电商系统架构设计系列(九):如何规划和设计分库分表?
上篇文章中,我给你留了一个思考题:分库分表该如何设计?
今天这篇文章,我们来聊一下如何规划和设计分库分表,以及要考虑哪些问题。
引言
当要解决海量数据的问题,就必须要用到分布式的存储集群了,因为 MySQL 本质上是一个单机数据库,所以很多场景下不是太适合存 TB 级别以上的数据。
但是,绝大部分的电商大厂,它的在线交易这部分的业务,比如说,订单、支付相关的系统,还是舍弃不了 MySQL,原因是,只有 MySQL 这类关系型数据库,才能提供金融级的事务保证。对于分布式事务,那些新的分布式数据库提供的所谓的分布式事务,多少都有点儿残血,目前还达不到这些交易类系统对数据一致性的要求。
那既然 MySQL 支持不了这么大的数据量,这么高的并发,还必须要用它,怎么解决这个问题呢?还是按照我们之前的文章跟你说的思想,分片,也就是拆分数据。1TB 的数据,一个库撑不住,我把它拆成 100 个库,每个库就只有 10GB 的数据了,这不就可以了么?这种拆分就是所谓的 MySQL 分库分表。
不过,思路是这样没错,分库分表实践起来是非常不容易的,有很多问题需要去思考和解决。
如何规划分库分表?
我们以订单表来举例子。首先需要思考的问题是,分库还是分表?分库呢,就是把数据拆分到不同的 MySQL 库中去,分表就是把数据拆分到同一个库的多张表里面。
在考虑到底是分库还是分表之前,我们需要先明确一个原则:
那就是能不拆就不拆,能少拆不多拆。
原因也很简单,你把数据拆分得越散,开发和维护起来就越麻烦,系统出问题的概率就越大。
基于这个原则我们想一下,什么情况下适合分表,什么情况下不得不分库?
那我们分库分表的目的是为了解决两个问题:
- 是数据量太大,查询慢的问题。这里面我们讲的“查询”其实主要是事务中的查询和更新操作,因为只读的查询可以通过缓存和主从分离来解决。解决查询慢,只要减少每次查询的数据总量就可以了,也就是说,分表就可以解决问题。
- 是为了应对高并发的问题。应对高并发的思想,一个数据库实例撑不住,就把并发请求分散到多个实例中去。所以,解决高并发的问题是需要分库的。
简单地说,数据量大,就分表;并发高,就分库。
一般情况下,我们的方案都需要同时做分库分表,这时候分多少个库,多少张表,分别用预估的并发量和数据量来计算就可以了,预估量建议为现有量的5-10倍。
另外,我个人不建议你在方案中考虑二次扩容的问题,也就是考虑未来的数据量,把这次分库分表设计的容量都填满了之后,数据如何再次分裂的问题。
现在技术和业务变化这么快,等真正到了那个时候,业务早就变了,可能新的技术也出来了,你之前设计的二次扩容方案大概率是用不上的,所以没必要为了这个而增加方案的复杂程度。
这里强调一下,越简单的设计可靠性越高。
如何选择 Sharding Key?
分库分表还有一个重要的问题是,选择一个合适的列或者说是属性,作为分表的依据,这个属性一般称为 Sharding Key。像我们上篇文章说到的归档历史订单的方法,它的 Sharding Key 就是订单完成时间。每次查询的时候,查询条件中必须带上这个时间,我们的程序就知道,三个月以前的数据查订单历史表,三个月内的数据查订单表,这就是一个简单的按照时间范围来分片的算法。
选择合适 Sharding Key 和分片算法非常重要,直接影响了分库分表的效果。我们首先来说如何选择 Sharding Key 的问题。
选择这个 Sharding Key 最重要的参考因素是,我们的业务是如何访问数据的。
比如我们把订单 ID 作为 Sharding Key 来拆分订单表,那拆分之后,如果我们按照订单 ID 来查订单,就需要先根据订单 ID 和分片算法计算出,我要查的这个订单它在哪个分片上,也就是哪个库哪张表中,然后再去那个分片执行查询就可以了。
但是,当我打开“我的订单”这个页面的时候,它的查询条件是用户 ID,这里没有订单 ID,那就没法知道我们要查的订单在哪个分片上,就没法查了。当然你要强行查的话,那就只能把所有分片都查一遍,再合并查询结果,这个就很麻烦,而且性能很差,还不能分页。
那要是把用户 ID 作为 Sharding Key 呢?也会面临同样的问题,使用订单 ID 作为查询条件来查订单的时候,就没办法找到订单在哪个分片了。这个问题的解决办法是,在生成订单 ID 的时候,把用户 ID 的后几位作为订单 ID 的一部分,比如说,可以规定,18 位订单号中,第 10-14 位是用户 ID 的后四位,这样按订单 ID 查询的时候,就可以根据订单 ID 中的用户 ID 找到分片。
那我们系统对订单的查询方式,肯定不只是按订单 ID 或者按用户 ID 这两种啊。比如说,商家希望看到的是自己店铺的订单,还有各种和订单相关的报表。对于这些查询需求,我们一旦对订单做了分库分表,就没法解决了。那怎么办呢?
一般的做法是,把订单数据同步到其他的存储系统中去,在其他的存储系统里面解决问题。比如说,我们可以再构建一个以店铺 ID 作为 Sharding Key 的只读订单库,专门供商家来使用。或者,把订单数据同步到 HDFS 中,然后用一些大数据技术来生成订单相关的报表。
所以你看,一旦做了分库分表,就会极大地限制数据库的查询能力,之前很简单的查询,分库分表之后,可能就没法实现了。
你要记得一句话:分库分表一定是,数据量和并发大到所有招数都不好使了(比如缓存),我们才拿出来的最后一招。
如何选择分片算法?
举个例子,我们能不能用订单完成时间作为 Sharding Key 呢?比如说,我分 12 个分片,每个月一个分片,这样对查询的兼容要好很多,毕竟查询条件中带上时间范围,让查询只落到某一个分片上,还是比较容易的,我在查询界面上强制用户必须指定时间范围就行了。
这种做法有个很大的问题,比如现在是 3 月份,那基本上所有的查询都集中在 3 月份这个分片上,其他 11 个分片都闲着,这样不仅浪费资源,很可能你 3 月那个分片根本抗不住几乎全部的并发请求。这个问题就是“热点问题”。
也就是说,我们希望并发请求和数据能均匀地分布到每一个分片上,尽量避免出现热点。这是选择分片算法时需要考虑的一个重要的因素。一般常用的分片算法就那么几种,刚刚讲到的按照时间范围分片的方法是其中的一种。
基于范围来分片容易产生热点问题,不适合作为订单的分片方法,但是这种分片方法的优点也很突出,那就是对查询非常友好,基本上只要加上一个时间范围的查询条件,原来该怎么查,分片之后还可以怎么查。范围分片特别适合那种数据量非常大,但并发访问量不大的 ToB 系统。比如说,电信运营商的监控系统,它可能要采集所有人手机的信号质量,然后做一些分析,这个数据量非常大,但是这个系统的使用者是运营商的工作人员,并发量很少。这种情况下就很适合范围分片。
一般来说,订单表都采用更均匀的哈希分片算法。比如说,我们要分 24 个分片,选定了 Sharding Key 是用户 ID,那我们决定某个用户的订单应该落到那个分片上的算法是,拿用户 ID 除以 24,得到的余数就是分片号。这是最简单的取模算法,一般就可以满足大部分要求了。当然也有一些更复杂的哈希算法,像一致性哈希之类的,特殊情况下也可以使用。
需要注意的一点是,哈希分片算法能够分得足够均匀的前提条件是,用户 ID 后几位数字必须是均匀分布的。比如说,你在生成用户 ID 的时候,自定义了一个用户 ID 的规则,最后一位 0 是男性,1 是女性,这样的用户 ID 哈希出来可能就没那么均匀,可能会出现热点。
还有一种分片的方法:查表法。查表法其实就是没有分片算法,决定某个 Sharding Key 落在哪个分片上,全靠人为来分配,分配的结果记录在一张表里面。每次执行查询的时候,先去表里查一下要找的数据在哪个分片中。
查表法的好处就是灵活,怎么分都可以,你用上面两种分片算法都没法分均匀的情况下,就可以用查表法,人为地来把数据分均匀了。查表法还有一个特好的地方是,它的分片是可以随时改变的。比如我发现某个分片已经是热点了,那我可以把这个分片再拆成几个分片,或者把这个分片的数据移到其他分片中去,然后修改一下分片映射表,就可以在线完成数据拆分了。
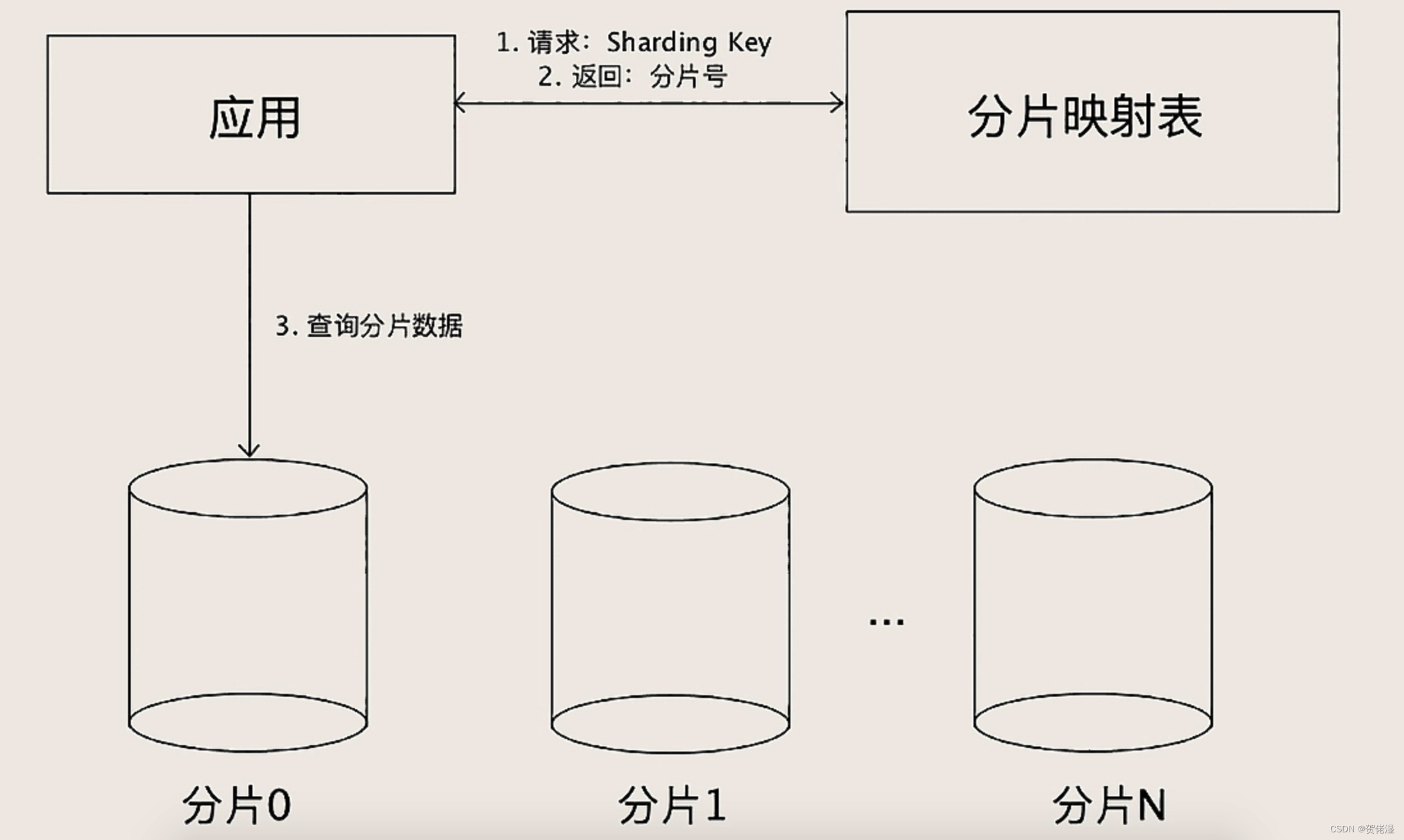
但你需要注意的是,分片映射表本身的数据不能太多,否则这个表反而成为热点和性能瓶颈了。查表法相对其他两种分片算法来说,缺点是需要二次查询,实现起来更复杂,性能上也稍微慢一些。但是,分片映射表可以通过缓存来加速查询,实际性能并不会慢很多。
总结
对 MySQL 这样的单机数据库来说,分库分表是应对海量数据和高并发的最后一招,分库分表之后,将会对数据查询有非常大的限制。
分多少个库需要用并发量来预估,分多少表需要用数据量来预估。选择 Sharding Key 的时候,一定要能兼容业务最常用的查询条件,让查询尽量落在一个分片中,分片之后无法兼容的查询,可以把数据同步到其他存储中去,来解决这个问题。
我们常用三种分片算法,范围分片容易产生热点问题,但对查询更友好,适合并发量不大的场景;哈希分片比较容易把数据和查询均匀地分布到所有分片中;查表法更灵活,但性能稍差。
对于订单表进行分库分表,一般按照用户 ID 作为 Sharding Key,采用哈希分片算法来均匀分布用户订单数据。为了能支持按订单号查询的需求,需要把用户 ID 的后几位放到订单号中去。
最后,还需要强调一下,我们所提到的这些分片相关的知识,不仅仅适用于 MySQL 的分库分表,你在使用其他分布式数据库的时候,一样会遇到如何分片、如何选择 Sharding Key 和分片算法的问题,它们的原理都是一样的,所以我们说的这些方法也都是通用的。
感谢阅读,如果你觉得这篇文章对你有一些启发,也欢迎把它分享给你的朋友。
思考题
怎么能避免写出慢SQL?
期待、欢迎你留言或在线联系,与我一起讨论交流,“一起学习,一起成长”。
上一篇文章
电商系统架构设计系列(八):订单数据越来越多,数据库越来越慢该怎么办?
推荐阅读
- 【架构】高可用高并发系统设计原则
- 【总结】互联网技术架构中常用的分库分表方案汇总
- 技术破局,业绩狂飙十倍:亿级电商平台重构大揭秘
- 当我们聊高并发时,到底是在聊什么?如何真正地掌握高并发设计能力?
- 微服务架构实战 - 我的经验分享总结2019(系统架构师)架构演进过程-从信息流架构到电商中台架构
系列分享
- Elasticsearch教程
- 微服务架构实战
- 架构思维成长系列
- 电商系统架构设计系列
------------------------------------------------------
------------------------------------------------------
我的CSDN主页
关于我(个人域名,更多我的信息)
我的开源项目集Github
期望和大家 一起学习,一起成长,共勉,O(∩_∩)O谢谢
如果你有任何建议,或想学习的知识,可与我一起讨论交流
欢迎交流问题,可加个人QQ 469580884,
或者,加我的群号 751925591,一起探讨交流问题
不讲虚的,只做实干家
Talk is cheap,show me the code
相关文章:
电商系统架构设计系列(九):如何规划和设计分库分表?
上篇文章中,我给你留了一个思考题:分库分表该如何设计? 今天这篇文章,我们来聊一下如何规划和设计分库分表,以及要考虑哪些问题。 引言 当要解决海量数据的问题,就必须要用到分布式的存储集群了ÿ…...

从Web 2.0到Web 3.0,互联网有哪些变革?
文章目录 Web 2.0时代:用户参与和社交互动Web 3.0时代:语义化和智能化影响和展望 🎉欢迎来到Java学习路线专栏~从Web 2.0到Web 3.0,互联网有哪些变革? ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页&#x…...
QT中资源文件resourcefile的使用,使用API完成页面布局
QT中资源文件resourcefile的使用 之前添加图标的方法使用资源文件的方法创建资源文件资源文件添加前缀资源文件添加资源使用资源文件中的资源 使用API完成布局使用QHBoxLayout完成水平布局使用QVBoxLayout完成垂直布局使用QGridLayout完成网格布局 在Qt中引入资源文件好处在于他…...

2337. 移动片段得到字符串
题目描述: 给你两个字符串 start 和 target ,长度均为 n 。每个字符串 仅 由字符 ‘L’、‘R’ 和 ‘_’ 组成,其中: 字符 ‘L’ 和 ‘R’ 表示片段,其中片段 ‘L’ 只有在其左侧直接存在一个 空位 时才能向 左 移动&a…...

Java并发编程第5讲——volatile关键字(万字详解)
volatile关键字大家并不陌生,尤其是在面试的时候,它被称为“轻量级的synchronized”。但是它并不容易完全被正确的理解,以至于很多程序员都不习惯去用它,处理并发问题的时候一律使用“万能”的sychronized来解决,然而如…...

6.小程序api分类
事件监听 以on开头,监听某个事件触发,例如:wx.WindowResize事件 同步 以Sync结尾的是同步,可以通过函数返回值直接获取,例如:wx.setStorageSync 异步 需要通过函数接收调用结果,例如&#…...
什么是PPS和TOD时序?授时防护设备是什么?
介绍 PPS和TOD PPS和TOD是两种用于精确时间同步的技术,它们在许多领域都有广泛的应用,总的来说,PPS和TOD被广泛应用于各种需要高度精确时间同步的领域,包括通信、测量、测试、系统集成和计算机网络等。 一、PPS PPS(…...
推荐一款好用的开源视频播放器(免费无广告)
mpv是一个自由开源的媒体播放器,它支持多种音频和视频格式,并且具有高度可定制性。mpv的设计理念是简洁、高效和功能强大。 软件特点: 1. 开源、跨平台。可以在Windows\Linux\MacOS\BSD等系统上使用,完全免费无广告。Windows版解压…...
STM32 CubeMX (第三步Freertos中断管理和软件定时)
STM32 CubeMX STM32 CubeMX (第三步Freertos中断管理和软件定时) STM32 CubeMX一、STM32 CubeMX设置时钟配置HAL时基选择TIM1(不要选择滴答定时器;滴答定时器留给OS系统做时基)使用STM32 CubeMX 库,配置Fre…...

Java虚拟机(JVM):堆溢出
一、概念 Java堆溢出(Java Heap Overflow)是指在Java程序中,当创建对象时,无法分配足够的内存空间来存储对象,导致堆内存溢出的情况。 Java堆是Java虚拟机中用于存储对象的一块内存区域。当程序创建对象时,…...
C语言,Linux,静态库编写方法,makefile与shell脚本的关系。
静态库编写: 编写.o文件gcc -c(小写) seqlist.c(需要和头文件、main.c文件在同一文件目录下) libs.a->去掉lib与.a剩下的为库的名称‘s’。 -ls是指库名为s。 -L库的路径。 makefile文件编写: CFLAGS-Wall -O2 -g -I ./inc/ LDFLAGS-L./lib/ -l…...
Php“牵手”淘宝商品详情页数据采集方法,淘宝API接口申请指南
淘宝天猫详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用。 一、…...

如何使用CSS实现一个全屏滚动效果(Fullpage Scroll)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 实现全屏滚动效果的CSS和JavaScript示例⭐ HTML 结构⭐ CSS 样式 (styles.css)⭐ JavaScript 代码 (script.js)⭐ 实现说明⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦…...
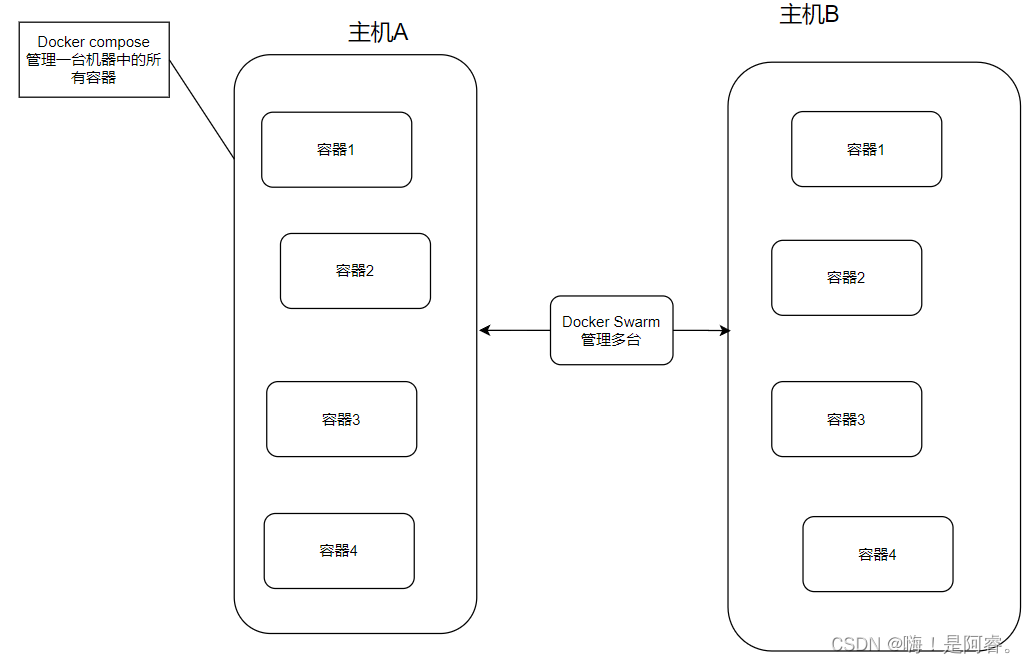
Docker之Compose
目录 前言 1.1Docker Swarm与Docker Compose 1.1.1Docker Swarm 1.1.2Docker Compose 1.1.2.1 三层容器 编辑 二、YAML 2.1YAML概述 2.2注意事项 2.3Docker Compose 环境安装 2.3.1下载 三、Docker-Compose配置常用字段 四、Docker-compose常用命令 五、Docker…...
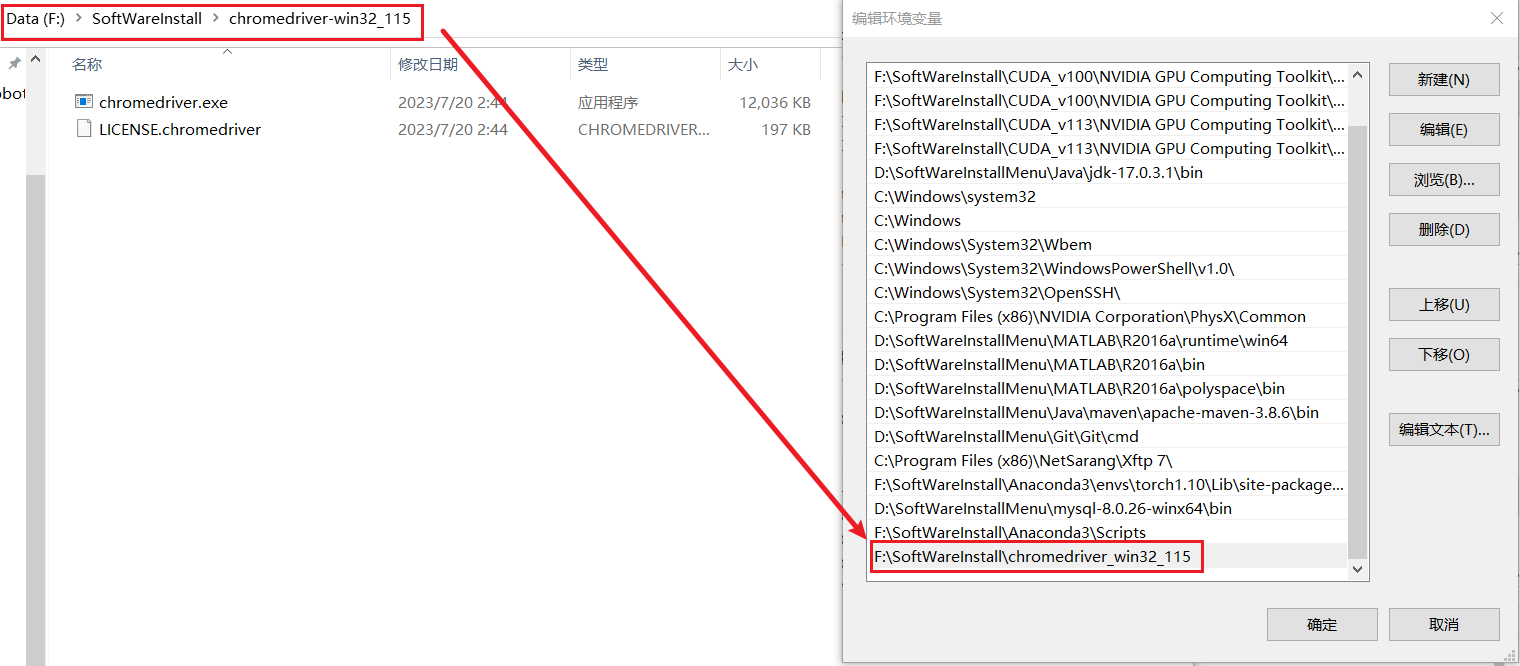
安装chromedriver 115,对应chrome版本115(经检验,116也可以使用)
目录 1. 查看Chrome浏览器的版本2. 找到对应的chromedriver3. 安装ChromeDriver 1. 查看Chrome浏览器的版本 点进这个网站查看:chrome://settings/help (真是的,上一秒还是115版本,更新后就是116版本了,好在chromedi…...

排序算法:插入排序
插入排序的思想非常简单,生活中有一个很常见的场景:在打扑克牌时,我们一边抓牌一边给扑克牌排序,每次摸一张牌,就将它插入手上已有的牌中合适的位置,逐渐完成整个排序。 插入排序有两种写法: 交…...

掌握AI助手的魔法工具:解密Prompt(提示)在AIGC时代的应用「上篇」
在当今的AIGC时代,我们面临着越来越多的人工智能技术和应用。其中一个引人注目的工具就是Prompt(提示)。它就像是一种魔法,可以让我们与AI助手进行更加互动和有针对性的对话。那么,让我们一起来了解一下Prompt…...

JMeter - 接口压力测试工具简单使用
【启动前配置】 启动JMeter前可以先配置语言和编码: 修改:E:\JMeter\apache-jmeter-5.5\bin\jmeter.properties文件中: 1.language=en # 指定语言 language=zh_CN 2.sampleresult.default.encoding=ISO-8859-1 # 指定编码 UTF-8 sampleresult.default.encoding=UTF-8 也…...

【C++入门到精通】C++入门 —— priority_queue(STL)优先队列
阅读导航 前言一、priority_queue简介1. 概念2. 特点 二、priority_queue使用1. 基本操作2. 底层结构 三、priority_queue模拟实现⭕ C代码⭕priority_queue中的仿函数 总结温馨提示 前言 ⭕文章绑定了VS平台下std::priority_queue的源码,大家可以下载了解一下&…...
静态代码扫描工具 Sonar 配置及使用
概览 Sonar 是一个用于代码质量管理的开放平台。通过插件机制,Sonar 可以集成不同的测试工具,代码分析工具,以及持续集成工具。与持续集成工具(例如 Hudson/Jenkins 等)不同,Sonar 并不是简单地把不同的代…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...