【三维重建】【深度学习】NeuS代码Pytorch实现--测试阶段代码解析(上)
【三维重建】【深度学习】NeuS代码Pytorch实现–测试阶段代码解析(上)
论文提出了一种新颖的神经表面重建方法,称为NeuS,用于从2D图像输入以高保真度重建对象和场景。在NeuS中建议将曲面表示为有符号距离函数(SDF)的零级集,并开发一种新的体绘制方法来训练神经SDF表示,因此即使没有掩模监督,也可以实现更准确的表面重建。NeuS在高质量的表面重建方面的性能优于现有技术,特别是对于具有复杂结构和自遮挡的对象和场景。本篇博文将根据代码执行流程解析测试阶段具体的功能模块代码。
文章目录
- 【三维重建】【深度学习】NeuS代码Pytorch实现--测试阶段代码解析(上)
- 前言
- save_checkpoint
- validate_image
- gen_rays_at
- validate_mesh
- extract_geometry
- extract_fields
- 总结
前言
在详细解析NeuS网络之前,首要任务是搭建NeuS【win10下参考教程】所需的运行环境,并完成模型的训练和测试,展开后续工作才有意义。
本博文将对NeuS测试阶段涉及的功能代码模块进行解析。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
这里的代码段是exp_runner.py文件的train函数部分,它是在属于广义上的训练阶段的一部分,但是由于不参与NeuS网络的更新,只是对NeuS网络进行阶段性验证,因此博主放到该博文中进行详细讲解。
if self.iter_step % self.save_freq == 0:self.save_checkpoint()if self.iter_step % self.val_freq == 0:self.validate_image()if self.iter_step % self.val_mesh_freq == 0:self.validate_mesh()self.update_learning_rate()if self.iter_step % len(image_perm) == 0:image_perm = self.get_image_perm()
save_checkpoint
属于exp_runner.py文件的Runner类中的成员方法,目的是保存完成阶段训练的NeuS权重。
def save_checkpoint(self):checkpoint = {'nerf': self.nerf_outside.state_dict(), # 各深度学习网络参数权重'sdf_network_fine': self.sdf_network.state_dict(),'variance_network_fine': self.deviation_network.state_dict(),'color_network_fine': self.color_network.state_dict(),'optimizer': self.optimizer.state_dict(), # 优化器'iter_step': self.iter_step, # 训练的次数}# 创建放置权重模型的文件夹os.makedirs(os.path.join(self.base_exp_dir, 'checkpoints'), exist_ok=True)# 保存torch.save(checkpoint, os.path.join(self.base_exp_dir, 'checkpoints', 'ckpt_{:0>6d}.pth'.format(self.iter_step)))
validate_image
阶段性的完成NeuS模型训练后,需要渲染图片并与真实的训练图片进行比较从而验证模型训练的效果。
首先需要gen_rays_at函数生成整张图片(下采样后)的光线rays,然后获取rays光线上采样点(前景)的最远点和最近点,最后通过renderer函数获取所需的结果。
def validate_image(self, idx=-1, resolution_level=-1):# 假设验证图像的序号小于0,随机获取一个图片序号if idx < 0:idx = np.random.randint(self.dataset.n_images)print('Validate: iter: {}, camera: {}'.format(self.iter_step, idx))if resolution_level < 0:# 下采样倍数resolution_level = self.validate_resolution_level# [W, H, 3]rays_o, rays_d = self.dataset.gen_rays_at(idx, resolution_level=resolution_level)H, W, _ = rays_o.shape# 按照batch_size切分,[W*H,3]=>tuple形式:W*H/batch_size个[batch_size, 3]rays_o = rays_o.reshape(-1, 3).split(self.batch_size)rays_d = rays_d.reshape(-1, 3).split(self.batch_size)out_rgb_fine = []out_normal_fine = []for rays_o_batch, rays_d_batch in zip(rays_o, rays_d):# 最近点和最远点near, far = self.dataset.near_far_from_sphere(rays_o_batch, rays_d_batch)# 背景颜色background_rgb = torch.ones([1, 3]) if self.use_white_bkgd else Nonerender_out = self.renderer.render(rays_o_batch,rays_d_batch,near,far,cos_anneal_ratio=self.get_cos_anneal_ratio(),background_rgb=background_rgb)def feasible(key): return (key in render_out) and (render_out[key] is not None)# 前景颜色if feasible('color_fine'):out_rgb_fine.append(render_out['color_fine'].detach().cpu().numpy())# 梯度信息和采样点权重if feasible('gradients') and feasible('weights'):n_samples = self.renderer.n_samples + self.renderer.n_importance# 梯度信息权重加成normals = render_out['gradients'] * render_out['weights'][:, :n_samples, None] # [batch_size,n_samples,3]# 采样点是否在球体内if feasible('inside_sphere'):# 只保留采样点在球体内的部分normals = normals * render_out['inside_sphere'][..., None] # [batch_size,n_samples,3]# normals是带有权重的有效梯度信息normals = normals.sum(dim=1).detach().cpu().numpy() # [batch_size,3]out_normal_fine.append(normals)del render_out
gen_rays_at
Dataset数据管理器的定义的函数,在models/dataset.py文件下。博主【NeuS总览】的博文中,已经简单介绍过这个过程。
def gen_rays_at(self, img_idx, resolution_level=1):"""Generate rays at world space from one camera.一个摄影机在世界空间中生成光线"""# 下采样倍数l = resolution_level# 获取2D图像上所有的像素点(下采样后的)tx = torch.linspace(0, self.W - 1, self.W // l)ty = torch.linspace(0, self.H - 1, self.H // l)# 生成网格用于生成坐标pixels_x, pixels_y = torch.meshgrid(tx, ty) # [W, H]# 相机坐标系下的方向向量:内参(逆)×像素坐标系p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # [W, H, 3]p = torch.matmul(self.intrinsics_all_inv[img_idx, None, None, :3, :3], p[:, :, :, None]).squeeze() # [W, H, 3]# 单位方向向量:对方向向量做归一化处理rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # [W, H, 3]# 世界坐标系下的方向向量:外参(逆)×相机坐标系rays_v = torch.matmul(self.pose_all[img_idx, None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # [W, H, 3]# 世界坐标系下的光心位置(外参的逆对应的平移矩阵t)rays_o = self.pose_all[img_idx, None, None, :3, 3].expand(rays_v.shape) # [W, H, 3]return rays_o.transpose(0, 1), rays_v.transpose(0, 1) # [H, W, 3]
代码的执行示意图如下图所示,函数返回了rays_o(光心)和rays_v(单位方向向量)。

注意区分训练过程和验证过程生成光线rays的不同,训练过程中是随机选取batch_size个像素点从而生成穿过这些像素点的光线rays,而验证过程是需要选取整个图片的所有像素点从而生成穿过整个图片像素点的光线rays。
validate_mesh
阶段性的完成NeuS模型训练后,同样需要三维重建出实物模型从而验证模型训练的效果。
首先需要划定重建的空间范围,然后通过绘制算法获取顶点坐标和面索引,最后输出实际的三维模型文件。
def validate_mesh(self, world_space=False, resolution=64, threshold=0.0):# 获取提取域(方体)的对角线顶点bound_min = torch.tensor(self.dataset.object_bbox_min, dtype=torch.float32)bound_max = torch.tensor(self.dataset.object_bbox_max, dtype=torch.float32)# 面绘制算法获取vertices顶点坐标和triangles面索引vertices, triangles =\self.renderer.extract_geometry(bound_min, bound_max, resolution=resolution, threshold=threshold)os.makedirs(os.path.join(self.base_exp_dir, 'meshes'), exist_ok=True)if world_space:# 再次缩放位移vertices = vertices * self.dataset.scale_mats_np[0][0, 0] + self.dataset.scale_mats_np[0][:3, 3][None]# 表示和操作三角网格模型mesh = trimesh.Trimesh(vertices, triangles)# 保存mesh模型mesh.export(os.path.join(self.base_exp_dir, 'meshes', '{:0>8d}.ply'.format(self.iter_step)))logging.info('End')
下图展示的是bound_min 和bound_max划定了三维重建范围。
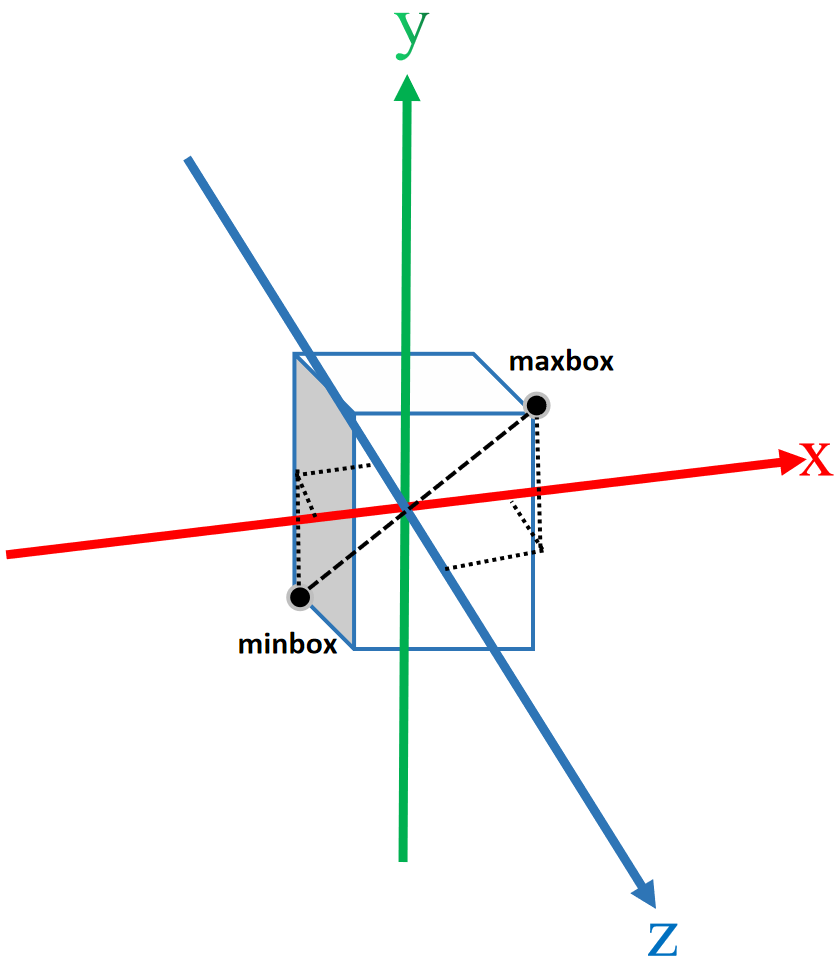
这里提醒一下,三维重建的范围和渲染成二维图片的范围是不一样的,都是各自有各自的设定,别搞混了。
extract_geometry
都在models/renderer.py文件下,这里源码作者做了个套娃,前一个extract_geometry是属于NeuSRenderer类的类成员方法,后一个是独立的函数。
def extract_geometry(self, bound_min, bound_max, resolution, threshold=0.0):return extract_geometry(bound_min,bound_max,resolution=resolution,threshold=threshold,query_func=lambda pts: -self.sdf_network.sdf(pts))
marching_cubes面绘制算法参考,extract_fields是为了获得三维重建范围每个点的sdf值。
def extract_geometry(bound_min, bound_max, resolution, threshold, query_func):print('threshold: {}'.format(threshold))# 获取提取域多的sdfu = extract_fields(bound_min, bound_max, resolution, query_func)# 面绘制算法# vertices 顶点坐标[N,3] N是根据具有情况而通过算法得出,与其他无关# triangles 面索引[M,3] 索引指向顶点坐标数组中的对应顶点,3个顶点一个面vertices, triangles = mcubes.marching_cubes(u, threshold)# 提取域的对角顶点b_max_np = bound_max.detach().cpu().numpy() # [3]b_min_np = bound_min.detach().cpu().numpy() # [3]# 缩小位移vertices = vertices / (resolution - 1.0) * (b_max_np - b_min_np)[None, :] + b_min_np[None, :]return vertices, triangles
extract_fields
该函数的作用是在三维重建范围内获取到合适的提取点(体素),并为每个提取点(体素)的计算出对应的sdf值。
def extract_fields(bound_min, bound_max, resolution, query_func):N = 64# 根据提取域(方体)的对角顶点,获取提取域在各xyz轴的范围(max-min)和单位刻度((max-min)/resolution)X = torch.linspace(bound_min[0], bound_max[0], resolution).split(N)Y = torch.linspace(bound_min[1], bound_max[1], resolution).split(N)Z = torch.linspace(bound_min[2], bound_max[2], resolution).split(N)# 初始化对应方体的sdf值u = np.zeros([resolution, resolution, resolution], dtype=np.float32)with torch.no_grad():for xi, xs in enumerate(X):for yi, ys in enumerate(Y):for zi, zs in enumerate(Z):# 网格化xx, yy, zz = torch.meshgrid(xs, ys, zs) # [N,N,N]# [N^3,3]pts = torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1), zz.reshape(-1, 1)], dim=-1)# 找到对应点的sdfval = query_func(pts).reshape(len(xs), len(ys), len(zs)).detach().cpu().numpy()# 为方体正确的赋sdf值u[xi * N: xi * N + len(xs), yi * N: yi * N + len(ys), zi * N: zi * N + len(zs)] = valreturn u
代码的执行示意图如下图所示,橙色方块就是提取点(体素),可以根据划分要求更细致的划分出更小的提取点(体素)。
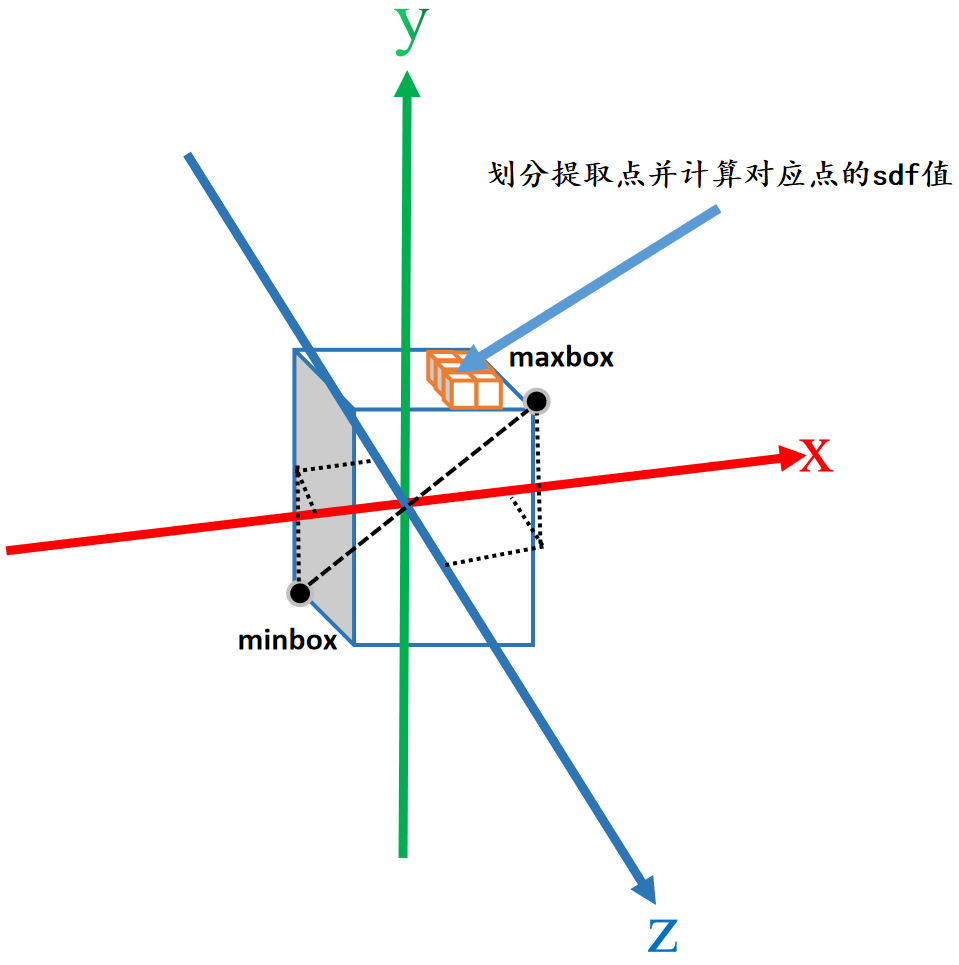
总结
尽可能简单、详细的介绍NeuS测试阶段部分代码:validate_image渲染图片和validate_mesh重建模型的过程。后续会讲解测试阶段的剩余代码。
相关文章:
【三维重建】【深度学习】NeuS代码Pytorch实现--测试阶段代码解析(上)
【三维重建】【深度学习】NeuS代码Pytorch实现–测试阶段代码解析(上) 论文提出了一种新颖的神经表面重建方法,称为NeuS,用于从2D图像输入以高保真度重建对象和场景。在NeuS中建议将曲面表示为有符号距离函数(SDF)的零级集,并开发一种新的体绘…...
day-24 代码随想录算法训练营(19)回溯part01
77.组合 思路一:回溯相当于枚举,所以我们遍历1-n的每一个数字,然后在遍历第i位的同时递归出第i1~n位的组合结果,跟树的形式相似。 如上图所示,当长度为k时,即退出递归可对遍历到第i位以及剩下位数与k进行比…...

Redis之SYNC与PSYNC命令
一、复制SYNC与PSYNC 在Redis主从架构中,主要有以下两种情形需要进行数据同步 (1)当新的服务器执行slave of 命令,成为主服务器的从服务器。这时候从服务器会向主服务器发送SYNC命令,请求全量同步数据,主服…...

共创无线物联网数字化新模式|协创数据×企企通采购与供应链管理平台项目成功上线
近日,全球无线物联网领先者『协创数据技术股份有限公司』(以下简称“协创数据”)SRM采购与供应链项目全面上线,并于近日与企企通召开成功召开项目上线总结会。 基于双方资源和优势,共同打造了物联网特色的数字化采购供…...

【深入理解jvm读书笔记】jvm如何进行内存分配
jvm如何进行内存分配 内存分配方式内存分配方式的选择并发场景下的内存分配内存空间的初始化构造函数 内存分配方式 指针碰撞空闲列表 指针碰撞法: 假设Java堆中内存是绝对规整的,所有被使用过的内存都被放在一边,空闲的内存被放在另一边&a…...
OpenCV使用CMake和MinGW-w64的编译安装
OpenCV使用CMake和MinGW-w64的编译安装中的问题 问题:gcc: error: long: No such file or directory** C:\PROGRA~2\Dev-Cpp\MinGW64\bin\windres.exe: preprocessing failed. modules\core\CMakeFiles\opencv_core.dir\build.make:1420: recipe for target ‘modul…...
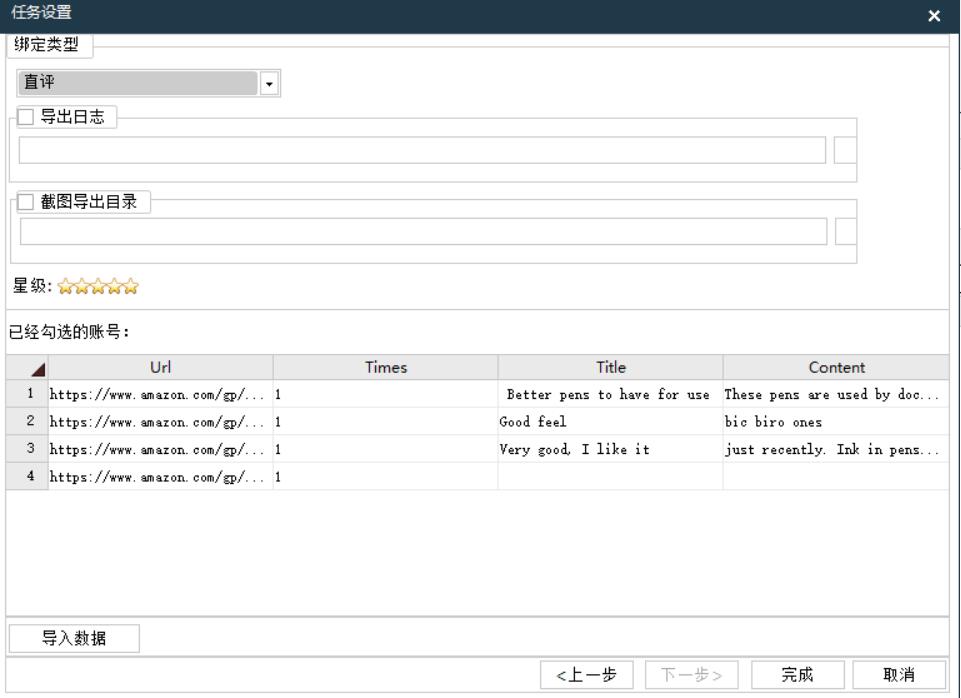
亚马逊买家怎么留评
亚马逊买家可以按照以下步骤在购买后留下产品评价: 1、登录亚马逊账户:首先,在网页浏览器中打开亚马逊网站,登录你的亚马逊账户。 2、找到订单:在页面上找到并点击你购买过的商品的"我的订单"或"订单…...
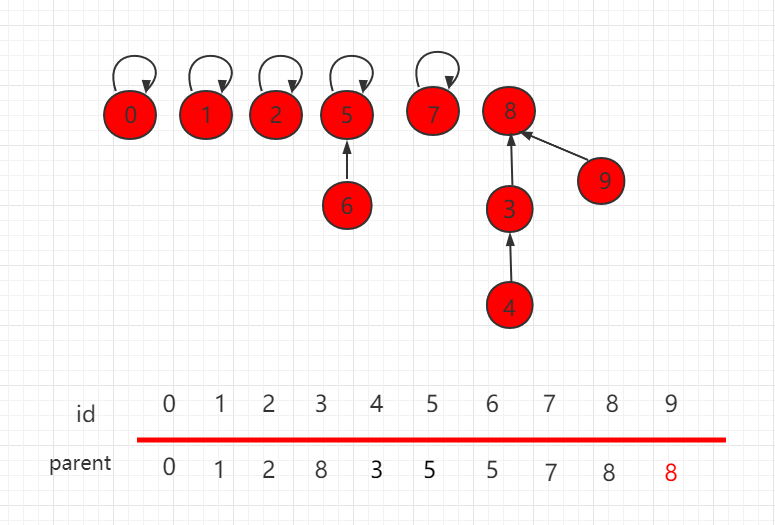
并查集 size 的优化(并查集 size 的优化)
目录 并查集 size 的优化 Java 实例代码 UnionFind3.java 文件代码: 并查集 size 的优化 按照上一小节的思路,我们把如下图所示的并查集,进行 union(4,9) 操作。 合并操作后的结构为: 可以发现,这个结构的树的层相对…...
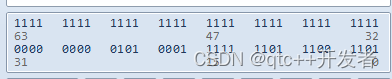
Qt关于hex转double,或者QByteArray转double
正常的00 ae 02 33这种类型的hex数据类型可以直接通过以下代码进行转换 double QDataConversion::hexToDouble(QByteArray p_buf) {double retValue 0;if(p_buf.size()>4){QString str1 byteArrayToHexStr(p_buf.mid(0,1));QString str2 byteArrayToHexStr(p_buf.mid(1,…...
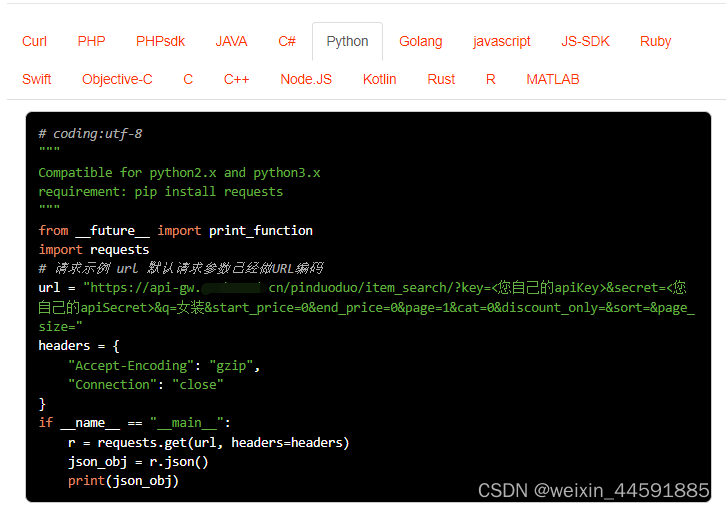
Java“牵手”根据关键词搜索(分类搜索)拼多多商品列表页面数据获取方法,拼多多API实现批量商品数据抓取示例
拼多多商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取拼多多商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问拼多多商城的网页来获取商品列表和详情信息。以下是两种常用方…...

Linux相关知识点
Linux是什么? Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的UNIX工具软件、应用程序和网络协议。它支持32位和64位硬件。 Linux内核 是一个Linux系统的内核&…...

常见的的数据结构
数组(Array):一组按顺序排列的元素的集合,可以通过索引访问和修改元素。 链表(Linked List):由一系列节点组成的数据结构,每个节点包含数据和指向下一个节点的指针。 栈࿰…...

专业心理咨询师助你轻装上阵,向内耗说不!
引言 身为技术人,你是否经常感觉自己被掏空了精力,行动力不佳?又或者觉得自己的工作没有成就和意义,工作状态持续不佳?你是否总有一种无法消除的疲惫?即使没有学习、工作,而是选择看剧、刷短视频…...

Ubuntu安装mysql5.7
目录 1. 更新系统软件包2. 安装MySQL 5.73. 启动MySQL 服务4. 设置MySQL root 密码5. 验证MySQL 安装6. 启用远程访问7. 创建新用户8. 为新用户授予权限9. mysql命令 以Ubuntu 18.04系统为例,安装MySQL 5.7。操作步骤如下: 1. 更新系统软件包 sudo apt…...

vue2,使用element中的Upload 上传文件,自定义上传http-request上传,上传附件支持多选,多个文件只发送一次请求,代码里有注释
复制直接使用,组件根据multiple是否多选来返回附件内容,支持多选就返回数据附件,则返回一个附件对象。 //uploadFiles.vue<template><div><el-uploadclass"avatar-uploader"action"#":accept"accep…...

flutter定位简单工具类
import package:permission_handler/permission_handler.dart;class PermissionUtil {/// 获取用户定位权限static Future<bool> getLocationStatus() async {Map<Permission, PermissionStatus> statuses await [Permission.location,].request();return statuse…...
java请求SAP系统,发起soap的xml报文,实体类转换,idea自动生成教程
1、将接口的网页地址,右键保存,然后修改文件后缀为wsdl文件 2、idea全局搜索 wsdl,找到自动转换javabean插件: 3、点击后,选择下载改完后缀的文件(选择): 4、将无用的class文件删除掉 5、请求sap的地址为…...
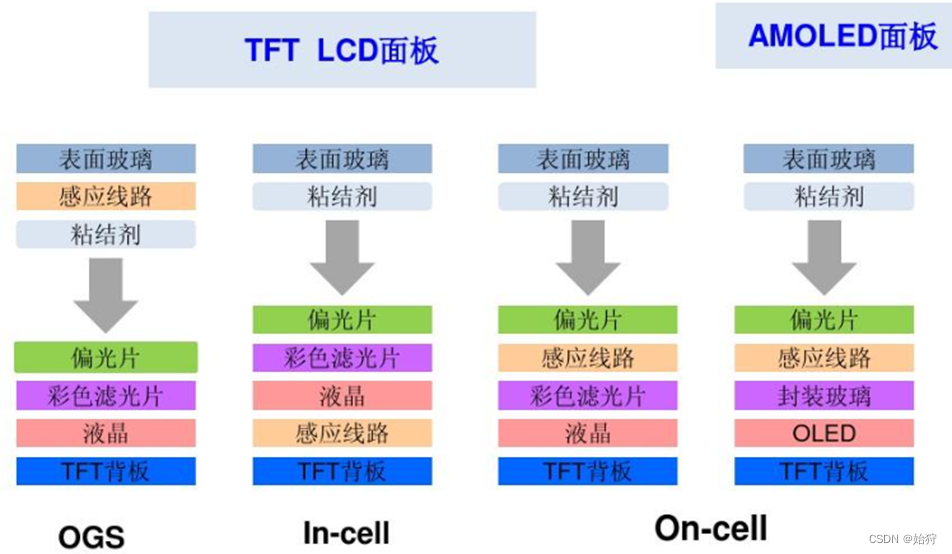
不同屏幕的触控技术
不同显示屏的触控技术原理有所不同。触摸屏的基本原理是,用手指或其他物体触摸安装在显示器前端的触摸屏时,所触摸的位置(以坐标形式)由触摸屏控制器检测,并通过接口(如RS-232串行口)送到CPU,从而确定输入的信息。 目前市场上常…...

深度解读thenable
在学习promise时,我们经常会遇到thenable一词。关于thenable,目前的资料解读不够通俗易懂,又或者脉络不够清晰,本文主要对thenable进行详细剖析,以便各位参考。笔者希望你能够仅凭这一篇文章,便能深度掌握该…...

原生无限极目录树详细讲解
原生无限级目录树 当涉及到原生的无限级目录树,我们可以使用递归算法来实现。以下是一个使用 JavaScript 实现原生无限级目录树的示例 介绍 原生无限级目录树是一种常见的数据结构,用于组织多层级的目录或分类数据。通过递归算法,我们可以…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...