python网络爬虫指南二:多线程网络爬虫、动态内容爬取(待续)
文章目录
- 一、多线程网络爬虫
- 1.1 线程的基础内容、`GIL`
- 1.2 创建线程的两种方式
- 1.3 `threading.Thread`类
- 1.4 线程常用方法和锁机制
- 1.5 生产者-消费者模式
- 1.5.1 生产者-消费者模式简介
- 1.5.2 `Condition` 类协调线程
- 1.6 线程中的安全队列
- 1.6 多线程爬取王者荣耀壁纸
- 1.6.1 网页分析
- 1.6.2 爬取第一页的壁纸
- 1.6.3 使用生产者-消费者模式进行多线程下载
- 二、动态网页爬取(待续)
- 2.1 动态网页基础知识
- 2.1.1 动态网页和静态网页
- 2.1.2 Ajax
- 2.1.3 动态网页的爬取
本文为马士兵教育《Python网络爬虫进阶指南》课程笔记,部分内容由AI生成。课件:第一章,第二章,第三章,第四章,第五章,第六章,第七章,第九章,第十章。
一、多线程网络爬虫
1.1 线程的基础内容、GIL
以下是一些基础概念:
- 程序:
- 编程语言编写的指令的集合,用于实现一定的功能;
- 程序本身只是一组静态的指令和数据,并不直接占用计算机的资源。
- 进程:
- 启动后的程序称为进程,一个进程至少有一个线程;
- 进程是操作系统中的执行单元,每个进程都包含了程序的执行所需的资源,如内存空间、文件句柄、系统状态等,所以进程之间相互独立、数据隔离;
- 进程通常由操作系统进行调度,以便在多个进程之间实现并发执行。
- 线程:
- 线程是CPU调度执行的基本单元,一个进程可以包含多个线程;
- 多个线程共享同一个进程的资源(除了CPU资源),包括内存空间和系统状态,所以线程之间可以更方便地进行数据交换
- 线程的引入是为了更有效地实现多任务并发,因为线程的创建和切换开销比进程要小得多。
综合来说,程序是一组指令和数据的集合,描述了任务的执行过程。进程是操作系统中的一个执行单元,包含了程序的执行所需的资源。线程是进程内的执行单元,多个线程共享进程的资源,用于实现更高效的多任务并发。
多个进程的多个线程同时进行时,CPU会通过调度算法来分配CPU时间片,以便每个进程的每个线程都能得到执行。常用的进程调度算法有:
- 先来先服务(FCFS): 按照进程或线程的到达时间先后顺序来分配CPU时间片。
- 优先级调度: 根据进程或线程的优先级来分配CPU时间片,优先级高的进程或线程将获得更多的CPU时间片。
- 轮转调度: 按照进程或线程的编号顺序来分配CPU时间片,每个进程或线程都将获得等量的CPU时间片。
- 抢占式调度: 允许操作系统在任何时候抢占正在执行的进程或线程,并将CPU时间片分配给其他进程或线程。这种调度方式确保了高响应性和公平性,但需要处理上下文切换的开销。
在多核CPU中,多个线程可以同时运行,但每个核心一次只能执行一个线程。操作系统使用线程调度算法来决定将哪些线程分配给哪些核心。线程调度的目标是最大程度地利用多核处理器的性能,以及确保线程间的平衡和公平性。
打开任务管理器,就可以看到当前电脑上活动的进程:

CPython 是 Python 编程语言的官方实现,是最常用的 Python 解释器之一,在多数情况下,“Python” 指的就是 CPython。
需要注意的是,尽管
CPython是最常用的 Python 实现,但也有其他的 Python 实现,如Jython(运行在 Java 虚拟机上)、IronPython(运行在 .NET 平台上)、PyPy(一个高性能的JIT编译器实现)、MicroPython(用于IoT设备和嵌入式系统。)等,它们在一些特定场景下具有独特的优势。
CPython 的一个重要特点是全局解释器锁(GIL),它限制了同一时刻只有一个线程能够执行 Python 代码。这意味着在多线程程序中,虽然可以使用多个线程,但是多个线程不能同时并行执行 Python 代码(一般是多个线程来回切换,等待的线程可以执行I/O等操作),这使得 CPython 在多核 CPU 上无法充分利用多核性能。
在执行计算密集型任务时(图像处理和视频编码、大规模矩阵运算、数据处理等),多线程并不能真正实现多核并行处理,因为多个线程无法同时在不同的核心上执行。此时建议使用 multiprocessing模块或 concurrent.futures模块来创建多个进程,充分利用多核处理器的并行计算能力。
每个进程都有自己独立的解释器和
GIL,因此可以在多个核心上并行执行计算密集型任务。
尽管 GIL 限制了多线程在计算密集型任务上的效果,但在处理 I/O 密集型任务时,多线程仍然是一个合适的模型。因为 I/O 操作(如文件读写、网络请求、数据库操作、图片上传下载、用户界面应用等)往往会涉及等待,此时线程可以在等待期间执行其他任务,从而充分利用 CPU 时间。
另外在单线程情况下,一个 I/O 操作的阻塞会导致整个程序暂停执行,直到 I/O 完成。使用多线程可以避免这种情况,因为其他线程仍然可以继续执行。
利用系统监测工具(如 top、htop 等)观察 CPU 使用率和等待 I/O 的情况。如果 CPU 使用率高且 I/O 等待时间相对较少,可能是计算密集型;如果 CPU 使用率较低且 I/O 等待时间较长,可能是 I/O 密集型,这只是一种粗略的判定方法。
1.2 创建线程的两种方式
Threading官方文档
Threading是一个Python 标准库,专用于进行python多线程编程。在 Python 中,有两种主要的方式来创建线程对象:
- 传递目标函数
import threading# 目标函数
def my_task(param):print("Thread task with param:", param)# 创建线程对象,传递目标函数和参数
my_thread = threading.Thread(target=my_task, args=("Hello",))
my_thread.start()
Thread task with param: Hello
- 继承 Thread 类
import threading# 如果不需要自定义属性,则不需要重写init方法
class MyThread(threading.Thread):def __init__(self, param):super().__init__()self.param = paramself.custom_data = ['Hello'] # 自定义属性,用于存储数据def run(self):print("Thread task with param:", self.param)self.custom_method() # 调用自定义方法def custom_method(self):print("Custom method called.")self.custom_data.append(self.param)def get_custom_data(self):return self.custom_data# 创建自定义线程对象
my_thread = MyThread("World")
my_thread.start()
my_thread.join()# 调用自定义方法和属性
custom_data = my_thread.get_custom_data()
print("Custom data:", custom_data)
Thread task with param: Hello
Custom method called.
Custom data: ['Hello','World']
在第一种方式中,我们直接创建了一个线程对象,传递目标函数和参数。在第二种方式中,我们继承了 Thread 类,并重写了 run 方法。在 run 方法中,我们首先执行线程任务,然后调用了自定义方法。在主线程中,我们调用了 get_custom_data 方法来获取自定义属性的值。
这两种方法都可以创建线程对象,但也有一些区别:
- 传递目标函数:简单直观,不需要创建新的类。如果你只需要简单并行执行某个函数,使用传递目标函数的方式会更方便
- 继承 Thread 类:这种方式是通过继承 Thread 类并重写其 run 方法来实现的。你可以在 run 方法中定义线程要执行的任务。这种方式适用于需要更多控制和封装的情况,可以在子类中添加自定义方法和属性,适用于复杂的多线程场景。
在继承
threading.Thread类并重写了run方法的情况下,如果你同时设置了target参数,实际上只有run方法会被调用。这是因为run方法是线程对象启动时默认要执行的方法,而target参数是用来指定替代的目标函数。
如果你重写了run方法,那么线程对象在启动时会自动调用你重写的run方法,而不会执行通过target参数指定的目标函数。因此,在这种情况下,设置target参数是没有意义的。
1.3 threading.Thread类
在python中,我们主要使用继承 threading.Thread类的方式来创建线程对象,下面介绍一下 Thread 类的语法和各个参数的含义。
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
group: 线程组,为了日后扩展 ThreadGroup 类实现而保留,目前不支持。target: 指定线程要执行的目标函数。线程对象在启动时会调用 run 方法,而 target 参数指定了在 run 方法中要执行的任务。name: 设置线程的名称(字符串标识)。- 线程的名称可以在多线程程序中用来识别和区分不同的线程。这在调试和理解多线程程序时非常有用。
- 在默认情况下,会以 “Thread-N” 的形式构造唯一名称,如果指定了 target 参数的话,就是 “Thread-N (target)” 的形式。
args: 传递给目标函数的位置参数(以元组形式)。kwargs: 传递给目标函数的关键字参数(以字典形式)。daemon: 设置线程是否为守护线程,默认为 False。在多线程程序中,有两种类型的线程:主线程(Main Thread)和守护线程(Daemon Thread)。- 主线程是程序的入口,它会等待所有的非守护线程执行完成后才结束,主线程结束意味着程序即将退出。
- 守护线程是一种后台线程。如果所有的非守护线程都结束了,守护线程会被强制终止,即使它的任务还没有执行完成,因此它们适用于一些不需要完全执行的后台任务,例如日志记录、监控等。
下面介绍一下Thread 类的主要方法和属性:
-
start()方法: 启动线程,调用线程对象的 run 方法执行线程任务。 -
join()方法: 等待线程执行完成。- 当调用线程对象的
join()方法时,主线程(或当前线程)将被阻塞,直到目标线程执行完成。 - 可选参数为
timeout,表示最长等待时间(s)。如果在指定的时间内目标线程未执行完成,主线程将继续执行。 - 如果不使用
join()方法,主线程可能会在目标线程执行之前就完成,所以join()方法可以保证线程之间的协调和正确的执行顺序
- 当调用线程对象的
-
is_alive()方法: 用于检查线程是否处于活动状态,即是否正在执行。 -
name属性: 用于获取或设置线程的名称。 -
ident属性: 用于获取线程的唯一标识符。 -
daemon属性: 用于设置线程是否为守护线程。守护线程会随着主线程的结束而结束。 -
target属性: 用于获取或设置线程要执行的目标函数。 -
args和kwargs属性: 用于获取线程函数的参数,分别是位置参数和关键字参数。
以下是一个示例,演示了如何使用 Thread 类的主要方法和属性:
import threading
import time
class MyThread(threading.Thread):def __init__(self, name, seconds):super().__init__()self.name = nameself.seconds = secondsself.custom_data = [] # 自定义属性,用于存储数据def run(self):print(f"Thread {self.name} is running for {self.seconds} seconds.")self.custom_method() # 调用自定义方法time.sleep(2)print(f"Thread {self.name} is complete.")def custom_method(self):print(f"Custom method of Thread {self.name} is called.")self.custom_data.append(self.name)def get_custom_data(self):return self.custom_data# 创建自定义线程对象并启动
thread = MyThread(name="MyThread", seconds=3)
thread.start()# 获取线程名称和标识符、活动状态和是否为守护程序
print("Thread name:", thread.name)
print("Thread identifier:", thread.ident)
print("Is thread alive:", my_thread.is_alive())
print("Is daemon thread:", my_thread.daemon)# 等待线程执行完成
thread.join()# 使用自定义方法和属性
custom_data = thread.get_custom_data()
print("Custom data for Thread:", custom_data)print("Main thread finished.")
Thread MyThread is running for 3 seconds.
Custom method of Thread MyThread is called.
Thread name: MyThread
Thread identifier: 7656
Is thread alive: False
Is daemon thread: False
Thread MyThread is complete.
Custom data for Thread: ['MyThread']
Main thread finished.
1.4 线程常用方法和锁机制
- 线程常用方法
| threading 模块函数 | 作用 |
|---|---|
threading.active_count() | 返回当前活动线程的数量,返回值与 enumerate() 所返回的列表长度一致 |
threading.current_thread() | 返回当前线程对象。 |
threading.enumerate() | 返回所有活动线程对象的列表,包括守护线程以及 current_thread() 创建的空线程 |
threading.main_thread() | 返回主线程对象。一般情况下,主线程是Python解释器开始时创建的线程 |
threading.get_ident() | 返回当前线程的标识符(非零的整数)。 |
- 线程的安全性和锁机制
在多线程编程中,当多个线程同时访问和操作共享资源时,可能会出现问题。例如,一个线程正在修改某个变量的值,而另一个线程也在同时访问并修改相同的变量。这可能导致数据不一致或者程序崩溃,下面以车站售票举例说明:
import threading
import timeticket = 100 # 全局变量def sale_ticket():# 在函数中要修改 ticket 全局变量的值,就必须在函数内部使用global ticket声明global ticketfor i in range(1000): # 模拟1000个人买票while ticket >0: # 持续售票,直到所有票都售完print(threading.current_thread().name + '--》正在出售第{}张票'.format(ticket))ticket -= 1time.sleep(0.1)def start():for i in range(2):t = threading.Thread(target=sale_ticket)t.start()if __name__ == '__main__':start() # 调用自定义的 start() 函数,创建线程对象并启动线程
Thread-1 (sale_ticket)--》正在出售第62张票
Thread-2 (sale_ticket)--》正在出售第61张票
Thread-1 (sale_ticket)--》正在出售第60张票Thread-8 (sale_ticket)--》正在出售第60张票Thread-1 (sale_ticket)--》正在出售第58张票
打印结果显示第60张票同时被两个线程操作,导致售票出错(线程是实时调度的,每次结果会不一样)。
为了避免这种竞争条件(多个线程在访问共享资源时发生的问题),我们可以使用锁来保护共享资源,确保一次只有一个线程可以访问资源。threading 模块就提供了 Lock 和 RLock 类来实现锁机制:
Lock锁: 互斥锁,也是最基本的锁,一次只允许一个线程持有锁,其他线程需要等待锁的释放。当一个线程获取了锁,其他线程将被阻塞,直到锁被释放。RLock锁:可重入锁 ,也称为递归锁。同一个线程可以多次获取同一个锁,而不会造成死锁。每次获取锁后,锁的计数器会增加,必须释放相同次数的锁,才能真正释放锁。
| 方法 | 作用 |
|---|---|
threading.Lock() | 创建锁对象 |
lock.acquire(blocking=True, timeout=None) | 获取锁,阻塞当前线程直到锁可用或超时。 |
lock.release() | 释放锁,允许其他线程获取锁。 |
lock.locked() | 返回 True 如果锁已经被某个线程获得,否则返回 False。 |
lock.__enter__() | 作为上下文管理器的一部分,用于获取锁。 |
lock.__exit__(exc_type, exc_value, traceback) | 作为上下文管理器的一部分,用于释放锁。 |
RLock 的创建和方法与 Lock 完全一致,就不再赘述。
我们可以手动调用 acquire() 和 release() 方法来管理锁的获取和释放,也可以使用下文管理器来完成。进入 with 语句块时,lock.__enter__() 方法被调用,获取锁;当退出 with 语句块时,lock.__exit__() 方法被调用,释放锁;所以使用with语句,会使得代码更加清晰和简洁。
import threading
import timeticket = 100 # 全局变量
lock = threading.Lock() # 创建一个线程锁def sale_ticket(): global ticketfor i in range(1000):while ticket >0: # 持续售票,直到所有票都售完with lock: # 使用线程锁进行同步print(threading.current_thread().name + '--》正在出售第{}张票'.format(ticket))ticket -= 1time.sleep(0.1)def start():for i in range(2):t = threading.Thread(target=sale_ticket)t.start()if __name__ == '__main__':start() # 调用自定义的 start() 函数,创建线程对象并启动线程
- 死锁
不正确地使用锁可能会导致死锁。死锁是指多个线程相互等待对方释放资源,从而陷入无法继续执行的状态。下面是一个比较经典的示例,展示了如何使用两个线程和两个锁来制造死锁的情况:
import threadinglock1 = threading.Lock()
lock2 = threading.Lock()def worker1():with lock1:print("Worker 1 acquired lock 1")# 为了模拟死锁,故意在获取第一个锁后休眠一段时间# 从而在 worker2 尝试获取 lock2 时,无法释放 lock1# 导致 worker1 和 worker2 互相等待import timetime.sleep(1)print("Worker 1 waiting for lock 2")with lock2:print("Worker 1 acquired lock 2")def worker2():with lock2:print("Worker 2 acquired lock 2")print("Worker 2 waiting for lock 1")with lock1:print("Worker 2 acquired lock 1")if __name__ == "__main__":thread1 = threading.Thread(target=worker1)thread2 = threading.Thread(target=worker2)thread1.start()thread2.start()thread1.join()thread2.join()print("Main thread finished")下面这段代码将 worker2 中的第一个锁获取由 lock2 改为了 lock1,这样两个线程都会按相同的顺序获取锁,避免了死锁情况的发生。
def worker2():with lock1: # 修改为使用相同的锁顺序print("Worker 2 acquired lock 1")print("Worker 2 waiting for lock 2")with lock2:print("Worker 2 acquired lock 2")
为了避免死锁,还可以考虑在获取锁之前,尽量减少或避免在锁内执行耗时操作。另外,使用超时机制(lock1.acquire(timeout=1))可以防止线程在获取锁时永久等待。
1.5 生产者-消费者模式
1.5.1 生产者-消费者模式简介
生产者-消费者模式(Producer-Consumer Pattern)是一种常见的多线程设计模式,用于解决生产者和消费者之间的协作问题。在这种模式中,有两类线程:
-
生产者(Producer): 负责生成(生产)数据或任务,并将它们放入共享的缓冲区(队列)中。生产者不断地生产数据,直到达到某个条件。如果缓冲区已满,生产者可能需要等待。
-
消费者(Consumer): 负责从共享的缓冲区中获取数据或任务,并进行处理。消费者不断地从缓冲区中获取数据,直到达到某个条件。如果缓冲区为空,消费者可能需要等待。
生产者-消费者模式的目标是实现生产者和消费者之间的有效协调,以避免资源竞争、提高效率和减少线程等待时间,下面是一个简单的示意图:
+----------------+ +----------------+ +----------------+
| 生产者 | | 缓冲区 | | 消费者 |
| |<--->| |<--->| |
| 生成数据并放入 | | 存储和协调数据 | | 从缓冲区获取 |
| 缓冲区中 | | 交换的地方 | | 数据并处理 |
+----------------+ +----------------+ +----------------+
下面是一个简单的示例:
import threading
import random
import timeg_money = 0
lock = threading.Lock() # 创建锁对象# 生产者线程类
class Producer(threading.Thread):def run(self):global g_moneyfor _ in range(10):with lock: # 获取锁,进入临界区money = random.randint(1, 1000)g_money += moneyprint(threading.current_thread().name, '挣了{}钱,当前余额为:{}'.format(money, g_money))time.sleep(0.1)# 消费者线程类
class Customer(threading.Thread):def run(self):global g_moneyfor _ in range(10):with lock: # 获取锁,进入临界区money = random.randint(1000, 10000)if money <= g_money:g_money -= moneyprint(threading.current_thread().name, '花了{}钱,当前余额为:{}'.format(money, g_money))else:print(threading.current_thread().name, '想花{}钱,但是余额不足,当前余额为:{}'.format(money, g_money))time.sleep(0.1)# 启动函数,创建生产者和消费者线程并启动
def start():for i in range(5):th = Producer(name='生产者{}'.format(i))th.start()for i in range(5):cust = Customer(name='--------消费者{}'.format(i))cust.start()if __name__ == '__main__':start()
这个代码示例模拟了生产者和消费者在对一个共享资源(g_money)进行读写操作时的情况。通过线程锁 lock 来确保每次只有一个线程可以对余额进行操作,避免了资源竞争和不一致的问题。每个线程都会进行多次操作,包括挣钱、花钱以及打印当前余额等。
1.5.2 Condition 类协调线程
我们执行刚刚模拟的生产者和消费者代码,会发现经常有余额不足时消费者想消费的情况,甚至是余额已经不足,但全部生产者却生产完成的情况。此时可以使用条件变量(Condition)来协调生产者和消费者线程之间的交互。
条件变量允许线程等待某个条件满足,以及在满足条件时通知其他线程。在 Python 的 threading 模块中,Condition 类提供了这种条件变量的机制。
Condition 对象本身也是一个锁对象,也可以使用acquire(self) 和 release(self)方法来获取和释放条件变量的锁,所以此时不需要再额外使用lock对象。Condition 类的主要方法和概念包括:
| 方法 | 描述 |
|---|---|
__init__(self, lock=None) | 构造函数,创建一个条件变量对象。可选参数为锁对象lock,用于在内部管理等待和通知操作的同步,否则会创建一个新的锁对象。 |
acquire(self) | 获取条件变量的锁。 |
release(self) | 释放条件变量的锁。 |
wait(self, timeout=None) | 释放锁,并进入等待状态,直到其他线程调用 notify() 或 notify_all() 来唤醒。唤醒后继续等待上锁可选参数 timeout,如果超过指定时间条件仍未满足,线程会重新获得锁并继续执行 |
notify(self, n=1) | 通知等待队列的中的一个线程条件已满足,并将其唤醒(默认第一个)。 |
notify_all(self) | 通知所有等待队列的中的线程条件已满足,并全部唤醒(唤醒必须在释放锁之前)。 |
使用 Condition 类的一般模式如下:
- 获取条件变量的锁。
- 检查某个条件是否满足,如果条件未满足,调用
wait()方法等待条件满足。 - 条件满足时,执行相关操作。
- 释放条件变量的锁。
下面是改进的代码:
import threading
import random
import timeg_money = 0
lock = threading.Condition() # 创建条件变量对象
g_time = 0# 生产者线程类
class Producer(threading.Thread):def run(self):global g_moneyglobal g_timefor _ in range(10):lock.acquire() # 获取条件锁money = random.randint(1, 1000)g_money += moneyg_time += 1print(threading.current_thread().name, '挣了{}钱,当前余额为:{}'.format(money, g_money))time.sleep(0.1)lock.notify_all() # 通知等待的消费者lock.release() # 释放锁# 消费者线程类
class Customer(threading.Thread):def run(self):global g_moneyfor _ in range(10):lock.acquire() # 获取锁money = random.randint(1000, 10000)while g_money < money: # 余额不足时一直等待if g_time >= 50: # 当已经进行了50次生产时,结束消费者线程lock.release()returnprint(threading.current_thread().name, '想花{}钱,但是余额不足,余额为:{}'.format(money, g_money))lock.wait() g_money -= money # 开始消费print(threading.current_thread().name, '------------花了{}钱,当前余额为:{}'.format(money, g_money))lock.release() # 释放锁# 启动函数,创建生产者和消费者线程并启动
def start():for i in range(5):th = Producer(name='生产者{0}'.format(i))th.start()for i in range(5):cust = Customer(name='--------消费者{}'.format(i))cust.start()if __name__ == '__main__':start()
- 增加全局变量
g_time表示生产次数。如果g_time达到 50 次生产,表示所有生产者都已经生产完毕,此时如果还是余额不足,则消费者线程将全部结束。 - 消费者线程需要购买商品,它在循环中检查当前余额是否足够,如果不够则一直保持等待。
- 当生产者线程挣钱后,会通过
lock.notify_all()通知等待的消费者线程。 - 这个过程使用条件变量和锁确保了生产者和消费者之间的同步,避免了竞争条件和死锁问题。
1.6 线程中的安全队列
python内置的queue 模块实现了队列格式,包括Queue(先进先出)、LifoQueue(后进先出、PriorityQueue(优先级队列)。这些队列类型都实现了线程安全的数据结构,允许多个线程同时操作队列而不会引发竞争条件等问题。使用这些队列类型,可以更方便地实现生产者-消费者模型、任务调度等多线程应用。下面是更详细的解释:
-
放入数据(Put):当生产者线程调用
put方法将数据放入队列时,队列会自动获得互斥锁,确保其他线程不能同时访问队列。一旦数据放入队列后,队列会释放互斥锁,然后使用条件变量通知正在等待数据的消费者线程。如果队列已满,生产者线程会被阻塞,直到队列有足够的空间。 -
获取数据(Get):当消费者线程调用
get方法获取数据时,队列会自动获得互斥锁,确保其他线程不能同时访问队列。如果队列为空,消费者线程会被阻塞,直到队列有数据可供消费。一旦数据被获取,队列会释放互斥锁,然后使用条件变量通知正在等待数据空间的生产者线程。 -
等待和通知(Wait and Notify):条件变量在等待和通知的过程中起到了重要作用。消费者线程调用
get方法时,如果队列为空,它会进入等待状态,同时释放互斥锁。当生产者线程放入新数据时,它会获取互斥锁,并通过条件变量通知等待的消费者线程。类似地,生产者线程在队列已满时也会进入等待状态,等待消费者线程释放空间。
总之,线程队列通过内部的互斥锁和条件变量,保证了多线程环境下的线程安全操作。这种机制有效地避免了竞争条件、死锁等多线程编程常见的问题,同时提供了方便的数据共享和线程间通信。
互斥锁(
Mutex):队列内部使用互斥锁来保护对队列数据的访问。互斥锁是一种同步机制,它确保在任何时刻只有一个线程能够访问被保护的数据。当一个线程需要操作队列中的数据时,它会尝试获得互斥锁。如果锁已经被其他线程持有,那么它会阻塞等待,直到锁被释放。
条件变量(Condition):队列内部使用条件变量来实现线程间的等待和通知机制。条件变量允许一个或多个线程等待特定的条件被满足,当条件满足时,条件变量会通知等待的线程继续执行。在线程队列中,条件变量通常用于告知消费者队列中有新数据可用,或者告知生产者队列不满。
队列的主要方法:
| 方法 | 描述 |
|---|---|
q = Queue(maxsize)q = LifoQueue(maxsize)q = PriorityQueue(maxsize) | 创建一个新的队列对象。maxsize 可选,用于设置队列的最大容量。 |
q.put(item, block=True, timeout=None) | 将 item 放入队列。默认 block 为 True表示队列满时阻塞等待,否则不阻塞。可选参数 timeout用于设置阻塞等待的时间。 |
q.get(block=True, timeout=None) | 从队列中获取一个元素,参数含义同get |
q.put_nowait(item)q.get_nowait() | 与 put 和 get 方法类似,但是不阻塞,如果队列已满或为空,会抛出异常。 |
q.qsize() | 返回当前队列中的元素数量。 |
q.empty() | 判断队列是否为空 |
q.full() | 判断队列是否已满 |
q.task_done() | 标记一个任务已完成。在消费者获取一个元素后,应该调用 task_done() 来通知队列这个任务已完成。 |
q.join() | 阻塞等待直到队列中所有的任务都被处理。 |
使用线程队列时,要避免线程阻塞,程序无法正常退出的情况
from queue import Queue q = Queue(5) # 创建一个容量为5的队列# 向队列中存放数据
for i in range(4):q.put(i)for _ in range(5):try:print(q.get(block=False)) # 尝试从队列中获取数据,不阻塞except :print('队列为空,程序结束')break
在上面的例子中,我们设置了设置q.get( block=False)表示队列为空时不被阻塞。否则,get操作将一直阻塞,直到队列中有数据可供获取,此时程序无法正常退出。你可以使用q.get_nowait()达到同样的效果。
下面是使用线程队列的一个简单示例:
from queue import Queue
import random
import time
import threading # 生产者线程函数,向队列中添加随机整数
def add_value(q):while True:q.put(random.randint(100, 1000)) # 将随机整数放入队列time.sleep(1) # 线程休眠1秒# 消费者线程函数,从队列中取出元素并打印
def get_value(q):while True:value = q.get() # 从队列中获取元素print('取出了元素: {0}'.format(value)) # 启动函数,创建队列和线程,并启动线程
def start():q = Queue(10) # 创建队列,最大容量为10t1 = threading.Thread(target=add_value, args=(q,)) t2 = threading.Thread(target=get_value, args=(q,)) t1.start() # 启动生产者线程t2.start() # 启动消费者线程if __name__ == '__main__':start() # 调用启动函数,开始执行生产者和消费者线程
args=(q,)表示将队列对象q放入元组中,然后将这个元组作为参数传递给线程函数(arg接受元组对象)。这样,在add_value和get_value函数内部,可以通过函数参数来访问这个队列对象。
1.6 多线程爬取王者荣耀壁纸
王者荣耀官网高清壁纸的网址是https://pvp.qq.com/web201605/wallpaper.shtml,每张壁纸都有7种尺寸。下面我们用爬虫代码,下载所有壁纸,每张壁纸包含所有尺寸。

1.6.1 网页分析
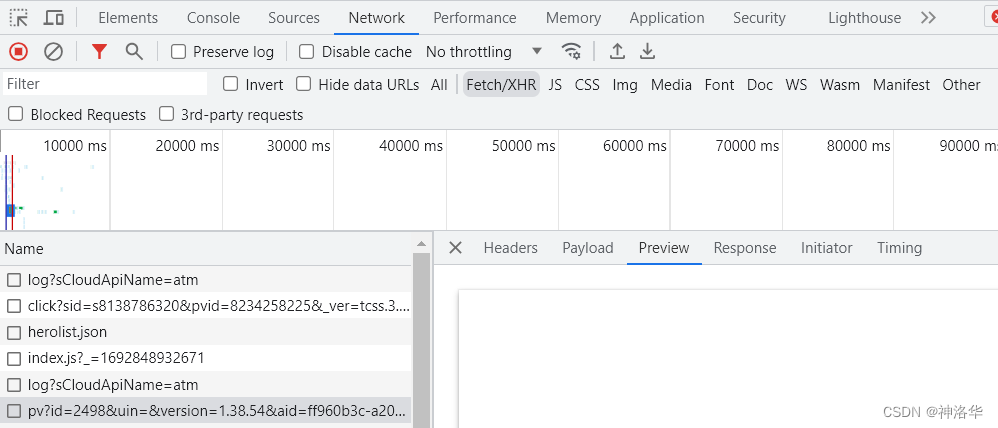
下面先判断这些壁纸图片是网页上的静态资源还是Ajax请求(有关内容详见本文2.1节),有两种方式。我们先启动开发者模式(F12)后刷新页面
- 通过地址栏判断:壁纸一共34页,跳转到下一页,发现地址栏URL没变,说 应该是
Ajax请求。点击Fetch/XHR,发现确实有Ajax请求(点击Preview还看不到图片)
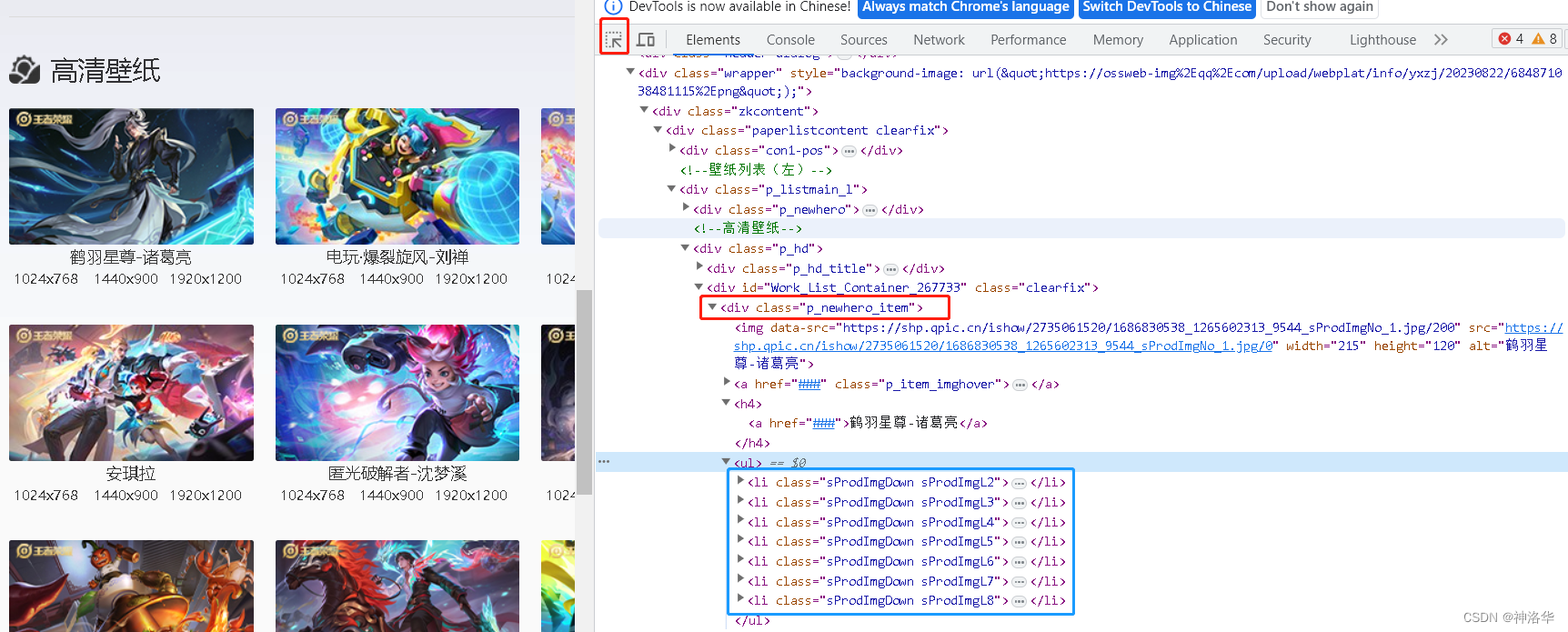
- 通过源代码判断。
- 我们打开element标签,用左侧箭头选取一张壁纸,定位到这张壁纸在element中的位置,发现其在标签
<div class="p_newhero_item">下,在下级标签ul中,还可以看到其余尺寸的信息。 - Ctrl+U打开网页源码,Ctrl+C复制刚才的标签信息进行查找,发现源码中确实有
<div class="p_newhero_item">标签,但是相关信息被注释掉了,这也说明这些壁纸是Ajax请求。

- 我们打开element标签,用左侧箭头选取一张壁纸,定位到这张壁纸在element中的位置,发现其在标签
这两种方式都表示,王者荣耀壁纸是Ajax请求。我们在ALL中选择worklist元素,在preview中展开可以看到一页中20张图片的信息,这里才是真实的数据源。
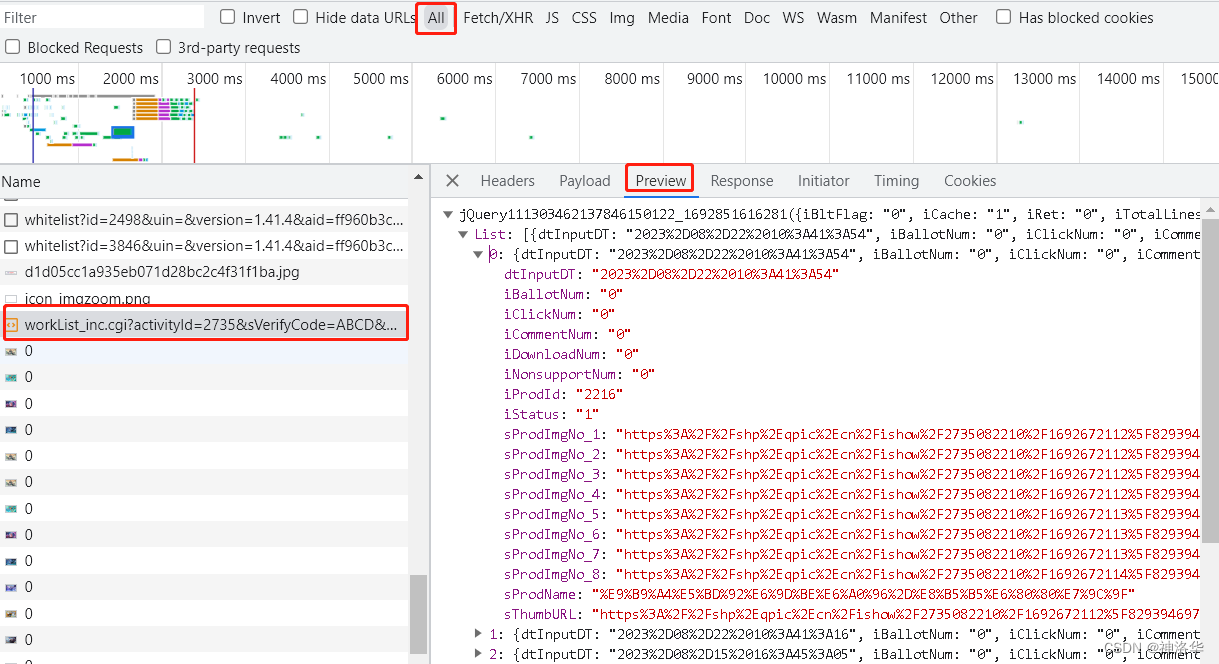
我们将这个数据源的Headers中的URL(其中page=0字段表示是第一页),复制粘贴到浏览器地址栏中,就可以看到其响应的数据:

再将这些数据全部复制粘贴在json.cn网页中,可以看到右侧显示栏报错,说明这还不是json格式,因为在json字典格式之外,最外侧还多了jQuery11130793949928178278_1692852974592()。我们将{}之外的这部分内容去掉,就可以看到json格式内容了。其中,每个object就是一张图片,sProdImg是每个尺寸的图片链接地址。

我们选择其中一个图片地址,粘贴在地址栏打开,发现打不开。这是因为URL被编码了,所以我们需要对其进行解码操作。
# 选择一张sProdImgNo_8.jpg,解析URL
from urllib import parseresult=parse.unquote('https%3A%2F%2Fshp.qpic.cn%2Fishow%2F2735081516%2F1692089105_829394697_8720_sProdImgNo_8.jpg%2F200')
#"http://shp.qpic.cn/ishow/2735032519/1585137454_84828260_27866_sProdImgNo_8.jpg/0"
print(result)
https://shp.qpic.cn/ishow/2735081516/1692089105_829394697_8720_sProdImgNo_8.jpg/200
我们打开解析的网址,发现图片非常小。我们在element中点选这张图片的最大尺寸,可以看到其地址信息为https://shp.qpic.cn/ishow/2735081516/1692089072_829394697_3690_sProdImgNo_1.jpg/0,与我们刚刚解析的地址区别,就是最后一个数字为0。我们将刚刚的解析地址最后一个数字改为0,就可以看到大尺寸的壁纸了。

所以,我们先要找到壁纸的数据源,然后解析URL,最后将URL末尾的数字200替换为0。
1.6.2 爬取第一页的壁纸
- 获取URL和请求头
URL就是刚刚第一页worklist元素,Headers中的Request URL,下拉还可以看到User-Agent信息。我们需要设置headers来应对反爬。建议在headers中还写一个Referer信息,表示是从哪个网址跳转过去的。

import requests # 定义headers,模拟浏览器请求
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36','referer': 'https://pvp.qq.com/web201605/wallpaper.shtml'
}url='https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery111304982467749514099_1692856287807&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1692856287809'
resp=requests.get(url,headers=headers)
print(resp.text)
我们运行此代码,可以看到返回的还不是json格式,同刚才讲的一样我们需要去除{}之外的内容。我们可以使用replace函数进行替换,然后用eval函数处理,就得到json格式数据。
此时也可以将URL中
&jsoncallback=jQuery111304982467749514099_1692856287807字段删除,返回的结果就是字典格式,然后可以用.json()方法将其转为json格式。
- 解析URL
接下来我们对json格式网页内容进行解析。在开发者模式中,所有壁纸信息都在List标签下,一共包含20个Object,每个Object的sProdImgNo_x标签中就是我们需要的壁纸URL。
我们可以写一个exact_url函数来提取这些壁纸URL(sProdImgNo_1到8),并对这些URL进行解析,然后将末尾的200替换为0。
- 获取壁纸名
最后,我们需要将每套壁纸都存在对应壁纸名的文件夹中。其中,壁纸名就是sProdName标签中的文本,只不过还要经过解析。比如下图的字符串,解析后就是“鹤归松栖-赵怀真”。

此时我们可以打印最终得到的壁纸名和对应的URL,看看结果是否显示正确。
import requests
from urllib import parse
from urllib import request
import osheaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36',
'referer': 'https://pvp.qq.com/web201605/wallpaper.shtml'
}def send_request():url='https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery111306942951976771379_1692875716815&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1692875716817'resp=requests.get(url,headers=headers).textstart_index,end_index = resp.find("(") + 1 ,resp.rfind(")") resp=resp[start_index:end_index]return eval(resp)# 提取每个Object中的sProdImgNo_{}标签指向的URL信息
def exact_url(data): # data就是json数据中的20个Object信息 image_url_lst=[]for i in range(1,9): # 提取8个sProdImgNo_标签下的URL信息并解码替换image_url=parse.unquote(data['sProdImgNo_{}'.format(i)]).replace('200','0')image_url_lst.append(image_url)return image_url_lstdef parse_json(json_data):d={} # 字典格式存储壁纸名称和对应的8个URLdata_lst=json_data['List']for data in data_lst:image_url_lst=exact_url(data) # 获取8个URLsProdName=parse.unquote(data['sProdName']) # 获取壁纸名称并解析为中文d[sProdName]=image_url_lstfor item in d:print(item,d[item])#save_jpg(d)def start():json_data=send_request()parse_json(json_data)
if __name__ == '__main__':start()
鹤归松栖-赵怀真 ['https://shp.qpic.cn/ishow/2735082210/1692672112_829394697_11169_sProdImgNo_1.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672112_829394697_11169_sProdImgNo_2.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672112_829394697_11169_sProdImgNo_3.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672112_829394697_11169_sProdImgNo_4.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672113_829394697_11169_sProdImgNo_5.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672113_829394697_11169_sProdImgNo_6.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672113_829394697_11169_sProdImgNo_7.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672114_829394697_11169_sProdImgNo_8.jpg/0']
鹤归松栖-云缨 ['https://shp.qpic.cn/ishow/2735082210/1692672073_829394697_8584_sProdImgNo_1.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672073_829394697_8584_sProdImgNo_2.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672073_829394697_8584_sProdImgNo_3.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672074_829394697_8584_sProdImgNo_4.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672074_829394697_8584_sProdImgNo_5.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672074_829394697_8584_sProdImgNo_6.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672075_829394697_8584_sProdImgNo_7.jpg/0', 'https://shp.qpic.cn/ishow/2735082210/1692672075_829394697_8584_sProdImgNo_8.jpg/0']
...
下面编写一个save_jpg函数,用于从壁纸的URL链接来下载图片。我们可以用urllib.request.urlretrieve(url,path)来完成此操作。
import osfolder_name='image'
if not os.path.exists(folder_name):os.mkdir(folder_name) # 在当前路径下创建image文件夹,用于保存爬取的图片print(f"'{folder_name}'文件夹已创建")def save_jpg(d): # d就是刚刚的{壁纸名:URL}字典,字典中key就是地址名for key in d: # 以壁纸名来命名存储的文件夹名,strip(' ')用于去除壁纸名中可能出现的空格dir_path=os.path.join('image',key.strip(' '))if not os.path.exists(dir_path):os.mkdir(dir_path)#下载图片并保存for index, image_url in enumerate(d[key]):img_path=os.path.join(dir_path,'{}.jpg').format(index+1)if not os.path.exists(img_path):request.urlretrieve(image_url,img_path)print('{}下载完毕'.format(d[key][index]))
1.6.3 使用生产者-消费者模式进行多线程下载
上一节的代码可以正常运行,但是单线程下载速度太慢了,特别是有34页壁纸,每一页20张,每张8个尺寸,一共就是5440张。
我们可以使用上一节讲的生产者-消费者安全队列进行多线程下载。其中,生产者队列存储的是每一页的壁纸URL,消费者队列负责从队列中取出壁纸URL,然后进行下载存储。
from queue import Queuepage_queue=Queue(34) # page_queue用于存储每一页的URL,容量34
image_url_queue=Queue(200) # 用于存储网页中每张壁纸的URL,容量大于160就行。
for i in range(0,34):page_url=f'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={i}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1595215093279'page_queue.put(page_url)
下面我们需要创建生产者线程。因为生产者需要从page_queue中取出page_url,然后将解析到的image_url放入image_url_queue中,所以生产者线程有page_queue,image_url_queue两个参数,这两个参数需要一开始就初始化。完整代码如下:(在URL中去除了&jsoncallback=jQuery111306942951976771379_1692875716815字段,这样就不需要额外处理URL)
import os
import requests
import threading
from urllib import parse
from queue import Queue
from urllib import requestheaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36',
'referer': 'https://pvp.qq.com/web201605/wallpaper.shtml'
}# 提取每个Object中的sProdImgNo_{}标签指向的URL信息
def exact_url(data): # data就是json数据中的20个Object信息 image_url_lst=[]for i in range(1,9): # 提取8个sProdImgNo_标签下的URL信息并解码替换image_url=parse.unquote(data['sProdImgNo_{}'.format(i)]).replace('200','0')image_url_lst.append(image_url)return image_url_lst #生产者线程,存储壁纸的名称和URL
class Producer(threading.Thread):def __init__(self,page_queue,image_url_queue):super().__init__()self.page_queue=page_queue # 存储页面URLself.image_url_queue=image_url_queue # 存储壁纸URLdef run(self):while not self.page_queue.empty(): # 如果页面URL队列不为空,就获取壁纸URLpage_url=self.page_queue.get()resp=requests.get(page_url,headers=headers)json_data=resp.json() d = {} # key和value分别是壁纸名和其URLdata_lst = json_data['List'] # 20个Object(壁纸)for data in data_lst:image_url_lst = exact_url(data) # 每张壁纸的8个URLsProdName = parse.unquote(data['sProdName']) # 壁纸名称d[sProdName] = image_url_lstfor key in d:# 拼接路径,注意,路径不能有特殊符号# 所以如果爬取到的壁纸名称有特殊符号,则需要处理。否则报错系统找不到指定的路径 dir_path = os.path.join('image', key.strip(' ').replace('·','').replace('1:1',''))if not os.path.exists(dir_path):os.mkdir(dir_path) # 创建每张壁纸的存储文件夹 for index, image_url in enumerate(d[key]):#生产图片的名称和url放入队列image_path=os.path.join(dir_path,f'{index+1}.jpg')self.image_url_queue.put({'image_path':image_path,'image_url':image_url})#消费者线程获取壁纸名称和URL,并进行本地下载
class Customer(threading.Thread):def __init__(self,image_url_queue):super().__init__()self.image_url_queue=image_url_queuedef run(self):while True:try:image=self.image_url_queue.get(timeout=20)request.urlretrieve(image['image_url'],image['image_path'])print(f'{image["image_path"]}下载完成')except:break#定义一个启动线程的函数
def start():page_queue=Queue(34) # page_queue用于存储每一页的URL,容量34image_url_queue=Queue(200) # 用于存储网页中每张壁纸的URLfor i in range(0,34):page_url=f'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={i}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1595215093279'page_queue.put(page_url)#创建生产者线程对象for i in range(5):t=Producer(page_queue,image_url_queue)t.start()#创建消费者线程对象for i in range(10):t=Customer(image_url_queue)t.start()
if __name__ == '__main__':start()
二、动态网页爬取(待续)
2.1 动态网页基础知识
2.1.1 动态网页和静态网页
动态网页和静态网页是两种不同类型的网页,它们在生成和呈现内容的方式上有所不同。
-
内容生成方式
- 静态网页的内容是在服务器上提前创建好的,是固定不变的,无论用户如何访问,都呈现相同的内容。
- 动态网页的内容是根据用户的请求或操作实时生成的,内容可以根据用户的请求、操作或其他因素而改变。
-
加载速度
- 静态网页通常是由 HTML、CSS 和少量 JavaScript 组成,不需要服务器端的处理,因此加载速度较快。
- 动态网页需要服务器在用户请求时动态生成内容,所以加载速度较慢。
-
互动性
- 动态网页具有更高的互动性,可以根据用户的输入、操作或其他条件来生成不同的内容,实现个性化的用户体验。
- 静态网页通常没有太多的互动性,用户只能浏览提前生成的内容。
-
更新和维护
- 静态网页的更新和维护较为简单,只需要替换文件即可。
- 动态网页可能需要更多的服务器端编程和数据库管理,因此在更新和维护上可能需要更多的工作。
总之,静态网页适用于内容相对固定、不需要频繁更新和个性化互动的情况,而动态网页适用于需要实时生成内容、提供个性化互动体验的场景(社交平台、电商平台、新闻/博客、在线游戏等)。
2.1.2 Ajax
Ajax(Asynchronous JavaScript and XML)是一种用于创建交互式、动态网页应用的技术。它允许在不刷新整个页面的情况下,通过在后台与服务器进行异步通信,更新页面的部分内容,为用户提供更好的体验。
Ajax 的核心思想是利用前端的 JavaScript 异步请求技术,将数据传输和处理与用户界面的呈现分离开来,从而实现更流畅的用户体验。传统上,在网页中,用户在与服务器进行通信时需要刷新整个页面,而 Ajax 可以在后台请求和处理数据,然后仅更新页面的特定部分,而不会影响其他内容。
Ajax 可以用于以下方面:
-
数据加载: 在页面加载后,使用 Ajax 可以异步加载数据,例如从服务器获取新闻、商品信息等,而不必等待整个页面加载完成。
-
表单提交: 使用 Ajax 可以在不刷新页面的情况下,将用户输入的数据发送到服务器进行处理,然后根据服务器响应更新页面内容。
-
实时更新: Ajax 可以用于实现实时更新功能,如实时聊天、社交媒体动态更新等。
-
用户反馈: 使用 Ajax 可以实现用户反馈功能,如点赞、评论等,无需刷新整个页面。
-
搜索建议: 在用户输入时,可以使用 Ajax 获取匹配的搜索建议,实现更好的用户体验。
-
动态表格: 可以使用 Ajax 在表格中动态加载数据,例如在分页中切换页面内容。
在之前的1.6章节中,点击王者荣耀壁纸的下一页按钮,可以发现地址栏的URL没有改变,但是壁纸的已经动态的更改了。另外在百度中搜索图片,随着我们鼠标的滑动,可以看到页面不停的加载进来更多的图片,而地址栏的地址也没有变化,这里也是使用到了Ajax 技术。
下面我们打开百度,搜索美女图片。在开发者模式中,选择Fetch/XHR就可以看到Ajax请求。
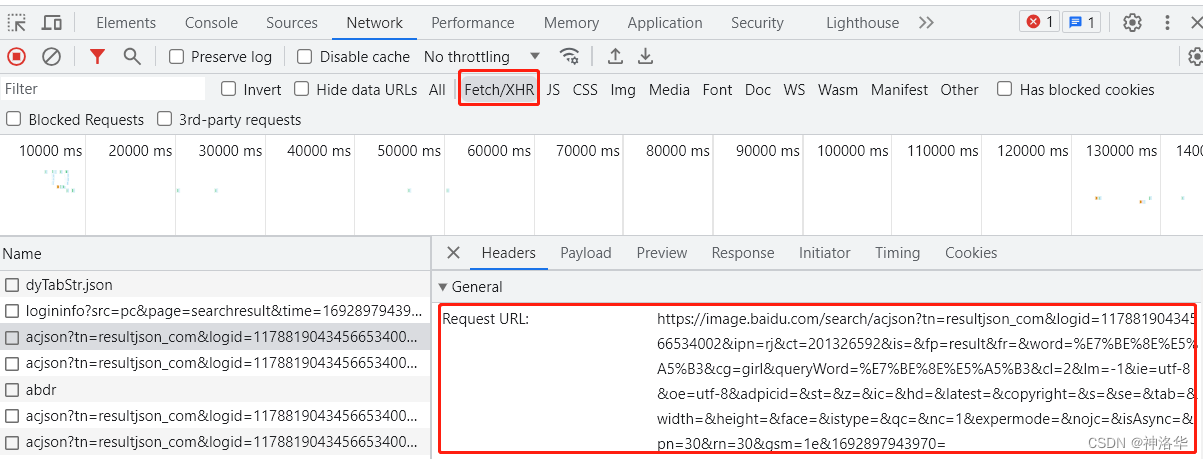
右侧的URL就是数据地址,将其在地址栏打开,显示的就是json格式的数据。复制之后在json.cn中粘贴,显示如下:

2.1.3 动态网页的爬取
静态网页的源代码都包含了完整的页面内容,所以可以使用基本的网络请求库(如requests)来获取网页的源代码,然后使用解析库(如Beautiful Soup)来提取所需的数据。
动态网页的内容是在用户请求时生成的,源代码可能并不包含所有的内容。比如动态网页的源代码中看不到通过Ajax加载的数据,只能看到地址栏URL加载的html代码。
对于动态网页的爬取,有三种方法:
-
分析 AJAX 请求: 动态网页通常通过 AJAX 请求获取额外的数据,你可以分析这些请求的 URL 和参数,然后使用 Python 的网络请求库来模拟这些请求,获取数据(例如1.6节中,我们分析出了壁纸数据的真实URL,然后在地址栏打开得到对应的json数据,再进行后续的解析)。
- 优点:可以直接请求到数据,解析难度小,代码量少,性能高。
- 缺点:分析接口比较复杂,众多request中,可能不知道哪一个包含真正的数据源,特别是一些经过JS混淆的接口(需要JS功底),而且容易被发现是爬虫程序。
-
模拟浏览器行为: 使用自动化测试工具或库(如
Selenium)模拟浏览器行为,完整加载和执行页面的 JavaScript,然后获取完整的页面内容。- 优点:浏览器能请求到的,
Selenium也能请求到,爬虫更稳定。 - 缺点:代码量多,性能低
- 优点:浏览器能请求到的,
-
API 调用: 如果网站提供 API 接口,你可以直接调用这些接口来获取数据,而无需解析整个网页。
这是一个示例页面
这是段落文本。

这是另一个段落文本。
相关文章:
python网络爬虫指南二:多线程网络爬虫、动态内容爬取(待续)
文章目录 一、多线程网络爬虫1.1 线程的基础内容、GIL1.2 创建线程的两种方式1.3 threading.Thread类1.4 线程常用方法和锁机制1.5 生产者-消费者模式1.5.1 生产者-消费者模式简介1.5.2 Condition 类协调线程 1.6 线程中的安全队列1.6 多线程爬取王者荣耀壁纸1.6.1 网页分析1.6…...

华为AirEgine9700S AC配置示例
Vlan97为管理Vlan <AirEgine9700S>dis cu Software Version V200R021C00SPC100 #sysname AirEgine9700S #http timeout 60http secure-server ssl-policy default_policyhttp secure-server server-source -i allhttp server enable #set np rss hash-mode 5-tuple # md…...

VUE3基础
一、vue-router v4.x 介绍 | Vue Router 1、安装 yarn add vue-routernext next代表最新的版本 2、路由配置 在src目录下,新建router/index.ts,具体配置如下 import {RouteRecordRaw,createRouter,createWebHashHistory} from vue-router const r…...
Qt应用开发(基础篇)——日历 QCalendarWidget
一、前言 QCalendarWidget类继承于QWidget,是Qt设计用来让用户更直观的选择日期的窗口部件。 时间微调输入框 QCalendarWidget根据年份和月份初始化,程序员也通过提供公共函数去改变他们,默认日期为当前的系统时间,用户通过鼠标和…...

Python学习笔记:正则表达式、逻辑运算符、lamda、二叉树遍历规则、类的判断
1.正则表达式如何写? 序号实例说明1.匹配任何字符(除换行符以外)2\d等效于[0-9],匹配数字3\D等效于[^0-9],匹配非数字4\s等效于[\t\r\n\f],匹配空格字符5\S等效于[^\t\r\n\f],匹配非空格字符6\w等效于[A-Za-z0-9]&…...

【滑动窗口】leetcode1004:最大连续1的个数
一.题目描述 最大连续1的个数 这道题要我们找最大连续1的个数,看到“连续”二字,我们要想到滑动窗口的方法。滑动窗口的研究对象是一个连续的区间,这个区间需要满足某个条件。那么本题要找的是怎样的区间呢?是一个通过翻转0后得到…...
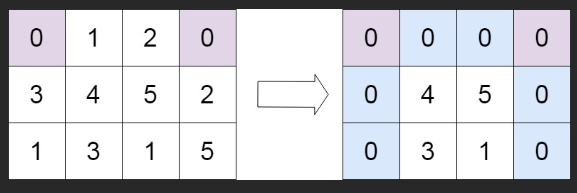
力扣:73. 矩阵置零(Python3)
题目: 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 来源:力扣(LeetCode) 链接:力扣(LeetCode)官网 - 全球极客挚…...

VB|基础语法 变量定义 函数定义 循环语句 IF判断语句等
文章目录 变量定义函数定义控制台输入输出switch case语句IF语句FOR循环语句不等于逻辑运算符 变量定义 int Dim 变量名 As Int32 0 string Dim 变量名 As String "" bool Dim 变量名 As Boolean False 枚举 Dim 变量名 As 枚举名 数组 Dim array(256) As String…...

Github 博客搭建
Github 博客搭建 准备工作 准备一个 github 账号;建立 github 仓库,仓库名为 username.github.io,同时设置仓库为 public;clone 仓库,写入一个 index.html 文件,推送到仓库(许多网上的教程会有…...
:通过交叉验证网格搜索机器学习的最优参数)
模型预测笔记(三):通过交叉验证网格搜索机器学习的最优参数
文章目录 网络搜索介绍步骤参数代码实现 网络搜索 介绍 网格搜索(Grid Search)是一种超参数优化方法,用于选择最佳的模型超参数组合。在机器学习中,超参数是在训练模型之前设置的参数,无法通过模型学习得到。网格搜索…...
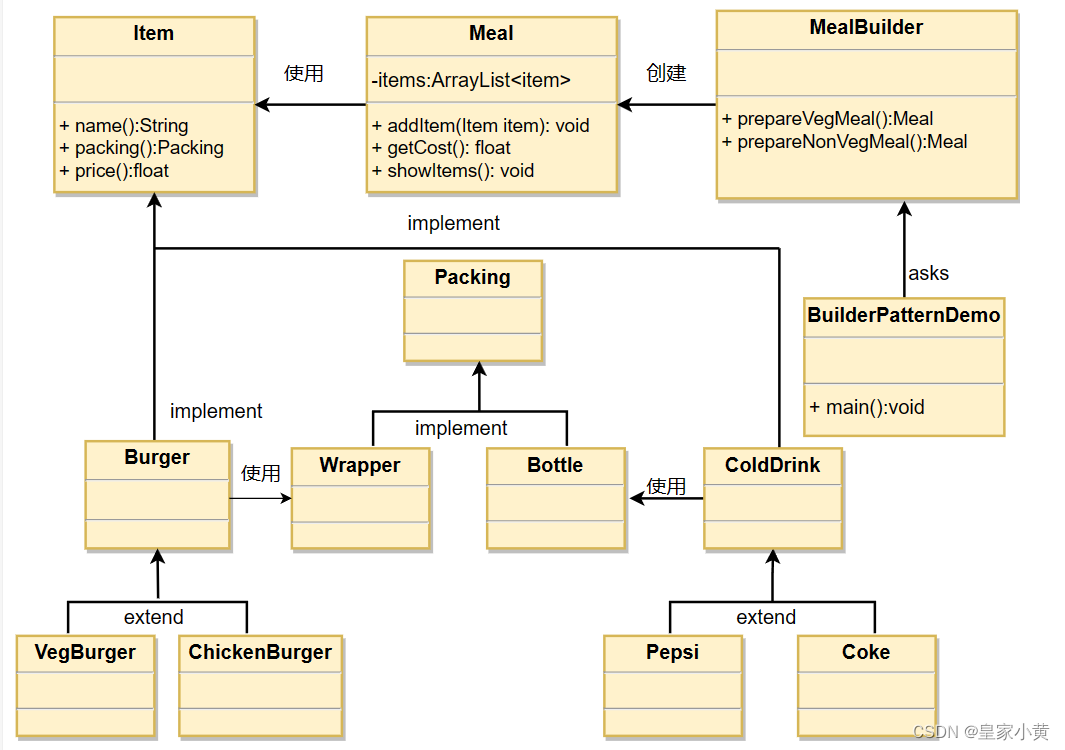
创建型模式-建造者模式
使用多个简单的对象一步一步构建成一个复杂的对象 主要解决:主要解决在软件系统中,有时候面临着"一个复杂对象"的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部…...
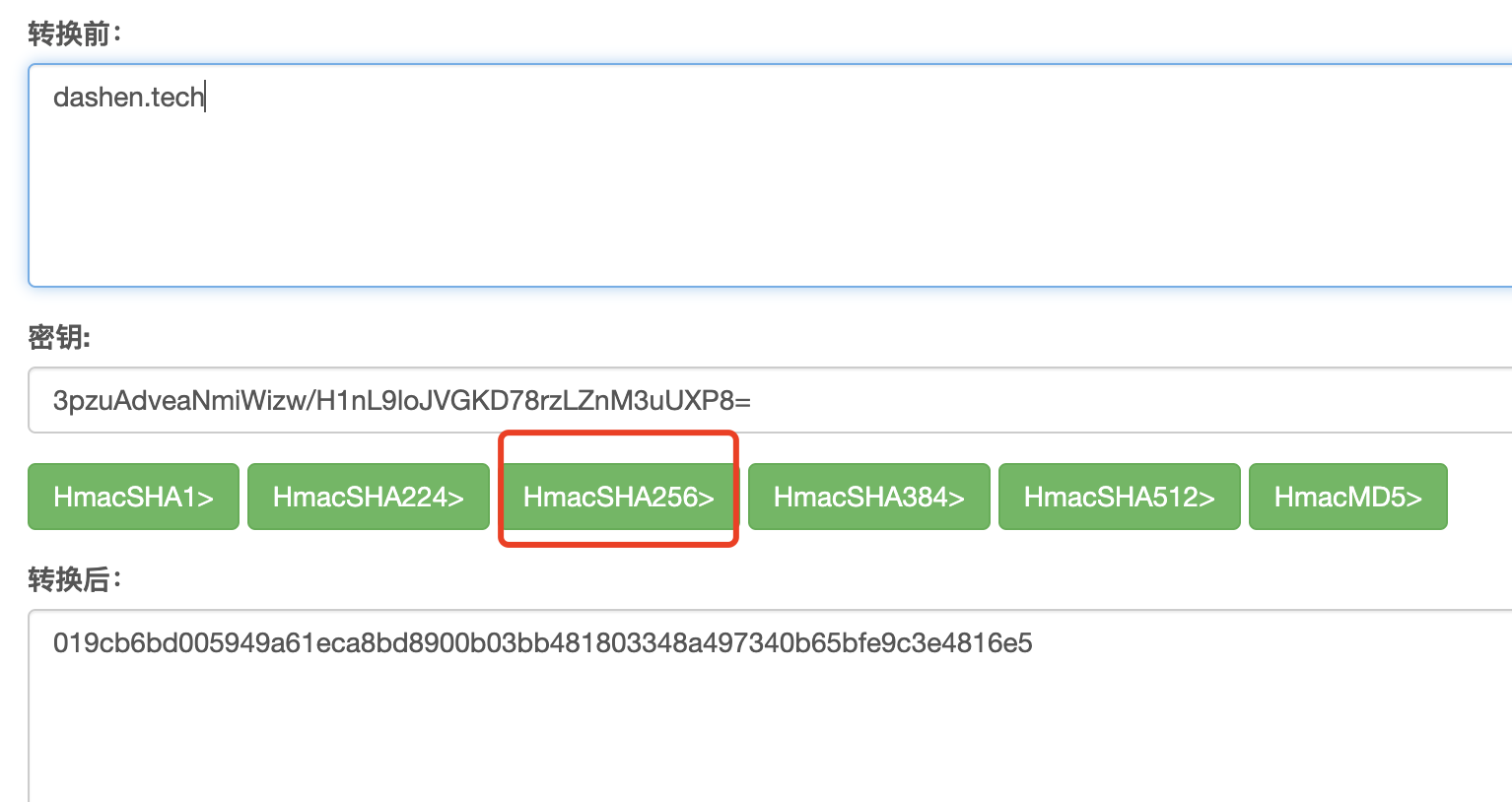
Rust常用加密算法
哈希运算(以Sha256为例) main.rs: use crypto::digest::Digest;use crypto::sha2::Sha256;fn main() { let input "dashen"; let mut sha Sha256::new(); sha.input_str(input); println!("{}", sha.result_str());} Cargo.toml: [package]n…...

[管理与领导-55]:IT基层管理者 - 扩展技能 - 1 - 时间管理 -2- 自律与自身作则,管理者管好自己时间的五步法
前言: 管理好自己的时间,不仅仅是理念,也是方法和流程。 步骤1:理清各种待办事项 当提到工作事项时,这通常指的是要完成或处理的工作任务或事务。这些事项可以包括以下内容: 任务分配:根据工作…...
--判断题)
电子商务员考试题库及答案(中级)--判断题
电子商务员题库 一、判断题 1.EDI就是按照商定的协议,将商业文件分类,并通过计算机网络,在贸易伙伴的计算机网络系统之间进行数据交换和自动处理。〔〕 2.相互通信的EDI的用户必须使用相同类型的计算机。〔 〕 3.EDI采用共同…...

(WAF)Web应用程序防火墙介绍
(WAF)Web应用程序防火墙介绍 1. WAF概述 Web应用程序防火墙(WAF)是一种关键的网络安全解决方案,用于保护Web应用程序免受各种网络攻击和威胁。随着互联网的不断发展,Web应用程序变得越来越复杂&#x…...

SpringMVC拦截器常见应用场景
在Spring MVC中,拦截器是通过实现HandlerInterceptor接口来定义的。该接口包含了三个方法: preHandle:在请求到达处理器之前执行,可以进行一些预处理操作。如果返回false,则请求将被拦截,不再继续执行后续的…...
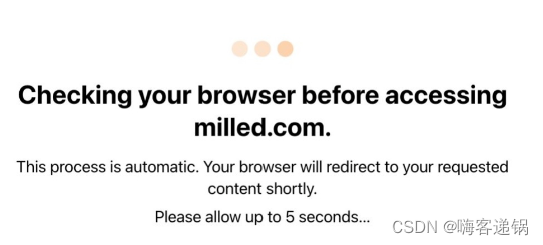
爬虫:绕过5秒盾Cloudflare和DDoS-GUARD
本文章仅供技术研究参考,勿做它用! 5秒盾的特点 <title>Just a moment...</title> 返回的页面中不是目标数据,而是包含上面的代码:Just a moment... 或者第一次打开网页的时候: 这几个特征就是被Cloud…...

数据仓库环境下的超市进销存系统结构
传统的进销存系统建立的以单一数据库为中心的数据组织模式,已经无 法满足决策分析对数据库系统的要求,而数据仓库技术的出现和发展,为上述问题 的解决提供了强有力的工具和手段。数据仓库是一种对多个分布式的、异构的数据 库提供统一查询…...
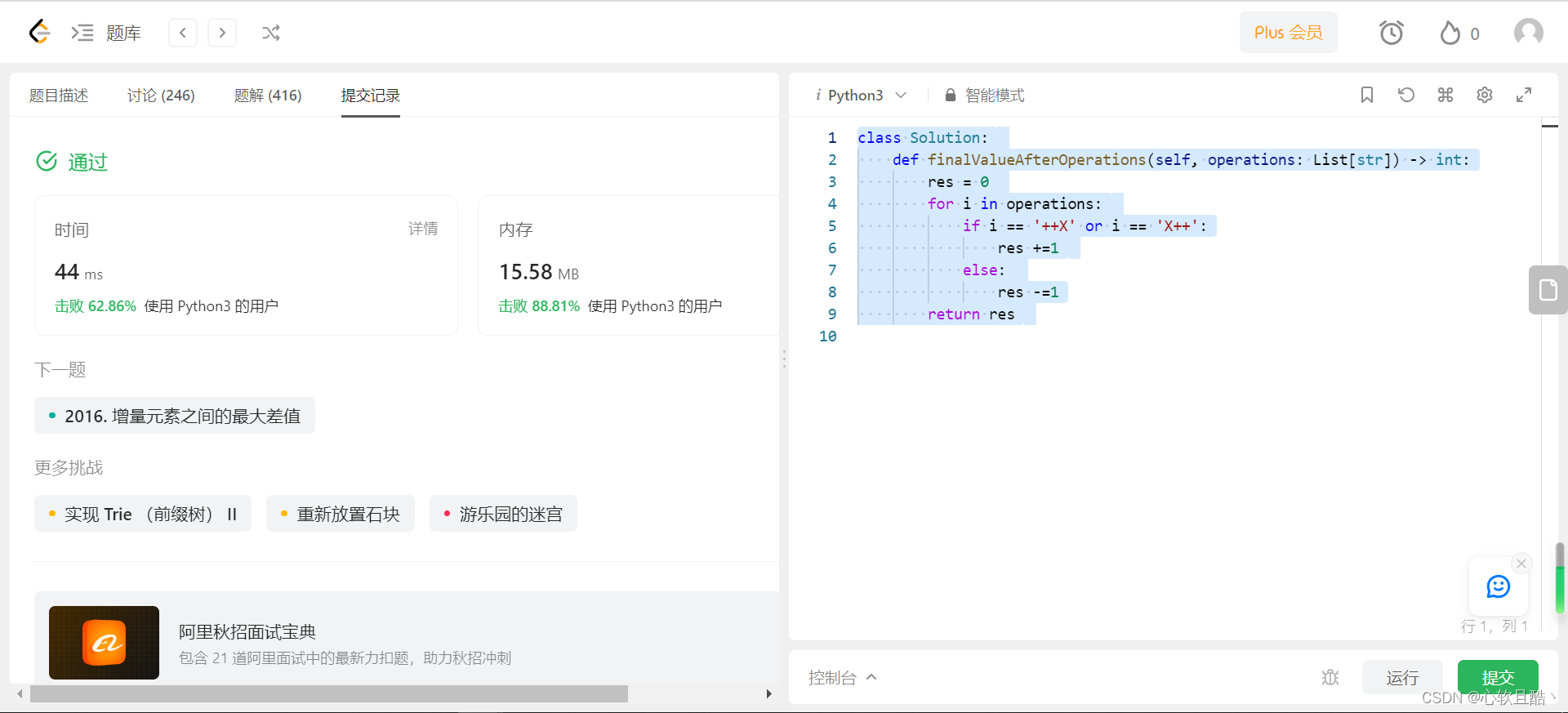
leetcode:2011. 执行操作后的变量值(python3解法)
难度:简单 存在一种仅支持 4 种操作和 1 个变量 X 的编程语言: X 和 X 使变量 X 的值 加 1--X 和 X-- 使变量 X 的值 减 1 最初,X 的值是 0 给你一个字符串数组 operations ,这是由操作组成的一个列表,返回执行所有操作…...

ubuntu下mysql
安装: sudo apt update sudo apt install my_sql 安装客户端: sudo apt-get install mysql-client sudo apt-get install libmysqlclient-dev 启动服务 启动方式之一: sudo service mysql start 检查服务器状态方式之一:sudo …...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...