ElasticSearch-安装部署全过程
目录
- 概念说明
- 什么是ElasticSearch
- 什么是Kibana
- 什么是RESTful API
- 提供服务
- 安装过程
- 安装ElasticSearch
- 1.下载ElasticSearch 安装包
- 2.解压安装包
- 3.进入解压之后的文件夹
- 4.创建一个data文件夹用来存储数据
- 5.进入config文件夹编辑elasticsearch.yml
- 6.修改内存配置
- 7.修改系统配置,编辑文件sysctl.conf,增加一行vm.max_map_count=262144,保存后退出
- 8.创建ES专用账号
- 8.1创建用户
- 8.2设置密码
- 8.3赋予权限
- 8.4设置用户的相关先限制
- 8.5执行sysctl -p 使配置生效
- 9.启动ElasticSearch服务
- 10.访问ElasticSearch服务,查看是否启动成功
- 安装Kibana
- 1.wget下载安装包
- 2.解压安装包
- 3.进入到kibana目录
- 4.编辑配置文件
- 5.启动Kinbana
- 6.访问Kinbana服务,查看是否启动成功
- 常见问题
- 总结提升
概念说明
什么是ElasticSearch
是一个开源的分布式搜索和分析引擎,它建立在 Apache Lucene 搜索引擎库之上。它提供了一个分布式、多租户的全文搜索引擎,具有强大的实时搜索和分析能力。Elasticsearch 是用 Java 语言编写的,并且提供了 RESTful API,使其易于集成和使用。
ElasticSearch 官网:https://www.elastic.co/cn/elasticsearch/
什么是Kibana
Kibana 是一个用于数据可视化和分析的开源工具。它提供了一个直观的 Web 界面,可以通过图表、仪表盘和报表等方式展示 Elasticsearch 中的数据。Kibana 支持实时数据可视化,并提供了强大的查询和过滤功能。它还可以与 Elasticsearch 进行深度集成,通过搜索和聚合数据来生成交互式报表和可视化图表。
什么是RESTful API
RESTful API 是一种设计风格和架构原则,用于构建可扩展的、可维护的网络服务。REST 是 Representational State Transfer 的缩写,它强调在网络中以资源为中心进行通信。
RESTful API 的设计原则包括:
基于资源:将网络服务中的数据和功能抽象为资源,每个资源都有一个唯一的标识符(URI)。客户端通过 URI 访问和操作资源。
统一接口:RESTful API 使用统一的接口定义,包括使用 HTTP 方法(GET、POST、PUT、DELETE)对资源进行操作,使用 HTTP 状态码表示操作结果,使用 MIME 类型指定数据的表示形式(如 JSON、XML)。
无状态性:每个请求都是独立的,服务器不会保存客户端的状态信息。客户端可以在请求中包含所有必要的信息,服务器根据请求进行处理并返回响应。
可缓存性:RESTful API 支持缓存,客户端可以缓存服务器返回的响应,减少网络传输和服务器负载。
分层系统:RESTful API 的架构是分层的,每一层都有特定的功能和责任。客户端可以通过中间层(如代理服务器)与服务器进行通信,而不需要了解底层的实现细节。
安全性:RESTful API 使用标准的安全机制(如 HTTPS、OAuth)来保护数据和通信的安全性。
RESTful API 的设计目标是简单、可扩展和易于理解。它可以被不同的客户端(如 Web 应用、移动应用)使用,并且可以与不同的后端服务进行集成。RESTful API 已经成为构建 Web 服务和应用程序的常用标准。
提供服务
-
「 实时搜索 」:Elasticsearch 提供了高性能的实时搜索功能,可以快速地从大量数据中检索相关的结果。
-
「 分布式架构」:Elasticsearch 使用分布式架构,可以在多个节点上存储和处理数据。这使得它具有高可用性、可伸缩性和容错性。
-
「 全文搜索 」:Elasticsearch 使用倒排索引技术,可以对文本数据进行全文搜索。它支持复杂的查询和过滤,可以根据相关性对搜索结果进行排序。
-
「数据分析」:Elasticsearch 提供了强大的数据聚合和分析功能,可以对大规模数据进行实时分析。它支持聚合、分组、统计和可视化等功能,帮助用户发现数据中的模式和趋势。
-
「 分布式文档存储」:Elasticsearch 使用 JSON 文档存储数据,每个文档都有一个唯一的 ID。它支持索引和搜索各种类型的数据,包括结构化、半结构化和非结构化数据。
安装过程
安装ElasticSearch
1.下载ElasticSearch 安装包
可以从官网上直接下载,然后在放到es服务器上,也可以使用wget命令的形式直接下载(下载比较慢)
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz
2.解压安装包
tar -xvf elasticsearch-7.6.2-linux-x86_64.tar.gz

3.进入解压之后的文件夹
cd elasticsearch-7.6.2
4.创建一个data文件夹用来存储数据
mkdir data

5.进入config文件夹编辑elasticsearch.yml
vi elasticsearch.yml
将以下注解解开
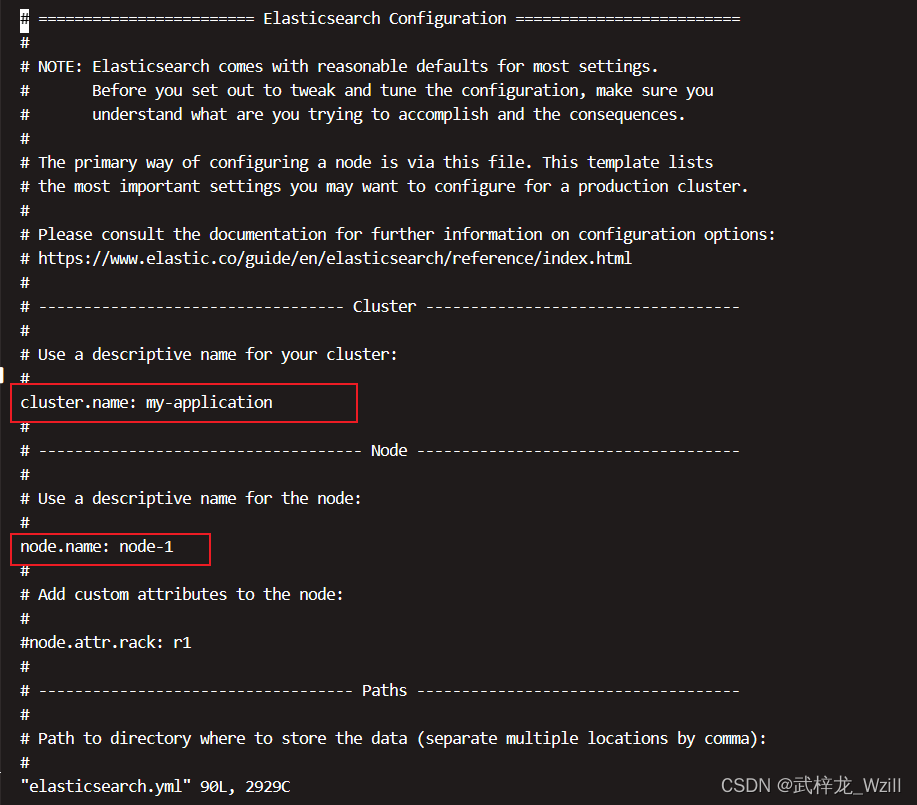
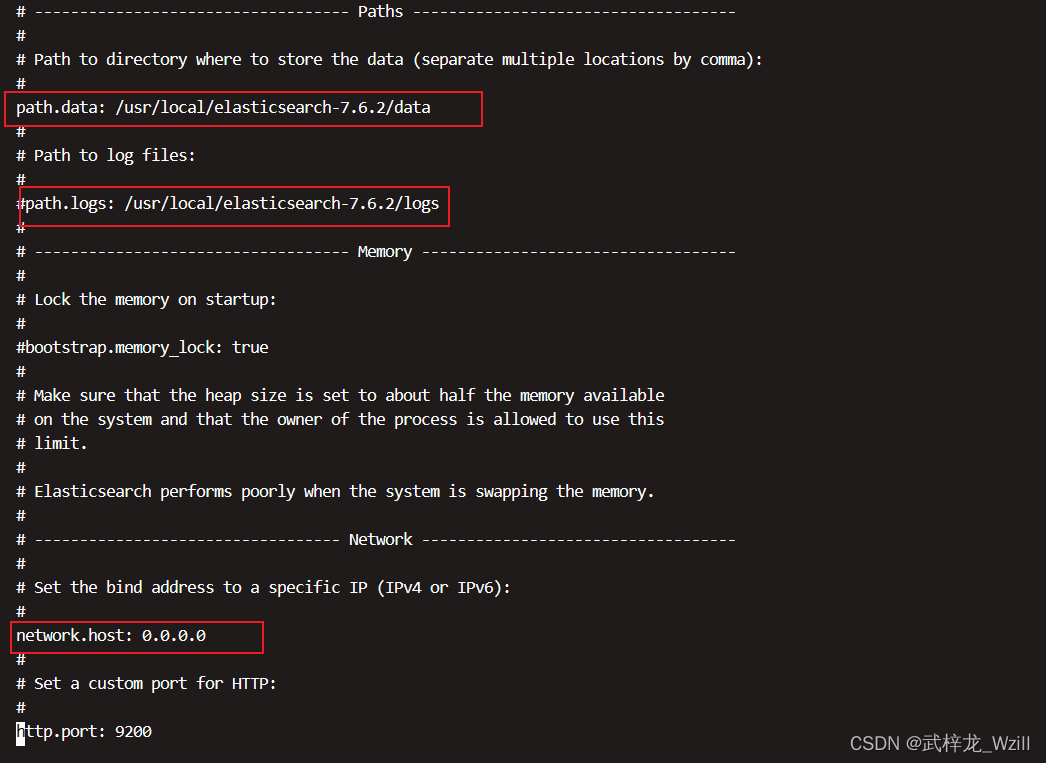
network.host修改为0.0.0.0,让所有的服务器都可以进行访问
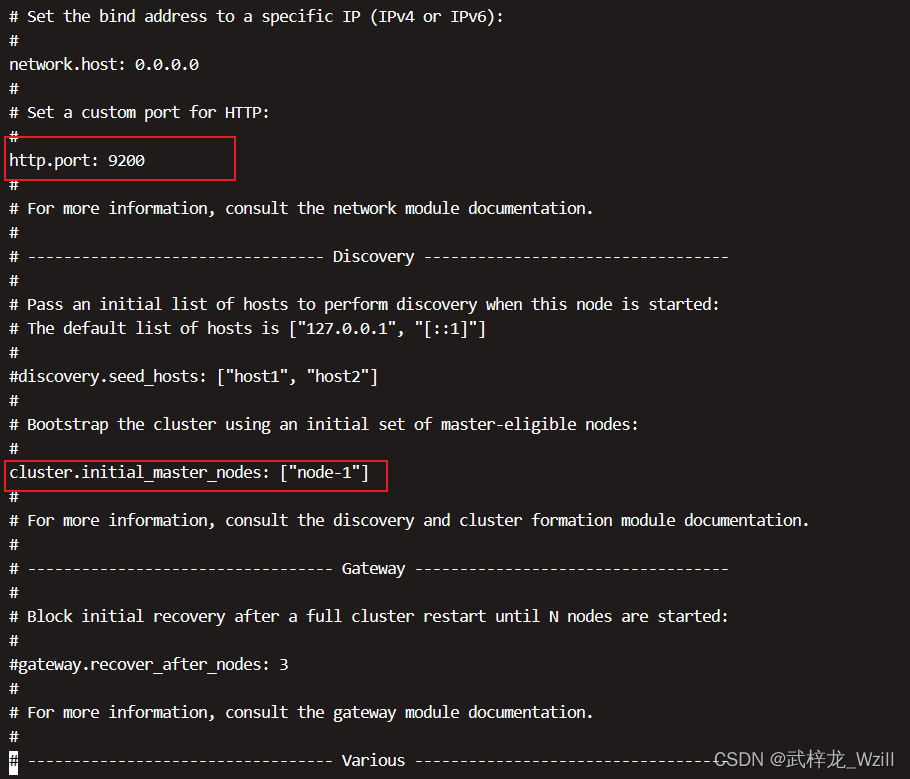
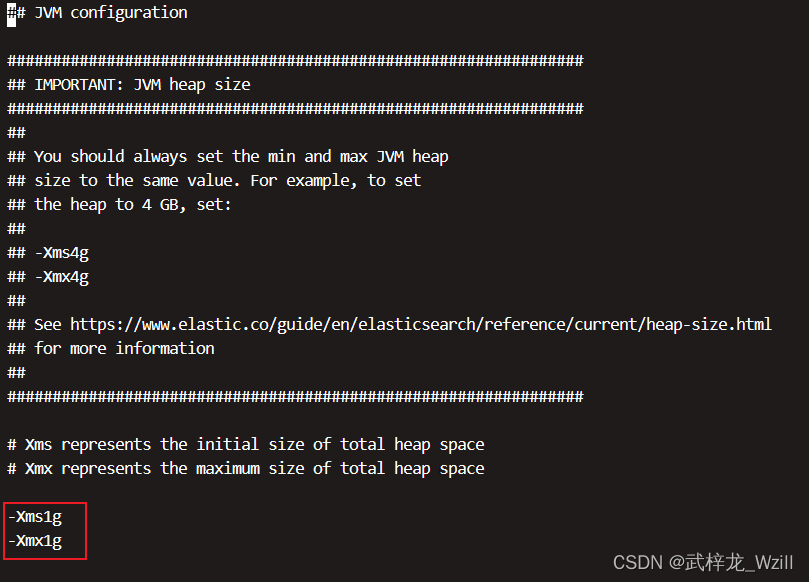
6.修改内存配置
vim ./config/jvm.options
7.修改系统配置,编辑文件sysctl.conf,增加一行vm.max_map_count=262144,保存后退出
sudo vim /etc/sysctl.conf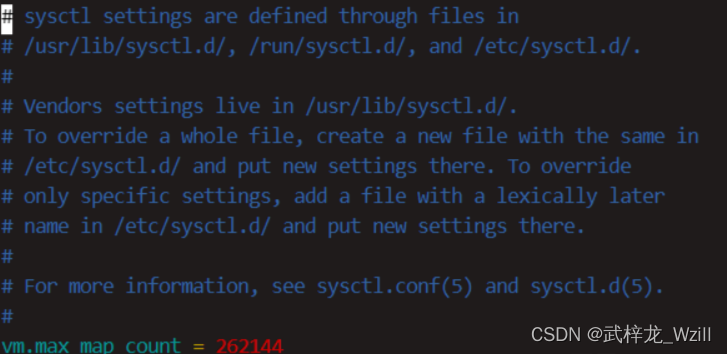
:wq
8.创建ES专用账号
ElasticSearch5.0之后不能使用root账号启动,所以需要创建ES用户并设置密码。
8.1创建用户
useradd user-es
8.2设置密码
sudo passwd 用户名
系统会提示你输入新密码两次。请注意,密码输入时不会显示在终端上,这是出于安全考虑。
8.3赋予权限
# 将es和kibana目录赋权限给新建用户,/usr/local为es所在上级目录
chown admin /usr/local -R
8.4设置用户的相关先限制
在linux中这些限制是分为软限制(soft limit)和硬限制(hard limit)的。他们的区别就是软限制可以在程序的进程中自行改变(突破限制),而硬限制则不行(除非程序进程有root权限)
-H :hard limit ,严格的设定,必定不能超过这个设定的数值,超过会报错
-S :soft limit ,警告的设定,可以超过这个设定值,但是若超过则有警告信息
vim /etc/security/limits.conf,在末尾加上:admin soft nofile 65536 #表示该用户的进程可以打开的最大文件描述符数,软限制
admin hard nofile 65536 #表示该用户的进程可以打开的最大文件描述符数,硬限制
admin soft nproc 4096 #单个用户可用的最大进程数量 ,软限制
admin hard nproc 4096 #单个用户可用的最大进程数量,硬限制vim /etc/security/limits.d/20-nproc.conf,增加:admin soft nproc 40968.5执行sysctl -p 使配置生效
sudo sysctl -p
9.启动ElasticSearch服务
在ES目录中执行以下命令:
前台执行 ./bin/elasticsearch
后台执行 nohup ./bin/elasticsearch > nohup.out 2>&1 &
10.访问ElasticSearch服务,查看是否启动成功
直接访问ip+端口号,咱们之前设置的端口号为9200
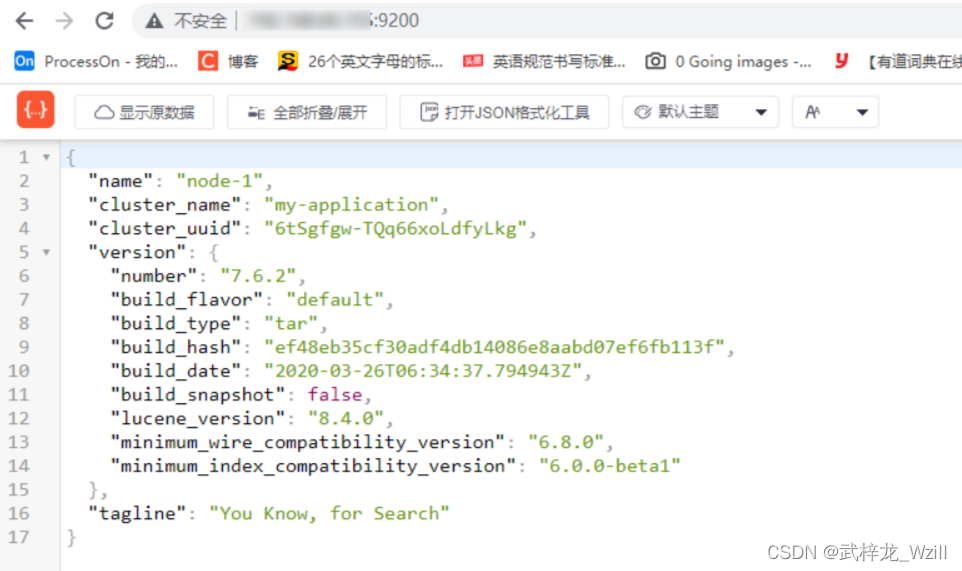
注:记得打开端口号,可参考博客:Linux如何打开指定端口号
安装Kibana
1.wget下载安装包
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
2.解压安装包
tar -xvf kibana-7.6.2-linux-x86_64.tar.gz
3.进入到kibana目录
cd kibana-7.6.2-linux-x86_64
4.编辑配置文件
vim config/kibana.yml# 添加以下内容:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://es的ip地址或域名:9200"]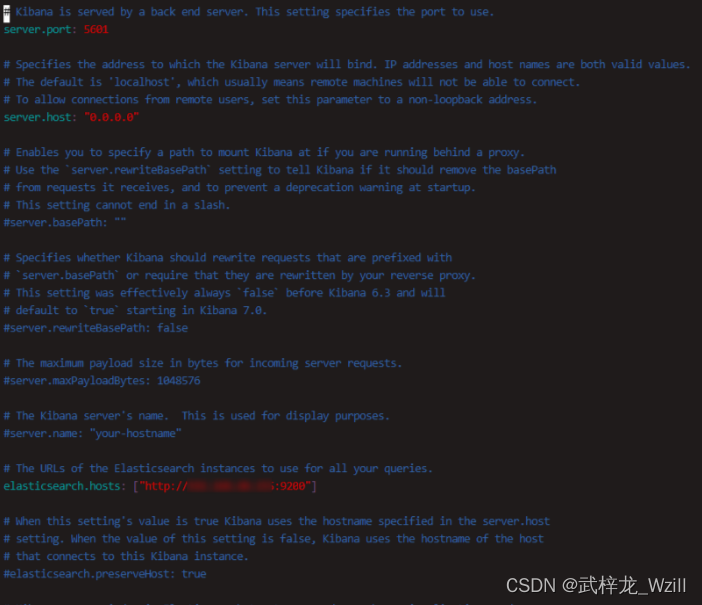
5.启动Kinbana
前台执行 ./bin/kinbana
后台执行 nohup ./bin/kinbana > nohup.out 2>&1 &
6.访问Kinbana服务,查看是否启动成功
直接访问ip+端口号,咱们之前设置的端口号为5601
常见问题
在启动的过程中经常会出现以下问题,基本上都是配置文件修改之后没有生效的原因
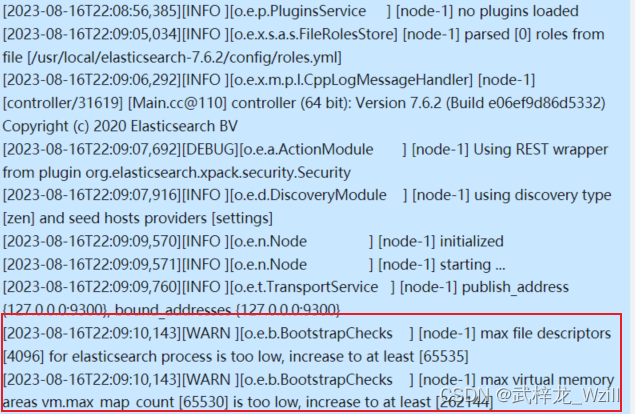
1.max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决方案:执行sudo vim /etc/security/limits.conf查看是否加上了如图配置。加上之后在执行sysctl -p ,再启动ES,如果依然出现相同的错误,则说明配置没有生效,重启服务器使用reboot命令,再启动ES,问题应该就可以解决了。
2.max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方案:解决方法:回到之间的步骤,配置ElasticSearch中的步骤五,执行sudo vim /etc/sysctl.conf查看是否加上了如图配置。加上之后在执行sysctl -p ,再启动ES,如果依然出现相同的错误,则说明配置没有生效,重启服务器使用reboot命令,再启动ES,问题应该就可以解决了。
总结提升
Elasticsearch 和 Kibana 的结合可以实现强大的搜索、分析和可视化功能。通过使用 Elasticsearch 的搜索和分析能力,可以轻松地对大量数据进行复杂的查询和聚合操作。而 Kibana 则提供了友好的界面,方便用户通过图表和仪表盘等方式直观地展示和分析数据。
相关文章:
ElasticSearch-安装部署全过程
本文已收录于专栏 《中间件合集》 目录 概念说明什么是ElasticSearch什么是Kibana什么是RESTful API 提供服务安装过程安装ElasticSearch1.下载ElasticSearch 安装包2.解压安装包3.进入解压之后的文件夹4.创建一个data文件夹用来存储数据5.进入config文件夹编辑elasticsearch.y…...

mathematica报错:Tag Plus is \ Protected
在使用化简函数Simplify的时候使用了规则的语法,但是规则可能没有使用等号。 例如 Simplify[(1 - c^2)/d^2, c^2 d^2 1]等号被认为是赋值符号,要修改为两个等号: Simplify[(1 - c^2)/d^2, c^2 d^2 1]这样就不会报错了。...
Python Django 模型概述与应用
今天来为大家介绍 Django 框架的模型部分,模型是真实数据的简单明确的描述,它包含了储存的数据所必要的字段和行为,Django 遵循 DRY Principle 。它的目标是你只需要定义数据模型,然后其它的杂七杂八代码你都不用关心,…...
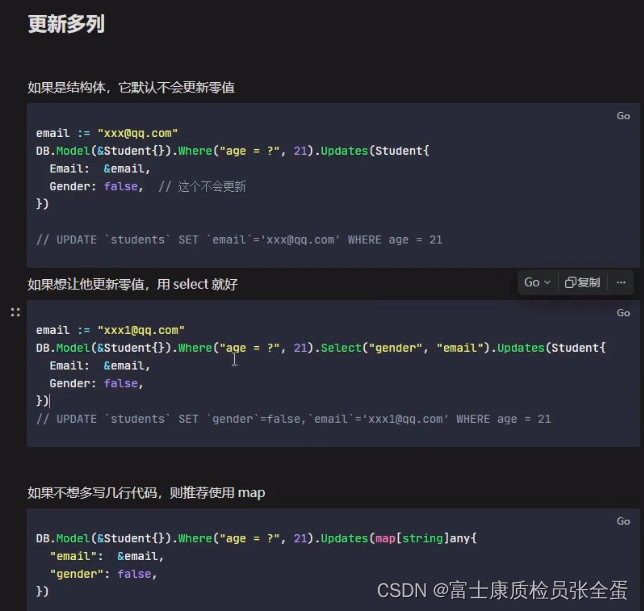
Golang Gorm 更新字段 save update updates
更新和删除操作的前提条件都是要在找到数据的情况下,先要查询到数据才可以做操作。 更新的前提的先查询到记录,Save保存所有字段,用于单个记录的全字段更新它会保控所有字段,即使零值也会保存。 在更新和删除之前,要利…...

springBoot 配置文件引入 redis 的相关参数说明
在Spring Boot应用中使用Redis作为缓存或数据存储时,可以在应用的配置文件中配置相关参数。下面是常用的Redis配置参数及其说明: spring.redis.host: Redis服务器主机地址,默认为localhost。spring.redis.port: Redis服务器端口,…...

Docker的使用心得:简化开发与部署的利器
开发与测试的无缝衔接: Docker让开发与测试之间的切换变得前所未有的顺畅。我可以在本地开发环境中创建一个与生产环境一致的Docker容器,这样不仅可以确保开发过程中不会出现意外问题,还可以在测试阶段避免不必要的繁琐配置。 跨平台的可移植…...

vue3 基于element plus对el-pagination进行二次封装
vue3 基于element plus对el-pagination进行二次封装 1、前言2、在components文件夹中新建pagination.vue文件3、在组件内使用分页 1、前言 在vue3项目中,如果每个列表页都敲一遍分页方法,显然是不合理的,那么,下面我将基于elemen…...

RuntimeError: result type Float can‘t be cast to the desired output type __int64报错解决方法
小白刚开始学习YOLOv5,跟随老哥的步骤走了一遍目标检测--手把手教你搭建自己的YOLOv5目标检测平台 最后训练最后一步出现RuntimeError: result type Float can‘t be cast to the desired output type __int64报错 解决方法:找到5.0版报错的loss.py中最…...

解析Python爬虫常见异常及处理方法
作为专业爬虫程序猿长期混迹于爬虫ip解决方案中,我们经常会遇到各种各样的异常情况。在爬虫开发过程中,处理这些异常是不可或缺的一部分。本文将为大家总结常见的Python爬虫异常,并分享相应的处理方法,帮助你避免绊倒在爬虫之路上…...
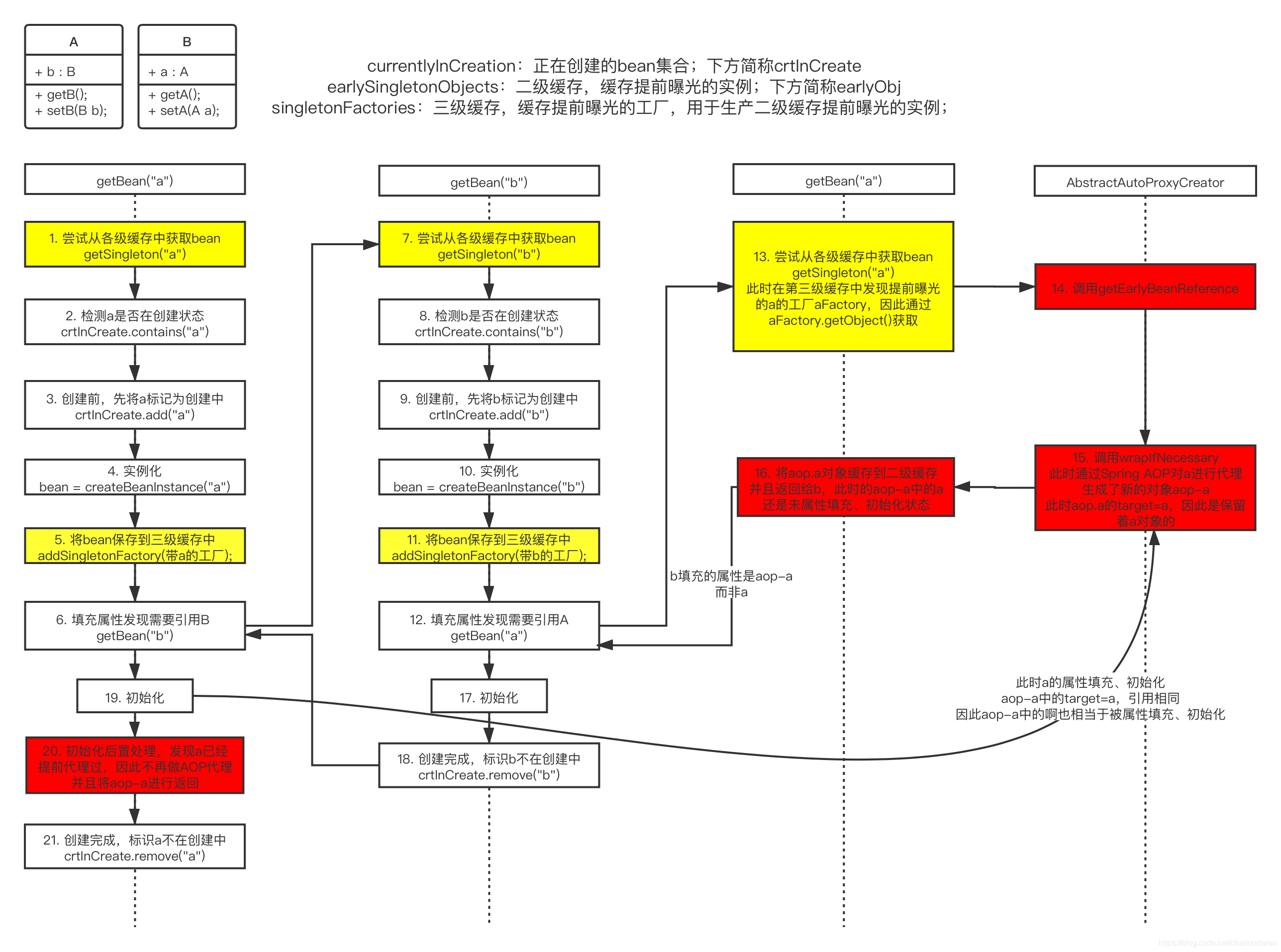
详解Spring的循环依赖问题、三级缓存解决方案源码分析
0、基础:Bean的生命周期 在Spring中,由于IOC的控制反转,创建对象不再是简单的new出来,而是交给Spring去创建,会经历一系列Bean的生命周期才创建出相应的对象。而循环依赖问题也是由Bean的生命周期过程导致的问题&#…...

oracle分析函数学习
0、建表及插入测试数据 --CREATE TEST TABLE AND INSERT TEST DATA. create table students (id number(15,0), area varchar2(10), stu_type varchar2(2), score number(20,2));insert into students values(1, 111, g, 80 ); insert into students values(1, 111, j, 80 ); …...

代码随想录训练营day17|110.平衡二叉树 257. 二叉树的所有路径 404.左叶子之和 v...
TOC 前言 代码随想录算法训练营day17 一、Leetcode 110.平衡二叉树 1.题目 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 示例 1&#x…...

C# Thread用法
C# 中的线程(Thread)是一种并发执行的机制,允许同时执行多个代码块,从而提高程序的性能和响应性。下面是关于如何使用 C# 线程的一些基本用法: 1. 创建线程: 使用 System.Threading 命名空间中的 Thread 类…...
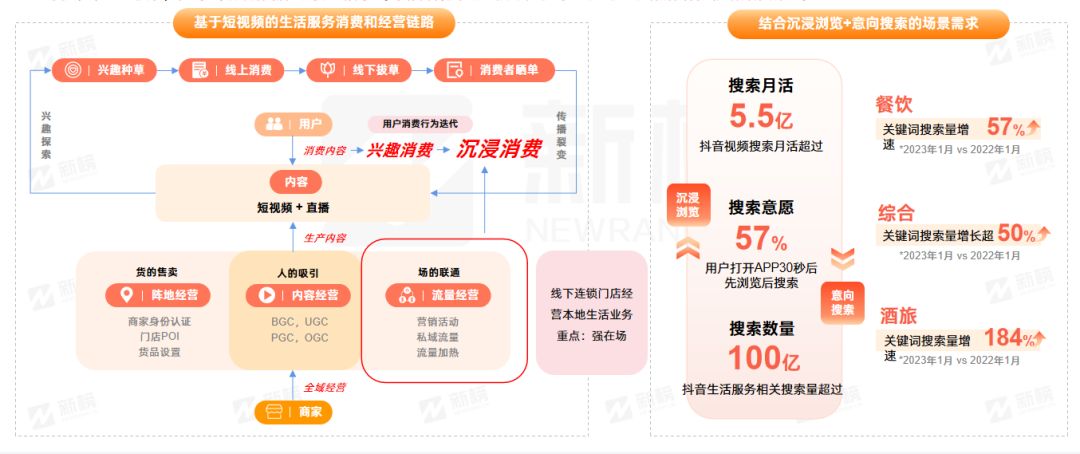
新榜 | CityWalk本地生活商业价值洞察报告
如果说现在有人问,最新的网络热词是什么? “CityWalk”,这可能是大多数人的答案。 近段时间,“CityWalk”刷屏了各种社交媒体,给网友们带来了一场“城市漫步”之旅。 脱离群体狂欢,这个在社交媒体引发热议的词汇背后又…...
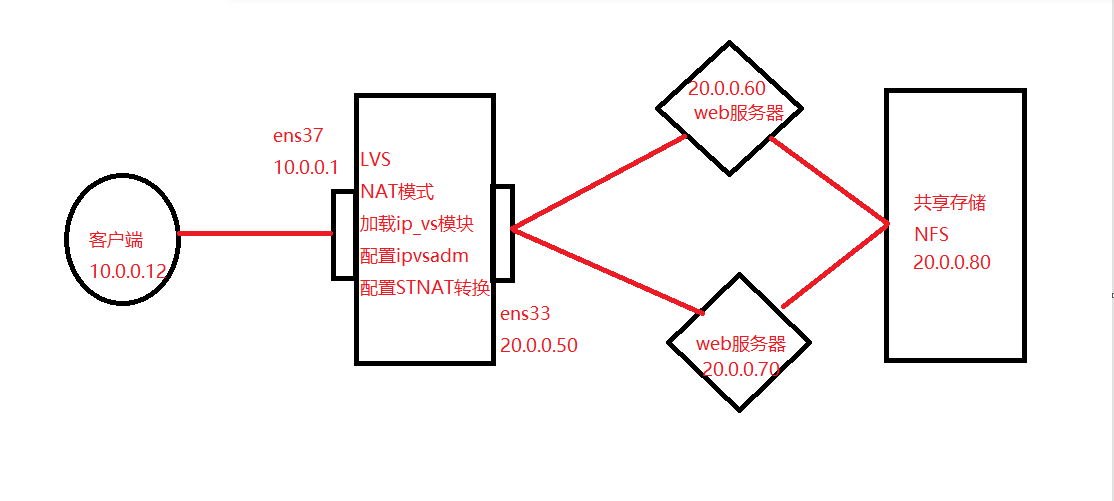
LVS负载均衡集群-NAT模式部署
集群 集群:将多台主机作为一个整体,然后对外提供相同的服务 集群使用场景:高并发的场景 集群的分类 1.负载均衡器集群 减少响应延迟,提高并发处理的能力 2,高可用集群 增强系统的稳定性可靠性&…...

C++学习笔记总结练习:effective 学习日志
准则 1.少使用define define所定义的常量会在预处理的时候被替代,出错编译器不容易找到错误。而且还没有作用范围限制,推荐使用constdefine宏定义的函数,容易出错,而且参数需要加上小括号,推荐使用inline有的类中例如…...

Vue教程(五):样式绑定——class和style
1、样式代码准备 样式提前准备 <style>.basic{width: 400px;height: 100px;border: 1px solid black;}.happy{border: 4px solid red;background-color: rgba(255, 255, 0, 0.644);background: linear-gradient(30deg, yellow, pink, orange, yellow);}.sad{border: 4px …...
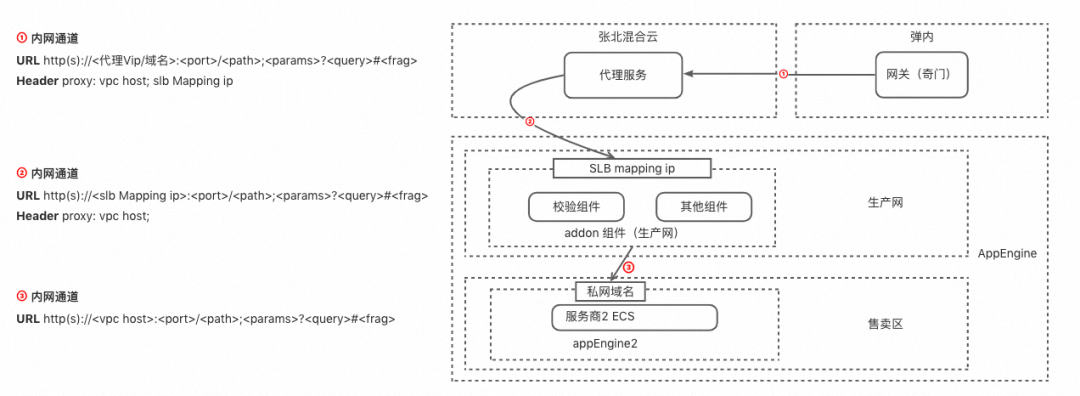
开放网关架构演进
作者:庄文弘(弘智) 淘宝开放平台是阿里与外部生态互联互通的重要开放途径,通过开放的产品技术把阿里经济体一系列基础服务,像水、电、煤一样输送给我们的商家、开发者、社区媒体以及其他合作伙伴,推动行业的…...

torch一些操作
Pytorch文档 Pytorch 官方文档 https://pytorch.org/docs/stable/index.html pytorch 里的一些基础tensor操作讲的不错 https://blog.csdn.net/abc13526222160/category_8614343.html 关于pytorch的Broadcast,合并与分割,数学运算,属性统计以及高阶操作 https://blog.csd…...
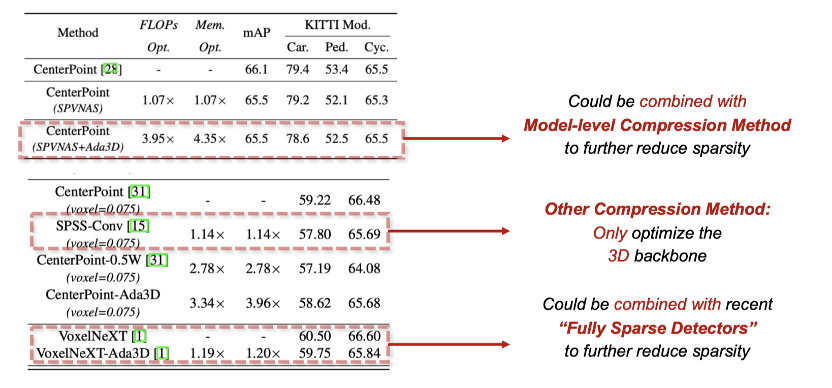
ICCV23 | Ada3D:利用动态推理挖掘3D感知任务中数据冗余性
论文地址:https://arxiv.org/abs/2307.08209 项目主页:https://a-suozhang.xyz/ada3d.github.io/ 01. 背景与动因 3D检测(3D Detection)任务是自动驾驶任务中的重要任务。由于自动驾驶任务的安全性至关重要(safety-critic),对感知算法的延…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...