四、MySQL性能优化
1、SQL性能优化
1、如何分析SQL的性能?
我们可以使用EXPLAIN命令来分析SQL的执行计划 ,执行计划是指一条SQL语句在经过MySQL查询优化器的选择后具体的执行方式
EXPLAIN并不会真的去执行相关的语句,而是通过查询优化器 对语句进行分析,找出最优的查询方案,并显示对应的信息。
2、**查询SQL尽量不要使用SELECT * ** ,而是 select 具体字段
select*会消耗更多CPU,无用字段增加网络带宽资源消耗,增加数据传输时间,可能导致索引失效
3、分页优化
普通的分页在数据量小的时候耗费时间还是比较短的,但如果数据量变大,达到百万甚至是千万级别,普通的分页耗费的时间就非常长了:
select 'score','name'from 'cur_order' order by 'score' desc limit 1000000,10 ;
如何优化?可以将上述SQL语句修改为子查询 ,先子查询出大于1000000的数据,然后从这里开始分页,分页的数据量会少很多。先查询出limit第一个参数对应的主键值,再根据这个主键值去过滤并分页,效率更快
select 'socre','name'from 'cur_order' where id >=(select id from 'cus_order'limit 1000000,1)limit 10
4、避免多表做join
超过三个表禁止join,需要join的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引
实际业务场景避免多表join的做法:
- 单表查询后在内存中自己做关联:对数据库做单表查询,再根据查询结果进行二次查询,以此类推,最后再进行关联
5、建议不要使用使用外键与级联
外键对分库分表不友好,维护起来很麻烦
6、选择合适的字段类型
- 可以将IP地址转换成整型数据存储,性能更好,占用空间也更小
MySQL提供了两个方法来处理IP地址:
INET_ATON() : 把ip转为无符号整型(4-8位)
INET_NTOA():把整型的ip转为地址
插入数据前,先用INET_ATON() 把ip地址转为整型,显示数据时,使用INET_NTOA() 把整型转换为ip地址.。
- 对于非负型的数据(自增ID,整型IP,年龄)来说,要优先使用无符号整型来存储
- 小数值类型(比如年龄,状态表示如0/1)优先使用TINYINT 类型
- 对于日期类型来说,DateTime类型耗费空间更大且没有时区信息,建议使用Timestamp
- 金额字段用decimal ,避免精度丢失
- 尽量使用自增id作为主键
自增id插入数据时,是有序的,不需要重新排序;如果是非自增id,在数据插入到B+树的叶子节点时,会先进行排序,性能非常低。所以主键id一定要自增。
不过,像分库分表这类场景就不建议使用自增id作为主键,应该使用分布式ID比如uuid
7、尽量用UNION ALL 代替 UNION
UNION会把两个结果集的所有数据放到临时表中后再进行去重操作 ,更耗时,更消耗CPU资源
UNION ALL 不会再对结果集进行去重操作,获取到的数据包含重复的项
8、批量操作
对于数据库中的数据更新,如果能使用批量操作就要尽量使用,减少请求数据库的次数,提高性能(例如插入数据时,一次性插入多条,而不是一条一条的插入)
9、优化慢SQL
首要要找到哪些SQL语句执行速度比较慢
开启慢查询日志功能(默认是关闭的)
set global slow_query_log = 'ON';
找到了慢SQL语句之后,通过EXPLAIN 命令分析对应的SELECT语句
MySQL慢查询如何优化?
- 检查是否走了索引,如果没有则优化SQL利用索引
- 检查所利用的索引,是否是最优索引
- 检查所查字段是否都是必须的,是否查询了过多字段,查出来了多余数据
- 检查表中数据是否过多,是否应该进行分库分表
- 检查数据库实例所在机器的性能配置,是否太低,是否可以适当增加资源
10、分页优化
- 如果知道查询结果只有一条或者只要最大/最小一条记录,建议用limit 1,加上limit 1 后只要找到对应的一条记录就不会继续往下扫描了,效率会大大提高
-- 反例
selectid,namefrom employee wherename='jay';-- 正例
selectid,namefrom employee wherename='jay'limit1;
11、联表查询
- Inner join ,left join , right join ,优先使用Inner join ,如果是left join,左边表结果尽量小;同理如果是right join,右表表结果尽量小
12、慎用distinct
- 慎用distinct关键字,因为当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,这个比较、过滤的过程会占用系统资源
2、MySQL性能优化
1、数据库命名规范
- 所有数据库对象名称必须使用小写字母并用下划线分割
- 所有数据库对象名称禁止使用MySQL关键字
- 数据库对象的命名要能做到见名识意,并且最好不要超过32个字符
- 临时库表必须以temp_ 为前缀并以日期为后缀,备份表必须以bak_ 为前缀并以日期为后缀
- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换 ,会造成列上的索引失效,导致查询效率降低)
2、数据库基本设计规范
- 所有表必须使用InnoDB存储引擎
- 数据库和表的字符集统一使用UTF8
如果数据库中有存储emoji表情的需要,字符集需要采用utf8mb4字符集
- 所有表和字段都需要添加注释
使用comment从句添加表和列的备注,维护数据字典
- 控制单表数据量的大小,建议控制在500万以内
数据量过大会造成修改表结构,备份,恢复都会有很大问题
可以用历史数据归档(应用于日志数据),分库分表(应用与业务数据)等手段控制数据量大小
-
经常一起使用的列放到一个表中,避免更多的关联操作
-
禁止在数据库中存储文件(比如图片)这类大的二进制数据
MySQL数据库可以存储文件(图片),是直接存储文件对应的二进制数据
不过还是建议不要在数据库中存储文件,会严重影响数据库性能,消耗过多存储空间
可以选择云服务厂商提供的开箱即用的文件存储服务,如阿里云的OSS对象存储,数据库只存储文件地址信息
3、数据库字段设计规范
- 优先选择符合存储需要的最小的数据类型
- 避免使用TEXT,BLOB数据类型,最常见的TEXT类型可以存储64K的数据
MySQL内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时就不能使用内存临时表,必须使用磁盘临时表进行,对于这样的数据,MySQL还要进行二次查询,会使sql性能变得很差
- 避免使用ENUM类型
修改ENUM类型需要使用ALTER语句
ENUM类型的ORDER BY操作效率低,需要额外操作
ENUM数据类型存在一些限制,比如建议不要使用数值作为ENUM的枚举类
- 尽可能把所有列定义为 NOT NULL
除非有特别的原因使用NULL值,应该总是让字段保持NOT NULL
索引NULL列需要额外的空间来保存,所以要占用更多的空间
进行比较和计算时要对NULL值做特别的处理
- 单表不要包含过多字段
4、索引设计规范
- 限制每张表上的索引数量,建议单张表索引不超过5个
- 禁止使用全文索引
- 禁止给表中每一列 都建立单独的索引
如果要用到多个列可以建立联合索引
- 每个InnoDB表必须有个主键
InnoDB是一种索引组织表,数据的存储的逻辑顺序和索引的顺序是相同的
InnoDB是按照主键索引的顺序来组织表的:
a. 不要使用更新频繁的列作为主键,不使用多列主键
b.不要使用UUID,MD5,字符串列作为主键(无法保证数据的顺序增长)
c.主键建议使用自增id值
- 选择索引列的顺序
建立索引的目的是:希望通过索引进行数据查找,减少随机IO,增加查询性能,索引能过滤出越少的数据,则从磁盘中读入的数据就越少,查询效率越高
a. 区分度最高的放在联合索引的最左侧
b.尽量把字段长度小的列放在联合索引的最左侧(字段长度越小,一页能存储的数据量越大,IO性能越好)
c.使用最频繁的列放到联合索引的左侧(比较少的建立一些索引)
- 避免建立冗余索引和重复索引
因为查询优化器是根据所有索引去选择执行方案,冗余索引或重复索引会增加优化器生成执行计划的时间,影响查询性能
- 对于频繁的查询优先考虑使用覆盖索引
覆盖索引就是包含了所有查询字段 的索引
比如,创建索引{a,b,c},查询语句:select b from user where b>1;索引覆盖了查询字段,会使用到覆盖索引,即不用进行回表查询
覆盖索引的好处:
a. 避免InnoDB表进行索引的二次查询 :对于非聚簇索引,叶子节点中保存的是索引字段和主键信息,当用非聚簇索引查询数据时,先找到对应的主键信息,然后通过主键信息回表到主键索引表中查具体数据 ,二次查询会降低查询效率。而覆盖索引,索引覆盖了查询字段,在非聚簇索引的叶子节点就能查到需要的数据,避免了对主键的二次查询,减少了IO操作,提升查询效率
b. 可以把随机IO变成顺序IO,加快查询效率 :由于覆盖索引是按键值的顺序存储的,对于IO密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的IO转变成索引查找的顺序IO
5、数据库SQL开发规范
- 优化对性能影响较大的SQL语句
优化慢查询SQL语句
- 充分利用表上已经存在的索引
- 禁止使用select *
- 禁止使用不含字段列表的insert语句
- 避免数据类型的隐式转换
- 避免使用子查询,可以把子查询优化为join操作
- 避免使用join关联太多的表
- 禁止使用order by rand()进行随机排序
- where从句中禁止对列进行函数转换和计算
- 拆分复杂的大SQL为多个小SQL
- 程序连接不同的数据库使用不同的账号,禁止跨库查询
6、数据库操作行为规范
- 超100万行的批量写操作,要分批多次进行操作
大批量操作可能会造成严重的主从延迟
binlog日志为row格式时会产生大量的日志
会产生大事务操作
- 禁止为程序使用的账号赋予super权限
super权限只能留给DBA处理问题的账号使用
- 对于程序连接数据库账号,遵循权限最小原则
程序使用数据库账号只能在一个DB下使用,不准跨库
程序使用的账号原则上不准有drop权限
3、读写分离
1、读写分离是什么?
读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上 ,大幅提升读性能

一般我们会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性,这样的架构实现起来比较简单,符合系统的写少读多的特点。
2、读写分离会带来什么问题?
读写分离对于提升数据库的并发非常有效,但是,同时会引来的问题:主库和从库的数据存在延迟,比如在写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致的问题。这就是主从同步延迟
解决方法:
- 强制读请求到主库处理
既然更改后,从库的数据过期,那就直接到主库中读取。通过Sharding-JDBC的HintManager分片键值管理器,我们可以强制使用主库
对于这种方案,我们可以将那些必须获取最新数据的读请求都交给主库处理
- 延迟读取
主库的数据同步到从库需要时间,那我们就等待时间之后再去从库读取数据。
3、实现读写分离
- 部署多台数据库,选择其中的一台作为主数据库,一台或多台作为从数据库
- 保证主数据库和从数据库之间的数据是实时同步的,这个过程也就是主从复制
- 系统将写请求交给主数据库处理,读请求交给从数据库处理
如何分离读写请求?
代理方式:在应用和数据中间加一个代理层,应用程序所有得到数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。类似功能的中间件有MySQL Router、Atlas等
组件方式:通过引入第三方组件来帮助我们读写请求,推荐使用sharding-jdbc,直接引入jar包即可使用,非常方便。
4、主从复制的原理
MySQL的binlog日志主要记录了MySQL数据库中数据的所有变化(数据库执行的所有DDL和DML语句),因此我们根据主库的binlog日志就能够将主库的数据同步到从库中
- 主库将数据库中数据的变化写入到binlog
- 从库连接主库
- 从库创建一个I/O线程向主库请求更新的binlog
- 主库会创建一个binlog dump线程来发送binlog,从库中的I/O线程负责接收
- 从库的I/O线程将接收到的binlog写入到relay log中
- 从库的SQL线程读取relay log 同步到数据本地(再执行一遍SQL)
4、分库分表
当数据库不足以支撑并发量,当表无法装下再多的数据,这时候采用分库分表来进行优化----前提是,SQL优化都已经用过了,还需要优化的情况下,才选择实现分库分表
1、分库
分库就是将数据库的数据分散到不同的数据库上,可以垂直分库,也可以水平分库
-
垂直分库:单一数据库按照业务进行划分,不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。比如将一个数据库的用户表、订单表、商品表分别单独拆分为各自的数据库,用户数据库、订单数据库、商品数据库
-
水平分库:同一张表按一定规则拆分到不同的数据库中,两个数据库中的这张表字段是一样的,解决了单表的存储和性能瓶颈的问题。比如当订单表数据量太大,可以对订单表水平分表,然后将切分好的2张订单表分别放在两个不同的数据库
2、分表
分表就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分
- 垂直分表:对数据表列的拆分,把一张列比较多的表拆分为多张表,不同表的结构不一样;比如可以将用户表的一些字段单独抽出来作为一个表
- 水平分表:对数据表行的拆分,解决单一表数据量过大的问题。比如可以将用户表拆分为多张用户表,字段一样表结构一样。
水平拆分只能解决数据量大的问题,表的结构并没有改变。为了提升性能,我们通常会将拆分后的多张表放在不同的数据库中,水平分表通常和水平分库同时出现
例如,当一个表有几百万条数据,有十几个字段,水平拆分就是,将几百万条数据分出一部分在另一个分库里,分库和原库结构完全一样,分表和原表结构也一样,就是数据不同;垂直拆分则是,将表中的字段分出一部分到分表里,这样分库和原库的结构和数据都不一样,分表和原表的结构和数据也不一样。水平是按照行来拆分,垂直是按照列来拆分
3、什么情况下需要分库分表?
- 单表的数据达到千万级别以上,数据库读写速度比较缓慢
- 数据库中的数据占用的空间越来越大,备份时间越来越长
- 应用的并发量太大
4、分库分表会带来什么问题?
- join操作,同一个数据库中的表分布在了不同的数据库,导致无法使用join操作。这样导致我们需要手动进行数据的封装,比如在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据
- 事务问题:同一个数据库中的表在不同的数据库,如果单个事务的操作涉及到多个数据库,数据库自带的事务就无法满足需求了
- 分布式id:分库之后,数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。为不同的数据节点生成去哪聚唯一主键,这就需要引入分布式id了
- 需要更多的数据库服务器,成本很高
尽量不做分库分表,会带来很多问题,如查询等都要重新排序
5、分布式数据层中间件
1、分布式数据层中间件是什么?
分布式数据访问层中间件,旨在为一个通用数据访问层服务,支持MySQL动态数据源、读写分离、分布式唯一主键生成器、分库分表、动态化配置 等功能。并且支持从客户端角度对数据源的各方面(比如连接池、SQL等)进行监控。
2、常见的数据层中间件:
- TDDL
淘宝根据自己的业务特点开发了TDDL框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的JDBC datasource实现
实现动态数据源、读写分离、分库分表
缺点:分库分表功能还未开源,当前公布文档较少,需要diamond(淘宝内部使用的一个管理持久配置的系统)
- Atlas
Qihoo 360开发维护的一个基于MySQL协议的数据中间层项目。它实现了MySQL的客户端与服务端协议,作为服务端与应用程序通信,同时作为客户端与MySQL通信
实现读写分离、单库分表
缺点:不支持分库分表
- MTDDL
美团点评分布式数据访问层中间件
实现动态数据源、读写分离、分库分表,与tddl类似
相关文章:
四、MySQL性能优化
1、SQL性能优化 1、如何分析SQL的性能? 我们可以使用EXPLAIN命令来分析SQL的执行计划 ,执行计划是指一条SQL语句在经过MySQL查询优化器的选择后具体的执行方式 EXPLAIN并不会真的去执行相关的语句,而是通过查询优化器 对语句进行分析&…...
Oracle Database12c数据库官网下载和安装教程
文章目录 下载安装Oracle自带的客户端工具使用 下载 进入oracle官网 点击下载连接之后右上角会有一个下载 我们只需要数据库本体就够了 运行这个下载器 等待下好之后即可 出现 Complete 之后代表下载成功,然后我们解压即可 安装 双击 双击setup.exe 根据…...

spring依赖注入详解(下)
Autowired注解依赖注入过程 一、findAutowireCandidates()实现 找出BeanFactory中类型为type的所有的Bean的名字,注意是名字,而不是Bean对象,因为我们可以根据BeanDefinition就能判断和当前type是不是匹配,不用生成Bean对象把re…...

python的dataframe常用处理方法
import pandas as pdclass DataFrameProcessor:staticmethoddef sort_by_column(df, by_column, ascendingTrue):"""根据指定列对DataFrame进行排序。Parameters:df (pd.DataFrame): 要排序的DataFrame。by_column (str): 要排序的列名。ascending (bool): True…...
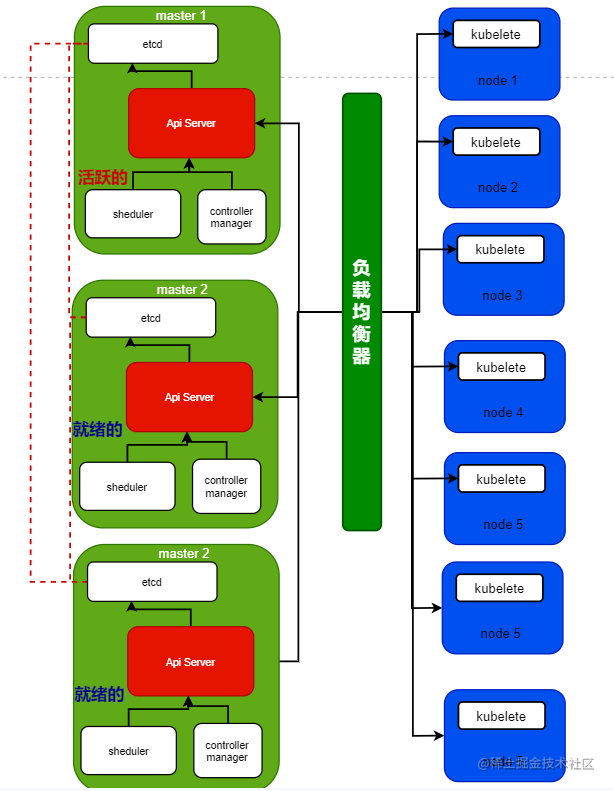
k8s 自身原理之高可用
说到高可用,咱们在使用主机环境的时候(非 k8s),咱做高可用有使用过这样的方式: 服务器做主备部署,当主节点和备节点同时存活的时候,只有主节点对外提供服务,备节点就等着主节点挂了…...

游乐场vr设备虚拟游乐园vr项目沉浸体验馆
在景区建设一个VR游乐场项目可以为游客提供一种新颖、刺激和沉浸式的游乐体验。提高游客的体验类型,以及景区的类目,从而可以吸引更多的人来体验。 1、市场调研:在决定建设VR游乐场项目之前,需要进行市场调研,了解当地…...

window10安装并使用oracle
1、现在oracle19c或者21c,下载链接如下 Database Software Downloads | Oracle 中国 2、安装好之后, 2.1PL/SQL连接方式 命令窗口输入sqlplus conn as sysdba 2.2DBeaver连接 输入IP、 端口默认1521 数据库默认是ORCL 用户名是system 角色是N…...
[Mac软件]AutoCAD 2024 for Mac(cad2024) v2024.3.61.182中文版支持M1/M2/intel
下载地址:前往黑果魏叔官网 AutoCAD是一款计算机辅助设计(CAD)软件,目前已经成为全球最受欢迎的CAD软件之一。它可以在二维和三维空间中创建精确的技术绘图,并且可以应用于各种行业,如建筑、土木工程、机械…...
的n种处理方案及效果)
Oracle 主从库目录不一致(异路径)的n种处理方案及效果
最近遇到了复制数据(DUPLICATE TARGET DATABASE TO xxx)的时候 Oracle 源和目标库目录不一致的问题,比较初级但也踩到一些坑,整理记录一下。主从库搭建的时候注意事项其实也类似,而且更通用,所以标题写的是…...
 - 简单工厂模式、工厂方法模式和抽象工厂模式)
创建型(一) - 简单工厂模式、工厂方法模式和抽象工厂模式
本文使用了王争老师设计模式课程中的例子,写的很清晰,而且中间穿插了代码优化。 由于设计模式就是解决问题的一种思路,所以每个设计模式会从问题出发,这样比较好理解设计模式出现的意义。 一、简单工厂模式 解决问题:…...

LeetCode3.无重复字符的最长子串
虽然是一道中等题,但我5分钟就写完了,而且是看完题就知道怎么写,这一看就知道双指针,一个左一个右,右指针往后移如果没有重复的长度1;如果有重复的,左指针往右移,那如何判断重复呢&a…...

鲁图中大许少辉博士八一新书《乡村振兴战略下传统村落文化旅游设计》山东省图书馆典藏
鲁图中大许少辉博士八一新书《乡村振兴战略下传统村落文化旅游设计》山东省图书馆典藏...
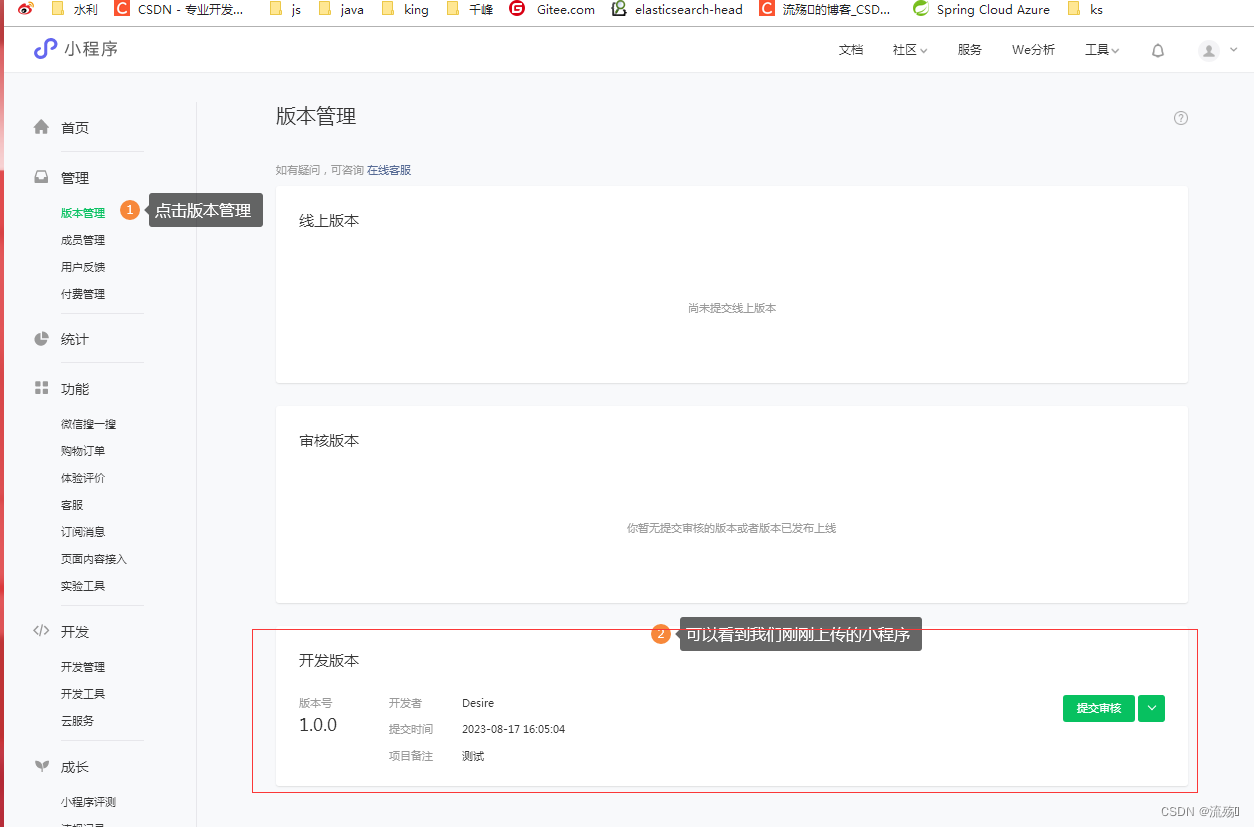
如何发布自己的小程序
小程序的基础内容组件 text: 文本支持长按选中的效果 <text selectable>151535313511</text> rich-text: 把HTML字符串渲染为对应的UI <rich-text nodes"<h1 stylecolor:red;>123</h1>"></rich-text> 小程序的…...

【微服务】spring 条件注解从使用到源码分析详解
目录 一、前言 二、spring 条件注解概述 2.1 条件注解Conditional介绍 2.2 Conditional扩展注解 2.2.1 Conditional扩展注解汇总 三、spring 条件注解案例演示 3.1 ConditionalOnBean 3.2 ConditionalOnMissingBean 3.2.1 使用在类上 3.2.2 使用场景补充 3.3 Condit…...

客户案例:高性能、大规模、高可靠的AIGC承载网络
客户是一家AIGC领域的公司,他们通过构建一套完整的内容生产系统,革新内容创作过程,让用户以更低成本完成内容创作。 客户网络需求汇总 RoCE的计算网络RoCE存储网络1.不少于600端口200G以太网接入端口,未来可扩容至至少1280端口1.…...

Flutter性能揭秘之RepaintBoundary
作者:xuyisheng Flutter会在屏幕上绘制Widget。如果一个Widget的内容需要更新,那就只能重绘了。尽管如此,Flutter同样会重新绘制一些Widget,而这些Widget的内容仍有部分未被改变。这可能会影响应用程序的执行性能,有时…...

29.Netty源码之服务端启动:创建EventLoopSelector流程
highlight: arduino-light 源码篇:从 Linux 出发深入剖析服务端启动流程 通过前几章课程的学习,我们已经对 Netty 的技术思想和基本原理有了初步的认识,从今天这节课开始我们将正式进入 Netty 核心源码学习的课程。希望能够通过源码解析的方式…...

Kotllin实现ArrayList的基本功能
前言 上次面试时,手写ArrayList竟然翻车,忘了里面的扩容与缩容的条件,再次实现一次,加深印象 源码讲了什么 实现了List列表和RandomAccess随机访问接口List具有增删改查功能,RandomAccess支持下标访问内部是一个扩容…...

C++的初步介绍,以及C++与C的区别
C和C的区别 C又称C plus plus,且C语言是对C语言的扩充,几乎支持所有的C语言语法;C语言:面向过程的语言(注重问题的解决方法和算法)C:面向对象的语言 (求解的方法)面向对…...

JDK 核心jar之 rt.jar
一、JDK目录展示 二、rt.jar 简介 2.1.JAR释义 在软件领域,JAR文件(Java归档,英语:Java Archive)是一种软件包文件格式,通常用于聚合大量的Java类文件、相关的元数据和资源(文本、图片等&…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...