ClickHouse(二十一):Clickhouse SQL DDL操作-临时表及视图

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. 临时表
1.1 创建临时表语法
1.2 示例
2. 视图
2.1 普通视图
2.2 物化视图
1. 临时表
ClickHouse支持临时表,临时表具备以下特征:
- 当会话结束或者链接中断时,临时表将随会话一起消失。
- 临时表仅能够使用Memory表引擎,创建临时表时不需要指定表引擎。
- 无法为临时表指定数据库。它是在数据库之外创建的,与会话绑定。
- 如果临时表与另一个表名称相同,那么当在查询时没有显式的指定db的情况下,将优先使用临时表。
- 对于分布式处理,查询中使用的临时表将被传递到远程服务器。
1.1 创建临时表语法
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...)注意:不需要指定表引擎,默认是Memory1.2 示例
#查看库 newdb下 表node1 :) show tables;SHOW TABLES┌─name────────┐│ t1 ││ t2 ││ t_log ││ t_stripelog ││ t_tinylog │└─────────────┘5 rows in set. Elapsed: 0.004 sec.#查询表 t_log表数据node1 :) select * from t_log;SELECT *FROM t_log┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 │└────┴─────┴─────┘┌─id─┬─name─┬─age─┐│ 3 │ 王五 │ 20 ││ 4 │ 马六 │ 21 ││ 5 │ 田七 │ 22 │└────┴─────┴─────┘5 rows in set. Elapsed: 0.004 sec.#创建临时表 t_log ,与当前库下的t_log同名node1 :) create temporary table t_log(id UInt8 ,name String);CREATE TEMPORARY TABLE t_log(`id` UInt8,`name` String)Ok.0 rows in set. Elapsed: 0.001 sec.#查询表 t_log的数据与结构,发现没有数据,这里查询的是临时表,结构如下:node1 :) desc t_log;DESCRIBE TABLE t_log┌─name─┬─type───┬│ id │ UInt8 ││ name │ String │└──────┴────────┴2 rows in set. Elapsed: 0.003 sec.#如果想要查询到库newdb下的t_log需要加上数据库名node1 :) select * from newdb.t_log;#切换库为default,同样还可以查询到表t_log,说明表不属于任何库node1 :) use default;node1 :) desc t_log;DESCRIBE TABLE t_log┌─name─┬─type───┬│ id │ UInt8 ││ name │ String │└──────┴────────┴2 rows in set. Elapsed: 0.004 sec.#退出客户端之后,重新登录,查询t_log不存在。node1 :) select * from t_log;Exception: Received from localhost:9000. DB::Exception: Table default.t_log doesn't exist..#也可以不退出客户端直接删除临时表node1 :) drop table t_log;DROP TABLE t_logOk.0 rows in set. Elapsed: 0.001 sec.注意:在大多数情况下,临时表不是手动创建的,而是在使用外部数据进行查询或分布式时创建的,可以使用ENGINE = Memory的表代替临时表。
2. 视图
ClickHouse中视图分为普通视图和物化视图,两者区别如图所示:
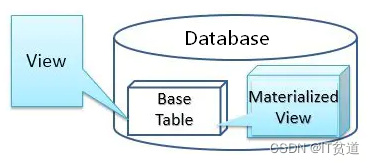
2.1 普通视图
普通视图不存储数据,它只是一层select 查询映射,类似于表的别名或者同义词,能简化查询,对原有表的查询性能没有增强的作用,具体性能依赖视图定义的语句,当从视图中查询时,视图只是替换了映射的查询语句。普通视图当基表删除后不可用。
- 创建普通视图语法:
CREATE [OR REPLACE] VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] AS SELECT ...- 示例:
#在库 newdb中创建表 personinfonode1 :) create table personinfo(id UInt8,name String,age UInt8,birthday Date) engine = Log;#向表 personinfo中插入如下数据:node1 :) insert into personinfo values (1,'张三',18,'2021-06-01');node1 :) insert into personinfo values (2,'李四',19,'2021-06-02');node1 :) insert into personinfo values (3,'王五',20,'2021-06-03');node1 :) insert into personinfo values (4,'马六',21,'2021-06-04');node1 :) insert into personinfo values (5,'田七',22,'2021-06-05');#查询表中的数据node1 :) select * from personinfo;SELECT *FROM personinfo┌─id─┬─name─┬─age─┬───birthday─┐│ 1 │ 张三 │ 18 │ 2021-06-01 ││ 2 │ 李四 │ 19 │ 2021-06-02 │└────┴──────┴─────┴────────────┘┌─id─┬─name─┬─age─┬───birthday─┐│ 3 │ 王五 │ 20 │ 2021-06-03 ││ 4 │ 马六 │ 21 │ 2021-06-04 ││ 5 │ 田七 │ 22 │ 2021-06-05 │└────┴──────┴─────┴────────────┘5 rows in set. Elapsed: 0.004 sec.#创建视图 person_view 映射查询子句node1 :) create view person_view as select name,birthday from personinfo;CREATE VIEW person_view ASSELECTname,birthdayFROM personinfoOk.0 rows in set. Elapsed: 0.009 sec.#查询视图person_view中的数据结果node1 :) select * from person_view;SELECT *FROM person_view┌─name─┬───birthday─┐│ 张三 │ 2021-06-01 ││ 李四 │ 2021-06-02 │└──────┴────────────┘┌─name─┬───birthday─┐│ 王五 │ 2021-06-03 ││ 马六 │ 2021-06-04 ││ 田七 │ 2021-06-05 │└──────┴────────────┘5 rows in set. Elapsed: 0.004 sec.#删除视图 使用drop即可node1 :) drop table person_view;DROP TABLE person_viewOk.0 rows in set. Elapsed: 0.002 sec.2.2 物化视图
物化视图是查询结果集的一份持久化存储,所以它与普通视图完全不同,而非常趋近于表。”查询结果集”的范围很宽泛,可以是基础表中部分数据的一份简单拷贝,也可以是多表join之后产生的结果或其子集,或者原始数据的聚合指标等等。
物化视图创建好之后,若源表被写入新数据则物化视图也会同步更新,POPULATE 关键字决定了物化视图的更新策略,若有POPULATE 则在创建视图的过程会将源表已经存在的数据一并导入,类似于 create table ... as,若无POPULATE 则物化视图在创建之后没有数据,只会在创建只有同步之后写入源表的数据,clickhouse 官方并不推荐使用populated,因为在创建物化视图的过程中同时写入的数据不能被插入物化视图。
物化视图是种特殊的数据表,创建时需要指定引擎,可以用show tables 查看。另外,物化视图不支持alter 操作。
产生物化视图的过程就叫做“物化”(materialization),广义地讲,物化视图是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路,所以用得好的话,它可以避免对基础表的频繁查询并复用结果,从而显著提升查询的性能。
- 物化视图创建语法:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...- 示例:
#在库 newdb 中创建物化视图 t_view1node1 :) create materialized view t_view1 engine = Log as select * from personinfo;#查询 所有表node1 :) show tables;SHOW TABLES┌─name───────────┐│ .inner.t_view1 ││ personinfo └────────────────┘2 rows in set. Elapsed: 0.004 sec.#向表 personinfo中插入如下数据:node1 :) insert into personinfo values (1,'张三',18,'2021-06-01');node1 :) insert into personinfo values (2,'李四',19,'2021-06-02');node1 :) insert into personinfo values (3,'王五',20,'2021-06-03');node1 :) insert into personinfo values (4,'马六',21,'2021-06-04');node1 :) insert into personinfo values (5,'田七',22,'2021-06-05');#查看物化视图 t_view1数据node1 :) select * from t_view1;SELECT *FROM t_view1┌─id─┬─name─┬─age─┬───birthday─┐│ 1 │ 张三 │ 18 │ 2021-06-01 ││ 2 │ 李四 │ 19 │ 2021-06-02 │└────┴──────┴─────┴────────────┘┌─id─┬─name─┬─age─┬───birthday─┐│ 3 │ 王五 │ 20 │ 2021-06-03 ││ 4 │ 马六 │ 21 │ 2021-06-04 ││ 5 │ 田七 │ 22 │ 2021-06-05 │└────┴──────┴─────┴────────────┘5 rows in set. Elapsed: 0.004 sec.#创建物化视图 t_view2node1 :) create materialized view t_view2 engine = Log as select count(name) as cnt from personinfo;#向表 personinfo中插入以下数据node1 :) insert into personinfo values (6,'赵八',23,'2021-06-06'),(7,'孙九',22,'2021-06-07');#查询物化视图表 t_view2数据,可以看到做了预计算,这里不能一条条插入,不然效果是每条数据都会生成一个结果。node1 :) select * from t_view2;SELECT *FROM t_view2┌─cnt─┐│ 2 │└─────┘1 rows in set. Elapsed: 0.004 sec.#删除物化视图node1 :) drop table t_view2;DROP TABLE t_view2Ok.0 rows in set. Elapsed: 0.001 sec.注意:当创建好物化视图t_view1时,可以进入到/var/lib/clickhouse/data/newdb目录下看到%2Einner%2Et_view1目录,当物化视图中同步基表数据时,目录中有对应的列文件和元数据记录文件,与普通创建表一样,有目录结构。
👨💻如需博文中的资料请私信博主。
相关文章:
ClickHouse(二十一):Clickhouse SQL DDL操作-临时表及视图
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

redis乐观锁+启用事务解决超卖
乐观锁用于监视库存(watch),然后接下来就启用事务。 启用事务,将减库存、下单这两个步骤,放到一个事务当中即可解决秒杀问题、防止超卖。 但是!!!乐观锁,会带来" …...

智能画笔:如何利用AI绘画API打造独特的创作风格
在当今数字化时代,人工智能的迅猛发展正深刻地影响着各个领域,艺术创作也不例外。AI绘画 API 作为一种创新的工具,为艺术家提供了独特的机会,使他们能够在创作过程中借助人工智能技术,打造出独具个性的创作风格。本文将…...

ElasticSearchConfig
1. 添加配置 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId></dependency>2. es 配置信息 import org.apache.http.HttpHost; import org.apache.http.auth.Au…...
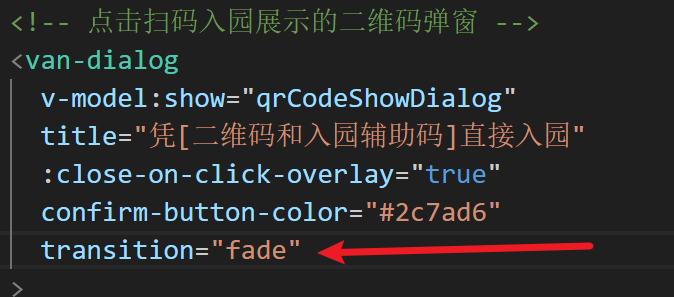
解决vant组件 van-dialog造成的页面闪动问题
解决方案:该问题是因为van-dialog默认是scale,将这个属性改为fade即可...

SpringBoot内嵌Tomcat连接池分析
文章目录 1 Tomcat连接池1.1 简介1.2 架构图1.2.1 JDK线程池架构图1.2.2 Tomcat线程架构 1.3 核心参数1.3.1 AcceptCount1.3.2 MaxConnections1.3.3 MinSpareThread/MaxThread1.3.4 MaxKeepAliveRequests1.3.5 ConnectionTimeout1.3.6 KeepAliveTimeout 1.4 核心内部线程1.4.1 …...

分布式协调服务中的几个常见算法
分布式协调服务中的几个常见算法包括: 1. 选主算法 用于从多个节点中选举出一个节点作为主节点或者领导者,常见的算法有Bully算法、Ring算法等。 2. 原子广播算法 用于向分布式系统中的所有节点广播消息,保证所有节点都可以收到消息,典型的两阶段提交协议实现了原子广播。…...

易服客工作室:Houzez主题 - 超级房地产WordPress主题/网站
Houzez主题是全球流行的房地产经纪人和公司的WordPress主题。 Houzez Theme是专业设计师创造一流设计的超级灵活起点。它具有您的客户(房地产经纪人或公司)甚至可能做梦也想不到的功能。 网址:Houzez主题 - 超级房地产WordPress主题/网站 - …...
mysql通过binlog日志恢复误删数据
1、先查看binlog功能是否开启 show variables like %log_bin%;log_bin为ON说明可以使用binlog恢复,如果为OFF说明没有开启binlog。 2、删除部分数据做测试 3、查找binlog文件位置 show variables like %datadir%;cd /var/lib/mysqlls -l删除数据时间是在文件154与…...
Istio入门体验系列——基于Istio的灰度发布实践
导言:灰度发布是指在项目迭代的过程中用平滑过渡的方式进行发布。灰度发布可以保证整体系统的稳定性,在初始发布的时候就可以发现、调整问题,以保证其影响度。作为Istio体验系列的第一站,本文基于Istio的流量治理机制,…...

CSS行内,内部,外部以及优先级
1.内联样式表: 将样式编写到style标签里 <style>.context {color: red;} </style> 2. 行内样式: 在 HTML 标签中使用 style 属性设置 CSS 样式 <div style"font-size: 18px;">行内样式</div> 3.外联样式࿱…...

LCA——最近公共祖先
LCA问题是指在一棵树中找到两个节点的最近公共祖先。最近公共祖先是指两个节点在树中的最近的共同祖先节点。例如,在下面这棵树中,节点 6 6 6和节点7的最近公共祖先是节点 3 3 3。 1/ \2 3/ \ / \4 5 6 7解决LCA问题的方法有很多种ÿ…...

游戏开发与硬件结合,开启全新游戏体验!
游戏与硬件的结合可以通过多种方式实现,从改善游戏体验到创造全新的游戏玩法。以下是一些常见的游戏与硬件结合的方式: 虚拟现实(VR)和增强现实(AR)技术:VR和AR技术使玩家能够沉浸式地体验游戏…...
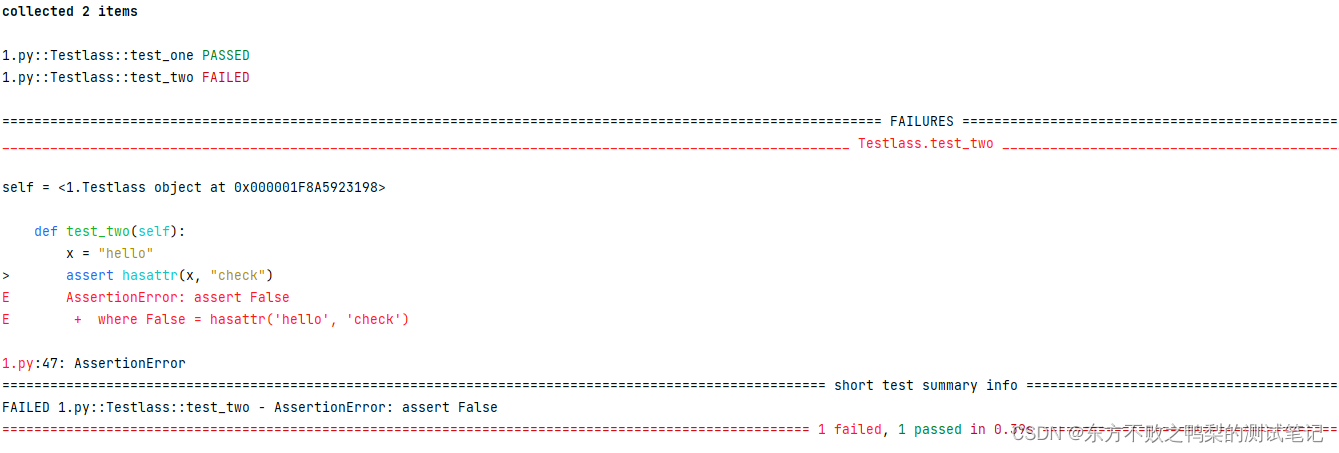
测试框架pytest教程(4)运行测试
运行测试文件 $ pytest -q test_example.py 会运行该文件内test_开头的测试方法 该-q/--quiet标志使输出保持简短 测试类 pytest的测试用例可以不写在类中,但如果写在类中,类名需要是Test开头,非Test开头的类下的test_方法不会被搜集为用…...
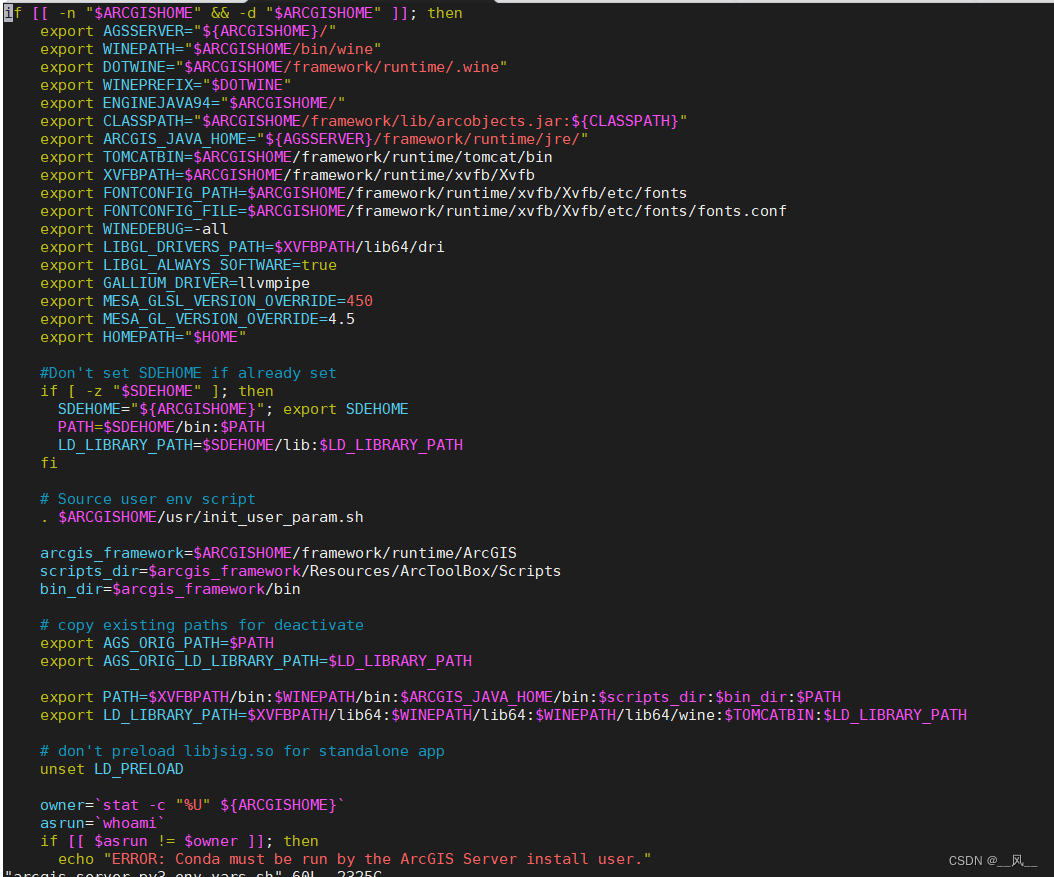
Linux 上 离线部署GeoScene Server Py3 运行时环境
默认安装ArcGIS Pro的时候,会自动部署上Python3环境,所以在windows上不需要考虑这个问题,但是linux默认并不部署Py3,因此需要单独部署,具体部署可以参考Linux 上 ArcGIS Server 的 Python 3 运行时—ArcGIS Server | A…...

Python+request+unittest实现接口测试框架集成实例
这篇文章主要介绍了Pythonrequestunittest实现接口测试框架集成实例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧 1、为什么要写代码实现接口自动化 大家知道很多接口测试工具可以实现对接口的测试…...
django/flask+python+vue汽车租赁管理系统_1ma2x
开发语言:Python 框架:django/flask Python版本:python3.7.7 数据库:mysql 数据库工具:Navicat 开发软件:PyCharm . 课题主要分为三大模块:即管理员模块、用户模块和普通管理员模块࿰…...

胜者打仗,就像高山上决开积水,势不可挡
胜者打仗,就像高山上决开积水,势不可挡 【安志强趣讲《孙子兵法》16讲】 【原文】 是故胜兵先胜而后求战,败兵先战而后求胜。善用兵者,修道而保法,故能为胜败之政。 【注释】 修道:指从各方面修治“先立于不…...

stm32的命令规则
stm32型号的说明:以STM32F103RBT6这个型号的芯片为例,该型号的组成为7个部分,其命名规则如下:...
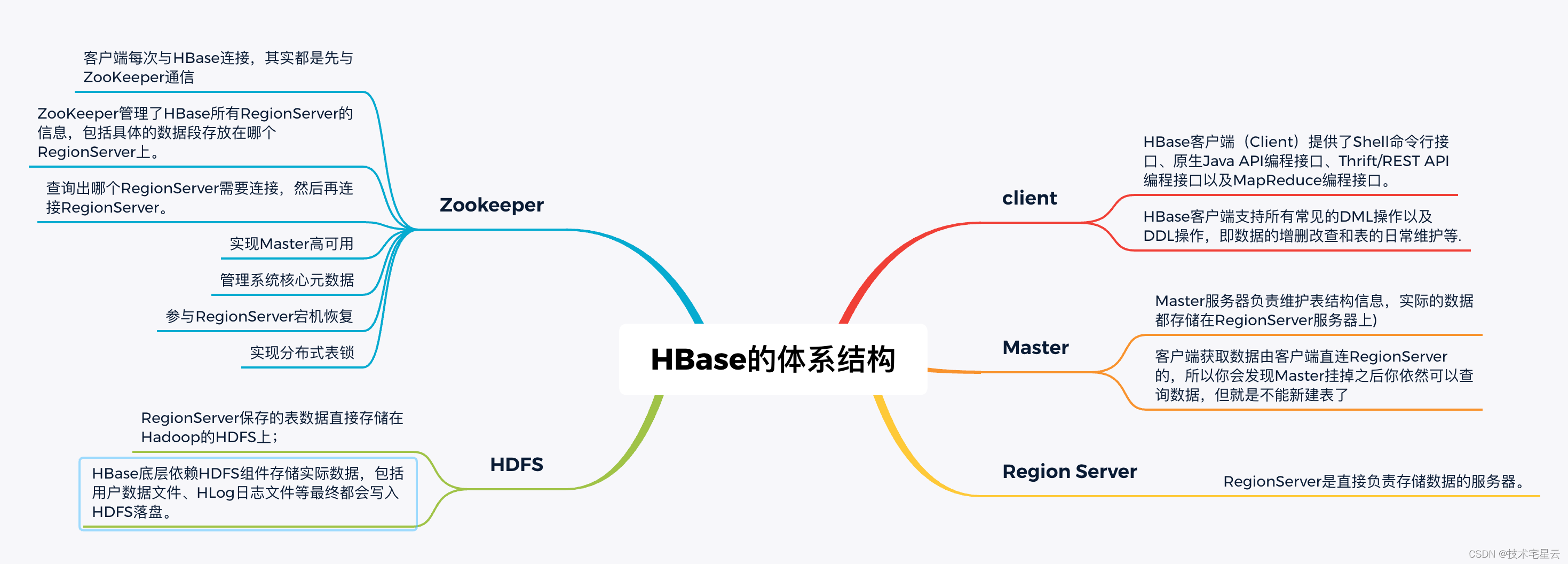
1. HBase中文学习手册之揭开Hbase的神秘面纱
揭开Hbase的神秘面纱 1.1 欢迎使用 Apache Hbase1.1.1 什么是 Hbase?1.1.2 Hbase的前世今生1.1.3 HBase的技术选型?1.1.3.1 不适合使用 HBase的场景1.1.3.2 适合使用 HBase的场景 1.1.4 HBase的特点1.1.4.1 HBase的优点1.1.4.2 HBase的缺点 1.1.5 HBase设计架构 1.…...

高效汉化方案:5分钟让Axure RP全面支持中文界面
高效汉化方案:5分钟让Axure RP全面支持中文界面 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为A…...

如何在Windows上轻松访问Linux分区:Ext2Read终极实用指南
如何在Windows上轻松访问Linux分区:Ext2Read终极实用指南 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否遇到过这样…...

2024最新PHP在线客服系统搭建指南:从宝塔面板配置到AI机器人集成
2024最新PHP在线客服系统搭建指南:从宝塔面板配置到AI机器人集成 在数字化转型浪潮中,实时在线客服系统已成为企业提升客户体验的核心工具。对于中小企业和个人开发者而言,如何快速部署一套功能完善且成本可控的客服解决方案?本文…...

基于Dify平台的Fish-Speech-1.5应用开发:零代码语音合成方案
基于Dify平台的Fish-Speech-1.5应用开发:零代码语音合成方案 1. 引言 想象一下,你只需要一段10秒的语音样本,就能让AI模仿这个声音说出任何你想要的内容——无论是中文、英文还是日语,都能保持原汁原味的语音特色。这就是Fish-S…...

Nanbeige 4.1-3B部署案例:中小企业私有化部署AI客服像素前端
Nanbeige 4.1-3B部署案例:中小企业私有化部署AI客服像素前端 1. 项目背景与价值 在中小企业数字化转型浪潮中,AI客服系统已成为提升服务效率的关键工具。传统AI客服界面往往过于单调,缺乏品牌特色和用户吸引力。Nanbeige 4.1-3B像素前端正是…...
)
Raycast 插件开发实战:从零到一实现中文 OCR 功能(含百度 API 配置指南)
Raycast 插件开发实战:从零构建中文OCR工具 引言 在效率工具领域,Raycast正以惊人的速度崛起。这款macOS平台的效率启动器不仅继承了Spotlight的快速响应特性,更通过开放的插件生态系统为用户提供了无限可能。作为一名长期关注生产力工具的…...

Pensieve代码覆盖率分析:提高项目稳定性的终极指南
Pensieve代码覆盖率分析:提高项目稳定性的终极指南 【免费下载链接】pensieve A passive recording project allows you to have complete control over your data. Automatically take screenshots of all your screens, index them, and save them locally. 项目…...

CVTE社招面试经验:Linux驱动与Android底层开发岗
该项目文档内容为CVTE公司社招面试记录,属于求职经验分享类文本,不包含任何嵌入式硬件设计、原理图、PCB、BOM、固件代码或可复现技术实现要素。其核心内容为Linux内核驱动与Android底层开发岗位的面试问答摘要,无硬件项目属性,不…...

技术迭代背景下B端拓客号码核验的困境与发展路径氪迹科技法人股东决策人号码核验系统
B端拓客精细化运营的深化,使得企业核心决策人(法人、股东、董监高)号码的核验与筛选,成为影响拓客成效的关键前置环节。其服务质量直接关联拓客投入产出比,更是各类拓客主体实现规模化发展的重要支撑。当前,…...

CoPaw模型版本管理与回滚实战:使用MLflow跟踪实验
CoPaw模型版本管理与回滚实战:使用MLflow跟踪实验 1. 为什么需要模型版本管理 在AI项目的实际开发中,模型迭代是家常便饭。你可能遇到过这种情况:上周的模型效果明明很好,这周更新后指标却突然下降,想找回之前的版本…...