回调函数。forEach()不会使用回调函数的返回值,返回值为undefined。…...
卸载Node.js
0 写在前面 无论您是因为什么原因要卸载Node.js都必须要卸载干净。 请阅读: 1 卸载步骤 1.1通过控制面板卸载node.js winR—>control.exe—>卸载程序—>卸载Node.js 等待—>卸载成功 1.2 删除安装时的nodejs文件夹 通过记忆或者Everthing搜索找…...

发表计算机SCI论文,会经历哪些过程? - 易智编译EaseEditing
一、选期刊。 一定要先选期刊。每本期刊都有自己的特色和方向,如果你的稿子已经成型,再去考虑期刊选择的问题,恐怕后期不是退稿就是要大面积修改稿子。 选期刊的标准没有一定的,主要是各单位都有自己的要求,当然小编…...

python中lambda的用法
1. lambada简单介绍 lambda 在Python编程中使用的频率非常高,我们通常提及的lambda表达式其实是python中的一类特殊的定义函数的形式,使用它可以定义一个匿名函数。即当你需要一个函数,但又不想费神去命名一个函数,这时候…...
网络安全协议(3)
作者简介:一名在校云计算网络运维学生、每天分享网络运维的学习经验、和学习笔记。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.当前流行操作系统的安全等级 1.Windows的安全等级 什么是EAL…...

102.第十九章 MySQL数据库 -- MySQL的备份和恢复(十二)
5.备份和恢复 5.1 备份恢复概述 5.1.1 为什么要备份 灾难恢复:硬件故障、软件故障、自然灾害、黑客攻击、误操作测试等数据丢失场景 参考链接: https://www.toutiao.com/a6939518201961251359/ 5.1.2 备份类型 完全备份,部分备份 完全备份:整个数据集 部分备份:只备份数…...
【C++】C++入门 类与对象(一)
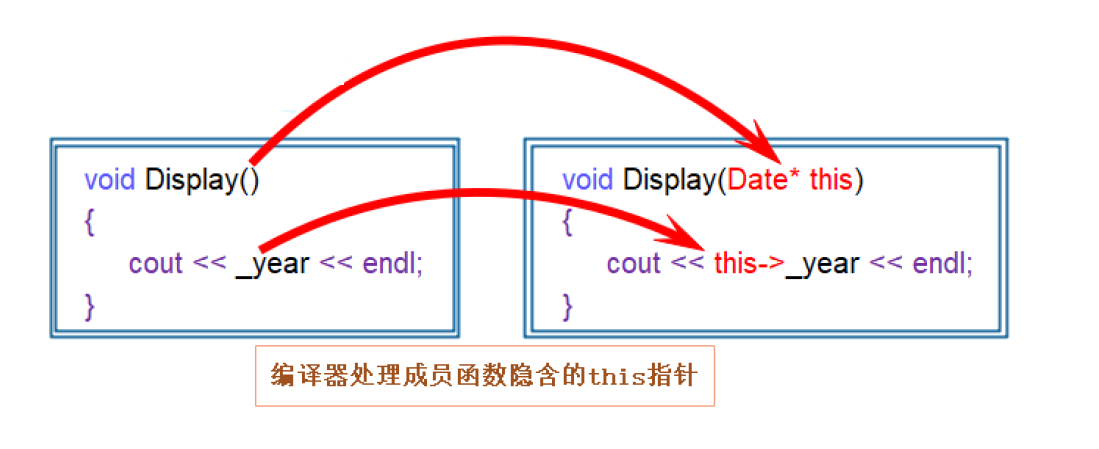
类与对象(一)一、类的引入二、类的定义1、类的两种定义方式:2、成员变量命名规则的建议:三、类的访问限定符及封装1、访问限定符2、封装四、类的实例化1、类的实例化概念2、类对象的大小的计算五、this指针this指针的特性一、类的…...

笔记_js运算符
目录二进制相关运算符移位运算符<<>>|(位或运算)参考文档二进制相关运算符 移位运算符 移位运算就是对二进制进行有规律的移位。 tips:进制转换文档链接 << “<<”运算符执行左移位运算。在移位运算过程中,符号位始终保持不变…...
java面试题(十九) Mybatis
4.1 谈谈MyBatis和JPA的区别 参考答案 ORM映射不同: MyBatis是半自动的ORM框架,提供数据库与结果集的映射; JPA(默认采用Hibernate实现)是全自动的ORM框架,提供对象与数据库的映射。 可移植性不同&…...

Linux系统位运算函数以及相应CPU ISA实现收录
以32位数据的二进制表示为例,习惯的写法是LSB在左,MSB在右,注意BIT序和大小端的字节序没有关系。Linux和BIT操作有关的接口在定义在头文件bitops.h中,bitops.h定义有两层,通用层和架构层,对应两个bitops.h&…...

logback配置文件---logback.xml
目录常识操作logback-spring.xml 示例参考于 https://blog.csdn.net/white_ice/article/details/85065219 https://blog.csdn.net/weixin_42592282/article/details/122109703 https://www.dianjilingqu.com/629077.html 常识 https://www.dianjilingqu.com/629077.html nod…...

Web前端-设计网站公共header
设计网站公共headerheader元素是一个具有引导和导航作用的结构元素,很多企业网站中都有一个非常重要的header元素,一般位于网页的开头,用来显示企业名称、企业logo图片、整个网站的导航条,以及Flash形式的广告条等。在本网站中&am…...

引用和指针傻傻分不清
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 目录 🐰引用和指针的区别 🌸从现象上看 🌸从编译上看 &am…...
MySQL面试题:关系型数据库SQL和非关系型数据库NoSQL
文章目录一、四大非关系型数据库与关系型数据库的对比1. 关系型数据库2. 基于列的数据库3. 键值对存储4. 文档存储5. 图形数据库参考文章(金文):四大非关系型数据库类型,你知道多少 参考文章:“行式存储”和“列式存储…...
1.Redis【介绍与安装】
1.常用数据库介绍 mysql的表类型[表引擎.存储引擎],memory表结构和表数据分开存储的,表结构保存在硬盘中,表数据保存在内存中memcache是一款软件,可以使用键值对的格式保存数据到内存中redis是意大利的工程师开发的开源免费的告诉缓存数据库,需要注意的是作者本身只开发了linu…...

DataStore快速上手1-preference
DataStore 概念 DataStore 可以存储两种类型的数据,一种是 preference,一种是 protobuf 每个进程在同一时间内仅能打开一个 DataStore 实例(或者通过其他管理手段来实现多个 DataStore 交替使用) 一个 DataStore 可以视为一张数…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...