CUDA虚拟内存管理
CUDA中的虚拟内存管理

文章目录
- CUDA中的虚拟内存管理
- 1. Introduction
- 2. Query for support
- 3. Allocating Physical Memory
- 3.1. Shareable Memory Allocations
- 3.2. Memory Type
- 3.2.1. Compressible Memory
- 4. Reserving a Virtual Address Range
- 5. Virtual Aliasing Support
- 6. Mapping Memory
- 7. Control Access Rights
1. Introduction
虚拟内存管理 API 为应用程序提供了一种直接管理统一虚拟地址空间的方法,该空间由 CUDA 提供,用于将物理内存映射到 GPU 可访问的虚拟地址。在 CUDA 10.2 中引入的这些 API 还提供了一种与其他进程和图形 API(如 OpenGL 和 Vulkan)进行互操作的新方法,并提供了用户可以调整以适应其应用程序的更新内存属性。
从历史上看,CUDA 编程模型中的内存分配调用(例如 cudaMalloc)返回了一个指向 GPU 内存的内存地址。这样获得的地址可以与任何 CUDA API 一起使用,也可以在设备内核中使用。但是,分配的内存无法根据用户的内存需求调整大小。为了增加分配的大小,用户必须显式分配更大的缓冲区,从初始分配中复制数据,释放它,然后继续跟踪新分配的地址。这通常会导致应用程序的性能降低和峰值内存利用率更高。本质上,用户有一个类似 malloc 的接口来分配 GPU 内存,但没有相应的 realloc 来补充它。虚拟内存管理 API 将地址和内存的概念解耦,并允许应用程序分别处理它们。 API 允许应用程序在他们认为合适的时候从虚拟地址范围映射和取消映射内存。
在通过 cudaEnablePeerAccess 启用对等设备访问内存分配的情况下,所有过去和未来的用户分配都映射到目标对等设备。这导致用户无意中支付了将所有 cudaMalloc 分配映射到对等设备的运行时成本。然而,在大多数情况下,应用程序通过仅与另一个设备共享少量分配进行通信,并且并非所有分配都需要映射到所有设备。使用虚拟内存管理,应用程序可以专门选择某些分配可从目标设备访问。
CUDA 虚拟内存管理 API 向用户提供细粒度控制,以管理应用程序中的 GPU 内存。它提供的 API 允许用户:
- 将分配在不同设备上的内存放入一个连续的 VA 范围内。
- 使用平台特定机制执行内存共享的进程间通信。
- 在支持它们的设备上选择更新的内存类型。
为了分配内存,虚拟内存管理编程模型公开了以下功能:
- 分配物理内存。
- 保留 VA 范围。
- 将分配的内存映射到 VA 范围。
- 控制映射范围的访问权限。
请注意,本节中描述的 API 套件需要支持 UVA 的系统。
2. Query for support
在尝试使用虚拟内存管理 API 之前,应用程序必须确保他们希望使用的设备支持 CUDA 虚拟内存管理。 以下代码示例显示了查询虚拟内存管理支持:
int deviceSupportsVmm;
CUresult result = cuDeviceGetAttribute(&deviceSupportsVmm, CU_DEVICE_ATTRIBUTE_VIRTUAL_MEMORY_MANAGEMENT_SUPPORTED, device);
if (deviceSupportsVmm != 0) {// `device` supports Virtual Memory Management
}3. Allocating Physical Memory
通过虚拟内存管理 API 进行内存分配的第一步是创建一个物理内存块,为分配提供支持。 为了分配物理内存,应用程序必须使用 cuMemCreate API。 此函数创建的分配没有任何设备或主机映射。 函数参数 CUmemGenericAllocationHandle 描述了要分配的内存的属性,例如分配的位置、分配是否要共享给另一个进程(或其他图形 API),或者要分配的内存的物理属性。 用户必须确保请求分配的大小必须与适当的粒度对齐。 可以使用 cuMemGetAllocationGranularity 查询有关分配粒度要求的信息。 以下代码片段显示了使用 cuMemCreate 分配物理内存:
CUmemGenericAllocationHandle allocatePhysicalMemory(int device, size_t size) {CUmemAllocationProp prop = {};prop.type = CU_MEM_ALLOCATION_TYPE_PINNED;prop.location.type = CU_MEM_LOCATION_TYPE_DEVICE;prop.location.id = device;cuMemGetAllocationGranularity(&granularity, &prop, CU_MEM_ALLOC_GRANULARITY_MINIMUM);// Ensure size matches granularity requirements for the allocationsize_t padded_size = ROUND_UP(size, granularity);// Allocate physical memoryCUmemGenericAllocationHandle allocHandle;cuMemCreate(&allocHandle, padded_size, &prop, 0);return allocHandle;
}由 cuMemCreate 分配的内存由它返回的 CUmemGenericAllocationHandle 引用。 这与 cudaMalloc风格的分配不同,后者返回一个指向 GPU 内存的指针,该指针可由在设备上执行的 CUDA 内核直接访问。 除了使用 cuMemGetAllocationPropertiesFromHandle 查询属性之外,分配的内存不能用于任何操作。 为了使此内存可访问,应用程序必须将此内存映射到由 cuMemAddressReserve 保留的 VA 范围,并为其提供适当的访问权限。 应用程序必须使用 cuMemRelease API 释放分配的内存。
3.1. Shareable Memory Allocations
使用 cuMemCreate 用户现在可以在分配时向 CUDA 指示他们已指定特定分配用于进程间通信或图形互操作目的。应用程序可以通过将 CUmemAllocationProp::requestedHandleTypes 设置为平台特定字段来完成此操作。在 Windows 上,当 CUmemAllocationProp::requestedHandleTypes 设置为 CU_MEM_HANDLE_TYPE_WIN32 时,应用程序还必须在 CUmemAllocationProp::win32HandleMetaData 中指定 LPSECURITYATTRIBUTES 属性。该安全属性定义了可以将导出的分配转移到其他进程的范围。
CUDA 虚拟内存管理 API 函数不支持传统的进程间通信函数及其内存。相反,它们公开了一种利用操作系统特定句柄的进程间通信的新机制。应用程序可以使用 cuMemExportToShareableHandle 获取与分配相对应的这些操作系统特定句柄。这样获得的句柄可以通过使用通常的 OS 本地机制进行传输,以进行进程间通信。接收进程应使用 cuMemImportFromShareableHandle 导入分配。
用户必须确保在尝试导出使用 cuMemCreate 分配的内存之前查询是否支持请求的句柄类型。以下代码片段说明了以特定平台方式查询句柄类型支持。
int deviceSupportsIpcHandle;
#if defined(__linux__)cuDeviceGetAttribute(&deviceSupportsIpcHandle, CU_DEVICE_ATTRIBUTE_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR_SUPPORTED, device));
#elsecuDeviceGetAttribute(&deviceSupportsIpcHandle, CU_DEVICE_ATTRIBUTE_HANDLE_TYPE_WIN32_HANDLE_SUPPORTED, device));
#endif
用户应适当设置 CUmemAllocationProp::requestedHandleTypes,如下所示:
#if defined(__linux__)prop.requestedHandleTypes = CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR;
#elseprop.requestedHandleTypes = CU_MEM_HANDLE_TYPE_WIN32;prop.win32HandleMetaData = // Windows specific LPSECURITYATTRIBUTES attribute.
#endifmemMapIpcDrv 示例可用作将 IPC 与虚拟内存管理分配一起使用的示例。
3.2. Memory Type
在 CUDA 10.2 之前,应用程序没有用户控制的方式来分配某些设备可能支持的任何特殊类型的内存。 使用 cuMemCreate 应用程序还可以使用 CUmemAllocationProp::allocFlags 指定内存类型要求,以选择任何特定的内存功能。 应用程序还必须确保分配设备支持请求的内存类型。
3.2.1. Compressible Memory
可压缩内存可用于加速对具有非结构化稀疏性和其他可压缩数据模式的数据的访问。 压缩可以节省 DRAM 带宽、L2 读取带宽和 L2 容量,具体取决于正在操作的数据。 想要在支持计算数据压缩的设备上分配可压缩内存的应用程序可以通过将 CUmemAllocationProp::allocFlags::compressionType 设置为 CU_MEM_ALLOCATION_COMP_GENERIC 来实现。 用户必须通过 CU_DEVICE_ATTRIBUTE_GENERIC_COMPRESSION_SUPPORTED 查询设备是否支持计算数据压缩。 以下代码片段说明了查询可压缩内存支持 cuDeviceGetAttribute。
int compressionSupported = 0;
cuDeviceGetAttribute(&compressionSupported, CU_DEVICE_ATTRIBUTE_GENERIC_COMPRESSION_SUPPORTED, device);在支持计算数据压缩的设备上,用户需要在分配时选择加入,如下所示:
prop.allocFlags.compressionType = CU_MEM_ALLOCATION_COMP_GENERIC;由于硬件资源有限等各种原因,分配的内存可能没有压缩属性,用户需要使用cuMemGetAllocationPropertiesFromHandle查询回分配内存的属性并检查压缩属性。
CUmemAllocationPropPrivate allocationProp = {};
cuMemGetAllocationPropertiesFromHandle(&allocationProp, allocationHandle);if (allocationProp.allocFlags.compressionType == CU_MEM_ALLOCATION_COMP_GENERIC)
{// Obtained compressible memory allocation
}4. Reserving a Virtual Address Range
由于使用虚拟内存管理,地址和内存的概念是不同的,因此应用程序必须划出一个地址范围,以容纳由 cuMemCreate 进行的内存分配。保留的地址范围必须至少与用户计划放入其中的所有物理内存分配大小的总和一样大。
应用程序可以通过将适当的参数传递给 cuMemAddressReserve 来保留虚拟地址范围。获得的地址范围不会有任何与之关联的设备或主机物理内存。保留的虚拟地址范围可以映射到属于系统中任何设备的内存块,从而为应用程序提供由属于不同设备的内存支持和映射的连续 VA 范围。应用程序应使用 cuMemAddressFree 将虚拟地址范围返回给 CUDA。用户必须确保在调用 cuMemAddressFree 之前未映射整个 VA 范围。这些函数在概念上类似于 mmap/munmap(在 Linux 上)或 VirtualAlloc/VirtualFree(在 Windows 上)函数。以下代码片段说明了该函数的用法:
CUdeviceptr ptr;
// `ptr` holds the returned start of virtual address range reserved.
CUresult result = cuMemAddressReserve(&ptr, size, 0, 0, 0); // alignment = 0 for default alignment5. Virtual Aliasing Support
虚拟内存管理 API 提供了一种创建多个虚拟内存映射或“代理”到相同分配的方法,该方法使用对具有不同虚拟地址的 cuMemMap 的多次调用,即所谓的虚拟别名。 除非在 PTX ISA 中另有说明,否则写入分配的一个代理被认为与同一内存的任何其他代理不一致和不连贯,直到写入设备操作(网格启动、memcpy、memset 等)完成。 在写入设备操作之前出现在 GPU 上但在写入设备操作完成后读取的网格也被认为具有不一致和不连贯的代理。
例如,下面的代码片段被认为是未定义的,假设设备指针 A 和 B 是相同内存分配的虚拟别名:
__global__ void foo(char *A, char *B) {*A = 0x1;printf(“%d\n”, *B); // Undefined behavior! *B can take on either
// the previous value or some value in-between.
}
以下是定义的行为,假设这两个内核是单调排序的(通过流或事件)。
__global__ void foo1(char *A) {*A = 0x1;
}__global__ void foo2(char *B) {printf(“%d\n”, *B); // *B == *A == 0x1 assuming foo2 waits for foo1
// to complete before launching
}cudaMemcpyAsync(B, input, size, stream1); // Aliases are allowed at
// operation boundaries
foo1<<<1,1,0,stream1>>>(A); // allowing foo1 to access A.
cudaEventRecord(event, stream1);
cudaStreamWaitEvent(stream2, event);
foo2<<<1,1,0,stream2>>>(B);
cudaStreamWaitEvent(stream3, event);
cudaMemcpyAsync(output, B, size, stream3); // Both launches of foo2 and// cudaMemcpy (which both// read) wait for foo1 (which writes)// to complete before proceeding
6. Mapping Memory
前两节分配的物理内存和挖出的虚拟地址空间代表了虚拟内存管理 API 引入的内存和地址区别。为了使分配的内存可用,用户必须首先将内存放在地址空间中。从 cuMemAddressReserve 获取的地址范围和从 cuMemCreate 或 cuMemImportFromShareableHandle 获取的物理分配必须通过 cuMemMap 相互关联。
用户可以关联来自多个设备的分配以驻留在连续的虚拟地址范围内,只要他们已经划分出足够的地址空间。为了解耦物理分配和地址范围,用户必须通过 cuMemUnmap 取消映射的地址。用户可以根据需要多次将内存映射和取消映射到同一地址范围,只要他们确保不会尝试在已映射的 VA 范围保留上创建映射。以下代码片段说明了该函数的用法:
CUdeviceptr ptr;
// `ptr`: address in the address range previously reserved by cuMemAddressReserve.
// `allocHandle`: CUmemGenericAllocationHandle obtained by a previous call to cuMemCreate.
CUresult result = cuMemMap(ptr, size, 0, allocHandle, 0);7. Control Access Rights
虚拟内存管理 API 使应用程序能够通过访问控制机制显式保护其 VA 范围。 使用 cuMemMap 将分配映射到地址范围的区域不会使地址可访问,并且如果被 CUDA 内核访问会导致程序崩溃。 用户必须使用 cuMemSetAccess 函数专门选择访问控制,该函数允许或限制特定设备对映射地址范围的访问。 以下代码片段说明了该函数的用法:
void setAccessOnDevice(int device, CUdeviceptr ptr, size_t size) {CUmemAccessDesc accessDesc = {};accessDesc.location.type = CU_MEM_LOCATION_TYPE_DEVICE;accessDesc.location.id = device;accessDesc.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE;// Make the address accessiblecuMemSetAccess(ptr, size, &accessDesc, 1);
}使用虚拟内存管理公开的访问控制机制允许用户明确他们希望与系统上的其他对等设备共享哪些分配。 如前所述,cudaEnablePeerAccess 强制将所有先前和将来的 cudaMalloc 分配映射到目标对等设备。 这在许多情况下很方便,因为用户不必担心跟踪每个分配到系统中每个设备的映射状态。 但是对于关心其应用程序性能的用户来说,这种方法具有性能影响。 通过分配粒度的访问控制,虚拟内存管理公开了一种机制,可以以最小的开销进行对等映射。
vectorAddMMAP 示例可用作使用虚拟内存管理 API 的示例。
相关文章:
CUDA虚拟内存管理
CUDA中的虚拟内存管理 文章目录CUDA中的虚拟内存管理1. Introduction2. Query for support3. Allocating Physical Memory3.1. Shareable Memory Allocations3.2. Memory Type3.2.1. Compressible Memory4. Reserving a Virtual Address Range5. Virtual Aliasing Support6. Ma…...
线程池小结
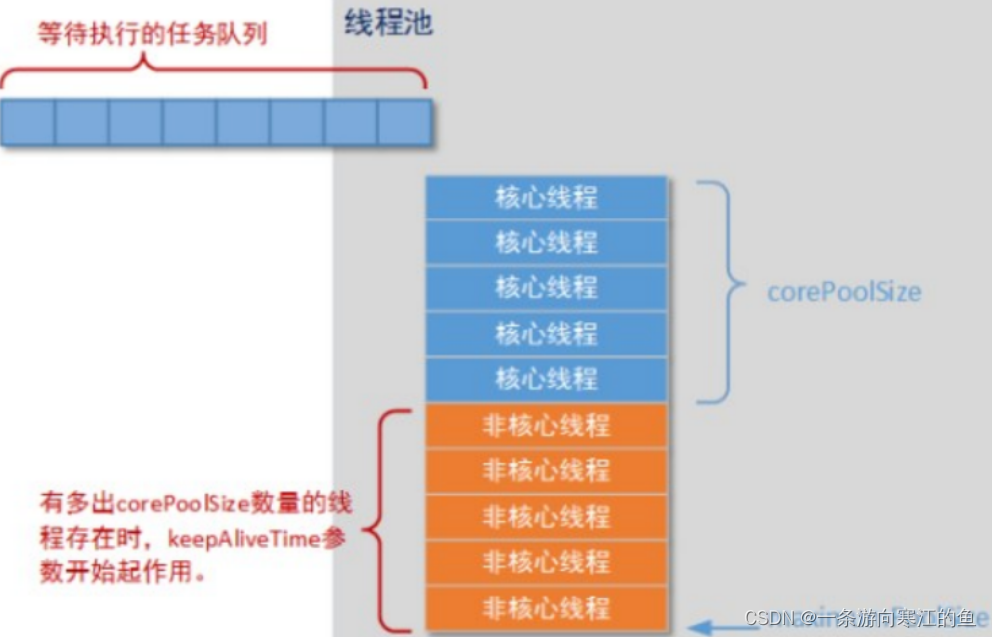
什么是线程池 线程池其实就是一种多线程处理形式,处理过程中可以将任务添加到队列中,然后在创建线程后自动启动这些任务。这里的线程就是我们前面学过的线程,这里的任务就是我们前面学过的实现了Runnable或Callable接口的实例对象; 为什么使用线程池 …...

vue3状态管理模式 Pinia
状态管理库 Pinia是Vue的专属状态管理库,它允许你跨组件或页面共享状态 1:安装与使用pinia 1.1 安装语法:npm install pinia1.2 创建一个pinia(根存储)并将其传递给应用程序 import { createApp } from vue import…...
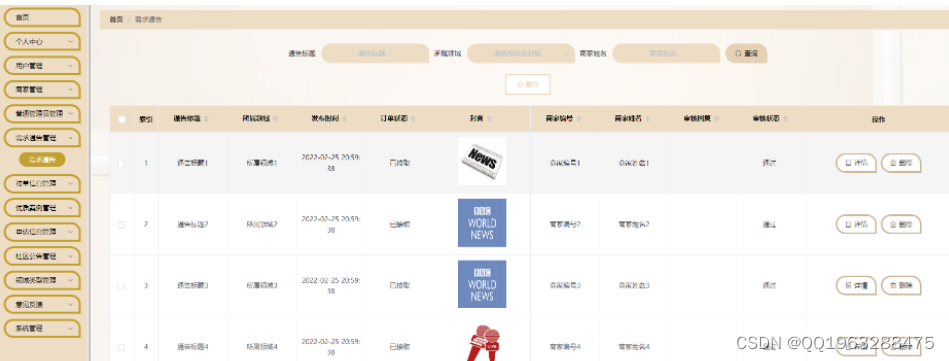
python基于django的自媒体社区交流平台
自媒体社区平台采用python技术,基于django框架,mysql数据库进行开发,实现了以下功能: 本系统主要包括管理员,用户,商家和普通管理员四个角色组成,主要包括以下功能: 1;前台:首页、需求通告、优质案例、帮助中心、意见反馈、个人中心、后台管理…...
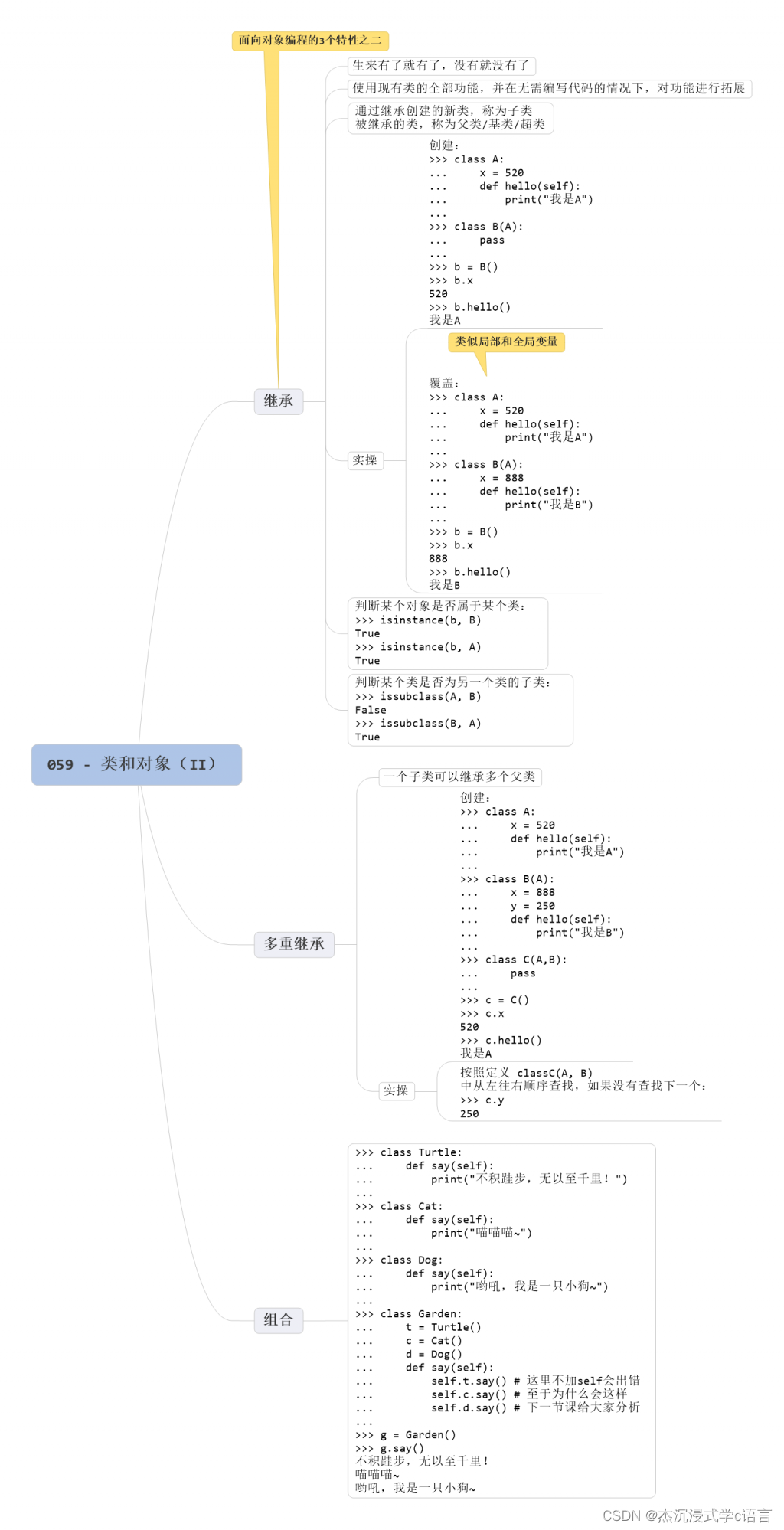
Python中类和对象(2)
1.继承 Python 的类是支持继承的:它可以使用现有类的所有功能,并在无需重新编写代码的情况下对这些功能进行扩展。 通过继承创建的新类称为 “子类”,被继承的类称为 “父类”、“基类” 或 “超类”。 继承语法是将父类写在子类类名后面的…...

SpringMvc入门
Spring与Web环境的集成 1.ApplicationContext应用上下文的获取方式 分析 之前获取应用上下文对象每次都是从容器中获取,编写时都需要new ClasspathXmlApplicationContext(Spring配置文件),这样的弊端就是配置加载多次应用上下文就创建多次。 在Web项目…...
设计模式之单例模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、单例模式是什么? 单例模式是一种创建型的软件设计模式,在工程项目中非常常见。通过单例模式的设计&am…...
贪心算法(基础)
目录 一、什么是贪心? (一)以教室调度问题为例 1. 问题 2. 具体做法如下 3. 因此将在这间教室上如下三堂课 4. 结论 (二)贪心算法介绍 1. 贪心算法一般解题步骤 二、最优装载问题 (一…...

【九宫格坐标排列 Objective-C语言】
一、这个案例做好之后的效果如图: 1.这个下载是可以点击的,当你点击之后,弹出一个框,过一会儿,框框自动消失,这里变成“已安装” 2.那么,我现在先问大家一句话:大家认为在这一个应用里面,它包含几个控件, 3个,哪3个:一个是图片框,一个是Label,一个是按钮, 这…...
Tomcat简介
目录 一、Tomcat简介 二、下载安装Tomcat 三、利用Tomcat部署静态页面 一、Tomcat简介 Tomcat是一个HTTP服务器,可以按照HTTP的格式来解析请求来调用用户指定的相关代码然后按照HTTP的格式来构造返回数据。 二、下载安装Tomcat 进入Tomcat官网选择与自己电脑…...
Python基础及函数解读(深度学习)
一、语句1.加注释单行注释:(1)在代码上面加注释: # 后面跟一个空格(2)在代码后面加注释:和代码相距两个空格, # 后面再跟一个空格多行注释:按住shift 点击三次"&am…...

车道线检测-PolyLaneNet 论文学习笔记
论文:《PolyLaneNet: Lane Estimation via Deep Polynomial Regression》代码:https://github.com/lucastabelini/PolyLaneNet地址:https://arxiv.org/pdf/2004.10924.pdf参考:https://blog.csdn.net/sinat_17456165/article/deta…...
)
GO——接口(下)
接口接口值警告:一个包含空指针值的接口不是nil接口sort.Interface接口http.Handler接口类型断言类型分支接口值 接口值,由两个部分组成,一个具体的类型和那个类型的值。它们被称为接口的动态类型和动态值。对于像Go语言这种静态类型的语言&…...
计算机网络之http02| HTTPS HTTP1.1的优化
post与get请求的区别 get 是获取资源,Post是向指定URI提交资源,相关信息放在body里 2.http有哪些优点 (1)简单 报文只有报文首部和报文主体,易于理解 (2)灵活易拓展 URI相应码、首部字段都没有…...

基于matlab使用神经网络清除海杂波
一、前言此示例演示如何使用深度学习工具箱™训练和评估卷积神经网络,以消除海上雷达 PPI 图像中的杂波返回。深度学习工具箱提供了一个框架,用于设计和实现具有算法、预训练模型和应用程序的深度神经网络。二、数据集该数据集包含 84 对合成雷达图像。每…...

每天10个前端小知识 【Day 8】
前端面试基础知识题 1. Javascript中如何实现函数缓存?函数缓存有哪些应用场景? 函数缓存,就是将函数运算过的结果进行缓存。本质上就是用空间(缓存存储)换时间(计算过程), 常用于…...
【项目精选】基于Java的敬老院管理系统的设计和实现
本系统主要是针对敬老院工作人员即管理员和员工设计的。敬老院管理系统 将IT技术为养老院提供一个接口便于管理信息,存储老人个人信息和其他信息,查找 和更新信息的养老院档案,节省了员工的劳动时间,大大降低了成本。 其主要功能包括: 系统管理员用户功能介绍&#…...
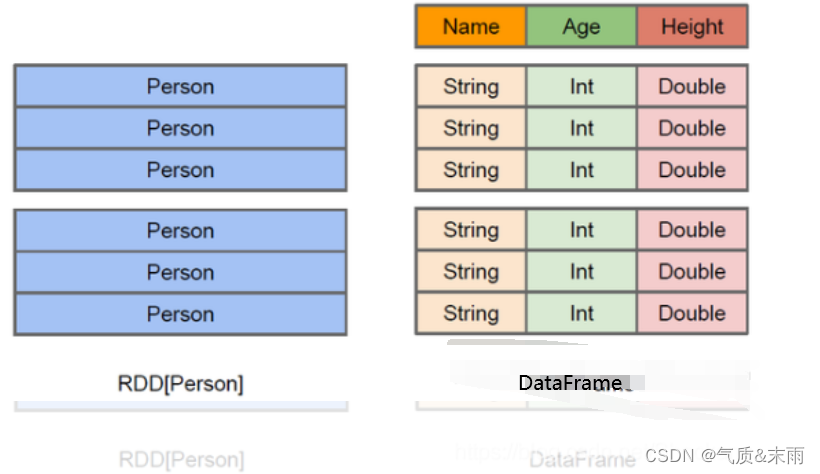
Spark SQL 介绍
文章目录Spark SQL1、Hive on SparkSQL2、SparkSQL 优点3、SparkSQL 特点1) 容易整合2) 统一的数据访问3) 兼容 Hive4) 标准的数据连接4、DataFrame 是什么5、DataSet 是什么Spark SQL Spark SQL 是 Spark 用于结构化数据(structured data) 处理的Spark模块。 1、Hive on Spa…...

升级到 CDP 后Hive on Tez 性能调整和故障排除指南
优化Hive on Tez查询永远不能以一种万能的方法来完成。查询的性能取决于数据的大小、文件类型、查询设计和查询模式。在性能测试期间,要评估和验证配置参数和任何 SQL 修改。建议在工作负载的性能测试期间一次进行一项更改,并且最好在生产环境中使用它们…...

理解HDFS工作流程与机制,看这篇文章就够了
HDFS(The Hadoop Distributed File System) 是最初由Yahoo提出的分布式文件系统,它主要用来: 1)存储大数据 2)为应用提供大数据高速读取的能力 重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升…...

Kook Zimage真实幻想Turbo作品集:这些梦幻场景竟然都是用AI画出来的
Kook Zimage真实幻想Turbo作品集:这些梦幻场景竟然都是用AI画出来的 1. 走进AI幻想艺术世界 你是否曾经幻想过这样的场景:月光下水晶翅膀的精灵在森林中起舞,或是蒸汽朋克风格的机械龙盘旋在未来都市上空?这些曾经只存在于画家笔…...

RVC模型开源社区贡献指南:GitHub Pull Request全流程解析
RVC模型开源社区贡献指南:GitHub Pull Request全流程解析 你是不是也用过RVC模型,觉得它很酷,甚至想过“要是能自己改点代码,让它更好用就好了”?或者,你发现了一个小bug,或者有个很棒的新功能…...

从特斯拉到蔚来:AUTOSAR NM网络管理在新能源车上的5个典型应用场景
从特斯拉到蔚来:AUTOSAR NM网络管理在新能源车上的5个典型应用场景 当一辆新能源车在深夜的停车场静静停放时,车内数十个ECU节点并非全部保持活跃状态。这种"按需唤醒"的智能协同机制,正是AUTOSAR NM(Network Managemen…...

答应我,不要再说自己不了解Spring源码的整体设计和实现细节了
Spring是我们Java程序员面试和工作都绕不开的重难点。很多粉丝就经常跟我反馈说由Spring衍生出来的一系列框架太多了,根本不知道从何下手;大家学习过程中大都不成体系,但面试的时候都上升到源码级别了,你不光要清楚了解Spring源码…...

TypeScript学习笔记 - P2
TypeScript学习笔记——类型1. 类型限制1. ts可以在变量声明时规定类型2. 如果变量的声明和赋值同时进行,ts会自动规定类型3. 对函数进行类型限制2. TS的类型1. 字面量类型2. any类型3. unknown类型4. void类型5. never类型6. object类型7. array类型8. tuple类型9.…...

从Element到pl-table:提升表格性能的5个关键技巧
从Element到pl-table:提升表格性能的5个关键技巧 【免费下载链接】pl-table A table based on element, 完美解决万级数据渲染卡顿问题 项目地址: https://gitcode.com/gh_mirrors/pl/pl-table 在现代前端开发中,表格组件是数据展示的核心工具&am…...

如何快速构建Docker与CI/CD流水线:Jenkinsfile编写指南
如何快速构建Docker与CI/CD流水线:Jenkinsfile编写指南 【免费下载链接】dockerfiles Various Dockerfiles I use on the desktop and on servers. 项目地址: https://gitcode.com/gh_mirrors/do/dockerfiles GitHub 加速计划 / do / dockerfiles 项目提供了…...
SFAFBR:一种自监督的人工特征偏置校正框架)
(论文速读)SFAFBR:一种自监督的人工特征偏置校正框架
论文题目:Artificial Feature Bias Rectified by Self-Supervised Learning for Rolling Bearings Fault Diagnosis Under Limited Labeled Vibration Signals(有限标记振动信号下滚动轴承故障诊断的自监督学习修正人工特征偏差)期刊…...

Qwen3-ASR-1.7B效果展示:韩语综艺对话→中文幽默点自动识别
Qwen3-ASR-1.7B效果展示:韩语综艺对话→中文幽默点自动识别 1. 引言:当AI听懂韩综笑点 你有没有看过韩语综艺节目,明明看到嘉宾笑得前仰后合,却因为语言障碍完全get不到笑点?那种"他们在笑什么"的困惑&…...

借助claudecode与快马平台,十分钟快速原型你的下一个应用创意
最近在构思一个个人博客网站,从零开始写代码总觉得有点费时费力。正好了解到InsCode(快马)平台集成了像claudecode这样的AI代码生成能力,就想着试试看能不能快速把想法变成可运行的原型。我的需求很明确:一个响应式主页展示我和文章列表&…...