VMware和ubuntu配置Hadoop环境
目录
一、获取VMware安装包
1、官网获取
1)首先先进入官网,官网首页是下面这样:
2)接着点击产品选项
3)进入后点击查看所有产品,然后在右上角选择排序方式为Z到A,然后向下滑动找到Workstation Pro,然后点击进去
4)然后点击下载试用版进行进入下载页面进行下载
5)点击 DOWNLOAD NOW 进行下载
2、从资料获取
二、安装VMware
1)点击下一步
2)勾选我接受许可协议中的条款,并点击下一步
3)勾选就按默认的勾选就ok,安装位置选一个自己需要安装的位置,然后点击下一步
4)这里的勾选根据自己的需要进行勾选(我这边是取消全部的勾选),并点击下一步
5)按默认的勾选就行,并点击下一步
6)点击安装,等待安装完成
7)安装完成后,运行VMware
8)输入密钥:MC60H-DWHD5-H80U9-6V85M-8280D,并点击继续
9)点击完成
10)点击完成后的界面如下
三、下载Ubuntu镜像文件
1、官网下载
2、从资料获取
四、开始配置Hadoop环境
1)首先打开安装好的VMware,并点击创建新的虚拟机
2) 出现下面界面,点击下一步(默认勾选的就ok)
3)勾选稍后安装操作系统,并点击下一步
4)然后选择并配置好下图的配置,并点击下一步
5)编辑自己想要的虚拟机名称,并选择位置,然后点击下一步
6)磁盘空间自行分配(本人分配40G),勾选将虚拟磁盘存储为单个文件,然后点击下一步
7)点击自定义硬件
8)内存分配2048MB(内存根据需要自行分配,最少1024MB),然后选择 新 CD/DVD,勾选使用 ISO 映像文件(之前下在好的文件),然后关闭
编辑 9)点击完成,之后出现下面界面,点击开启此虚拟机
10)按下Enter键
11)选择自己需要的语言后,并点击安装 Ubuntu 编辑
12)选择默认勾选就可以,然后点击继续
13)默认勾选就行,然后点击继续
14)默认勾选就ok,点击现在安装
15)点击继续
16)点击继续
17)输入自己需要的姓名和密码,并勾选自动登录,然后点击继续,会出现以下界面,等待这个过程完成
18)按住 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 hadoop :
19) 输入下面的命令,为创建的用户 hadoop 设置密码 hadoop(这里密码可自己设置):
20)使用下面的命令设置密码,可以简单设置为 hadoop
21)为了方便部署,使用下面命令为 hadoop 用添加管理员权限
22)注销当前用户(注销位置在右上角那),使用刚才创建的用户登录
23)登录进去后,打开命令窗口,首先使用下面命令对软件进行更新
24)使用下面命令安装 openssh -server
25)ssh每次登录还是需要密码。我们使用下面这些命令配置成无密码登录
26)安装JAVA 环境
27)安装 Hadoop
28)Hadoop 伪分布式配置
本博客主要是为了学校课程”大数据与云计算“需要安装Hadoop而写,希望这篇博客对各位阅读这篇博客的人有所帮助。废话不多说,下面直接开始配置教程。
一、获取VMware安装包
VMware获取方法有很多种,这里我准备了官网获取和从我准备的资料中获取。
1、官网获取
1)首先先进入官网,官网首页是下面这样:

2)接着点击产品选项
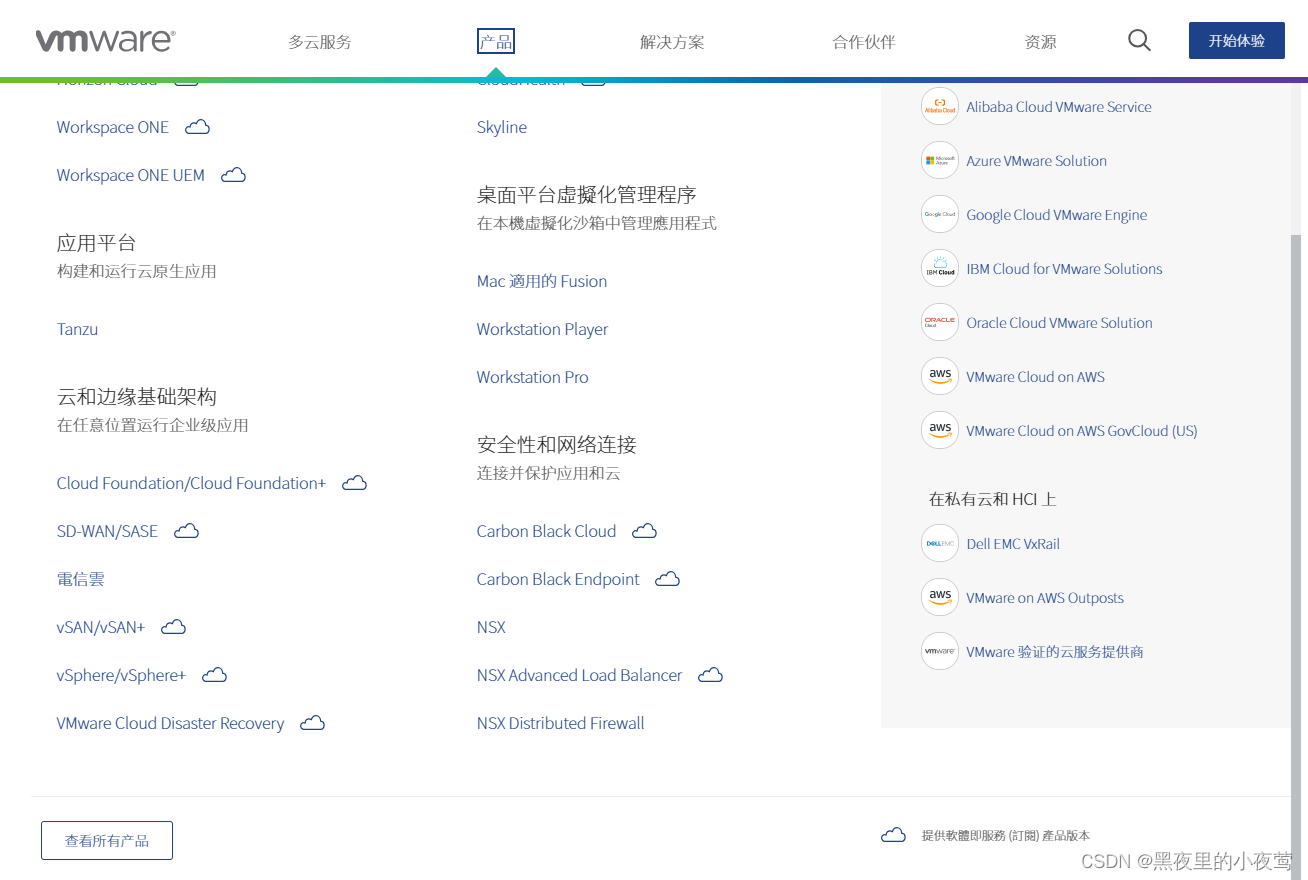
3)进入后点击查看所有产品,然后在右上角选择排序方式为Z到A,然后向下滑动找到Workstation Pro,然后点击进去

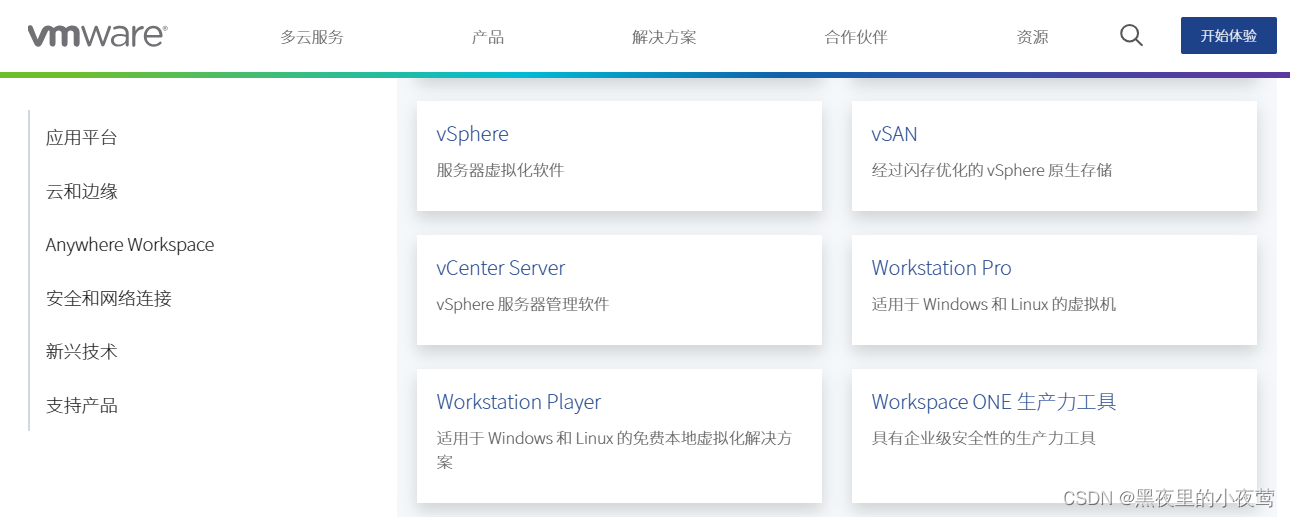
4)然后点击下载试用版进行进入下载页面进行下载

5)点击 DOWNLOAD NOW 进行下载

2、从资料获取
阿里云盘:https://www.aliyundrive.com/s/nVT1oCtk6rC
提取码:4pu8
二、安装VMware
点击下载好的VMware安装包进行安装。

1)点击下一步

2)勾选我接受许可协议中的条款,并点击下一步
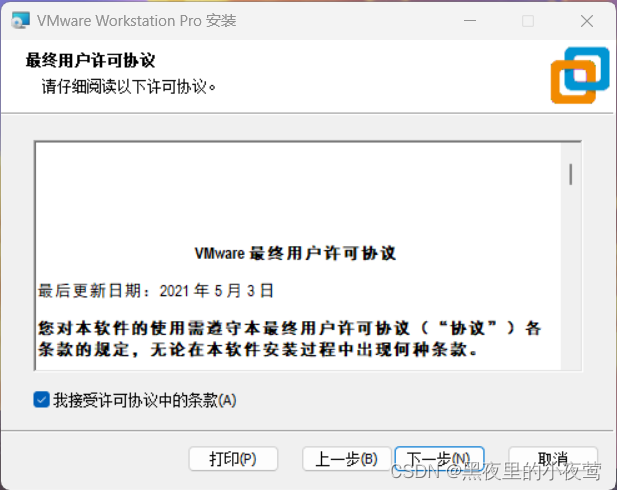
3)勾选就按默认的勾选就ok,安装位置选一个自己需要安装的位置,然后点击下一步
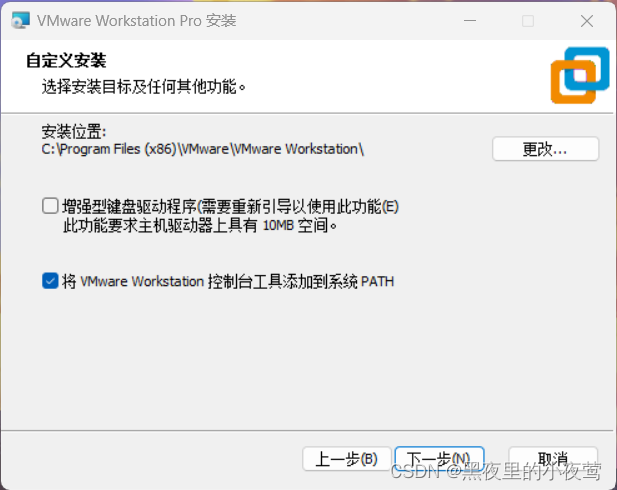
4)这里的勾选根据自己的需要进行勾选(我这边是取消全部的勾选),并点击下一步

5)按默认的勾选就行,并点击下一步

6)点击安装,等待安装完成

7)安装完成后,运行VMware
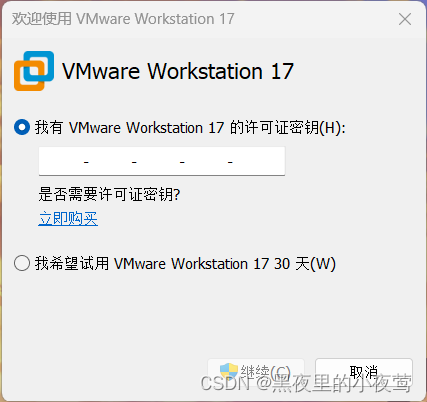
8)输入密钥:MC60H-DWHD5-H80U9-6V85M-8280D,并点击继续

9)点击完成

10)点击完成后的界面如下
 三、下载Ubuntu镜像文件
三、下载Ubuntu镜像文件
1、官网下载
官网:Download Ubuntu Desktop | Download | Ubuntu
官网界面如下:
1)点击右下角的 Download 22.03.3 进行下载(LTS是长期支持版本,选择这个版本),并等待下载完成
2、从资料获取
阿里云盘:https://www.aliyundrive.com/s/nVT1oCtk6rC
提取码:4pu8
四、开始配置Hadoop环境
1)首先打开安装好的VMware,并点击创建新的虚拟机

2) 出现下面界面,点击下一步(默认勾选的就ok)

3)勾选稍后安装操作系统,并点击下一步
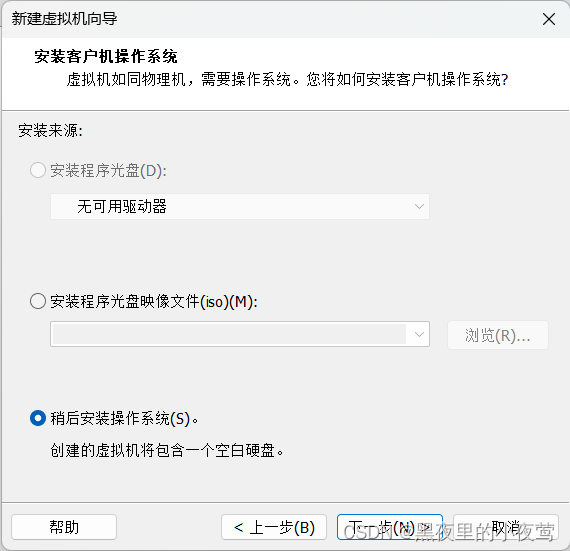
4)然后选择并配置好下图的配置,并点击下一步
5)编辑自己想要的虚拟机名称,并选择位置,然后点击下一步
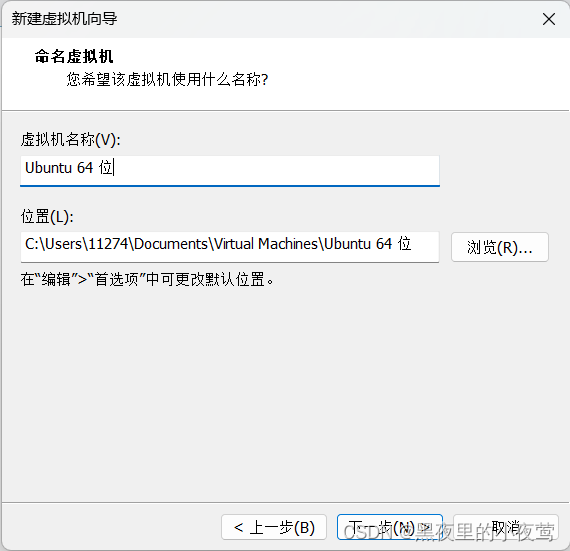
6)磁盘空间自行分配(本人分配40G),勾选将虚拟磁盘存储为单个文件,然后点击下一步

7)点击自定义硬件
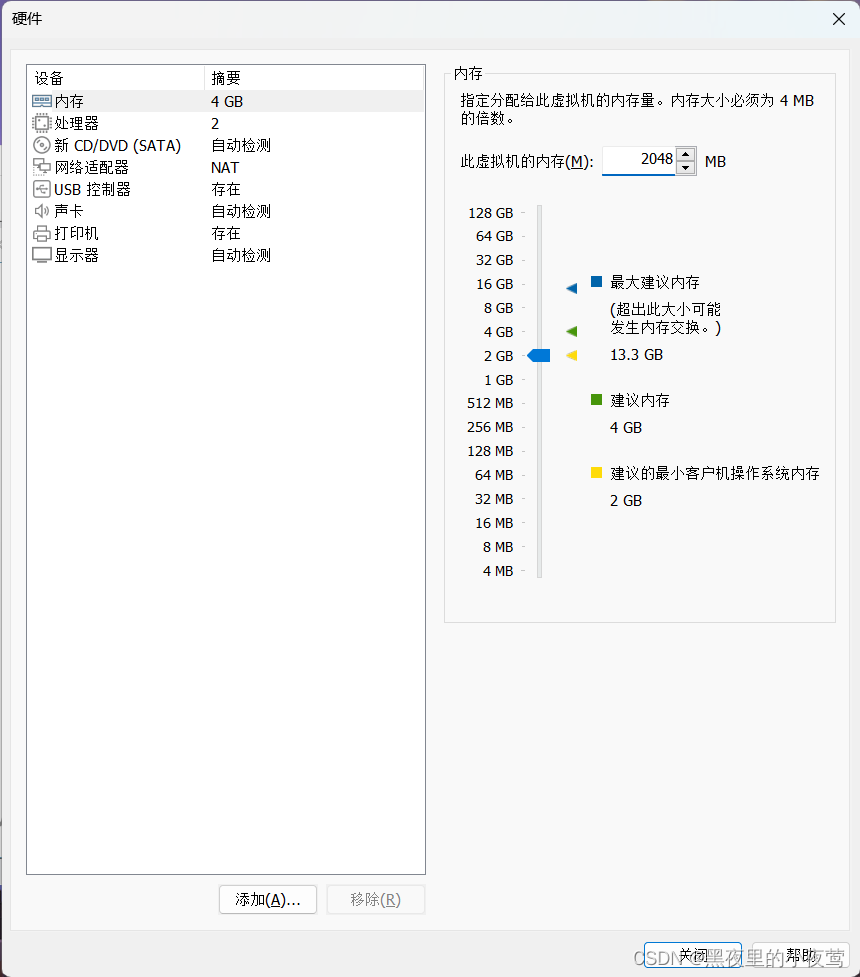
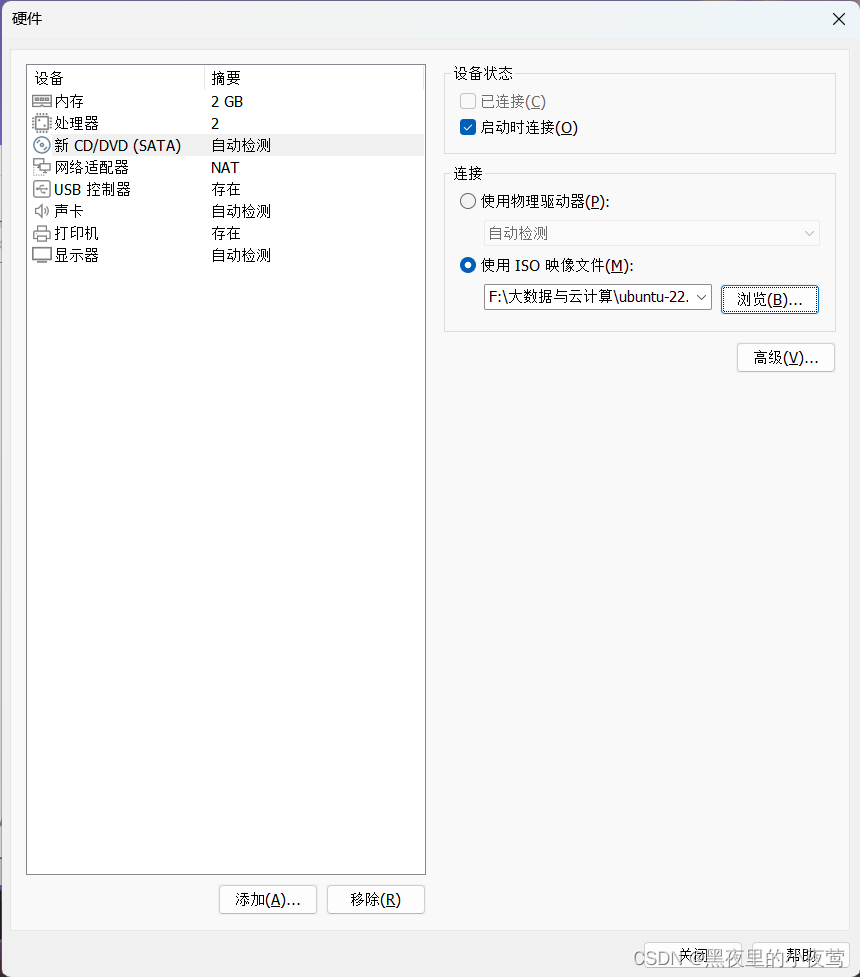
8)内存分配2048MB(内存根据需要自行分配,最少1024MB),然后选择 新 CD/DVD,勾选使用 ISO 映像文件(之前下在好的文件),然后关闭
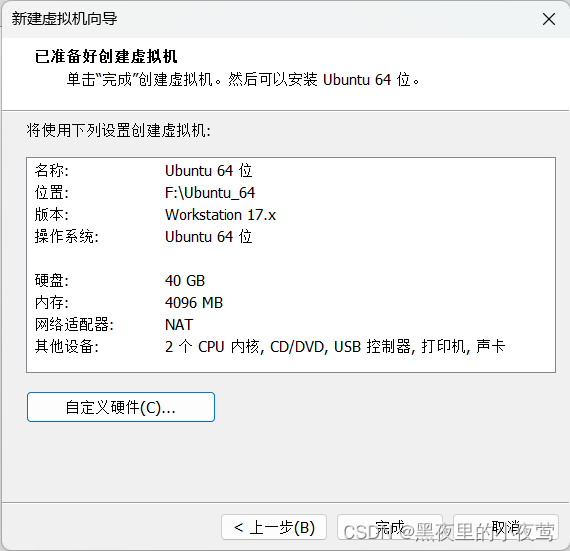
 9)点击完成,之后出现下面界面,点击开启此虚拟机
9)点击完成,之后出现下面界面,点击开启此虚拟机

10)按下Enter键
11)选择自己需要的语言后,并点击安装 Ubuntu 
12)选择默认勾选就可以,然后点击继续
13)默认勾选就行,然后点击继续
14)默认勾选就ok,点击现在安装

15)点击继续

16)点击继续

17)输入自己需要的姓名和密码,并勾选自动登录,然后点击继续,会出现以下界面,等待这个过程完成
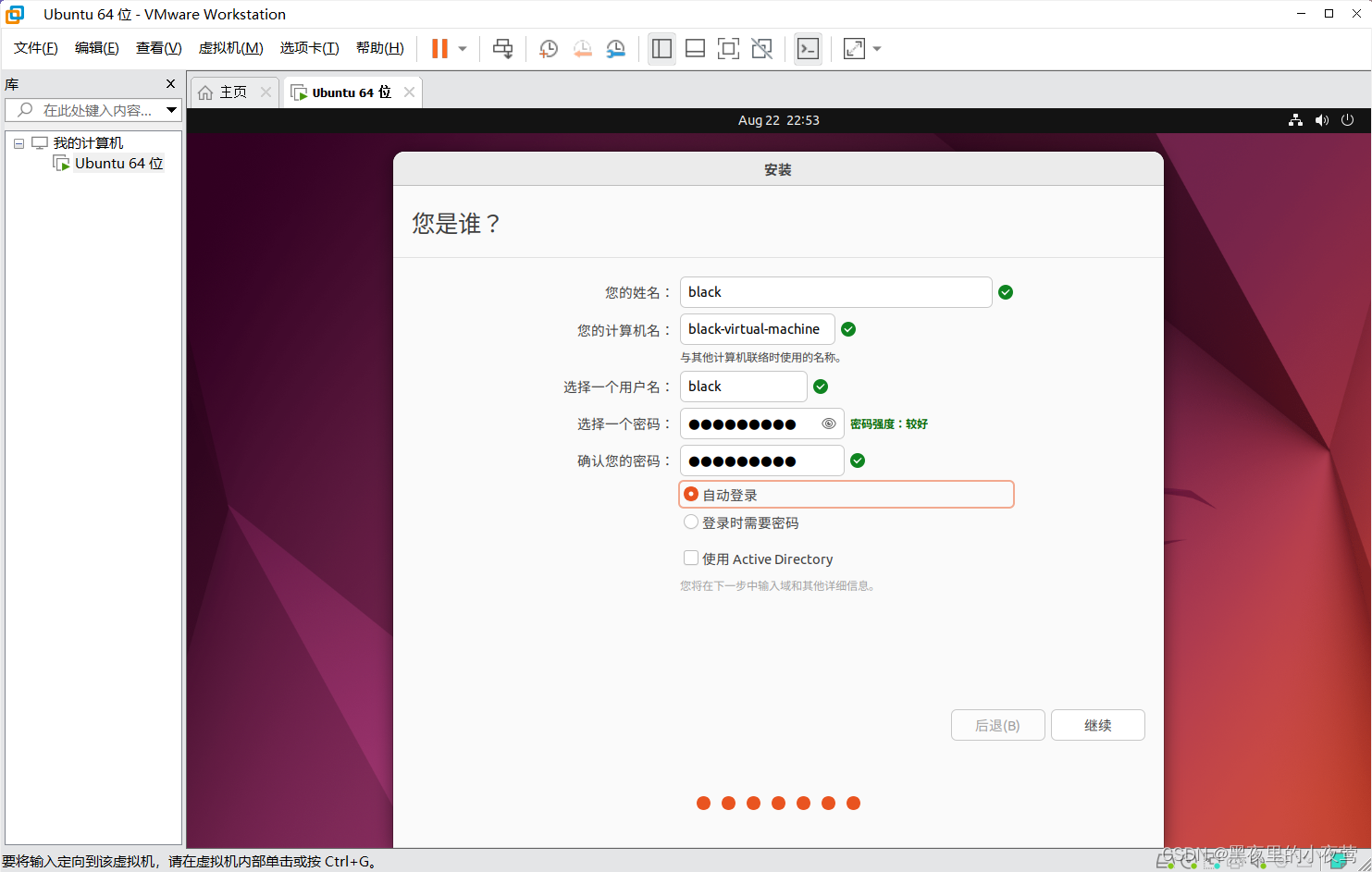

18)按住 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 hadoop :
sudo useradd –m hadoop –s /bin/bash
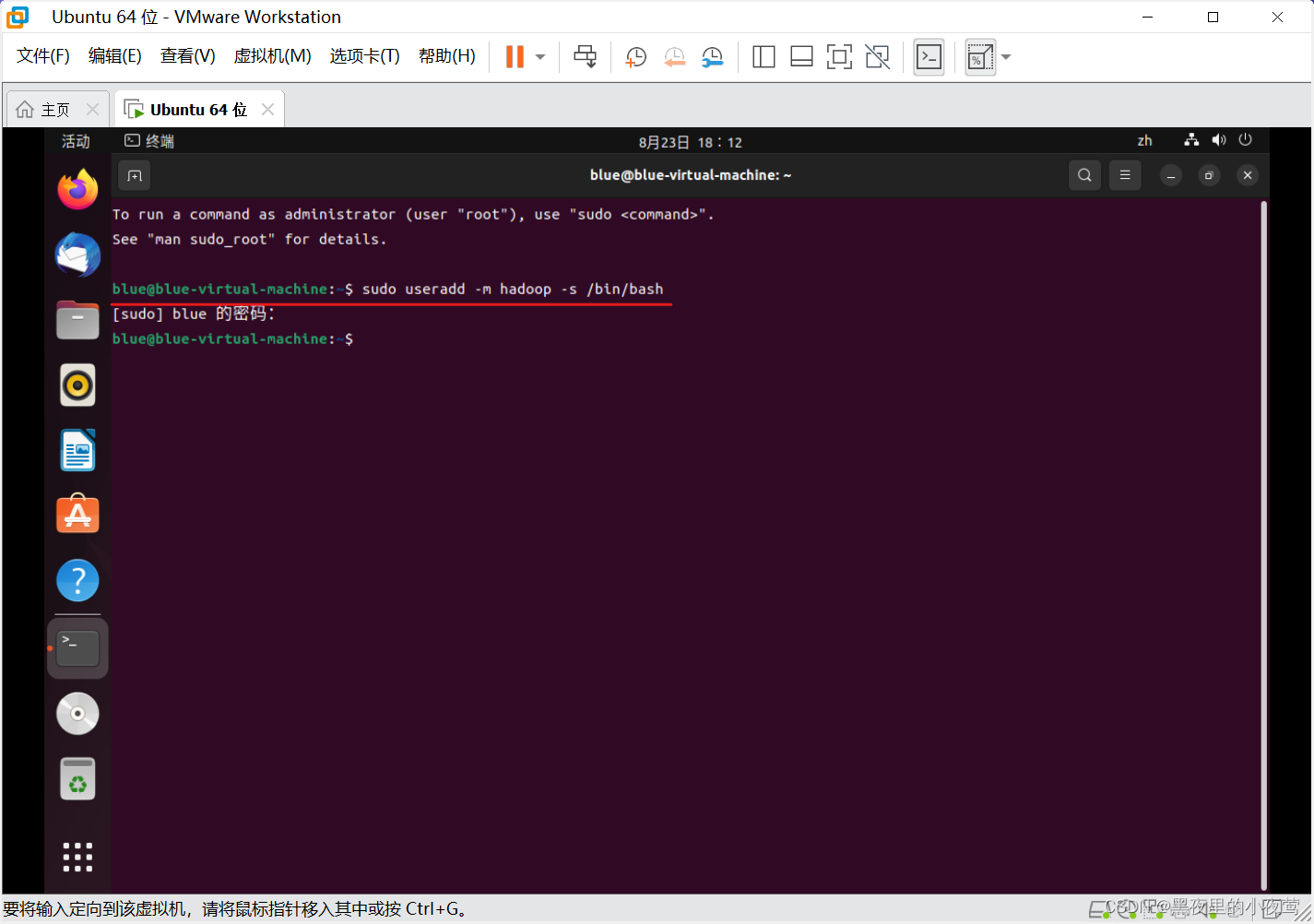
注:这里的密码是我们创建的用户密码(我这里创建的是 blue 用户)
19) 输入下面的命令,为创建的用户 hadoop 设置密码 hadoop(这里密码可自己设置):
sudo passwd hadoop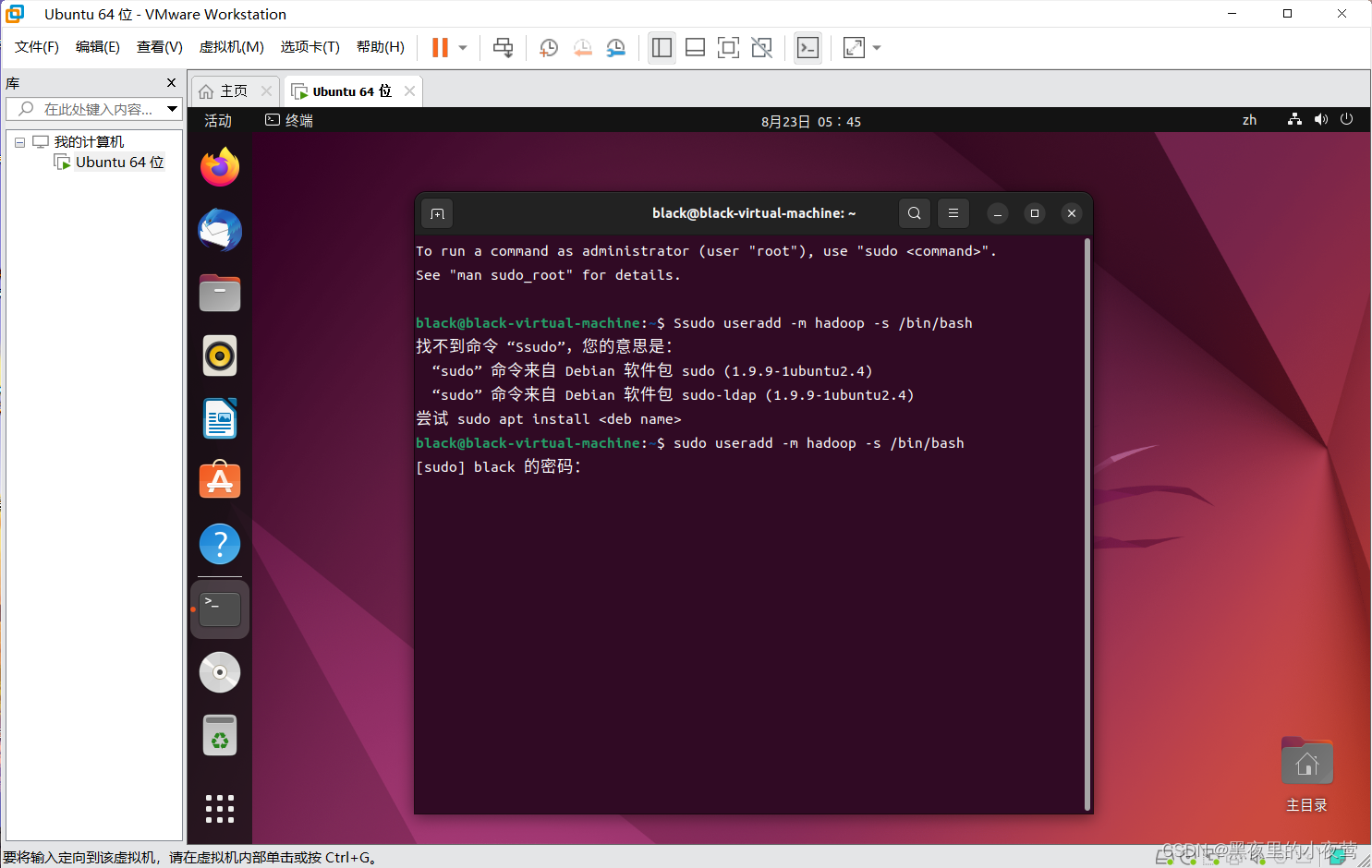
20)使用下面的命令设置密码,可以简单设置为 hadoop
sudo passwd hadoop
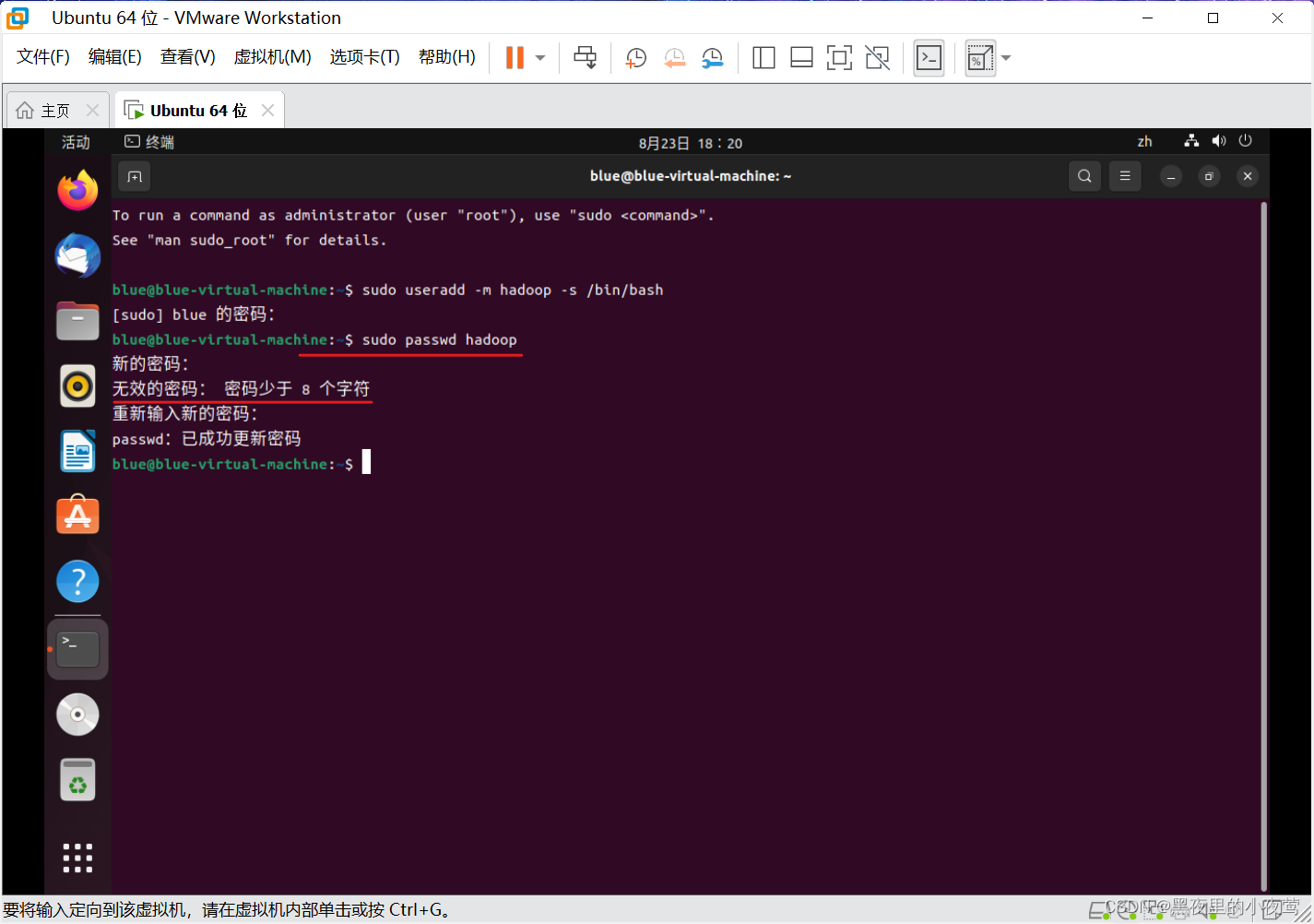
注:
1. 这里输入的密码是不可见的,直接输入就可以
2.如果出现 无效密码: 密码至少 8 个字符,只需要把之前设置的密码重新输入即可
21)为了方便部署,使用下面命令为 hadoop 用添加管理员权限
sudo adduser hadoop sudo
22)注销当前用户(注销位置在右上角那),使用刚才创建的用户登录

选择刚才我们创建的用户(这里为 hadoop)

输入为用户 hadoop 设置的密码,登录进去
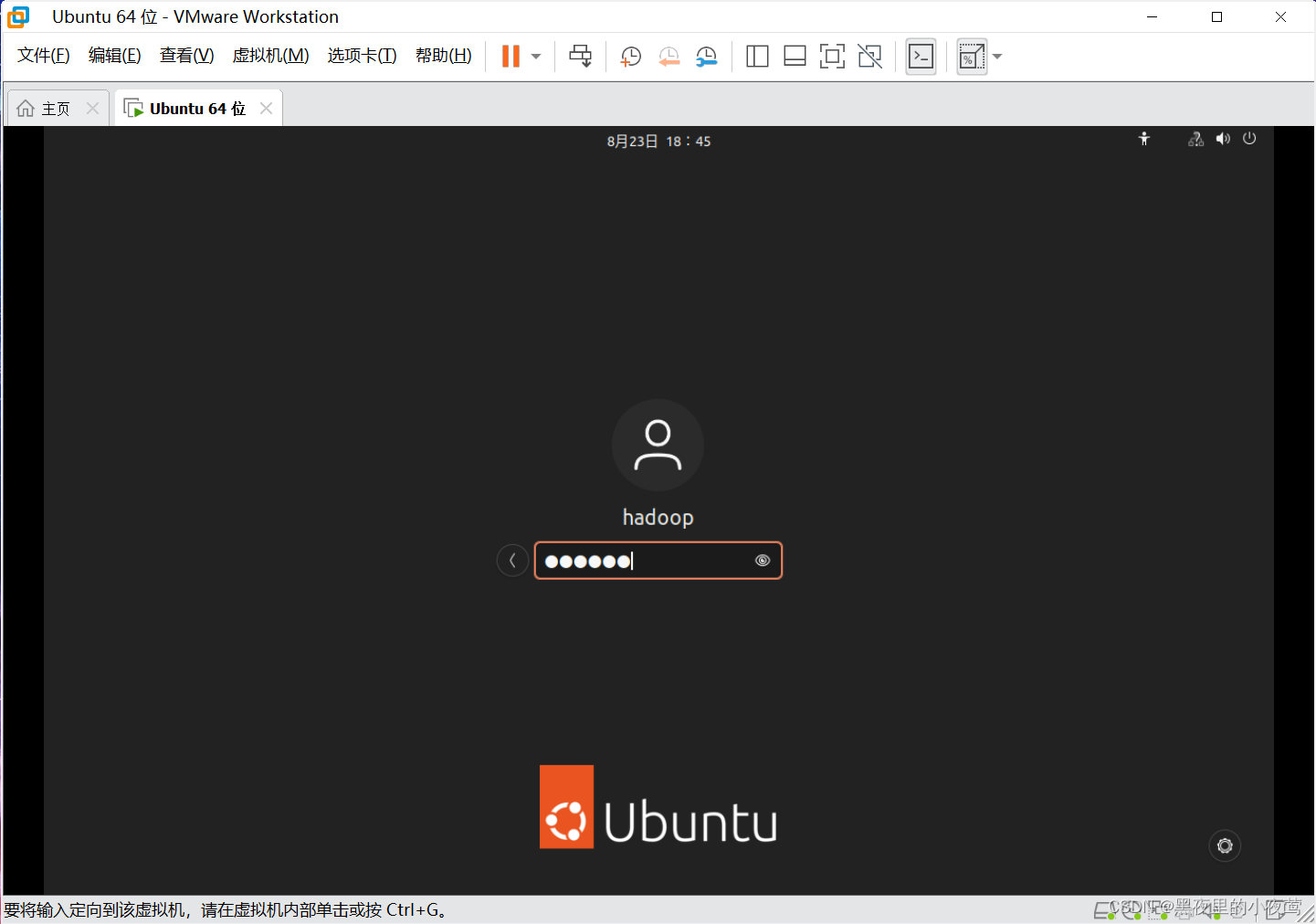
23)登录进去后,打开命令窗口,首先使用下面命令对软件进行更新
sudo apt-get install
24)使用下面命令安装 openssh -server
sudo apt-get install openssh-server
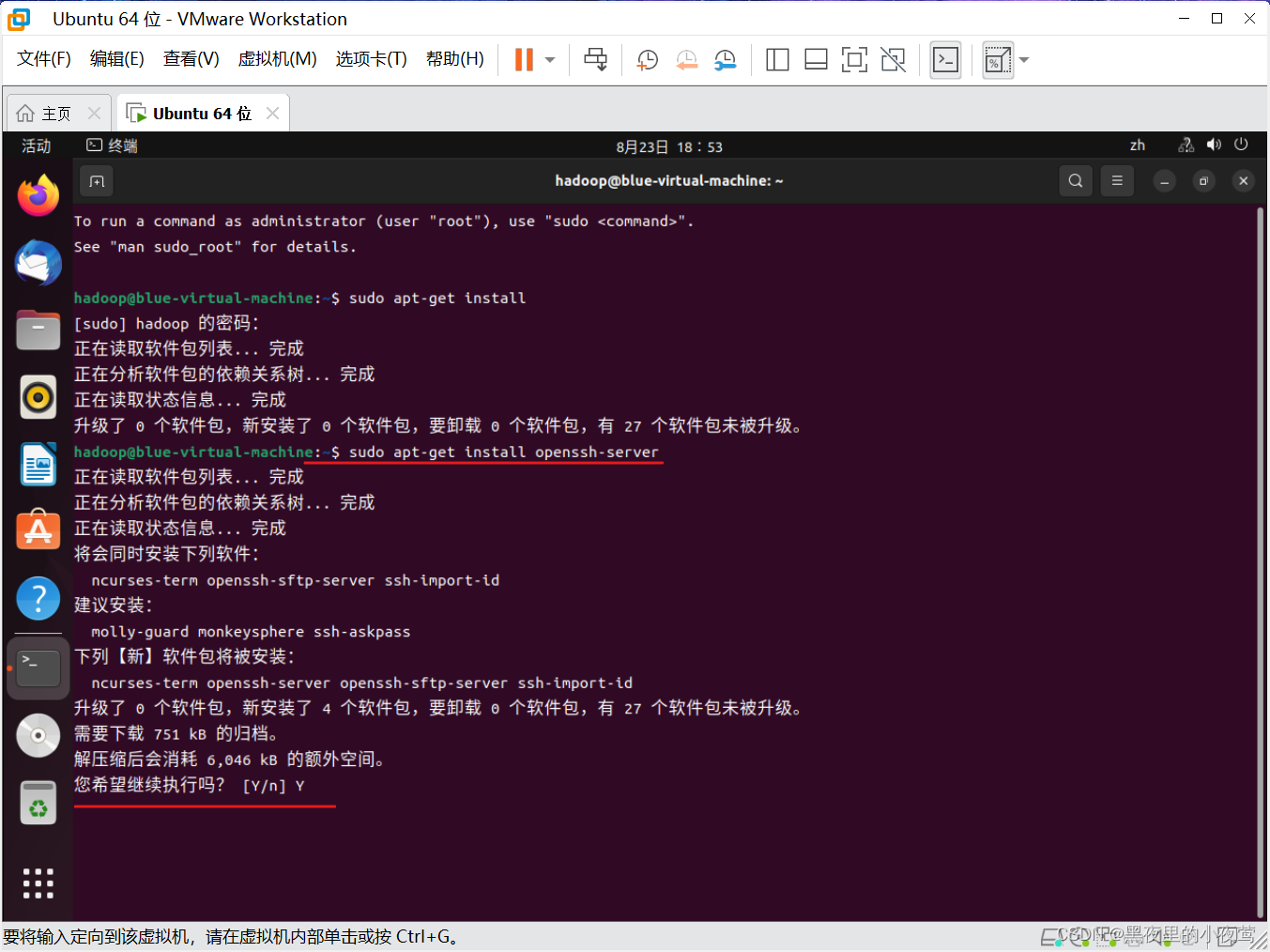
注:如果出现 您希望继续执行吗?[Y/n] ,输入 Y 并按 Enter
25)ssh每次登录还是需要密码。我们使用下面这些命令配置成无密码登录
首先,使用下面命令实现 ssh 首次登录
ssh localhost
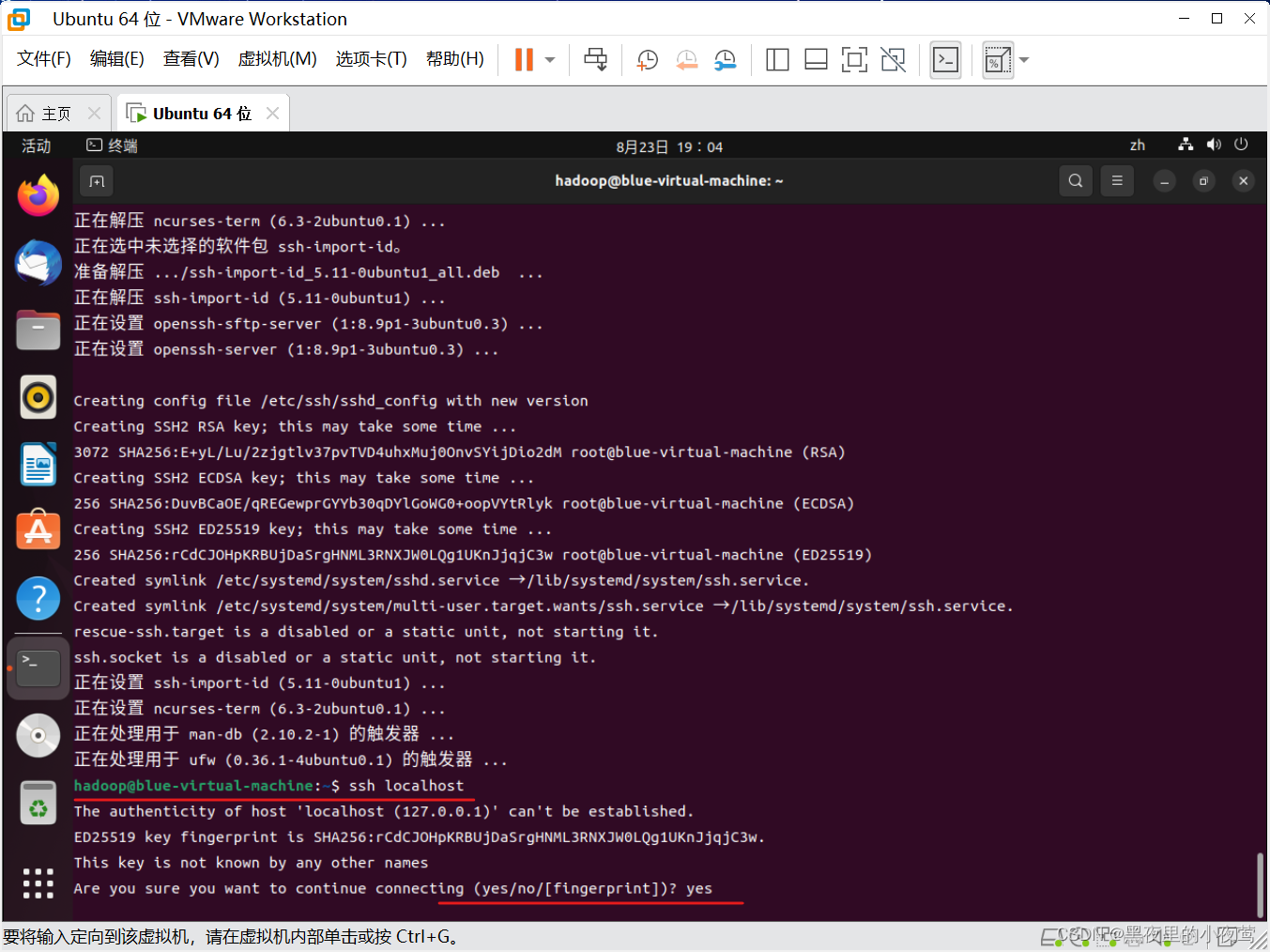
注:
1.选择 yes
2.密码输入我们创建 hadoop 设置的密码
使用下面命令退出刚才登录的 ssh,回到我们原先的终端窗口
exit使用下面命令,进入 ssh 目录里
cd ~/.ssh/利用 ssh-keygen 生成密钥
ssh-keygen –t rsa #会有提示,按回车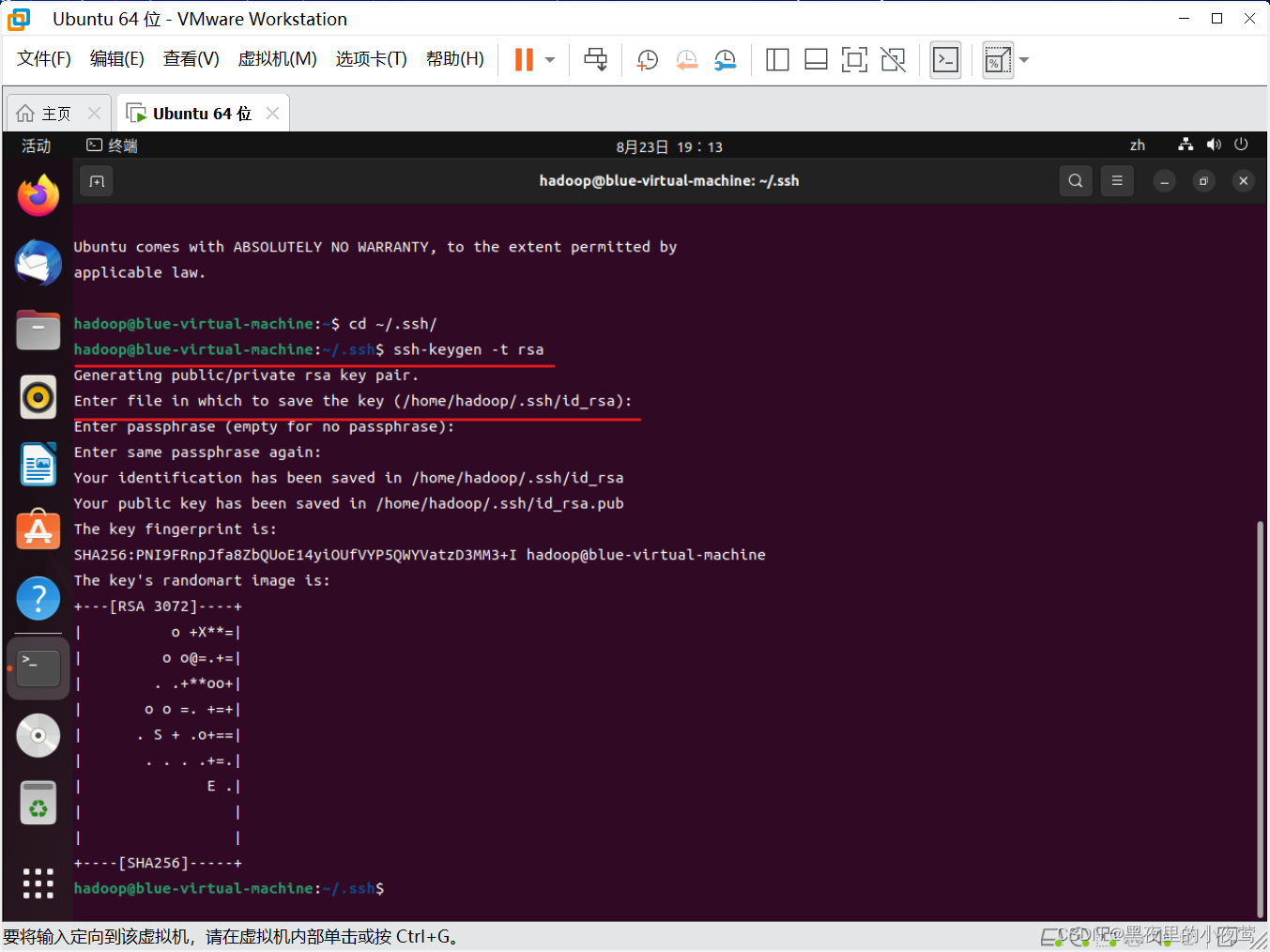
利用下面命令将密码加入到授权中,此时再使用 ssh localhost 命令就不用登录密码
cat ./id_rsa.pub >> ./authorized_keys #加入授权26)安装JAVA 环境
使用下面命令安装 jdk
sudo apt-get install openjdk-8-jdk
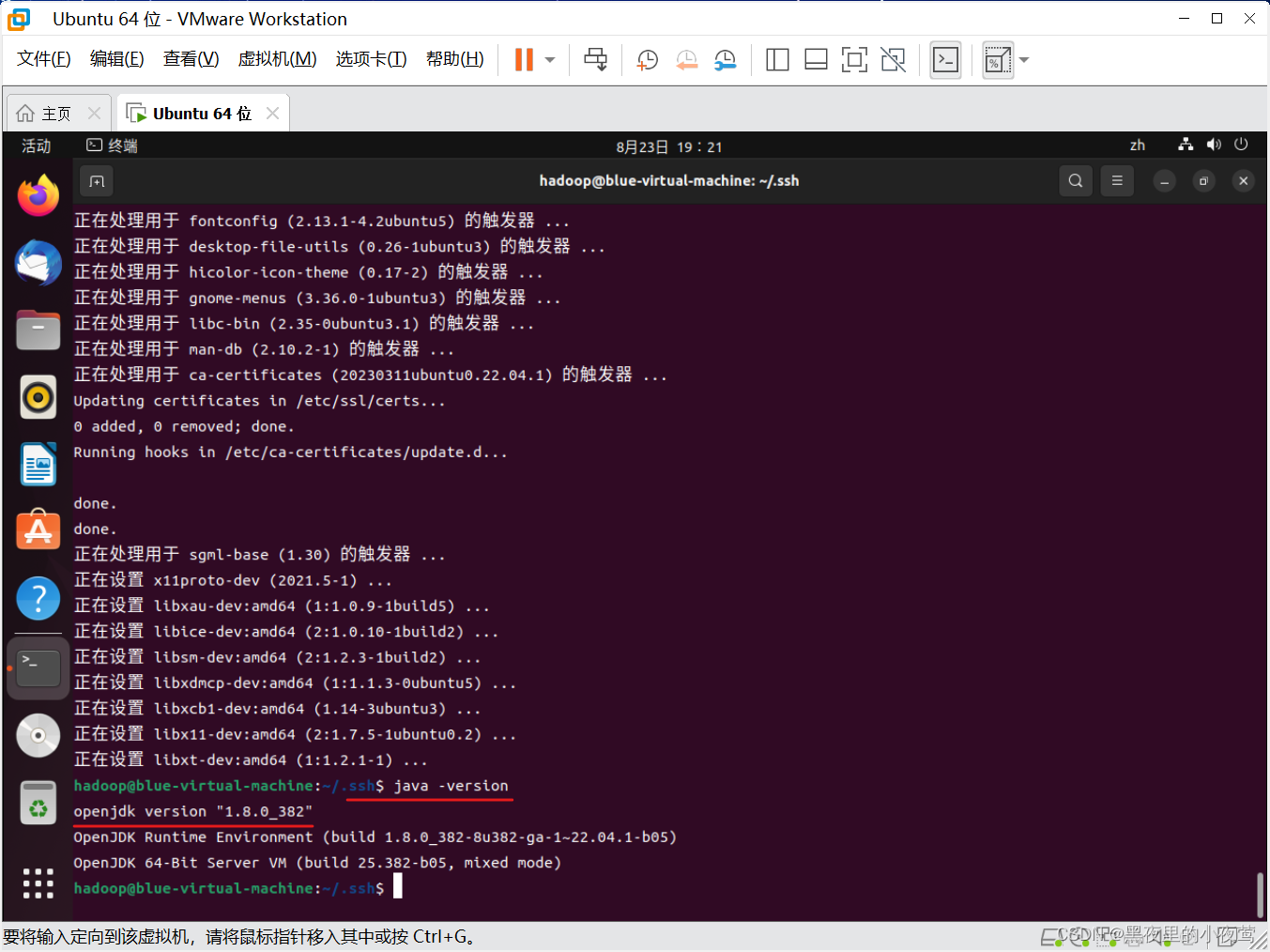
使用下面命令查看Java版本,看看是否安装成功
java -version
使用下面命令进入文件并配置 JAVA_HOME
gedit ~/.bashrcexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# = 左右不能有空格
注:修改后记得点击保存,然后点击关闭
使用下面命令使上面编辑的环境变量生效
source ~/.bashrc使用下面的命令,看我们设置的环境变量是否生效
echo $JAVA_HOME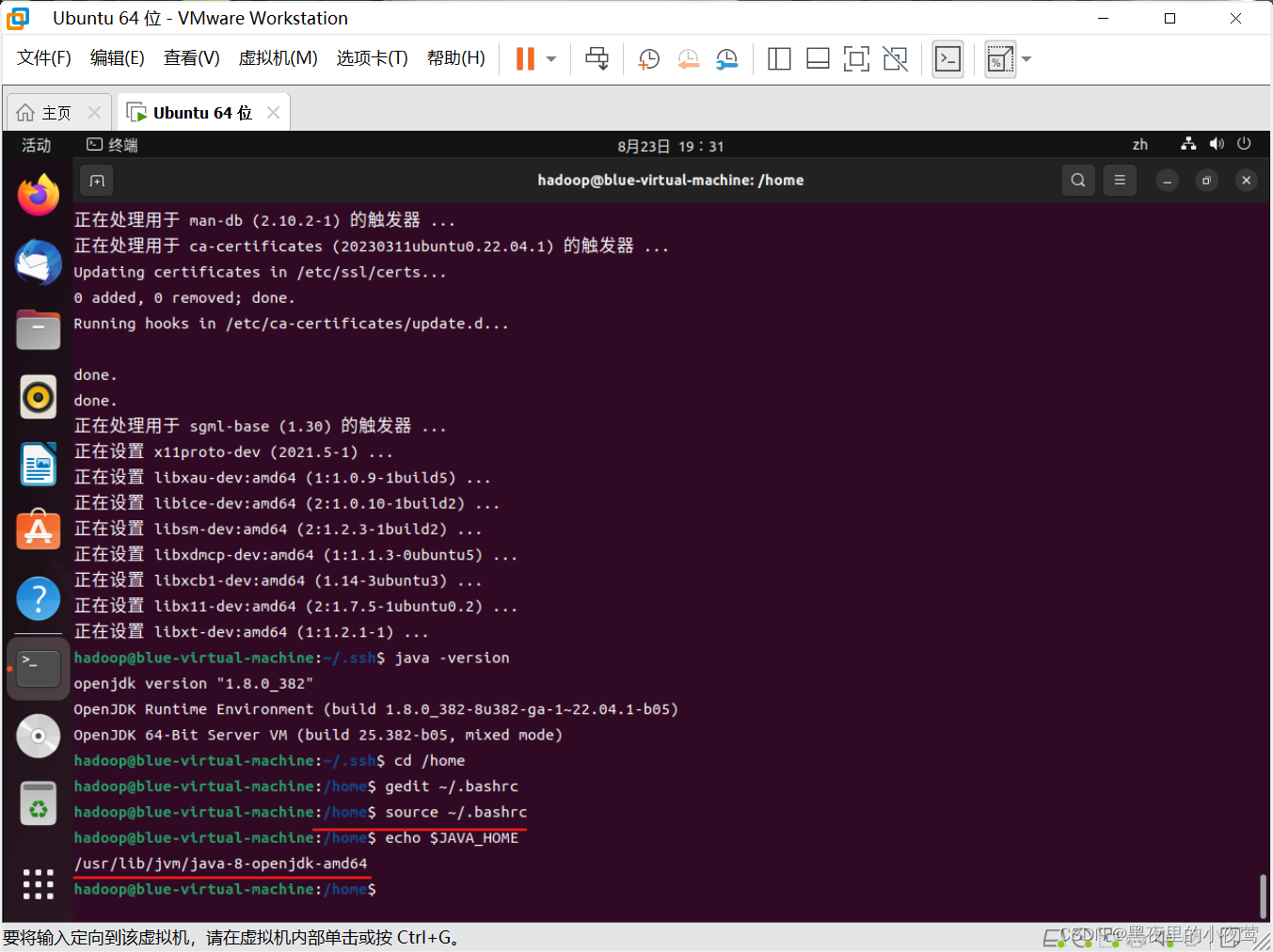
27)安装 Hadoop
Hadoop的安装包可以去官网安装,但是由于官网的下载速度不行,这里提供一个镜像网站进行下载Hadoop。
镜像网址:Index of /apache/hadoop (tsinghua.edu.cn)
进入此网站后,选择 common/
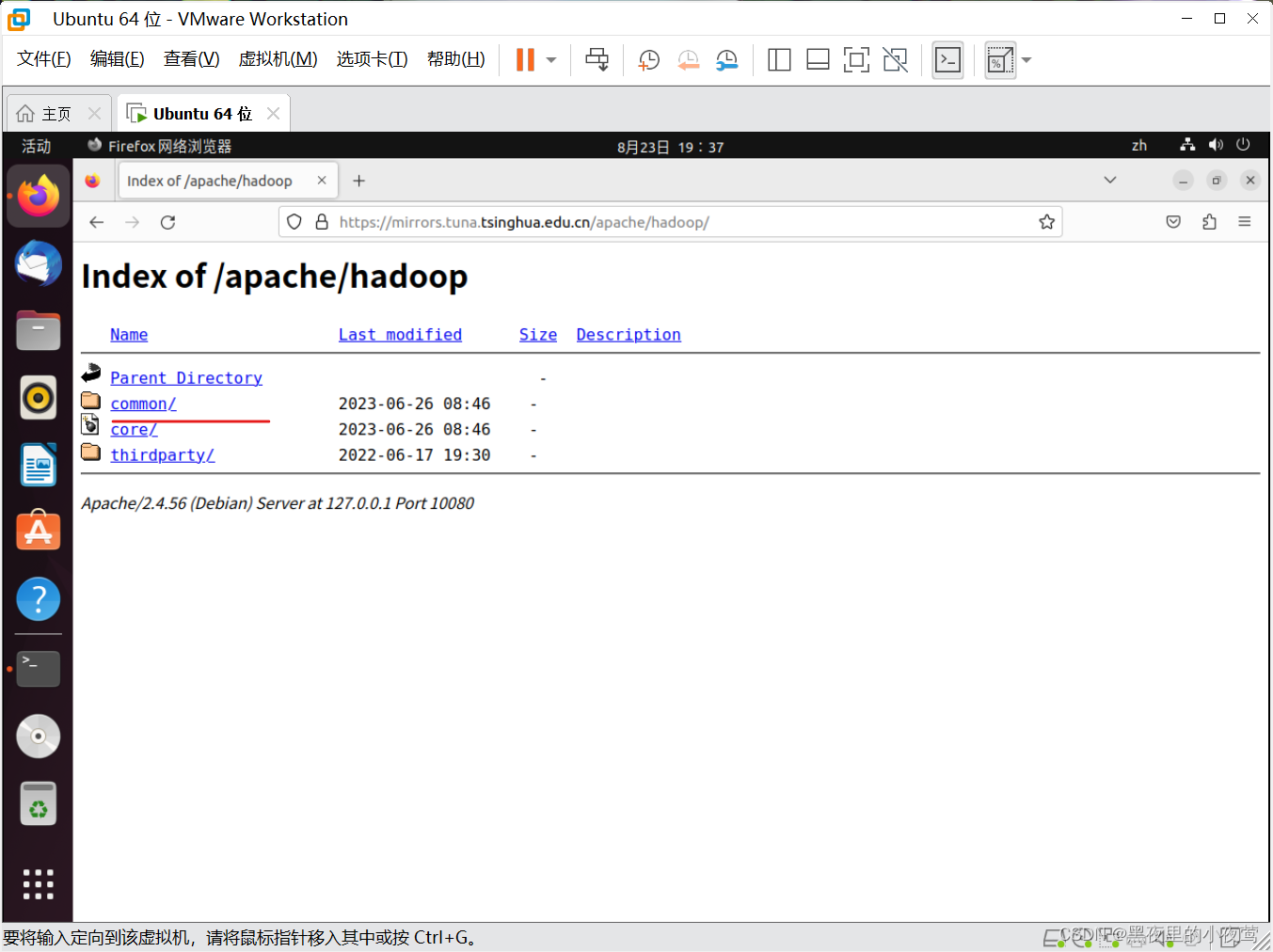
然后选择自己需要的版本进行下载,但注意选择扩展名为 .tar.gz 这个格式的,这是编译好的。我这里下载的版本是 hadoop-2.10.2.tar.gz
 下载完成后,使用下面命令进行解压操作(将原先的命令窗口关闭再打开,然后输入下面命令)
下载完成后,使用下面命令进行解压操作(将原先的命令窗口关闭再打开,然后输入下面命令)
sudo tar -zxf ~/下载/hadoop-2.10.2.tar.gz -C /usr/local # 解压到/usr/local中
# 版本是自己下载的对于版本,我这里是 hadoop-2.10.2注:
1.切换 中\英文 的方式为 super + space
windows:win + 空格
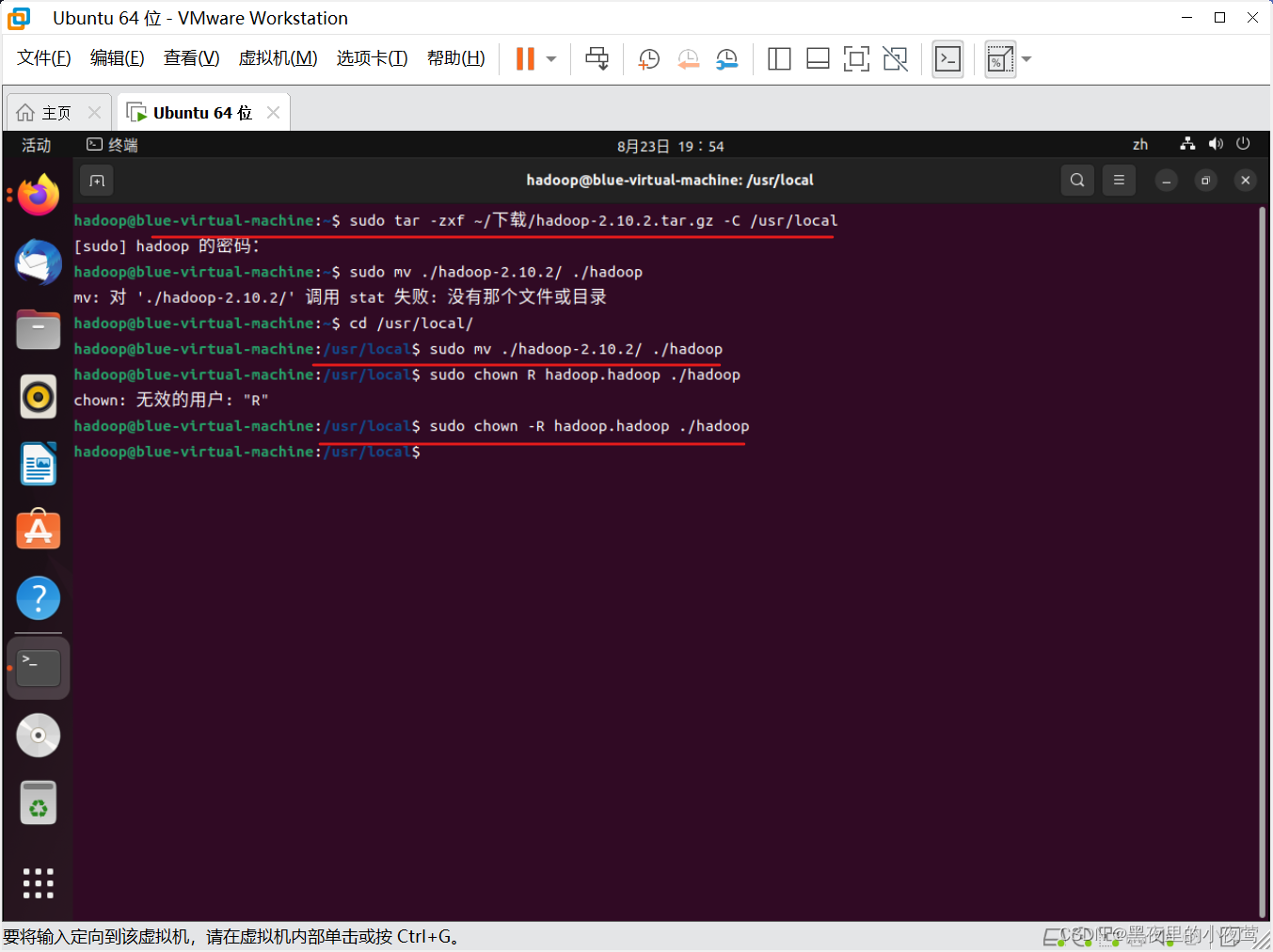
先使用下面命令进入文件夹(必须在使用命令将文件夹改名前,使用此命令)
cd /usr/local/
使用下面的命令,将文件夹名改为 hadoop
sudo mv ./hadoop-2.10.2/ ./hadoop # 将文件夹名改为hadoop使用下面命令修改文件权限
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
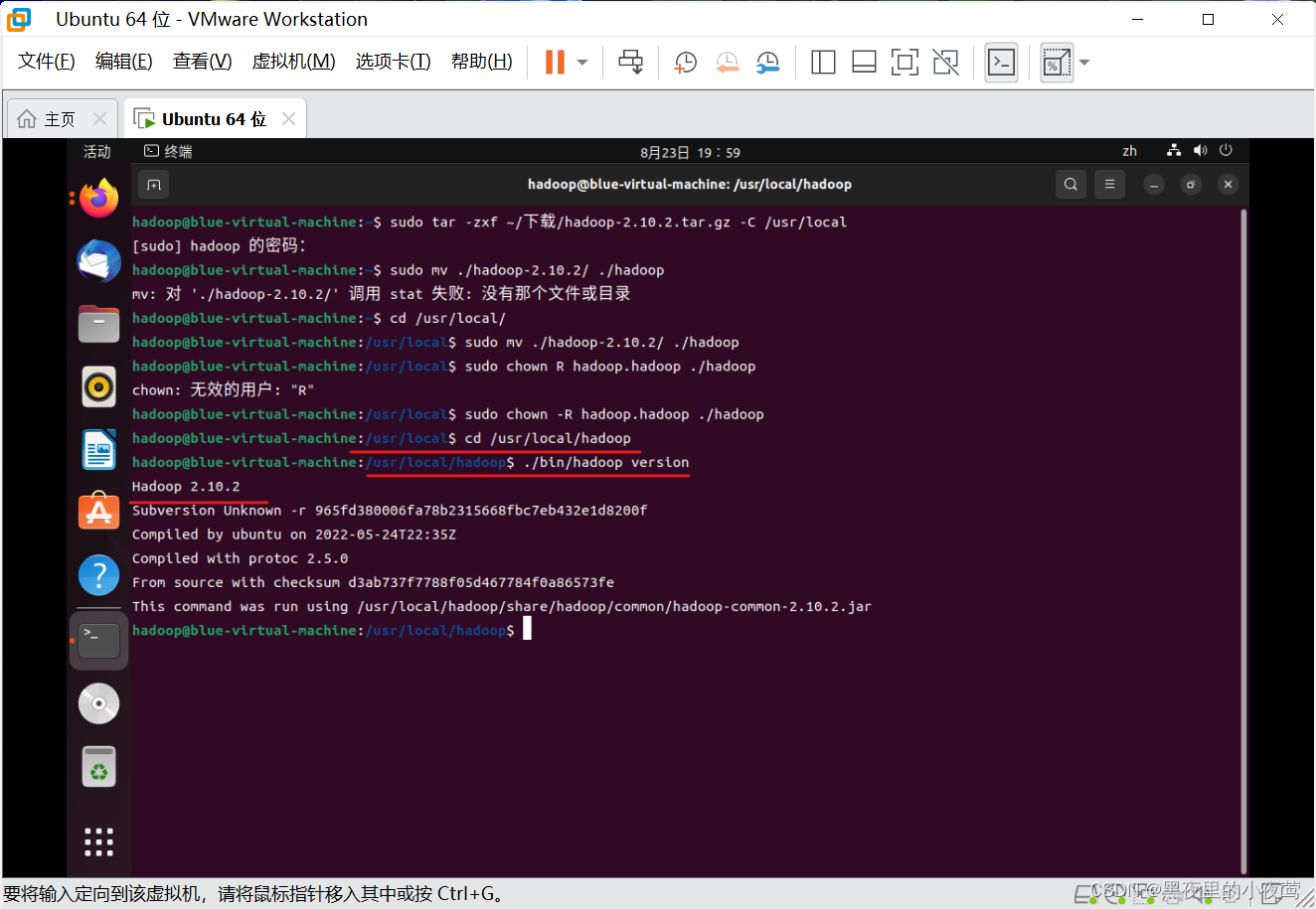
先使用下面命令进入到hadoop 文件夹
cd /usr/local/hadoop然后用如下命令查看我们解压的Hadoop是否可用
./bin/hadoop version
28)Hadoop 伪分布式配置
Hadoop 伪分布式配置需要修改core-site.xml和hdfs-site.xml配置文件。先使用下面命令进入到hadoop 文件夹
cd /usr/local/hadoop使用下面命令对core-site.xml文件进行配置
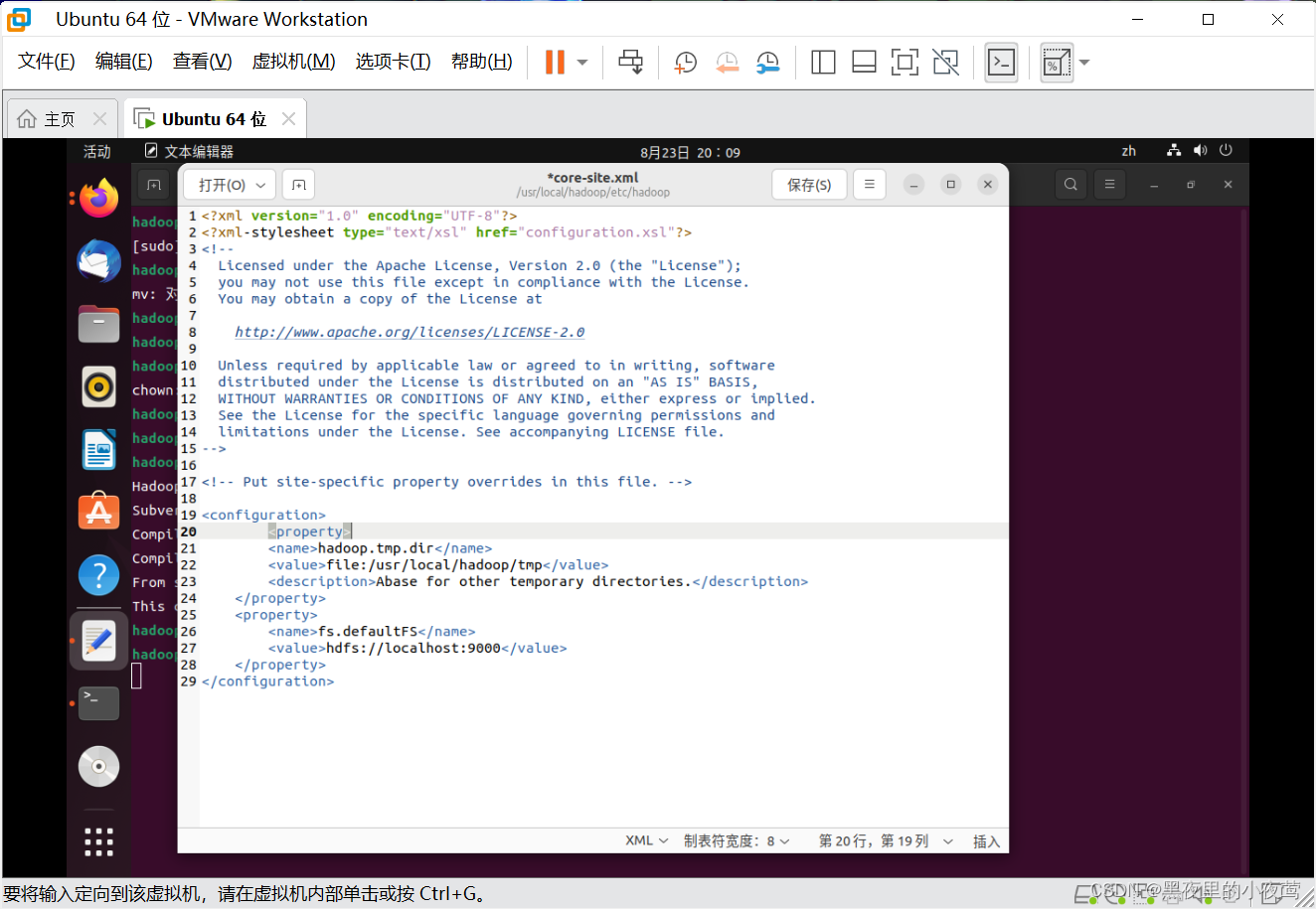
gedit ./etc/hadoop/core-site.xml利用下面代码进行配置core-site.xml文件(注意点击保存)
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
使用下面命令对hdfs-site.xml文件进行配置
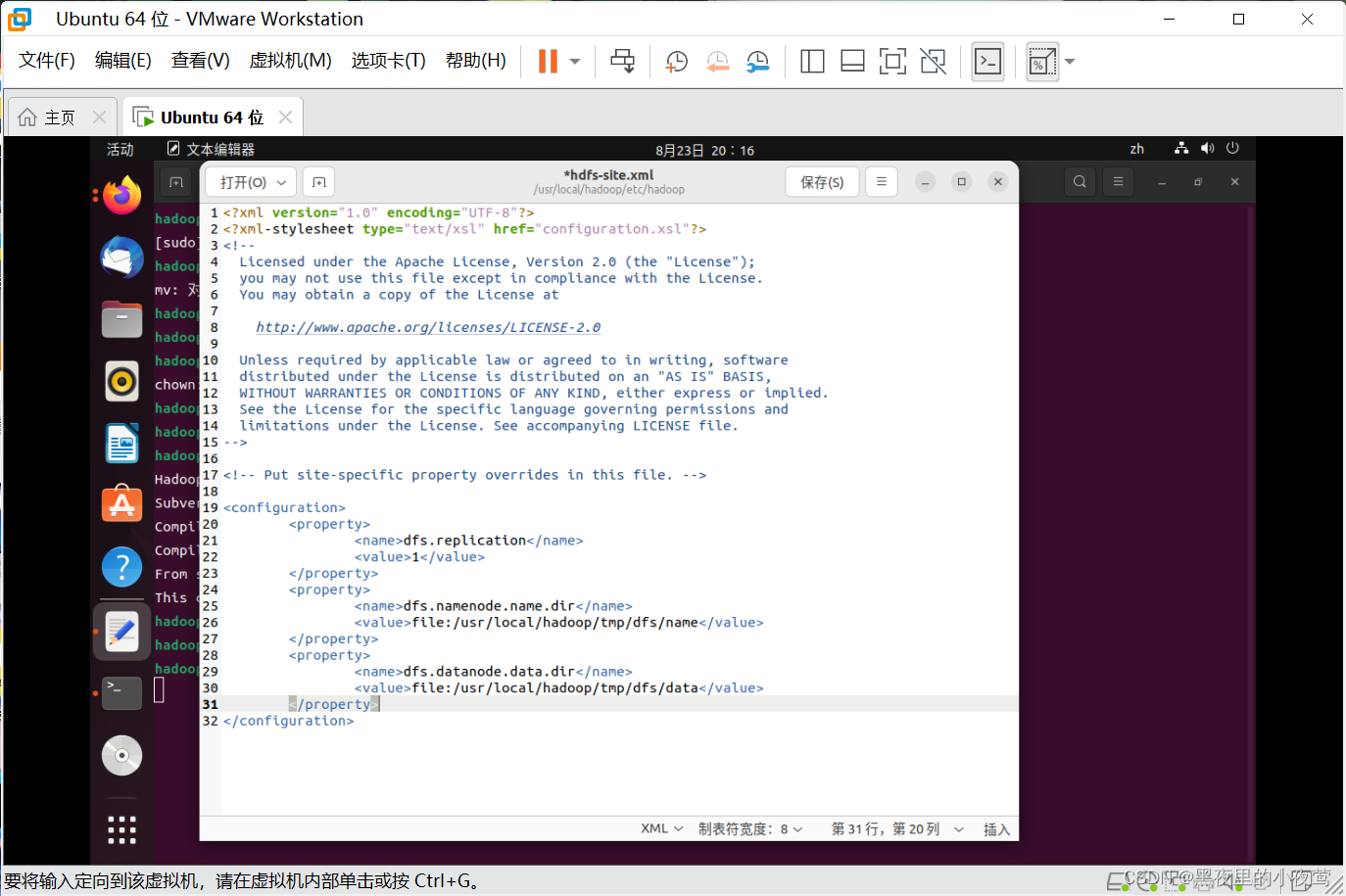
gedit ./etc/hadoop/hdfs-site.xml利用下面代码进行配置hdfs-site.xml文件(注意点击保存)
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
</configuration>
配置完成后,执行 NameNode 的格式化
./bin/hdfs namenode -format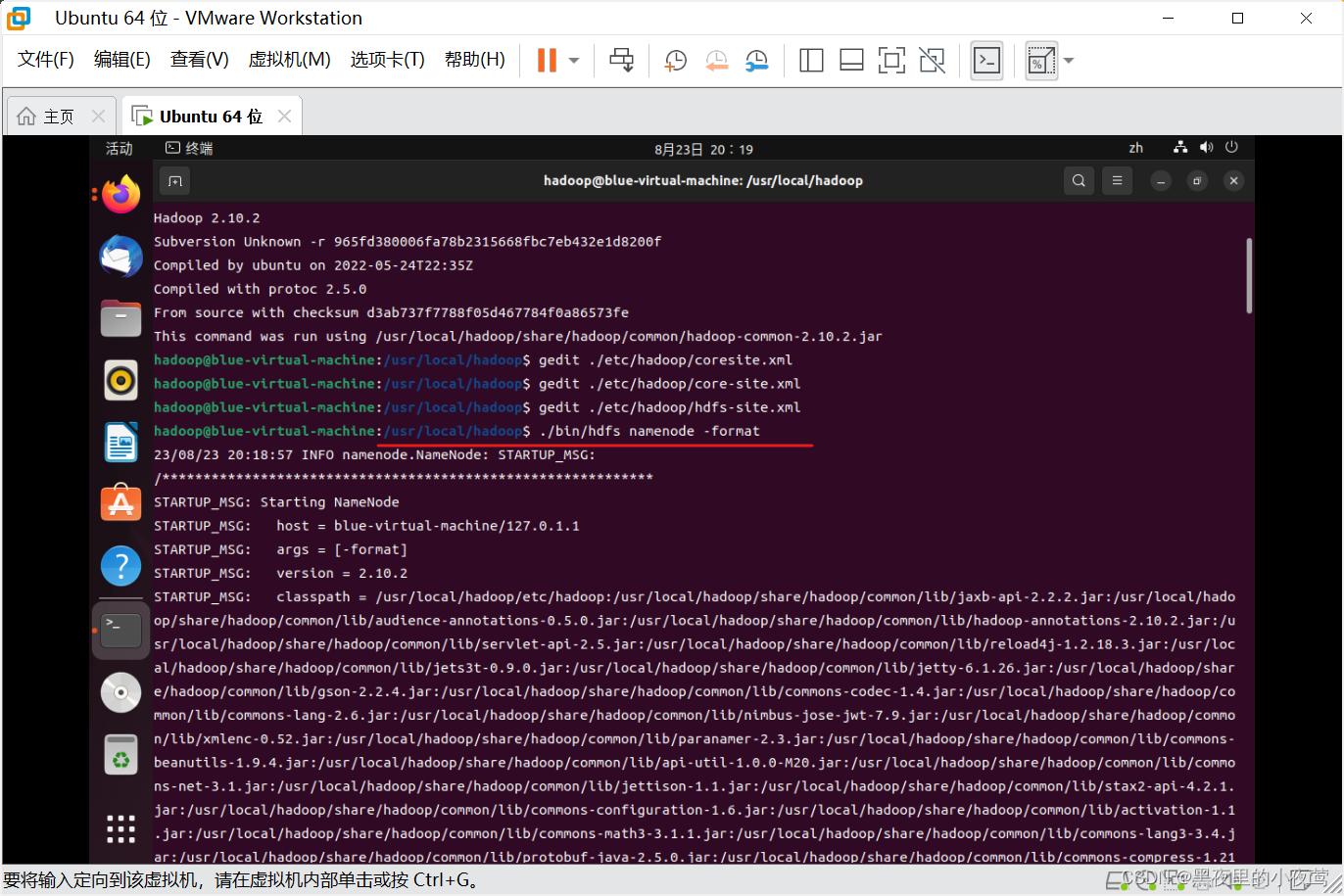
接着使用下面命令开启 NameNode 和 DataNode 守护进程
./sbin/start-dfs.shjps # 判断是否成功启动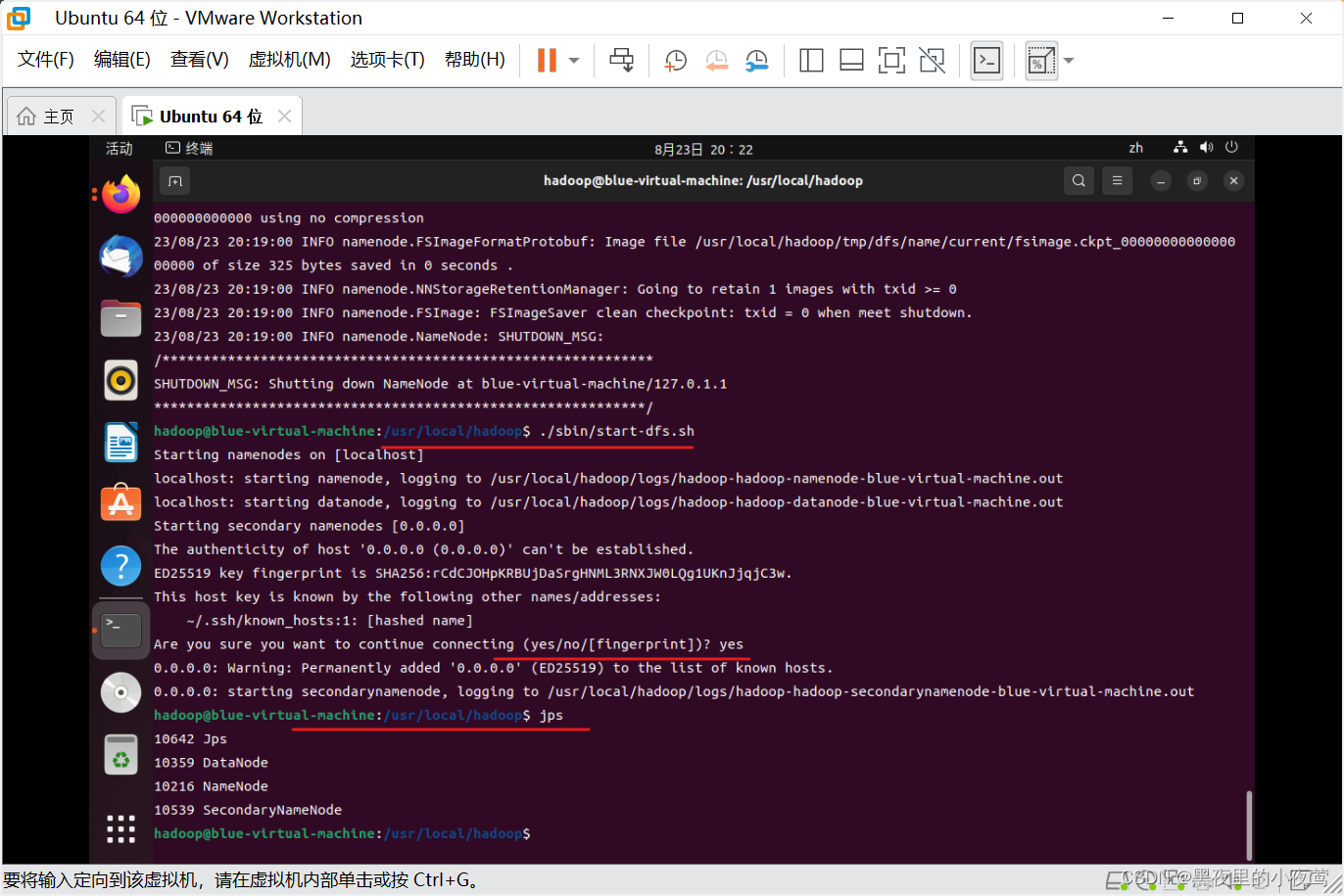
然后在浏览器输入下面网址,访问 Web 界面
http://localhost:50070
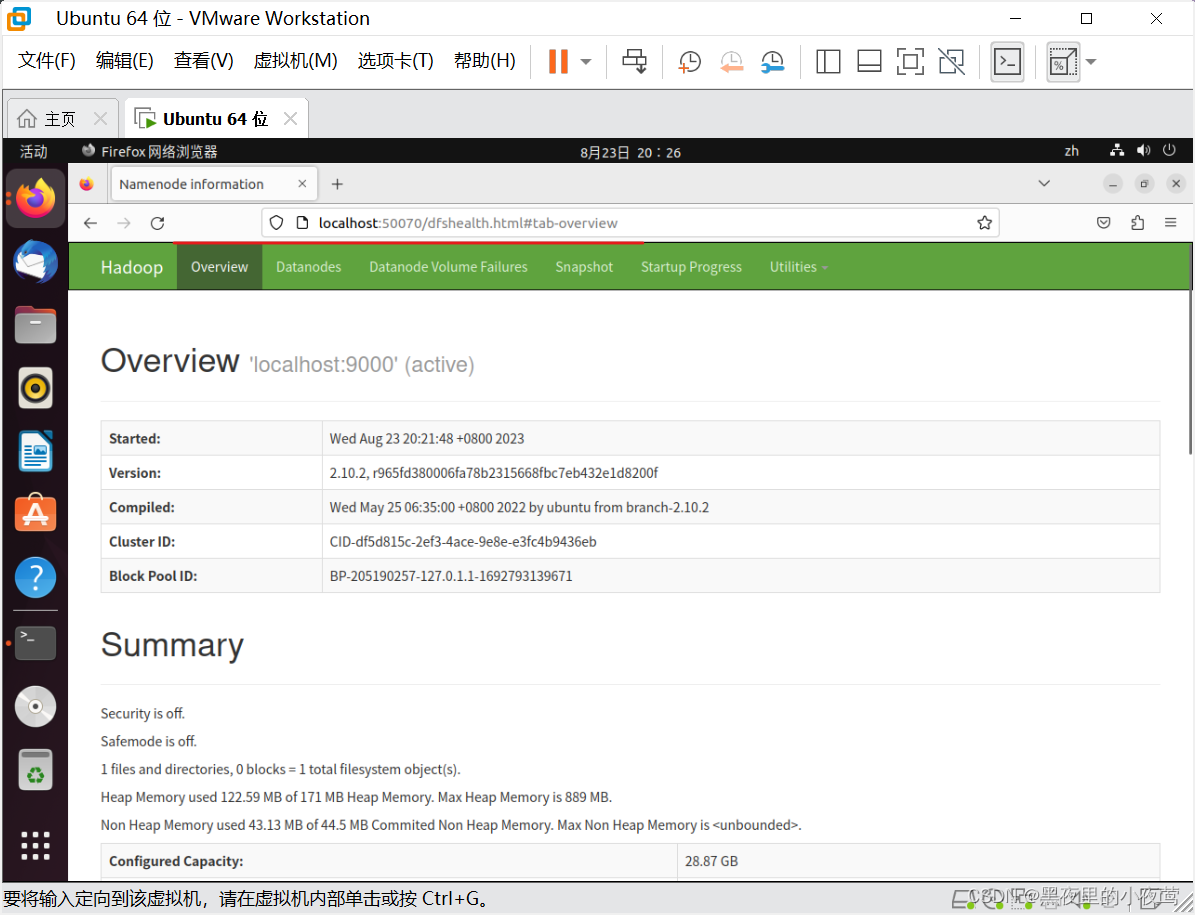
注:
Hadoop 3.x 起,启动端口变成了9870,而不是50070.(我下载的 Hadoop 2.x,故用端口 50070)
至此,配置完成,各位观看老爷感觉不错的话,能留下一个小小的点赞不过分吗,同时也希望各位生活愉快、事事顺心。

相关文章:
VMware和ubuntu配置Hadoop环境
目录 一、获取VMware安装包 1、官网获取 1)首先先进入官网,官网首页是下面这样: 2)接着点击产品选项 3)进入后点击查看所有产品,然后在右上角选择排序方式为Z到A,然后向下滑动找到Workstation…...
uview2.0自定义tabbar
tabbar组件 <template><u-tabbar :value"tab" change"changeTab" :fixed"true" :border"true" :placeholder"true":safeAreaInsetBottom"true"><u-tabbar-item text"消息" icon"c…...
Star History 月度开源精选|Llama 2 及周边生态特辑
7 月 18 日,Meta 发布了 Llama,大语言模型 Llama 1 的进阶版,可以自由免费用于研究和商业,支持私有化部署。 所以本期 Star History 的主题是:帮助你快速把 Llama 2 在自己机器上跑起来的开源工具,无论你的…...

修改电脑上路由表使笔记本默认走无线
如果笔记本上即连接了有线,也连接了无线,默认电脑会走有线的,通过route print命令查看路由表就可以看出来,因为无线的“metric”跳数要比有线的高 解决方法: 如果想实现让默认走无线,就需要修改自己电脑的…...

Spring Cache的介绍以及怎么使用(redis)
Spring Cache 文章目录 Spring Cache1、Spring Cache介绍2、Spring Cache常用注解2.1、EnableCaching注解2.2、CachePut注解2.3、CacheEvict注解2.4、Cacheable注解 3、Spring Cache使用方式--redis 1、Spring Cache介绍 Spring Cache是一个框架,实现了基于注解的缓…...

软考高级系统架构设计师系列论文六十九:论信息系统的安全风险评估
一、信息系统相关知识点 软考高级信息系统项目管理师系列之四十三:信息系统安全管理软考高级系统架构设计师:系统安全分析与设计...
Ubuntu系统安装之后首需要做的事情
Ubuntu系统的初步环境搭建 1、换源2、显卡3、浏览器4、输入法5、终端6、ROS7、VSCode8、设置时间与win一致9、 TimeShift10、 Anaconda(考虑装不装) 1、换源 点开Software&&Update,找到Ubuntu Software中的Download from,…...

Qt——QPushButton控件的常见属性、方法和信号
Qt中QPushButton控件的常见属性、方法和信号 一、QPushButton控件常见属性 一、QPushButton控件常见方法 一、QPushButton控件常见信号 一、QPushButton控件常见属性(Properties) 1. text: 描述:按钮上显示的文本。 用法: butto…...
5.5 基于ISOLAR-A的系统级设计与配置方法(上))
AUTOSAR规范与ECU软件开发(实践篇)5.5 基于ISOLAR-A的系统级设计与配置方法(上)
目录 前言 1 系统配置输入文件创建与导入 2、 Composition SWC建立 前言 如前所述, AUTOSAR支持整车级别的软件架构设计, 开发人员可以进行整车级别的软件组件定义, 再将这些软件组件分配到各个ECU中, 这就是AUTOSAR系统级设计需要完成的主要任务。 下面结合AUTOSAR方法论…...
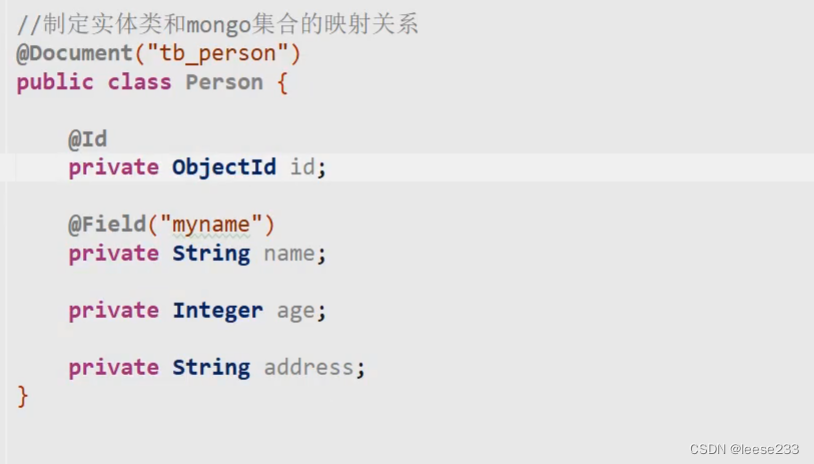
mongoDB的CRUD
...
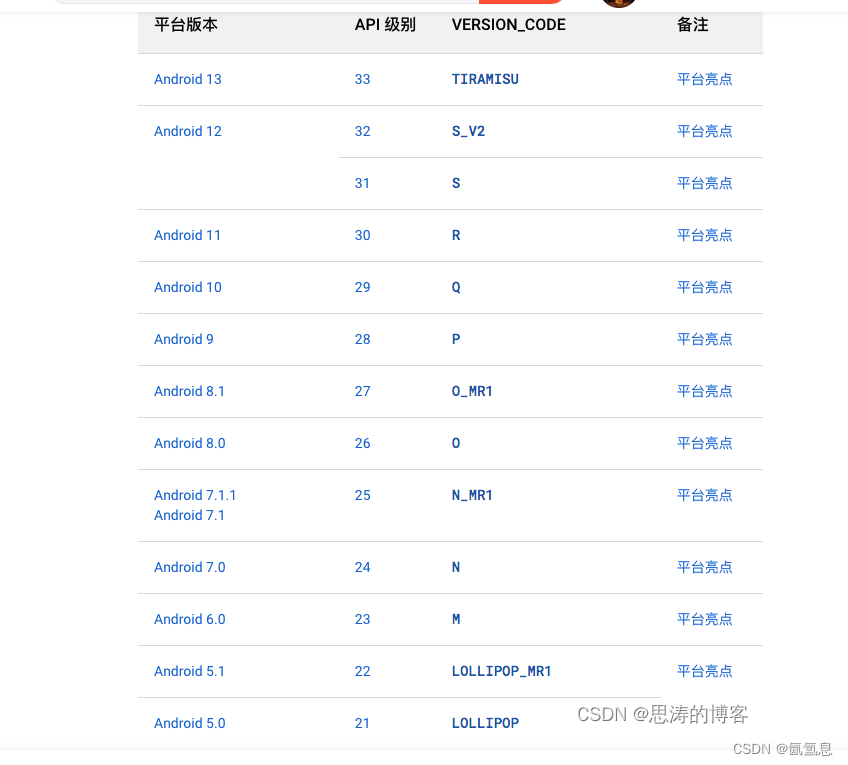
flutter TARGET_SDK_VERSION和android 13
config.gradle ext{SDK_VERSION 33MIN_SDK_VERSION 23TARGET_SDK_VERSION 33COMPILE_SDK_VERSION SDK_VERSIONBUILD_TOOL_VERSION "33.0.0"//兼容库版本SUPPORT_LIB_VERSION "33.0.0"}app/build.gradle里面的 defaultConfig {// TODO: Specify your…...

大数据Flink(六十六):Flink的重要概念和小结
文章目录 Flink的重要概念和小结 一、数据流图(Dataflow Graph)...
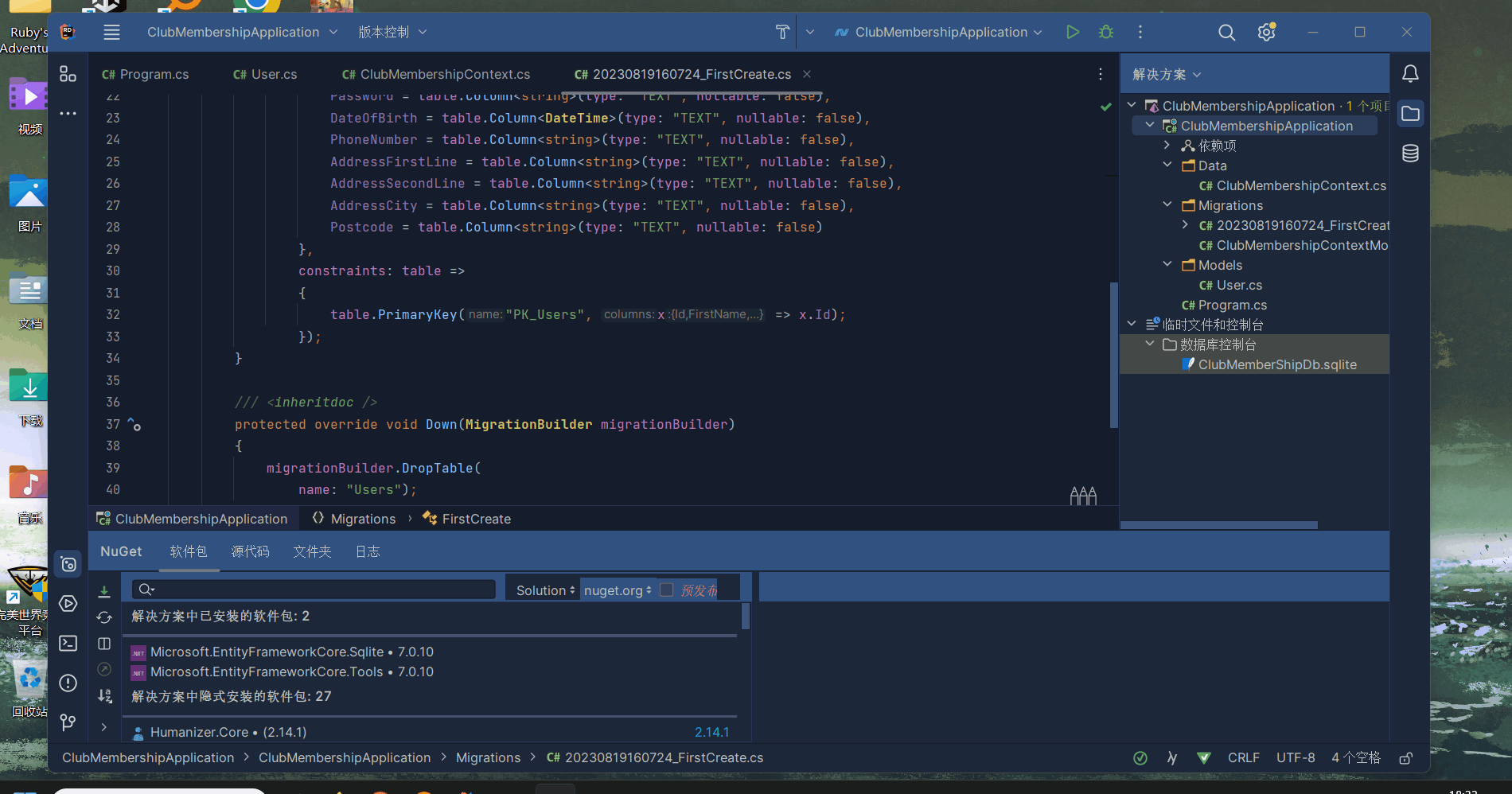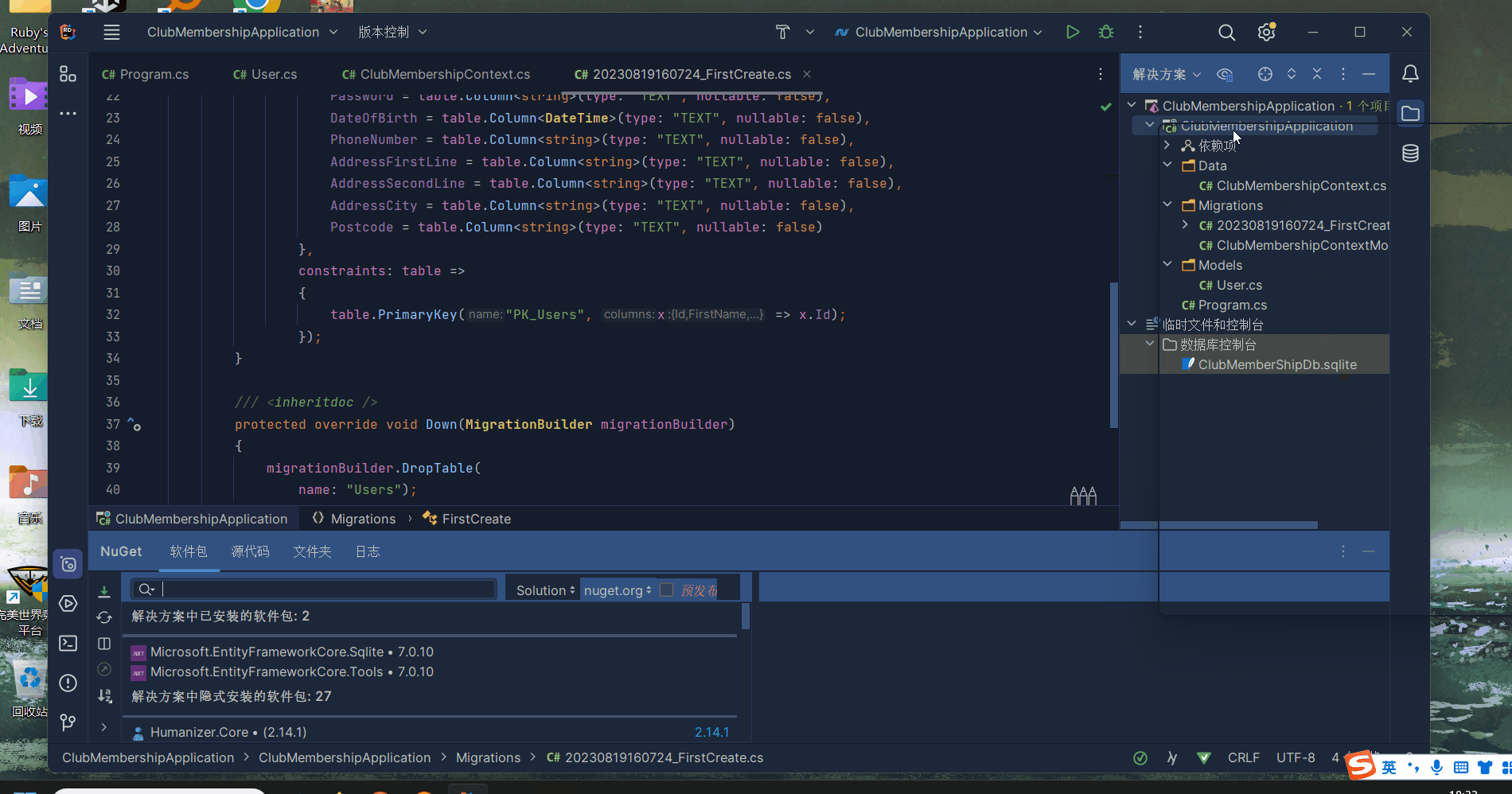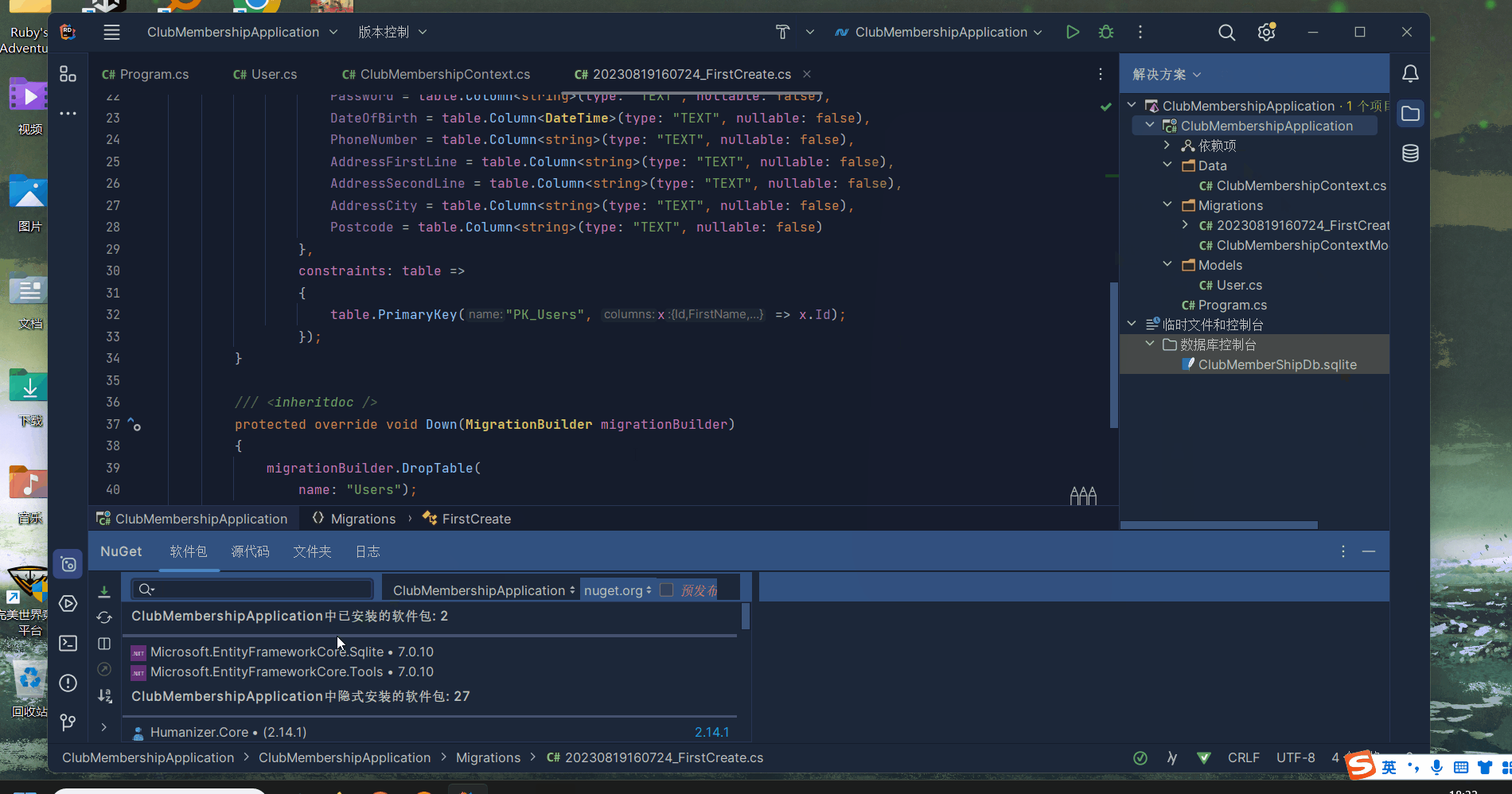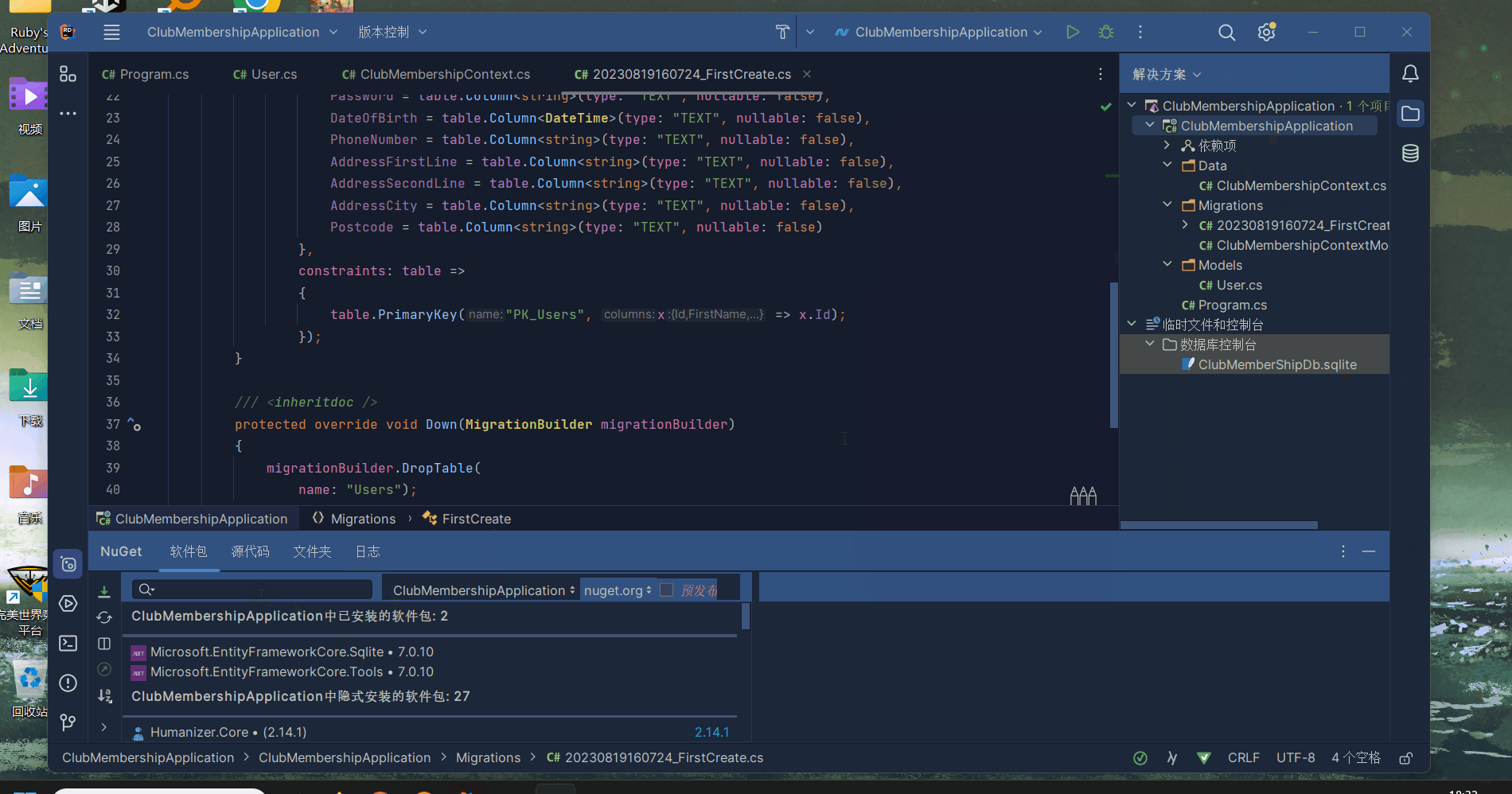
Rider 添加NuGet软件包 (NuGet Package)
如图,在解决方案中选择自己的项目右键,点击管理 NuGet 软件包即可 在搜索栏中搜索自己要使用的软件包安装即可使用...
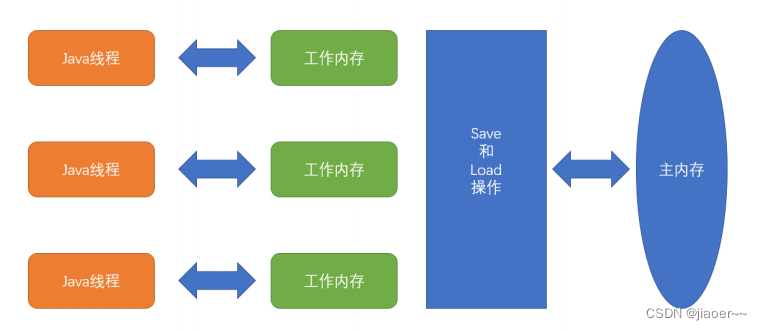
什么是JVM ?
一、JVM 简介 JVM 是 Java Virtual Machine 的简称,意为 Java 虚拟机。 虚拟机是指通过软件模拟的具有完整硬件功能的、运行在一个完全隔离的环境中的完整计算机系统。 常见的虚拟机: JVM 、 VMwave 、 Virtual Box 。 JVM 和其他两个虚拟机的区别…...

【大数据】Hive 中的批量数据导入
Hive 中的批量数据导入 在博客【大数据】Hive 表中插入多条数据 中,我简单介绍了几种向 Hive 表中插入数据的方法。然而更多的时候,我们并不是一条数据一条数据的插入,而是以批量导入的方式。在本文中,我将较为全面地介绍几种向 H…...
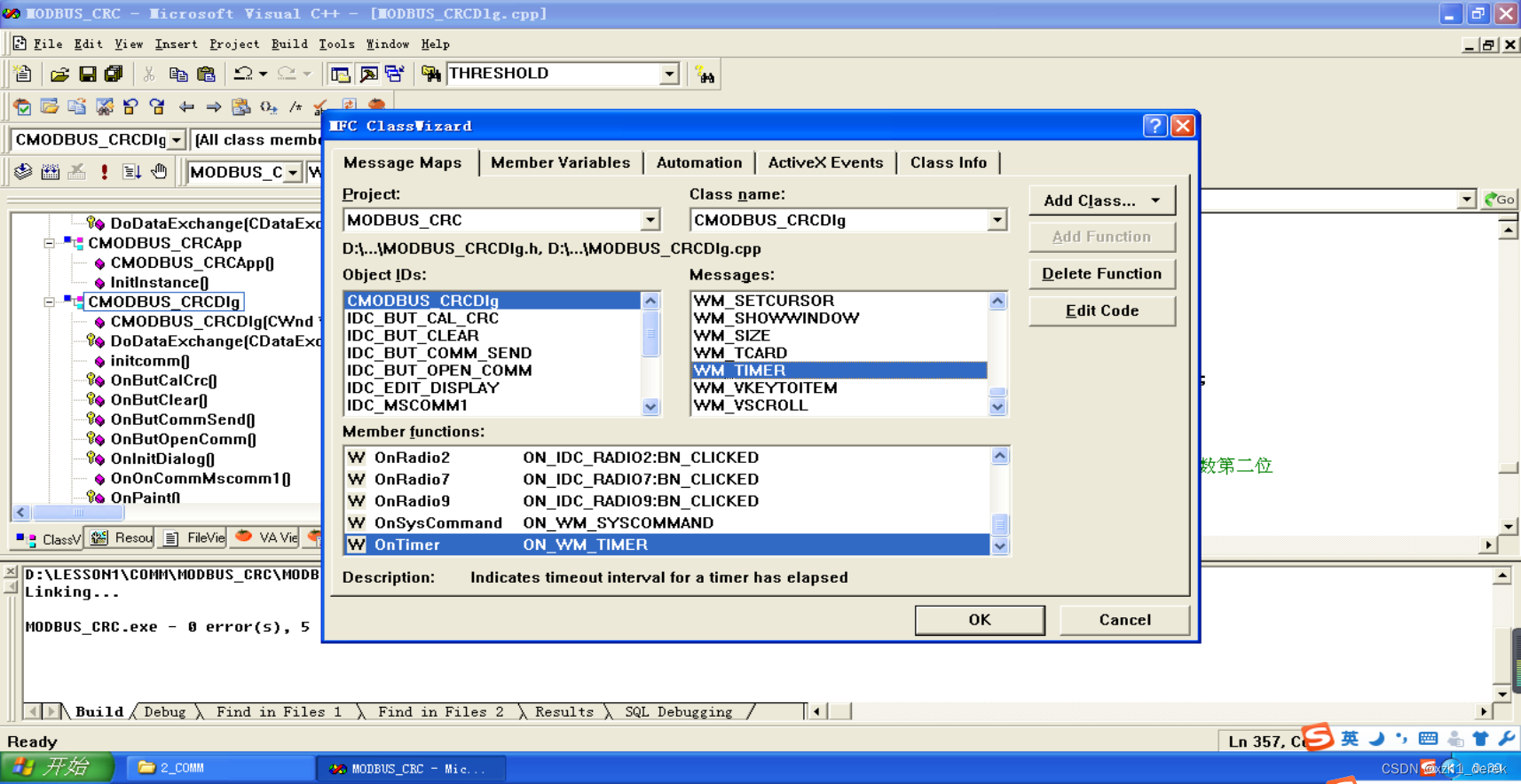
【Modbus通信实验三】数据切片问题
在做两个串口相互通信的实验中,当发送频率快一点时偶尔会遇到以下情景,即一次send中把原数据拆成两份发送,就会导致CRC校验错误。下图中6字节数据拆成42是把SetRThreshold()阈值设为2,当设为1的情况下则会拆成51。 一开始以为是缓…...
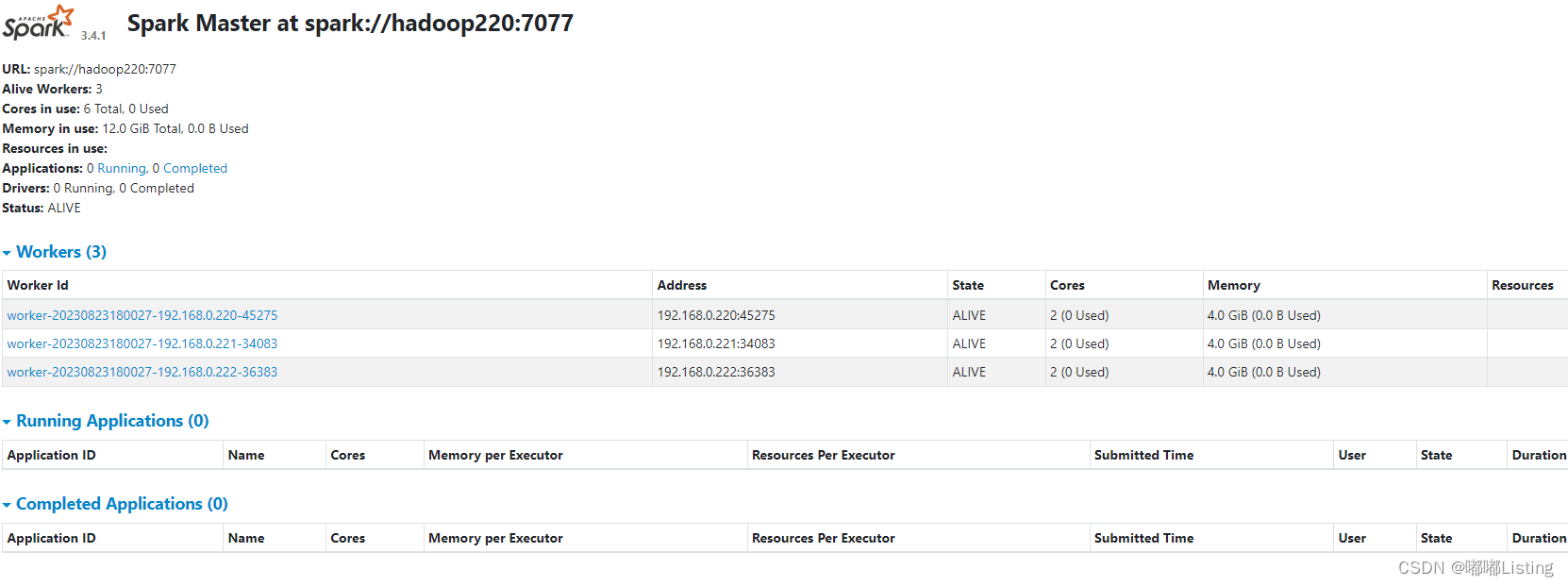
记录《现有docker中安装spark3.4.1》
基础docker环境中存储hadoop3--方便后续查看 参考: 实践: export JAVA_HOME/opt/apache/jdk1.8.0_333 export SPARK_MASTER_IP192.168.0.220 export SPARK_WORKER_MEMORY4g export SPARK_WORKER_CORES2 export SPARK_EXECUTOR_MEMORY4g export HADOOP_H…...

【3ds Max】练习——制作衣柜
目录 步骤 一、制作衣柜顶部 二、制作衣柜门板 三、制作衣柜底部 四、制作柜子腿部 五、制作柜子底板 步骤 一、制作衣柜顶部 1. 首先创建一个平面,然后将图片素材拖入平面 2. 平面大小和图片尺寸比例保持一致 3. 单机鼠标右键,选择对象属性 勾选…...

Spring-MVC的数据响应-19
在访问服务端MVC的时候,这个controller层进行相应操作之后 他要做两件事:页面跳转和返回字符串,在做完这些操作之后,我们一般进行页面展示:排除页面展示之外,有些需求可能直接回写给我们一些数据: 页面跳…...
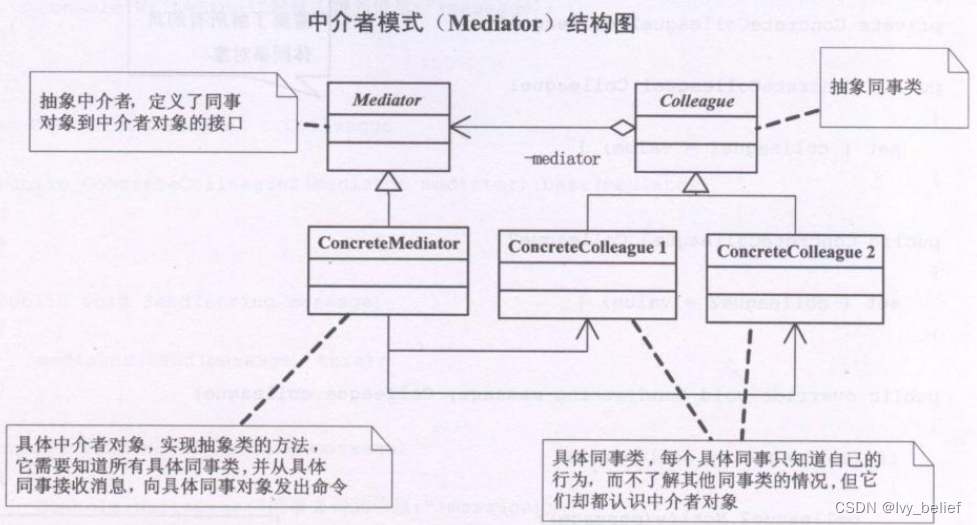
(三)行为模式:5、中介者模式(Mediator Pattern)(C++示例)
目录 1、中介者模式(Mediator Pattern)含义 2、中介者模式的UML图学习 3、中介者模式的应用场景 4、中介者模式的优缺点 (1)优点 (2)缺点 5、C实现中介者模式的实例 1、中介者模式(Media…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...
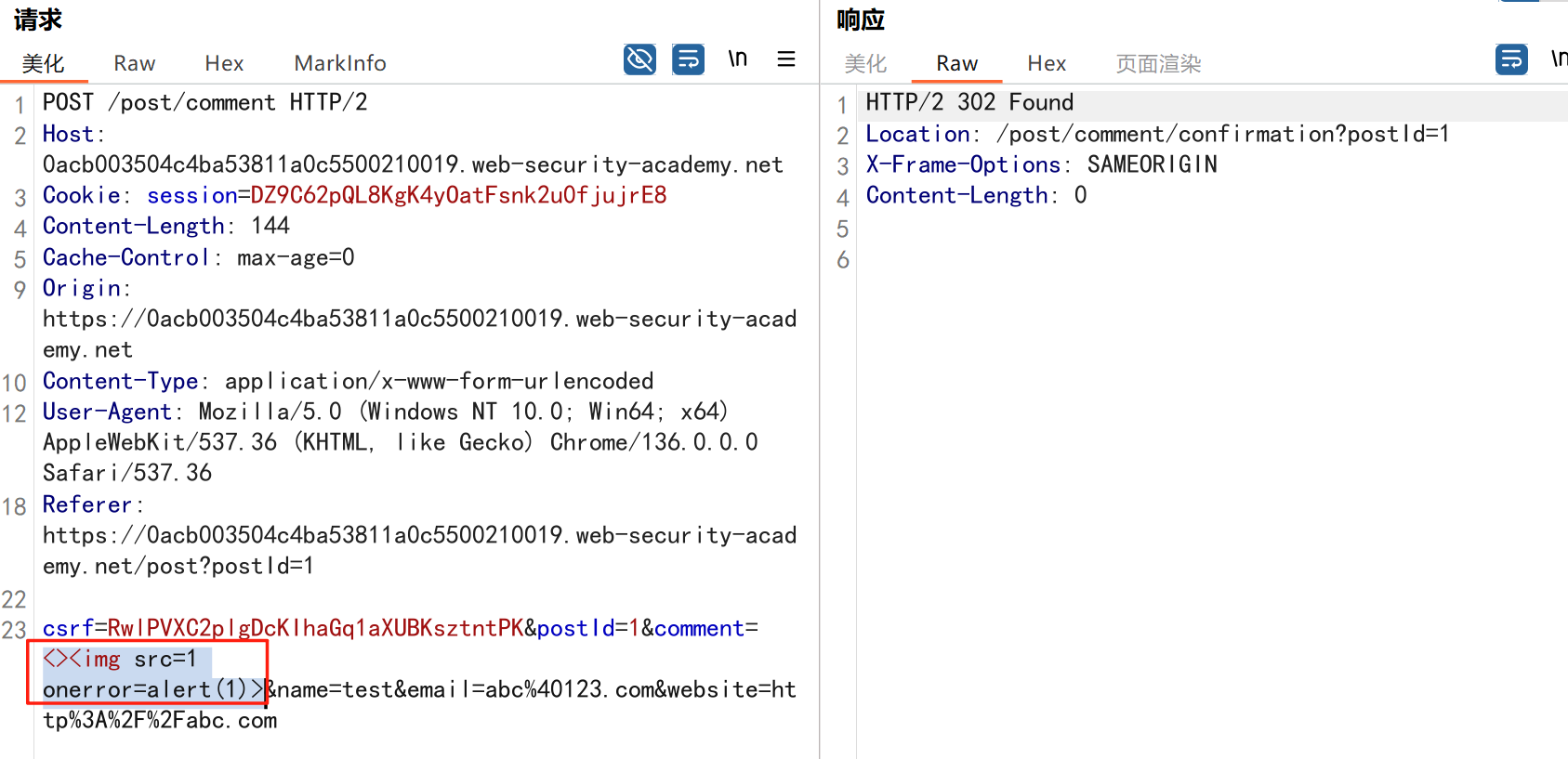
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...