ChatGLM-6B微调记录
目录
- GLM-130B和ChatGLM-6B
- ChatGLM-6B直接部署
- 基于PEFT的LoRA微调ChatGLM-6B
GLM-130B和ChatGLM-6B
对于三类主要预训练框架:
- autoregressive(无条件生成),GPT的训练目标是从左到右的文本生成。
- autoencoding(语言理解,比如BERT、ALBERT、RoBERTa、DeBERTa),encoder-decoder(有条件生成)。其训练目标是对文本进行随机掩码,然后预测被掩码的词。
- 基于encoder-decoder的T5,编码器中的注意力是双向的,解码器中的注意力是单向的,可同时应⽤于⾃然语⾔理解任务和⽣成任务,但T5为了达到和RoBERTa和DeBERTa相似的性能,往往需要更多的参数量。T5的训练目标是接受一段文本,从左到右生成另一段文本。
为了统一,GLM在结构和训练目标上兼容三种预训练模型。在结构上,通过attention mask实现同时存在单向注意力和双向注意力:

当attention mask是全1矩阵的时候,这时的注意力是双向的,当attention mask是三角矩阵时,比如上图,注意力就变成单向。因此,GLM可以在只使⽤Transformer编码器的情况下,⾃定义attention mask来兼容三种模型结构。具体回顾 LLM中的微调演变与LLM架构类型-LLM的架构分类。
训练时,GLM采用自回归空格填充任务,用于兼容三种模型的训练目标,先采样输入文本中部分片段,将其替换为[MASK] token,然后预测[MASK]所对应的文本片段,与掩码语⾔模型不同的是,预测的过程是自回归方式:

- 当被mask的片段长度为1,等价于BERT(掩码语言建模),当全部文本都被mask,等价于GPT(无条件语言生成),当将文本1和文本2拼接在一起,然后将文本2整体mask后,等价于T5(条件语言生成)。
GLM有两个交替优化的训练目标:
- 文档级别的生成:从文档中随机采样一个文本片段进行掩码,片段的长度为文档长度的50%-100%;
- 句子级别的生成:从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%;
GLM-130B是拥有1300亿参数的中英双语模型,在96块A100上训练了60天。ChatGLM-6B基于GLM架构,具有62亿参数,无量化的情况下占用显存13G,INT8量化后支持在单张11G显存的2080Ti上推理,INT4量化后只需6G显存进行推理,7G显存做P-Tuning v2微调。ChatGLM-6B以GLM-130B为基座,加入code预训练,并进行SFT和RLHF,支持中文问答。
关于量化
INT8量化是一种将深度学习模型中的权重和激活值从32位浮点数(FP32)减少到8位整数(INT8)的技术,这可以减少计算资源需求,降低能耗,量化通常包括以下步骤:
- 选择量化范围:确定权重和激活的最小值和最大值;
- 量化映射:根据范围将32位浮点数映射为8位整数;
- 反量化:将8位整数转回浮点数用于计算。
ChatGLM-6B直接部署
首先获取项目:
$ git clone https://github.com/THUDM/ChatGLM-6B
$ cd ChatGLM-6B
注意环境配置:torch版本不低于1.10,transformers为4.27.1,下载模型文件:
$ git clone https://huggingface.co/THUDM/chatglm-6b
直接新建my_demo.py:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print("response: ", response)
print("history: ", history)
response, history = model.chat(tokenizer, "如何提高弹跳", history=history)
print("response: ", response)
print("history: ", history)
生成的答案为(同时打印了历史信息):

也可以交互式问答,注意修改cli_demo.py中的模型路径:
$ python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史(history),输入 stop 终止程序。
也可以利用gradio可视化界面,注意修改web_demo.py中的模型路径:
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2htmltokenizer = AutoTokenizer.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
运行web_demo.py即可:

默认情况下,模型以 FP16 精度加载,运行模型需要大概 13GB 显存。
基于PEFT的LoRA微调ChatGLM-6B
官方基于P-Tuning v2微调,此处我们使用非官方项目ChatGLM-Tuning基于LoRA微调:
$ git clone https://github.com/mymusise/ChatGLM-Tuning
$ cd ChatGLM-Tuning
首先新建data_process.sh进行数据处理:
python cover_alpaca2jsonl.py \--data_path data/alpaca_data.json \--save_path data/alpaca_data.jsonl \
alpaca_data.json包含用于微调Alpaca模型的52k指令数据(回顾 LLaMA-7B微调记录)。data_process.sh用于将这52k数据处理为ChatGLM-6B的格式。
对于alpaca_data.json,包含 instruction,input,output,格式为:
[{"instruction": "Give three tips for staying healthy.","input": "","output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."},...{"instruction": "Edit the following sentence (highlight changes in bold)","input": "We use computers for gaming and entertainment","output": "We use computers for gaming, entertainment, and work."}
]
处理后的alpaca_data.jsonl包含context,target,格式为:
{"context": "Instruction: Give three tips for staying healthy.\nAnswer: ", "target": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."}
{"context": "Instruction: Edit the following sentence (highlight changes in bold)\nInput: We use computers for gaming and entertainment\nAnswer: ", "target": "We use computers for gaming, entertainment, and work."}
可以看到这个格式正好符合前面所提到的GLM的训练目标。
下一步,新建token.sh将数据token化,首先修改tokenize_dataset_rows.py中, 函数read_jsonl内的模型路径:
model_name = "/data/temp/my-alpaca-lora/chatglm-6b"
token.sh为:
python tokenize_dataset_rows.py \--jsonl_path data/alpaca_data.jsonl \--save_path data/alpaca \--max_seq_length 200 \--skip_overlength False \
然后新建finetune.sh执行微调,注意修改finetune.py中的模型路径:
tokenizer = AutoTokenizer.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", trust_remote_code=True)def main():...# init modelmodel = AutoModel.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", load_in_8bit=True, trust_remote_code=True, device_map="auto")
finetune.sh为:
python finetune.py \--dataset_path data/alpaca \--lora_rank 8 \--per_device_train_batch_size 6 \--gradient_accumulation_steps 1 \--max_steps 52000 \--save_steps 1000 \--save_total_limit 2 \--learning_rate 1e-4 \--fp16 \--remove_unused_columns false \--logging_steps 50 \--output_dir output \
额外说明,在finetune.py,通过get_peft_model将模型封装为带有LoRA分支的模型:
model = AutoModel.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", load_in_8bit=True, trust_remote_code=True, device_map="auto")
...
# setup peft
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=finetune_args.lora_rank,lora_alpha=32,lora_dropout=0.1)
model = get_peft_model(model, peft_config)
其余训练内容都可以不变,这样就能进行LoRA优化。
微调后,通过以下方式加载模型:
from peft import PeftModelmodel = AutoModel.from_pretrained("/data/temp/my-alpaca-lora/chatglm-6b", trust_remote_code=True, load_in_8bit=True, device_map='auto')model = PeftModel.from_pretrained(model, "./output/")
相关文章:
ChatGLM-6B微调记录
目录 GLM-130B和ChatGLM-6BChatGLM-6B直接部署基于PEFT的LoRA微调ChatGLM-6B GLM-130B和ChatGLM-6B 对于三类主要预训练框架: autoregressive(无条件生成),GPT的训练目标是从左到右的文本生成。autoencoding(语言理解…...

Linux Kernel 4.12 或将新增优化分析工具
到 7 月初,Linux Kernel 4.12 预计将为修复所有安全漏洞而奠定基础,另外新增的是一个分析工具,对于开发者优化启动时间时会有所帮助。 新的「个别任务统一模型」(Per-Task Consistency Model)为主要核心实时修补&#…...
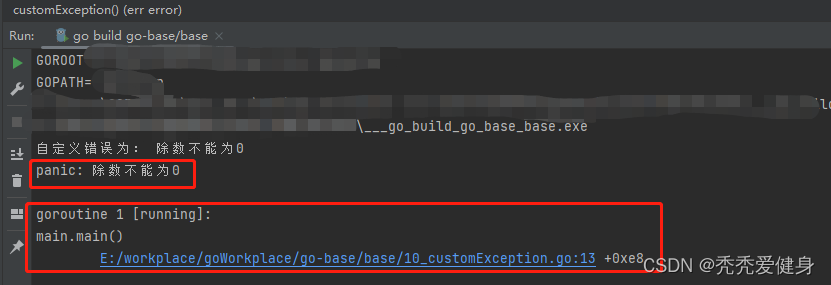
【30天熟悉Go语言】10 Go异常处理机制
作者:秃秃爱健身,多平台博客专家,某大厂后端开发,个人IP起于源码分析文章 😋。 源码系列专栏:Spring MVC源码系列、Spring Boot源码系列、SpringCloud源码系列(含:Ribbon、Feign&…...

飞机打方块(四)游戏结束
一、游戏结束显示 1.新建节点 1.新建gameover节点 2.绑定canvas 3.新建gameover容器 4.新建文本节点 2.游戏结束逻辑 Barrier.ts update(dt: number) {//将自身生命值取整let num Math.floor(this.num);//在Label上显示this.num_lb.string num.toString();//获取GameCo…...

保研之旅1:西北工业大学电子信息学院夏令营
💥💥💞💞欢迎来到本博客❤️❤️💥💥 本人持续分享更多关于电子通信专业内容以及嵌入式和单片机的知识,如果大家喜欢,别忘点个赞加个关注哦,让我们一起共同进步~ &#x…...

[WMCTF 2023] crypto
似乎退步不了,这个比赛基本不会了,就作了两个简单题。 SIGNIN 第1个是签到题 from Crypto.Util.number import * from random import randrange from secret import flagdef pr(msg):print(msg)pr(br"""........ …...
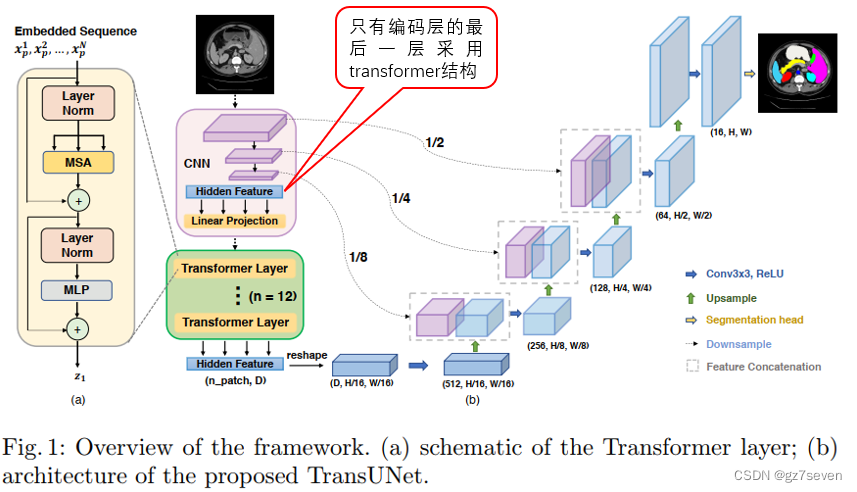
图像分割unet系列------TransUnet详解
图像分割unet系列------TransUnet详解 1、TransUnet结构2、我关心的问题3、总结与展望TransUnet发表于2021年,它是对UNet非常重要的改进,专为医学图像分割任务设计,特别用于在医学图像中分割器官或病变等解剖结构。 1、TransUnet结构 TransUNet在U-Net模型的基础上引入了混合…...
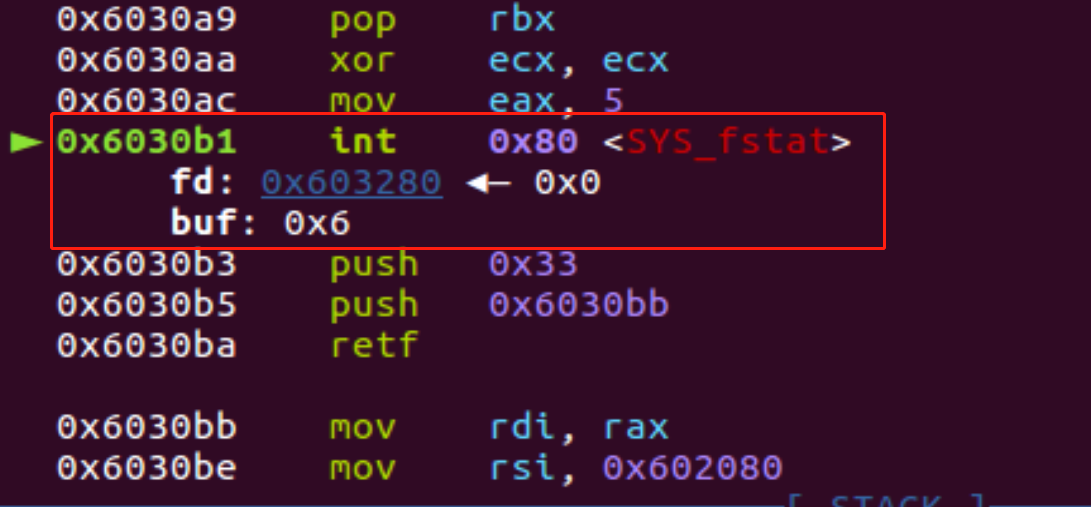
ASCII码-shellcode的技巧
网上已经有成熟的工具了,所以就简单记录一下工具怎么用吧 https://github.com/TaQini/alpha3 https://github.com/veritas501/ae64.git https://github.com/rcx/shellcode_encoder 结合题目来看吧,没有开启NX保护,基本这类型题目九成九都…...

spring cloud 之 dubbo nacos整合
整体思路: 搭建本地nacos服务,详见docker安装nacos_xgjj68163的博客-CSDN博客 共三个工程,生产者服务、消费者服务、生产者和消费者共同依赖的接口工程(打成jar,供生产者和消费者依赖); …...
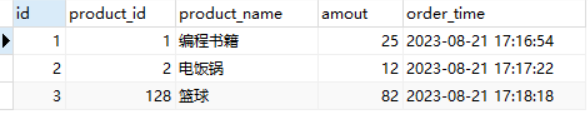
MySQL如何进行表之间的关联更新
在实际编程工作或运维实践中,对MySQL数据库表进行关联更新是一种比较常见的应用场景,比如在电商系统中,订单表里保存了商品名称的信息(冗余字段设计),但如果商品名称发生变化,则需要通过关联商品…...
Docker创建 LNMP 服务+Wordpress 网站平台
Docker创建 LNMP 服务Wordpress 网站平台 一.环境及准备工作 1.项目环境 公司在实际的生产环境中,需要使用 Docker 技术在一台主机上创建 LNMP 服务并运行 Wordpress 网站平台。然后对此服务进行相关的性能调优和管理工作。 容器 系统 IP地址 软件 nginx centos…...
node没有自动安装npm时,如何手动安装 npm
之前写过一篇使用 nvm 管理 node 版本的文章,node版本管理(Windows) 有时候,我们使用 nvm 下载 node 时,node 没有自动下载 npm ,此时就需要我们自己手动下载 npm 1、下载 npm下载地址:&…...
C# 使用递归方法实现汉诺塔步数计算
C# 使用递归方法实现汉诺塔步数计算 Part 1 什么是递归Part 2 汉诺塔Part 3 程序 Part 1 什么是递归 举一个例子:计算从 1 到 x 的总和 public int SumFrom1ToX(int x) {if(x 1){return 1;}else{int result x SumFrom1ToX_2(x - 1); // 调用自己return result…...

窗口函数大揭秘!轻松计算数据累计占比,玩转数据分析的绝佳利器
上一篇文章《如何用窗口函数实现排名计算》中小编为大家介绍了窗口函数在排名计算场景中的应用,但实际上窗口函数除了可以进行单行计算,还可以在每行上打开一个指定大小的计算窗口,这个计算窗口可以由SQL中的语句具体指定,大到整个…...

健康检测智能睡眠床垫方案
《2022中国睡眠质量调查报告》调查结果显示,16%的被调查者存在夜间睡眠时间不足6个小时,表现为24点以后才上床睡觉,并且在6点之前起床;有83.81%的被调查者经常受到睡眠问题困扰,其中入睡困难占2…...
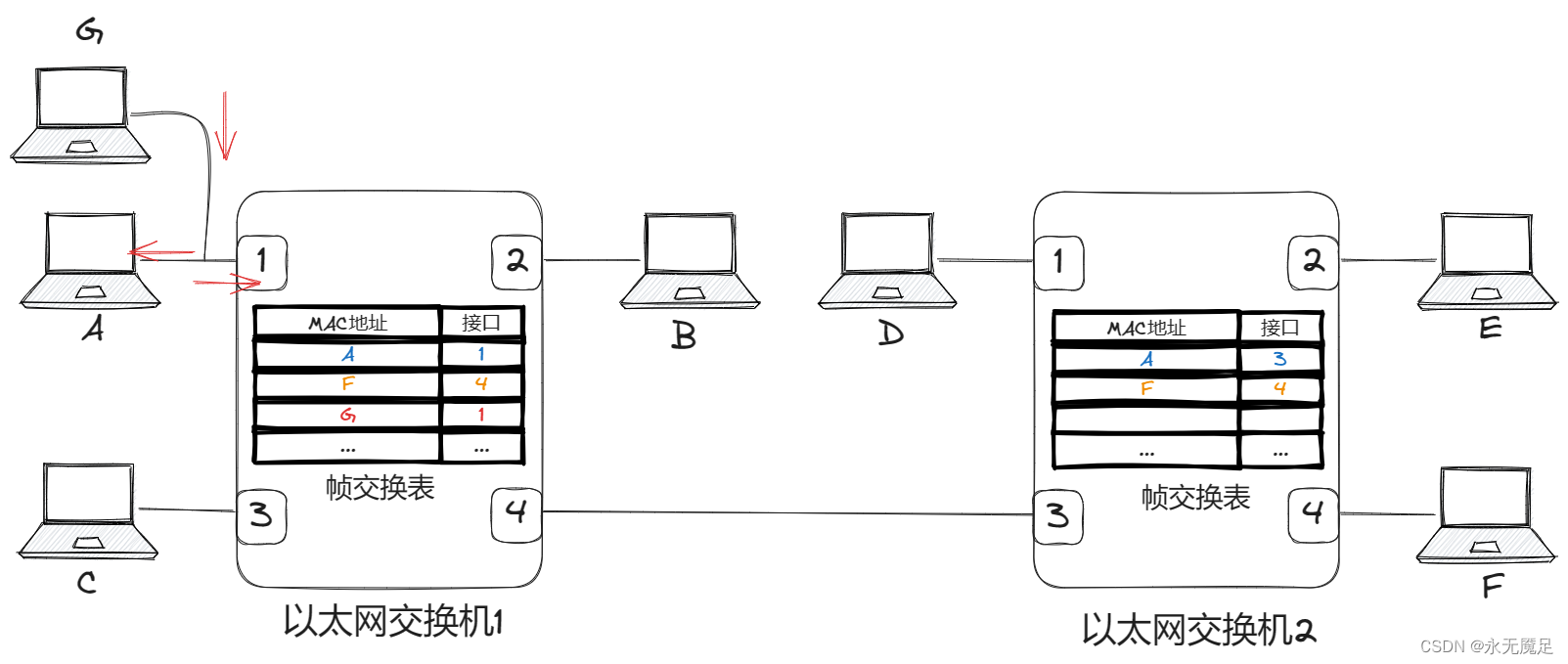
计网第三章(数据链路层)(五)
目录 一、以太网交换机自学习和转发帧的过程 1.两层交换机和三层交换机 2.以太网交换机的基本原理 3.具体实现过程 一、以太网交换机自学习和转发帧的过程 1.两层交换机和三层交换机 大家可能注意到平常做题时有叫两层交换机,或者三层交换机的。 两层交换机就…...

嵌入式系统中常见内存的划分方法
看到有小伙伴在讨论关于单片机内存的话题,今天就结合STM32给大家描述一下常见的划分区域。 在一个STM32程序代码中,从内存高地址到内存低地址,依次分布着栈区、堆区、全局区(静态区)、常量区、代码区,其中全…...

深入理解与实现:常见搜索算法的Java示例
深入理解与实现:常见搜索算法的Java示例 搜索算法在计算机科学中扮演着重要角色,用于在数据集中查找特定元素或解决问题。在本篇博客中,我们将深入探讨图算法的一个重要分支:图的搜索算法。具体而言,我们将介绍图的深…...
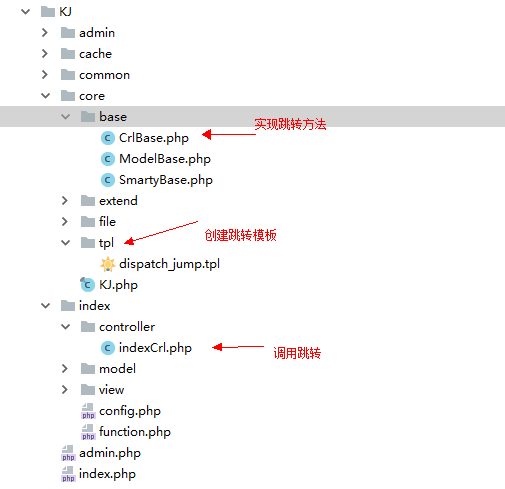
PHP自己的框架实现操作成功失败跳转(完善篇四)
1、实现效果,操作成功后失败成功自动跳转 2、创建操作成功失败跳转方法CrlBase.php /**成功后跳转*跳转地址$url* 跳转显示信息$msg* 等待时间$wait* 是否自动跳转$jump*/protected function ok($urlNULL,$msg操作成功,$wait3,$jump1){$code1;include KJ_CORE./tp…...
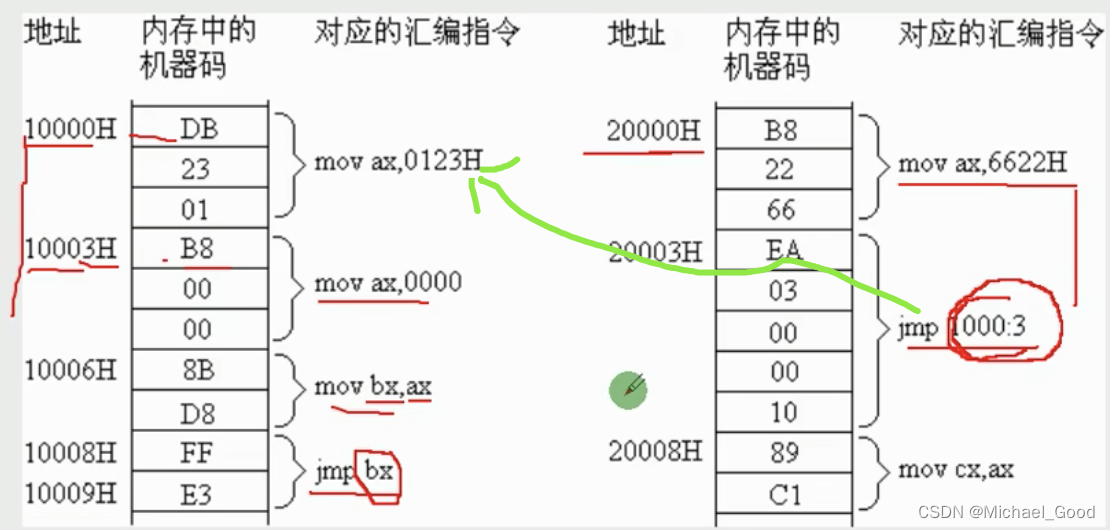
【汇编语言】CS、IP寄存器
文章目录 修改CS、IP的指令转移指令jmp问题分析 修改CS、IP的指令 理论:CPU执行何处的指令,取决于CS:IP应用:程序员可以通过改变CS、IP中的内容,进行控制CPU即将要执行的目标指令;问题:如何改变CS、IP中的…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...