什么是JVM ?
一、JVM 简介

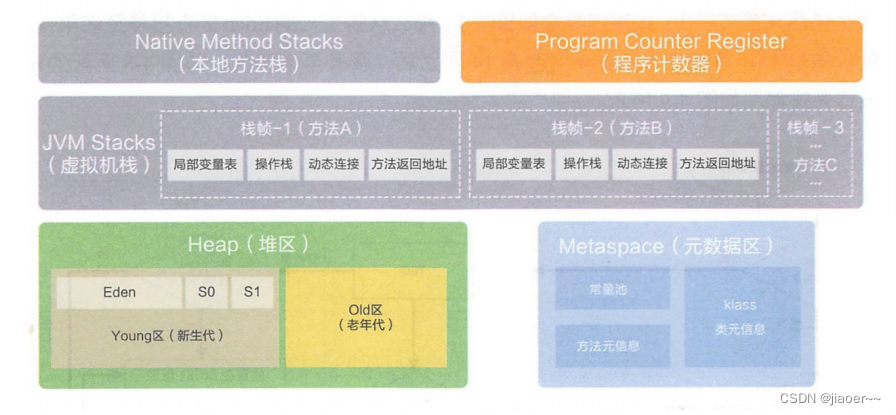
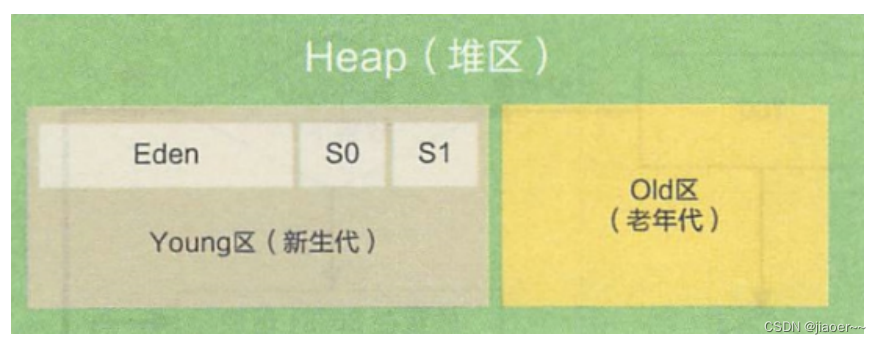
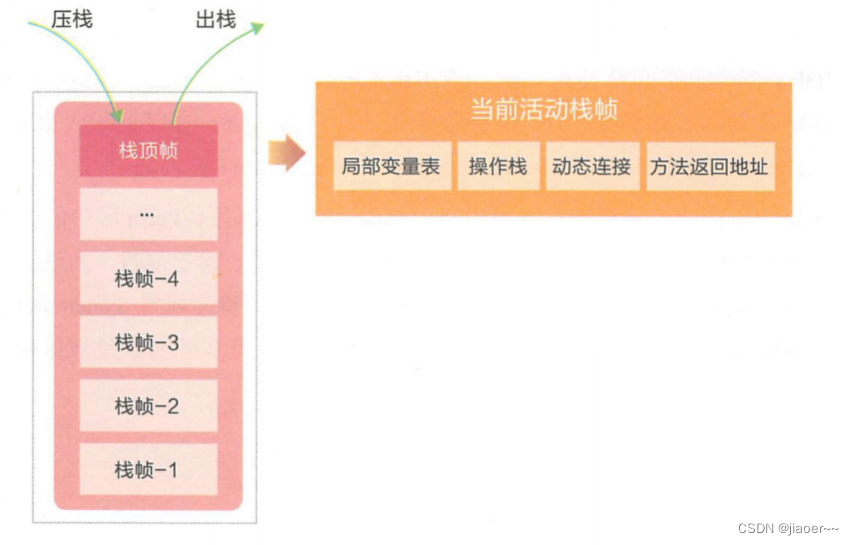
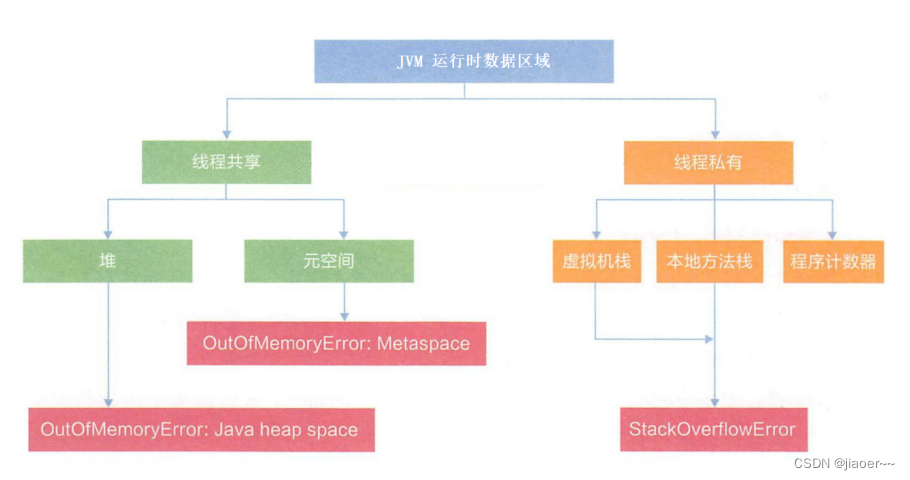
3.6 内存布局中的异常问题


/**
* JVM 参数为:-Xmx20m -Xms20m -XX:+HeapDumpOnOutOfMemoryError
* @author 38134
*
*/
public class Test {static class OOMObject {}
public static void main(String[] args) {List<OOMObject> list =new ArrayList<>();while(true) {list.add(new OOMObject());}}
}public static void main(String[] args) {
List<OOMObject> list =
new ArrayList<>();
while(true) {
list.add(new OOMObject());
}
}
}
/**
* JVM参数为:-Xss128k
* @author 38134
*
*/
public class Test {
private int stackLength = 1;
public void stackLeak() {
stackLength++;
stackLeak();
}
public static void main(String[] args) {
Test test = new Test();
try {
test.stackLeak();
} catch (Throwable e) {
System.out.println("Stack Length: "+test.stackLength);
throw e;
}
}
}/**
* JVM参数为:-Xss2M
* @author 38134
*
*/
public class Test {private void dontStop() {while(true) {}}public void stackLeakByThread() {while(true) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {dontStop(); }});thread.start();}}public static void main(String[] args) {Test test = new Test();test.stackLeakByThread();}
}
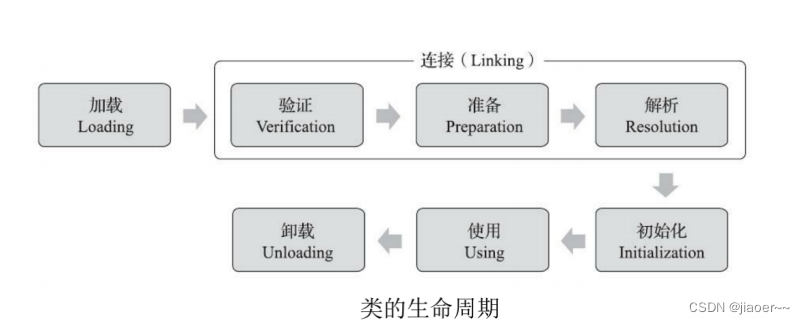
public class JdbcTest {public static void main(String[] args){Connection connection = null;try {connection =
DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/test", "root",
"awakeyo");} catch (SQLException e) {e.printStackTrace();}System.out.println(connection.getClass().getClassLoader());System.out.println(Thread.currentThread().getContextClassLoader());System.out.println(Connection.class.getClassLoader());}
}

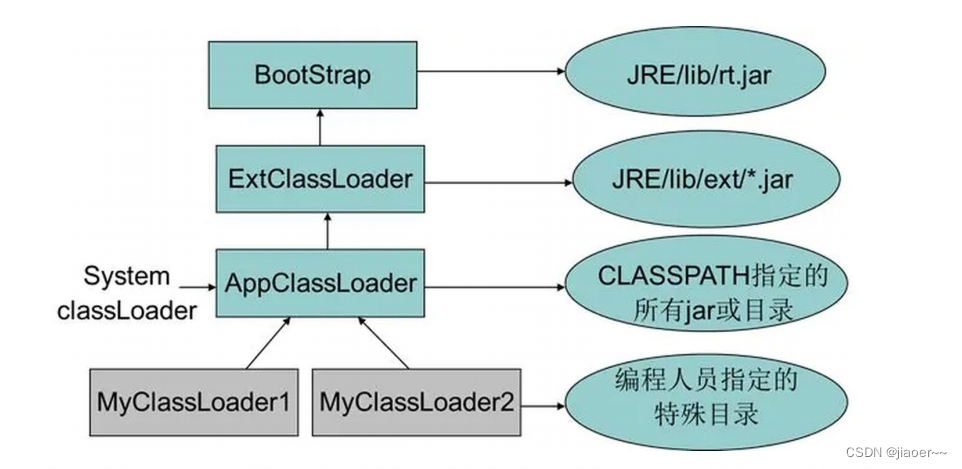
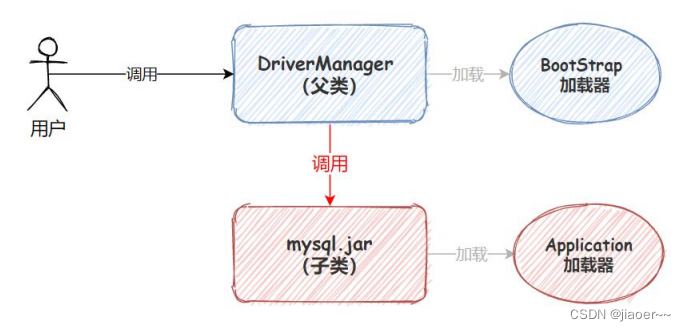
由双亲委派模型的加载流程可知 rt.jar 是有顶级父类 Bootstrap ClassLoader 加载的,如下图所示:
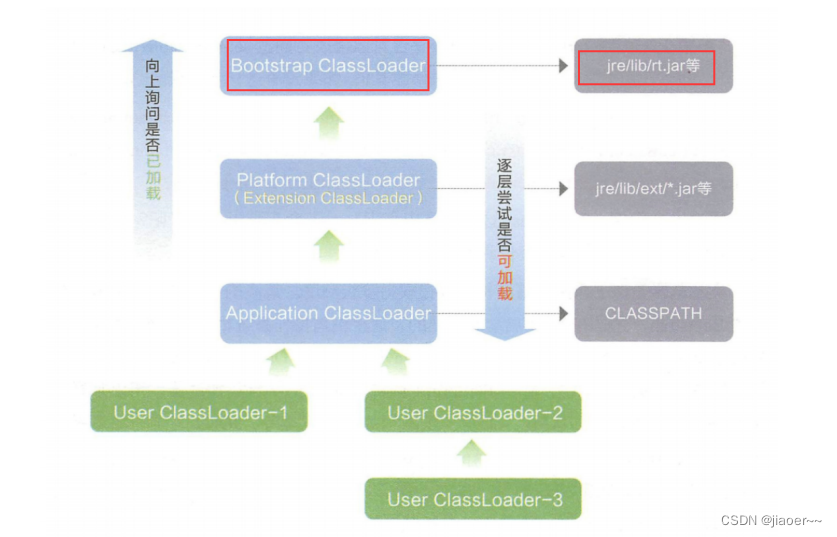
@CallerSensitive
public static Connection getConnection(String url,
java.util.Properties info) throws SQLException {return (getConnection(url, info, Reflection.getCallerClass()));
}
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws
SQLException {ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;synchronized(DriverManager.class) {// synchronize loading of the correct classloader.if (callerCL == null) {//获取线程上下为类加载器callerCL = Thread.currentThread().getContextClassLoader();}}if(url == null) {throw new SQLException("The url cannot be null", "08001");}println("DriverManager.getConnection(\"" + url + "\")");SQLException reason = null;for(DriverInfo aDriver : registeredDrivers) {// isDriverAllowed 对于 mysql 连接 jar 进行加载if(isDriverAllowed(aDriver.driver, callerCL)) {try {println(" trying " +
aDriver.driver.getClass().getName());Connection con = aDriver.driver.connect(url, info);if (con != null) {// Success!println("getConnection returning " +
aDriver.driver.getClass().getName());return (con);}} catch (SQLException ex) {if (reason == null) {reason = ex;}}} else {println(" skipping: " + aDriver.getClass().getName());}}if (reason != null) {println("getConnection failed: " + reason);throw reason;}println("getConnection: no suitable driver found for "+ url);throw new SQLException("No suitable driver found for "+ url, "08001");}
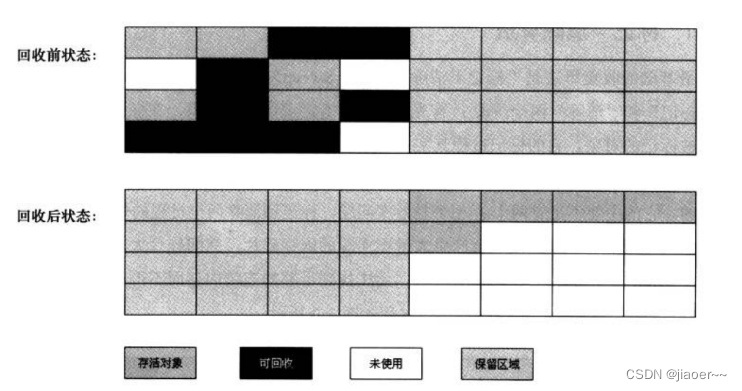
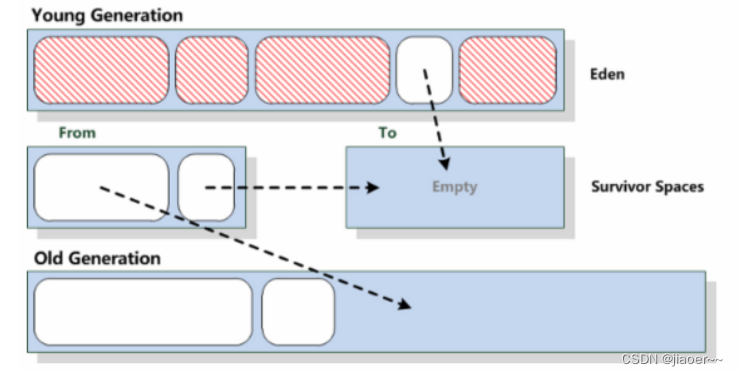
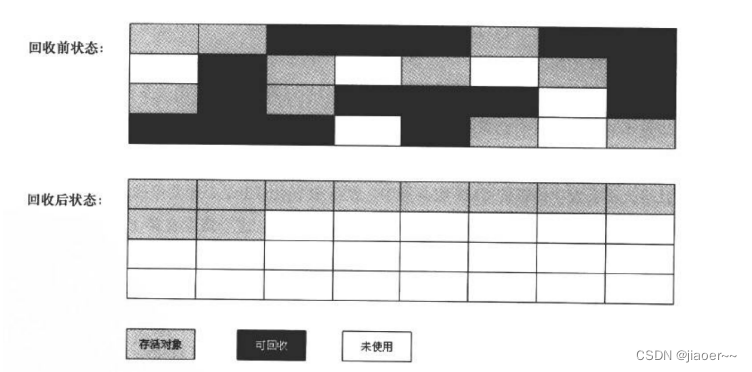
5.垃圾回收相关
/**
* JVM参数 :-XX:+PrintGC
* @author 38134
*
*/
public class Test {public Object instance = null;private static int _1MB = 1024 * 1024;private byte[] bigSize = new byte[2 * _1MB];public static void testGC() {Test test1 = new Test();Test test2 = new Test();test1.instance = test2;test2.instance = test1;test1 = null;test2 = null;// 强制jvm进行垃圾回收System.gc();}public static void main(String[] args) {testGC();}
}[GC (System.gc()) 6092K->856K(125952K), 0.0007504 secs]

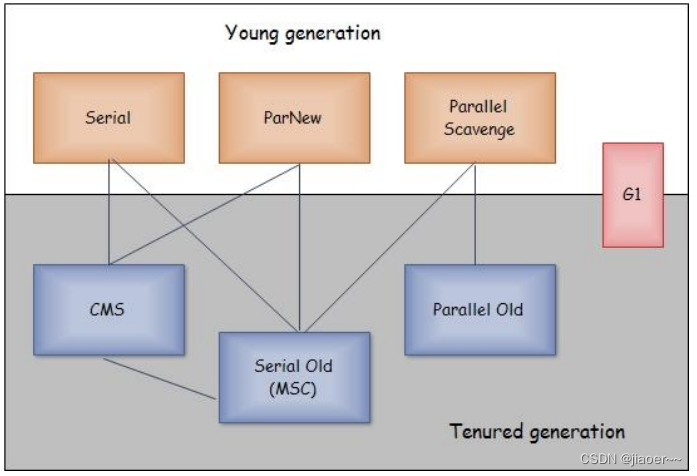



XX:MaxGCPauseMillis 控制最大的垃圾收集停顿时间
XX:GCRatio 直接设置吞吐量的大小


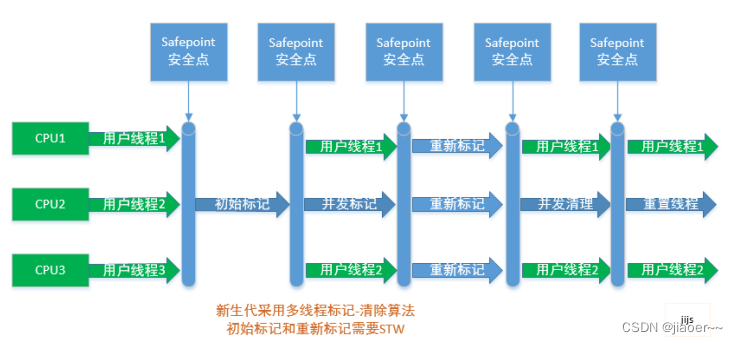
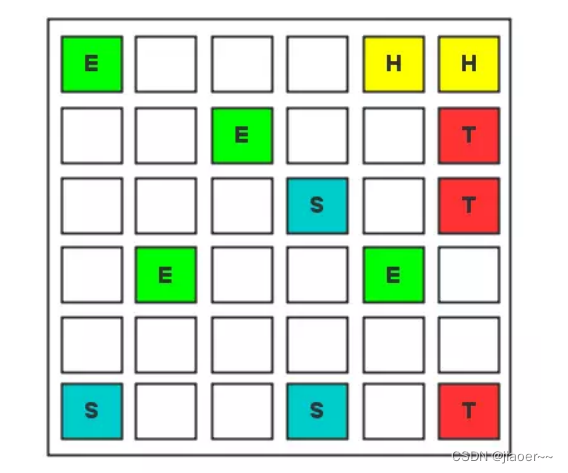
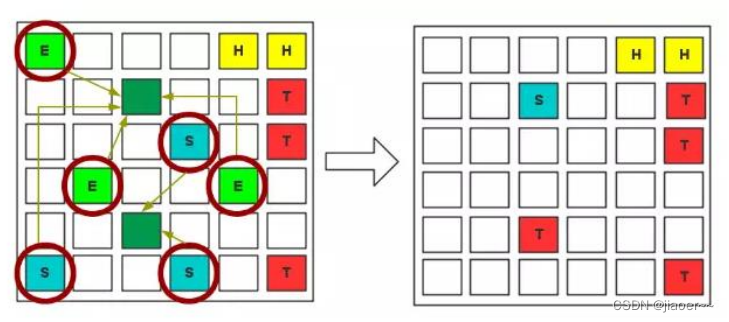


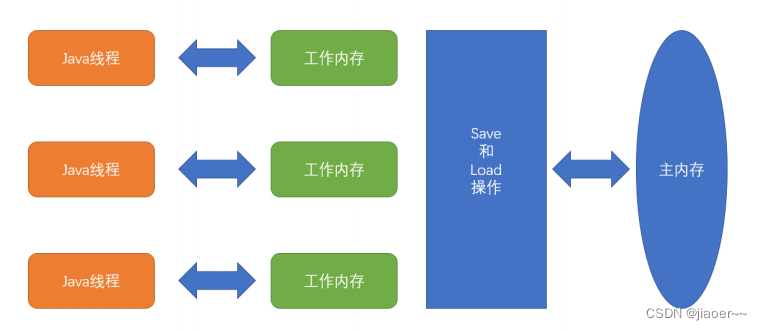
② 内存间交互操作
package com.company;
public class Main {public static volatile int num = 0;public static void increase() {num++;}public static void main(String[] args) {Thread[] threads = new Thread[10];for (int i = 0; i < 10; i++) {threads[i] = new Thread(new Runnable() {@Overridepublic void run() {for (int j = 0; j < 100; j++) {increase();}}});threads[i].start();}while (Thread.activeCount() > 2) {Thread.yield();}System.out.println(num);}
}volatile boolean shutdownRequested;
public void shutdown() {shutdownRequested = true;
}
public void work() {while(!shutdownRequested) {//do stuff}
}//x、y为非volatile变量
//flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5Map configOptions;
char[] configText;
volatile boolean initialized = false;
//假设以下代码在线程A执行
//模拟读取配置文件信息,当读取完成后将initialized设置为true以通知其他线程配置可用
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfigOptions(configText,configOptions);
initialized = true;
//假设以下代码在线程B执行
//等待initialized为true,代表线程A已经把配置信息初始化完成
while(!initialized) {sleep();
}
//使用线程A初始化好的配置信息
doSomethingWithConfig();public static Singleton getSingleton(){if(instance==null){ //Single Checkedsynchronized (Singleton.class){if(instance==null){ //Double Checkedinstance=new Singleton();} }}return instance;
}class Singleton{// 确保产生的对象完整性private volatile static Singleton instance = null;private Singleton() {}public static Singleton getInstance() {if(instance==null) { // 检查对象是否初始化synchronized (Singleton.class) {if(instance==null) // 确保多线程情况下对象只有一个instance = new Singleton();}}return instance;}
}相关文章:
什么是JVM ?
一、JVM 简介 JVM 是 Java Virtual Machine 的简称,意为 Java 虚拟机。 虚拟机是指通过软件模拟的具有完整硬件功能的、运行在一个完全隔离的环境中的完整计算机系统。 常见的虚拟机: JVM 、 VMwave 、 Virtual Box 。 JVM 和其他两个虚拟机的区别…...

【大数据】Hive 中的批量数据导入
Hive 中的批量数据导入 在博客【大数据】Hive 表中插入多条数据 中,我简单介绍了几种向 Hive 表中插入数据的方法。然而更多的时候,我们并不是一条数据一条数据的插入,而是以批量导入的方式。在本文中,我将较为全面地介绍几种向 H…...
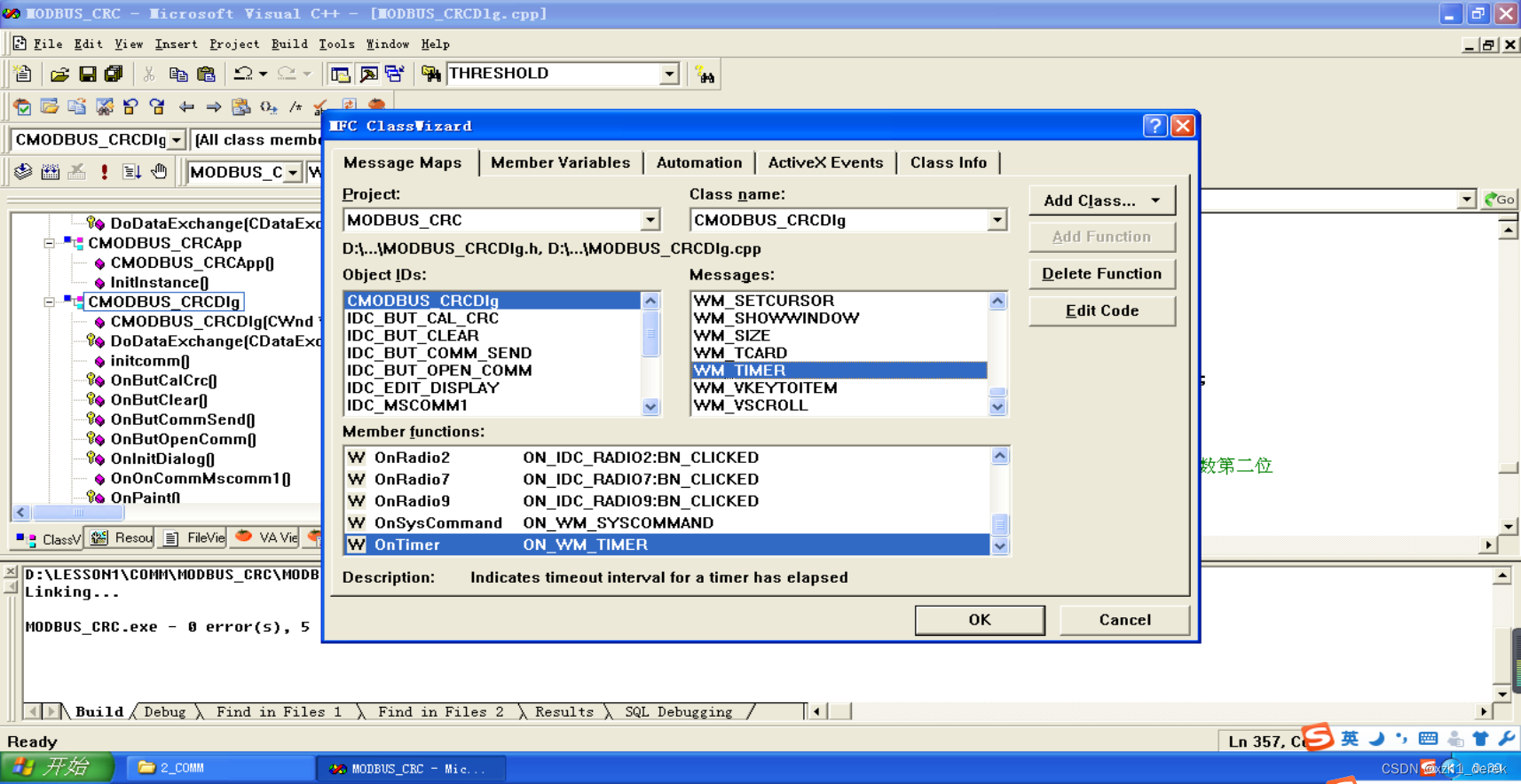
【Modbus通信实验三】数据切片问题
在做两个串口相互通信的实验中,当发送频率快一点时偶尔会遇到以下情景,即一次send中把原数据拆成两份发送,就会导致CRC校验错误。下图中6字节数据拆成42是把SetRThreshold()阈值设为2,当设为1的情况下则会拆成51。 一开始以为是缓…...
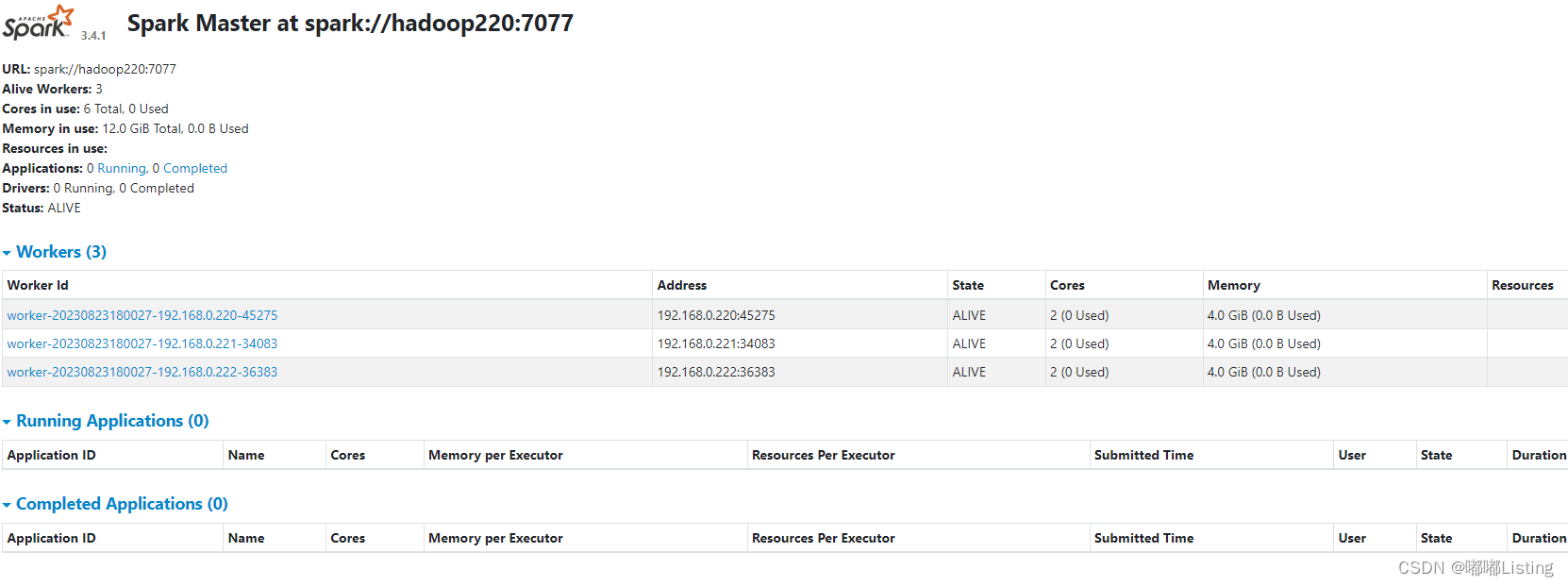
记录《现有docker中安装spark3.4.1》
基础docker环境中存储hadoop3--方便后续查看 参考: 实践: export JAVA_HOME/opt/apache/jdk1.8.0_333 export SPARK_MASTER_IP192.168.0.220 export SPARK_WORKER_MEMORY4g export SPARK_WORKER_CORES2 export SPARK_EXECUTOR_MEMORY4g export HADOOP_H…...

【3ds Max】练习——制作衣柜
目录 步骤 一、制作衣柜顶部 二、制作衣柜门板 三、制作衣柜底部 四、制作柜子腿部 五、制作柜子底板 步骤 一、制作衣柜顶部 1. 首先创建一个平面,然后将图片素材拖入平面 2. 平面大小和图片尺寸比例保持一致 3. 单机鼠标右键,选择对象属性 勾选…...

Spring-MVC的数据响应-19
在访问服务端MVC的时候,这个controller层进行相应操作之后 他要做两件事:页面跳转和返回字符串,在做完这些操作之后,我们一般进行页面展示:排除页面展示之外,有些需求可能直接回写给我们一些数据: 页面跳…...
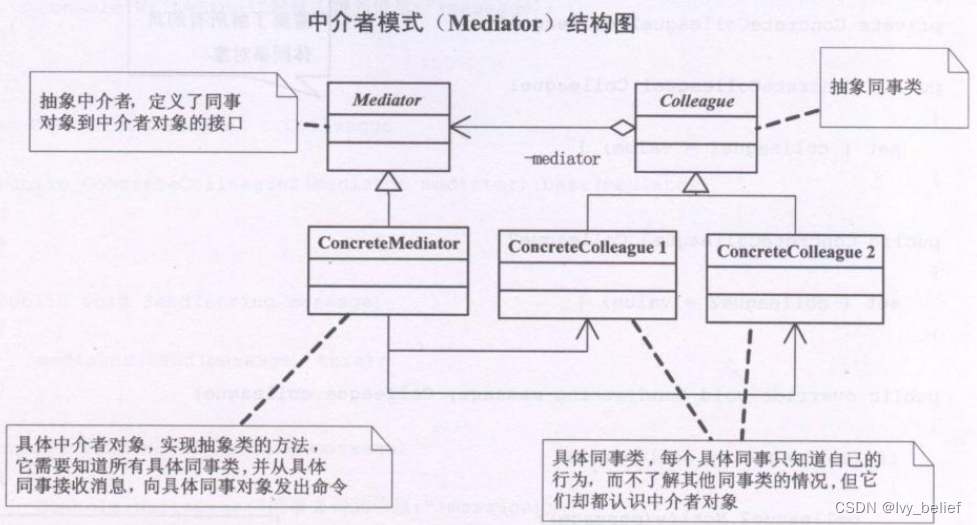
(三)行为模式:5、中介者模式(Mediator Pattern)(C++示例)
目录 1、中介者模式(Mediator Pattern)含义 2、中介者模式的UML图学习 3、中介者模式的应用场景 4、中介者模式的优缺点 (1)优点 (2)缺点 5、C实现中介者模式的实例 1、中介者模式(Media…...

期权是什么?期权的优缺点是什么?
期权是一种合约,有看涨期权和看跌期权两种类型,也就是做多和做空两个方向,走势标的物对应大盘指数,这也是期权与其他金融工具的主要区别之一,可以用于套利,对冲股票和激进下跌的风险,下文介绍期…...

目标检测任务数据集的数据增强中,图像垂直翻转和xml标注文件坐标调整
需求: 数据集的数据增强中,有时需要用到图像垂直翻转的操作,图像垂直翻转后,对应的xml标注文件也需要做坐标的调整。 解决方法: 使用pythonopencvimport xml.etree.ElementTree对图像垂直翻转和xml标…...

html5提供的FileReader是一种异步文件读取文件中的数据
前言:FileReader是一种异步文件读取机制,结合input:file可以很方便的读取本地文件。 input:file 在介绍FileReader之前,先简单介绍input的file类型。 <input type"file" id"file"> input的file类型会渲染为一个按…...

Linux学习记录——이십오 多线程(2)
文章目录 1、理解原生线程库线程局部存储 2、互斥1、并发代码(抢票)2、锁3、互斥锁的实现原理 3、线程封装1、线程本体2、封装锁 4、线程安全5、死锁6、线程同步1、条件变量1、接口2、demo代码 1、理解原生线程库 线程库在物理内存中存在,也…...
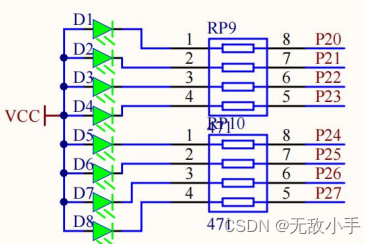
单片机(二)使用位移 让灯亮
一:硬件电路 P2 口: P2.0~ P2.7 是这些 I0 口 LED 阳极接 电源 , P20 口 为低电平 可以让 LED灯 亮 二:软件实现部分 两种 ① 通过循环 来展示从左 到右 #include "reg52.h"#define LED_PORT P2 // 定义单片机的P2端…...

探究代理服务器在网络安全与爬虫中的双重作用
在如今高度互联的世界中,代理服务器已经成为网络安全和爬虫开发的关键工具。本文将深入探讨Socks5代理、IP代理、网络安全、爬虫、HTTP等关键词,以揭示代理服务器在这两个领域中的双重作用,以及如何充分利用这些技术来保障安全和获取数据。 …...
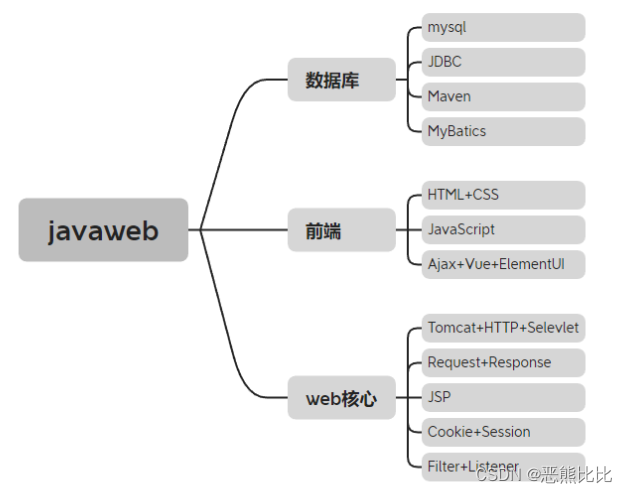
JavaWeb-学习目录
技术栈介绍 文章目录 1.数据库:1.1 Mysql1.2 JDBC1.3 Maven1.4 Mybatis 2.前端2.1 HTMLCSSJS2.2 AjaxVueElementUI 3. Web核心3.1 TomcatHttpServlet3.2 RequestResponse3.3 JSP3.4 CookieSession3.5 FilterListener 1.数据库: 1.1 Mysql mysql&#…...

C语言题目 - 调用qsort函数对数组进行排序
题目 如题 思路 其实没什么难的,只要严格按照 qsort 函数的参数来填充即可,这里要用到函数指针。 qsort 函数的原型如下: void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void *)); 参数说明&…...
Matplotlib学习笔记
Matplotlib数据可视化库 jupyter notebook优势 画图优势,画图与数据展示同时进行。数据展示优势,不需要二次运行,结果数据会保留。 Matplotlib画图工具 专用于开发2D图表以渐进、交互式方式实现数据可视化 常规绘图方法 子图与标注 想要…...

对比flink cdc和canal获取mysql binlog优缺点
Flink CDC和Canal都是用于获取MySQL binlog的工具,但是有以下几点优缺点对比: Flink CDC是一个基于Flink的库,可以直接在Flink中使用,无需额外的组件或服务,而Canal是一个独立的服务,需要单独部署和运行&a…...
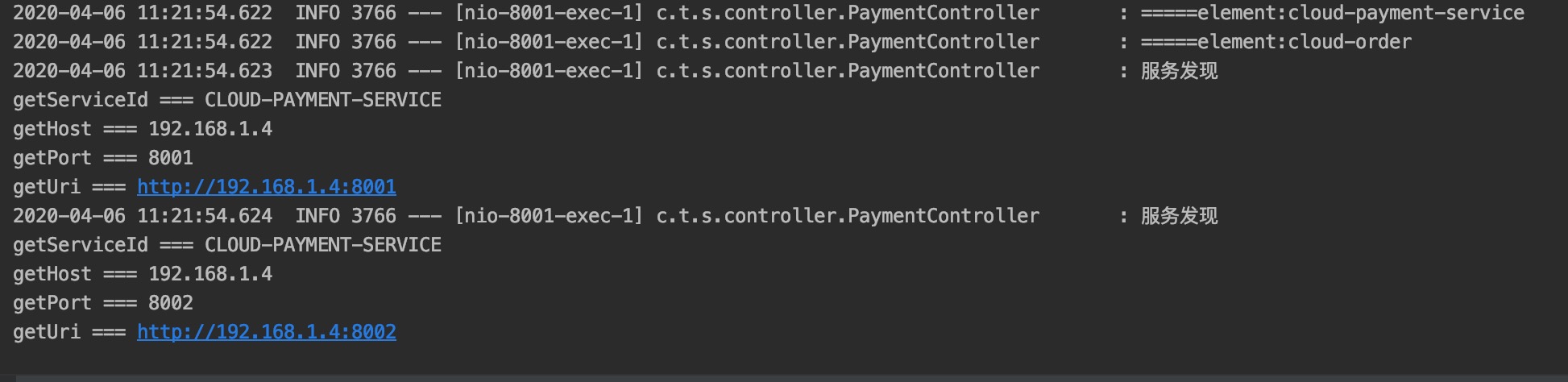
SpringCloud学习笔记(三)_服务提供者集群与服务发现Discovery
服务提供者集群 既然SpringCloud的是微服务结构,那么对于同一种服务,当然不可能只有一个节点,需要部署多个节点 架构图如下: 由上可以看出存在多个同一种服务提供者(Service Provider) 搭建服务提供者集…...
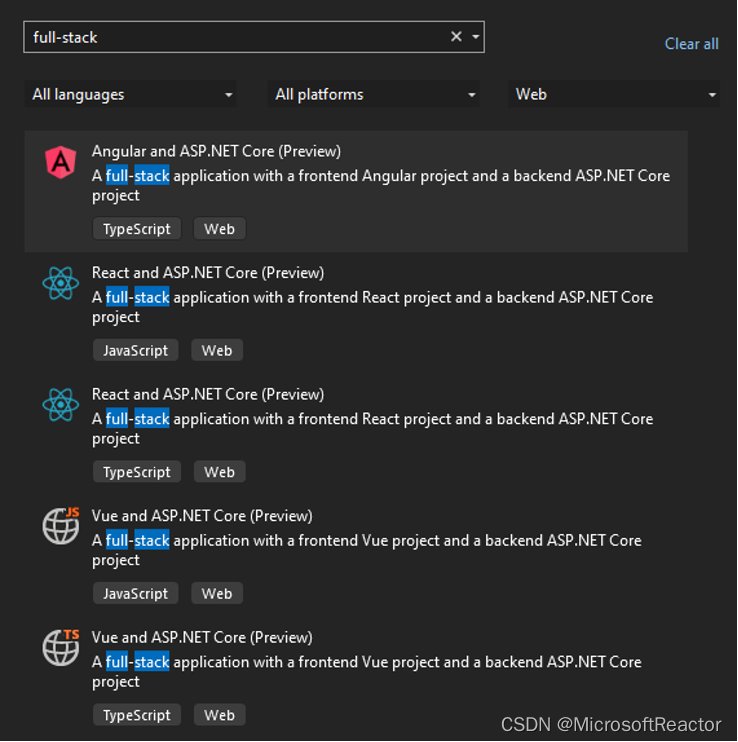
.NET 8 Preview 7 中的 ASP.NET Core 更新
作者:Daniel Roth 排版:Alan Wang .NET 8 Preview 7 现在已经发布,其中包括了对 ASP.NET Core 的许多重要更新。 以下是预览版本中新增功能的摘要: 服务器和中间件 防伪中间件 API 编写 最小 API 的防伪集成 Native AOT 请求委托…...

Ajax+Vue+ElementUI
文章目录 1.Ajax1.1 介绍1.2 Ajax快速入门1.3 案例-用户注册时,检测用户名是否数据库已经存在1.4 Axios1.4.1 Axios快速入门1.4.2 请求别名 1.5 JSON1.5.1 Json的基础语法1.5.2 FastJson的使用5.3.2 Fastjson 使用 2. Vue2.1 介绍2.2 Vue快速入门2.3 Vue常用指令和生…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...