高性能MySQL实战(三):性能优化
大家好,我是 方圆。这篇主要介绍对慢 SQL 优化的一些手段,而在讲解具体的优化措施之前,我想先对 EXPLAIN 进行介绍,它是我们在分析查询时必要的操作,理解了它输出结果的内容更有利于我们优化 SQL。为了方便大家的阅读,在下文中规定类似 key1 的表示二级索引,key_part1 表示联合索引的第一部分,unique_key1 则表示唯一二级索引,primary_key 表示主键索引。高性能MySQL实战(一):表结构 和 高性能MySQL实战(二):索引 是本文的前置知识,欢迎大家阅读。原文收录在我的 Github: enthusiasm 中,欢迎Star和获取原文。
1. Explain 详解
Explain 是我们在对慢 SQL 进行优化前常用语句,它能分析具体的查询计划,从而让我们有目的地去进行优化。本节则主要是让大家看懂 Explain 查询结果的每一列是干啥用的,我们先简要的来看一下各个列的作用:
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中,每个 SELECT 关键字都对应一个唯一的 id。在连接查询中,记录的 id 值都是相同的;在多个 SELECT 关键字的查询中,查询优化器可能会对子查询进行优化,使得多条 SELECT 记录的 id 值相同 |
| select_type | 查询类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际使用的索引 |
| key_len | 实际使用的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 针对预估的需要读取的记录,经过搜索条件过滤后剩余记录条数的百分比。在单表查询中没什么意义,在连表查询中可以计算出在驱动表执行完查询后,还需要对被驱动表执行多少次查询 |
| Extra | 额外的备注信息 |
其中大部分列在描述信息中已经解释的足够清楚,下面我们主要对一些必要的列进行详述:
1.1 select_type
-
SIMPLE: 查询语句中 不包含 UNION 或者子查询 的查询
-
PRIMARY: 对于包含 UNION、UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其中最左边查询的 select_type 是 PRIMARY
-
UNION: 对于包含 UNION 和 UNION ALL 的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询以外,其余小查询的 select_type 都是 UNION
-
UNION RESULT: MySQL 选择使用临时表来完成 UNION 查询的去重,针对该临时表的查询的 select_type 是 UNION RESULT
-
DEPENDENT UNION: UNION 查询相关的类型
-
SUBQUERY, DEPENDENT SUBQUERY, MATERIALIZED: 子查询相关的类型
-
DERIVED: 在包含派生表的查询中,以物化派生表的方式执行的查询
1.2 type
-
const: 通过 主键 或 唯一二级索引 与常数的等值比较来定位 一条记录,如果是联合索引,则只有在索引列的每一个列都与常数进行等值比较时,这个 const 访问才有效
-
ref: 通过 二级索引 与常数进行等值比较,形成的扫描区间为单点扫描区间的访问
-
ref_or_null: 相比于 ref 多扫描了一些值为 NULL 的二级索引列
-
range: 使用索引执行查询时,对应的扫描区间为 若干个单点扫描区间或者范围扫描区间 的访问
-
index: 使用覆盖索引,并扫描全部二级索引的访问。另外,当通过全表扫描对使用 InnoDB 引擎的表执行查询时,如果添加了 ORDER BY 主键 的语句,那么该语句在执行时也会被认为是 index 访问
-
fulltext: 全文索引访问
-
all: 全表扫描
-
eq_ref: 执行 连接查询 时,如果被驱动表是通过 主键或者不允许为 NULL 的唯一二级索引 等值匹配的方式进行访问
在外连接中,ON 语句是专门为 “驱动表中的记录在被驱动表中找不到匹配纪录时,对应的被驱动表记录的各个字段使用 NULL 来填充” 场景提出的;在内连接中,ON 和 WHERE 的作用一致
-
unique_subquery: 针对的是一些包含 IN 子查询的查询语句,如果查询优化器决定将 IN 子查询转换成 EXISTS 子查询,而且子查询在转换之后 可以使用主键或者为允许为 NULL 的唯一二级索引进行等值匹配
-
index_subquery: 与 unique_subquery 类似,只不过在访问时使用的是 普通二级索引
-
index_merge: 存在索引合并
-
system: 当表中只有一条记录并且使用的存储引擎的统计数据是精确的(如 MyISAM 和 MEMORY)
1.3 ref
当访问方法是 const、ref、ref_or_null、eq_ref、unique_subquery 和 index_subquery 其中之一时,ref 列展示的是与索引列进行 等值匹配 的东西是啥:
-
const: 表示是一个常数
-
func: 表示是一个函数
-
DBName.TableName.columnName: 表示某个数据库某个表中的某个列
1.4 Extra
-
No Table used: 查询语句中没有 FROM 子句
-
Impossible WHERE: 查询语句中的 WHERE 条件始终为 FALSE
-
No matching min/max row: 当查询中有 min 或 max 聚合函数时,但是没有记录符合 WHERE 条件
-
Using Index: 使用了覆盖索引
-
Using Index condition: 在执行查询语句时使用了索引条件下推特性
索引条件下推:它是针对 二级索引 查询条件做的优化,在对二级索引条件进行判断时,会将所有该索引相关列的条件都判断完成后,符合条件再执行回表操作,不符合条件则不再执行回表,这样做减少了回表操作的次数,从而减少了 I/O。
如下例子:
select * from specific_table where key1 > ‘a’ and key1 like ‘%b’;
索引条件下推会将 key1 所有条件判断完而不是只判断完 key1 > ‘a’ 就去回表。
-
Using join buffer(Block Nested Loop): 表示在执行连接查询时,被驱动表不能有效地利用索引加快访问速度,而是使用内存块来加快查询
-
Using intersect(index_name, …)、Using union(index_name, …) 和 Using sort union(index_name, …): 表示使用 Intersection 索引合并、Union 索引合并或 Sort-Union 索引合并执行查询(下文有介绍)
-
Using filesort: 文件排序,排序无法使用到索引只能在内存或者磁盘中进行排序
-
Using temporary: 查询时使用到了内部临时表
2. 优化考虑点
基于访问类型优化
在前文中我们已经详细介绍了 EXPLAIN 语句中的访问类型(type),如果一个查询的访问类型并不是我们预期的,那么最简单直接的解决办法是为搜索条件列 增加合适的索引。
减少扫描行数的优化
在有些情况下,简单地增加索引并不能解决问题,比如执行如下 SQL:
select name, count(name) from specific_table group by key1;
这条 SQL 执行完毕后可能只返回几行数据,但是因为有 COUNT 聚合函数,需要扫描的数据可能会有成千上万行,这取决于表中数据量总数。对于这种 扫描大量数据却只返回少数行 的情况,通常可以通过 增加单独的汇总表 进行优化,当然这需要在应用层增加相应的逻辑对汇总表的数据进行维护。
除此之外,还可以通过 重写复杂查询 的方式来优化,下面我们对重写查询时需要考虑的方向进行介绍:
一个复杂查询还是多个简单查询?
这是一个值得考虑的问题。将复杂查询拆成多个简单查询,尽可能地减少数据库的工作,并将一些处理逻辑拿到应用层处理,因为 MySQL 处理简单查询很高效,所以通常情况下这么做能够提高效率。
切分处理
在实际工作中,对数据量较大的数据库表进行结转(或删除)时通常会采用 切分处理 的方法,将一个大查询分成小查询,每个查询的作用是一样的,只不过操作的数据量不同,各个小查询执行完毕后,大查询的任务也就处理完成了。
一次性结转大量数据可能会锁住很多数据、占满整个事务日志、耗尽系统资源和阻塞很多小的查询等,为了避免这种情况,通常在一次数据结转任务中只操作 一万条左右 数据,这样对服务器影响最小,而且可以在每次结转完成时,都 暂停一会儿 再去执行下一次任务,这样做可以将压力分散到一个比较长的时间段中,大大降低对服务器的影响和减少持有锁的时间。
优化联结查询
阿里巴巴开发手册中提到过一点,联表查询时联表的数量不超过 3 个。如果联表过多,我们需要将其拆成多个查询或多个单表查询(单表查询的 缓存效率会更高),查询被分解后,查询间的锁竞争会减少。除此之外,联表查询还需要注意以下两点:
-
确保 ON 或者 USING 子句中的列上有索引
-
确保任何 GROUP BY 和 ORDER BY 中的表达式只涉及一个表中的列,这样 MySQL 才有可能使用索引来优化这个查询
IN() 条件与 OR 条件
一般情况下我们认为 IN() 完全等价于多个 OR 条件,但是在 MySQL 中这两者是有区别的。MySQL 在处理 IN() 条件时,会将列表中的数据先进行排序,然后通过二分查找的方式来确定列表中的值是否满足条件,这是一个时间复杂度为 O(logn) 的操作,如果等价地转换成 OR 查询,它的时间复杂度为 O(n),所以在 IN() 条件中有大量取值时,MySQL 的处理速度会更快。
查询时索引是否失效
-
如果不是按照索引的最左列开始查找,则无法使用索引
-
如果跳过了联合索引中的列,则无法使用索引或只能使用部分索引。有如下 SQL,其中 key_part1、key_part2 和 key_part3 是按顺序的联合索引
select key_part1, key_part2, key_part3 from specific_table where key_part1 = 1 and key_part3 = 3;在查询条件中略过了 key_part2,那么只能使用到索引的第一列,如果略过的是 key_part1 那么就无法使用到这个联合索引了
-
如果查询中有某列的范围查询,则其右边所有列都无法使用索引优化查询或排序。针对这种情况,如果范围查询列值的数量有限,那么可以通过 使用 OR 连接的多个等值匹配来替代范围查询
-
如果在搜索条件中列名不以列名的形式单独出现,而是使用了表达式或者函数,那么无法使用索引,如下 SQL 所示,key1 列以 key1 * 2 的形式出现,不会使用到索引
select * from specific_table where key1 * 2 > 4; -
如果针对变长字段使用 % 开头的模糊查询时,则不会使用索引。这个比较好理解,因为 MySQL 对字符串的排列是按照一个个字符排序的,在开头使用 % 则无法完成比较只能使用全表扫描了
排序时索引是否失效
-
如果 ORDER BY 语句后面的列的顺序没有按照联合索引的列顺序给出,则无法使用索引
-
如果发生 ASC、DESC 混用,则无法使用索引
有如下 SQL,其中 key_part1 和 key_part2 是按顺序的联合索引,执行时不能使用索引
select key_part1, key_part2 from specific_table order by key_part1, key_part2 desc;在 MySQL 8.0 版本,可以支持 ASC 和 DESC 混用使用索引
-
如果排序列包含非同一索引的列,则无法使用到索引,如下 SQL 所示
select id, key1, key2 from specific_table order by key1, key2;因为它们非同一索引,在 key1 相同的情况下,是不会按照 key2 列进行排序的,所以用不到索引
-
如果排序列是某个联合索引的索引列,但是这些排序列在联合索引中并不连续,那么也无法使用到索引。如下 SQL 所示,因为该联合索引在按照 key_part1 排序后是没有再按照 key_part3 进行排序的,所以无法使用索引
select key_part1, key_part3 from specific_table order by key_part1, key_part3; -
如果排序列不是以单独列名的形式出现在 ORDER BY 语句中,则无法使用索引。如下 SQL 所示,在排序时使用了函数,所以无法使用索引
select id, key1, key2 from specific_table order by upper(key1)
索引列不为空的优化
当需要 Min() 和 Max() 操作时,索引列不为空可以让它们更高效。比如要找到某一列的最小值,只需要查询对应 B-Tree 索引的最左端记录,查询优化器会将这个表达式看做一个常数对待,而且能够在 ESPLAIN 结果的 Extra 列中发现 “Select tables optimized away”。
重复索引和冗余索引
重复索引指的是在相同的列上按照相同顺序创建的相同类型的索引,如下 SQL 所示:
create table specific_table (id int not null primary key,unique key(id)
)engine=InnoDB;
它在 id 列上创建了两个相同的索引,需要将其中的唯一索引移除。
冗余索引通常发生在为表添加新的索引时,比如在已有索引(column_a),再添加一个索引(column_a, column_b),这就是发生了冗余索引的情况,因为第二个联合索引能够发挥和单列索引一样的作用。
大多数情况下都不需要冗余索引,我们应该尽量扩展已有的索引而不是创建新的索引。
是否存在索引合并
在多列上独立地创建多个单列索引,大部分情况下并不能提高 MySQL 的查询性能。
MySQL 中有一种 “索引合并” 的策略,它可以 使用表中的多个单列索引 来定位指定的数据行,并将扫描结果进行合并。索引合并的策略有时候非常不错,但更多的时候,它说明了表中的 索引建的比较糟糕:
-
当查询优化器需要对多个索引合并时,通常意味着需要一个包含所有相关列的联合索引,而不是多个独立的单列索引
-
当优化器需要对多个索引做合并操作时,通常需要在算法的缓存、排序和合并操作上耗费大量 CPU 和内存资源,尤其是当其中有些索引列值的选择性不高且需要合并扫描返回的大量数据时
-
优化器不会将这些操作算在查询成本中,这会使得查询的成本被“低估”,导致执行计划还不如进行全表扫描
通常来说,我们需要考虑 重建索引 或者 使用 UNION 改写查询。除此之外,可以通过修改 optimizer_switch 参数来关闭索引合并功能,如下 SQL:
SELECT @@optimizer_switch;-- 改成 index_merge=off
set optimizer_switch = 'index_merge=off, ...';
还可以使用 IGNORE INDEX 语法让优化器来忽略到某些索引,从而避免优化器使用包含该索引的索引合并执行计划:
select * from specific_table ignore index(index_name)
where column_name = #{value};
除了在发生索引合并时考虑忽略索引,也需要在执行查询时因无法形成合适的扫描区间,达不到减少扫描记录的数量的目的时,考虑忽略索引而使用全表扫描。
下面我们介绍三种索引合并的类型,让大家对索引合并有一个更加充分的了解:它们分别是 Intersection 索引合并、Union 索引合并 和 Sort-Union 索引合并。
Intersection 索引合并
我们看如下查询:
select * from specific_table where key1 = 'a' and key2 = 'b';
我们都能清楚的是:在索引列值相同的情况下,二级索引记录是按照主键值的大小排序的,那么可以将 key1 筛选出的主键值和 key2 筛选出的主键值 取交集,根据结果再去执行回表操作,这相比于分别对 key1 和 key2 筛选出的主键值都去做回表的开销要低,这种情况使用的是 Intersection 索引合并策略。
Union 索引合并
我们看如下查询:
select * from specific_table where key1 = 'a' or key2 = 'b';
将 key1 筛选出的主键值和 key2 筛选出的主键值 取并集,再根据结果去做回表操作,这种做法被称为 Union 索引合并,它可能相比于直接做全表扫描的开销要低。需要注意的是:Union 索引合并要求二级索引筛选出的主键值是有序的,如果主键值无序则需要考虑 Sort-Union 索引合并。
Sort-Union 索引合并
有如下查询:
select * from specific_table where key1 < 'a' or key2 > 'b';
我们将上述查询条件更改成了范围查询条件,现在各索引筛选出的主键值是无序的,所以无法使用 Union 索引合并,而 Sort-Union 索引合并正是在 Union 索引合并的基础上添加了排序操作:将 key1 筛选出的主键值和 key2 筛选出的主键值 进行排序,这样就能够继续使用 Union 索引合并了。
优化 COUNT()
当我们需要 统计有值的结果 时,需要在 COUNT() 条件内指定列名或 COUNT(0);当我们需要 统计所有的行数 时,需要指定为 COUNT(*),它会忽略所有列而直接统计所有行数。明白了这两点之后,我们做数据统计能够更清晰的传达意图。
通常来说,COUNT() 查询需要扫描大量的数据行才能获得精确的结果,所以比较难优化。如果业务场景不要求完全精确,我们可以 使用 EXPLAIN 估算的行数 rows 来代替;或者,我们去掉一些查询条件中的约束,删除 DISTINCT 来避免排序操作,这些做法都可能使统计查询性能提高。
优化 UNION 查询
在我们使用 UNION 查询时,如果不需要消除重复的行,一定要使用 UNION ALL,因为如果没有 ALL 关键字,MySQL 会给临时表加上 DISTINCT,这会对数据做去重,代价比较高。此外,我们可以将 WHERE、LIMIT 和 ORDER BY 语句应用到每个查询中,这样能够让 MySQL 对它们更好地进行优化。
优化 OFFSET
在分页查询中,OFFSET 会导致 MySQL 扫描大量不需要的行然后再抛弃掉,比如 LIMIT 1000, 20 这个表达式,它会查询 1020 条数据然后将前 1000 条抛弃掉,这样做的代价非常高。
我们可以通过采用 书签 的方式记录上次读取数据的“位置”,那么下次查询就能直接从该位置开始扫描,避免使用 OFFSET。比如说,每页展示 20 条数据,我们记录下来当前所在页面的数据 ID 值为 200,那么我们看下一页的数据时,查询 SQL 如下:
select * from specific_table
where id <= 180
limit 20;
不过,这种情况也有不足,它没有办法指定页码进行查询,比如说我现在想看第 5 页的数据,我们没办法计算对应页具体的 ID 值范围。除非我们能够保证 ID 值是单调递增且没有删除过数据的,这样的话, ID 值是连续的,我们就能轻易的计算出第 5 页的数据的 ID 值是从 120 开始的。这样做的好处是无论翻页到多么靠后,它的性能都很好。
使用 WITH ROLLUP 优化 GROUP BY
我们通常使用 GROUP BY 做分组聚合查询,如果还要对分组后的结果再次求和,可以使用 WITH ROLLUP 操作,但是更好的办法还是将 WITH ROLLUP 的处理拿到应用层去做。
OPTIMIZE TABLE
如果我们 删除了很多数据,或者在插入数据时,不是按照主键的递增顺序插入的,很可能会因此产生很多内存碎片,影响数据查询的效率。这是因为在删除数据时,MySQL 并不会立即将它们清除并整理空间,而是将它们标记为删除,通过 OPTIMIZE TABLE 可以将空间进行整理,减少内存碎片。
InnoDB 引擎并不支持 OPTIMIZE TABLE 操作,它会提示如下信息:
OPTIMIZE TABLE specific_table;-- Table does not support optimize, doing recreate + analyze instead
我们可以通过不做任何操作的 ALTER 命令来重建表达到以上目的:
alter table specific_table engine=InnoDB;
执行完成后,我们通过如下 SQL 查看执行情况,如果 data_free 列为 0,说明我们空间碎片整理成功
show table status from specific_db like specific_table;
不过,多数情况下不需要执行该操作。
找到并修复损坏的表
可能因硬件问题、MySQL 本身的缺陷或者操作系统的问题导致索引损坏,当然这种问题非常少见,我们可以通过如下 SQL 来检查大多数表和索引的错误:
check table specific_table;
如果发现异常的话,可以通过如下 SQL 进行修复:
repair table specific_table;-- 如果存储引擎不支持上述操作的话,也可通过表重建来完成
alter table specific_table engine=InnoDB;
巨人的肩膀
-
《高性能MySQL 第四版》:第七、八章
-
《MySQL 是怎样运行的》:第七、十、十一、十四、十五章
-
MySQL:optimizer_switch
-
8.9.4 Index Hints
-
mysql进阶:optimize table命令
相关文章:
:性能优化)
高性能MySQL实战(三):性能优化
大家好,我是 方圆。这篇主要介绍对慢 SQL 优化的一些手段,而在讲解具体的优化措施之前,我想先对 EXPLAIN 进行介绍,它是我们在分析查询时必要的操作,理解了它输出结果的内容更有利于我们优化 SQL。为了方便大家的阅读&…...

198. 打家劫舍
题目 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存放…...
Pydev·离线git包
Pydev离线git包 1.下载离线git包:eclipse.egit.repository-4.4.0.201606070830-r.zip 2.将解压后目录:eclipse.egit.repository-4.4.0.201606070830-r\plugins下的jar文件放到 ide\eclipse\plugins目录下 3.重启pydevIDE 百度搜索站长工具:h…...

Vue-12.集成postcss.config.js
PostCSS 介绍 PostCSS 是一个用于处理样式的工具,可以通过插件来定制其行为。以下是一些常用的 PostCSS 插件和 API 的介绍: Autoprefixer: 这是一个流行的 PostCSS 插件,用于自动添加浏览器前缀,以确保您的样式在不同浏览器中具…...

基于前端技术原生HTML、JS、CSS 电子病历编辑器源码
电子病历系统采取结构化与自由式录入的新模式,自由书写,轻松录入。实现病人医疗记录(包含有首页、病程记录、检查检验结果、医嘱、手术记录、护理记录等等。)的保存、管理、传输和重现,取代手写纸张病历。不仅实现了纸…...

Linux环境下远程访问SVN服务:SVN内网穿透的详细配置与操作指南
文章目录 前言1. Ubuntu安装SVN服务2. 修改配置文件2.1 修改svnserve.conf文件2.2 修改passwd文件2.3 修改authz文件 3. 启动svn服务4. 内网穿透4.1 安装cpolar内网穿透4.2 创建隧道映射本地端口 5. 测试公网访问6. 配置固定公网TCP端口地址6.1 保留一个固定的公网TCP端口地址6…...
创建k8s operator
目录 1.前提条件 2.进一步准备 2.1.安装golang 2.2.安装code(vscode的linux版本) 2.3.安装kubebuilder 3.开始创建Operator 3.1.什么是operator? 3.2.GV & GVK & GVR 3.3.创建operator 3.3.1. 生成工程框架 3.3.2.生成api(GVK) …...
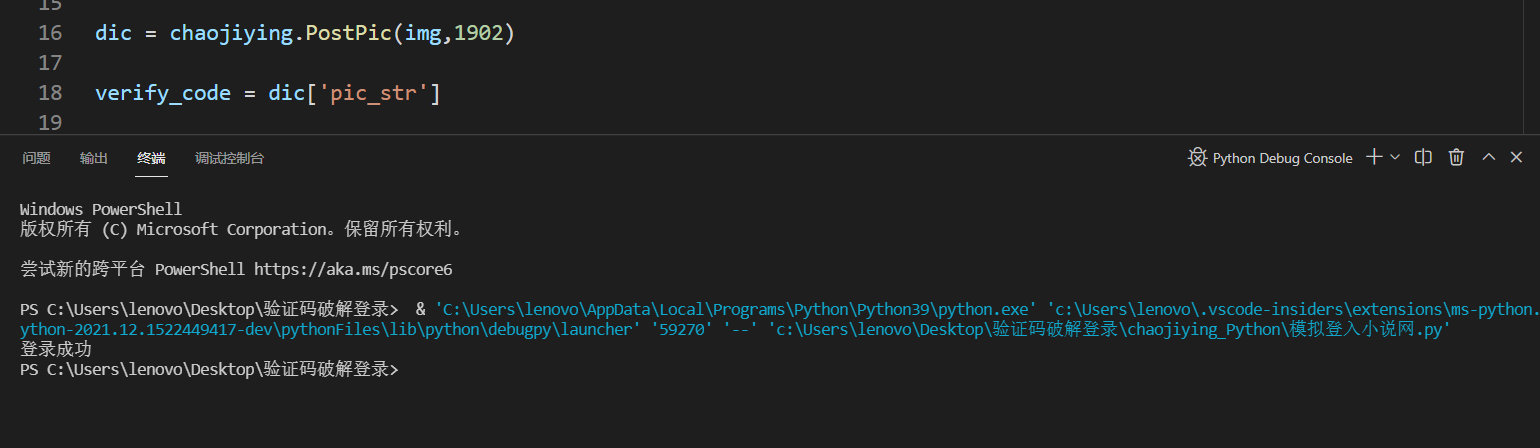
python模拟登入某平台+破解验证码
概述 python模拟登录平台,遇见验证码识别!用最简单的方法seleniumda破解验证码,来自动登录平台 详细 python用seleniumxpath模拟登录破解验证码 先随便找个小说平台用户登陆 - 书海小说网用户登陆 - 书海小说网用户登陆 - 书海小说网 准…...

【图像分割】理论篇(2)经典图像分割网络基于vgg16的Unet
UNet 是一种用于图像分割任务的深度学习架构,最早由 Olaf Ronneberger、Philipp Fischer 和 Thomas Brox 在2015年的论文 "U-Net: Convolutional Networks for Biomedical Image Segmentation" 中提出。UNet 在医学图像分割等领域取得了显著的成功&#x…...
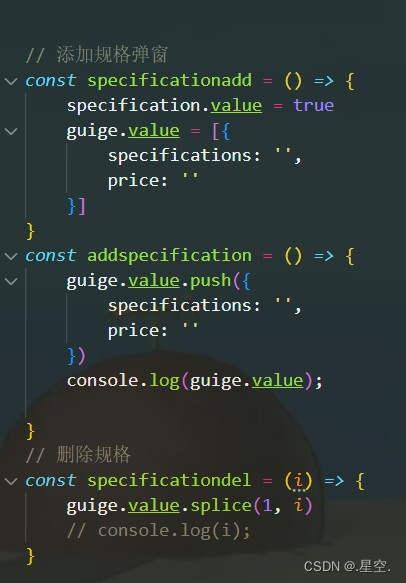
vue插入重复的html内容
vue添加重复的html内容是通过绑定一个数组来v-for循环实现的。 效果展示: 首先创建数组,里面为重复内容的数量,里面默认存在一个初始值。 然后通过v-for来绑定这个数组,循环数据。 通过添加点击事件,来增加或删除数组…...

计算机网络-物理层(三)-信道的极限容量
计算机网络-物理层(三)-信道的极限容量 当信号在信道中传输失真不严重时,在信道的输出端,这些信号可以被识别 当信号在信道中,传输失真严重时,在信道的输出端就难以识别 造成失真的因素 码元传输速率信号传输距离噪声干扰传输媒…...
Http/Websocket协议的长连接和短连接的错误认识详细解读(史上最通俗)
从一个问题聊起: Http/Websocket 都称为一种协议,能用现实中的例子来解释协议吗? AI 举例: 您(客户端): 您坐在餐厅桌子上,想点一份菜单。 服务员(服务器)…...
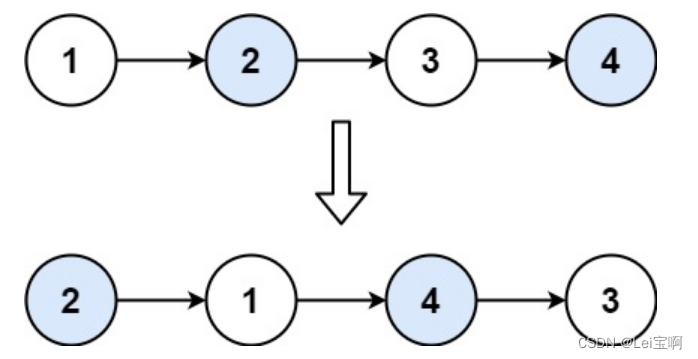
两两交换链表中的节点
你存在,我深深的脑海里~ 题目: 示例: 思路: 这个题有点类似于反转一个单链表,不同的地方在于这个题不全反转,所以我们不同的地方在于此题多用了一个prve指针保存n1的前一个节点,以及头的改变&a…...
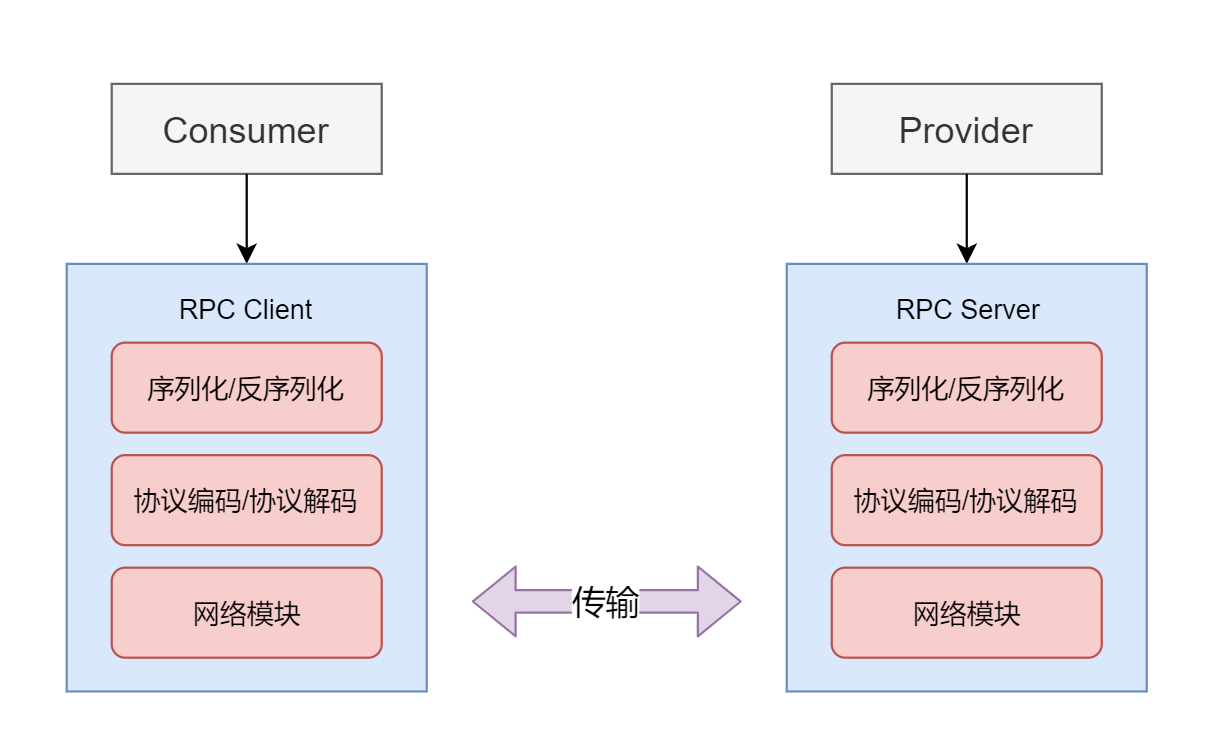
HTTP与RPC的取舍
HTTP与RPC的取舍 HTTP和RPC都是常用的网络通信协议,它们各有优劣。选择何种协议,主要取决于应用的需求和场景。 HTTP和RPC都有各自的优点和缺点,首先我们对两种协议进行一个总结。 HTTP协议图 HTTP的优点: 广泛的支持࿱…...
)
微前端学习(上)
一、课程目标 微前端概念;现有方案利弊;Single-spa实现原理;掌握使用qiankun搭建微应用;二、课程大纲 微前端背景现在web应用面临的问题微前端的价值微前端应用具备哪些能力微前端解决方案有哪些基于qiankun的实践1、微前端背景 2014年: Martin Fowler和James Lewis共同提…...

【Axure视频教程】标签版多选下拉列表
今天教大家在Axure里如何制作标签版多选下拉列表的原型模板,该模板用中继器制作,制作完成后使用也方便,只需要在中继器表格里维护选项信息,即可自动生成交互效果,包括显示隐藏选项列表,选中和取消选中选项&…...

Sharepoint2013必备软件安装路径
SP2013是最后一个有foundation版本的,后续各个版本都是server版,要买lisence。免费的可以用,但安装组件有些链接已经失效了,自己手动下载的路径备份一下,已经下载好的完整版,在文章最后可以直接下载&#x…...
)
C++day4(关系运算符的重载)
关系运算符重载的作用:可以让两个自定义类型对象进行对比操作。 代码实现关系运算符的重载: #include <iostream>using namespace std;class Person {// friend const Person operator(const Person &L, const Person &R); private:int …...

农业水价综合改革系统主要组成
一、系统概述 农业水价改革灌区信息化系统主要由感知采集层、网络传输层、系统应用层等部分组成。通过无线技术、感知层技术与新型应用的有效结合,可以用于各种业务的传送,充分满足灌区监测站间的物与物互联,农业生产的自动化和信息化相结合。…...
启动多个CMD窗口并执行命令)
使用批处理文件(.bat)启动多个CMD窗口并执行命令
由于每次启动本机的mongodb和kafka,都需要进入相关目录进行启动,操作相对繁琐,于是想起了批处理来帮忙一键启动。 在桌面新建一个txt文件,改后缀名为.bat,并加上下面的代码。 cd /d D:\env-java\mongodb-win32-x86_64…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...