Elasticsearch(十二)搜索---搜索匹配功能③--布尔查询及filter查询原理
一、前言
本节主要学习ES匹配查询中的布尔查询以及布尔查询中比较特殊的filter查询及其原理。
复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。
布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些子查询之间的逻辑关系是"与",即所有子查询的结果都为true时布尔查询结果才为真。布尔查询还可以按照各个子查询的具体匹配程度对文档进行打分计算,除了比较特殊的must not查询和filter查询之外,这个后面会详解。
布尔查询支持的子查询主要有4种,各子查询的名称和功能如下表:
| 子查询名称 | 功能 |
|---|---|
| must | 必须匹配该查询条件 |
| should | 可以匹配该查询条件 |
| must not | 必须不匹配该查询条件,且不进行打分计算 |
| filter | 必须匹配过滤条件,且不进行打分计算 |
下面将逐一进行讲解
二、布尔查询
2.1、must查询
当查询中包含must查询时,相当于逻辑查询中的"与"查询。命中的文档必须匹配该子查询的结果,并且ES会将该子查询与文档的匹配程度值加入总得分里。must搜索包含一个数组,可以把其他的搜索匹配查询及布尔查询放入其中。
以下示例使用must查询城市范围为上海和南昌且创建时间范围在2021-02-27 22:00:00到2024-02-27 22:00:00,DSL如下:
POST /hotel/_search
{"query": {"bool": {"must": [{"terms": { //第一个terms子查询,城市为上海和南昌"city": ["上海","南昌"]}},{"range": { //第二个range子查询,时间范围为2021-02-27 22:00:00到2024-02-27 22:00:00,包括边界"create_time": { "gte": "2021-02-27 22:00:00","lte": "2024-02-27 22:00:00"}}}]}}
}
结果如下图,可以看到结果是同时满足的且我们发现是有打分的
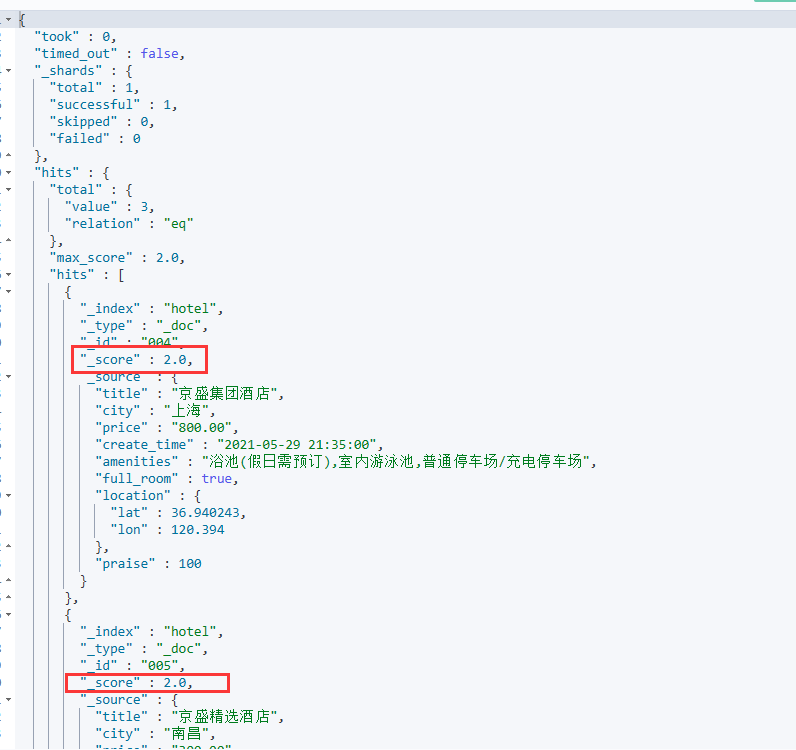
在java客户端上构建must搜索时,可以使用QueryBuilder.boolQuery().must()进行构建,上面的must查询例子改写成Java客户端请求的形式为:
Service层(private方法在后面的查询中通用,不会再展示)
public List<Hotel> mustQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("city", hotelDocRequest.getCities());Date createTimeStart = hotelDocRequest.getCreateTimeStart();String createTimeStartToSearch = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(createTimeStart);Date createTimeEnd = hotelDocRequest.getCreateTimeEnd();String createTimeEndToSearch = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(createTimeEnd);RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("create_time").gte(createTimeStartToSearch).lte(createTimeEndToSearch);BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(rangeQueryBuilder).must(termsQueryBuilder);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}private String getNotNullIndexName(HotelDocRequest hotelDocRequest) {String indexName = hotelDocRequest.getIndexName();if (CharSequenceUtil.isBlank(indexName)) {throw new SearchException("索引名不能为空");}return indexName;}private List<Hotel> getQueryResult(SearchRequest searchRequest) throws IOException {ArrayList<Hotel> resultList = new ArrayList<>();SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);RestStatus status = searchResponse.status();if (status != RestStatus.OK) {return Collections.emptyList();}SearchHits searchHits = searchResponse.getHits();for (SearchHit searchHit : searchHits) {Hotel hotelResult = new Hotel();hotelResult.setId(searchHit.getId()); //文档_idhotelResult.setIndex(searchHit.getIndex()); //索引名称hotelResult.setScore(searchHit.getScore()); //文档得分//转换为MapMap<String, Object> dataMap = searchHit.getSourceAsMap();hotelResult.setTitle((String) dataMap.get("title"));hotelResult.setCity((String) dataMap.get("city"));Object price = dataMap.get("price");if(price != null){hotelResult.setPrice(Double.valueOf((String)price));}resultList.add(hotelResult);}return resultList;}
controller层:
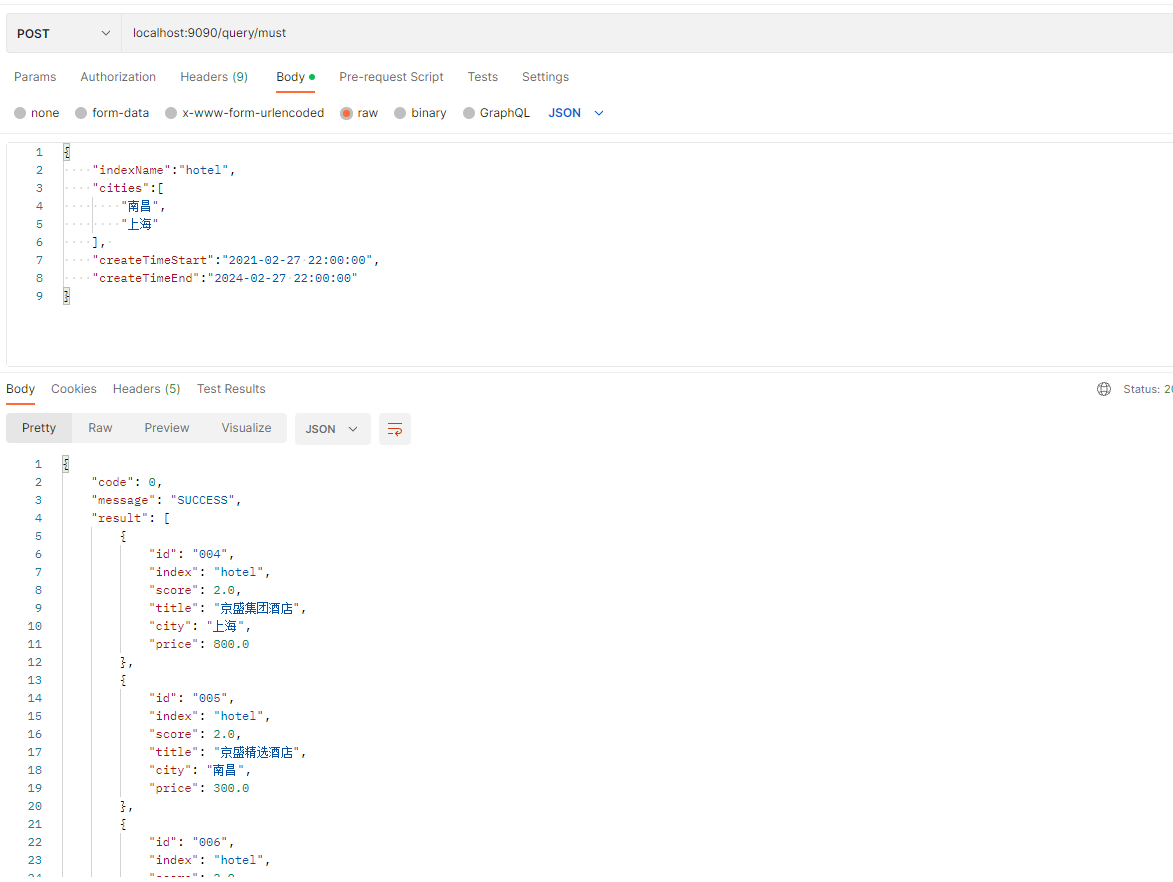
@PostMapping("/query/must")public FoundationResponse<List<Hotel>> mustQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.mustQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
postman调用:
2.2、should查询
当查询中包含should查询时,表示当前查询为"或"查询。命中的文档可以匹配该查询中的一个或多个子查询的结果,并且ES会将该查询与文档的匹配程度加入总得分里。should查询包含一个数组,可以把其他的查询匹配的查询及布尔查询放入其中:
例如,我这边需要查询城市为上海或北京的酒店:
DSL如下:
POST /hotel/_search
{"query": {"bool": {"should": [{"term": {"city": {"value": "上海"}}},{"term": {"city": {"value": "北京"}}}]}}
}
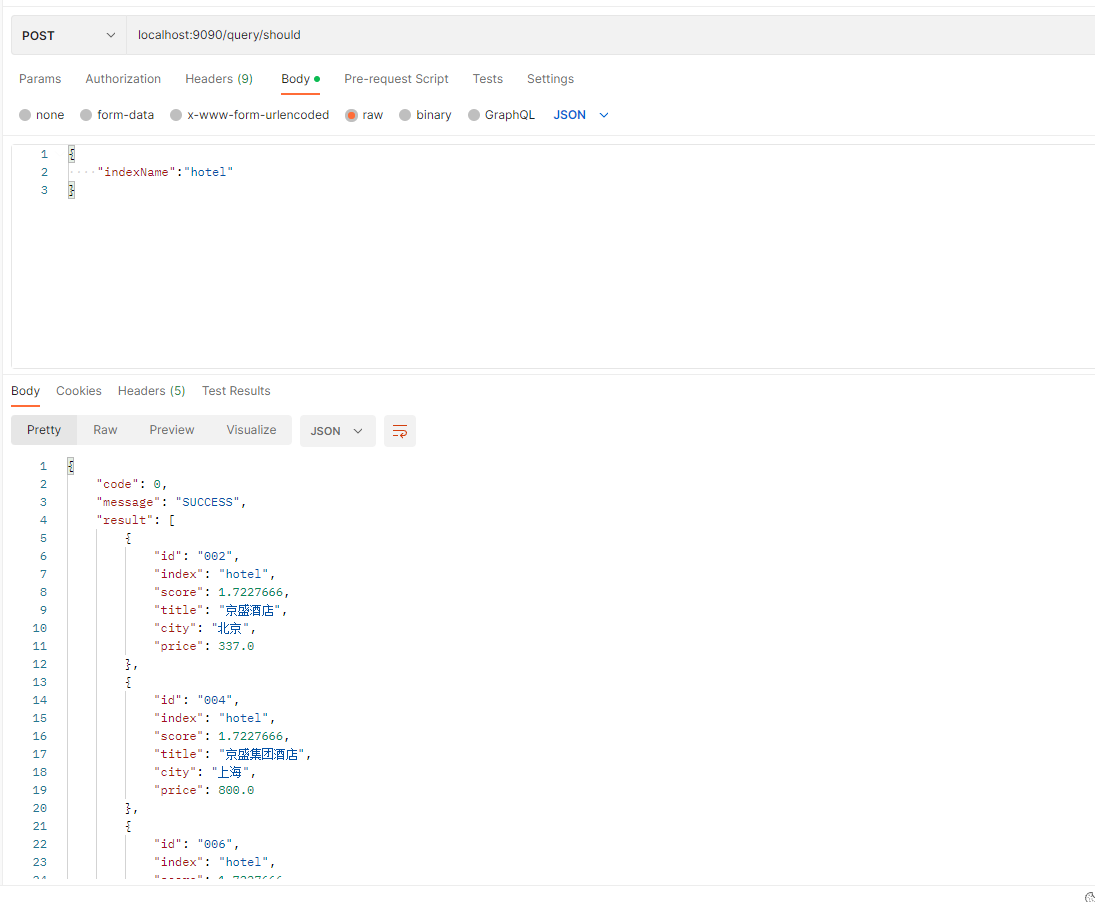
查询结果如图所示:
可以看到城市为上海或者北京的酒店全部被查询出来了。且有根据匹配程度打分

在java客户端上构建should搜索时,可以使用QueryBuilder.boolQuery().should()进行构建,上面的should查询例子改写成Java客户端请求的形式为:
Service层:
public List<Hotel> shouldQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "北京");TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("city", "上海");BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.should(termQueryBuilder1).should(termQueryBuilder2);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
controller层:
@PostMapping("/query/should")public FoundationResponse<List<Hotel>> shouldQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.shouldQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
postman调用演示
2.3、must not查询
当查询中包含must not查询时,表示当前查询为"非"查询。命中的文档不能匹配该查询中的一个或多个子查询的结果。must not查询包含一个数组,可以把其他的查询匹配的查询及布尔查询放入,与上面的2个布尔查询不同,must not查询不会进行打分操作
must not查询是用来排除与指定条件匹配的文档的。它的作用是将与条件匹配的文档从结果中排除掉,而不是对这些文档进行打分。因此,must not查询不涉及打分,仅仅关注匹配与不匹配。这一点和后面的filter查询原理上是一样的:
例如,我这边需要查询城市既不为上海也不是北京的酒店:
DSL如下:
POST /hotel/_search
{"query": {"bool": {"must_not": [{"term": {"city": {"value": "上海"}}},{"term": {"city": {"value": "北京"}}}]}}
}
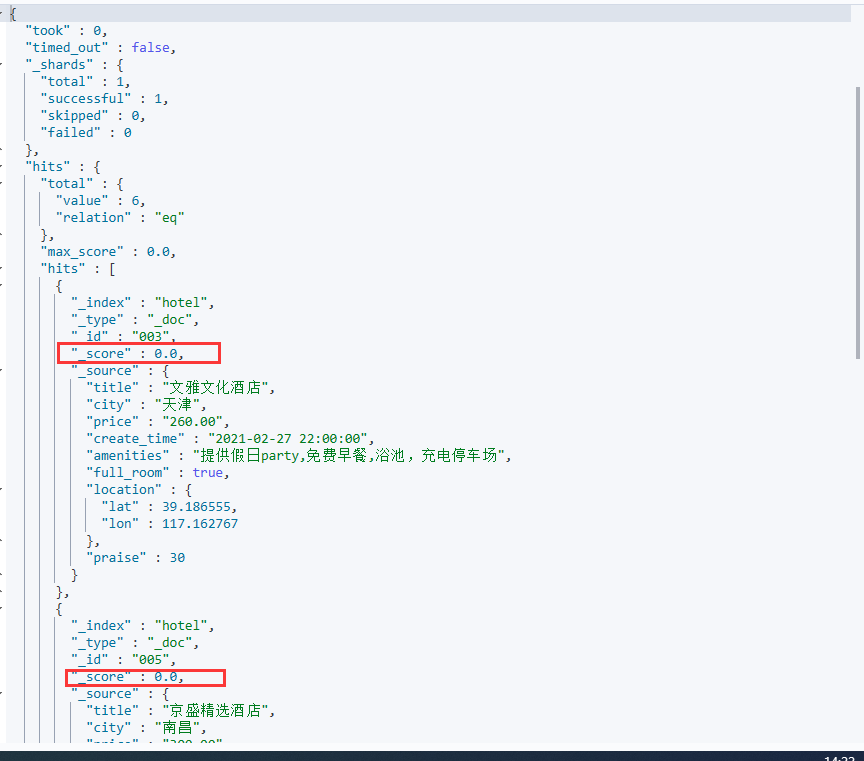
查询结果如图所示:
可以看到查询出来的节点城市均不为北京或者上海。但是并有根据匹配程度打分:
在java客户端上构建must not搜索时,可以使用QueryBuilder.boolQuery().mustNot()进行构建,上面的must not查询例子改写成Java客户端请求的形式为:
Service层:
public List<Hotel> mustNotQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "北京");TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("city", "上海");BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.mustNot(termQueryBuilder1).mustNot(termQueryBuilder2);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
controller层:
@PostMapping("/query/must_not")public FoundationResponse<List<Hotel>> mustNotQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.mustNotQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
postman查询:
2.4、filter查询
filter查询即过滤查询,该查询是布尔查询里非常独特的一种查询,如果说前面的must not查询用于排除与条件匹配的文档,将这些文档从查询结果中排除掉。filter查询就是用于精确过滤文档,它只关注文档是否符合条件,将匹配的文档包含在结果中。他们都不进行打分、排序或相关性计算,只担心是否匹配。但是filter和must not原理上还是存在一些区别,这个后面讲,先对功能进行讲解:
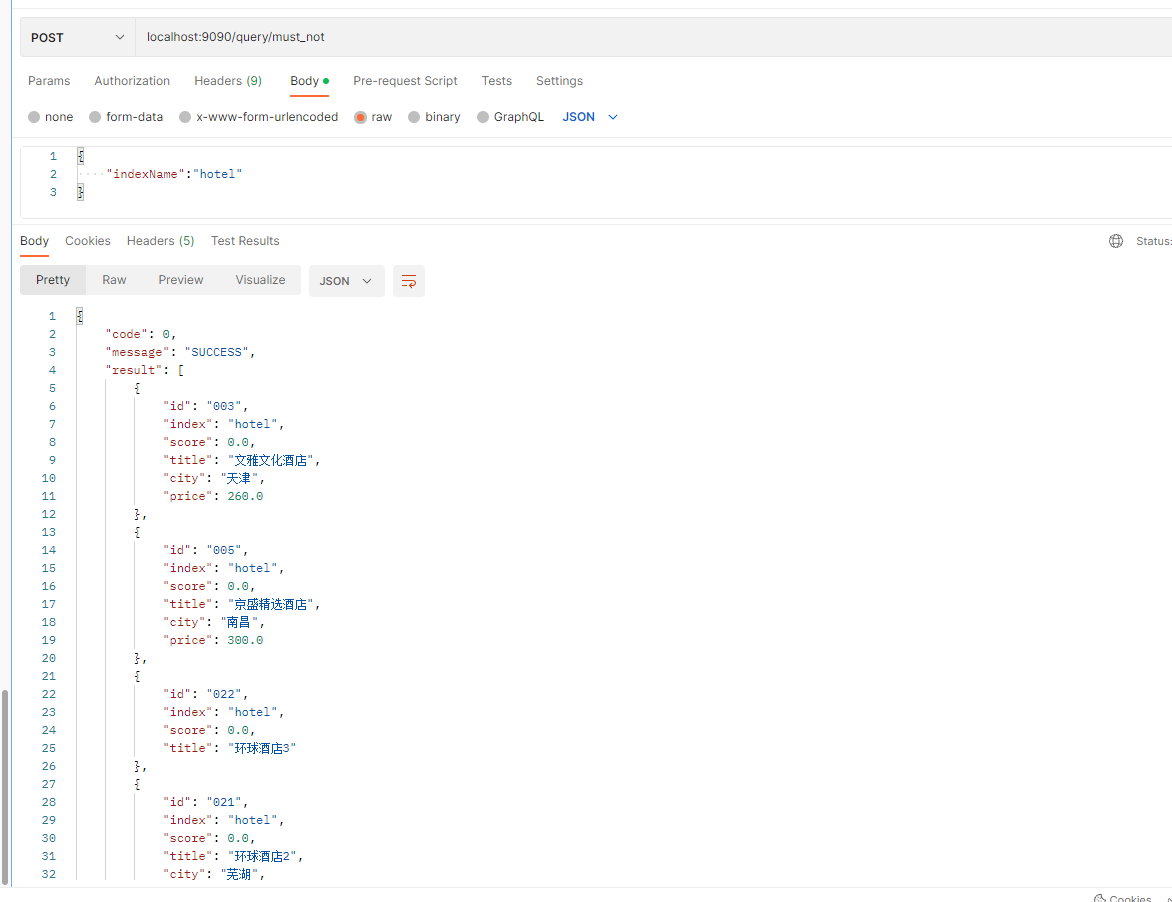
例如我要查询城市是上海且已经满员的酒店:
POST /hotel/_search
{"query": {"bool": {"filter": [{"term": {"city": {"value": "上海"}}},{"term": {"full_room": {"value": true}}}]}}
}
可以看出查询的条件中符合指纹上海且满员,且并没有进行打分
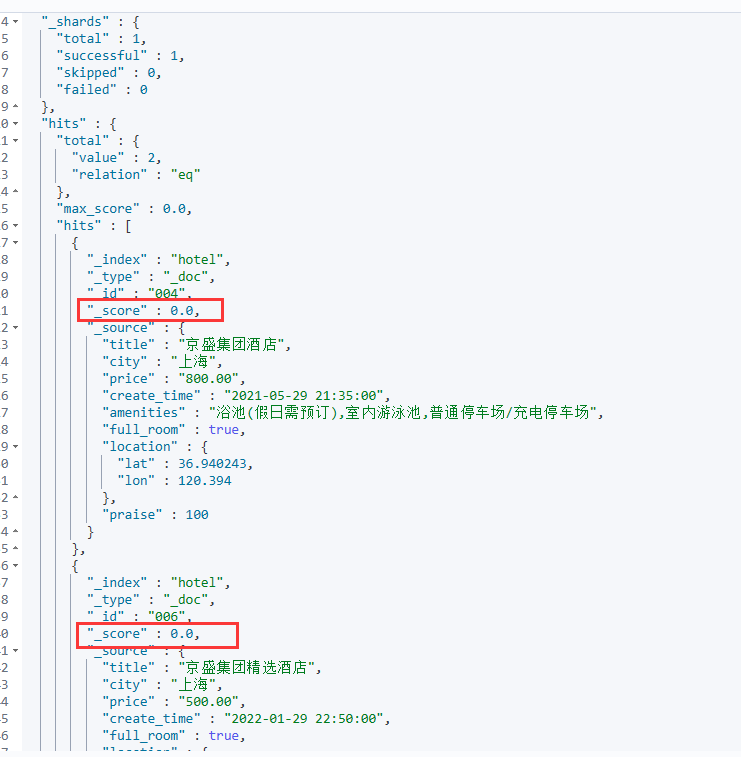
而filter查询会在布尔查询初始阶段进行执行,并将符合条件的文档结果保存下来,接着才会去执行剩余的查询,不管你写的顺序!例如我先写must再写filter,ES执行器也会先执行filter过滤,在过滤后得到的剩余文档中再去执行其他的布尔查询,这样的目的是为了提高查询效率,因为filter查询会将文档集合进行过滤,只保留满足条件的文档,再将这些文档传递给must查询进行进一步的条件匹配和评分。
filter查询主要目的是根据指定的条件来快速地过滤掉不符合条件的文档,以减少后续的计算和评分操作。
请注意,当使用filter查询时,Elasticsearch会对搜索结果进行缓存,以进一步提高性能。缓存可在后续的相同查询中重复使用,除非索引数据发生更改。这使得过滤器查询非常适合用于频繁执行的静态条件过滤
在java客户端上构建filter搜索时,可以使用QueryBuilders.boolQuery.filter()进行构建,例如我要查询城市是上海且已经满员的酒店改写成java客户端请求的形式为:
service层:
public List<Hotel> filterQuery(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "上海");TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("full_room", true);BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.filter(termQueryBuilder1).filter(termQueryBuilder2);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
controller层:
@PostMapping("/query/filter")public FoundationResponse<List<Hotel>> filterQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.filterQuery(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
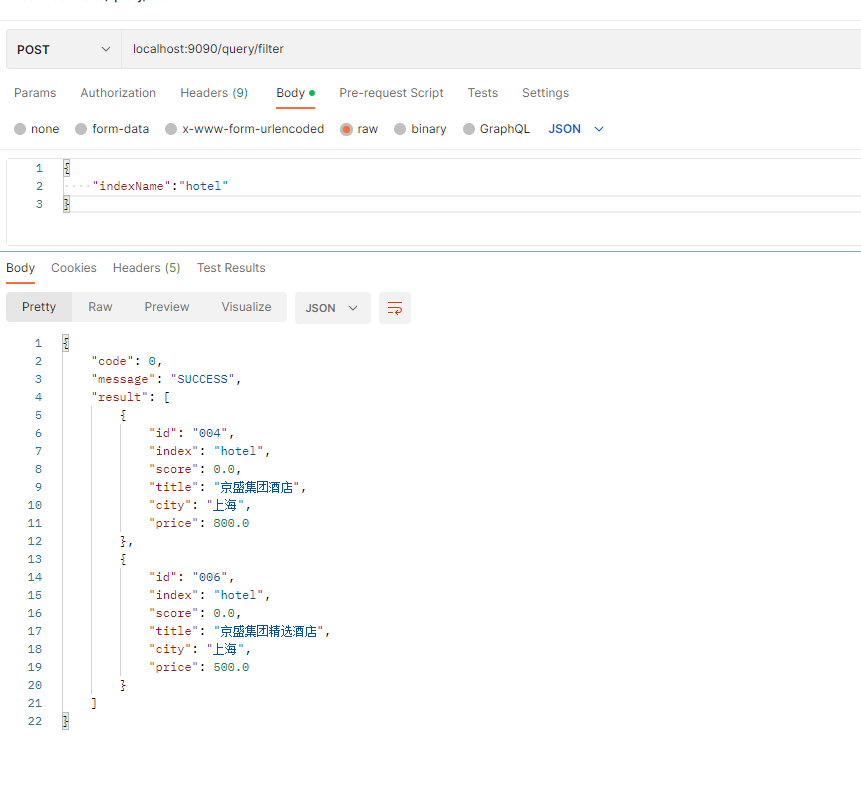
postman调用:
三、filter查询原理
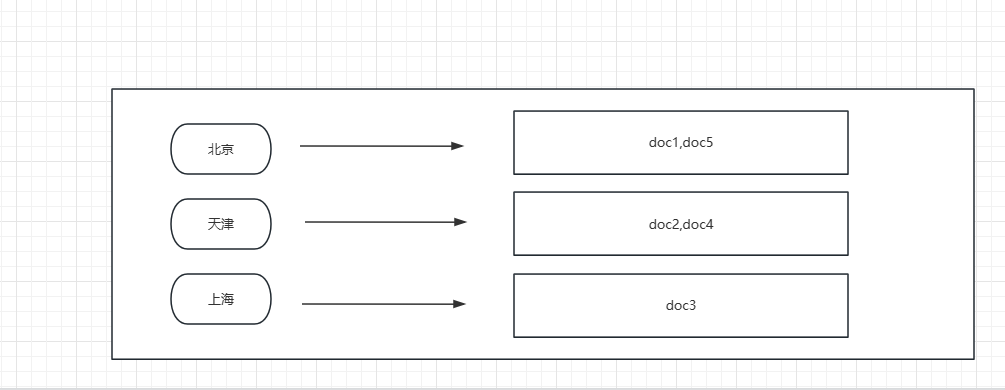
假设当前有5个文档,ES对于city字段的倒排索引结构如图所示:
ES对于满房字段倒排的索引结构如图所示:
下面以同时查询city为北京,且不满房为例,讲解ES内部执行filter查询的工作步骤。
当ES执行过滤条件时,会查询缓存是否有city字段值为“北京”对应的bitset数组。bitset,中文为位图,它可以用非常紧凑的格式来表示给定范围内的连续数据。如果查询缓存中有对应的Bitset数据,则取出备用;反之,则ES在查询后会对查询条件进行bitset的构建并将其放入缓存中。同时,ES也会考察满房字段为false是否有意对应的bitset数据。如果有,则取出备用;如果没有,ES也会进行bitset的构建。
假设city字段值为“北京”,缓存中没有对应的Bitset数据,则bitset构建的过程如下:
首先,ES在倒排索引中查找字段city值为“北京”字符串的文档,这里为doc1和doc5。然后为所有文档构建bitset数组,数组中每个元素的值用来表示对应位置的文档是否和查询条件匹配,0表示未匹配,1表示匹配。在本例中,doc1和doc5匹配“北京”,对应位置的值为1;doc2、doc3、doc4不匹配,对应的位置为0。最终,本例的bitset数组为[1,0,0,0,1],满房字段同理。之所以用bitset表示文档和query的匹配结果,是因为该结构不仅节省空间而且后续操作时也能节省时间。
接下来ES会遍历查询条件的bitset数组,按照文档命中是否进行文档过滤。当一个请求中有多个filter查询条件时,ES会构建多个bitset数组。为提升效率,ES会从最稀疏的数组(0的元素多于非0元素,反之为稠密数组)开始便遍历,因为遍历稀疏的数组可以过滤掉更多的文档。此时,城市为“北京”对应的bitset比满房为false的Bitset更加稀疏,因此先遍历城市为“北京”的bitset,再遍历满房为false的bitset。遍历的过程中也进行了位运算,每次运算的结果都逐渐接近符合条件的结果。遍历计算完这两个Bitset后,得到匹配所有过滤条件的文档,即doc1和doc5。
正如上面的介绍,如果查询内包含filter,那么ES首先就从缓存中搜索这个filter条件是否有执行记录,是否有对应的bitset缓存可查询。如果有,则从缓存中查询;如果没有,则为filter中的每个查询项新建bitset并且缓存。以供后续其他带有filter的查询可以先在缓存中查询。也就是说,ES对于bitset是可重用的,这种重用的机制叫作filter cache(过滤器缓存)。
filter cache会跟踪每一个filter查询,ES筛选一部分filter查询的bitset进行缓存。首先,这些过滤条件要在最近256个查询中出现过;其次,这些过滤条件的次数必须超过某个阈值。
另外,filter cache是有自动更新机制的,即如果有新增文档或者文档或者文档被修改过,那么filter cache对应的过滤条件中的bitset将被更新。例如城市为“北京”过滤条件对应的bitset为[1,0,0,0,1],如果文档4的城市被修改为“北京”,则“北京”过滤条件对应的bitset会被自动更新为[1,0,0,1,1].
filter查询带来的效益远不止这些,使用filter查询的子句是不计算分数的,这可以减少不小的时间开销。而之前提到的must not查询同样也不进行打分,但是must not是没有和filter cache这样的缓存机制的。filter查询和must_not查询都是用于筛选文档的查询类型,它们不会对文档进行评分。Filter查询适用于需要快速过滤大量文档的场景,而must_not查询适用于排除不需要的文档。在实际使用中,可以根据具体需求选择合适的查询类型。
为提升查询效率,对于简单的term级别匹配查询,应该根据自己的实际业务场景选择合适的查询语句,需要确定这些查询项是否都需要进行打分操作,如果某些匹配条件不需要打分操作的话,那么需要把这些查询全部改为filter形式,让查询更加高效。
相关文章:
Elasticsearch(十二)搜索---搜索匹配功能③--布尔查询及filter查询原理
一、前言 本节主要学习ES匹配查询中的布尔查询以及布尔查询中比较特殊的filter查询及其原理。 复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。 布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些…...
解决Windows下的docker desktop无法启动问题
以管理员权限运行cmd 报错: docker: error during connect: Post http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.40/containers/create: open //./pipe/docker_engine: The system cannot find the file specified. In the default daemon configuration on Windows,…...
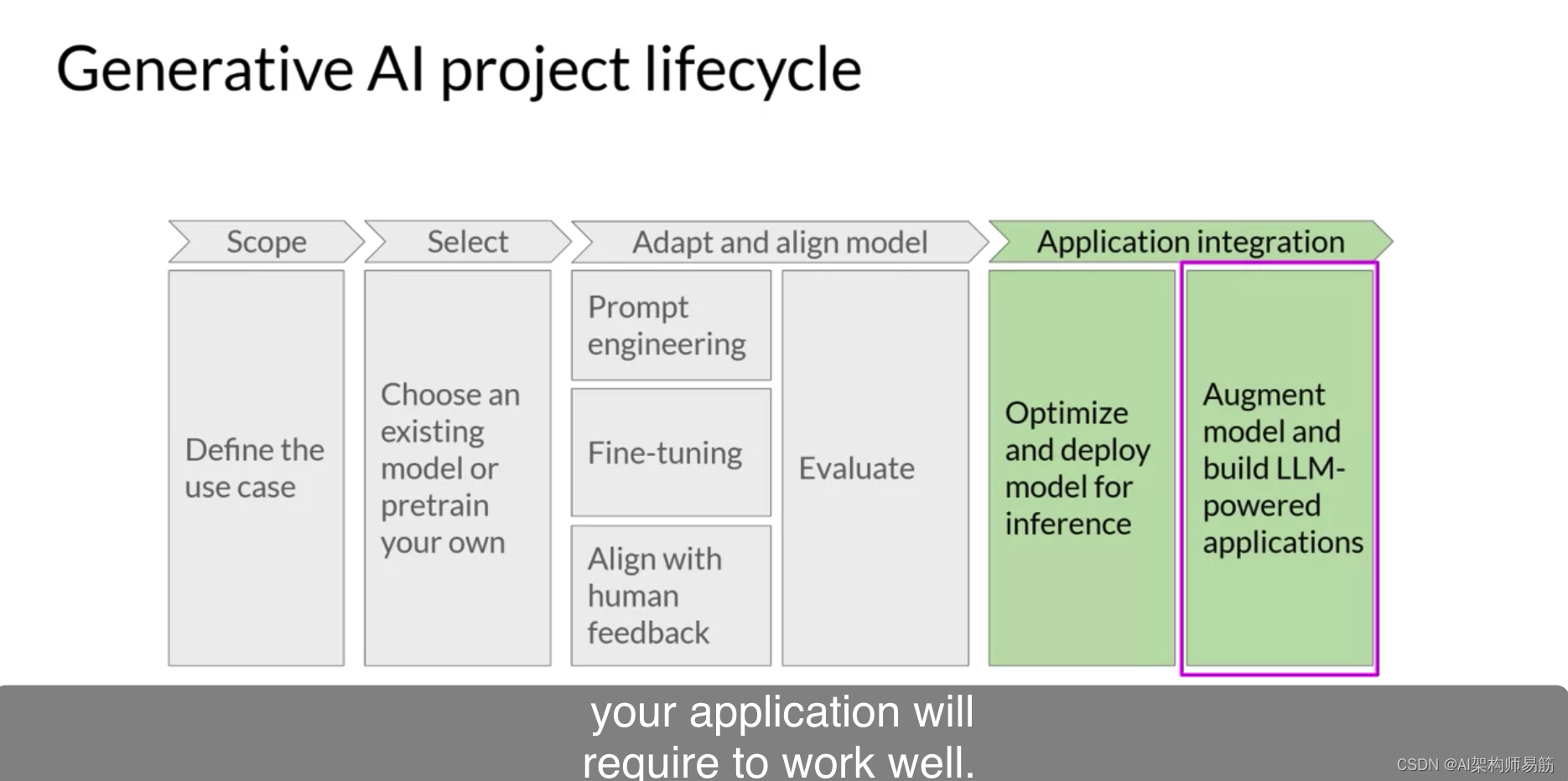
LLM生成式 AI 项目生命周期Generative AI project lifecycle
在本课程的其余部分中,您将学习开发和部署LLM驱动应用所需的技巧。在这个视频中,您将了解一个能帮助您完成此工作的生成式AI项目生命周期。此框架列出了从构思到启动项目所需的任务。到课程结束时,您应该对您需要做的重要决策、可能遇到的困难…...

java高并发系列 - 第13天:JUC中的Condition对象
java高并发系列 - 第13天:JUC中的Condition对象 java高并发系列第13篇文章 本文内容 synchronized中实现线程等待和唤醒Condition简介及常用方法介绍及相关示例使用Condition实现生产者消费者使用Condition实现同步阻塞队列Object对象中的wait(),notify()方法,用于线程等待…...

【TTY子系统】printf与printk深入驱动解析
tty子系统解析 tty子系统是一个庞大且复杂,也是内核维护者所头大的子系统。 At a first glance, the TTY layer wouldn’t seem like it should be all that challenging. It is, after all, just a simple char device which is charged with transferring byte-o…...

无涯教程-PHP - 全局变量函数
全局变量 与局部变量相反,可以在程序的任何部分访问全局变量。通过将关键字 GLOBAL 放置在应被识别为全局变量的前面,可以很方便地实现这一目标。 <?php$somevar15;function addit() {GLOBAL $somevar;$somevar;print "Somevar is $somevar";}addit(); ?> …...
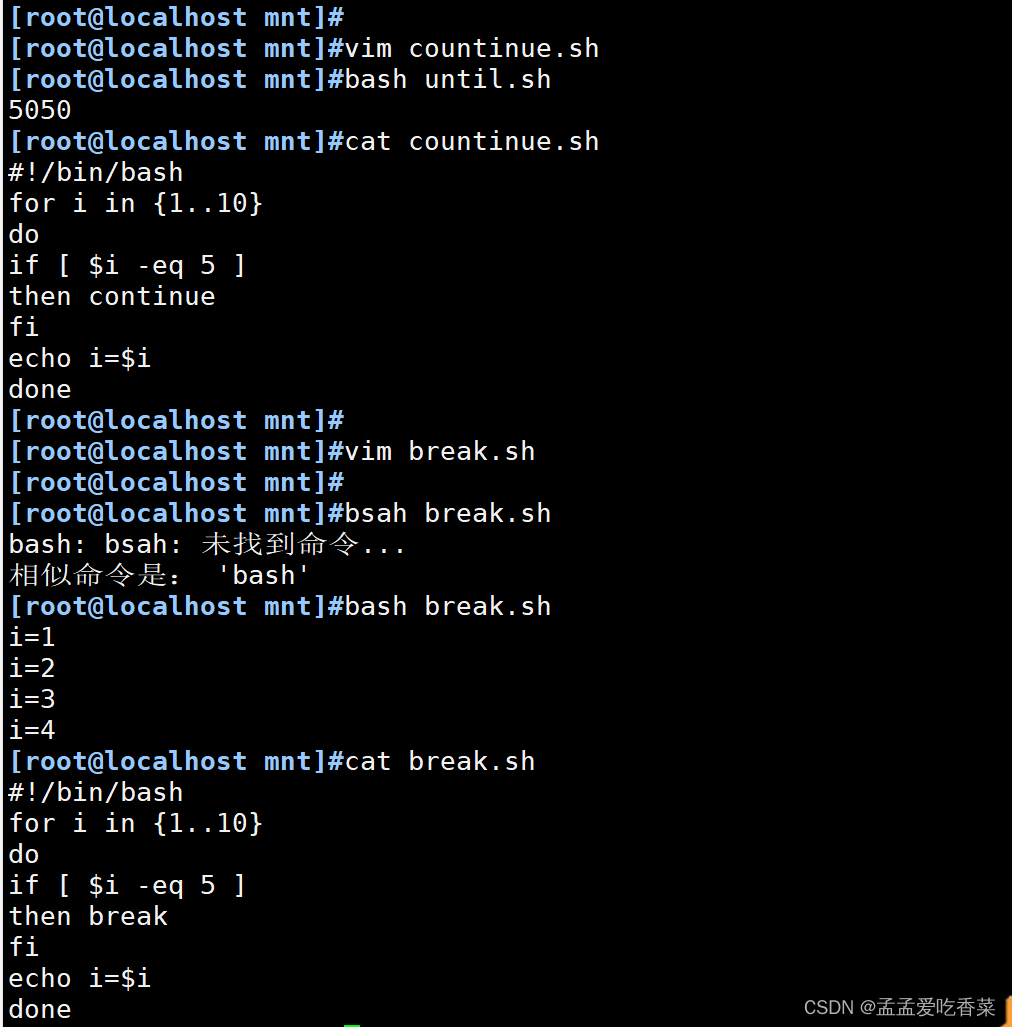
shell脚本之循环语句
循环语句 循环含义 将某代码段重复运行多次,通常有进入循环的条件和退出循环的条件 for循环语句 一般知道循环次数使用for循环 第一类 格式1: for名称 in 取值次数;do;done; 格式2: for 名称 in {取值列表} do done# 打印20次 for i i…...

派森 #P122. 峰值查找
描述 给定一个长度为n的列表nums,请你找到峰值并返回其索引。数组可能包含多个峰值,在这种情况下,返回任何一个所在位置即可。 (1)峰值元素是指其值严格大于左右相邻值的元素。严格大于即不能有等于; &…...

基础网络详解4--HTTP CookieSession 思考
一、cookie技术思考 一台多用户浏览器发起了三笔请求,将某款产品放入购物车中,A一次,选择了篮球;B两次,第一次选了足球,第二次选了钢笔。如何确认选择篮球、足球、钢笔的请求属于谁呢?如果不确认…...

14. 利用Canvas自制时钟组件
1. 说明 在自定义时钟组件时,使用到的基本控件主要是Canvas,在绘制相关元素时有两种方式:一种时在同一个canvas中绘制所有的部件元素,这样需要不断的对画笔和画布的属性进行保存和恢复,容易混乱;另一种就是…...
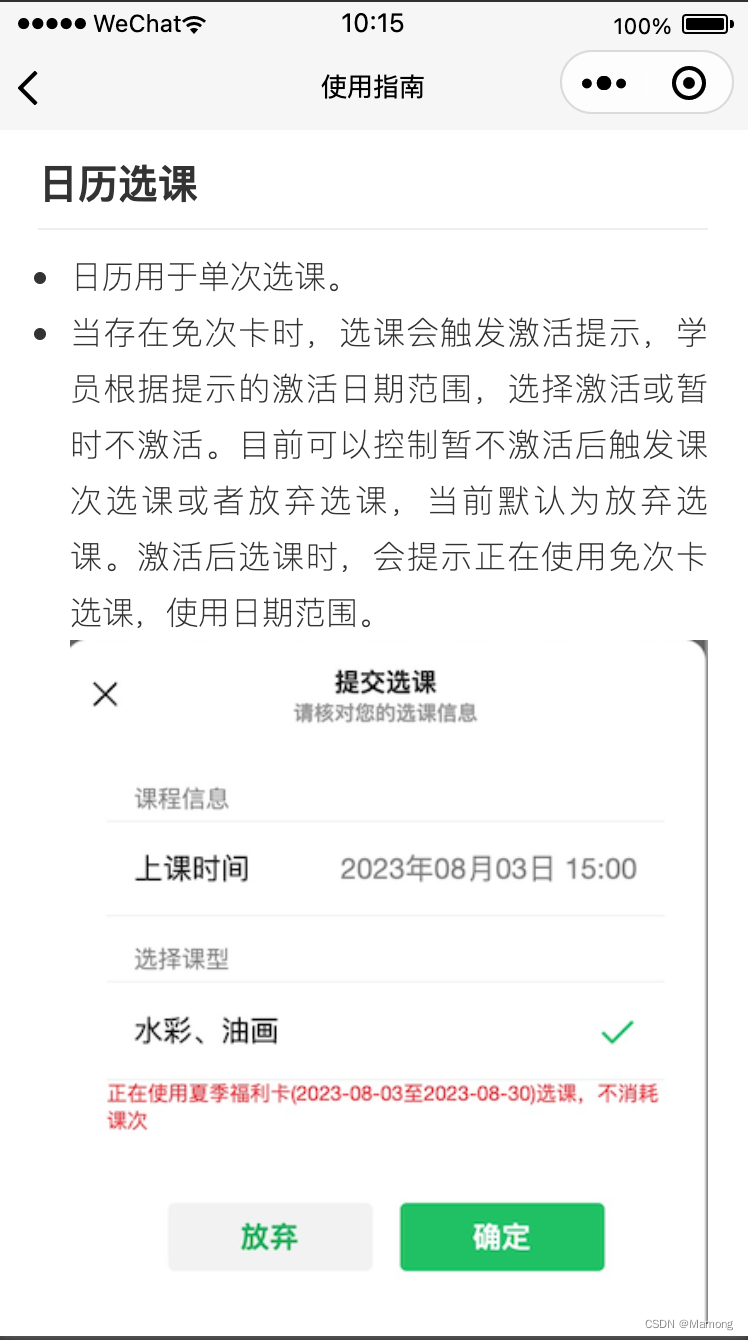
微信小程序使用云存储和Markdown开发页面
最近想在一个小程序里加入一个使用指南的页面,考虑到数据存储和减少页面的开发工作量,决定尝试在云存储里上传Markdown文件,微信小程序端负责解析和渲染。小程序端使用到一个库Towxml。 Towxml Towxml是一个可将HTML、Markdown转为微信小程…...
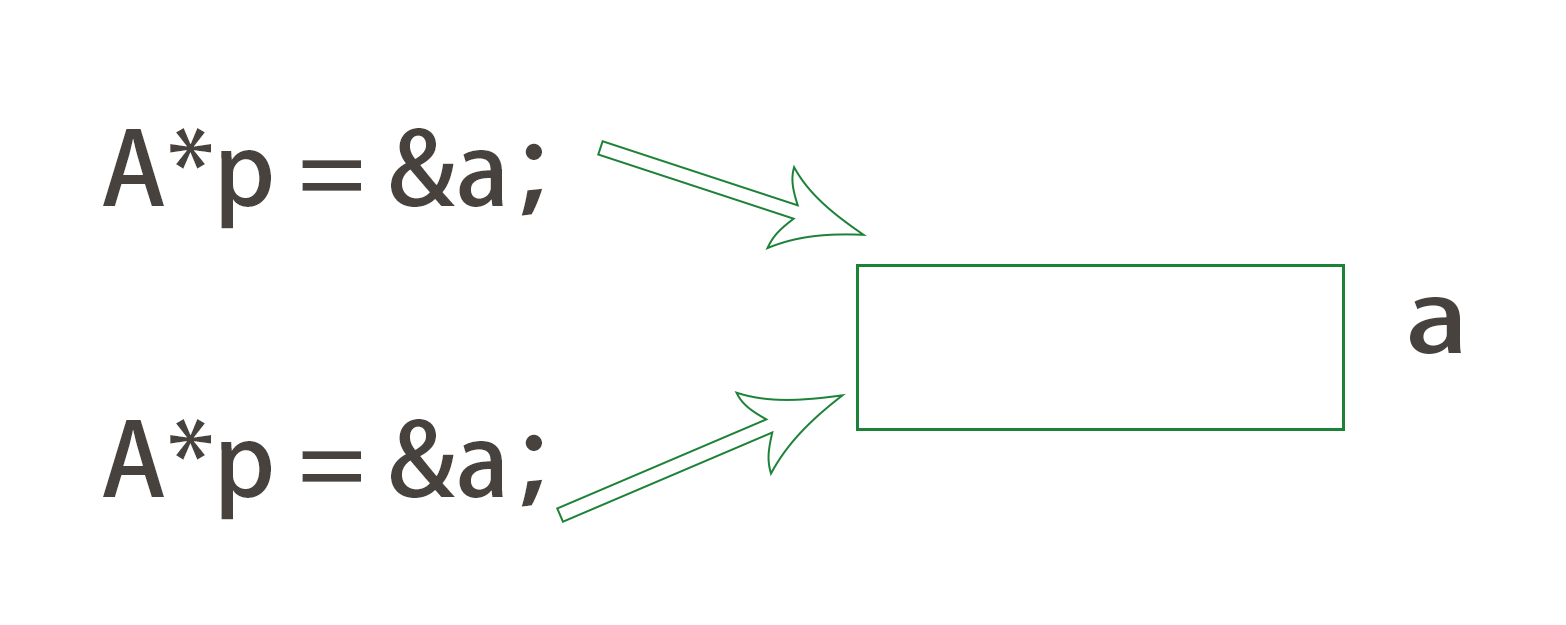
【C++】运算符重载 | 赋值运算符重载
Ⅰ. 运算符重载 引入 ❓什么叫运算符重载? 就是:运用函数,将现有的运算符重新定义,使其能满足各种自定义类型的运算。 回想一下,我们以前运算的对象是不是都是int、char这种内置类型? 那我们自定义的“…...
Python学习 -- 类对象从创建到常用函数
在Python编程中,类是一种强大的工具,用于创建具有共同属性和行为的对象。本篇博客将详细介绍Python中类和对象的创建,类的属性和方法,以及一些常用的类函数,通过丰富的代码例子来帮助读者深入理解。 一、类和对象的创…...
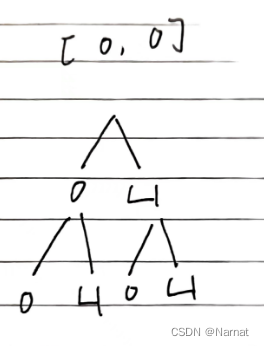
数组分割(2023省蓝桥杯)n种讨论 JAVA
目录 1、题目描述:2、前言:3、动态规划(bug):3、递归 剪枝(超时):4、数学(正解): 1、题目描述: 小蓝有一个长度为 N 的数组 A [A0, A1,…, AN−…...
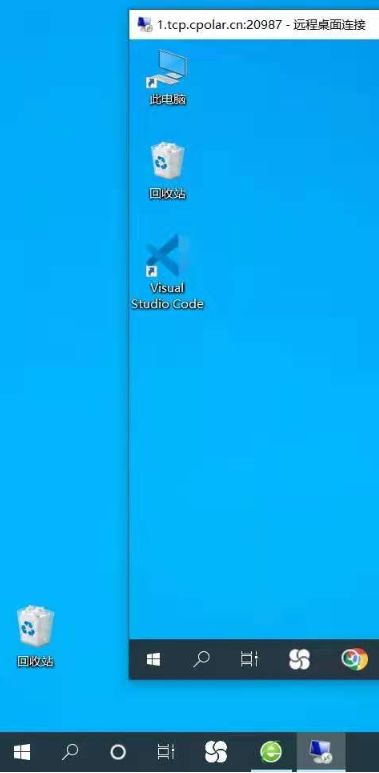
很好的启用window10专业版系统自带的远程桌面
启用window10专业版系统自带的远程桌面 文章目录 启用window10专业版系统自带的远程桌面前言1.找到远程桌面的开关2. 找到“应用”项目3. 打开需要远程操作的电脑远程桌面功能 总结 前言 Windows操作系统作为应用最广泛的个人电脑操作系统,在我们身边几乎随处可见。…...

TCP定制协议,序列化和反序列化
目录 前言 1.理解协议 2.网络版本计算器 2.1设计思路 2.2接口设计 2.3代码实现: 2.4编译测试 总结 前言 在之前的文章中,我们说TCP是面向字节流的,但是可能对于面向字节流这个概念,其实并不理解的,今天我们要介…...

YOLOX在启智AI GPU/CPU平台部署笔记
文章目录 1. 概述2. 部署2.1 拉取YOLOX源码2.2 拉取模型文件yolox_s.pth2.3 安装依赖包2.4 安装yolox2.5 测试运行2.6 运行报错处理2.6.1 ImportError: libGL.so.1: cannot open shared object file: No such file or directory2.6.2 ImportError: libgthread-2.0.so.0: cannot…...

23种设计模式攻关
👍一、创建者模式 🔖1.1、单例模式 单例模式(Singleton Pattern),用于确保一个类只有一个实例,并提供全局访问点。 在某些情况下,我们需要确保一个类只能有一个实例,比如数据库连接…...
【jsthreeJS】入门three,并实现3D汽车展示厅,附带全码
首先放个最终效果图: 三维(3D)概念: 三维(3D)是一个描述物体在三个空间坐标轴上的位置和形态的概念。相比于二维(2D)只有长度和宽度的平面,三维增加了高度或深度这一维度…...

unity将结构体/列表与json字符串相互转化
编写Unity程序时,面对大量需要传输或者保存的数据时,为了避免编写重复的代码,故采用NewtonJson插件来将定义好的结构体以及列表等转为json字符串来进行保存和传输。 具体代码如下: using System; using System.IO; using Newtons…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...