redis学习笔记 - 进阶部分
文章目录
- redis单线程如何处理并发的客户端,以及为何单线程快?
- redis的发展历程:
- redis单线程和多线程的体现:
- redis3.x单线程时代但性能很快的主要原因:
- redis4.x开始引入多线程:
- redis6/redis7引入多线程IO:
- 数据库和缓存的一致性:
- “**双检加锁**”策略,避免缓存击穿的问题:
- 4种更新策略:
- 成熟的工程方案-->监听mysql的变动,并通知redis:
- 传统的MySQL的主从复制:
- canal的工作原理:
- 布隆过滤器:
- 应用场景:
- 原理:
- 缓存创建的问题:
- redis缓存淘汰机制:
- redis内存管理:
- 三种不同的过期键删除策略:
- redis缓存淘汰策略:
- redis配置文件:
- LRU和LFU的区别:
- 配置性能建议:
- redis经典的五大类型源码及底层实现:
- 底层数据结构:
- redis字典数据库kv键值对是什么?
- 怎么实现的键值对数据库?
- string数据结构:
- SDS简单动态字符串:
- 3大物理编码方式:
- int:
- embstr:
- raw:
- 三种编码的转变逻辑:
- hash数据结构:
- redis6:
- redis7:
- list数据结构:
- redis6:
- redis7:
- set数据结构:
- zset数据结构:
- skiplist跳表:
- 引出:
- 特性:
- 适用场景:
- 缺点:
redis单线程如何处理并发的客户端,以及为何单线程快?
redis的发展历程:

redis单线程和多线程的体现:
单线程:主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。

多线程:主要是指Redis的其他功能,如持久化RDB/AOF、异步删除、集群数据同步等,这些均由额外的线程(独立redis命令工作线程)执行的。
总结:Redis命令工作线程是单线程的,但对整个Redis来说,是多线程的。
注意:多线程主要是为了提高CPU的利用率,但redis是基于内存操作的,它的性能瓶颈可能是内存和网络带宽而非CPU,且多线程会带来的数据同步问题和切换的开销,故采用单线程足矣。
redis3.x单线程时代但性能很快的主要原因:
- 基于内存的操作:redis所有数据都存在内存中,且所有运算都是内存级别的。
- 数据结构简单:这些简单的数据结构查找和操作的时间大部分复杂度都是O(1)。
- 多路复用和非阻塞IO:IO多路复用监听socket客户端连接,即可实现一个线程处理多个请求,避免了IO阻塞操作。
- 避免了上下文切换:单线程模型,避免了不必要的上下文切换和多线程竞争,且不会导致死锁问题。
redis4.x开始引入多线程:
主要目的:解决redis3.x单线程原子命令操作,带来的经典的问题:大key删除造成主线程(工作线程)卡顿的问题。
于是在 Redis 4.0 中就新增了多线程的模块,主要是为了解决删除数据效率比较低的问题的。
| 异步操作: |
|---|
unlink key |
flushdb async |
flushall async |
| 把删除工作交给了后台的子线程,达到“异步惰性删除”数据的目的 |
惰性删除lazy free:本质是将某些cost(时间复杂度,即占用主线程cpu时间片)较高删除操作,从redis主线程剥离让子线程来处理,极大地减少主线阻塞时间,从而减少删除导致性能和稳定性问题。
redis6/redis7引入多线程IO:
前面提到了,redis是基于内存操作的,它主要的性能瓶颈可能是内存和网络带宽而非CPU。
Redis的之前的单线程架构,虽然有些命令操作可以用后台线程或子进程执行(比如数据删除、快照生成、AOF重写)。随着网络硬件的性能提升,单个主线程处理网络请求(读写命令)的速度跟不上底层网络硬件的速度,故Redis的性能瓶颈就会转嫁在网络IO的处理上。
Redis6/7采用多个IO线程来处理网络请求,提高网络请求的并发处理,对于读写操作命令仍然使用单个工作线程来处理。
- Redis处理请求时,网络处理经常是瓶颈,通过多个IO线程并行处理网络操作,可以提升实例的整体处理性能。
- 使用单线程执行命令操作,就不用为了保证Lua脚本、事务的原子性,额外开发多线程互斥加锁机制了。

从Redis6开始,多 I/O 线程的提升读写性能,的主要实现思路:将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的“Socket的读取、请求解析、写入”单独外包出去,剩下的命令执行仍然由主线程串行执行,并和内存的数据交互。


总结:redis快的原因是:数据结构简单+内存+“IO多路复用(epoll)+多线程网络IO”+“工作线程为单线程”(避免了线程切换和保证线程同步、死锁等问题的产生)。
- IO多路复用可保证单个线程监听多个文件描述符fd(即多个客户端的连接)(避免了每个客户端连接创建一个线程造成的资源浪费和性能下降),进而提高单线程的网络IO的吞吐能力。

- 实际应用中,当发现CPU开销不大但吞吐量却没有提升,则可考虑开启redis7中的多线程网络IO机制,来提升网络IO的吞吐量。
数据库和缓存的一致性:

一致性的解决方案:给缓存设置过期时间,定期清理缓存并回写。
如果数据库写成功,即使缓存更新失败但只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,从而实现一致性的目的。

“双检加锁”策略,避免缓存击穿的问题:
当redis中查找数据没有时,加锁(防止高并发的请求同时查找该键值,导致缓存击穿问题)之后(加锁后,只有一个线程去查mysql其余的线程在阻塞等待,等该线程回写数据到redis中,则直接查询redis即可)二次查询还是没有则查询mysql并回写到redis中。
4种更新策略:
-
先更新数据库,再更新缓存:
异常情况一:更新myql成功后,再回写更新redis失败,则会导致在该数据过期之前,访问到的是“脏数据”。
异常情况二:并发对同一个数据改写,且先更新mysql再更新redis,由于执行过程抢占CPU资源,可能会导致出现redis和mysql的数据不一致的问题。
-
先更新缓存,再更新数据库:
异常情况:并发对同一个数据改写,且先更新缓存,再更新数据库,由于执行过程抢占CPU资源,可能会导致出现redis和mysql的数据不一致的问题。
-
先删除缓存,再更新数据库:
异常情况:
-
A线程delete掉redis中的数据,之后给mysql更新数据,结果网络阻塞,一直没更新成功。
-
B线程来读取,先去读redis里数据(已经被A线程删除了,故没有命中),此时,B会从mysql获取旧值并回写到redis中,导致的问题:刚被A线程删除的旧数据有极大可能又被写回了。
最终,导致mysql和redis中的数据不一致,即redis中的是旧数据。
“延迟双删”的策略:线程A sleep一段时间时间后,再次删除redis中的该数据(删除操作可以异步完成)。
- 这段sleep的时间 > 线程B读取数据再写入缓存的时间。
- 目的:确保读请求结束后,写请求可以删除读请求造成的缓存脏数据。
- sleep的时间如何确定?
- 自定估算读mysql数据和写redis缓存的时间。
- 启动后台监控程序,如
WatchDog监控工程。
无法解决的遗留问题:
- 先删除缓存值再更新数据库,有可能导致高并发的请求因缓存缺失而访问数据库,导致打满mysql。
- 如果业务应用中,读取数据库和写缓存的时间不好估算,那延迟双删中的sleep时间就不好设置。
-
-
先更新数据库,再删除缓存(推荐使用):
-
如果业务层要求必须读取一致性的数据,那就需要在更新数据库时,先在Redis缓存客户端暂停并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性,但实际的生产环境中不推荐(严重影响并发性能)。
实际的生产环境中,分布式下很难满足“实时一致性”,一般都考虑的是最终的一致性。
-
最终的一致性实现方案:

- 把要删除的缓存值/要更新的数据库值暂存到消息队列(如Kafka/RabbitMQ等)中。
- 当程序没能成功删除缓存值/更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
- 如果能够成功地删除或更新(保证了数据库和缓存的数据一致性),就将这些值从消息队列中去除,否则还需要再次进行重试。
- 如果重试超过的一定次数后还未成功,就需要向业务层发送报错信息,通知运维人员处理。
-
总结:
| 策略 | 高并发多线程条件下 | 问题 | 现象 | 解决方案 |
|---|---|---|---|---|
| 先删除redis缓存,再更新mysql | 无 | 缓存删除成功但数据库更新失败 | 程序从数据库中读到旧值 | 再次更新数据库,重试 |
| 有 | 缓存删除成功但数据库更新中…有并发读请求 | 并发请求从数据库读到旧值并回写到redis,导致后续(该键值过期前)都是从redis读取到旧值 | 延迟双删 | |
| 先更新mysql,再删除redis缓存(推荐,该方式可实现最终一致性) | 无 | 数据库更新成功,但缓存删除失败 | 该键值过期前,程序从redis中读到旧值 | 再次删除缓存,重试 |
| 有 | 数据库更新成功但缓存删除中…有并发读请求 | 并发请求从缓存读到旧值 | 等待redis删除完成,这段时间有数据不一致,短暂存在。 |
成熟的工程方案–>监听mysql的变动,并通知redis:
要保证数据库和redis强一致性是不可能的,肯定有少许时间的不一致。canal是阿里的一套组件,用来监听mysql master发送的类似binary log的数据,然后让消息者去消费。

传统的MySQL的主从复制:

MySQL的主从复制将经过如下步骤:
-
当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件 bin log 中;
-
salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变。
如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
-
同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
-
slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件 relay log 中;
-
salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
-
最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
canal的工作原理:

- canal 模拟 MySQL slave 的交互协议,伪装自己是 MySQL slave,向 MySQL master 发送 dump 协议;
- MySQL master 收到 dump 请求,开始推送 bin log 给 slave,即 canel;
- canel 解析 bin log 对象(原始为 bytes 流)。
详细介绍:Canal 采集MySQL binlog日志。
canel的作用:
- 数据库镜像;
- 数据库实时备份;
- 索引构建和实时维护(拆分异构索引、倒排索引等);
- 业务cache的刷新;
- 带业务逻辑的增量数据处理;
布隆过滤器:
应用场景:
-
解决缓存穿透的问题:当查询一个数据库也不存在的数据时,会造成每次先redis查不到之后都去访问数据库。
造成的后果:当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
使用布隆过滤器解决缓存穿透的问题:把已存在数据的key存在布隆过滤器中。
-
如果布隆过滤器中不存在该条数据,则数据库中一定不存在该数据,可直接返回;(避免了缓存击穿问题)
-
如果布隆过滤器中已存在(可能数据库也不存在该数据),先去查询缓存redis,没有再去查询Mysql数据库。


-
-
黑名单校验,识别垃圾邮件:
解决方案:把所有亿万个黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可(布隆过滤器中没有该邮件地址,则该地址一定不在黑名单中,即一定不是垃圾邮件)。
-
白名单校验,识别出合法用户;

-
准确快速的判断50亿个电话号码中,是否存在这10万个?
原理:
-
底层结构:由初值为0的bit数组和一系列无偏hash函数(无偏主要是为了分布均匀,尽可能的避免hash冲突)构成,用来快速判断集合中是否存在某个元素。存在一定的误判概率。

-
目的:在不保存数据信息的前提下,只是在内存中做一个是否存在的标记flag。
实现高效的插入和查询(不能删除元素,会导致误判率增加(布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素)),且用极少的内存空间,但返回的结果是不确定的并不完美(判断不存在时,则一定不存在;判断为存在时,可能不存在)。
总结:布隆过滤器判断一个元素不在一个集合中,则该元素一定不在该集合中。判断为存在时,可能不存在。
-
添加key:用所有hash函数进行计算
int index = hash(key) % bloom_filter_len,并将这些索引对应的位置均置1。
查询key:只要有其中一位是0,就表示这个key不存在,但如果都是1则不一定存在对应的key。

-
误判:指多个输入经过哈希后相同的 bit 位被置1了,这样就无法判断究竟是哪个输入产生的,即误判的根源在于相同的 bit 位被多次映射且置1。
-
当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,即重新分配一个size更大的过滤器并将所有历史元素批量添加进去。
缓存创建的问题:

redis缓存淘汰机制:
redis内存管理:
-
redis配置文件:
maxmemory参数设置了redis占用的最大内存,单位是bytes字节。默认情况下,64位操作系统不限制内存大小,32位系统最多使用3G(推荐占用物理内存的3/4)。
-
通过
config get maxmemory 104857600和config get maxmemory命令,来设置和获取redis的最大内存占用。info memory,可查看redis的内存使用情况。
注意:如果redis中的数据未设置过期时间,且已到达maxmemory的内存上限,这时再添加数据会OOM。为避免这种问题,引入了内存淘汰机制。
三种不同的过期键删除策略:
-
立即删除:redis不可能时时刻刻遍历所有被设置了过期时间的key,而且一直选择立即删除的话,会产生大量的CPU性能消耗,同时也会影响数据的读取操作。
总结:用处理器性能换取内存空间,即用时间换空间。
-
惰性删除(
lazyfree-lazy-eviction=yes开启):数据到达过期时间不做处理,等下次访问时,发现已过期则删除。存在的问题:如果已过期的数据,一段时间内均未访问到,则会白白占用内存空间。
总结:对memory不友好,用内存空间换取处理器性能,即用空间换时间。
-
定期(抽检key)删除(前两种策略的折中):每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行时长和频率,来减少删除操作对CPU时间的影响(服务器要根据实际情况,合理设置删除操作的执行时长、频率)。
周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度:
- CPU性能占用设置有峰值,检测频度可自定义设置;
- 内存压力不是很大,长期占用内存的冷数据会被持续清理;
总结:周期性抽查内存空间(随机抽查,重点抽查)。
上述“惰性删除、定期(抽检)删除”中,惰性删除时从未被点中使用过,定期删除时从未被抽查到,均会造成大量过期key堆积在内存中,导致redis内存空间紧张。
redis缓存淘汰策略:
redis配置文件:

- noeviction:不会驱逐任何key,表示即使内存达到上限也不进行置换,之后所有能引起内存增加的命令都会返回error。
- volatile-lru:对所有设置了过期时间的key使用LRU算法,进行删除。
- allkeys-lru:对所有key使用LRU算法进行删除,优先删除最近最不常使用的key。
- volatile-lfu:对所有设置了过期时间的key使用LFU算法,进行删除。
- allkeys-lfu:对所有key使用LFU算法,进行删除。
- volatile-random:对所有设置了过期时间的key,进行随机删除。
- allkeys-random:对所有key,进行随机删除。
- volatile-ttl:删除快过期的key。
LRU和LFU的区别:
- LRU:最近最少使用页面置换算法,淘汰最长时间未被使用的页面,看页面最后一次被使用到发生调度的时间长短,首先淘汰最长时间未被使用的页面。
- LFU:最近最不常用页面置换算法,淘汰一定时期内被访问次数最少的页,看一定时间段内页面被使用的频率,淘汰一定时期内被访问次数最少的页。
配置性能建议:
- 避免存储bigkey。
- 开启惰性删除,
lazyfree-lazy-eviction=yes。
redis经典的五大类型源码及底层实现:
底层数据结构:



-
字符串:Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
int:8个字节的长整型。
embstr:小于等于44个字节的字符串。
raw:大于44个字节的字符串。
-
哈希:
ziplist(压缩列表):当哈希类型元素个数小于
hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,故比hashtable更加节省内存。hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因大量元素会导致ziplist的读写效率下降,而hashtable的读写时间复杂度为
O(1)。 -
列表:
ziplist(压缩列表):当列表的元素个数小于
list-max-ziplist-entries配置(默认512个)、同时列表中每个元素的值都小于list-max-ziplist-value时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
注意:redis7之后,
quicklist会将ziplist和linkedlist的结合,即以ziplist为节点的双向链表linkedlist。 -
集合:
intset(整数集合):当集合中的元素都是整数且元素个数小于
set-max-intset-entries配置(默认512个)时,Redis会用intset来作为集合的内部实现,从而减少内存的使用。hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
-
有序集合:
ziplist(压缩列表):当有序集合的元素个数小于
zset-max-ziplist- entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,从而有效的减少内存使用。skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
注意:redis7会将ziplist换成了listpack,其通过每个节点记录自己的长度且放在节点的尾部,彻底解决掉了 ziplist 存在的连锁更新的问题。
redis字典数据库kv键值对是什么?
怎么实现的键值对数据库?
key:一般都是String类型的字符串对象。
value:是redis对象,如字符串对象,集合类型的对象:list对象,set对象,hash对象,zset对象。



注意:每个键值对,都会有一个dictEntry。redis中,每个对象都是一个redisObject结构体,redisObject中定义了type和encoding字段对不同的数据类型加以区别,即简单来说:redisObject就是string、hash、list、set、zset的父类。


string数据结构:
SDS简单动态字符串:
采用len记录字符串的长度,比起c语言用\0作为字符串的终止判断更安全。采用预分配alloc的机制,大大降低了内存碎片的产生。

注意:embstr和raw类型的底层数据结构,就是SDS(简单动态字符串)。
| 底层编码方式 | 细节说明 |
|---|---|
| int | Long类型整数时,RedisObject中的ptr指针直接赋值为整数数据,不再额外的指针再指向整数了,节省了指针的空间开销。 |
| embstr | 当待保存的字符串小于等于44字节时,embstr类型将会调用内存分配函数,只分配一块连续的内存空间,空间中依次包含 redisObject 与 sdshdr 两个数据结构,让元数据、指针和SDS是一块连续内存区域,避免产生内存碎片。 |
| raw | 当待保存的字符串大于44字节时,SDS的数据量变多变大了,会给SDS分配多的空间并用指针指向SDS结构,raw 类型将会调用两次内存分配函数,分配两块内存空间,一块用于包含 redisObject 结构,而另一块用于包含 sdshdr 结构。 |

3大物理编码方式:
int:
保存long型(长整型)的64位(8字节)有符号整数。

注意:int最多是19位,且浮点数在redis内部会用字符串保存。
embstr:
代表embstr格式的SDS(Simple Dynamic String)简单动态字符串,保存长度小于44字节的字符串。

优点:使用连续的内存空间存储,避免了内存碎片的产生。
raw:
保存长度大于44字节的字符串。

三种编码的转变逻辑:

hash数据结构:
hash的两种编码:redis6 --> ziplist + hashtable 、redis7 --> listpack + hashtable 。
redis6:
hash-max-ziplist-entries:使用压缩列表保存时,哈希集合中的最大元素个数。
hash-max-ziplist-value:使用压缩列表保存时,哈希集合中单个元素的最大长度。
Hash类型键的字段个数 小于hash-max-ziplist-entries并且每个字段名和字段值的长度 小于hash-max-ziplist-value时,Redis才会使用OBJ_ENCODING_ZIPLIST来存储该键,任意一个不满足则会转换为OBJ_ENCODING_HT的编码方式。
一旦底层编码从压缩列表OBJ_ENCODING_ZIPLIST转为了哈希表OBJ_ENCODING_HT,Hash类型就会一直用哈希表进行保存而不会再转回压缩列表了,但在节省内存空间方面哈希表就没有压缩列表高效了。

OBJ_ENCODING_HT这种编码方式内部才是真正的哈希表结构,称为字典结构,其可以实现O(1)复杂度的读写操作,因此效率很高。从OBJ_ENCODING_HT类型到底层真正的散列表数据结构是一层层嵌套下去的,组织关系见面图:

侧面证明:每个键值对都有一个dictEntry节点。
ziplist压缩列表,是一种紧凑的连续存储的“双向链表”编码格式(每个节点不再存储prev、next指针,而是存储上一个节点和当前节点的长度),以部分的读写性能为代价,换取极高的内存空间利用率。 一般适用于字段个数少,字段值也比较小的场景。



最主要的是节点zlentry中,包含了前一个节点的长度prevrawlensize、当前节点的长度lensize、当前节点的类型encoding和当前节点的实际数据p。
总结:
- ziplist为了节省内存,采用紧凑的连续存储格式。
- ziplist作为一个双向链表,可在时间复杂度为O(1)下,从头部、尾部进行pop、push,即头插尾插效率高。
- 致命缺点:插入/更新元素时,可能会出现连锁更新现象,导致其被listpack替换。
- 一般适用于字段个数少,字段值也比较小的场景。过多的字段,会导致查询/插入效率的降低。
redis7:
hash-max-listpack-entries:使用压缩列表保存时,哈希集合中的最大元素个数。
hash-max-listpack-value:使用压缩列表保存时,哈希集合中单个元素的最大长度。
Hash类型键的字段个数 小于hash-max-listpack-entries并且每个字段名和字段值的长度 小于hash-max-listpack-value时,Redis才会使用OBJ_ENCODING_LISTPACK来存储该键,任意一个不满足则会转换为OBJ_ENCODING_HT的编码方式。
有了ziplist,为何还需要listpack紧凑列表?
-
ziplist压缩列表的每个节点中 prevlen 属性,记录前一个节点占用的长度,

- 如果前一个节点的长度 < 254bytes,则 prevlen 属性需要占用 1bytes 来存储前一个节点的长度值。
- 如果前一个节点的长度 >= 254bytes,则 prevlen 属性需要占用 5bytes 来存储前一个节点的长度值。
-
压缩列表新增某个元素或修改某个元素时,如果空间不够,压缩列表占用的内存空间就需要重新分配。
当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起连锁更新问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能下降。

-
listpack 是 Redis 设计用来取代掉 ziplist 的数据结构,它通过每个节点记录自己的长度且放在节点的尾部,来彻底解决掉了 ziplist 存在的连锁更新的问题。

list数据结构:
ziplist压缩列表和linkedlist双端链表的对比:
- ziplist的优点:内存紧凑,访问效率高;缺点:更新效率低,可能引发“连锁更新”的问题。
- linkedlist的优点:节点的修改效率高;缺点:需要额外的内存开销,节点较多时会产生大量的内存碎片。
总结:quicklist结合了ziplist和linkedlist的优点,是“双向链表 + 压缩列表”组合:链表中每个元素是一个压缩列表。
list中quicklist的两种编码:redis6 --> linkedlist + ziplist 、redis7 --> linkedlist + listpack 。
redis6:



- ziplist 压缩配置
list-compress-depth,表示一个 quicklist 两端不被压缩的节点个数。这里的节点是指 quicklist 双向链表的节点,而非 ziplist 里面的数据项个数。取值含义如下:
0:是 Redis 的默认值,表示都不压缩。1:quicklist 两端各有1个节点不压缩,中间的节点压缩。2:quicklist 两端各有2个节点不压缩,中间的节点压缩。3:quicklist 两端各有3个节点不压缩,中间的节点压缩。
- ziplist 中 entry 配置
list-max-ziplist-size
-
当取正值时,表示按照数据项个数来限定每个 quicklist 节点上的 ziplist 长度。
比如,当这个参数配置成5的时候,表示每个 quicklist 节点的 ziplist 最多包含5个数据项。
-
当取负值时,表示按照占用字节数来限定每个 quicklist 节点上的 ziplist 长度。这时,它只能取 -1 到 -5 这五个值。
取值含义如下:
-5:每个 quicklist 节点上的 ziplist 大小不能超过64 Kb。(注:1kb => 1024 bytes)-4:每个 quicklist 节点上的 ziplist 大小不能超过32 Kb。-3:每个 quicklist 节点上的 ziplist 大小不能超过16 Kb。-2(Redis的默认值):每个 quicklist 节点上的 ziplist 大小不能超过8 Kb。-1:每个 quicklist 节点上的 ziplist 大小不能超过4 Kb。
redis7:

主要与redis6的区别(listpack 替换了 ziplist):即通过每个节点记录自己的长度且放在节点的尾部,来彻底解决掉了 ziplist 存在的连锁更新的问题。
set数据结构:
两种编码格式:intset、hashtable。

zset数据结构:
编码格式:redis6 --> ziplist + skiplist、redis7 --> listpack + skiplist。

- 当有序集合中包含的元素数量超过服务器属性
zset_max_ziplist_entries的值(默认值为 128 )时 - 有序集合中新添加元素的长度大于服务器属性
zset_max_ziplist_value的值(默认值为 64 )时
,redis会使用跳跃表 skiplist 作为有序集合的底层实现,否则会使用 ziplist/listpack。
skiplist跳表:
引出:
对于一个单链表来讲,即便链表中存储的数据是有序的,如果要想在其中查找某个数据,也只能从头到尾遍历链表,时间复杂度很高O(N)。
解决方法:升维,即最典型的空间换时间解决方案。实现细节问题:
- 链表无法进行二分查找,故借鉴数据库索引的思想,提取出链表中关键节点(作为索引),先在关键节点上查找,再进入下层链表查找,提取多层关键节点,就形成了跳跃表。
- 由于索引也要占据一定空间的,所以,索引添加的越多,空间占用的越多。

特性:
- skiplist就是实现二分查找的有序链表,即“跳表=链表+多级索引”。
- 跳表的时间复杂度
O(logN),空间复杂度O(N)。

适用场景:
只有在**数据量较大且读多写少**的情况下,才能体现出来优势。
缺点:
维护成本相对要高,新增/删除元素时需要把所有索引都更新一遍,且为了保证原始链表中数据的有序性需要先找到要动作的位置,之后才能插入/删除并更新索引。
相关文章:
redis学习笔记 - 进阶部分
文章目录 redis单线程如何处理并发的客户端,以及为何单线程快?redis的发展历程:redis单线程和多线程的体现:redis3.x单线程时代但性能很快的主要原因:redis4.x开始引入多线程:redis6/redis7引入多线程IO&am…...
SE5 - BM1684 人工智能边缘开发板入门指南 -- 模型转换、交叉编译、yolov5、目标追踪
介绍 我们属于SoC模式,即我们在x86主机上基于tpu-nntc和libsophon完成模型的编译量化与程序的交叉编译,部署时将编译好的程序拷贝至SoC平台(1684开发板/SE微服务器/SM模组)中执行。 注:以下都是在Ubuntu20.04系统上操…...
基于Java+SpringBoot+vue前后端分离英语知识应用网站设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

vue使用vue-router报错
报错1. app.js:172 Uncaught TypeError: vue_router__WEBPACK_IMPORTED_MODULE_0__.default is not a constructor at eval (index.js:4:1) at ./src/router/index.js (app.js:108:1) at webpack_require (app.js:169:33) at fn (app.js:442:21) at eval (main.js:7:71) at ./…...
编写Dockerfile制作Web应用系统nginx镜像,生成镜像nginx:v1.1,并推送其到私有仓库。
环境: CentOS 7 Linux 3.10.0-1160.el7.x86_64 具体要求如下: (1)基于centos基础镜像; (2)指定作者信息; (3)安装nginx服务,将提供的dest目录…...

js 类、原型及class
js 一直允许定义类。ES6新增了相关语法(包括class关键字)让创建类更容易。新语法创建的类和老式的类原理相同。js 的类和基于原型的继承机制与Java等语言中的类和继承机制有着本质区别。 1 类和原型 类意味着一组对象从同一个原型对象继承属性。因此,原型对象是…...
day-30 代码随想录算法训练营 回溯part06
332.重新安排行程 思路:使用unordered_map记录起点机场对应到达机场,内部使用map记录到达机场的次数(因为map会进行排序,可以求出最小路径) class Solution { public:vector<string>res;unordered_map<stri…...
)
txt、pcd、las、ply 格式点云基本的读写和显示 (附 python c++ 代码)
一、文本(txt) 1.1、存储结构 使用文本格式存储的点云数据文件结构比较简单,每个点是一行记录,点的信息存储格式为 x y z或者 x y z r g b。 1.2、读取 读取文本格式的点云数据时,可以按照一般的文本读取方法,这里记录一下如何使用open3d读取txt格式的点云数据 impo…...
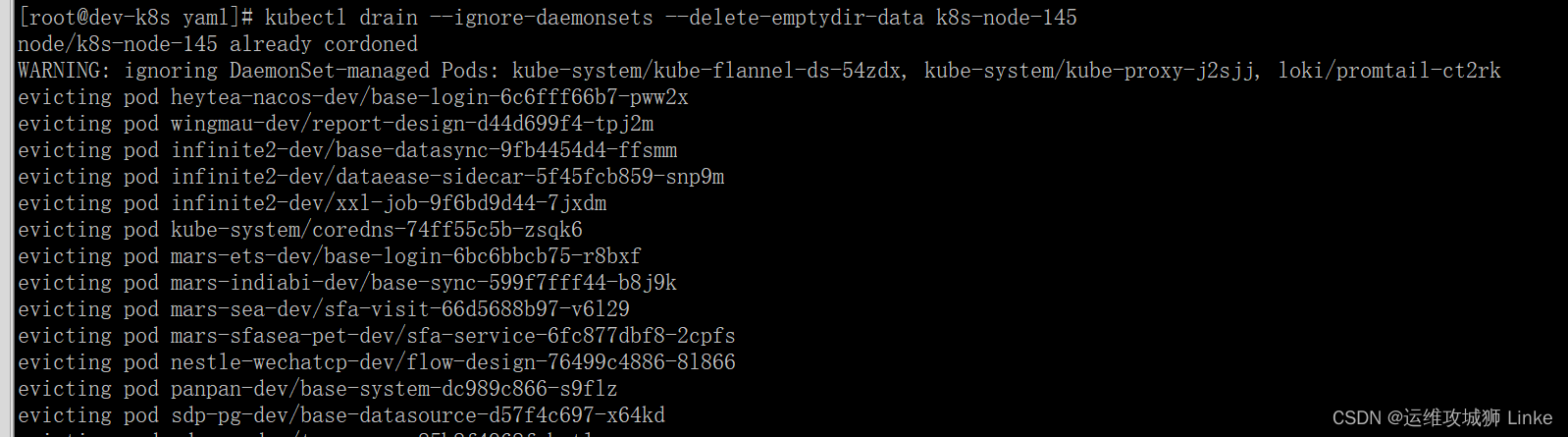
k8s节点pod驱逐、污点标记
一、设置污点,禁止pod被调度到节点上 kubectl cordon k8s-node-145 设置完成后,可以看到该节点附带了 SchedulingDisabled 的标记 二、驱逐节点上运行的pod到其他节点 kubectl drain --ignore-daemonsets --delete-emptydir-data k8s-node-145 显示被驱逐…...
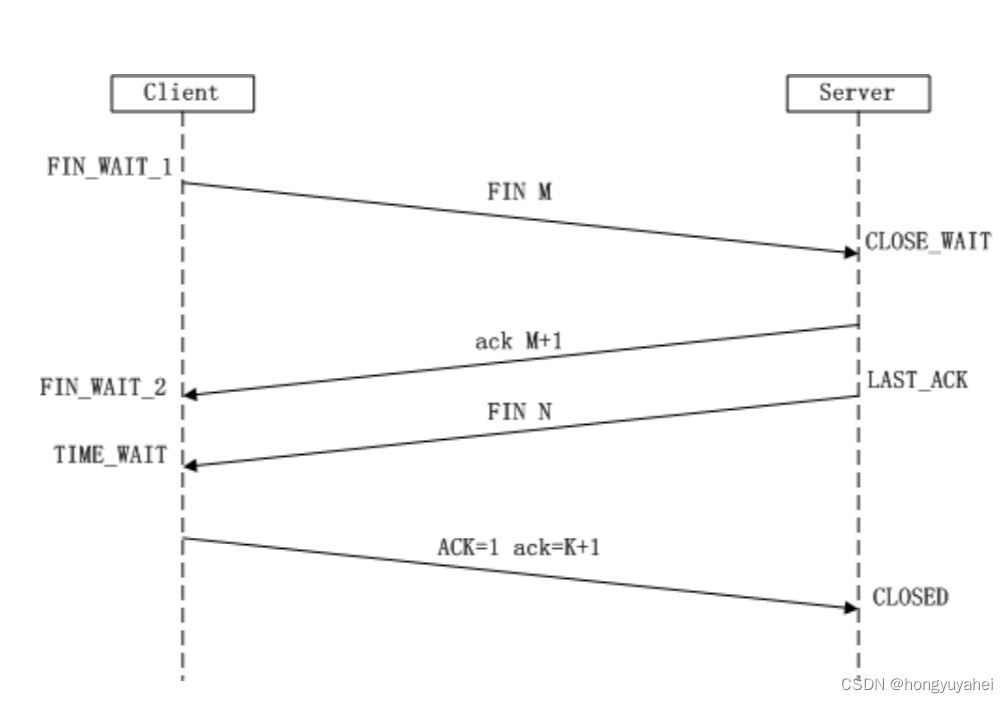
【项目 计网6】 4.17 TCP三次握手 4.18滑动窗口 4.19TCP四次挥手
文章目录 4.17 TCP三次握手4.18滑动窗口4.19TCP四次挥手 4.17 TCP三次握手 TCP 是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的“连接”,其实是客户端和服务器的内存里保存的一份关于对方的信息ÿ…...

茶叶小笔记
文章目录 茶叶的作用茶叶的主要成分茶多酚氨基酸(蛋白质)生物碱 茶叶的分类乌龙茶铁观音(安溪) 绿茶龙井(西湖)龙井43 绿茶(日照)毛尖(信阳毛尖)太平猴魁六安瓜片 红茶金骏眉大红袍 白茶云南白茶 黄茶黑茶花草茶 茶叶的形状过期茶的利用茶叶蛋大排档泡澡泡脚除湿除臭 茶渣的利用…...
安全开发-JS应用NodeJS指南原型链污染Express框架功能实现审计WebPack打包器第三方库JQuery安装使用安全检测
文章内容 环境搭建-NodeJS-解析安装&库安装安全问题-NodeJS-注入&RCE&原型链案例分析-NodeJS-CTF题目&源码审计打包器-WebPack-使用&安全第三方库-JQuery-使用&安全 环境搭建-NodeJS-解析安装&库安装 Node.js是运行在服务端的JavaScript 文档参考…...
Android JNI系列详解之CMake编译工具的使用
一、CMake工具的介绍 如图所示,CMake工具的主要作用是,将C/C编写的native源文件编译打包生成库文件(包含动态库或者静态库文件),集成到Android中使用。 二、CMake编译工具的使用 使用主要是配置两个文件:CM…...

springboot中关于继承WebMvcConfigurationSupport后自定义的全局Jackson失效解决方法,localdate返回数组问题
一般情况下我们在config里增加jackson的全局配置文件就能满足基本的序列化需求,比如前后端传参的问题。 Configuration public class JacksonConfig {public static final String LOCAL_TIME_PATTERN "HH:mm:ss";public static final String LOCAL_DATE…...

LeetCode 面试题 02.03. 删除中间节点
文章目录 一、题目二、C# 题解 一、题目 若链表中的某个节点,既不是链表头节点,也不是链表尾节点,则称其为该链表的「中间节点」。 假定已知链表的某一个中间节点,请实现一种算法,将该节点从链表中删除。 例如&#x…...

Redis知识点总结
概述 Redis诞生于2009年,全称是Remote Dictionarty Server(远程词典服务器) 只支持单线程 非关联:主要指的是表中没有主外键等概念 Redis是一款内存数据库,主要存储键值对类型的数据 基本用法 注意:该操作是在cli中进行的 键名…...
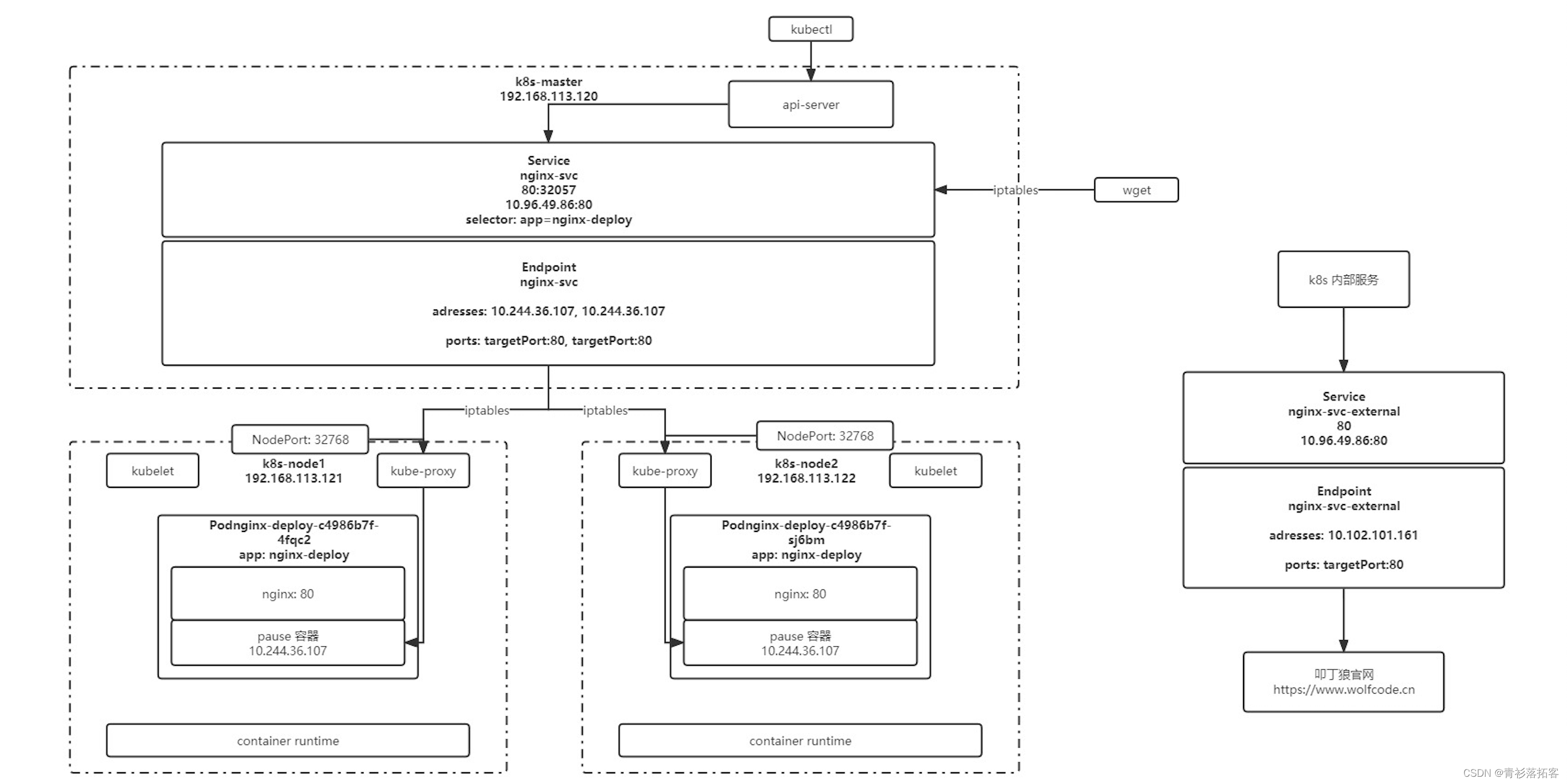
(四)k8s实战-服务发现
一、Service 1、配置文件 apiVersion: v1 kind: Service metadata:name: nginx-svclabels:app: nginx-svc spec:ports:- name: http # service 端口配置的名称protocol: TCP # 端口绑定的协议,支持 TCP、UDP、SCTP,默认为 TCPport: 80 # service 自己的…...
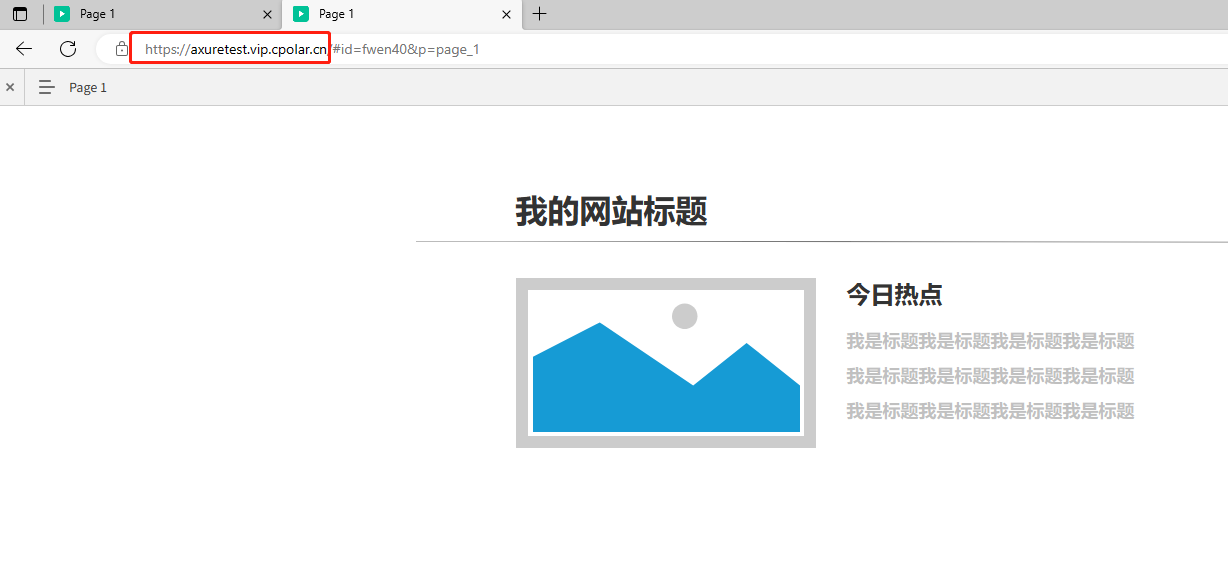
AxureRP制作静态站点发布互联网,内网穿透实现公网访问
AxureRP制作静态站点发布互联网,内网穿透实现公网访问 文章目录 AxureRP制作静态站点发布互联网,内网穿透实现公网访问前言1.在AxureRP中生成HTML文件2.配置IIS服务3.添加防火墙安全策略4.使用cpolar内网穿透实现公网访问4.1 登录cpolar web ui管理界面4…...

[Go版]算法通关村第十四关白银——堆高效解决的经典问题(在数组找第K大的元素、堆排序、合并K个排序链表)
目录 题目:在数组中找第K大的元素解法1:维护长度为k的最小堆,遍历n-k个元素,逐一和堆顶值对比后,和堆顶交换,最后返回堆顶复杂度:时间复杂度 O ( k ( n − k ) l o g k ) O(k(n-k)logk) O(k(n−…...

『FastGithub』一款.Net开源的稳定可靠Github加速神器,轻松解决GitHub访问难题
📣读完这篇文章里你能收获到 如何使用FastGithub解决Github无法访问问题了解FastGithub的工作原理 文章目录 一、前言二、项目介绍三、访问加速原理四、FastGithub安装1. 项目下载2. 解压双击运行3. 运行效果4. GitHub访问效果 一、前言 作为开发者,会…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
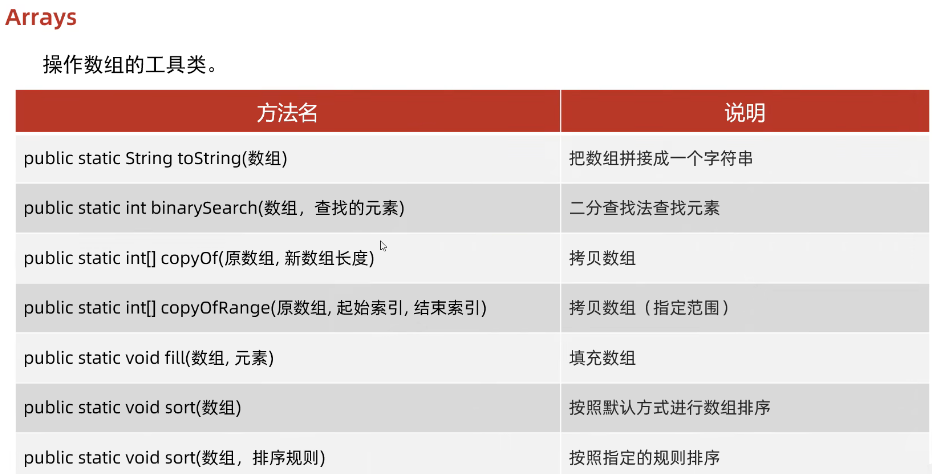
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...