YOLOv5算法改进(4)— 添加CA注意力机制

前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。在许多视觉任务中,输入数据通常由多个通道组成,例如图像中的RGB通道或视频中的时间序列帧。传统的卷积神经网络(CNN)在处理这些通道时通常是独立地对每个通道进行操作,忽略了通道之间的相互作用。CA注意力机制通过引入通道注意力来解决这个问题。它能够自动学习到不同通道之间的关联性和重要性,从而增强模型对输入数据的建模能力。具体来说,CA注意力机制通过计算每个通道的权重,使得模型能够更加关注重要的通道,并抑制不重要的通道。这样可以提高模型在处理多通道输入数据时的表达能力和性能。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
目录
🚀1.论文
🚀2.CA注意力机制的原理及实现
🚀3.添加CA注意力机制的好处
🚀4.添加CA注意力机制的方法
💥💥步骤1:在common.py中添加CA模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:修改yolov5s_CA.yaml文件
💥💥步骤5:验证是否加入成功
💥💥步骤6:修改train.py中的'--cfg'默认参数
🚀5.添加C3_CA注意力机制的方法(在C3模块中添加)
💥💥步骤1:在common.py中添加CABottleneck和C3_CA模块
💥💥步骤2:在yolo.py文件里parse_model函数中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.论文
目前,轻量级网络的注意力机制大都采用 SE 模块,仅考虑了通道间的信息,忽略了位置信息。尽管后来的 BAM 和 CBAM 尝试在降低通道数后通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。为此,论文提出了新的高效注意力机制CA(coordinate attention),能够将横向和纵向的位置信息编码到 channel attention 中,使得移动网络能够关注大范围的位置信息又不会带来过多的计算量。🌴

论文题目:Coordinate Attention for Efficient Mobile Network Design
论文地址:https://arxiv.org/abs/2103.02907
代码实现:GitHub - houqb/CoordAttention: Code for our CVPR2021 paper coordinate attention
🚀2.CA注意力机制的原理及实现
CA(Channel Attention)注意力机制是一种在深度学习中常用的注意力机制之一,用于增强模型对于不同通道(channel)之间的特征关联性。📚
其原理如下:👇
(1)输入特征经过卷积等操作得到中间特征表示。
(2)中间特征表示经过两个并行的操作:全局平均池化和全局最大池化,得到全局特征描述。
(3)全局特征描述通过两个全连接层生成注意力权重。
(4)注意力权重与中间特征表示相乘,得到加权后的特征表示。
(5)加权后的特征表示经过适当的调整(如残差连接)后,作为下一层的输入。
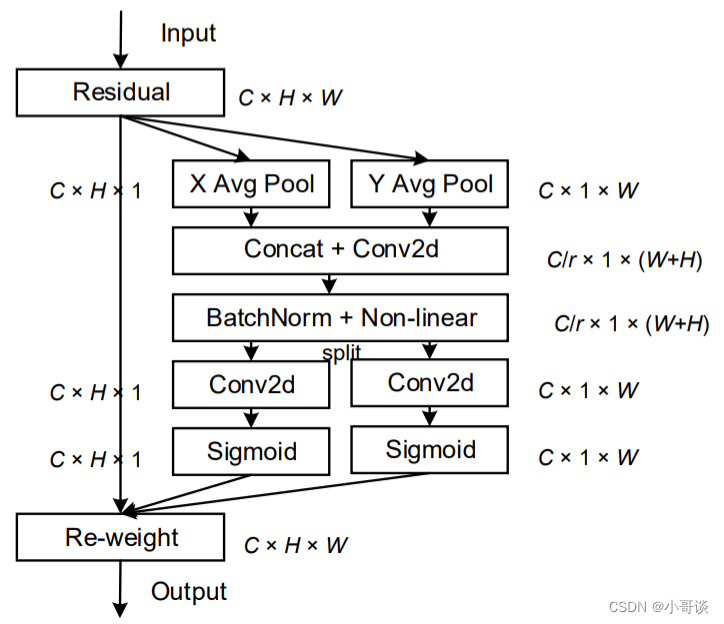
CA注意力的实现如图所示,可以认为分为两个并行阶段:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。假设输入进来的特征层的形状为[C, H, W],在经过宽方向的平均池化后,获得的特征层shape为[C, H, 1],此时我们将特征映射到了高维度上;在经过高方向的平均池化后,获得的特征层shape为[C, 1, W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C, 1, H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C, 1, H]和[C, 1, W],之后进行转置。获得两个特征层[C, H, 1]和[C, 1, W]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况,乘上原有的特征就是CA注意力机制。✅
🚀3.添加CA注意力机制的好处
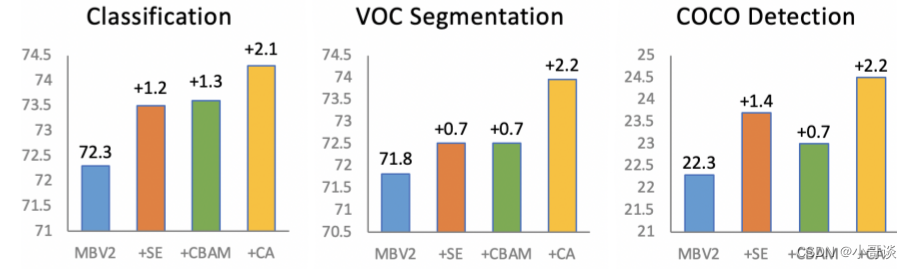
作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。其为即插即用的注意力模块,能插入任何经典网络。🍉
加入CA注意力机制的好处包括:
(1)增强特征表达:CA注意力机制能够自适应地选择和调整不同通道的特征权重,从而更好地表达输入数据。它可以帮助模型发现和利用输入数据中重要的通道信息,提高特征的判别能力和区分性。
(2)减少冗余信息:通过抑制不重要的通道,CA注意力机制可以减少输入数据中的冗余信息,提高模型对关键特征的关注度。这有助于降低模型的计算复杂度,并提高模型的泛化能力。
(3)提升模型性能:加入CA注意力机制可以显著提高模型在多通道输入数据上的性能。它能够帮助模型更好地捕捉到通道之间的相关性和依赖关系,从而提高模型对输入数据的理解能力。
综上所述,加入CA注意力机制可以有效地增强模型对多通道输入数据的建模能力,提高模型性能和泛化能力。它在图像处理、视频分析等任务中具有重要的应用价值。🌿
🚀4.添加CA注意力机制的方法
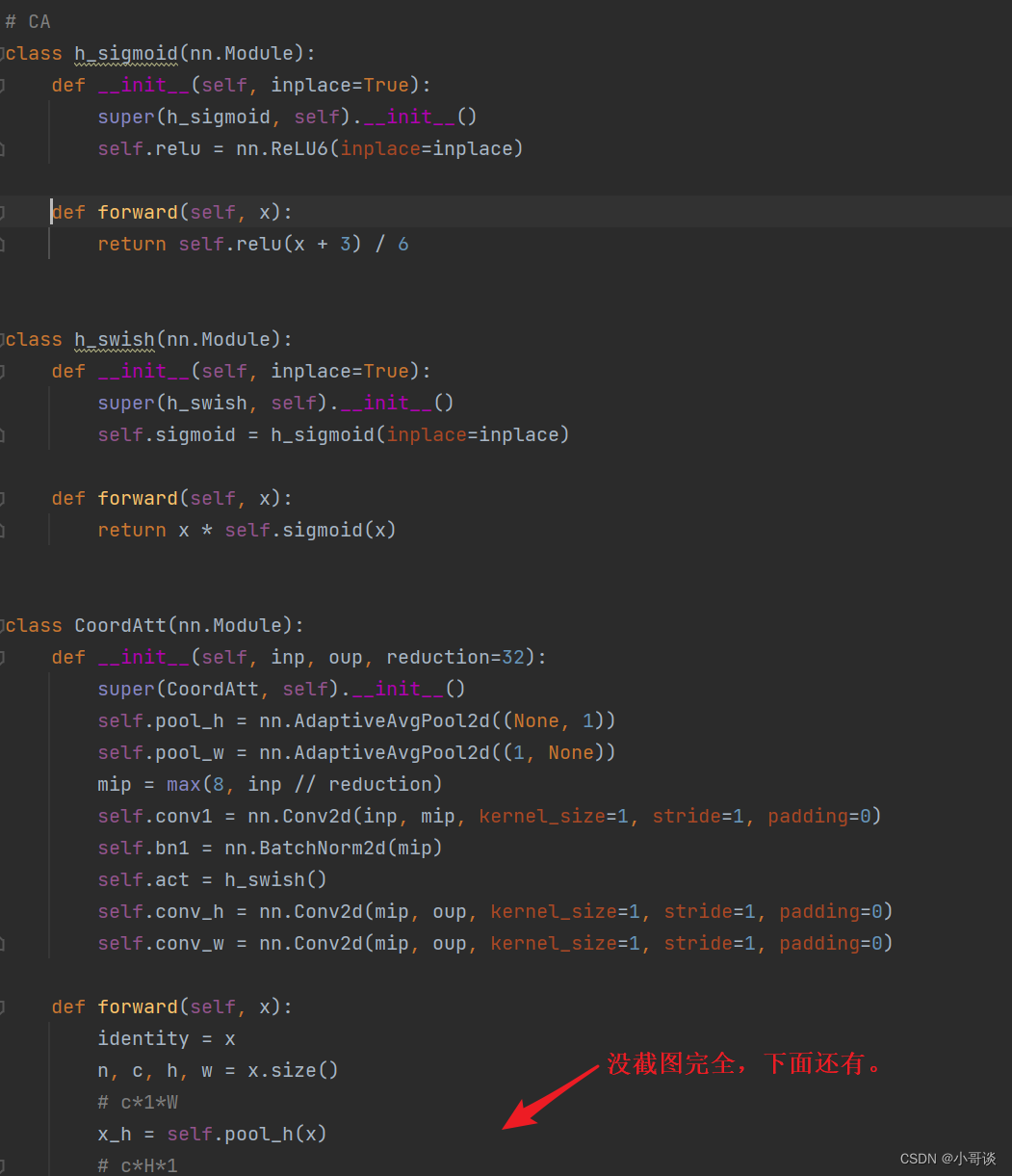
💥💥步骤1:在common.py中添加CA模块
将下面的CA模块的代码复制粘贴到common.py文件的末尾。
# CA
class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6
class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)class CoordAtt(nn.Module):def __init__(self, inp, oup, reduction=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn, c, h, w = x.size()#c*1*Wx_h = self.pool_h(x)#c*H*1#C*1*hx_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)#C*1*(h+w)y = self.conv1(y)y = self.bn1(y)y = self.act(y)x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out具体如下图所示:
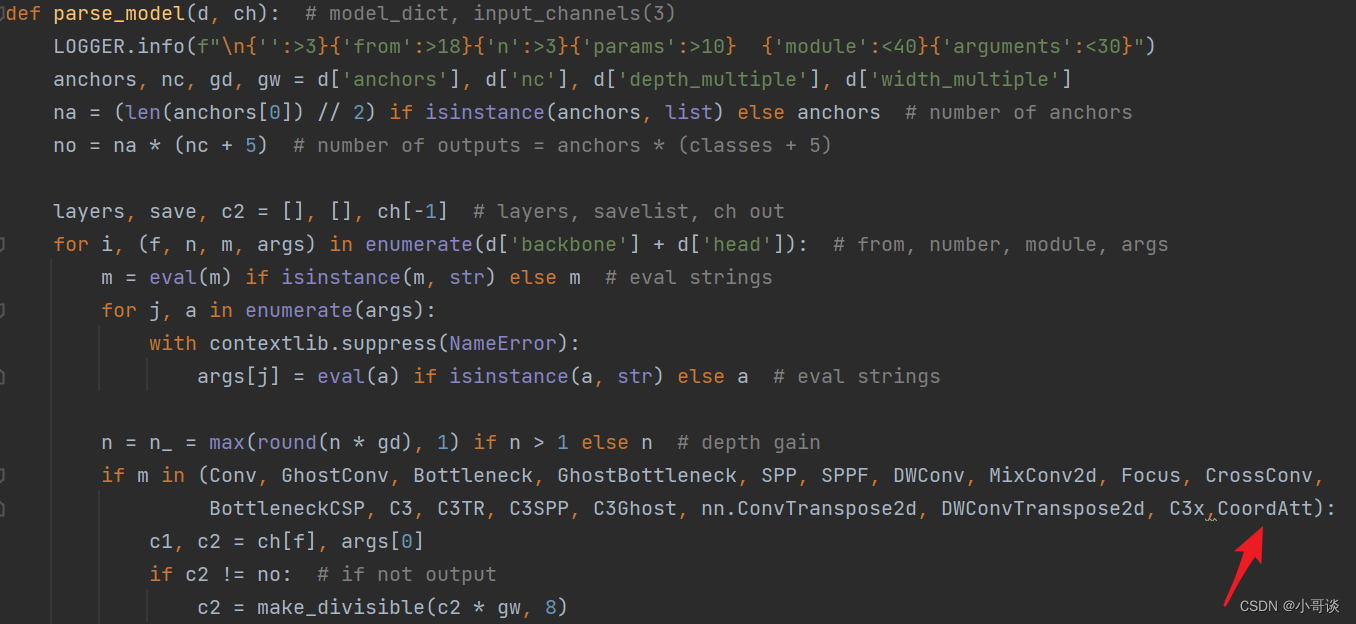
💥💥步骤2:在yolo.py文件中加入类名
首先在yolo.py文件中找到parse_model函数,然后将 CoordAtt 添加到这个注册表里。
💥💥步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并命名为yolov5s_CA.yaml。
💥💥步骤4:修改yolov5s_CA.yaml文件
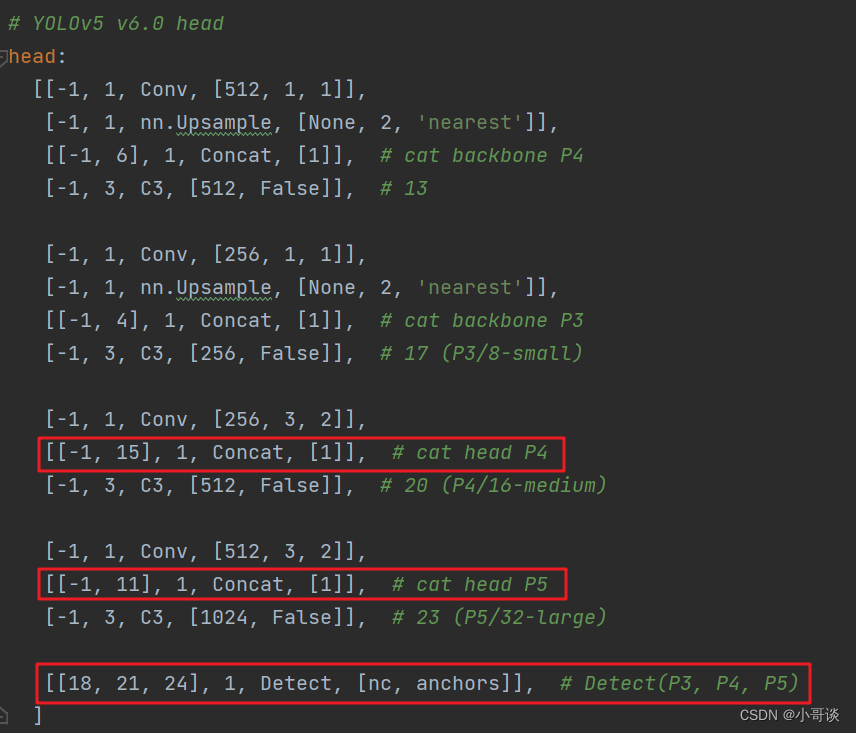
本步骤是修改yolov5s_CA.yaml,将CA模块添加到我们想添加的位置。在这里,我将[-1,1,CoordAtt,[1024]]添加到SPPF的上一层,即下图中所示位置。

说明:♨️♨️♨️
注意力机制可以加在Backbone、Neck、Head等部分,常见的有两种:一种是在主干的SPPF前面添加一层;二是将Backbone中的C3全部替换。不同的位置效果可能不同,需要我们去反复测试。
这里需要注意一个问题,当在网络中添加新的层之后,那么该层网络后面的层的编号会发生变化。原本Detect指定的是[17,20,23]层,所以,我们在添加了CA模块之后,也要对这里进行修改,即原来的17层,变成18层,原来的20层,变成21层,原来的23层,变成24层;所以这里需要改为[18,21,24]。同样的,Concat的系数也要修改,这样才能保持原来的网络结构不会发生特别大的改变,我们刚才把CA模块加到了第9层,所以第9层之后的编号都需要加1,这里我们把后面两个Concat的系数分别由[-1,14],[-1,10]改为[-1,15],[-1,11]。🌻
具体如下图所示:
💥💥步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_CA.yaml。


然后运行yolo.py,得到结果。

找到了CA模块,说明我们添加成功了。🎉🎉🎉
💥💥步骤6:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_CA.yaml',然后就可以开始进行训练了。🎈🎈🎈
🚀5.添加C3_CA注意力机制的方法(在C3模块中添加)
上面是单独添加注意力层,接下来的方法是在C3模块中加入注意力层。这个策略是将CA注意力机制添加到Bottleneck,替换Backbone中所有的C3模块。🌳
💥💥步骤1:在common.py中添加CABottleneck和C3_CA模块
将下面的代码复制粘贴到common.py文件的末尾。
# CA
class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)class CABottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=32): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2# self.ca=CoordAtt(c1,c2,ratio)self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, c1 // ratio)self.conv1 = nn.Conv2d(c1, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0)def forward(self, x):x1 = self.cv2(self.cv1(x))n, c, h, w = x.size()# c*1*Wx_h = self.pool_h(x1)# c*H*1# C*1*hx_w = self.pool_w(x1).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)# C*1*(h+w)y = self.conv1(y)y = self.bn1(y)y = self.act(y)x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = x1 * a_w * a_h# out=self.ca(x1)*x1return x + out if self.add else outclass C3_CA(C3):# C3 module with CABottleneck()def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channelsself.m = nn.Sequential(*(CABottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))💥💥步骤2:在yolo.py文件里parse_model函数中加入类名
在yolo.py文件的parse_model函数中,加入CABottleneck、C3_CA这两个模块。
💥💥步骤3:创建自定义yaml文件
按照上面的步骤创建yolov5s_C3_CA.yaml文件,替换4个C3模块。

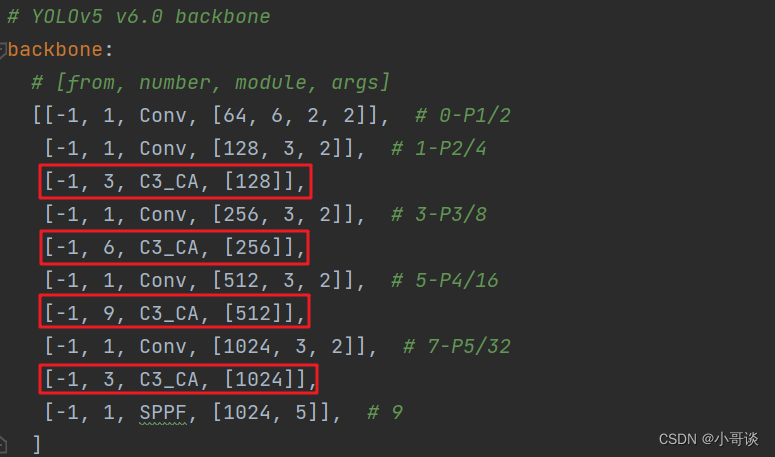
💥💥步骤4:验证是否加入成功
在yolo.py文件里配置刚才我们自定义的yolov5s_C3_CA.yaml,然后运行。
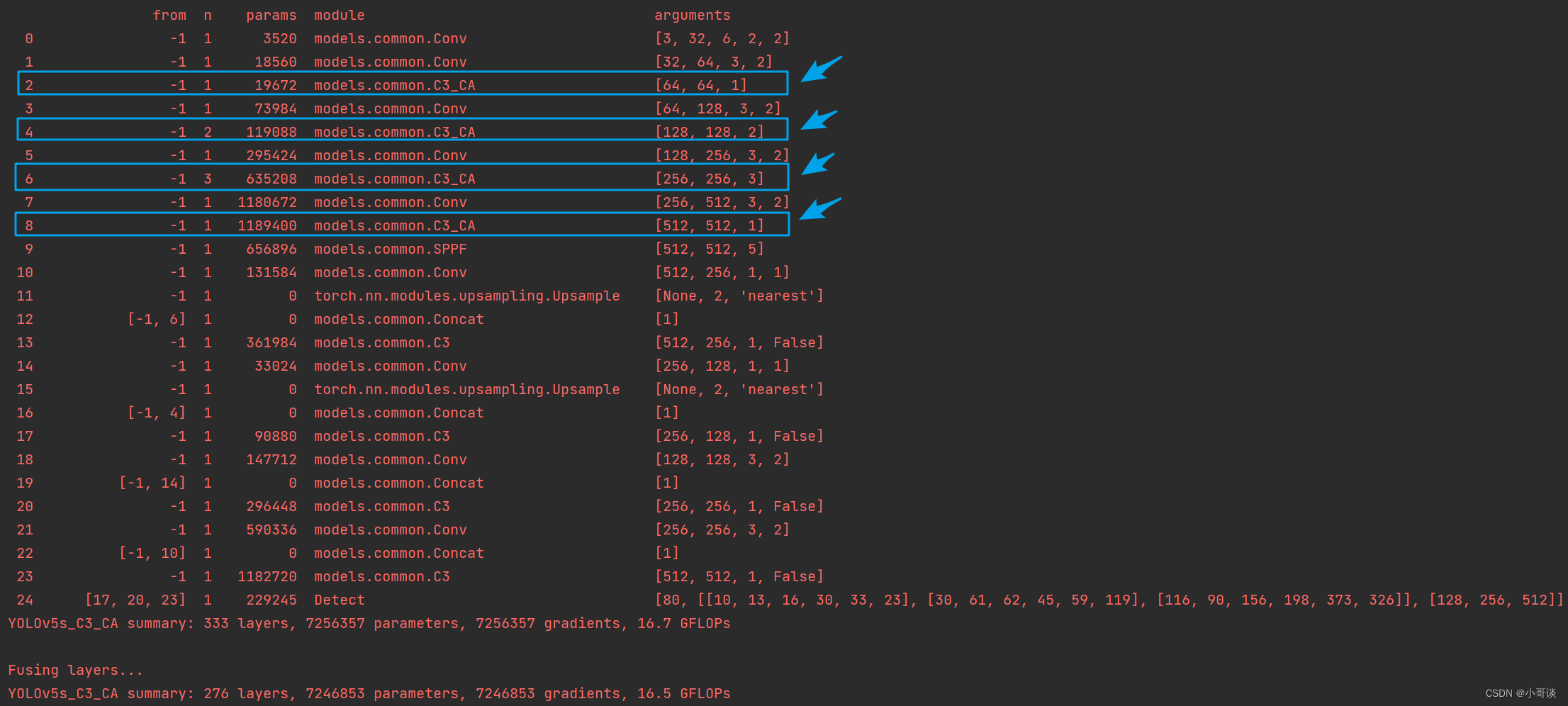
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_C3_CA.yaml',然后就可以开始进行训练了。🎈🎈🎈

相关文章:
YOLOv5算法改进(4)— 添加CA注意力机制
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。在许多视觉任务中,输入数据通常由多个通道组成,例如图像中的RGB通道或…...

无涯教程-PHP - XML GET
XML Get已用于从xml文件获取节点值。以下示例显示了如何从xml获取数据。 Note.xml 是xml文件,可以通过php文件访问。 <SUBJECT><COURSE>Android</COURSE><COUNTRY>India</COUNTRY><COMPANY>LearnFk</COMPANY><PRICE…...
Spark Standalone环境搭建及测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 篇一:Linux系统下配置java环境 篇二:hadoop伪分布式搭建(超详细) 篇三:hadoop完全分布式集群搭建(超详细…...

【PHP】流程控制-ifswitchforwhiledo-whilecontinuebreak
文章目录 流程控制顺序结构分支结构if分支switch分支 循环结构for循环while循环do-while循环continue和break 流程控制 顺序结构:代码从上往下,顺序执行。(代码执行的最基本结构) 分支结构:给定一个条件,…...

Pytorch-day04-模型构建-checkpoint
PyTorch 模型构建 1、GPU配置2、数据预处理3、划分训练集、验证集、测试集4、选择模型5、设定损失函数&优化方法6、模型效果评估 #导入常用包 import os import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torchvision.transfor…...
使用Xshell7控制多台服务同时安装ZK最新版集群服务
一: 环境准备: 主机名称 主机IP 节点 (集群内通讯端口|选举leader|cline端提供服务)端口 docker0 192.168.1.100 node-0 2888 | 3888 | 2181 docker1 192.168.1.101 node-1 2888 | 388…...

python numpy array dtype和astype类型转换的区别
Python3 本身对整数的支持做了提升,可以支持无限长度的整数:比如: b 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffPython的模块numpy array定义的数组在windows和MACOS上默认长度是…...

浮动属性样式
🍓浮动属性 属性名称中文注释备注float设置盒子浮动left左浮动,right右浮动,none不浮动clear清除浮动left清除左浮动,right清除右浮动,both左右浮动都清除(注意:clear清除浮动一般只有作用在块…...

keepalived双机热备 (四十五)
一、概述 Keepalived 是一个基于 VRRP 协议来实现的 LVS 服务高可用方案,可以解决静态路由出现的单点故障问题。 原理 在一个 LVS 服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器…...
SpringBoot整合阿里云OSS,实现图片上传
在项目中,将图片等文件资源上传到阿里云的OSS,减少服务器压力。 项目中导入阿里云的SDK <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.10.2</version>…...

Dynaminc Programming相关
目录 3.1 最长回文子串(中等):标志位 3.2 最大子数组和(中等):动态规划 3.3 爬楼梯(简单):动态规划 3.4 买卖股票的最佳时机(简单)࿱…...
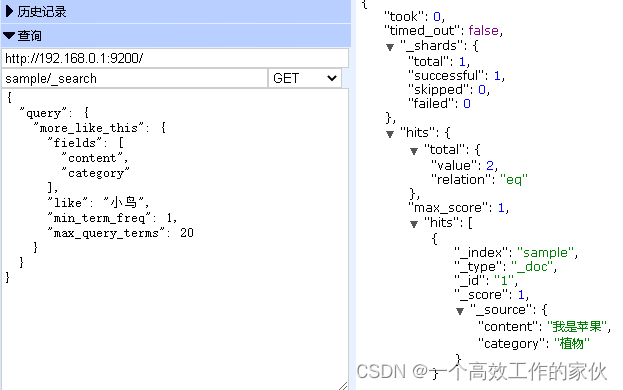
使用 Elasticsearch 轻松进行中文文本分类
本文记录下使用 Elasticsearch 进行文本分类,当我第一次偶然发现 Elasticsearch 时,就被它的易用性、速度和配置选项所吸引。每次使用 Elasticsearch,我都能找到一种更为简单的方法来解决我一贯通过传统的自然语言处理 (NLP) 工具和技术来解决…...

MNN学习笔记(八):使用MNN推理Mediapipe模型
1.项目说明 最近需要用到一些mediapipe中的模型功能,于是尝试对mediapipe中的一些模型进行转换,并使用MNN进行推理;主要模型包括:图像分类、人脸检测及人脸关键点mesh、手掌检测及手势关键点、人体检测及人体关键点、图像嵌入特征…...

主力吸筹指标及其分析和使用说明
文章目录 主力吸筹指标指标代码分析使用说明使用配图主力吸筹指标 VAR1:=REF(LOW,1); VAR2:=SMA(MAX(LOW-VAR1,0),3,1)/SMA(ABS(LOW-VAR1),3,1)*100; VAR3:=EMA(VAR2,3); VAR4:=LLV(LOW,34); VAR5:=HHV(VAR3,34); VAR7:=EMA(IF(LOW<=VAR4,(VAR3+VAR5*2)/2,0),3); /*底线:0,…...
Python高光谱遥感数据处理与高光谱遥感机器学习方法教程
详情点击链接:Python高光谱遥感数据处理与高光谱遥感机器学习方法教程 第一:高光谱基础 一:高光谱遥感基本 01)高光谱遥感 02)光的波长 03)光谱分辨率 04)高光谱遥感的历史和发展 二:高光谱传感器与数据获取 01)高光谱遥感…...
【洛谷】P1678 烦恼的高考志愿
原题链接:https://www.luogu.com.cn/problem/P1678 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 将每个学校的分数线用sort()升序排序,再二分查找每个学校的分数线,通过二分找到每个同学估分附近的分数线。 最后…...

开机自启CPU设置定频
sudo apt-get install expect sudo apt-get install cpufrequtils具体步骤如下: 安装 cpufrequtils 工具 ⚫ sudo apt-get install cpufrequtils ⚫ 需要联网下载修改配置文件 ⚫ sudo vi /etc/init.d/cpufrequtils ⚫ 将 GOVERNOR“ondemand” 改为: &g…...
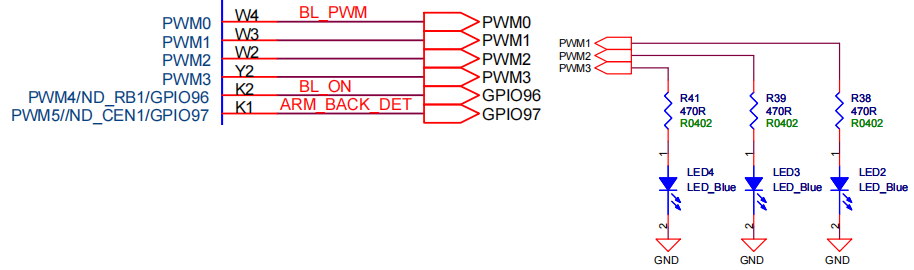
嵌入式Linux开发实操(十二):PWM接口开发
# 前言 使用pwm实现LED点灯,可以说是嵌入式系统的一个基本案例。那么嵌入式linux系统下又如何实现pwm点led灯呢? # PWM在嵌入式linux下的操作指令 实际使用效果如下,可以通过shell指令将开发板对应的LED灯点亮。 点亮3个LED,则分别使用pwm1、pwm2和pwm3。 # PWM引脚的硬…...

消息中间件介绍
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。当今市面上有很多主流的消息中间件,如ActiveMQ、RabbitMQ,Kafka,还有阿里巴巴…...

[Unity] 基础的编程思想, 组件式开发
熟悉 C# 开发的朋友, 在刚进入 Unity 开发时, 不可避免的会有一些迷惑, 例如不清楚 Unity 自己的思想, 如何设计与架构一个应用程序之类的. 本篇文章简要的介绍一下 Unity 的基础编程思想. 独立 Unity 很少使用 C# 的标准库, 例如 C# 的网络, 事件驱动, 对象模型, 这些概念在 …...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...