ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由
ES是一个分布式框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由。
ES的高可用架构,总体如下图:
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
ES基本概念名词
Cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
Shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。
分片的数量只能在索引创建前指定,并且索引创建后不能更改。(why,大家可以独立思考一下!)
分片数由index.number_of_shards在索引创建的时候指定,如果需要修改主分片数,需要重建索引:
1 按照需要创建一个新的索引;
2 reindex把索引现有的数据同步到新索引中;
3 别名绑定新创建的索引上;
规避主分片不能修改的问题的方法,官方的说明:
我们当前的选择只有一个就是将数据重新索引至一个拥有更多分片的一个更大的索引,但这样做将消耗的时间是我们无法提供的。
通过事先规划,我们可以使用 预分配 的方式来完全避免这个问题。
注意:ES在不断升级,在ES6.1开始,已经%50支持修改主分片的操作。
在老版本的ES(例如2.3版本)中, index的shard数量定好后,就不能再修改,除非重建数据才能实现。
从ES6.1开始,ES 支持split操作,可以在线操作扩大shard的数量(注意:操作期间也需要对index锁写)
从ES7.0开始,split时候,不再需要加参数 index.number_of_routing_shards
在 这个split的过程中, 它会先复制全量数据,然后再去做删除多余数据的操作,需要注意磁盘空间的占用。
所以,可以理解为,ES还是没有完全 支持修改主分片的操作。 不到万不得已,不建议在线修改主分片。
replicas
代表索引副本,es可以设置多个索引的副本。
副本的作用:
一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
Recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配;
挂掉的节点重新启动时也会进行数据恢复。
总览:ES集群中的五大角色
在Elasticsearch中,有五大角色,主要如下:
Master Node:主节点
主节点,该节点不和应用创建连接,每个节点都保存了集群状态.
master节点控制整个集群的元数据。
只有Master Node节点可以修改节点状态信息及元数据(metadata)的处理,比如索引的新增、删除、分片路由分配、所有索引和相关 Mapping 、Setting 配置等等。
从资源占用的角度来说:master节点不占用磁盘IO和CPU,内存使用量一般, 没有data 节点高
Master eligible nodes:合格主节点
合格节点,每个节点部署后不修改配置信息,默认就是一个 eligible 节点.
有资格成为Master节点但暂时并不是Master的节点被称为 eligible 节点,该节点可以参加选主流程,成为Mastere节点.
该节点只是与集群保持心跳,判断Master是否存活,如果Master故障则参加新一轮的Master选举。
从资源占用的角度来说:eligible节点比Master节点更节省资源,因为它还未成为 Master 节点,只是有资格成功Master节点。
Data Node:数据节点
数据节点,改节点用于建立文档索引, 接收 应用创建连接、接收索引请求,接收用户的搜索请求
data节点真正存储数据,ES集群的性能取决于该节点的个数(每个节点最优配置的情况下),
data节点的分片执行查询语句获得查询结果后将结果反馈给Coordinating节点,在查询的过程中非常消耗硬件资源,如果在分片配置及优化没做好的情况下,进行一次查询非常缓慢(硬件配置也要跟上数据量)。
数据节点:保存包含索引文档的分片数据,执行CRUD、搜索、聚合相关的操作。属于:内存、CPU、IO密集型,对硬件资源要求高。
从资源占用的角度来说:data节点会占用大量的CPU、IO和内存
Coordinating Node:协调节点(/路由节点/client节点)
协调节点,该节点专用与接收应用的查询连接、接受搜索请求,但其本身不负责存储数据
协调节点的职责:
接受客户端搜索请求后将请求转发到与查询条件相关的多个data节点的分片上,然后多个data节点的分片执行查询语句或者查询结果再返回给协调节点,协调节点把各个data节点的返回结果进行整合、排序等一系列操作后再将最终结果返回给用户请求。
搜索请求在两个阶段中执行(query 和 fetch),这两个阶段由接收客户端请求的节点 - 协调节点协调。
在请求query 阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行请求并将其结果返回给协调节点。
在收集fetch阶段,协调节点将每个数据节点的结果汇集为单个全局结果集。
从资源占用的角度来说:协调节点,可当负责均衡节点,该节点不占用io、cpu和内存
Ingest Node:ingest节点
ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
Ingest节点处理时机——在数据被索引之前,通过预定义好的处理管道对数据进行预处理。默认情况下,所有节点都启用Ingest,因此任何节点都可以处理Ingest任务。
我们也可以创建专用的Ingest节点。
详解:Coordinating Only Nodes
ES 本身是一个分布式的计算集群,每个 Node 都可以响应用户的请求,包括 Master Node、Data Node,它们都有完整的 Cluster State 信息。
正如我们知道的一样,在某个 Node 收到用户请求的时候,会将请求转发到集群中所有索引相关的 Node 上,之后将每个 Node 的计算结果合并后返回给请求方。
我们暂且将这个 Node 称为查询节点,整个过程跟分布式数据库原理类似。那问题来了,这个查询节点如果在并发和数据量比较大的情况下,由于数据的聚合可能会让内存和网络出现瓶颈。
因此,在职责分离指导思想的前提下,这些操作我们也应该从这些角色中剥离出来,官方称它是 Coordinating Nodes,只负责路由用户的请求,包括读、写等操作,对内存、网络和 CPU 要求比较高。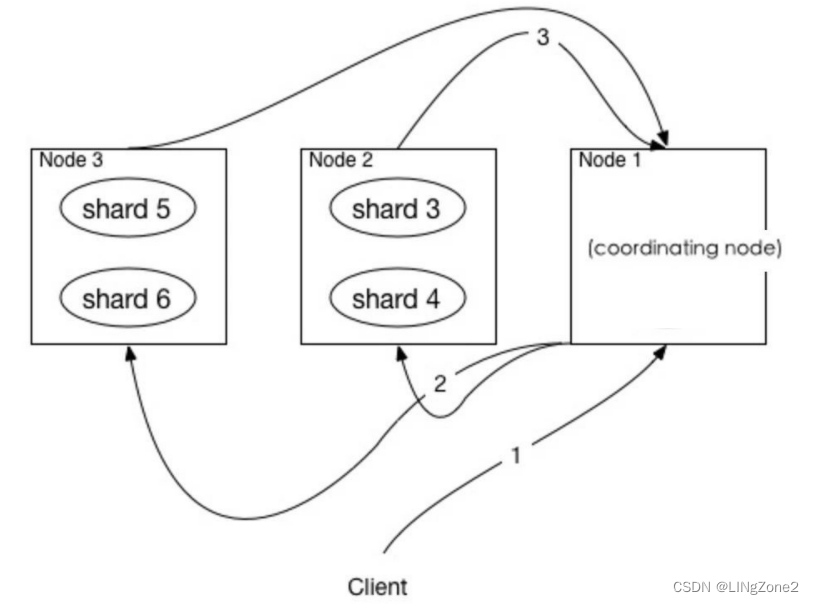
本质上,Coordinating Only Nodes 可以笼统的理解为是一个负载均衡器,或者反向代理,只负责读,本身不写数据。
它的配置是:
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
增加 Coordinating Nodes 的数量可以提高 API 请求响应的性能, 提升集群的吞吐量
我们也可以针对不同量级的 Index 分配独立的 Coordinating Nodes 来满足请求性能。
那是不是越多越好呢?
在一定范围内是肯定的,但凡事有个度,过了负作用就会突显,太多的话会给集群增加负担。
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
详解:Ingest Node:ingest节点
由于其他几种类型节点和用途都很好理解,无非主节点、数据节点、路由节点。
但是,Ingest不好理解。
Ingest的用途:
可以把Ingest节点的功能抽象为:大数据处理环节的“ETL”——抽取、转换、加载。
Ingest的用途:
1)ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
2)Ingest节点 可用于执行常见的数据转换和丰富。 处理器配置为形成管道。 在写入时,Ingest Node有20个内置处理器,例如grok,date,gsub,小写/大写,删除和重命名。
3)在批量请求或索引操作之前,Ingest节点拦截请求,并对文档进行处理。
Ingest的例子:
一个例子是,可以是日期处理器,其用于解析字段中的日期。
另一个例子是:转换处理器,它将字段值转换为目标类型,例如将字符串转换为整数。
ingest 节点能解决什么问题?
上面的Ingest节点介绍太官方,看不大懂怎么办?来个实战场景例子吧。
思考问题1:线上写入数据改字段需求
如何在数据写入阶段修改字段名(不是修改字段值)?
思考问题2:线上业务数据添加特定字段需求
如何在批量写入数据的时候,每条document插入实时时间戳?
这时,脑海里开始对已有的知识点进行搜索。
针对思考问题1:字段值的修改无非:update,update_by_query?但是字段名呢?貌似没有相关接口或实现。
针对思考问题2:插入的时候,业务层面处理,读取当前时间并写入貌似可以,有没有不动业务层面的字段的方法呢?
答案是有的,这就是Ingest节点的妙处。
Ingest的实操体验
针对问题1:
如何在数据写入阶段修改字段名(不是修改字段值)?
PUT _ingest/pipeline/rename_hostname
{
"processors": [
{
"field": "hostname",
"target_field": "host",
"ignore_missing": true
}
}
]
}
PUT server
POST server/values/?pipeline=rename_hostname
{
"hostname": "myserver"
}
如上,借助Ingest节点的 rename_hostname管道的预处理功能,实现了字段名称的变更:由hostname改成host。
针对问题2:
线上业务数据添加特定字段需求**
PUT _ingest/pipeline/indexed_at
{
"description": "Adds indexed_at timestamp to documents",
"processors": [
{
"set": {
"field": "_source.indexed_at",
"value": "{{_ingest.timestamp}}"
}
}
]
}
PUT ms-test
{
"settings": {
"index.default_pipeline": "indexed_at"
}
}
POST ms-test/_doc/1
{"title":"just testing"}
如上,通过indexed_at管道的set处理器与ms-test的索引层面关联操作, ms-test索引每插入一篇document,都会自动添加一个字段index_at=最新时间戳。
6.5版本ES验证ok。
Ingest节点的核心原理
在实际文档索引发生之前,使用Ingest节点预处理文档。Ingest节点拦截批量和索引请求,它应用转换,然后将文档传递回索引或Bulk API。
强调一下: Ingest节点处理时机——在数据被索引之前,通过预定义好的处理管道对数据进行预处理。
默认情况下,所有节点都启用Ingest,因此任何节点都可以处理Ingest任务。我们也可以创建专用的Ingest节点。
要禁用节点的Ingest功能,需要在elasticsearch.yml 设置如下:
node.ingest:false
Ingest节点的核心原理, 涉及几个知识点:
1、预处理 pre-process
要在数据索引化(indexing)之前预处理文档。
2、管道 pipeline
每个预处理过程可以指定包含一个或多个处理器的管道。
管道的实际组成:
{
"description" : "...",
"processors" : [ ... ]
}
description:管道功能描述。
processors:注意是数组,可以指定1个或多个处理器。
3、处理器 processors
每个处理器以某种特定方式转换文档。
例如,管道可能有一个从文档中删除字段的处理器,然后是另一个重命名字段的处理器。
这样,再反过来看第4部分就很好理解了。
Ingest API
Ingest API共分为4种操作,分别对应:
PUT(新增)、
GET(获取)、
DELETE(删除)、
Simulate (仿真模拟)。
模拟管道AP Simulate 针对请求正文中提供的文档集执行特定管道。
除此之外,高阶操作包括:
1、支持复杂条件的Nested类型的操作;
2、限定条件的管道操作;
3、限定条件的正则操作等。
详细内容,参见官网即可。
常见的处理器有如下28种,举例:
append处理器:添加1个或1组字段值;
convert处理器:支持类型转换。
建议:没必要都过一遍,根据业务需求,反查文档即可。
Ingest节点和Logstash Filter 啥区别?
业务选型中,肯定会问到这个问题。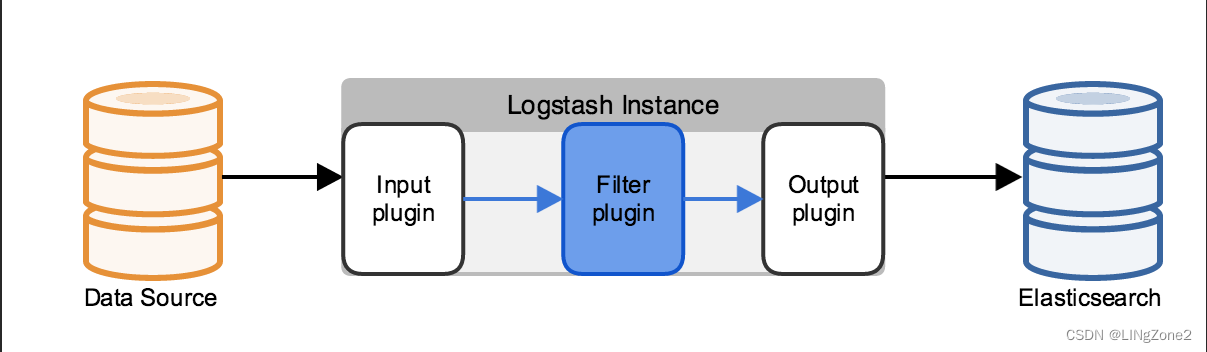
区别一:支持的数据源不同。
Logstash:大量的输入和输出插件(比如:kafka,redis等)可供使用,还可用来支持一系列不同的架构。
Ingest节点:不能从外部来源(例如消息队列或数据库)提取数据,必须批量bulk或索引index请求将数据推送到 Elasticsearch.
区别二:应对数据激增的能力不同。
Logstash:Logstash 可在本地对数据进行缓冲以应对采集骤升情况。如前所述,Logstash 同时还支持与大量不同的消息队列类型进行集成。
Ingest节点:极限情况下会出现:在长时间无法联系上 Elasticsearch 或者 Elasticsearch 无法接受数据的情况下,均有可能会丢失数据。
区别三:处理能力不同。
Logstash:支持的插件和功能点较Ingest节点多很多。
Ingest节点:支持28类处理器操作。Ingest节点管道只能在单一事件的上下文中运行。Ingest通常不能调用其他系统或者从磁盘中读取数据。
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
详解:一次ES搜索的两阶段
ES的搜索过程,目标是符合搜索条件的文档,这些文档可能散落在各个node、各个shard中,
ES的搜索,需要找到匹配的文档,并且把从各个node,各个shard返回的结果进行汇总、排序,组成一个最终的结果排序列表,才算完成一个搜索过程。
一次搜索请求在两个阶段中执行(query 和 fetch),这两个阶段由接收客户端请求的节点 (协调节点)协调。
在请求query 阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行请求并将其结果返回给协调节点。
在收集fetch阶段,协调节点将每个数据节点的结果汇集为单个全局结果集。
我们将按两阶段的方式对这个过程进行讲解。
phase 1: query 查询阶段
假定我们的ES集群有三个node,number_of_primary_shards为3,replica shard为1,我们执行一个这样的查询请求:
GET /music/children/_search
{
"from": 980,
"size": 20
}
query 查询阶段的过程示意图如下: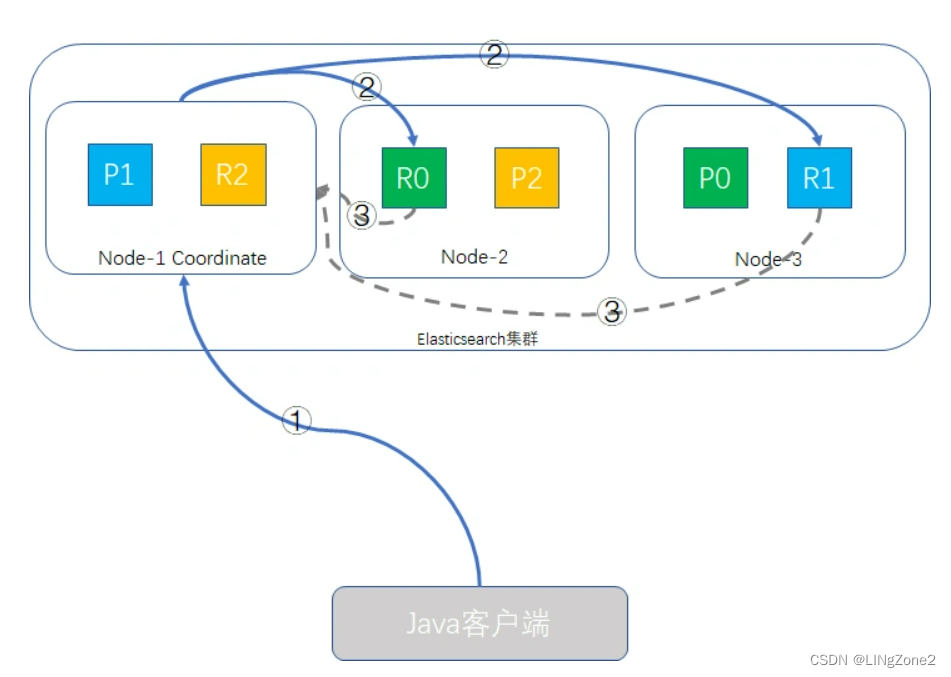
query 查询阶段的过程示如下:
Java客户端发起查询请求,接受请求的node-1成为Coordinate Node(协调者),该node会创建一个priority queue,长度为from + size即1000。
Coordinate Node将请求分发到所有的primary shard或replica shard中,每个shard在本地创建一个同样大小的priority queue,长度也为from + size,用于存储该shard执行查询的结果。
每个shard将各自priority queue的元素返回给Coordinate Node,元素内只包含文档的ID和排序值(如_score),Coordinate Node将合并所有的元素到自己的priority queue中,并完成排序动作,最终根据from、size值对结果进行截取。
补充说明:
哪个node接收客户端的请求,该node就会成为Coordinate Node。
Coordinate Node转发请求时,会根据负载均衡算法分配到同一分片的primary shard或replica shard上,注意,这里是或,不是与。
为什么说replica值设置得大一些, 可以增加系统吞吐量呢 ?
原理就在这里
Coordinate Node的查询请求负载均衡算法会轮询所有的可用shard,并发场景时就会有更多的硬件资源(CPU、内存,IO)会参与其中,系统整体的吞吐量就能提升。
此查询过程Coordinate Node得到是轻量级的文档元素信息,只包含文档ID和_score这些信息,这样可以减轻网络负载,因为分页过程中,大部分的数据是会丢弃掉的。
phase 2: fetch取回阶段
在完成了查询阶段后,此时Coordinate Node已经得到查询的列表,但列表内的元素只有文档ID和_score信息,并无实际的_source内容,取回阶段就是根据文档ID,取到完整的文档对象的过程。
如下图所示:
fetch取回阶段的过程示意图如下: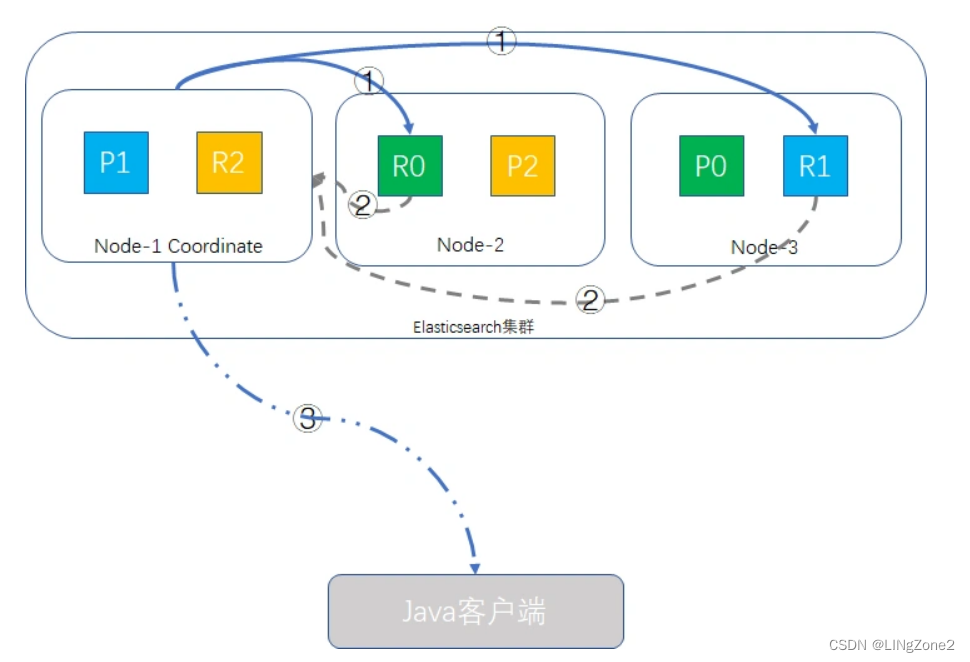
Coordinate Node根据from、size信息截取要取回文档的ID,如{"from": 980, "size": 20},则取第981到第1000这20条数据,其余丢弃,from/size为空则默认取前10条,向其他shard发出mget请求。
shard接收到请求后,根据_source参数(可选)加载文档信息,返回给Coordinate Node。
一旦所有的shard都返回了结果,Coordinate Node将结果返回给客户端。
注意:
使用from和size进行分页时,传递信息给Coordinate Node的每个shard,都创建了一个from + size长度的队列,并且Coordinate Node需要对所有传过来的数据进行排序,工作量为number_of_shards * (from + size),然后从里面挑出size数量的文档,如果from值特别大,那么会带来极大的硬件资源浪费,鉴于此原因,强烈建议不要使用深分页。
不过深分页操作很少符合人的行为,翻几页还看不到想要的结果,人的第一反应是换一个搜索条件
只有机器人或爬虫才这么不知疲倦地一直翻页, 直到服务器崩溃。
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
ES的副本高可用架构
ES核心存放的核心数据是索引。
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。
通过将一个单独的索引分为多个分片,解决单一索引的大小过大,导致的搜索效率问题。
分片之后,由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储。
每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards。
如果ES实现了集群的话,会将单台服务器节点的索引文件使用分片技术,分布式存放在多个不同的物理机器上。
分片就是将数据拆分成多台节点进行存放,这样做是为了提升索引、搜索效率。
通过 _setting API可以查询到索引的元数据: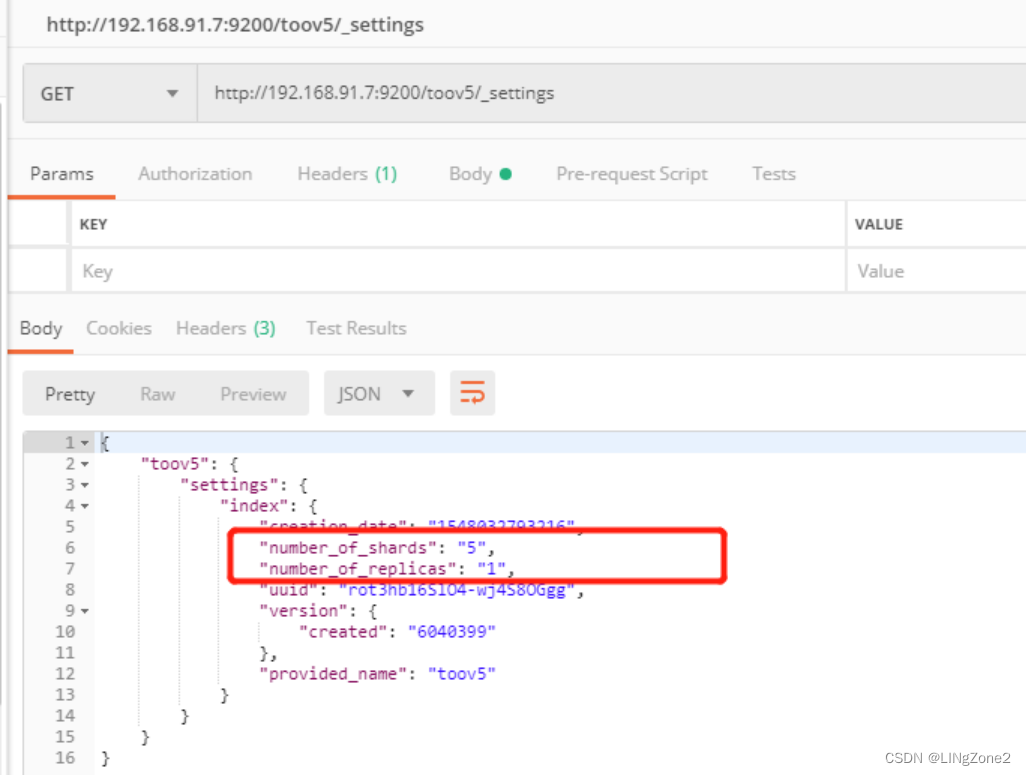
两个很重要的数据:
5: 每个索引拆分5片存储
1:备份一份
注意:索引的主分片primary shards定义好后,后面不能做修改。
分片的副本
在ES分片技术中,分为主(primary)分片、副(replicas)分片。
为了实现高可用数据的高可用、高并发,主分片可以有对应的副本分片replics shards。
replic shards分片承载了负责容错、以及请求的负载均衡。
**注意: **
每一个主分片为了实现高可用,都会有自己对应的副本分片
分片对应的副本分片不能存放同一台服务器上(单台ES没有副本用分片的)。
主分片primary shards可以和其他replics shards存放在同一个node节点上。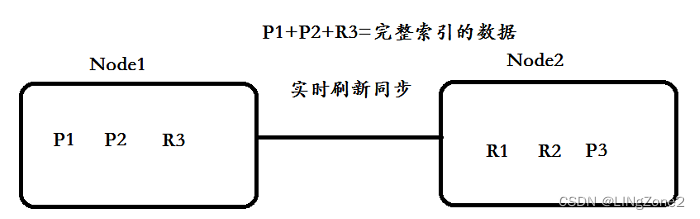
在往主分片服务器存放数据时候,会对应实时同步到备用分片服务器: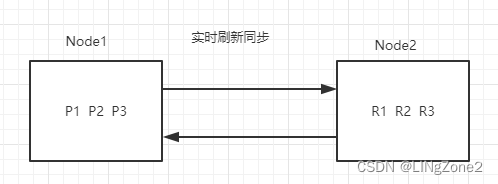
但是查询时候,所有(主、备)分片都参与查询。由协调节点进行负载均衡。
分片的存放
假设一个索引:
number_of_shards=3
number_of_replicas=3
3个分片,每个分片一个 副本,总共6个shard。
放在一个3个data node的集群中,具体的存放方式为:
三个节点 6/3 为 2 每个节点存放两个分片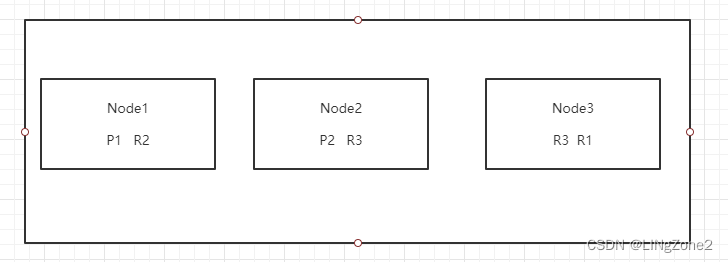
在创建索引时候,主分片数量定义好后是不能修改的
修改副的分片 number_of_replica =2
3个主分片6个备分片, 一共9个分片,具体的存放方式为:
从高可用/高并发的角度出发,官方建议, shard为 节点的平方数 !!
节点的扩容
假设data node由2个节点,扩容到3个节点。
主分片3 备份1, 主分片3个 ,每个主分片对应的1个备分片,
总的shard数=3*2=6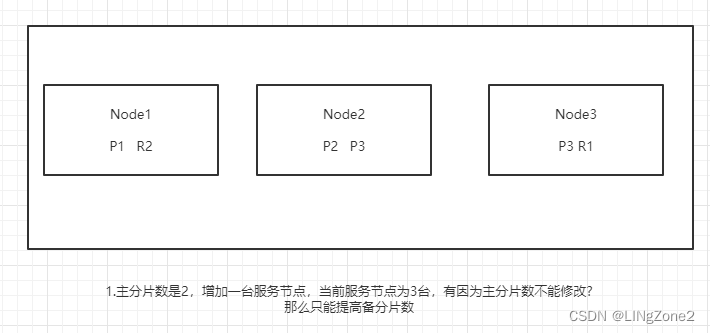
那么官方达到建议, shard为 节点的平方数。
按照官方的建议,如果每个主分片,可以对应的2个备分片,总共的分片数=3*3=9。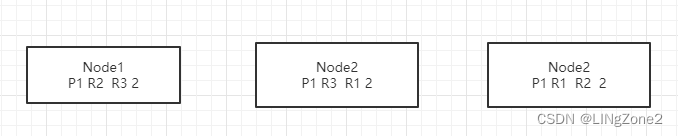
百亿数据的分片和节点规划
百亿数据,放在数据库的量是多少?
假设 1T 。
实际的生产经验,一个shard应该是30-50G比较合理,机械硬盘,不建议大于50G
磁盘好的话,比如SSD固态硬盘,这个可以大点,比如100G
如果是1T,一个分片50G,建议你最少primary shards 20个
从高可用/高并发的角度出发,官方建议, shard为 节点的平方数 !!
所以,replicas 可以根据节点数来推算。
比如10 个Data node,10 X 10=100, 则副本数可以为 4 ,(4+1)*20=100
注意:副本太多有很大的副作用,集群内部的需要保障primary 和 replica 的数据一致性,需要的网络流量消耗与 CPU消耗会大大提升。
数据路由
documnet routing(数据路由)
当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。
路由算法:shard = hash(routing) % number_of_primary_shards
如果number_of_primary_shards在查询的时候取余发生的变化,无法获取到该数据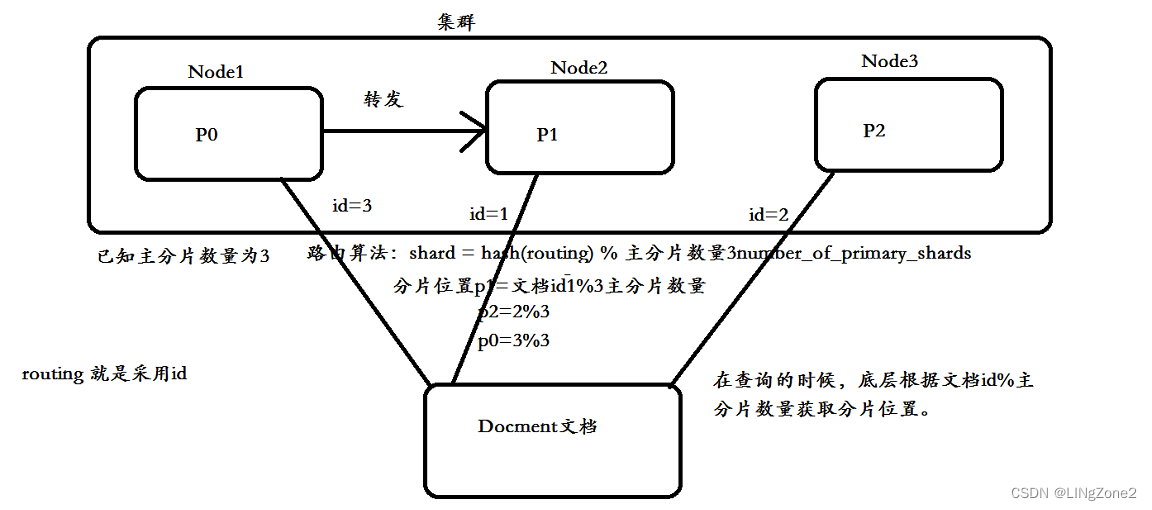
注意:索引的主分片数量定义好后,不能被修改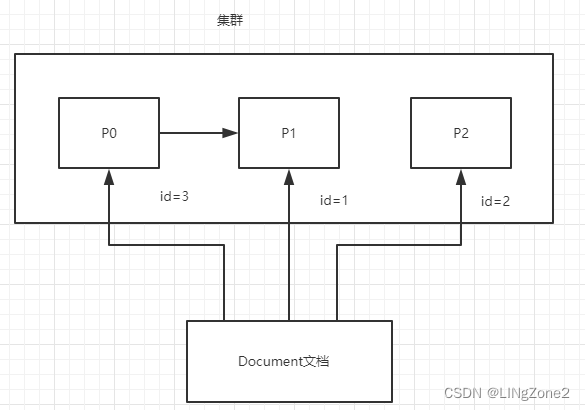
已知主分片数量为3,
路由算法: shard = hash(routing) % 主分片数量3
分片位置 p1 = % 3 , p2 =2%3 , p0=3%3
routing 就是采用 id
在查询时候,底层根据文档 id % 主分片数量获取分片位置
计算的算法 取模时候 除数改变了 查询时候 怎么办?!
所以 不能乱改啊~
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
ES集群的架构规划
首先是集群节点的角色规划。
一个节点在默认角色
Elasticsearch的员工 Christian_Dahlqvist解读如下:
一个节点的缺省配置是:主节点+数据节点两属性为一身。
对于3-5个节点的小集群来讲,通常让所有节点存储数据和具有获得主节点的资格。你可以将任何请求发送给任何节点,并且由于所有节点都具有集群状态的副本,它们知道如何路由请求。
通常只有较大的集群才能开始分离专用主节点、数据节点。 对于许多用户场景,路由节点根本不一定是必需的。
专用协调节点(也称为client节点或路由节点)从数据节点中消除了聚合/查询的请求解析和最终阶段,并允许他们专注于处理数据。
在多大程度上这对集群有好处将因情况而异。 通常我会说,在查询大量使用情况下路由节点更常见。
实际上,一个节点在默认情况下会同时扮演:Master Node,Data Node 和 Ingest Node。
节点类型 配置参数 默认值
Master Eligible node.master true
Data node.data true
Ingest node.ingest true
Coordinating only 无 设置上面 3 个参数全为 false,节点为协调节点
节点的角色建议
分环境:
在开发环境,一个节点可以承担多种角色;
生产环境中,需要根据数据量,写入和查询的吞吐量,选择合适的部署方式,建议设置单一角色的节点(dedicated node);
ES2.X及之前版本节点角色概述
注意,在ES2.X及之前, 节点的角色有点不一样,具体如下:
ES5.X节点角色清单
注意,在ES5.X及之后, 节点的角色基本稳定下来了,具体如下:
配置节点类型
开发环境中一个节点可以承担多种角色
生产环境中,应该设置单一的角色
节点类型 配置参数 默认值
Master node.master true
Master eligible node.master true
Data node.data true
Coordinating 无 每个节点都是协调节点,设置其它节点全部为false则为协调节点
Ingest node.ingest true
两个属性的四种组合
Master和Data两个角色,这些功能是由三个属性控制的。
1. node.master
node.data
3. node.ingest
默认情况下这三个属性的值都是true。
默认情况下,elasticsearch 集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务,做预处理。
node.master:这个属性表示节点是否具有成为主节点的资格
注意:此属性的值为 true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。所以,这个属性只是代表这个节点是不是具有主节点选举资格。
node.data:这个属性表示节点是否存储数据。
组合1
node.master: true AND node.data: true AND node.ingest: true
这种组合表示这个节点既有成为主节点的资格,又可以存储数据,还可以作为预处理节点
这个时候如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。
elasticsearch 默认是:每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,这样相当于 主节点 和 数据节点 的角色混合到一块了。
组合2
node.master: false AND node.data: **true **AND node.ingest: false
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点我们称为 data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。
后期提供存储和查询服务
组合3
node.master: true AND node.data: falseAND node.ingest: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。这个节点我们称为master节点
组合4
node.master: false AND node.data: falseAND node.ingest: true
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个 client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
在新版 ElasticSearch5.x 之后该节点称之为:coordinate 节点,其中还增加了一个叫:ingest 节点,用于预处理数据(索引和搜索阶段都可以用到)。
当然,作为一般应用是不需要这个预处理节点做什么额外的预处理过程,那么这个节点和我们称之为 client 节点之间可以看做是等同的,我们在代码中配置访问节点就都可以配置这些 ingest 节点即可。
不同角色节点 的配置选择
Dedicated Master Eligible Node
负责集群状态的管理;
使用低配置的 CPU,RAM 和磁盘;
Dedicated Data Node
负责数据存储及处理客户端请求;
使用高配置的 CPU,RAM 和磁盘;
Dedicated Ingest Node
负责数据处理;
使用高配置的 CPU,中等配置的 RAM,低配置的磁盘;
Coordinating only Node
高配或中配的 CPU,高配或中配的 RAM,低配的磁盘;
生产环境中,建议为一些大的集群配置 Coordinating Only Node,其扮演的角色:
Load Balancer,降低 Master 和 Data Nodes 的负载;
负责搜索结果的 Gather 和 Reduce;
有时无法预知客户端会发送怎样的请求,大量占用内存的聚合操作,比如一个深度聚合可能会发生 OOM;
高可用ES部署的基本原则
配置 多个Dedicated Master Node
为什么要配置 多个Dedicated Master Node?
从高可用 & 避免脑裂的角度出发,需要配置多个 Dedicated Master Node
一般在生产环境中配置 3 台,当有1 台丢失的时候,其余的节点会被提升成活跃主节点;
一个集群必须有一台活跃的主节点,负责分片管理,索引创建,集群管理等操作;
Elasticsearch集群至少三个Master实例,并且,生产建议每个es实例部署在不同的设备上,三个Master节点最多只能故障一台Master节点,数据不会丢失; 如果三个节点故障两个节点,则造成数据丢失并无法组成集群。
三台Master做集群,其中一台被真正选为了Master,那么其它两台就是 eligible 节点。
Master Node 和 Data Node 或 Coordinating Node 分开部署
如果 Master Node 和 Data Node 或 Coordinating Node 混合部署
Data Node 相对有比较大的内存占用;
Coordinating Node 有时候会有开销很高的查询,导致 OOM;
这些都有可能影响 Master 节点,导致集群的不稳定;
Data Node 水平扩展
在Elasticsearch集群中,此节点应该是最多的。
Data Node 在以下两种场景,可以不断扩展:
当磁盘容量无法满足时,可以增加 Data Node;
当磁盘读写压力大时,可以增加 Data Node;
内存建议:
假如一台机器部署了一个ES实例,则ES最大可用内存,不要超过物理内存的50%;
ES最大可用内存,最多不可超过32G;
如果单台机器上部署了多个ES实例,则多个ES实例内存相加等于物理内存的50%。
每1GB堆内存对应集群的分片,建议保持在20个以内;
分片建议:
每个分片大小不要超过30G,硬盘条件好的话,不建议超过100G.
Coordinating Node 水平扩展
当系统中有大量复杂查询及聚合的时候,增加 Coordinating Node,提升查询和聚合的性能;
可以在 Coordinating Node 前配置 LB,软件或硬件实现,此时 Application 只需要和 LB 交互;
读写分离与LB负载均衡
读请求发到 Coordinating Node;
写请求发到 Ingest Node;
Coordinating Node 和 Ingest Node 前都可以配置 LB;
高可用ES的部署源规划
小型的ES集群的节点架构
小型的ES集群,就是3/5/7这种少于10个节点的集群。
对于3个节点、5个节点甚至更多节点角色的配置,Elasticsearch官网、国内外论坛、博客都没有明确的定义。
小型的ES集群的节点角色规划:
1)对于Ingest节点,如果我们没有格式转换、类型转换等需求,直接设置为false。
2)3-5个节点属于轻量级集群,要保证主节点个数满足((节点数/2)+1)。
3)轻量级集群,节点的多重属性如:Master&Data设置为同一个节点可以理解的。
4)如果进一步优化,5节点可以将Master和Data再分离。
大型的ES集群的节点架构
ES数据库最好的高可用集群部署架构为:
三台服务器做master节点
N(比如20)台服务器作为data节点(存储资源要大)
N(比如2)台做ingest节点(用于数据转换,可以提高ES查询效率)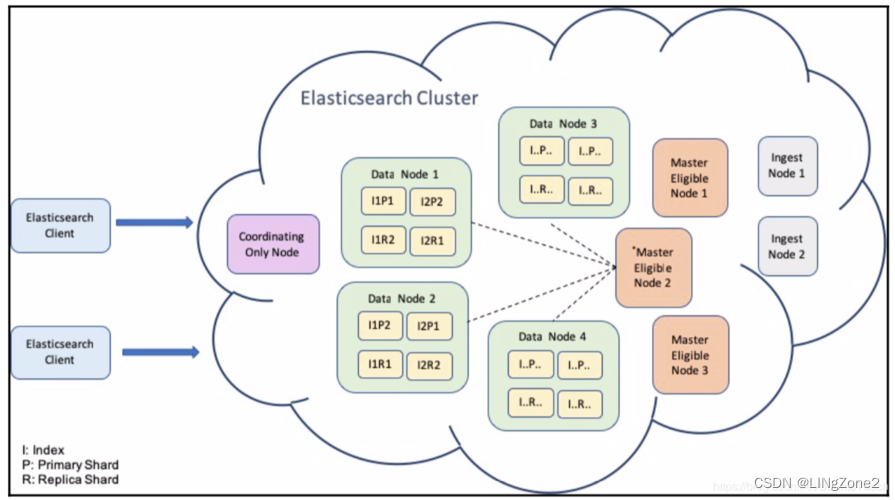
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
高可用进阶:异地多活部署场景(多个data center)
异地多活部署场景, 可以在多个data center 部署多套ES集群。
在多个data center的部署场景。 如何进一步保证ES集群的高可用呢
读高可用架构
这几个集群需要确保有相同的数据。通过gtm进行流量路由,将用户的读请求,路由到最优的集群。
GTM主要用来做数据的读取。
具体的读高可用架构图如下: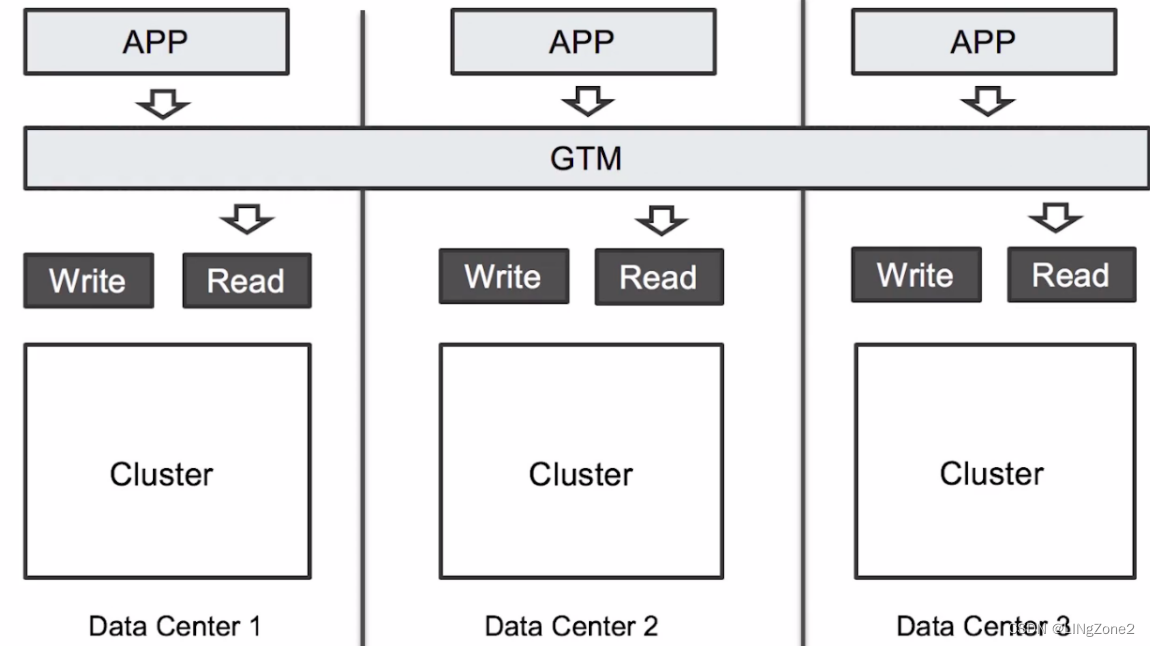
如何保证数据一致性
两种方案:
需要程序分别写入这几个集群,保持数据一致。
或者就写入一个集群 ,使用es的跨集群复制确保数据一致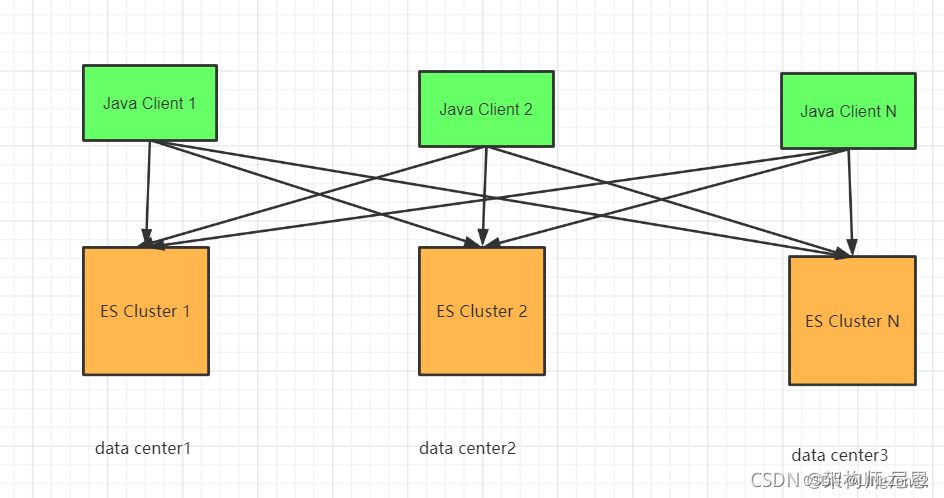
一致性保障策略1:集群多写
需要程序分别写入这几个集群,保持数据一致
由于建立索引的及时性,没有那么高,更多的情况,是写入消息队列。
各个数据中心的程序,去消费消息队列中的数据。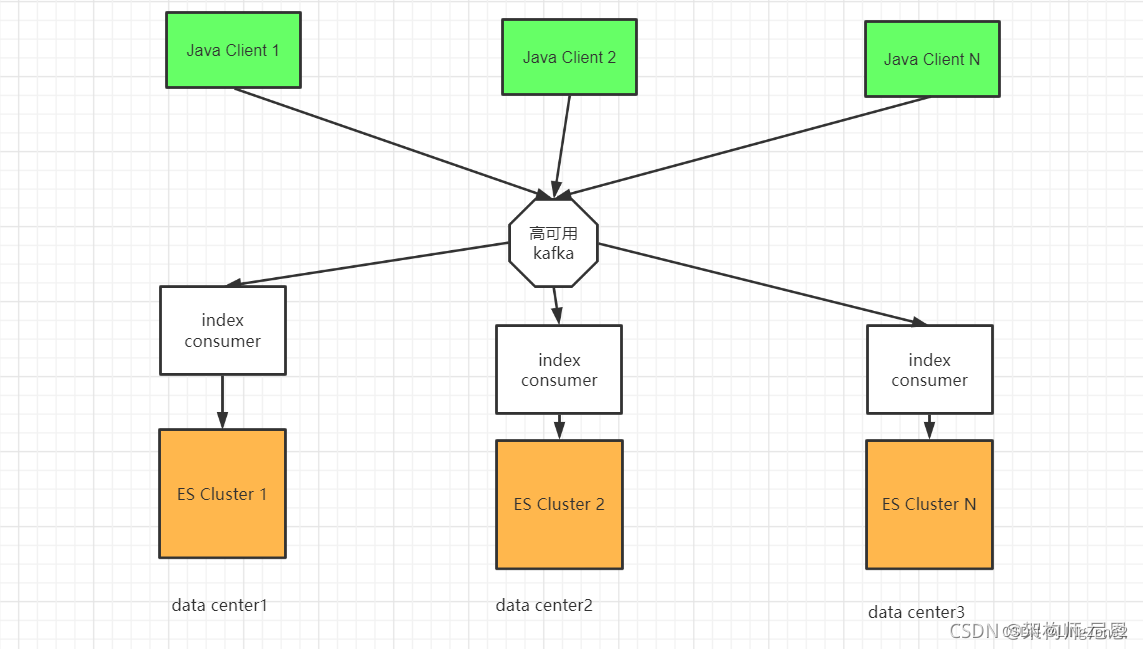
一致性保障策略2:ES的跨集群复制
Elasticsearch(后面统称ES) cross-cluster replication (后面统称CCR)是ES 6.5的一个测试特性,是ES 6.7的的一个全局高可用特性。
CCR将索引复制到其他ES集群,可以解决多个用例,包括跨数据中心高可用(HA),灾难恢复(DR)和CDN样体系结构,最终实现ES集群的高可用。
CCR没有所谓的冲突监测,如果要独立flower,只需要暂定同步,关闭索引,取消对leader的关注,重新打开索引即可。
CCR 是双向的
CCR 这个特性可以让你将一个集群的索引数据同步复制到远程的另外一个集群上面去。或者反过来,将一个远程的集群的索引数据同步的复制到本地 Elasticsearch 集群中来。
CCR 可以复制到多个集群
CCR允许不同的索引复制到一个或多个ES 集群中。
集群复制类似于数据订阅的方式,一个集群的数据可以被多个集群订阅,也就是可以被复制到多个集群上面去。
CCR 工作在索引层面
CCR 工作在索引层面,使用 Pull 的模式,Follower 索引主动的去 Pull Leader 的数据。
CCR 有两个角色,一个是 Leader,表示数据的源头,另外一个Follower,表示数据的订阅方,得到的是数据副本。
CCR是一个leader/fllower架构,leader可以进行任何操作,但是fllower则不能进行写入操作,fllower的mapping和setting也是跟随leader的变化而变化,无需进行单独的修改。
CCR不是免费的特性
这个特性是 Elasticsearch 的商业特性,需要白金订阅。
CCR的使用场景
异地多活多data center 集群高可用以及灾难恢复
全球化多data center 实现数据的就近访问(地理)
集中式的报告集群
第一个场景,关于保证 Elasticsearch 集群的高可用和灾难恢复。
通过部署多套 Elasticsearch 集群,并且分布在不同地域的数据中心,然后接着 CCR,将数据做一个实时的同步,假如其中一个数据中心失联或者因为不可抗力的因素,如台风、地震,我们照样还能通过访问剩下的集群来获取完整的数据,如下图示意: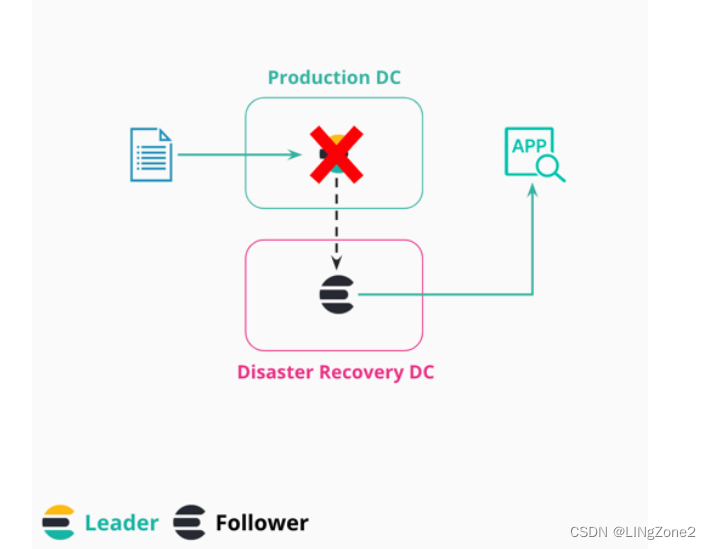
当 Production DC 失联之后,我们可以立即切换到 Disaster Recovery DC。
第二个场景,数据的就近访问。
假设是一个大集团,有总公司和分公司,通过按地理位置来划分分公司自己的业务集群,不同城市的业务数据可以使用各自的集群,这样能够更快的进行当地业务的处理,不过也有一些数据,可能是总公司下发的数据,各个分公司都只能读,比如一些元数据,我们借助 CCR,可以把这部分数据下发到各个分公司的 Elasticsearch 集群,这样每个分公司都能实时的获取到最新的数据,并且直接访问各自的本地集群就可以了,大大提升访问速度。
上图中,Central DC 借助 CCR 实时的同步下发数据到 Singapore DC、Canada DC 和 Ireland DC。
第三个场景:就是做集中式的报告分析。
接上面的案例,我们反过来处理我们的业务数据,我们将每个分公司的业务数据实时的同步到总公司的 Elasticsearch 集群,这样总公司就有了每个分公司的完整数据,这样进行报告分析的时候,就可以直接的在总公司的 Elasticsearch 集群里面进行快速的可视化分析了。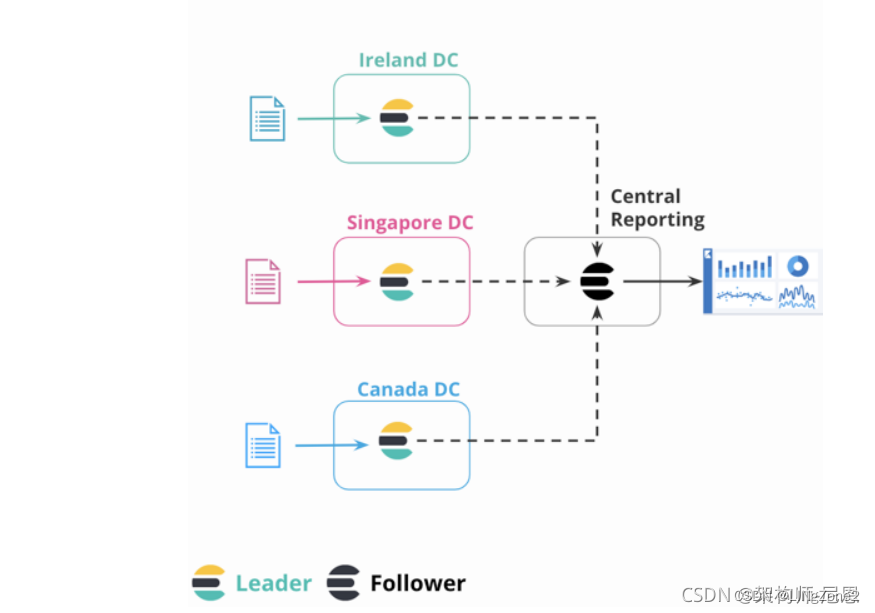
CCR 如何使用
说了这么多 CCR 的适用场景,那接下来我们来看一下具体如何使用吧。
假设我有两个机器,北京集群(192.168.1.100:9300)和深圳集群(192.168.3.100:9300),这俩个集群之间的网络是互通的。现在我们希望把北京集群的销售数据同步到深圳集群上去。
第一步,在北京集群上,设置 Leader 索引
这个 Leader Index 需要设置好允许 Soft Deletes,这个参数非常重要,CCR 依赖这个特性来,如果这个索引之前没有开启过这个参数,需要重新创建索引才行。
比如,我创建一个 bj_sales 这个索引:
PUT bj_sales
{
"settings": {
"index.soft_deletes.retention.operations": 2000,
"index.soft_deletes.enabled": true
}
}
现在,这个 bj_sales 就已经具备跨集群复制的能力了。
第二步,北京集群,创建几条销售数据。
POST bj_sales/doc/
{
"name":"Jack Ma",
"age":40
}
POST bj_sales/doc/
{
"name":"Pony Ma",
"age":40
}
第三步,在深圳集群上,把北京集群的信息加到远程集群里面去。
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"bj": {
"seeds": [
"192.168.1.100:9300"
]
}
}
}
}
}
bj 是我们能够在深圳集群里面访问北京集群的命名空间。
第四步,我们在深圳集群里面通过 CCR API 创建一个索引,并订阅北京机器的 bj_sales 这个索引。
PUT /bj_sales_replica/_ccr/follow
{
"remote_cluster" : "bj",
"leader_index" : "bj_sales"
}
bj_sales_replica 是我们将要创建在深圳集群上的索引名称,remote 集群是 bj,订阅了对方的 bj_sales 索引。
第五步,验证
如果不出意外,我们在深圳集群上,应该就会创建一个新的 bj_sales_replica 的索引,并且里面会有两条数据,我们可以验证一下,如下:
GET bj_sales_replica/_search
返回结果如下:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 1.0,
"hits" : [
{
"_index" : "bj_sales_replica",
"_type" : "doc",
"_id" : "iNZYymcBGbeu9hnEe7-G",
"_score" : 1.0,
"_source" : {
"name" : "Pony Ma",
"age" : 40
}
},
{
"_index" : "bj_sales_replica",
"_type" : "doc",
"_id" : "QdZYymcBGbeu9hnEJb-Z",
"_score" : 1.0,
"_source" : {
"name" : "Jack Ma",
"age" : 40
}
}
]
}
}
果然,自动将远程集群的数据复制过来了。
继续验证,数据同步
我们在北京集群上,继续新增数据和删除数据,看看深圳集群是否都能正常同步。
POST bj_sales/doc/5
{
"name":"Tony",
"age":30
}
DELETE bj_sales/doc/5
相关文章:
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由
ES是一个分布式框架,隐藏了复杂的处理机制,核心数据分片机制、集群发现、分片负载均衡请求路由。 ES的高可用架构,总体如下图: 说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面…...

xml和json互转工具类
分享一个json与xml互转的工具类,非常好用 一、maven依赖 <!-->json 和 xm 互转</!--><dependency><groupId>org.dom4j</groupId><artifactId>dom4j</artifactId><version>2.1.3</version></dependency&g…...

Windows系统下MMDeploy预编译包的使用
Windows系统下MMDeploy预编译包的使用 MMDeploy步入v1版本后安装/使用难度大幅下降,这里以部署MMDetection项目的Faster R-CNN模型为例,将PyTorch模型转换为ONNX进而转换为Engine模型,部署到TensorRT后端,实现高效推理,…...
yolov5自定义模型训练二
前期准备好了用于训练识别是否有火灾的数据集后就可以开始修改yolo相关文件来进行训练 数据集放到yolov5目录里 在data目录下新建yaml文件设置数据集信息如下 在model文件夹下新增新的model文件 开始训练 训练出错 确认后是对训练数据集文件夹里的文件名字有要求,原…...
)
Spring框架获取用户真实IP(注解式)
文章目录 一、最终使用效果(ClientIp 注解获取)二、实现代码1.注解2.方法参数解析器(Resolver)3.全局增加Resolver配置 Spring 框架没有现成工具可以方便提取客户端的IP地址,普遍做法就是通过 HttpServletRequest 的 g…...

利用 IDEA IDE 的轻量编辑模式快速查看和编辑工程外的文本文件
作为程序员, 我们都知道 IDE 的很好用的, 它的文本编辑器功能也非常的强大, 用起来非常便捷. 在长年累月的使用中, 我们也变得对其非常熟悉, 以致于使用起其它简单地轻量级的文本编辑器来, 比如什么记事本, Notepad, UltraEdit 等等呀, 觉得既不方便又不熟悉. 关键是很多的操作…...
MyBatisx代码生成
MyBatisx代码生成 1.创建数据库表 CREATE TABLE sys_good (good_id int(11) NOT NULL,good_name varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,good_desc varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,PRIMARY KEY (good_id) ) ENGINEInnoDB DEFAULT CHA…...

【日记】文章更新计划
首发博客地址[1] 状态 这两天也没加班,也没干什么活。不知道怎么回事,到家就想睡觉。所以这两天睡得很早,基本上 11 点之前就睡了,文章也就鸽了两天。 计划 今早起来感觉还是要自律,我写文章的初衷是为了学习。基于这个…...

UML用例图三种关系(重点)-架构真题(十七)
某项目包括A、B、C、D四道工序,各道工序之间的衔接关系、正常进度下各工序所需的时间和直接费用、赶工进度下所需的时间和直接费用如下表所示。该项目每天需要间接费用为4.5万元,根据此表,最低成本完成需要()天。&…...

分层解耦介绍
三层架构 Controller:控制层,接受前端发送的请求,对请求进行处理,并响应数据 service:业务逻辑层,处理具体业务逻辑 dao:数据访问层,负责数据访问操作,包括数据的增、删、…...
Nginx百科之gzip压缩、黑白名单、防盗链、零拷贝、跨域、双机热备
引言 早期的业务都是基于单体节点部署,由于前期访问流量不大,因此单体结构也可满足需求,但随着业务增长,流量也越来越大,那么最终单台服务器受到的访问压力也会逐步增高。时间一长,单台服务器性能无法跟上业…...
git通过fork-merge request实现多人协同
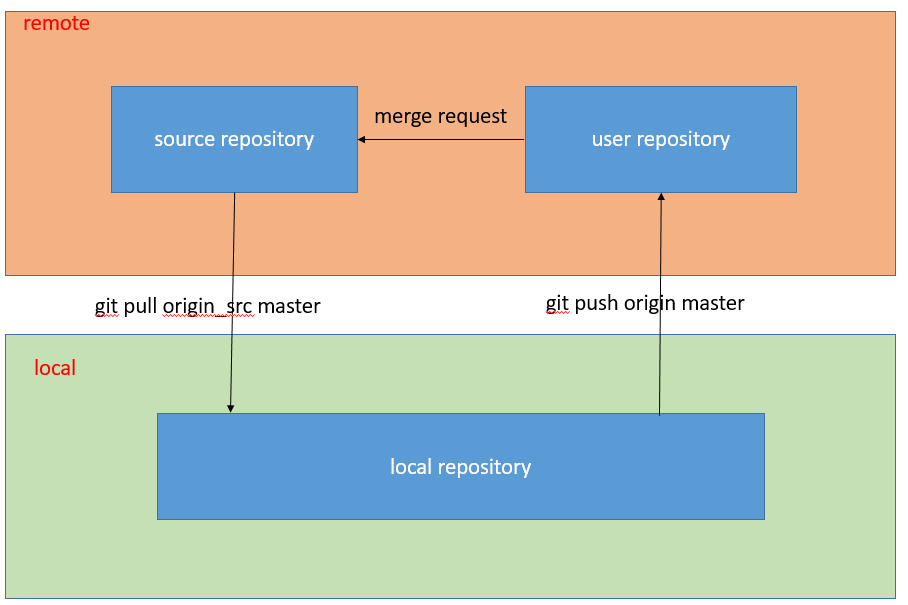
一、问题 对于一个项目,如果需要多人协同开发,大家都在原始仓库中进行修改提交,经常会发生冲突,而且一不小心会把别人的代码内容覆盖掉。为了避免这样的问题,git提供了fork-merge request这样的协同方式。 二、仓库框…...

元素居中的方法总结
目录 垂直居中 行内元素垂直居中 单行文本垂直居中 1.line-height: 200px; 多行文本垂直居中 1.tablevertical-align:middle 块级元素垂直居中 1.display: flex;align-items: center; 2.使用position top margin-top 水平居中 行内元素水平居中 1.text-align:cente…...

后端面试话术集锦第一篇:spring面试话术
这是后端面试集锦第一篇博文——spring面试话术❗❗❗ 1. 介绍一下spring 关于spring,我们平时做项目一直都在用,不管是使用ssh还是使用ssm,都可以整合。 Spring主要就三点,也就是核心思想: IOC控制反转 DI依赖注入 AOP切面编程 我先说说IOC吧,IOC就是spring里的控制反…...
elasticsearch8.9.1集群搭建
目录 1.官网文档 2.安装步骤 2.1 环境准备 2.2 添加用户 2.3 修改文件profile文件 2.4 修改elasticsearch.yml 2.5 修改 sysctl.conf 3.启动 3.1 切换到kibana 3.2 启动elasticsearch 3.3 启动kibana 3.4 验证节点情况 1.官网文档 elasticsearch文档:ht…...
前端调用电脑摄像头
项目中需要前端调用,所以做了如下操作 先看一下效果吧 主要是基于vue3,通过canvas把画面转成base64的形式,然后是把base64转成 file文件,最后调用了一下上传接口 以下是代码 进入页面先调用一下摄像头 navigator.mediaDevices.ge…...

网络编程day1——进程间通信-socket套接字
基本特征:socket是一种接口技术,被抽象了一种文件操作,可以让同一计算机中的不同进程之间通信,也可以让不同计算机中的进程之间通信(网络通信) 本地进程间通信编程模型: 进程A …...
Android-关于页面卡顿的排查工具与监测方案
作者:一碗清汤面 前言 关于卡顿这件事已经是老生常谈了,卡顿对于用户来说是敏感的,容易被用户直接感受到的。那么究其原因,卡顿该如何定义,对于卡顿的发生该如何排查问题,当线上用户卡顿时,在线…...
VueX 与Pinia 一篇搞懂
VueX 简介 Vue官方:状态管理工具 状态管理是什么 需要在多个组件中共享的状态、且是响应式的、一个变,全都改变。 例如一些全局要用的的状态信息:用户登录状态、用户名称、地理位置信息、购物车中商品、等等 这时候我们就需要这么一个工…...
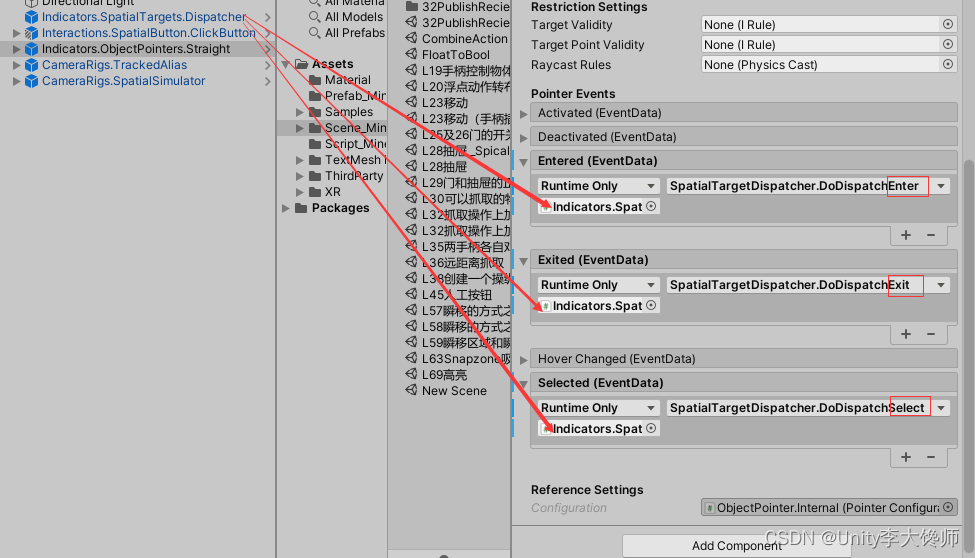
指针与空间按钮的交互
文章目录 原理案例:“直线指针”和“点击按钮”的交互1、效果2、步骤 原理 指针不能直接和空间按钮交互,得借助一个中间层——分发器——它分发指针的进入、退出、选择事件,空间按钮自动监听这些事件 案例:“直线指针”和“点击…...

用树莓派和SG90舵机实现摄像头云台控制:从零调试到精准转动
树莓派SG90舵机打造智能摄像头云台:从硬件连接到PID调参全指南 当你想用树莓派控制摄像头实现自动追踪或远程监控时,一个灵活可靠的云台系统是核心。SG90这类微型舵机因其体积小、价格低成为DIY项目的首选,但要让它们实现精准平滑的运动控制…...
)
Claude Code 进行“从头重写”的项目 Claw Code全面介绍(claw-code)
一个对泄露的 Claude Code 进行“从头重写”的项目,已成为 GitHub 上增长最快的仓库。一、项目是什么 claw-code(仓库全名写作 Rewriting Project Claw Code)是一个围绕「智能体 Harness( harness:把模型、工具、会话与…...

[具身智能-220]:“关节空间”与“操作空间”
在机器人学中,关节空间 (Joint Space) 和 操作空间 (Operational Space) 是描述机器人运动的两种基本方式,它们之间通过运动学相互关联。理解这两个概念是进行机器人轨迹规划和控制的基础。简单来说,关节空间关注机器人“内部”的关节状态&am…...

ModTheSpire终极指南:解锁《杀戮尖塔》无限可能的模组加载器
ModTheSpire终极指南:解锁《杀戮尖塔》无限可能的模组加载器 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire ModTheSpire是专为《杀戮尖塔》设计的开源模组加载器ÿ…...

剪映API技术解析:如何通过代码驱动实现视频剪辑自动化与效率革命
剪映API技术解析:如何通过代码驱动实现视频剪辑自动化与效率革命 【免费下载链接】JianYingApi Third Party JianYing Api. 第三方剪映Api 项目地址: https://gitcode.com/gh_mirrors/ji/JianYingApi 在视频内容创作进入工业化生产的今天,传统手动…...

从隔离菜谱到通用烹饪指南:Cook用户体验设计的完整演进之路
从隔离菜谱到通用烹饪指南:Cook用户体验设计的完整演进之路 【免费下载链接】cook 🍲 好的,今天我们来做菜!OK, Lets Cook! 项目地址: https://gitcode.com/gh_mirrors/co/cook 在数字化时代,烹饪应用已成为厨房…...

突破音乐格式限制的全方位解决方案:让你的音频文件重获自由
突破音乐格式限制的全方位解决方案:让你的音频文件重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: …...
AFSS :防遗忘采样策略)
(论文速读)AFSS :防遗忘采样策略
论文题目:Does YOLO Really Need to See Every Training Image in Every Epoch?(YOLO真的需要查看每个epoch的每个训练图像吗?)会议:CVPR2026摘要:YOLO检测器以其快速的推理速度而闻名,但是训练它们仍然非…...

小米智能家居与Home Assistant零门槛实战:从集成到优化全流程指南
小米智能家居与Home Assistant零门槛实战:从集成到优化全流程指南 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 小米智能家居集成项目(ha_xia…...

xArm机械臂电气接口全解析:从末端法兰到RS485的实战避坑指南
xArm机械臂电气接口全解析:从末端法兰到RS485的实战避坑指南 在工业自动化领域,机械臂的电气接口设计往往是决定系统稳定性的关键因素。作为国内领先的协作机器人品牌,xArm以其出色的性价比和开放性接口设计赢得了众多工程师的青睐。但当我们…...