neo4j 图数据库 springboot
一.安装
neo4j社区版在liunx安装部署
https://blog.csdn.net/u013946356/article/details/81736232
二.知识图数据导入
参考:https://notemi.cn/neo4j-import-csv-file-data.html
http://openkg.cn/dataset/ch4masterpieces
放在对应的import文件夹下面

导入数据
LOAD CSV WITH HEADERS FROM "file:///xiyouji.csv" AS line
MERGE (p:person{name:line.head});LOAD CSV WITH HEADERS FROM "file:///xiyouji.csv" AS line
MERGE (p:person{name:line.tail});LOAD CSV WITH HEADERS FROM "file:///xiyouji.csv" AS line
match (from:person{name:line.tail}),(to:person{name:line.head})
merge (from)-[r:rel{label:line.label,relation:line.relation}]->(to)
三.neo4j 语法
官网地址:https://neo4j.com/docs/cypher-manual/3.5/clauses/match/
创建节点(多次执行,会创建相同的多个节点)CREATE (john:Person {name: 'John'})
CREATE (joe:Person {name: 'Joe'})
CREATE (steve:Person {name: 'Steve'})
CREATE (sara:Person {name: 'Sara'})
CREATE (maria:Person {name: 'Maria'})
CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve)
CREATE (john)-[:FRIEND]->(sara)-[:FRIEND]->(maria)CREATE (adam:User { name: 'Adam' }),(pernilla:User { name: 'Pernilla' }),(david:User { name: 'David'}),(adam)-[:FRIEND]->(pernilla),(pernilla)-[:FRIEND]->(david)多个标签到节点
m:节点名
标签名称:Cinema,Film,Movie,Picture
CREATE (m:Movie:Cinema:Film:Picture)MERGE 如果节点不存在,会创建,如果节点的属性没有跟现有节点匹配上,则会创建新节点CREATE (N0:Person {chauffeurName: 'John Brown', name: 'Charlie Sheen', bornIn: 'New York'})下面就会创建新的节点
MERGE (charlie { name: 'Charlie Sheen', age: 10 })
RETURN charlieMERGE (charlie { name: 'Charlie Sheen', age: 20 })
RETURN charlie下面不会创建新的节点
MERGE (charlie { name: 'Charlie Sheen',bornIn: 'New York'})
RETURN charlie如果“keanu”节点不存在,则创建节点,设置属性created
如果存,则设置属性lastSeen,多个属性逗号分隔
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
ON MATCH SET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeenMATCH (p:Info) where id (p)=195
MATCH (n:Info) where id (n)=196
MERGE (p)-[r:HAVE]->(n)
RETURN r查询查询所有
MATCH (n)
RETURN n符号 -- 表示与关系相关,而不考虑关系的类型或方向
MATCH (:Person { name: 'Oliver Stone' })--(movie:Movie)
RETURN movie.title等价于返回节点和关系
MATCH p =(actor { name: 'Charlie Sheen' })-[:ACTED_IN*2]-(co_actor)
RETURN relationships(p)查询两个点的单个最短路径
MATCH (start:Person {name: 'Charlie Sheen'}), (end:Person {name: 'Michael Douglas'})
MATCH path = shortestPath((start)-[*]-(end))
RETURN pathAll shortest paths 所有最短路径
MATCH (martin:Person { name: 'Martin Sheen' }),(michael:Person { name: 'Michael Douglas' }), p = allShortestPaths((martin)-[*]-(michael))
RETURN p查询多关系的
MATCH (wallstreet { title: 'Wall Street' })<-[:ACTED_IN|:DIRECTED]-(person)
RETURN person.name查朋友的朋友
MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof)
RETURN john.name, fof.name匹配他们的朋友,并仅返回那些具有以“S”开头的“name”属性的关注用户
MATCH (user)-[:FRIEND]->(follower)
WHERE user.name IN ['Joe', 'John', 'Sara', 'Maria', 'Steve'] AND follower.name =~ 'S.*'
RETURN user.name, follower.name找到朋友数大于1的
MATCH (n {name: 'John'})-[:FRIEND]-(friend)
WITH n, count(friend) AS friendsCount
WHERE friendsCount > 1
RETURN n, friendsCount查询叫Maria的人是哪一层关系
MATCH (me:Person {name: 'John'})-[:FRIEND*1..3]-(friend:Person {name: 'Maria'})
RETURN CASEWHEN size((me)-[:FRIEND]-(friend)) > 0 THEN 'Friend'WHEN size((me)-[:FRIEND]-()-[:FRIEND]-(friend)) > 0 THEN 'Friend of Friend'WHEN size((me)-[:FRIEND]-()-[:FRIEND]-()-[:FRIEND]-(friend)) > 0 THEN 'Friend of Friend of Friend'ELSE 'Not Connected'
END AS relationship拼接属性[]来查询,过滤动态计算的节点属性
CREATE (a:Restaurant { name: 'Hungry Jo', rating_hygiene: 10, rating_food: 7 }),(b:Restaurant { name: 'Buttercup Tea Rooms', rating_hygiene: 5, rating_food: 6 }),(c1:Category { name: 'hygiene' }),(c2:Category { name: 'food' })
WITH a, b, c1, c2
MATCH (restaurant:Restaurant),(category:Category)
WHERE restaurant["rating_" + category.name]> 6
RETURN DISTINCT restaurant.nameUNWIND关键字用于展开列表或集合中的元素
WITH关键字用于将查询结果传递给下一个查询子句,它类似于SQL中的SELECT子句,可以用于选择和重命名列、聚合、排序等操作WITH ['John', 'Mark', 'Jonathan', 'Bill'] AS somenames
UNWIND somenames AS names
WITH names AS candidate
WHERE candidate STARTS WITH 'Jo'
RETURN candidate方括号将从起始索引 1 提取元素,直到(但不包括)结束索引 3
WITH ['Anne', 'John', 'Bill', 'Diane', 'Eve'] AS names
RETURN names[1..3] AS result从'Anders'开始,找到所有匹配的节点,按名称降序排列并获得顶部结果,
然后找到与该顶部结果连接的所有节点,并返回它们的名称。
MATCH (n { name: 'Anders' })--(m)
WITH m
ORDER BY m.name DESC LIMIT 1
MATCH (m)--(o)
RETURN o.name使用 exists() 函数仅包含存在属性的节点或关系。
MATCH (n)
WHERE exists(n.belt)
RETURN n.name, n.belt使用 STARTS WITH 进行前缀字符串搜索
使用 ENDS WITH 进行后缀字符串搜索
使用 CONTAINS 进行子字符串搜索
MATCH (n)
WHERE n.name STARTS WITH 'Pet'
RETURN n.name, n.age不以'y'结尾
MATCH (n)
WHERE NOT n.name ENDS WITH 'y'
RETURN n.name, n.age使用正则表达式进行匹配
不区分大小写的正则表达式
MATCH (n)
WHERE n.name =~ '(?i)Tim.*'
RETURN n.name, n.age排序,跳过,限制
MATCH (n)
RETURN n.name
ORDER BY n.name desc
SKIP 1
LIMIT 2MATCH (e:Employee)
WHERE e.id IS NOT NULL
RETURN e.id,e.name,e.sal,e.deptnoMATCH (e:Employee)
WHERE e.id IN [123,124]
RETURN e.id,SUBSTRING(e.name,0,4),e.sal,e.deptnoMATCH (e:Employee)
RETURN SUM(e.sal),AVG(e.sal)关系
最小长度为 3,最大长度为 5。它描述了 4 个节点和 3 个关系、5 个节点和 4 个关系或 6 个节点和 5 个关系的图,所有这些都在一条路径中连接在一起。
(a)-[*3..5]->(b)(a)-[*3..]->(b)
(a)-[*..5]->(b)
任意长度的路径
(a)-[*]->(b)MATCH (e:Customer),(cc:CreditCard)
CREATE (e)-[r:DO_SHOPPING_WITH ]->(cc)如果节点之间没有KNOWS关系则创建
MATCH (charlie:Person { name: 'Charlie Sheen' }),(oliver:Person { name: 'Oliver Stone' })
MERGE (charlie)-[r:KNOWS]-(oliver)
RETURN r存在的点,创建带属性的关系
MATCH (cust:Info),(cc:OneId)
where Id(cust)=152 and Id(cc)= 98
CREATE (cust)-[r:one_with{createTime:"2023-08-14",priority:1,uid:"111",delete:0}]->(cc)
RETURN r复制节点关系,删除原有节点关系
MATCH (a:Info)-[r:one_with]->(b:OneId)
WHERE Id(a)=152 and Id(b)= 98
WITH a, b, r
MATCH (c:OneId)
WHERE Id(c)= 170
CREATE (a)-[newR:one_with]->(c)
SET newR = r
DELETE r
RETURN a, c,newR双向关联
MATCH (a:Node {name: 'A'})
MATCH (b:Node {name: 'B'})
CREATE (a)-[:RELATIONSHIP_TYPE]->(b), (b)-[:RELATIONSHIP_TYPE]->(a)新增节点和关系MATCH (fb1:FaceBookProfile1)-[like:LIKES]->(fb2:FaceBookProfile2)
RETURN likeCREATE (video1:YoutubeVideo1{title:"Action Movie1",updated_by:"Abc",uploaded_date:"10/10/2010"})
-[movie:ACTION_MOVIES{rating:1}]->
(video2:YoutubeVideo2{title:"Action Movie2",updated_by:"Xyz",uploaded_date:"12/12/2012"}) 查询关系MATCH (cust)-[r:DO_SHOPPING_WITH]->(cc)
RETURN cust,cc删除所有节点和关系
MATCH (n)
DETACH DELETE nDELETE操作用于删除节点和关联关系
删除节点MATCH (start)-[r:HAVE]->(end) where id(r)=152 DELETE r删除关系和节点(多条关键全删)
MATCH (cc: CreditCard)-[rel]-(c:Customer)
DELETE rel,cc,cREMOVE操作用于删除标签和属性。
删除属性
match(c:Book) where c.id=122 REMOVE c.price return c删除标签
MATCH (n { name: 'David' })
REMOVE n:person:gay
RETURN n.name, labels(n) AS labelsset添加属性和修改属性值MATCH (book:Book)
SET book.title = 'superstar',book.price=100
RETURN book+= 增加修改属性
CREATE (a:Person { name: 'Jane', age: 20 })
WITH a
MATCH (p:Person { name: 'Jane' })
SET p += { name: 'Ellen', livesIn: 'London' }
RETURN p.name, p.age, p.livesInMATCH (n {name: 'John'})-[:FRIEND]-(friend)
WITH n, count(friend) AS friendsCount
SET n.friendsCount = friendsCount
RETURN n.friendsCount增加多个标签
MATCH (n { name: 'David' })
SET n:person:gay
RETURN n.name, labels(n) AS labelsFOREACH
从A节点到D节点的路径上都增加一个属性
MATCH p =(begin)-[*]->(END )
WHERE begin.name = 'A' AND END .name = 'D'
FOREACH (n IN nodes(p)| SET n.marked = TRUE )UNION合并
需要加 as 别名 保持一致,不然报错MATCH (cc:CreditCard) RETURN cc.id as id,cc.number as number
UNION
MATCH (dc:DebitCard) RETURN dc.id as id ,dc.number as numberID和TYPE关系函数来检索关系的Id和类型详细信息。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN ID(movie),TYPE(movie)它用于知道关系的开始节点。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN STARTNODE(movie)它用于知道关系的结束节点。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN ENDNODE(movie)创建索引(相同标签名称的所有节点的属性创建索引)
CREATE INDEX ON :Customer (name)删除索引DROP INDEX ON :Customer (name)唯一索引
CREATE CONSTRAINT ON (cc:CreditCard)
ASSERT cc.number IS UNIQUE删除唯一索引DROP CONSTRAINT ON (cc:CreditCard)
ASSERT cc.number IS UNIQUEUNWIND [{key: 'key1', val: 'val1', insert: true, priority: 'priority1'}, {key: 'key2', val: 'val2', insert: true, priority: 'priority2'}] AS data
MERGE (n:Label {key: data.key, val: data.val})
ON CREATE SET n.insert = data.insert, n.priority = data.priority
RETURN nWITH ['John', 'Mark', 'Jonathan', 'Bill'] AS names
WITH names AS candidate
WHERE candidate STARTS WITH 'Jo'
RETURN candidate导入数据
LOAD CSV WITH HEADERS FROM "file:///xiyouji.csv" AS line
MERGE (p:person{name:line.head});LOAD CSV WITH HEADERS FROM "file:///xiyouji.csv" AS line
MERGE (p:person{name:line.tail});LOAD CSV WITH HEADERS FROM "file:///xiyouji.csv" AS line
match (from:person{name:line.tail}),(to:person{name:line.head})
merge (from)-[r:rel{label:line.label,relation:line.relation}]->(to)UNWIND $rows as row MATCH (startNode) WHERE ID(startNode) = row.startNodeId WITH row,startNode MATCH (endNode) WHERE ID(endNode) = row.endNodeId
CREATE (startNode)-[rel:`one_with`]->(endNode) SET rel += row.props RETURN row.relRef as ref, ID(rel) as id, $type as type with params {type=rel, rows=[{startNodeId=177, relRef=-12, endNodeId=176, props={uid=646257b2-cfed-4e14-aa43-88e2af0d0ea5, createTime=2023-08-17 09 59 53, priority=0, delete=0}}]}
四.举例
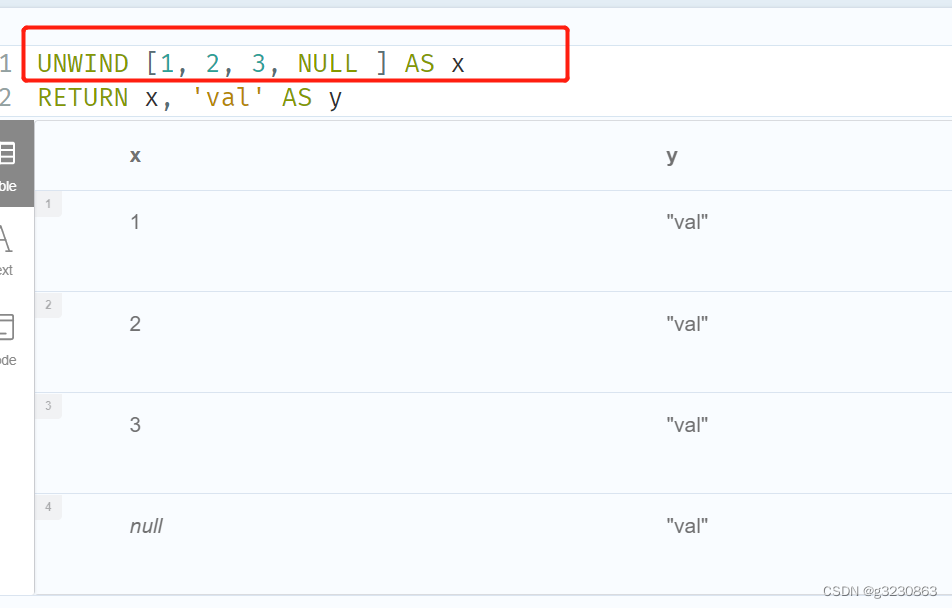
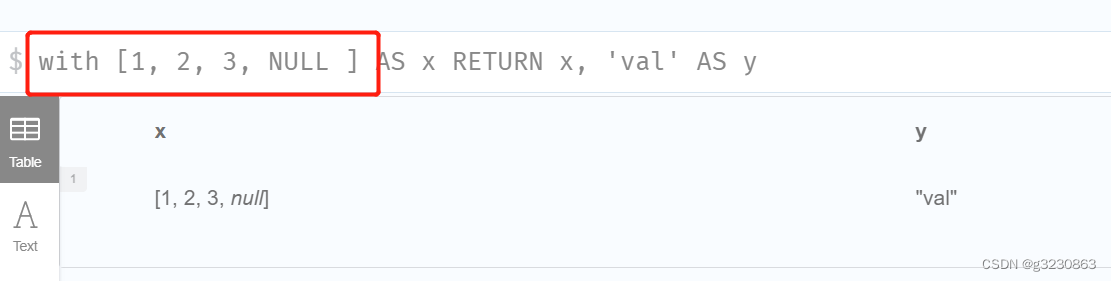
UNWIND 将列表里的值展开
CREATE (N0:Person {name: 'Anders'})
CREATE (N1:Person {name: 'Becky'})
CREATE (N2:Person {name: 'Cesar'})
CREATE (N3:Person {name: 'Dilshad'})
CREATE (N4:Person {name: 'George'})
CREATE (N5:Person {name: 'Filipa'})CREATE (N0)-[:KNOWS]->(N3)
CREATE (N0)-[:KNOWS]->(N2)
CREATE (N0)-[:KNOWS]->(N1)
CREATE (N1)-[:KNOWS]->(N4)
CREATE (N2)-[:KNOWS]->(N4)
CREATE (N3)-[:KNOWS]->(N5)
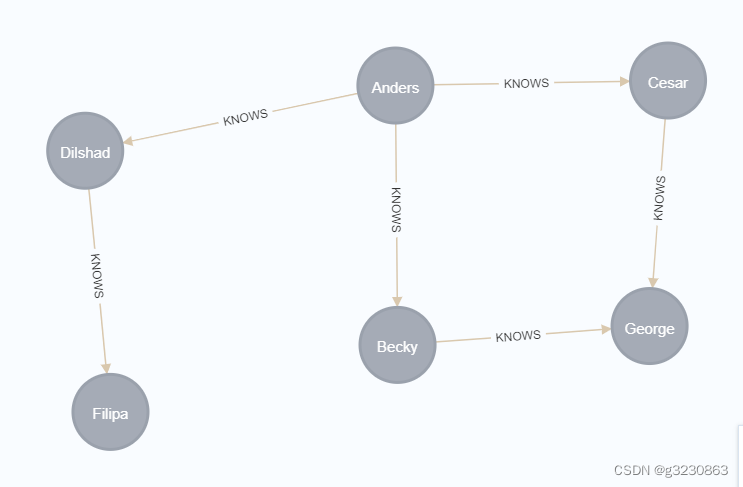
MATCH (me)-[:KNOWS*1..2]-(remote_friend)
WHERE me.name = 'Filipa'
RETURN remote_friend.name
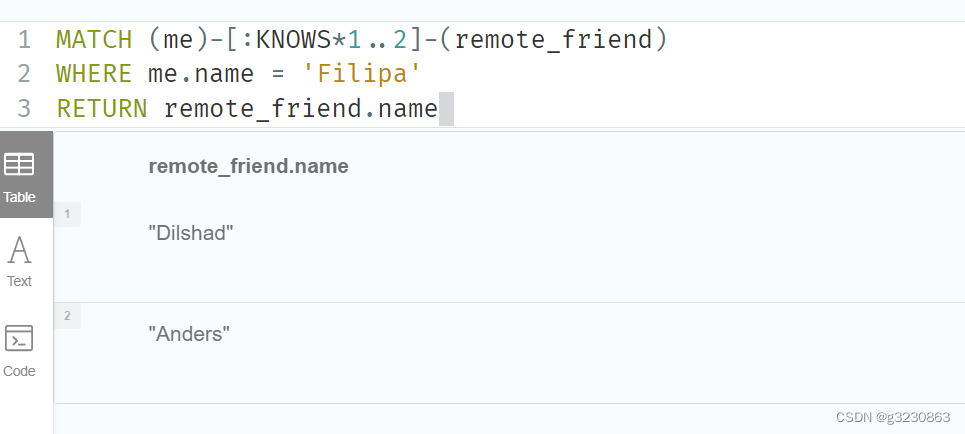
请注意,可变长度关系不能与 CREATE 和 MERGE 一起使用
五. 与springboot 整合
下面实现了Neo4j Spring动态起始节点类型
https://www.codeleading.com/article/35872569441/
举例:
自定义Cypher语句
public interface OneDynamicRepository extends Neo4jRepository<OneDynamic, Long> {@Query("MATCH (startNode:Info) where Id(startNode)=$startId MATCH (endNode:OneId) where Id(endNode)=$endId MERGE (startNode)-[r:one_with{ priority: $priority, type:$type ,uid:$uid , delete:0 } ]->(endNode) RETURN r,startNode,endNode ")List<OneDynamic> mergeRelationship(@Param("startId") Long startId, @Param("endId") Long endId , @Param("priority") Integer priority,@Param("type") String type,@Param("uid") String uid);
}
相关文章:
neo4j 图数据库 springboot
一.安装 neo4j社区版在liunx安装部署 https://blog.csdn.net/u013946356/article/details/81736232 二.知识图数据导入 参考:https://notemi.cn/neo4j-import-csv-file-data.html http://openkg.cn/dataset/ch4masterpieces 放在对应的import文件夹下面 导入数据 LOAD C…...
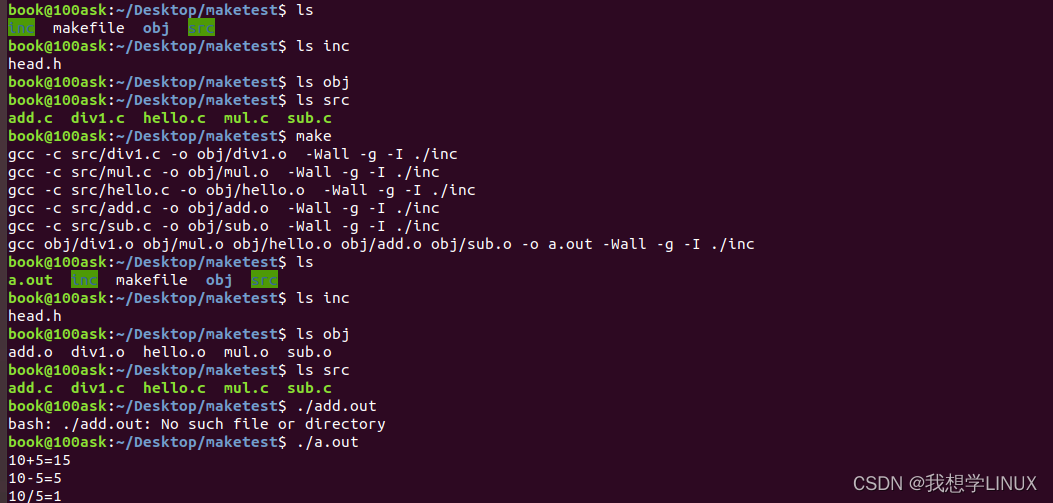
Linux下的系统编程——makefile入门(四)
前言: 或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员,makefile还是要懂。这就好像现在有这么多的HTML的编辑器,但如果你想成为一个专…...

Mybatis的综合案例-学生信息查询系统 用于校验是否真正学习掌握了动态SQL
Mybatis的综合案例-学生信息查询系统 需求一:当用户输入的学生姓名不为空,则只根据学生信息进行查询; 当用户输入的学生姓名为空,且专业不为空,那么就根据学生专业进行学生的查询 需求二:查询所有id值小于5的学生信息…...
)
力扣:70. 爬楼梯(Python3)
题目: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 来源:力扣(LeetCode) 链接:力扣(LeetCode)官网 - 全球极客…...
陕西广电 HG6341C FiberHome烽火 光猫获取超级密码 改桥接模式 提升网速
光猫默认的路由模式实测在100M宽带下只能跑到60M左右,只有改成桥接模式才能跑满,不损失性能。但是改桥接需要给运营商打电话,有的时候不想麻烦他们,这时获取超级密码进行更改就是一个不错的选择了 分析 之前写了一篇HGU B2 光猫的…...

无涯教程-PHP - 移除的扩展
以下扩展已从PHP 7开始删除- eregmssqlmysqlsybase_ct 以下SAPI已从PHP 7开始删除- aolserverapacheapache_hooksapache2filtercaudiumcontinuityisapimilternsapiphttpdpi3webroxenthttpdtuxwebjames PHP - 移除的扩展 - 无涯教程网无涯教程网提供以下扩展已从PHP 7开始删除…...
笔记:transformer系列
1、和其他网络的比较 自注意力机制适合处理长文本,并行度好,在GPU上,CNN和Self-attention性能差不多,在TPU(Tensor Processing Uni)效果更好。 总结: 自注意力池化层将当做key,value,query来…...

Mysql socket连接测试
配置如下: socket /data/mysql/data/mysql.sock //套接字文件 在数据库没有任何连接的情况下,可以看到3306端口和socket端口都在监听 [mysqlt3-dtpoc-dtpoc-web04 bin]$ netstat -an | grep -i 3306 tcp 0 0 0.0.0.0:3306 0.…...

探究分布式操作系统的本质
探究分布式操作系统的本质 有一位网友问,分布式操作系统的本质是什么,今天就来说说这个话题。 首先,我们需要明确什么是分布式操作系统。 从大范围来理解,分布式操作系统是传统单机操作系统的延伸,可以看作是在多台独…...
opencv-dnn
# utils_words.txt 标签文件 import osimage_types (".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff")def list_images(basePath, containsNone):# return the set of files that are validreturn list_file…...

如何选择合适的开源许可证?
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

【前端】深入解析CSS:选择器、显示模式、背景属性和特征剖析
目录 一、前言二、CSS的复合选择器1、后代选择器①、语法②、注意事项 2、子选择器①、语法②、注意事项 3、并集选择器①、语法②、注意事项 4、链接伪类选择器①、语法②、注意事项 三、CSS元素显示模式转换1、转换为块元素display:block2、转换为行内元素display:inline3、转…...
| 动态规划Part04:01背包)
算法训练营第三十四天(8.23)| 动态规划Part04:01背包
目录 Leecode 1049.最后一块石头的重量II Leecode 494.目标和 Leecode 474.一和零 Leecode 1049.最后一块石头的重量II 题目地址:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目类型:01背包 class Solution { public:int…...

【python】tkinter使用多进程打包成exe后multiprocessing无法关闭对应进程
这是由于multiprocessing模块在Windows操作系统下使用fork方法创建子进程时会导致打包成exe后无法正常运行的问题。 可以尝试使用freeze_support函数来解决这个问题。freeze_support函数是在Windows操作系统下用于支持multiprocessing模块的函数。 下面是一个示例代码&#x…...
)
Redis工具类(缓存操作,Object转换成JSON数据)
依赖spring-data-redis-2.4.1.jar Component Data public class RedisUtils {Autowiredprivate RedisTemplate<String, Object> redisTemplate;Resource(name "stringRedisTemplate")private ValueOperations<String, String> valueOperations;/*** 默…...

Linux 下 Java Socket 编程报 java.net.Exception:Permission denied (权限不足)
本人用Linux部署springboot项目时遇见这个错误,原因很简单,就是端口号没有选对。 在linux系统中,端口号再1024以下的需要root权限,只要把端口改成大于1024的就可以了,但避开一些软件的默认端口,如Tomcat的8…...
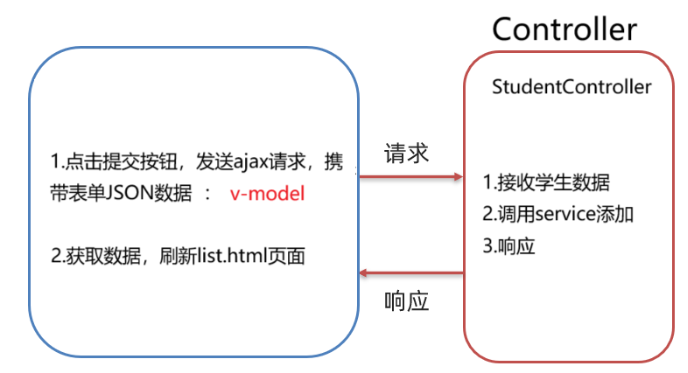
IDEA项目实践——VUE介绍与案例分析
系列文章目录 IDEA项目实践——JavaWeb简介以及Servlet编程实战 IDEA项目实践——Spring集成mybatis、spring当中的事务 IDEA项目实践——Spring当中的切面AOP IDEWA项目实践——mybatis的一些基本原理以及案例 IDEA项目实践——Spring框架简介,以及IOC注解 I…...

vue-canvas基本使用和注意事项-动画闪烁效果-自适应适配不同分辨率问题
前言 canvas画布是html的新特性,熟悉画布我们可以完成很多拖拽,标注,动画的功能 使用canvas实现一个小例子很容易,但是真正在项目中使用时,我们需要注意的地方有很多 canvas基本原理就是它基于渲染方法,根…...

Jmeter 如何才能做好接口测试?
现在对测试人员的要求越来越高,不仅仅要做好功能测试,对接口测试的需求也越来越多! 所以也越来越多的同学问,怎样才能做好接口测试? 要真正的做好接口测试,并且弄懂如何测试接口,需要从如下几…...
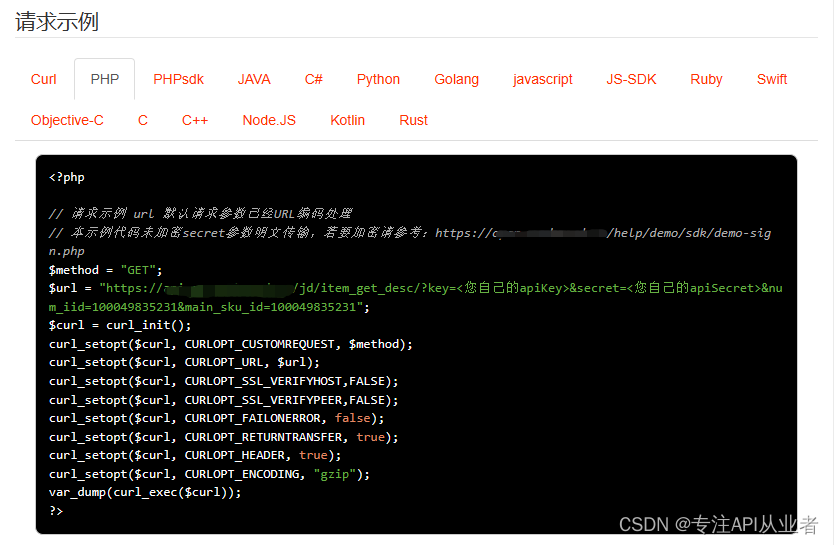
电商平台京东平台获得京东商品描述API接口演示案例
京东商品描述API接口可以获取京东商品描述: 详细介绍商品的特点和功能,让消费者能够了解商品的具体用途和效果。 使用简洁明了的语言,避免使用过于专业的术语和长句子,让消费者能够轻松理解。 重点突出商品的卖点和优势,让消费者能够更加清晰地了解商品的价值 …...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...

小智AI+MCP
什么是小智AI和MCP 如果还不清楚的先看往期文章 手搓小智AI聊天机器人 MCP 深度解析:AI 的USB接口 如何使用小智MCP 1.刷支持mcp的小智固件 2.下载官方MCP的示例代码 Github:https://github.com/78/mcp-calculator 安这个步骤执行 其中MCP_ENDPOI…...
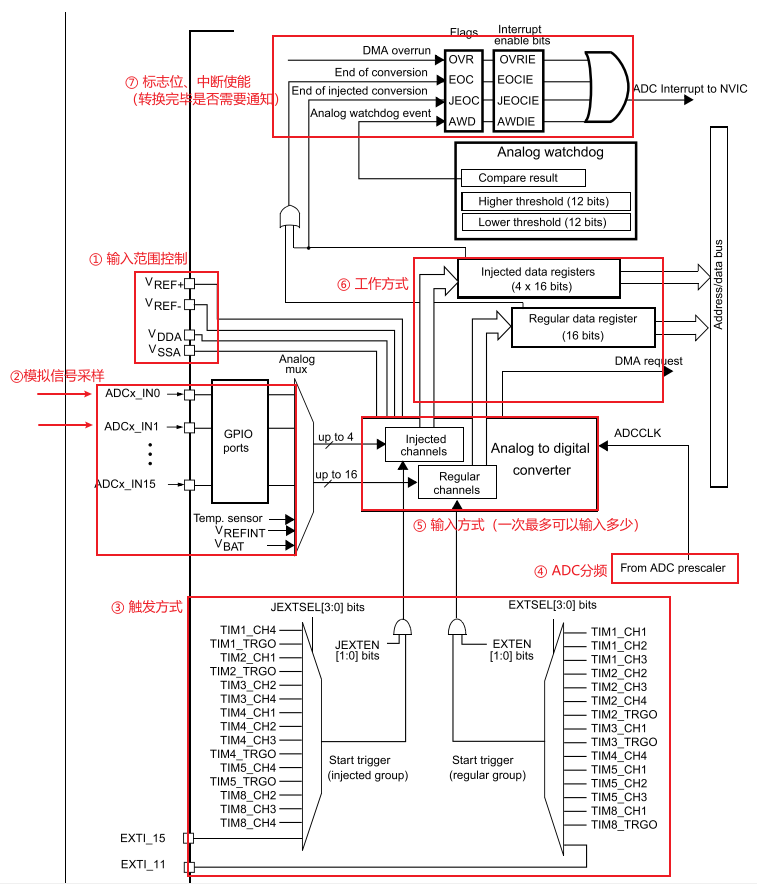
深入解析光敏传感技术:嵌入式仿真平台如何重塑电子工程教学
一、光敏传感技术的物理本质与系统级实现挑战 光敏电阻作为经典的光电传感器件,其工作原理根植于半导体材料的光电导效应。当入射光子能量超过材料带隙宽度时,价带电子受激发跃迁至导带,形成电子-空穴对,导致材料电导率显著提升。…...

第22节 Node.js JXcore 打包
Node.js是一个开放源代码、跨平台的、用于服务器端和网络应用的运行环境。 JXcore是一个支持多线程的 Node.js 发行版本,基本不需要对你现有的代码做任何改动就可以直接线程安全地以多线程运行。 本文主要介绍JXcore的打包功能。 JXcore 安装 下载JXcore安装包&a…...