C++最易读手撸神经网络两隐藏层(任意Nodes每层)梯度下降230820a
这是史上最简单、清晰,最易读的……
C++语言编写的 带正向传播、反向传播(Forward ……和Back Propagation)……任意Nodes数的人工神经元神经网络……。
大一学生、甚至中学生可以读懂。
适合于,没学过高数的程序员……照猫画虎编写人工智能、深度学习之神经网络,梯度下降……
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
“我在网上看到过很多神经网络的实现方法,但这一篇是最简单、最清晰的。”
一位来自Umass的华人小哥Along Asong,写了篇神经网络入门教程,在线代码网站Repl.it联合创始人Amjad Masad看完以后,给予如是评价。
// c++神经网络手撸20梯度下降22_230820a.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
#include<iostream>
#include<vector>
#include<iomanip> //std::setprecision
#include<sstream> //std::getline std::stof()using namespace std;
//
float Loss误差损失之和001 = 0.0;class NN神经网络NN {private: int inputNode输入层之节点数s, hidden01Node隐藏层01结点数s, hidden22Nodes, outputNode输出层结点数s;vector<vector<float>> 输入层到第1隐藏层之权重矩阵, 隐藏层1到第二隐藏层2之权重矩阵1to2, 隐藏22到输出层de权重矩阵; //这些变量为矩阵vector<float> 隐藏层1偏置1, 隐藏层2偏置2, O输出偏置o;vector<float>隐藏层1数据1, 隐藏层2数据2, 输出数据output;void initLayer每一层的WeightsAndBiases(vector<vector<float>>& weights权重, vector<float>& biases偏置){for (size_t i = 0; i < weights权重.size(); ++i) {//for110ifor (size_t j = 0; j < weights权重[0].size(); ++j) { weights权重[i][j] = ((rand() % 2) - 1) / 1.0; }biases偏置[i] = ((rand() % 2) - 1) / 1.0;}//for110i}//void initLayerWeightsAndBiases(void initWeightsAndBiases初始化权重和偏置矩阵() {initLayer每一层的WeightsAndBiases(输入层到第1隐藏层之权重矩阵, 隐藏层1偏置1);initLayer每一层的WeightsAndBiases(隐藏层1到第二隐藏层2之权重矩阵1to2, 隐藏层2偏置2);initLayer每一层的WeightsAndBiases(隐藏22到输出层de权重矩阵 , O输出偏置o);}//激活函数-激活的过程vector<float> activate(const vector<float>& inputs, const vector< vector<float>>& weights, const vector<float>& biases) {vector<float> layer_output(weights.size(), 0.0);for (size_t i = 0; i < weights.size(); i++) {for (size_t j = 0; j < inputs.size(); j++) {layer_output[i] += inputs[j] * weights[i][j];}//for220jlayer_output[i] += biases[i];layer_output[i] = sigmoid(layer_output[i]);}//for110ireturn layer_output;}//vector<float> activate//subtract求差:两个 向量的差std::vector<float> subtract(const std::vector<float>& a, const std::vector<float>& b) {std::vector<float> result(a.size(), 0.0);for (size_t i = 0; i < a.size(); i++) {result[i] = a[i] - b[i];}return result;}//vector<float>subtract//dotT点乘std::vector<float> dotT(const std::vector<float>& a, const std::vector<std::vector<float>>& b) {std::vector<float> result(b[0].size(), 0.0);for (size_t i = 0; i < b[0].size(); i++) {for (size_t j = 0; j < a.size(); j++) {result[i] += a[j] * b[j][i];}}return result;}//更新权重矩阵s(们), 和偏置(向量)S们void updateWeights(const std::vector<float>& inputs, const std::vector<float>& errors, const std::vector<float>& outputs,std::vector<std::vector<float>>& weights, std::vector<float>& biases, float lr) {for (size_t i = 0; i < weights.size(); i++) {for (size_t j = 0; j < weights[0].size(); j++) {weights[i][j] += lr * errors[i] * sigmoid导函数prime(outputs[i]) * inputs[j];}biases[i] += lr * errors[i] * sigmoid导函数prime(outputs[i]);}}//void updateWeights(public:NN神经网络NN(int inputNode输入层之节点数s, int hidden01Node隐藏层01结点数s, int hidden22Nodes, int outputNode输出层结点数s):inputNode输入层之节点数s(inputNode输入层之节点数s), hidden01Node隐藏层01结点数s(hidden01Node隐藏层01结点数s), hidden22Nodes(hidden22Nodes), outputNode输出层结点数s(outputNode输出层结点数s){srand(time(NULL));//初始换权重矩阵输入层到第1隐藏层之权重矩阵.resize(hidden01Node隐藏层01结点数s, vector<float>(inputNode输入层之节点数s));隐藏层1到第二隐藏层2之权重矩阵1to2.resize(hidden22Nodes, vector<float>(hidden01Node隐藏层01结点数s));隐藏22到输出层de权重矩阵.resize(outputNode输出层结点数s, vector<float>(hidden22Nodes));//隐藏层1偏置1.resize(hidden01Node隐藏层01结点数s);隐藏层2偏置2.resize(hidden22Nodes);O输出偏置o.resize(outputNode输出层结点数s);initWeightsAndBiases初始化权重和偏置矩阵();}//NN神经网络NN(i//sigmoid激活函数及导数float sigmoid(float x){ return 1.0 / (1.0 + exp(-x)); }float sigmoid导函数prime(float x) { return x * (1 - x); }//Forward前向传播vector<float> predict(const vector<float>& input输入数据) {//用激活函数sigmoid-激活的过程隐藏层1数据1 = activate(input输入数据, 输入层到第1隐藏层之权重矩阵, 隐藏层1偏置1); //激活函数// 第一隐藏层到第二隐藏层隐藏层2数据2 = activate(隐藏层1数据1, 隐藏层1到第二隐藏层2之权重矩阵1to2, 隐藏层2偏置2);//hidden1, wh1h2, bias_h2);// 第二隐藏层到输出层输出数据output = activate(隐藏层2数据2, 隐藏22到输出层de权重矩阵, O输出偏置o);// , wh2o, bias_o);return 输出数据output;}//vector<float>predict(// 反向传播//Backpropagationvoid train(const vector<float>& inputs, const vector<float>& target目标数据s, float lr学习率) {vector<float> output尝试的输出数据s = predict(inputs);// 输出层误差vector<float> output_error输出误差s = subtract(target目标数据s, output尝试的输出数据s);//Loss误差损失之和001 = 0.0;for (int ii = 0; ii < outputNode输出层结点数s; ++ii) { Loss误差损失之和001 += fabs(output_error输出误差s[ii]); }//=========================================================================// 隐藏层2误差vector<float> hidden2_errors = dotT(output_error输出误差s, 隐藏22到输出层de权重矩阵);// 隐藏层1误差vector<float> hidden1_errors = dotT(hidden2_errors, 隐藏层1到第二隐藏层2之权重矩阵1to2);// 更新权重: 隐藏层2到输出层(的权重矩阵updateWeights(隐藏层2数据2, output_error输出误差s, output尝试的输出数据s, 隐藏22到输出层de权重矩阵, O输出偏置o, lr学习率);// 更新权重: 隐藏层1到隐藏层2updateWeights(隐藏层1数据1, hidden2_errors, 隐藏层2数据2, 隐藏层1到第二隐藏层2之权重矩阵1to2, 隐藏层2偏置2, lr学习率);// 更新权重: 输入层到隐藏层1的权重矩阵)updateWeights(inputs, hidden1_errors, 隐藏层1数据1, 输入层到第1隐藏层之权重矩阵, 隐藏层1偏置1, lr学习率);}// void train(// // 反向传播//Backpropagation};//class NN神经网络NN {#define Num训练数据的个数s 5
int main()
{NN神经网络NN nn(9, 11, 4, 2);// 11, 10, 4);// Exampleint 训练数据的个数s = Num训练数据的个数s;std::vector<float> input[Num训练数据的个数s];/* input[0] = {0,1,0, 0,1,0, 0,1,0}; //1“竖线”或 “1”字{ 1.0, 0.5, 0.25, 0.125 };input[1] = { 0,0,0, 1,1,1,0,0,0 }; //-“横线”或 “-”减号{ 1.0, 0.5, 0.25, 0.125 };input[2] = { 0,1,0, 1,1,1, 0,1,0 }; //+“+”加号{ 1.0, 0.5, 0.25, 0.125 };input[3] = { 0,1,0, 0,1.2, 0, 0,1, 0 }; // '1'或 '|'字型{ 1.0, 0.5, 0.25, 0.125 };input[4] = { 1,1,0, 1,0,1.2, 1,1,1 }; //“口”字型+{ 1.0, 0.5, 0.25, 0.125 };std::vector<float> target[Num训练数据的个数s];target[0] = { 1.0, 0,0,0 };// , 0};//1 , 0}; //0.0, 1.0, 0.5}; //{ 0.0, 1.0 };target[1] = { 0, 1.0 ,0,0 };// , 0};//- 91.0, 0};// , 0, 0}; //target[2] = { 0,0,1.0,0 };// , 0};//+ 1.0, 0.5};target[3] = { 1.0 ,0,0, 0.5 };// , 0}; //1target[4] = { 0,0,0,0 };// , 1.0}; //“口”*/vector<float> target[Num训练数据的个数s];input[0] = { 0,0,0, 1,1,1, 0,0,0 }; target[0] = { 0, 1 }; //"-"input[1] = { 0,1,0, 0,1,0, 0,1,0 }; target[1] = { 1.0, 0 };input[2] = { 1,1,1, 0,0,0, 0,0,0 }; target[2] = { 0, 0.5 };input[3] = { 0,0,1, 0,0,1, 0,0,1 }; target[3] = { 0.9, 0 };for (int i = 0; i < 50000; ++i) {//for110ifor (int jj = 0; jj < Num训练数据的个数s - 1; ++jj) {//for (auto& val: input ) {nn.train(input[jj], target[jj], 0.001);if (0 ==i % 10000) { cout << "[Lost:" << Loss误差损失之和001 << endl; }}//for220jj}//for110icout << endl;//--------------------------------------input[1] = { 0,0,0, 1,1, 0.98, 0,0,0 }; //1/ std::vector<float> outpu输出数据001t = nn.predict(input[0]);for (auto& val : outpu输出数据001t)std::cout << std::fixed << std::setprecision(9) << val << " ";cout << endl;//-------------------------------------------------------------std::string str0001;do {std::cout << std::endl << "请输入一个字符串(要求字符串是包含9个由逗号分隔的数字的字符串,如 1,2,0,0,5,0,0,8,9等): " << std::endl;std::getline(std::cin, str0001);std::stringstream s01s001(str0001);for (int i = 0; i < 9; ++i) {std::string temp;std::getline(s01s001, temp, ',');input[1][i] = (float)std::stof(temp); // 将字符串转化为整数}std::cout << "数字数组为: ";for (int i = 0; i < 9; ++i) {std::cout << input[1][i] << " ";}outpu输出数据001t = nn.predict(input[1]);std::cout << std::endl;for (auto& val : outpu输出数据001t)std::cout << std::fixed << std::setprecision(9) << val << " ";} while (true);// 1 == 1);//======================================cout << "Hello World!\n";
}//相关文章:
梯度下降230820a)
C++最易读手撸神经网络两隐藏层(任意Nodes每层)梯度下降230820a
这是史上最简单、清晰,最易读的…… C语言编写的 带正向传播、反向传播(Forward ……和Back Propagation)……任意Nodes数的人工神经元神经网络……。 大一学生、甚至中学生可以读懂。 适合于,没学过高数的程序员……照猫画虎编写人工智能、…...

机器学习理论笔记(二):数据集划分以及模型选择
文章目录 1 前言2 经验误差与过拟合3 训练集与测试集的划分方法3.1 留出法(Hold-out)3.2 交叉验证法(Cross Validation)3.3 自助法(Bootstrap) 4 调参与最终模型5 结语 1 前言 欢迎来到蓝色是天的机器学习…...
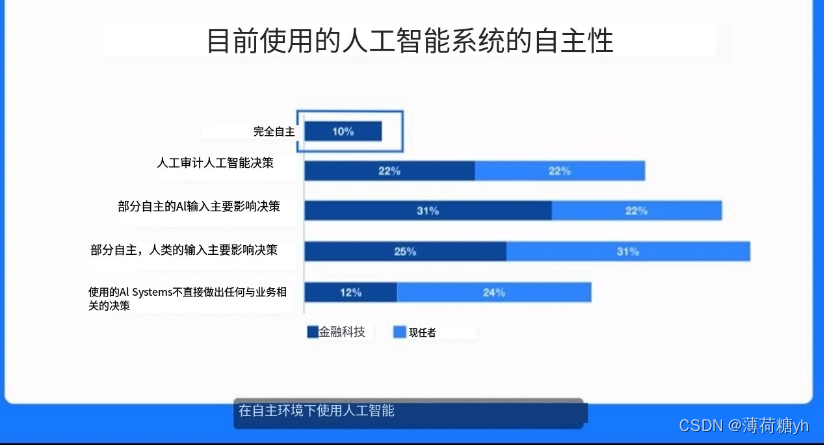
10*1000【2】
知识: -----------金融科技背后的技术---------------- -------------三个数字化趋势 1.数据爆炸:internet of everything(iot);实时贡献数据;公有云服务->提供了灵活的计算和存储。 2.由计算能力驱动的&#x…...

“探秘JS加密算法:MD5、Base64、DES/AES、RSA你都知道吗?”
目录 1、什么是JS、JS反爬是什么?JS逆向是什么? 2、JS逆向的大致流程 3、逆向的环境搭建 3.1、安装node.js 3.2、安装js代码调试工具(vscode) 3.3、安装PyExecJs模块 4、JS常见加密算法 4.1、Base64算法 4.2、MD5算法 4.3、DES/AES算法 4.2.2 AES与DES的…...
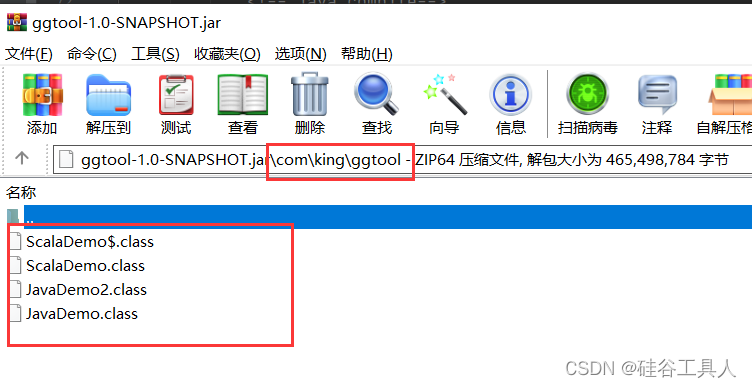
Spark项目Java和Scala混合打包编译
文章目录 项目结构Pom完整文件编译查看 实际开发用有时候引用自己写的一些java工具类,但是整个项目是scala开发的spark程序,在项目打包时需要考虑到java和scala混合在一起编译。 今天看到之前很久之前写的一些打包编译文章,发现很多地方不太对…...
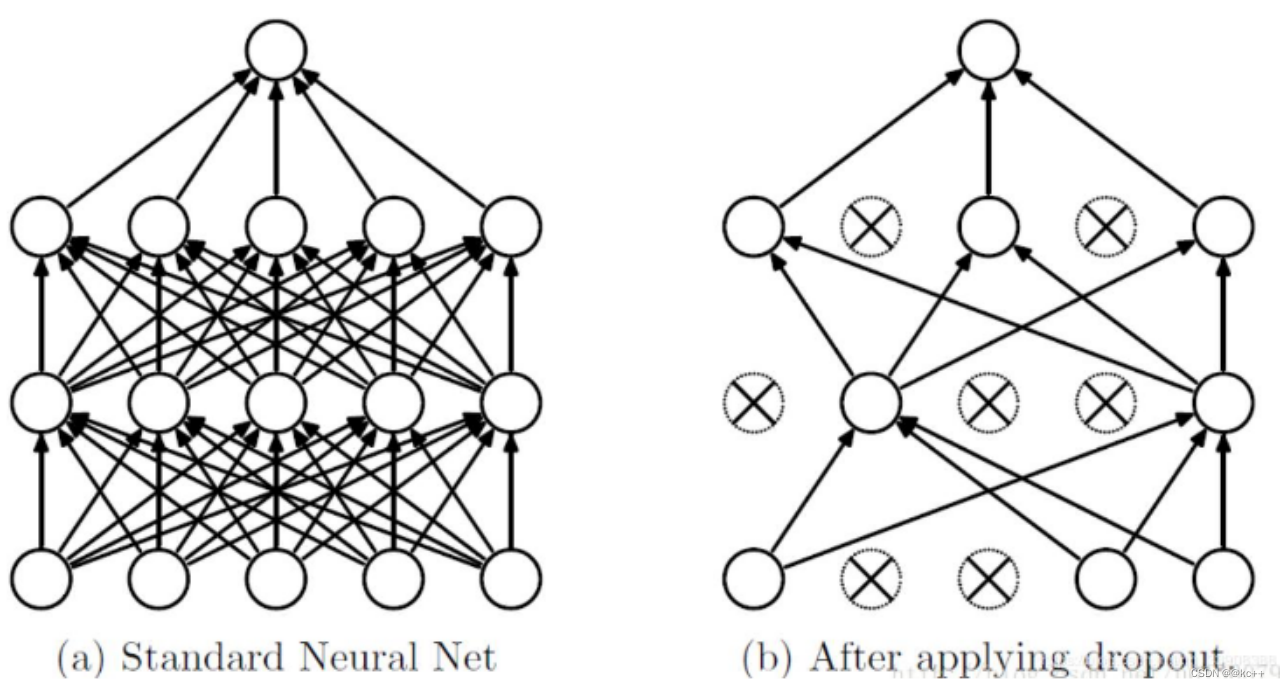
深度学习处理文本(NLP)
文章目录 引言1. 反向传播1.1 实例流程实现1.2 前向传播1.3 计算损失1.4 反向传播误差1.5 更新权重1.6 迭代1.7 BackPropagation & Adam 代码实例 2. 优化器 -- Adam2.1 Adam解析2.2 代码实例 3. NLP任务4. 神经网络处理文本4.1 step1 字符数值化4.2 step 2 矩阵转化为向量…...
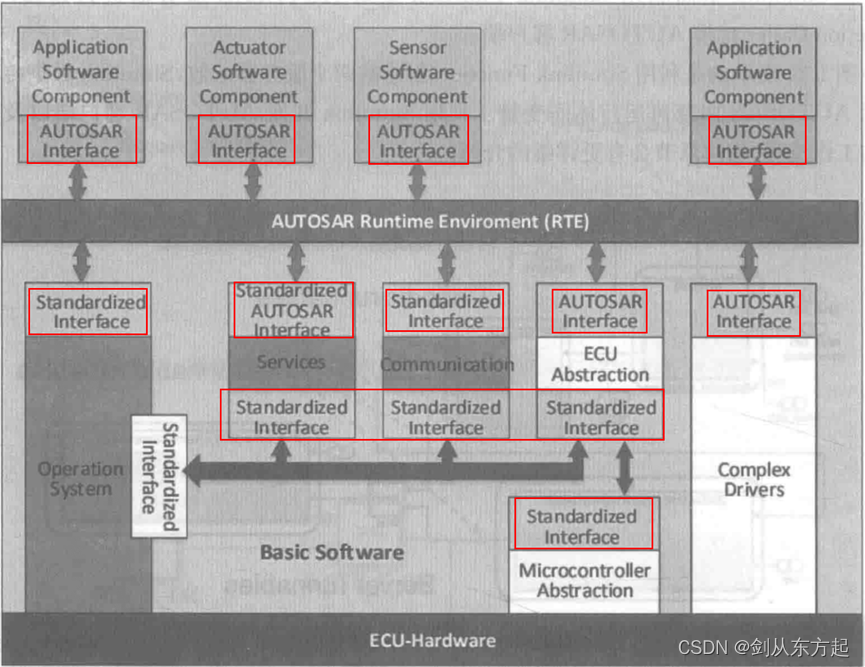
汽车电子笔记之:AUTOSAR方法论及基础概念
目录 1、AUTOSAR方法论 2、AUTOSAR的BSW 2.1、MCAL 2.2、ECU抽象层 2.3、服务层 2.4、复杂驱动 3、AUTOSAR的RTE 4、AUTOSAR的应用层 4.1、SWC 4.2、AUTOSAR的通信 4.3、AUTOSAR软件接口 1、AUTOSAR方法论 AUTOSAR为汽车电子软件系统开发过程定义了一套通用的技术方法…...

鼠标拖拽盒子移动
目录 需求思路代码页面展示【补充】纯js实现 需求 浮动的盒子添加鼠标拖拽功能 思路 给需要拖动的盒子添加鼠标按下事件鼠标按下后获取鼠标点击位置与盒子边缘的距离给 document 添加鼠标移动事件鼠标移动过程中,将盒子的位置进行重新定位侦听 document 鼠标弹起&a…...

AUTOSAR从入门到精通-【应用篇】面向车联网的车辆攻击方法及入侵检测
目录 前言 国内外研究现状 (1)车辆攻击方法的研究 (2)车辆安全防护技术的研究...
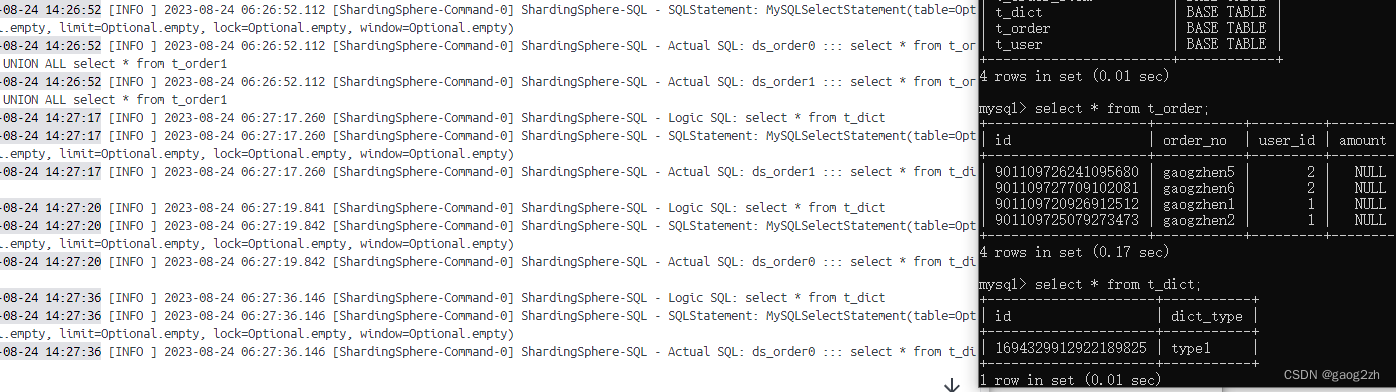
0101prox-shardingsphere-中间件
1 启动ShardingSphere-Proxy 1.1 获取 目前 ShardingSphere-Proxy 提供了 3 种获取方式: 二进制发布包DockerHelm 这里我们使用Docker安装。 1.2 使用Docker安装 step1:启动Docker容器 docker run -d \ -v /Users/gaogzhen/data/docker/shardings…...

FactoryBean和BeanFactory:Spring IOC容器的两个重要角色简介
目录 一、简介 二、BeanFactory 三、FactoryBean 四、区别 五、使用场景 总结 一、简介 在Spring框架中,IOC(Inversion of Control)容器是一个核心组件,它负责管理和配置Java对象及其依赖关系,实现了控制反转&a…...
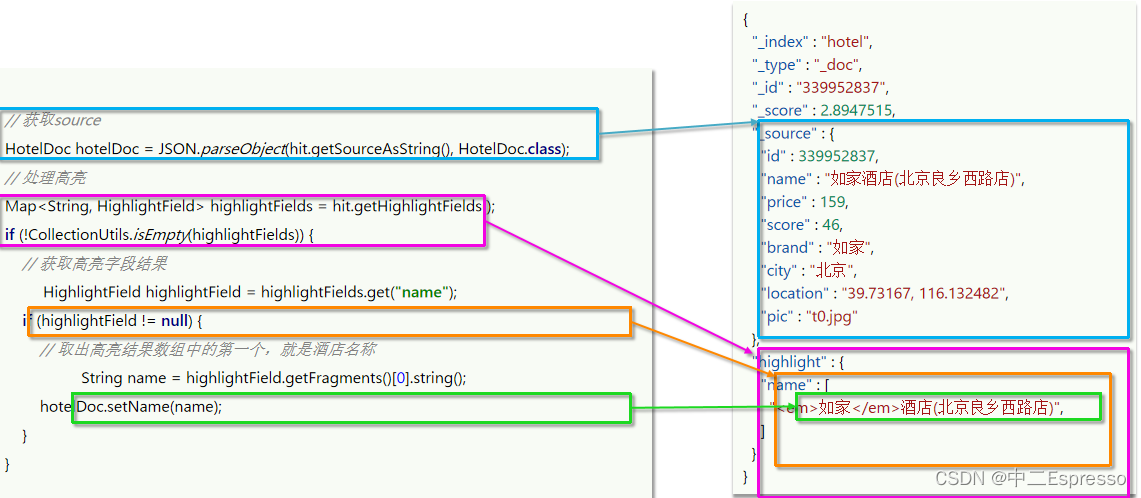
微服务中间件--分布式搜索ES
分布式搜索ES 11.分布式搜索 ESa.介绍ESb.IK分词器c.索引库操作 (类似于MYSQL的Table)d.查看、删除、修改 索引库e.文档操作 (类似MYSQL的数据)1) 添加文档2) 查看文档3) 删除文档4) 修改文档 f.RestClient操作索引库1) 创建索引库2) 删除索引库/判断索引库 g.RestClient操作文…...
触摸屏与PLC之间 EtherNet/IP无线以太网通信
在实际系统中,同一个车间里分布多台PLC,用触摸屏集中控制。通常所有设备距离在几十米到上百米不等。在有通讯需求的时候,如果布线的话,工程量较大耽误工期,这种情况下比较适合采用无线通信方式。 本方案以MCGS触摸屏和…...

Crontab定时任务运行Docker容器(Ubuntu 20)
对于一些离线预测任务,或者D1天的预测任务,可以简单地采用Crontab做定时调用项目代码运行项目 Crontab简介: Linux crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令&…...
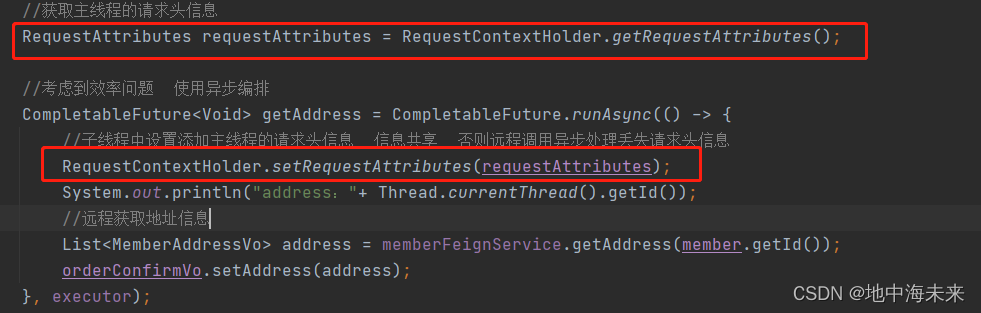
Fegin异步情况丢失上下文问题
在微服务的开发中,我们经常需要服务之间的调用,并且为了提高效率使用异步的方式进行服务之间的调用,在这种异步的调用情况下会有一个严重的问题,丢失上文下 通过以上图片可以看出异步丢失上下文的原因是不在同一个线程,…...

《Linux从练气到飞升》No.17 进程创建
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...

python + pyside2,pyside6,运行错误
在visual studio code运行pyside的时候报错 qt.qpa.plugin: Could not find the Qt platform plugin “windows“ in 后来发现在cmd命令行可以正常运行,应该是VScode和虚拟机类似的问题。 额外设置一下环境变量就可以了。 执行print(os.path.dirname(PySide6.__f…...
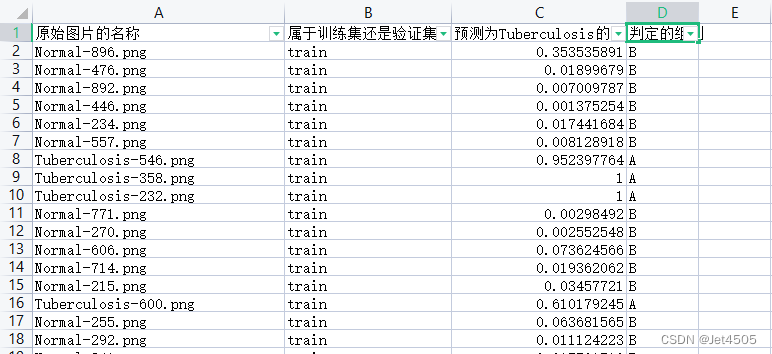
第60步 深度学习图像识别:误判病例分析(Pytorch)
基于WIN10的64位系统演示 一、写在前面 上期内容基于Tensorflow环境做了误判病例分析(传送门),考虑到不少模型在Tensorflow环境没有迁移学习的预训练模型,因此有必要在Pytorch环境也搞搞误判病例分析。 本期以SqueezeNet模型为…...
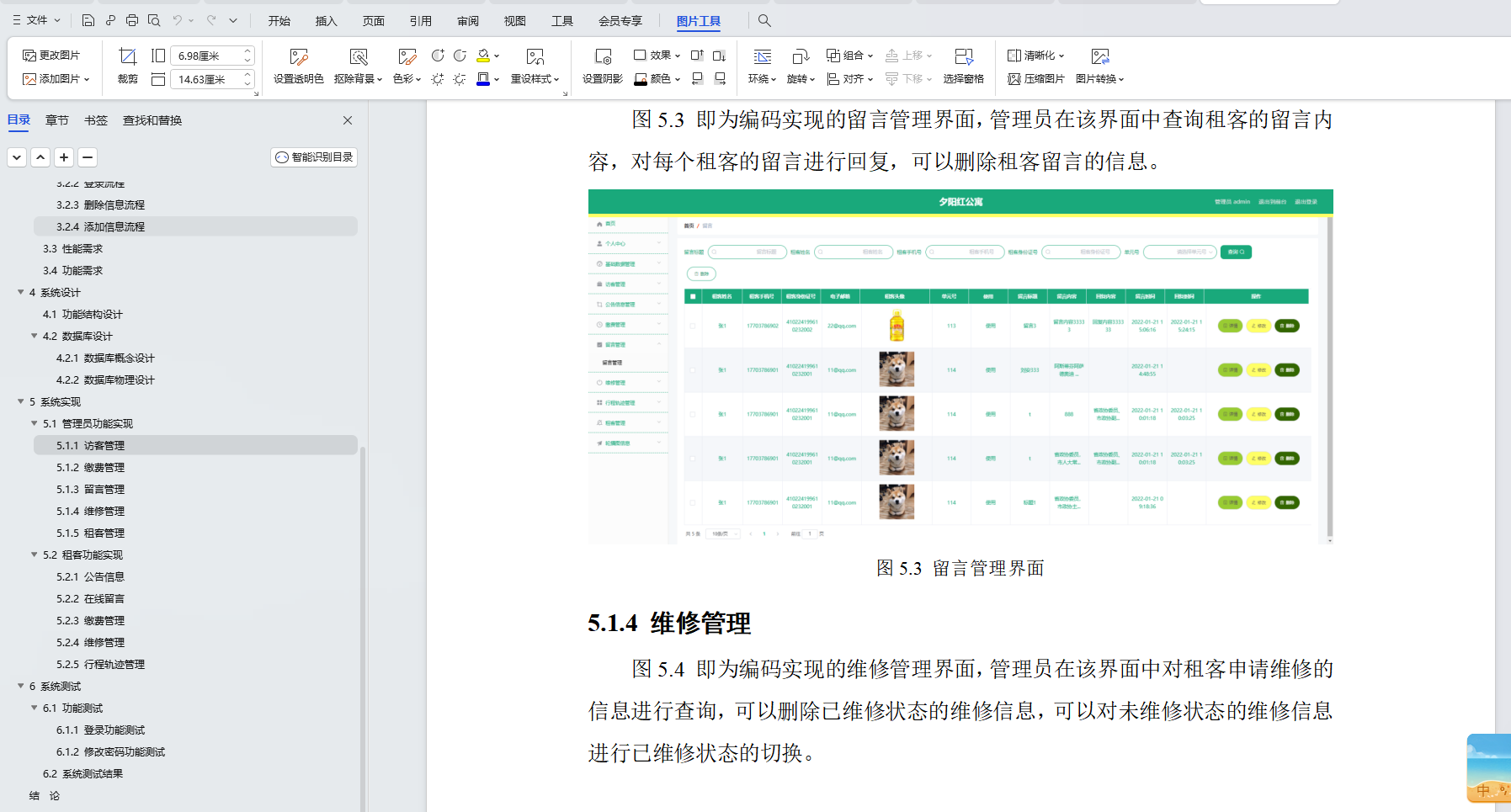
基于Java+SpringBoot+vue前后端分离夕阳红公寓管理系统设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

远控木马病毒分析
一、病毒简介 SHA256:880a402919ba4e896f6b4b2595ecb7c06c987b025af73494342584aaa84544a1 MD5:0902b9ff0eae8584921f70d12ae7b391 SHA1:f71b9183e035e7f0039961b0ac750010808ebb01 二、行为分析 同样在我们win7虚拟机中,使用火绒剑进行监控,分析行为…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...