理解HDFS工作流程与机制,看这篇文章就够了
HDFS(The Hadoop Distributed File System) 是最初由Yahoo提出的分布式文件系统,它主要用来:
1)存储大数据
2)为应用提供大数据高速读取的能力
重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升带来的好处。
HDFS工作流程与机制
⚫ HDFS集群角色与职责
⚫ HDFS写数据流程(上传文件)
⚫ HDFS读数据流程(下载文件)
官方架构图

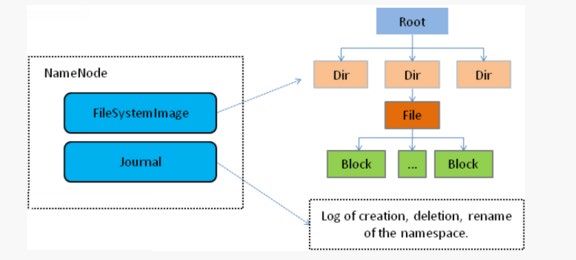
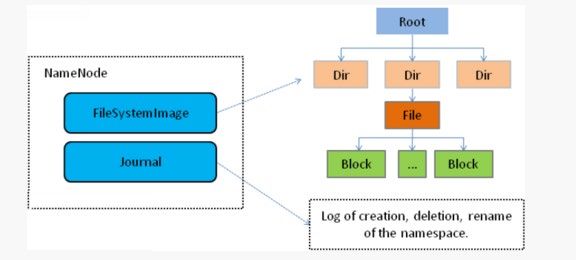
主角色:namenode
⚫ NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
⚫ NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
⚫ 基于此,NameNode成为了访问HDFS的唯一入口。

NameNode内部通过内存和磁盘文件两种方式管理元数据。
⚫ 其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log(Journal)编辑日志。
从角色:datanode
⚫ DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
⚫ DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。

主角色辅助角色: secondarynamenode
⚫ Secondary NameNode充当NameNode的辅助节点,但不能替代NameNode。
⚫ 主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”。

namenode职责
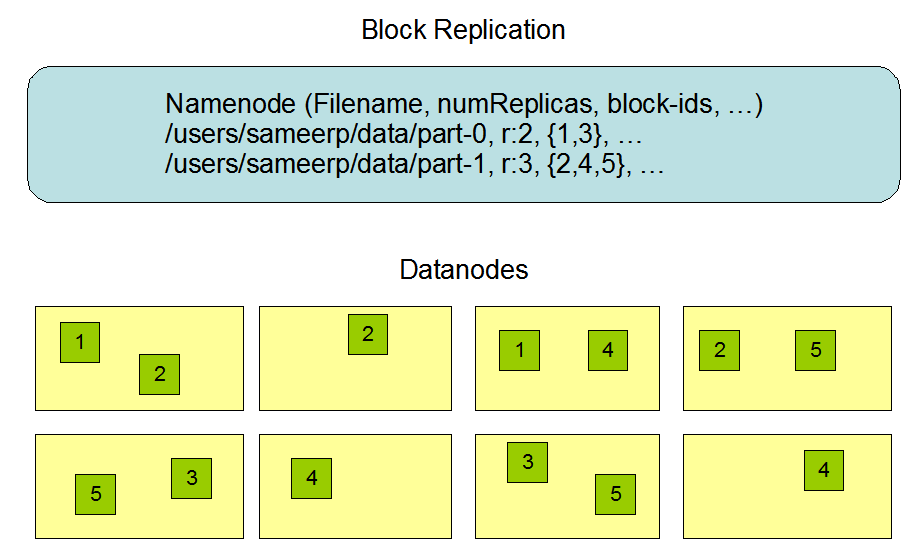
⚫ NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据。
⚫ NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
⚫ NameNode不持久化存储每个文件中各个块所在的datanode的位置信息,这些信息会在系统启动时从DataNode 重建。
⚫ NameNode是Hadoop集群中的单点故障。
⚫ NameNode所在机器通常会配置有大量内存(RAM)。
datanode职责
⚫ DataNode负责最终数据块block的存储。是集群的从角色,也称为Slave。
⚫ DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表。
⚫ 当某个DataNode关闭时,不会影响数据的可用性。 NameNode将安排由其他DataNode管理的块进行副本复制 。
⚫ DataNode所在机器通常配置有大量的硬盘空间,因为实际数据存储在DataNode中。
HDFS写数据流程(上传文件)
写数据完整流程图

核心概念--Pipeline管道
Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
⚫ 客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
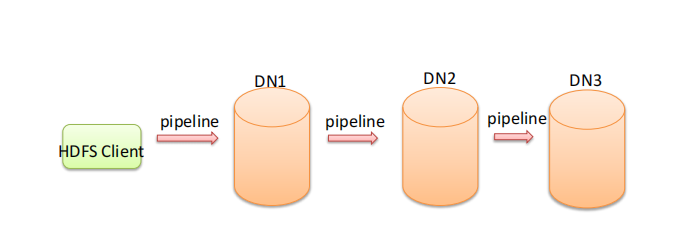
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
⚫ 因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时 的连接,最小化推送所有数据的延时。
⚫ 在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
核心概念--ACK应答响应
⚫ ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
⚫ 在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。
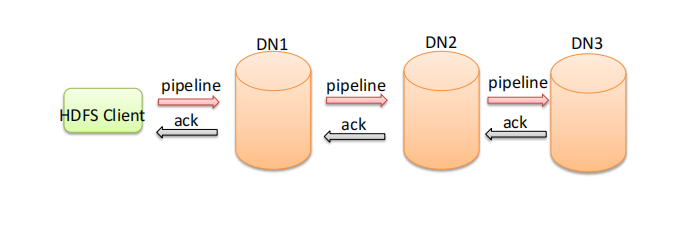
核心概念--默认3副本存储策略
⚫ 默认副本存储策略是由
BlockPlacementPolicyDefault指定。
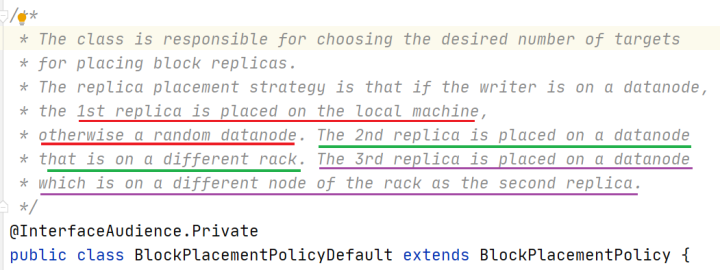
核心概念--默认3副本存储策略
⚫ 第一块副本:优先客户端本地,否则随机
⚫ 第二块副本:不同于第一块副本的不同机架。
⚫ 第三块副本:第二块副本相同机架不同机器。

1、HDFS客户端创建对象实例DistributedFileSystem, 该对象中封装了与HDFS文件系统操作的相关方法。
2、调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过 ,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。

3、客户端通过FSDataOutputStream输出流开始写入数据。
4、客户端写入数据时,将数据分成一个个数据包(packet 默认64k), 内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储。
DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。
5、传输的反方向上,会通过ACK机制校验数据包传输是否成功;
6、客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
7、DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回 。
最小复制是由参数
dfs.namenode.replication.min指定,默认是1.
HDFS读数据流程(下载文件)
读数据完整流程图

1、HDFS客户端创建对象实例DistributedFileSystem, 调用该对象的open()方法来打开希望读取的文件。
2、DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置(分批次读取)信息。
对于每个块,namenode返回具有该块所有副本的datanode位置地址列表,并且该地址列表是排序好的,与客户端的网络拓扑距离近的排序靠前。
3、DistributedFileSystem将FSDataInputStream输入流返回到客户端以供其读取数据。
4、客户端在FSDataInputStream输入流上调用read()方法。然后,已存储DataNode地址的InputStream连接到文件中第一个块的最近的DataNode。数据从DataNode流回客户端,结果客户端可以在流上重复调用read()
5、当该块结束时,FSDataInputStream将关闭与DataNode的连接,然后寻找下一个block块的最佳datanode位置。
这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。
6、一旦客户端完成读取,就对FSDataInputStream调用close()方法。
大数据基础:
开发入门Linux入门→MySQL数据库
核心基础Hadoop
数仓技术Hive数仓项目
PB内存计算Python入门→Python进阶→pyspark框架→Hive+Spark项目
Python+大数据开发
Linux入门:
新版Linux零基础快速入门到精通,全涵盖linux系统知识、常用软件环境部署、Shell脚本、云平台实践、大数据集群项目实战等
MySQL数据库:MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
Hadoop入门:大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程
Hive数仓项目:大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
PB内存计算
Python入门:python教程,8天python从入门到精通,学python看这套就够了
Python编程进阶:Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
spark3.2从基础到精通:Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
Hive+Spark离线数仓工业项目实战:全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
注意事项:大数据学习要业务驱动,不要技术驱动:数据科学的核心能力是解决问题。
大数据的核心目标是数据驱动的智能化,要解决具体的问题,不管是科学研究问题,还是商业决策问题,抑或是政府管理问题。
所以学习之前要明确问题,理解问题,所谓问题导向、目标导向,这个明确之后再研究和选择合适的技术加以应用,这样才有针对性,言必hadoop,spark的大数据分析是不严谨的。
相关文章:
理解HDFS工作流程与机制,看这篇文章就够了
HDFS(The Hadoop Distributed File System) 是最初由Yahoo提出的分布式文件系统,它主要用来: 1)存储大数据 2)为应用提供大数据高速读取的能力 重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升…...

Intel处理器分页机制
分页模式 Intel 64位处理器支持3种分页模式: 32-bit分页PAE分页IA-32e分页 32-bit分页 32-bit分页模式支持两种页面大小:4KB以及4MB。 4KB页面的线性地址转换 4MB页面的线性地址转换 PAE分页模式 PAE分页模式支持两种页面大小:4KB以及…...
Linux常用命令
linux常用命令创建一个目录mkdir 命令可以创建新目录。mkdir 是 make directory 的缩写。[rootiZ2ze66tzux2otcpbvie88Z ~]# ls [rootiZ2ze66tzux2otcpbvie88Z ~]# mkdir web [rootiZ2ze66tzux2otcpbvie88Z ~]# ls web [rootiZ2ze66tzux2otcpbvie88Z ~]# 创建一个文件2.1 在 Li…...

基于STM32设计的音乐播放器
一、项目背景与设计思路 1.1 项目背景 时代进步,科学技术的不断创新,促进电子产品的不断更迭换代,各种新功能和新技术的电子产品牵引着消费者的眼球。人们生活水平的逐渐提高,对娱乐消费市场需求日益扩大,而其消费电子产品在市场中的占有份额越来越举足轻重。目前消费电…...

微服务开发
目录 微服务配置管理 权限认证 批处理 定时任务 异步 微服务调用 (协议)...
【(C语言)数据结构奋斗100天】二叉树(上)
【(C语言)数据结构奋斗100天】二叉树(上) 🏠个人主页:泡泡牛奶 🌵系列专栏:数据结构奋斗100天 本期所介绍的是二叉树,那么什么是二叉树呢?在知道答案之前,请大家思考一下…...
Java 验证二叉搜索树
验证二叉搜索树中等给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。示例 1&…...

C/C++单项选择题标准化考试系统[2023-02-09]
C/C单项选择题标准化考试系统[2023-02-09] ©3.17 单项选择题标准化考试系统 【难度系数】5级 【任务描述】 设计一个单项选择题的考试系统,可实现试题维护、自动组卷等功能。 【功能描述】 (1)管理员功能: 试题管理:每个试题包括题干、四个备选答案标准答案…...
爱了爱了,这些顶级的 Python 工具包太棒了
Python 语言向来以丰富的第三方库而闻名,今天来介绍几个非常nice的库,有趣好玩且强大!推荐好好学习。 文章目录技术交流数据采集AKShareTuShareGoPUPGeneralNewsExtractor爬虫playwright-pythonawesome-python-login-modelDecryptLoginScylla…...
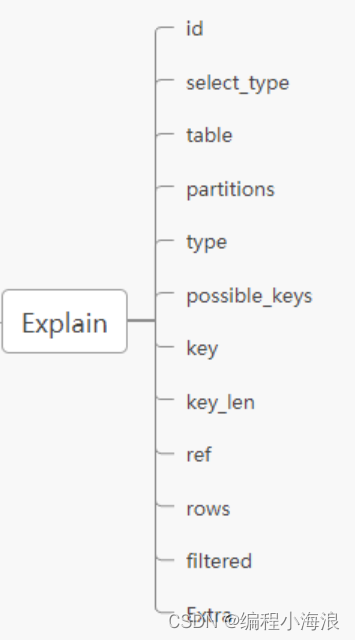
【Explain详解与索引优化最佳实践】
摘要 explain命令是查看MySQL查询优化器如何执行查询的主要方法,可以很好的分析SQL语句的执行情况。每当遇到执行慢(在业务角度)的SQL,都可以使用explain检查SQL的执行情况,并根据explain的结果相应的去调优SQL等。 …...
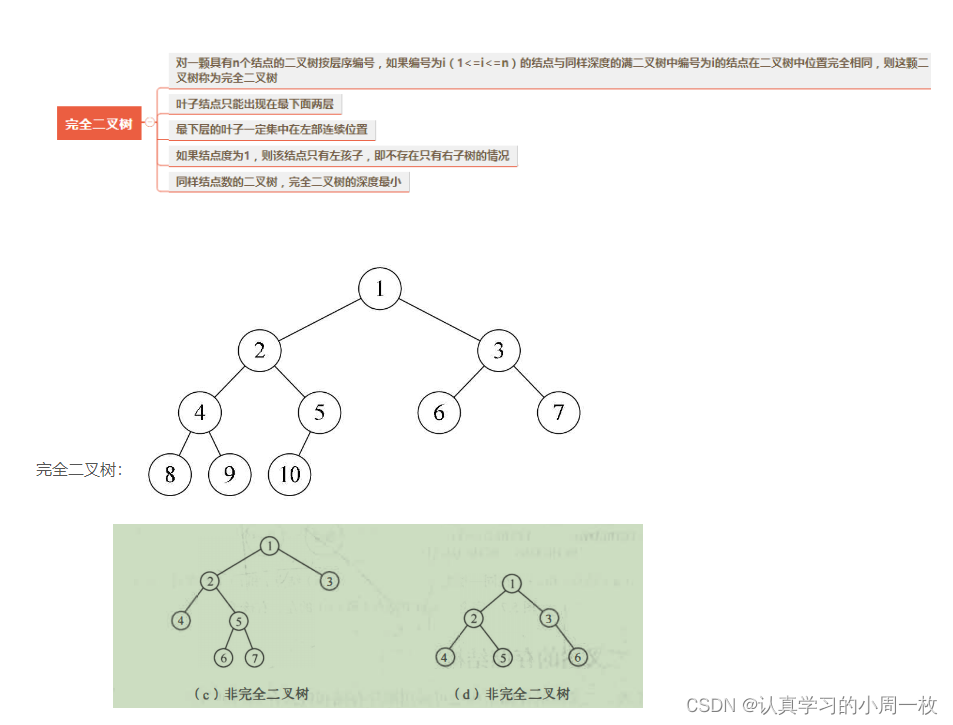
【树和二叉树】数据结构二叉树和树的概念认识
前言:在之前,我们已经把栈和队列的相关概念以及实现的方法进行了学习,今天我们将认识一个新的知识“树”!!! 目录1.树概念及结构1.1树的概念1.2树的结构1.3树的相关概念1.4 树的表示1.5 树在实际中的运用&a…...

通达信收费接口查询可申购新股c++源码分享
有很多股民在做股票交易时为了实现盈利会借助第三三方炒股工具帮助自己,那么通达信收费接口就是人们常用到的,今天小编来分享一下通达信收费接口查询可申购新股c源码: std::cout << " 查询可申购新股: category 12 \n"; c…...
。)
【C#设计模式】创建型设计模式 (单例,工厂)。
c# 创建型设计模式 1.单例设计模式c# 单例JS 单例(ES6)c# 扩展方法c# 如果窗体非单例(tips:窗口可以容器化)2.工厂设计模式JS 简单工厂(ES6)C# 简单工厂C# params关键词(自定义参数个数)JS 手写JQuery(委托,工厂方式隐藏细节)JS ...四种用法C# 偷懒工厂1.单例设计模式 …...
Ubuntu 22.04 LTS 入门安装配置优化、开发软件安装一条龙
Ubuntu 22.04 LTS 入门安装配置&优化、开发软件安装 例行前言 最近在抉择手上空余的笔记本(X220 i7-2620M,Sk Hynix ddr3 8G*2 ,Samsung MINISATA 256G)拿来运行什么系统比较好,早年间我或许还会去继续使用Win…...
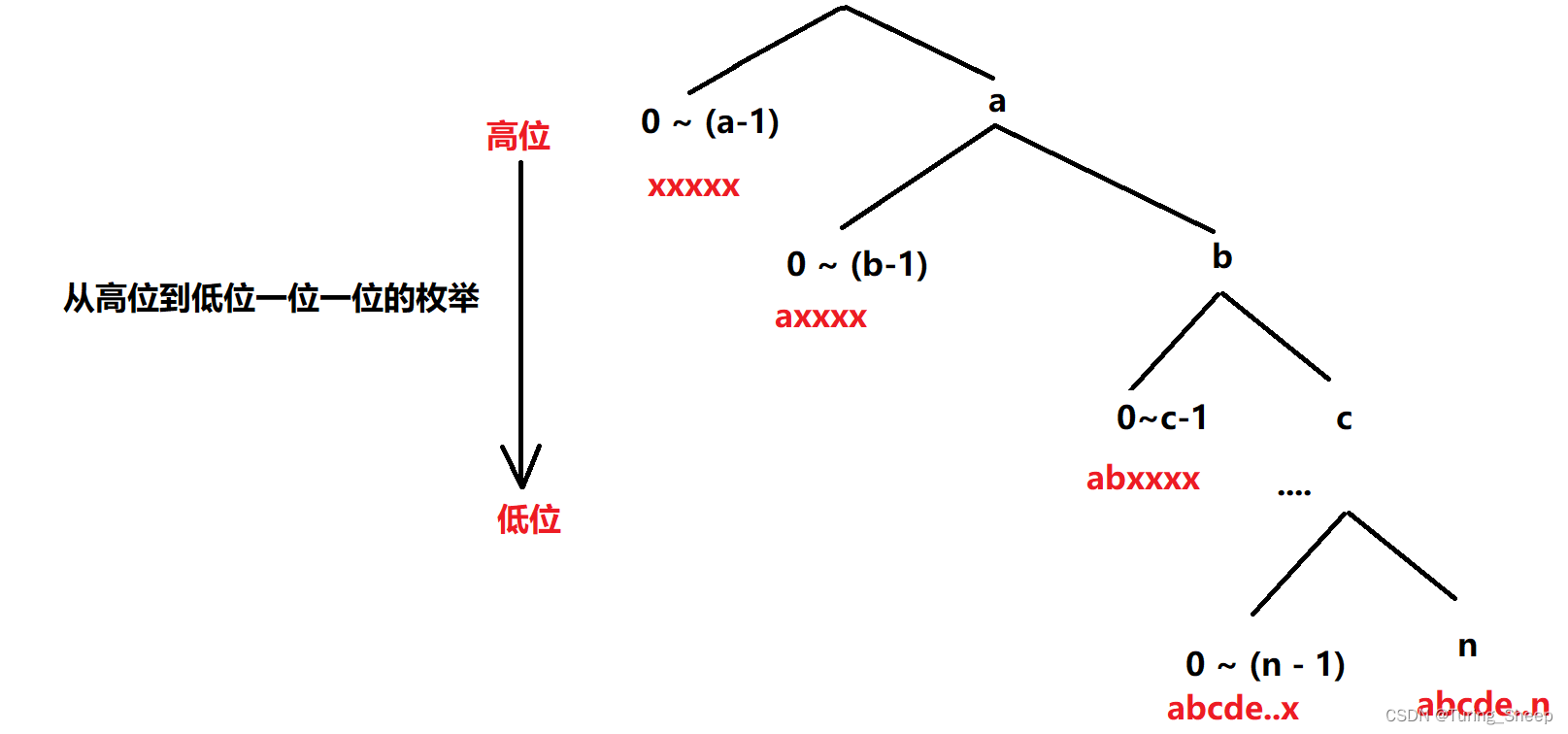
第五十章 动态规划——数位DP模型
第五十章 动态规划——数位DP模型一、什么是数位DP数位DP的识别数位DP的思路二、例题1、AcWing 1083. Windy数(数位DP)2、AcWing 1082. 数字游戏(数位DP)3、AcWing 1081. 度的数量(数位DP)一、什么是数位DP…...
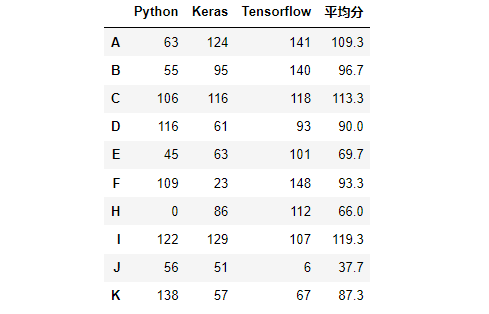
02- pandas 数据库 (机器学习)
pandas 数据库重点: pandas 的主要数据结构: Series (一维数据)与 DataFrame (二维数据)。 pd.DataFrame(data np.random.randint(0,151,size (5,3)), # 生成pandas数据 index [Danial,Brandon,softpo,Ella,Cindy], # 行索引 …...

学Qt想系统的学习,看哪本书?
Qt 是一个跨平台应用开发框架(framework),它是用 C语言写的一套类库。使用 Qt 能为 桌面计算机、服务器、移动设备甚至单片机开发各种应用(application),特别是图形用户界面 (graphical user in…...
)
2023年网络安全比赛--跨站脚本攻击②中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.访问服务器网站目录1,根据页面信息完成条件,将获取到弹框信息作为flag提交; 2.访问服务器网站目录2,根据页面信息完成条件,将获取到弹框信息作为flag提交; 3.访问服务器网站目录3,根据页面信息完成条件,将获取到弹框信息…...

网络安全实验室4.注入关
4.注入关 1.最简单的SQL注入 url:http://lab1.xseclab.com/sqli2_3265b4852c13383560327d1c31550b60/index.php 查看源代码,登录名为admin 最简单的SQL注入,登录名写入一个常规的注入语句: admin’ or ‘1’1 密码随便填,验证…...

领域搜索算法之经典The Lin-Kernighan algorithm
领域搜索算法之经典The Lin-Kernighan algorithmThe Lin-Kernighan algorithm关于算法性能提升的约束参考文献领域搜索算法是TSP问题中的三大经典搜索算法之一,另外两种分别是回路构造算法和组合算法。 而这篇文章要介绍的The Lin-Kernighan algorithm属于领域搜索算…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...