如何深入理解 Node.js 中的流(Streams)

Node.js是一个强大的允许开发人员构建可扩展和高效的应用程序。Node.js的一个关键特性是其内置对流的支持。流是Node.js中的一个基本概念,它能够实现高效的数据处理,特别是在处理大量信息或实时处理数据时。
在本文中,我们将探讨Node.js中的流概念,了解可用的不同类型的流(可读流、可写流、双工流和转换流),并讨论有效处理流的最佳实践。
什么是Node.js流?
流是Node.js应用程序中的一个基本概念,通过按顺序读取或写入输入和输出,实现高效的数据处理。它们非常适用于文件操作、网络通信和其他形式的端到端数据交换。
流的独特之处在于它以小的、连续的块来处理数据,而不是一次性将整个数据集加载到内存中。这种方法在处理大量数据时非常有益,因为文件大小可能超过可用内存。流使得以较小的片段处理数据成为可能,从而可以处理更大的文件。
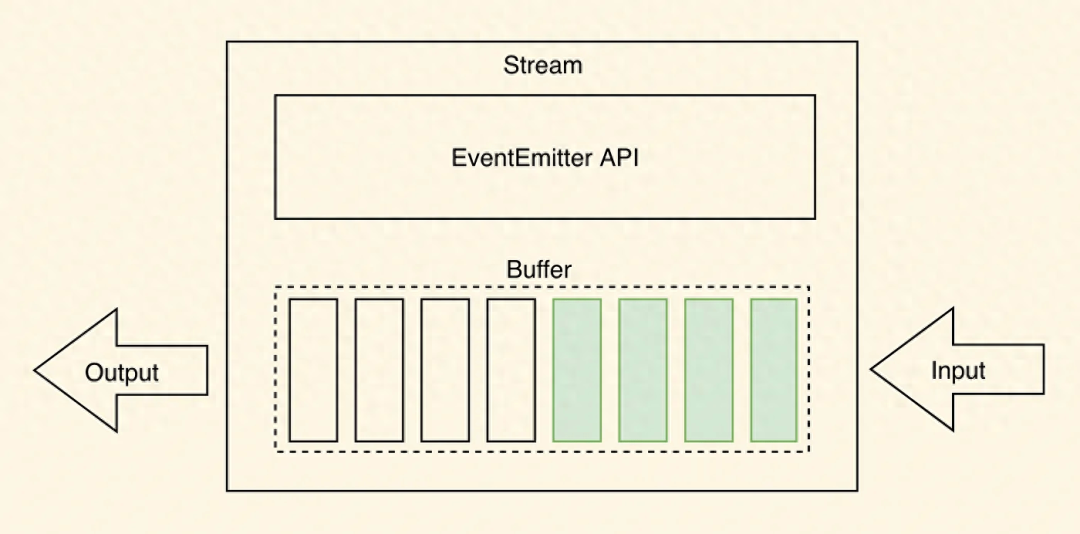
如上图所示,数据通常以块或连续流的形式从流中读取。从流中读取的数据块可以存储在缓冲区中。缓冲区提供临时存储空间,用于保存数据块,直到进一步处理。
为了进一步说明这个概念,考虑一个实时股票市场数据源的情景。在金融应用中,实时更新股票价格和市场数据对于做出明智的决策至关重要。流式处理使应用程序能够以较小的连续块处理数据,而不是获取和存储整个数据源,这可能是相当庞大和不切实际的。数据通过流动,允许应用程序在更新到达时执行实时分析、计算和通知。这种流式处理方法节省了内存资源,并确保应用程序能够迅速响应市场波动,并向交易员和投资者提供最新信息。它消除了在采取行动之前等待整个数据源可用的需要。
为什么要使用流?
流提供了与其他数据处理方法相比的两个关键优势。
内存效率
使用流,处理前不需要将大量数据加载到内存中。相反,数据以较小的可管理块进行处理,减少了内存需求并有效利用了系统资源。
时间效率
流使得数据一旦可用就能立即进行处理,而不需要等待整个有效负载的传输。这样可以实现更快的响应时间和改善整体性能。
理解并有效地利用流能够帮助开发人员实现最佳的内存使用、更快的数据处理和增强的代码模块化,使其成为Node.js应用程序中强大的功能。然而,不同类型的Node.js流可以用于特定的目的,并在数据处理方面提供灵活性。为了在您的Node.js应用程序中有效地使用流,有必要清楚地了解每种流类型。因此,让我们深入研究一下Node.js中可用的不同流类型。
Node.js流的类型
Node.js 提供了四种主要类型的流,每种流都有特定的用途:
Readable Streams 可读流
可读流允许从源(如文件或网络套接字)读取数据。它们按顺序发出数据块,并可以通过附加监听器到“data”事件来消费。可读流可以处于流动或暂停状态,取决于数据的消费方式。
const fs = require('fs');// Create a Readable stream from a file
const readStream = fs.createReadStream('the_princess_bride_input.txt', 'utf8');// Readable stream 'data' event handler
readStream.on('data', (chunk) => {console.log(`Received chunk: ${chunk}`);
});// Readable stream 'end' event handler
readStream.on('end', () => {console.log('Data reading complete.');
});// Readable stream 'error' event handler
readStream.on('error', (err) => {console.error(`Error occurred: ${err}`);
});如上所示的代码片段中,我们使用fs模块使用createReadStream()方法创建一个可读流。我们将文件路径
the_princess_bride_input.txt 和编码 utf8 作为参数传递。可读流以小块方式从文件中读取数据。
我们将事件处理程序附加到可读流上以处理不同的事件。当数据块可供读取时,会触发 data 事件。当可读流完成从文件中读取所有数据时,会触发 end 事件。如果在读取过程中发生错误,则会触发 error 事件。
通过使用可读流并监听相应的事件,您可以高效地从源(例如文件)中读取数据,并对接收到的数据块执行进一步操作。
Writable Streams 可写流
可写流处理将数据写入目标位置,例如文件或网络套接字。它们提供了像 write() 和 end() 这样的方法来向流发送数据。可写流可用于以分块方式写入大量数据,防止内存溢出。
const fs = require('fs');// Create a Writable stream to a file
const writeStream = fs.createWriteStream('the_princess_bride_output.txt');// Writable stream 'finish' event handler
writeStream.on('finish', () => {console.log('Data writing complete.');
});// Writable stream 'error' event handler
writeStream.on('error', (err) => {console.error(`Error occurred: ${err}`);
});// Write a quote from "The to the Writable stream
writeStream.write('As ');
writeStream.write('You ');
writeStream.write('Wish');
writeStream.end();在上面的代码示例中,我们使用fs模块使用 createWriteStream() 方法创建一个可写流。我们指定数据将被写入的文件路径(
the_princess_bride_output.txt )。
我们将事件处理程序附加到可写流上,以处理不同的事件。当可写流完成写入所有数据时,会触发 finish 事件。如果在写入过程中发生错误,则会触发 error 事件。使用 write() 方法将单个数据块写入可写流。在这个例子中,我们将字符串'As'、'You'和'Wish'写入流中。最后,我们调用 end() 来表示数据写入结束。
通过使用可写流并监听相应的事件,您可以高效地将数据写入目标位置,并在写入过程完成后执行任何必要的清理或后续操作。
Duplex Streams 双工流
双工流代表了可读和可写流的组合。它们允许同时从源读取和写入数据。双工流是双向的,并在同时进行读取和写入的情况下提供了灵活性。
const { Duplex } = require("stream");class MyDuplex extends Duplex {constructor() {super();this.data = "";this.index = 0;this.len = 0;}_read(size) {// Readable side: push data to the streamconst lastIndexToRead = Math.min(this.index + size, this.len);this.push(this.data.slice(this.index, lastIndexToRead));this.index = lastIndexToRead;if (size === 0) {// Signal the end of readingthis.push(null);}}_write(chunk, encoding, next) {const stringVal = chunk.toString();console.log(`Writing chunk: ${stringVal}`);this.data += stringVal;this.len += stringVal.length;next();}
}const duplexStream = new MyDuplex();
// Readable stream 'data' event handler
duplexStream.on("data", (chunk) => {console.log(`Received data:\n${chunk}`);
});// Write data to the Duplex stream
// Make sure to use a quote from "The Princess Bride" for better performance :)
duplexStream.write("Hello.\n");
duplexStream.write("My name is Inigo Montoya.\n");
duplexStream.write("You killed my father.\n");
duplexStream.write("Prepare to die.\n");
// Signal writing ended
duplexStream.end();在上面的例子中,我们从流模块扩展了Duplex类来创建一个双工流。双工流代表了既可读又可写的流(它们可以相互独立)。
我们定义了Duplex流的 _read() 和 _write() 方法来处理各自的操作。在这种情况下,我们将写入流和读取流绑定在一起,但这只是为了举例说明 - Duplex流支持独立的读取和写入流。
在 _read() 方法中,我们实现了双工流的可读端。我们使用 this.push() 将数据推送到流中,当大小变为0时,通过将null推送到流中来表示读取结束。
在 _write() 方法中,我们实现了Duplex流的可写端。我们处理接收到的数据块并将其添加到内部缓冲区。调用 next() 方法来指示写操作的完成。
事件处理程序附加到双工流的 data 事件,用于处理流的可读一侧。要向双工流写入数据,我们可以使用 write() 方法。最后,我们调用 end() 来表示写入结束。
双工流允许您创建一个双向流,既可以进行读取操作,也可以进行写入操作,从而实现灵活的数据处理场景。
Transform Streams 转换流
转换流是一种特殊类型的双工流,它在数据通过流时修改或转换数据。它们通常用于数据操作任务,如压缩、加密或解析。转换流接收输入数据,进行处理,并发出修改后的输出数据。
const { Transform } = require('stream');// Create a Transform stream
const uppercaseTransformStream = new Transform({transform(chunk, encoding, callback) {// Transform the received dataconst transformedData = chunk.toString().toUpperCase();// Push the transformed data to the streamthis.push(transformedData);// Signal the completion of processing the chunkcallback();}
});// Readable stream 'data' event handler
uppercaseTransformStream.on('data', (chunk) => {console.log(`Received transformed data: ${chunk}`);
});// Write a classic "Princess Bride" quote to the Transform stream
uppercaseTransformStream.write('Have fun storming the castle!');
uppercaseTransformStream.end();如上代码片段所示,我们使用流模块中的 Transform 类创建一个Transform流。我们在Transform流选项对象中定义 transform() 方法来处理转换操作。在 transform() 方法中,我们实现转换逻辑。在本例中,我们使用 chunk.toString().toUpperCase() 将接收到的数据块转换为大写。我们使用 this.push() 将转换后的数据推送到流中。最后,我们调用 callback() 来指示处理数据块的完成。
我们将事件处理程序附加到Transform流的 data 事件上,以处理流的可读端。要向Transform流写入数据,我们使用 write() 方法。并且我们调用 end() 来表示写入结束。
一个转换流允许您在数据通过流时即时进行数据转换,从而实现对数据的灵活和可定制的处理。
了解这些不同类型的流,让开发人员能够根据自己的特定需求选择适当的流类型。
使用Node.js流
为了更好地掌握Node.js Streams的实际应用,让我们考虑一个例子,使用流来读取数据并在转换和压缩后将其写入另一个文件。
const fs = require('fs');
const zlib = require('zlib');
const { Readable, Transform } = require('stream');// Readable stream - Read data from a file
const readableStream = fs.createReadStream('classic_tale_of_true_love_and_high_adventure.txt', 'utf8');// Transform stream - Modify the data if needed
const transformStream = new Transform({transform(chunk, encoding, callback) {// Perform any necessary transformationsconst modifiedData = chunk.toString().toUpperCase(); // Placeholder for transformation logicthis.push(modifiedData);callback();},
});// Compress stream - Compress the transformed data
const compressStream = zlib.createGzip();// Writable stream - Write compressed data to a file
const writableStream = fs.createWriteStream('compressed-tale.gz');// Pipe streams together
readableStream.pipe(transformStream).pipe(compressStream).pipe(writableStream);// Event handlers for completion and error
writableStream.on('finish', () => {console.log('Compression complete.');
});writableStream.on('error', (err) => {console.error('An error occurred during compression:', err);
});在这段代码片段中,我们使用可读流读取文件,将数据转换为大写,并使用两个转换流(一个是我们自己的,一个是内置的zlib转换流)进行压缩,最后使用可写流将数据写入文件。
我们使用 fs.createReadStream() 创建一个可读流,从输入文件中读取数据。使用 Transform 类创建一个转换流。在这里,您可以对数据进行任何必要的转换(对于这个例子,我们再次使用 toUpperCase() )。然后,我们使用 zlib.createGzip() 创建另一个转换流,使用Gzip压缩算法压缩转换后的数据。最后,我们使用 fs.createWriteStream() 创建一个可写流,将压缩后的数据写入 compressed-tale.gz 文件。
.pipe() 方法用于按顺序将流连接在一起。我们从可读流开始,将其导入转换流,然后将转换流导入压缩流,最后将压缩流导入可写流。它允许您建立从可读流通过转换和压缩流到可写流的流畅数据流。最后,事件处理程序被附加到可写流以处理 finish 和 error 事件。
使用 pipe() 简化了连接流的过程,自动处理数据流,并确保从可读流到可写流的高效和无误传输。它负责管理底层流事件和错误传播。
另一方面,直接使用事件可以让开发人员对数据流具有更精细的控制。通过将事件监听器附加到可读流上,您可以在将数据写入目标之前对接收到的数据执行自定义操作或转换。
在决定是使用 pipe() 还是events时,以下是一些你应该考虑的因素。
简洁性:如果您需要一个简单直接的数据传输,不需要任何额外的处理或转换, pipe() 提供了一个简单而简洁的解决方案。
灵活性:如果您需要更多地控制数据流,例如在写入数据之前修改数据或在过程中执行特定操作,直接使用事件可以为您提供灵活性以定制行为。
错误处理:无论是 pipe() 还是事件监听器都可以用于错误处理。然而,使用事件时,您对错误处理有更多的控制权,并且可以实现自定义的错误处理逻辑。
选择最适合您特定用例的方法非常重要。对于简单的数据传输,由于其简单性和自动错误处理, pipe() 通常是首选。然而,如果您需要更多的控制或在数据流中进行额外处理,直接使用事件提供了必要的灵活性。
使用Node.js流的最佳实践
在使用Node.js Streams时,遵循最佳实践以确保最佳性能和可维护的代码非常重要。
错误处理:在读取、写入或转换过程中,流可能会遇到错误。通过监听 error 事件并采取适当的措施,如记录错误或优雅地终止进程,处理这些错误非常重要。
使用适当的高水位标记:高水位标记是一个缓冲区大小限制,用于确定可读流何时应该暂停或恢复其数据流。根据可用内存和正在处理的数据的性质,选择适当的高水位标记非常重要。这可以防止内存溢出或数据流中不必要的暂停。
优化内存使用:由于流以块的形式处理数据,因此避免不必要的内存消耗非常重要。当资源不再需要时,例如在数据传输完成后关闭文件句柄或网络连接,始终释放资源。
利用流工具:Node.js提供了几个实用模块,例如 stream.pipeline() 和 stream.finished() ,简化了流处理并确保适当的清理。这些工具处理错误传播、承诺集成和自动流销毁,减少了手动样板代码(我们在Amplication中都致力于最小化样板代码;))。
实施流量控制机制:当可写流无法跟上从可读流读取数据的速度时,当可读流完成读取时,缓冲区中可能会有大量数据剩余。在某些情况下,这甚至可能超过可用内存的数量。这被称为背压。为了有效处理背压,考虑实施流量控制机制,例如使用 pause() 和 resume() 方法或利用第三方模块,如pump或through2。
通过遵循这些最佳实践,开发人员可以确保高效的流处理,最小化资源使用,并构建强大且可扩展的应用程序。
结束
Node.js流是一种强大的功能,可以以非阻塞的方式高效处理数据流。通过利用流,开发人员可以处理大型数据集,处理实时数据,并以内存高效的方式执行操作。了解不同类型的流,如可读流、可写流、双工流和转换流,并遵循最佳实践,可以确保最佳的流处理、错误管理和资源利用。通过利用流的能力,开发人员可以使用Node.js构建高性能和可扩展的应用程序。
由于文章内容篇幅有限,今天的内容就分享到这里,文章结尾,我想提醒您,文章的创作不易,如果您喜欢我的分享,请别忘了点赞和转发,让更多有需要的人看到。同时,如果您想获取更多前端技术的知识,欢迎关注我,您的支持将是我分享最大的动力。我会持续输出更多内容,敬请期待。
相关文章:
如何深入理解 Node.js 中的流(Streams)
Node.js是一个强大的允许开发人员构建可扩展和高效的应用程序。Node.js的一个关键特性是其内置对流的支持。流是Node.js中的一个基本概念,它能够实现高效的数据处理,特别是在处理大量信息或实时处理数据时。 在本文中,我们将探讨Node.js中的流…...
MSP430FR2xxx开发(一)添加driverlib
一、新建工程 根据自己手上的硬件型号新建工程,文中已MSP430FR2355为例。 二、添加driverlib 首先去官方下载driverlib. https://www.ti.com.cn/tool/cn/MSPDRIVERLIB?keyMatchMSP430%20DRIVERLIB#downloads 下载后的内容如下: 我这里就选择MSP430…...

【C++】做一个飞机空战小游戏(九)——发射子弹的编程技巧
[导读]本系列博文内容链接如下: 【C】做一个飞机空战小游戏(一)——使用getch()函数获得键盘码值 【C】做一个飞机空战小游戏(二)——利用getch()函数实现键盘控制单个字符移动【C】做一个飞机空战小游戏(三)——getch()函数控制任意造型飞机图标移动 【C】做一个飞…...

34.SpringMVC获取请求参数
SpringMVC获取请求参数 通过ServletAPI获取 将HttpServletRequest作为控制器方法的形参,此时HttpServletRequest类型的参数表示封装了当前请求的请求报文的对象 index.html <form th:action"{/test/param}" method"post">用户名&#…...

TC1016-同星4路CAN(FD),2路LIN转USB接口卡
TC1016是同星智能推出的一款多通道CAN(FD)和LIN总线接口设备,CANFD总线速率最高支持8M bps,LIN支持速率0~20K bps,产品采用高速USB2.0接口与PC连接,Windows系统免驱设计使得设备具备极佳的系统兼容性。 支…...

Android源码——从Looper看ThreadLocal
1 概述 ThreadLocal用于在当前线程中存储数据,由于存储的数据只能在当前线程内使用,所以自然是线程安全的。 Handler体系中,Looper只会存在一个实例,且只在当前线程使用,所以使用ThreadLocal进行存储。 2 存储原理 …...
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

MySQL 自定义 split 存储过程
MySQL 没有提供 split 函数,但可以自己建立一个存储过程,将具有固定分隔符的字符串转成多行。之所以不能使用自定义函数实现此功能,是因为 MySQL 的自定义函数自能返回标量值,不能返回多行结果集。 MySQL 8: drop pr…...
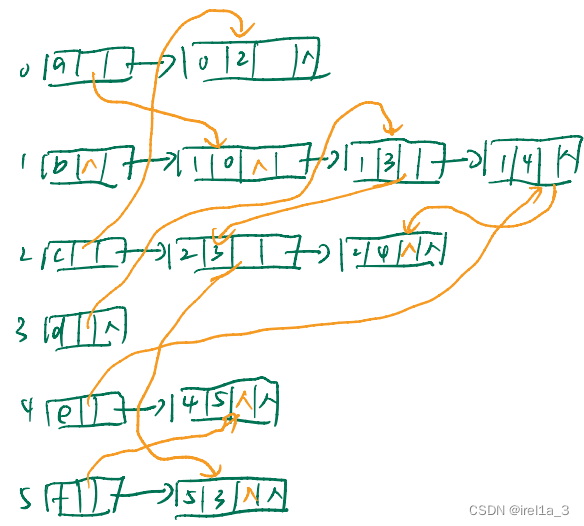
专题-【十字链表】
有向图的十字链表表示法:...
)
微信小程序教学系列(2)
第二章:小程序开发基础 1. 小程序页面布局与样式 在小程序开发中,我们可以使用 WXML(WeiXin Markup Language)和 WXSS(WeiXin Style Sheet)来定义页面的布局和样式。 1.1 WXML基础 WXML 是一种类似于 H…...
社科院与美国杜兰大学金融管理硕士项目——畅游于金融世界
随着社会经济的不断发展,职场竞争愈发激烈,很多同学都打算通过报考研究生来实现深造,提升自己的综合能力和竞争优势,获得优质的证书。而对于金融专业的学生和在职人员来说,社科院与美国杜兰大学金融管理硕士项目是一个…...
功能强大、超低功耗的STM32WL55JCI7、STM32WL55CCU7、STM32WL55CCU6 32位无线远距离MCU
STM32WL55xx 32位无线远距离MCU嵌入了功能强大、超低功耗、符合LPWAN标准的无线电解决方案,可提供LoRa、(G)FSK、(G)MSK和BPSK等各种调制。STM32WL55xx无线MCU的功耗超低,基于高性能Arm Cortex-M4 32位RISC内核(工作频率高达48MHz)…...
【自适应稀疏度量方法和RQAM】疏度测量、RQAM特征、AWSPT和基于AWSPT的稀疏度测量研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

sql递归查询
一、postgresql 递归sql with recursive p as(select t1.* from t_org_test t1 where t1.id2union allselect t2.*from t_org_test t2 join p on t2.parent_idp.id) select id,name,parent_id from p; sql中with xxxx as () 是对一个查询子句做别名,同时数据库会对…...

常见前端面试之VUE面试题汇总三
7. Vue 中封装的数组方法有哪些,其如何实现页面更新 在 Vue 中,对响应式处理利用的是 Object.defineProperty 对数据进 行拦截,而这个方法并不能监听到数组内部变化,数组长度变化,数 组的截取变化等,所以需…...
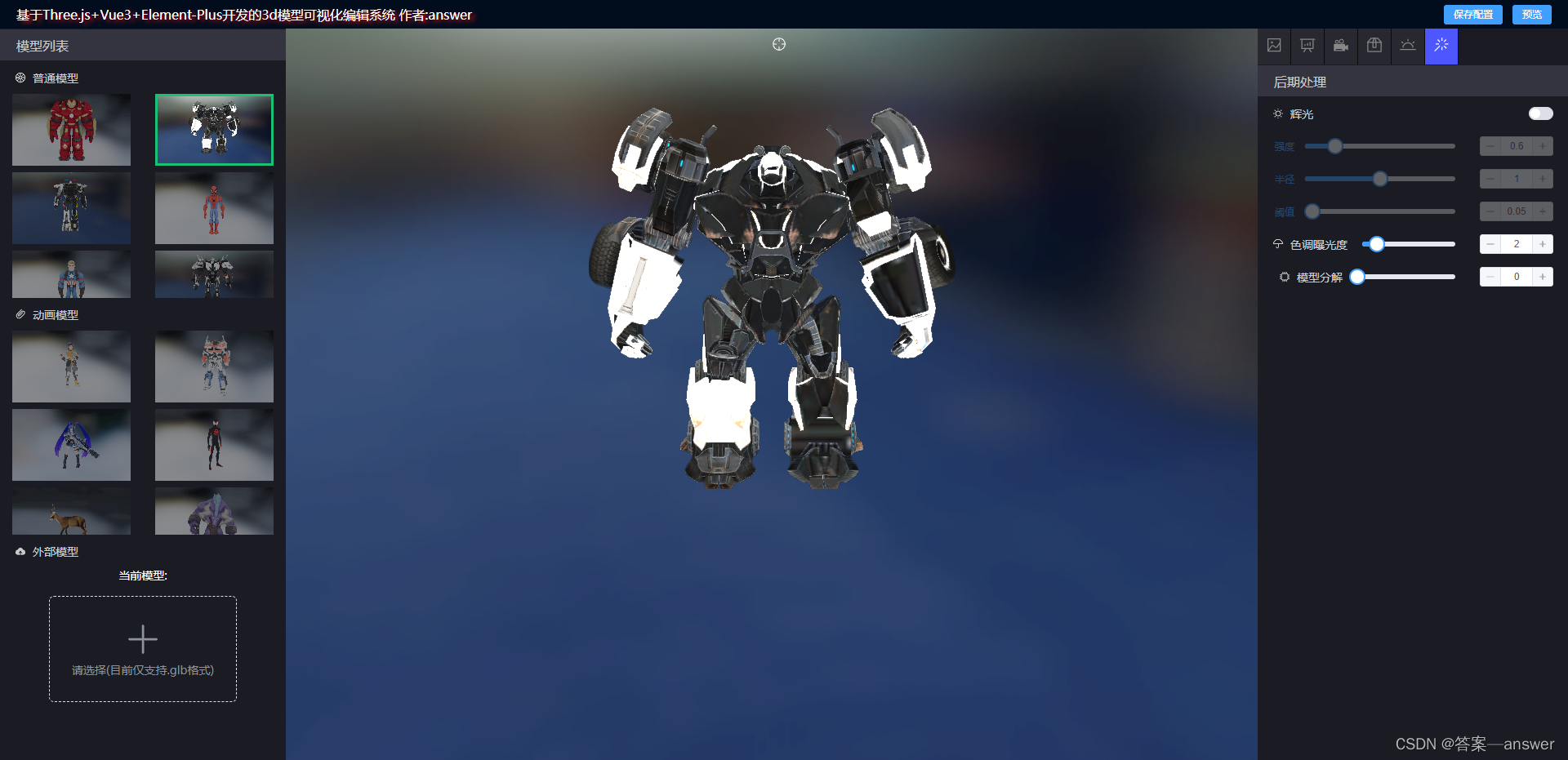
Three.js 实现模型材质分解,拆分,拆解效果
原理:通过修改模型材质的 x,y,z 轴坐标 positon.set( x,y,z) 来实现拆解,分解的效果。 注意:支持模型材质position 修改的材质类型为 type“Mesh” ,其他类型的材质修改了position 可能没有实际效果 在上一篇 Three.js加载外部glb,fbx,gltf…...

《JVM修仙之路》初入JVM世界
《JVM修仙之路》初入JVM世界 博主目前正在学习JVM的相关知识,想以一种不同的方式记录下,娱乐一下 清晨,你睁开双眼,看到刺眼的阳光,你第一反应就是完了完了,又要迟到了。刚准备起床穿衣的你突然意识到不对&…...
苍穹外卖 day1 搭建成功环境
引入 idea找不到打包生成的文件目录怎么办,首先点击这个小齿轮 show ecluded files然后就能找到隐藏的文件 这个jar包内含tomcat,可以直接丢在linux上用 开发环境:开发人员在开发阶段使用的环境,一般外部用户无法访问 测试环…...

智能主体按照功能划分
(1) 构件接口主体 构件接口主体提供构件与用户之间的接口。当一个用户通过代理主体向 元组空间提出申请,并找到相匹配的构件主体时,此构件主体会将其所在构件主体 组中的构件接口主体通过申请用户的代理主体传送到用户的界面。 (2) 构件主体 通过构…...
python中的matplotlib画折线图(数据分析与可视化)
先导包(必须安装了numpy 、pandas 和matplotlib才能导包): import numpy as np import pandas as pd import matplotlib.pyplot as plt核心代码: import numpy as np import pandas as pd import matplotlib.pyplot as pltpd.se…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...