数据结构(2)
冒泡排序:
1.比较相邻的两个元素。如果前一个元素比后一个元素大,则交换两者位置。
2.对每一对相邻元素做相同工作,从第一对元素到最后一对元素,最后的一个元素就是最大的元素。

for(int i=a.length-1;i>0;i--){for (int j = 0; j <i; j++) {
if (greater(a[j],a[j+1])){
exch(a,j,j+1);
}
}
}时间复杂度为(n^2)
选择排序:
1.每次遍历过程中,都是假定第一个索引处的元素为最小值,和其他索引处的值依次进行比较,如果当前索引大于其他索引处的值,则认为这个索引为最小值,找出其索引
2.交换两个元素
for (int i=0;i<=a.length-2;i++){
//假定本次遍历,最小值所在的索引是i
int minIndex=i;
for (int j=i+1;j<a.length;j++){
if (greater(a[minIndex],a[j])){
//跟换最小值所在的索引
minIndex=j;
}
}
//交换i索引处和minIndex索引处的值
exch(a,i,minIndex);
}时间复杂度为O(n^2)
插入排序:
1.将所有元素分为两组,已排序和未排序。
2.把未排序中的第一个元素,向已排序中插入
3.倒叙遍历已排序的元素,依次和待插入的元素进行比较,直到找到一个元素小于等于待插入元素,那就将待插入元素放到这个位置,其余元素向后一位。

for (int i=1;i<a.length;i++){
//当前元素为a[i],依次和i前面的元素比较,找到一个小于等于a[i]的元素
for (int j=i;j>0;j--){
if (greater(a[j-1],a[j])){
//交换元素
exch(a,j-1,j);
}else {
//找到了该元素,结束
break;
}
}时间复杂度为O(n^2)
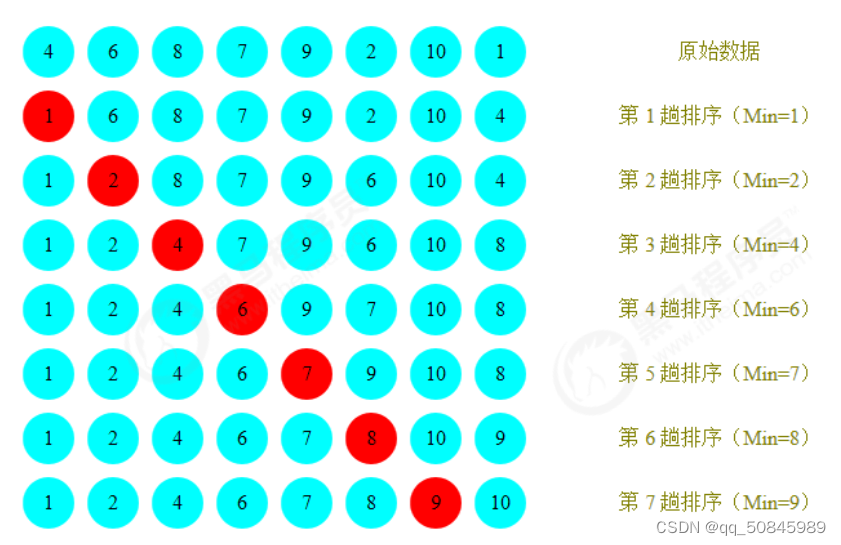
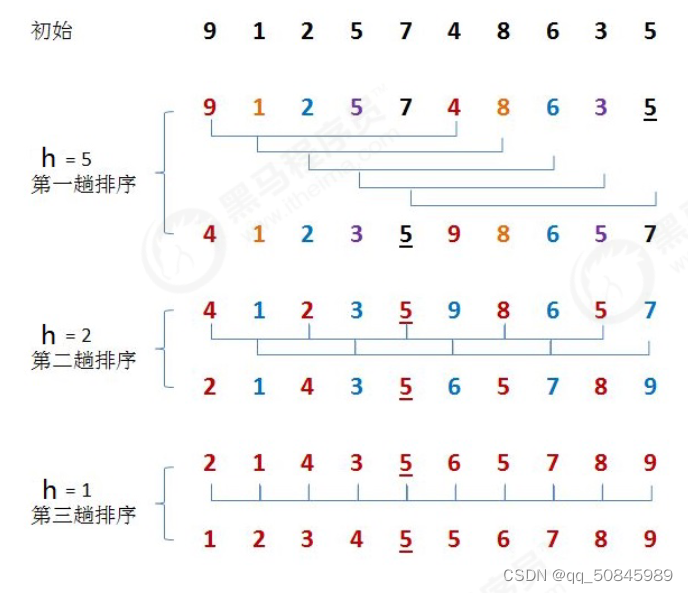
哈希排序:
1.选定一个增长量h,按照增长量作为分组的依据,对数据进行分组
2.对分好的每一组进行插入排序
3.减少增长量,直至为1,重复第二步
int N = a.length;
//确定增长量h的最大值
int h=1;
while(h<N/2){
h=h*2+1;
}
//当增长量h小于1,排序结束
while(h>=1){
//找到待插入的元素
for (int i=h;i<N;i++){
//a[i]就是待插入的元素
//把a[i]插入到a[i-h],a[i-2h],a[i-3h]...序列中
for (int j=i;j>=h;j-=h){
//a[j]就是待插入元素,依次和a[j-h],a[j-2h],a[j-3h]进行比较,如果a[j]小,那么
交换位置,如果不小于,a[j]大,则插入完成。
if (greater(a[j-h],a[j])){
exch(a,j,j-h);
}else{
break;
}
}
}
h/=2;
}在处理大批量数据时,希尔排序的性能确实高于插入排序。
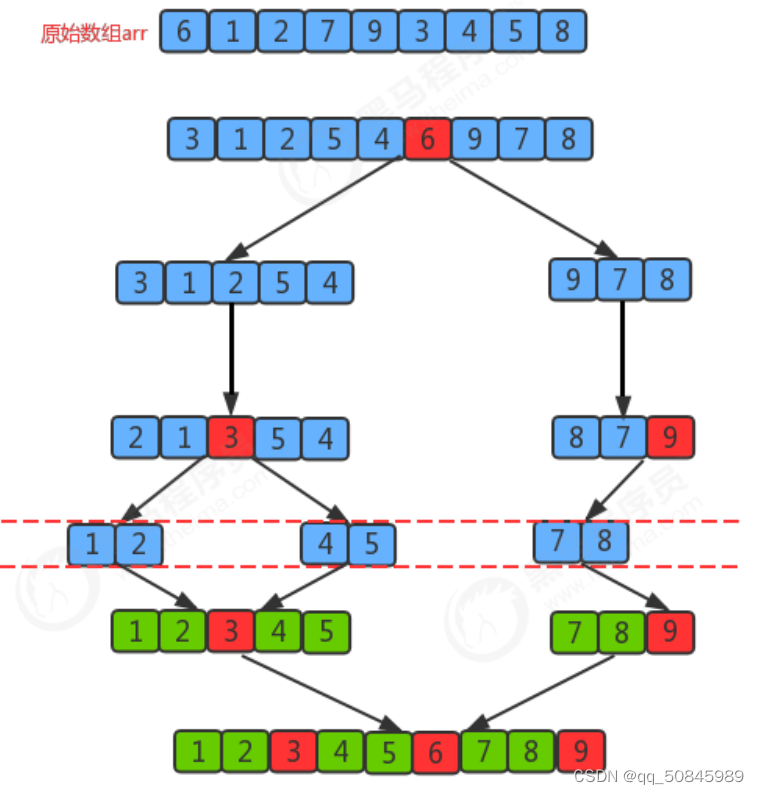
归并排序:
在方法内部调用方法本身就是递归。
1.尽可能将一组 数据拆分为两个元素相等的子组,并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是1为止。将两个元素进行比较,放到辅助队列,将辅助队列进行替换原来的队列。
2.将相邻的两个子组进行合并为一个有序的大组
3.重复步骤2,直到只有一个大组。

归并排序代码实现:
//排序代码
public class Merge {
private static Comparable[] assist;//归并所需要的辅助数组
/*
对数组a中的元素进行排序
*/
public static void sort(Comparable[] a) {
assist = new Comparable[a.length];
int lo = 0;
int hi = a.length-1;
sort(a, lo, hi);
}
/*
对数组a中从lo到hi的元素进行排序
*/
private static void sort(Comparable[] a, int lo, int hi) {
if (hi <= lo) {
return;
}
int mid = lo + (hi - lo) / 2;
//对lo到mid之间的元素进行排序;
sort(a, lo, mid);
//对mid+1到hi之间的元素进行排序;
sort(a, mid+1, hi);
//对lo到mid这组数据和mid到hi这组数据进行归并
merge(a, lo, mid, hi);
}
/*
对数组中,从lo到mid为一组,从mid+1到hi为一组,对这两组数据进行归并
*/
private static void merge(Comparable[] a, int lo, int mid, int hi) {
//lo到mid这组数据和mid+1到hi这组数据归并到辅助数组assist对应的索引处
int i = lo;//定义一个指针,指向assist数组中开始填充数据的索引
int p1 = lo;//定义一个指针,指向第一组数据的第一个元素
int p2 = mid + 1;//定义一个指针,指向第二组数据的第一个元素
//比较左边小组和右边小组中的元素大小,哪个小,就把哪个数据填充到assist数组中
while (p1 <= mid && p2 <= hi) {
if (less(a[p1], a[p2])) {
assist[i++] = a[p1++];
} else {
assist[i++] = a[p2++];
}
}
//上面的循环结束后,如果退出循环的条件是p1<=mid,则证明左边小组中的数据已经归并完毕,如果退
出循环的条件是p2<=hi,则证明右边小组的数据已经填充完毕;
//所以需要把未填充完毕的数据继续填充到assist中,//下面两个循环,只会执行其中的一个
while(p1<=mid){
assist[i++]=a[p1++];
}
while(p2<=hi){
assist[i++]=a[p2++];
}
//到现在为止,assist数组中,从lo到hi的元素是有序的,再把数据拷贝到a数组中对应的索引处
for (int index=lo;index<=hi;index++){
a[index]=assist[index];
}
}缺点;需要申请额外的数组空间,空间复杂度上升,以空间换时间。
快速排序:
快速排序是对冒泡排序的一种改进。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
1.初次设定第一个元素为分界值,从右向左找小于分界值的元素,从左往右找大于分界值的元素,替换两个元素,直到两个指针重叠。以此元素为分界值,通过分界值将数组分为两部分
2.大于等于分界值放到右边数组右边,小于等于放到左边
3.左右两边数据独立排序。对于左侧数组取一个分界值,分为两部分,左侧数据较小,右侧数据较大。右侧数据也是类似处理。
4.重复上述过程,递归处理。递归处理完左侧和右侧数据,排完序后,整个数组的排序就完成了。
public static void sort(Comparable[] a) {
int lo = 0;
int hi = a.length - 1;
sort(a, lo,hi);
}
private static void sort(Comparable[] a, int lo, int hi) {
if (hi<=lo){
return;
}
//对a数组中,从lo到hi的元素进行切分
int partition = partition(a, lo, hi);
//对左边分组中的元素进行排序
//对右边分组中的元素进行排序
sort(a,lo,partition-1);
sort(a,partition+1,hi);
}
public static int partition(Comparable[] a, int lo, int hi) {
Comparable key=a[lo];//把最左边的元素当做基准值
int left=lo;//定义一个左侧指针,初始指向最左边的元素
int right=hi+1;//定义一个右侧指针,初始指向左右侧的元素下一个位置
//进行切分
while(true){
//先从右往左扫描,找到一个比基准值小的元素
while(less(key,a[--right])){//循环停止,证明找到了一个比基准值小的元素
if (right==lo){
break;//已经扫描到最左边了,无需继续扫描
}
}
//再从左往右扫描,找一个比基准值大的元素
while(less(a[++left],key)){//循环停止,证明找到了一个比基准值大的元素
if (left==hi){
break;//已经扫描到了最右边了,无需继续扫描
}
}
if (left>=right){
//扫描完了所有元素,结束循环
break;
}else{
//交换left和right索引处的元素
exch(a,left,right);
}
}
//交换最后rigth索引处和基准值所在的索引处的值
exch(a,lo,right);
return right;//right就是切分的界限
}归并排序将数组分成两个子数组分别排序,并将有序的子数组归并从而将整个数组排序。
快速排序的方式则是当两个数组都有序时,整个数组自然就有序了。
相关文章:
数据结构(2)
冒泡排序: 1.比较相邻的两个元素。如果前一个元素比后一个元素大,则交换两者位置。 2.对每一对相邻元素做相同工作,从第一对元素到最后一对元素,最后的一个元素就是最大的元素。 for(int ia.length-1;i>0;i--){for (int j 0…...
使用ELK(ES+Logstash+Filebeat+Kibana)收集nginx的日志
文章目录 Nginx日志格式修改配置logstash收集nginx日志引入Redis收集日志写入redis从redis中读取日志 引入FilebeatFilebeat简介Filebeat安装和配置 配置nginx转发ES和kibanaELK设置账号和密码 书接上回:《ELK中Logstash的基本配置和用法》 Nginx日志格式修改 默认…...

TDengine server连接遇到的坑
一、TDengine安装 TDengine目前只有linux版本的server端,安装教程参考 https://zhuanlan.zhihu.com/p/302413259 二、TDengine连接 TDengine连接目前支持两种方式,一种是原生连接,该方法的默认端口号为6030;另一种是REST API连…...

什么是NetDevOps
NetDevOps 是一种新兴的方法,它结合了 NetOps 和 DevOps 的流程,即将网络自动化集成到开发过程中。NetDevOps 的目标是将虚拟化、自动化和 API 集成到网络基础架构中,并实现开发和运营团队之间的无缝协作。 开发运营(DevOps&…...

中小金融机构数字化转型最大的挑战是什么?
中国银保监会办公厅印发的《关于银行业保险业数字化转型的指导意见》强调,银行保险机构要加强顶层设计和统筹规划,科学制定数字化转型战略,统筹推进工作,并从战略规划与组织流程建设、业务经营管理数字化、数据能力建设、科技能力…...
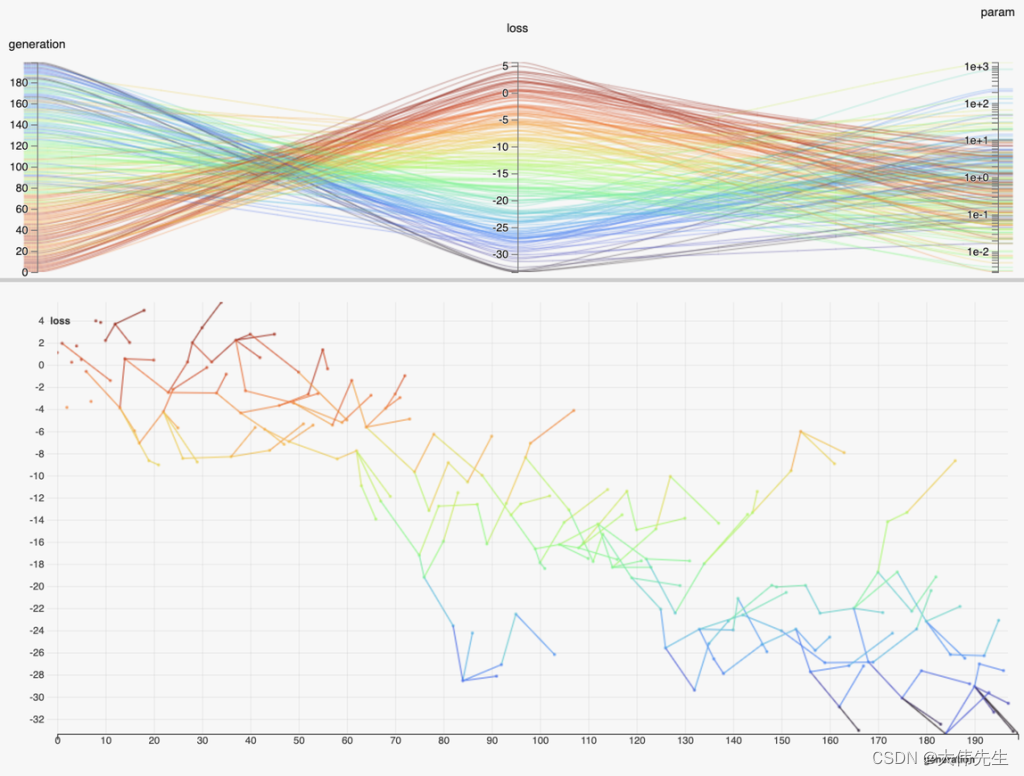
Facebook HiPlot “让理解高维数据变得容易”
在这个全球信息化的时代,数据量呈爆炸式增长,数据的复杂性也是如此。如何有效地处理高维数据并找到隐藏在其中的相关性和模式是一个严峻的挑战。近年来,可视化和可视化分析已被应用于该任务,并取得了一些积极成果。Facebook的新Hi…...
)
【python】:python新设备环境移植(requirements.txt)
环境移植 condapip conda 你可以使用conda命令来创建一个包含所有已安装包的requirements.txt文件,并将其复制到新电脑上。然后,你可以在新电脑上使用pip命令来安装这些包及其依赖项。 以下是一个示例命令: conda list --export > requ…...
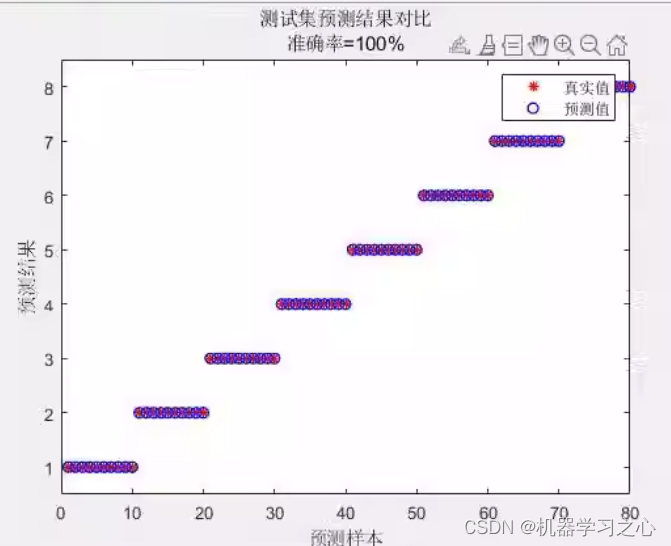
分类预测 | MATLAB实现1D-2D-CNN-GRU的多通道输入数据分类预测
分类预测 | MATLAB实现1D-2D-CNN-GRU的多通道输入数据分类预测 目录 分类预测 | MATLAB实现1D-2D-CNN-GRU的多通道输入数据分类预测分类效果基本介绍程序设计参考资料 分类效果 基本介绍 结合1D时序-2D图像多模态融合的CNN-GRU故障识别算法,基于一维时序信号和二维图…...

【LeetCode】125. 验证回文串 - 双指针
这里写自定义目录标题 2023-8-24 09:31:12 125. 验证回文串 2023-8-24 09:31:12 最关键的是 注意 题目中的 “字母和数字都属于字母数字字符。” 使用ascii码进行判断就行了 class Solution {public boolean isPalindrome(String s) {int p 0, q s.length() - 1;while (…...

centos7设置java后端项目开机自启【脚本、开机自启】
1.切换目录 cd /etc/init.d/2.编辑脚本 vim wbs-service-start.sh编辑内容 #!/bin/bash # chkconfig: 2345 80 90 # description: auto_runnohup java -jar /usr/java/wbs-service.jar > /dev/null 2>&1 & echo $! > /var/run/wbs-service.pid3.添加进入系…...
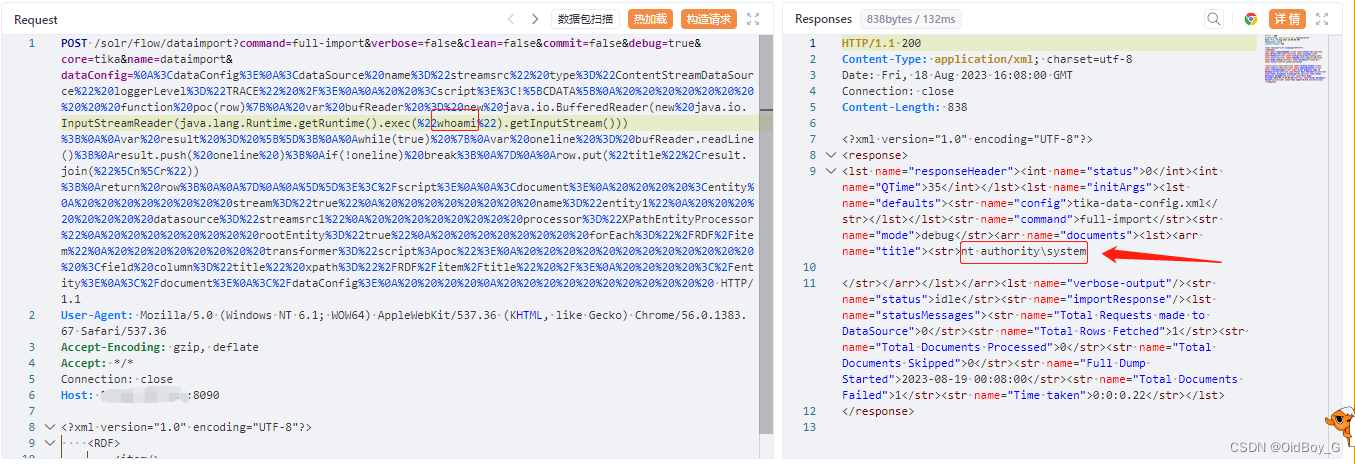
亿赛通电子文档安全管理系统 RCE漏洞复现(QVD-2023-19262)
0x01 产品简介 亿赛通电子文档安全管理系统(简称:CDG)是一款电子文档安全加密软件,该系统利用驱动层透明加密技术,通过对电子文档的加密保护,防止内部员工泄密和外部人员非法窃取企业核心重要数据资产&…...

一文读懂 Nuxt.js 服务端组件
服务端组件在 Web 开发生态系统中变得越来越普遍。传统上,在单页面应用中,即使是服务端渲染的应用,服务端仅与第一次加载相关,之后将由客户端接管。这意味着 Web 应用的每个部分都必须能够在客户端和服务端上渲染。 相反…...
LeetCode--HOT100题(39)
目录 题目描述:101. 对称二叉树(简单)题目接口解题思路代码 PS: 题目描述:101. 对称二叉树(简单) 给你一个二叉树的根节点 root , 检查它是否轴对称。 LeetCode做题链接:LeetCode-…...
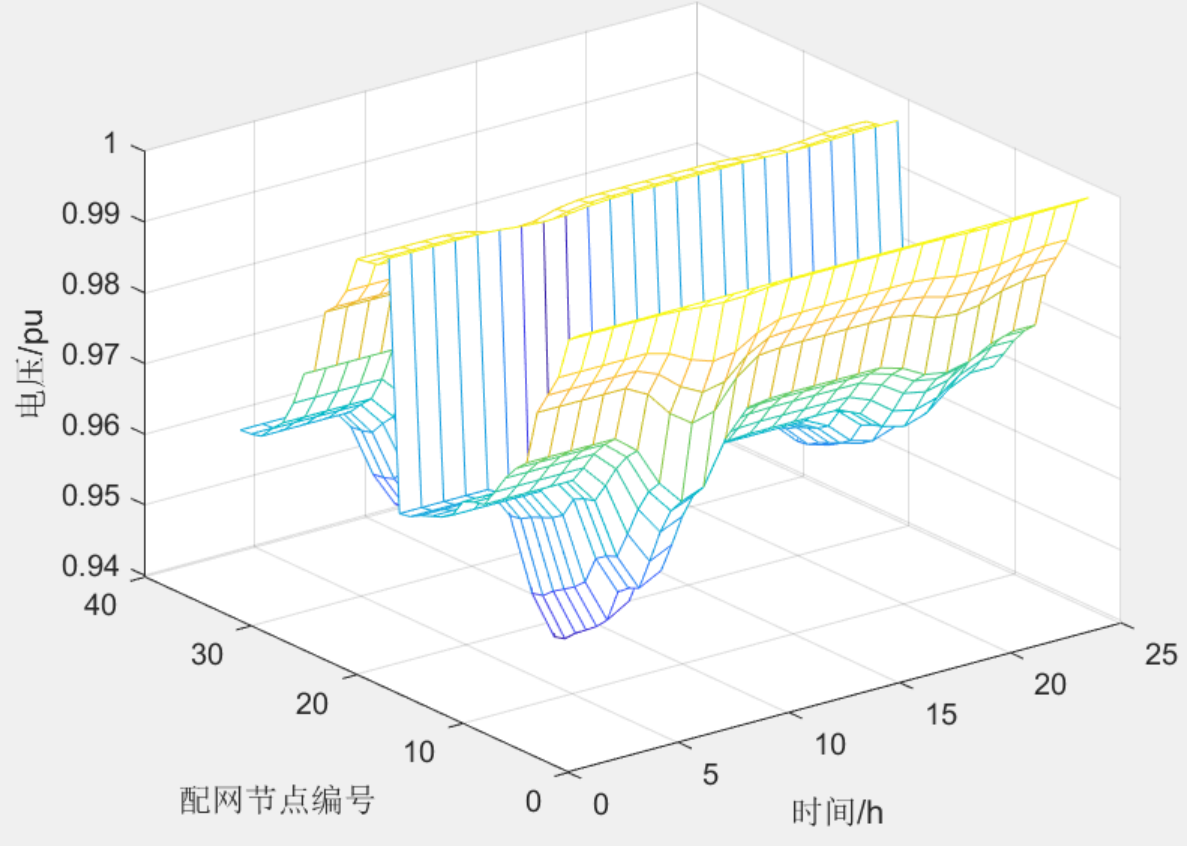
“车-路-网”电动汽车充电负荷时空分布预测(matlab)
目录 1 主要内容 2 部分代码 3 程序结果 4 下载链接 1 主要内容 该程序参考《基于动态交通信息的电动汽车充电负荷时空分布预测》和《基于动态交通信息的电动汽车充电需求预测模型及其对配网的影响分析》文献模型,考虑私家车、出租车和共用车三类交通工具特性和…...
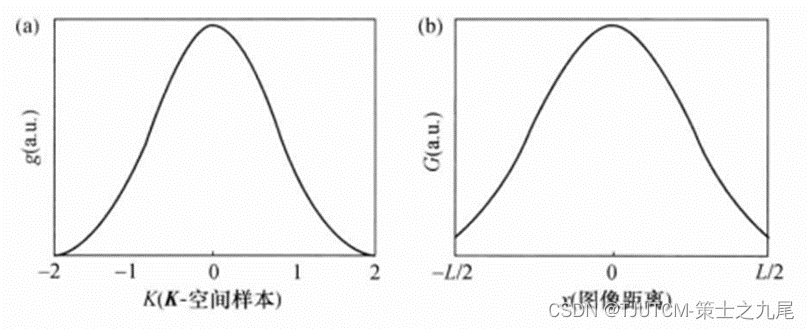
【核磁共振成像】方格化重建
目录 一、缩放比例二、方格化变换的基础三、重建时间四、方格化核 一、缩放比例 对于笛卡尔K空间直线轨迹数据可直接用FFT重建,而如果K空间轨迹的任何部分都是非均匀取样的 可用DFT直接重建,有时称为共轭相位重建,但此法太慢不实用。把数据再…...

JAVA中时间戳和LocalDateTime的互转
时间戳转LocalDateTime: 要将时间戳转换为LocalDateTime并将LocalDateTime转换回时间戳,使用Java的java.time包。以下是示例代码: import java.time.Instant; import java.time.LocalDateTime; import java.time.ZoneId;public class Times…...

无涯教程-进程 - 创建终止
到现在为止,我们知道无论何时执行程序,都会创建一个进程,并且该进程将在执行完成后终止,如果我们需要在程序中创建一个进程,并且可能希望为其安排其他任务,该怎么办。能做到吗?是的,显然是通过…...
LLMs参考资料第一周以及BloombergGPT特定领域的训练 Domain-specific training: BloombergGPT
1. 第1周资源 以下是本周视频中讨论的研究论文的链接。您不需要理解这些论文中讨论的所有技术细节 - 您已经看到了您需要回答讲座视频中的测验的最重要的要点。 然而,如果您想更仔细地查看原始研究,您可以通过以下链接阅读这些论文和文章。 1.1 Trans…...

LeetCode字符串数组最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: 输入:strs [“dog”,“raceca…...
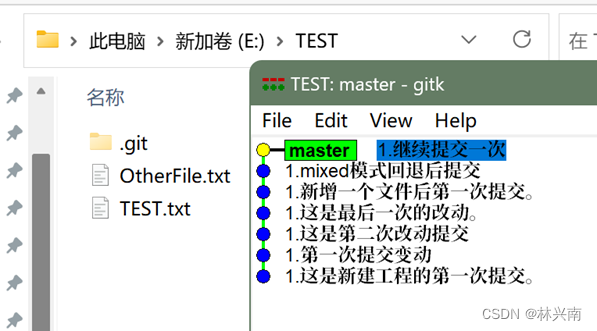
Git gui教程---第八篇 Git gui的使用 创建一个分支
一般情况下一个主分支下代码稳定的情况下会新建出一个分支,然后在分支上修改,修改完成稳定后再合并到主分支上。 或者几个人合作写一份代码,每个人各一个分支,测试稳定再合并到主分支上。 在git gui选择菜单栏“分支”࿰…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...
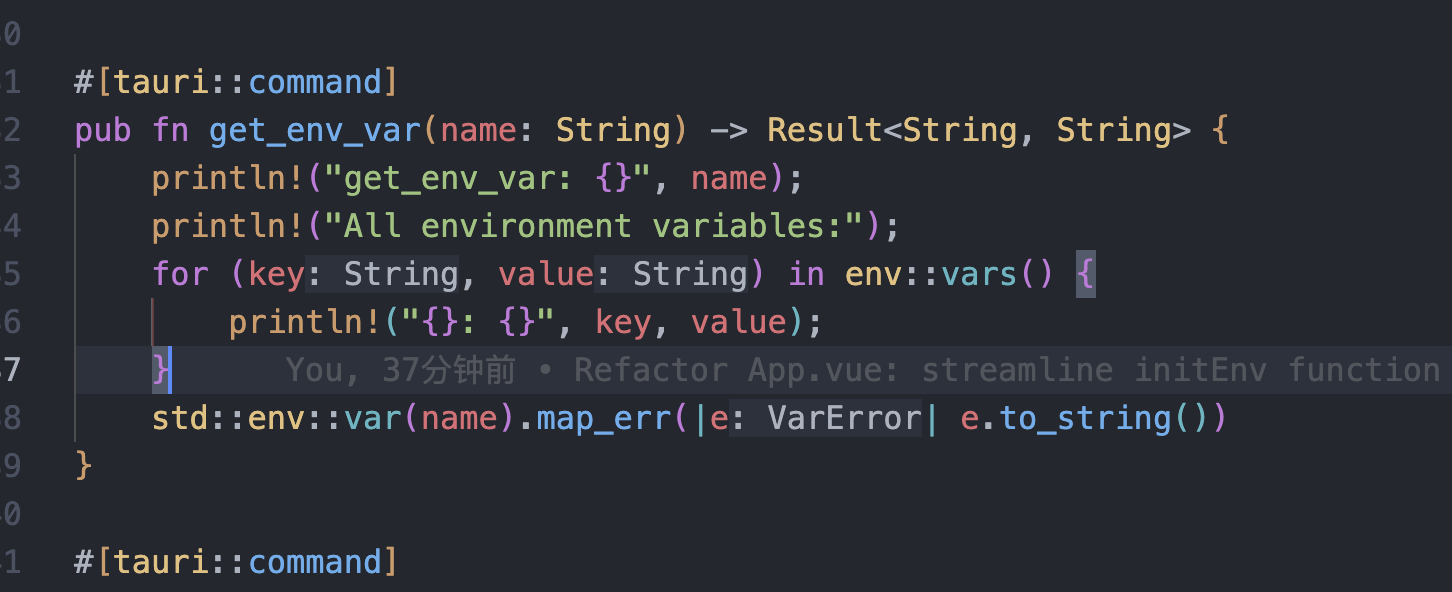
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...
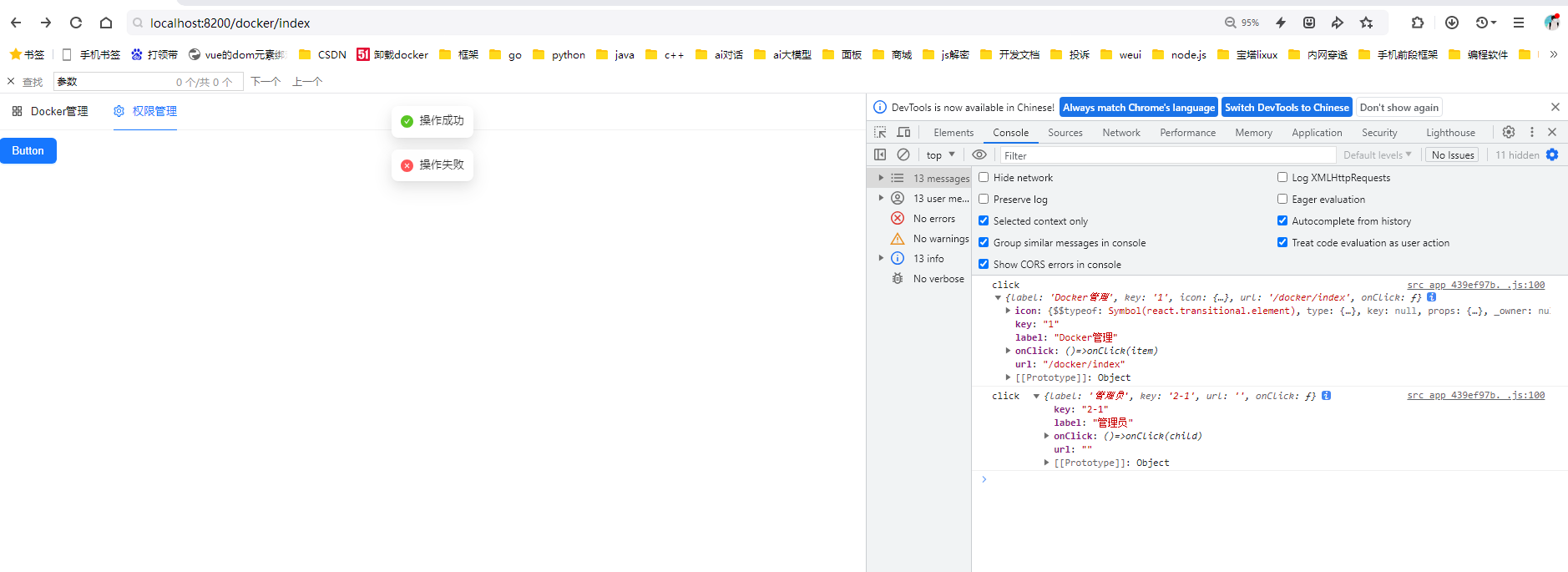
react菜单,动态绑定点击事件,菜单分离出去单独的js文件,Ant框架
1、菜单文件treeTop.js // 顶部菜单 import { AppstoreOutlined, SettingOutlined } from ant-design/icons; // 定义菜单项数据 const treeTop [{label: Docker管理,key: 1,icon: <AppstoreOutlined />,url:"/docker/index"},{label: 权限管理,key: 2,icon:…...

Git 命令全流程总结
以下是从初始化到版本控制、查看记录、撤回操作的 Git 命令全流程总结,按操作场景分类整理: 一、初始化与基础操作 操作命令初始化仓库git init添加所有文件到暂存区git add .提交到本地仓库git commit -m "提交描述"首次提交需配置身份git c…...
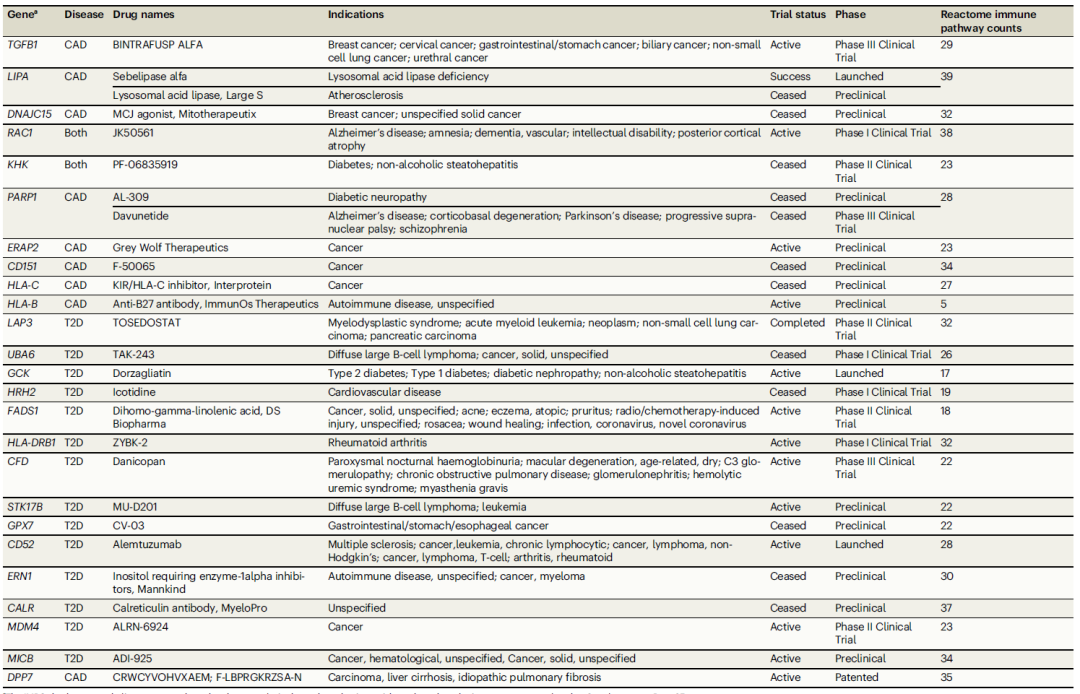
中科院1区顶刊|IF14+:多组学MR联合单细胞时空分析,锁定心血管代谢疾病的免疫治疗新靶点
中科院1区顶刊|IF14:多组学MR联合单细胞时空分析,锁定心血管代谢疾病的免疫治疗新靶点 当下,免疫与代谢性疾病的关联研究已成为生命科学领域的前沿热点。随着研究的深入,我们愈发清晰地认识到免疫系统与代谢系统之间存在着极为复…...
:PyQuery 框架)
Python爬虫(四):PyQuery 框架
PyQuery 框架详解与对比 BeautifulSoup 第一部分:PyQuery 框架介绍 1. PyQuery 是什么? PyQuery 是一个 Python 的 HTML/XML 解析库,它采用了 jQuery 的语法风格,让开发者能够用类似前端 jQuery 的方式处理文档解析。它的核心特…...

中国政务数据安全建设细化及市场需求分析
(基于新《政务数据共享条例》及相关法规) 一、引言 近年来,中国政府高度重视数字政府建设和数据要素市场化配置改革。《政务数据共享条例》(以下简称“《共享条例》”)的发布,与《中华人民共和国数据安全法》(以下简称“《数据安全法》”)、《中华人民共和国个人信息…...