深度学习知识总结2:主要涉及深度学习基础知识、卷积神经网络和循环神经网络
往期链接:Summer 1 : Summarize linear neural networks and multi-layer perceptron
Summer 2: Summarize CNN and RNN
文章目录
- Summer 2: Summarize CNN and RNN
- Part 1 Deep Learning
- > 层和块
- > 参数管理和延后初始化
- > 读写文件和GPU
- Part 2 CNN
- > 从全连接到图像卷积
- > 填充、步幅、多通道和池化层
- > LeNet
- > AlexNet
- > VGG
- > NiN
- > GoogLeNet
- > 批量规范化(batch normalization)
- > ResNet(残差网络)
- > DenseNet
- Part 3 DNN
- > 序列模型
- > 文本预处理和语言模型
- > 循环神经网络
- > 通过时间反向传播
- > GRU门控循环单元
- > LSTM长短期记忆网络
- > 深度循环神经网络
- > 双向循环神经网络
- > ***机器翻译与数据集***
- > 编码器-解码器架构(解决输入输出可变问题)
- > 序列到序列的学习seq2seq
- > 束搜索beam search
Part 1 Deep Learning
> 层和块
- 在深度学习中,许多模型架构中的层组普遍以各种重复模式排列,所以引入块的概念。块可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的。
- 从编程角度看,块由类(Class)表示,它的任何子类都需要定义前向传播函数、存储必需的参数、同时具有反向传播函数(一般由系统自动实现,所以不用编写反向传播代码,在调用net时,自动计算)。
net(x)实际上是net.__call__(X)的缩写,在nn.Module类中,定义了__call__方法,使模型实例能够像函数一样进行调用,输入数据并返回预测结果。而调用则是默认调用forward方法,并返回前向传播的结果。- 新版本API使用
nn.LazyLinear(outputnum)代替nn.Linear(inputnum, outputnum),让我们可以不用特定指定输入数,程序会根据我们的输入,自动调节。
- 顺序块则通过
Sequential实现层和块的串联。 - 自定义层:
- 定义参数:
nn.Parameter - 定义前向传播
- 定义参数:
> 参数管理和延后初始化
- 参数访问:当通过Sequential类定义模型时, 我们可以通过索引来访问模型的任意层。如在一个
nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))模型中使用net[2].state_dict()检查第二个全连接层的参数(因为激活函数纵使通常没有参数,也要算作一层,可以用print(net)查看网络结构),也可以使用.weight和.bias来分别访问权重和偏置,同时还可以用net[2].weight.grad来访问其权重的梯度。 - 参数初始化:
- 内置默认初始化:
nn.init - 自定义初始化
- 内置默认初始化:
- 参数绑定:在多个层间共享参数。要实现共享参数,可以定义一个稠密层,后使用它的参数来设置另一个层的参数。它们不仅值相等,而且由相同的张量表示。在反向传播时,同一个稠密层的梯度会进行相加,使其在网络中形成累积。之后会根据相加的梯度统一更新稠密层的参数。
- 延后初始化:等到模型第一次传递数据时,动态推断每层的大小,而不是实现指定。
nn.LazyLinear
> 读写文件和GPU
- 加载和保存模型参数:
- 训练完模型后保存参数:
torch.save(net.state_dict(),'filename.params') - 要恢复参数,需要构建相应的模型:
MLP.load_state_dict(torch.load('filename.params')),同时将模型设置为评估模式:MLP.eval()。
- 训练完模型后保存参数:
- 使用GPU进行训练:
- 创建张量时,设置
device='cuda:0' - 为了使用方便,我们构建了两个函数:
def try_gpu(i=0):和def try_all_gpus():来代替直接指定cuda:0。 - 复制:
Z = X.cuda(1),将X从显卡0复制到显卡1。因为只有在同一个GPU上才能进行运算。 - 将模型参数放在GPU上进行训练:
net = net.to(device=try_gpu()),同样需要将特征X放入GPU中,即可执行训练。
- 创建张量时,设置
Part 2 CNN
> 从全连接到图像卷积
对于高维感知数据,例如图像本身就拥有丰富的结构可以被机器模型使用,所以MLP这种缺少结构的网络需要大量参数就会变得不实用,CNN则是可以利用自然图像中的一些已知结构的创造性方法。
- 不变性:CNN系统化不变性的概念,从而基于这个模型使用较少的参数来学习有用的表示。
- 平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应。在一个位置学习到的特征,可以在其他位置识别到类似的特征,不受平移的影响
- 局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系。最终,可以聚合这些局部特征,以在整个图像级别进行预测。利用局部性的原理,通过卷积操作在图像的不同区域上提取特征,然后通过池化操作聚合这些特征。
- 不变性原则的数学表示:在多层感知机中,我们将二维图片展成一维向量,但这样就失去了图片中的空间信息
- 所以在卷积神经网络里,我们保留输入和输出的空间结构,即输入和输出都是二维的,所以权重矩阵也就被替换成了四阶权重张量。
- 卷积的命名是因为对输入
X和隐藏表示(输出)H的计算过程引入平移不变性之后的变式形式与数学上离散值的卷积公式相似。 - 引入局部性后,计算公式被进一步限制了a,b的取值,我们将$H[i,j] = u + \sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} V[a,b] \cdot X[i+a,j+b] $成为一个卷积层。自此,参数
V的维度由四维下降到了二维,参数量减少i*j倍。
- 通道:图像其实是一个由高度、宽度和颜色组成的三维张量。 前两个轴与像素的空间位置有关,而第三个轴可以看作每个像素的多维表示。所以索引更改为三维的同时,卷积的参数也调整为三维,同时由于输出也需要多通道(特征映射),所以我们需要在参数
V中添加第四个坐标。即$H[i,j,d] = u[d] + \sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} \sum_c V[a,b,c,d] \cdot X[i+a,j+b,c] $ 多个输入和输出通道使模型在每个空间位置可以获取图像的多方面特征。(在pytorch中,多个输入通道相加后,才会添加一个偏置b) - 互相关运算(卷积):在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。 当卷积窗口滑动到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得出了这一位置的输出张量值。 输出矩阵大小=输入大小-卷积核大小+1。即 ( n h − k h + 1 ) ∗ ( n w − k w + 1 ) (n_h-k_h+1) * (n_w-k_w+1) (nh−kh+1)∗(nw−kw+1)。
- 卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。 所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。
- 在卷积神经网络中,对于某一层的任意元素,其感受野是指在前向传播期间可能影响计算的所有元素(来自所有先前层)。因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。
> 填充、步幅、多通道和池化层
填充和步幅会影响卷积输出形状。
- 填充:防止丢失边缘像素。影响输出形状如下: ( n h − k h + p h + 1 ) ∗ ( n w − k w + p w + 1 ) (n_h-k_h+p_h+1) * (n_w-k_w+p_w+1) (nh−kh+ph+1)∗(nw−kw+pw+1),其中 p h , p w p_h,p_w ph,pw分别表示行填充(上下都算)和列填充(左右都算)。要使输入和输出形状保持不变,只需要设置填充量=核形状-1。
- 所以卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。 选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
- 步幅:有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素,每次滑动元素的数量称为步幅。影响输出形状如下: ⌊ ( n h − k h + p h + s h ) / s h ⌋ ∗ ⌊ ( n w − k w + p w + s w ) / s w ⌋ \left \lfloor (n_h-k_h+p_h+s_h)/s_h \right \rfloor * \left \lfloor(n_w-k_w+p_w+s_w)/s_w\right \rfloor ⌊(nh−kh+ph+sh)/sh⌋∗⌊(nw−kw+pw+sw)/sw⌋,如果设置了 p h = k h − 1 , p w = k w − 1 p_h = k_h -1,p_w = k_w -1 ph=kh−1,pw=kw−1,同时输入的高度和宽度可以被垂直和水平步幅整除,则输出形状简化为$(n_h/s_h) * (n_w/s_w) $。
- 总之,填充可以增加输出的高度和宽度。这常用来使输出与输入具有相同的高和宽。步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的(是一个大于1的整数)。
- 多输入通道互相关运算就是对每个通道执行互相关操作,然后将每个通道的结果相加。
- 多输出通道的互相关运算中,每个输出通道先获取所有的输入通道,再以对应该输出通道的卷积核计算出结果。即如果是多输入和多输出的情况下,在完成多输入后(计算各个输入通道的值求和)会生成一个输出通道[0]的值,接着复制X,修改卷积核K的值,再完成一次多输入计算(计算各个输入通道的值求和)生成输出通道[1]的值,重复上述步骤,直到生成指定数量的输出通道值。
- 1 x 1卷积层:因为使用了最小窗口,1x1卷积失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力。 我们可以将1x1卷积层看作在每个像素位置应用的全连接层,以 c i c_i ci个输入值转换为 c 0 c_0 c0个输出值。1x1卷积层通常用于调整网络层的通道数量和控制模型复杂性。
- 汇聚层(池化层):双重作用1.降低卷积层对位置的敏感性,2.同时降低对空间降采样表示的敏感性。池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值,这是与卷积层最大的不同。
- 使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度),汇聚层的输出通道数与输入通道数相同。
> LeNet
- LeNet(LeNet-5)由两个部分组成:
- 卷积编码器:由两个卷积层组成;
- 每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。
- 全连接层密集块:由三个全连接层组成。
- 为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。
- 卷积编码器:由两个卷积层组成;
- 卷积的输出形状由批量大小、通道数、高度、宽度决定。
- 准确率函数的写法。
> AlexNet
在一段时期内,机器学习都需要手工对特征数据集进行预处理,更大或更干净的数据集、或是稍微改进的特征提取,比任何学习算法带来的进步要大得多
- 而AlexNet则认为特征不应该被设计,而是应该被学习。同时它也首次证明了学习到的特征可以超越手工设计的特征。(表征学习)
- AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
- AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
> VGG
通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构
- 经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。
- 与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- VGG发现了发现深层且窄的卷积(即3x3)比较浅层且宽的卷积更有效。
> NiN
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。
AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。 或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。 网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机。
- 卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度。 另外,全连接层的输入和输出通常是分别对应于样本和特征的二维张量。
- NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。 如果我们将权重连接到每个空间位置,我们可以将其视为1x1卷积层,或作为在每个像素位置上独立作用的全连接层。 从另一个角度看,即将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)。
- NiN块以一个普通卷积层开始,后面是两个1x1的卷积层(使用两个是因为经验和实践结果)。这两个1x1卷积层充当带有ReLU激活函数的逐像素全连接层。
- NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。 相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层,生成一个对数几率 (logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。移除全连接层可减少过拟合,同时显著减少NiN的参数。
> GoogLeNet
GoogLeNet最大的贡献是解决了什么样大小的卷积核最合适的问题。毕竟,以前流行的网络使用小到1x1,大到11x11的卷积核。GoogLeNet的一个观点是,有时使用不同大小的卷积核组合是有利的。
- Inception块:GoogleNet的基本卷积块。四条并行路径组成,最后在每条线路的输出在通道维度上连结。Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用1x1卷积层减少每像素级别上的通道维数从而降低模型复杂度。
- GoogLeNet这个网络如此有效归功于:可以用各种滤波器尺寸探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。同时,可以为不同的滤波器分配不同数量的参数。
- GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
> 批量规范化(batch normalization)
(1).数据预处理的方式通常会对最终结果产生巨大影响。比如:标准化输入特征,使其平均值为0,方差为1。 直观地说,这种标准化可以很好地与我们的优化器配合使用,因为它可以将参数的量级进行统一。(2)对于典型的多层感知机或卷积神经网络,中间层的变量(如层感知机中的仿射变换输出)可能具有更广的变化范围,模型的参数也随着训练更新变换莫测。(3).深层的网络很复杂,容易过拟合。 这意味着正则化变得更加重要。
- 批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去其均值(小批量的对应特征)并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。正是由于这个基于批量统计的标准化,才有了批量规范化的名称。
- 只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。(大小为1时,隐藏单元减去均值将变为0)
- 批量规范化表达式: B N ( x ) = γ ⊙ x − μ ^ B σ ^ B + β . \mathrm{BN}(\mathbf{x}) = \boldsymbol{\gamma} \odot \frac{\mathbf{x} - \hat{\boldsymbol{\mu}}_\mathcal{B}}{\hat{\boldsymbol{\sigma}}_\mathcal{B}} + \boldsymbol{\beta}. BN(x)=γ⊙σ^Bx−μ^B+β. 其中 拉伸参数 γ \gamma γ 和 偏移参数 β \beta β 是需要与其他模型参数一起学习的参数。由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每一层主动居中,并将它们重新调整为给定的平均值和大小。(通过小批量样本的均值 μ ^ B \hat{\boldsymbol{\mu}}_\mathcal{B} μ^B和小批量样本标准差 σ ^ B \hat{\boldsymbol{\sigma}}_\mathcal{B} σ^B)。
- 方差估计值中会添加一个小的正数常量,以确保我们永远不会尝试除以零。优化中的各种噪声源通常会导致更快的训练和较少的过拟合:这种变化似乎是正则化的一种形式(尚未由理论原因)。
- 批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。
- 批量规范化应用于仿射函数与激活层之间。对全连接层,作用在特征维上;对卷积层,作用在通道维。
- 通常情况下,我们用一个单独的函数定义其数学原理,比如说batch_norm。 然后,我们将此功能集成到一个自定义层中,其代码主要处理数据移动到训练设备(如GPU)、分配和初始化任何必需的变量、跟踪移动平均线(此处为均值和方差)等问题。
- 批量归一化可以解决顶部参数和底部参数更新速度不统一的问题。可以加速收敛速度(因为将所有的隐藏输出数据转移到同分布,可以使用更大的学习率来收敛模型),但一般不改变模型精度。
> ResNet(残差网络)
- 嵌套函数类:随着神经网络层的加深,我们觉得更强大的网络模型架构可以使我们通过训练更加接近我们想找到的函数,但对于非嵌套函数类,较复杂的函数类不能保证更接近我们相要的“真”函数。这种现象在嵌套函数类中不会发生。因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。
- 对于深度神经网络,如果我们能将新添加的层训练成恒等映射 f ( x ) = x f(x) = x f(x)=x,那么新模型和原模型将同样有效。残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
- 残差块:残差块加入快速通道(跳跃连接)来得到 f ( x ) = x + g ( x ) f(x) = x + g(x) f(x)=x+g(x),即在残差块中,输入可通过跨层数据线路更快地向前传播。新增加的块应该去拟合残差映射 f ( x ) − x f(x) - x f(x)−x,这个差分就是网络需要学习的变化部分,即残差,而非 f ( x ) f(x) f(x)。残差映射在现实中往往更容易优化。这种结构更容易让网络学习到变化而不是完整的特征映射,有助于解决退化问题。
- ResNet模型:ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的7x7卷积层后,接步幅为2的3x3的最大汇聚层。不同之处在于ResNet每个卷积层后增加了批量规范化层。最开始是ResNet18,表示这种模块一共有1+4*4+1=18个卷积层。
- 当梯度传播回来时,由于残差连接(也称为residual connection)直接将原始输入连接到后面的层,梯度可以更轻松地通过这些连接流回较早的层,避免了梯度在深层网络中逐渐消失的问题。
> DenseNet
- ResNet和DenseNet的关键区别在于,DenseNet输出是连接,而不是如ResNet的简单相加。最后,将这些展开式结合到多层感知机中,再次减少特征的数量。
- 由于每个稠密块都会带来通道数的增加,使用过多则会过于复杂化模型。 而过渡层可以用来控制模型复杂度。 它通过1x1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
Part 3 DNN
> 序列模型
“Embedding”(嵌入)是在机器学习和自然语言处理(NLP)领域中常用的概念。它是一种将离散型数据(如文字、类别等)映射到连续型向量空间中的技术。嵌入的目的是将高维、离散的数据转换为低维、连续的表示,在NLP中,最常见的嵌入是词嵌入(Word Embedding)。词嵌入是将单词映射到一个向量空间中的向量,使得在向量空间中相似的单词在语义上也是相似的,从而使得计算机可以更好地理解单词之间的关系。嵌入的一个重要特点是它们能够捕捉数据之间的语义关系和相似性,因此在许多任务中能够帮助模型更好地处理数据。
- 处理语音、文本、视频、股价等序列数据(时间动力学)需要统计工具(不独立随机变量及其概率)和新的深度神经网络架构。
- 跟回归模型主要的一个区别是:输入的数量随着某个序列(例如时间)而变化,我们需要一个近似方法来简化这种计算。
- 自回归模型(马尔可夫假设):假设在现实情况下相当长的序列 x t − 1 , . . . , x 1 x_{t-1},...,x_1 xt−1,...,x1可能是不必要的, 因此我们只需要满足某个长度为$\tau 的时间跨度 , 即使用 的时间跨度,即使用 的时间跨度,即使用x_{t-1},…,x_{t-\tau} 观测序列。最直接的好处就是参数的数量总是不变的。给定 观测序列。最直接的好处就是参数的数量总是不变的。给定 观测序列。最直接的好处就是参数的数量总是不变的。给定t-1 个数据,去计算 个数据,去计算 个数据,去计算p({x_t}) 概率,对条件概率建模,可以发现是对见过的数据应用模型 概率,对条件概率建模,可以发现是对见过的数据应用模型 概率,对条件概率建模,可以发现是对见过的数据应用模型f$,故称自回归模型。
- 隐变量自回归(潜变量模型):隐变量自回归模型结合了自回归和潜在变量建模的思想,以更准确地捕捉数据的内在结构和动态变化。引入潜变量来概括历史信息 h t h_t ht,并且同时更新预测值 x t = P ( x t ∣ h t ) x_t = P(x_t|h_t) xt=P(xt∣ht)和历史信息 h t = g ( h t − 1 , x t − 1 ) h_t = g(h_{t-1},x_{t-1}) ht=g(ht−1,xt−1)。,
- 在序列模型中基于静止动力学和马尔可夫过程,可将预测连续值和离散值的问题分别转化为之前的线性回归和逻辑回归问题,问题的关键是基于 τ \tau τ去构建特征-标签对。
- 单步预测和K步预测:在单步预测中,每次只预测未来一个时间步的值。在K步预测中,一次性预测未来K个时间步的值。这意味着模型不仅考虑了当前的历史数据,还会使用更多的未来信息来预测。
- 对于时间是向前推进的因果模型,正向估计通常比反向估计更容易。
> 文本预处理和语言模型
-
解析文本的常见处理步骤:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
-
拓展:Python数据类型中值得注意的点:
- 与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如
word[0] = 'm'会导致错误。 - List列表[ ]可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
- 与Python字符串不一样的是,列表中的元素是可以改变的,且List 内置了有很多方法,例如 append()、pop() 等等。
- Python 中的集合(Set){ }是一种无序、可变的数据类型,用于存储唯一的元素。集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作.
- 列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。(key-value)
- bytes 类型表示的是不可变的二进制序列,bytes 类型通常用于处理二进制数据,比如图像文件、音频文件、视频文件等等,使用 b 前缀可以创建bytes对象。
- 与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如
-
词元化,形成语料库(Corpus):tokenize函数将文本行列表(lines)作为输入,列表中的每个元素是一个文本序列(如一条文本行)。每个文本序列又被拆分成一个词元列表,词元(token)是文本的基本单位。最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
-
词表(Vacab):用来将字符串类型的词元映射到从开始的数字索引中。对唯一词元进行统计,统计结果称为语料。根据每个唯一词元的出现频率,为其分配一个数字索引。 很少出现的词元通常被移除,这可以降低复杂性。
-
语言模型:语言模型的目标是估计文本序列的联合概率。为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。拉普拉斯平滑可以有效地处理结构丰富而频率不足的低频词词组,但很容易无效,因为我们需要存储所有的计数,而且完全忽略了单词的意思。
-
自然语言统计:最常出现的词往往是没有语义的词语即停用词(stop words)。词频通常以一种明确的方式迅速衰减,单词的频率满足普夫定律,即第 i i i(以出现频率降序排列)个单词出现的频率 n i n_i ni,正比于 1 i α \frac{1}{i^\alpha} iα1。 α \alpha α是刻画分布的指数。
-
n元语法(n-gram):基于前面的n-1个词去预测下一个词,即涉及n个变量的概率公式被称为n元语法。使用1,2,3元语法证明,单词序列都遵循普夫定律,且词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构需要学习。统计方法通常采用n元语法做语言处理,它通过截断相关性,为处理长序列提供了一种实用的模型。但长序列存在一个问题:它们很少出现或者从不出现。
-
读取长序列数据:
- 随机采样:每个样本都是在原始的长序列上任意捕获的子序列。
- 顺序分区:除了对原始序列可以随机抽样外, 我们还可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的。即相比于随机采样,后者可以保证来自两个相邻的小批量中的子序列在原始序列上也是相邻的。
-
语言模型相对于序列模型,生成序列时滑动的方式不一样。序列模型,每次滑动一格,而语言模型每次滑动 τ \tau τ格。语言模型的好处是,每个数据不会被频繁使用多次,即每个数据不会重复存在在多个子序列中。产生的子序列数量会变少,从而减少内存开销等。所以相应的每个子序列X对应的输出y是一个比X序列向后移动一个位置的序列,而不像序列模型中,一组x序列仅仅对应该序列后的一个y值。
> 循环神经网络
开启第一个针对序列模型的神经网络,之前n元语法等多数采用统计学习方法。
- 在n元语法模型中,对于时间步 t − ( n − 1 ) t-(n-1) t−(n−1)之前的单词, 如果我们想将其可能产生的影响合并到 x t x_t xt上, 需要引入更多的历史信息,即增加 n n n,然而模型参数的数量也会随之呈指数增长,因为词表V(含有V个不同的词)要存储 V n V^n Vn个序列,这是一个语法的组合性”或“词汇爆炸”问题。实际上,语言中实际出现的n-gram序列数量远远少于所有可能的组合。很多组合是不合法的,也就是说,在语料库中并没有出现过。这导致了数据的稀疏性。其次长期依赖问题可能变得突出,因为在长序列中,过去的信息可能变得模糊,难以捕捉到更远处的依赖关系。
- 那么我们考虑使用隐变量(也称隐状态),隐变量 h t − 1 h_t-1 ht−1存储了到时间步 t − 1 t-1 t−1的序列状态。使用隐变量模型(eg.Topic Model)可以在一定程度上解决长期依赖问题。这些模型引入了潜在变量,从而将序列数据映射到更低维度的表示。这些潜在变量可以捕捉到更抽象的语义信息和主题结构,而不仅仅是局部的上下文信息。这使得模型更能够捕捉到文本数据的整体模式。循环神经网络(recurrent neural networks,RNNs) 是具有隐状态的神经网络。
- 循环神经网络与多层感知机不同的是,在每一个时间步 t t t保存了前一个时间步的隐藏变量 H t − 1 H_{t-1} Ht−1,并引入了一个新的权重参数 W h h ∈ R h ∗ h W_{hh}\in R^{h * h} Whh∈Rh∗h,来描述如何在当前时间步中使用前一个时间步的隐藏变量。由于隐状态的计算是循环的,故得名循环神经网络。其中执行计算层被称为循环层。
- 循环神经网络的参数开销不会随着时间步的增加而增加。在任意时间步 t t t,隐状态的计算可以被视为:
- 拼接当前时间步的输入和前一时间步的隐状态;
- 将拼接的结果送入带有激活函数的全连接层。 全连接层的输出是当前时间步的隐状态。
- 基于循环神经网络可以构建字符级语言模型和单词级语言模型。
- 困惑度(Perplexity):度量语言模型的质量。可以通过像线性回归一样计算序列的似然概率来度量模型的质量,但其难以理解和比较。所以我们采用softmax回归中谈到的信息论,即通过一个序列中所有的 n 个词元的交叉熵损失的平均值来衡量。上述值取指数便是困惑度,可以理解为下一个词元的实际选择数的调和平均数。模型越好,困惑都越接近1,模型越差,困惑度越接近于无穷大。
- 在循环神经网络中,每个词元都表示为一个数字索引, 将这些索引直接输入神经网络可能会使学习变得困难。所以通常将每个词元表示为更具表现力的特征向量。最简单的为独热编码。第i个词元的独热编码就是一个长度为N的全0向量,并将第i处的元素设置为1。这也使得每次采样的小批量数据由二维张量
(批量大小,时间步数)变为三维张量(时间步数,批量大小,词表大小),这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。 - 梯度剪裁:由于时间步的存在,导致容易产生梯度爆炸问题。梯度剪裁的基本思想是设置一个阈值,当梯度的范数(或某些情况下,每个梯度分量的绝对值)超过这个阈值时,就对梯度进行缩放,使其范数不超过阈值。
- 循环神经网络模型在训练以前需要初始化状态,不过随机抽样和顺序划分使用初始化方法不同。当使用顺序划分时,我们需要分离梯度以减少计算量。在进行任何预测之前,模型通过预热期进行自我更新(例如,获得比初始值更好的隐状态)。
- 高级API的循环神经网络层返回一个输出和一个更新后的隐状态,我们还需要计算整个模型的输出层。
> 通过时间反向传播
- “时间反向传播”(BPTT)实际上是循环神经网络中反向传播技术的一个特定应用,仅仅适用于反向传播在具有隐状态的序列模型。隐状态序列模型前向传播一次一个时间步地遍历三元组(输入 x t x_t xt,隐状态 h t h_{t} ht,输出 o t o_t ot),然后通过一个目标函数在所有个T时间步内评估输出和对应的标签之间的差异。但反向传播中,目标函数L关于隐变量层的参数 w h w_h wh的梯度计算可以由链式法则递归计算,但当t很大时,这个链就会变得很长,一方面需要大量的存储与计算资源,另一方面可能会导致初始条件的微小变化就可能会对结果产生巨大的影响。所以我们几乎不会采用完全计算的方式,而是采用截断时间步。
- 截断是计算方便性和数值稳定性的需要。截断包括:规则截断和随机截断。随机阶段使用序列来实现。遗憾的是,虽然随机截断在理论上具有吸引力, 但很可能是由于多种因素在实践中并不比常规截断更好。 首先,在对过去若干个时间步经过反向传播后, 观测结果足以捕获实际的依赖关系。 其次,增加的方差抵消了时间步数越多梯度越精确的事实。 第三,我们真正想要的是只有短范围交互的模型。 因此,模型需要的正是截断的通过时间反向传播方法所具备的轻度正则化效果。
- 矩阵的高次幂可能导致神经网络特征值的发散或消失,将以梯度爆炸或梯度消失的形式表现。
- 由于通过时间反向传播是反向传播在循环神经网络中的应用方式, 所以训练循环神经网络交替使用前向传播和通过时间反向传播。 通过时间反向传播依次计算并存储上述梯度。 具体而言,存储的中间值会被重复使用,以避免重复计算。
> GRU门控循环单元
- 门控循环单元与普通的循环神经网络之间的关键区别在于:前者支持隐状态的门控。这意味着模型有专门的机制来确定应该何时更新隐状态,以及应该何时重置隐状态。这些机制的参数都是可以学习的。门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系。
- 重置门有助于捕获序列中的短期依赖关系。通过sigmoid函数使 R t ∈ [ 0 , 1 ] {R_t} \in [0,1] Rt∈[0,1] ,让重置门与常规隐状态更新机制集成,得到在时间步t的候选隐状态,可以减少以往状态的影响,候选隐状态通过tanh激活函数保持在[-1,1]之间。
- 更新门有助于捕获序列中的长期依赖关系。通过sigmoid函数使 Z t ∈ [ 0 , 1 ] {Z_t} \in [0,1] Zt∈[0,1] ,在旧的隐状态和新的候选态中按元素的凸组合完成隐藏状态的选举。
- 重置门打开时,门控循环单元包含基本循环神经网络;更新门打开时,门控循环单元可以跳过子序列。
- 门的大小和隐变量的大小都是 n ∗ h n*h n∗h,即批量大小 x 隐藏单元数量。
> LSTM长短期记忆网络
- 跟GRU思想相似,但比GRU早提出20年,且模型较为复杂。
- 输入门、输出门、遗忘门。
- 长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
- 长短期记忆网络可以缓解梯度消失和梯度爆炸。
- 由于序列的长距离依赖性,训练长短期记忆网络 和其他序列模型(例如门控循环单元)的成本是相当高的。 在后面的内容中,我们将讲述更高级的替代模型,如Transformer。
> 深度循环神经网络
- 我们可以将多层循环神经网络堆叠在一起,通过对几个简单层的组合,产生了一个灵活的机制。一个具有L个隐藏层的深度循环神经网络,每个隐状态都连续地传递到当前层的下一个时间步和下一层的当前时间步。
- 有许多不同风格的深度循环神经网络, 如长短期记忆网络、门控循环单元、或经典循环神经网络。 这些模型在深度学习框架的高级API中都有涵盖。
- 总体而言,深度循环神经网络需要大量的调参(如学习率和修剪) 来确保合适的收敛,模型的初始化也需要谨慎。
> 双向循环神经网络
- 隐马尔可夫模型中的动态规划。
- 双向循环神经网络通过添加反向传递信息的隐藏层,使之能够提供与隐马尔可夫模型类似的前瞻能力。在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定
- 现代深度网络的设计原则: 首先使用经典统计模型的函数依赖类型,然后将其参数化为通用形式。
- 在计算过程中,我们需要将前向隐状态和反向隐状态连接起来,获得需要送入输出层的隐状态 H t ∈ R n ∗ 2 h H_t \in R^{n*2h} Ht∈Rn∗2h。
- 双向循环神经网络的梯度链唱,训练代价高,主要用于序列编码和给定双向上下文的观测估计。
> 机器翻译与数据集
- 语言模型是自然语言处理的关键,而机器翻译是语言模型最成功的基准测试, 因为机器翻译正是将输入序列转换成输出序列的序列转换模型的核心问题。
- 统计机器翻译和神经机器翻译。我们注重端到端的神经机器翻译学习。与之前单一语言的语料库不同,机器翻译的数据集是由源语言和目标语言的文本序列对组成的。因此,我们需要一种完全不同的方法来预处理机器翻译数据集,而不是复用语言模型的预处理程序。
- 在机器翻译中,更喜欢使用单词级词元化 (最先进的模型可能使用更高级的词元化技术)。使用单词级词元化时的词表大小,将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,我们可以将低频词元视为相同的未知词元。
- 通过截断和填充文本序列,可以保证所有的文本序列都具有相同的长度,以便以小批量的方式加载。类似于语言模型中的num_steps(时间步的大小)。
> 编码器-解码器架构(解决输入输出可变问题)
- 编码器(encoder):它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。
- 解码器(decoder):它将固定形状的编码状态映射到长度可变的序列。这被称为编码器-解码器(encoder-decoder)架构。
> 序列到序列的学习seq2seq
- 输入序列的信息被编码到循环神经网络编码器的隐状态中。为了连续生成输出序列的词元,独立的循环神经网络解码器是基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元。
- 编码器可以使用双向循环神经网络构造编码器。Embedding层用来获取输入序列中每个词元的特征向量,embedding层的权重是一个矩阵, 其行数等于输入词表的大小,列数等于特征向量的维度,对于任意输入词元的索引i, 嵌入层获取权重矩阵的第i行以返回其特征向量。Embedding层的引入,以其低维、稠密的特性代替了独特编码。
- BLED用于预测序列的评估,它通过测量预测序列和标签序列之间的元语法的匹配度来评估预测。
- 在“编码器-解码器”训练中,强制教学方法将原始输出序列(而非预测结果)输入解码器。
> 束搜索beam search
- seq2seq中我们使用了贪心搜索来预测序列,但可能不是最优的。每次选择概率最大的作为输出。
- 束搜索介于效率(贪心)和精度(穷举)之间。
相关文章:

深度学习知识总结2:主要涉及深度学习基础知识、卷积神经网络和循环神经网络
往期链接:Summer 1 : Summarize linear neural networks and multi-layer perceptron Summer 2: Summarize CNN and RNN 文章目录 Summer 2: Summarize CNN and RNNPart 1 Deep Learning> 层和块> 参数管理和延后初始化> 读写文件和GPU Part 2 CNN> 从…...
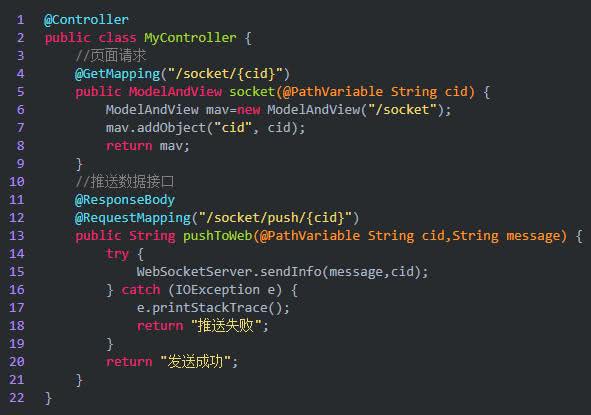
Spring Boot 集成 WebSocket 实现服务端推送消息到客户端
WebSocket 简介 WebSocket 协议是基于 TCP 的一种新的网络协议,它实现了浏览器与服务器全双工(full-duplex)通信—允许服务器主动发送信息给客户端,这样就可以实现从客户端发送消息到服务器,而服务器又可以转发消息到客…...

vr游乐场项目投资方案VR主题游乐馆互动体验
VR文旅景区沉浸互动体验项目是指利用虚拟现实技术在文旅景区中创建沉浸式的互动体验项目。通过虚拟现实技术,游客可以身临其境地体验景区的风景和文化,与虚拟场景中的元素进行互动。 普乐蛙VR设备 普乐蛙VR设备案例分享 这种项目可以为游客带来全新的旅游…...
)
chrom扩展开发配合百度图像文字识别实现自动登录(后端.net core web api)
好久没做浏览器插件开发了,因为公司堡垒机,每次登录都要输入账号密码和验证码。太浪费时间了,就想着做一个右键菜单形式的扩展。 实现思路也很简单,在这里做下记录,方便下次开发参考。 一,先来了解下chro…...

香港服务器怎么打开SSH
SSH是一种远程登录协议,可以通过加密方式在网络上安全地传输数据。它允许用户在远程服务器上执行命令,管理文件和目录,并进行其他系统管理任务。 如何打开SSH服务? 1.确认已安装OpenSSH服务器: 你可以通过命令sudoapt-geti…...
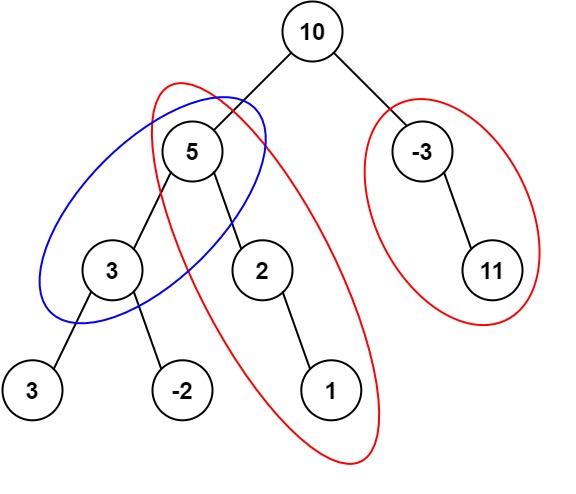
【LeetCode】437.路径总和Ⅲ
题目 给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。 路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节…...

Mybatis-plus中操作JSON字段
1.实体类上要加上自动映射 TableName(value "school", autoResultMap true)2.json字段上加上json处理器 TableField(value "cover_url", typeHandler JacksonTypeHandler.class)private List<String> cover_url;参考博客 http://www.dedeyun.co…...
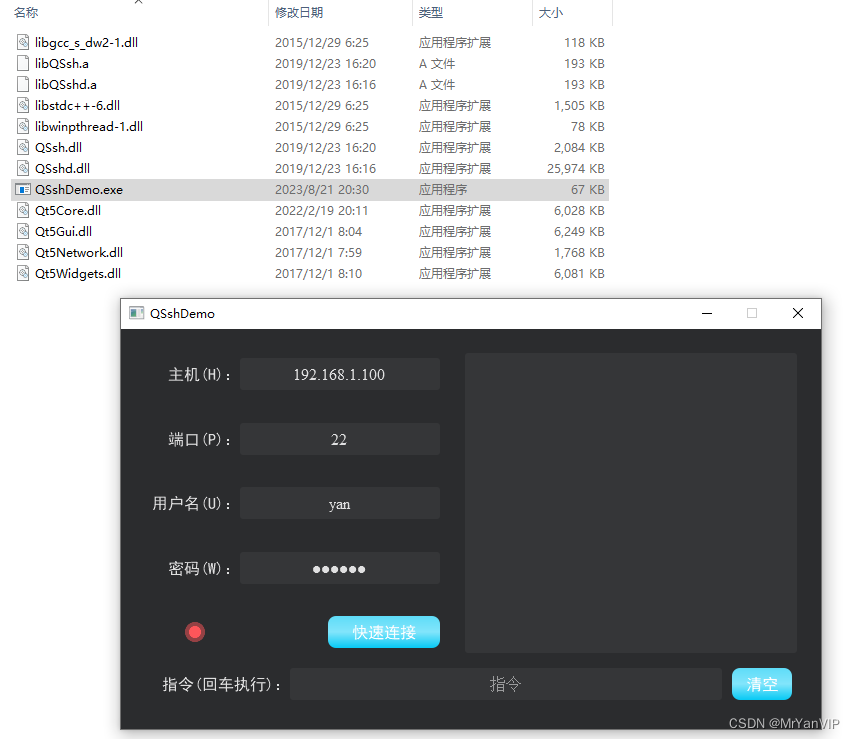
第十五课、Windows 下打包发布 Qt 应用程序
功能描述:讲解了 Windows 下打包发布 Qt 应用程序的三种方法,并对比优缺点 一、利用 windepolyqt 工具打包发布 Qt 提供了一个 windeployqt 工具来自动创建可部署的文件夹。 打包发布流程: 1. 新建一个文件夹,将编译后的可执行…...
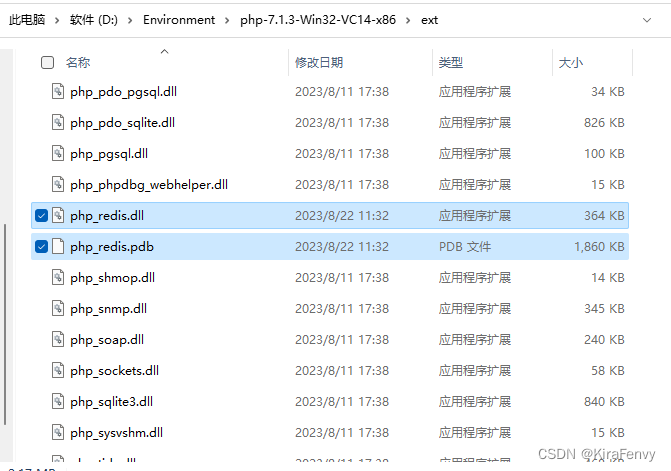
【php】windows下php运行已有php web项目环境配置教程
php环境配置教程 php安装composer安装扩展安装redis扩展安装 composer install 本文操作系统使用的是win11,软件PhpStorm 2023.1 php安装 要安装的php版本可以在composer.json看到,下载安装对应版本 windows下载地址https://windows.php.net/download …...

【mybatis】 mybatis在mysql 更新update 操作 更新时间字段按照年月日时分秒格式 更新为当前时间...
参考链接 【mybatis】 mybatis在mysql 更新update 操作 更新时间字段按照年月日时分秒格式 更新为当前时间…...

C++动态规划经典案例解析之合并石子
1. 前言 区间类型问题,指求一个数列中某一段区间的值,包括求和、最值等简单或复杂问题。此类问题也适用于动态规划思想。 如前缀和就是极简单的区间问题。如有如下数组: int nums[]{3,1,7,9,12,78,32,5,10,11,21,32,45,22}现给定区间信息[…...

go MongoDB
安装 go get go.mongodb.org/mongo-driver/mongo package mongodbexampleimport ("context""fmt""ginapi/structs""time""go.mongodb.org/mongo-driver/bson""go.mongodb.org/mongo-driver/bson/primitive""…...
--优先队列)
算法与数据结构(八)--优先队列
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除,在某些情况下,我们可能需要找出队列中的最大值或者最小值。 例如使用一个队列保存计算机的任务,一般情况下计算机的任务都是有优先级的ÿ…...

React 全栈体系(三)
第二章 React面向组件编程 四、组件三大核心属性3: refs与事件处理 1. 效果 需求: 自定义组件, 功能说明如下: 点击按钮, 提示第一个输入框中的值当第2个输入框失去焦点时, 提示这个输入框中的值 2. 理解 组件内的标签可以定义ref属性来标识自己 3. 编码 3.1 字符串形式…...

腾讯云下一代CDN -- EdgeOne加速MinIO对象存储
省流 使用MinIO作为EdgeOne的源站。 背景介绍 项目中需要一个兼容S3协议的对象存储服务,腾讯云的COS虽然也兼容S3协议,但是也只是支持简单的上传下载,对于上传的时候同时打标签这种需求,就不兼容S3了。所以决定自建一个对象存储…...

GitLab-CI 指南
GitLab CI 指南 前置工作 部署GitLab 部署GitLab-Runner 注册Runner到GitLab docker exec -it gitlab-runner bash # 进入容器 gitlab-runner register #调用register命令开始注册 # 在Gitlab Setting中找到Runners,如下图所示Enter the GitLab instance URL (for example, …...
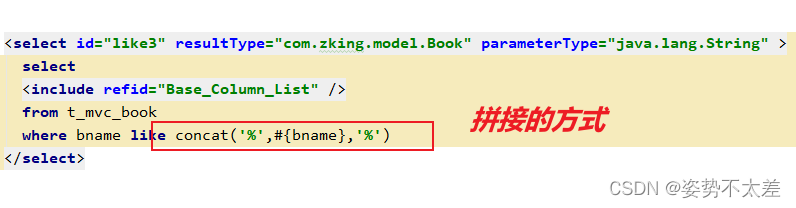
MyBatis的核心技术掌握,简单易懂(上)
目录 一.MyBatis中的动态SQL 二.MyBatis中的模糊查询 1. # 符号 2. $ 符号 ---问题 ---所以大家知道 # 和 $ 在MyBatis中的模糊查询中的区别了嘛?? 三.MyBatis 中的结果映射 1. resultType: 2. resultMap: ---问题 ---…...

Redisson自定义序列化
Redisson自定义序列化_redisson 序列化_yzh_1346983557的博客-CSDN博客 redis存取的数据一定是可序列化的,而可序列化方式可以自定义。如果不同客户端设置的可序列化方式不一样,会导致读取不一致的问题。常见的序列化方式有几下几种...
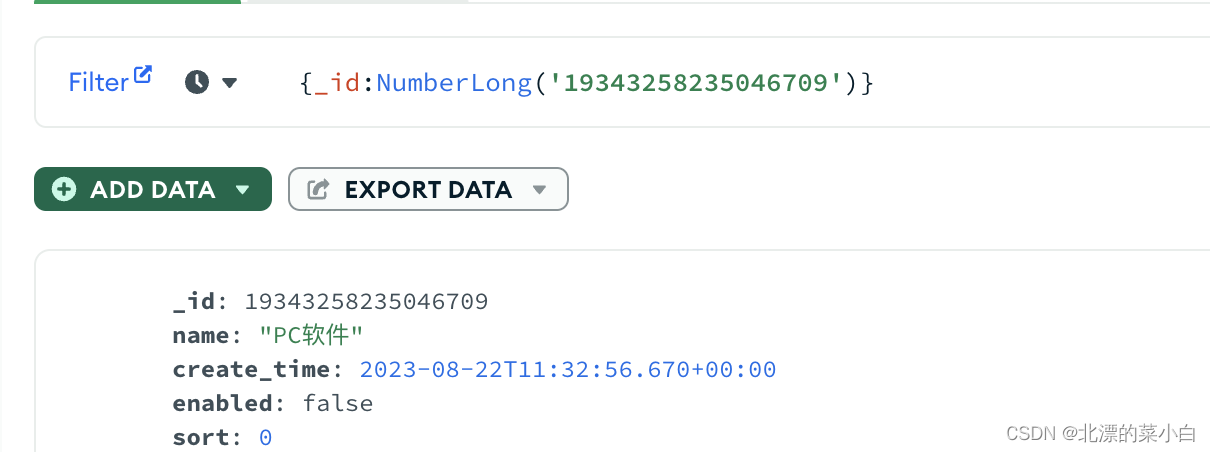
MongoDB Long 类型 shell 查询
场景 1、某数据ID为Long类型,JAVA 定义实体类 Id Long id 2、查询数据库,此数据存在 3、使用 shell 查询,查不到数据 4、JAVA代码查询Query.query 不受任何影响 分析 尝试解决(一) long 在 mongo中为 int64 类型…...
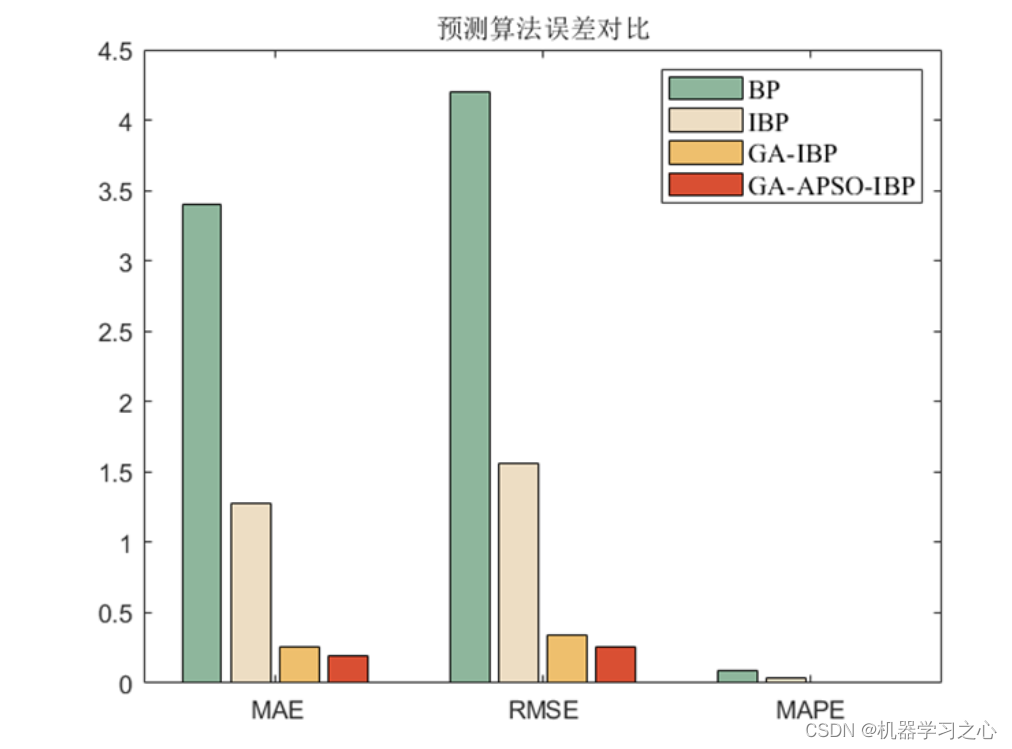
回归预测 | MATLAB实现GA-APSO-IBP改进遗传-粒子群算法优化双层BP神经网络多输入单输出回归预测
回归预测 | MATLAB实现GA-APSO-IBP改进遗传-粒子群算法优化双层BP神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现GA-APSO-IBP改进遗传-粒子群算法优化双层BP神经网络多输入单输出回归预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现GA-…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...
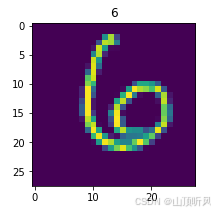
MLP实战二:MLP 实现图像数字多分类
任务 实战(二):MLP 实现图像多分类 基于 mnist 数据集,建立 mlp 模型,实现 0-9 数字的十分类 task: 1、实现 mnist 数据载入,可视化图形数字; 2、完成数据预处理:图像数据维度转换与…...