【大数据】图解 Hadoop 生态系统及其组件
图解 Hadoop 生态系统及其组件
- 1.HDFS
- 2.MapReduce
- 3.YARN
- 4.Hive
- 5.Pig
- 6.Mahout
- 7.HBase
- 8.Zookeeper
- 9.Sqoop
- 10.Flume
- 11.Oozie
- 12.Ambari
- 13.Spark
在了解 Hadoop 生态系统及其组件之前,我们首先了解一下 Hadoop 的三大组件,即 HDFS、MapReduce、YARN,它们共同构成了 Hadoop 分布式计算框架的 核心。
-
HDFS(
Hadoop Distributed File System):HDFS 是 Hadoop 的 分布式文件系统,它是将大规模数据分散存储在多个节点上的基础。HDFS 主要负责数据的存储和管理,可以将大数据集分成多个数据块,并将这些数据块分配到不同的计算节点上存储,提高数据的可靠性和处理效率。 -
MapReduce:MapReduce 是 Hadoop 的 分布式计算框架,它提供了一种简单的编程模型,通过将大规模数据分解成多个小任务并行处理,可以大大提高数据处理的效率。MapReduce 模型包括 Map 和 Reduce 两个阶段,其中 Map 阶段将数据分解成多个小块进行处理,Reduce 阶段将处理结果合并。
-
YARN(
Yet Another Resource Negotiator):YARN 是 Hadoop 的 资源管理器,它负责为多个应用程序分配和管理计算资源,可以有效地提高计算资源的利用率。YARN 可以将集群中的计算资源划分为多个容器,为不同的应用程序提供适当的资源,并监控和管理各个应用程序的运行状态。

1.HDFS
HDFS 是 Hadoop 的分布式文件系统,旨在在廉价硬件上存储大型文件。它具有高度容错能力,并为应用程序提供高吞吐量。 HDFS 最适合那些拥有非常大数据集的应用程序。
Hadoop HDFS 文件系统提供 Master 和 Slave 架构。主节点运行 Namenode 守护进程,从节点运行 Datanode 守护进程。

2.MapReduce
MapReduce 是 Hadoop 的数据处理层,它将任务分成小块,并将这些小块分配给通过网络连接的许多机器,并将所有事件组装成最后的事件数据集。 MapReduce 所需的基本细节是键值对。所有数据,无论是否结构化,在通过 MapReduce 模型传递之前都需要转换为键值对。在 MapReduce 框架中,处理单元被移至数据,而不是将数据移至处理单元。

3.YARN
YARN 代表 Yet Another Resource Negotiator,它是 Hadoop 集群的资源管理器。 YARN 用于实现 Hadoop 集群中的资源管理和作业调度。 YARN 的主要思想是将作业调度和资源管理拆分到各个进程中进行操作。
YARN 提供了两个守护进程;第一个称为资源管理器(Resource Manager),第二个称为节点管理器(Node Manager)。这两个组件都用于处理 YARN 中的数据计算。资源管理器运行在 Hadoop 集群的主节点上,并协商所有应用程序中的资源,而节点管理器托管在所有从节点上。节点管理器的职责是监视容器、资源使用情况(例如 CPU、内存、磁盘和网络)并向资源管理器提供详细信息。

4.Hive
Hive 是 Hadoop 的 数据仓库 项目。 Hive 旨在促进非正式数据汇总、即席查询和大量数据的解释。借助 HiveQL,用户可以对 HDFS 中的数据集存储执行即席查询,并使用该数据进行进一步分析。 Hive还支持自定义的用户定义函数,用户可以使用这些函数来执行自定义分析。
让我们了解 Apache Hive 如何处理 SQL 查询:
- 用户将使用命令行或 Web UI 向驱动程序(例如 ODBC / JDBC)提交查询。
- 驱动程序将借助查询编译器来解析查询以检查语法 / 查询计划。
- 编译器将向元数据数据库发送元数据请求。
- 作为响应,Metastore 将向编译器提供元数据。
- 现在编译器的任务是验证规范并将计划重新发送给驱动程序。
- 现在驱动程序将向执行引擎发送执行计划。
- 该程序将作为映射缩减作业执行。执行引擎将作业发送到名称节点作业跟踪器,并为该作业分配一个存在于数据节点中的任务跟踪器,并在此处执行查询。
- 查询执行后,执行引擎将从数据节点接收结果。
- 执行引擎将结果值发送给驱动程序。
- 驱动程序会将结果发送到 Hive 接口(用户)。

5.Pig
Pig 由 Yahoo 开发,用于分析存储在 Hadoop HDFS 中的大数据。 Pig 提供了一个分析海量数据集的平台,该平台由用于通信数据分析应用程序的高级语言组成,并与用于评估这些程序的基础设施相链接。
Pig 具有以下关键属性:
- 优化机会:Pig 提供了查询优化,帮助用户专注于意义而不是效率。
- 可扩展性:Pig 提供了创建用户定义函数以进行特殊用途处理的功能。

6.Mahout
Mahout 是一个用于 创建机器学习应用程序的框架。它提供了一组丰富的组件,您可以通过选择的算法构建定制的推荐系统。 Mahout 的开发目的是提供执行、可扩展性和合规性。
以下是定义这些关键抽象的 Mahout 接口的重要包:
DataModelUserSimilarityItemSimilarityUserNeighborhood

7.HBase
HBase 是继 Google Bigtable 之后创建的分布式、开源、版本化、非关系型数据库。它是 Hadoop 生态系统的重要组件,利用 HDFS 的容错功能,提供对数据的实时读写访问。 HBase 尽管是数据库,但也可以称为数据存储系统,因为它不提供触发器、查询语言和二级索引等 RDBMS 功能。
HBase 具有以下功能:
- 它提供持续的模块化可扩展性。
- 它提供定期的读取和写入。
- 直观且可配置的表分片。
- RegionServer 之间的自动故障转移支持。
- 它提供中央基类,用于支持带有 Apache HBase 表的 Hadoop MapReduce 作业。
- 使用 Java API 进行客户端访问很简单。
- 查询谓词通过服务器端过滤器下推。
- 它提供了 Thrift 网关和 REST-ful Web 服务,支持 XML、Protobuf 和二进制数据编码选择。

8.Zookeeper
Zookeeper 充当 Hadoop 不同服务之间的协调者,用于维护配置信息、命名、提供分布式同步、提供群组服务。 Zookeeper 用于修复这些新部署在分布式环境中的应用程序的错误和竞争条件。

9.Sqoop
Sqoop 是一个数据传输工具,用于在 Hadoop 和关系数据库之间传输数据。它用于将数据从关系数据库管理系统(MySQL 或 Oracle)或大型机导入到 Hadoop(HDFS),并在 Hadoop MapReduce 中转换数据。它还用于将数据导出回 RDBMS。 Sqoop 使用 map-reduce 来导入和导出数据,因此它具有并行处理和容错特性。

10.Flume
Flume 是一种类似于 Sqoop 的日志传输工具,但它适用于非结构化数据(日志),而 Sqoop 用于结构化和非结构化数据。 Flume 是一个可靠、分布式且可用的系统,用于高效地收集、聚合大量日志数据并将其从许多不同的源移动到 HDFS。它不仅限于日志数据聚合,还可以用于传输大量事件数据。
Flume 具有以下三个组件:
SourceChannelSink

11.Oozie
Oozie 是一个 工作流调度框架,用于调度 Hadoop Map / Reduce 和 Pig 作业。 Apache Oozie 工作流程是 Hadoop Map / Reduce 作业、Pig 作业等操作的集合,排列在控制依赖 DAG(有向无环图)中。从一个动作到另一个动作的 “控制依赖性” 表明,除非第一个动作完成,否则另一个动作不会开始。
Oozie 工作流有以下两个节点,即 控制流节点 和 操作节点。
-
控制流节点(
Control Flow Nodes):这些节点用于提供控制工作流执行路径的机制。 -
操作节点(
Action Node):操作节点提供了一种机制,工作流通过该机制触发计算 / 处理任务的执行,例如 Hadoop MapReduce、HDFS、Pig、SSH、HTTP 作业 。

12.Ambari
Ambari 用于配置、管理和监控 Apache Hadoop 集群。
它向系统管理员提供以下任务:
-
Hadoop 集群的配置:它提供了一种在任意数量的节点上安装 Hadoop 服务的媒介。它还处理集群的 Hadoop 服务配置。
-
Hadoop 集群的管理:它提供了一个中央控制来管理 Hadoop 服务,例如整个集群的启动、停止和重新配置。
-
Hadoop 集群监控:它提供了一个用于监控 Hadoop 集群的仪表板(例如节点关闭、剩余磁盘空间不足等)。

13.Spark
Spark 是一个通用且快速的集群计算系统。它是一个非常强大的大数据工具。 Spark 提供了 Python、Scala、Java、R 等多种语言的丰富 API。 Spark 支持 Spark SQL、GraphX、MLlib、Spark Streaming、R 等高级工具。这些工具用于执行不同类型的操作,我们将在 Spark 部分中看到。

相关文章:
【大数据】图解 Hadoop 生态系统及其组件
图解 Hadoop 生态系统及其组件 1.HDFS2.MapReduce3.YARN4.Hive5.Pig6.Mahout7.HBase8.Zookeeper9.Sqoop10.Flume11.Oozie12.Ambari13.Spark 在了解 Hadoop 生态系统及其组件之前,我们首先了解一下 Hadoop 的三大组件,即 HDFS、MapReduce、YARN࿰…...
c++ qt--事件过滤(第七部分)
c qt–事件过滤(第七部分) 一.为什么要用事件过滤 上一篇博客中我们用到了事件来进行一些更加细致的操作,如监控鼠标的按下与抬起,但是我们发现如果有很多的组件那每个组件都要创建一个类,这样就显得很麻烦ÿ…...

Inventor软件安装包分享(附安装教程)
目录 一、软件简介 二、软件下载 一、软件简介 Inventor软件是一款由Autodesk公司开发的三维计算机辅助设计(CAD)软件,主要用于机械设计和工程领域。它基于参数化建模技术,可以创建出复杂的三维模型,并且提供了丰富的…...

STM32F103 4G Cat.1模块EC200S使用
一、简介 EC200S-CN 是移远通信最近推出的 LTE Cat 1 无线通信模块,支持最大下行速率 10Mbps 和最大上行速率 5Mbps,具有超高的性价比;同时在封装上兼容移远通信多网络制式 LTE Standard EC2x(EC25、EC21、EC20 R2.0、EC20 R2.1&a…...

38、springboot为 spring mvc 提供的静态资源管理,覆盖和添加静态资源目录
springboot为 spring mvc 提供的静态资源管理 ★ Spring Boot为Spring MVC提供了默认的静态资源管理: ▲ 默认的四个静态资源目录: /META-INF/resources > /resources > /static > /public ▲ ResourceProperties.java类的源代码࿰…...

Go 输出函数
Go语言拥有三个用于输出文本的函数: Print()Println()Printf() Print() 函数以其默认格式打印其参数。 示例 打印 i 和 j 的值: package mainimport "fmt"func main() {var i, j string "Hello", "World"fmt.Print(…...
 测试点全过)
L1-037 A除以B(Python实现) 测试点全过
题目 真的是简单题哈 —— 给定两个绝对值不超过100的整数A和B,要求你按照“ A / B 商 A/B商 A/B商”的格式输出结果。 输入格式 输入在第一行给出两个整数 A A A和 B ( − 100 ≤ A , B ≤ 100 ) B(−100≤A,B≤100࿰…...
睿思BI旗舰版V5.3正式发布
发布时间:2023-7-20 主要更新内容: 1.增加3D地图功能 2.增加水球图 3.增加扇形图,在数据大屏 - 自定义组件中定义。 4.增加指标引导线功能,在数据大屏 - 自定义组件中定义。 5.详情页增加回调函数功能。 6.大屏/仪表盘模版下载,…...

基于Jenkins自动化部署PHP环境---基于rsync部署
基于基于Jenkins自动打包并部署Tomcat环境_学习新鲜事物的博客-CSDN博客环境 准备git仓库 [rootgit ~]# su - git 上一次登录:五 8月 25 15:09:12 CST 2023从 192.168.50.53pts/2 上 [gitgit ~]$ mkdir php.git [gitgit ~]$ cd php.git/ [gitgit php.git]$ git --b…...
学信息系统项目管理师第4版系列02_法律法规
1. 信息安全的法律体系可分为四个层面 1.1. 一般性法律法规,如宪法、国家安全法,国家秘密法 1.2. 规范和惩罚信息网络犯罪的法律,如刑法、《全国人大常委会关于维护互联网安全的决定》等 1.3. 直接针对信息安全的特别规定,如《…...
【大数据】Doris:基于 MPP 架构的高性能实时分析型数据库
Doris:基于 MPP 架构的高性能实时分析型数据库 1.Doris 介绍 Apache Doris 是一个基于 MPP(Massively Parallel Processing,大规模并行处理)架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知ÿ…...
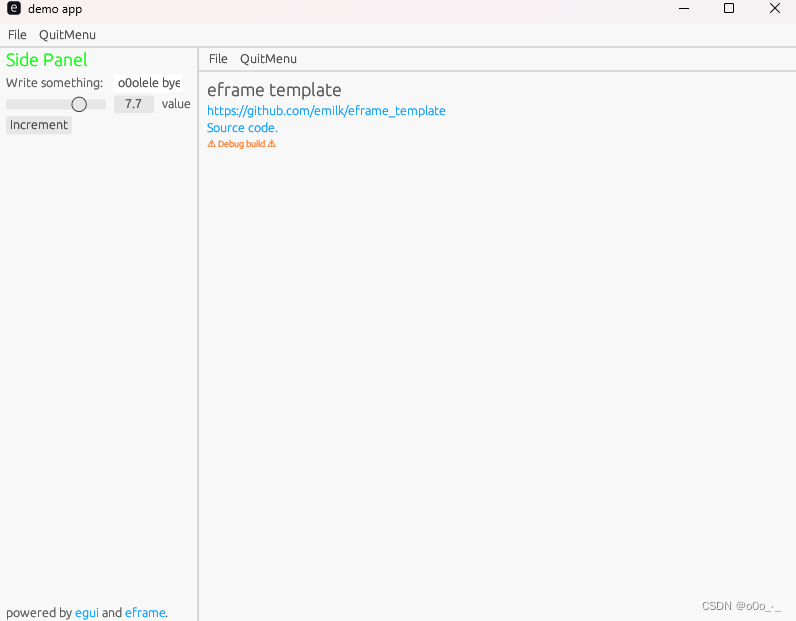
【rust/egui】(五)看看template的app.rs:SidePanel、CentralPanel以及heading
说在前面 rust新手,egui没啥找到啥教程,这里自己记录下学习过程环境:windows11 22H2rust版本:rustc 1.71.1egui版本:0.22.0eframe版本:0.22.0上一篇:这里 SidePanel 侧边栏,如下图 …...

MTK6833_MT6833核心板_天玑700安卓5G核心板规格性能介绍
MTK6833安卓核心板采用台积电 7nm 制程的5G SoC,2*Cortex-A766*Cortex-A55架构,搭载Android12.0操作系统,主频最高达2.2GHz 。内置 5G 双载波聚合技术(2CC)及双 5G SIM 卡功能,实现优异的功耗表现及实时连网…...

Maven-Java代码格式化插件spring-javaformat
TOC 官方文档:点击进入 前言 项目研发过程中,随着团队人员的增加变更环境配置的不同,有些同学甚至没有格式化代码的习惯,导致编码风格不统一杂乱无章,为解决这一问题引入Spring提供的格式化代码插件。插件支持多种方…...

设计模式之八:模板方法模式
泡咖啡和泡茶的共同点: 把水煮沸沸水冲泡咖啡/茶叶冲泡后的水倒入杯子添加糖和牛奶/柠檬 class CoffeineBeverage { public:void prepareRecipe(){boilWater();brew();pourInCup();addCondiments();}private:void boilWater(){std::cout << "Boiling w…...

hive可以删除单条数据吗
参考: hive只操作几条数据特别慢 hive可以删除单条数据吗_柳随风的技术博客_51CTO博客...

python3-Flask实现Api接口
1、:python3-Flask实现Api接口_flask api_Shiro to kuro的博客-CSDN博客 2、 Flask框架的web开发01(Restful API接口规范)_flask patch post_~须尽欢的博客-CSDN博客...

微分享 - 超实用开发日常排查问题Linux运维命令
目录 CPUCPU基本信息CPU使用情况ps 命令可用于确定哪个进程占用了 CPU 内存free 网络查看端口curl 常用命令 文件df 、du 区别磁盘使用情况文件大小文件下载压缩&解压缩查找文件查找文件内容 进程CPU 使用来升序排序内存 使用升序排序 其他常用操作系统进本信息赋予文件执行…...
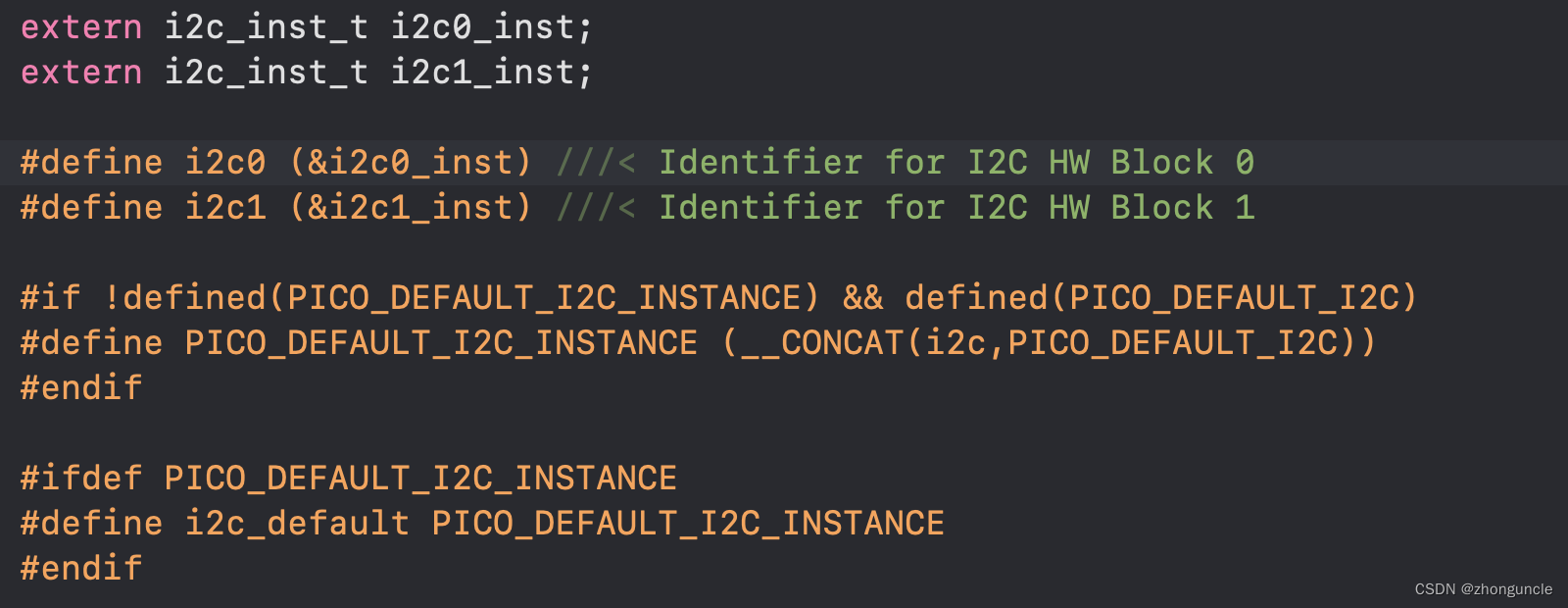
Pico如何使用C/C++选择哪个I2C控制器,以及SDA和SCL针脚
本文一开始讲述了解决方案,后面是我做的笔记,用来讲述我的发现流程和探究的 Pico I2C 代码结构。 前提知识 首先要说明一点:Pico 有两个 I2C,也就是两套 SDA 和 SCL。这点你可以在针脚图中名字看出,比如下图的 Pin 4…...
求生之路2私人服务器开服搭建教程centos
求生之路2私人服务器开服搭建教程centos 大家好我是艾西,朋友想玩求生之路2(left4dead2)重回经典。Steam玩起来有时候没有那么得劲,于是问我有没有可能自己搭建一个玩玩。今天跟大家分享的就是求生之路2的自己用服务器搭建的一个心路历程。 ࿰…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...