【BASH】回顾与知识点梳理(三十九)
【BASH】回顾与知识点梳理 三十九
- 三十九. make、tarball、函数库及软件校验
- 39.1 用 make 进行宏编译
- 为什么要用 make
- makefile 的基本语法与变量
- 39.2 Tarball 的管理与建议
- 使用原始码管理软件所需要的基础软件
- Tarball 安装的基本步骤
- 一般 Tarball 软件安装的建议事项 (如何移除?升级?)
- 一个简单的范例、利用 ntp 来示范
- 利用 patch 更新原始码
- 39.3 函式库管理
- 动态与静态函式库
- ldconfig 与 /etc/ld.so.conf
- 程序的动态函式库解析: ldd
- 39.4 检验软件正确性
该系列目录 --> 【BASH】回顾与知识点梳理(目录)
三十九. make、tarball、函数库及软件校验
39.1 用 make 进行宏编译
在本章一开始我们提到过 make 的功能是可以简化编译过程里面所下达的指令,同时还具有很多很方便的功能!那么底下咱们就来试看看使用 make 简化下达编译指令的流程吧!
为什么要用 make
先来想象一个案例,假设我的执行档里面包含了四个原始码文件,分别是 main.c haha.c sin_value.c cos_value.c 这四个文件,这四个文件的目的是:
- main.c :主要的目的是让用户输入角度数据与呼叫其他三支子程序;
- haha.c :输出一堆有的没有的讯息而已;
- sin_value.c :计算使用者输入的角度(360) sin 数值;
- cos_value.c :计算使用者输入的角度(360) cos 数值。
这四个文件目前已无法找到了,所以笔者记录下鸟哥的执行过程
由于这四个文件里面包含了相关性,并且还用到数学函式在里面,所以如果你想要让这个程序可以跑, 那么就需要这样编译:
# 1. 先进行目标文件的编译,最终会有四个 *.o 的档名出现:
[root@study ~]# gcc -c main.c
[root@study ~]# gcc -c haha.c
[root@study ~]# gcc -c sin_value.c
[root@study ~]# gcc -c cos_value.c
# 2. 再进行连结成为执行档,并加入 libm 的数学函式,以产生 main 执行档:
[root@study ~]# gcc -o main main.o haha.o sin_value.o cos_value.o -lm
# 3. 本程序的执行结果,必须输入姓名、360 度角的角度值来计算:
[root@study ~]# ./main
Please input your name: VBird <==这里先输入名字
Please enter the degree angle (ex> 90): 30 <==输入以 360 度角为主的角度
Hi, Dear VBird, nice to meet you. <==这三行为输出的结果喔!
The Sin is: 0.50
The Cos is: 0.87
编译的过程需要进行好多动作啊!而且如果要重新编译,则上述的流程得要重新来一遍,光是找出这些指令就够烦人的了! 如果可以的话,能不能一个步骤就给他完成上面所有的动作呢?那就利用make 这个工具吧! 先试看看在这个目录下建立一个名为 makefile 的文件,内容如下:
# 1. 先编辑 makefile 这个规则文件,内容只要作出 main 这个执行档
[root@study ~]# vim makefile
main: main.o haha.o sin_value.o cos_value.ogcc -o main main.o haha.o sin_value.o cos_value.o -lm
# 注意:第二行的 gcc 之前是 <tab> 按键产生的空格喔!# 2. 尝试使用 makefile 制订的规则进行编译的行为:
[root@study ~]# rm -f main *.o <==先将之前的目标文件去除
[root@study ~]# make
cc -c -o main.o main.c
cc -c -o haha.o haha.c
cc -c -o sin_value.o sin_value.c
cc -c -o cos_value.o cos_value.c
gcc -o main main.o haha.o sin_value.o cos_value.o -lm
# 此时 make 会去读取 makefile 的内容,并根据内容直接去给他编译相关的文件啰!# 3. 在不删除任何文件的情况下,重新执行一次编译的动作:
[root@study ~]# make
make: `main' is up to date.
# 看到了吧!是否很方便呢!只会进行更新 (update) 的动作而已。
或许你会说:『如果我建立一个 shell script 来将上面的所有动作都集结在一起,不是具有同样的效果吗?』呵呵! 效果当然不一样,以上面的测试为例,我们仅写出 main 需要的目标文件,结果 make 会主动的去判断每个目标文件相关的原始码文件,并直接予以编译,最后再直接进行连结的动作! 真的是很方便啊!此外,如果我们更动过某些原始码文件,则 make 也可以主动的判断哪一个原始码与相关的目标文件文件有更新过, 并仅更新该文件,如此一来,将可大大的节省很多编译的时间呢!要知道,某些程序在进行编译的行为时,会消耗很多的 CPU 资源呢!所以说, make 有这些好处:
- 简化编译时所需要下达的指令;
- 若在编译完成之后,修改了某个原始码文件,则 make 仅会针对被修改了的文件进行编译,其他的 object file 不会被更动;
- 最后可以依照相依性来更新 (update) 执行档。
既然 make 有这么多的优点,那么我们当然就得好好的了解一下 make 这个令人关心的家伙啦!而make 里面最需要注意的大概就是那个规则文件,也就是 makefile 这个文件的语法啦!所以底下我们就针对 makefile 的语法来加以介绍啰。
makefile 的基本语法与变量
make 的语法可是相当的多而复杂的,有兴趣的话可以到 GNU 去查阅相关的说明,鸟哥这里仅列出一些基本的规则,重点在于让读者们未来在接触原始码时,不会太紧张啊! 好了,基本的makefile 规则是这样的:
目标(target): 目标文件 1 目标文件 2
<tab> gcc -o 欲建立的执行文件 目标文件 1 目标文件 2
那个目标 (target) 就是我们想要建立的信息,而目标文件就是具有相关性的 object files ,那建立执行文件的语法就是以<tab>按键开头的那一行!特别给他留意喔,『命令行必须要以 tab 按键作为开头』才行!他的规则基本上是这样的:
- 在 makefile 当中的 # 代表批注;
<tab>需要在命令行 (例如 gcc 这个编译程序指令) 的第一个字符;- 目标 (target) 与相依文件(就是目标文件)之间需以『
:』隔开。
同样的,我们以刚刚上一个小节的范例进一步说明,如果我想要有两个以上的执行动作时, 例如下达一个指令就直接清除掉所有的目标文件与执行文件,该如何制作呢?
# 1. 先编辑 makefile 来建立新的规则,此规则的目标名称为 clean :
[root@study ~]# vi makefile
main: main.o haha.o sin_value.o cos_value.ogcc -o main main.o haha.o sin_value.o cos_value.o -lm
clean:rm -f main main.o haha.o sin_value.o cos_value.o
# 2. 以新的目标 (clean) 测试看看执行 make 的结果:
[root@study ~]# make clean <==就是这里!透过 make 以 clean 为目标
rm -rf main main.o haha.o sin_value.o cos_value.o
如此一来,我们的 makefile 里面就具有至少两个目标,分别是 main 与 clean ,如果我们想要建立main 的话,输入『make main』,如果想要清除有的没的,输入『make clean』即可啊!而如果想要先清除目标文件再编译 main 这个程序的话,就可以这样输入:『make clean main』,如下所示:
[root@study ~]# make clean main
rm -rf main main.o haha.o sin_value.o cos_value.o
cc -c -o main.o main.c
cc -c -o haha.o haha.c
cc -c -o sin_value.o sin_value.c
cc -c -o cos_value.o cos_value.c
gcc -o main main.o haha.o sin_value.o cos_value.o -lm
这样就很清楚了吧!但是,你是否会觉得,咦! makefile 里面怎么重复的数据这么多啊!没错!所以我们可以再藉由 shell script 那时学到的『变数』来更简化 makefile 喔:
[root@study ~]# vi makefile
LIBS = -lm
OBJS = main.o haha.o sin_value.o cos_value.o
main: ${OBJS}gcc -o main ${OBJS} ${LIBS}
clean:rm -f main ${OBJS}
与 bash shell script 的语法有点不太相同,变量的基本语法为:
- 变量与变量内容以『=』隔开,同时两边可以具有空格;
- 变量左边不可以有
<tab>,例如上面范例的第一行 LIBS 左边不可以是<tab>; - 变量与变量内容在『
=』两边不能具有『:』; - 在习惯上,变数最好是以『
大写字母』为主; - 运用变量时,以
${变量}或$(变量)使用; - 在该 shell 的
环境变量是可以被套用的,例如提到的CFLAGS这个变数! - 在指令列模式也可以给予变量。
由于 gcc 在进行编译的行为时,会主动的去读取 CFLAGS 这个环境变量,所以,你可以直接在 shell 定义出这个环境变量,也可以在 makefile 文件里面去定义,更可以在指令列当中给予这个咚咚呢!例如:
[root@study ~]# CFLAGS="-Wall" make clean main
# 这个动作在上 make 进行编译时,会去取用 CFLAGS 的变量内容!
也可以这样:
[root@study ~]# vi makefile
LIBS = -lm
OBJS = main.o haha.o sin_value.o cos_value.o
CFLAGS = -Wall
main: ${OBJS}
gcc -o main ${OBJS} ${LIBS}
clean:
rm -f main ${OBJS}
咦!我可以利用指令列进行环境变量的输入,也可以在文件内直接指定环境变量,那万一这个CFLAGS 的内容在指令列与 makefile 里面并不相同时,以那个方式输入的为主?呵呵!问了个好问题啊! 环境变量取用的规则是这样的:
- make 指令列后面加上的环境变量为优先;
- makefile 里面指定的环境变量第二;
- shell 原本具有的环境变量第三。
此外,还有一些特殊的变量需要了解的喔:
$@:代表目前的目标(target)
所以我也可以将 makefile 改成:
[root@study ~]# vi makefile
LIBS = -lm
OBJS = main.o haha.o sin_value.o cos_value.o
CFLAGS = -Wall
main: ${OBJS}gcc -o $@ ${OBJS} ${LIBS} <==那个 $@ 就是 main !
clean:rm -f main ${OBJS}
39.2 Tarball 的管理与建议
Tarball 的安装是可以跨平台的,因为 C 语言的程序代码在各个平台上面是可以共通的, 只是需要的编译程序可能并不相同而已。例如 Linux 上面用 gcc 而 Windows 上面也有相关的 C 编译程序啊~所以呢,同样的一组原始码,既可以在 CentOS Linux 上面编译,也可以在 SuSE Linux 上面编译,当然,也可以在大部分的 Unix 平台上面编译成功的!
使用原始码管理软件所需要的基础软件
从原始码的说明我们晓得要制作一个 binary program 需要很多咚咚的呢!这包括底下这些基础的软件:
- gcc 或 cc 等 C 语言编译程序 (compiler)
没有编译程序怎么进行编译的动作?所以 C compiler 是一定要有的。不过 Linux 上面有众多的编译程序,其中当然以 GNU 的 gcc 是首选的自由软件编译程序啰!事实上很多在 Linux 平台上面发展的软件的原始码,原本就是以 gcc 为底来设计的呢。 - make 及 autoconfig 等软件
一般来说,以 Tarball 方式释出的软件当中,为了简化编译的流程,通常都是配合前几个小节提到的 make 这个指令来依据目标文件的相依性而进行编译。但是我们也知道说 make 需要makefile 这个文件的规则,那由于不同的系统里面可能具有的基础软件环境并不相同, 所以就需要侦测用户的作业环境,好自行建立一个 makefile 文件。这个自行侦测的小程序也必须要藉由autoconfig 这个相关的软件来辅助才行。 - 需要 Kernel 提供的 Library 以及相关的 Include 文件
很多的软件在发展的时候都是直接取用系统核心提供的函式库与 include 文件的,这样才可以与这个操作系统兼容啊!尤其是在『驱动程序方面的模块 』,例如网络卡、声卡、USB 等驱动程序在安装的时候,常常是需要核心提供的相关信息的。在 Red Hat 的系统当中 (包含Fedora/CentOS 等系列) ,这个核心相关的功能通常都是被包含在 kernel-source 或 kernel-header 这些软件名称当中,所以记得要安装这些软件喔!
如果你希望未来可以自行安装一些以Tarball 方式释出的软件时,记得请自行挑选想要安装的软件名称喔!例如在 CentOS 或者是 Red Hat 当中记得选择 Development Tools 以及 Kernel Source Development 等相关字眼的软件群集呢。
在 CentOS 当中,如果你已经有网络可以连上 Internet 的话,那么就可以使用下一章会谈到的 yum 啰! 透过 yum 的软件群组安装功能,你可以这样做:
- 如果是要安装 gcc 等软件开发工具,请使用『 yum groupinstall “Development Tools” 』
- 若待安装的软件需要图形接口支持,一般还需要『 yum groupinstall “X Software Development” 』
- 若安装的软件较旧,可能需要『 yum groupinstall “Legacy Software Development” 』
Tarball 安装的基本步骤
整个安装的基础动作大多是这样的:
- 取得原始档:将 tarball 文件在 /usr/local/src 目录下解压缩;
- 取得步骤流程:进入新建立的目录底下,去查阅 INSTALL 与 README 等相关文件内容 (很重要的步骤!);
- 相依属性软件安装:根据 INSTALL/README 的内容察看并安装好一些相依的软件 (非必要);
- 建立 makefile:以自动侦测程序 (configure 或 config) 侦测作业环境,并建立 Makefile 这个文件;
- 编译:以 make 这个程序并使用该目录下的 Makefile 做为他的参数配置文件,来进行 make (编译或其他) 的动作;
- 安装:以 make 这个程序,并以 Makefile 这个参数配置文件,依据 install 这个目标 (target) 的指定来安装到正确的路径!
我们底下约略提一下大部分的 tarball 软件之安装的指令下达方式:
./configure
这个步骤就是在建立 Makefile这个文件啰!通常程序开发者会写一支 scripts 来检查你的 Linux 系统、相关的软件属性等等,这个步骤相当的重要, 因为未来你的安装信息都是这一步骤内完成的!另外,这个步骤的相关信息应该要参考一下该目录下的 README 或 INSTALL 相关的文件!make clean
make 会读取 Makefile 中关于 clean 的工作。这个步骤不一定会有,但是希望执行一下,因为他可以去除目标文件!因为谁也不确定原始码里面到底有没有包含上次编译过的目标文件 (*.o) 存在,所以当然还是清除一下比较妥当的。 至少等一下新编译出来的执行档我们可以确定是使用自己的机器所编译完成的嘛!make
make 会依据 Makefile 当中的预设工作进行编译的行为!编译的工作主要是进行 gcc 来将原始码编译成为可以被执行的 object files,但是这些 object files 通常还需要一些函式库之类的 link 后,才能产生一个完整的执行档!使用 make 就是要将原始码编译成为可以被执行的可执行文件,而这个可执行文件会放置在目前所在的目录之下, 尚未被安装到预定安装的目录中;- make install
通常这就是最后的安装步骤了,make 会依据 Makefile 这个文件里面关于 install 的项目,将上一个步骤所编译完成的数据给他安装到预定的目录中,就完成安装啦!
请注意,上面的步骤是一步一步来进行的,而其中只要一个步骤无法成功,那么后续的步骤就完全没有办法进行的!
一般 Tarball 软件安装的建议事项 (如何移除?升级?)
通常我们会建议大家将自己安装的软件放置在 /usr/local 下,至于原始码 (Tarball)则建议放置在 /usr/local/src (src 为 source 的缩写)底下啊。
再来,让我们先来看一看 Linux distribution 默认的安装软件的路径会用到哪些?我们以 apache 这个软件来说明的话:
- /etc/httpd
- /usr/lib
- /usr/bin
- /usr/share/man
我们会发现软件的内容大致上是摆在 etc, lib, bin, man 等目录当中,分别代表『配置文件、函式库、执行档、联机帮助档』。
那么你是以 tarball 来安装时呢?如果是放在预设的 /usr/local 里面,由于 /usr/local 原本就默认这几个目录了,所以你的数据就会被放在:
- /usr/local/etc
- /usr/local/bin
- /usr/local/lib
- /usr/local/man
但是如果你每个软件都选择在这个默认的路径下安装的话, 那么所有的软件的文件都将放置在这四个目录当中,因此,如果你都安装在这个目录下的话, 那么未来再想要升级或移除的时候,就会比较难以追查文件的来源啰! 而如果你在安装的时候选择的是单独的目录,例如我将 apache 安装在/usr/local/apache 当中,那么你的文件目录就会变成:
- /usr/local/apache/etc
- /usr/local/apache/bin
- /usr/local/apache/lib
- /usr/local/apache/man
呵呵!单一软件的文件都在同一个目录之下,那么要移除该软件就简单的多了! 只要将该目录移除即可视为该软件已经被移除啰!以上面为例,我想要移除 apache 只要下达『rm -rf /usr/local/apache』就算移除这个软件啦!当然啰,实际安装的时候还是得视该软件的 Makefile 里头的 install 信息才能知道到底他的安装情况为何的。因为例如 sendmail 的安装就很麻烦…
由于 Tarball 在升级与安装上面具有这些特色,亦即 Tarball 在反安装上面具有比较高的难度 (如果你没有好好规划的话~),所以,为了方便 Tarball 的管理,通常鸟哥会这样建议使用者:
- 最好将 tarball 的
原始数据解压缩到/usr/local/src当中; 安装时,最好安装到/usr/local这个默认路径下;- 考虑未来的反安装步骤,最好可以将每个软件单独的安装在 /usr/local 底下;
- 为安装到单独目录的软件之 man page 加入 man path 搜寻:
如果你安装的软件放置到 /usr/local/software/ ,那么 man page 搜寻的设定中,可能就得要在/etc/man_db.conf 内的 40~50 行左右处,写入如下的一行:
MANPATH_MAP /usr/local/software/bin /usr/local/software/man
这样才可以使用 man 来查询该软件的在线文件啰!
时至今日,老实说,真的不太需要有 tarball 的安装了!CentOS/Fedora 有个 RPM 补遗计划,就是俗称的 EPEL 计划,相关网址说明如下:
https://fedoraproject.org/wiki/EPEL~一般学界会用到的软件都在里头~ 除非你要用的软件是专属软件 (要钱的) 或者是比较冷门的件,否则都有好心的网友帮我们打包好了啦! ^_^
一个简单的范例、利用 ntp 来示范
假设我对这个软件的要求是这样的:
-
假设 ntp-4...tar.gz 这个文件放置在 /root 这个目录下;
-
原始码请解开在 /usr/local/src 底下;
-
我要安装到 /usr/local/ntp 这个目录中;
-
解压缩下载的 tarball ,并参阅 README/INSTALL 文件
[root@study ~]# cd /usr/local/src <==切换目录
[root@study src]# tar -zxvf /root/ntp-4.2.8p3.tar.gz <==解压缩到此目录
ntp-4.2.8p3/ <==会建立这个目录喔!
ntp-4.2.8p3/CommitLog
....(底下省略)....
[root@study src]# cd ntp-4.2.8p3
[root@study ntp-4.2.8p3]# vi INSTALL <==记得 README 也要看一下!
# 特别看一下 28 行到 54 行之间的安装简介!可以了解如何安装的流程喔!
- 检查 configure 支持参数,并实际建置 makefile 规则文件
[root@study ntp*]# ./configure --help | more <==查询可用的参数有哪些--prefix=PREFIX install architecture-independent files in PREFIX--enable-all-clocks + include all suitable non-PARSE clocks:--enable-parse-clocks - include all suitable PARSE clocks:
# 上面列出的是比较重要的,或者是你可能需要的参数功能!
[root@study ntp*]# ./configure --prefix=/usr/local/ntp \
> --enable-all-clocks --enable-parse-clocks <==开始建立 makefile
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
....(中间省略)....
checking for gcc... gcc <==也有找到 gcc 编译程序了!
....(中间省略)....
config.status: creating Makefile <==现在知道这个重要性了吧?
config.status: creating config.h
config.status: creating evconfig-private.h
config.status: executing depfiles commands
config.status: executing libtool commands
一般来说 configure 设定参数较重要的就是那个--prefix=/path了,–prefix 后面接的路径就是『这个软件未来要安装到那个目录去?』如果你没有指定 --prefix=/path 这个参数,通常预设参数就是/usr/local 至于其他的参数意义就得要参考 ./configure --help 了! 这个动作完成之后会产生 makefile 或 Makefile 这个文件。当然啦,这个侦测检查的过程会显示在屏幕上,特别留意关于 gcc 的检查,还有最重要的是最后需要成功的建立起 Makefile 才行!
- 最后开始编译与安装噜!
[root@study ntp*]# make clean; make
[root@study ntp*]# make check
[root@study ntp*]# make install
# 将数据给他安装在 /usr/local/ntp 底下
利用 patch 更新原始码
事实上,当我们发现一些软件的漏洞,通常是某一段程序代码写的不好所致。因此, 所谓的『更新原始码』常常是只有更改部分文件的小部分内容而已。既然如此的话, 那么我们是否可以就那些被更动的文件来进行修改就可以咯?也就是说, 旧版本到新版本间没有更动过的文件就不要理他,仅将有修订过的文件部分来处理即可。
- 测试旧版程序的功能
[root@study ~]# tar -zxvf main-0.1.tgz
[root@study ~]# cd main-0.1
[root@study main-0.1]# make clean main
[root@study main-0.1]# ./main
version 0.1
Please input your name: VBird
Please enter the degree angle (ex> 90): 45
Hi, Dear VBird, nice to meet you.
The Sin is: 0.71
The Cos is: 0.71
与之前的结果非常类似,只是鸟哥将 Makefile 直接给您了!但如果你下达 make install 时,系统会告知没有 install 的 target 啊!而且版本是 0.1 也告知了。那么如何更新到 0.2 版呢?透过这个patch 文件吧!这个文件的内容有点像这样:
- 查阅 patch file 内容
[root@study main-0.1]# vim ~/main_0.1_to_0.2.patch
diff -Naur main-0.1/cos_value.c main-0.2/cos_value.c #
--- main-0.1/cos_value.c 2015-09-04 14:46:59.200444001 +0800
+++ main-0.2/cos_value.c 2015-09-04 14:47:10.215444000 +0800
@@ -7,5 +7,5 @@
{float value;
....(底下省略)....
上面表格内有#的部分,那代表使用 diff 去比较时,被比较的两个文件所在路径,这个路径非常的重要喔! 因为 patch 的基本语法如下:
patch -p 数字 < patch_file
特别留意那个『 -p 数字』,那是与 patch_file 里面列出的文件名有关的信息。假如在 patch_file 第一行写的是这样:
*** /home/guest/example/expatch.old
那么当我下达『 patch -p0 < patch_file 』时,则更新的文件是『 /home/guest/example/expatch.old 』,如果『 patch -p1 < patch_file』,则更新的文件为『home/guest/example/expatch.old』,如果『patch -p4 < patch_file』则更新『expatch.old』,也就是说, **-pxx 那个 xx 代表『拿掉几个斜线(/)』**的意思!这样可以理解了吗? 好了,根据刚刚上头的资料,我们可以发现比较的文件是在 main-0.1/xxx 与main-0.2/xxx , 所以说,如果你是在 main-0.1 底下,并且想要处理更新时,就得要拿掉一个目录 (因为并没有 main-0.2 的目录存在, 我们是在当前的目录进行更新的!),因此使用的是 -p1 才对喔!所以:
- 更新原始码,并且重新编译程序!
[root@study main-0.1]# patch -p1 < ../main_0.1_to_0.2.patch
patching file cos_value.c
patching file main.c
patching file Makefile
patching file sin_value.c
# 请注意,鸟哥目前所在目录是在 main-0.1 底下喔!注意与 patch 文件的相对路径!
# 虽然有五个文件,但其实只有四个文件有修改过喔!上面显示有改过的文件!
[root@study main-0.1]# make clean main
[root@study main-0.1]# ./main
version 0.2
Please input your name: VBird
Please enter the degree angle (ex> 90): 45
Hi, Dear VBird, nice to meet you.
The sin(45.000000) is: 0.71
The cos(45.000000) is: 0.71
# 你可以发现,输出的结果中版本变了,输出信息多了括号 () 喔!
[root@study main-0.1]# make install <==将他安装到 /usr/local/bin 给大家用
cp -a main /usr/local/bin
[root@study main-0.1]# main <==直接输入指令可执行!
[root@study main-0.1]# make uninstall <==移除此软件!
rm -f /usr/local/bin/main
很有趣的练习吧!所以你只要下载 patch file 就能够对你的软件原始码更新了!只不过更新了原始码并非软件就更新!你还是得要将该软件进行编译后,才会是最终正确的软件喔! 因为 patch 的功能主要仅只是更新原始码文件而已!切记切记!此外,如果你 patch 错误呢?没关系的!我们的 patch 是可以还原的啊!透过『 patch -R < ../main_0.1_to_0.2.patch 』就可以还原啦!很有趣吧!
39.3 函式库管理
在我们的 Linux 操作系统当中,函式库是很重要的一个项目。 因为很多的软件之间都会互相取用彼此提供的函式库来进行特殊功能的运作, 例如很多需要验证身份的程序都习惯利用 PAM 这个模块提供的验证机制来实作,而很多网络联机机制则习惯利用 SSL 函式库来进行联机加密的机制。所以说,函式库的利用是很重要的。不过, 函式库又依照是否被编译到程序内部而分为动态与静态函式库,这两者之间有何差异?哪一种函式库比较好? 底下我们就来谈一谈先!
动态与静态函式库
函式库的类型有哪些?依据函式库被使用的类型而分为两大类,分别是静态(Static) 与动态 (Dynamic) 函式库两类。底下我们来谈一谈这两种类行的函式库吧!
-
静态函式库的特色:
- 扩展名:(
扩展名为 .a)
这类的函式库通常扩展名为 libxxx.a 的类型; - 编译行为:
这类函式库在编译的时候会直接整合到执行程序当中,所以利用静态函式库编译成的文件会比较大一些喔; - 独立执行的状态:
这类函式库最大的优点,就是编译成功的可执行文件可以独立执行,而不需要再向外部要求读取函式库的内容 (请参照动态函式库的说明)。 - 升级难易度:
虽然执行档可以独立执行,但因为函式库是直接整合到执行档中, 因此若函式库升级时,整个执行档必须要重新编译才能将新版的函式库整合到程序当中。 也就是说,在升级方面,只要函式库升级了,所有将此函式库纳入的程序都需要重新编译!
- 扩展名:(
-
动态函式库的特色
- 扩展名:(
扩展名为 .so)
这类函式库通常扩展名为 libxxx.so 的类型; - 编译行为:
动态函式库与静态函式库的编译行为差异挺大的。 与静态函式库被整个捉到程序中不同的,动态函式库在编译的时候,在程序里面只有一个『指向 (Pointer)』的位置而已。也就是说,动态函式库的内容并没有被整合到执行档当中,而是当执行档要使用到函式库的机制时, 程序才会去读取函式库来使用。由于执行文件当中仅具有指向动态函式库所在的指标而已, 并不包含函式库的内容,所以他的文件会比较小一点。 - 独立执行的状态:
这类型的函式库所编译出来的程序不能被独立执行, 因为当我们使用到函式库的机制时,程序才会去读取函式库,所以函式库文件『必须要存在』才行,而且,函式库的『所在目录也不能改变』,因为我们的可执行文件里面仅有『指标』亦即当要取用该动态函式库时, 程序会主动去某个路径下读取,呵呵!所以动态函式库可不能随意移动或删除,会影响很多相依的程序软件喔! - 升级难易度:
虽然这类型的执行档无法独立运作,然而由于是具有指向的功能, 所以,当函式库升级后,执行档根本不需要进行重新编译的行为,因为执行档会直接指向新的函式库文件 (前提是函式库新旧版本的档名相同喔!)。
- 扩展名:(
目前的 Linux distribution 比较倾向于使用动态函式库,因为如同上面提到的最重要的一点, 就是函式库的升级方便!由于 Linux 系统里面的软件相依性太复杂了,如果使用太多的静态函式库,那么升级某一个函式库时, 都会对整个系统造成很大的冲击!因为其他相依的执行档也要同时重新编译啊! 这个时候动态函式库可就有用多了,因为只要动态函式库升级就好,其他的软件根本无须变动。
那么这些函式库放置在哪里呢?绝大多数的函式库都放置在:/lib64, /lib 目录下! 此外,Linux 系统里面很多的函式库其实 kernel 就提供了,那么 kernel 的函式库放在哪里?呵呵!就是在 /lib/modules 里面啦!里面的数据可多着呢!不过要注意的是, 不同版本的核心提供的函式库差异性是挺大的,所以 kernel 2.4.xx 版本的系统不要想将核心换成 2.6.xx 喔! 很容易由于函式库的不同而导致很多原本可以执行的软件无法顺利运作呢!
ldconfig 与 /etc/ld.so.conf
在了解了动态与静态函式库,也知道我们目前的 Linux 大多是将函式库做成动态函式库之后,再来要知道的就是,那有没有办法增加函式库的读取效能? 我们知道内存的访问速度是硬盘的好几倍,所以,如果我们将常用到的动态函式库先加载内存当中 (快取, cache),如此一来,当软件要取用动态函式库时,就不需要从头由硬盘里面读出啰! 这样不就可以增进动态函式库的读取速度?没错,是这样的!这个时候就需要 ldconfig 与 /etc/ld.so.conf 的协助了。
如何将动态函式库加载高速缓存当中呢?
- 首先,我们必须要在 /etc/ld.so.conf 里面写下『 想要读入高速缓存当中的动态函式库所在的目录』,注意喔, 是目录而不是文件;
- 接下来则是利用 ldconfig 这个执行档将 /etc/ld.so.conf 的资料读入快取当中;
- 同时也将数据记录一份在 /etc/ld.so.cache 这个文件当中吶!
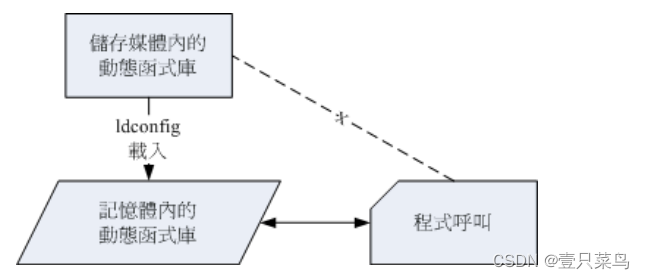
事实上, ldconfig 还可以用来判断动态函式库的链接信息呢!赶紧利用 CentOS 来测试看看。假设妳想要将目前你系统下的 mariadb 函式库加入到快取当中时,可以这样做:
[root@study ~]# ldconfig [-f conf] [ -C cache]
[root@study ~]# ldconfig [-p]
选项与参数:
-f conf :那个 conf 指的是某个文件名,也就是说,使用 conf 作为 libarary 函式库的取得路径,而不以 /etc/ld.so.conf 为默认值
-C cache:那个 cache 指的是某个文件名,也就是说,使用 cache 作为快取暂存的函式库资料,而不以 /etc/ld.so.cache 为默认值
-p :列出目前有的所有函式库资料内容 (在 /etc/ld.so.cache 内的资料!)
# 范例一:假设我的 Mariadb 数据库函式库在 /usr/lib64/mysql 当中,如何读进 cache ?
[root@study ~]# vim /etc/ld.so.conf.d/vbird.conf
/usr/lib64/mysql <==这一行新增的啦!
[root@study ~]# ldconfig <==画面上不会显示任何的信息,不要太紧张!正常的!
[root@study ~]# ldconfig -p
924 libs found in cache `/etc/ld.so.cache'p11-kit-trust.so (libc6,x86-64) => /lib64/p11-kit-trust.solibzapojit-0.0.so.0 (libc6,x86-64) => /lib64/libzapojit-0.0.so.0
....(底下省略)....
# 函式库名称 => 该函式库实际路径
透过上面的动作,我们可以将 Mariadb 的相关函式库给他读入快取当中,这样可以加快函式库读取的效率呢! 在某些时候,你可能会自行加入某些 Tarball 安装的动态函式库,而你想要让这些动态函式库的相关连结可以被读入到快取当中, 这个时候你可以将动态函式库所在的目录名称写入/etc/ld.so.conf.d/yourfile.conf 当中,然后执行 ldconfig 就可以啦!
程序的动态函式库解析: ldd
说了这么多,那么我如何判断某个可执行的 binary 文件含有什么动态函式库呢?很简单,利用 ldd 就可以晓得了!例如我想要知道 /usr/bin/passwd 这个程序含有的动态函式库有哪些,可以这样做:
[root@study ~]# ldd [-vdr] [filename]
选项与参数:
-v :列出所有内容信息;
-d :重新将资料有遗失的 link 点秀出来!
-r :将 ELF 有关的错误内容秀出来!
# 范例一:找出 /usr/bin/passwd 这个文件的函式库数据
[root@study ~]# ldd /usr/bin/passwd
....(前面省略)....libpam.so.0 => /lib64/libpam.so.0 (0x00007f5e683dd000) <==PAM 模块libpam_misc.so.0 => /lib64/libpam_misc.so.0 (0x00007f5e681d8000)libaudit.so.1 => /lib64/libaudit.so.1 (0x00007f5e67fb1000) <==SELinuxlibselinux.so.1 => /lib64/libselinux.so.1 (0x00007f5e67d8c000) <==SELinux
....(底下省略)....
# 我们前言的部分不是一直提到 passwd 有使用到 pam 的模块吗!怎么知道?
# 利用 ldd 察看一下这个文件,看到 libpam.so 了吧?这就是 pam 提供的函式库# 范例二:找出 /lib64/libc.so.6 这个函式的相关其他函式库!
[root@study ~]# ldd -v /lib64/libc.so.6/lib64/ld-linux-x86-64.so.2 (0x00007f7acc68f000)linux-vdso.so.1 => (0x00007fffa975b000)Version information: <==使用 -v 选项,增加显示其他版本信息!/lib64/libc.so.6:ld-linux-x86-64.so.2 (GLIBC_2.3) => /lib64/ld-linux-x86-64.so.2ld-linux-x86-64.so.2 (GLIBC_PRIVATE) => /lib64/ld-linux-x86-64.so.2
39.4 检验软件正确性
目前有多种机制可以计算文件的指纹码,我们选择使用较为广泛的 MD5, SHA1 或 SHA256 加密机制来处理
[root@study ~]# md5sum/sha1sum/sha256sum [-bct] filename
[root@study ~]# md5sum/sha1sum/sha256sum [--status|--warn] --check filename
选项与参数:
-b :使用 binary 的读档方式,默认为 Windows/DOS 文件型态的读取方式;
-c :检验文件指纹;
-t :以文字型态来读取文件指纹。
# 范例一:将刚刚的文件下载后,测试看看指纹码
[root@study ~]# md5sum ntp-4.2.8p3.tar.gz
b98b0cbb72f6df04608e1dd5f313808b ntp-4.2.8p3.tar.gz
# 看!显示的编码是否与上面相同呢?赶紧测试看看!
一般而言,每个系统里面的文件内容大概都不相同,例如你的系统中的 /etc/passwd 这个登入信息文件与我的一定不一样,因为我们的用户与密码、 Shell 及家目录等大概都不相同,所以由 md5sum 这个文件指纹分析程序所自行计算出来的指纹表当然就不相同啰!
好了,那么如何应用这个东西呢?基本上,你必须要在你的 Linux 系统上为你的这些重要的文件进行指纹数据库的建立 (好像在做户口调查!),将底下这些文件建立数据库:
- /etc/passwd
- /etc/shadow (假如你不让用户改密码了)
- /etc/group
- /usr/bin/passwd
- /sbin/rpcbind
- /bin/login (这个也很容易被骇!)
- /bin/ls
- /bin/ps
- /bin/top
这几个文件最容易被修改了!因为很多木马程序执行的时候,还是会有所谓的『执行序, PID』为了怕被 root 追查出来,所以他们都会修改这些检查排程的文件,如果你可以替这些文件建立指纹数据库 (就是使用 md5sum 检查一次,将该文件指纹记录下来,然后常常以 shell script 的方式由程序自行来检查指纹表是否不同了!),那么对于文件系统会比较安全啦!
该系列目录 --> 【BASH】回顾与知识点梳理(目录)
相关文章:
【BASH】回顾与知识点梳理(三十九)
【BASH】回顾与知识点梳理 三十九 三十九. make、tarball、函数库及软件校验39.1 用 make 进行宏编译为什么要用 makemakefile 的基本语法与变量 39.2 Tarball 的管理与建议使用原始码管理软件所需要的基础软件Tarball 安装的基本步骤一般 Tarball 软件安装的建议事项 (如何移除…...

蓝蓝设计-UI设计公司案例-HMI列车监控系统界面设计解决方案
2013年,为加拿大庞巴迪(Bombardier)设计列车监控系统界面设计。 2015-至今,为中车集团旗下若干公司提供HMI列车监控系统界面设计,综合考虑中车特点、城轨车、动车组的不同需求以及HMI硬键屏和触摸 屏的不同操作方式,重构框架设计、交互设计、…...

Blazor前后端框架Known-V1.2.13
V1.2.13 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazo…...

vue 复制文本
一个常用的库就是 clipboard.js,它可以帮助您实现跨浏览器的复制到剪贴板功能 首先,安装 clipboard.js: cnpm install clipboard 创建一个 Vue 组件并使用 clipboard.js: <template><div><input v-model"…...
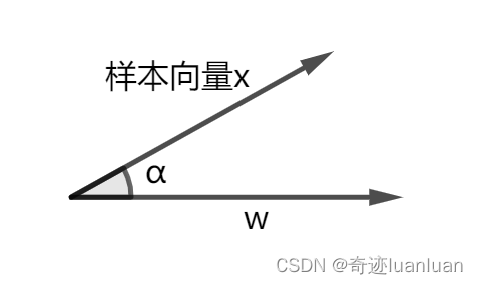
西瓜书第三章
广义线性模型 考虑单点可微函数 g ( ⋅ ) g(\cdot) g(⋅),令 y g − 1 ( ω T x b ) yg^{-1}(\omega^{T}xb) yg−1(ωTxb),这样得到的模型称为“广义线性模型”,其中函数 g ( ⋅ ) g(\cdot) g(⋅)称为“联系函数”。显然,对数线…...

关于python如何使用sqlalchemy连接sap_hana数据库
1.先安装sqlalchemy pip install sqlalchemy 2.from sqlalchemy import create_engine 3.创建数据库连接方式: 假设数据连接方式如下: usernameH_TEOPT passwordww122222 jdbcUrljdbc:sap://192.163.1.161:21681/?currentschema 那么使用sqlalchemy 的…...
)
微信小程序教学系列(5)
微信小程序教学系列 第五章:小程序发布与推广 第一节:小程序发布流程介绍 小伙伴们,欢迎来到第五章的教学啦!在这一章中,我们将一起来探索小程序的发布与推广流程。你准备好了吗?让我们开始吧࿰…...

【计算机网络篇】TCP协议
✅作者简介:大家好,我是小杨 📃个人主页:「小杨」的csdn博客 🐳希望大家多多支持🥰一起进步呀! TCP协议 1,TCP 简介 TCP(Transmission Control Protocol)是…...

Disruptor并发编程框架
Disruptor是一款高性能的并发编程框架,主要具有以下特点和功能: 1. RingBuffer环形数据结构 Disruptor的核心数据结构是RingBuffer环形队列,用于存储客户端的并发数据并在生产者和消费者之间传递。队列以批量方式的顺序存储,可以高效地进行并发读写操作。 2. 无锁设计 Disrup…...

matlab 点云精配准(1)——point to point ICP(点到点的ICP)
目录 一、算法原理参考文献二、代码实现三、结果展示四、参考链接本文由CSDN点云侠原创,爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、算法原理 参考文献 [1] BESL P J,MCKAY N D.A method for registration of 3-Dshapes[J].IEEE Tran…...
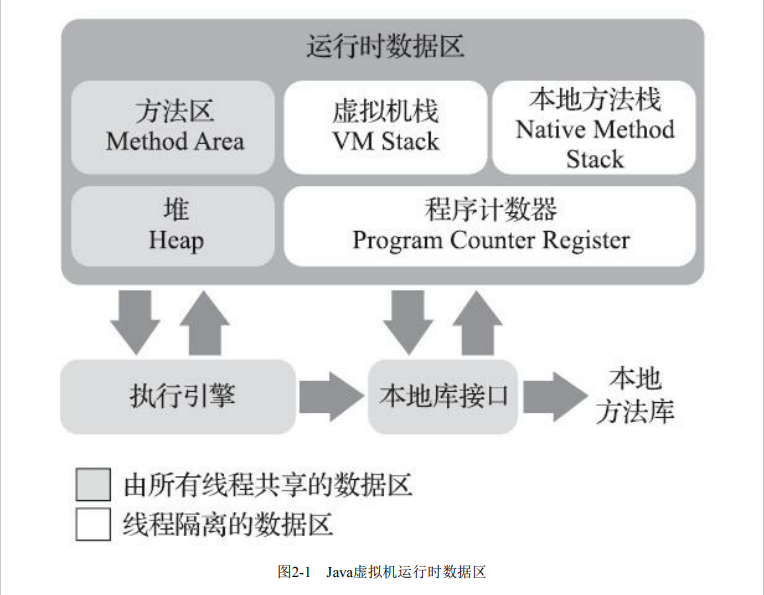
【JVM】运行时数据区域
文章目录 说明程序计数器虚拟机栈本地方法栈Java堆方法区运行时常量池直接内存 说明 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直…...

uniapp踩坑合集
1、onPullDownRefresh下拉刷新不生效 pages.json对应的style中enablePullDownRefresh设置为true,开启下拉刷新 {"path" : "pages/list/list","style" :{"navigationBarTitleText": "页面标题名称","enable…...

再JAVA中如何使用qsort对类进行排序?
目录 结论: 解析: 结论: import java.util.Arrays;class Person implements Comparable<Person>{public String name;public int age;public Person(String name, int age) {this.name name;this.age age;}Overridepublic Stri…...
docker安装clickhouse
安装 docker安装 创建clickhouse目录 mkdir -P /data/clickhouse/datamkdir -P /data/clickhouse/confmkdir -P /data/clickhouse/log 拉取镜像 这里直接拉取最新镜像, 如果需要某个特定版本, 则再拉取的时候指定版本号即可. docker pull clickhouse/clickhouse-server 启动临…...
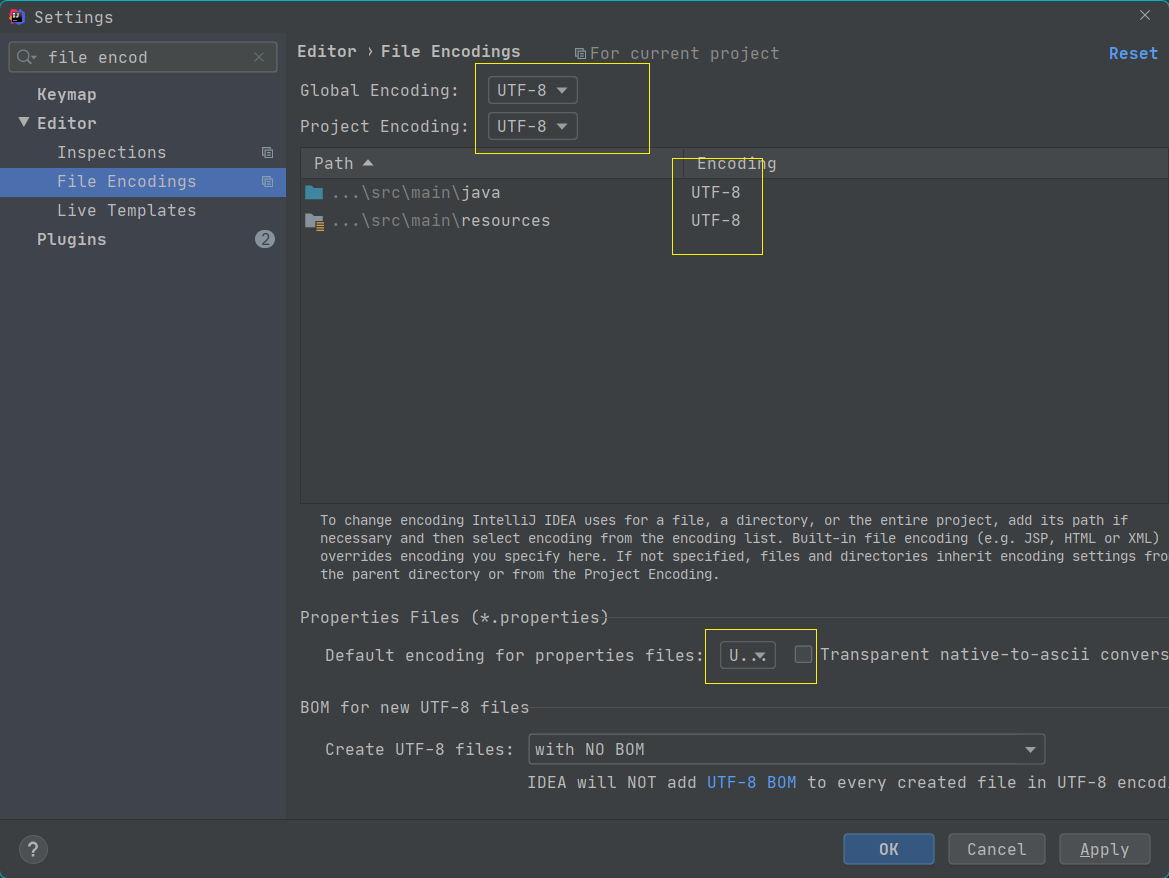
解决`idea`中`database`工具查询起别名乱码问题
文章目录 解决idea中database工具查询起别名乱码问题场景复现如何解决方式一 设置编码方式二:修改字体 原因说明 解决idea中database工具查询起别名乱码问题 场景复现 使用Idea做查询的并且起别名出现了中文乱码 如何解决 方式一 设置编码 settings->输入框输…...
UE4/5Niagara粒子特效之Niagara_Particles官方案例:1.5->2.3
目录 之前的文章: 1.5 Blend Attributes by Value 发射器更新 粒子生成 粒子更新 2.1 Static Beams 编辑 发射器更新: 粒子生成 粒子更新 2.2 Dynamic Beams 没有开始模拟前的效果是: 开始模拟后的效果是: 发射器更新 …...
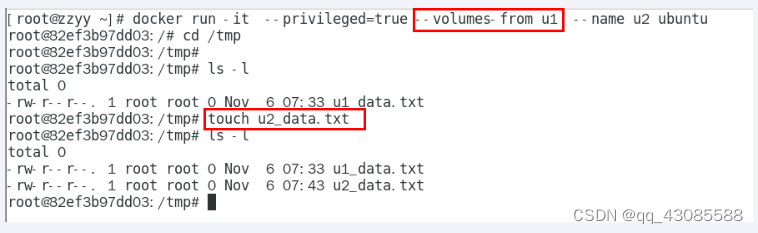
Docker 容器数据卷
Docker挂载主机目录访问如果出现cannot open directory .: Permission denied 解决办法:在挂载目录后多加一个--privilegedtrue参数即可 如果是CentOS7安全模块会比之前系统版本加强,不安全的会先禁止,所以目录挂载的情况被默认为不安全的行…...
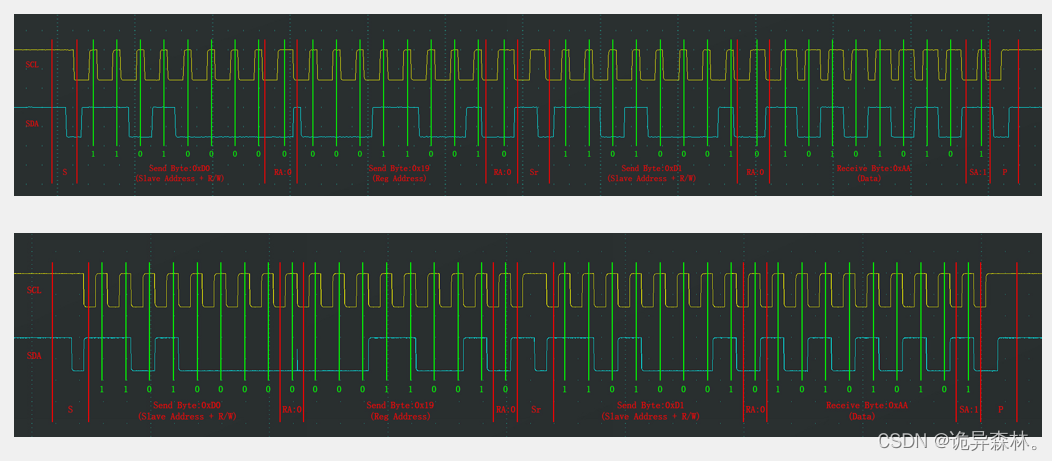
STM32--MPU6050与I2C外设
文章目录 前言MPU6050参数电路MPU6050框图 IIC外设框图 IIC的基本结构软件IIC实现MPU6050硬件IIC实现MPU6050 前言 在51单片机专栏中,用过I2C通信来进行实现AT24C02的数据存储; 里面介绍的是利用程序的编程来实现I2C的时序,进而实现AT24C02与…...

项目管理实战笔记1:项目管理常识
序 看了下极客时间的《项目管理实战》,觉得跟之前学习PMP的标准资料还是有所侧重。重新整理下,相比书上繁杂的知识,这个更通俗易懂。 1 角色转换:三大误区 误区1:事必躬亲 自己做事情是可控的,做项目依赖…...
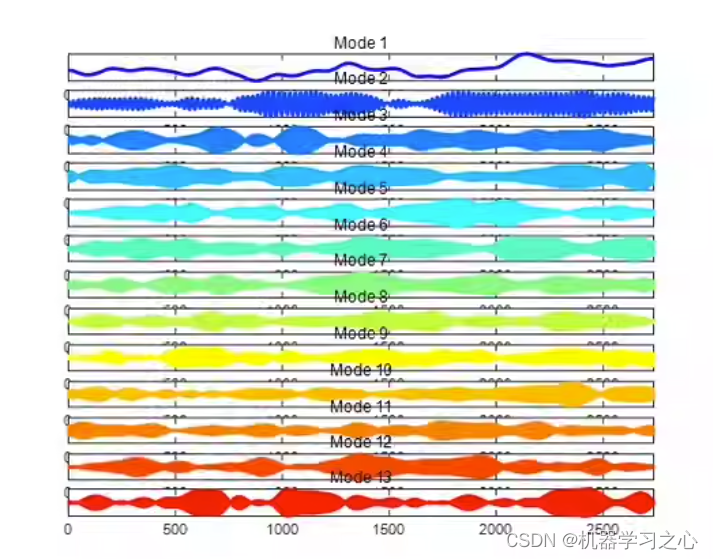
时序分解 | MATLAB实现基于SVMD逐次变分模态分解的信号分解分量可视化
时序分解 | MATLAB实现基于SVMD逐次变分模态分解的信号分解分量可视化 目录 时序分解 | MATLAB实现基于SVMD逐次变分模态分解的信号分解分量可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 SVMD分解算法,分解结果可视化,MATLAB程序ÿ…...

IT自动化运维平台建设解决方案:三阶段演进思路、平台架构与核心能力、关键功能模块、典型自动化场景与执行流程
该方案提出从人工运维向自动化、智能化演进,核心是通过统一平台整合Zabbix监控、脚本管理与工单系统,实现告警自动治愈与周期性任务自动化执行。方案采用分批推进策略,旨在提升效率、保障业务连续性并降低人为风险,最终落地智能化…...

openclaw连接飞书操作表格
01意义 将智能助手从电脑网页端连接到手机飞书,从此无需守在电脑前,用手机就能随时指挥它干活。未来,飞书中需要手动操作的任务,都可以交由 AI 智能助手来完成。它还能帮你构建企业知识库,随着飞书终端 CLI 能力的增强…...

8086 汇编报错全总结与归纳
一、可能遇到的所有错误汇总错误代码错误含义触发行(你的代码)核心根源A2048Must be index or base registermov [ax],1H、add [dx],[ax]8086 硬件不支持用非BX通用寄存器做内存间接寻址A2035Operand must have sizemov [bx],1H汇编器无法判断操作数是 8…...

软件开发常见骗局有哪些?
虚假高薪招聘陷阱以“零经验高薪入职”“包就业”为噱头,要求求职者付费培训。实际培训内容质量低下,承诺的就业机会无法兑现,甚至诱导贷款支付培训费用。外包项目诈骗谎称有高额预算项目外包,要求开发者支付“保证金”或“预付款…...

GitHub被封杀后:开源难民在区块链的逃亡
对于全球软件开发者而言,GitHub不仅是代码仓库,更是数字时代的公共广场与精神家园。然而,近年来一系列地缘政治风波与技术壁垒,使得这片曾经自由的土地不断竖起高墙。从伊朗、俄罗斯开发者账号的全面封禁,到针对特定IP…...

Codesys软运动控制进阶:用SMC_FreeEncoder为ECAT轴搭建一个“虚拟手轮”调试工具
Codesys软运动控制进阶:用SMC_FreeEncoder为ECAT轴搭建虚拟手轮调试工具 在自动化设备开发周期中,机械安装与电气调试往往存在时间差。当机械部件尚未就位或伺服驱动器临时故障时,如何提前验证运动控制逻辑?传统做法是等待硬件就绪…...

douyin-downloader:从素材焦虑到创作自由的抖音内容获取方案
douyin-downloader:从素材焦虑到创作自由的抖音内容获取方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...
)
WinForm实战:C#如何优雅地调用外部exe并传递多个参数(附完整代码示例)
WinForm实战:C#如何优雅地调用外部exe并传递多个参数(附完整代码示例) 在Windows桌面应用开发中,经常需要与其他程序进行交互。想象这样一个场景:你正在开发一个数据可视化工具,需要调用Python脚本处理原始…...

连锁经营行业商旅平台选型指南与测评排名Top 6:多门店与全链路商旅管控方案
2026年4月的第一周,艾美咨询发布了《2026年中国连锁经营行业商旅管理数字化白皮书》,数据显示国内规模以上连锁经营企业的商旅支出占整体运营成本的8.7%,其中私车公用、门店巡检类商旅的合规漏洞造成的浪费占总商旅支出的19.2%,连…...
:银行系统JNI迁移真实压测数据全披露)
Java原生互操作终极方案(JEP 454/459/460深度落地):银行系统JNI迁移真实压测数据全披露
第一章:Java原生互操作终极方案(JEP 454/459/460深度落地):银行系统JNI迁移真实压测数据全披露在某国有大型商业银行核心支付清算子系统中,我们完成了从传统JNI到JEP 454(Foreign Function & Memory AP…...