Pytorch-day07-模型保存与读取
PyTorch 模型保存&读取
- 模型存储
- 模型单卡存储&多卡存储
- 模型单卡读取&多卡读取
1、模型存储
- PyTorch存储模型主要采用pkl,pt,pth三种格式,就使用层面来说没有区别
- PyTorch模型主要包含两个部分:模型结构和权重。其中模型是继承nn.Module的类,权重的数据结构是一个字典(key是层名,value是权重向量)
- 存储也由此分为两种形式:存储整个模型(包括结构和权重)和只存储模型权重(推荐)。
import torch
from torchvision import models
model = models.resnet50(pretrained=True)
save_dir = './resnet50.pth'# 保存整个 模型结构+权重
torch.save(model, save_dir)
# 保存 模型权重
torch.save(model.state_dict, save_dir)# pt, pth和pkl三种数据格式均支持模型权重和整个模型的存储
2、模型单卡存储&多卡存储
- PyTorch中将模型和数据放到GPU上有两种方式——.cuda()和.to(device)
- 注:如果要使用多卡训练的话,需要对模型使用torch.nn.DataParallel
2.1、nn.DataParrallel
<CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-puyISgkD-1692613764220)(attachment:image.png)]
- module即表示你定义的模型
- device_ids表示你训练的device
- output_device这个参数表示输出结果的device,而这最后一个参数output_device一般情况下是省略不写的,那么默认就是在device_ids[0]
注:因此一般情况下第一张显卡的内存使用占比会更多
import os
import torch
from torchvision import models
#单卡
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 如果是多卡改成类似0,1,2
model = model.cuda() # 单卡
#print(model)
---------------------------------------------------------------------------RuntimeError Traceback (most recent call last)~\AppData\Local\Temp/ipykernel_7460/77570021.py in <module>1 import os2 os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 如果是多卡改成类似0,1,2
----> 3 model = model.cuda() # 单卡D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in cuda(self, device)903 Module: self904 """
--> 905 return self._apply(lambda t: t.cuda(device))906 907 def ipu(self: T, device: Optional[Union[int, device]] = None) -> T:D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in _apply(self, fn)795 def _apply(self, fn):796 for module in self.children():
--> 797 module._apply(fn)798 799 def compute_should_use_set_data(tensor, tensor_applied):D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in _apply(self, fn)818 # `with torch.no_grad():`819 with torch.no_grad():
--> 820 param_applied = fn(param)821 should_use_set_data = compute_should_use_set_data(param, param_applied)822 if should_use_set_data:D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in <lambda>(t)903 Module: self904 """
--> 905 return self._apply(lambda t: t.cuda(device))906 907 def ipu(self: T, device: Optional[Union[int, device]] = None) -> T:D:\Users\xulele\Anaconda3\lib\site-packages\torch\cuda\__init__.py in _lazy_init()245 if 'CUDA_MODULE_LOADING' not in os.environ:246 os.environ['CUDA_MODULE_LOADING'] = 'LAZY'
--> 247 torch._C._cuda_init()248 # Some of the queued calls may reentrantly call _lazy_init();249 # we need to just return without initializing in that case.RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0G4NTv1z-1692613764220)(attachment:ed8eb711294e4c6e3e43690ddb2bf66.png)]
#多卡
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
model = torch.nn.DataParallel(model).cuda() # 多卡
#print(model)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eHt1Dn8t-1692613764221)(attachment:image.png)]
2.3、单卡保存+单卡加载
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet50(pretrained=True)
model.cuda()save_dir = 'resnet50.pt' #保存路径# 保存+读取整个模型
torch.save(model, save_dir)
loaded_model = torch.load(save_dir)
loaded_model.cuda()# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
# 先加载模型结构
loaded_model = models.resnet50()
# 在加载模型权重
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model.cuda()
---------------------------------------------------------------------------RuntimeError Traceback (most recent call last)~\AppData\Local\Temp/ipykernel_7460/585340704.py in <module>5 os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号6 model = models.resnet50(pretrained=True)
----> 7 model.cuda()8 9 save_dir = 'resnet50.pt' #保存路径D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in cuda(self, device)903 Module: self904 """
--> 905 return self._apply(lambda t: t.cuda(device))906 907 def ipu(self: T, device: Optional[Union[int, device]] = None) -> T:D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in _apply(self, fn)795 def _apply(self, fn):796 for module in self.children():
--> 797 module._apply(fn)798 799 def compute_should_use_set_data(tensor, tensor_applied):D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in _apply(self, fn)818 # `with torch.no_grad():`819 with torch.no_grad():
--> 820 param_applied = fn(param)821 should_use_set_data = compute_should_use_set_data(param, param_applied)822 if should_use_set_data:D:\Users\xulele\Anaconda3\lib\site-packages\torch\nn\modules\module.py in <lambda>(t)903 Module: self904 """
--> 905 return self._apply(lambda t: t.cuda(device))906 907 def ipu(self: T, device: Optional[Union[int, device]] = None) -> T:D:\Users\xulele\Anaconda3\lib\site-packages\torch\cuda\__init__.py in _lazy_init()245 if 'CUDA_MODULE_LOADING' not in os.environ:246 os.environ['CUDA_MODULE_LOADING'] = 'LAZY'
--> 247 torch._C._cuda_init()248 # Some of the queued calls may reentrantly call _lazy_init();249 # we need to just return without initializing in that case.RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx
2.4、单卡保存+多卡加载
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet50(pretrained=True)
model.cuda()# 保存+读取整个模型
torch.save(model, save_dir)os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir)
loaded_model = nn.DataParallel(loaded_model).cuda()# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = models.resnet50() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model = nn.DataParallel(loaded_model).cuda()
2.5、多卡保存+单卡加载
核心问题:如何去掉权重字典键名中的"module",以保证模型的统一性
- 对于加载整个模型,直接提取模型的module属性即可
- 对于加载模型权重,保存模型时保存模型的module属性对应的权重
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号model = models.resnet50(pretrained=True)
model = nn.DataParallel(model).cuda()# 保存+读取整个模型
torch.save(model, save_dir)os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir).module
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号model = models.resnet50(pretrained=True)
model = nn.DataParallel(model).cuda()# 保存权重
torch.save(model.module.state_dict(), save_dir)#加载模型权重
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = models.resnet50() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model.cuda()2.6、多卡保存+多卡加载
保存整个模型时会同时保存所使用的GPU id等信息,读取时若这些信息和当前使用的GPU信息不符则可能会报错或者程序不按预定状态运行。可能出现以下2个问题:
- 1、读取整个模型再使用nn.DataParallel进行分布式训练设置,这种情况很可能会造成保存的整个模型中GPU id和读取环境下设置的GPU id不符,训练时数据所在device和模型所在device不一致而报错
- 2、读取整个模型而不使用nn.DataParallel进行分布式训练设置,发现程序会自动使用设备的前n个GPU进行训练(n是保存的模型使用的GPU个数)。此时如果指定的GPU个数少于n,则会报错
建议方案:
- 只模型权重,之后再使用nn.DataParallel进行分布式训练设置则没有问题
- 因此多卡模式下建议使用权重的方式存储和读取模型
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号model = models.resnet50(pretrained=True)
model = nn.DataParallel(model).cuda()# 保存+读取模型权重,强烈建议!!
torch.save(model.state_dict(), save_dir)
#加载模型 权重
loaded_model = models.resnet50() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir)))
loaded_model = nn.DataParallel(loaded_model).cuda()
建议
- 不管是单卡保存还是多卡保存,建议以保存模型权重为主
- 不管是单卡还是多卡,先load模型权重,再指定是多卡加载(nn.DataParallel)或单卡(cuda)
# 使用案例(截取片段代码)My_model.eval()
test_total_loss = 0
test_total_correct = 0
test_total_num = 0past_test_loss = 0 #上一轮的loss
save_model_step = 10 # 每10步保存一次modelfor iter,(images,labels) in enumerate(test_loader):images = images.to(device)labels = labels.to(device)outputs = My_model(images)loss = criterion(outputs,labels)test_total_correct += (outputs.argmax(1) == labels).sum().item()test_total_loss += loss.item()test_total_num += labels.shape[0]test_loss = test_total_loss / test_total_numprint("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100))# model saveif test_loss<past_test_loss:#保存模型权重torch.save(model.state_dict(), save_dir)#保存 模型权重+模型结构#torch.save(model, save_dir)if iter % save_model_step == 0:#保存模型权重torch.save(model.state_dict(), save_dir)#保存 模型权重+模型结构#torch.save(model, save_dir)past_test_loss = test_loss单卡保存&单卡读取 案例
Google Colab:https://colab.research.google.com/drive/1hEOeqXYm4BfulY6d30QCI4HrFmCmmTQu?usp=sharing
相关文章:

Pytorch-day07-模型保存与读取
PyTorch 模型保存&读取 模型存储模型单卡存储&多卡存储模型单卡读取&多卡读取 1、模型存储 PyTorch存储模型主要采用pkl,pt,pth三种格式,就使用层面来说没有区别PyTorch模型主要包含两个部分:模型结构和权重。其中模型是继承n…...

【C语言每日一题】01. Hello, World!
题目来源:http://noi.openjudge.cn/ch0101/01/ 01. Hello, World! 总时间限制: 1000ms 内存限制: 65536kB 问题描述 对于大部分编程语言来说,编写一个能够输出“Hello, World!”的程序往往是最基本、最简单的。因此,这个程序常常作为一个初…...
arm: day8
1.中断实验:按键控制led灯 流程: key.h /*************************************************************************> File Name: include/key.h> Created Time: 2023年08月21日 星期一 17时03分20秒***************************************…...

k8s容器加入host解析字段
一、通过edit或path来修改 kubectl edit deploy /xxxxx. x-n cattle-system xxxxx为你的资源对象名称 二、添加字段 三、code hostAliases:- hostnames:- www.rancher.localip: 10.10.2.180...

浅谈开发过程中完善的注释的重要性
第一部分:引言 1.1 简述编程注释的定义和功能 编程注释是一种在源代码中添加的辅助性文字,它不参与编译或执行,但对于理解源代码起着至关重要的作用。注释可以简单地描述代码的功能,也可以详细地解释算法的工作原理、设计决策的…...
Docker 微服务实战
1. 通过IDEA新建一个普通微服务模块 1.1 建Module docker_boot 1.2 改写pom <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance&…...
JupyterHub实战应用
一、JupyerHub jupyter notebook 是一个非常有用的工具,我们可以在浏览器中任意编辑调试我们的python代码,并且支持markdown 语法,可以说是科研利器。但是这种情况适合个人使用,也就是jupyter notebook以我们自己的主机作为服务器…...
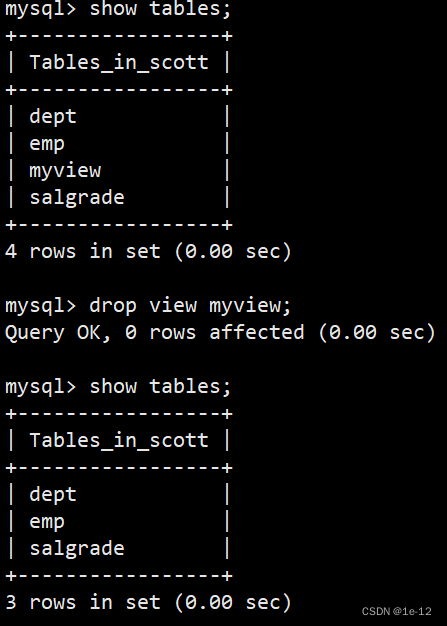
【MySQL】视图
目录 一、什么是视图 二、视图的操作 2.1 创建视图 2.2 删除视图 三、视图规则和限制 一、什么是视图 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。视图的数据变化会影响到基表(创建视图所…...
基于 Android 剧院购票APP的开发与设计
摘要:近年来,随着社会的发展和科技方面的创新,越来越多的人选择使用手机应用程序来购买剧场票。本文将探讨基于 Android 平台的剧院购票应用程序的开发和设计。该应用程序将为用户提供浏览剧场列表、查看剧场详情、选择座位并购买剧场票的功能…...

反转链表II
江湖一笑浪滔滔,红尘尽忘了 题目 示例 思路 链表这部分的题,不少都离不开单链表的反转,参考:反转一个单链表 这道题加上哨兵位的话会简单很多,如果不加的话,还需要分情况一下,像是从头节点开始…...

HTML 和 CSS 来实现毛玻璃效果(Glassmorphism)
毛玻璃效果简介 它的主要特征就是半透明的背景,以及阴影和边框。 同时还要为背景加上模糊效果,使得背景之后的元素根据自身内容产生漂亮的“变形”效果,示例: 代码实现 首先,创建一个 HTML 文件,写入如下…...
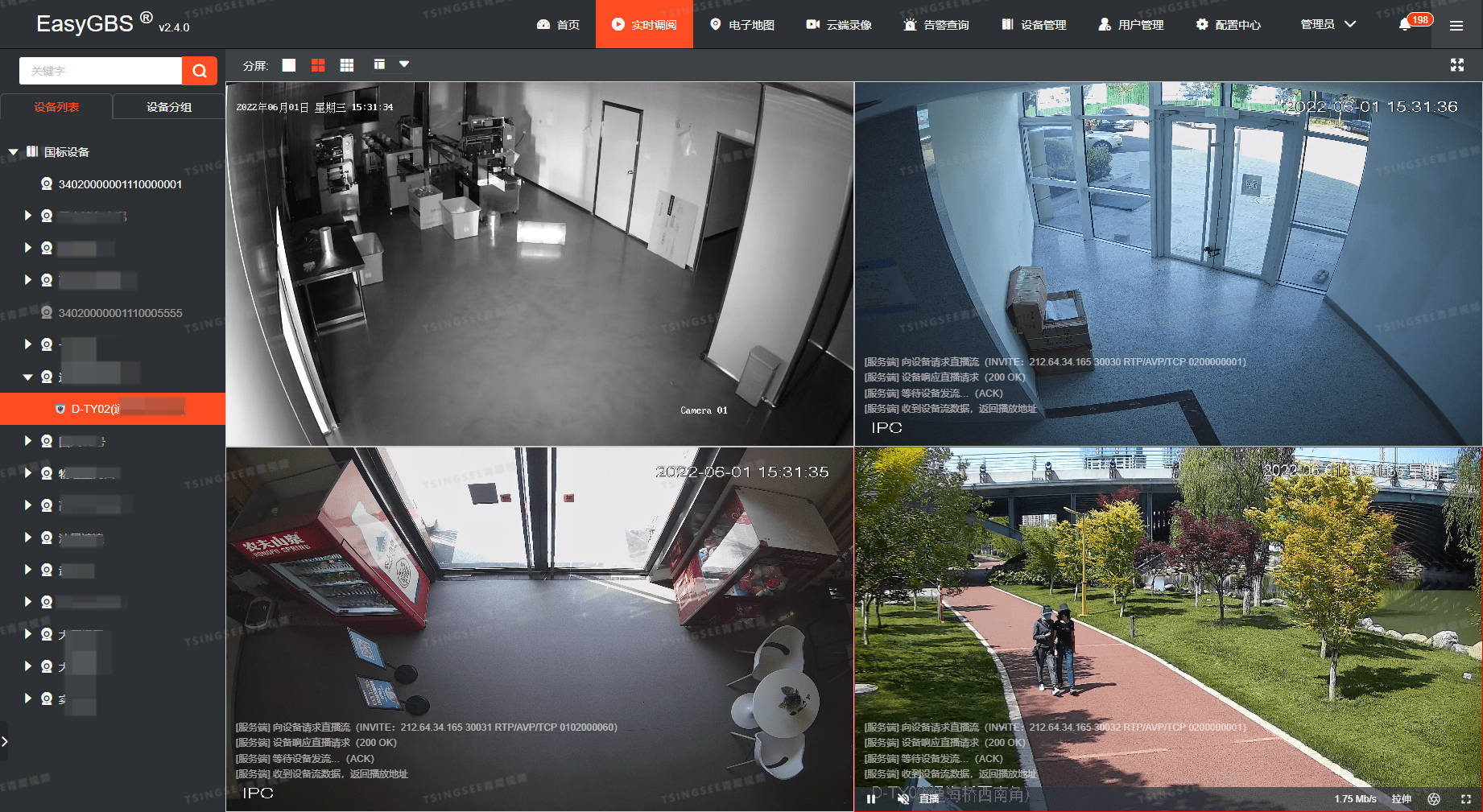
【技术】国标GB28181视频平台EasyGBS通过对应密钥上传到其他平台展示的详细步骤
国标GB28181协议视频平台EasyGBS是基于国标GB28181协议的视频云服务平台,支持多路设备同时接入,并对多平台、多终端分发出RTSP、RTMP、FLV、HLS、WebRTC等格式的视频流。平台可提供视频监控直播、云端录像、云存储、检索回放、智能告警、语音对讲、平台级…...

SpeedBI数据可视化工具:浏览器上做分析
SpeedBI数据分析云是一种在浏览器上进行数据可视化分析的工具,它能够将数据以可视化的形式呈现出来,并支持多种数据源和图表类型。 所有操作,均在浏览器上进行 在浏览器中打开SpeedBI数据分析云官网,点击【免费使用】进入&#…...
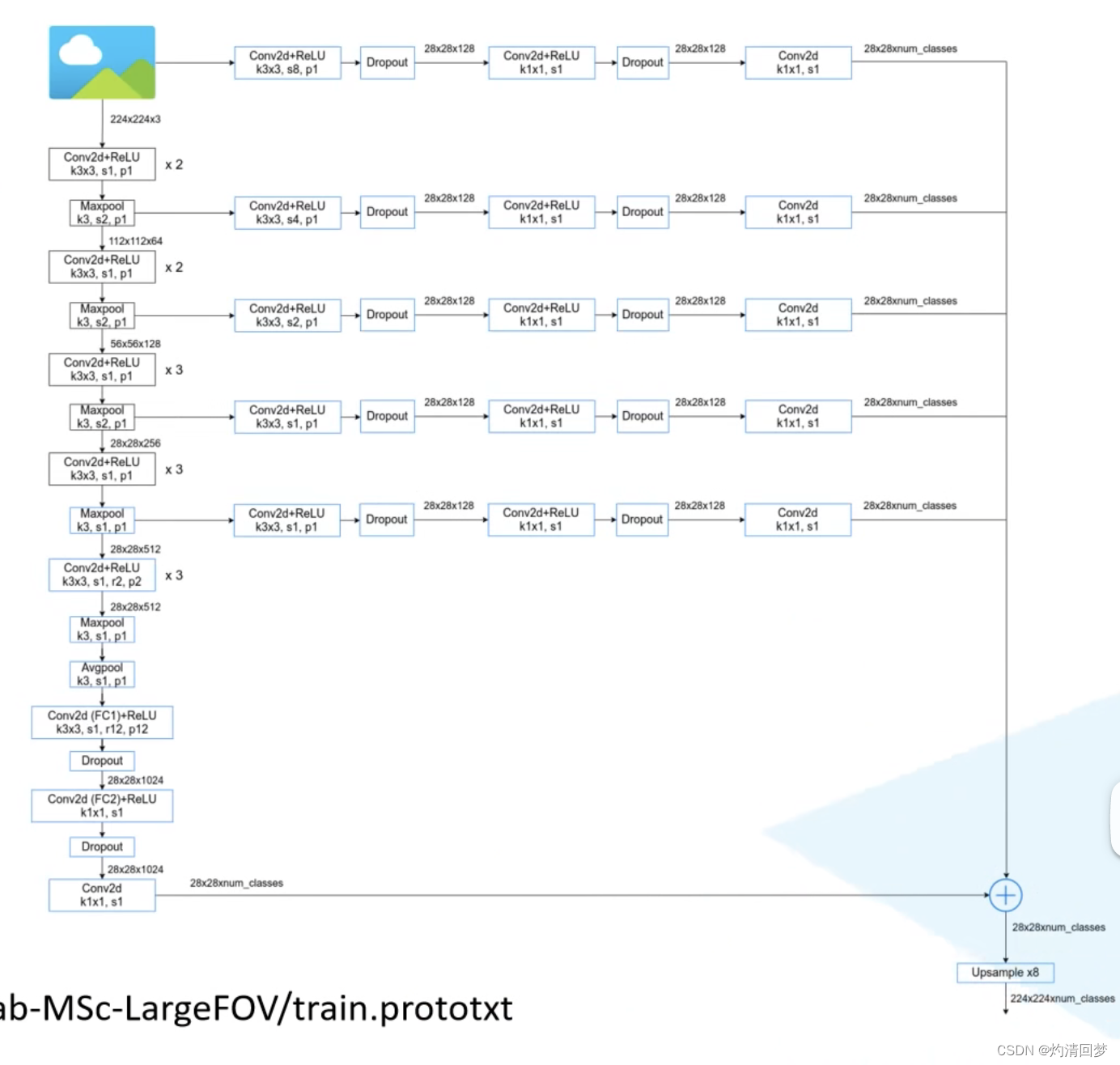
8.21笔记
Deeplab-MSc-LargrFOC 此图除了主输出之外,还有五个支线输出,他们池化层与VGG网络不同,其中卷积核大小是3,而VGG中卷积核大小为2(这个网络一开始是基于VGG网络提出的,因为那时候提出比较早,没有…...

MyBatis-Plus中公共字段的统一处理
数据库中一些表的公共字段,例如修改时间、修改人、创建时间、创建人,我们一般都是这样来处理的: employee.setCreateTime(LocalDateTime.now()); employee.setUpdateTime(LocalDateTime.now()); employee.setCreateUser(UserHolder.get()); …...

SQL的导出与导入
1、导入 使用命令行导入 1.登录sql界面; 2.create database Demo新建一个库; 3.选中数据库use Demo;选中导入路径source D:Demo.sql; 4.查看表show tables; 2、导出 整个sql mysqldump -u username -ppassword dbname > dbname.sq…...
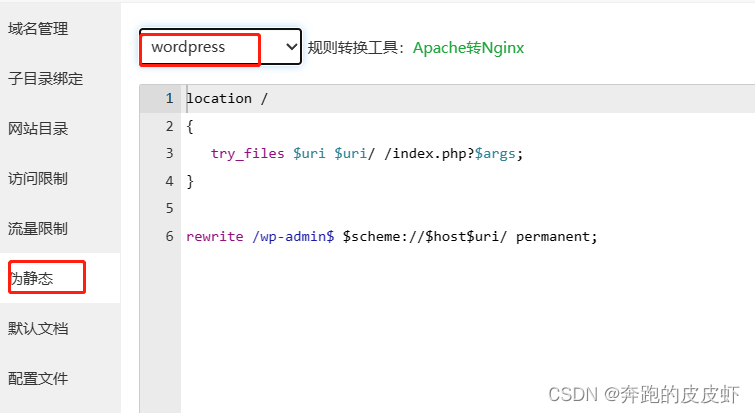
记录一次wordpress项目的发布过程
背景:发布一套已完成的代码到线上,有完整的代码包,sql文件,环境是linux 宝塔。无wordpress相关经验。 过程:正常的发布代码 问题1:访问自己的域名后跳转到别的域名。 解决: 修改数据表wp_optio…...

HTML详解连载(8)
HTML详解连载(8) 专栏链接 [link](http://t.csdn.cn/xF0H3)下面进行专栏介绍 开始喽浮动-产品区域布局场景 解决方法清除浮动方法一:额外标签发方法二:单伪元素法方法三:双伪元素法方法四:overflow浮动-总结…...
Linux系统之安装OneNav个人书签管理器
Linux系统之安装OneNav个人书签管理器 一、OneNav介绍1.OneNav简介2.OneNav特点 二、本地环境介绍2.1 本地环境规划2.2 本次实践介绍 三、检查本地环境3.1 检查本地操作系统版本3.2 检查系统内核版本3.3 检查本地yum仓库状态 四、安装httpd服务4.1 安装httpd4.2 启动httpd服务4…...

主程技术分享: 游戏项目帧同步,状态同步如何选
网络游戏开发项目中帧同步,状态同步如何选? 网络游戏的核心技术之一就是玩家的网络同步,主流的网络同步有”帧同步”与”状态同步”。今天我们来分析一下这两种同步模式。同时教大家如何在自己的项目中采用最合适的同步方式。接下来从以下3个方面来阐述: 对啦&…...

手把手教你用Llama-3.2V-11B-cot:像聊天一样轻松实现图片智能分析
手把手教你用Llama-3.2V-11B-cot:像聊天一样轻松实现图片智能分析 1. 引言:当视觉大模型遇上聊天式交互 想象一下,你正面对一张复杂的医学影像或工程图纸,需要快速理解其中的关键信息。传统方法可能需要专业培训或反复查阅资料&…...

基于hadoop+spark+hive 机器学习物流管理系统 货运路线规划系统 智慧交通 计算机毕业设计 Echarts可视化
1、项目介绍 技术栈: Python语言、Django框架、Echarts可视化、MySQL数据库、HTML、报表、物流信息、多角色登录、物流管理该系统采用python和django两种常见的框架,通过MVT来实现对数据集 成和分析,从而更好地满足各种需求。此外,…...

RexUniNLU硬件加速:TensorRT推理优化实践
RexUniNLU硬件加速:TensorRT推理优化实践 想让你的RexUniNLU模型推理速度飞起来吗?尤其是在T4这类消费级显卡上,看着模型慢悠悠地吐出结果,是不是有点着急?今天咱们就来聊聊怎么用TensorRT给RexUniNLU“打一针强心剂”…...

NaViL-9B多模态提示工程:图文联合prompt编写技巧与示例
NaViL-9B多模态提示工程:图文联合prompt编写技巧与示例 1. 多模态模型简介 NaViL-9B是一款原生支持多模态交互的大语言模型,能够同时处理文本和图像输入。与传统的纯文本模型不同,它具备视觉理解能力,可以分析图片内容并与用户进…...
如何让Windows任务栏变透明?TranslucentTB完整教程指南
如何让Windows任务栏变透明?TranslucentTB完整教程指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要为你的Windows桌面…...
Pixel Dream Workshop 助力前端开发:Vue.js 项目动态视觉素材生成指南
Pixel Dream Workshop 助力前端开发:Vue.js 项目动态视觉素材生成指南 1. 为什么前端开发者需要关注视觉素材生成 作为一名Vue.js开发者,你可能经常遇到这样的困扰:产品经理突然要求给新功能加个炫酷的Banner图,设计师资源紧张排…...

从零构建企业级Text2Sql应用:Vanna私有化部署与Dify工作流集成
1. 企业级Text2Sql应用的核心价值 想象一下,财务部门的同事对着Excel表格发愁:"能不能帮我找出上季度华东区销售额超过50万的所有客户?"传统做法需要找IT部门提需求,等开发人员写SQL查询,流程可能长达数三天…...

算力虚拟化技术:如何实现算力的高效分配与复用
算力虚拟化技术:如何实现算力的高效分配与复用📚 本章学习目标:深入理解如何实现算力的高效分配与复用的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《云原生、云边端一体化与算力基建…...
)
野火指南者开发板+LVGL实战:3.2寸电阻屏GUI移植全流程(附避坑指南)
野火指南者开发板LVGL实战:3.2寸电阻屏GUI移植全流程(附避坑指南) 在嵌入式开发中,为设备添加美观的用户界面往往能大幅提升产品体验。对于STM32开发者而言,野火指南者开发板搭配3.2寸电阻触摸屏是一个性价比极高的硬件…...

C++动态内存/内存管理
文章目录 前言 一、内存分区 二、C 语言动态内存(标准库函数) 1.核心函数 2.代码示例 3.关键注意点 三、C 动态内存(关键字 / 操作符) 1.核心用法 (1)单个对象 (2)数组对象…...