美团增量数仓建设新进展
摘要:本文整理自美团系统研发工程师汤楚熙,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分:
- 建设背景
- 核心能力设计与优化
- 业务实践
- 未来展望
点击查看原文视频 & 演讲PPT
一、美团增量数仓的建设背景
美团数仓架构的诞生是基于这样的技术假设:“随着业务数据越积越多,增量数据 / 存量数据 的比值呈下降趋势,采用增量计算模式性价比更高。”
当然也与底层技术的发展有很强的相关性,Flink、Hudi 等具备增量计算、更新能力的技术框架,为增量数仓落地的提供了必要条件。
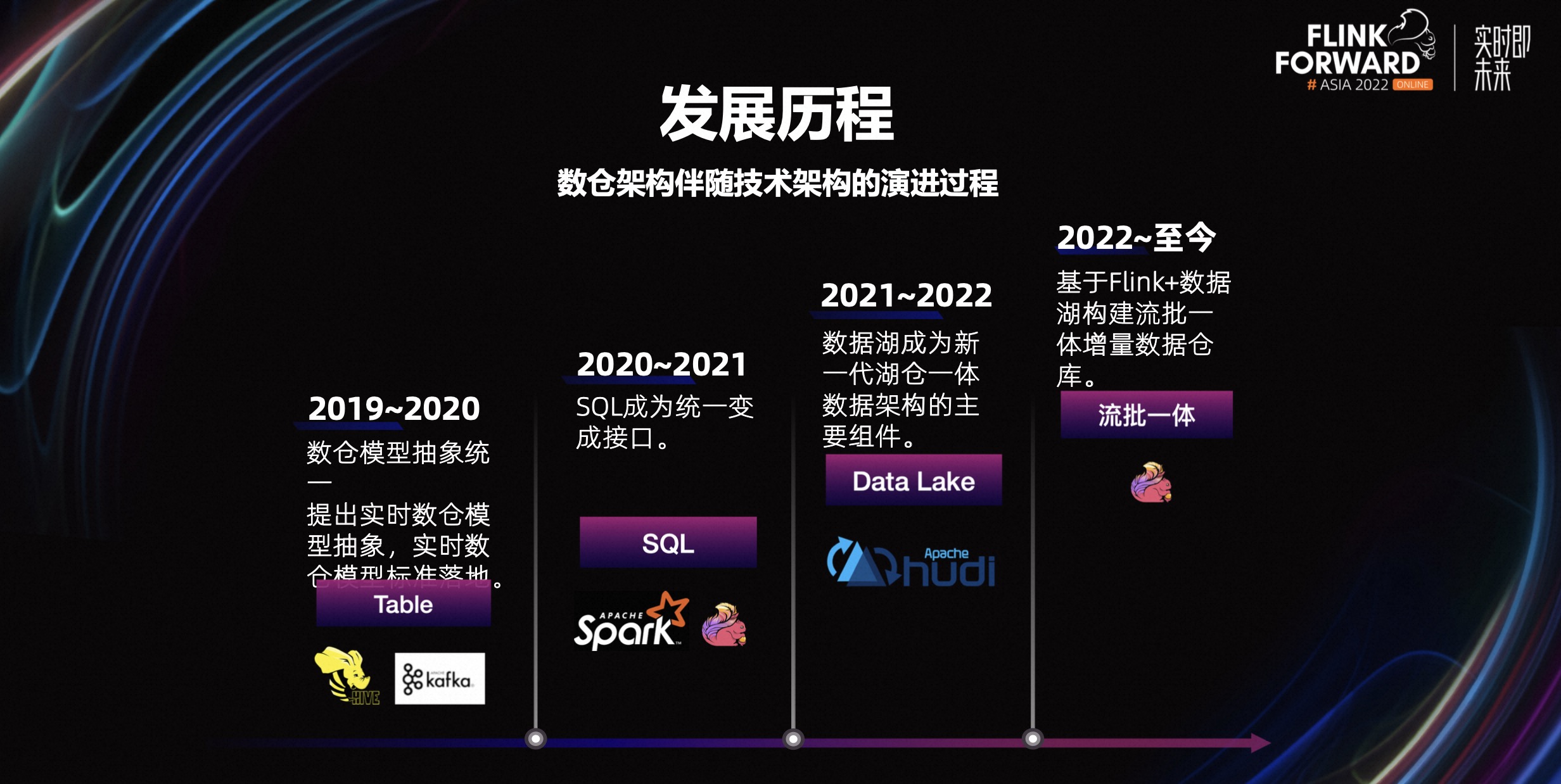
从时间线上看,增量数仓架构的演进过程可大致划分为三个阶段:
- 第一个阶段,2019 到 2020 年。这个阶段,业务希望在离线数仓的能力之上,得到更新鲜的数据,即实时数仓。所以我们借鉴了离线数仓的模型概念,提出了实时数仓的模型抽象。
- 第二个阶段,2020 到 2021。这个阶段实时数仓的生产任务还大量依赖 JavaAPI,对开发效率有较大的影响,所以我们要加快 FlinkSQL 的落地,提升数仓开发的效率。
- 第三个阶段,从 2021 年到现在。这个阶段随着数据湖技术的逐渐成熟,我们开始尝试整合离线跟实时数仓架构,进而提出了一套增量数仓的新架构。
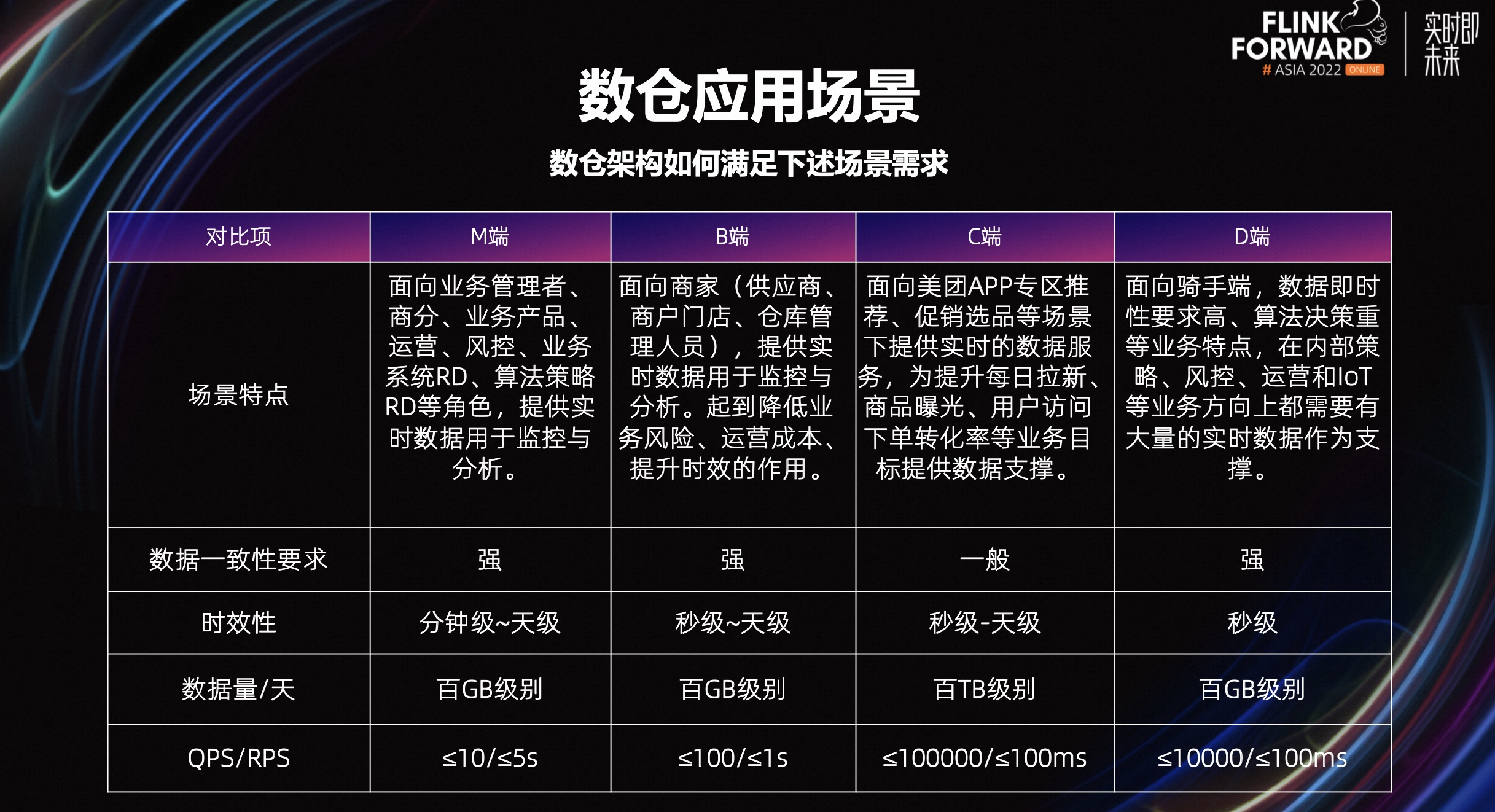
目前美团内部会有 M、B、C、D 端等四大类业务场景,不同的场景之间对数据一致性、时效性的要求有交叉,但又不完全相同,需要寻找一套尽可能适配所有这些场景的技术架构。
首先我们会想到的是 Lambda 架构,它会通过实时链路解决高时效性的用数场景的需求;并通过离线链路来解决一些长业务周期的指标计算的需求;以及对数据一致性要求较高的场景的用数需求。
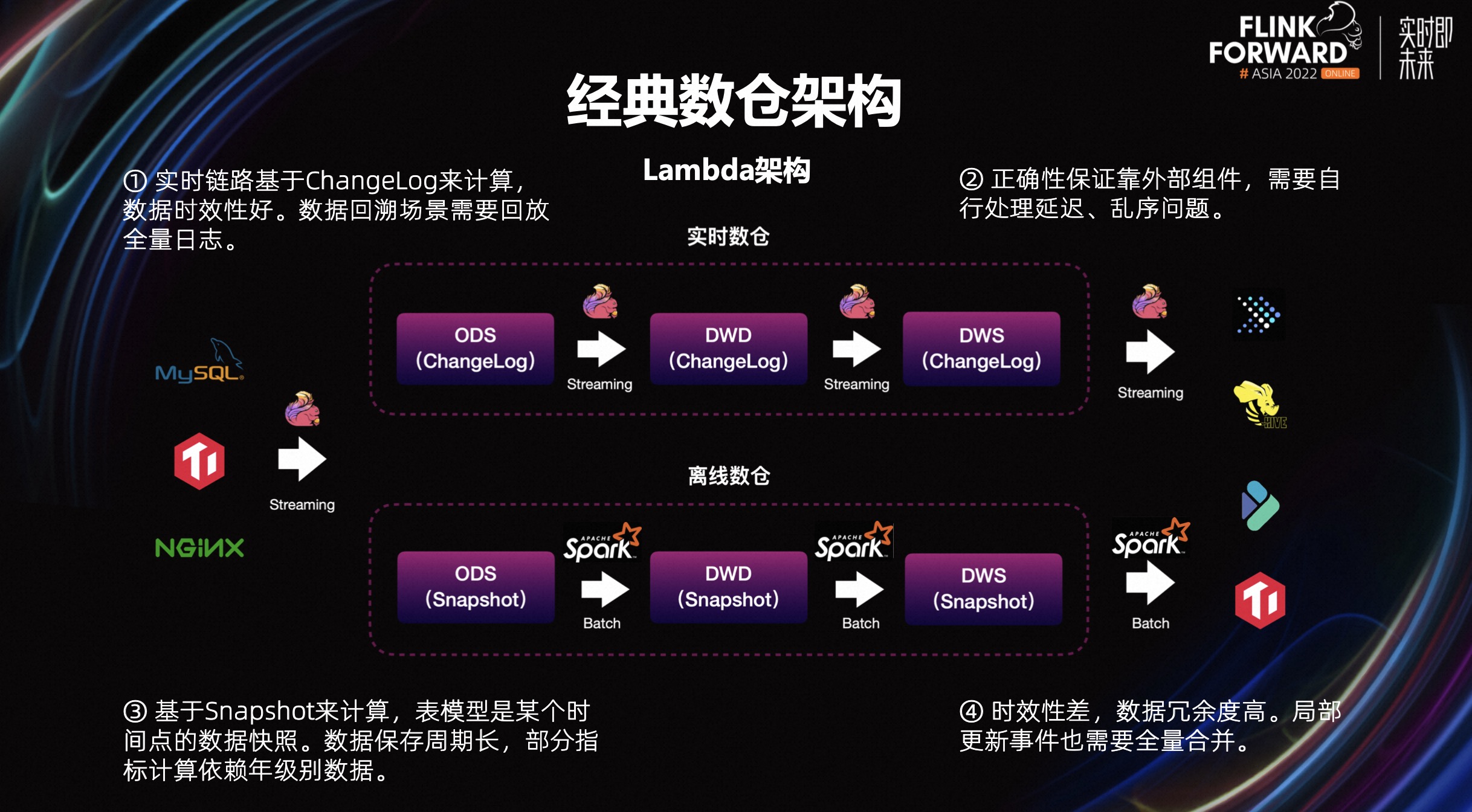
Lambda 架构最大的问题生产链路过于复杂,一方面造成较高的资源成本,另外是高昂运维的成本。
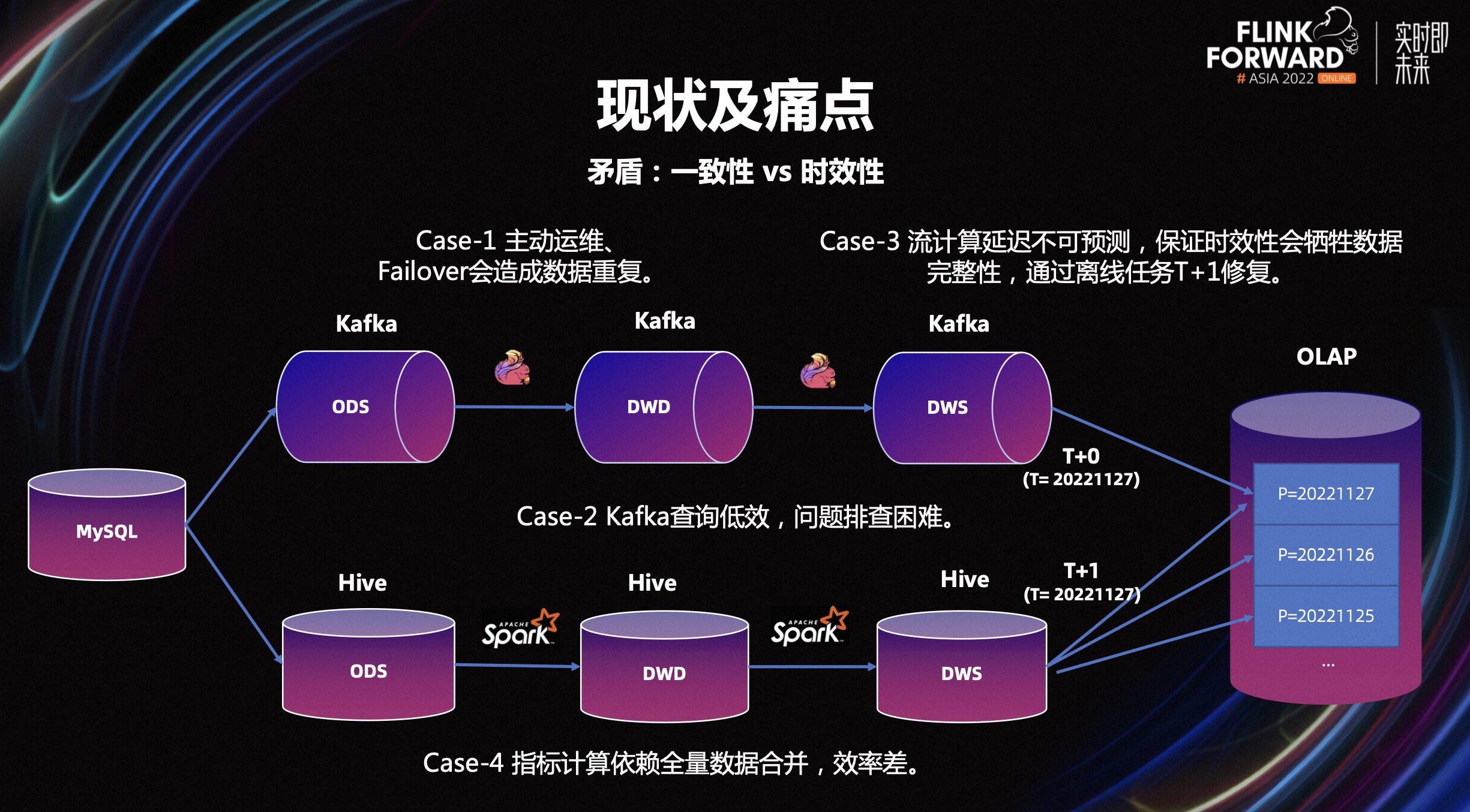
比如对高数据新鲜度的场景,高度依赖 Kafka,而其最初的架构设计就没有充分考虑到对数据一致性的保证。
业务会通过排序、幂等处理等手段牺牲计算资源,达成了数据一致性。
此外还有的问题是,运维门槛高。一个的典型的案例是,美团某 B 端业务场景对数据新鲜度要求较高,其交易主题表要求在 Flink 作业中保留 180 天状态数据,单任务状态大小>50TB,改口径后的直接消费上游 MQ 回溯数据,时长会超过 1 天,业务方很难接受,目前只能被动改造成先刷离线不变数据,再刷增量变更数据。
对时延不敏感,但需要能够灵活的将数据按不同粒度进行组织访问的离线场景,重度依赖于 Hive,而其的最初也并未考虑到数据高效的更新的能力。
典型的例子是,离线数仓最新快照事实表的生产场景,这种类型数据在业务上很常见,要求将上游的按天、小时生产的 DeltaRecord 与下游表中的存量数据快照做 Merge,理论上只需从存量快照数据中按 DeltaRecord 的 key 取出全部变更记录,Merge 之后再覆盖写即可。但当前离线数仓的普遍做法是全量加载存量快照数据,再与增量数据做归并排序后取最新一条,未变更记录的加载是非必要且浪费资源的。
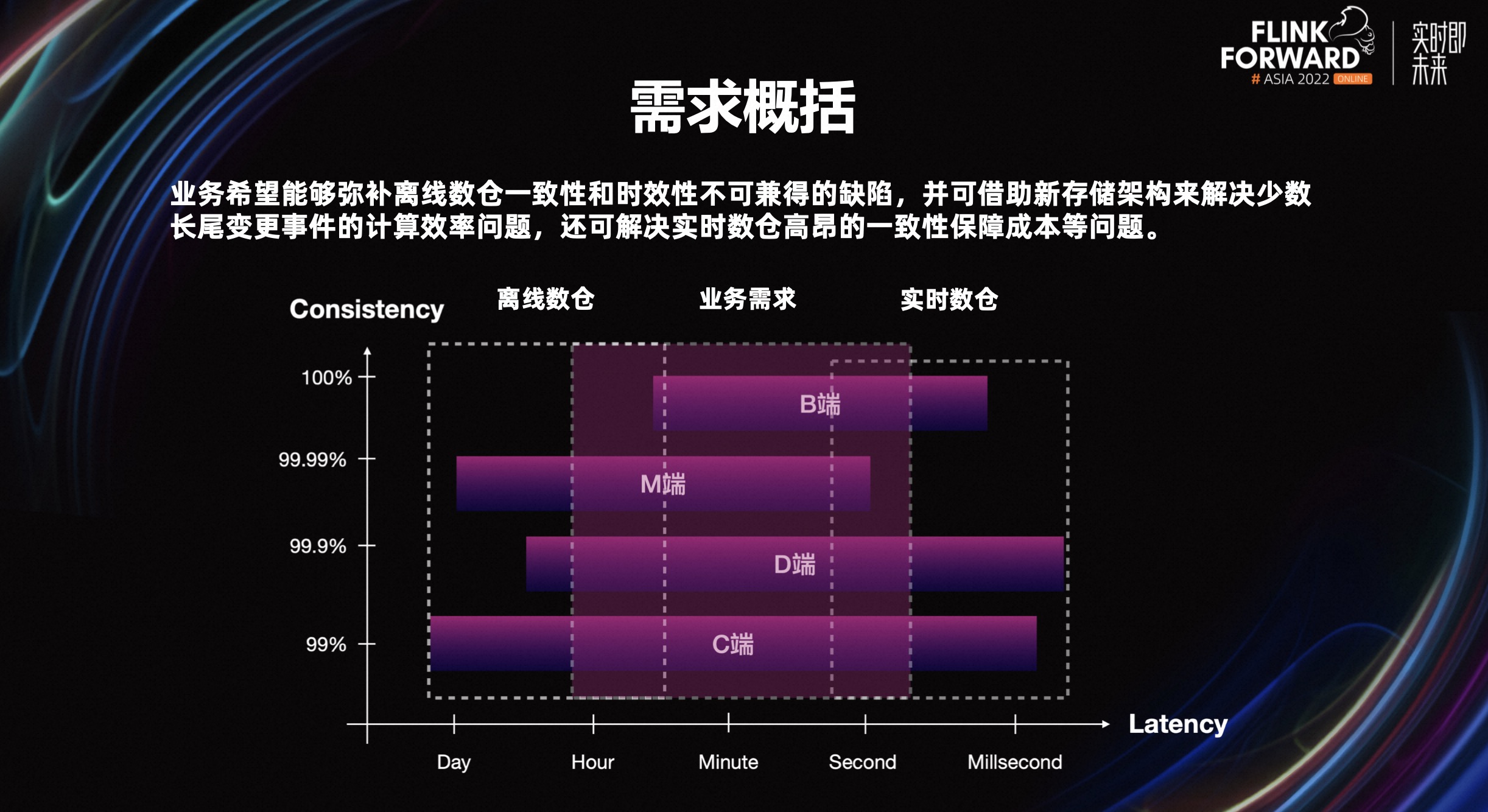
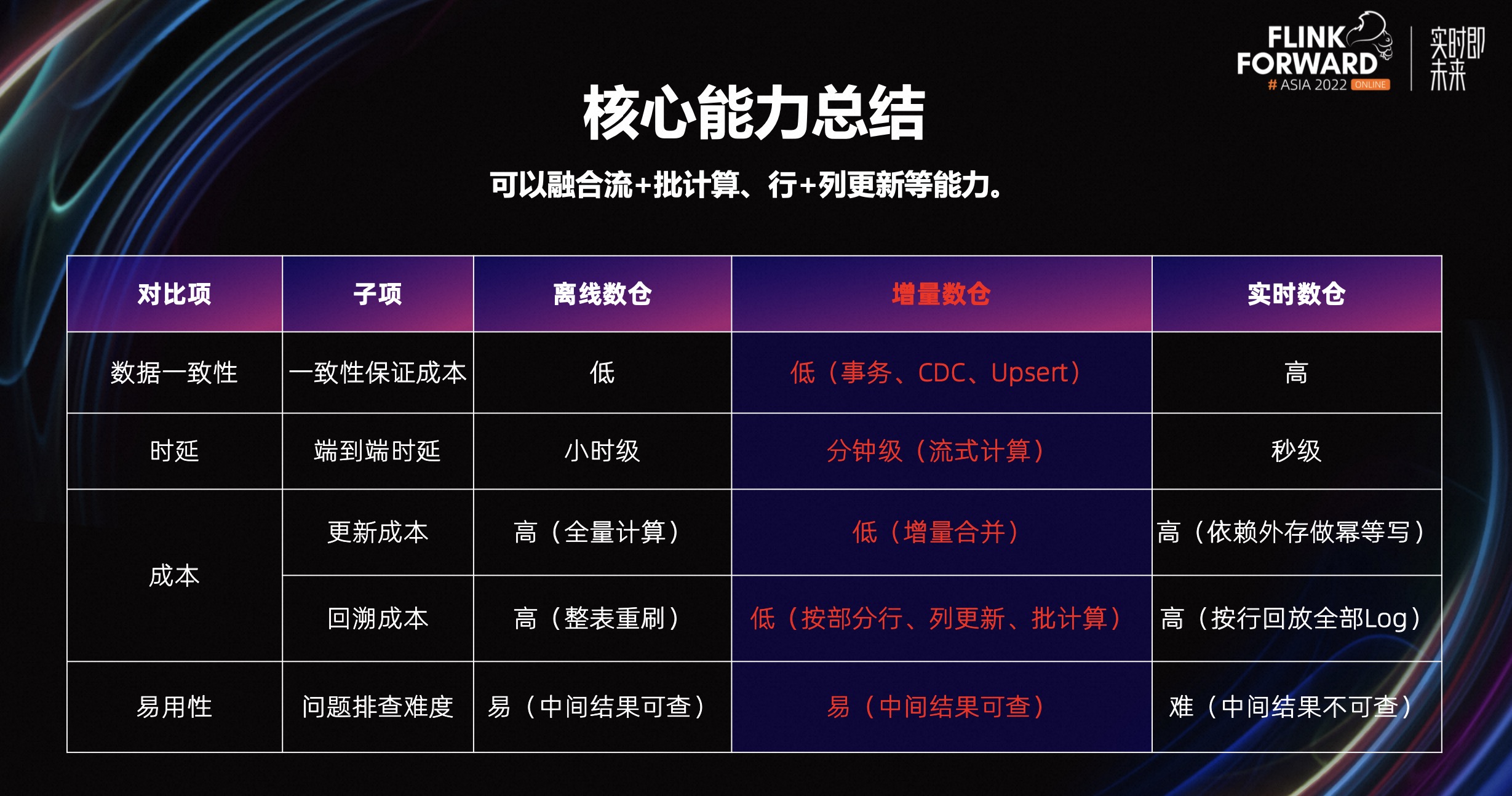
我们期望增量数仓架构,能够很好的同时兼顾数据的时效性和数据一致性,并且低成本的完成数据的合并计算、高效组织。
相对基于 Kafka 构建的实时数仓来看,增量数仓需要提升回溯场景的效率、降低为保证数据一致性的资源开销。
相对基于 Hive 构建离线数仓,在没有就绪时间提前的前提要求下,可继续沿用批模式来执行增量数据合并,提升计算效率。
二、核心能力设计与优化
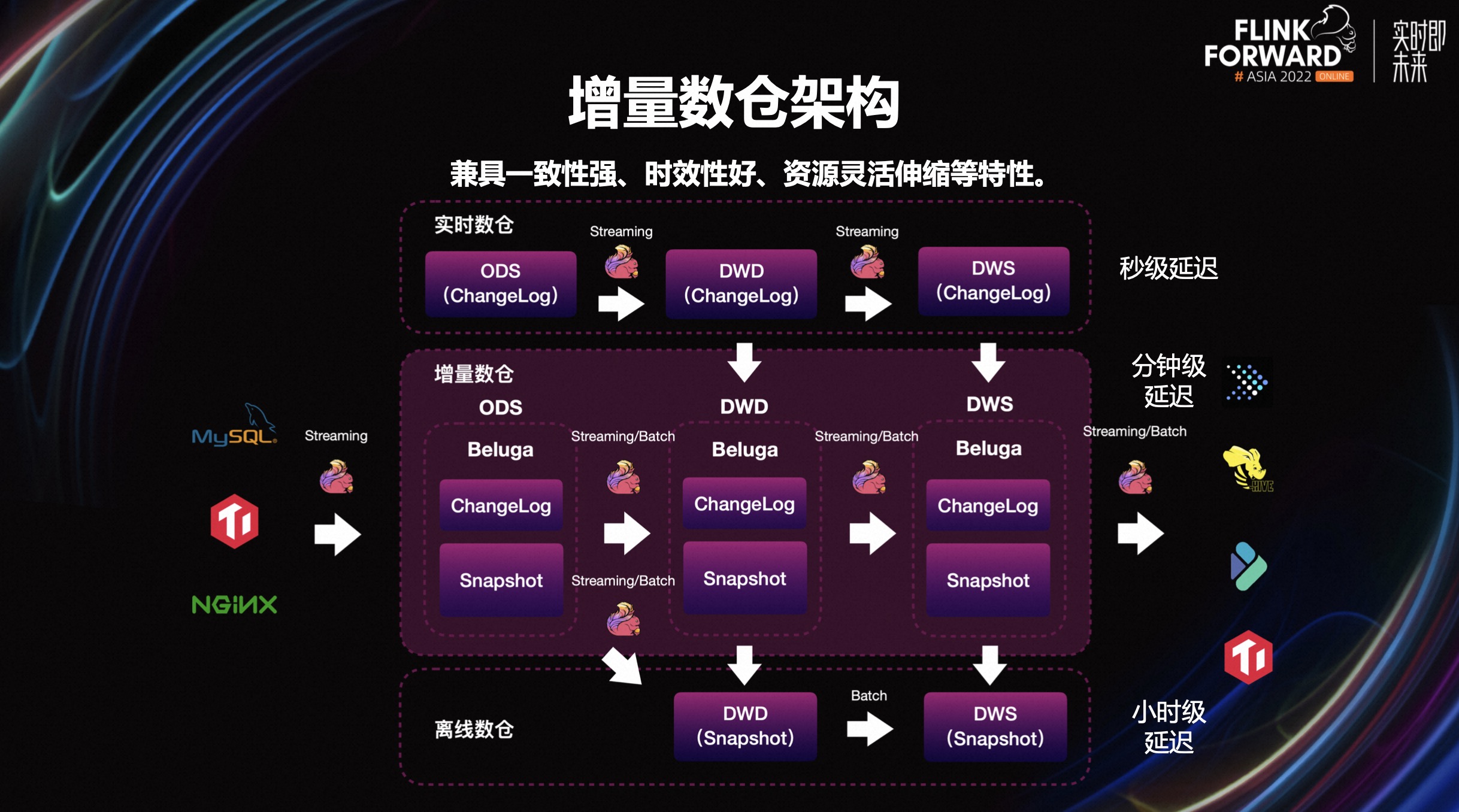
2.1 增量数仓存储架构
实现增量计算、更新,引入了一套支持事务管理、主键和 CDC 能力,可同时按部分行和列进行更新,并且对查询友好的新的存储引擎。这个新存储引擎的名字我们内部叫做 Beluga,它的基本架构是在 Hudi 的基础上,加以改造而来。
改造 Hudi 的动机是,最初 v0.8 不支持 CDC。考虑到了这点,我们引入 Hbase(KV)来生产 Changelog。
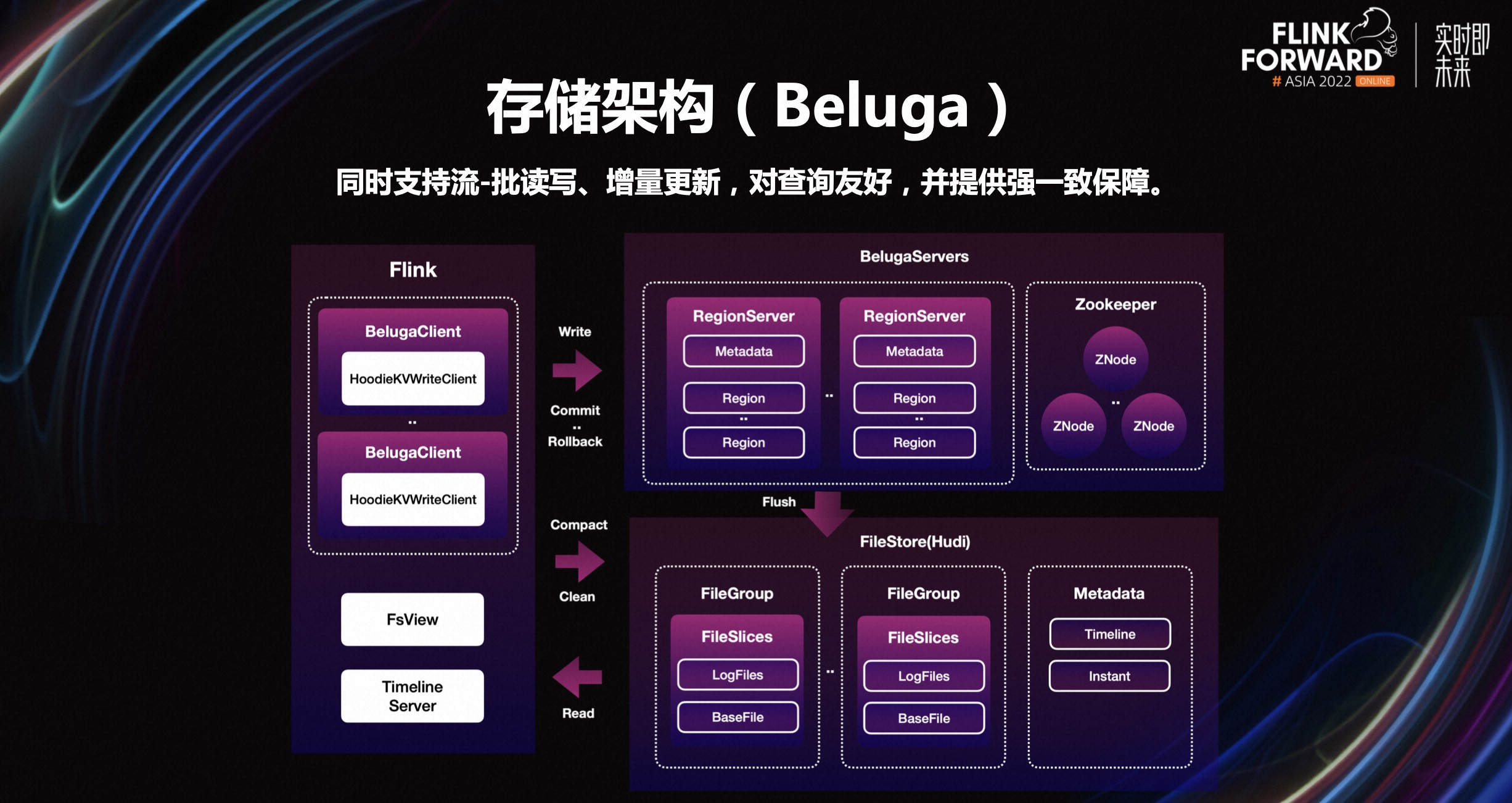
Beluga 有三个核心模块:
- Beluga Client,运行在Flink作业中,主要用来处理读写请求和事务的协调。
- Beluga Server,是基于 Hbase 来改造实现的,主要承担数据的更新、ChangeLog 的生产能力。
- Beluga File Store,这层是基于 Hudi 来实现,主要用于存储 CDC 数据和快照数据。
2.2 优化分桶策略
Beluga 的增量行更新能力,是借助数据分桶来实现的。
第一步使 Hbase 和 Hudi 的分桶模型统一。 这里将 Hbase 的 HRegion 和 Hudi 的 FileGroup 做了一一映射,共同组成了一个分桶。新记录会先过 Hbase 的 Region,然后按需生产出 Changelog,将数据刷入 Hudi。
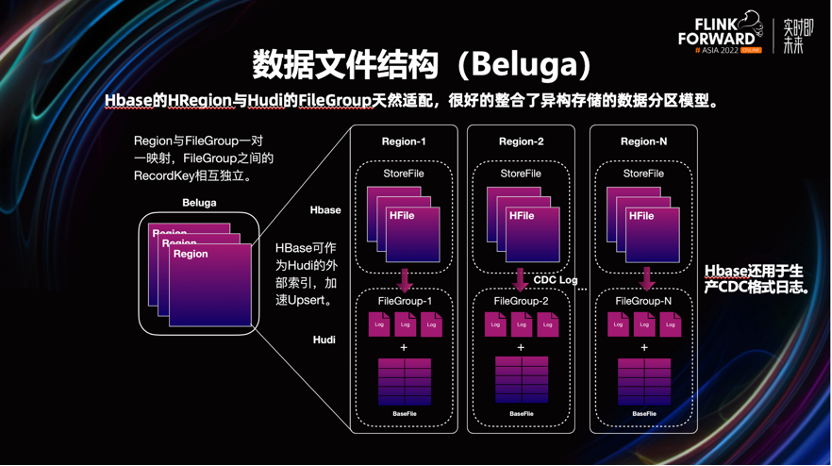
这样做的好处是,Hudi 本身就可以将 Hbase 作为其外部索引,可以提升数据的更新效率。
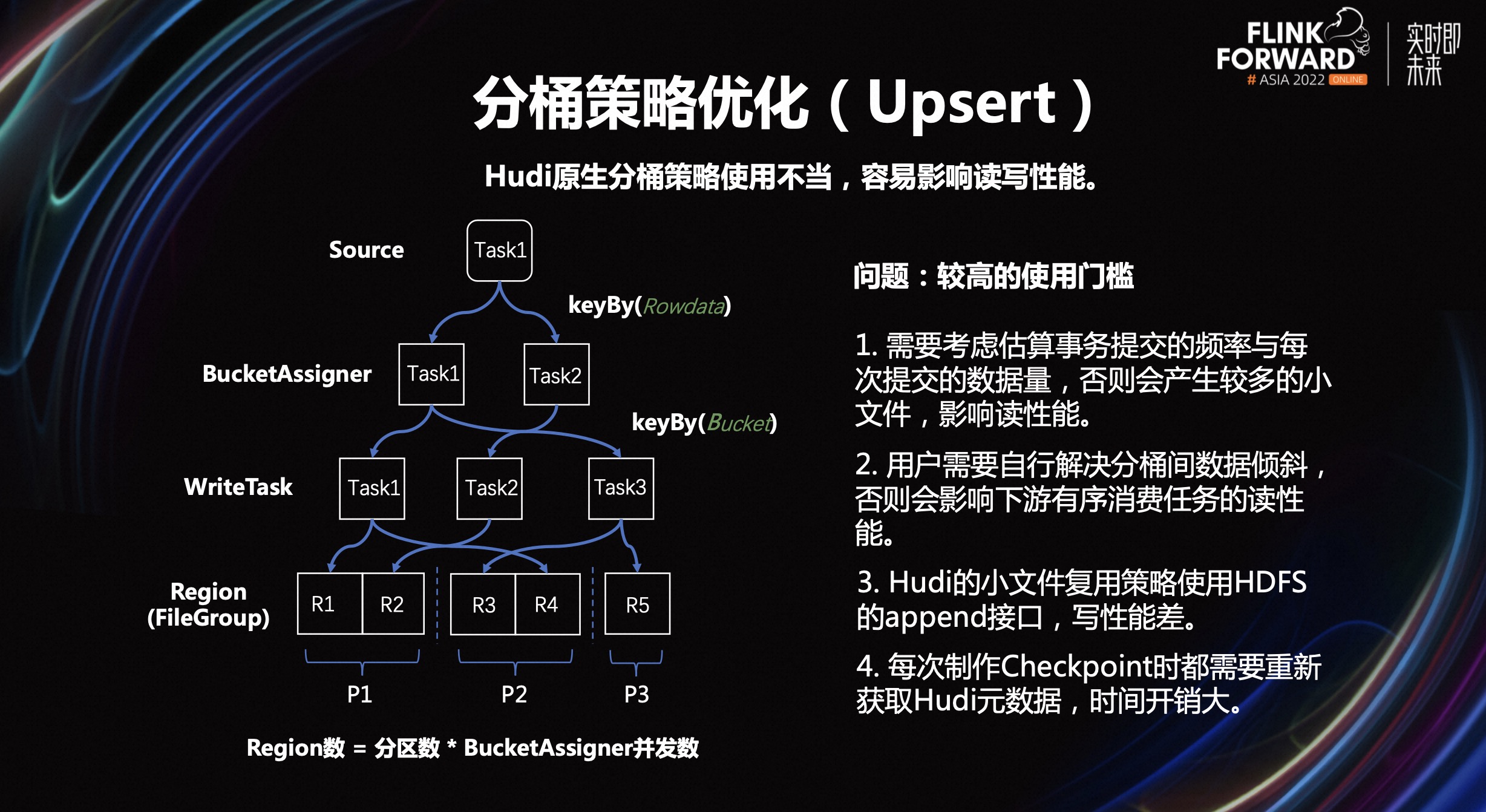
前期测试过程中发现,Hudi 原生的分桶策略,想要正确使用,是有比较高的门槛的。这个门槛高主要体现在,使用不当会造成性能表现不佳:
- 需要考虑估算事务提交的频率与每次提交的数据量,否则会产生较多的小文件,影响读性能。
- 用户需要自行解决分桶间数据倾斜,否则会影响下游有序消费任务的读性能。
- Hudi 的小文件复用策略使用 HDFS 的 append 接口,写性能差。
- 每次制作 Checkpoint 时,需要重新获取 Hudi 元数据,时间开销大。
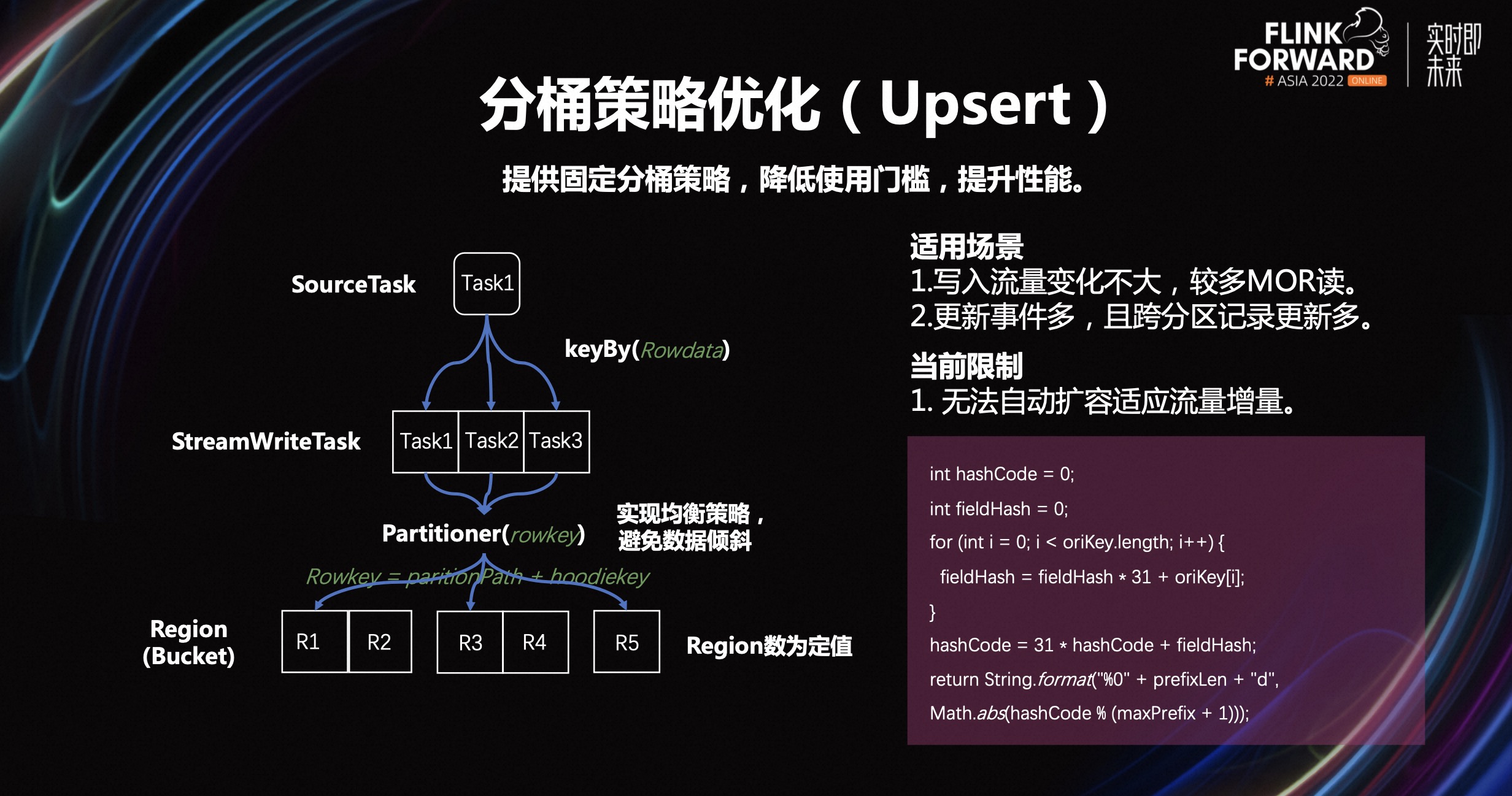
为了解决这些问题,Beluga 设计了一套固定分桶策略。通过这套新分桶策略,我们在数据写入前就确定了其所属的分桶,而不是随着时间的变化,动态的增加分桶,这样有效控制了文件数的增长。
并且由于引入了 Hbase,对于数据更新操作,可以减少通过 HDFS 拉取文件构造元数据和索引的频率,进一步提升读写性能。
面对数据倾斜问题,我们加入了一套均衡算法,最大程度上保证分桶间的数据量保持均衡。
2.3 CDC 数据格式优化
Hudi 原生 CDC 能力,依赖 Flink 的回撤机制产生的 Changelog 来实现,但测试的过程中,发现存在数据不一致的风险。
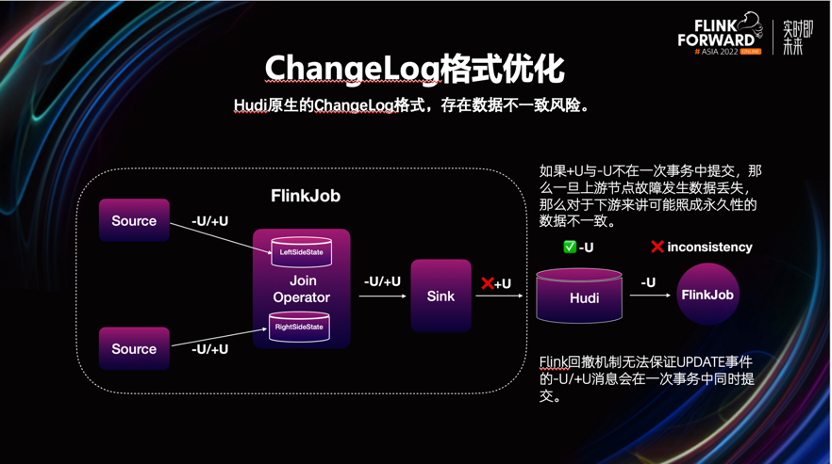
从上图中可以看到,Flink 回撤机制无法保证,UPDATE 事件的-U/+U 消息在一次事务中,同时提交。如果+U 与-U 不在一次事务中提交,一旦上游节点发生故障,导致数据丢失。对于下游来讲,可能造成永久性的数据不一致。为此,我们进行了如下优化。
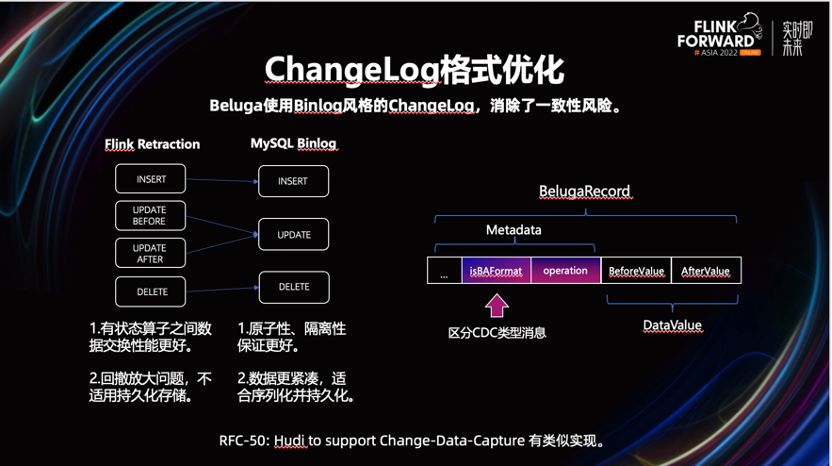
从左图中我们可以看到,我们将 UPDATE 事件的 UPDATE_BEFORE 与 UPDATE_AFTER 事件合并到一条记录中,类似 MySQL 的 Binlog。
这样可以保证更好的原子性,消除了数据不一致的风险。并且一定程度的使数据更紧凑,一定程度的减少序列化的开销。而且我们也了解到 Hudi 在 0.13 后也会采用类似的设计。
2.4 扩展有状态计算场景
建设实时数仓过程中,我们发现 Beluga 还可以低成本的解决一些有状态计算场景问题。
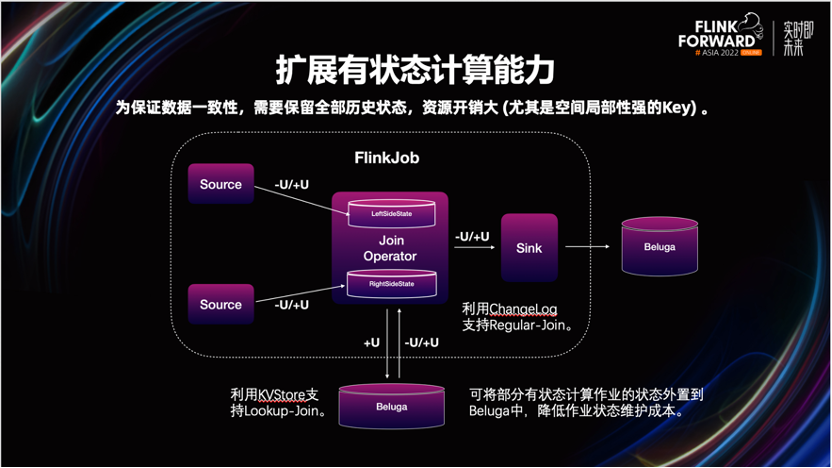
比如当业务遇到长周期的多流数据关联时,为了保证数据的一致性,需要在 Flink 状态中保留很长一段时间的数据快照。一方面,由于状态量过大,影响 Checkpoint 制作的稳定性。另一方面,由于 Flink 内部状态无法在多作业进行共享,有些作为公共维表的数据存储,存在资源浪费。
针对这种场景,我们可以通过 Beluga 的 Hbase 自带的 Cell 级别的更新能力,实现一些长周期、双流关联的业务场景需求。理论上我们还可以借助 Hbase 的点查能力,支持维度关联 Lookup-join 的场景。
一方面,可以缓解 Checkpoint 的压力。另一方面,数据可跨作业共享,资源利用率也得到了提升。
2.5 批流一体数据生产、运维能力
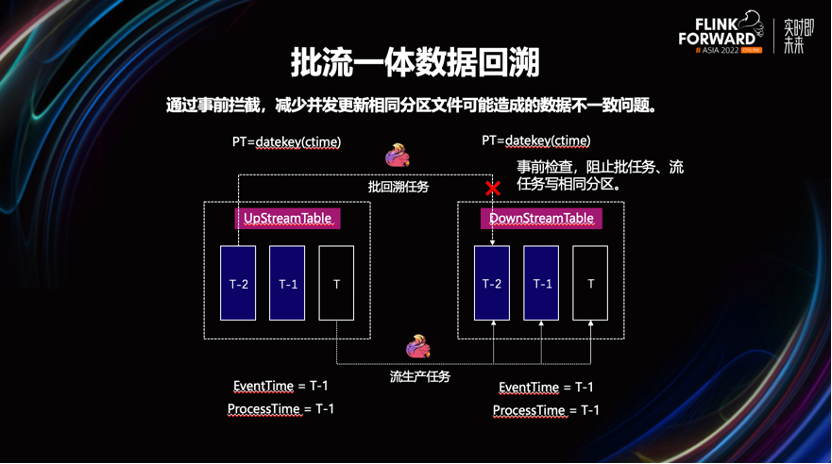
数据回溯是很常见的运维场景,已知在达到相同的计算吞吐量的情况下,流计算模式,要比批模式运行使用更多的计算资源。所以这里会采用 Flink 批任务完成数据的回溯。
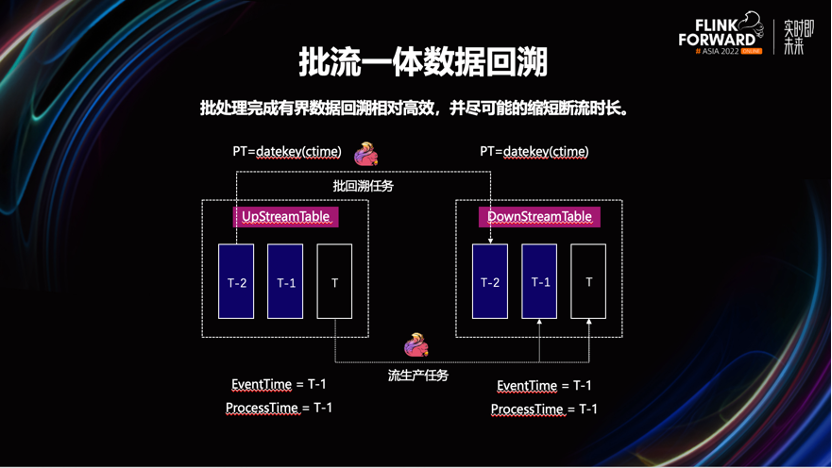
我们发现,公司一些业务的业务数据的状态流转周期不固定。如一张事实表,按照事件时间进行分区后,它最近几个物理分区内的数据都有可能被流任务更新。
如果此时不加限制的使用批任务,就可能会覆盖更新鲜的数据,影响最终计算结果。属于典型的写到写的并发冲突。
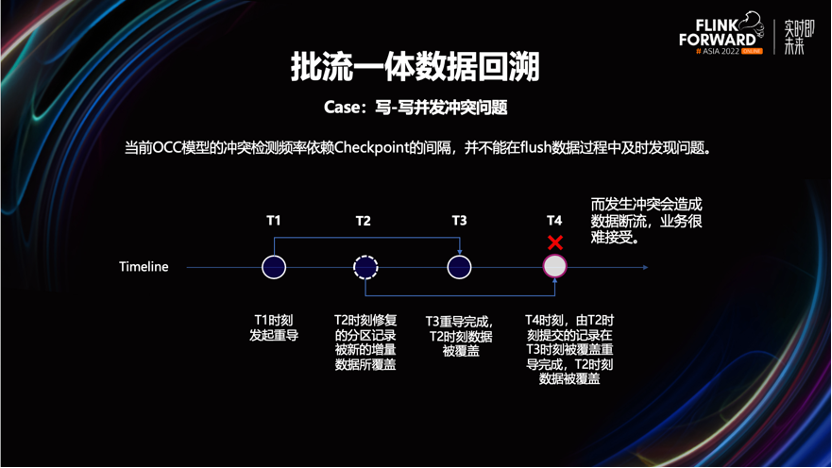
要解决这个问题,会让业务先停掉流计算任务,再用批任务进行数据覆盖更新。完成批覆盖写之后,再重新启动流任务,回补断流期间的数据。
在一些无写冲突的情况下,可以不停掉流计算任务。等到批任务完成数据更新后,再结合实际情况,选择通过流任务来回放批未覆盖到的分区数据。这样可以一定程度的减少断流时长,加快了数据回溯的过程。
为了避免用户误操作,我们在工具链层面,对可能有并发写冲突风险的作业,进行事前拦截。
三、业务实践
下面这部分讲一下,业务如何借助增量数仓改进其数仓架构问题,重点介绍以下三个案例:
-
案例一:通过增量的计算模式加速数据入仓,从而解决离线数仓就绪时间晚的问题。
-
案例二:如何利用新的技术架构,通过增量计算模式,有效提升一些事实表生产效率。
-
案例三:业务如何通过批流一体增量数据生产架构,提升数仓的开发运维效率。

3.1 案例一:如何加速数据入仓
采用增量数仓架构出现之前,业务数据入仓大概要分为以下几个关键步骤。先将 Binlog 和服务器日志收集到 Kafka 中,然后再落 Hive。此刻数据并没有完成清洗和加工,无法直接交付给业务使用。接下来再通过一个批处理任务,对 Hive 上的原始日志进行清洗和转换,落入 Hive 新表。这时才算正式完成数据入仓。
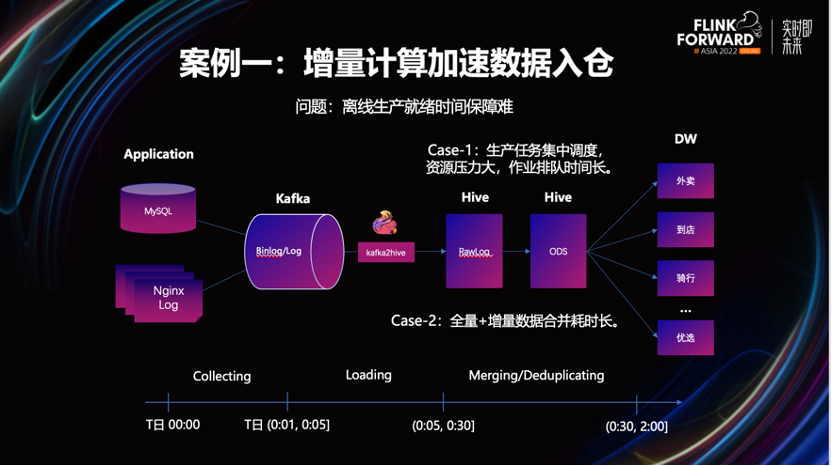
这种方案主要面临以下两点问题:
-
由于采用批计算模式,凌晨发起任务集中调度时,因资源不足而引起作业大量排队,从而影响作业就绪时间。
-
Binlog 的增量日志需要与 ODS 表中已存在的全量日志进行合并,才能交付给下游使用的。这个行为的时间开销也较大,会影响到 ODS 层数据的就绪时间。
在美团的用户行为日志明细数据入仓的场景中,业务的原始日志收集、落 Hive 的过程,问题都不大。但从原始日志清洗出 PV/MV 事件表时,数据的产出时间很不稳定。
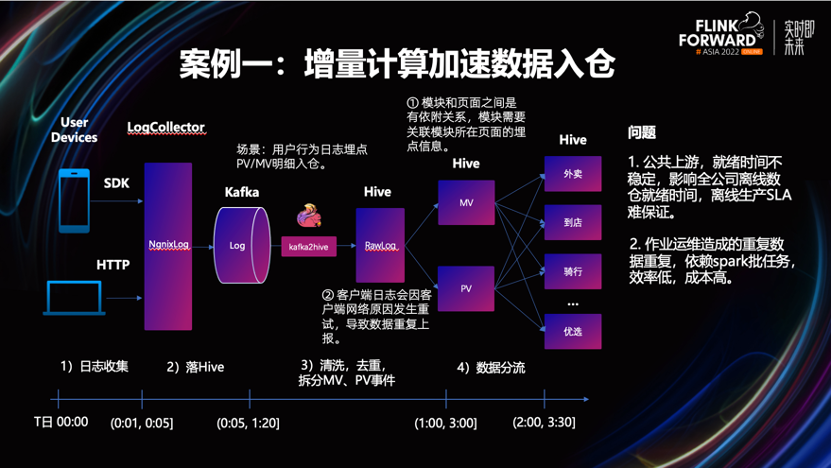
从图上我们可以看到,一些极端情况下,这个过程可能持续到两个小时以上,业务的影响面很大。针对此问题,我们对入仓流程进行了增量化的改造。由 Flink 进行流处理,之后再结合下游业务的实际需求,将清洗后的数据有选择的落 Hive 或 Beluga,对接离线数仓和增量数仓。

改造后效果非常明显。流量数据的就绪时间提前了两小时以上,因不在依赖凌晨的调度,也不会因为资源不足而造成作业长期处于 Pending 状态,资源的利用率得到了提升。
3.2 案例二,通过增量计算模式来提升计算效率
场景-1:提升明细快照表合并效率。
业务想要一个体现最新的业务进展数据快照。在离数仓的计算模式下,得到这个快照需采用批模式,合并每天新增的变更事件到存量快照中。
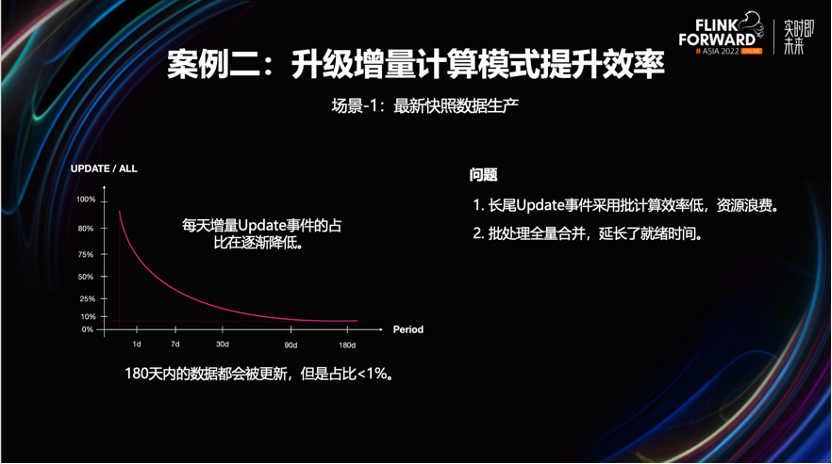
比如图中的例子,在 T-1日产生了一条半年前订单的更新状态。为了保证 fact 层能够提供最新的业务快照,与业务库保持一致。需要将这张表近半年的全部分区,进行一次覆盖更新,计算效率是很差。

为了这么小比例的状态变更,需要拉全量数据进行合并。资源效率和数据就绪时间,都有较大的负面影响,实际这类明细数据生产非常适合用 Beluga 的增量更新能力,提升合并效率。
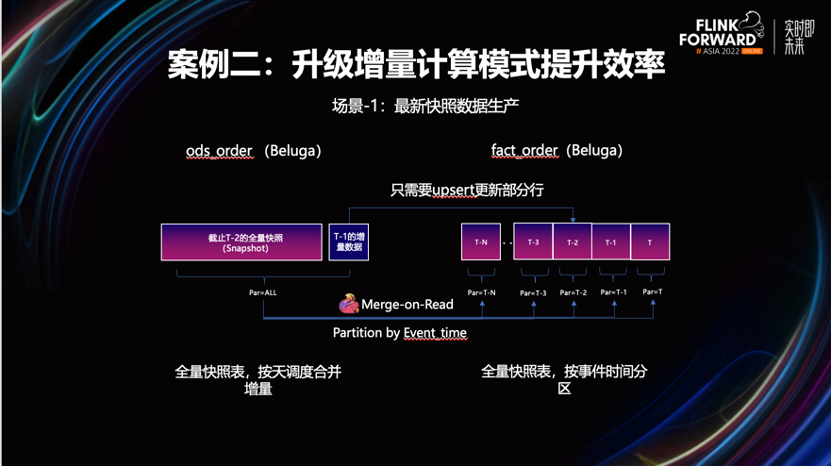
经过改造后,业务不再需要为少量数据的更新行为,重建整张表,有效的节省计算资源开销,进一步提升了数据时效性。
场景-2:提升累计快照事实表的计算效率
本质上属于累计窗口计算语义。如图所示,上游是一张增量明细表,它将每天的增量数据作为独立分区进行存储。下游表则是一张累计快照事实表,每天会创建一个新的分区,用于存储业务某一时刻,到当前的最新数据的累计值。
按照当前离线数仓的生产模式,每天都需要将上游表的所有分区全部读出来,做一次合并,计算出截止到当天的累计快照值,再写到下游表的新分区中。
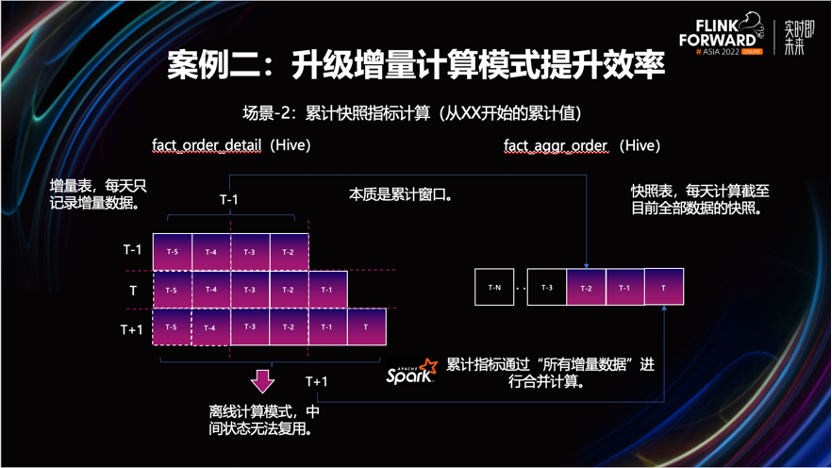
但这样会面临一个问题,随着累计天数的增加,前一天累计好的结果,并未被直接用在算第二天的累计指标的计算过程中。每天都需要拉取上游表全部的分区数据,重新进行计算。这样会造成计算的开销越来越大,这个计算效率非常不理想。

下面介绍下如何通过增量数仓来解决这个问题。

针对这类场景,可以通过 Flink 的流计算模式,将每天新增的增量数据与已经算好的累计状态,在 Flink 作业中直接合并。不仅能够有效利用中间状态,还能够实时将计算后的结果,更新到下游表中,使计算效率和数据新鲜度,都得到了一定的提升。
3.3 案例三,通过增量计算模式来提升计算效率
业务的需求是,既要支持对数据延迟比较敏感并且数据一致性要求较高的 BI 场景,也要支持依赖较长历史周期数据算法的训练场景。
为了保证高时效性,并且不能有太多的重复数据。业务将实时数仓的 Kafka 数据,灌入到 Doris 中,利用 Doris 的主键模型去重。再按 10min 的调度周期,支持较高时效性要求的BI报表查询场景。
另外对于一些算法场景,不但需要长时间周期的特征数据,还需定期与 Hive 上的历史数据做合并。
链路很复杂,会带来大量不必要的运维工作。与此同时,链路上多处依赖调度系统,这会给就绪时间,带来很多不确定性,更不用提数据一致性的保证。
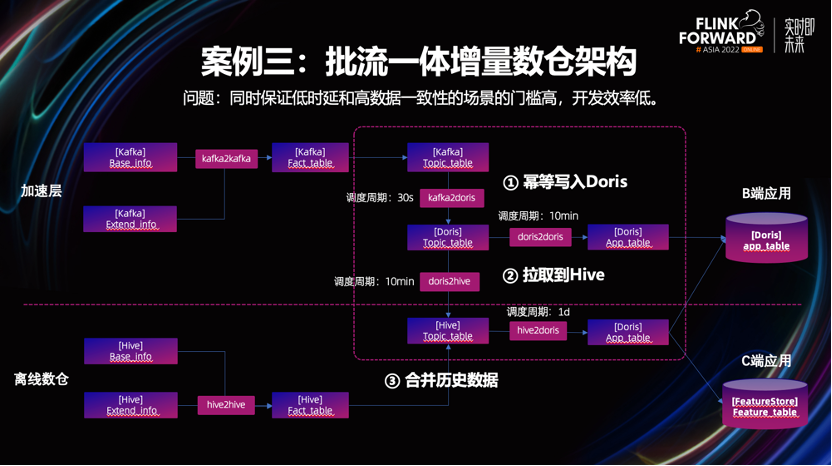
下面看下增量数仓是如何解决这些问题的。
-
通过 Beluga 替换掉 Kafka 和 Doris。因 Beluga 可保证数据的幂等写和强一致性。可以使用 Flink 流任务,替换掉了原有微批任务,保证数据的时效性。
-
通过 Beluga 存储全量历史快照数据,即使业务的指标需要依赖时间跨度很长的历史数据,也可以基于 Beluga 完成指标计算。
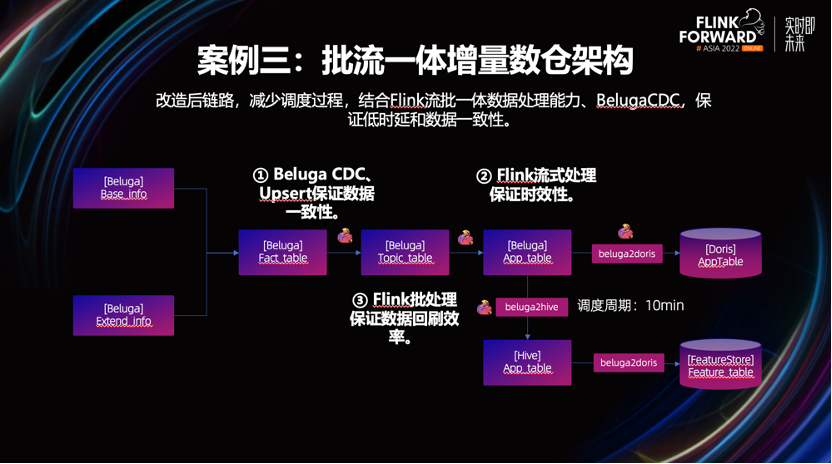
改造后,可以看到链路精简了许多,有效提升了开发运维效率,且削减了部分冗余资源。
四、未来展望
最后,分享下增量数仓的未来的建设规划。
- 持续完善 Beluga 的功能和架构,支持批量更新部分列的能力、点查的能力、还有高效的并发控制能力。
- 我们还会对 Beluga 的事务提交效率进行改进,支持秒级的事务提交,帮助业务以较低的成本,将离线数仓任务迁移至增量数仓的工具等能力。
- 在平台化的工作方面,需要一套统一的数仓接入服务,具备流、批任务托管和调度的开发平台。
点击查看原文视频 & 演讲PPT
相关文章:
美团增量数仓建设新进展
摘要:本文整理自美团系统研发工程师汤楚熙,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分: 建设背景核心能力设计与优化业务实践未来展望 点击查看原文视频 & 演讲PPT 一、美团增量数仓的建设背景 美团数仓架…...

LeetCode解法汇总2337. 移动片段得到字符串
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你两个字…...

Fpass与Fstop
在MATLAB中,“Fpass”、“Fstop”、"Apass"和"Astop"是数字滤波器设计中常用的参数。它们用于定义滤波器的频率响应和滤波器的性能。 "Fpass"表示通带频率,指的是滤波器允许通过的频率范围。在数字滤波器设计中࿰…...
Java快速入门体验
Java快速入门体验 一、环境信息1.1 硬件信息1.2 软件信息 二、Maven安装2.1 Maven介绍2.2 Maven安装包下载2.3 Maven安装2.4 Maven初始化 三、Java安装3.1 JDK下载3.2 JDK安装3.3 JDK初始化 四、开发环境搭建4.1 安装开发工具4.2 关联Maven环境4.2.1 新建JAVA项目4.2.2 Maven与…...

父组件传给子组件的数据是异步的,为什么会导致子组件比父组件先执行?
当父组件传递给子组件的数据是异步获取的时候,可能会导致子组件先执行的问题。这是因为在 Vue 的更新机制中,当组件的模板开始渲染时,会立即触发子组件的创建和挂载过程,而父组件的数据可能还没有完全加载完成。 具体来说…...
泛型编程 学习笔记
#include "iostream"using namespace std;template<typename T> void Print(T a) {cout << a << endl; }int main() {int a 5;double b 2.3;char c e;string d "sdfasd";Print(a);Print(b);Print(c);Print(d);return 0; } 它可以不用…...

电脑文件删除了可以找回吗?分享一种简单恢复删除电脑文件办法!
电脑文件删除了可以找回吗?可以。在原理上讲电脑删除的文件是有希望恢复的,因为操作系统在删除文件的时候并会不会立刻将文件彻底删除。当文件被删除的时候,其文件记录被删除,并且被文件占用的磁盘空间被标记为空闲。 这样对于用户…...
event模块)
Pygame编程(4)event模块
Pygame编程(4)event模块 函数示例 函数 pygame.event.pump 让 Pygame 内部自动处理事件pygame.event.get 从队列中获取事件pygame.event.poll 从队列中获取一个事件pygame.event.wait 等待并从队列中获取一个事件pygame.event.peek 检测某类型事件是否在…...

Python数据采集实战-使用BeautifulSoup框架解析HTML文档并提取所需内容(附源码和实现效果)
实现功能 使用BeautifulSoup框架解析HTML文档并提取所需内容的例子:假设我们要从以下HTML文档中提取所有超链接的链接地址 实现代码 from bs4 import BeautifulSoup import requests# 发送请求并获取HTML文档 url "https://www.baidu.com" response r…...
Java“牵手”天猫商品列表数据,关键词搜索天猫商品数据接口,天猫API申请指南
天猫商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取天猫商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问天猫商城的网页来获取商品详情信息。以下是两种常用方法的介绍&…...
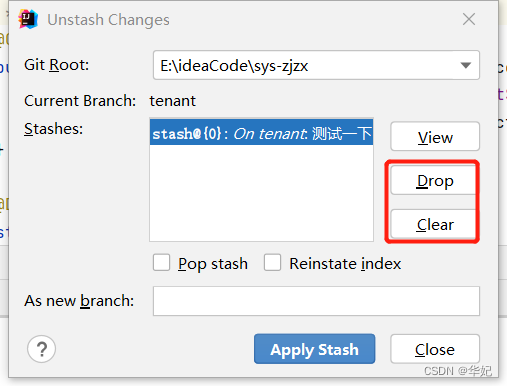
idea切换Git分支时保存未提交的文件
解决方案 我们现在有三个分支,如下图: 我们目前在tenant分支上进行开发,需要去修复master的Bug,假设我们在tenant分支上修改了一个文件,如下图: 方法一:使用Shelve Changes 1、选中tenant上你不…...

Qt串口通信学习文档
这是官方文档,我也在学习。 QSerialPort Class | Qt Serial Port 5.15.14https://doc.qt.io/qt-5/qserialport.html...

018-时间处理库,预处理
018-时间处理库,预处理 ⼀、C语⾔的时间处理库 time.h是C/C++中的⽇期和时间头⽂件,通过他可以获取系统时间及时间格式 转换 time库中常⽤函数介绍 1、函数名称: time 2、函数名称: localtime 3、函数名称: asctime 4、函数名称: ctime 5、函数名称: gmtime 6、函数名…...
Sketch 98 中文版-mac矢量绘图设计
Sketch是一款专为Mac操作系统设计的矢量图形编辑软件,被广泛应用于UI/UX设计、网页设计、移动应用设计等领域。Sketch提供了各种工具和功能,包括绘图、图形设计、排版等,可以帮助设计师轻松地创建高质量的矢量图形和模型。Sketch的主要特点包…...

Springboot继承Keycloak实现单点登陆与退出
由于网上博客大部分都只有登陆没有退出,自己花了一些时间研究了一下,这里将相关内容进行记录,基于Keyclaok 20的版本,实现springboot服务单点登录与退出 一、依赖 <!-- 在父工程中 --> <dependencyManagement><d…...
天眼查接口 查询企业信息API 企查查接口
item_get-获得tyc详情 tyc.item_get 公共参数 请求地址: https://api-gw.cn/tyc/item_get 名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中࿰…...
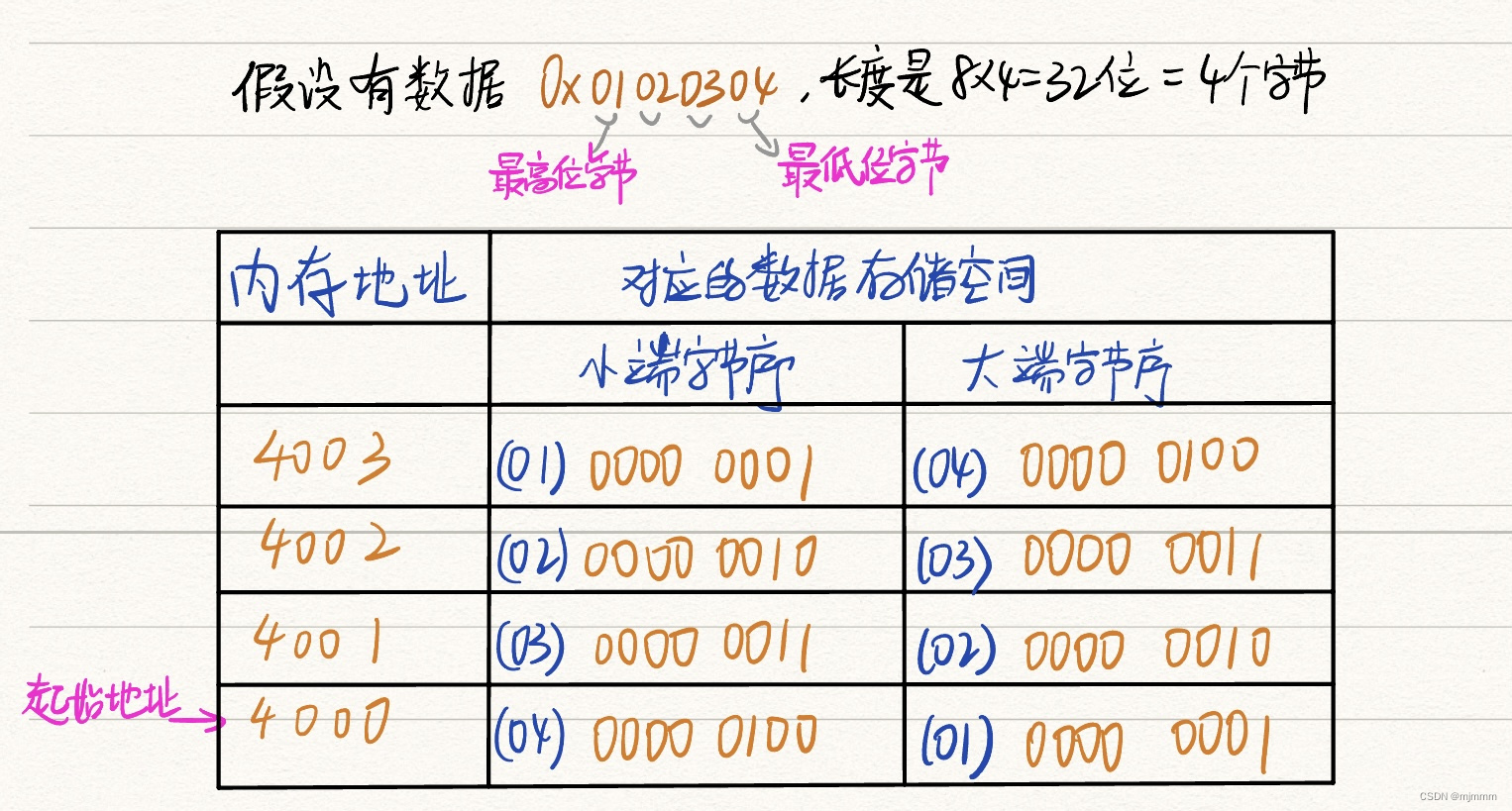
Linux 网络编程 和 字节序的概念
网络编程概述 不同于之前学习的所有通讯方法,多基于Linux内核实现,只能在同一个系统中不同进程或线程间通讯,Linux的网络编程可以实现真正的多机通讯! 两个不相关的终端要实现通讯,必须依赖网络,通过地址…...

unet pytorch
1.单机多卡版本:代码中的DistributedDataParallel (DDP) 部分对应单机多卡的分布式训练方式 import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from torchvisi…...
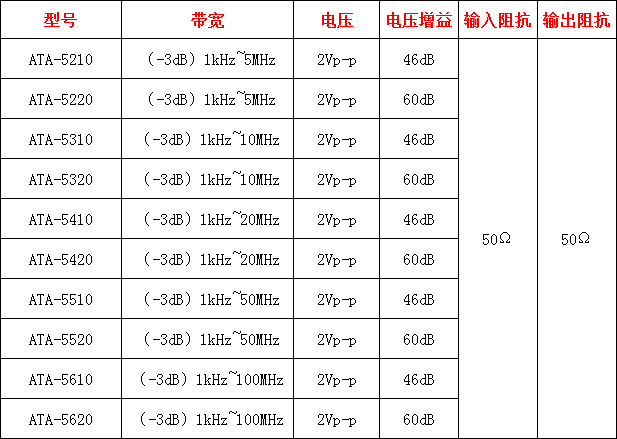
前置微小信号放大器的作用是什么
前置微小信号放大器是一种电子设备,用于将弱信号放大到足够的水平以供后续处理。它在许多领域都有广泛的应用,如通信系统、无线电接收机、传感器接口等。 前置微小信号放大器的主要作用是增加信号的强度。当我们处理微弱信号时,如果不进行放大…...
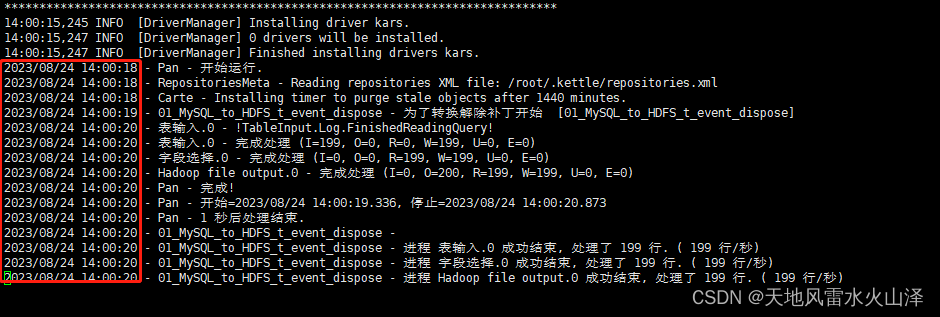
一百六十五、Kettle——用海豚调度器调度Linux资源库中的kettle任务脚本(亲测、附流程截图)
一、目的 在Linux上脚本运行kettle的转换任务、无论是Linux本地还是Linux资源库都成功后,接下来就是用海豚调度Linux上kettle任务 尤其是团队开发中,基本都要使用共享资源库,所以我直接使用海豚调度Linux资源库的kettle任务脚本 二、前提条…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...