GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM
一、前言
想要轻松快速地使用您自己的数据微调和培训大型语言模型(LLM)?我们知道训练大型语言模型具有挑战性并需要耗费大量计算资源,包括收集和优化数据集、确定合适的模型及编写训练代码等。今天我们将介绍一种实验性新方法,实现特定任务高性能模型的训练。
我们的目标是最大程度地简化模型微调训练过程,使您能够在最短时间内从构思转化为高性能的完全训练的模型。以微调开源模型LLaMa 2为例,整个过程只需提供任务描述,系统便会为您生成数据集、解析成正确的数据格式并微调 LLaMA 2 模型。轻松实现快速的微调和推理过程!
二、GPT-LLM-Trainer 介绍
GPT-LLM-Trainer 是一种全新、经济实惠且最简单的方法来训练大型语言模型。这个项目旨在探索一种新的训练高性能任务专用模型的流程,摆脱所有复杂的步骤,使你更容易从一个想法转变为完全训练好的模型。你只需输入任务描述,系统就会从头开始生成数据集,将其转换为你想要的任何格式,并为你进行模型微调。你可以在Google Colab上轻松的训练大型语言模型。GPT-LLM-Trainer 模型训练器利用 GPT-4 模型来简化整个过程,包括以下三个关键阶段:
- 数据生成阶段:利用 GPT-4 模型根据提供的输入用例生成多样化的提示和响应数据。
- 系统消息生成:通过为模型的交互设计最佳系统提示。
- 微调模型过程:生成数据集后,系统会自动将其拆分为训练集和验证集,为您微调模型,并为推理做好准备。
GPT大型语言模型训练器的主要优势在于它可以摆脱复杂的步骤,让用户更容易地从一个想法转变为完全训练好的模型。你只需输入任务描述,系统就会从头开始生成数据集,将其转换为你想要的任何格式,并为你进行模型微调。在这种情况下,你将使用LLaMa 2进行微调。
三、如何使用自己的数据微调LLM
这里主要介绍如何在Google Colab上训练LLaMA 2大型语言模型的实现步骤。首先,我们需要收集和整理数据集,将其格式化并选择合适的模型。接下来,我们需要编写训练代码,并将所有这些整合在一起进行训练。这个过程可能会遇到很多困难和挑战,但是通过使用GPT大型语言模型训练器,我们可以大大简化这个过程。
3.1、描述你的模型
我们通过尝试一种新的方法,可以轻松地根据你输入的任务描述来构建特定任务的模型。首先,尽可能的使用GPU,可以在Google Colab中设置可用的 GPU,然后创建模型,只需要在提示中描述您想要构建的模型。 具有描述性且清晰。你可以通过更改 Hyperparameters 单元格中的 model_name 来更改要微调的模型。
3.2、数据生成步骤
在这里写下您的prompt提示。 描述性越强、越清晰越好!
然后,选择生成数据时使用的temperature(0 到 1 之间)。 较低的值非常适合精确的任务,例如编写代码,而较大的值更适合创造性的任务,例如编写故事。
最后,选择您想要生成的示例数量。 生成的数据越多,a) 花费的时间就越长,b) 数据生成的成本就越高。 但一般来说,更多的例子会产生更高质量的模型。 100 通常是最低启动值。
prompt = "一个能够接收中文中类似猜灯谜的问题,并用经过深思熟虑、逐步推理的方式以中文回答的模型。"
temperature = .4
number_of_examples = 100先安装OpenAI依赖。
!pip install openai一旦你确定了提示,就可以执行下面的代码生成数据集。这可能需要比预期更长的时间。
import os
import openai
import randomopenai.api_key = "YOUR KEY HERE"def generate_example(prompt, prev_examples, temperature=.5):messages=[{"role": "system","content": f"您正在生成将用于训练机器学习模型的数据。\n\n您将获得我们想要训练的模型的高级描述,并由此生成数据样本,每个样本都有一个提示/ 响应对。\n\n您将按照以下格式执行此操作:\n````\nprompt\n------------\n$prompt_goes_here\n---------- -\n\nresponse\n-----------\n$response_goes_here\n------------\n```\n\n只能有一对提示/响应 每轮都会生成。\n\n对于每一轮,使示例比上一轮稍微复杂一点,同时确保多样性。\n\n确保您的样本是独特且多样化的,但高质量和复杂性足以训练一个良好的样本 执行模型。\n\n这是我们要训练的模型类型:\n`{prompt}`"}]if len(prev_examples) > 0:if len(prev_examples) > 10:prev_examples = random.sample(prev_examples, 10)for example in prev_examples:messages.append({"role": "assistant","content": example})response = openai.ChatCompletion.create(model="gpt-4",messages=messages,temperature=temperature,max_tokens=1354,)return response.choices[0].message['content']# Generate examples
prev_examples = []
for i in range(number_of_examples):print(f'Generating example {i}')example = generate_example(prompt, prev_examples, temperature)prev_examples.append(example)print(prev_examples)生成完数据集,我们还需要生成系统消息。
def generate_system_message(prompt):response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "system","content": "您将获得我们正在训练的模型的高级描述,并据此生成一个简单的系统提示以供该模型使用。 请记住,您不是生成用于数据生成的系统消息 - 您正在生成用于推理的系统消息。 一个好的格式是“给定 $INPUT_DATA,您将 $WHAT_THE_MODEL_SHOULD_DO。”。\n\n使其尽可能简洁。 在响应中只包含系统提示符。\n\n例如,切勿编写:`\"$SYSTEM_PROMPT_HERE\"`。\n\n应该类似于:`$SYSTEM_PROMPT_HERE`。"},{"role": "user","content": prompt.strip(),}],temperature=temperature,max_tokens=500,)return response.choices[0].message['content']system_message = generate_system_message(prompt)print(f'系统消息: `{system_message}`。 如果您想要更好的结果,请随意重新运行此单元格。')接下来,我们将示例放入数据框中,并将它们转换为最终的数据集对。
import pandas as pd# 初始化列表以存储提示和响应
prompts = []
responses = []# 从示例中解析出提示和响应
for example in prev_examples:try:split_example = example.split('-----------')prompts.append(split_example[1].strip())responses.append(split_example[3].strip())except:pass# 创建数据框
df = pd.DataFrame({'prompt': prompts,'response': responses
})# 删除重复项
df = df.drop_duplicates()print('有 ' + str(len(df)) + ' 成功生成的示例。 以下是前几个:')df.head()将数据分为训练集和测试集。
# 将数据分为训练集和测试集,其中 90% 在训练集中
train_df = df.sample(frac=0.9, random_state=42)
test_df = df.drop(train_df.index)# 将数据帧保存到 .jsonl 文件
train_df.to_json('train.jsonl', orient='records', lines=True)
test_df.to_json('test.jsonl', orient='records', lines=True)3.3、安装必要的库
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7import os
import torch
from datasets import load_dataset
from transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,HfArgumentParser,TrainingArguments,pipeline,logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer3.4、定义超参数
model_name = "NousResearch/llama-2-7b-chat-hf" # 如果您有权访问官方 LLaMA 2 模型“meta-llama/Llama-2-7b-chat-hf”,请使用此选项,但请记住,您需要传递 Hugging Face 键参数
dataset_name = "/content/train.jsonl"
new_model = "llama-2-7b-custom"
lora_r = 64
lora_alpha = 16
lora_dropout = 0.1
use_4bit = True
bnb_4bit_compute_dtype = "float16"
bnb_4bit_quant_type = "nf4"
use_nested_quant = False
output_dir = "./results"
num_train_epochs = 1
fp16 = False
bf16 = False
per_device_train_batch_size = 4
per_device_eval_batch_size = 4
gradient_accumulation_steps = 1
gradient_checkpointing = True
max_grad_norm = 0.3
learning_rate = 2e-4
weight_decay = 0.001
optim = "paged_adamw_32bit"
lr_scheduler_type = "constant"
max_steps = -1
warmup_ratio = 0.03
group_by_length = True
save_steps = 25
logging_steps = 5
max_seq_length = None
packing = False
device_map = {"": 0}3.5、加载数据集并训练
# 加载数据集
train_dataset = load_dataset('json', data_files='/content/train.jsonl', split="train")
valid_dataset = load_dataset('json', data_files='/content/test.jsonl', split="train")# 预处理数据集
train_dataset_mapped = train_dataset.map(lambda examples: {'text': [f'[INST] <<SYS>>\n{system_message.strip()}\n<</SYS>>\n\n' + prompt + ' [/INST] ' + response for prompt, response in zip(examples['prompt'], examples['response'])]}, batched=True)
valid_dataset_mapped = valid_dataset.map(lambda examples: {'text': [f'[INST] <<SYS>>\n{system_message.strip()}\n<</SYS>>\n\n' + prompt + ' [/INST] ' + response for prompt, response in zip(examples['prompt'], examples['response'])]}, batched=True)compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_config = BitsAndBytesConfig(load_in_4bit=use_4bit,bnb_4bit_quant_type=bnb_4bit_quant_type,bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=use_nested_quant,
)
model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config,device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
peft_config = LoraConfig(lora_alpha=lora_alpha,lora_dropout=lora_dropout,r=lora_r,bias="none",task_type="CAUSAL_LM",
)
# 设置训练参数
training_arguments = TrainingArguments(output_dir=output_dir,num_train_epochs=num_train_epochs,per_device_train_batch_size=per_device_train_batch_size,gradient_accumulation_steps=gradient_accumulation_steps,optim=optim,save_steps=save_steps,logging_steps=logging_steps,learning_rate=learning_rate,weight_decay=weight_decay,fp16=fp16,bf16=bf16,max_grad_norm=max_grad_norm,max_steps=max_steps,warmup_ratio=warmup_ratio,group_by_length=group_by_length,lr_scheduler_type=lr_scheduler_type,report_to="all",evaluation_strategy="steps",eval_steps=5 # 每 20 步评估一次
)
# 设置监督微调参数
trainer = SFTTrainer(model=model,train_dataset=train_dataset_mapped,eval_dataset=valid_dataset_mapped, # 在此处传递验证数据集peft_config=peft_config,dataset_text_field="text",max_seq_length=max_seq_length,tokenizer=tokenizer,args=training_arguments,packing=packing,
)
trainer.train()
trainer.model.save_pretrained(new_model)# 单元 4:测试模型
logging.set_verbosity(logging.CRITICAL)
prompt = f"[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n编写一个反转字符串的函数。 [/INST]" # 将此处的命令替换为与您的任务相关的命令
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(prompt)
print(result[0]['generated_text'])3.6、运行推理
from transformers import pipelineprompt = f"[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n编写一个反转字符串的函数。 [/INST]" # 将此处的命令替换为与您的任务相关的命令
num_new_tokens = 100 # 更改为您想要生成的新令牌的数量# 计算提示中的标记数量
num_prompt_tokens = len(tokenizer(prompt)['input_ids'])# 计算一代的最大长度
max_length = num_prompt_tokens + num_new_tokensgen = pipeline('text-generation', model=model, tokenizer=tokenizer, max_length=max_length)
result = gen(prompt)
print(result[0]['generated_text'].replace(prompt, ''))3.7、合并模型并存储在 Google Drive 中
# 合并并保存微调后的模型
from google.colab import drive
drive.mount('/content/drive')model_path = "/content/drive/MyDrive/llama-2-7b-custom" # 更改为您的首选路径# 在 FP16 中重新加载模型并将其与 LoRA 权重合并
base_model = AutoModelForCausalLM.from_pretrained(model_name,low_cpu_mem_usage=True,return_dict=True,torch_dtype=torch.float16,device_map=device_map,
)
model = PeftModel.from_pretrained(base_model, new_model)
model = model.merge_and_unload()# 重新加载分词器以保存它
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"# 保存合并后的模型
model.save_pretrained(model_path)
tokenizer.save_pretrained(model_path)3.8、从 Drive 加载微调模型并运行推理
from google.colab import drive
from transformers import AutoModelForCausalLM, AutoTokenizerdrive.mount('/content/drive')model_path = "/content/drive/MyDrive/llama-2-7b-custom" # 更改为保存模型的路径model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)3.9、测试微调训练后的模型
from transformers import pipelineprompt = "请问,哪个字一年四季都不会凋零?" # 更改为您想要的提示
gen = pipeline('text-generation', model=model, tokenizer=tokenizer)
result = gen(prompt)
print(result[0]['generated_text'])四、总结
本文主要介绍了如何使用GPT大型语言模型训练器来训练你自己的大型语言模型;如何利用GPT-4的强大功能来简化训练过程,并确保你的模型能够实现最佳性能;最后介绍了如何在谷歌Colab上训练大型语言模型的实用技巧和步骤。GPT-LLM-Trainer 是一款经济实惠且易于使用的工具,用于使用您自己的数据训练大型语言模型。它简化了收集、提炼、格式化、选择和训练数据集的复杂过程,并根据您的任务描述为您微调模型。使用此工具,您可以生成各种提示、优化系统提示、拆分数据集、定义超参数以及在 Google Colab 或本地 Jupyter Notebook 上高效运行推理。
五、References
- GPT-LLM-Trainer Github Repo:https://github.com/mshumer/gpt-llm-trainer
- Jupyter Notebook 的完整代码: https://github.com/Crossme0809/frenzyTechAI/blob/main/fine-tuned-llm-trainer/How_to_Fine_Tune_and_Train_LLMs_With_FAST_GPT_LLM_Trainer.ipynb
相关文章:

GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM
一、前言 想要轻松快速地使用您自己的数据微调和培训大型语言模型(LLM)?我们知道训练大型语言模型具有挑战性并需要耗费大量计算资源,包括收集和优化数据集、确定合适的模型及编写训练代码等。今天我们将介绍一种实验性新方法&am…...
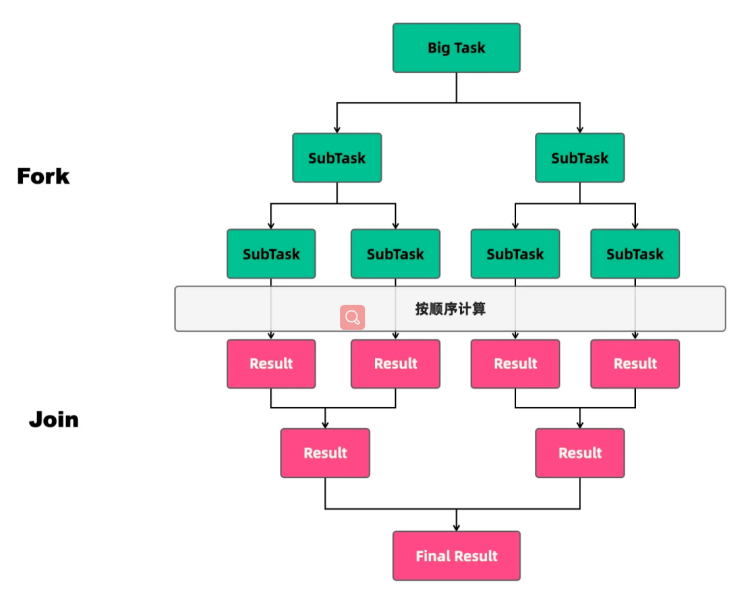
深入理解ForkJoin
任务类型 线程池执行的任务可以分为两种:CPU密集型任务和IO密集型任务。在实际的业务场景中,我们需要根据任务的类型来选择对应的策略,最终达到充分并合理地使用CPU和内存等资源,最大限度地提高程序性能的目的。 CPU密集型任务 …...
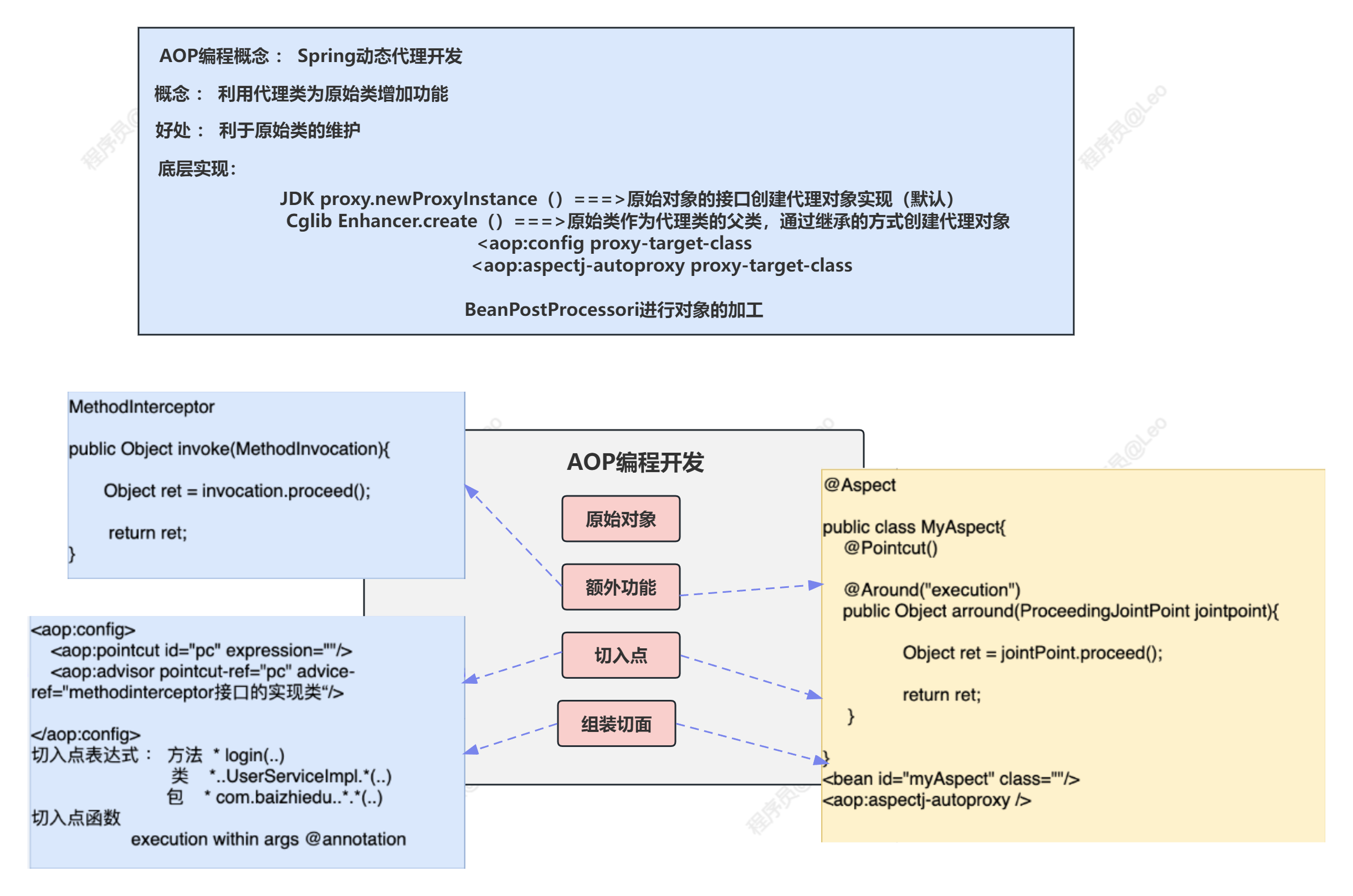
Spring5学习笔记—AOP编程
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: Spring专栏 ✨特色专栏: M…...

适用于 Docker 用户的 kubectl
适用于 Docker 用户的 kubectl 你可以使用 Kubernetes 命令行工具 kubectl 与 API 服务器进行交互。如果你熟悉 Docker 命令行工具, 则使用 kubectl 非常简单。但是,Docker 命令和 kubectl 命令之间有一些区别。以下显示了 Docker 子命令, 并…...

网络安全设备篇——加密机
加密机是一种专门用于数据加密和解密的网络安全设备。它通过使用密码学算法对数据进行加密,从而保护数据的机密性和完整性。加密机通常被用于保护敏感数据,如金融信息、个人身份信息等。 加密机的主要功能包括: 数据加密:加密机使…...

Rust 基础入门 —— 2.3.所有权和借用
Rust 的最主要光芒: 内存安全 。 实现方式: 所有权系统。 写在前面的序言 因为我们这里实际讲述的内容是关于 内存安全的,所以我们最好先复习一下内存的知识。 然后我们,需要理解的就只有所有权概念,以及为了开发便…...

Node.js-Express框架基本使用
Express介绍 Express是基于 node.js 的web应用开发框架,是一个封装好的工具包,便于开发web应用(HTTP服务) Express基本使用 // 1.安装 npm i express // 2.导入 express 模块 const express require("express"); // 3…...
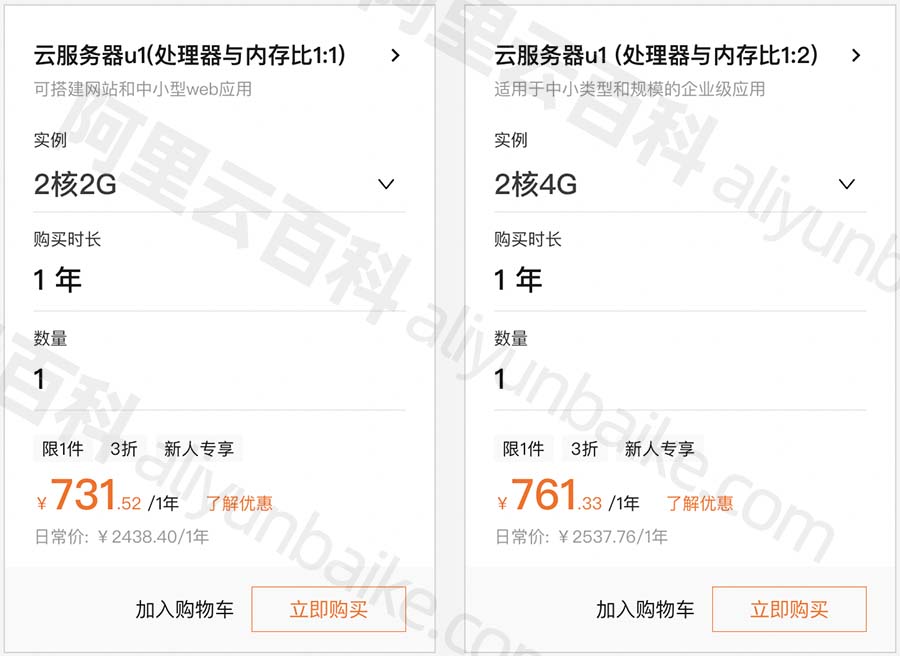
阿里云通用算力型u1云服务器CPU性能详细说明
阿里云服务器u1是通用算力型云服务器,CPU采用2.5 GHz主频的Intel(R) Xeon(R) Platinum处理器,通用算力型u1云服务器不适用于游戏和高频交易等需要极致性能的应用场景及对业务性能一致性有强诉求的应用场景(比如业务HA场景主备机需要性能一致)ÿ…...

设计模式之创建者模式
文章目录 一、介绍二、应用三、案例1. 麦当劳11随心配2. 代码演示3. 演示结果 四、优缺点五、送给读者 一、介绍 建造者模式(Builder Pattern)属于创建型设计模式,很多博客文章的对它的作用解释为用于将复杂对象的创建过程与其细节表示分离。但对于初学者来说&…...
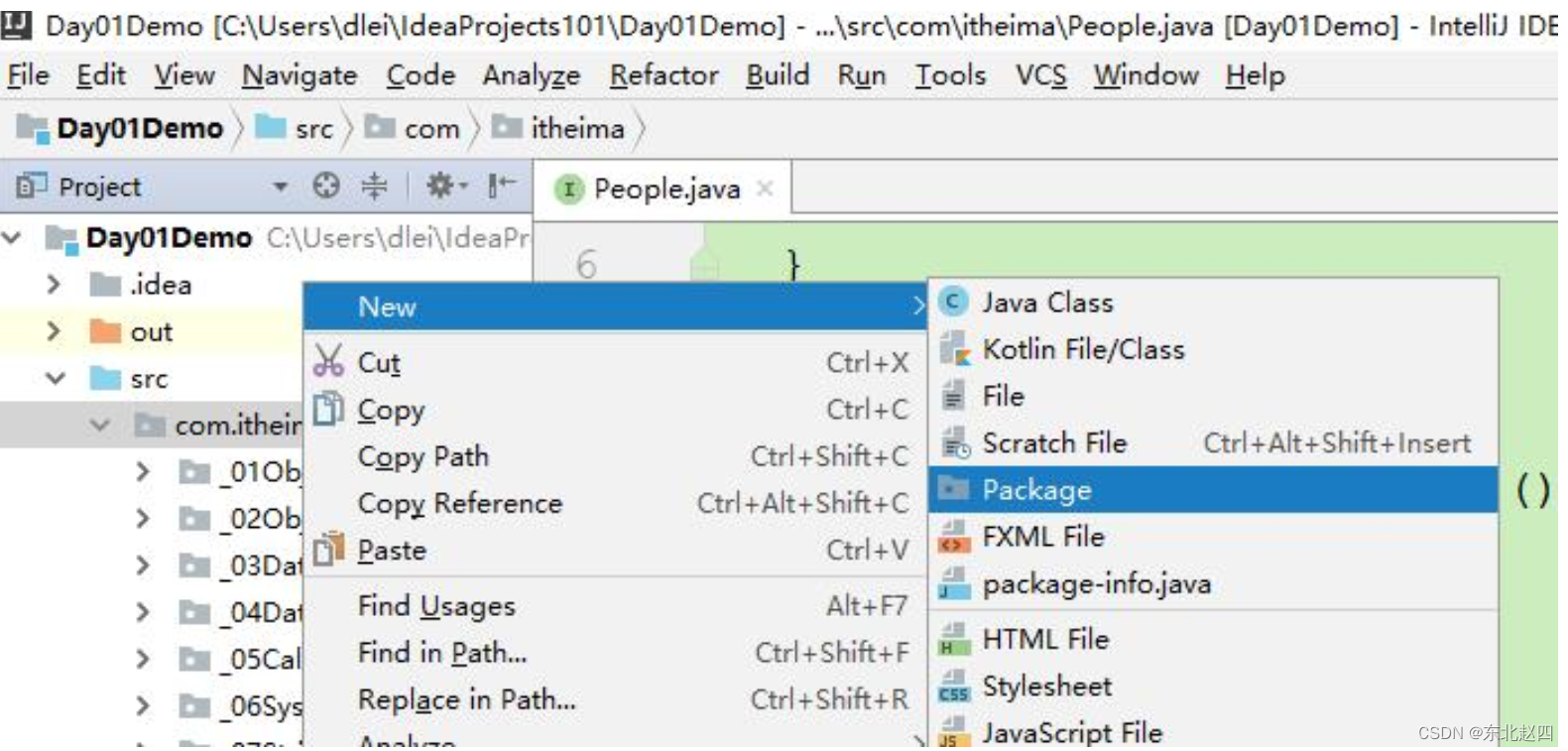
Java之包,权限修饰符,final关键字详解
包 2.1 包 包在操作系统中其实就是一个文件夹。包是用来分门别类的管理技术,不同的技术类放在不同的包下,方便管理和维护。 在IDEA项目中,建包的操作如下: 包名的命名规范: 路径名.路径名.xxx.xxx // 例如ÿ…...

“深入解析JVM:Java虚拟机内部原理揭秘“
标题:深入解析JVM:Java虚拟机内部原理揭秘 摘要:本文将深入探讨Java虚拟机(JVM)的内部原理,包括JVM的架构、运行时数据区域、垃圾回收机制以及即时编译器等重要组成部分。通过对JVM内部原理的解析…...
Mac下Jmeter安装及基本使用
本篇文章只是简单的介绍下Jmeter的下载安装和最基本使用 1、初识Jmeter 前一段时间客户端app自测的过程中,有偶现请求某个接口返回数据为空的问题,领导让我循环100次请求这个接口,看看有没有结果为空的问题。听同事说有Jmeter的专业测试工具…...

云计算与边缘计算:加速数字化转型的关键驱动力
云计算和边缘计算技术正以惊人的速度改变着企业的业务和基础架构。这些先进的技术为企业带来了灵活性、可扩展性和成本效益的优势,重新定义了业务运作的方式。 云计算是通过互联网将计算资源提供给用户的一种服务模式。通过云计算,企业可以将应用程序、…...
TheGem主题 - 创意多用途和高性能WooCommerce WordPress主题/网站
TheGem主题概述 – 适合所有人的TheGem 作为设计元素、样式和功能的终极 Web 构建工具箱而设计和开发,TheGem主题将帮助您在几分钟内构建一个令人印象深刻的高性能网站,而无需触及一行代码。不要在编码上浪费时间,探索你的创造力!…...

Pytorch-day10-模型部署推理-checkpoint
模型部署&推理 模型部署模型推理 我们会将PyTorch训练好的模型转换为ONNX 格式,然后使用ONNX Runtime运行它进行推理 1、ONNX ONNX( Open Neural Network Exchange) 是 Facebook (现Meta) 和微软在2017年共同发布的,用于标准描述计算图的一种格式…...

vue使用websocket
建立websocket.js // 信息提示 import { Message } from element-ui // 引入用户id import { getTenantId, getAccessToken } from /utils/auth// websocket地址 var url ws://192.168.2.20:48081/websocket/message // websocket实例 var ws // 重连定时器实例 var tt // w…...

jmeter入门:接口压力测试全解析
一.对接口压力测试 1.配置 1.添加线程组(参数上文有解释 这里不介绍) 2.添加取样器 不用解释一看就知道填什么。。。 3.添加头信息(否则请求头对不上) 也不用解释。。。 4.配置监听器 可以尝试使用这几个监听器。 2.聚合结果…...

go、java、.net、C#、nodejs、vue、react、python程序问题进群咨询
1、面试辅导 2、程序辅导 3、一对一腾讯会议辅导 3、业务逻辑辅导 4、各种bug帮你解决。 5、培训小白 6、顺利拿到offer...

树莓派4B最新系统Bullseye 64 bit使用xrdp远程桌面黑屏卡顿问题
1、树莓派换源 打开源文件 sudo nano /etc/apt/sources.list注释原来的,更换为清华源 deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main contrib non-free deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main contrib no…...

EasyExcel入门介绍及工具类,网络下载excel
前言:在这里分享自己第一次使用EasyExcel并且编写工具类,且在接口中支持excel文件下载的一系列流程,包含所有前后端(JSJAVA)完整代码,可以根据自己需要自行提取,仅供参考。 一.引入EasyExcel依赖…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...