【C++】unordered_map和unordered_set的使用 及 OJ练习
文章目录
- 前言
- 1. unordered系列关联式容器
- 2. map、set系列容器和unordered_map、unordered_set系列容器的区别
- 3. unordered_map和unordered_set的使用
- 4. set与unordered_set性能对比
- 5. OJ练习
- 5.1 在长度 2N 的数组中找出重复 N 次的元素
- 思路分析
- AC代码
- 5.2 两个数组的交集
- 思路分析
- AC代码
- 5.3 两个数组的交集 II
- 思路分析
- AC代码
- 5.4 存在重复元素
- 思路分析
- AC代码
- 5.5 两句话中的不常见单词
- 思路分析
- AC代码
前言
在前面的文章中,我们已经学习了STL中底层为红黑树结构的一系列关联式容器——set/multiset 和 map/multimap(C++98)
1. unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次。
在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本一样,只是其底层结构不同。
本文中只对unordered_map和unordered_set进行介绍,
unordered_multimap和unordered_multiset大家可自行查看文档介绍。
2. map、set系列容器和unordered_map、unordered_set系列容器的区别
首先我们来简单说一下前面学的不带unordered的几个容器和这篇文章学习的unordered系列的容器有什么区别。
首先,它们的底层结构是不一样的:
我们前面学习的那一系列关联式容器——
set/multiset 和 map/multimap它们的底层结构是红黑树,而我们这篇文章要学的unordered系列的——unordered_map/unordered_multimap、unordered_set/unordered_multiset它们的底层是哈希表,至于什么是哈希表,大家有的可能听说过,有的可能没有,没关系,我们后面会讲。
同样的,unordered系列中,带multi的和不带multi的区别也是允许键值重复出现和不允许重复出现的问题。
其次,从名字上我们其实就能得出它们的第二个区别:
unordered不就是无序的意思嘛。
所以,map和set我们用迭代器遍历,得到的是有序的序列,二unordered系列,我们去遍历的话,得到的是无序的。
其实单从使用上来说最大的区别就是这个。
那说到迭代器,它们的迭代器也是有区别的:
map和set系列它们的迭代器是双向迭代器,而unordered系列它们的迭代器是单向迭代器。
3. unordered_map和unordered_set的使用
其实单从使用来说,大家如果学会了我们之前讲的C++98的那几个关联式容器——set/multiset 和 map/multimap的使用的话,那C++11的这4个unordered系列的关联式容器其实大家就直接可以用了,因为它们的用法基本一致,常用的接口都差不多。
所以下面我们就简单介绍一下它们的使用,然后做一些练习,另外还有一些东西是需要我们学了它们的底层才能看懂的,这篇文章我们也先不做讲解。
首先我们可以看一下unordered_map的接口:
常用的接口还是那几个,跟map的用法一样,还有一些看不懂的,我们现在不用管,那些是跟他的底层结构哈希有关的。
另外我们会注意到它的迭代器没有rbegin、rend,因为它的迭代器是单向的嘛,都不支持反向遍历。

然后unordered_set我们也可以简单看一下:
接口也都差不多,只是set系列的没有[]和at接口
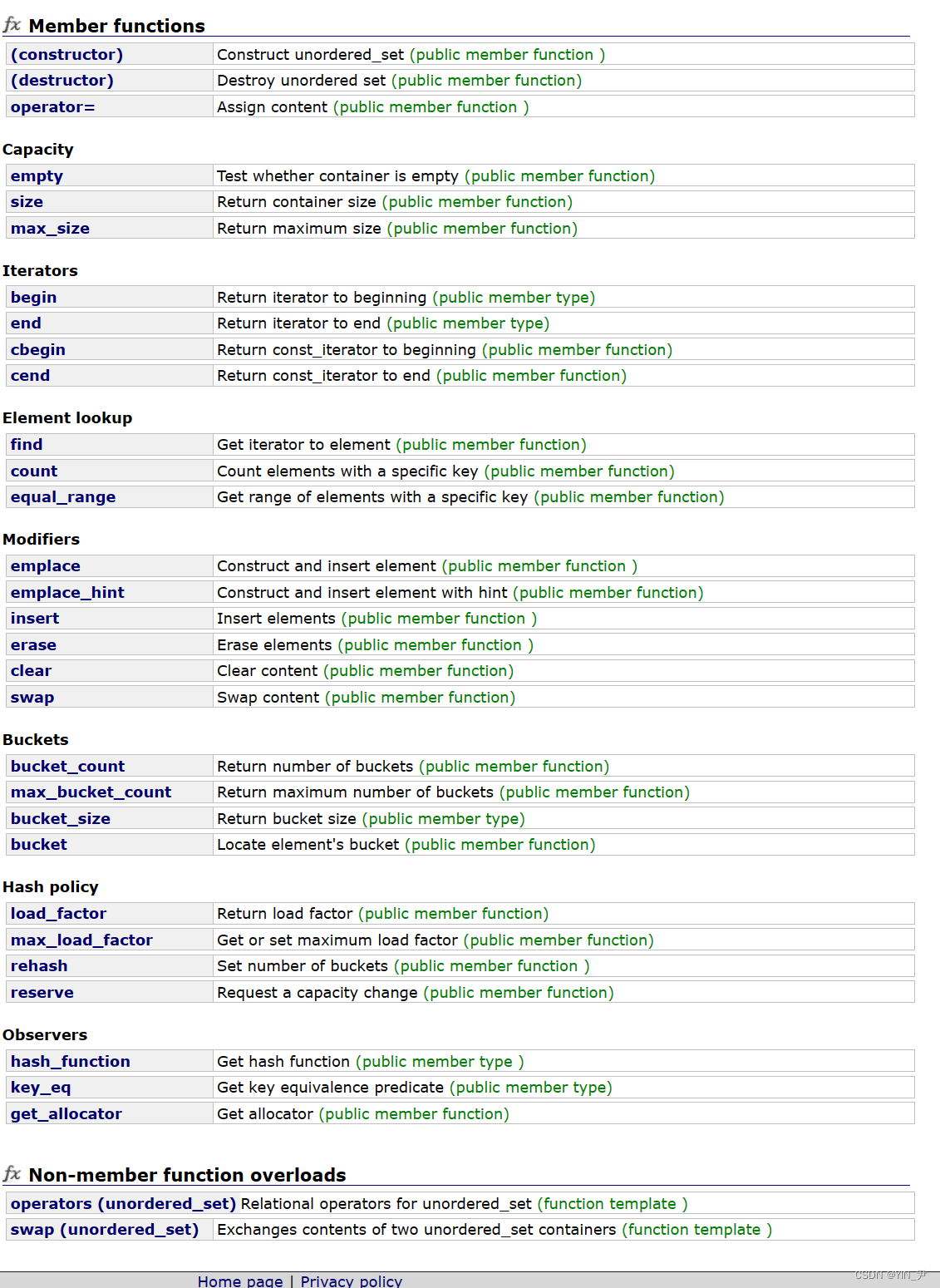
还是给大家简单演示一下它的使用吧:
这使用起来是不是跟set差不多啊,只不过我们看到它这里遍历是无序的。
当然也可以用迭代器遍历。
我们可以跟set对比一下
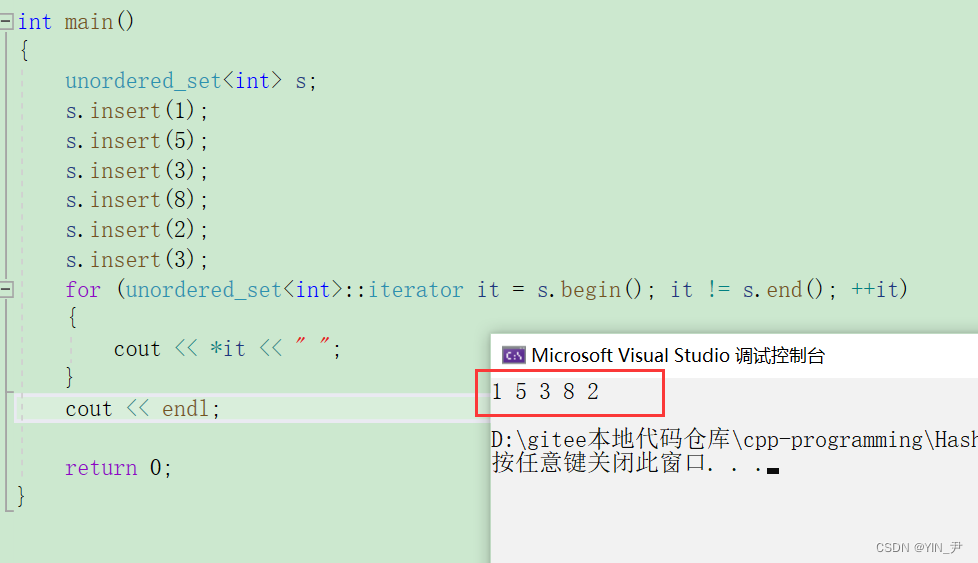

那unordered_map,也简单演示一下:
我们可以用unordered_map来跑一下那个统计次数的程序:
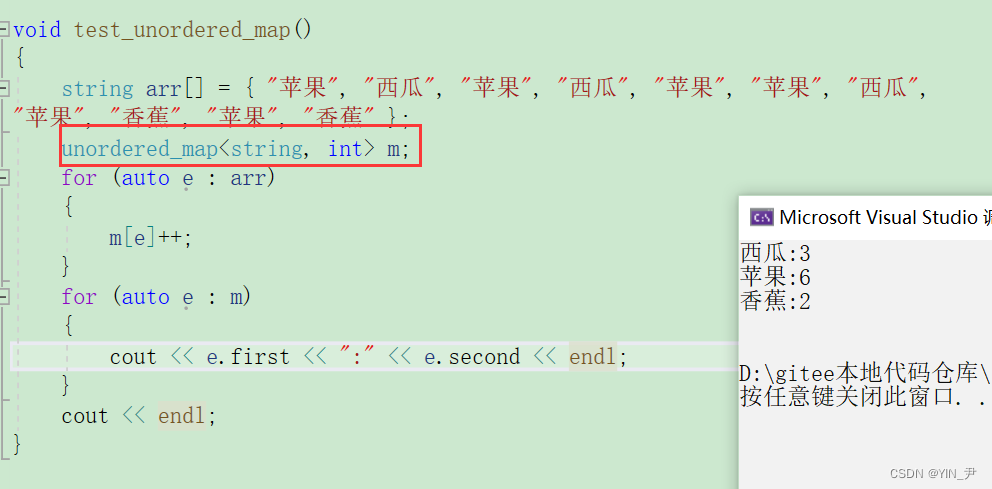
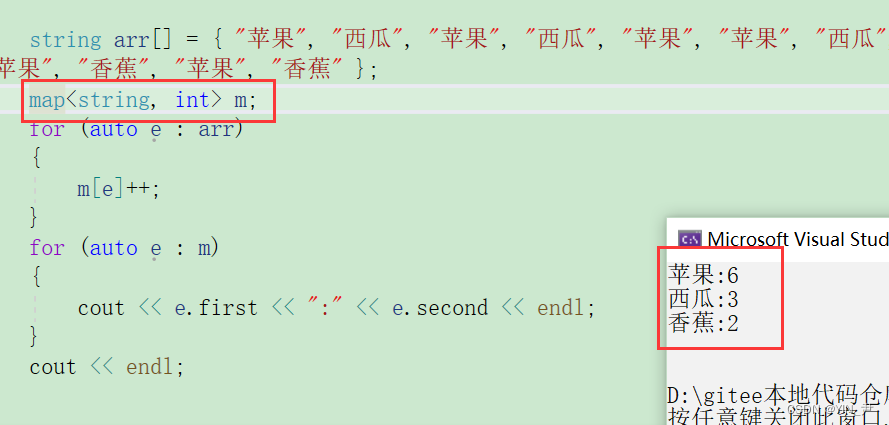
同样我们可以和map对比一下
其实还是有序无序的区别,只不过这里按照key排序,我们的key是汉字(水果名称),所以不太好看排序的效果。
当然这种场景的话其实顺序也不重要了。
那大家思考一下,既然它们好像跟map和set差不多,那为什么还要提高unordered系列呢?有什么优势吗?
其实在文档里面也有一些说明
比如我们看unordered_map
🆗,由于它底层使用的哈希结构,使得它们能够更快的按照键值去访问某个元素。

4. set与unordered_set性能对比
那我这里呢也提供了一段代码,以set和unordered_set为例来测试对比一下它们的性能:
因为unordered系列和非unordered系列它们底层的数据结构都是一样的,所以我们这里拿一组去对比就可以了
先看一下代码吧:
int main()
{const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand((unsigned int)time(nullptr));for (size_t i = 0; i < N; ++i){v.push_back(rand());//v.push_back(rand()+i);//v.push_back(i);}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;cout << s.size() << endl;cout << us.size() << endl << endl;;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
}
简单解释一下这段代码:
其实就是搞了一个set和一个unordered_set,然后我们去控制产生一些随机数,先放到一个vector里面,再分别插入到set和一个unordered_set里面,对比它们插入、查找、删除的性能。
插入之后我们还统计了一下实际插入的个数,因为rand函数产生的随机数是有限的。
我们来测试几组:
先来10万个随机数
我们可以看到unordered_set三种操作都是比较快的,但是大家看到虽然我们产生10万个随机数,但是实际插入只有3万多个,因为rand产生的随机数会有大量重复值。
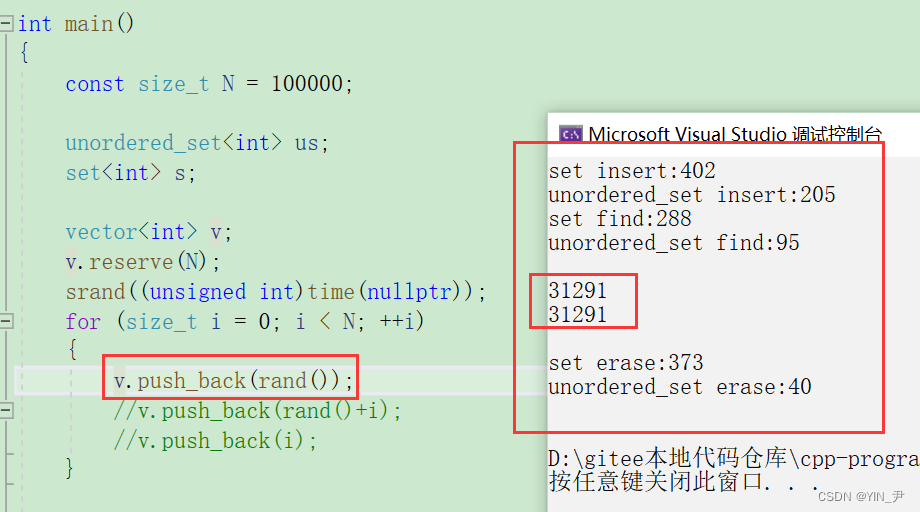
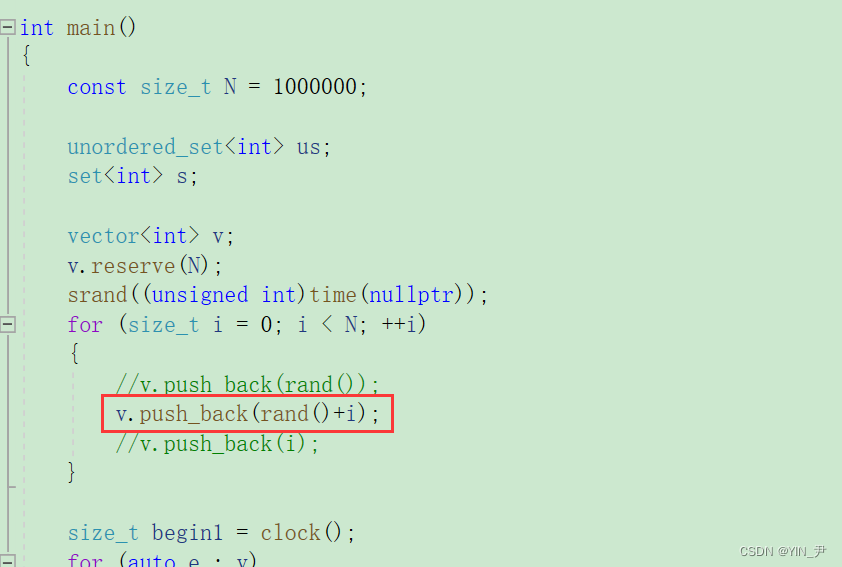
如果想减少数据有大量重复,可以用这个:
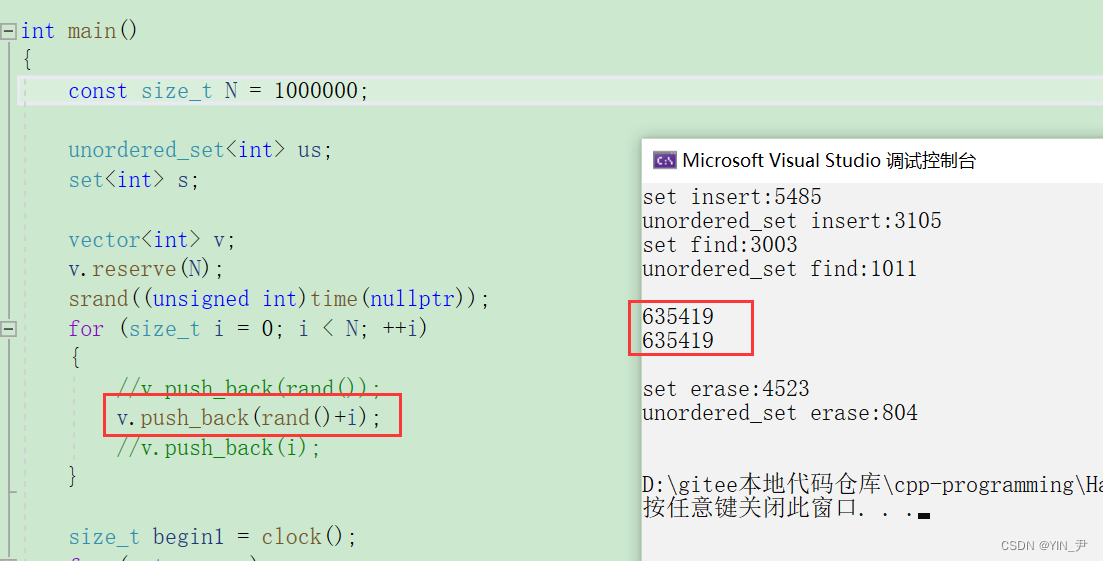
对每次产生的随机数加一个i,因为i每次是不同的嘛,这样重复数据肯定会减少
运行一下
大家自己对比一下
当然我们可以插入i,这样就没有重复值了
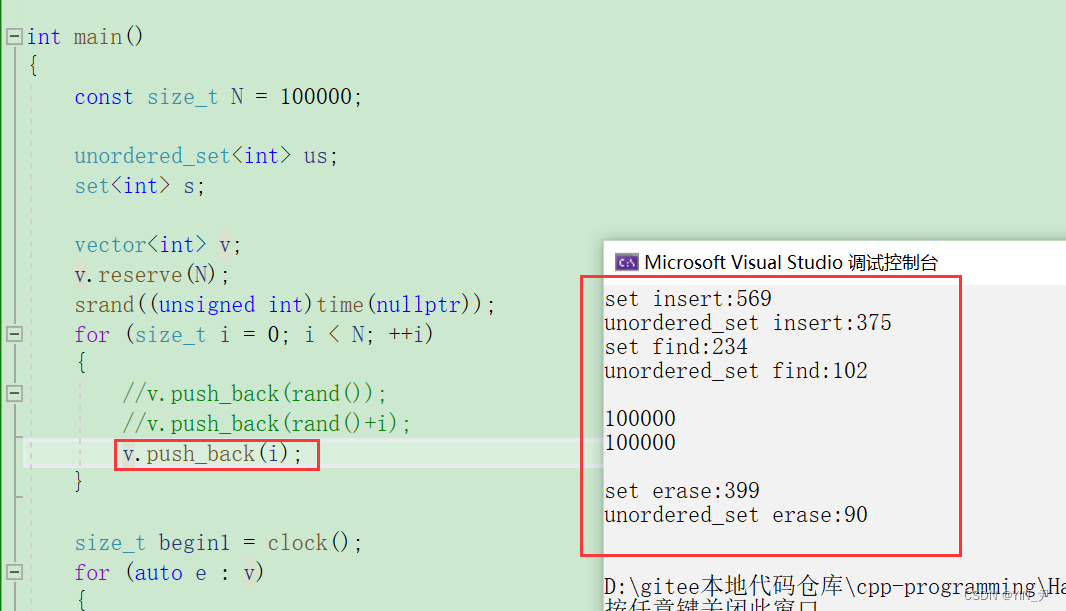
所以:
综合而言,unordered系列的效率是比较高的,尤其是find的效率(因为它底层的哈希结构,这个我们后面会讲)。
当然大家不要太关注我们上面的测试结果,因为可能在某些特定场景下unordered系列的插入删除这样操作不一定有map/set快(比如如果一直插入有序数据的话,set底层红黑树就会一直向一边旋转,最终就会比较平衡,那它的插入删除就不一定比unordered差了),但它的查找一定是很快的。
所以我们说的是综合各种场景而言,unordered系列的综合性能是较好的。
5. OJ练习
下面我们来做几道相关的OJ题
5.1 在长度 2N 的数组中找出重复 N 次的元素
题目链接: link

思路分析
这道题给我们一个长度为2n的数组,其中有一个元素恰好出现n次,我们要找到并返回这个元素。
那我们是不是统计出次数就好办了,统计出次数然后找到次数为n的返回就行了,那统计次数的话我们就可以用unordered_map(当然map也可以)。
AC代码
写一下代码:
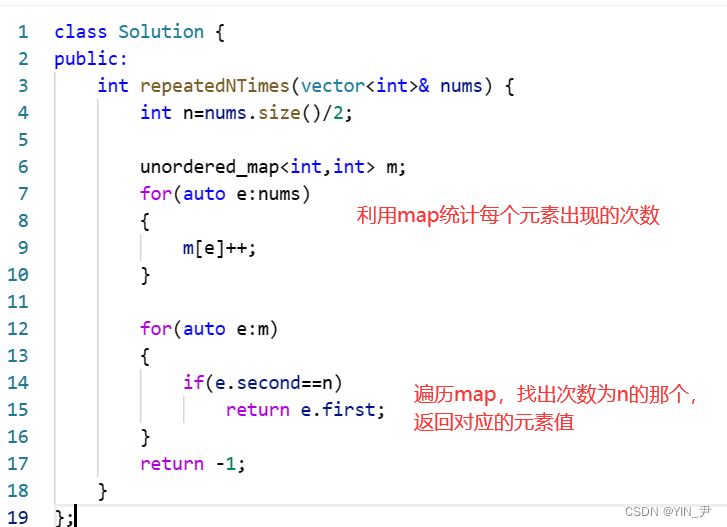
class Solution {
public:int repeatedNTimes(vector<int>& nums) {int n=nums.size()/2;unordered_map<int,int> m;for(auto e:nums){m[e]++;}for(auto e:m){if(e.second==n)return e.first;}return -1;}
};
5.2 两个数组的交集
题目链接: link
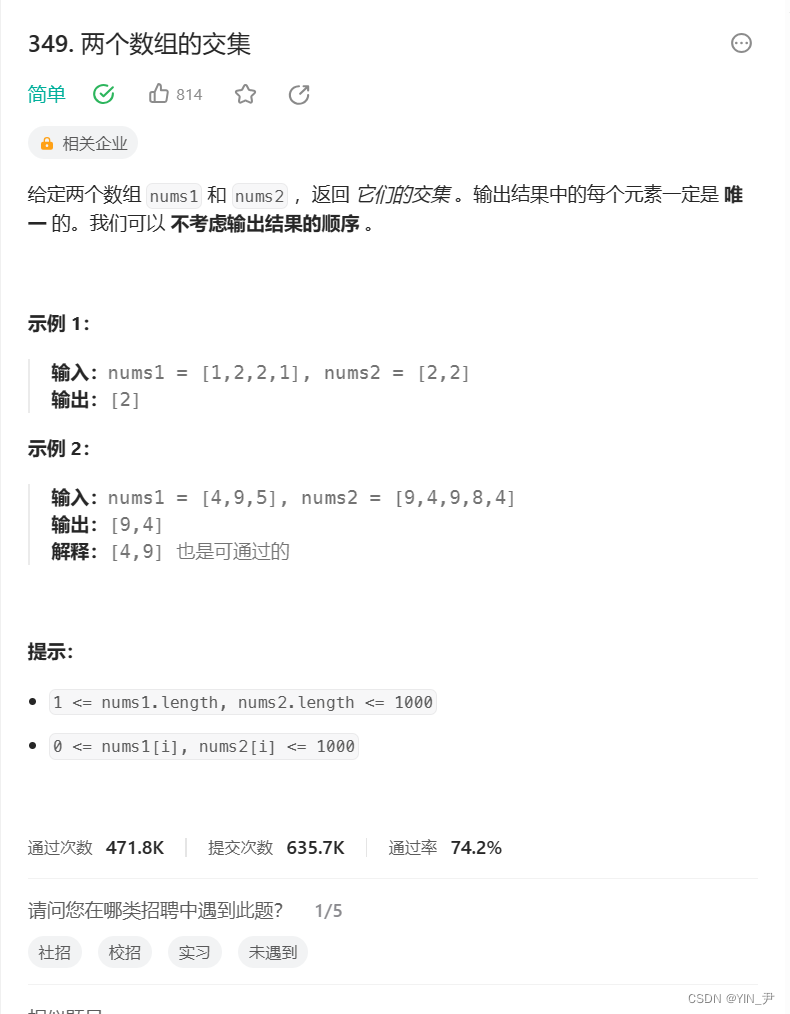
这道题我们是不是前面刚做过啊,当时我们用set去搞的,set达到一个排序+去重的效果,然后就好办了(具体解法大家可以去看之前文章的讲解)。
那我们今天学的是unordered_set,它不会进行排序,那我们要怎么解决?
思路分析
那这道题其实只用unordered_set也能搞:
unordered_set虽然不能排序,但是也是可以去重的,首先我们先对两个数组进行去重。
然后,我们遍历其中一个数组,遍历的同时去依次判断当前元素在不在另一个数组中,如果在,就是交集。
AC代码

class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> s1(nums1.begin(),nums1.end());unordered_set<int> s2(nums2.begin(),nums2.end());vector<int> ret;for(auto e:s1){if(s2.find(e)!=s2.end()){ret.push_back(e);}}return ret;}
};
5.3 两个数组的交集 II
题目链接: link

来看这道题,是上一题的一个升级版,还是求交集,但是多了一些要去:
返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果在两数组中出现次数不一致,则考虑取较小值)。
但是它没有要去输出结果中每个元素是唯一的。
怎么搞?
思路分析
那这道题的关键其实在于控制这个次数:
最终返回的交集中,每个元素出现的次数要和它们在两个数组中出现的次数一样,如果在两个数组中出现次数不一样,则取较小值。
所以我们可以这样搞:
用unordered_map(当然map也可以)先统计出一个数组每个元素的个数。
然后遍历第二个数组,依次取每个元素判断其是否在map中存在等效键(用count接口),如果存在就是交集,放入vector里面并让其对应的次数–,如果次数减到0了,就从map中删除掉,因为此时它的个数已经等于它在两数组中出现次数的较小值了。
如果不删除,后面在第二个数组中再遇到的话,次数就会超。
如果但看思路不太理解的话可以结合下面的代码看。
AC代码
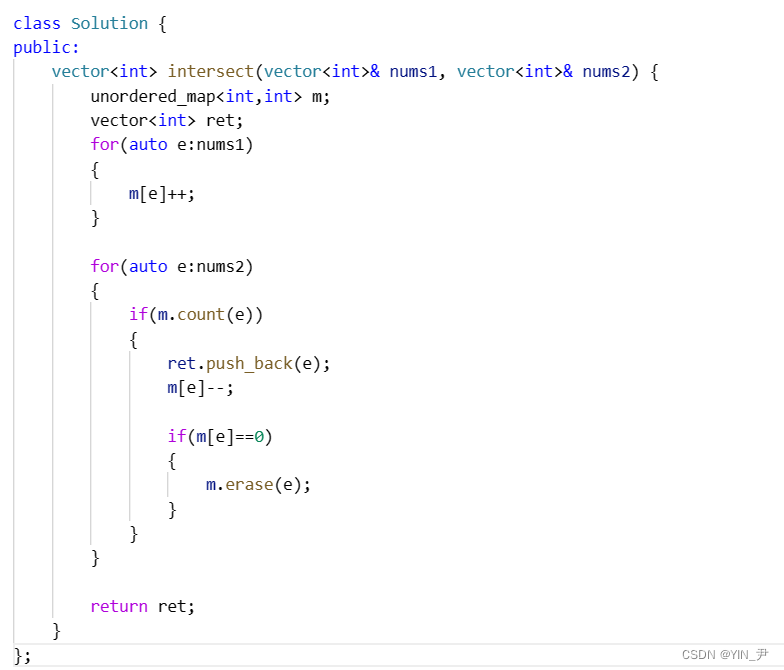
class Solution {
public:vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {unordered_map<int,int> m;vector<int> ret;for(auto e:nums1){m[e]++;}for(auto e:nums2){if(m.count(e)){ret.push_back(e);m[e]--;if(m[e]==0){m.erase(e);}}}return ret;}
};
5.4 存在重复元素
题目链接: link

这道题给我们一个数组,如果存在任意一个值出现至少两次,就返回true,否则返回false。
思路分析
那这个太简单了,统计一下次数,判断有没有次数大于等于2的就行了
AC代码
class Solution {
public:bool containsDuplicate(vector<int>& nums) {unordered_map<int,int> m;for(auto e:nums){m[e]++;}for(auto e:m){if(e.second>=2)return true;}return false;}
};
5.5 两句话中的不常见单词
题目链接: link

这道题其实就是让我们找出在两句话中只出现一次的那些单词。
思路分析
那其实思路很简单:
只要统计出这两句话中每个单词出现的次数就行了,次数为1的就是要找到不常用单词。
而这道题麻烦的是他给我们的是两个字符串,所以我们要统计单词次数的话可以先按空格把单词分割出来,放到一个vector里面,这样比较好统计。
AC代码
class Solution {
public:vector<string> uncommonFromSentences(string s1, string s2) {//加个空格,把两句话合二为一string s=s1+' '+s2;//按空格拆分句子中的单词放到vector里面vector<string> v;string word;for(auto e:s){if(e!=' '){word+=e;}else{v.push_back(word);word.clear();}}//最后结束没有空格,所以要多push一次v.push_back(word);//统计次数unordered_map<string,int> m;vector<string> ret;for(auto e:v){m[e]++;}//只出现一次的单词就是不常用单词for(auto e:m){if(e.second==1){ret.push_back(e.first);}}return ret;}
};

相关文章:
【C++】unordered_map和unordered_set的使用 及 OJ练习
文章目录 前言1. unordered系列关联式容器2. map、set系列容器和unordered_map、unordered_set系列容器的区别3. unordered_map和unordered_set的使用4. set与unordered_set性能对比5. OJ练习5.1 在长度 2N 的数组中找出重复 N 次的元素思路分析AC代码 5.2 两个数组的交集思路分…...
初识 JVM 01
JVM JRE JDK的关系 JVM 的内存机构 程序计数器 java指令的执行流程: 1 右侧的java源代码编译为左侧的java字节码(右侧第一个方块对应左侧第一个方块) 2 字节码 经过解释器 变为机器码 3 机器码就可以被cpu来执行 程序计数器的作用就…...

FPGA应用学习笔记----I2S和总结
时序一致在慢时序方便得多 增加了时序分布和分析的复杂性 使用fifo会开销大量资源...
归并排序之从微观看递归
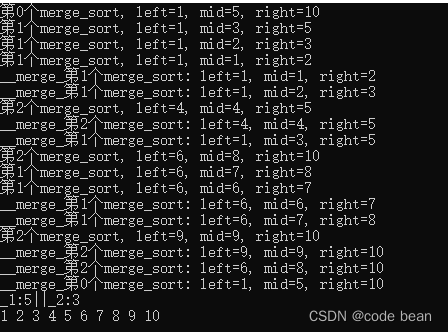
前言 这次,并不是具体讨论归并排序算法,而是利用归并排序算法,探讨一下递归。归并排序的特点在于连续使用了两次递归调用,这次我们将从微观上观察递归全过程,从本质上理解递归,如果能看完,你一…...

Pytorch-day07-模型保存与读取
PyTorch 模型保存&读取 模型存储模型单卡存储&多卡存储模型单卡读取&多卡读取 1、模型存储 PyTorch存储模型主要采用pkl,pt,pth三种格式,就使用层面来说没有区别PyTorch模型主要包含两个部分:模型结构和权重。其中模型是继承n…...

【C语言每日一题】01. Hello, World!
题目来源:http://noi.openjudge.cn/ch0101/01/ 01. Hello, World! 总时间限制: 1000ms 内存限制: 65536kB 问题描述 对于大部分编程语言来说,编写一个能够输出“Hello, World!”的程序往往是最基本、最简单的。因此,这个程序常常作为一个初…...
arm: day8
1.中断实验:按键控制led灯 流程: key.h /*************************************************************************> File Name: include/key.h> Created Time: 2023年08月21日 星期一 17时03分20秒***************************************…...

k8s容器加入host解析字段
一、通过edit或path来修改 kubectl edit deploy /xxxxx. x-n cattle-system xxxxx为你的资源对象名称 二、添加字段 三、code hostAliases:- hostnames:- www.rancher.localip: 10.10.2.180...

浅谈开发过程中完善的注释的重要性
第一部分:引言 1.1 简述编程注释的定义和功能 编程注释是一种在源代码中添加的辅助性文字,它不参与编译或执行,但对于理解源代码起着至关重要的作用。注释可以简单地描述代码的功能,也可以详细地解释算法的工作原理、设计决策的…...
Docker 微服务实战
1. 通过IDEA新建一个普通微服务模块 1.1 建Module docker_boot 1.2 改写pom <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance&…...
JupyterHub实战应用
一、JupyerHub jupyter notebook 是一个非常有用的工具,我们可以在浏览器中任意编辑调试我们的python代码,并且支持markdown 语法,可以说是科研利器。但是这种情况适合个人使用,也就是jupyter notebook以我们自己的主机作为服务器…...
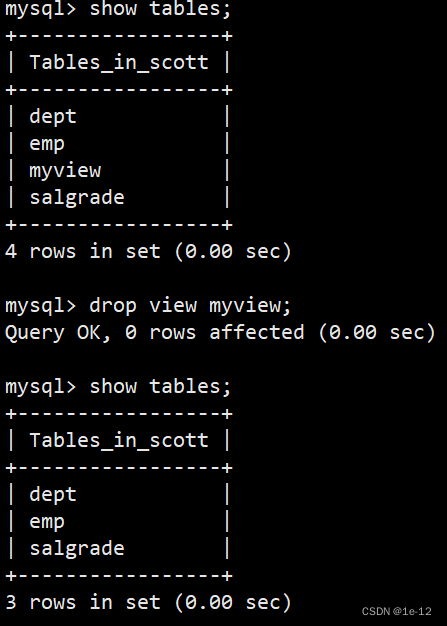
【MySQL】视图
目录 一、什么是视图 二、视图的操作 2.1 创建视图 2.2 删除视图 三、视图规则和限制 一、什么是视图 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。视图的数据变化会影响到基表(创建视图所…...
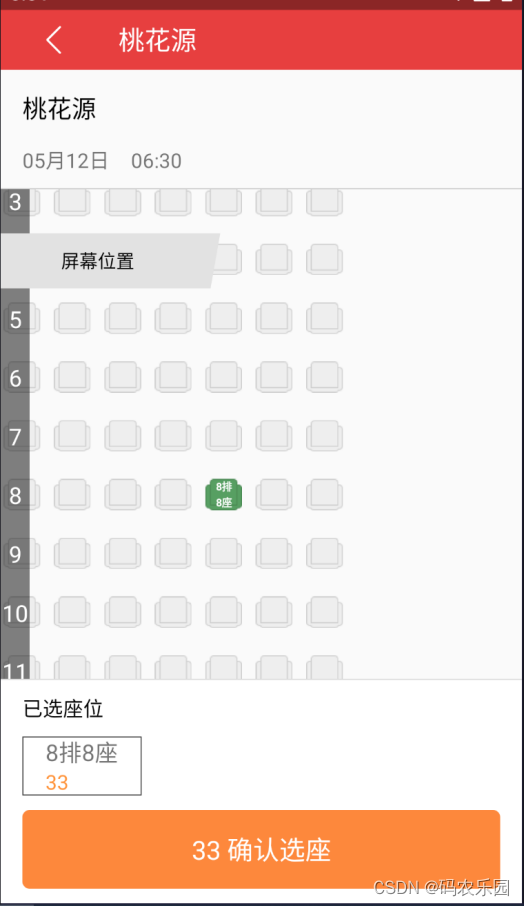
基于 Android 剧院购票APP的开发与设计
摘要:近年来,随着社会的发展和科技方面的创新,越来越多的人选择使用手机应用程序来购买剧场票。本文将探讨基于 Android 平台的剧院购票应用程序的开发和设计。该应用程序将为用户提供浏览剧场列表、查看剧场详情、选择座位并购买剧场票的功能…...

反转链表II
江湖一笑浪滔滔,红尘尽忘了 题目 示例 思路 链表这部分的题,不少都离不开单链表的反转,参考:反转一个单链表 这道题加上哨兵位的话会简单很多,如果不加的话,还需要分情况一下,像是从头节点开始…...

HTML 和 CSS 来实现毛玻璃效果(Glassmorphism)
毛玻璃效果简介 它的主要特征就是半透明的背景,以及阴影和边框。 同时还要为背景加上模糊效果,使得背景之后的元素根据自身内容产生漂亮的“变形”效果,示例: 代码实现 首先,创建一个 HTML 文件,写入如下…...
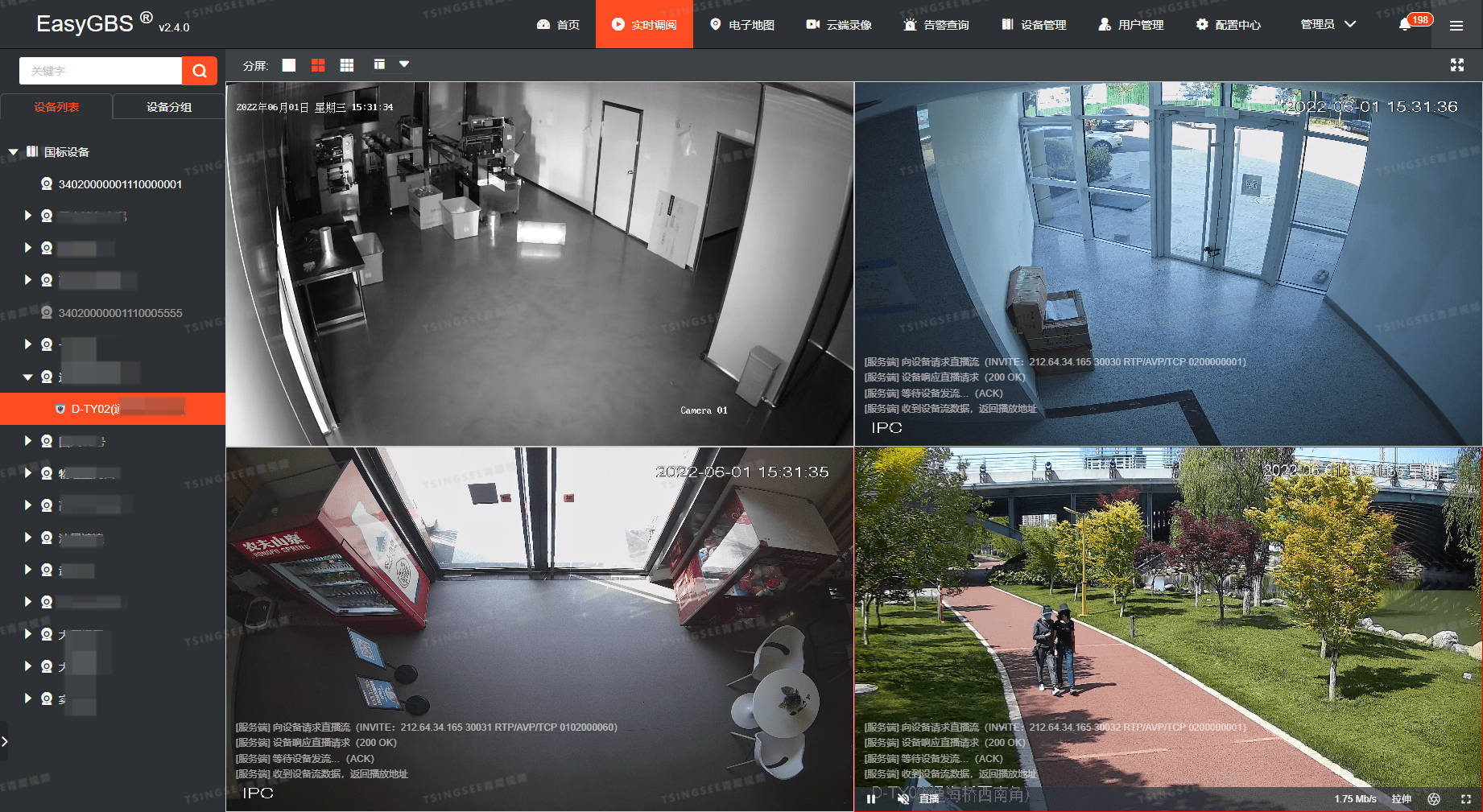
【技术】国标GB28181视频平台EasyGBS通过对应密钥上传到其他平台展示的详细步骤
国标GB28181协议视频平台EasyGBS是基于国标GB28181协议的视频云服务平台,支持多路设备同时接入,并对多平台、多终端分发出RTSP、RTMP、FLV、HLS、WebRTC等格式的视频流。平台可提供视频监控直播、云端录像、云存储、检索回放、智能告警、语音对讲、平台级…...

SpeedBI数据可视化工具:浏览器上做分析
SpeedBI数据分析云是一种在浏览器上进行数据可视化分析的工具,它能够将数据以可视化的形式呈现出来,并支持多种数据源和图表类型。 所有操作,均在浏览器上进行 在浏览器中打开SpeedBI数据分析云官网,点击【免费使用】进入&#…...
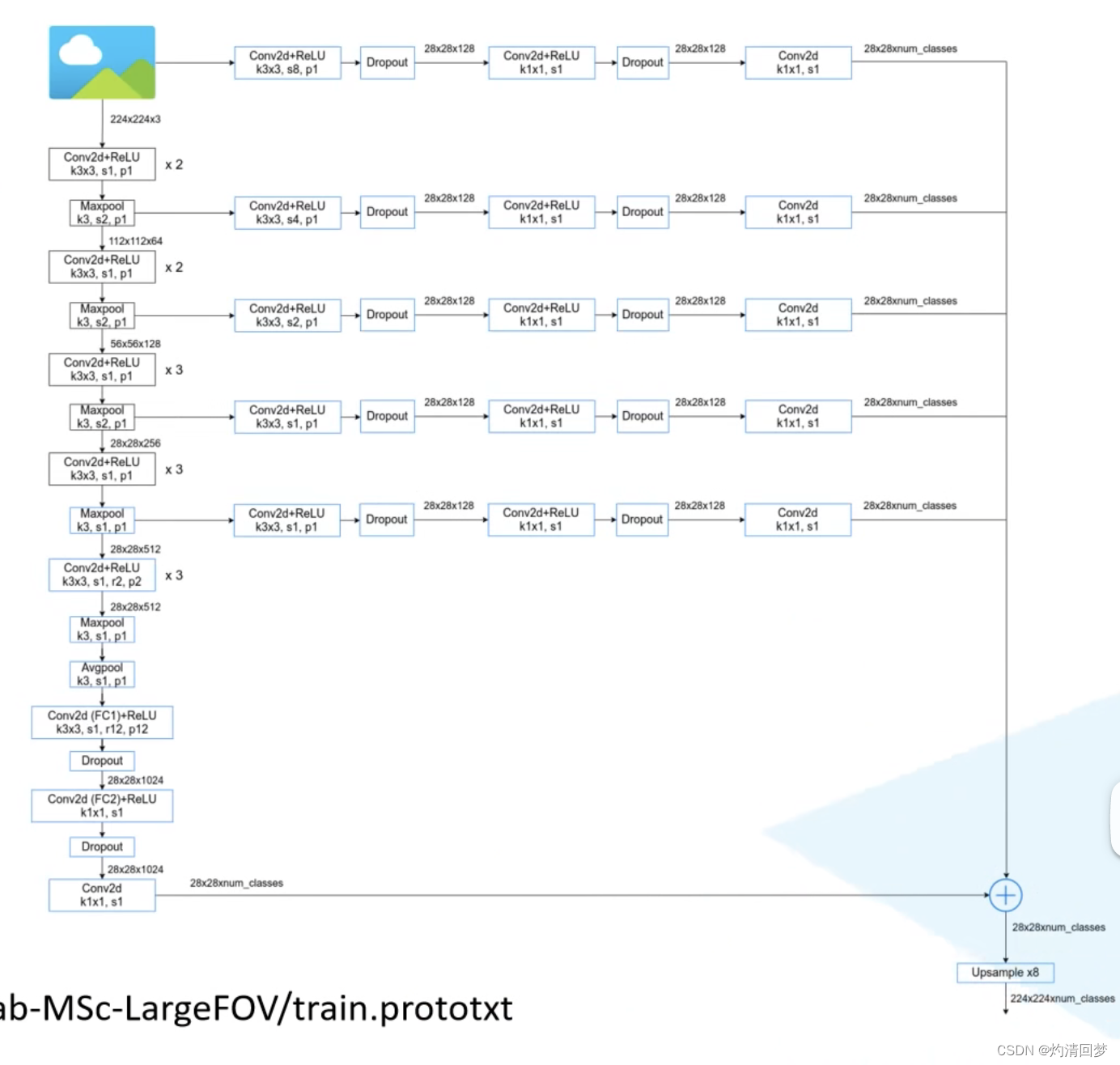
8.21笔记
Deeplab-MSc-LargrFOC 此图除了主输出之外,还有五个支线输出,他们池化层与VGG网络不同,其中卷积核大小是3,而VGG中卷积核大小为2(这个网络一开始是基于VGG网络提出的,因为那时候提出比较早,没有…...

MyBatis-Plus中公共字段的统一处理
数据库中一些表的公共字段,例如修改时间、修改人、创建时间、创建人,我们一般都是这样来处理的: employee.setCreateTime(LocalDateTime.now()); employee.setUpdateTime(LocalDateTime.now()); employee.setCreateUser(UserHolder.get()); …...

SQL的导出与导入
1、导入 使用命令行导入 1.登录sql界面; 2.create database Demo新建一个库; 3.选中数据库use Demo;选中导入路径source D:Demo.sql; 4.查看表show tables; 2、导出 整个sql mysqldump -u username -ppassword dbname > dbname.sq…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...