如何利用 ChatGPT 进行自动数据清理和预处理
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景
ChatGPT 已经成为一把可用于多种应用的瑞士军刀,并且有大量的空间将 ChatGPT 集成到数据科学工作流程中。
如果您曾经在真实数据集上训练过机器学习模型,您就会知道数据清理和预处理的步骤对于构建可靠的机器学习模型非常重要。在本指南中,我们将了解如何使用 ChatGPT 在示例数据集上执行这些任务。
我们将使用 UCI 机器学习存储库中的银行营销数据集,并提示 ChatGPT 执行以下操作:
- 获取并加载数据集
- 检查缺失值
- 对分类变量进行编码
您可以通过登录您的 OpenAI 帐户并开始新的 ChatGPT 会话来跟进。如果你愿意,你也可以在谷歌Colab中编码。
获取和加载数据集
数据集有几个不同版本。我们将使用银行满.csv。
提示:今天我们将对真实数据集进行数据清理和预处理。编写代码以执行以下操作:1. 从 UCI 机器学习存储库中提取银行营销数据集。使用请求或 urllib 等库。2. 下载 zip 文件,解压缩内容,并将银行已满.csv文件读取到 pandas 数据帧中(称为数据)。
在数据集中获取和读取的代码如下:
import pandas as pd
import urllib
import zipfile# URL of the dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank.zip"# Fetch and extract the dataset
urllib.request.urlretrieve(url, "bank.zip")with zipfile.ZipFile("bank.zip", "r") as zip_ref:zip_ref.extractall()# Load the dataset into a pandas DataFrame
data = pd.read_csv("bank-full.csv", delimiter=";",skipinitialspace=True)获取数据集的基本信息
让我们更好地理解数据集。
# Display the first few rows of the dataset
print(data.head())这输出:
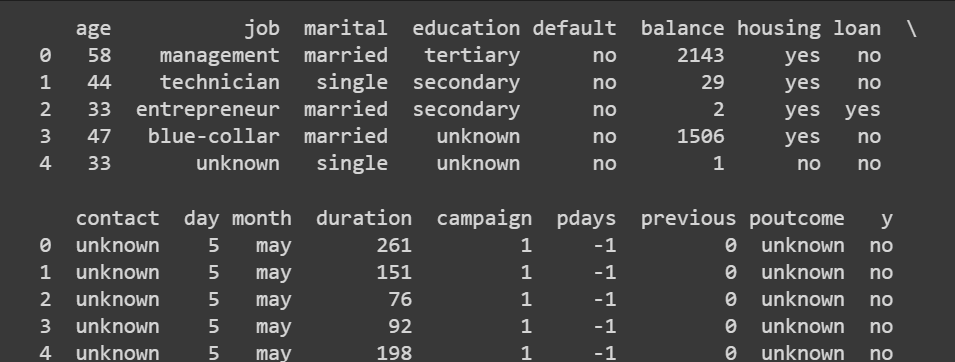
截断的输出 data.head()
提示:使用 pandas 获取数据帧的维度、列的描述性统计信息以及各种列的数据类型。
这一步并不需要提示 ChatGPT,因为 pandas 方法非常简单。
# Get the dimensions of the dataset (rows, columns)
print(data.shape)Output >>> (45211, 17)我们有超过 45000 条记录和 16 个特征(因为 17 个也包括输出标签)。
# Get statistical summary of numerical columns
print(data.describe())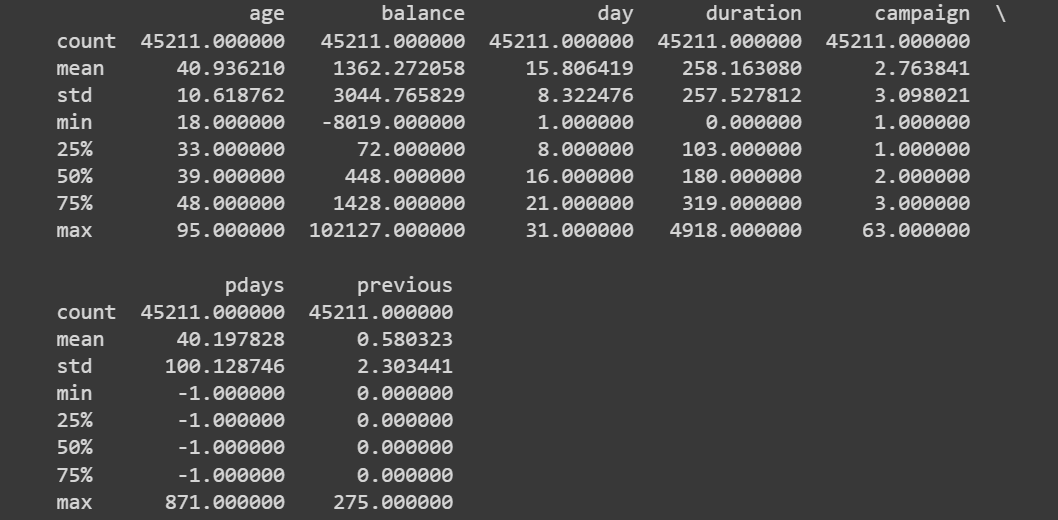
数据.describe() 的截断输出
获取各个列的数据类型的概述也很有帮助。当我们对分类变量进行编码时,我们将仔细研究它们。
# Check data types of each column
print(data.dtypes)Output >>>age int64
job object
marital object
education object
default object
balance int64
housing object
loan object
contact object
day int64
month object
duration int64
campaign int64
pdays int64
previous int64
poutcome object
y object
dtype: object到目前为止,我们已经了解了银行营销数据集。输出标签表示客户是否会订阅定期存款。该数据集包含多个要素,例如年龄、月份、教育程度、婚姻状况、先前广告系列的结果等。
检查缺失值
提示:我想知道每列中缺失值的数量。请给我代码来做这件事。使用熊猫。
# Check for missing values in each column
missing_values = data.isnull().sum()
print(missing_values)下面是输出:
Output >>>age 0
job 0
marital 0
education 0
default 0
balance 0
housing 0
loan 0
contact 0
day 0
month 0
duration 0
campaign 0
pdays 0
previous 0
poutcome 0
y 0
dtype: int64此版本的银行营销数据集(包含超过 45000 条记录)没有任何缺失值。但实际上,大多数真实世界的数据集都有缺失值。您应该使用合适的插补技术来处理缺失值。
作为可选的练习,您可以在此处添加一个步骤,提示 ChatGPT 从列的子集中删除一小部分值,以便您可以练习如何处理缺失值。
编码分类变量
下一步是对数据集中的分类变量进行编码。我们将首先获取所有分类列的列表。
提示:提供代码以获取此数据集中所有分类列的列表。
# Count the number of categorical variables
categorical_columns = data.select_dtypes(include=['object']).columns
print(categorical_columns)
num_categorical_variables = len(categorical_columns)# Display the count
print("Number of categorical variables:", num_categorical_variables)分类列列表还包括输出标签 y。但是,让我们先关注其他分类变量。
Output >>>
Index(['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact','month', 'poutcome', 'y'],dtype='object')
Number of categorical variables: 10仔细查看分类变量的值
接下来,让我们看看每个分类变量采用的值。
提示:我想了解每个分类变量采用的各种值。给熊猫代码来做到这一点。
# Get the different values and their counts for each categorical column
categorical_columns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
for column in categorical_columns:value_counts = data[column].value_counts()print(f"Column: {column}")print(value_counts,"\n")输出很难解析:
Output >>>Column: job
blue-collar 9732
management 9458
technician 7597
admin. 5171
services 4154
retired 2264
self-employed 1579
entrepreneur 1487
unemployed 1303
housemaid 1240
student 938
unknown 288
Name: job, dtype: int64 ...
...
...
Column: poutcome
unknown 36959
failure 4901
other 1840
success 1511
Name: poutcome, dtype: int64 可视化分类变量的值
让我们提示 ChatGPT 创建一个可视化,以便更容易理解分类变量采用的值。
提示:我想要一个显示每个分类变量取值的图。排除输出标签 y。包括所有其他分类变量。
我们开始吧!
import matplotlib.pyplot as plt# Get the different values and their counts for each categorical column
categorical_columns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']# Set up the subplot grid
fig, axes = plt.subplots(3, 3, figsize=(10,8))# Iterate over each categorical column and plot the value counts
for i, column in enumerate(categorical_columns):row = i // 3col = i % 3value_counts = data[column].value_counts()ax = axes[row, col]value_counts.plot(kind='bar', ax=ax)ax.set_xlabel(column)ax.set_ylabel('Count')ax.set_title(f'{column.title()} Value Counts')# Adjust spacing between subplots
plt.tight_layout()# Show the plot
plt.show()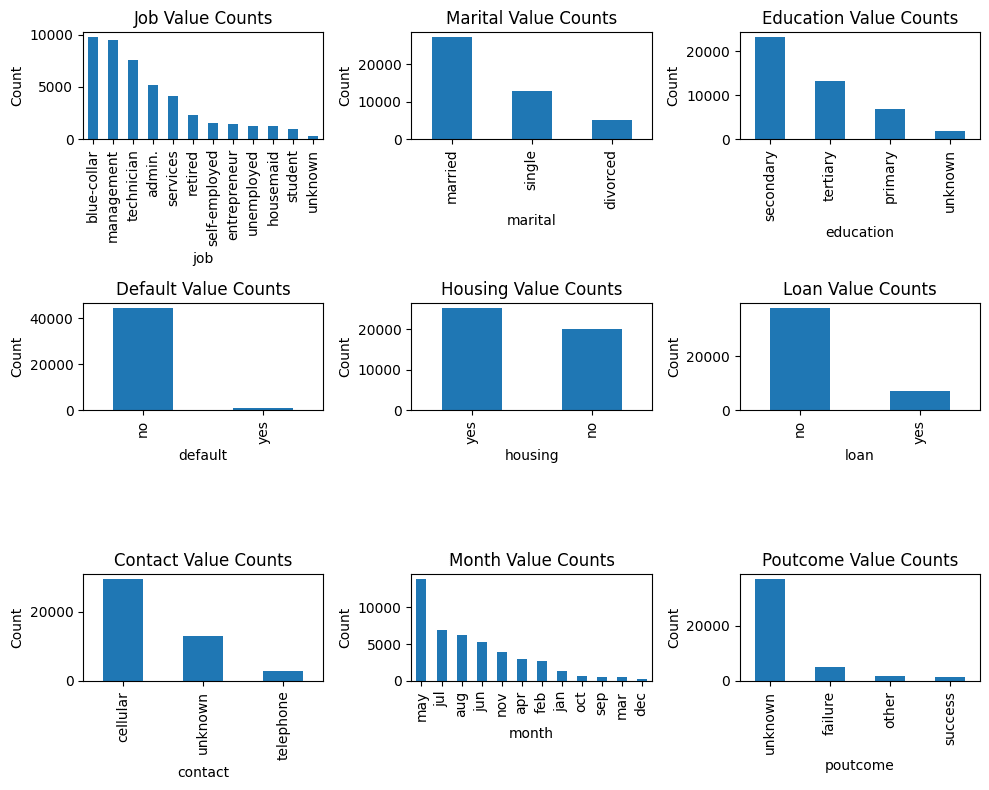
分类变量的值
独热编码
对于分类列的子集,我们可以使用独热编码。
提示:给 pandas 代码以对列列表执行独热编码。
我们使用从熊猫到独热编码以下列:get_dummies
# Select the categorical columns (excluding education and poutcome)
categorical_columns = ['job', 'marital', 'default', 'housing', 'loan', 'contact']# Perform one-hot encoding
encoded_data = pd.get_dummies(data, columns=categorical_columns)提示:我想打印出新添加列的前几行。编写代码以执行相同的操作。
# Select the newly added columns
new_columns = encoded_data.columns.difference(data.columns)# Print the head of the newly added columns
print(encoded_data[new_columns].head())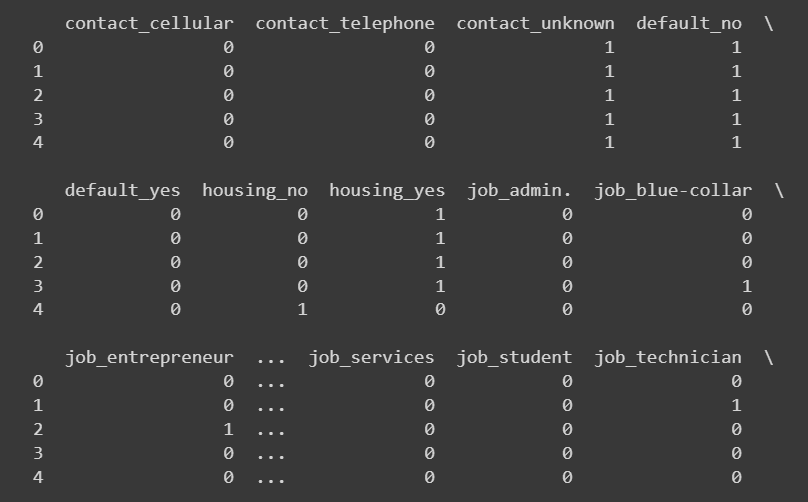
截断的输出 encoded_data['new_colums'].head()
定义自定义映射
对于“education”和“poutcome”(先前结果)等变量的列,而不是独热编码,最好使用自定义映射在值之间进行一定程度的比较。
此外,当我们使用独热编码来编码一个分类变量时,该变量采用 k 个不同的值 k 个新列。对于像“月”这样的分类列,如果不添加太多信息,这将是多余的。
因此,对于这两种情况,我们将定义一个自定义映射,然后转换值。我们可以提示 ChatGPT 获取一个通用代码片段,然后我们可以修改该代码片段以定义特定列的映射。
提示:我想做一个自定义映射来编码一些分类变量。首先给我一个通用代码片段,该代码片段定义了从分类列中的唯一值到一组不同输出值的自定义映射。然后,我们应该使用此映射来转换列中的值。
# Define the custom mapping dictionary
custom_mapping = {'category1': 'value1','category2': 'value2','category3': 'value3',# Add more categories and corresponding values as needed
}# Specify the categorical column
categorical_column = 'column_name' # Replace 'column_name' with the actual column name# Perform the mapping using the custom mapping dictionary
data[categorical_column] = data[categorical_column].map(custom_mapping)对于“月”列,让我们像这样转换月份字符串:
# Define the mapping dictionary for months
month_mapping = {'jan': 1,'feb': 2,'mar': 3,'apr': 4,'may': 5,'jun': 6,'jul': 7,'aug': 8,'sep': 9,'oct': 10,'nov': 11,'dec': 12
}# Map the values in the month column
encoded_data['month'] = encoded_data['month'].map(month_mapping)让我们将“结果”和“教育”列映射到数值,如下所示:
# Define the custom mapping for poutcome and education
poutcome_mapping = {'unknown': 0,'failure': 1,'other': 2,'success': 3
}education_mapping = {'unknown': 0,'primary': 1,'secondary': 2,'tertiary': 3
}# Perform ordinal encoding using pandas map
encoded_data['poutcome'] = encoded_data['poutcome'].map(poutcome_mapping)
encoded_data['education'] = encoded_data['education'].map(education_mapping)# Select the newly added columns
new_columns = ['month','poutcome', 'education']# Print the head of the newly added columns
print(encoded_data[new_columns].head(10))对输出标签进行编码
我们还将输出标签“是”和“否”分别映射到 1 和 0。
encoded_data['y'] = encoded_data['y'].replace({'no': 0, 'yes': 1})
print(encoded_data['y'])Output >>>0 0
1 0
2 0
3 0
4 0..
45206 1
45207 1
45208 1
45209 0
45210 0
Name: y, Length: 45211, dtype: int64回想一下,我们对“住房”、“默认”和“贷款”列使用了独热编码。由于这些列还采用“是”和“否”值,因此您还可以将“是”和“否”分别映射到 1 和 0。
可视化类标签的分布
检查类标签的分布也很有帮助,这样我们就可以在需要时在构建模型时考虑类不平衡。
提示:我想了解类标签的分布。请给我代码以生成合适的图。
以下是在Seaborn中生成计数图的代码:
import seaborn as sns
import matplotlib.pyplot as plt# Plot the distribution of output labels
sns.countplot(data=data, x='y')
plt.xlabel('Output Label')
plt.ylabel('Count')
plt.title('Output Label Distribution')
plt.show()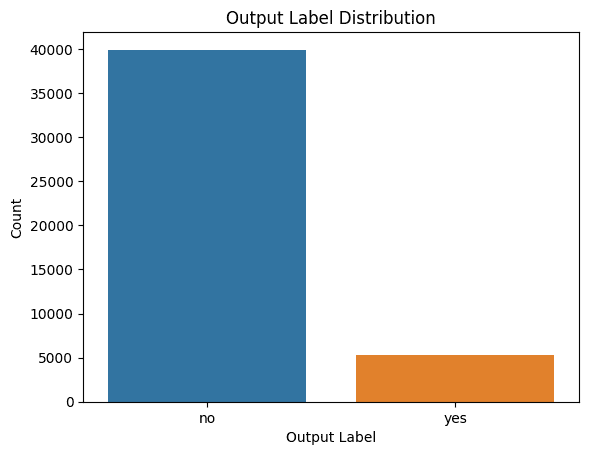
类标签的分发
我们看到存在阶级失衡。因此,如果要构建模型,则应确保使用适当的重采样方法解决类不平衡问题。
通用数据清理和预处理管道
尽管数据清理和预处理需要开发人员的努力,但让我们尝试获取一个通用的步骤序列,该步骤序列对于简单的数据集来说相当有效。
提示:您能否根据我们到目前为止所做的工作给我一个通用的数据清理和预处理管道。获取数据集的基本信息,检查和处理缺失值,标识分类列,并对分类列进行编码。只使用熊猫。
这是:
import pandas as pd# Load the dataset into a DataFrame
data = pd.read_csv('data.csv')# Step 1: Basic Info
print(data.info())# Step 2: Missing Values
missing_values = data.isnull().sum()
print(missing_values)# Step 3: Handle Missing Values
# Identify columns with missing values
columns_with_missing_values = missing_values[missing_values > 0].index# Impute missing values using fillna() or other suitable method
data[columns_with_missing_values] = data[columns_with_missing_values].fillna(data[columns_with_missing_values].mean())# Step 4: Get Categorical Columns
categorical_columns = data.select_dtypes(include=['object']).columns# Step 5: Encode Categorical Columns
# Perform ordinal encoding or one-hot encoding using pandas' get_dummies() function
encoded_data = pd.get_dummies(data, columns=categorical_columns)# Print the encoded data
print(encoded_data.head())总结
可以看出,与 ChatGPT 协同作用的数据科学专业知识可以帮助使数据清理和预处理更简单、更快捷。现在,您已经准备好了预处理的数据集,您可以通过在此银行营销数据集上构建一个简单的预测模型来进一步实现这一点。
原文链接:如何利用 ChatGPT 进行自动数据清理和预处理 (mvrlink.com)
相关文章:
如何利用 ChatGPT 进行自动数据清理和预处理
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景 ChatGPT 已经成为一把可用于多种应用的瑞士军刀,并且有大量的空间将 ChatGPT 集成到数据科学工作流程中。 如果您曾经在真实数据集上训练过机器学习模型,您就会知道数据清理和预…...
PHP“牵手”淘宝商品评论数据采集方法,淘宝API接口申请指南
淘宝天猫商品评论数据接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用…...

你更喜欢哪一个:VueJS 还是 ReactJS?
观点列表: 1、如果你想在 HTML 中使用 JS,请使用 Vue; 如果你想在 JS 中使用 HTML,请使用 React。 当然,如果您希望在 JS 中使用 HTML,请将 Vue 与 JSX 结合使用。 2、Svelte:我喜欢它&#…...
PyTorch学习笔记(十六)——利用GPU训练
一、方式一 网络模型、损失函数、数据(包括输入、标注) 找到以上三种变量,调用它们的.cuda(),再返回即可 if torch.cuda.is_available():mynn mynn.cuda() if torch.cuda.is_available():loss_function loss_function.cuda(…...
【实战】十一、看板页面及任务组页面开发(三) —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(二十五)
文章目录 一、项目起航:项目初始化与配置二、React 与 Hook 应用:实现项目列表三、TS 应用:JS神助攻 - 强类型四、JWT、用户认证与异步请求五、CSS 其实很简单 - 用 CSS-in-JS 添加样式六、用户体验优化 - 加载中和错误状态处理七、Hook&…...

金额千位符自定义指令
自定义指令文件 moneyFormat.js /*** v-money 金额千分位转换*/export default {inserted: inputFormatter({// 格式化函数formatter(num, util) {if(num null || num || num undefined || typeof(num) undefined){return }if(util 万元 || util 万){return formatMone…...

请不要用 JSON 作为配置文件,使用JSON做配置文件的缺点
我最近关注到有的项目使用JSON作为配置文件。我觉得这不是个好主意。 这不是JSON的设计目的,因此也不是它擅长的。JSON旨在成为一种“轻量级数据交换格式”,并声称它“易于人类读写”和“易于机器解析和生成”。 作为一种数据交换格式,JSON是…...
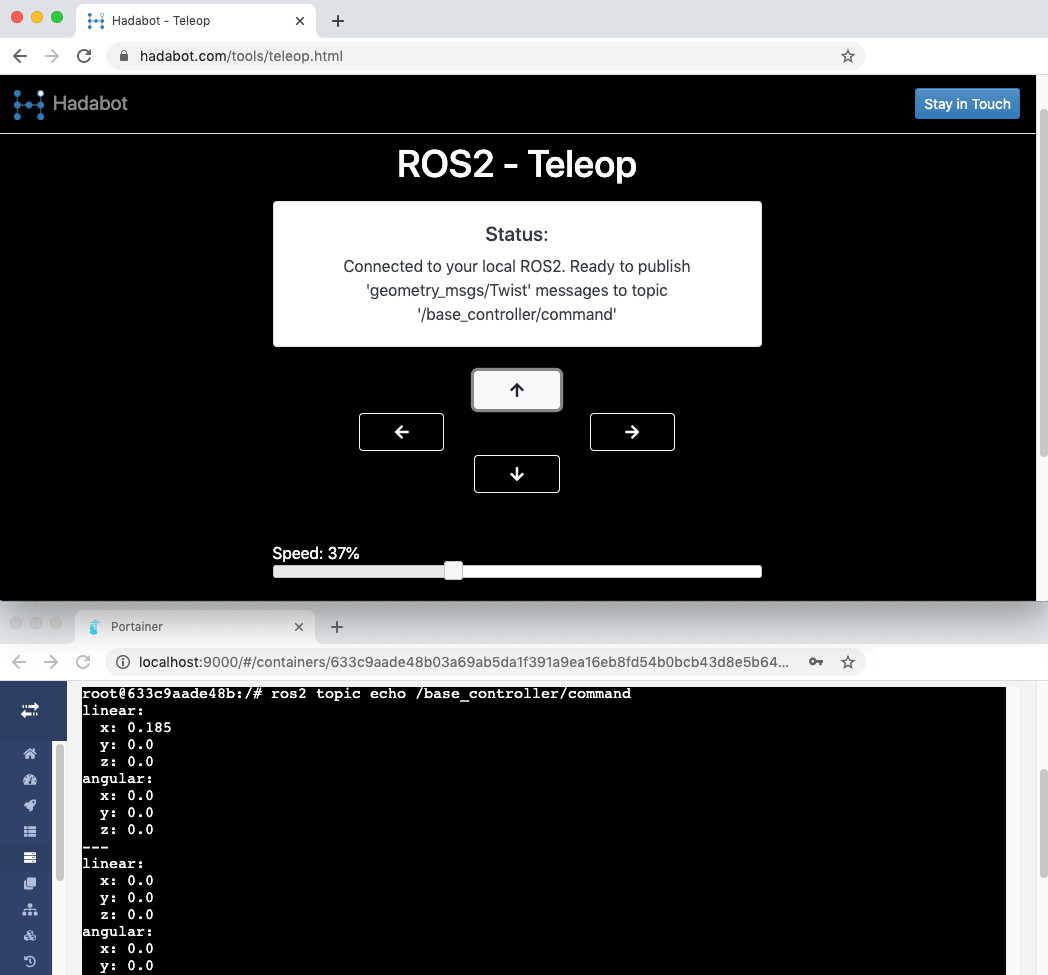
Hadabot:从网络浏览器操作 ROS2 远程控制器
一、说明 Hadabot Hadabot是一个学习ROS2和机器人技术的机器人套件。使用 Hadabot,您将能够以最小的挫败感和恐吓来构建和编程物理 ROS2 机器人。Hadabot套件目前正在开发中。它将仅针对ROS2功能,并强调基于Web的用户界面。 随着开发的进展&a…...

Kotlin 协程
Kotlin 协程(Coroutines)是一种轻量级的并发编程解决方案,旨在简化异步操作和多线程编程。它提供了一种顺序和非阻塞的方式来处理并发任务,使得代码可以更加简洁和易于理解。Kotlin 协程通过提供一套高级 API,使并发代…...
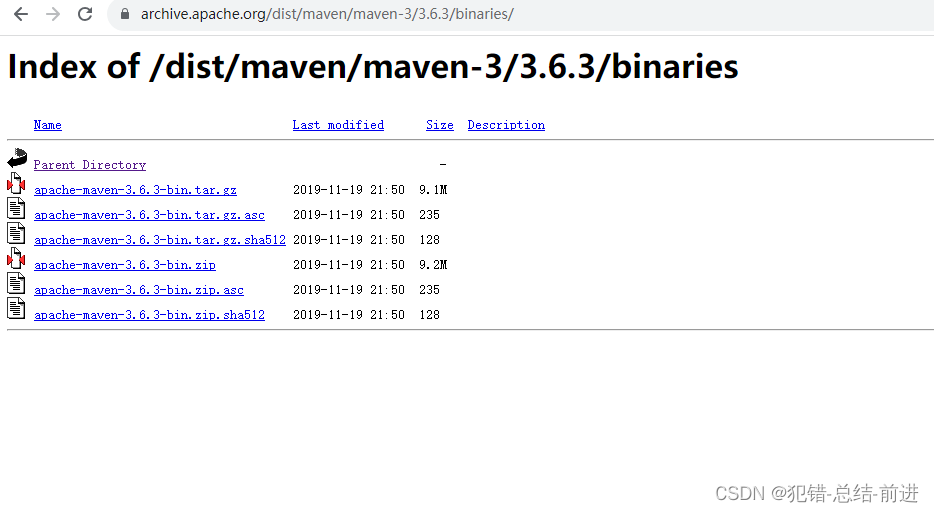
maven 从官网下载指定版本
1. 进入官网下载页面 Maven – Download Apache Maven 点击下图所示链接 2. 进入文件页,选择需要的版本 3. 选binaries 4. 选文件,下载即可...

数据结构---串(赋值,求子串,比较,定位)
目录 一.初始化 顺序表中串的存储 串的链式存储 二.赋值操作:将str赋值给S 链式表 顺序表 三.复制操作:将chars复制到str中 链式表 顺序表 四.判空操作 链式表 顺序表 五.清空操作 六.串联结 链式表 顺序表 七.求子串 链式表 顺序表…...
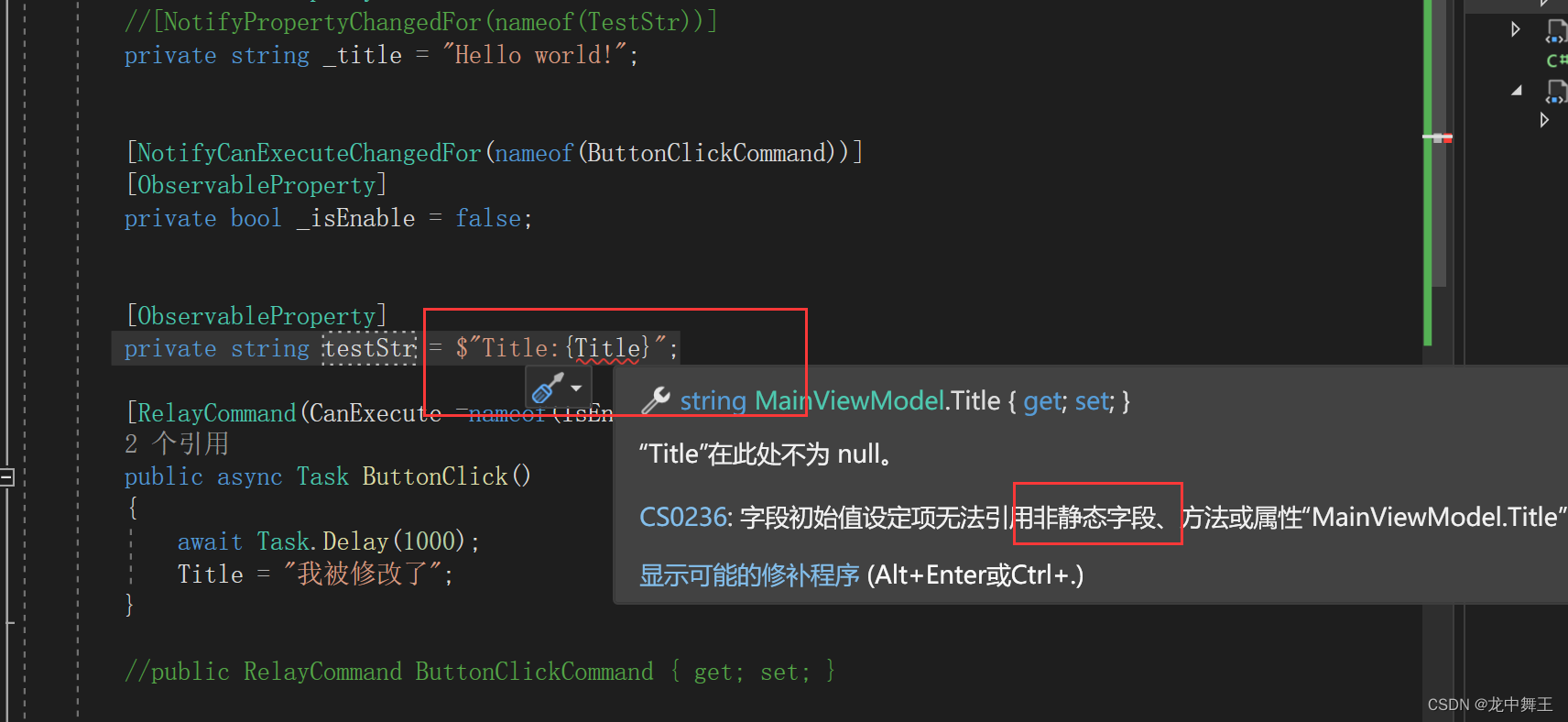
WPF CommunityToolkit.Mvvm
文章目录 前言ToolkitNuget安装简单使用SetProperty,通知更新RealyCommandCanExecute 新功能,代码生成器ObservablePropertyNotifyCanExecuteChangedForRelayCommand其他功能对应关系 NotifyPropertyChangedFor 前言 CommunityToolkit.Mvvm(…...

Vue开发中如何解决国际化语言切换问题
Vue开发中如何解决国际化语言切换问题 引言: 在如今的全球化时代,应用程序的国际化变得越来越重要。为了让不同地区的用户能够更好地使用应用程序,我们需要对内容进行本地化,以适应不同语言和文化环境。对于使用Vue进行开发的应用…...
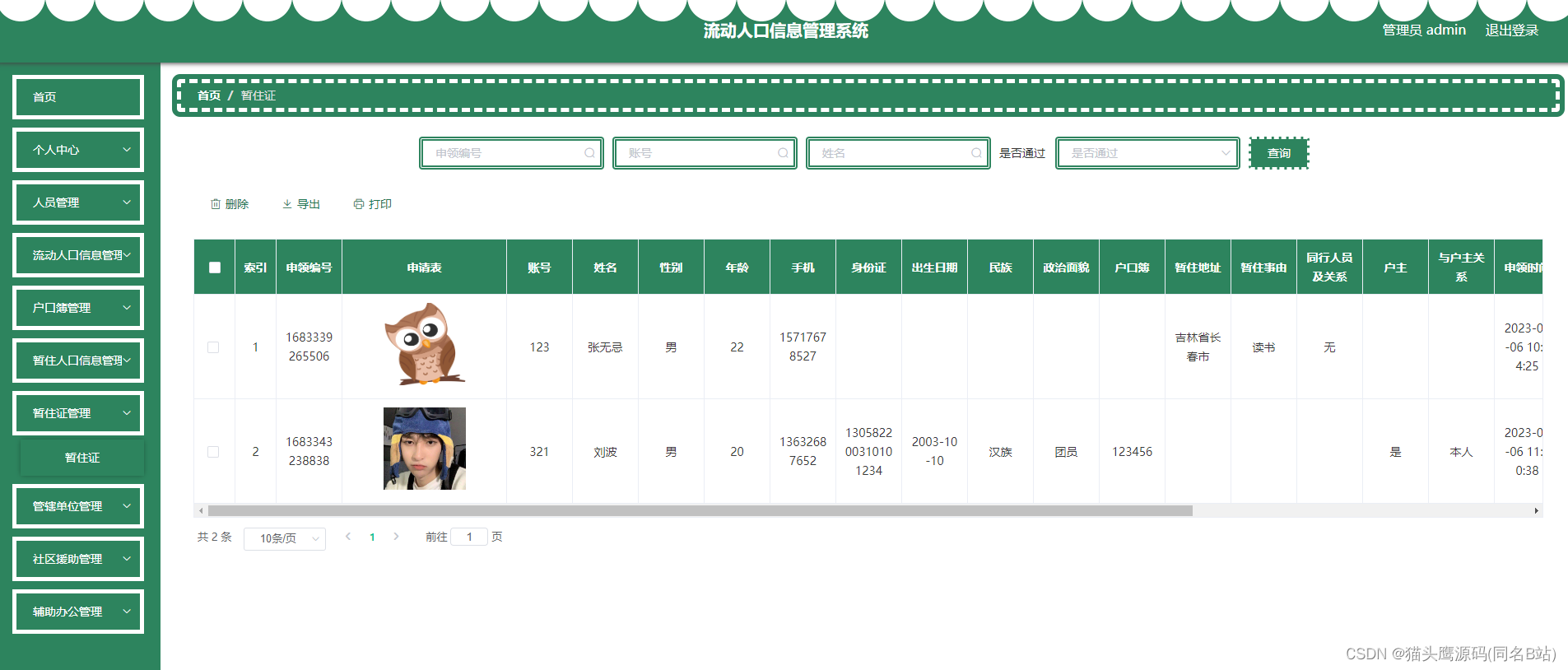
基于springboot+vue的流动人口登记系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

Stable Diffusion的使用以及各种资源
Stable Diffsuion资源目录 SD简述sd安装模型下载关键词,描述语句插件管理controlNet自己训练模型 SD简述 Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如…...

Redis 分布式锁的实现方式
一般来说,在对数据进行“加锁”时,程序首先需要通过获取(acquire)锁来得到对数据排他性访问的能力,然后才能对数据执行一系列操作,最后还要将锁释放(release)给其他程序。 对于能够…...

VMware上搭建的虚拟机突然本地无法连接服务器
长时间没有使用VMware 虚拟机了,今天突然登录上去,启动虚拟服务器后发现本地等不了了, 经过排查发现是开启了:VirtualBox Host-Only Network 关闭之后就本机就可以直连服务器了...

JDBC回顾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 JDBC回顾 前言一、JDBC1.JDBC是什么?2.如何使用?(1)注册驱动(2)获取连接(3)操作…...

mq 消息队列 mqtt emqx ActiveMQ RabbitMQ RocketMQ
省流: 十几年前,淘宝的notify,借鉴ActiveMQ。京东的ActiveMQ集群几百台,后面改成JMQ。 Linkedin的kafka,因为是scala,国内很多人不熟。淘宝的人把kafka用java写了一遍,取名metaq,后…...

沃尔玛卖家必看!解决订单被Kan、Feng号问题的终极方案!
近期有很多沃尔玛卖家和工作室联系到我提到说在沃尔玛平台上下单,买家号出现副款义常订单被k掉,是什么原因、我们该如何去解决呢? 以下是一些可能导至你的测评订单被k单的原因: 1.技术问题:有时,网站或系…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...