SparkML机器学习
SparkML
机器学习: 让机器学会人的学习行为, 通过算法和数据来模拟或实现人类的学习行为,使之不断改善自身性能。
机器学习的步骤:
- 加载数据
- 特征工程
- 数据筛选: 选取适合训练的特征列, 例如用户id就不适合, 因为它特性太显著.
- 数据转化:
- 将字符串的数据转化数据类型, 因为模型训练的数据不能为字符串.
- 将多个特征列转化为一个向量列, 因为spark机器学习要求数据输入只能为一个特征列
- 数据缩放:
- 把所有的特征缩放到0~1之间,都处于相同的量纲大小范围内.
- 公式:(特征值- 当前特征最小值)/ (当前特征最大值- 当前特征最小值)
- 模型训练
- 创建模型: 机器学习算法对象.fit(train_df) 以此来创建模型
- 预测数据: 模型.transform(test_df) 多返回一个预测列
- 模型评估
- 有监督 :有监督学习是指训练模型时使用的训练数据是标识好的数据, 也就是说数据集既有特征列也有目标列.
- 分类问题(目标值为离散的): 预测数据和目标值进行对比, 查看预测成功的几率
- 回归问题(目标值为连续的): 求测试集预测结果与目标值标准差:方差开根号
- 无监督KMeans的 :
- sse:表示数据样本与它所属的簇中心之间的距离(差异度)平方之和
- sc: (b-a)/max(a,b)
- a: 样本i到同一簇内其他点不相似程度(欧式距离,余弦定理…)的平均值
- b: 样本I到其他簇的平均不相似度的最小值
- 模型上线: 模型的保存和加载
MLLib机器学习库简介:
MLLIB是Spark的机器学习库。提供了利用Spark构建大规模和易用性的机器学习平台,组件:
- ML 算法:包括了分类、回归、聚类、降维、协同过滤
- Featurization特征化:特征抽取、特征转换、特征降维、特征选择
- Pipelines管道:tools for constructing, evaluating, and tuning ML Pipelines
- Persistence持久化:模型的保存、读取、管道操作
- Utilities:提供了线性代数、统计学以及数据处理工具
数据加载
因为现在所用的ml库只支持Dataframe格式的数据, 因此需要加载df的数据, 例如读取csv文件:
data_df = spark.read.format('csv') \.option('header', True) \.option('inferSchema', True) \.load('./a.txt')
特征工程
StringIndexer
将字符串类型转化为数值类型, 因为机器学习要求输入必须是数值类型.
如果有多列需要转化, 则需要写多个StringIndexer函数, 下一个函数的输入是这个函数的输出.
from pyspark.ml.feature import StringIndexer
from pyspark.sql import SparkSessionif __name__ == '__main__':# 创建spark运行环境spark = SparkSession.builder.appName("stringIndexer test") \.master('local[*]').getOrCreate()# 创建测试df# id | category# ----|----------# 0 | a# 1 | b# 2 | c# 3 | a# 4 | a# 5 | cdf = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")], ["id", "category"])# 将df中的字符串列转化数值列stringIndexer = StringIndexer(inputCol='category', outputCol='categoryIndex')# 先调用fit方法创建模型model = stringIndexer.fit(df)# 再调用transform方法进行模型计算返回结果result_df = model.transform(df)result_df.show()# +---+--------+-------------+# | id|category|categoryIndex|# +---+--------+-------------+# | 0| a| 0.0|# | 1| b| 2.0|# | 2| c| 1.0|# | 3| a| 0.0|# | 4| a| 0.0|# | 5| c| 1.0|# +---+--------+-------------+# 根据字符出再频数排序(倒序),分开转化为[0.0, 1.0, 2.0, ....., numLabels]
IndexToString
与StringIndexer结合使用,IndexToString将一列标签索引映射
回包含原始标签作为字符串的列。一个常见的用例是从标签生成索引StringIndexer,使用这些索引训练模型,并从预测索引列中检索原始标签IndexToString。
from pyspark.ml.feature import StringIndexer, IndexToString
from pyspark.sql import SparkSessionif __name__ == '__main__':# 创建spark运行环境spark = SparkSession.builder.appName("stringIndexer test") \.master('local[*]').getOrCreate()# 创建测试df# id | category# ----|----------# 0 | a# 1 | b# 2 | c# 3 | a# 4 | a# 5 | cdf = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")], ["id", "category"])# 将df中的字符串列转化数值列stringIndexer = StringIndexer(inputCol='category', outputCol='categoryIndex')# 先调用fit方法创建模型model = stringIndexer.fit(df)# 再调用transform方法进行模型计算返回结果result_df = model.transform(df)result_df.show()# +---+--------+-------------+# | id|category|categoryIndex|# +---+--------+-------------+# | 0| a| 0.0|# | 1| b| 2.0|# | 2| c| 1.0|# | 3| a| 0.0|# | 4| a| 0.0|# | 5| c| 1.0|# +---+--------+-------------+# 根据字符出再频数排序(倒序),分开转化为[0.0, 1.0, 2.0, ....., numLabels]index2String = IndexToString(inputCol='categoryIndex', outputCol='categoryString')# 直接调用transform计算结果string_result_df = index2String.transform(result_df)string_result_df.show()# +---+--------+-------------+--------------+# | id|category|categoryIndex|categoryString|# +---+--------+-------------+--------------+# | 0| a| 0.0| a|# | 1| b| 2.0| b|# | 2| c| 1.0| c|# | 3| a| 0.0| a|# | 4| a| 0.0| a|# | 5| c| 1.0| c|# +---+--------+-------------+--------------+
MinmaxScaler
特征缩放(归一化处理):(特征值- 当前特征最小值)/ (当前特征最大值- 当前特征最小值)
- 作用:把所有的特征缩放到0~1之间,都处于相同的量纲大小范围内
- 场景:当特征之间量纲(取值大小)差距比较大的时候,需要先做特征缩放(归一化)
from pyspark.ml.feature import MinMaxScaler
from pyspark.ml.linalg import Vectors
from pyspark.sql import SparkSessionif __name__ == '__main__':# 创建spark运行环境spark = SparkSession.builder.appName("stringIndexer test") \.master('local[*]').getOrCreate()# 创建测试DFdataFrame = spark.createDataFrame([(0, Vectors.dense([1.0, 0.1, -1.0]),),(1, Vectors.dense([2.0, 1.1, 1.0]),),(2, Vectors.dense([3.0, 10.1, 3.0]),)], ["id", "features"])# 对特征列进行特征缩放minmaxScaler = MinMaxScaler(inputCol='features', outputCol='scaledFeatures')# 调用fit方法创建模型,调用transform方法进行模型计算result_df = minmaxScaler.fit(dataFrame).transform(dataFrame)result_df.show()# +---+--------------+--------------+# | id| features|scaledFeatures|# +---+--------------+--------------+# | 0|[1.0,0.1,-1.0]| [0.0,0.0,0.0]|# | 1| [2.0,1.1,1.0]| [0.5,0.1,0.5]|# | 2|[3.0,10.1,3.0]| [1.0,1.0,1.0]|# +---+--------------+--------------+
VectorAssembler
- 作用:VectorAssembler是一个变换器,它将给定的列表组合到一个向量列中。
- 场景:在模型训练前, 我们要把模型训练用到的所有特征, 都放到一列中, 并且需要是向量的形式,,这个是Spark MLlib的硬性要求(模型训练传数据的时候, 只接收一列数据),只要涉及模型训练就会使用到VectorAssember。
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import MinMaxScaler, VectorAssembler
from pyspark.ml.linalg import Vectors
from pyspark.sql import SparkSessionif __name__ == '__main__':# 创建spark运行环境spark = SparkSession.builder.appName("stringIndexer test") \.master('local[*]').getOrCreate()# 创建测试数据df = spark.createDataFrame([(0, 18, 1.0, Vectors.dense([0.0, 10.0, 0.5]), 1.0)],["id", "hour", "mobile", "userFeatures", "clicked"])# 把模型计算需要的特征列都封装到一个向量列中vectorAssembler = VectorAssembler(inputCols=['hour', 'mobile', 'userFeatures', 'clicked'], outputCol='features')vectorAssembler.transform(df).show(truncate=False)# +---+----+------+--------------+-------+---------------------------+# |id |hour|mobile|userFeatures |clicked|features |# +---+----+------+--------------+-------+---------------------------+# |0 |18 |1.0 |[0.0,10.0,0.5]|1.0 |[18.0,1.0,0.0,10.0,0.5,1.0]|# +---+----+------+--------------+-------+---------------------------+
模型训练和评估
KMeans无监督聚类算法
算法原理:
k-means其实包含两层内容:K表示初始中心点个数(计划聚类数),means求中心点到其他数据点距离的平均值, K自己设置(2,3,4,5,6,7,8)
具体步骤如下:
- 随机选取K个中心点
- 求每个元素点和每个中心点的欧氏距离
- 如果元素点离某个中心点距离最近, 则归属与该中心点(簇cluster)
- 求每个簇中所有元素点的平均值, 以此作为新的一个中心点
- 重复2-4步骤, 进行迭代计算, 直到达到终止迭代条件
- 最大迭代次数,默认是20次
- 本次中心点和上次中心点重合(这里的重合不是指完全重合, 存在一定的误差范围)
特点:
优点:速度快,简单
- 对处理大数据集,该算法保持可伸缩性和高效率。
- 当簇近似为高斯分布时,它的效果较好。
缺点:最终结果跟初始点选择相关,容易陷入局部最优
- k均值算法中k是实现者给定的,这个k值的选定是非常难估计的。
- k均值的聚类算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,当数据量大的时候,算法开销很大。
- k均值是求得局部最优解的算法,所以对于初始化时选取的k个聚类的中心比较敏感,不同点的中心选取策略可能带来不同的聚类结果。
- 对噪声点和孤立点数据敏感。
KMeans一般是其他聚类方法的基础算法,如谱聚类。
评估方法:
- sse:表示数据样本与它所属的簇中心之间的距离(差异度)平方之和
- sc: (b-a)/max(a,b)
- a: 样本i到同一簇内其他点不相似程度(欧式距离,余弦定理…)的平均值
- b: 样本I到其他簇的平均不相似度的最小值
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
from pyspark.ml.feature import VectorAssembler
from pyspark.sql import SparkSessionif __name__ == '__main__':# 创建spark运行环境spark = SparkSession.builder \.appName("kmeans 算法实现") \.master('local[*]') \.getOrCreate()# ====================== 1、加载数据 ===================data_df = spark.read.format('csv') \.option('header', True) \.option('inferSchema', True) \.load('/tmp/pycharm_project_488/com/itheima/data/test.txt')# data_df.show()# +-----------+----+# |Weightindex|PH值|# +-----------+----+# | 1.0| 1.0|# | 2.0| 1.0|# | 4.0| 3.0|# | 5.0| 4.0|# +-----------+----+# ===================== 2、特征工程 =======================# 将特征列封装到一个向量列中assembler = VectorAssembler(inputCols=['Weightindex', 'PH值'], outputCol='features')vector_df = assembler.transform(data_df)# vector_df.show()# +-----------+----+---------+# |Weightindex|PH值| features|# +-----------+----+---------+# | 1.0| 1.0|[1.0,1.0]|# | 2.0| 1.0|[2.0,1.0]|# | 4.0| 3.0|[4.0,3.0]|# | 5.0| 4.0|[5.0,4.0]|# +-----------+----+---------+# ===================== 3、模型训练 =======================# featuresCol 设置特征列# k 设置簇数量# predictionCol 设置目标列# seed 随机种子# initMode: str = 'k-means||' k-means++kmeans = KMeans(featuresCol='features', k=2, predictionCol='prediction', seed=125)# 先调用fit方法创建模型model = kmeans.fit(vector_df)# 再调用transform方法计算结果result_df = model.transform(vector_df)# result_df.show()# +-----------+----+---------+----------+# |Weightindex|PH值| features|prediction|# +-----------+----+---------+----------+# | 1.0| 1.0|[1.0,1.0]| 0|# | 2.0| 1.0|[2.0,1.0]| 0|# | 4.0| 3.0|[4.0,3.0]| 1|# | 5.0| 4.0|[5.0,4.0]| 1|# +-----------+----+---------+----------+# ======================== 4、模型评估 ====================evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='features')# 计算轮廓系数sc = evaluator.evaluate(result_df)print("轮廓系数:", sc) # 轮廓系数: 0.8967364744598525# 获取中心点信息centers = model.clusterCenters()print("中心点信息:", centers) # 中心点信息: [array([1.5, 1. ]), array([4.5, 3.5])]# 中心点可以是计算得到的虚拟点
决策树有监督分类问题算法
概述:
决策树算法是一种监督学习算法,英文是Decision tree。
决策树是一个类似于流程图的树结构:其中,每个内部结点表示一个特征或属性,而每个树叶结点代表一个分类。树的最顶层是根结点。使用决策树分类时就是将实例分配到叶节点的类中。该叶节点所属的类就是该节点的分类。
决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的then就是一种选择或决策。程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
生成步骤:
构建决策树包括三个步骤:
特征选择:选取有较强分类能力的特征。
决策树生成:典型的算法有ID3、C4.5、CART,它们生成决策树过程相似,ID3是采用
信息增益作为特征选择度量,而C4.5采用信息增益率、CART基尼指数。决策树剪枝:剪枝原因是决策树生成算法生成的树对训练数据的预测很准确,但是对于未知数据分类很差,这就产生了
过拟合的现象。
- 过拟合:训练集表现较好,但是测试集表现不好可以通过剪枝(减少特征列)
- 欠拟合:训练集表现不好,测试集表现不好,通过增加特征列解决
算法介绍:
D3算法步骤:
- 计算每个特征的信息增益=经验熵-条件熵:整个数据集的信息熵-当前节点的信息熵
- 使用信息增益最大的特征将数据集 S 拆分为子集
- 使用该特征(信息增益最大的特征)作为决策树的一个节点
- 使用剩余特征对子集重复上述(1,2,3)过程
C4.5算法介绍:
C4.5 是计算信息增益率 :信息增益/当前特征取值的信息熵
解决ID3决策树缺点
- 当前特征列的取值越多时,信息增益越大
- ID3会偏向于选择特征列取值比较多的特征列
cart模型算法:Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归,其学习算法分为下面两步:
(1)决策树生成:用训练数据生成决策树,生成树尽可能大。
(2)决策树剪枝:基于损失函数最小化的剪枝,用验证数据对生成的数据进行剪枝。
Cart算法通过计算
基尼指数(GINI)来选择特征:基尼指数=1-∑Pi²
- 信息增益(ID3)、信息增益率(C4.5)值越大,则说明优先选择该特征。
- 基尼指数值越小(cart),则说明优先选择该特征。
模型评估:
将测试的预测列正确的数/测试的数据条数 = 预测正确率
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.sql import SparkSessionif __name__ == '__main__':
# 创建spark运行环境
spark = SparkSession.builder.getOrCreate()# 构建测试数据df
iris_df = spark.read.format('csv')\.option('header', True)\.option('inferSchema', True)\.option('sep', ',')\.load("/tmp/pycharm_project_488/com/itheima/data/iris.csv")iris_df.show()# 特征工程-特征转换
indexer = StringIndexer().setInputCol("class").setOutputCol("label")indexer_df = indexer.fit(iris_df).transform(iris_df)indexer_df.show()
# 特征工程-特征选择
assembler = VectorAssembler().setInputCols(['sepal_length', 'sepal_width', 'petal_length', 'petal_width']).setOutputCol('features')vector_df = assembler.transform(indexer_df)vector_df.show()# 切分数据集
(train_df, test_df) = vector_df.randomSplit([0.8, 0.2], seed=123)# 模型训练
classifier = DecisionTreeClassifier() \.setFeaturesCol('features') \.setLabelCol('label') \.setPredictionCol('prediction') \.setMaxDepth(4) \.setImpurity('gini')# 通过训练数据集构建模型
model = classifier.fit(train_df)# 使用模型对训练数据集进行预测计算
train_result = model.transform(train_df)
train_result.show()
# 使用模型对测试数据集进行预测计算
test_result = model.transform(test_df)
test_result.show()# 模型评估
print("训练集的准确率:", (train_result.filter("label == prediction").count() / train_result.count()))
print("测试集的准确率:", (test_result.filter("label == prediction").count() / test_result.count()))evaluator = MulticlassClassificationEvaluator(predictionCol='prediction', labelCol='label')print("训练集的准确率", evaluator.evaluate(train_result))
print("测试集的准确率", evaluator.evaluate(test_result))
模型上线
Pipeline介绍:从Spark1.2版本之后引入了ML Pipeline,经过多个版本的发展,SparkMl克服了Mllib在处理复杂机器学习问题的一些不足,如工作比较复杂,流程不够清晰等,向用户提供基于DataFrame之上的更高层次的API库,以方便的构建复杂的机器学习工作流式应用,使得整个机器学习构建过程更加简单、高效和规范。
Pipeline功能:
- 减少代码量
- 流程更清晰
- pipeline中所有stage的入参都是相同
pipeline = Pipeline().setStages([indexer, assembler, classifier])
model = pipeline.fit(iris_df)
result_df = model.transform(iris_df)
result_df.show()
模型保存:
model.save('hdfs:///model/usegmodel')
# 模型保存时路径下要求没有文件, 如果有文件会报错
模型加载:
model = PipelineModel.load('hdfs:///model/usegmodel')
result_df2 = model.transform(source_df)
result_df2.show()
# 如果能使用Pipeline 尽量使用Pipeline, 保存一个Pipelinemodel , 加载模型后 ,对后续数据进行分类会很简单
相关文章:

SparkML机器学习
SparkML 机器学习: 让机器学会人的学习行为, 通过算法和数据来模拟或实现人类的学习行为,使之不断改善自身性能。 机器学习的步骤: 加载数据特征工程 数据筛选: 选取适合训练的特征列, 例如用户id就不适合, 因为它特性太显著.数据转化: 将字符串的数据转化数据类型…...

vue Promise 对象 等待所有异步处理完成 再继续处理
1 定义数据集合 用来搜集所有数据 let promises []; // 用来存储所有的 Promise 对象 2 promise对象 异步 返回数据 同时添加数据到promises 列表 // 依次读取列表元素的表 for (let symbol of symbolList) {let promise new Promise((resolve, reject) > { // 将请求…...
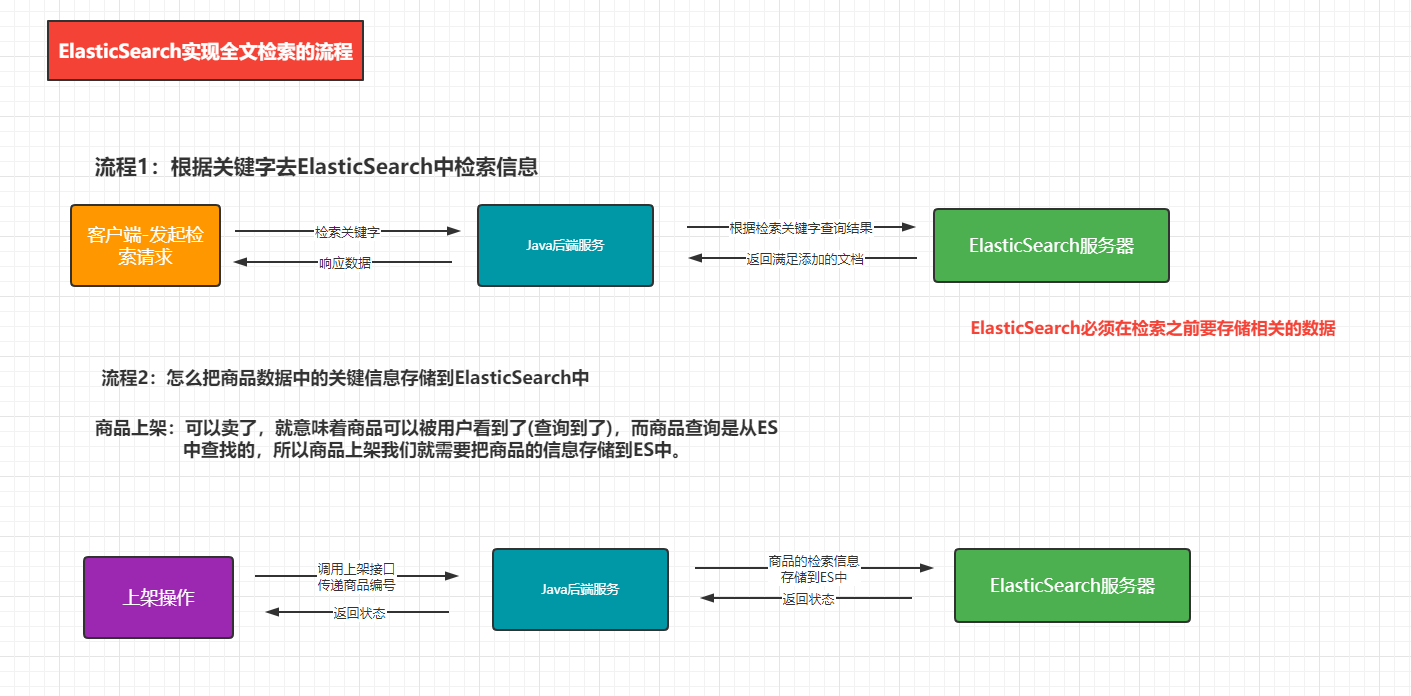
【业务功能篇84】微服务SpringCloud-ElasticSearch-Kibanan-电商实例应用
一、商品上架功能 ElasticSearch实现商城系统中全文检索的流程。 1.商品ES模型 商品的映射关系 PUT product {"mappings": {"properties": {"skuId": {"type": "long"},"spuId": {"type": "ke…...
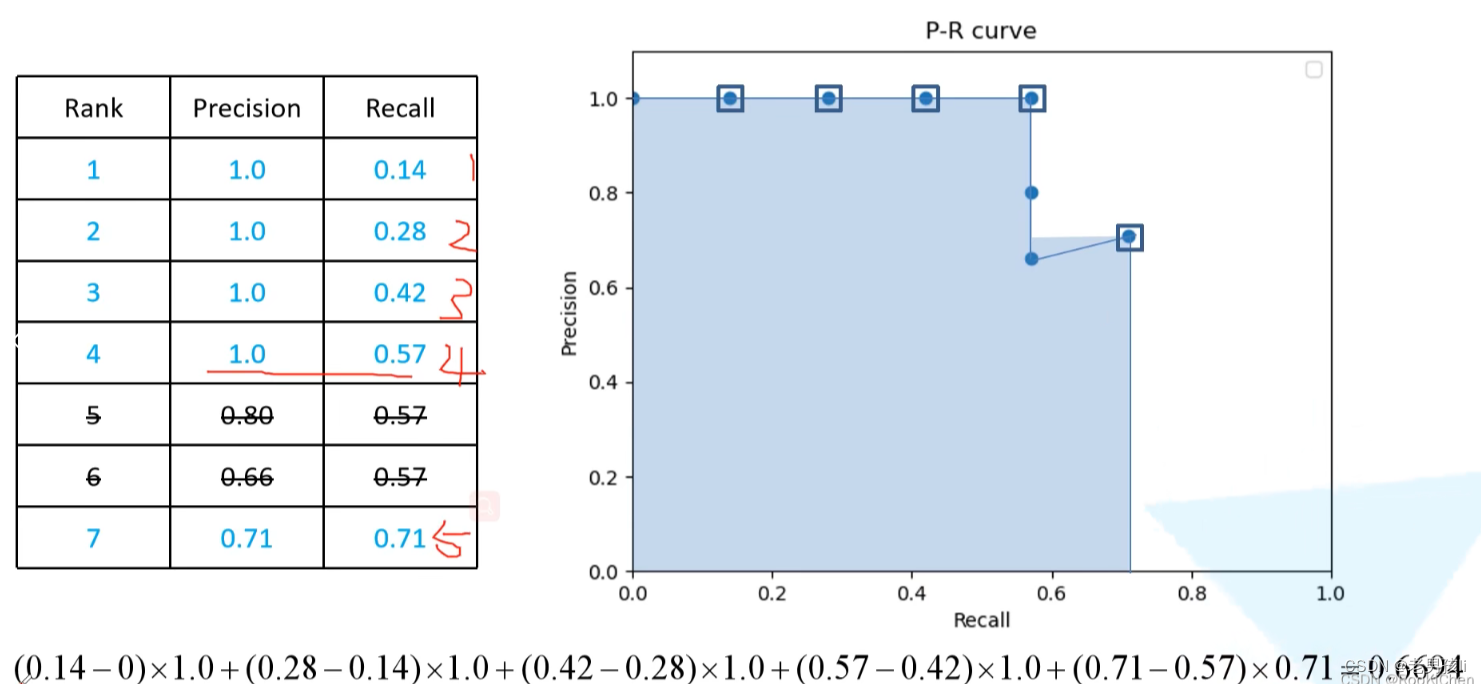
图像检索,目标检测map的实现
一、图像检索指标Rank1,map 参考:https://blog.csdn.net/weixin_41427758/article/details/81188164?spm1001.2014.3001.5506 1.Rank1: rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中。 常用的为rank1:首…...
Docker容器学习:Dockerfile制作Web应用系统nginx镜像
目录 编写Dockerfile 1.文件内容需求: 2.编写Dockerfile: 3.开始构建镜像 4.现在我们运行一个容器,查看我们的网页是否可访问 推送镜像到私有仓库 1.把要上传的镜像打上合适的标签 2.登录harbor仓库 3.上传镜像 编写Dockerfile 1.文…...

【vue3.0 引入Element Plus步骤与使用】
全局引入Element Plus 1. 安装 Element Plus2. 引入 Element Plus3. 使用 Element Plus 组件 Element Plus 是一个基于 Vue 3.0 的 UI 组件库,它是 Element UI 的升级版。Element Plus 的设计理念是简单、易用、高效,具有良好的可定制性和扩展性。下面是…...

金融客户敏感信息的“精细化管控”新范式
目 录 01 客户信息保护三箭齐发,金融IT亟需把握四个原则 02 制度制约阻碍信息保护的精细化管控 03 敏感信息精细化管控范式的6个关键设计 04 分阶段实施,形成敏感信息管控的长效运营的机制 05 未来,新挑战与新机遇并存 …...

Starrocks--数据插入方式
Starrocks 数据插入方式 Starrocks是一款快速、可伸缩的分布式OLAP数据库,支持多种数据插入方式。下面将详细介绍几种常用的数据插入方式,并提供选择建议。 1. 批量加载(Bulk Load) 批量加载是通过将本地文件或HDFS文件导入到S…...

Java学数据结构(3)——树Tree B树 红黑树 Java标准库中的集合Set与映射Map 使用多个映射Map的案例
目录 引出B树插入insert删除remove 红黑树(red black tree)自底向上的插入自顶向下红黑树自顶向下的删除 标准库中的集合Set与映射Map关于Set接口关于Map接口TreeSet类和TreeMap类的实现使用多个映射Map:一个词典的案例方案一:使用一个Map对象方案二&…...

Vue3.0极速入门 - 环境安装新建项目
Vue介绍 Vue.js 是什么 Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整…...

android 使用libyuv 图像转换
libyuv 是一个开源的图像处理库,它提供了一系列函数用于处理YUV格式的图像。在 JNI(Java Native Interface)中使用 libyuv,你需要先在你的 C 代码中包含 libyuv,然后编写 JNI 函数来调用 libyuv 的函数。 以下是一个简…...

奥比中光:进击具身智能,打造机器人之眼
大数据产业创新服务媒体 ——聚焦数据 改变商业 跨过奇点的生成式人工智能是一个缸中大脑,只有赋予形体,才能与物理世界产生互动。 在5月的ITF世界半导体大会上,英伟达创世人兼CEO黄仁勋说,人工智能的下一波浪潮将是具身智能。 8…...
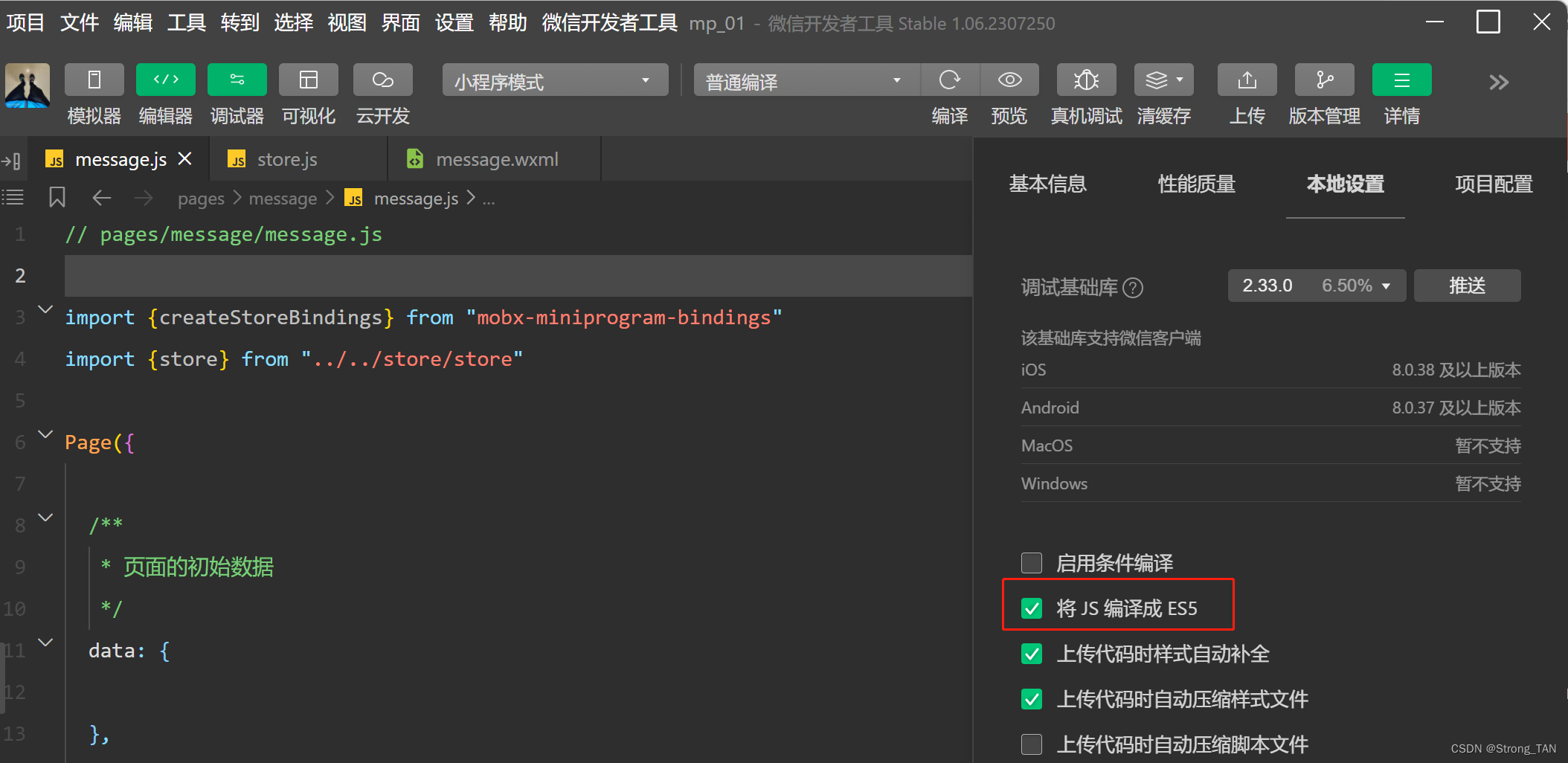
微信小程序报错: SyntaxError: Cannot use import statement outside a module
微信小程序数据绑定,导包出现了: “SyntaxError: Cannot use import statement outside a module” 排查问题步骤记录,共勉 1.出现问题代码: import {createStoreBindings} from "mobx-miniprogram-bindings"import {store} from …...
Ruoyi微服务启动流程
1、执行sql 执行sql ry-quarty.sql ry_2023706.sql 到ry-cloud 数据库 2、下载nacos 修改配置文件 修改连接地址 启动nacos 看到下面的配置文件即为成功 修改配置文件里面的数据库连接信息 3、修改nacos 为单机启动 4、启动项目即可 nacos自取 链接: https://pan.baidu…...
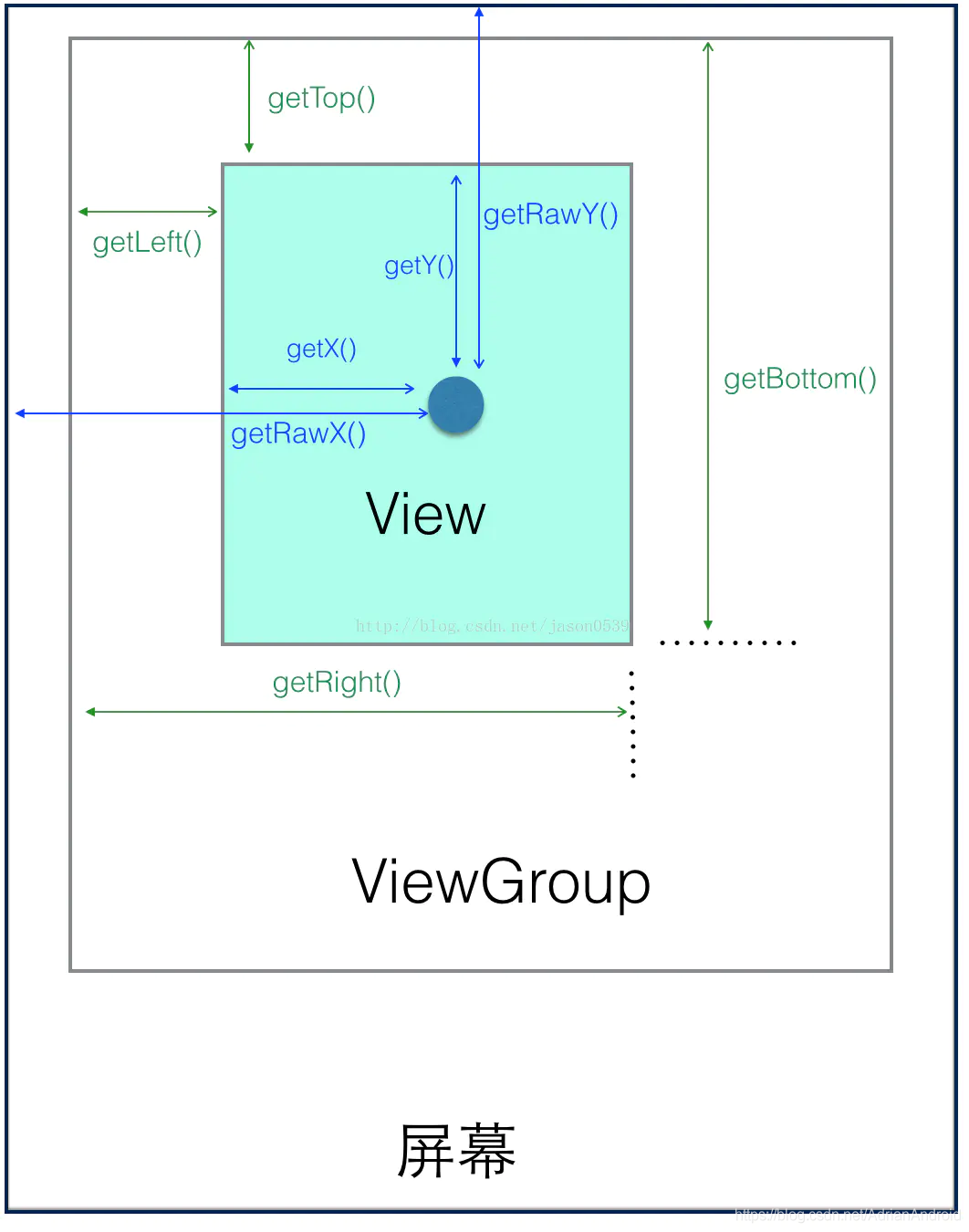
Android scrollTo、scrollBy、以及scroller详解 自定义ViewPager
Scroller VelocityTracker VelocityTracker 是一个速度跟踪器,通过用户操作时(通常在 View 的 onTouchEvent 方法中)传进去一系列的 Event,该类就可以计算出用户手指滑动的速度,开发者可以方便地获取这些参数去做其他…...
Aidex 移动端快速开发框架# RuoYi-Uniapp项目,uniapp vue app项目跨域问题
参考地址: manifest.json官方配置文档:manifest.json 应用配置 | uni-app官网 Chrome 调试跨域问题解决方案之插件篇: uni-app H5跨域问题解决方案(CORS、Cross-Origin) - DCloud问答 其实uni-app官方有解决跨域的办…...

JVM7:垃圾回收是什么?从运行时数据区看垃圾回收到底回收哪块区域?垃圾回收如何去回收?垃圾回收策略,引用计数算法及循环引用问题,可达性分析算法
垃圾回收是什么?从运行时数据区看垃圾回收到底回收哪块区域? 垃圾回收如何去回收? 垃圾回收策略 引用计数算法及循环引用问题 可达性分析算法 垃圾回收是什么?从运行时数据区看垃圾回收到底回收哪块区域?垃圾回收如何去…...

NFT Insider #104:The Sandbox:全新土地销售活动 Turkishverse 来袭
引言:NFT Insider由NFT收藏组织WHALE Members、BeepCrypto联合出品,浓缩每周NFT新闻,为大家带来关于NFT最全面、最新鲜、最有价值的讯息。每期周报将从NFT市场数据,艺术新闻类,游戏新闻类,虚拟世界类&#…...
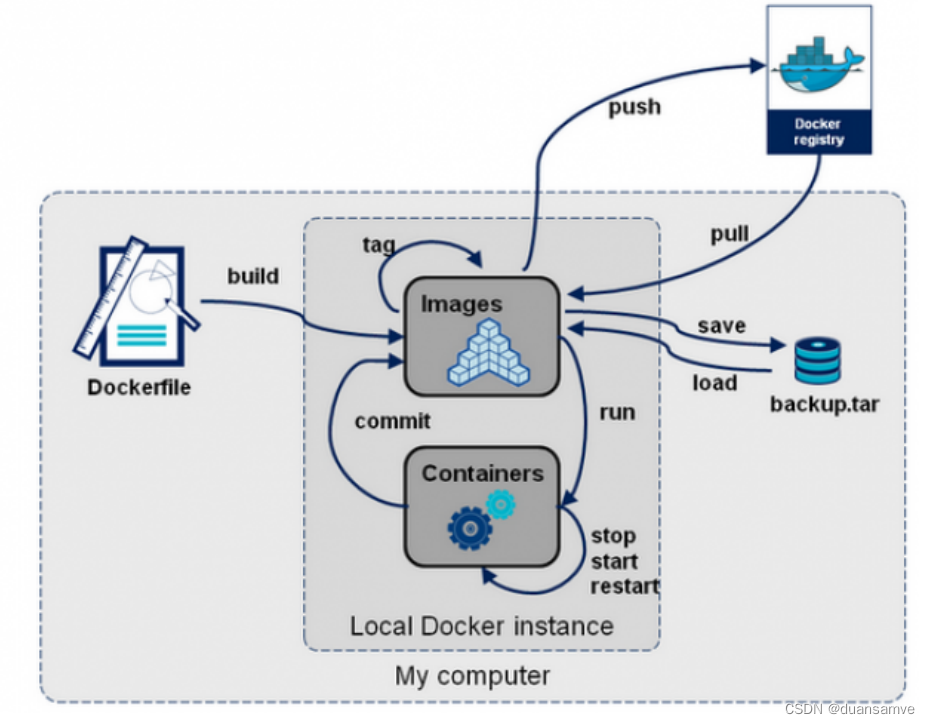
Docker架构及原理
一、Docker的架构图 二、底层原理 Docker是怎么工作的? Docker是一个Client-Server结构的系统,Docker守护进程运行在主机上, 然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。 容器…...
VScode使用SSH连接linux
1、官网下载和安装软件 https://code.visualstudio.com/Download 2、安装插件 单击左侧扩展选项,搜索插件安装 总共需要安装的插件如下所示 3、配置连接服务器的账号 安装完后会在左侧生成了远程连接的图标,单击此图标,然后选择设置图标…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...