More Effective C++学习笔记(4)
目录
- 条款16:谨记 80 - 20 法则
- 条款17:考虑使用lazy evaluation(缓式评估)
- 条款18:分期摊还预期的计算成本
- 条款19:了解临时对象来源
- 条款20:协助完成 “ 返回值优化 ”
- 条款21:利用重载技术避免隐式类型转换
- 条款22:考虑以操作符复合形式取代独身形式
- 条款23:考虑使用其他程序库
- 条款24:了解虚拟函数、多继承、虚基类和RTTI(运行时类型辨识)所需的代价
条款16:谨记 80 - 20 法则
- 一个程序80%的资源用于20%的代码上。软件的整体性能几乎总是由构成要素的一小部分决定。你不仅需要找出造成问题的那一小段瓶颈所在,还必须找出办法来改善位于瓶颈处的程序性能。
- 大部分人采用“猜”的方法寻找瓶颈,有一定道理,更好地是借助一些程序分析器,测量每段代码运行时间、消耗的内存空间、函数被调用的频繁度(深究是否有临时对象产生)等所在意的资源。
- 借助可重现程序问题的数据帮忙解决问题。
条款17:考虑使用lazy evaluation(缓式评估)
- 从效率的观点来看,最佳的计算就是根本不计算,关键在于拖延战术。当你使用了lazy evaluation后,采用此种方法的类将推迟计算工作直到系统确实需要这些计算的结果。如果不需要结果,将不用进行计算。
- 区分读写:读操作效率远高于写操作(可能要先产生一个副本,然后再赋值);
- 缓式取出:当生产一个体积很大的对象时,只生产对象的“外壳”,不从磁盘读数据。当对象内的某个字段被需要了,程序才从硬盘取回对应的字段数据。如下例,其中指针可以被换成智能指针。
class LargeObject {
public:LargeObject(ObjectID id); const string& field1() const;int field2() const;double field3() const;const string& field4() const;...
private:ObjectID oid; mutable string *field1Value; //参见下面有关mutable int *field2Value; // "mutable"的讨论mutable double *field3Value;mutable string *field4Value;...
};
LargeObject::LargeObject(ObjectID id)
: oid(id), field1Value(0), field2Value(0), field3Value(0), ...
{}
const string& LargeObject::field1() const
{if (field1Value == 0) {从数据库中为filed 1读取数据,使field1Value 指向这个值;} return *field1Value;
}
当你试图在const成员函数里修改数据时,编译器会出现问题。最好的方法是声明字段指针为mutable,这表示在任何函数里它们都能被修改,甚至在const成员函数里,相当于告诉编译器“我知道我在干啥,没事儿!”。
如果不支持mutable,可以用**“冒牌this”法:产生一个非const指针指向this所指对象**:
const string& LargeObject::field1() const
{// 声明指针, fakeThis, 其与this指向同样的对象// 但是已经去掉了对象的常量属性LargeObject * const fakeThis =const_cast<LargeObject* const>(this); if (field1Value == 0) {fakeThis->field1Value = // 这赋值是正确的,the appropriate data // 因为fakeThis指向的from the database; //对象不是const} return *field1Value;
}
- 当有大量的运算时(例如矩阵运算),可用自定义的数据结构简单的表示两者关系,但具体运算只在需要运算结果的时候进行计算,且大多数时候只需要所有运算结果中的一部分。
- 如果你的计算式必要的,lazy evaluation并不会为你的程序节省任何工作或者时间,反而会因为增加了新的数据结构而增加了时间和内存消耗。只有当你的程序被要求执行某些计算,并且这些计算中有部分计算是可以避免的,lazy evaluation才有效。
条款18:分期摊还预期的计算成本
- over-eager evaluation:超前进度地做 “ 要求以外 ” 的更多工作。例如程序常常需要用到某种结果,我们在得到新数据就计算一次结果进行保存,这样真正要用的时候速度就会很快,降低每次计算的平均成本。
- caching(缓存)那些已经被计算出来而以后还有可能需要的值:
int findCubicleNumber(const string& employeeName)
{// 定义静态map,存储 (employee name, cubicle number)// pairs. 这个 map 是local cache。typedef map<string, int> CubicleMap;static CubicleMap cubes; // try to find an entry for employeeName in the cache;// the STL iterator "it" will then point to the found// entry, if there is one (see Item 35 for details)CubicleMap::iterator it = cubes.find(employeeName); if (it == cubes.end()) {int cubicle =the result of looking up employeeName's cubiclenumber in the database; cubes[employeeName] = cubicle; // add the pair// (employeeName, cubicle)// to the cachereturn cubicle;}else {return (*it).second;}
}
这个方法是使用局部缓存,用开销相对不大的内存中查询来替代开销较大的数据库查询。假如隔间号被不止一次地频繁需要,在findCubicleNumber内使用缓存会减少返回隔间号的平均开销。
- Prefetching(预提取):每次划分出必须比要求更多的资源。例如磁盘控制器从磁盘读取数据时,经验显示如果需要一个地方的数据,则很可能也需要它旁边的数据,可一次性多读取些相邻的数据。动态数组会一次划分出比要求大小更大的数组,保证数组表面上是动态可扩容的。
- 更快的速度经常会消耗更多的内存。Cache运算结果需要更多的内存,但是一旦需要被缓存的结果时就能减少需要重新生成的时间。Prefetch需要空间放置被prefetch的东西,但是它减少了访问它们所需的时间。
条款19:了解临时对象来源
- 临时对象产生的两种情况:(1)为了使函数成功调用而进行隐式类型转换;(2)函数返回对象时。
- 函数参数隐式类型转换:当传入函数的实参和形参类型不符且编译器可以进行隐式转换时,编译器会以实参作为函数参数(例如char)所需类型(string)的构造函数(构造函数string(char))的参数,生成一个临时对象,作为对应同类型的函数形参,直到函数返回,临时对象被销毁。
// 返回ch在str中出现的次数
size_t countChar(const string& str, char ch);
char buffer[MAX_STRING_LEN];
char c;
// 读入到一个字符和字符串中,用setw
// 避免缓存溢出,当读取一个字符串时
cin >> c >> setw(MAX_STRING_LEN) >> buffer;
cout << "There are " << countChar(buffer, c)<< " occurrences of the character " << c<< " in " << buffer << endl;
- 仅当通过传值(by value)方式传递对象或传递常量引用(reference-to-const)参数时,才会发生这些隐式类型转换。当传递一个非常量引用(reference-to-non-const)参数对象,就不会发生。C++语言禁止为非常量引用(reference-to-non-const)产生临时对象,因为非常量引用表明可能修改引用对象,如果允许隐式转换,那么引用的就是临时对象,而修改临时对象没有任何意义。
- 对于大多数返回对象的函数来说,难以被另一个函数替代,从而没有办法避免构造和释放返回值对象。
条款20:协助完成 “ 返回值优化 ”
- 采用返回指针的方法来避免临时对象生成可能会造成使用语法不自然(c = (ab))、资源泄漏(忘记删除指针对象)。
const Rational * operator*(const Rational& lhs,const Rational& rhs);
Rational a = 10;
Rational b(1, 2);
Rational c = *(a * b); //你觉得这样很“正常”么?
- 采用返回引用的方法可能会造成返回的引用已经被销毁。
// 另一种危险的方法 (和不正确的)方法,用来
// 避免返回对象
const Rational& operator*(const Rational& lhs,const Rational& rhs)
{Rational result(lhs.numerator() * rhs.numerator(),lhs.denominator() * rhs.denominator());return result;//返回时,其指向的对象已经不存在了
}
- 所以很大程度上无法避免使用by-value的方式返回对象。把你的努力引导到寻找减少返回对象的开销上来,而不是去消除对象本身。
- 可以使用某种特殊的写法来撰写函数,使它在返回对象时,能够让编译器自动进行优化,消除临时对象成本。如下例,产生一个临时对象,然后将复制临时对象,当作返回值。但是这样,编译器就会被允许消除在operator*内的临时变量和operator*返回的临时变量。它们能在为目标c分配的内存里构造return表达式定义的对象,只需要付出一个构造函数的成本。许多编译器都支持这一优化。:
// 一种高效和正确的方法,用来实现
// 返回对象的函数
const Rational operator*(const Rational& lhs,const Rational& rhs)
{return Rational(lhs.numerator() * rhs.numerator(),lhs.denominator() * rhs.denominator());
}
Rational a = 10;
Rational b(1, 2);
Rational c = a * b; // 在这里调用operator*
条款21:利用重载技术避免隐式类型转换
- 定义更多情况下的最佳匹配重载函数,使得编译器选择最佳匹配的重载函数调用,避免进行类型转换;
- C++规定每个 “ 重载操作符 ” 必须获得至少一个 “ 用户自定义类型 ” 的自变量。
- 有时候增加一大堆重载函数不一定是件好事。
条款22:考虑以操作符复合形式取代独身形式
- 确保操作符的复合形式(x+=1)与独身形式(x=x+1)之间的自然关系能够存在,可以以前者为基础实现后者,也便于维护。
class Rational {
public:...Rational& operator+=(const Rational& rhs);Rational& operator-=(const Rational& rhs);
};// operator+ 根据operator+=实现;
const Rational operator+(const Rational& lhs,const Rational& rhs)
{return Rational(lhs) += rhs;
}
// operator- 根据 operator -= 来实现
const Rational operator-(const Rational& lhs,const Rational& rhs)
{return Rational(lhs) -= rhs;
}
- 一般而言,复合操作符比其独身形式效率更高,因为独身形式要返回一个新对象,从而在临时对象的构造和释放上有一些开销。然而,复合操作符可以经过编译器优化后把结果直接写到左边的参数里,因此不需要生成临时对象来容纳返回值。
- 如果同时提供某个操作符的复合形式和独身形式,便允许你的客户在效率和便利性之间做取舍。如下代码,前者易撰写和维护,后者效率更高。
Rational a, b, c, d, result;
...
result = a + b + c + d; // 可能用了3个临时对象// 每个operator+ 调用使用1个
还是这样编写:
result = a; //不用临时对象
result += b; //不用临时对象
result += c; //不用临时对象
result += d; //不用临时对象
- 匿名对象比命名对象更容易清除,因此当我们面对在命名对象和临时对象间进行选择时,用临时对象更好一些。它使你耗费的开销不会比命名的对象还多。
//消耗一个匿名对象,编译器有机会实现“返回值优化”,把匿名对象直接写入接收函数返回对象的变量中
template<class T>
const T operator+(const T& lhs, const T& rhs)
{ return T(lhs) += rhs; }//消耗一个命名对象result,函数调用完毕后被析构,没有机会消除这一消耗
template<class T>
const T operator+(const T& lhs, const T& rhs)
{T result(lhs); // 拷贝lhs 到 result中return result += rhs; // rhs与它相加并返回结果
}
条款23:考虑使用其他程序库
- 具有相同功能的不同的程序库在性能上采取不同的权衡措施,所以一旦你找到软件的瓶颈,你应该知道是否可能通过替换程序库来消除瓶颈。比如如果你的程序有I/O瓶颈,你可以考虑用stdio替代iostream。
条款24:了解虚拟函数、多继承、虚基类和RTTI(运行时类型辨识)所需的代价
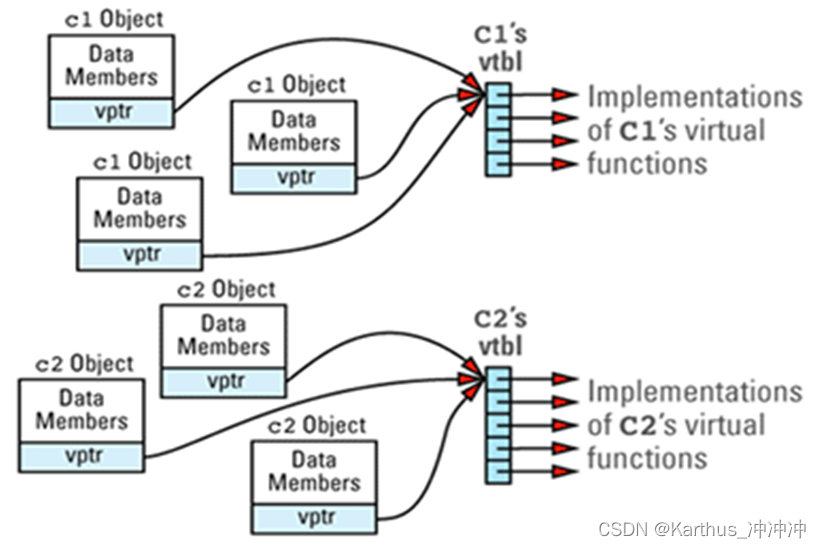
- 一个虚函数表vtbl通常是一个函数指针数组(或链表)。在程序中的每个类只要声明了虚函数或继承了虚函数,它就有自己的vtbl,并且类中vtbl的项目是指向虚函数实现体的函数指针。每个类保留一份虚函数表。
class C1 {
public:C1();virtual ~C1();virtual void f1();virtual int f2(char c) const;virtual void f3(const string& s);void f4() const;...
};

class C2: public C1 {
public:C2(); // 非虚函数virtual ~C2(); // 重定义函数virtual void f1(); // 重定义函数virtual void f5(char *str); // 新的虚函数...
};
-
虚函数指针vptr:每个声明了虚函数的对象都带有它,它是一个看不见的数据成员,指向对应类的virtual table。
-
虚函数的三个成本:每个类都有一个虚函数表、每个有虚函数的对象都有一个虚函数指针、放弃inline(inline在编译器将调用函数展开,而虚函数在运行期才确定)。
-
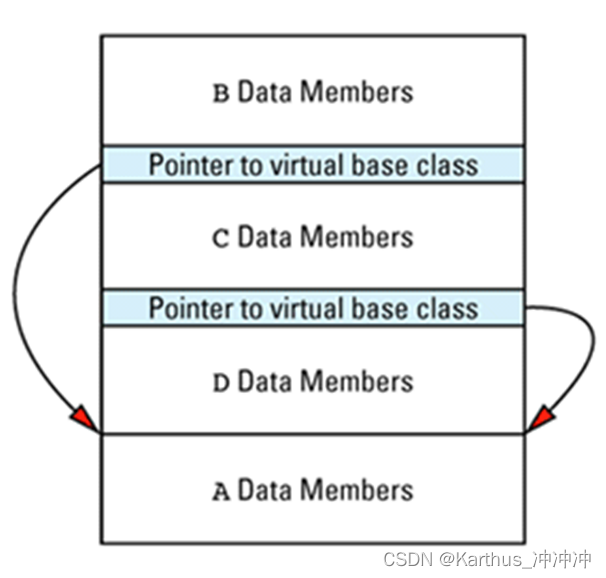
多继承往往导致虚基类的需求。因为继承会导致继承体系的所有成员被继承被复制,对象体积迅速增大。虚基类可避免大量的复制现象,不过虚基类也会增加一定的成本,类对象中可能有多个虚指针(隐藏指针)。

-
运行期类型辨别(RTTI):类的相关信息存储在类型为type_info的对象里,能通过使用typeid操作符访问一个类的type_info对象。RTTI耗费的空间是在每个类的vtbl中的占用的额外单元再加上存储type_info对象的空间。

相关文章:
More Effective C++学习笔记(4)
目录 条款16:谨记 80 - 20 法则条款17:考虑使用lazy evaluation(缓式评估)条款18:分期摊还预期的计算成本条款19:了解临时对象来源条款20:协助完成 “ 返回值优化 ”条款21:利用重载…...
概率密度函数 累积分布函数
概率密度函数:是指想要求得面积的图形表达式,注意只是表达式,要乘上区间才是概率,所以概率密度并不是概率,而是概率的分布程度。 为什么要引入概率密度,可能是因为连续变量,无法求出某个变量的…...

基于OpenCV实战(基础知识二)
目录 简介 1.ROI区域 2.边界填充 3.数值计算 4.图像融合 简介 OpenCV是一个流行的开源计算机视觉库,由英特尔公司发起发展。它提供了超过2500个优化算法和许多工具包,可用于灰度、彩色、深度、基于特征和运动跟踪等的图像处理和计算机视觉应用。Ope…...

PhantomJS+java 后端生成echart图表的图片
PhantomJSjava 后端生成echart图表的图片 前言源码效果实现echarts-convertPhantomJS实现echarts截图得到图片java延时读取base64数据 参考 前言 该项目仅用作个人学习使用 源码 地址 docker镜像: registry.cn-chengdu.aliyuncs.com/qinjie/java-phantomjs:1.0 …...
vue3 基础知识 ( webpack 基础知识)05
你好 文章目录 一、组件二、如何支持SFC三、webpack 打包工具四、webpack 依赖图五、webpack 代码分包 一、组件 使用组件中我们可以获得非常多的特性: 代码的高亮;ES6、CommonJS的模块化能力;组件作用域的CSS;可以使用预处理器来…...
建设项目WORD)
1.4亿X区智慧城市数字平台及城市大脑(运营中心)建设项目WORD
导读:原文《1.4亿X区智慧城市数字平台及城市大脑(运营中心)建设项目WORD》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 部分内…...
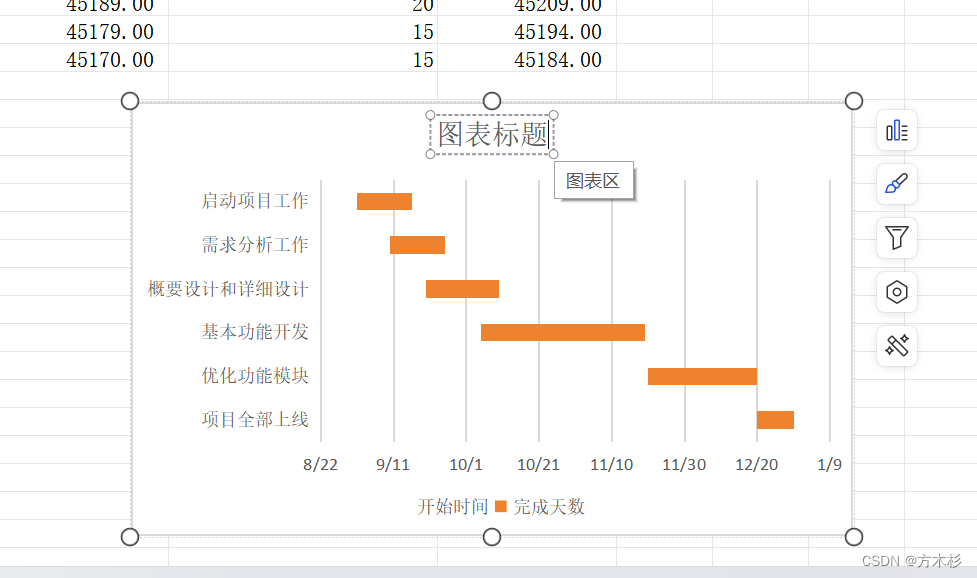
wps 画项目进度甘特图
效果如上 步骤一: 创建excel 表格 步骤二: 选中开始时间和结束时间两列数据,右键设置单元格格式 步骤三: 选择数值,点击确定,将日期转成数值。 步骤四:插入图表 选中任务,开始时间…...

【⑭MySQL | 数据类型(二)】字符串 | 二进制类型
前言 ✨欢迎来到小K的MySQL专栏,本节将为大家带来MySQL字符串 | 二进制类型类型的分享✨ 目录 前言5 字符串类型6 二进制类型总结 5 字符串类型 字符串类型用来存储字符串数据,还可以存储图片和声音的二进制数据。字符串可以区分或者不区分大小写的串比…...
Java smslib包开发
上一篇文章我详细介绍RXTXcomm的安装方法和简单代码,如果小伙伴涉及到需要使用手机短信模块完成短信收发需求的话,可以使用到smslib进行开发。 首先还是同样的,将整个smslib包源码导入项目,并且将它所需依赖一起进行导入 导入完成之后,我们就可以对smslib包进行二次开发了 下面…...
职业技术培训内容介绍
泰迪职业技术培训包括:Python技术应用、大数据技术应用、机器学习、大数据分析 、人工智能技术应用。 职业技术培训-Python技术应用 “Python技术应用工程师”职业技术认证是由工业和信息化部教育与考试中心推出一套专业化、科学化、系统化的人才考核标准&…...
6.2 ETAS RTA系列工具入门)
AUTOSAR规范与ECU软件开发(实践篇)6.2 ETAS RTA系列工具入门
目录 1、 RTA系列工具安装方法 (1) ETAS RTA-RTE的安装方法 (2) ETAS RTA-BSW的安装方法...
vue3的hooks你可以了解一下
更详细的hooks了解参考这个大佬的文章:掘金:Hooks和Mixins之间的区别 刚开始我简单看了几篇文章感觉Hooks这个东西很普通,甚至感觉还不如vue2的mixin好用。还有export import 感觉和普通定义一个utils文件使用没什么区别。但是Hooks这个东西肯…...
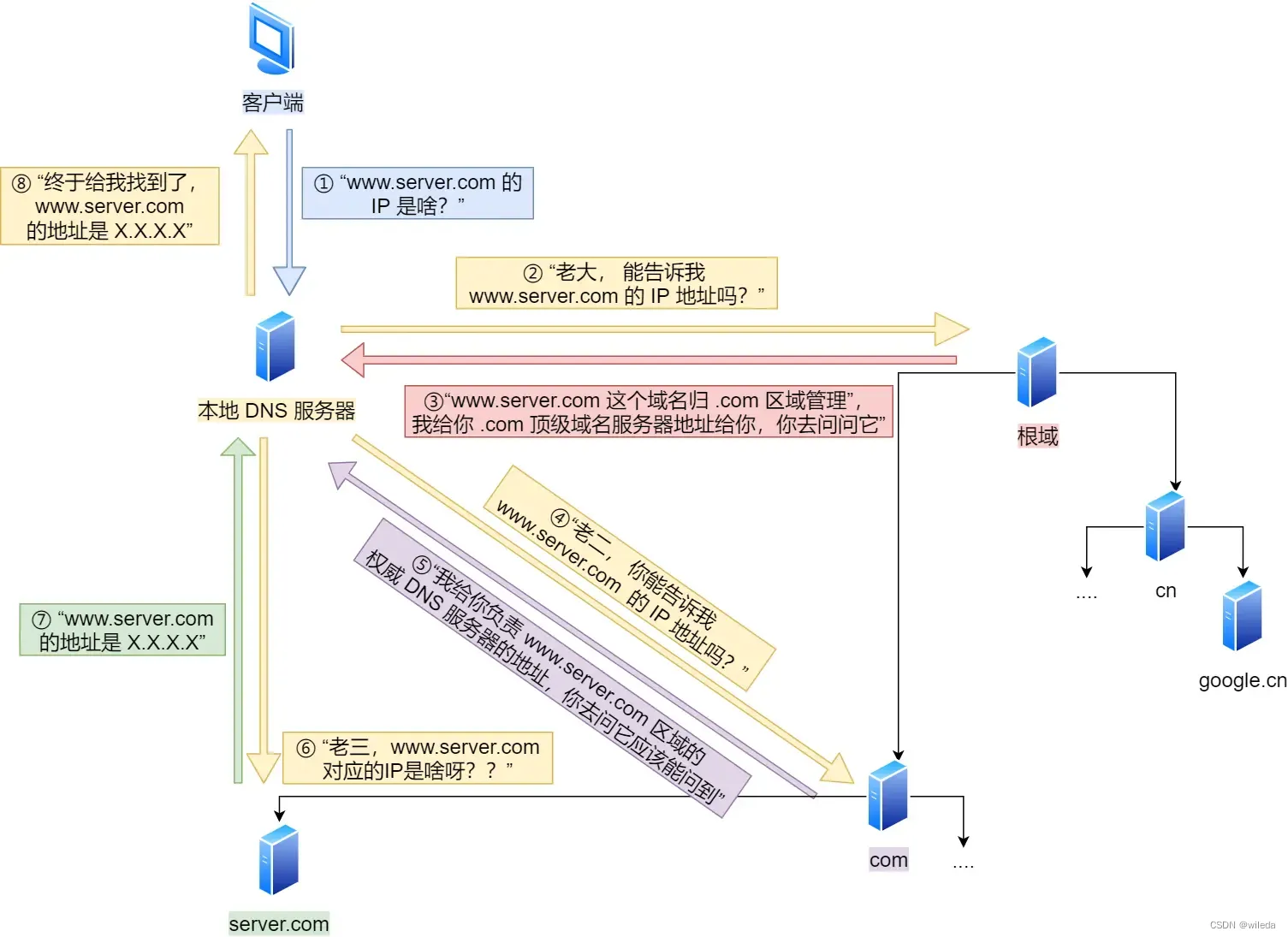
面试之HTTP
1.HTTP与HTTPS的区别 HTTP运行在TCP之上;HTTPS是运行在SSL之上,SSL运行在TCP之上两者使用的端口不同:HTTP使用的是80端口,HTTPS使用的是443端口安全性不同:HTTP没有加密,安全性较差;HTTPS有加密…...
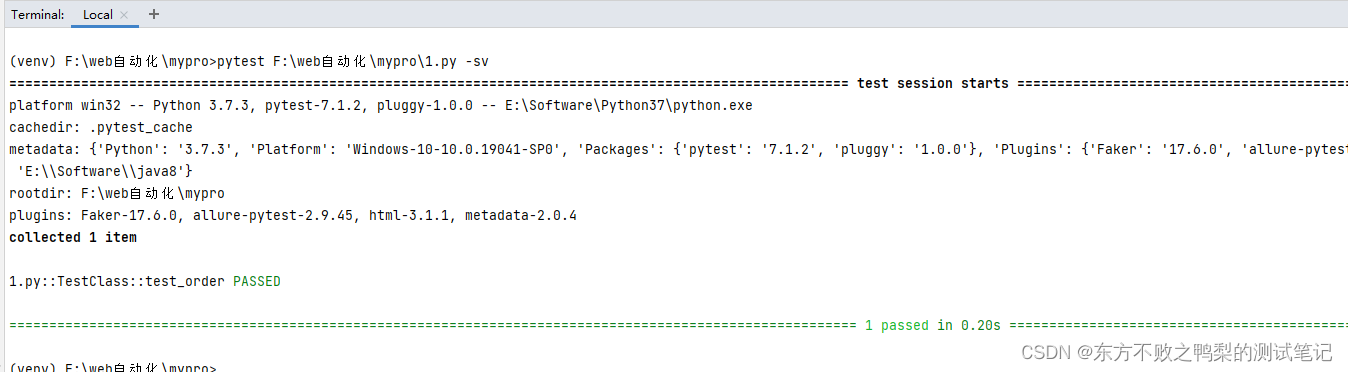
测试框架pytest教程(3)夹具-@pytest.fixture
内置fixture Fixture使用pytest.fixture装饰,pytest有一些内置的fixture 命令可以查看内置fixture pytest --fixtures fixture范围 在pytest中,夹具(fixtures)具有不同的作用范围(scope),用于…...
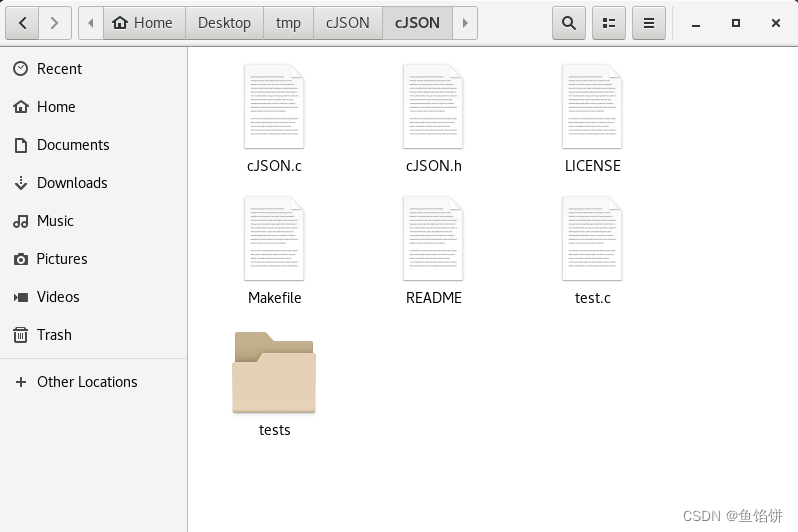
GNU make系列之介绍Makefile
一.欢迎来到我的酒馆 在本章节介绍Makefile。 目录 一.欢迎来到我的酒馆二.GNU make 预览三.一个简单的Makefile四.make程序如何处理Makefile文件五.在Makefile中使用变量 二.GNU make 预览 2.1 GNU make工具会自动决定哪些程序需要被重新编译,并且执行相应的命令来…...

Java8新特性之——方法引用
文章目录 一、简介二、举例实例方法引用(实例对象::实例方法名)静态方法引用(类名::静态方法名)类成员方法引用(类名::实例方法名)构造方法引用(类名::new)数组构造方法引用…...

等保测评--安全区域边界--测评方法
安全子类--边界防护 a) 应保证跨越边界的访问和数据流通过边界设备提供的受控接口进行通信; 一、测评对象 网闸、防火墙、路由器、交换机和无线接入网关设备等提供访问控制功能的设备或相关组件 二、测评实施 1)应核查在网络边界处是否部署访问控制设备&#x…...
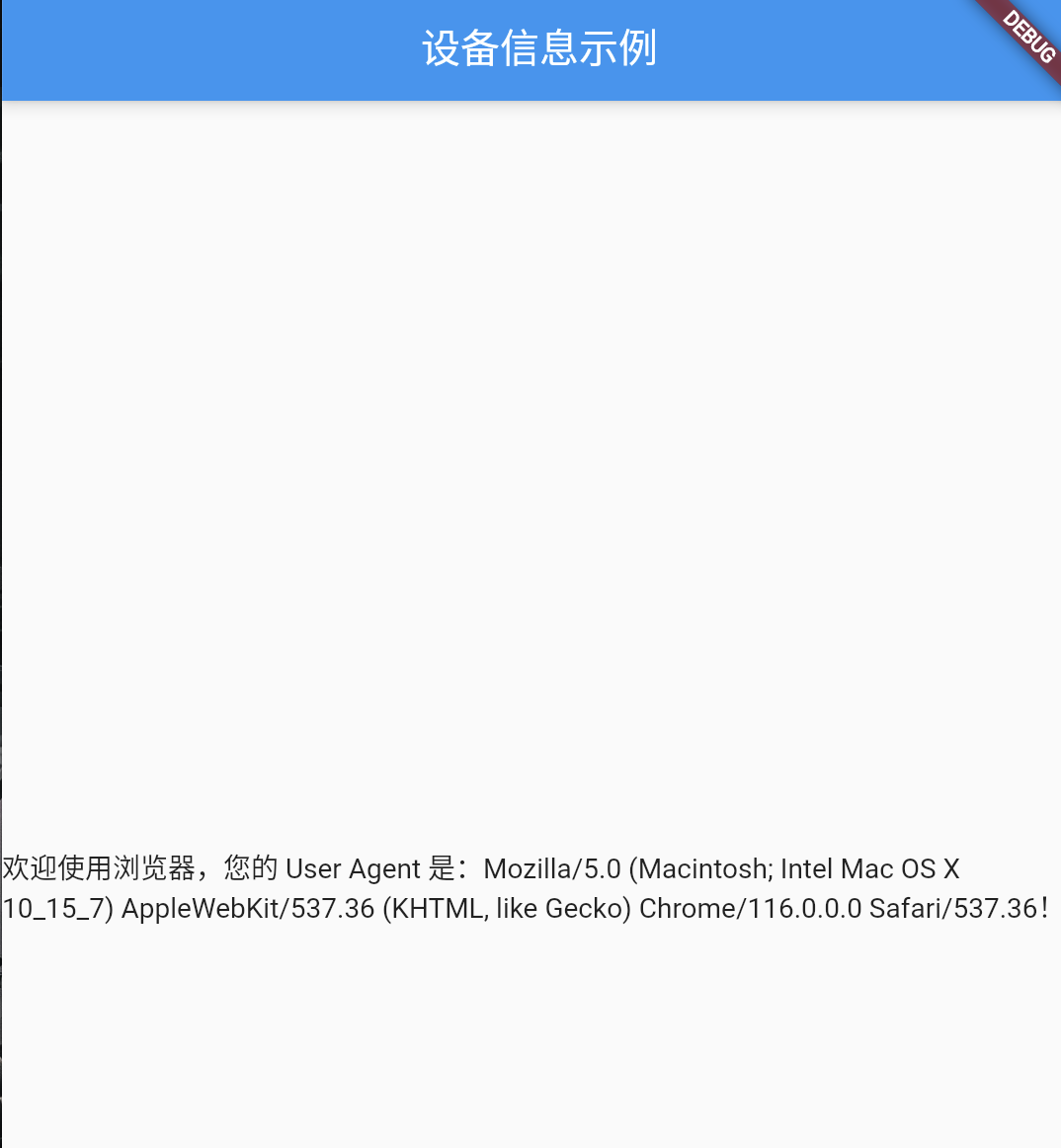
【Flutter】Flutter 使用 device_info_plus 获取设备的制造商、型号等信息
【Flutter】Flutter 使用 device_info_plus 获取设备的制造商、型号等信息 文章目录 一、前言二、安装和基本使用三、实际业务中的用法四、完整示例五、总结 一、前言 在这篇博客中,我将为你介绍一个非常实用的 Flutter 插件:device_info_plus。这个插件…...

Flink、Yarn架构,以Flink on Yarn部署原理详解
Flink、Yarn架构,以Flink on Yarn部署原理详解 Flink 架构概览 Apache Flink是一个开源的分布式流处理框架,它可以处理实时数据流和批处理数据。Flink的架构原理是其实现的基础,架构原理可以分为以下四个部分:JobManager、TaskM…...

软考高级系统架构设计师系列论文八十三:论软件设计模式的应用
软考高级系统架构设计师系列论文八十三:论软件设计模式的应用 一、软件设计模式相关知识点二、摘要三、正文四、总结一、软件设计模式相关知识点 软考高级系统架构设计师系列之:面向构件的软件设计,构件平台与典型架构...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...