fastdeploy部署多线程/进程paddle ocr(python flask框架 )
部署参考:https://github.com/PaddlePaddle/FastDeploy/blob/develop/tutorials/multi_thread/python/pipeline/README_CN.md
安装
cpu: pip install fastdeploy-python
gpu :pip install fastdeploy-gpu-python
#下载部署示例代码
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd FastDeploy/tutorials/multi_thread/python/pipeline# 下载模型,图片和字典文件
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
tar xvf ch_PP-OCRv3_det_infer.tarwget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tarwget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
tar xvf ch_PP-OCRv3_rec_infer.tarwget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpgwget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
命令:
多线程
python multi_thread_process_ocr.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image_path xxx/xxx --device gpu --thread_num 3
多进程
python multi_thread_process_ocr.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image_path xxx/xxx --device gpu --use_multi_process True --process_num 3
问题
多进程图片分配有bug
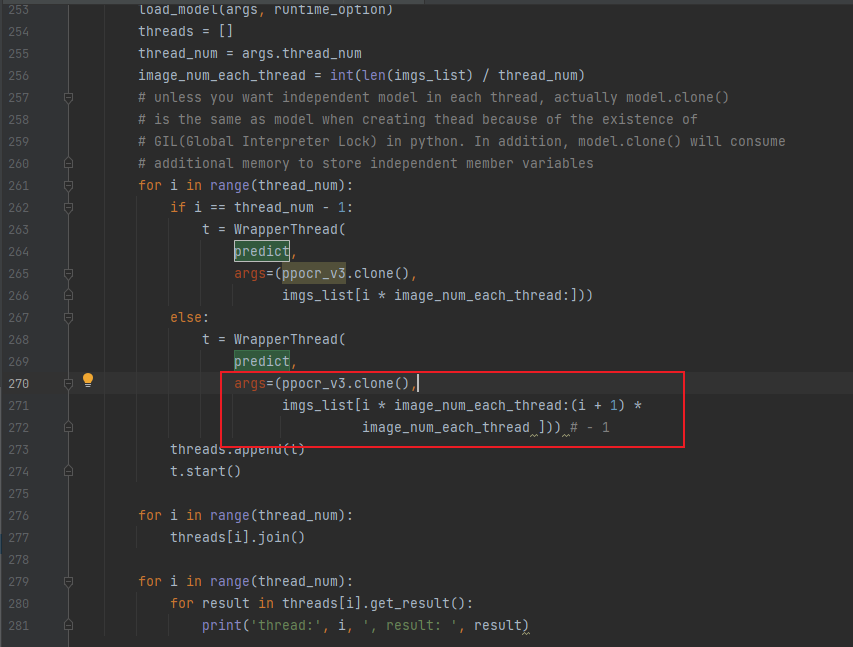
文件:multi_thread_process_ocr.py
原始代码:270行
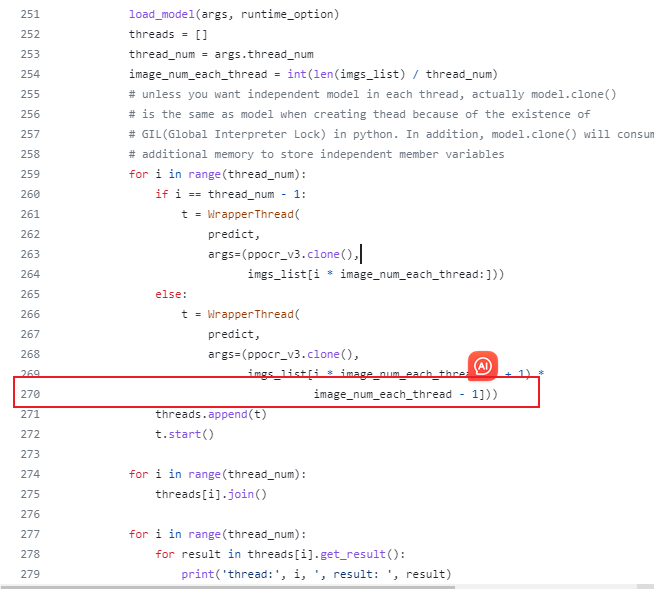
修改为如下,去掉1
ModuleNotFoundError: No module named ‘example’
因为安装包不对,fastdeploy与fastdeploy-python不是同一个包
CUDA error(3), initialization error.
----------------------Error Message Summary:----------------------ExternalError: CUDA error(3), initialization error. [Hint: Please search for the error code(3) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /home/fastdeploy/develop/paddle_build/v0.0.0/Paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:251)
参考:
PaddlePaddle——问题解决:使用Python multiprocessing时报错:CUDA error(3), initialization error.
https://github.com/PaddlePaddle/PaddleDetection/issues/2241
paddle 相关模块只在方法里面引用,要在多进程外有 import 这些模块
flask部署
发送列表类型的图片base64编码,返回列表类型的字符串
注意server端文件放在FastDeploy/tutorials/multi_thread/python/pipeline目录下
创建server端
from threading import Threadimport cv2
import os
from multiprocessing import Pool
import sysimport fastdeploy as fd
import numpy as np
import base64
from PIL import Image
from io import BytesIO
from sqlalchemy import create_engine, textfrom flask import Flask, request, jsonify
import argparse
import ast# watch -n 0.1 nvidia-smidef parse_arguments():parser = argparse.ArgumentParser()parser.add_argument("--det_model",# required=True,type=str,default='ch_PP-OCRv3_det_infer',help="Path of Detection model of PPOCR.")parser.add_argument("--cls_model",# required=True,type=str,default='ch_ppocr_mobile_v2.0_cls_infer',help="Path of Classification model of PPOCR.")parser.add_argument("--rec_model",# required=True,type=str,default='ch_PP-OCRv3_rec_infer',help="Path of Recognization model of PPOCR.")parser.add_argument("--rec_label_file",# required=True,type=str,default='ppocr_keys_v1.txt',help="Path of Recognization model of PPOCR.")# parser.add_argument(# "--image_path",# type=str,# required=True,# help="The directory or path or file list of the images to be predicted."# )parser.add_argument("--device",type=str,default='gpu', # cpuhelp="Type of inference device, support 'cpu', 'kunlunxin' or 'gpu'.")parser.add_argument("--backend",type=str,default="default",help="Type of inference backend, support ort/trt/paddle/openvino, default 'openvino' for cpu, 'tensorrt' for gpu")parser.add_argument("--device_id",type=int,default=0,help="Define which GPU card used to run model.")parser.add_argument("--cpu_thread_num",type=int,default=9,help="Number of threads while inference on CPU.")parser.add_argument("--cls_bs",type=int,default=1,help="Classification model inference batch size.")parser.add_argument("--rec_bs",type=int,default=6,help="Recognition model inference batch size")parser.add_argument("--thread_num", type=int, default=1, help="thread num")parser.add_argument("--use_multi_process",type=ast.literal_eval,default=True,help="Wether to use multi process.")parser.add_argument("--process_num", type=int, default=5, help="process num")return parser.parse_args()def get_image_list(image_path):image_list = []if os.path.isfile(image_path):image_list.append(image_path)# load image in a directoryelif os.path.isdir(image_path):for root, dirs, files in os.walk(image_path):for f in files:image_list.append(os.path.join(root, f))else:raise FileNotFoundError('{} is not found. it should be a path of image, or a directory including images.'.format(image_path))if len(image_list) == 0:raise RuntimeError('There are not image file in `--image_path`={}'.format(image_path))return image_listdef build_option(args):option = fd.RuntimeOption()if args.device.lower() == "gpu":option.use_gpu(args.device_id)option.set_cpu_thread_num(args.cpu_thread_num)if args.device.lower() == "kunlunxin":option.use_kunlunxin()return optionif args.backend.lower() == "trt":assert args.device.lower() == "gpu", "TensorRT backend require inference on device GPU."option.use_trt_backend()elif args.backend.lower() == "pptrt":assert args.device.lower() == "gpu", "Paddle-TensorRT backend require inference on device GPU."option.use_trt_backend()option.enable_paddle_trt_collect_shape()option.enable_paddle_to_trt()elif args.backend.lower() == "ort":option.use_ort_backend()elif args.backend.lower() == "paddle":option.use_paddle_infer_backend()elif args.backend.lower() == "openvino":assert args.device.lower() == "cpu", "OpenVINO backend require inference on device CPU."option.use_openvino_backend()return optiondef load_model(args, runtime_option):# Detection模型, 检测文字框det_model_file = os.path.join(args.det_model, "inference.pdmodel")det_params_file = os.path.join(args.det_model, "inference.pdiparams")# Classification模型,方向分类,可选cls_model_file = os.path.join(args.cls_model, "inference.pdmodel")cls_params_file = os.path.join(args.cls_model, "inference.pdiparams")# Recognition模型,文字识别模型rec_model_file = os.path.join(args.rec_model, "inference.pdmodel")rec_params_file = os.path.join(args.rec_model, "inference.pdiparams")rec_label_file = args.rec_label_file# PPOCR的cls和rec模型现在已经支持推理一个Batch的数据# 定义下面两个变量后, 可用于设置trt输入shape, 并在PPOCR模型初始化后, 完成Batch推理设置cls_batch_size = 1rec_batch_size = 6# 当使用TRT时,分别给三个模型的runtime设置动态shape,并完成模型的创建.# 注意: 需要在检测模型创建完成后,再设置分类模型的动态输入并创建分类模型, 识别模型同理.# 如果用户想要自己改动检测模型的输入shape, 我们建议用户把检测模型的长和高设置为32的倍数.det_option = runtime_optiondet_option.set_trt_input_shape("x", [1, 3, 64, 64], [1, 3, 640, 640],[1, 3, 960, 960])# 用户可以把TRT引擎文件保存至本地#det_option.set_trt_cache_file(args.det_model + "/det_trt_cache.trt")global det_modeldet_model = fd.vision.ocr.DBDetector(det_model_file, det_params_file, runtime_option=det_option)cls_option = runtime_optioncls_option.set_trt_input_shape("x", [1, 3, 48, 10],[cls_batch_size, 3, 48, 320],[cls_batch_size, 3, 48, 1024])# 用户可以把TRT引擎文件保存至本地# cls_option.set_trt_cache_file(args.cls_model + "/cls_trt_cache.trt")global cls_modelcls_model = fd.vision.ocr.Classifier(cls_model_file, cls_params_file, runtime_option=cls_option)rec_option = runtime_optionrec_option.set_trt_input_shape("x", [1, 3, 48, 10],[rec_batch_size, 3, 48, 320],[rec_batch_size, 3, 48, 2304])# 用户可以把TRT引擎文件保存至本地#rec_option.set_trt_cache_file(args.rec_model + "/rec_trt_cache.trt")global rec_modelrec_model = fd.vision.ocr.Recognizer(rec_model_file,rec_params_file,rec_label_file,runtime_option=rec_option)# 创建PP-OCR,串联3个模型,其中cls_model可选,如无需求,可设置为Noneglobal ppocr_v3ppocr_v3 = fd.vision.ocr.PPOCRv3(det_model=det_model, cls_model=cls_model, rec_model=rec_model)# 给cls和rec模型设置推理时的batch size# 此值能为-1, 和1到正无穷# 当此值为-1时, cls和rec模型的batch size将默认和det模型检测出的框的数量相同ppocr_v3.cls_batch_size = cls_batch_sizeppocr_v3.rec_batch_size = rec_batch_sizedef predict(model, img_list):result_list = []# predict ppocr resultfor image in img_list:im = cv2.imread(image)result = model.predict(im)result_list.append(result)return result_listdef process_predict(image):# predict ppocr resultim = cv2.imread(image)result = ppocr_v3.predict(im)print(result)def process_predict_text(base64_str):image = base64_to_bgr(base64_str)result = ppocr_v3.predict(image)# print(result)return ''.join(result.text) #不能直接返回OCR对象序列化会失败def cv_show(img):'''展示图片@param img:@param name:@return:'''cv2.namedWindow('name', cv2.WINDOW_KEEPRATIO) # cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIOcv2.imshow('name', img)cv2.waitKey(0)cv2.destroyAllWindows()def base64_to_bgr(base64_str):base64_hex = base64.b64decode(base64_str)image = BytesIO(base64_hex)img = Image.open(image)if img.mode=='RGBA':width = img.widthheight = img.heightimg2 = Image.new('RGB', size=(width, height), color=(255, 255, 255))img2.paste(img, (0, 0), mask=img)image_array = np.array(img2)else:image_array = np.array(img)image = cv2.cvtColor(image_array, cv2.COLOR_RGB2BGR)return imageclass WrapperThread(Thread):def __init__(self, func, args):super(WrapperThread, self).__init__()self.func = funcself.args = args# self.result = self.func(*self.args)def run(self):self.result = self.func(*self.args)def get_result(self):return self.resultdef ocr_image_list(imgs_list):args = parse_arguments()# 对于三个模型,均采用同样的部署配置# 用户也可根据自行需求分别配置runtime_option = build_option(args)if args.use_multi_process:process_num = args.process_numwith Pool(process_num,initializer=load_model,initargs=(args, runtime_option)) as pool:#results = pool.map(process_predict_text, imgs_list)# pool.map(process_predict, imgs_list)# 进一步处理结果for i, result in enumerate(results):print(i, result)else:load_model(args, runtime_option)threads = []thread_num = args.thread_numimage_num_each_thread = int(len(imgs_list) / thread_num)# unless you want independent model in each thread, actually model.clone()# is the same as model when creating thead because of the existence of# GIL(Global Interpreter Lock) in python. In addition, model.clone() will consume# additional memory to store independent member variablesfor i in range(thread_num):if i == thread_num - 1:t = WrapperThread(predict,args=(ppocr_v3.clone(),imgs_list[i * image_num_each_thread:]))else:t = WrapperThread(predict,args=(ppocr_v3.clone(),imgs_list[i * image_num_each_thread:(i + 1) *image_num_each_thread])) # - 1threads.append(t)t.start()for i in range(thread_num):threads[i].join()for i in range(thread_num):for result in threads[i].get_result():print('thread:', i, ', result: ', result)@app.route('/ocr/submit', methods=['POST'])
def ocr():args = parse_arguments()process_num = 1#args.process_numruntime_option = build_option(args)data = request.get_json()# 获取 Base64 数据base64_str = data['img_base64']with Pool(process_num, initializer=load_model, initargs=(args, runtime_option)) as pool:results = pool.map(process_predict_text, base64_str)# 返回响应response = {'message': 'Data received', 'result': results}return jsonify(response)import json
import pandas as pd
import timeif __name__ == '__main__':app.run(host='192.168.xxx.xxx', port=5000)client 端
import base64
import sysimport requests
import json
# 读取图像文件
with open('./pic/img.png', 'rb') as image_file:# 将图像文件内容读取为字节流image_data = image_file.read()# 将图像字节流进行 Base64 编码
img_base64 = base64.b64encode(image_data)data = {'img_base64': [img_base64.decode('utf-8')] }headers = {'Content-Type': 'application/json'
}response = requests.post("http://192.168.xxx.xxx:5000/ocr/submit", data=json.dumps(data),headers = headers)if response.status_code == 200:result = response.json()print(result['result'])
else:print('Error:', response.status_code)
相关文章:
fastdeploy部署多线程/进程paddle ocr(python flask框架 )
部署参考:https://github.com/PaddlePaddle/FastDeploy/blob/develop/tutorials/multi_thread/python/pipeline/README_CN.md 安装 cpu: pip install fastdeploy-python gpu :pip install fastdeploy-gpu-python #下载部署示例代码 git cl…...
【图论】拓扑排序
一.定义 拓扑排序是一种对有向无环图(DAG)进行排序的算法,使得图中的每个顶点在排序中都位于其依赖的顶点之后。它通常用于表示一些任务之间的依赖关系,例如在一个项目中,某些任务必须在其他任务之前完成。 拓扑排序的…...
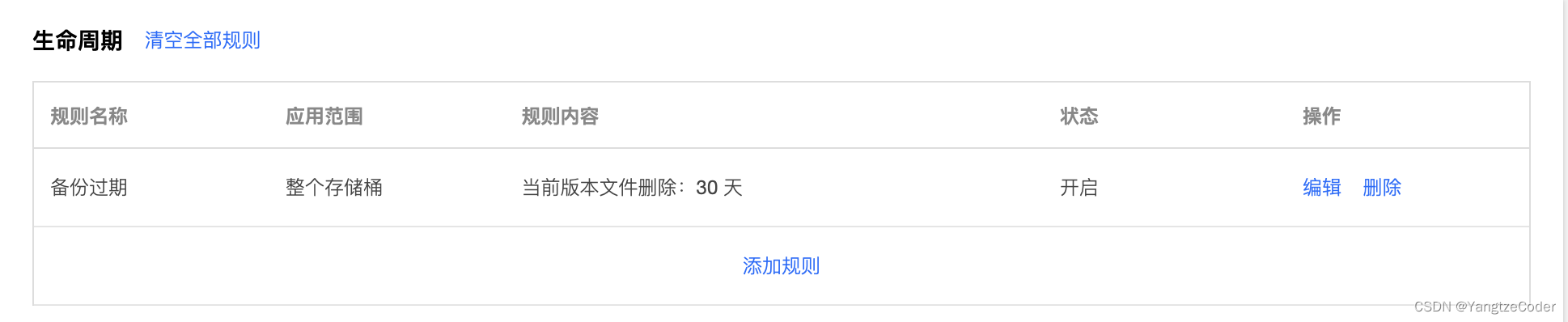
自动化备份方案
背景说明 网上有很多教程,写的都是从零搭建一个什么什么,基本上都是从无到有的教程,但是,很少有文章提及搭建好之后如何备份,这次通过请教GitHub Copilot Chat,生成几个备份脚本,以备后用。 注…...
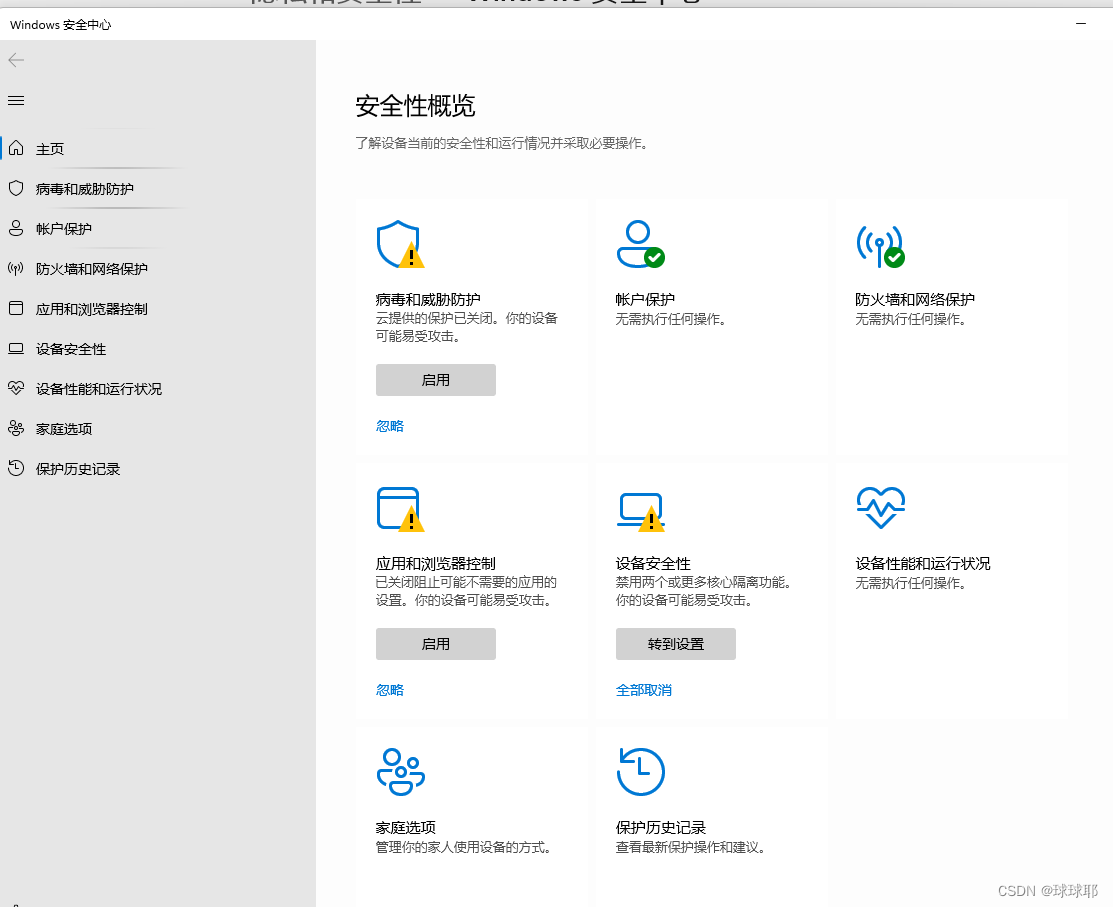
win11出现安全中心空白和IT管理员已限制对此应用的某些区域的访问
问题 windows安全中心服务被禁用 winr 输入services.msc 找到windows安全中心服务查看是否被禁用,改为启动,不可以改动看第三条 打开设置,找到应用—windows安全中心–终止–修复–重置 重启如果还是不行看第四条 家庭版系统需要打开gped…...

github实用指令(实验室打工人入门必备)
博主进入实验室啦,作为一只手残党决定在这里分享一些常用的github使用情景和操作指南来解救其他手残党。 内容随着情景增加实时更新。如果只有没几个内容说明场景不多(相信对手残党而言是再好不过的消息) 情景一:…...
6. 激活层
6.1 非线性激活 ① inplace为原地替换,若为True,则变量的值被替换。若为False,则会创建一个新变量,将函数处理后的值赋值给新变量,原始变量的值没有修改。 import torch from torch import nn from torch.nn import …...
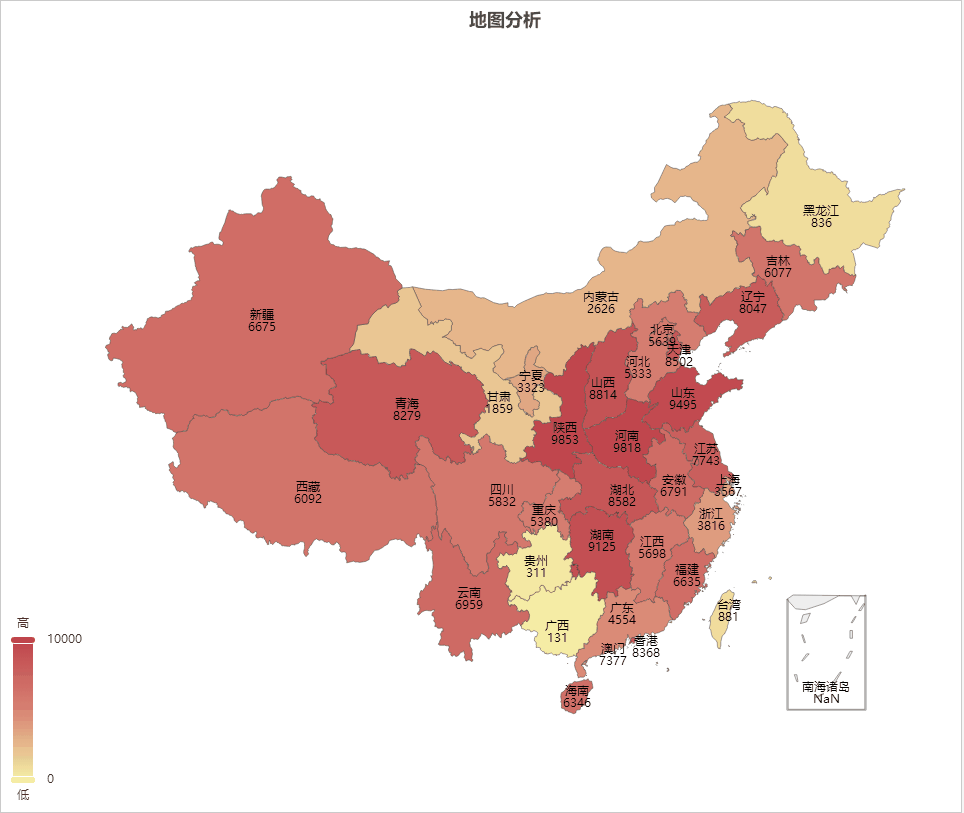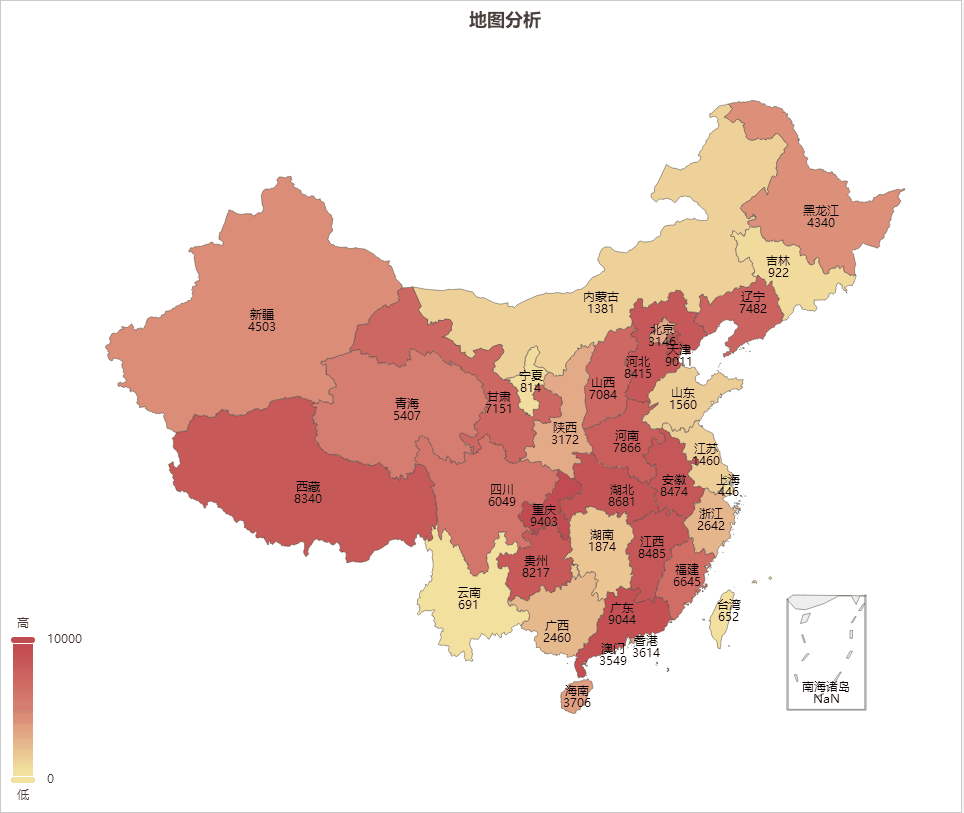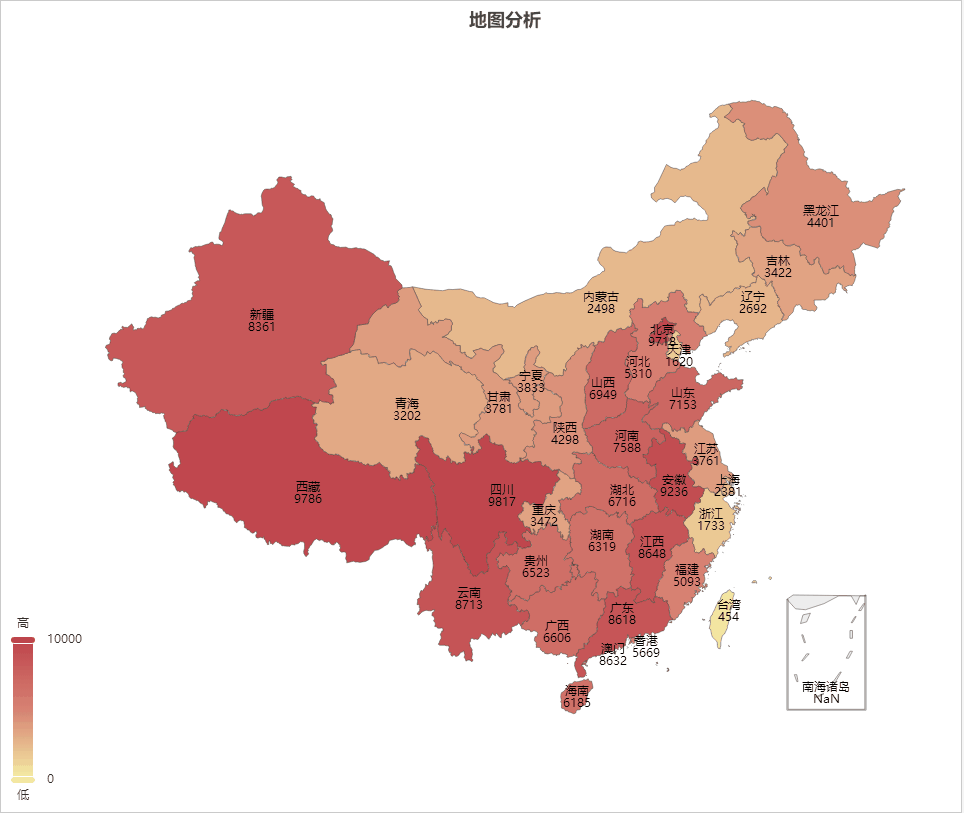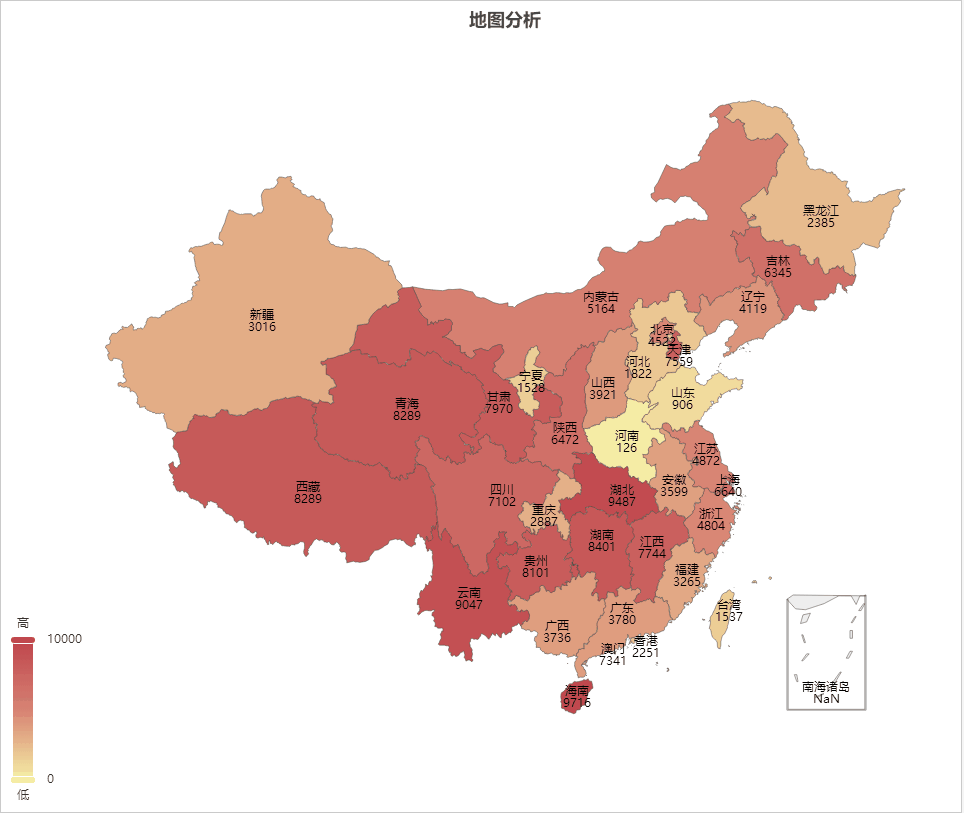
AIGC ChatGPT 制作地图可视化分析
地图可视化分析是一种将数据通过地图的形式进行展示的方法,可以让人们更加直观、快速、准确的理解和分析数据。以下是地图可视化分析的一些主要好处: 加强数据理解:地图可视化可以将抽象的数字转化为直观的图形,帮助我们更好地理解复杂的数据集。 揭示地理模式:地理位置是…...
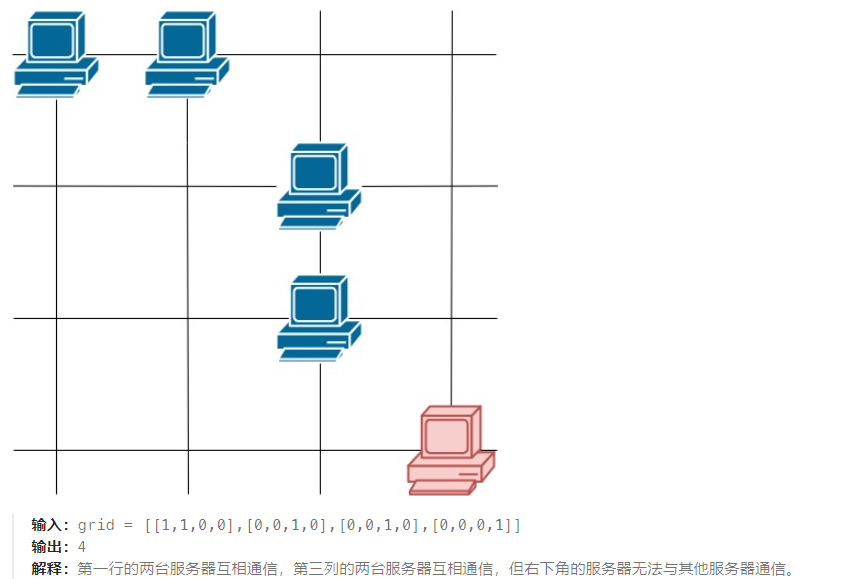
2023-08-24 LeetCode每日一题(统计参与通信的服务器)
2023-08-24每日一题 一、题目编号 1267. 统计参与通信的服务器二、题目链接 点击跳转到题目位置 三、题目描述 这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。 如果两台…...

前端实习day35
今天是下早班的一天,下完班直接赶车回广州了,吐槽一下深圳站管理得真得差,候车厅小,人巨多,而且进站口的标识也很少,绕了好久才找到!下次再也不去了。 今天是改bug的一天,但是有半天…...

Linux安装jupyter notebook
1. Linux安装jupyter notebook 1.1 生成配置文件 这里在conda环境中安装。 jupyter notebook --generate-config --allow-root上面命令是生成配置文件,并且允许使用root用户运行。配置文件默认生成到~/.jupyter/jupyter_notebook_config.py。 具体解释如下&…...

【猿灰灰赠书活动 - 03期】- 【RHCSA/RHCE 红帽Linux认证学习指南(第7版) EX200 EX300】
说明:博文为大家争取福利,与清华大学出版社合作进行送书活动 图书:《RHCSA/RHCE 红帽Linux认证学习指南(第7版) EX200 & EX300》 一、好书推荐 图书介绍 《RHCSA/RHCE 红帽Linux认证学习指南(第7版) EX200 & E…...

当 Tubi 遇到 Ruby
有人说 Tubi 作为 RubyConf China 金牌赞助商,明明用极具吸引力的 Elixir 后端工程师岗位和高品质的 Elixir Meetup,“拐走了”一批又一批 Rubyist 投身于 Elixir 开发中,却依然让人想在 Tubi 展台前多停留一会儿。 为什么工程师、校友甚至 …...
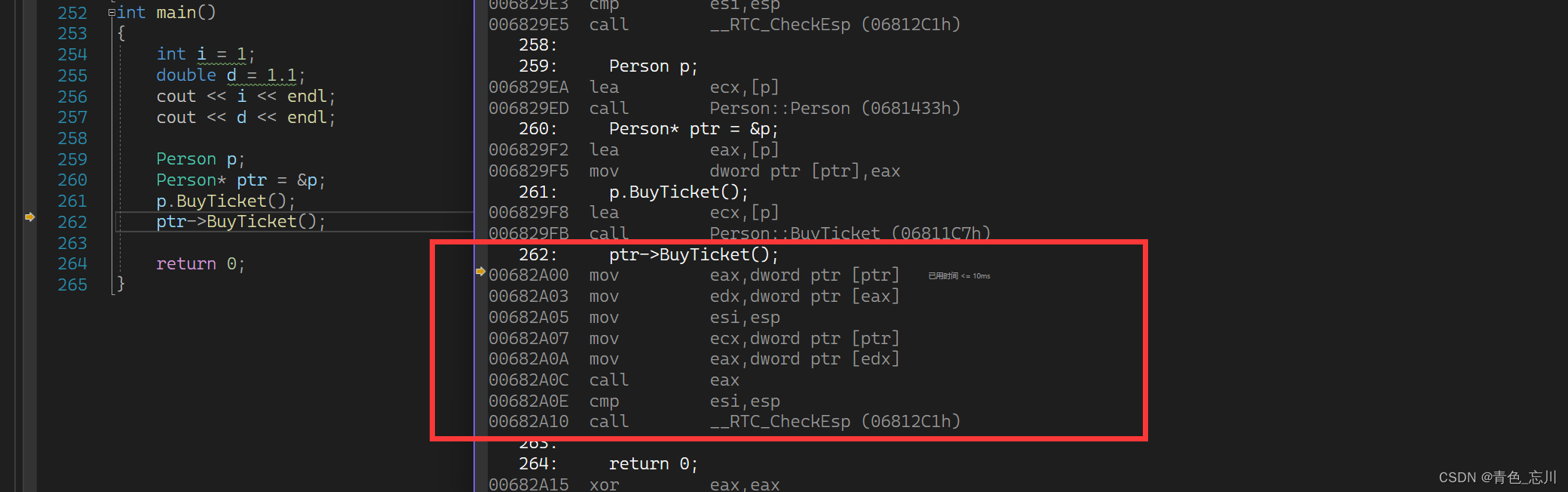
【C++从0到王者】第二十四站:多态的底层原理
文章目录 前言一、虚函数表二、一道经典的例题三、深度剖析多态的条件之一:为什么必须是父类的指针或引用四、深度剖析多态的条件之二:为什么是虚函数的重写/覆盖?五、虚函数表的一些总结六、关于Func3的验证七、动态绑定与静态绑定八、总结 …...

Java从入门到精通24==》数据库、SQL基本语句、DDL语句
Java从入门到精通24》数据库、SQL基本语句、DDL语句 2023.8.27 文章目录 <center>Java从入门到精通24》数据库、SQL基本语句、DDL语句一、什么是数据库二、数据库的优缺点1、使用数据库的优点:2、使用数据库的缺点: 三、MySQL基本语句四、DDL语句 …...
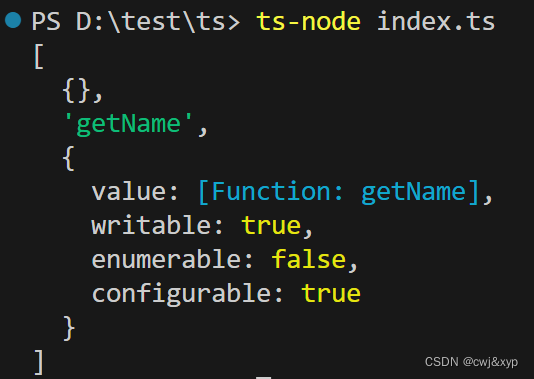
学习ts(十)装饰器
定义 装饰器是一种特殊类型的声明,它能够被附加到类声明,方法,访问符,属性或参数上,是一种在不改变原类和使用继承的情况下,动态的扩展对象功能。 装饰器使用expression形式,其中expression必须…...
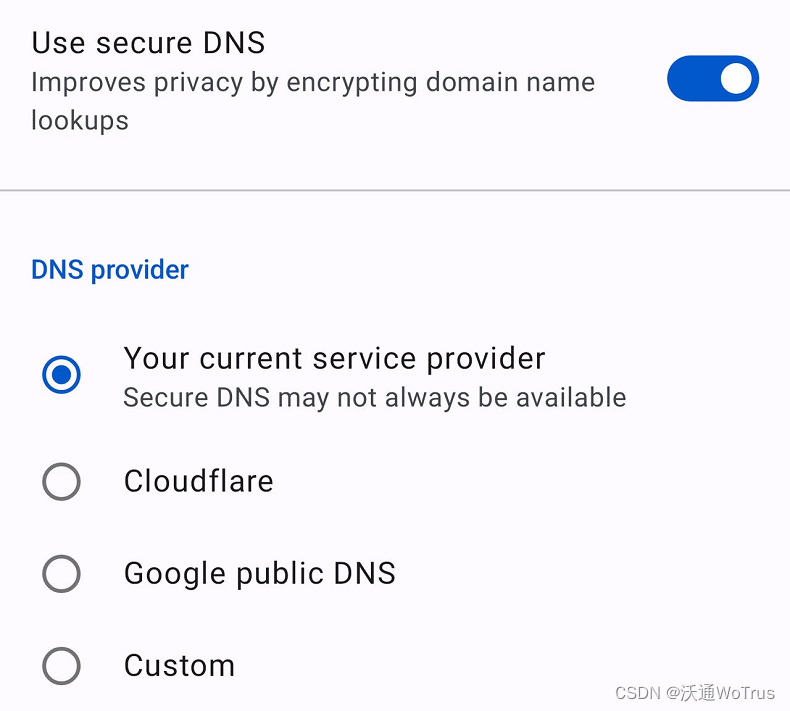
如何在 Opera 中启用DNS over HTTPS
DNS over HTTPS(基于HTTPS的DNS)是一种更安全的浏览方式,但大多数 Web 浏览器默认情况下不启用它。了解如何在 Opera 浏览器中启用该功能。 您可能不知道这一点,但您的网络浏览器并不像您希望的那样私密或安全。您会看到ÿ…...

STM32 F103C8T6学习笔记13:IIC通信—AHT10温湿度传感器模块
今日学习一下这款AHT10 温湿度传感器模块,给我的OLED手环添加上测温湿度的功能。 文章提供源码、测试工程下载、测试效果图。 目录 AHT10温湿度传感器: 特性: 连接方式: 适用场所范围: 程序设计: 设…...

QT基础使用:组件和代码关联(信号和槽)
自动关联 ui文件在设计环境下,能看到的组件可以使用鼠标右键选择“转到槽”就是开始组件和动作关联。 在自动关联这个过程中软件自动动作的部分 需要对前面头文件进行保存,才能使得声明的函数能够使用。为了方便,自动关联时先对所有文件…...
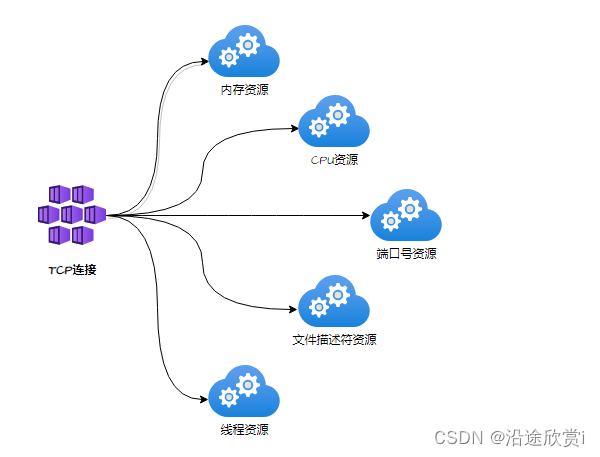
TCP最大连接数问题总结
最大TCP连接数量限制有:可用端口号数量、文件描述符数量、线程、内存、CPU等。每个TCP连接都需要以下资源,如图所示: 1、可用端口号限制 Q:一台主机可以有多少端口号?端口号与TCP连接?是否能修改&#x…...

【Docker】云原生利用Docker确保环境安全、部署的安全性、安全问题的主要表现和新兴技术产生
前言 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。 云原生利用Docker确保环境安全、部署的…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...