Oracle的学习心得和知识总结(二十九)|Oracle数据库数据库回放功能之论文三翻译及学习
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Oracle Real Application Testing 官网首页,点击前往
7、Oracle 21C RAT Testing Guide,点击前往
8、Oracle Database 19c:Real Application Testing Overview,点击前往
9、数据库回放白皮书 11g,点击前往
10、论文三 原文地址,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
Oracle数据库数据库回放功能之论文三翻译及学习
- 文章快速说明索引
- 摘要
- 类别和主题描述符
- 一般条款
- 关键词
- 介绍
- 真正的测试
- 测试支持
- 捕获生产工作负载
- 重放生产工作负载
- 用例
- 捕获
- 捕获点
- 工作负载源
- 捕获代理
- 工作负载内容
- 开销
- 过滤器
- 重放
- 概念
- 重放测试成功
- 事务模型
- 时间模型
- 数据库重放架构
- 捕获处理
- 工作负载驱动程序
- 基于SCN的同步
- 重放时数据替换
- 重放分歧
- 重放选项
- 重放报告
- 案例分析
- 方法
- 结果
- 变革影响评估
- 捕获开销
- 事务模型
- 相关工作
- 结论
- 参考

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!
学习内容:(详见目录)
1、Oracle数据库数据库回放功能之论文三翻译及学习
学习时间:
2023年08月26日 00:34:57
学习产出:
1、Oracle数据库数据库回放功能之论文三翻译及学习
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();version
-----------------------------------------------------------------------------PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0Version 19.3.0.0.0SQL>
#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)mysql>
摘要
本文介绍了 Oracle Database Replay,这是一种测试 信息系统的关系数据库管理系统 组件更改(软件升级、硬件更改等)的新颖方法。数据库重放使测试系统能够承受真实的生产系统工作负载,这有助于 在生产系统上实施计划的更改之前 识别所有潜在问题。可以以最小的开销捕获生产数据库系统的任何有趣期间的工作负载。
捕获的工作负载可用于驱动测试系统,同时保持实际生产工作负载的并发性和负载特性。因此,使用数据库重放的测试结果可以 在应用这些更改之前确定更改对生产系统的影响 提供非常高的保证。本文介绍了数据库重放的体系结构以及证明其作为测试方法的有用性的实验结果。
类别和主题描述符
H.2.m [数据库管理]:杂项
一般条款
管理、测量、绩效、验证。
关键词
捕获、数据库、记录、重放、测试。
介绍
大型关键业务应用程序非常复杂,并且负载和使用模式变化很大。同时他们还期望在响应时间、吞吐量、正常运行时间和可用性方面提供一定的服务保证。为了保持竞争力并应对不断增长的需求,大型信息系统的运营商努力通过部署最新技术来保持其系统的最新状态。信息技术的不断进步要求变化的速度不断加快。
对生产系统进行任何更改(例如升级数据库或修改配置)都需要进行广泛的测试和验证,然后才能应用这些更改。为了在生产系统中实施更改之前有信心,需要将测试系统暴露在与生产环境中经历的工作负载非常相似的工作负载中。就目前的技术而言,接近实际测试几乎是不可能的。当前的测试方法通常无法预测经常困扰生产系统变化的问题。因此,在大多数信息系统环境中,生产系统的任何改变都是非常不情愿的。
在几乎所有 IT 环境中,关系数据库管理系统 (RDBMS) 都发挥着重要作用:它为企业中几乎所有数据提供安全的事务存储和快速可扩展的检索。因此,安全地执行 RDBMS 组件更改的能力至关重要。随着企业中典型数据规模的不断扩大,以及新的需求对 RDBMS 提出了新的要求,生产系统需要对其数据库系统进行频繁的更改。一些可能的更改包括:
- RDBMS 的软件升级
- 硬件或操作系统更改(例如从单个主机迁移到集群系统)
- 数据物理组织的变化(添加或删除索引)
广泛的测试通常无法发现很多问题。因此,由于新的错误、不期望的查询计划更改和新的资源争用点,更改经常会导致问题。
与 RDBMS 更改相关的问题以及由此导致的DBA们不愿意实施这些更改是当前测试过程的缺陷造成的。 当前测试在许多方面失败的主要原因之一是无法使测试系统承受实际的生产工作负载。测试 RDBMS 更改的常见方法如下:
- 试图模仿生产系统场景的特制测试脚本:这些脚本要么是手动编写的,要么是由负载生成工具(例如[8])生成的。此方法无法重现生产工作负载的并发特征
- 真实用户测试:真实用户被要求像使用生产系统一样使用测试系统,希望在测试过程中暴露潜在的问题。这种方法是随机的、耗时的,并且无法重现生产环境中周期性变化的负载模式
- 模拟:为像 RDBMS 这样的复杂系统定义适当的模拟模型几乎是不可能的。因此,该方法仅适用于较小规模的系统
Oracle Database Replay解决了真实数据库测试的问题。它允许记录生产系统上的生产工作负载,同时对性能影响最小。 捕获的工作负载包含捕获期间向 RDBMS 发出的所有请求以及所有并发和事务信息。然后,人们可以使用捕获的工作负载来驱动任何测试系统并在生产中实施之前测试任何更改。Database Replay的主要贡献在于:利用捕获的工作负载,它可以准确地重现测试系统上生产工作负载的并发和负载特征。因此,在使用实际工作负载进行测试后,数据库管理员可以确信在生产 RDBMS 中实施更改时不会出现任何意外。
本文的结构如下:
- 首先概述了数据库重放的测试工作流程和方法
- 然后详细介绍了捕获基础设施的架构
- 然后介绍了重放基础设施的架构
- 然后介绍了使用数据库重放的案例研究
- 然后概述了相关工作
- 最后总结了数据库重放的演示
真正的测试
现代信息系统通常包含两个不同的环境:生产系统和测试系统。生产系统是企业的生命线,肩负着服务于企业信息技术需求的重任。没有在测试系统上进行广泛测试,任何更改都不应应用于任何实时生产系统。测试系统的设置是为了准确地反映生产系统的架构和设置,以便能够进行真实的测试。本节概述如何将Database Replay用作测试工具。
测试支持
对信息基础设施的RDBMS组件的任何更改都可以使用Database Replay进行测试。
-
例如,可以测试RDBMS上的以下修改:RDBMS软件升级和补丁、模式更改(新的索引和数据分区方案)和配置更改(从更改初始化参数到从单个主机设置移动到集群数据库)
-
此外,RDBMS层下面的以下软件或硬件更改也可以使用Database Replay进行测试:操作系统升级或操作系统更改(例如,从windows迁移到linux),硬件更改(例如,新的cpu,更多的内存)和存储系统更改
-
不能测试的更改是RDBMS之上的任何更改,例如对中间层或应用程序客户端的更改
捕获生产工作负载
测试的最佳工作负载是实际的生产工作负载。Oracle 11g 允许任何正在运行的 RDBMS 实例开始捕获传入的工作负载。用户需要选择一个感兴趣的常规业务操作时段,为工作负载找到足够的磁盘空间并开始捕获工作负载。工作负载存储在操作系统文件中用户指定的目录中。对生产系统的影响很小(参见第 3 节),并且从应用程序的角度来看,RDBMS 继续正常运行。即使在捕获错误或磁盘空间不足的情况下,生产系统也不会受到影响。
可以使用工作负载过滤器的定义来微调捕获。用户可以通过设置会话属性、用户 ID 和其他工作负载特定属性的过滤器来指定要在捕获的工作负载中排除或包含的工作负载部分。用户还可以 指定应捕获工作负载的时间 或者 手动停止捕获。用户完成捕获后,他们可以将捕获的工作负载转移到测试系统,在那里可以开始真正的测试。
重放生产工作负载
生产工作负载的重放旨在对测试系统上的 RDBMS 施加压力,以确定测试系统配置是否适合在生产环境中使用。一般来说,测试由 4 个不同的阶段组成:
- 设置测试系统
- 定义测试工作负载
- 运行工作负载
- 分析结果
使用数据库重放时,步骤 2 是不必要的,因为工作负载已明确定义:它是在生产系统中捕获的。因此,测试开发人员不需要了解应用程序并花时间编写测试代码,这节省了 RDBMS 测试中通常非常耗时的阶段。
在测试系统设置开始时,数据库状态需要恢复到逻辑上与捕获开始时相同的状态。有多种工具可以实现此目的,因为备份/恢复是最容易理解的 RDBMS 技术之一,因此我们不会在本文中详细介绍此过程。预处理:重放开始之前的最后一步是处理工作负载(请参阅第 4.2.1 节)。这将创建重放所需的必要元数据,并且只需执行一次。然后,可以根据需要多次重放已处理的工作负载。
捕获的工作负载需要发送到测试 RDBMS。为此,我们使用一个或多个重放客户端。重放客户端是一个特殊的可执行文件,它读取捕获的工作负载并将其提交到数据库(请参阅 4.2.2),并且是 Oracle 11g RDBMS 软件的一部分。所需的重放客户端数量取决于捕获的工作负载的最大并发性,并且可以使用提供的实用程序进行估计。重放客户端替换捕获期间存在的原始客户端(例如应用程序中间层)。
启动重放客户端后,用户可以开始重放。重放是使用存储过程定义的 API 进行控制的。这里可以看一下本人之前的博客:
- Oracle的学习心得和知识总结(十四)|Oracle数据库Real Application Testing之DBMS_WORKLOAD_CAPTURE包技术详解,点击前往
- Oracle的学习心得和知识总结(十五)|Oracle数据库Real Application Testing之DBMS_WORKLOAD_REPLAY包技术详解,点击前往
- …
因此,要启动重放,用户需要连接到 RDBMS 并调用适当的存储过程。然后,服务器向所有连接的客户端发送一条消息,以便它们开始发出工作负载。在重放期间,重放客户端读取捕获的工作负载并将其转换为对数据库的适当请求。RDBMS 为每个客户端分配一部分工作负载。所有重放客户端生成的聚合工作负载模拟了生产工作负载。
例如,如果在捕获期间有 10000 个用户连接到 RDBMS,则在重放期间,这 10000 个用户将按照相同的连接和请求模式进行连接。因此,测试 RDBMS 在捕获期间承受与生产系统相同的负载和请求率。此外,RDBMS 通过维护捕获期间看到的数据依赖性来确保重放的请求执行有意义的工作(请参阅第 4.2.3 节)。例如,如果请求在捕获期间更新了 10000 行,则在重放期间,RDBMS 将确保该请求在插入这 10000 行的上一个请求之后执行。结果是,使用捕获和重放测试可以使测试系统承受生产工作负载并执行实际测试。
当重放正在进行时,RDBMS 仍然可以正常访问。这意味着所有可用的性能监控工具(例如 ADDM 和 ASH [12])都可用于在重放期间监控 RDBMS。此外,额外的工作负载可以与重放并行执行,以进一步加载服务器。重放可以随时停止,也可以运行直至完成,直到消耗掉捕获的工作负载。重放完成后,RDBMS 会生成报告,帮助确定重放的质量并比较捕获和重放的关键点。可以使用相同的捕获工作负载重复执行重放。显然,数据库状态必须在每次重放之前适当恢复。

用例
变更影响测试 是数据库捕获和重放测试最有用的测试用例之一。RDBMS 层或以下的任何可想到的更改都可以在实施之前进行可靠的测试。一个非常重要的用例是升级测试。人们可以针对 Oracle 11g 测试系统重放 Oracle 10g 生产工作负载,以便在升级生产服务器之前发现问题。另一个测试应用是将服务器硬件从单实例系统更改为集群系统时。
可以针对集群数据库以更高的请求速率重放捕获的工作负载,以计算出性能增益。通过以高于捕获期间观察到的速率发出捕获的请求来实现增加的请求速率。从一种操作系统迁移到另一种操作系统时可以应用相同的方法。跨操作系统的测试是可能的,因为捕获的工作负载是独立于平台的。服务器问题的确定性调试是数据库重放测试的另一个很好的用例。我们的经验表明,使用数据库重放进行测试期间发现的绝大多数问题始终是可重现的。
捕获
本节详细介绍如何捕获 RDBMS 工作负载。捕获的目标是记录 RDBMS 上的所有必要活动,这些活动需要在测试系统上忠实地重现相同的活动。此外,这需要以最小的 RDBMS 开销来完成。
捕获点
捕获 RDBMS 工作负载需要对 RDBMS 的软件堆栈进行检测,或者使用某些外部组件来捕获 RDBMS 与其客户端之间的网络流量。我们选择遵循前一种方法,因为它允许捕获的数据与协议无关,并且可以记录重放所需的 RDBMS 内部数据(参见第 4.2.4 节)。此外,所有捕获探针capture probes都放置在 RDBMS 软件堆栈中的客户端-服务器协议层下方。这确保了所有捕获的数据都是独立于协议和平台的。
工作负载源
RDBMS 工作负载可分为 2 个基本类别:
- 外部客户端请求
- 内部客户端请求
外部客户端是应用程序或应用程序服务器中间层。来自此类客户端的所有活动都会被捕获。内部客户端被视为后台进程,例如维护任务或调度程序作业。不会捕获来自这些客户端的工作负载,因为它预计会在重放期间出现。
例如,如果客户端发出调度作业的请求,则该请求将被捕获,但调度作业的执行不会被捕获。稍后,在重放期间,作业的调度将被重放,这将导致调度的作业在重放系统中被执行。如果我们捕获了计划的作业,我们将在重放系统上运行同一作业的 2 个实例。
捕获代理
RDBMS 内核的工具构成了捕获基础设施。它提供捕获服务,供记录工作负载的实体(捕获代理)使用。更具体地说,捕获代理是为外部客户端请求提供服务的 Oracle 服务器进程。由于 Oracle 服务器进程捕获自身,因此不需要额外的捕获代理。启用工作负载捕获后,服务器进程使用捕获服务将工作负载记录到普通操作系统文件(捕获文件)中。所有进程都写入一个目录,即捕获目录。出于性能原因,捕获的工作负载不会存储在数据库中,因为这需要生成撤消/重做信息。
捕获基础设施还设计用于在集群配置中与 Oracle RDBMS 配合使用。仅在启动和停止时需要协调。在这两种情况下,跨实例消息传递用于启动和停止所有实例上的捕获。集群环境中的一个复杂问题源于捕获目录可能无法共享这一事实。在这种情况下,所有实例的所有目录的内容必须合并到一个目录中以供重放。
工作负载内容
捕获一段时间内的 RDBMS 工作负载会为每个 RDBMS 服务器进程生成一个文件。每个捕获的进程文件(捕获文件)包含来自 1 个或多个数据库会话的工作负载。数据库会话是用户登录和注销之间的一组交互。多个会话可以复用到 1 个数据库服务器进程中。每个会话由连续的服务请求或数据库调用组成。SQL 查询、表更新、提交以及从大对象读取的调用都是数据库调用的示例。
数据库调用分为两类:每个捕获的调用要么是提交操作,要么是非提交操作。
提交操作是提交捕获会话已完成的工作的调用。提交操作的示例有:
- COMMIT
- 通过自动提交发出的insert
- CREATE TABLE 语句,该语句始终在内部提交
非提交操作是不提交任何数据的调用。非提交操作的示例有:
- SELECT 查询
- UPDATE 语句
- INSERT 语句
在重放的上下文中,提交和非提交操作之间的区别将变得更加清晰(第 4.2.3 节)。区分的基本原理是提交操作会修改数据库状态并可能影响后续调用的结果。请注意,DML 操作会修改数据库状态,但由于事务隔离,更改仅对发出该操作的会话可见。因此,任何更改数据的未提交操作都不会影响任何其他会话。
每个记录调用都包含足够的信息,可以在重放期间准确再现call内容。这些信息可以分为三类:
- 用户数据:这是从客户端发送到 RDBMS 的数据
- 服务器响应数据:这是从服务器发送回用户的数据
- 系统数据:该数据是 RDBMS 内核的内部数据,不会返回给用户,但对于重放至关重要
捕获的大部分数据属于用户数据类别。更具体地说,此数据包含用户请求的完整 SQL 文本、所有绑定值以及所有非 SQL 请求及其参数(例如操作大对象的调用)。记录的用户数据不包含作为用户请求的一部分执行的系统 SQL(例如目录查询)。同样,我们只记录 PLSQL ([12]) 脚本的全文,而不记录作为脚本一部分执行的每个单独的用户 SQL。
从服务器发送回客户端的数据可能非常大,因为它主要包含查询结果。记录工作负载的所有查询结果是不可行的,因为这会产生很高的开销。尽管如此,我们需要捕获有关用户请求结果的足够数据,以便我们知道他们处理了多少数据以及是否有任何错误。因此,捕获的服务器响应数据包含受用户请求影响/返回的行数和错误代码。此外,由于将在第4.2.4节中说明的原因,系统特定数据(作为查询结果的一部分)被捕获。此类数据包括行标识符(无需索引即可直接访问行的 ROWID)、大对象定位器和结果集句柄。
系统数据是 RDBMS 内核内部数据,仅在重放期间需要。系统数据的一部分是定时信息。此外,捕获的系统数据包含系统更改号 (SCN),该系统更改号表征执行捕获的调用的数据库状态,并确定该调用是提交操作还是非提交操作。SCN 是一个标记,定义数据库在特定时间点的已提交版本。Oracle 为每个提交的事务分配一个唯一的 SCN。这些 SCN 用于确保数据库服务器内的隔离和读取一致性。
每个调用都包含与调用开始执行时数据库状态相对应的 SCN。该SCN称为等待SCNwait-for SCN。此外,每个提交操作都包含提交 SCN,该 SCN 与 提交操作之后和任何后续提交操作之前 的数据库状态相对应。两个 SCN 的重要性将在第 4.2.3 节中变得清晰。最后,序列生成器返回的值(以及为简单起见而省略的其他系统函数)是捕获的系统数据的一部分。这些值在重放期间使用,如第 4.2.4 节所示。

图2描述了捕获的两个典型数据库调用以及捕获的一些关键信息:
- 第一个调用是一个非提交操作,对应于一个绑定的选择查询。作为该调用的一部分,我们捕获调用的开始和结束时间、调用的类型(SELECT…)、执行查询的环境SCN(等待SCN)、全文、绑定数据、该结果集的内部ID(游标号1)以及该调用获取的行数。将与重放期间的行数进行比较,以确定此调用是否在重放期间执行相同的工作
- 第二个调用是一个提交操作,它对应于一个包含更新语句和提交的PLSQL脚本。同样,捕获完整的语句文本、绑定、调用开始和结束时间。除了等待SCN之外,调用还包含提交SCN,它定义语句执行后立即的数据库状态
捕获文件是遵循自描述self-describing可扩展格式的普通二进制文件。捕获文件中的数据与平台无关,因此可以捕获在64位Linux操作系统上运行的oracle数据库的工作负载,然后在32位Windows系统上重放工作负载。此外,无论将来添加多少个新探测,该格式都自动允许向后兼容先前存在的捕获。
开销
正如预期的那样,捕获基础设施给运行的工作负载增加了一些开销。目标是使捕获开销尽可能小。为此,缓冲I/O与代码优化一起使用。此外,每个进程只捕获一次重复的数据(例如来自重复执行的SQL文本)。结果是,对于大多数工作负载,开销足够合理,因此可以在整个生产中打开捕获。此外,关键的生产系统通常是过度供应的over-provisioned,因此捕获的额外开销是可以接受的。例如,在TPC-C基准测试[18]上启用捕获只会减少大约4.5%的事务吞吐量。
捕获开销依赖于工作负载。但是,它与RDBMS执行的工作不成比例。它与为了能够重放调用而需要捕获的数据成正比。例如,如果工作负载主要由非常复杂的查询调用组成,每个查询都需要很长时间才能执行,那么开销将是最小的,因为每个时间单位捕获的数据很小:对于执行该查询的每个调用,每个会话只捕获一次复杂查询的文本。相反,如果工作负载是插入密集型的,则开销可能非常大。The reason is that each captured insert will contain all the inserted data in addition to the INSERT statement. 图3显示了开销如何根据工作负载的类型而变化:

捕获的空间要求也取决于工作负载,因此不可能进行可靠的估计。所需的空间大致等于通过网络从客户端发送到服务器的数据。由于性能开销是一个大问题,因此工作负载数据在捕获期间不会被压缩。为了估计所需的磁盘空间,可以在系统处理感兴趣的工作负载时打开一小段时间的捕获,然后推断捕获的潜在持续时间。
过滤器
捕获基础设施还提供根据工作负载属性(用户、会话 ID、集群实例编号、会话状态等)过滤特定工作负载的功能。定义的过滤器完全指定了一部分工作负载,有两种使用模式:包含模式和排除模式。如果指定了包含模式,则仅捕获过滤器指定的工作负载。否则(排除模式)不会捕获过滤器指定的工作负载。在 RDBMS 为多个独立应用程序提供服务的情况下,过滤器非常有用。在这种情况下,可以指定适当的过滤器来捕获来自一个特定应用程序的工作负载。然后可以单独测试该工作负载。
重放
Replay 的高级目标是让测试 RDBMS 承受实际的工作负载。这意味着重放将使测试系统处理具有与真实工作负载几乎相同的并发性和事务特性的负载。捕获基础设施提供所有必要数据的重放,以便在测试系统上重新创建相同的工作负载。本节在介绍Oracle 11g数据库重放的具体设计和实现之前,我们将简要介绍基本的重放概念。
概念
重放测试成功
为了确定重放是否能够实现其目标,我们需要一种衡量成功的方法。此方法的目标是确定捕获的工作负载的重放是否适合准确测试预期的更改。我们使用工作负载的三个基本特征来确定重放是否成功:
- 工作负载后的最终数据库状态
- 并发和请求率特征
- 返回给客户端的结果
如果重放从与捕获的工作负载相同的数据库状态开始、在相同的系统上运行并且在这三个工作负载特征方面表现出与捕获的工作负载相同的行为,则重放成功。
这样的重放实现了最终状态一致性、结果一致性和请求速率一致性。Such a replay achieves end state consistency, result consistency and request rate consistency.
请注意,现有技术可以创建分别实现上述每个特征的工作负载。例如,可以处理数据库的重做日志redo log并创建一个工作负载,该工作负载将实现与生成重做日志的工作负载相同的最终状态。但是,此工作负载不会有任何有意义的并发性,并且不会执行任何查询,仅执行更新。此外,这些更新是块级别的更改。因此,如果更新包含可能涉及大量处理的 WHERE 子句,则更新将会丢失。数据库重放面临的挑战是创建一个工作负载,同时保留测试系统环境中真实工作负载的所有三个特征。实际上,几乎不可能在捕获的工作负载的所有 3 个特征上实现 100% 的一致性。尽管如此,每个特性的近似值仍将为测试提供高的置信度。

事务模型
为了实现最终状态一致性和结果一致性,我们定义了重放事务模型,用于确定捕获的调用的重放顺序。该模型基于将捕获的数据库调用分类为提交操作和非提交操作。这种区别基于以下事实:提交操作会更改数据库状态并使新状态对所有后续操作可见。由于任何调用的结果都取决于数据库状态,因此重放必须确保每个调用 C 都遵循适当的提交操作,以满足结果一致性和最终数据库最终状态一致性。在当前版本的数据库重放中,适当的提交操作是整个捕获的 C 工作负载中最近的提交操作。
此外,非提交操作不需要相对于其他非提交操作进行排序。这允许两个后续提交操作之间的并发。图 4 显示了重放如何满足事务模型。例如,在调用 1 和 5 之间,调用 2、4、8 和 9 在重放期间可以按任意顺序执行,但必须在 1 之后。当然,属于同一执行线程的调用按照重放期间记录的顺序发出:9 总是在 8 之后。
当前用于数据库重放的事务模型假设每个提交操作都会影响每个后续调用。这是一个粗略模型,即使两个捕获的调用不相关,也可能会考虑它们。例如,在图 4 中,考虑调用 7 和 10。如果 10 向表 T1 提交更新,而 7 从表 T2 中进行选择,则模型将认为 7 依赖于 10,即使它们并非如此。可以使用更精细的事务模型进行数据库重放,该模型仅考虑捕获的调用之间的真实依赖关系。对于数据库重放的第一个版本,我们选择使用更简单的模型有几个原因。在捕获期间,定义事务依赖性所需的信息很小,这有利于捕获开销。
此外,在重放期间强制执行调用顺序很简单,不会对重放工作负载产生明显干扰。早期原型的实验表明,当前使用的简单事务模型足以确保数据库最终状态和结果的一致性,同时保持捕获期间观察到的请求率。
时间模型
为了满足请求率一致性,事务模型是不够的,因为它只定义了重放调用的顺序,而不是它们的时间。为了使重放能够准确地重新创建捕获期间观察到的请求速率,需要计时信息。为此,我们定义了两个不同的时间维度:
- 连接时间:这是捕获(重放)开始与捕获进程的第一个捕获调用(重放进程的重放调用)开始之间的时间。
- 思考时间:这是同一执行线程(捕获或重放的服务器进程)中调用结束与下一次调用开始之间的时间。
为了实现请求率一致性,重放必须维护每个重放进程的捕获期间观察到的连接时间,以及每个重放进程内任何连续调用对之间捕获期间观察到的思考时间,前提是调用执行时间在捕获和重放之间不发生变化。实际上,从捕获到重放,调用执行时间会有所不同。4.2.2 节描述了实践中如何维持请求率。
数据库重放架构
Oracle 11g 数据库重放功能是上一节中介绍的事务模型和时间模型的实现。在正确设置的测试系统上使用捕获的工作负载,数据库重放可实现与捕获相关的高度最终状态一致性、请求率一致性和结果一致性。本节解释这是如何实现的。
捕获处理
捕获处理是一次性读取所有捕获的工作负载并生成重放所需的元数据的操作。该元数据由四个部分组成:
- 在重放期间命令提交操作所需的数据。(SCN顺序表)
- 系统生成的值的集合,用于系统功能的重放时间模拟。(SYSID 表)
- 捕获的进程用于连接数据库的连接描述符的集合。
- 工作负载驱动程序基础设施所使用的工作负载的摘要。(连接队列)
SCN 顺序表包含与工作负载中的提交操作相对应的行。每行包含以下列:
提交 SCN(第 4.2.3 节)、调用 ID 和文件 ID
该表按提交 SCN 排序,并按照更改数据库状态的顺序包含所有提交操作。我们无法使用时间来排序提交操作的原因是实际提交可能发生在数据库调用中的任何位置。调用可以以所有可能的方式重叠,因此只有 SCN 可以确定哪个调用首先将其更改提交到数据库。该表在重放期间使用以实现事务模型。
SYSID 表包含系统生成的 id 值(第 4.2.4 节)。这些表之一包含每个调用序列值。在捕获期间,我们记录 S.NEXTVAL 和 S.CURRVAL 的返回值,其中 S 是序列生成器。这些值在重放期间使用,而不是 S.NEXTVAL 和 S.CURRVAL 的实际重放时间返回值。序列表中的每一行都包含对调用及其所属序列的引用以及此调用消耗的一系列值。一行或多行可以对应于捕获的调用。
连接描述符的集合用于在重放之前初始化连接映射表。捕获的连接描述符在重放中无效。因此,在重放开始之前,用户必须将它们映射到新的有效连接描述符。
连接队列是一个单个文件,其中包含每个捕获的进程的条目。这些条目按连接时间排序,并包含工作负载驱动程序基础结构使用的信息,如第 4.2.2 节中所述。
捕获处理是一种一次性操作(指的是:预处理),它将捕获的工作负载转换为重放文件replay files。回放文件可以任意多次回放。
工作负载驱动程序
工作负载驱动程序是 读取捕获的工作负载并在重放期间将其发送到 RDBMS 的基础设施。它由一个或多个重放客户端进程(重放客户端replay clients)组成。每个重放客户端进程(多线程应用程序)都是作为 RDBMS 发行版的一部分。每个重放客户端线程(重放线程)读取一个捕获的进程文件,并将其内容解释为对 RDBMS 的适当数据库调用。重放客户端是常规 OCI 客户端 ([12]),因此可以远程连接到 RDBMS。这使得在多个主机上启动重放客户端成为可能。工作负载驱动程序基础设施取代了捕获期间存在的任何客户端/中间clients/middle层,并负责将工作负载驱动到服务器。
捕获数据中的协议独立性使重放客户端协议的选择变得复杂。可以想象,重放客户端可以根据捕获期间使用的协议在重放期间使用多种协议。然而,这将导致多语言代码库(例如用于 JDBC 客户端代码的 Java 和用于 OCI 客户端代码的 C)具有大量代码重复,并且难以维护。
这种技术难度加上 RDBMS 中的协议特定代码不是测试的主要焦点这一事实,导致了功能重放functional replay的采用。功能重放规定每个重放的调用在 RDBMS 内执行的工作方面与捕获的调用等效,无论用于将调用从客户端发送到服务器的协议如何。因此,根据设计,重放客户端仅使用一种协议与服务器通信:Oracle 调用接口 (OCI)。每个捕获的调用都会转换为适当的 OCI 接口调用序列。
捕获的工作负载可能包含数千个文件,并且可能需要重放连接到 RDBMS 的数千个并发会话。因此,可用于驱动工作负载的重放客户端的数量需要适当扩展。为了实现可扩展性,重放客户端不会相互通信,而是由服务器进行协调。数据库重放包含一个校准实用程序,可根据工作负载并发性和可用硬件建议所需的重放客户端数量。
开始重放的过程分为两步。首先,RDBMS 处于特殊状态(准备状态),等待重放客户端连接。然后,用户通过将它们指向准备好的 RDBMS 来启动任意多个重放客户端。启动客户端后,用户无法再与其交互;客户端完全由 RDBMS 服务器控制。用户可以通过服务器 API 与 RDBMS 连接来启动重放。在重放开始时,服务器确定已连接的客户端数量,向每个客户端发送重放选项(第 4.2.6 节),并以循环方式在它们之间分发所有捕获文件。此时,每个客户端都确切地知道它将重放哪些捕获文件。然后,它将信号发送到每个重放客户端以开始发出捕获的工作负载。
工作负载驱动程序基础设施的任务是实现重放时间模型,以确保请求率的一致性。重放期间的连接时间由工作负载处理生成的连接队列决定。一旦重放开始,每个重放客户端都会扫描整个连接队列。对于队列中的每个条目,重放客户端都会检查该条目指向的捕获文件是否属于 RDBMS 分配的客户端工作负载。
如果确实如此,客户端会在适当的时间点生成一个重放线程。该线程是完全独立的,不与其他线程通信。重放线程只有在满足捕获中的连接时间指定的定时(指的是:思考时间)后才开始扫描相应的捕获文件并连接到服务器。要使用的连接端点由客户端从服务器读取的连接映射表确定。
重放线程专门维护时间模型中规定的思考时间。在连续调用之间,重放线程会休眠适当的时间,以满足其正在重放的捕获进程的捕获请求率。因此,由于每个线程努力在本地维护请求率,因此在全局范围内维护了聚合请求率要求。时间模型思考时间要求假设调用执行时间从捕获到重放没有变化。事实上,这几乎永远不会是真的。因此,重放线程维持从思考时间中减去的累积时间不足,以维持捕获的请求率。因此,如果重放调用平均速度较慢,则思考时间会缩短以维持请求速率(图 5)。
但是,如果平均调用速度更快,则思考时间不会延长,即使这与请求速率一致性相矛盾。原因是,如果测试 RDBMS 可以处理工作负载,那么让重放以更高的速率运行更适合测试目的。时间不足可能会变得如此之高,以至于需要将睡眠时间减少到零。此时重放无法维持捕获的请求速率并开始运行较慢。

基于SCN的同步
基于SCN的同步是数据库重放实现最终状态一致性和结果一致性的手段。这个基础结构驻留在RDBMS服务器中,由重放的服务器进程使用。每个捕获的调用都包含一个等待SCN,每个提交操作还包含一个提交SCN。从概念上讲,为了实现结果一致性,确保每个重放的调用C都在重放提交操作A之后执行就足够了。提交操作A是在C之前捕获的最近一次提交操作。在Oracle RDBMS中总是如此,因为没有“脏读”dirty reads。因此,SCN可以提供所需的顺序。
捕获的提交 SCN 值用于在重放期间维护重放时钟replay clock。重放时钟与模拟时钟类似,它是由特定事件推进advanced的。在重放的情况下,这些事件是提交操作。每个提交操作都会将时钟设置为其提交 SCN 和当前时钟的最大值。每个重放调用(提交和非提交操作)都会观察重放时钟。在每次调用开始时的重放期间,执行该调用的服务器进程会检查重放时钟的值。如果重放调用的等待 SCN 小于或等于重放时钟,则允许执行该调用。否则,调用将被阻止,等待时钟推进发布。当一个提交操作 A 将时钟推进到新值时,就会发生此发布。时钟值是使用捕获处理期间生成的 SCN 顺序表计算的(该表的相应部分在重放期间缓存在内存中)。
时钟的新值是通过取SCN顺序表中紧接在A之后的提交动作B的提交SCN并减去1来计算的。
/*然后,执行 A 的服务器进程将发布所有具有等待 SCN 小于或等于新时钟值的挂起调用的等待进程。Then the server process that executed A posts all waiting processes that have pending calls with a wait-for SCN less than or equal to the new value of the clock. */
请注意,重放期间的系统 SCN 不用于重放目的,因此它不必与捕获的 SCN 值匹配。
图 5 显示了在重放期间同步 2 个会话的示例。右侧显示了具有记录的 SCN 值的相应调用。SCN 值单调递增。在重放期间,调用 A12 需要比捕获期间更长的时间才能完成。这会导致调用 A22 等待,因为重放时钟仍为 10。A12 完成后,它使重放时钟为 14 并发布 A22。将 A24 的提交 SCN 减一得到 14,这是新的时钟值。同样,A15 等待 A24 发布。实际上,重放时钟机制比本示例中的更为复杂。为了说明的目的,该概念相对于实际实现进行了简化。
重放时钟保存在 RDBMS 的全局内存中。对于集群 RDBMS,每个实例都维护自己的重放时钟。这些时钟通过跨实例消息传递保持同步。从概念上讲,每个提交操作都会使用一些优化将新的重放时钟广播到所有集群实例,这些优化超出了本文的范围。请注意,在重放期间,只有来自重放客户端的会话才使用 SCN 排序基础设施。因此,即使重放正在进行,数据库仍然可用于服务常规工作负载。
数据库中的Gating calls有时可能会导致重放引发的死锁。原因是服务器可能会阻止调用 C,该调用 C 持有另一个提交操作 A 完成所需的资源(例如锁或闩锁)。如果 C 正在(传递地 transitively)等待 A 将产生的重放时钟值,则重放将挂起。为了避免重放期间出现此类挂起,后台进程会通过跟踪等待链定期检查此类死锁,并通过发布执行阻止提交操作继续的调用的进程来解决这些死锁。这种类型的死锁解决方案与 Oracle 中使用的常用死锁解决机制不同,因为所选的死锁检测受害者实际上并未被迫中止事务。相反,允许它继续而不等待重放时钟,直到它放弃它所持有的资源(通常是锁定)(即直到下一次提交),以便等待这些资源的时钟计时器可以取得进展并推进重放时钟。
重放时数据替换
理论上,实现事务模型应该足以实现最终状态一致性和结果一致性。但是,在某些情况下,重放的调用不会执行与捕获期间相同的工作。当调用包含 在重放系统中无效的系统相关数据 时,就会发生这种情况。Oracle RDBMS 中的此类数据包括行标识符 (rowids)、大对象定位符 (lob locators) 和结果引用 (ref 游标)。如果这些值是绑定值的一部分,则重放客户端会将它们重新映射到运行时正确的值。以下示例说明了运行时重新映射(图 6)。捕获作为选择列表的一部分返回给客户端的 rowid (1)。然后相同的 rowid 被捕获为内绑定 (2)。在重放期间,捕获的与 select 语句 (3) 关联的 rowid 使重放客户端期望 rowid 的重放时间值。此时,在捕获的 rowid 和重放期间看到的 rowid 之间建立了关联。当重放更新时 (4),将使用重放时间 rowid。这将使更新成功并更新员工行。
重放时数据替换也发生在服务器中。服务器介入特殊的服务器端功能,例如序列生成器。当重放调用使用序列值时,重放基础结构会查找由捕获处理生成的捕获序列值(第 4.2.1 节)。然后,重放的调用会配备与捕获期间看到的完全相同的值。如果在重放期间未更改序列值,则重放的调用很可能会使用与捕获期间使用的序列值不同的序列值,因此会出现分歧。此外,使用序列值替换可确保成功重放包含使用序列生成的数据的请求。例如,如果应用程序使用序列生成器创建了购物车 ID,则该 ID 在重放期间将是相同的。因此,在重放期间,使用此 ID 的每次更新都会成功。

重放分歧
如果出现以下情况,重放的调用将被视为分歧:
- 重放期间影响的行数与捕获期间影响的行数不同
- 如果重放期间发现错误,并且捕获期间没有错误或错误代码不同
捕获的数据不包含任何结果(第 3.4 节),因此我们无法知道重放期间的调用实际上是否具有与捕获期间相同的结果。但出于重放的目的,行计数和错误值足以指示重放的调用是否执行与其捕获的计数器部分相同的工作。此外,我们希望用户拥有应用程序级别的验证脚本来评估重放的正确性。即使使用提交排序和重放时数据替换,结果一致性也不总是可能的。存在一些极端情况,导致重放期间可能出现数据分歧。在我们试验的所有工作负载中,这些情况只出现在一小部分调用中,并且并没有使重放作为测试工具的价值失效。造成差异的一些示例原因如下:
- PLSQL 脚本内的多次提交。在这种情况下,我们将整个 PLSQL 块视为单个提交操作,并且不会在 PLSQL 块内的语句和来自其他会话的调用之间强制执行提交顺序
- PLSQL 脚本内的应用程序逻辑。PLSQL 脚本包含在重放期间可能遵循不同路径的应用程序逻辑。因此,重放的调用可以执行不同的工作。当应用程序逻辑依赖于不驻留在数据库中的数据(即一天中的时间、客户端主机名等)时尤其如此
- 捕获开始时的飞行中
in-flight会话。这些会话可能包含对捕获开始之前未提交的数据进行操作的调用。这些调用将会出现分歧,因为飞行中会话中缺失的部分将不会被重放 - 对外部实体的引用。当捕获的调用使用诸如指向远程数据库的数据库链接之类的设施时,如果远程链接不存在,则在重放期间它将失败
- 与预定作业交互。如果测试系统中执行的计划作业与某些重放会话中的相同用户数据进行交互,则可能会出现分歧,因为我们不会在计划程序作业中排序提交
在大多数实际情况下,Replay 致力于最大限度地减少重放差异。作为测试工具,我们假设由于极端情况而导致的一些差异是可以容忍的。
重放选项
在所有测试场景中,严格的最终状态一致性、请求率一致性和结果一致性可能并不总是理想的。因此,重放提供了针对每个测试用例适当调整重放行为的选项。可以打开或关闭提交顺序。在重放期间不需要最小数据分歧的情况下,无提交顺序可能是合适的。因此,绕过重放同步基础设施可以消除任何同步synchronization开销。此模式也可用于压力测试,我们不希望缓慢的提交操作来减慢本来会等待的调用。
其余三个重放选项(连接时间尺度、思考时间尺度和自动速率)调整重放的请求速率。默认情况下,连接时间比例和思考时间比例设置为 100%,这是请求率一致性所必需的。它们可以根据情况进行调整。
例如,当尝试在 4 节点 RAC 系统上重放单个实例捕获时,与单个实例设置相比,该系统可以处理高达 4 倍的请求率,可以将思考时间比例设置为 25%,从而使重播客户端发出的工作负载的请求率提高四倍。默认情况下,自动速率处于启用状态,在这种情况下,重放线程将尝试通过适当减少思考时间来维持捕获的请求速率。如果关闭自动速率,捕获的思考时间不会减少以补偿较长的执行调用。
重放报告
每次重放后,都会向用户呈现大量特定于重放的报告:一份是捕获后的报告,一份是每次重放后的报告。此外,所有广泛的性能报告(AWR、比较周期、ASH…)和oracle性能顾问(ADDM [4])都可以在重放期间或之后使用。本文的目的是展示这些报告的一般使用方式,而不是准确地详细描述它们。

捕获报告包含以下数据:捕获了多少个调用、过滤掉了总数据库工作负载的百分比、捕获期间发现了多少错误、支持重放的调用数、消耗了多少 CPU 等。重放报告的目的是使用户能够确定是否捕获了正确的工作负载,是否可以重放该工作负载。它还提供了捕获期间的简明性能摘要。
重放报告将一些关键捕获数据与相应的重放数据并置(参见图7)。这些数据包括运行时间、CPU使用情况、IO活动等。重放报告的一个部分都是专门讨论重放分歧的。报告行计数发散的平均幅度以及重放期间的新误差和变化误差。此报告的目的是帮助用户确定重放的工作负载是否是有效的测试。例如,如果数据差异幅度太高,那么重放的工作负载行为就不太可能指示测试系统在生产环境中的执行情况。然而,如果重放差异非常小,但是经过的时间差异非常大,以至于不能归因于潜在的重放同步开销。那么就可以得出结论,测试系统包含相对于捕获系统的更改,使其性能更差。如果捕获报告和重放报告都表明重放按照预期运行了测试系统,那么可以使用进一步的性能特定测试工具来深入到特定的性能区域(例如IO、CPU、锁争用等)。
案例分析
本节展示如何将数据库重放用于实际测试。目标是通过实验评估并确认重放的测试结果可用于预测当更改应用于生产系统时,测试中的实际工作负载将如何表现。
方法
由于使用来自实时系统的真实生产工作负载来验证数据库重放的有用性是不可能的,我们将使用两种尽可能接近现实的工作负载:
- 使用真实客户应用程序和数据创建的oracle内部基准测试(IB)
- TPC-C,一种广泛使用的OLTP系统建模基准测试[18]
IB 工作负载是根据真实的 Oracle 客户建模的,该客户维护一个用于创建、存储和检索各种资产的保险报价的系统。该系统由保险代理人使用,保险代理人通过执行客户使用的真实保险应用程序的工作流程来模拟。我们选择使用IB的主要原因是因为它在oracle内部被广泛用于多种用途,并且效果非常好。该工作负载的数据由 71 个表和这些表上的 57 个索引组成,数据库大小约为 5GB。在工作负载模拟期间,800 个用户连接到 RDBMS 并计算保险报价。我们在“热”warm系统上一次运行工作负载约 50 分钟。TPC-C 工作负载使用了 20 个仓库和 5 个工作负载生成器。TPC-C 的运行时间约为 32 分钟。
运行 RDBMS 的系统是运行 Oracle Enterprise Linux 内核 2.6.9 的双 CPU(超线程 32 位 Intel Xeon,3.2Ghz)。该系统有 6GB 内存,但对于 IB 工作负载,RDBMS 被分配了 800MB 用于共享内存和 300MB 用于数据缓冲区高速缓存。捕获的工作负载被定向到与用于数据库的磁盘不同的磁盘。对于重放客户端,我们使用具有相同特征的不同主机,这为我们提供了足够的容量来分别为 IB 和 TPC-C 运行 5 个重放客户端和 1 个重放客户端。
我们实验中测试的变化是对表的高级压缩,这也是oracle 11中的一个新特性[12]。在我们的场景中,我们想要确定数据库重放是否可用于预测压缩对实际工作负载的影响。实验场景如下:首先我们运行真实的工作负载(IB 或 TPC-C)并捕获它。然后,我们以完全同步模式重放捕获的工作负载(保持提交顺序和捕获请求率)并验证重放是否具有预期的数据差异。在这两种情况下,不存在分歧,这意味着每个重放的调用在重放期间对相同数据执行与捕获期间相同的工作。唯一的差异实例是在 IB 基准测试中发现的,其中 ORA-1002 错误(抓取过程中乱序)变成了 ORA-15566 错误(不可重放错误)(参见图 7)。这种类型的分歧是因为我们还无法重放调用以使其出现 ORA-1002 错误。第一次重放后,我们为每个工作负载使用的所有表启用高级压缩,并执行另一次重放。最后,我们在压缩和不压缩的情况下运行真实的工作负载。Oracle 自动工作负载存储库 (AWR) 功能 [12] 用于对图 8 所示的运行对之间的关键指标进行性能比较。每个运行执行 2 到 3 次以确保可重复性。

结果
变革影响评估
在图 8 中,对实际工作负载和重放工作负载 (1) 之间的性能进行了比较,以确认两次运行都以类似的方式运行 RDBMS。有压缩和无压缩的工作负载之间的性能比较 (2) 应得出与有压缩和无压缩的重放之间的性能比较 (3) 相同的结论。图 9 显示了 (2) 和 (3) 之间的相对度量差异的比率。比率计算如下:
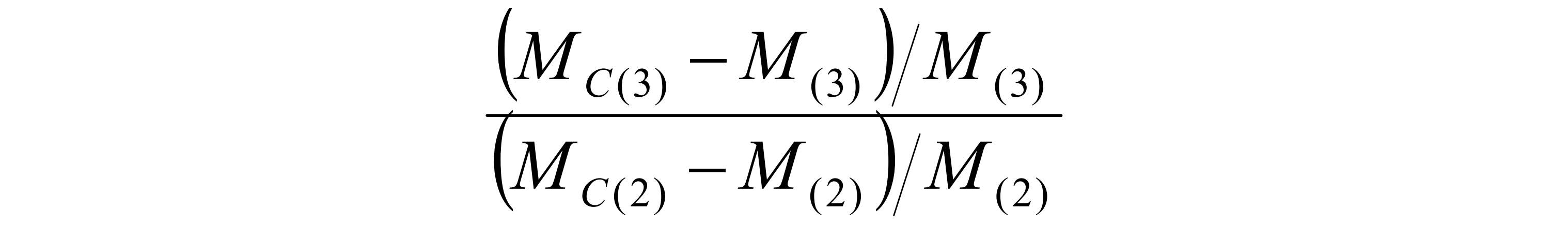
在等式中,MC 表示打开压缩时的度量值,M 表示关闭压缩时的值。下标 (3) 和 (2) 指的是图 8 中运行之间的比较。图 9 中所示的比率适用于以下指标:
- ET:工作负载消耗的时间
- CT:工作负载消耗的总CPU时间
- SQL1CPU、SQL2CPU、SQL3CPU:启用压缩时选定 SQL 语句(更新和查询)的总 CPU 时间,具有可测量的变化。它们是两个工作负载之间不同的 SQL
- WRITES:数据表空间的写入总数
理想情况下,所有比率都应为+1。数据库重放始终能够正确预测变化的方向,并提供对变化幅度的良好了解。不幸的是,我们无法公布绝对数字,但比率可以表明重放如何指向变化的方向。此外,由于篇幅限制,我们无法在本节中包含完整的 AWR 报告。
捕获开销
正如 3.5 节中提到的,捕获的开销高度依赖于工作负载。因此,TPC-C 基准测试运行的 4.5% 吞吐量下降仅表明具有类似特征的实际工作负载在捕获期间将受到怎样的影响。另一个有趣的开销是存储捕获的工作负载所需的空间开销。在我们的实验中,IB 和 TPC-C 的捕获大小分别为 2.7 GB 和 0.32 GB。这些数字同样具有指示性,并且取决于工作量。可以看出,IB 和 TPC-C 之间的工作负载写入速率差异很大:54MB/分钟和 1MB/分钟。
事务模型
在第 4.1.1 节中,我们介绍了重放测试成功的概念。在我们的案例研究中,重放测试在各个方面的成功率为 100%:
- 工作负载后的最终数据库状态
- 并发和请求率特征
- 返回给客户端的结果
第 1 项和第 3 项的实现是因为我们使用的基准具有以下特征:
- 在开始工作负载捕获之前定义明确的初始状态
- 捕获的请求均未使用不受支持或罕见的功能(例如管道或对外部实体的引用)
- PL/SQL 脚本内部不存在可能导致重放分歧的重要应用程序逻辑
实现了并发性和请求率的一致性。以IB基准测试为例,重放的运行时间几乎与捕获的运行时间相同(捕获:49.30分钟;重放49.41分钟),所有重放请求都成功,并执行与捕获期间相同的工作。因此,重放的实际工作速率非常接近捕获的速率(捕获:每秒243.4个事务;重放:每秒243.2个事务)。在实际环境中,我们预计要达到我们在本案例研究中所达到的事务模型的成功程度会更加困难。但是,使用捕获和重放报告以及Oracle RDBMS提供的现有工作负载报告,用户应该能够确定给定的重放是否足够准确地反映了生产工作负载,以便用作确定生产环境中更改的影响的指南。
相关工作
Microsoft SQL Server 具有捕获和基于 SQL Trace [14] 基础结构的不协调重放功能。该基础设施提供基于通用事件的跟踪。SQL Profiler 通过允许重放跟踪来实现 SQL Server 中的重放功能。然而,SQL Server 中的重放不维护事务依赖性和会话协调,并且不力求重放请求的结果一致性。此外,尚不清楚是否可以在生产系统的整个工作负载上以合理的开销启用 SQL Trace。
Quest Benchmark 工厂 [6] 尝试为 Oracle RDBMS 提供捕获和重放功能。重放基于 Oracle SQL 跟踪 [12],这是一种将用户会话跟踪到文本文件的工具。该解决方案的缺点是,由于开销非常高,无法为生产系统启用 SQL 跟踪。它旨在仅跟踪孤立的会话来诊断问题。此外,它不包含实现提交排序和会话协调所需的事务信息,类似于 SQL Server 方法。
LoadRunner 性能测试工具 [8] 可用于针对测试系统生成负载。它是一种非常流行的负载生成工具,用于测试整个软件堆栈,包括应用程序、中间层和 RDBMS。它通常用于 RDBMS 压力测试。用户与应用程序前端的交互被记录。生成的跟踪被参数化并用于模拟任意数量用户的负载。此方法的缺点是捕获的工作负载仅包含生产工作流程的一小部分,因为通常无法捕获真实用户。此外,生成的请求是随机的,并且可能并不总是在 RDBMS 中发挥有用的作用。
此外,它使得仅 RDBMS 的测试变得麻烦,因为它需要存在中间层。[17] 采用了与 LoadRunner 类似的方法,重点是自动化 Web 应用程序的重放测试。
VMWare [20] 为其新虚拟机提供了一项实验性功能,允许记录和重放虚拟机活动。这种方法在操作系统级别进行捕获,远低于 RDBMS 级别,并且重点是程序调试,因为它允许精确复制虚拟机的操作和状态,从而实现确定性调试。它并非旨在测试对虚拟机上运行的任何软件的更改。
程序的确定性重放已被认为是一种实现确定性调试和测试的方法。[2] 中的工作描述了一种确定性重放 Java 应用程序的方法。所遵循的方法类似于数据库重放,因为它们识别 Java 程序中的同步点并在 Java 虚拟机内引入基于时钟的线程调度程序。[7] 也采用了类似的方法。在并行系统中,确定性调试至关重要。[11]提出了一种基于即时回放的并行系统调试方法。[10] 中提出的工作遵循与文件系统上下文中的数据库重放非常相似的方法。文件系统跟踪用于捕获虚拟文件系统 (VFS) 级别的活动,该层是抽象文件系统特定接口的层。然后使用这些跟踪以不同的速度重放捕获的活动以进行压力测试。
[5] 中描述了用于测试数据库应用程序的另一种工作负载生成方法,该方法使用应用程序代码和数据库模式作为输入来生成应用程序的用户输入以及用于彻底测试应用程序和数据库的数据。生成的工作负载用于驱动应用程序,以尝试实现广泛的代码覆盖率。[1] 中的工作提出了一种查询感知方法来生成测试数据库。它强调了测试查询在测试数据库上执行时产生所需的间歇性和最终结果的重要性。数据库重放并不追求中间结果的一致性,而是追求最终结果的一致性。中间结果对工作负载的影响是测试变更的一部分。
有大量文献提出了用于测试的数据库和查询生成方法([3]、[9]、[19]、[13]、[15] 和 [16])。数据库重放首次使得使用真实数据和真实用户工作负载进行 RDBMS 测试成为可能。Oracle Database Replay 是真实应用程序测试功能的一部分,该功能还包括 SQL 性能分析器 (SPA) [21]。SPA 可以将正在运行的 RDBMS 的 SQL 捕获到 SQL 调优集中,该调优集是唯一 SQL 语句以及性能和计划信息的集合。SQL调优集可以在测试环境中使用来单独执行单个SQL的单元测试。因此,Database Replay 和 SPA 相辅相成,提供了一组强大的工具:Database Replay 面向使用真实工作负载的全面吞吐量测试,而 SPA 面向单元测试,详细探索 SQL 语句的各个方面。
结论
在当今快速发展的 IT 环境中,变化是无情的,但对于数据中心经理和管理员来说并不一定很困难。数据库重放可以使测试系统承受生产质量工作负载,从而有助于将更改的不良影响降至最低。可以高度自信地快速评估变化,并在生产系统受到负面影响之前采取纠正措施。据我们所知,没有其他数据库供应商提供接近真实测试的工具。
参考
[1] C. Binnig, D. Kossman, E. Lo, M.T. Özsu. QAGen: generating query-aware test databases. ACM SIGMOD international conference on Management of data 2007
[2] J.D. Choi, H. Srinivasan. Deterministic Replay of Java Multithreaded Applications. Proceedings of the SIGMETRICS symposium on Parallel and distributed tools 1998.
[3] DTM Data Generator. http://www.sqledit.com/dg/
[4] K. Dias, M. Ramacher, U. Shaft, V. Venkataramani, G. Wood. Automatic Performance Diagnosis and Tuning in Oracle. CIDR 2005
[5] M. Emmi, R. Majumdar, K. Sen. Dynamic test input generation for database applications. International symposium on Software testing and analysis 2007.
[6] C. Fernandez, J. Leslie. Predicting and Preventing Performance Bottlenecks in Oracle 10g. Technical Brief, http://www.quest.com.
[7] A. Georges, M. Christiaens, M. Ronsse, K. De Bosschere. JaRec: a portable record/replay environment for multi-threaded Java applications. Software -Practice & Experience. May 2004.
[8] HP LoadRunner. http://www.hp.com.
[9] IBM DB2 Test Database Generator. http://www-306.ibm.com/software/data/db2imstools/db2tools/db2tdbg/
[10] N. Joukov, T. Wong, E. Zadok. Accurate and efficient replaying of file system traces. USENIX Conference on File and Storage Technologies 2005.
[11] T.J. LeBlanc, J.M. Mellor-Crummey. Debugging Parallel Programs with Instant Replay. IEEE Transactions on Computers 1987.
[12] Oracle 11g Documentation. http://www.oracle.com/pls/db111/db111.homepage.
[13] M. Poess, J.M. Stephens. Generating thousand benchmark queries in seconds. VLDB 2004
[14] SQL Server Profiler, RDBMS Documentation, http://msdn.microsoft.com.
[15] D.R. Slutz. Massive Stochastic Testing of SQL. VLDB 1998
[16] J. Gray, P. Sundaresan, S. Englert, K. Baclawski, P.J. Weinberger. Quickly generating billion-record SIGMOD 1994
[17] S. Sprenkle, E. Gibson, S. Sampath, L. Pollock. Automated Replay and Failure Detection for Web Applications. 20th IEEE/ACM international Conference on Automated software engineering ASE '05
[18] TPC-C, http://www.tpc.org.
[19] J. M. Stephens,M. Poess. Mudd: a multi-dimensional data generator. WOSP 2004.
[20] VMWare Workstation 6 Record and Replay. http://www.vmware.com.
[21] K. Yagoub, P. Belknap, B. Dageville, K. Dias, S. Joshi, and H. Yu. Oracle’s SQL Performance Analyzer. IEEE Data Engineering Bulletin. March 2008 Vol. 31 No. 15
[18] TPC-C, http://www.tpc.org.
[19] J. M. Stephens,M. Poess. Mudd: a multi-dimensional data generator. WOSP 2004.
[20] VMWare Workstation 6 Record and Replay. http://www.vmware.com.
[21] K. Yagoub, P. Belknap, B. Dageville, K. Dias, S. Joshi, and H. Yu. Oracle’s SQL Performance Analyzer. IEEE Data Engineering Bulletin. March 2008 Vol. 31 No. 1
相关文章:
Oracle的学习心得和知识总结(二十九)|Oracle数据库数据库回放功能之论文三翻译及学习
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《Oracle Database SQL Language Reference》 2、参考书籍:《PostgreSQL中文手册》 3、EDB Postgres Advanced Server User Gui…...

新版100句学完7000雅思单词
新版100句学完7000雅思单词 1. As the medical world continues to grapple with what’s acceptable and what’s not, it is clear that companies must continue to be heavily scrutinized for their sales and marketing strategies.(剑桥雅思6) 随着医学界持续努力解决…...
MATLAB图论合集(三)Dijkstra算法计算最短路径
本贴介绍最短路径的计算,实现方式为迪杰斯特拉算法;对于弗洛伊德算法,区别在于计算了所有结点之间的最短路径,考虑到MATLAB计算的便捷性,计算时只需要反复使用迪杰斯特拉即可,暂不介绍弗洛伊德的实现 迪杰斯…...

MySQL 8.0.xx 版本解决group by分组的问题
因为版本升级5.7版本以下是没有这个问题的,8.0版本以上会出现分组问题 1055 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column test1.sys_t.id which is not functionally dependent on columns in GROUP BY clause; t…...
设计模式—原型模式(Prototype)
目录 一、什么是原型模式? 二、原型模式具有什么优缺点吗? 三、有什么缺点? 四、什么时候用原型模式? 五、代码展示 ①、简历代码初步实现 ②、原型模式 ③、简历的原型实现 ④、深复制 ⑤、浅复制 一、什么是原型模式&…...
【pytorch】Unfold和Fold的互逆操作
1. 参数定义 Unfold https://pytorch.org/docs/stable/generated/torch.nn.Unfold.html#torch.nn.Unfold Fold https://pytorch.org/docs/stable/generated/torch.nn.Fold.html#torch.nn.Fold 注意:参数当中的padding是在四周边补零,而当fold后的尺寸…...

【AI】《动手学-深度学习-PyTorch版》笔记(二十一):目标检测
AI学习目录汇总 1、简述 通过前面的学习,已经了解了图像分类模型的原理及实现。图像分类是假定图像中只有一个目标,算法上是对整个图像做的分类。 下面我们来学习“目标检测”,即从一张图像中找出需要的目标,并标记出位置。 2、边界框 边界框:bounding box,就是一个方…...
畅捷通T+用户中locked勒索病毒后该怎么办?勒索病毒解密数据恢复
Locked勒索病毒是一种近年来在全球范围内引起广泛关注的网络安全威胁程序。它是一种加密货币劫持病毒,专门用于加密用户的数据并要求其支付赎金。Locked勒索病毒通过攻击各种系统漏洞和网络薄弱环节,使用户计算机受到感染并被加密锁定时,无法…...
神仙般的css动画参考网址,使用animate.css
Animate.css | A cross-browser library of CSS animations.Animate.css is a library of ready-to-use, cross-browser animations for you to use in your projects. Great for emphasis, home pages, sliders, and attention-guiding hints.https://animate.style/这里面有很…...

江西抚州新能源汽车3d扫描零部件逆向抄数测量改装-CASAIM中科广电
汽车改装除了在外观方面越来越受到消费者的青睐,在性能和实用性提升上面的需求也是日趋增多,能快速有效地对客户指定汽车零部件进行一个改装,是每一个汽车改装企业和工程师的追求,也是未来消费者个性化差异化的要求。下面CASAIM中…...
数据结构学习 --4 串
数据结构学习 --1 绪论 数据结构学习 --2 线性表 数据结构学习 --3 栈,队列和数组 数据结构学习 --4 串 数据结构学习 --5 树和二叉树 数据结构学习 --6 图 数据结构学习 --7 查找 数据结构学习 --8 排序 本人学习记录使用 希望对大家帮助 不当之处希望大家帮忙纠正…...

探索Kotlin K2编译器和Java编译器的功能和能力
文章首发地址 Kotlin K2编译器是Kotlin语言的编译器,负责将Kotlin源代码转换为Java字节码或者其他目标平台的代码。K2编译器是Kotlin语言的核心组件之一,它的主要功能是将Kotlin代码编译为可在JVM上运行的字节码。 K2编译器快速介绍 编译过程ÿ…...

如何安装chromadb
下载最新版本的python3.10 因为chromadb需要sqlite3的最小版本是3.35.0 使用如下命令安装 pip install chromadb 安装完毕后在python3的命令行窗口输入 import chromadb 如果不报错代表成功,如果报错sqlite3的最小版本是3.35.0,使用如下方式解决 …...

vue实现把字符串中的所有@内容,替换成带标签的
前言: 目前有个需求是,要把输入框里面的还有姓名高亮。 要求: 1、必须用 v-html ,带标签的给他渲染 2、把字符串中的全部查找出来,替换掉,注意要过滤已经替换好的,不然就是无限循环了 实现方法:…...

「MySQL-00」MySQL在Linux上的安装、登录与删除
目录 一、安装MySQL 0. 安装前请先执行一遍删除操作,把预装或残留的MySQL删除掉 1. 安装yum源 (解决了在哪里找MySQL的问题) 2. 安装哪个版本的MySQL 二、启动和登录MySQL 三、删除MySQL / MariaDB 安装与卸载前,建议先将用户切换…...

8月29-31日上课内容 第五章
第一章...

数据库导出工具
之前根据数据库升级需求,需要导出旧版本数据(sqlserver 6.5),利用c# winfrom写了一个小工具,导出数据。 →→→→→多了不说,少了不唠。进入正题→→→→ 连接数据库:输入数据库信息 连接成功…...
ChatGPT 制作可视化柱形图突出显示第1名与最后1名
对比分析柱形图的用法。在图表中显示最大值与最小值。 像这样的动态图表的展示只需要给ChatGPT,AIGC,OpenAI 发送一个指令就可以了, 人工智能会快速的写出HTML与JS代码来实现。 请使用HTML,JS,Echarts完成一个对比分析柱形图,在图表中突出显示第1名和最后1名用单独一种不…...

前端学习记录~2023.8.10~JavaScript重难点实例精讲~第6章 Ajax
第 6 章 Ajax 前言6.1 Ajax的基本原理及执行过程6.1.1 XMLHttpRequest对象(1)XMLHttpRequest对象的函数(2)XMLHttpRequest对象的属性 6.1.2 XMLHttpRequest对象生命周期(1)创建XMLHttpRequest对象ÿ…...
)
2023年Java核心技术第九篇(篇篇万字精讲)
目录 十七 . 并发相关基础概念 17.1 线程安全 17.2 保证线程安全的两个方法 17.2.1 封装 17.2.2 不可变 17.2.2.1 final 和 immutable解释 17.3 线程安全的基本特性 17.3.1 原子性(Atomicity) 17.3.2 可见性(Visibility) 17.3.2.1…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...