Java——HashMap和HashTable的区别
Java——HashMap和HashTable的区别
- Java HashMap和HashTable的区别
- 1. 继承的父类
- 2. 线程安全性
- 3. null值问题
- 4. 初始容量及扩容方式
- 5. 遍历方式
- 6. 计算`hash`值方式
Java HashMap和HashTable的区别
1. 继承的父类
都实现了Map、Cloneable(可复制)、Serializable(可序列化)接口。
HashMap: 继承自AbstractMap类。
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {}
HashTable: 继承自Dictionary类。
public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, java.io.Serializable {}
2. 线程安全性
HashMap: 线程不安全,效率高。在多线程并发的环境下,可能会产生死循环,数据覆盖等问题。
参考:
https://www.jianshu.com/p/e2f75c8cce01
https://www.cnblogs.com/developer_chan/p/10450908.html
HashTable: 线程安全,效率低。
3. null值问题
HashMap: 允许null值作为key或value。只有一个key可以为null,可以多个null为value.
Map<Integer, Integer> map = new HashMap<>();
map.put(null, 12);
System.out.println(map.get(null)); // 12
map.put(1, null);
map.put(2, null);
System.out.println(map.get(1)); // null
System.out.println(map.get(2)); // null
HashTable: 不允许null值作为key或value
Hashtable<Integer, Integer> hashtable = new Hashtable<>();
hashtable.put(null, 12); // java.lang.NullPointerException
hashtable.put(1, null); // java.lang.NullPointerException
4. 初始容量及扩容方式
HashMap: hash数组默认大小为16,扩容方式:16 * 2
/*** The default initial capacity - MUST be a power of two.*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** Initializes or doubles table size. If null, allocates in* accord with initial capacity target held in field threshold.* Otherwise, because we are using power-of-two expansion, the* elements from each bin must either stay at same index, or move* with a power of two offset in the new table.** @return the table*/
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)// 将阈值扩大为2倍newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaults// 当threshold的为0的使用默认的容量,也就是16newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})// 新建一个数组长度为原来2倍的数组Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order//HashMap在JDK1.8的时候改善了扩容机制,原数组索引i上的链表不需要再反转。// 扩容之后的索引位置只能是i或者i+oldCap(原数组的长度)// 所以我们只需要看hashcode新增的bit为0或者1。// 假如是0扩容之后就在新数组索引i位置,新增为1,就在索引i+oldCap位置Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// 新增bit为0,扩容之后在新数组的索引不变if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else { //新增bit为1,扩容之后在新数组索引变为i+oldCap(原数组的长度)if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) { loTail.next = null;//数组索引位置不变,插入原索引位置newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;//数组索引位置变化为j + oldCapnewTab[j + oldCap] = hiHead;}}}}}return newTab;
}
HashTable: hash数组默认大小为11,扩容方式:old * 2 + 1
/*** Increases the capacity of and internally reorganizes this* hashtable, in order to accommodate and access its entries more* efficiently. This method is called automatically when the* number of keys in the hashtable exceeds this hashtable's capacity* and load factor.*/
@SuppressWarnings("unchecked")
protected void rehash() {int oldCapacity = table.length;Entry<?,?>[] oldMap = table;// overflow-conscious code// 扩容为 old * 2 + 1int newCapacity = (oldCapacity << 1) + 1;if (newCapacity - MAX_ARRAY_SIZE > 0) {if (oldCapacity == MAX_ARRAY_SIZE)// Keep running with MAX_ARRAY_SIZE bucketsreturn;newCapacity = MAX_ARRAY_SIZE;}// 新建长度为old * 2 + 1的数组Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];modCount++;threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);table = newMap;for (int i = oldCapacity ; i-- > 0 ;) {for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {Entry<K,V> e = old;old = old.next;int index = (e.hash & 0x7FFFFFFF) % newCapacity;// 使用头插法将链表反序e.next = (Entry<K,V>)newMap[index];newMap[index] = e;}}
}
5. 遍历方式
Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式。
HashMap实现 Iterator,支持fast-fail,当有其它线程改变了HashMap的结构(增加,删除,修改元素),将会抛出ConcurrentModificationException。不过,通过Iterator的remove()方法移除元素则不会抛出ConcurrentModificationException异常。Hashtable的Iterator遍历支持fast-fail,用 Enumeration不支持fast-fail。
6. 计算hash值方式
HashMap: 根据元素的key计算出一个hash值,然后再用这个hash值来计算得到最终的位置。
HashMap为了提高计算效率,将哈希表的大小固定为了2的幂,这样在取模预算时,不需要做除法,只需要做位运算。效率虽然提高了,但是hash冲突却也增加了。因为它得出的hash值的低位相同的概率比较高,而计算位运算为了解决这个问题,HashMap重新根据hashcode计算hash值后,又对hash值做了一些运算来打散数据。使得取得的位置更加分散,从而减少了hash冲突。当然了,为了高效,HashMap只做了一些简单的位处理。从而不至于把使用2的幂次方带来的效率提升给抵消掉。例如通过h ^ (h >>> 16)无符号位右移。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}// 类似的原理 (table.length-1) & hash(key)
public native int hashCode();
HashTable: Hashtable直接使用key对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数法来获得最终的位置。然而除法运算是非常耗费时间的,效率很低。
public synchronized V put(K key, V value) {// Make sure the value is not nullif (value == null) {throw new NullPointerException();}// Makes sure the key is not already in the hashtable.Entry<?,?> tab[] = table;// 直接使用 key对象的 hashcodeint hash = key.hashCode();// 0x7FFFFFFF转换为10进制之后是Intger.MAX_VALUE,也就是2^31 - 1int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")Entry<K,V> entry = (Entry<K,V>)tab[index];for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}addEntry(hash, key, value, index);return null;
}
相关文章:

Java——HashMap和HashTable的区别
Java——HashMap和HashTable的区别 Java HashMap和HashTable的区别1. 继承的父类2. 线程安全性3. null值问题4. 初始容量及扩容方式5. 遍历方式6. 计算hash值方式 Java HashMap和HashTable的区别 1. 继承的父类 都实现了Map、Cloneable(可复制)、Seria…...
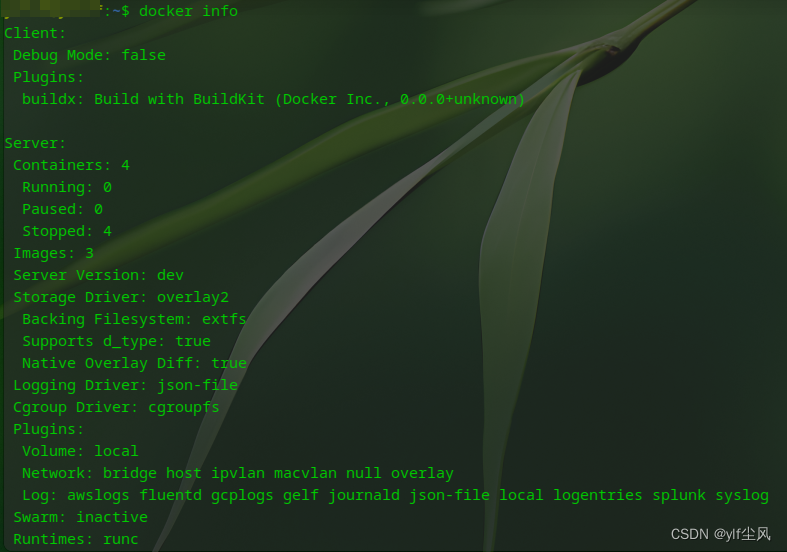
Docker去除sudo权限
Docker去除sudo权限 使用docker命令时,每次都要sudo提权,否则就会报错提示无权限。 1.查看docker用户组及成员 sudo cat /etc/group | grep docker2.添加docker用户组 sudo groupadd docker3.添加用户到docker组 sudo gpasswd -a ${USER} docker4.增…...

【ROS系统】Ubuntu22.04系统中安装ROS2系统_ubuntu 安装ros2_GoesM
【ROS系统】Ubuntu22.04系统中安装ROS2系统_ubuntu 安装ros2_GoesM Excerpt ROS仿真、专为自动驾驶研发提供的系统平台_ubuntu 安装ros2 参考博客:ROS 安装详细教程 —— Ubuntu22.0.4 LTS 安装 Part 0. 准备 首先,我们需要一个Ubuntu系统。 Part 1. …...
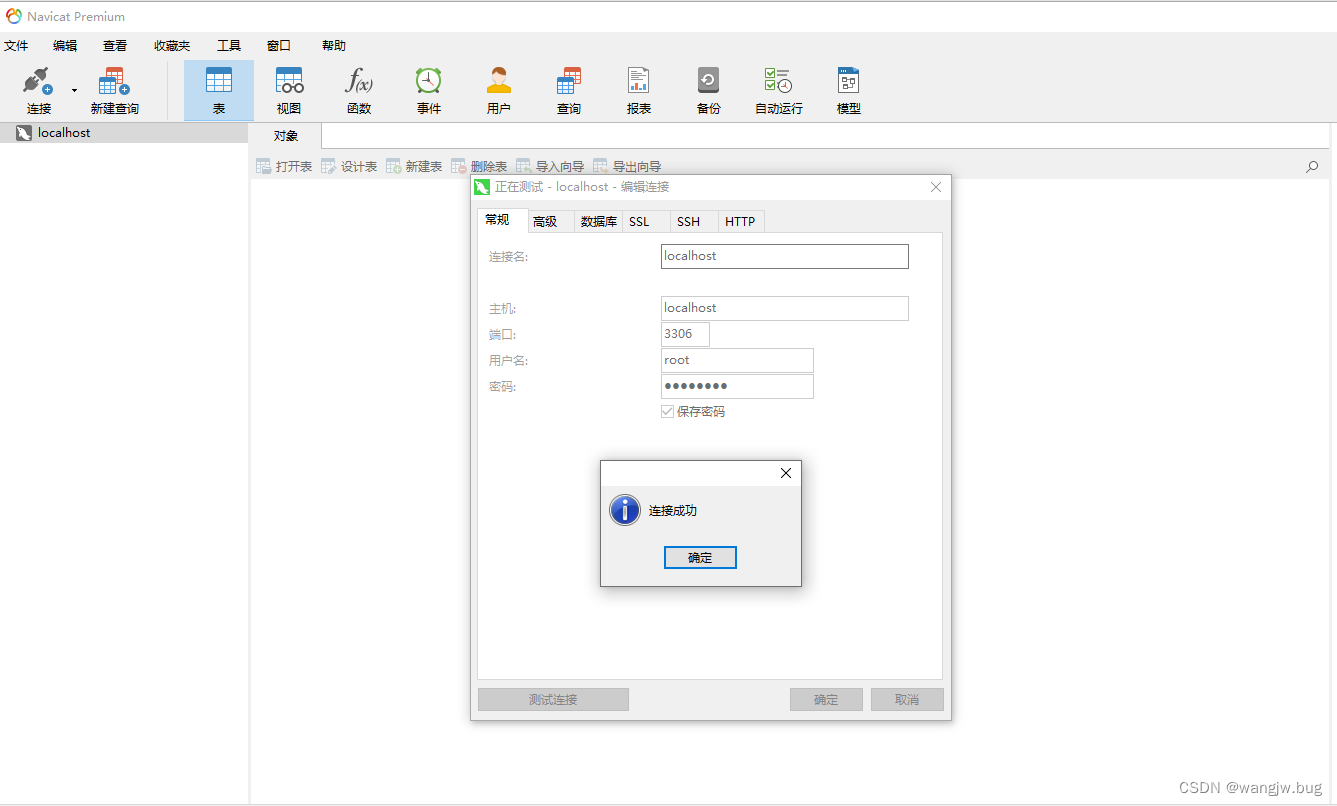
MySQL8.0.22安装过程记录(个人笔记)
1.点击下载MySQL 2.解压到本地磁盘(注意路径中不要有中文) 3.在解压目录创建my.ini文件 文件内容为 [mysql] # 设置mysql客户端默认字符集 default-character-setutf8[mysqld] # 设置端口 port 3306 # 设计mysql的安装路径 basedirE:\01.app\05.Tool…...

Python中pip和conda的爱恨情仇
在使用pip和conda时,是否也有过以下的疑惑??? 目前只总结了以下常见的几种混淆,如有学者还有其它疑惑,欢迎留言讨论,我会解答更新,帮助自己理清的同时,也帮助其他同样困…...
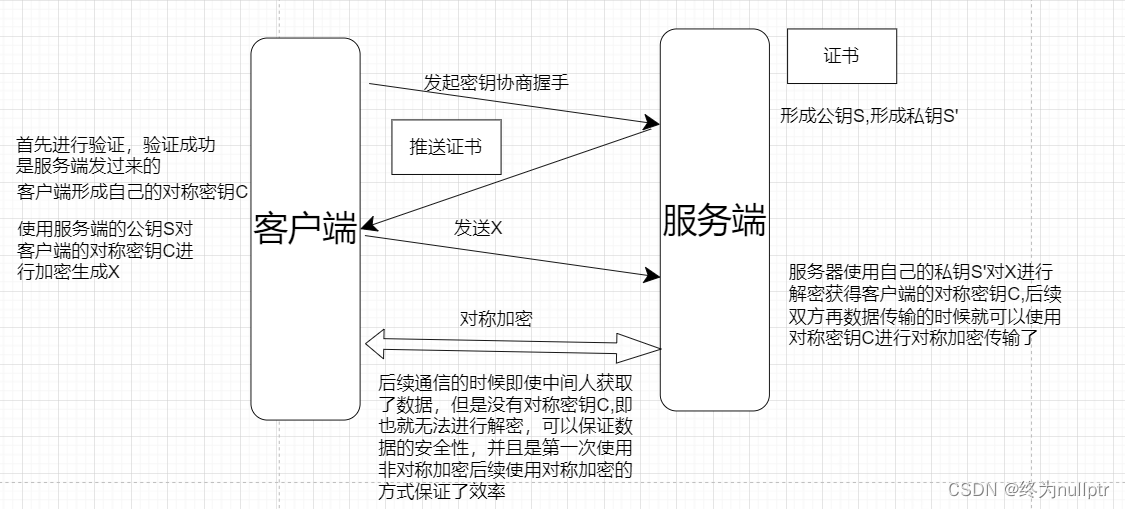
HTTPS协议原理
目录 前言 1.理解加密和解密 2.为什么要加密 3.常见的加密方式 3.1对称加密 3.2非对称加密 4.数据摘要和数据指纹 5. 数字签名 6.HTTPS的加密策略 6.1只使用对称加密 6.2使用非对称加密 6.2.1服务端使用非对称加密 6.2.2双方都使用非对称加密 6.3对称加密非对称加…...

C语言每日一练------Day(6)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今日练习题关键字:整数转换 异或 💓博主csdn个人主页:小小unicorn…...
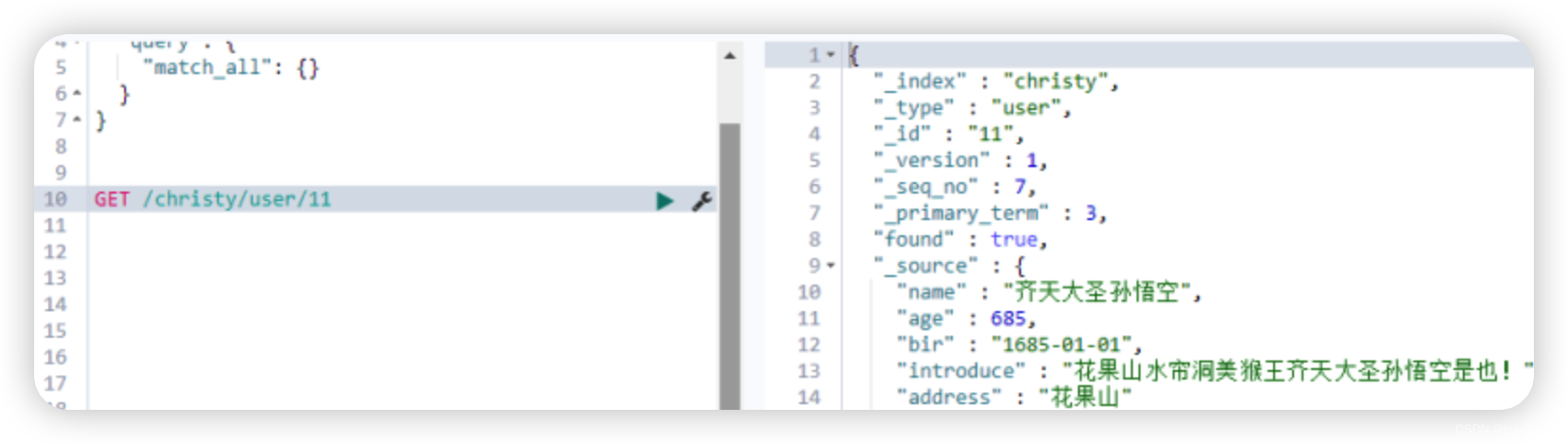
springboot中使用ElasticSearch
引入依赖 修改我们的pom.xml,加入spring-boot-starter-data-elasticsearch <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>编写配…...
十二、集合(2)
本章概要 添加元素组集合的打印列表 List 添加元素组 在 java.util 包中的 Arrays 和 Collections 类中都有很多实用的方法,可以在一个 Collection 中添加一组元素。 Arrays.asList() 方法接受一个数组或是逗号分隔的元素列表(使用可变参数ÿ…...
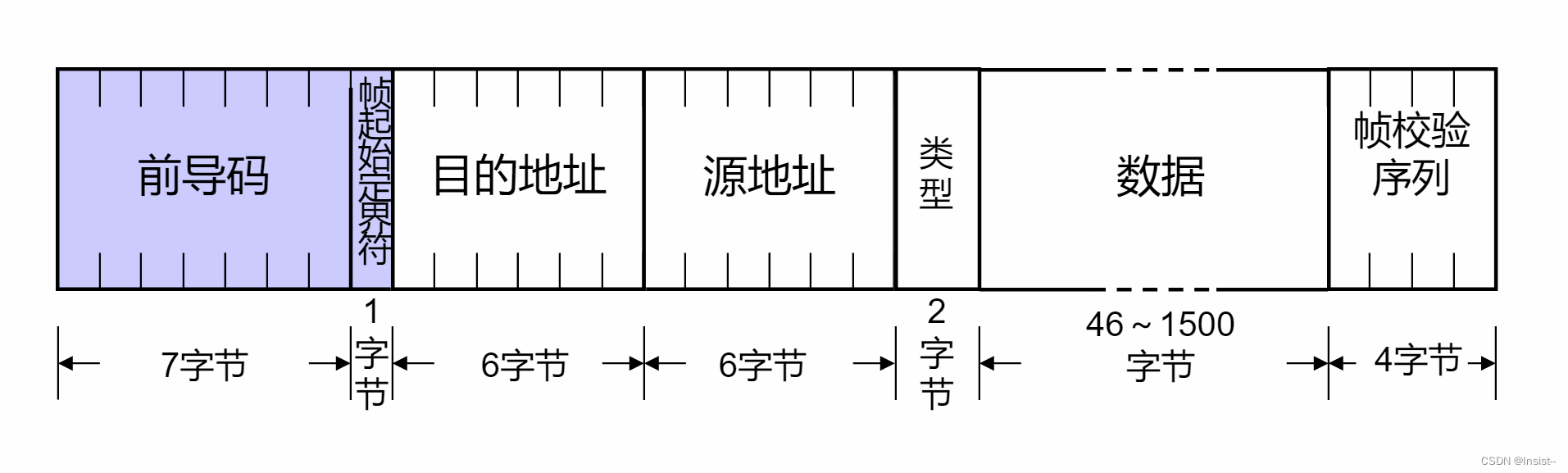
【网络设备】交换机的概念、工作原理、功能以及以太网帧格式
个人主页:insist--个人主页 本文专栏:网络基础——带你走进网络世界 本专栏会持续更新网络基础知识,希望大家多多支持,让我们一起探索这个神奇而广阔的网络世界。 目录 一、认识交换机 二、交换机的主要功能 1、数…...
研磨设计模式day11观察者模式
目录 场景 代码示例 定义 观察者模式的优缺点 本质 何时选用 简单变型-区别对待观察者 场景 我是一家报社,每当我发布一个新的报纸时,所有订阅我家报社的读者都可以接收到 代码示例 报纸对象 package day11观察者模式;import java.util.Observ…...

第八周第二天学习总结 | MySQL入门及练习学习第四天
实操练习: 1.建立一个员工表和与之对应的部门表 2.建立外键约束 3.使用多表查询,直接查询部门表和员工表 发现:有很多多余的因笛卡尔乘积而带来的多余输出内容 我想要的到简单明了的数据结果,要消除多于因笛卡尔乘积带来的输出…...

WPF数据转换
在基本绑定中,信息从源到目标的传递过程中没有任何变化。这看起来是符合逻辑的,但我们并不总是希望出现这种行为。通常,数据源使用的是低级表达方式,我们可能不希望直接在用户界面使用这种低级表达方式。WPF提供了两个工具&#x…...

《Go 语言第一课》课程学习笔记(十三)
方法 认识 Go 方法 Go 语言从设计伊始,就不支持经典的面向对象语法元素,比如类、对象、继承,等等,但 Go 语言仍保留了名为“方法(method)”的语法元素。当然,Go 语言中的方法和面向对象中的方…...

基于RUM高效治理网站用户体验入门-价值篇
用户体验 用户体验基本包含访问网站的性能、可用性和正确性。通俗的讲,就是一把通过用户访问测量【设计者】意图的尺子。 本文目的 网站如何传递出设计者的意图,可能页面加载时间太长、或者页面在用户的浏览器中渲染时间太慢,或者第三方设备…...

Unity之Photon PUN2开发多人游戏如何实现组队功能
前言 Photon Unity Networking 2 (PUN2) 是一款基于Photon Cloud的Unity多人游戏开发框架。它提供了一系列易于使用的API和工具,使开发者可以快速构建多人戏,并轻松处理多人游戏中的网络同步、房间管理、玩家匹配等问题。 我们在查看Pun2的Demo时,会发现Demo中自带了一个简…...
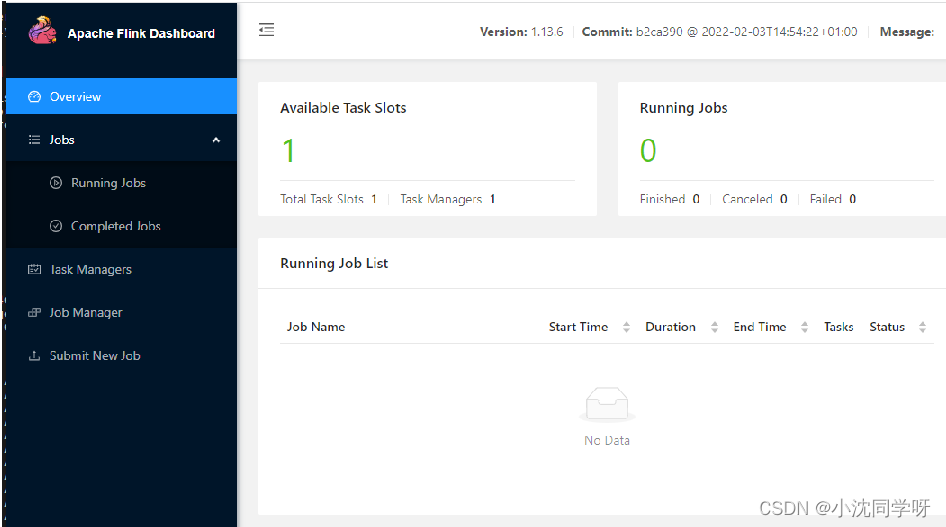
大数据Flink简介与架构剖析并搭建基础运行环境
文章目录 前言Flink 简介Flink 集群剖析Flink应用场景Flink基础运行环境搭建Docker安装docker-compose文件编写创建并运行容器访问Flink web界面 前言 前面我们分别介绍了大数据计算框架Hadoop与Spark,虽然他们有的有着良好的分布式文件系统和分布式计算引擎,有的有…...
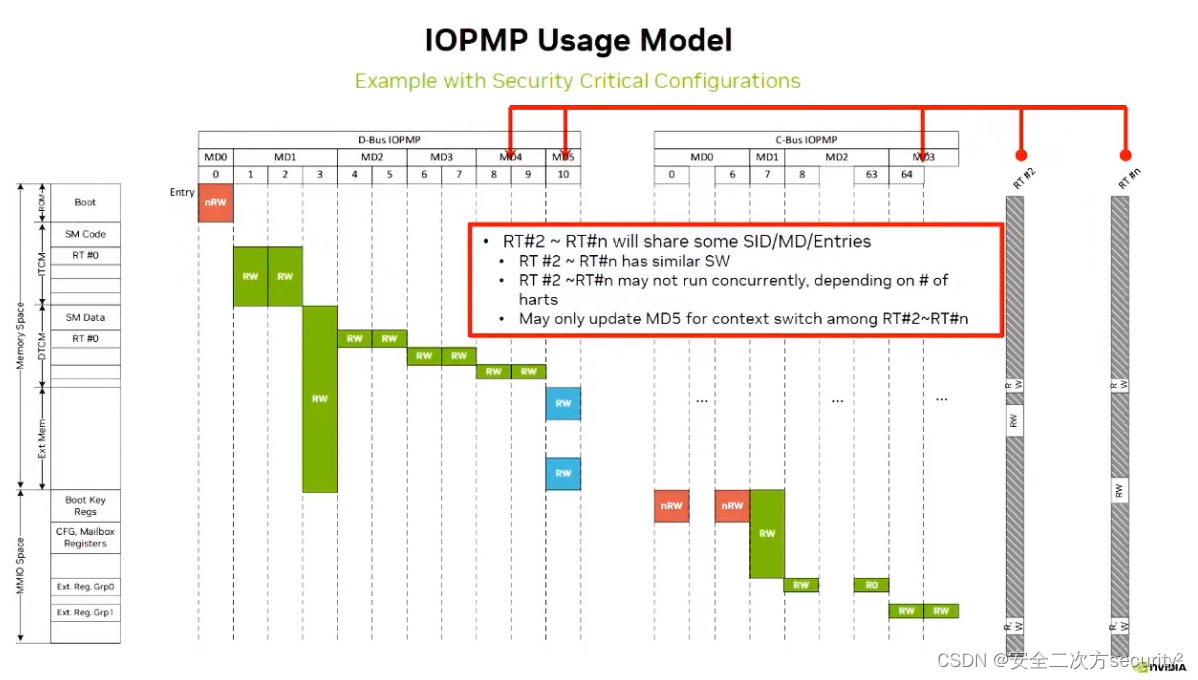
RISC-V IOPMP实际用例-Rapid-k模型在NVIDIA上的应用
安全之安全(security)博客目录导读 2023 RISC-V中国峰会 安全相关议题汇总 说明:本文参考RISC-V 2023中国峰会如下议题,版权归原作者所有。...
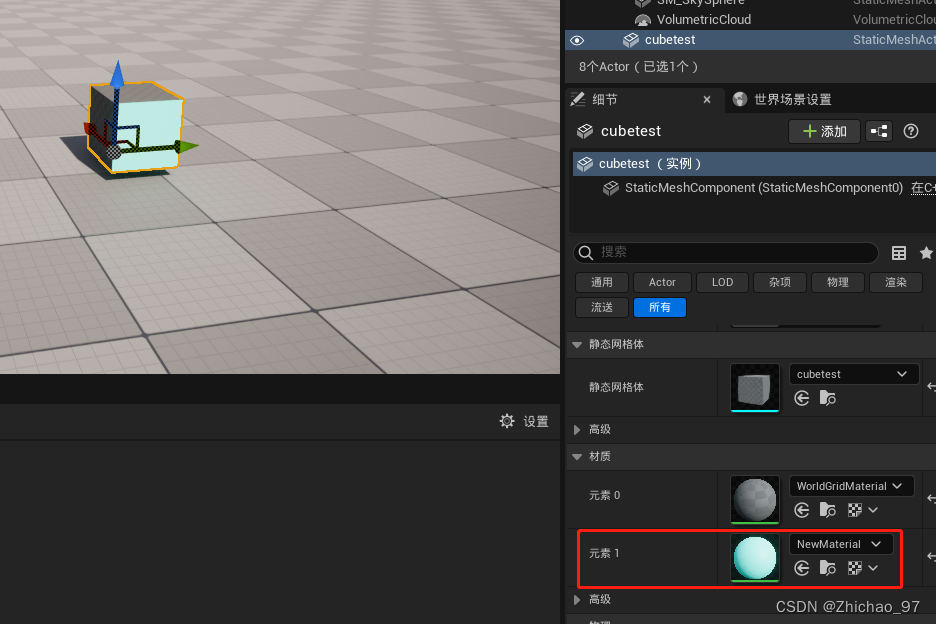
【UE5】给模型指定面添加自定义材质
实现步骤 1. 首先我们向UE中导入一个简单的模型,可以看到目前该模型的材质插槽只有一个,当我们修改材质时会使得模型整体的材质全部改变,如果我们只想改变模型的某些面的材质就需要继续做后续操作。 2. 选择建模模式 3. 在模式工具栏中点击…...

mall:redis项目源码解析
文章目录 一、mall开源项目1.1 来源1.2 项目转移1.3 项目克隆 二、Redis 非关系型数据库2.1 Redis简介2.2 分布式后端项目的使用流程2.3 分布式后端项目的使用场景2.4 常见的缓存问题 三、源码解析3.1 集成与配置3.1.1 导入依赖3.1.2 添加配置3.1.3 全局跨域配置 3.2 Redis测试…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

ubuntu22.04 安装docker 和docker-compose
首先你要确保没有docker环境或者使用命令删掉docker sudo apt-get remove docker docker-engine docker.io containerd runc安装docker 更新软件环境 sudo apt update sudo apt upgrade下载docker依赖和GPG 密钥 # 依赖 apt-get install ca-certificates curl gnupg lsb-rel…...