[oneAPI] 使用字符级 RNN 生成名称
[oneAPI] 使用字符级 RNN 生成名称
- oneAPI特殊写法
- 使用字符级 RNN 生成名称
- Intel® Optimization for PyTorch
- 数据下载
- 加载数据并对数据进行处理
- 创建网络
- 训练过程
- 准备训练
- 训练网络
- 结果
- 参考资料
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
oneAPI特殊写法
import intel_extension_for_pytorch as ipex# Device configuration
device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')rnn = RNN(n_letters, 128, n_letters)
optim = torch.optim.SGD(rnn.parameters(), lr=0.01)'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
rnn, optim = ipex.optimize(rnn, optimizer=optim)criterion = nn.NLLLoss()
使用字符级 RNN 生成名称
为了深入探索语言模型在分类和生成方面的卓越能力,我们特意设计了一个独特的任务。此任务的独特之处在于,它旨在综合学习多种语言的词义特征,以确保生成的内容与各种语言的词组相关性一致。
在任务的具体描述中,我们提供了一个多语言数据集,这个数据集包含多种语言的文本。通过这个数据集,我们的目标是使模型能够在生成名称时融合不同语言的特征。具体来说,我们会提供一个词的开头作为提示,然后模型将能够根据这个开头生成对应语言的名称,从而将不同语言的词意和语法特征进行完美融合。
通过这一任务,我们旨在实现一个在多语言环境中具有卓越生成和分类能力的语言模型。通过学习并融合不同语言的词义和语法特征,我们让使模型具备更广泛的应用潜力,能够在不同语境下生成准确、符合语法规则的名称。
> python sample.py Russian RUS
Rovakov
Uantov
Shavakov> python sample.py German GER
Gerren
Ereng
Rosher> python sample.py Spanish SPA
Salla
Parer
Allan> python sample.py Chinese CHI
Chan
Hang
Iun
Intel® Optimization for PyTorch
在本次实验中,我们利用PyTorch和Intel® Optimization for PyTorch的强大功能,对PyTorch进行了精心的优化和扩展。这些优化举措极大地增强了PyTorch在各种任务中的性能,尤其是在英特尔硬件上的表现更加突出。通过这些优化策略,我们的模型在训练和推断过程中变得更加敏捷和高效,显著地减少了计算时间,提高了整体效能。我们通过深度融合硬件和软件的精巧设计,成功地释放了硬件潜力,使得模型的训练和应用变得更加快速和高效。这一系列优化举措为人工智能应用开辟了新的前景,带来了全新的可能性。
数据下载
从这里下载数据 并将其解压到当前目录。
加载数据并对数据进行处理
简而言之,有一堆data/names/[Language].txt每行都有一个名称的纯文本文件。我们将行分割成一个数组,将 Unicode 转换为 ASCII,最后得到一个字典。{language: [names …]}
from io import open
import glob
import os
import unicodedata
import stringall_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS markerdef findFiles(path): return glob.glob(path)# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn'and c in all_letters)# Read a file and split into lines
def readLines(filename):with open(filename, encoding='utf-8') as some_file:return [unicodeToAscii(line.strip()) for line in some_file]# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
for filename in findFiles('data/names/*.txt'):category = os.path.splitext(os.path.basename(filename))[0]all_categories.append(category)lines = readLines(filename)category_lines[category] = linesn_categories = len(all_categories)if n_categories == 0:raise RuntimeError('Data not found. Make sure that you downloaded data ''from https://download.pytorch.org/tutorial/data.zip and extract it to ''the current directory.')print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
Output:
# categories: 18 ['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']
O'Neal
创建网络
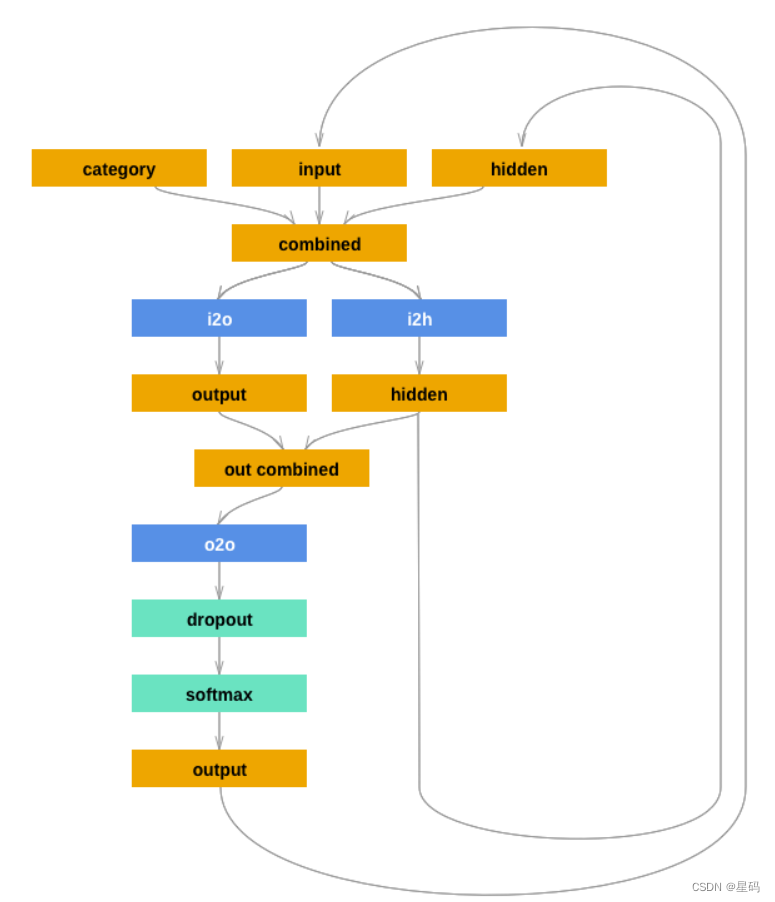
序列到序列网络,或 seq2seq 网络,或编码器解码器网络,是由两个称为编码器和解码器的 RNN 组成的模型。编码器读取输入序列并输出单个向量,解码器读取该向量以产生输出序列。
我添加了第二个线性层o2o(在组合隐藏层和输出层之后)以赋予其更多的功能。还有一个 dropout 层,它以给定的概率(此处为 0.1)随机将部分输入归零,通常用于模糊输入以防止过度拟合。在这里,我们在网络末端使用它来故意添加一些混乱并增加采样多样性。
######################################################################
# Creating the Network
# ====================
import torch
import torch.nn as nnimport intel_extension_for_pytorch as ipexclass RNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNN, self).__init__()self.hidden_size = hidden_sizeself.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)self.o2o = nn.Linear(hidden_size + output_size, output_size)self.dropout = nn.Dropout(0.1)self.softmax = nn.LogSoftmax(dim=1)def forward(self, category, input, hidden):input_combined = torch.cat((category, input, hidden), 1)hidden = self.i2h(input_combined)output = self.i2o(input_combined)output_combined = torch.cat((hidden, output), 1)output = self.o2o(output_combined)output = self.dropout(output)output = self.softmax(output)return output, hiddendef initHidden(self):return torch.zeros(1, self.hidden_size)
训练过程
准备训练
import random# Random item from a list
def randomChoice(l):return l[random.randint(0, len(l) - 1)]# Get a random category and random line from that category
def randomTrainingPair():category = randomChoice(all_categories)line = randomChoice(category_lines[category])return category, line
# One-hot vector for category
def categoryTensor(category):li = all_categories.index(category)tensor = torch.zeros(1, n_categories)tensor[0][li] = 1return tensor# One-hot matrix of first to last letters (not including EOS) for input
def inputTensor(line):tensor = torch.zeros(len(line), 1, n_letters)for li in range(len(line)):letter = line[li]tensor[li][0][all_letters.find(letter)] = 1return tensor# ``LongTensor`` of second letter to end (EOS) for target
def targetTensor(line):letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]letter_indexes.append(n_letters - 1) # EOSreturn torch.LongTensor(letter_indexes)
为了训练过程中的方便,我们将创建一个randomTrainingExample 函数来获取随机(类别、线)对并将它们转换为所需的(类别、输入、目标)张量。
# Make category, input, and target tensors from a random category, line pair
def randomTrainingExample():category, line = randomTrainingPair()category_tensor = categoryTensor(category)input_line_tensor = inputTensor(line)target_line_tensor = targetTensor(line)return category_tensor, input_line_tensor, target_line_tensor
训练网络
criterion = nn.NLLLoss()learning_rate = 0.0005def train(category_tensor, input_line_tensor, target_line_tensor):target_line_tensor.unsqueeze_(-1)hidden = rnn.initHidden()rnn.zero_grad()loss = torch.Tensor([0]) # you can also just simply use ``loss = 0``for i in range(input_line_tensor.size(0)):output, hidden = rnn(category_tensor, input_line_tensor[i], hidden)l = criterion(output, target_line_tensor[i])loss += lloss.backward()for p in rnn.parameters():p.data.add_(p.grad.data, alpha=-learning_rate)return output, loss.item() / input_line_tensor.size(0)
为了跟踪训练需要多长时间,我添加了一个 timeSince(timestamp)返回人类可读字符串的函数:
import time
import mathdef timeSince(since):now = time.time()s = now - sincem = math.floor(s / 60)s -= m * 60return '%dm %ds' % (m, s)
训练就像平常一样 - 多次调用训练并等待几分钟,打印当前时间和每个print_every 示例的损失,并存储每个plot_every示例的平均损失all_losses以供稍后绘制。
rnn = RNN(n_letters, 128, n_letters)n_iters = 100000
print_every = 5000
plot_every = 500
all_losses = []
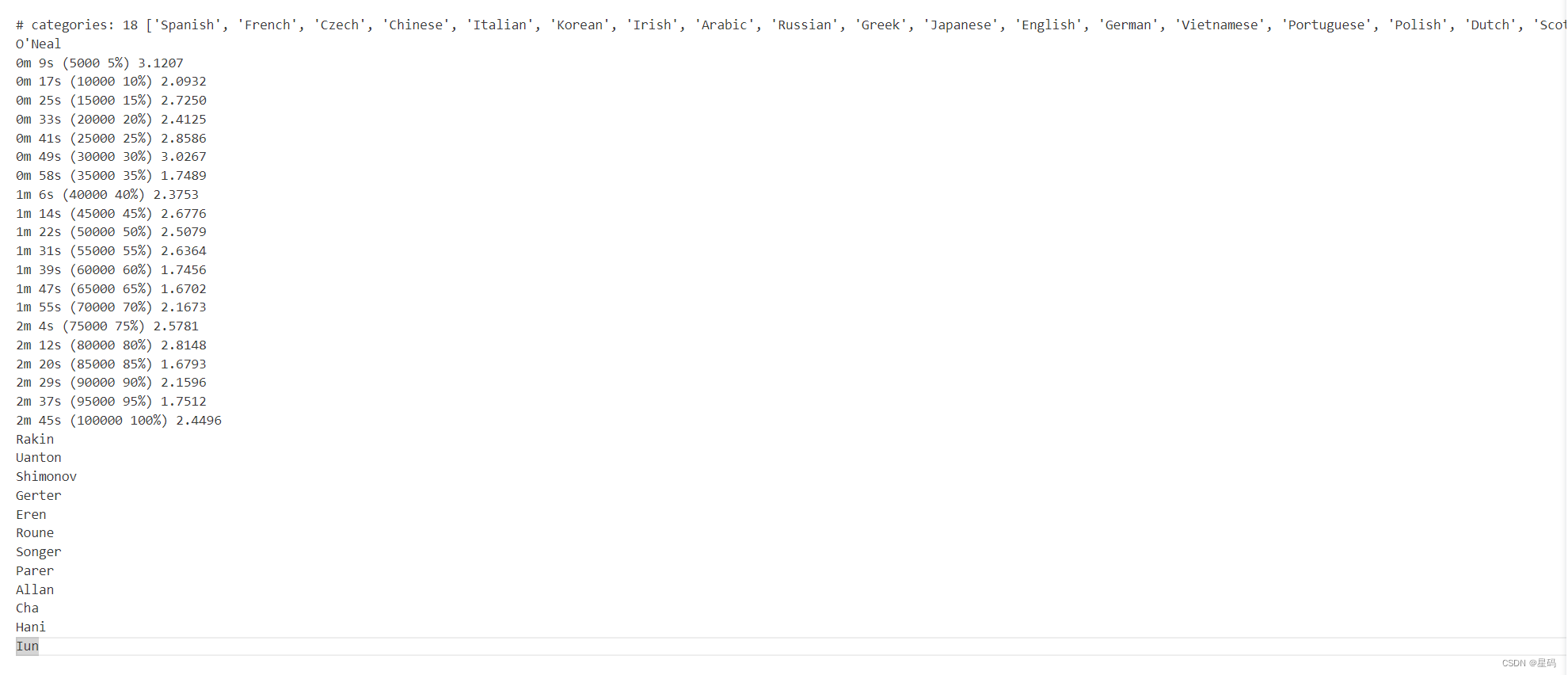
total_loss = 0 # Reset every ``plot_every`` ``iters``start = time.time()for iter in range(1, n_iters + 1):output, loss = train(*randomTrainingExample())total_loss += lossif iter % print_every == 0:print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss))if iter % plot_every == 0:all_losses.append(total_loss / plot_every)total_loss = 0
结果
参考资料
https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html#
相关文章:
[oneAPI] 使用字符级 RNN 生成名称
[oneAPI] 使用字符级 RNN 生成名称 oneAPI特殊写法使用字符级 RNN 生成名称Intel Optimization for PyTorch数据下载加载数据并对数据进行处理创建网络训练过程准备训练训练网络 结果 参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517…...
【ROS】参数服务器--理论模型与参数操作(C++)
一、概念介绍 参数服务器在ROS中主要用于实现不同节点之间的数据共享。参数服务器相当于是独立于所有节点的一个公共容器,可以将数据存储在该容器中,被不同的节点调用,当然不同的节点也可以往其中存储数据。 作用:存储一些多节点…...
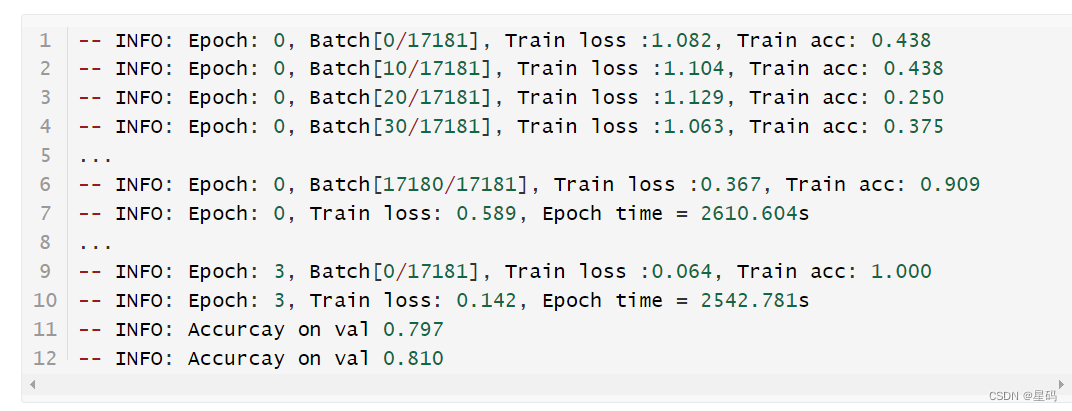
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务 Intel DevCloud for oneAPI 和 Intel Optimization for PyTorch基于BERT预训练模型的英文文本蕴含任务语料介绍数据集构建 模型训练 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0…...
【洛谷】P1163 银行贷款
原题链接:https://www.luogu.com.cn/problem/P1163 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 这题需要注意的是利率按月累计这句话,也就是相当于“利滚利”。 我们定义sum变量表示贷款原值,money表示每月支付…...
Java版工程行业管理系统源码-专业的工程管理软件-提供一站式服务 em
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工…...
kafka--技术文档--基本docker中安装<单机>-linux
安装zookeeper 阿丹小科普: Kafka在0.11.0.0版本之后不再依赖Zookeeper,而是使用基于Raft协议的Kafka自身的仲裁机制来替代Zookeeper。具体来说,Kafka 2.8.0版本是第一个不需要Zookeeper就可以运行Kafka的版本,这被称为Kafka Raf…...

回归预测 | MATLAB实现WOA-RF鲸鱼优化算法优化随机森林算法多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现WOA-RF鲸鱼优化算法优化随机森林算法多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现WOA-RF鲸鱼优化算法优化随机森林算法多输入单输出回归预测(多指标,多图)效果一览…...

Linux系统安全——NAT(SNAT、DNAT)
目录 NAT SNAT SNAT实际操作 DNAT DNAT实际操作 NAT NAT: network address translation,支持PREROUTING,INPUT,OUTPUT,POSTROUTING四个链 请求报文:修改源/目标IP, 响应报文:修改源/目标…...

uniapp项目添加人脸识别功能,可用作登录,付款,流程审批前的安全校验
本案例使用了hbuilder插件商城中的活体检验插件,可自行前往作者处下载查看, 效果图如下 此插件需要在manifest.json中勾选 实现流程 1:前往hbuilder插件市场下载插件 2:在页面中导入import face from "/uni_modules/mcc-…...

SpringBoot面试题
Spring Boot的启动流程主要分为以下几个步骤: 加载Spring Boot配置文件,初始化Spring Boot环境和核心组件,如ApplicationContext上下文环境、自动装配机制等。 执行SpringApplication.run()方法,执行所有Spring Boot自动配置的Be…...
Git相关命令
SSH密钥文件 Github里面S设置SH公钥有两者选择方式 账号下的每个仓库都设置一个公钥,因为GitHub官方要求每个仓库的公钥都不能相同,所以每个账号都要搞一个密钥(很麻烦)给账号分配一个公钥,然后这个公钥就可以在这个…...
《HeadFirst设计模式(第二版)》第八章代码——模板方法模式
代码文件目录: CaffeineBeverage package Chapter8_TemplateMethodPattern;/*** Author 竹心* Date 2023/8/17**/public abstract class CaffeineBeverage {final void prepareRecipe(){boilWater();brew();pourInCup();//这里使用钩子customerWantsCondiments()来…...

RESTful API,以及如何使用它构建 web 应用程序
RESTful API是一种基于HTTP协议的API设计风格,它的核心思想是将资源作为 API 的核心,使用 HTTP 的 GET、POST、PUT、DELETE 等方法对这些资源进行操作,并通过 URL 来定位资源。 RESTful API的特点包括: 资源是 API 的核心使用 H…...
Git+Gitee使用分享
GitGitee快速入门 创建仓库 初始化本地仓库 验证本地git是否安装好 打开cmd窗口,输入git 这样就OK。 Git 全局设置:(只需要设置一次) 这台电脑如果是第一次使用git,就需要这样初始化一下,这样才知道是谁提交到仓库了。 git confi…...

【3D激光SLAM】LOAM源代码解析--transformMaintenance.cpp
系列文章目录 【3D激光SLAM】LOAM源代码解析–scanRegistration.cpp 【3D激光SLAM】LOAM源代码解析–laserOdometry.cpp 【3D激光SLAM】LOAM源代码解析–laserMapping.cpp 【3D激光SLAM】LOAM源代码解析–transformMaintenance.cpp 写在前面 本系列文章将对LOAM源代码进行讲解…...

DiscuzQ 二开教程(7)——二次开发版本部署文档
DiscuzQ 二开教程(7)——二次开发版本部署文档 源码:Discuz-Q-V3: 本仓库为Discuz-Q V3.0.211111 版本的二次开发版本,是将DiscuzQ官方仓库进行合并代码(All in One)整理后的仓库,使用更方便。…...
u盘数据丢失但占内存如何恢复?不要着急,这里有拯救方案
U盘数据丢失但占内存如何恢复?数据丢失是一种让人非常头疼的问题,尤其是当我们的U盘数据丢失了,但内存仍然被占用时,更令人困惑和焦虑。然而,不要慌张!在本文中,将为大家介绍一些有效的方法来恢…...

springboot日志文件名称为什么叫logback-spring.xml
如题,为什么springboot日志配置文件叫logback-spring.xml? 在整个项目中搜索 logback-spring.xml 并没有搜索到。 先看一下 org.springframework.boot.context.logging.LoggingApplicationListener#initialize protected void initialize(ConfigurableEn…...
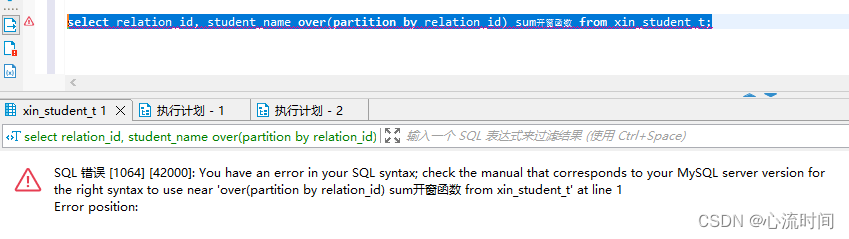
Mysql 开窗函数(窗口函数)
文章目录 全部数据示例1(说明)开窗函数可以比groupby多查出条件列外的字段,开窗函数主要是为了跟聚合函数一起使用,达到分组统计效果,并且开窗函数的结果集基本都是跟总行数一样示例2示例3示例4错误示例1错误示例2错误…...

计算机视觉之图像特征提取
图像特征提取是计算机视觉中的重要任务,它有助于识别、分类、检测和跟踪对象。以下是一些常用的图像特征提取算法及其简介: 颜色直方图(Color Histogram): 简介:颜色直方图表示图像中各种颜色的分布情况。通…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...