【100天精通python】Day45:python网络爬虫开发_ Scrapy 爬虫框架
目录
1 Scrapy 的简介
2 Scrapy选择器
3 快速创建Scrapy 爬虫
4 下载器与爬虫中间件
5 使用管道Pielines
1 Scrapy 的简介
Scrapy 是一个用于爬取网站数据并进行数据提取的开源网络爬虫框架。它使用 Python 编程语言编写,并提供了一套强大的工具和库,帮助用户在网页上浏览和抓取数据。Scrapy 旨在简化爬虫开发流程,提供了高度可定制的机制来处理各种网站的数据抓取需求。
以下是 Scrapy 框架的一些主要特点和组件:
请求和响应管理: Scrapy 提供了一个异步的请求和响应管理系统,允许用户发出 HTTP 请求并处理返回的 HTML 或其他数据。
数据提取: Scrapy 使用基于 XPath 或 CSS 选择器的数据提取方法,使用户能够方便地从网页中提取所需数据。
中间件: Scrapy 允许用户定义中间件来自定义请求和响应的处理过程,例如修改请求头、处理代理等。
管道: 管道是 Scrapy 中用于处理数据的组件,您可以在管道中对抓取到的数据进行清洗、处理、存储等操作。
调度器: 调度器负责管理请求的发送顺序,以及处理并发请求的方式,确保爬虫在合理的速率下访问网站。
自动限速: Scrapy 自带自动限速功能,以避免对目标网站造成过多负担。
异步支持: Scrapy 支持异步处理,能够高效地执行多个请求和处理操作。
扩展性: 您可以根据需要编写扩展来定制 Scrapy 的行为,如添加新的中间件、管道等。
命令行工具: Scrapy 提供了命令行工具,方便用户创建、管理和运行爬虫。
文档丰富: Scrapy 提供详细的官方文档和教程,使新用户能够快速入门,并且为高级用户提供深入了解框架的资源。
总之,Scrapy 是一个功能强大且高度可定制的网络爬虫框架,适用于各种规模的数据抓取项目,从简单的数据收集任务到复杂的数据挖掘和分析。无论您是初学者还是有经验的开发人员,都可以利用 Scrapy 快速有效地构建和管理爬虫。
2 Scrapy选择器
Scrapy 提供了两种主要的选择器用于从网页中提取数据:基于 XPath 的选择器和基于 CSS 的选择器。这两种选择器都能够让您轻松地从 HTML 或 XML 文档中定位和提取所需的数据。
基于 XPath 的选择器: XPath(XML Path Language)是一种用于在 XML 文档中定位元素的语言。在 Scrapy 中,XPath 选择器允许您通过路径表达式来选择和提取数据。以下是一些常见的 XPath 表达式示例:
- 选择元素:
//elementName(选取所有名称为 elementName 的元素)- 选择特定路径下的元素:
//parent/child(选取 parent 元素下的所有 child 元素)- 选择具有特定属性的元素:
//element[@attribute='value'](选取具有 attribute 属性且值为 value 的元素)基于 CSS 的选择器: CSS(Cascading Style Sheets)选择器在网页设计中常用于样式设置,但它们也可以用于从 HTML 文档中选择元素。Scrapy 中的 CSS 选择器允许您使用类似于 CSS 选择器的语法来定位和提取数据。以下是一些常见的 CSS 选择器示例:
- 选择元素:
elementName(选取所有名称为 elementName 的元素)- 选择类:
.className(选取所有具有 className 类的元素)- 选择 ID:
#idName(选取具有 idName ID 的元素)- 选择路径下的元素:
parent > child(选取 parent 元素下的所有 child 元素)
在 Scrapy 中,您可以使用这些选择器来定位和提取网页中的数据。以下是使用 Scrapy 选择器的示例代码:
from scrapy.selector import Selectorhtml_content = """
<html><body><div class="container"><h1>Title</h1><p>Paragraph 1</p><p>Paragraph 2</p></div></body>
</html>
"""selector = Selector(text=html_content)# 使用 XPath 选择器提取数据
title = selector.xpath("//h1/text()").get()
paragraphs = selector.xpath("//p/text()").getall()# 使用 CSS 选择器提取数据
title = selector.css("h1::text").get()
paragraphs = selector.css("p::text").getall()
无论您选择使用 XPath 还是 CSS 选择器,Scrapy 都提供了方便的方法来从网页中提取所需的数据,使数据抓取任务变得更加简单和高效。
3 快速创建Scrapy 爬虫
创建一个简单的 Scrapy 爬虫可以分为以下几个步骤。以下示例将引导您创建一个爬取名言的简单爬虫。
- 安装 Scrapy: 首先,您需要确保已经安装了 Python 和 Scrapy。如果尚未安装 Scrapy,可以使用以下命令进行安装:
pip install scrapy
创建新的 Scrapy 项目: 在命令行中,导航到您希望创建项目的目录,并运行以下命令来创建新的 Scrapy 项目:
scrapy startproject quotes_spider
这将在当前目录下创建一个名为 "quotes_spider" 的项目目录。
(1)创建爬虫: 在项目目录下,进入到 "quotes_spider" 目录,并运行以下命令来创建一个爬虫:
cd quotes_spider
scrapy genspider quotes quotes.toscrape.com
这将创建一个名为 "quotes" 的爬虫,它将从 "quotes.toscrape.com" 网站爬取数据。
(2)编辑爬虫代码: 在 "quotes_spider/spiders" 目录下找到名为 "quotes.py" 的文件,这是刚刚创建的爬虫文件。使用您喜欢的编辑器打开该文件,并编辑 start_urls 和 parse 方法:
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"start_urls = ['http://quotes.toscrape.com/page/1/',]def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('span small::text').get(),}next_page = response.css('li.next a::attr(href)').get()if next_page is not None:yield response.follow(next_page, self.parse)
在这个示例爬虫中,我们从名言网站爬取名言文本和作者信息。parse 方法负责从网页中提取数据,并通过使用 response.follow 方法来跟踪下一页链接。
(3)运行爬虫: 回到项目目录("quotes_spider" 目录)并运行以下命令来运行爬虫:
scrapy crawl quotes
爬虫将开始访问起始 URL,抓取数据并显示在终端上。
这是一个简单的 Scrapy 爬虫创建过程示例。实际上,您可以根据需要定制爬虫的各个方面,包括请求头、管道、中间件等。通过阅读 Scrapy 的官方文档,您可以深入了解如何创建更复杂和定制的爬虫。
4 下载器与爬虫中间件
在 Scrapy 框架中,下载器中间件和爬虫中间件是两种不同类型的中间件,用于在请求/响应的处理流程中插入自定义的逻辑。它们分别位于请求的发送和响应的接收过程中,允许您对网络请求和数据处理进行修改和控制。
下载器中间件(Downloader Middleware): 下载器中间件位于请求发送过程中,负责对请求进行处理,以及在响应返回之前的操作。这些中间件可以用于修改请求头、设置代理、处理cookies等。下载器中间件可以在全局范围或特定爬虫范围内进行配置。
一些常见的下载器中间件操作包括:
- 修改请求头,以模拟不同类型的浏览器请求。
- 配置代理服务器,用于隐藏爬虫的真实 IP 地址。
- 处理 cookies,以保持会话状态。
- 对请求进行重试和错误处理。
- 控制请求的并发性。
爬虫中间件(Spider Middleware): 爬虫中间件位于响应接收和数据处理过程中,负责对响应和提取的数据进行处理。这些中间件可以用于修改爬取到的数据、处理异常、进行数据转换等。爬虫中间件可以在全局范围或特定爬虫范围内进行配置。
一些常见的爬虫中间件操作包括:
- 对从网页中提取的数据进行预处理和清洗。
- 自定义数据转换,如日期格式化、文本处理等。
- 处理异常,如被封 IP 的处理策略。
- 控制数据的流向和过滤。
配置中间件在 Scrapy 的 settings.py 文件中进行。您可以为每个中间件设置优先级,以确定它们在处理流程中的顺序。更具体地说,下载器中间件的优先级较高的将首先处理请求,而爬虫中间件的优先级较高的将首先处理响应和提取的数据。
以下是一个简单的示例,展示了如何配置下载器和爬虫中间件:
# settings.pyDOWNLOADER_MIDDLEWARES = {'myproject.middlewares.MyDownloaderMiddleware': 543,
}SPIDER_MIDDLEWARES = {'myproject.middlewares.MySpiderMiddleware': 543,
}
在上面的示例中,
myproject.middlewares.MyDownloaderMiddleware和myproject.middlewares.MySpiderMiddleware分别是自定义的下载器和爬虫中间件。它们的优先级设置为 543。通过使用下载器和爬虫中间件,您可以在请求和响应的处理流程中插入自定义的逻辑,实现更灵活、高效和符合您需求的爬虫。
5 使用管道Pielines
在 Scrapy 中,管道(Pipeline)是用于处理爬虫抓取到的数据的组件。它允许您在数据从爬虫抓取到最终保存或处理的过程中进行多个操作,如数据清洗、验证、存储到数据库、导出到文件等。Scrapy 的管道提供了一种灵活且可定制的方式来处理爬取的数据流。
以下是如何使用管道来处理爬取到的数据:
(1)启用管道: 在 Scrapy 的配置文件(settings.py)中,您需要启用并配置管道。您可以在 ITEM_PIPELINES 设置中指定要使用的管道类及其优先级。优先级是一个整数值,较小的值表示较高的优先级。
# settings.pyITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
在上面的示例中,myproject.pipelines.MyPipeline 是您自定义的管道类,优先级被设置为 300。
(2)创建管道类: 在项目中创建一个管道类,该类将处理爬虫抓取到的数据。您需要实现一些方法来处理数据,例如 process_item 方法。
# pipelines.pyclass MyPipeline:def process_item(self, item, spider):# 在这里处理数据,可以进行清洗、验证、存储等操作return item
在上面的示例中,process_item 方法接收两个参数:item 表示爬虫抓取到的数据项,spider 表示当前爬虫实例。
(3)处理数据: 在管道类的 process_item 方法中,您可以对数据进行各种操作,如数据清洗、格式化、验证等。您还可以将数据保存到数据库、导出到文件等。
以下是一个简单的示例,展示了如何在管道中处理爬取到的数据并保存到 JSON 文件中:
# pipelines.pyimport jsonclass MyPipeline:def open_spider(self, spider):self.file = open('data.json', 'w')def close_spider(self, spider):self.file.close()def process_item(self, item, spider):data = {'text': item['text'],'author': item['author']}json.dump(data, self.file)self.file.write('\n')return item
在上面的示例中,
open_spider和close_spider方法在爬虫开始和结束时分别被调用,打开和关闭数据文件。process_item方法将数据提取并保存到 JSON 文件中。通过配置和编写自定义的管道类,您可以对爬取到的数据进行各种操作,从而实现高度定制化的数据处理流程。
相关文章:

【100天精通python】Day45:python网络爬虫开发_ Scrapy 爬虫框架
目录 1 Scrapy 的简介 2 Scrapy选择器 3 快速创建Scrapy 爬虫 4 下载器与爬虫中间件 5 使用管道Pielines 1 Scrapy 的简介 Scrapy 是一个用于爬取网站数据并进行数据提取的开源网络爬虫框架。它使用 Python 编程语言编写,并提供了一套强大的工具和库࿰…...

怎么写出更好的高质量内容输出
为了更好地输出高质量的内容,不仅仅需要了解写作的基本原则,还需要深入挖掘目标读者的需求、持续的自我提升以及对信息的严格筛选。以下是一些建议,帮助你更好地输出高质量的内容: 1.充分了解你的受众 调查和了解你的目标读者&am…...

HJ31 单词倒排 题解
题目描述:单词倒排_牛客题霸_牛客网 (nowcoder.com) 对字符串中的所有单词进行倒排。 1、构成单词的字符只有26个大写或小写英文字母; 2、非构成单词的字符均视为单词间隔符; 3、要求倒排后的单词间隔符以一个空格表示;如果原字符…...

LeetCode42.接雨水
这道题呢可以按列来累加,就是先算第1列的水的高度然后再加上第2列水的高度……一直加到最后就是能加的水的高度,我想到了这里然后就想第i列的水其实就是第i-1列和i1列中最小的高度减去第i列的高度,但是其实并不是,比如示例中的第5…...
优化时间流:区间调度问题的探索与解决
在浩如烟海的信息时代,时间的有效管理成为了一门不可或缺的艺术。无论是生活中的琐事,还是工作中的任务,时间都在无声地流逝,挑战着我们的智慧。正如时间在日常生活中具有的宝贵价值一样,在计算机科学领域,…...
【Python】强化学习:原理与Python实战
搞懂大模型的智能基因,RLHF系统设计关键问答 RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)虽是热门概念,并非包治百病的万用仙丹。本问答探讨RLHF的适用范围、优缺点和可能遇到的问题ÿ…...

设计模式——合成复用原则
文章目录 合成复用原则设计原则核心思想合成案例聚合案例继承案例优缺点 合成复用原则 原则是尽量使用合成/聚合的方式,而不是使用继承 设计原则核心思想 找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。…...

基于OpenCV实战(基础知识一)
目录 简介 1.计算机眼中的图像 2.图片的读取、显示与保存 3.视频的读取与显示 简介 OpenCV是一个流行的开源计算机视觉库,由英特尔公司发起发展。它提供了超过2500个优化算法和许多工具包,可用于灰度、彩色、深度、基于特征和运动跟踪等的图像处理和…...

如何高效的接入第三方接口
作为程序员的我们,经常会接到领导的安排,接入某某的接口,方面我们如何如何, 例如:领导在1号时给作为员工的你说,最近系统需要增加一个新的支付方式,一会和对方技术组建一个群,有什么问题,可以直接在群里说,最近还说,尽快接入,客户等着用,让你在5号前,完成接入工…...

docker pip下载依赖超时或失败问题解决
Docker容器使用pip安装Python库时超时,可能是由于多种原因。以下是一些建议和解决方法: 使用国内镜像源: 如果你位于中国,可以尝试更换到国内的镜像源。例如,可以使用阿里云、腾讯云、清华大学提供的镜像。 你可以在Dockerfile中添…...

python并发编程
一、程序提速的方法 二、python对并发编程的支持 多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成;多进程:multiprocess,利用多核CPU的能力,真正的并行执行任务&am…...

【面试题】:前端怎么实现权限设计及遇到的bug
一.权限的概念 前端权限分为页面权限、按钮权限、API权限。 二.页面权限的实现过程 ①用户登录进去调用获取用户信息接口,后端会给我们返回一个权限标识符 ②在获取到数据之后,我们就要判断用户能访问到哪些页面,我们可以在vuex中permission模块中的action…...

Vue 2 插槽
可以先阅读组件基础-简单了解通过插槽分发内容。 一、插槽定义 插槽将子组件标签间的内容分发到子组件模板的<slot>标签位置。 如果没有<slot>标签,那么该内容将被丢弃。 二、编译作用域 内容在哪个作用域编译,就可以访问哪个作用域的数据…...

Spring 容器启动耗时统计
为了了解 Spring 为什么会启动那么久,于是看了看怎么统计一下加载 Bean 的耗时。 极简版 几行代码搞定。 import org.springframework.beans.BeansException; import org.springframework.beans.factory.config.BeanPostProcessor;import java.util.HashMap; imp…...

1. 优化算法学习
参考文献 1609:An overview of gradient descent optimization algorithms 从 SGD 到 Adam —— 深度学习优化算法概览(一) - 知乎 机器学习札记 - 知乎...

再获荣誉丨通付盾WAAP解决方案获“金鼎奖”优秀金融科技解决方案
今年四月,2023中国国际金融展在首钢会展中心成功落下帷幕。中国国际金融展作为金融开放创新成果的展示、交流、传播平台,历经多年发展,已成为展示中国金融发展成就、宣传金融改革成果、促进金融产业创新和推动金融信息化发展的有效平台。 “金鼎奖”评选…...

【腾讯云 TDSQL-C Serverless 产品测评】“橡皮筋“一样的数据库『MySQL高压篇』
【腾讯云 TDSQL-C Serverless 产品测评】"橡皮筋"一样的数据库 活动介绍服务一览何为TDSQL ?Serverless 似曾相识? 降本增效,不再口号?动手环节 --- "压力"山大实验前瞻稍作简介资源扩缩范围(CCU&…...

python http文件上传
server端代码 import os import cgi from http.server import SimpleHTTPRequestHandler, HTTPServer# 服务器地址和端口 host = 0.0.0.0 port = 8080# 处理文件上传的请求 class FileUploadHandler(SimpleHTTPRequestHandler):def do_POST(self):# 解析多部分表单数据form = …...

Android学习之路(9) Intent
Intent 是一个消息传递对象,您可以用来从其他应用组件请求操作。尽管 Intent 可以通过多种方式促进组件之间的通信,但其基本用例主要包括以下三个: 启动 Activity Activity 表示应用中的一个屏幕。通过将 Intent 传递给 startActivity()&…...
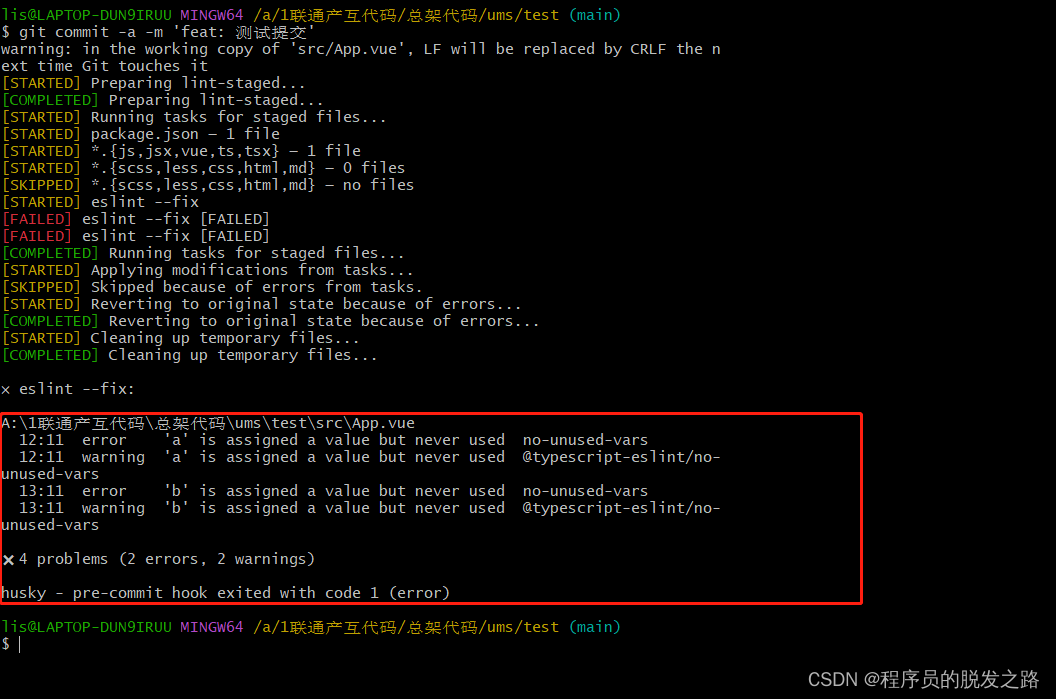
vue项目配置git提交规范
vue项目配置git提交规范 一、背景介绍二、husky、lint-staged、commitlint/cli1.husky2.lint-staged3.commitlint/cli 三、具体使用1.安装依赖2.运行初始化脚本3.在package.json中配置lint-staged4.根目录新增 commitlint.config.js 4.提交测试1.提示信息格式错误时2.eslint校验…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
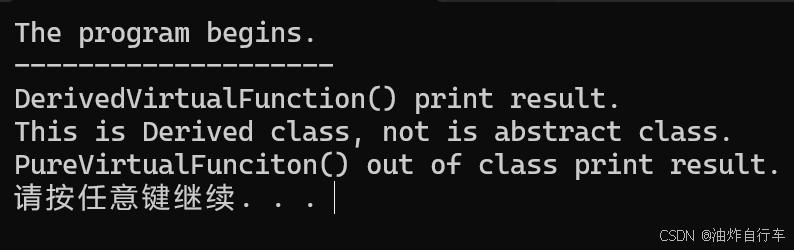
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...