pm4py使用指南(非机翻)
目录
- 1. 日志数据读取及预处理
- (1)查看case和event数量
- (2)查看起始事件和结束事件
- (3)时间戳格式的问题
- 2. 日志数据过滤
- 3. 流程发现
- 4. 模型转化
- 5. 模型可视化
1. 日志数据读取及预处理
通过 pandas库 读取csv文件,每一行代表一条活动记录,一般必须要有的信息是 case_id 事件id , activity_name 活动名称,time 时间戳,此外还可以包含 事件类型、活动成本等额外的信息以供进一步分析。pm4py官网提供了一个小样本数据集可用于探索该库的使用。
case_id;activity;timestamp;costs;resource
3;register request;2010-12-30 14:32:00+01:00;50;Pete
3;examine casually;2010-12-30 15:06:00+01:00;400;Mike
3;check ticket;2010-12-30 16:34:00+01:00;100;Ellen
3;decide;2011-01-06 09:18:00+01:00;200;Sara
3;reinitiate request;2011-01-06 12:18:00+01:00;200;Sara
(1)查看case和event数量
数据读取完成之后,可以获取该事件日志的一些基本信息。注意:这里 case/ trace 表示一个案例,即一次完整的流程,每个case_id 对应了很多可分隔的步骤(也即具体的 事件event / 活动activity) 。后面不再强调这一点,但都会按照这种方式进行叙述,因此需要明确区分 case 和 event 。
event_log = pandas.read_csv(file_path, sep=';') # 读取日志文件
num_events = len(event_log) # 获取日志文件的活动数目
num_cases = len(event_log.case_id.unique()) # 查看有多少次完整的案例记录
(2)查看起始事件和结束事件
此外,通过pm4py提供的函数还可以查看开始活动和结束活动都是哪些。
# 指定case_id,activity_key,timestamp_key分别对应哪个数据列
event_log = pm4py.format_dataframe(event_log, case_id='case_id', activity_key='activity',timestamp_key='timestamp')start_activities = pm4py.get_start_activities(event_log) # 起始事件
end_activities = pm4py.get_end_activities(event_log) # 结束事件
print("Start activities: {}\nEnd activities: {}".format(start_activities, end_activities))
pm4py.format_dataframe 将数据表转换为pm4py中的通用格式,它会创建事件日志的副本,并将分配的列重命名为pm4py中使用的标准列名,列case_id会重命名为case:concept:name,activity 列重命名为concept:name,timestamp列重命名为time:timestamp。
pm4py.get_start_activities 和pm4py.get_end_activities 函数返回一个字典,给出起始事件及结束事件分别出现在第一个和最后一个的次数。
(3)时间戳格式的问题
PM4Py利用内置的panda函数自动检测输入数据中的时间戳格式。但是,pandas 会孤立地查看每一行中的时间戳值。这就存在一些问题,如果提供的值是2020-01-18,即,首先是年份,然后是月份,然后是日期,在某些情况下,2020-02-01的值可能被错误地解释为1月2日,即,而不是2月1日。为了解决这个问题,可以向format_dataframe()方法提供一个额外的参数 times_format 。在本例中,时间戳格式为%Y-%m-%d%H:%m:%S%z。通常建议指定时间戳格式。
2. 日志数据过滤
现实中的日志数据通常是复杂、多变、有噪声的,为了得到良好的过程模型,有必要对数据进行仔细的过滤,PM4Py中有各种预构建的过滤器来实现这个需求。
- filter_start_activities(log, activities, retain=True) :此函数根据给定的起点事件过滤事件日志对象。
activities用于指定所关注的 起始事件 的集合;retain设置为True 表示 保留所有以activities中的事件开头的case,为 False 则删除所有以activities中的事件开头的case。 activities 和 retain这两个参数在其他函数中也是一样的,因此后面不再介绍。 - filter_end_activities(log,activities,retain=True):根据给定的终点事件过滤事件日志对象。
- filter_event_attribute_values(log,attribute_key,values,level=“case”,retain=True):根据事件属性过滤事件日志。
attribute_key是表示要筛选的属性键的字符串,values参数指定一组允许的值。如果level参数设置为“case”,表示在case-level进行属性值的过滤,一个case所包含的多个event中,至少一个event的属性值满足要求,那么整个case的所有事件都将被保留。如果level参数值设置为“event”,则只保留属性为指定值的事件。 - filter_trace_attribute_values(log,attribute_key,values,retain=True):仅保留(如果retain设置为False,则删除)具有所提供attribute_key的属性值并列在相应值集合中的跟踪。
- filter_variants(log,variants,retain=True):保留 满足特定执行顺序 的轨迹。例如,在大型日志中,我们希望保留描述执行序列“a”、“b”、“c”的所有轨迹。
variations参数是活动名称列表的集合,例如variations=[['a','b','c']]。 - filter_directly_follows_relation(log,relationship,retain=True):此函数筛选包含指定“直接跟随关系”的所有轨迹。这样的关系只是一对活动,例如
('a', 'b')表示在轨迹中’a’后面直接跟着 ‘b’ ,轨迹<'a','b','c','d'>包含直接跟在后面的对(‘a’,‘b’),(‘b’,‘c’)和(‘c’,‘d’)。relationship参数是一组元组,包含活动名称。 - filter_eventually_follows_relation(log,relationship,retain=True):此函数的跟随关系更宽松,允许两个活动之间有其他的活动,只需要这两个活动的前后关系满足要求即可。例如,当我们调用具有关系
(“a”, “b”)的函数时,在某个点观察到活动“a”,在之后某个点观察到活动“b”即可。 - filter_time_range(log, dt1, dt2, mode=’events’) :根据时间戳 dt1 和 dt2 定义的给定时间范围过滤事件日志。时间戳的格式应为
datetime.datetime。筛选器有三种模式(默认为“events”):‘events’:保留在时间范围之内的事件‘traces_contained’:保留完全在时间范围之内的轨迹‘traces_intersecting’:保留至少有一个事件在时间范围之内的轨迹
filtered = pm4py.filter_start_activities(log, {'register request'})filtered = pm4py.filter_start_activities(log, {'register request TYPO!'})filtered = pm4py.filter_end_activities(log, {'pay compensation'})filtered = pm4py.filter_event_attribute_values(log, 'org:resource', {'Pete', 'Mike'})filtered = pm4py.filter_event_attribute_values(log, 'org:resource', {'Pete', 'Mike'}, level='event')filtered = pm4py.filter_trace_attribute_values(log, 'concept:name', {'3', '4'})filtered = pm4py.filter_trace_attribute_values(log, 'concept:name', {'3', '4'}, retain=False)filtered = pm4py.filter_variants(log, [['register request', 'check ticket', 'examine casually', 'decide', 'pay compensation']])filtered = pm4py.filter_variants(log, [['register request', 'check ticket', 'examine casually', 'decide', 'reject request']])filtered = pm4py.filter_directly_follows_relation(log, [('check ticket', 'examine casually')])filtered = pm4py.filter_eventually_follows_relation(log, [('examine casually', 'reject request')])filtered = pm4py.filter_time_range(log, dt.datetime(2010, 12, 30), dt.datetime(2010, 12, 31), mode='events')filtered = pm4py.filter_time_range(log, dt.datetime(2010, 12, 30), dt.datetime(2010, 12, 31),mode='traces_contained')filtered = pm4py.filter_time_range(log, dt.datetime(2010, 12, 30), dt.datetime(2010, 12, 31),mode='traces_intersecting')
3. 流程发现
流程发现模块用于从事件日志中生成流程模型,pm4py实现了多种流程发现算法,并且可以生成不同种类的过程模型。PM4Py目前支持三种不同的流程建模符号,分别是:
- BPMN,即 Business Process Modeling Notation;
- Petri网,Petri网是一种更加数学化的建模表示,Petri网的行为通常更难理解,然而由于其数学性质,Petri网通常不那么模糊。在本教程中,我们将主要关注BPMN模型和流程树。
- 过程树 Process Tree,过程树表示Petri网的严格子集,并以分层的方式描述过程行为。
pm4py中的流程发现根据所使用的 算法 和 模型 对应着不同的函数,具体如下表所示(表中只是其中部分),然后本文会对这些函数的使用方法和参数进行具体的介绍:

- discover_petri_net_alpha()(这类函数一般都需要下面四个参数,因此后面省略不再介绍)
- log: Union[EventLog, DataFrame] 事件日志
- activity_key: str = ‘concept:name’ ,指定活动名称列
- timestamp_key: str = ‘time:timestamp’,指定表示时间的列
- case_id_key: str = ‘case:concept:name’) ,指定轨迹 id 列
- Return type:
Tuple[PetriNet, Marking, Marking]
- discover_petri_net_ilp()
- alpha(float):序列编码图 (sequence encoding graph)的噪声阈值,1.0=no filtering, 0.0=greatest filtering
- Return type:
Tuple[PetriNet, Marking, Marking]
- discover_petri_net_inductive()
- noise_threshold (float) :噪声阈值 (default: 0.0)
- multi_processing (bool) :boolean that enables/disables multiprocessing in inductive miner(?)
- discover_petri_net_heuristics()
- dependency_threshold (float) : dependency threshold (default: 0.5)
- and_threshold (float): AND threshold (default: 0.65)
- loop_two_threshold (float) :loop two threshold (default: 0.5)
- discover_process_tree_inductive()
- noise_threshold (float) : noise threshold (default: 0.0)
- multi_processing (bool) :boolean that enables/disables multiprocessing in inductive miner
- Return type:
ProcessTree
- discover_heuristics_net()
- dependency_threshold (float) : dependency threshold (default: 0.5)
- and_threshold (float): AND threshold (default: 0.65)
- loop_two_threshold (float) :loop two threshold (default: 0.5)
- min_act_count (int):活动的最小发生次数,大于该阈值才会纳入模型中
- min_dfg_occurrences (int):活动的最小发生次数,大于该阈值才会被作为DFG的一条弧
- decoration (str) :弧上的标注 可选 ‘frequency’ 频率 或 ‘performance’ 性能)
- Return type:
HeuristicsNet
- discover_bpmn_inductive()
- noise_threshold (float) : noise threshold (default: 0.0)
- multi_processing (bool) :boolean that enables/disables multiprocessing in inductive miner
- Return type:
BPMN
4. 模型转化
在介绍绘图之前,先介绍一下各个流程模型之间的转化。pm4py的convert模块提供了多种函数实现 petri 网,过程树,BPMN等模型的转换。
- convert_to_bpmn():输入 petri net 或process tree,返回BPMN
- convert_to_petri_net() :输入BPMN 或process tree,返回 petri net
- convert_to_process_tree():输入BPMN 或 petri net ,返回process tree
process_tree = pm4py.discover_process_tree_inductive(log) # 流程树bpmn_model = pm4py.convert_to_bpmn(process_tree) # 将流程树转换为BPMN
5. 模型可视化
- view_petri_net()
- petri_net (PetriNet):传入要绘制的petri网
- initial_marking : Initial marking 起始标记 im
- final_marking:Final marking 终点标记 fm(im和fm在前面使用流程发现函数时会随着petri网一起生成三元组)
- format (str) :输出图片的格式
- bgcolor (str) :背景颜色,默认白色(default: white)
- decorations :与Petri网元素相关的装饰(颜色、标签)
- debug (bool):启用 / 禁用debug模式
- save_vis_petri_net()
- 参数同上,但是多了一个 file_path 用于指定文件保存位置
BPMN,过程树绘制的函数也都类似,view_xxxx() 用于模型可视化展示,save_vis_xxxx() 用于文件保存,一般可以设置 format 文件类型 和 bgcolor背景颜色。
net, im, fm = pm4py.discover_petri_net_inductive(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')
pm4py.view_petri_net(net, im, fm, format='svg')
相关文章:
pm4py使用指南(非机翻)
目录 1. 日志数据读取及预处理(1)查看case和event数量(2)查看起始事件和结束事件(3)时间戳格式的问题 2. 日志数据过滤3. 流程发现4. 模型转化5. 模型可视化 1. 日志数据读取及预处理 通过 pandas库 读取c…...

ChatGPT帮助提升工作效率和质量:完成时间下降40%,质量评分上升 18%
自ChatGPT去年11月发布以来,人们就开始使用它来协助工作,热心的用户利用它帮助撰写各种内容,从宣传材料到沟通话术再到调研报告。 两名MIT经济学研究生近日在《科学》杂志上发表的一项新研究表明,ChatGPT可能有助于减少员工之…...

第二章 搜索
本篇博文是笔者归纳汇总的AcWing基础课题集,方便读者后期复盘巩固~ PS:本篇文章只给出完整的算法实现,并没有讲解具体的算法思路。如果想看算法思路,可以阅读笔者往期写过的文章(或许会有),也可…...
transform_train.json文件解析
transform_train.json 文件内容解析transform_matrix 文件内容解析 {"camera_angle_x": 0.6911112070083618,"frames": [{"file_path": "./train/r_0","rotation": 0.012566370614359171,"transform_matrix": [[…...
Wlan——锐捷零漫游网络解决方案以及相关配置
目录 零漫游介绍 一代零漫游 二代单频率零漫游 二代双频率零漫游 锐捷零漫游方案总结 锐捷零漫游方案的配置 配置无线信号的信道 开启关闭5G零漫游 查看配置 零漫游介绍 普通的漫游和零漫游的区别 普通漫游 漫游是由一个AP到另一个AP或者一个射频卡到另一个射频卡的漫…...

分布式锁系列之zookeeper分布式锁和mysql分布式锁
目录 介绍 下载安装 基本指令编辑 java集成zookeeper 官方提供版 永久节点 临时节点编辑 永久序列化节点 判断当前节点是否存在 获取当前节点中的数据内容 获取当前节点的子节点 更新节点内容 删除节点 zookeeper实现分布式锁 Mysql实现分布式锁 总结 介绍 ZooK…...

Ubuntu部署PHP7.4
系统版本:Ubuntu22.04 PHP版本: 7.4 Mysql版本:8.0 Nginx版本: 最新 1. 更新系统 首先,确保系统包是最新的: sudo apt update && sudo apt upgrade -y2. 安装 Nginx Nginx 在默认的 Ubuntu 仓库中,因此安装…...
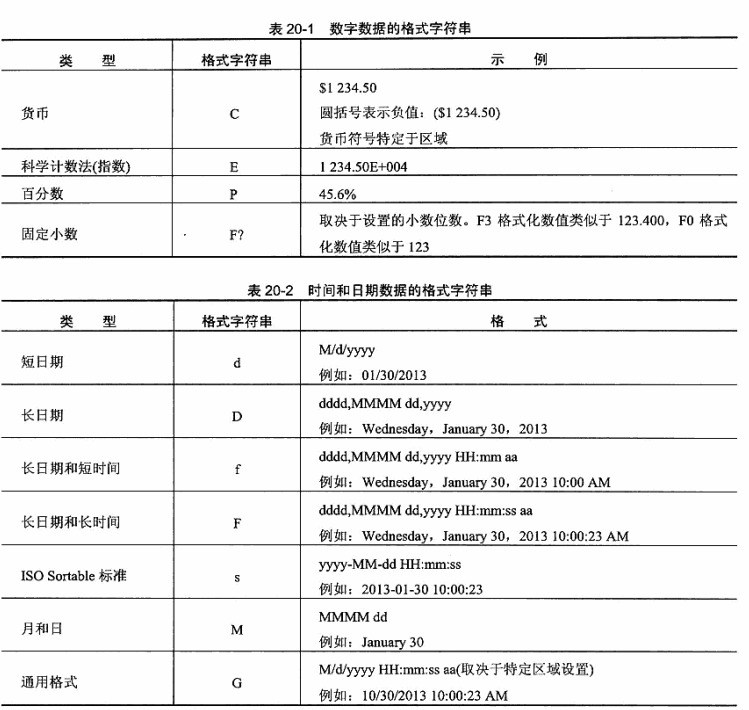
WPF中的数据转换-StringFormat
WPF中的数据转换-StringFormat 前言 字符串格式化。使用该功能可以通过设置Binding.StringFormat属性对文本形式的数据进行转换——例如包含日期和数字的字符串。对于至少一半的格式化任务,字符串格式化是一种便捷的技术。 使用 当设置Binding.StringFormat属性…...

java.lang.UnsupportedOperationException解决方法
java.lang.UnsupportedOperationException解决方法 先放错误信息业务场景报错分析先看报错代码位置进入源码查看至此 真相大白 解决方法总结 先放错误信息 业务场景 已知有学生 张三李四王五赵六 等人 private List<String> nameList Arrays.asList("张三", &…...
docker for window更改到非系统盘的使用记录
1、使用Hyper-v模式的docker安装 2、安装docker for windows后安装目录没办法自己选择,固定在c盘 卸载后通过命令行方式设置软连接方式后重新安装来让其安装到软连接的d盘,解决c盘空间问题 mklink /j "C:\Program Files\Docker" "D:\Pr…...

day 38 | ● 518. 零钱兑换 II ● 377. 组合总和 Ⅳ
518. 零钱兑换 II 这道题就是完全背包问题,因为可以选择的数量是无限的。所以第二层的遍历顺序就是从前往后。 因为是次数问题,递推公式是 的,初值应该设定为dp【0】 1,否则无法进行累加。 func change(amount int, coins []i…...

写得了代码,焊得了板!嵌入式开发工程师必修之代码管理方案(中)
目录 2.2 分仓、权限与依赖问题 2.3 基于 Git 进行多仓管理 Git submodule Git subtree Script/CMake Git-Repo Conan 本文来自 武让 极狐GitLab 高级解决方案架构师 🌟 前一篇文章,作者介绍了嵌入式开发场景的代码管理特点与诉求,以及…...

Interlij IDEA 运行 ruoyi 后端项目。错误: 找不到或无法加载主类 com.ruoyi.auth.RuoYiAuthApplication
错误: 找不到或无法加载主类 com.ruoyi.auth.RuoYiAuthApplication 用了 IDEA运行,参考以下issue删除.idea目录也没有用 (官方文档写是用Eclipse运行) 错误: 找不到或无法加载主类 com.ruoyi.auth.RuoYiAuthApplication Issue #I48N2X 若依/RuoYi-C…...

相机设置报错记录
Camera->SetPosition(0.0, -980, 0.0);Camera->SetFocalPoint(0.0, 0.0, 0.0);Camera->SetViewUp(0.0, 1.0, 0.0);上述代码出现错误提示Resetting view-up since view plane normal is parallel,这个时候是viewup方向与投影方向平行了,而出现的…...

Vue3中搜索表单的二次封装
最近使用Vue3ElementPlus开发项目,从整体上构思组件的封装。能写成组件的内容都进行封装,方便多个地方使用。 受AntDesign的启发,在项目中有搜索表单table分页的地方可以封装为一个组件,只需要对组件传入table的列,组成…...

百度23Q2财报最新发布:营收利润加速增长,AI+生态战略渐显规模
百度集团-SW(9888.HK)Q2财报已于2023/08/22(美东)盘前发布,二季度百度集团整体收入实现341亿元,同比增长15%;归属百度的净利润(non-GAAP)达到80亿元,同比增长44%。营收和利润双双实现大幅增长,超市场预期。其中,百度核…...

一个pdf文件分割成两个
# -- coding: utf-8 --** import PyPDF2 # 打开原始PDF文件 # with open(zhongguojinxiandaishi.pdf, rb) as pdf_file: # pdf_reader PyPDF2.PdfReader(pdf_file) # num_pages len(pdf_reader.pages) # # # 确定分割点(例如,将页面一分为二࿰…...

Android 保存图片
这个主要讲的InputStream去保存。 如果需要BItmap与InputStream相互转换可以参考 Android Bitmap、InputStream、Drawable、byte[]、Base64之间的转换关系 保存图片我们需要考虑系统版本,Q前后还是不一样的。 /*** 保存图片* param context 上下文* param inputS…...
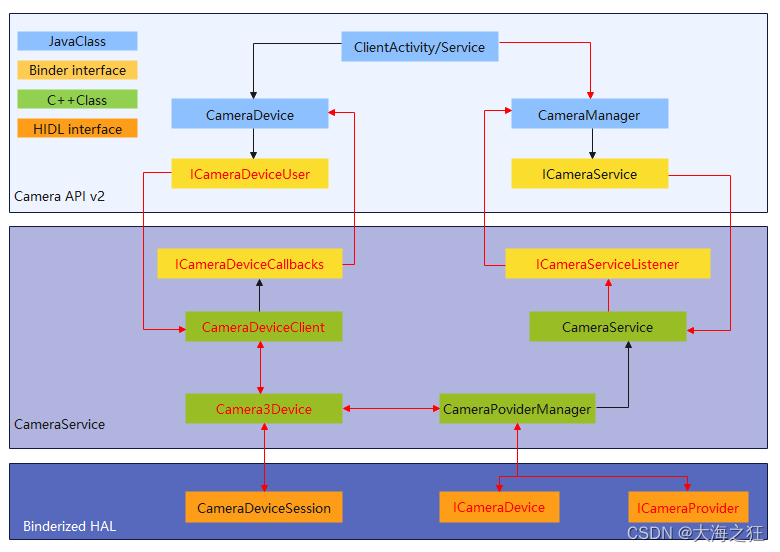
Android相机-架构
引言: 主要是针对CameraAPI v2 HAL3的架构对Android相机系统进行梳理。 相机架构 App和FrameWork Camera API v2位于: packages/apps/Camer2 frameworks/ex/camera2 应用框架级别,使用Camera2 API与相机的硬件进行交互。通过调用Binder接口…...
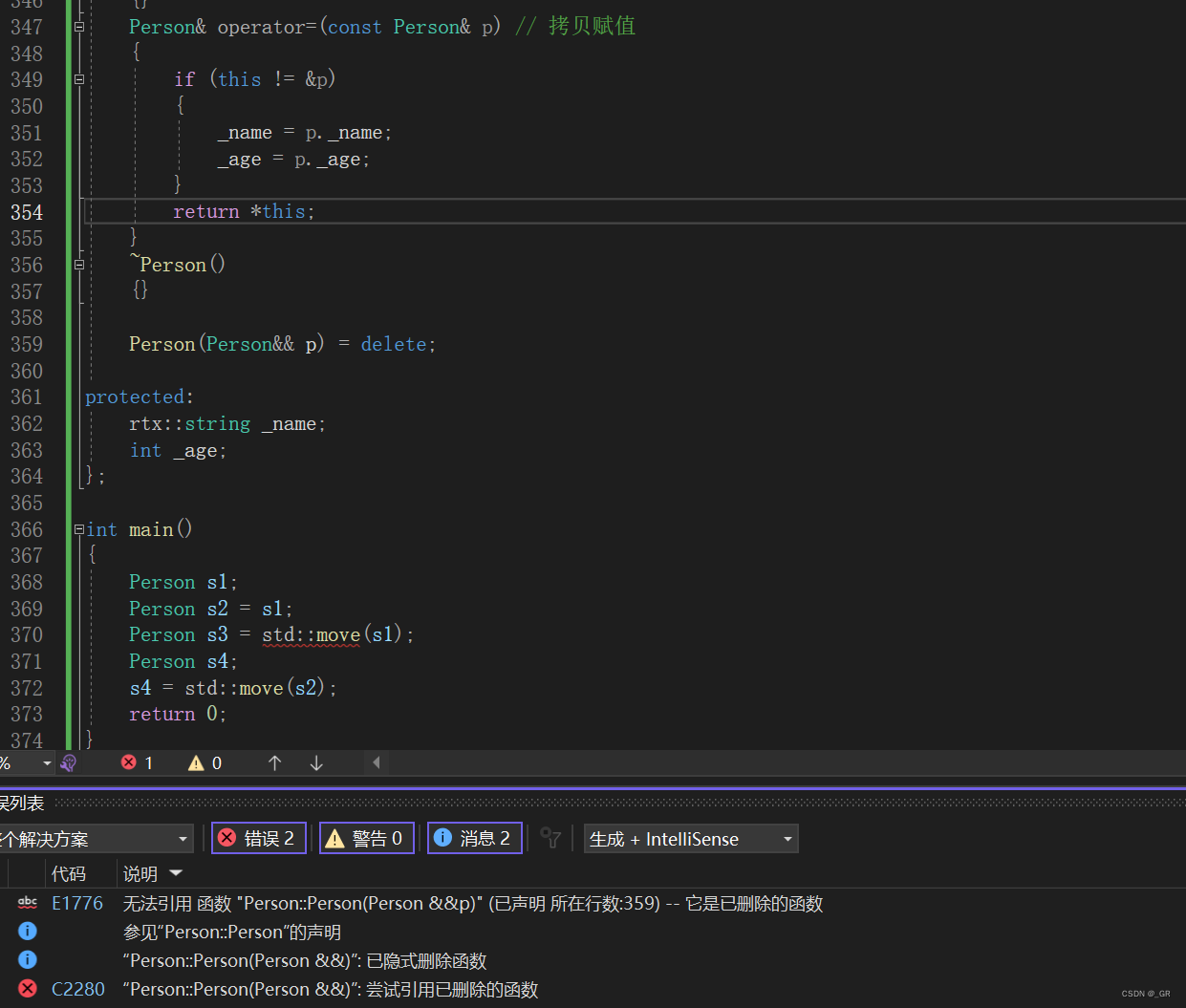
从C语言到C++_33(C++11_上)initializer_list+右值引用+完美转发+移动构造/赋值
目录 1. 列表初始化initializer_list 2. 前面提到的一些知识点 2.1 小语法 2.2 STL中的一些变化 3. 右值和右值引用 3.1 右值和右值引用概念 3.2 右值引用类型的左值属性 3.3 左值引用与右值引用比较 3.4 右值引用的使用场景 3.4.1 左值引用的功能和短板 3.4.2 移动…...

IT行业的项目经理考不考PMP证书?我劝你看完这篇在决定!
作为在 IT 圈摸爬滚打 8 年,从后端开发一路转型项目经理、带过 10 大小项目的老学长,最近总被身边技术小伙伴追问:想转 PM,必须考 PMP 吗?没证书就做不好项目管理吗?今天就用过来人的经验,跟大…...

一个月突变!Linux内核大佬懵了:上个月还是“AI垃圾”,这个月AI Bug报告却突然靠谱?
整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)最近在做开源项目维护的开发者,可能会有一种奇怪的错觉:Bug 似乎报告变多了,而且变准了——更准确地说,是 AI 报的 Bug,突然开始“靠谱了”。…...

ESP32 RMT硬件驱动RF遥控库:替代rc-switch的异步OOK方案
1. 项目概述RCSwitchRmt 是一款专为 ESP32 系列微控制器设计的射频(RF)OOK(On-Off Keying,开关键控)通信库,其核心目标是提供一种现代、异步、非阻塞的硬件驱动型替代方案,以取代广为人知但已显…...

小米智能家居无缝接入Home Assistant的3种高效方法
小米智能家居无缝接入Home Assistant的3种高效方法 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home Xiaomi Home集成是小米官方为Home Assistant提供的智能家居集成组件…...

指挥OpenClaw抓取数据折腾了一夜,我终于想到了邪修玩法
这段时间玩小龙虾玩得真上头,突然想起之前一直想要统计公众号的数据。 这工作交给小龙虾妥妥能胜任啊!但是吧……实际上执行出来的结果却不是这样的。 因为小白本地使用的是OpenClawAtomgit的方案,Atomgit主打一个不费一分钱,免…...

ai赋能开发:让快马智能助手帮你诊断和优化openclaw ubuntu部署难题
最近在Ubuntu上部署OpenClaw项目时,遇到了不少头疼的问题。从依赖冲突到参数调优,每一步都可能踩坑。不过我发现,借助AI辅助开发工具,这些问题可以变得更可控。今天就来分享下如何构建一个AI工具箱来优化OpenClaw的部署和开发体验…...

从“看见光点”到“看懂世界”:视觉重建让这个世界变得更近一些
三十多年前,“让盲人重新看见”更像一句带有未来感的科学想象。而今天,这件事已经进入临床试验和真实的人体研究。视觉重建之所以被视为脑机接口里最具挑战性的方向之一,不只是因为它要解决“能不能刺激大脑”的问题,更因为它要回…...

推荐算法闲谈:如何在不同业务场景下理解和拆解核心指标
巧解决的是能不能学好,而指标分析解决的是这次改动是否真正创造了业务价值,以及为什么。一个非常常见、但又极易被忽视的事实是:推荐系统并不存在一套放之四海而皆准的核心业务指标。不同产品形态、不同交互方式、不同公司发展阶段࿰…...

效果实测:Image-to-Video如何将风景照变成动态视频?
效果实测:Image-to-Video如何将风景照变成动态视频? 1. 惊艳的开场:静态照片"活"起来了 想象一下,你手机里那些美丽的风景照片突然"活"了过来——海浪开始翻滚,云朵缓缓飘动,树叶在微…...

intv_ai_mk11详细步骤:24GB单卡部署Llama模型并启用Web UI全流程
24GB单卡部署Llama模型并启用Web UI全流程指南 1. 环境准备与快速部署 在开始部署intv_ai_mk11模型前,我们需要确保硬件和软件环境满足基本要求。这个中等规模的Llama架构模型可以在单张24GB显存的GPU上流畅运行,非常适合个人开发者和小型团队使用。 …...